Embed Size (px)
Citation preview

Information Theoretical Complexities in Developing a
Bilingual Corpus: Critical comparison Hindi and Marathi
Sonal Khosla
Haridasa Acharya
Symbiosis International University Symbiosis International University
Abstract
A critical comparison of Hindi and Marathi
languages and its implications for building a
bilingual corpus with IT perspective is
presented here. We strongly believe that the
efforts required to build a corpus can be
reduced if the similarities between the
languages can be properly accommodated in
the design and development of the corpus. If
the corpus is domain specific then the
similarities can further be exploited to arrive
at a more practicable design and the efforts
can be reduced. The paper also attempts to
discuss challenges faced in building the
corpus due to the dissimilarities of the two
languages.
As a first step towards such design, we have
attempted to provide formal definitions of
the basic concepts in terms which could be
understood better by IT designers. Results
from two elementary experiments have been
used to get insight into the complexities
involved in the design of a bilingual corpus.
Hypothesis have been laid and established
which could help in understanding the
complexities involved in design and
development of a bilingual corpus.
1. Introduction
1.1 . Human language is a most
exciting and demanding puzzle
Theoretical CL (Computational Linguistics)
takes up issues in theoretical linguistics and
cognitive science. Formal theories have
reached a degree of complexity that can only
be managed by employing computers [22].
Models simulating aspects of the human
language faculty facilitate implementing
them as computer programs, which in turn
constitute the basis for the evaluation and
further development of the theories. Natural
language applications which are built to run
on computers have tremendous importance.
First thing that is required when natural
language applications are written is support
of a good corpus. A corpus is a
representative of any language and makes
itself useful for any linguistic analysis [16].
Building a corpus or may be parallel corpora
is a task which has both linguistic aspects
and information theoretical aspects to be
taken care of. When we say applications, in
today‘s scenario we expect practically every
application to run off-line on office
computers or client machines at the end user
level with possible web support.
1.2 Bilingual Applications
If one is concerned with two natural
languages at a time, then a Bilingual Corpus
is what is needed. Computational Linguists
have defined various characteristics of a
good bilingual corpus [12][24] . However
from the point of view of using computers as
the cognitive artifacts in applications we
need to identify the IT related aspects.
Storage formats, appropriate choice of data
bases, proper choice of tagging tools,
aligning tools while building the corpus
assume tremendous importance [24].
Facilitating easy browsing, providing proper
API so that software developers can easily
write application which naturally interface
with the corpus are the factors one should be
worried about while building bilingual
corpus.
Sonal Khosla et al, Int.J.Computer Technology & Applications,Vol 6 (1),93-110
IJCTA | Jan-Feb 2015 Available [email protected]
93
ISSN:2229-6093

In this article we propose to compare languages Hindi and Marathi. The comparison will have
three important parts. The initial part would be a formalization of some of the basic concepts
followed by our idea of how these similarities and dissimilarities listed in part one can be tackled
while building a bilingual corpus. Second part would be the linguistic similarities and
dissimilarities, where we base our arguments on what earlier researchers have written. Third and
the last part would be results of a very limited experimentation and their results which support a
few hypotheses.
We feel that earlier researchers have concentrated more on Linguistic aspects, both pure and
computational in nature, and have not provided adequate linkage to down to earth software
engineering requirements. It is hoped that this article will help the developers in getting clearer
picture of the corpus and in turn the selection of software environments to support related projects
will be easier.
We have preferred to use the word e-corpus to emphasize the fact that the format will be
electronic, stored in such a way that it is readily accessible to anyone who is a computer literate. It
will be easily browsable without any special browser specifications thus hindering the process.
And those who are developers can develop applications with interfaces which use the corpus at the
back-end that can be easily created. As the title of the paper indicates the chosen languages are
Hindi and Marathi.
2. Basic Definitions and Formal Theoretical Aspects
Firstly we attempt the formalization of the basic definitions and concepts which is the first step
towards building an e_corpus.
2.1 Notations and Symbols
Table 1 gives the list of symbols and notations that are used in this article.
Symbol Notation Meaning
F file A file is logical storage unit of a computer, which is a collection of
data and information in the form of texts,pictures etc.
P Paragraph
A paragraph is a suitable sub-division of contents of a file defined
by paragraph delimiters which can be specially defined spaces, new
line characters and other special characters . A file can always be
divided into finite no of paragraphs, conversely a file is a union of
paragraphs.
S sentence
A sentence is a set of tokens(words/punctuation
marks/numerals/dates etc.) having a meaning in itself, which
conveys a statement, question, exclamation and command.
In Hindi, a sentence ends in a viraam, question mark or exclamation
mark.
In Marathi, a sentence ends in a full stop, question mark or
exclamation mark.
1.3 Objective of current paper
Sonal Khosla et al, Int.J.Computer Technology & Applications,Vol 6 (1),93-110
IJCTA | Jan-Feb 2015 Available [email protected]
94
ISSN:2229-6093

K token
A token is a smallest unit of a sentence to be processed which can be
a word, punctuation marks, numerals etc. It is usually enclosed by
two blank characters or two punctuation marks. It represents one
morphosyntactic unit.
W word A word is a sequence of characters/syllables with a defined meaning
and space on either side
C character A character over here is referred to a syllable where a syllable is a
unit of spoken language.
L Lemma
A lemma is the canonical form of the token or the token itself. It is
the base form of the word representing all word forms belonging to
the same word.
L Language_type Language refers to the language in particular i.e. Hindi and Marathi
t tag
Tag is a lexical category given to a particular token in a sentence.
The lexical category is picked from the standard POS tagset given in
Table 2.
Table 1. List of Symbols , Notations with their meanings
2.2
2.3 Formal Definitions
We present here the formal definitions that
are requisite in building an e-corpus.
[ Most of the following definitions have been adapted from
( William H Wilson, 2012,
http://www.cse.unsw.edu.au/~billw/nlpdict.html.]
Def 1: Part of speech, POS (Lexical
category)
A set POS, also called a tagset, = {t1,
t2, t3,.....}, where each element corresponds
to a role which can be played by a word. It is
a linguistic category.
Def 2: An ordered pair {w, t} is called a
tagged-word if w is the word and t is its
lexical category.
It should be remembered that same word
may have different tags, when they appear in
different sentences depending on the context
[8]. A list of tags is given in Table 2.
Def 3 : Part-of-speech tagging is the
process of labelling each word, w in each
sentence, s with its part of speech category, t.
We will assume that an e-corpus
should always be a tagged-corpus to be apt
for use in natural language processing
applications. Further we will assume that the
tag-sets are unique, within an e-corpus. In
our work we have used the tagset given
in Table No 2 , taken from the POS Tagset
[4] developed at Language Technology
Research Centre at IIIT, Hyderabad. Note
that there are exactly 26 number of
tags, with 21 basic ones, and these are,
common to all Indian languages , and this is
the complete set.
