Embed Size (px)
Citation preview

Information Retrieval
Domenico Strigari
Dominik Wißkirchen
2009-12-22

Definition
“Information retrieval (IR) is finding material (usually documents) of an unstructured nature (usually text) that satisfies an information need from within large collections (usually stored on computers).”
Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze, Introduction to Information Retrieval, Cambridge University Press. 2008.

Anfänge des Information Retrievals
• durch die Anordnung von Büchern nach bestimmten Kriterien kann eine Relevanz des Buchmaterials dargestellt werden
folglich ein hoher manueller Aufwand
oft keine eindeutige Zuordnung zu einem Thema
• Schlagwortkataloge sollen die Standorte der Bücher klären (Thesauri)

Thesauri
• „Als Thesaurus bezeichnet man ein Modell, das versucht, ein Themengebiet genau zu beschreiben und zu repräsentieren. Es besteht aus einer systematisch geordneten Sammlung von Begriffen, die in thematischer Beziehung zueinander stehen. …“ (Wikipedia)
• Bsp.: Sofa, Tisch, Schrank (Oberbegriff: Mobiliar)

In welchem Datenbestand sucht ein IR-System?
• Im Gegensatz zu einer Büchersammlung bzw. einer selbst angelegten Datensammlung sucht ein IR-System in einem Datenbestand der,…
viel heterogener ist
unterschiedlichste Qualitäten besitzt
verschiedenste Formate aufweist

Einsatzgebiete & Beispiele
• Internetsuchmaschinen (Google, Google Web Alerts, Yahoo u.v.m.)
• Literatursuche / Bibliotheken
• Spamfilter
• Mailsuche
• MacOS X Spotlight
• Windows Instant Search
• Suche nach Quelltexten bspw. über Koders
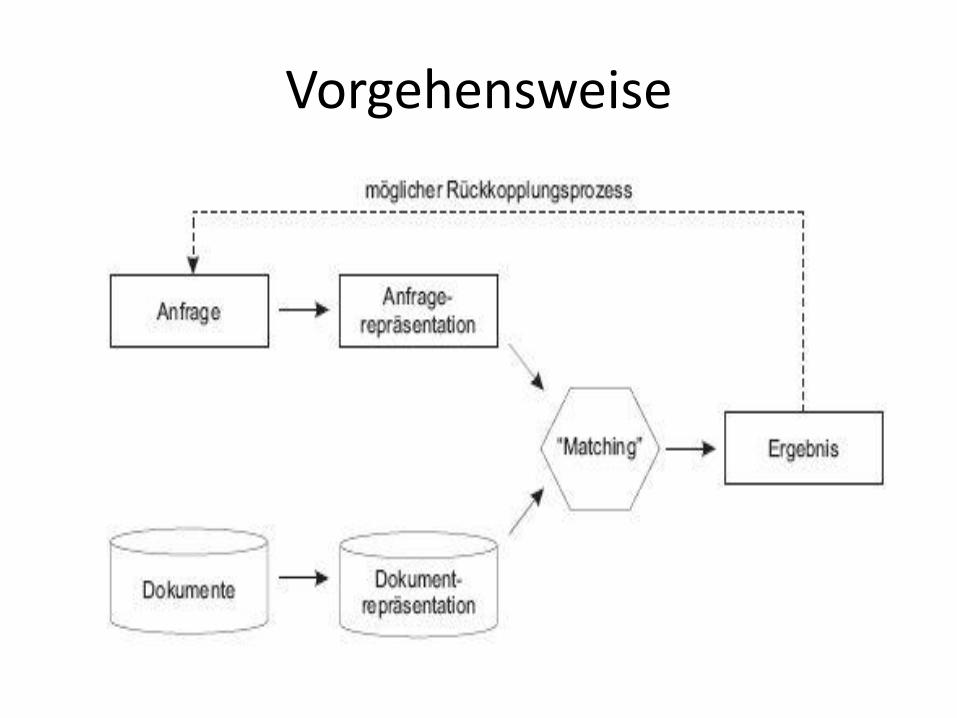
Vorgehensweise
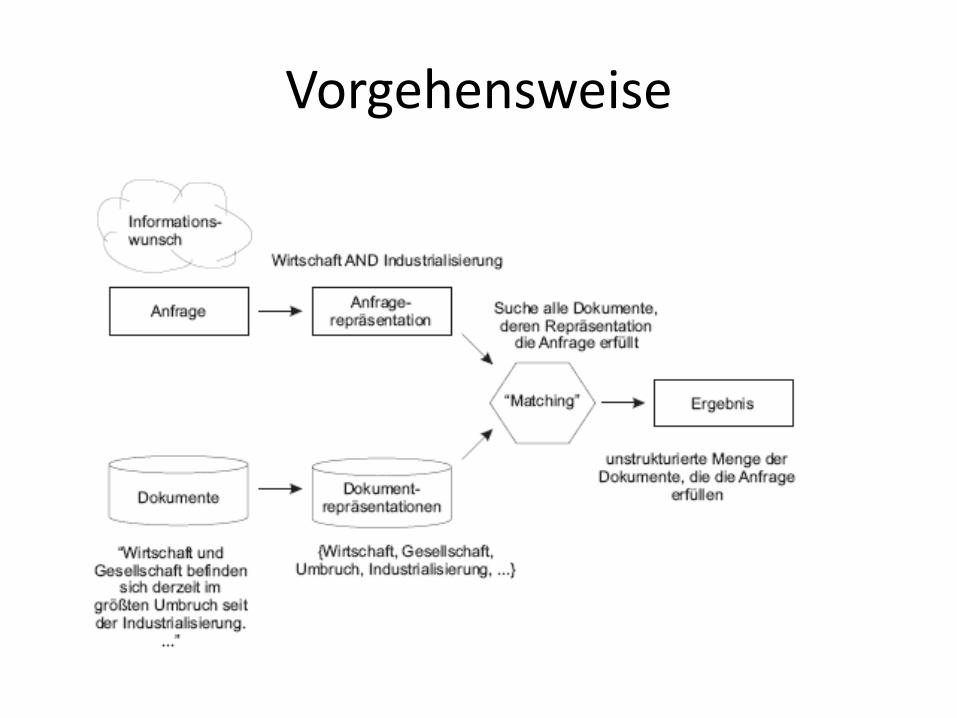
Vorgehensweise