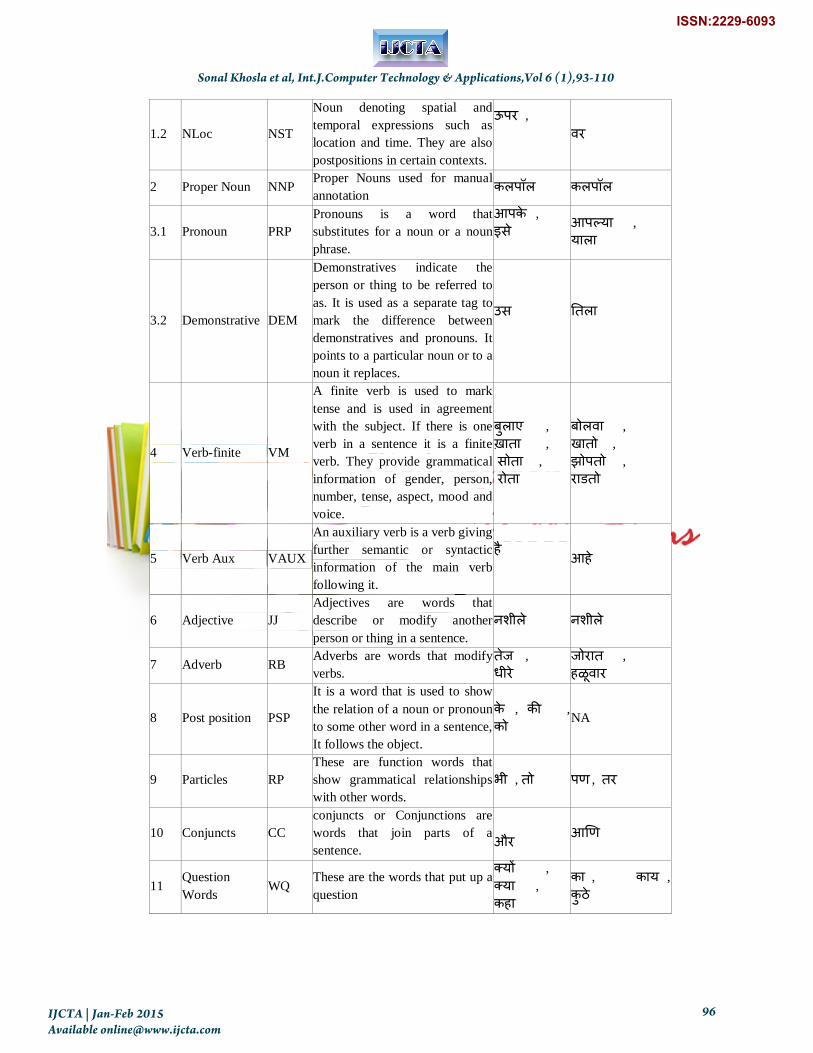
Table 2: POS Tagset for Indian Languages
Sl.
No. Category
Tag
Name Remarks/Discussion
Example
(Hindi)
Examples
(Marathi)
1.1 Noun NN Common Noun घयघयाहट ,
सेलन
घयघयाहट ,
सेलन
Sonal Khosla et al, Int.J.Computer Technology & Applications,Vol 6 (1),93-110
IJCTA | Jan-Feb 2015 Available [email protected]
95
ISSN:2229-6093
1.2 NLoc NST
Noun denoting spatial and
temporal expressions such as
location and time. They are also
postpositions in certain contexts.
ऊऩय ,
लय
2 Proper Noun NNP Proper Nouns used for manual
annotation करऩॉर करऩॉर
3.1 Pronoun PRP
Pronouns is a word that
substitutes for a noun or a noun
phrase.
आऩके ,
इसे
आऩल्मा ,
मारा
3.2 Demonstrative DEM
Demonstratives indicate the
person or thing to be referred to
as. It is used as a separate tag to
mark the difference between
demonstratives and pronouns. It
points to a particular noun or to a
noun it replaces.
उस
तिरा
4 Verb-finite VM
A finite verb is used to mark
tense and is used in agreement
with the subject. If there is one
verb in a sentence it is a finite
verb. They provide grammatical
information of gender, person,
number, tense, aspect, mood and
voice.
फुराए ,
खािा ,
सोिा ,
योिा
फोरला ,
खािो ,
झोऩिो ,
याडिो
5 Verb Aux VAUX
An auxiliary verb is a verb giving
further semantic or syntactic
information of the main verb
following it.
है
आहे
6 Adjective JJ
Adjectives are words that
describe or modify another
person or thing in a sentence.
नळीरे नळीरे
7 Adverb RB Adverbs are words that modify
verbs.
िजे ,
धीये
जोयाि ,
हऱूलाय
8 Post position PSP
It is a word that is used to show
the relation of a noun or pronoun
to some other word in a sentence,
It follows the object.
के , की ,
को NA
9 Particles RP
These are function words that
show grammatical relationships
with other words.
बी , िो ऩण , िय
10 Conjuncts CC
conjuncts or Conjunctions are
words that join parts of a
sentence.
औय आणण
11 Question
Words WQ
These are the words that put up a
question
क्मों ,
क्मा ,
कहा
का , काम ,
कुठे
Sonal Khosla et al, Int.J.Computer Technology & Applications,Vol 6 (1),93-110
IJCTA | Jan-Feb 2015 Available [email protected]
96
ISSN:2229-6093

12.1 Quantifiers QF
These are the words that tell us
how many or how much. They
generally precede or modify
nouns.
सबी ,
फहुि ,
थोडा ,
कभ
सगऱे ,
जास्ि , .थोड ,
कमभ
12.2 Cardinal QC
These words are the cardinal
numbers in the language which
quantify and are adjectives
referring to quantity
फीस , एक ,
दो , िीन
लीस , एक ,
दोन , तिन
12.3 Ordinal QO
Ordinal numbers are words that
represent the relative position of
an item in an ordered sequence
ऩहरा ,
दसूया ,
िीसया
ऩहहरा ,
दसुया ,
तिसया
12.4 Classifier CL
classifier is a word which
accompanies a noun in certain
grammatical contexts and
generally reflects some kind of
conceptual classification of
nouns.
NA NA
13 Intensifier INTF These are the words that
intensifies adjectives or adverbs
खफू ,
फहुि ,
थोडा ,
कभ
खऩू ,
जास्ि , .थोड ,
कमभ
14 Interjection INJ
Interjections are words that used
to exclaim, protest or command.
They can sometimes be used by
themselves.
अये , हा
अये , हो
15 Negation NEG These are the negative words in a
language. नही नाही
16 Quotative UT
A quotative introduces a quote. It
is typically a verb and some
indian languages use it.
17 Special Symbol SYM
It is used to tag all the special
symbols which cannot be
categorised in any other category
? , : ; ! ? , : ; ! .
18 Compounds C
These are the words that are
combined together to represent a
single word.
रार यक्ि
कोमळकाए
रार यक्ि
ऩेळी
19 Reduplicative RDP
It is used to mark those words in
Indian languages that are
repeated consecutively.
छोटे
छोटे छोटे छोटे
20 Echo ECH
This category is designed for
representing words in Indian
languages that do not have any
place in dictionary and can be
called as ―nonsense words‖
दलाई
ळलाई
NA
21 Unknown UNK
This category is used to mark the
words whose category is not
known which may be loan words
or foreign words.
Sonal Khosla et al, Int.J.Computer Technology & Applications,Vol 6 (1),93-110
IJCTA | Jan-Feb 2015 Available [email protected]
97
ISSN:2229-6093

Def 4: We will ref to tagset as defined in
Table 2 as the default tag-set.
Def 5 : Storage format is the standardized
format that is used to store the metadata so
that it is machine readable and interpretable.
There are many standardized formats for
encoding like
Text Encoding Initiative (TEI),
Translation Memory Exchange
(TMX)
Corpus Encoding Standard for
XML (XCES)[24]
IMS corpus WorkBench
Each of the formats have their own
advantages and disadvantages. We feel that
the choice of the format, by the corpus
builder, will not create any incompatibility
in respect of choice of tagging tool or even
alignment tools at later stage at the time of
actual building of the e_corpus.
Def 6: A RAW_resource is always a Pair of
TEXT files in the corresponding languages
namely L1 and L2 using Unicode, one being
translation of the other for a bilingual corpus.
This means, we are avoiding usage of
resources which could contain images, or
sound files and also assuming that the Raw
resource is in UNICODE format. Further,
this means that a resource is input into the
corpus only when the builder is satisfied
with its translation into the other language.
Def 7: Sum total of sizes of all
RAW_resource files in number of Bytes
would be referred to as the size of the
Corpus.
Obviously the actual fingerprint of the total
content would be far larger than the ‗size of
the Corpus‘ as that would include processed
files, accompanying software resources etc.
Def 8: Length of a sentence, s will be
always specified as ‗number of tokens‘, k.
Token length of a sentence and byte length
of a sentence are two different metrics
which we will need when we analyze. Hence
a separate definition of byte length is
proposed. Tokens are words separated by a
token delimiter.
Def 9: The Byte length of a Sentence is the
total no. of bytes that constitute a sentence
which includes white spaces and one byte
for the sentence delimiter.
Choice of the Data Base System: Use of a
Data Base System is a necessity while
building a Corpus. XML would be treated as
the default Database unless otherwise
specified. Reason for choice of XML as the
default database system is its
interoperability with most of the platforms
and programming languages, its software
and hardware independence when it comes
to way of storing information. Since
Unicode is supported it is ideal for storing
text of any language, and would allow use of
simple text editors when it comes to the
content part [24]. Most of the developmental
tools will have natural compatibility with
XML.
The other options could be any of the
Standard Relational Database like MySQL,
Oracle etc. Choice of Database should not
affect the usability of the corpus.
Def 10: Paragraph is a subdivision of the
text file of finite length, identified by special
delimiters like spaces, new line characters,
tabs etc. Sometimes it may be indicated in
number of sentences.
Def 11: Context_Tags is a set of tags,
predefined (Like set of PoS tags) , which
can be associated with each of the
paragraphs.
There can be different classes of tags:
linguistic, situational and cultural [19].
Sonal Khosla et al, Int.J.Computer Technology & Applications,Vol 6 (1),93-110
IJCTA | Jan-Feb 2015 Available [email protected]
98
ISSN:2229-6093

Def 12: Context_tagging is the process of
tagging each paragraph in a text-file, with
predefined tags.
Def 13: Since we are concerned with a
bilingual product, the concept of ―Direction‖
assumes considerable importance. The e-
corpus will have a direction specified as one
of the elements of the set {Uni, Bi}.
If the choice is Uni, then the aligning will be
‗L1 to L2‘ or ‗L2 to L1‘ which again will be
clearly specified in the definition. Choice
‗Bi‘ would mean bi-directional and needs no
further specification since it would any way
be symmetric. A bidirectional corpus any
way would include both unidirectional
corpora into it as a recoverable sub-corpus
[12]. The corpus will have various sub
corpora that will be aligned (text by text /
paragraph by paragraph, sentence by
sentence, phrase by phrase and word by
word) [12].
Having defined the basic components in
clear formal terms, now we are in a position
to provide a good implementable definition
of monolingual e_corpus and bilingual
e_corpus.
Def 14: Bilingual e_corpus
Bilingual e_corpus is a Quadruplet
{Lan_Names, RawLang_Files,
ProLang_Files, SoftwareToManage }
with following characteristics
1. It has a specified pair of languages
associated with it. {Lan_Names = (L1,
L2)}
2. It constitutes of a ―repository‖ of contents
included in containers
{ RawLang_Files, ProLang_Files }
combined size of which will be called
the size of corpus.
RawLang_Files are a collection of
resources, which are basically Pairs of text
files as defined in Def 6, whereas
ProLang_Files are the XML files
which provide exact alignment and tagging
of Raw resources.
3. It is ―Intelligent” in the sense that
adequate interfaces provided to add
/modify/delete info,
perform various linguistic
operations
allows to browse and extract
information for user applications
(and Lot more related
functionalities )
4. It has a software component
―SoftToManage”
an integrated package with utilities
required
to manage the repository and which
also contains
proper API s , which will facilitate
application
development in Java/C++ .
5. It is noiseless (possible noise is spelling
mistakes, incorrect translations, incorrect
character encoding, missing words). In short
it will have no linguistic inconsistencies)
The ProLang_Files is essentially a
collection of
tagged -repositories etc.
obtained from the RawLang_Files,
arranged and structured in such a way so
as to facilitate the Utilities in SoftToMange
to work properly.
Def 15: Context
Context is the physical
environment in which a word is used [19]. A
word can have a different POS tag based on
the context in which it is used [13]. Lexical
ambiguity that arises in different situations
can be resolved using the contextual
information available in the text [13].
3. Linguistic Similarities and their
Information Theoretic
Implications
Sonal Khosla et al, Int.J.Computer Technology & Applications,Vol 6 (1),93-110
IJCTA | Jan-Feb 2015 Available [email protected]
99
ISSN:2229-6093

Challenges faced by developers in building a
bilingual corpus for Hindi and Marathi pair
of languages are many. The basic definitions
discussed earlier in Section 2 and the
functional requirements specified in the
definition of a bilingual corpus are not easy
to meet. Through a study of the similarities
and dissimilarities of the pair of languages
one can possibly counter some of the
challenges and reduce complexities.
3.1 Vocabulary
Indian languages share a common origin and
are known to have a common vocabulary of
around 40 to 80 percent [9]. Hindi and
Marathi is one such pair of Indo-aryan
languages, being derived from Devanagari
script. They are known to be sister
languages and have significant proportion of
common vocabulary [18]. Words that are
phonologically and lexically similar are
defined to be as Cognates. [18] [14]. Out of
the corpus of 6 million words created by
Central Institute of Indian Languages for
Marathi and Hindi language, 44.5% are
cognate. Though sometimes these cognitive
words may have different meanings posing a
problem of Word sense disambiguation in
front of developers. These differences are
due to the difference in the Marathi and
Hindi grammatical rules in the construction
of verbs and its placement. Some words
retain their meanings and have similar
meanings while others have become
associated with different concepts [18]. The
problems arising due to bilingualism are
reduced when the rate of cognates available
in the two languages are higher [14]. Some examples of cognates in Hindi and
Marathi are given below: Same origin; same meaning: The word ―Utsuk‖ means curious
in both Hindi and Marathi. Same origin; different meaning: The word ―shikhsa‖ in Hindi means
education, while the same word in Marathi
means Punishment. Since there are very less similar words in the
two languages having different meanings.
The work involved in building lexical
resources can be reduced by taking care of
these cognates.
So from the designer‘s perspective we may
conclude that A good bilingual corpus
faces the problems related to
BIGDATA, i.e. problem of
Volume, Variety and Velocity. The common part of the
vocabulary, and presence of
cognitive words will certainly
reduce the Volume of Corpus,
significantly.
3.2 Script & Alphabet Set
The set of symbols of each language is
unified into a single collection identified as
a single script. These collection of symbols
and scripts, then serve as a reserve from
which symbols are taken to write multiple
languages.
Hindi and Marathi are derived from
Devanagari script for writing, which is a
phonetic script. Devanagari script used for
Hindi and Marathi have 12 pure vowels, two
additional loan vowels taken from the
Sanskrit and one loan vowel from English
[9][10].There are 34 pure consonants, 5
traditional conjuncts, 7 loan consonants and
2 traditional signs in Devanagari script and
each consonant have 14 variations through
integration of 14 vowels, which produces
507 different alphabetical characters[9][11].