Vorgehensweise
1. Eine Anfrage die den Informationswunsch repräsentiert
2. Ein mögliches Matching erzeugt ein Ergebnis
3. Relevance Feedback sorgt nun für eine manuelle Gewichtung der Ergebnisse
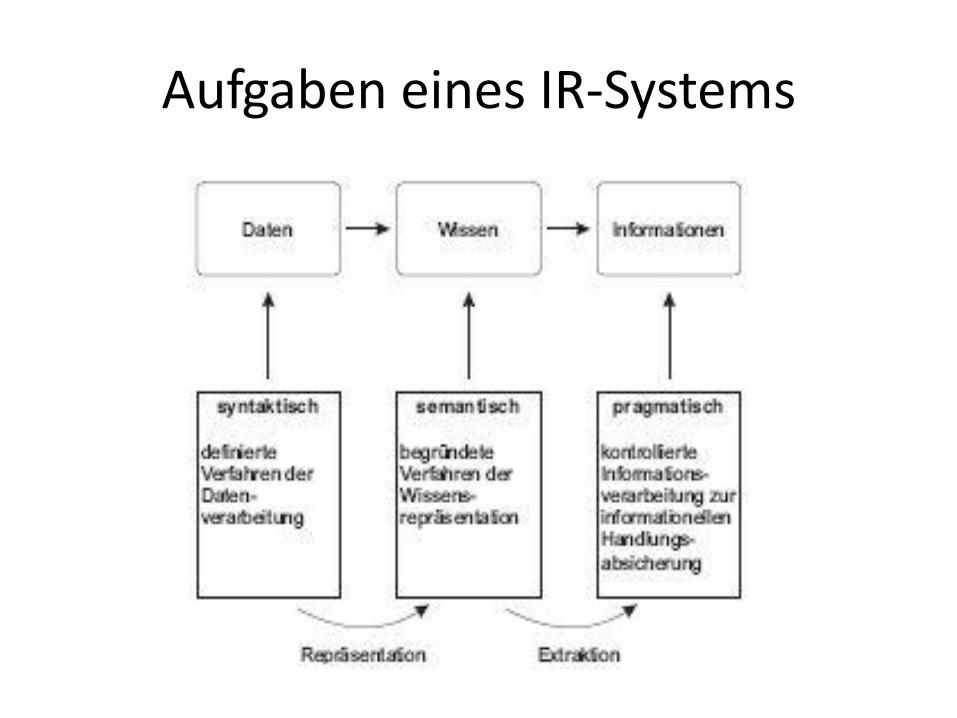
Aufgaben eines IR-Systems