Apart from ऱ / which is used only in
Marathi language, consonants are identical.
In Marathi glyphs are preferred for U+0932
devanagari letter la and U+0936 devanagari
letter sha[2].
The different committees of the Department
of Electronics and the Department of
Official Language, Govt. of India have
developed a universal code, which is the
Indian Standard Code for Information
Interchange (ISCII). The ISCII code is a
super set of all the characters required in the
ten Brahmi based Indian scripts. It is based
on the standard ASCII code [1].
Sonal Khosla et al, Int.J.Computer Technology & Applications,Vol 6 (1),93-110
IJCTA | Jan-Feb 2015 Available [email protected]
100
ISSN:2229-6093

Unicode has also encoded the Indian
language scripts and is based on the Indian
national standard, ISCII. the Unicode
standard has encoded the Devanagari
characters in the same relative position as in
the ISCII-1988 standard. This enables one to
one mapping between different scripts in the
Indian family [2]. The Range of codes for
Devanagari in The Unicode Standard
Version 7. 0 is 0900–097F [2].
Since the script and the Alphabet set is
similar in both languages,so Unicode to
ISCII and vice versa is not language specific,
but is dependent on the script.
Whenever we download or procure
raw files or documents in Hindi or Marathi
for inclusion in a repository they are passed
or produced through some document
editors. In most cases they need to be
converted into a plain text resource using
a code converter. Font Suvidha
[http://www.fontsuvidha.com/] is one of its
kind software developed to convert writing
in devnagari scripts like Hindi, Marathi, and
many other languages written in different
fonts to Unicode and vice versa.
Availability of many such converters is a
tremendous advantage for a corpus builder.
Some tools also have language detection
feature to leave English text unchanged so
that documents with mixed contents
(English, Hindi or Marathi) can be easily
handled.
Hypothesis : The commonality
of Devanagari script between the two
languages has made development of such
Unicode-converters possible. (One
Unicode converter can handle RAW files
from both the languages)
3.3 Phonology
Phonology of a language is an important
feature. Most often phonetically similar
words have similar spellings. Devanagari
being a phonetic script, this aspect can be
used to match misspelled words or
missing/muted words [11].
For example, the words ―aaya‖ and ―gaya‖
rhyme similar to ―aala‖ and ―gela‖ in
Marathi and have similar meanings as well.
Even in the below example of sentences, the
words िनाल and िणाल rhyme similar
and have similar spellings.
Hindi: िनाल कभ कये |
Marathi: िणाल कभी कया .
ण sound is more frequently used in Marathi
Due to the phonetic similarity of different
alphabets [7] and several features and
sounds shared across Indian languages [5],
an optimal keyboard common to all
languages is possible. The different
committees of the Department of Electronics
and the Department of Official Language,
Govt. of India have been evolving different
codes and keyboards which could cater to all
the Indian scripts.
Hypothesis: Due to an overlap in
vocabulary of Hindi and Marathi, words
having similar pronunciation and which
rhyme together, they can be directly
taken in the corpus to be equivalent
words having similar meanings.
The Hypothesis said above is supported by
the experiments described in Section 5.
Although phonology aspect is more
applicable in building a speech corpus, still
we have attempted to list the differences in
Table 3 which needs to be taken care of.
Sonal Khosla et al, Int.J.Computer Technology & Applications,Vol 6 (1),93-110
IJCTA | Jan-Feb 2015 Available [email protected]
101
ISSN:2229-6093

Table 3. Difference in pronunciation of certain consonants in Hindi and Marathi.
Consonants Marathi Hindi
च , ज, झ and प Multiple pronunciation Single pronunciation
ऋ /ru/ /ri/ and similar to Sanskrit
T, TH, D, DH, t, th, d dh
words ending with these
consonants are prolonged
in pronunciation
No change
च and ज are dental-alveolar in Marathi only, while these are alveolar in Hindi.
3.4 Grammar
This is one aspect that needs to be studied
considerably to build a highly accurate
bilingual corpus. Table 4 gives a
comprehensive list of similarities and
dissimilarities in grammar in the two
languages [20][21]
Hindi is a highly inflected language and
requires the modification of a word to
represent different grammatical categories
such as tense, mood, voice, aspect, person
etc. It adds prefixes and suffixes to form
words. The inflection of verbs is called as
conjugation and the inflection of nouns,
adjectives and pronouns is called declension.
Hindi uses postpositions (PSP) rather than
prepositions for case marking and auxiliaries.
In Marathi, postpositions are added to the
word preceding it. It also adds suffixes to
roots to build words [20][21].
While doing conversion from Hindi to
Marathi, the PSP‘s like के , भे or है are
removed in Marathi and added as a
morphological phenomena[11] or
grammatical information in the word itself.
It is converted to a syntactic feature in
Marathi [23]. Hence these PSP‘s in Hindi do
not find any translation equivalent in
Marathi and are irrelevant while doing Word
alignment.
Multiple words in Hindi are converted into a
single compound word in Marathi. Mean
sentence length of Hindi is 15.95 while that
of Marathi is 9.54[3]. This is attributed to
the fact that Marathi forms compound words.
The pilot experiment also conducted shows
that the sentence length in Hindi is always
greater than the sentence length in Marathi.
Section 5 shows the exact statistics of the
sentence length in the pilot study done.
For e.g. In the given sentence pair taken
from test data.
Hindi: क्मा ददद ळयीय के
अन्म अगंो भें पैरिा है ?
Marathi: ही लेदना ळयीयाच्मा
अन्म बागाि ऩसयिे का ?
The words ळयीय के gets converted to
ळयीयाच्मा in Marathi and the words
अगंो भें forms the compound word
बागाि . It is also seen that the PSP‘s के
and भें gets converted into a syntactic
feature in Marathi.
Sonal Khosla et al, Int.J.Computer Technology & Applications,Vol 6 (1),93-110
IJCTA | Jan-Feb 2015 Available [email protected]
102
ISSN:2229-6093
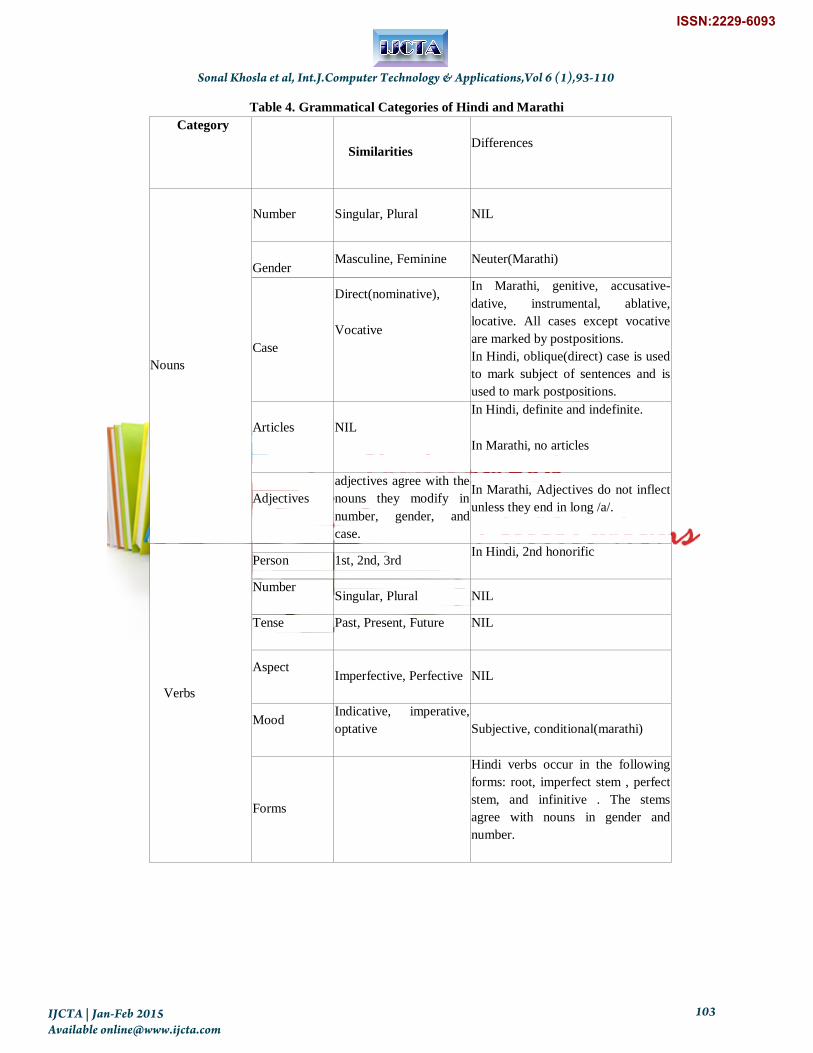
Table 4. Grammatical Categories of Hindi and Marathi
Category
Similarities Differences
Nouns
Number Singular, Plural
NIL
Gender Masculine, Feminine Neuter(Marathi)
Case
Direct(nominative),
Vocative
In Marathi, genitive, accusative-
dative, instrumental, ablative,
locative. All cases except vocative
are marked by postpositions.
In Hindi, oblique(direct) case is used
to mark subject of sentences and is
used to mark postpositions.
Articles
NIL
In Hindi, definite and indefinite.
In Marathi, no articles
Adjectives
adjectives agree with the
nouns they modify in
number, gender, and
case.
In Marathi, Adjectives do not inflect
unless they end in long /a/.
Verbs
Person 1st, 2nd, 3rd In Hindi, 2nd honorific
Number
Singular, Plural NIL
Tense
Past, Present, Future
NIL
Aspect
Imperfective, Perfective
NIL
Mood
Indicative, imperative,
optative
Subjective, conditional(marathi)
Forms
Hindi verbs occur in the following
forms: root, imperfect stem , perfect
stem, and infinitive . The stems
agree with nouns in gender and
number.
Sonal Khosla et al, Int.J.Computer Technology & Applications,Vol 6 (1),93-110
IJCTA | Jan-Feb 2015 Available [email protected]
103
ISSN:2229-6093
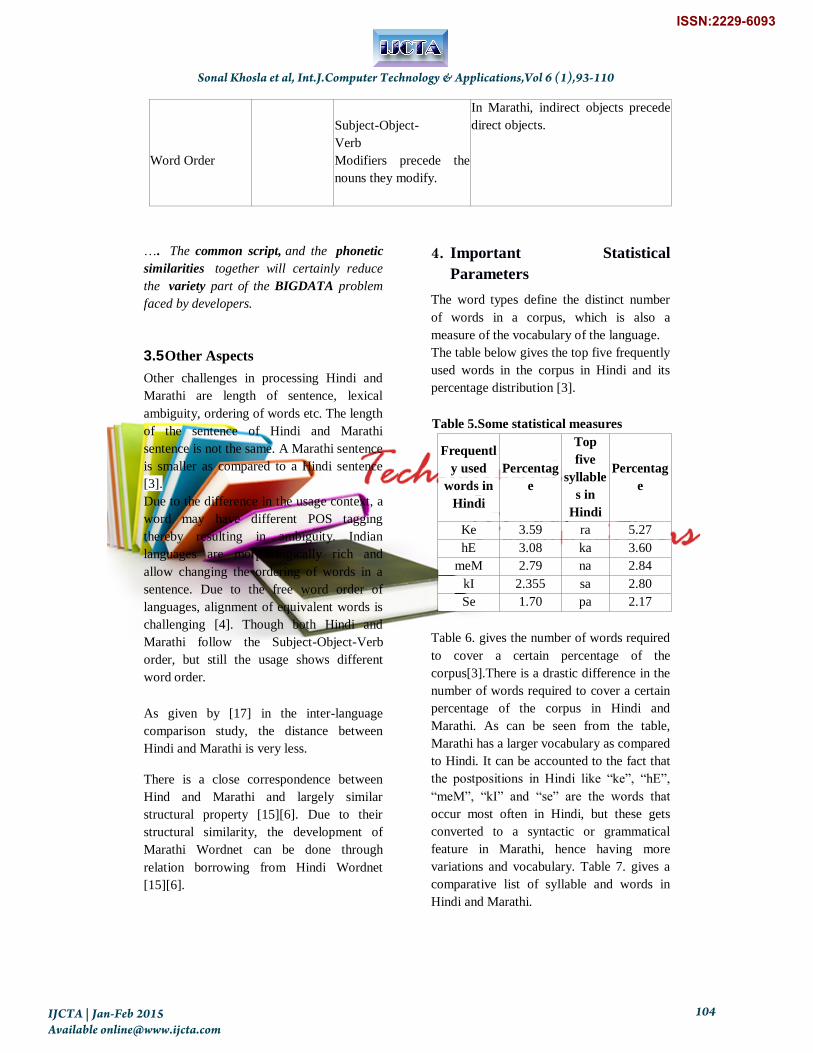
Word Order
Subject-Object-
Verb
Modifiers precede the
nouns they modify.
In Marathi, indirect objects precede
direct objects.
…. The common script, and the phonetic
similarities together will certainly reduce
the variety part of the BIGDATA problem
faced by developers.
3.5 Other Aspects
Other challenges in processing Hindi and
Marathi are length of sentence, lexical
ambiguity, ordering of words etc. The length
of the sentence of Hindi and Marathi
sentence is not the same. A Marathi sentence
is smaller as compared to a Hindi sentence
[3].
Due to the difference in the usage context, a
word may have different POS tagging
thereby resulting in ambiguity. Indian
languages are morphologically rich and
allow changing the ordering of words in a
sentence. Due to the free word order of
languages, alignment of equivalent words is
challenging [4]. Though both Hindi and
Marathi follow the Subject-Object-Verb
order, but still the usage shows different
word order.
As given by [17] in the inter-language
comparison study, the distance between
Hindi and Marathi is very less.
There is a close correspondence between
Hind and Marathi and largely similar
structural property [15][6]. Due to their
structural similarity, the development of
Marathi Wordnet can be done through
relation borrowing from Hindi Wordnet
[15][6].
4. Important Statistical
Parameters
The word types define the distinct number
of words in a corpus, which is also a
measure of the vocabulary of the language.
The table below gives the top five frequently
used words in the corpus in Hindi and its
percentage distribution [3].
Table 5.Some statistical measures
Frequentl
y used
words in
Hindi
Percentag
e
Top
five
syllable
s in
Hindi
Percentag
e
Ke 3.59 ra 5.27
hE 3.08 ka 3.60
meM 2.79 na 2.84
kI 2.355 sa 2.80
Se 1.70 pa 2.17
Table 6. gives the number of words required
to cover a certain percentage of the
corpus[3].There is a drastic difference in the
number of words required to cover a certain
percentage of the corpus in Hindi and
Marathi. As can be seen from the table,
Marathi has a larger vocabulary as compared
to Hindi. It can be accounted to the fact that
the postpositions in Hindi like ―ke‖, ―hE‖,
―meM‖, ―kI‖ and ―se‖ are the words that
occur most often in Hindi, but these gets
converted to a syntactic or grammatical
feature in Marathi, hence having more
variations and vocabulary. Table 7. gives a
comparative list of syllable and words in
Hindi and Marathi.