Repräsentation und Extraktion
• Der Übergang von Daten zu Wissen wird Repräsentation genannt
• Der Übergang von Wissen zu Information wird Extraktion genannt

Repräsentation und Extraktion
• Bsp.: DSC002.jpg
keine Semantik
Repräsentation bspw. durch: „Konzert von ACDC“
Texte besser repräsentierbar als Bilder, aber ebenfalls vage
Extraktion bezieht das gewünschte Wissen aus dem gespeicherten Wissen

Fakten Retrieval vs. Information Retrieval
• IR nicht zu verwechseln mit „klassischer“ Suche in relationalen Datenbanken (strukturierte Daten)
• Fakten Retrieval erzeugt ein Exact Match
• IR erzeugt hingegen ein Partial Match oder ein Best Match
• SQL (klassische Suche) sorgt jedoch bspw. durch „order by“ für ein Partial Match

Fakten Retrieval vs. Information Retrieval
• Beim IR haben die Dokumente unterschiedliche Informationen (polythetisch), wobei sich FR monothetisch verhält
• Das Information Retrieval ist induktiv, weil es vom Informationswunsch auf eine Vielzahl von ähnliche Dokumenten schließt , beim FR findet eine Herleitung des Besonderem aus dem Allgemeinen statt (deduktiv).

Partial Match Beispiel
• Seien die gesuchten Begriffe:
Katzen, Hunde, Maus
nach Eingabe in einer Suchmaschine ergeben sich zwar keine Exact Matches aber es kann ein Ranking erstellt werden
Die Dokumente mit häufigem Vorkommen der Begriffe werden als erstes gelistet und die anderen später (Relevanz)

Wichtige Begriffe
• Wort, Stoppwort, Term, Token, Type
• Tokenisierung
• Normalisierung
– Stemming
– Lemmatisierung
– Kanonisation
• Query Expansion

Begriffe: Einheiten
• Wort: Zeichensequenz/ein String
• Stoppwort: häufig auftretende Wörter mit geringer semantischer Relevanz
Stoppwortlisten
• Term: Normalisiertes Wort
• Token: Instanz eines Terms
• Type: Klasse von Token/Termen

Tokenisierung
• Zerlegung von Text in geeignete Einheiten (Token)
– Bsp: Computerlinguistik im Wintersemester 2009/2010
• Computerlinguistik
• im
• Wintersemester
• 2009
• 2010

Tokenisierung - Problemfälle
Mehrwortlexeme: Computerlinguistik 1 oder 2 Token?
Eigennamen: Paul-Dieter
Währungsangaben: $2.50, 2,50€
Datumsangaben: 24.12.2009, 24. Dez. 2009
...