Sonal Khosla et al, Int.J.Computer Technology & Applications,Vol 6 (1),93-110
IJCTA | Jan-Feb 2015 Available [email protected]
104
ISSN:2229-6093
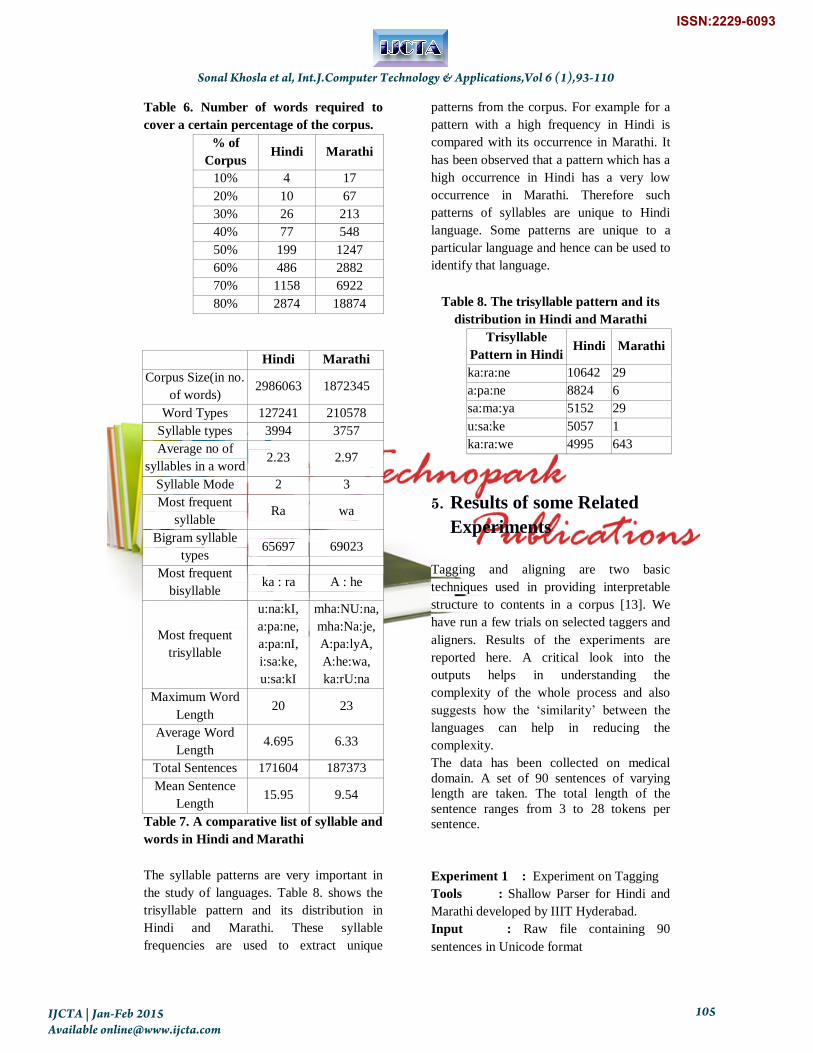
Table 6. Number of words required to
cover a certain percentage of the corpus.
% of
Corpus Hindi Marathi
10% 4 17
20% 10 67
30% 26 213
40% 77 548
50% 199 1247
60% 486 2882
70% 1158 6922
80% 2874 18874
Hindi Marathi
Corpus Size(in no.
of words) 2986063 1872345
Word Types 127241 210578
Syllable types 3994 3757
Average no of
syllables in a word 2.23 2.97
Syllable Mode 2 3
Most frequent
syllable Ra wa
Bigram syllable
types 65697 69023
Most frequent
bisyllable ka : ra A : he
Most frequent
trisyllable
u:na:kI,
a:pa:ne,
a:pa:nI,
i:sa:ke,
u:sa:kI
mha:NU:na,
mha:Na:je,
A:pa:lyA,
A:he:wa,
ka:rU:na
Maximum Word
Length 20 23
Average Word
Length 4.695 6.33
Total Sentences 171604 187373
Mean Sentence
Length 15.95 9.54
Table 7. A comparative list of syllable and
words in Hindi and Marathi
The syllable patterns are very important in
the study of languages. Table 8. shows the
trisyllable pattern and its distribution in
Hindi and Marathi. These syllable
frequencies are used to extract unique
patterns from the corpus. For example for a
pattern with a high frequency in Hindi is
compared with its occurrence in Marathi. It
has been observed that a pattern which has a
high occurrence in Hindi has a very low
occurrence in Marathi. Therefore such
patterns of syllables are unique to Hindi
language. Some patterns are unique to a
particular language and hence can be used to
identify that language.
Table 8. The trisyllable pattern and its
distribution in Hindi and Marathi
Trisyllable
Pattern in Hindi Hindi Marathi
ka:ra:ne 10642 29
a:pa:ne 8824 6
sa:ma:ya 5152 29
u:sa:ke 5057 1
ka:ra:we 4995 643
5. Results of some Related
Experiments
Tagging and aligning are two basic
techniques used in providing interpretable
structure to contents in a corpus [13]. We
have run a few trials on selected taggers and
aligners. Results of the experiments are
reported here. A critical look into the
outputs helps in understanding the
complexity of the whole process and also
suggests how the ‗similarity‘ between the
languages can help in reducing the
complexity.
The data has been collected on medical
domain. A set of 90 sentences of varying
length are taken. The total length of the
sentence ranges from 3 to 28 tokens per
sentence.
Experiment 1 : Experiment on Tagging
Tools : Shallow Parser for Hindi and
Marathi developed by IIIT Hyderabad.
Input : Raw file containing 90
sentences in Unicode format
Sonal Khosla et al, Int.J.Computer Technology & Applications,Vol 6 (1),93-110
IJCTA | Jan-Feb 2015 Available [email protected]
105
ISSN:2229-6093
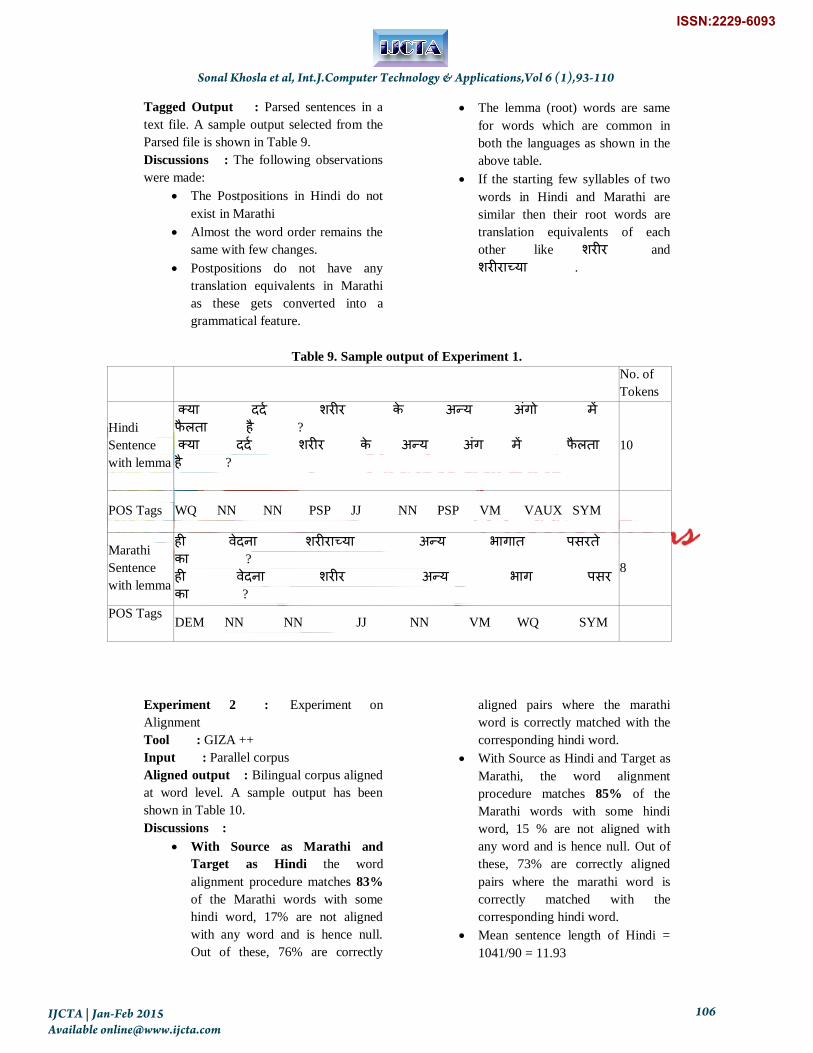
Tagged Output : Parsed sentences in a
text file. A sample output selected from the
Parsed file is shown in Table 9.
Discussions : The following observations
were made:
The Postpositions in Hindi do not
exist in Marathi
Almost the word order remains the
same with few changes.
Postpositions do not have any
translation equivalents in Marathi
as these gets converted into a
grammatical feature.
The lemma (root) words are same
for words which are common in
both the languages as shown in the
above table.
If the starting few syllables of two
words in Hindi and Marathi are
similar then their root words are
translation equivalents of each
other like ळयीय and
ळयीयाच्मा .
Table 9. Sample output of Experiment 1.
No. of
Tokens
Hindi
Sentence
with lemma
क्मा ददद ळयीय के अन्म अगंो भें
पैरिा है ?
क्मा ददद ळयीय के अन्म अगं भें पैरिा
है ?
10
POS Tags WQ NN NN PSP JJ NN PSP VM VAUX SYM
Marathi
Sentence
with lemma
ही लेदना ळयीयाच्मा अन्म बागाि ऩसयिे
का ?
ही लेदना ळयीय अन्म बाग ऩसय
का ?
8
POS Tags
DEM NN NN JJ NN VM WQ SYM
Experiment 2 : Experiment on
Alignment
Tool : GIZA ++
Input : Parallel corpus
Aligned output : Bilingual corpus aligned
at word level. A sample output has been
shown in Table 10.
Discussions :
With Source as Marathi and
Target as Hindi the word
alignment procedure matches 83%
of the Marathi words with some
hindi word, 17% are not aligned
with any word and is hence null.
Out of these, 76% are correctly
aligned pairs where the marathi
word is correctly matched with the
corresponding hindi word.
With Source as Hindi and Target as
Marathi, the word alignment
procedure matches 85% of the
Marathi words with some hindi
word, 15 % are not aligned with
any word and is hence null. Out of
these, 73% are correctly aligned
pairs where the marathi word is
correctly matched with the
corresponding hindi word.
Mean sentence length of Hindi =
1041/90 = 11.93
Sonal Khosla et al, Int.J.Computer Technology & Applications,Vol 6 (1),93-110
IJCTA | Jan-Feb 2015 Available [email protected]
106
ISSN:2229-6093

Mean Sentence length of Marathi =
811/90 = 9.11
Average distance between the
length of sentences = 2.75
25% of the Hindi Words are also
present in Marathi and 33% of the
Marathi words are also present in
Hindi which indicates the
commonality of vocabulary.
Mean difference between length of
sentence is 2.75 which means that the
Marathi sentence is bigger than a Hindi
sentence by approx 2.75 words. This helps
us in making an assumption that a long
sentence gets translated to a long one
while short sentence gets translated into a
short one.
The following is the output of GIZA++.
Table No. 10 shows the serial number
assigned to each word by the tool.
क्मा ({ 1 }) ददद ({ 2 })
ळयीय ({ 3 }) के ({ }) अन्म
({ 4 }) अगंो ({ 5 }) भें ({ })
पैरिा ({ 6 7 }) है ({ }) ?
({ 8 })
Table 10. Sample output of Experminent No. 2
Sl. No of
Words 1 2 3 4 5 6 7 8 9 10
Source
Sentence (Hindi)
क्मा
ददद ळयीय के अन्म अगंो भें पैरिा है ?
Target
Sentence (Marathi)
ही
लेदना ळयीयाच्मा अन्म बागाि ऩसयिे का ?
As can be seen from the output of GIZA++ ,
each word in hindi is assigned to some word
in Marathi. For eg. क्मा ({ 1 }) means
that the word क्मा is aligned to the first
word in Marathi and ददद ({ 2 }) means
the word ददद in the Hind sentence is
aligned to the 2nd word in the Marathi
sentence. If no equivalence is found, the
word is assigned null.
Out of the 10 hindi words, 7 words have
been aligned to some marathi word and the
rest 3 words are not aligned and are shown
as empty brackets. Out of the 7 words, the
correctly aligned words are 5. Four words
are given as one to one mapping, while the
word पैरिा ({ 6 7 }) is aligned to the
6th and 7th word of the marathi sentence,
hence is an example of one-to-many
mapping.
Result of alignment on GIZA ++ with
Marathi as source and Hindi as target
sentence
The experiment was repeated with Marathi
as the source sentence and Hindi as the
target sentence.
ही ({ 1 }) लेदना ({ 2 })
ळयीयाच्मा ({ 3 }) अन्म ({ 5 })
बागाि ({ 7 8 }) ऩसयिे ({ 6 })
का ({ 9 }) ? ({ 10 })
All the marathi words in the source sentence
has been aligned to some hindi word. There
is no null assignment in this case.
Sonal Khosla et al, Int.J.Computer Technology & Applications,Vol 6 (1),93-110
IJCTA | Jan-Feb 2015 Available [email protected]
107
ISSN:2229-6093

A summary of the statistics in Experiment
No. 1 and Experiment No. 2 is given in
Table 11.
Table 11. Summarize results of Experiment No. 1 and Experiment No. 2
ns = No. of sentences ls = length of sentence(no of words) Tw = Total words C=
Categories created by GIZA++
V=vocabulary (distinct words)
cp = correctly aligned pairs cw= common words nu = null assignments
p:q = Hindi:marathi (ratio) alignments H= Hindi, M= Marathi
Alignment Ratio
Set No L ns ls Tw C V cp cw nu 1:2 1:3 1:4 1:5 1:6
I H 24 16-28 435 100 224 112 92 169 35 7 1 0 0
M 24 9-20 328 100 242
II H 36 9-14 425 100 250 168 101 149 27 7 1 1 1
M 36 7-13 337 100 251
III H 30 1-8 181 100 150 56 52 41 2 1 0 0 0
M 30 3-6 146 100 132
All H 90 3-20 1041 100 488 465 121 358 64 14 5 1 0
M 90 3-20 811 100 526
All M 90 3-20 811 100 526 616 171 55 60 37 11 4 1
H 90 3-20 1041 100 488
6. CONCLUSIONS AND DISCUSSIONS
In this article an attempt has been made
to formalize the very concept of a bilingual
corpus with appropriate definitions in terms
of Information Technology, so that the
concepts are better understood by
a developer and hence would become better
implementable .