Normalisierung: Stemming
• Prozess der Stammfindung
• Probleme:
– Ungenau, „schwammig“
– Bsp-Stamm: oper
• operational research
• operating system
• operative dentistry
• Besser: Lemmatisierung

Normalisierung: Lemmatisierung
• Prozess der Grundformbestimmung
• Morphologisches Wissen wird zur Findung des Lemmas genutzt
• Reduktion der flektierten Wörter auf die Grundform (Lemma)

Normalisierung: Kanonisation
• Bildung von Äquivalenzklassen
– Computer-Linguistik
– Computerlinguistik
– USA
– U.S.A.
• Mapping auf nur einen Term

Query Expansion
• Erweiterung der Anfrage um Synonyme
– Auto
– PKW, Automobil, Kraftwagen
• Problemfälle
– windows
• Windows
– window
• windows, aber nicht Windows

Retrievalmodelle
• Mengentheoretische Modelle– Boolean Retrieval Model
– …
• Algebraische Modelle– Vector Space Retrieval Model
– …
• Wahrscheinlichkeitsmodelle– Binary Independence Model
– …

Boolean Retrieval Beispiel
• Ausgangslage:
– Textkorpus: Shakespeare Werke
• Gesucht:
– Alle Werke, die die Begriffe ‚Brutus‘, ‚Caesar‘ aber nicht ‚Calpurnia‘ beinhalten
• Naiver Ansatz:
– „Grepping“ (=Volltextsuche mit regulären Audrücken)

Boolean Retrieval Beispiel
Ebd., S. 4

Vor-/Nachteile Boolean Retrieval
+ ermöglicht AND, OR, NOT Abfragen
+ Schneller als „Grepping“
- Keine Berücksichtigung
- der Nähe (proximity)
- der Häufigkeit (frequency)
- der Reihenfolge (order)
- Keine Gewichtung von Termen möglich
Kein Ranking der Ergebnisse
- Keine Berücksichtigung von Tippfehlern

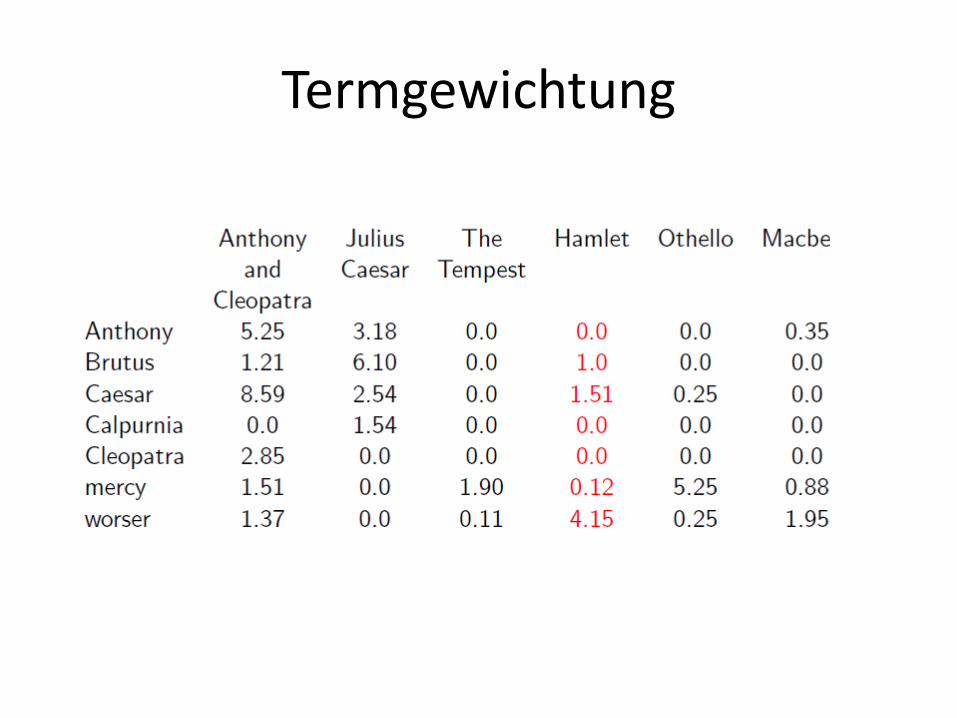
Termgewichtung
Grundgedanke:
• Bewertung von Term/Dokument-Paaren durch einen Score‚ der die Relevanz des Terms für das Dokument wiedergibt
• Ansätze
– Weighted Zone Scoring
– Termfrequenz