Since our focus is on Hindi and Marathi
bilingual e_corpus, a study of
similarities between the two languages has
been presented with a view of
extracting proper help in reducing the
complexity of the bilingual corpus. Various
hypothesis stated in Sec 3, should provide
help to a developer.
Results of a few experiments in tagging
and aligning are presented as evidences to
some of the observations made earlier,
which further strengthen our belief that a
corpus designer can exploit the similarities
to his advantage.
References
[1] Anonymous, Script Grammar for
Marathi language. Technical Report.
Technology development for
Indian languages Programme of DIT,
Govt. of India in association with
CDAC. Ver 1.4-2.
Sonal Khosla et al, Int.J.Computer Technology & Applications,Vol 6 (1),93-110
IJCTA | Jan-Feb 2015 Available [email protected]
108
ISSN:2229-6093

[2] Julie D. Allen. 2012. The Unicode
Standard / the Unicode Consortium—
Version 6.2. Technical Report. Published in
Mountain View, CA. ISBN 978-1- 936213-
07-8. September 2012.
[3] Akshar Bharati, Prakash Rao, Rajeev
Sangal and S.M.Bendre. 2002. Basic
Statistical analysis of corpus
and cross comparison among corpora.
In Proceedings of 2002 International
Conference on Natural Language
Processing, Mumbai, India. (2002).
[4] Akshar Bharati, Rajeev Sangal, Dipti
Mishra Sharma and Lakshmi Bai. 2006.
AnnCorra : Annotating Corpora
Guidelines For POS And Chunk
Annotation For Indian
Languages. Language
Technologies Research Centre,
Technical Report, IIIT, Hyderabad,
2006.
[5] Peri Bhaskararao. 2011. Salient Phonetic
features of Indian languages in speech
technology. Sadhana Vol .36, Part 5, pp.
587- 599. http:// dx.doi.org/
10.1007/ s12046-011-0039-z. (October
2011).
[6] Pushpak Bhattacharya, Debasri
Chakrabarti and Vaijayanthi M.Sarma. 2006.
Complex Predicates in Indian
language Wordnets. Language
Resources and Evaluation, Vol.
40. pp. 331-355. (2006).
[7] Sandeep Chaware and Srikantha Rao.
2011. Rule based phonetic matching
approach for Hindi and Marathi.
Computer Science and Engineering: An
International Journal(CSEIJ) , vol.1,
No.3. DOI : http:// 10.5121 /cseij
2011(August 2011).
[8] Niladri Sekhar Dash. 2008. Corpus
Linguistics: An Introduction. India: Pearson
Education-Longman Publishing
Co., pp. 208, ISBN: 81-317-1603- 1, 2008.
[9] M.L.Dhore, S.K.Dixit and R.M.Dhore.
2012a. Hindi and Marathi to English NE
Transliteration Tool using
Phonology and Stress Analysis.Proceedings
of 24th International Conference
on Computational Linguistics:
Demonstration Papers at IIT
Bombay, pages 111–118(2012).
[10] M.L.Dhore, S.K.Dixit and R.M.Dhore.
2012b. Issues in Hindi to English and
Marathi to English Machine
transliteration of Named Entities.
International Journal of Computer
Applications, Vol. 51, No.14
(August 2012).
[11] M.L.Dhore, R.M.Dhore and
P.H.Rathod. 2013. Transliteration by
Orthography or Phonology for Hindi and
Marathi to English: Case Study.
International Journal of Natural
Language Computing, Vol.2, No.5 (October
2013). DOI : 10.5121/ijnlc.2013.2501.
[12] A.Frankenberg-Garcia. 2009.
Compiling and Using a Parallel corpus for
research in translation.
International Journal of Translation,
vol.21(1), pp.57-71, (2009).
[13] Nisheeth Joshi, Hemant Darbari and Iti
Mathur. 2013. HMM Based POS tagger
for Indian languages. Jan Zizka
(Eds) : CCSIT, SIPP, AISC, PDCTA –
2013, pp.341–349, 2013. CS & IT-
CSCP 2013, DOI :
10.5121/csit.2013.3639(2013).
[14] Rujvi Kamat, Manisha Ghate, Tamar
H.Gollan, Rachel Meyer, Florin Vaida,
Robert K.Heaton, Scott Letendre,
Donald Franklin, Terry Alexander,
Igor Grant, Sanjay Mehendale and
Thomas D.Marcotte. 2012. Effects
of Marathi-Hindi bilingualism on
Sonal Khosla et al, Int.J.Computer Technology & Applications,Vol 6 (1),93-110
IJCTA | Jan-Feb 2015 Available [email protected]
109
ISSN:2229-6093

Neuropsychological performance.
Journal of International
Neuropsychological Society, Vol. 18,Issue
02, pp.305–313, March, 2012.
http://dx.doi.org/10.1017/S1355617
711001731.
[15] J. Ramanand, Akshay Ukey, Brahm
Kiran Singh and Pushpak Bhattacharyya.
2007. Mapping and
Structural analysis of Multilingual
Wordnets. Bulletin of the IEEE
Computer Society Technical
Committee on Data Engineering,
30(1). (March 2007).
[16] Shikar Kr. Sharma, Himadri Barali
, Ambeshwar Gogoi, Ratul Ch. Deka and
Anup Kr. Burman. 2012. A
structured approach for building
Assamese corpus: Insights
, Applications and Challenges. In
Proceedings of the 10th Workshop
on Asian Language Resources
, COLING 2012, pages 21-28.
[17] Anil Kumar Singh and Harshit Surana
. 2007a. Can corpus based measures be
used for comparative study o
f languages. In Proceedings of Ninth Meeting
of the ACL Special Interest Group in
Computational Morphology and
Phonology, pp 40–47, Prague. (June 2007).
[18] Anil Kumar Singh and Harshit Surana
. 2007b. Study of Cognates among South
Asian languages for the purpos
e of Building Lexical Resources. Journa
l of Language Technology. Dept. o
f IT, Govt. of India. 2007.
[19] Lichao Song. 2010. The role of context
in Discourse Analysis. Journal of
Language teaching and Research,
Vol. 1, No. 6, pp. 876-879. doi: 10.4304/
jltr.1.6.876-879( November 2010).
[20] Irene Thompson. 2014. About World
languages: Hindi. http://
aboutworldlanguages.com/ hindi.
(July 2014).
[21] Irene Thompson. 2014. About World
languages: Marathi. http://
aboutworldlanguages.com/ marathi.
(December 2014).
[22] Hans Uszkoreit. 2000. What is
Computational Linguistics. http:// coli.uni-
saarland.de/~hansu/what_is_cl.html
[23] Christopher C. Yang and Kar Wing Li.
2003. Automatic construction of
English/Chinese parallel corpora.
Journal of the American Society for
Information Science and
Technology. Vol. 54, Issue 8 , p.p 730-
742. http:// dx.doi.org/ 10.1002/
asi.10261 (June 2003).
[24] Johann Gamper and Paolo Dongilli,
―Primary data encoding of a bilingual
corpus‖, In Proceedings of the 11th Annual
Meeting of the GLDV, Frankfurt a/M,
Germany, July, 1999.
Sonal Khosla et al, Int.J.Computer Technology & Applications,Vol 6 (1),93-110
IJCTA | Jan-Feb 2015 Available [email protected]
110
ISSN:2229-6093





