Termgewichtung
• Termfrequenz (tft,d):
– Häugkeit eines Term t innerhalb eines Dokuments d
• Berechnung des Scores für ein Anfrage/Dokument-Paar:
Score(q; d) =
• Problem:
– kein direkter Zusammenhang Häufigkeit/Relevanz (insbesondere bei langen Dokumenten)
qt
dttf ,
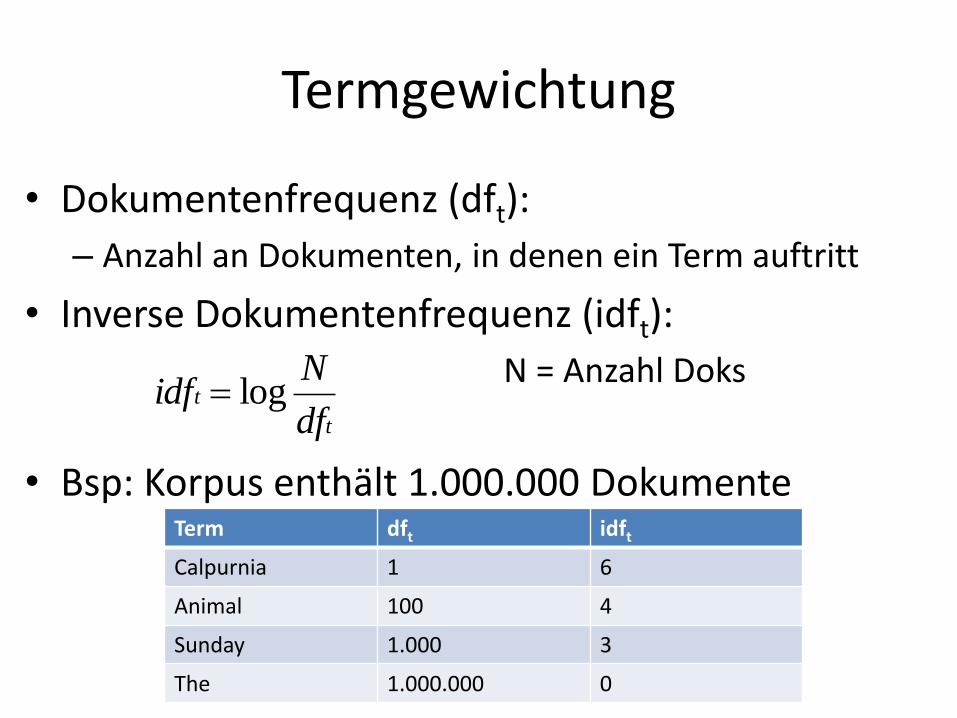
Termgewichtung
• Dokumentenfrequenz (dft):
– Anzahl an Dokumenten, in denen ein Term auftritt
• Inverse Dokumentenfrequenz (idft):
N = Anzahl Doks
• Bsp: Korpus enthält 1.000.000 Dokumente
t
t
df
Nidf log
Term dft idft
Calpurnia 1 6
Animal 100 4
Sunday 1.000 3
The 1.000.000 0

Termgewichtung
• Termgewichtung (tf-idft,d)
– Beschreibt die Gewichtung eines Terms innerhalb eines Dokuments (bezogen auf einen geg. Korpus)
tdtddt idftftf-idf ,
Term tft idft tf-idft,d
Calpurnia 7 6 42
Animal 10 4 40
Sunday 12 3 36
The 964 0 0
Termgewichtung

Quellen
• Andreas Henrich, Information Retrieval 1
Grundlagen, Modelle und Anwendungen
Version: 1.2 (Rev: 5727, Stand: 7. Januar 2008)
Otto-Friedrich-Universität Bamberg
Lehrstuhl für Medieninformatik, 2001 – 2008
• Christopher D. Manning, Prabhakar Raghavan, Hinrich Schütze, An Introduction to Information Retrieval, Cambridge University Press, Cambridge, England, 2009
• Online Unterlagen des Information-Retrieval Kurses im WS2009 der Uni Köln von Claes Neuefeind und Fabian Steeg: http://www.spinfo.phil-fak.uni-koeln.de/spinfo-informationretrieval.html





























