Embed Size (px)
Citation preview

Information Extraction
Yunyao Li
EECS /SI 76703/29/2006

The ProblemDate
Time: Start - End
Speaker
Person
Location

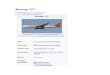
What is “Information Extraction”Filling slots in a database from sub-segments of text.As a task:
October 14, 2002, 4:00 a.m. PT
For years, Microsoft Corporation CEO Bill Gates railed against the economic philosophy of open-source software with Orwellian fervor, denouncing its communal licensing as a "cancer" that stifled technological innovation.
Today, Microsoft claims to "love" the open-source concept, by which software code is made public to encourage improvement and development by outside programmers. Gates himself says Microsoft will gladly disclose its crown jewels--the coveted code behind the Windows operating system--to select customers.
"We can be open source. We love the concept of shared source," said Bill Veghte, a Microsoft VP. "That's a super-important shift for us in terms of code access.“
Richard Stallman, founder of the Free Software Foundation, countered saying…
NAME TITLE ORGANIZATION
Courtesy of William W. Cohen

What is “Information Extraction”Filling slots in a database from sub-segments of text.As a task:
Courtesy of William W. Cohen
October 14, 2002, 4:00 a.m. PT
For years, Microsoft Corporation CEO Bill Gates railed against the economic philosophy of open-source software with Orwellian fervor, denouncing its communal licensing as a "cancer" that stifled technological innovation.
Today, Microsoft claims to "love" the open-source concept, by which software code is made public to encourage improvement and development by outside programmers. Gates himself says Microsoft will gladly disclose its crown jewels--the coveted code behind the Windows operating system--to select customers.
"We can be open source. We love the concept of shared source," said Bill Veghte, a Microsoft VP. "That's a super-important shift for us in terms of code access.“
Richard Stallman, founder of the Free Software Foundation, countered saying…
NAME TITLE ORGANIZATIONBill Gates CEO MicrosoftBill Veghte VP MicrosoftRichard Stallman founder Free Soft..
IE
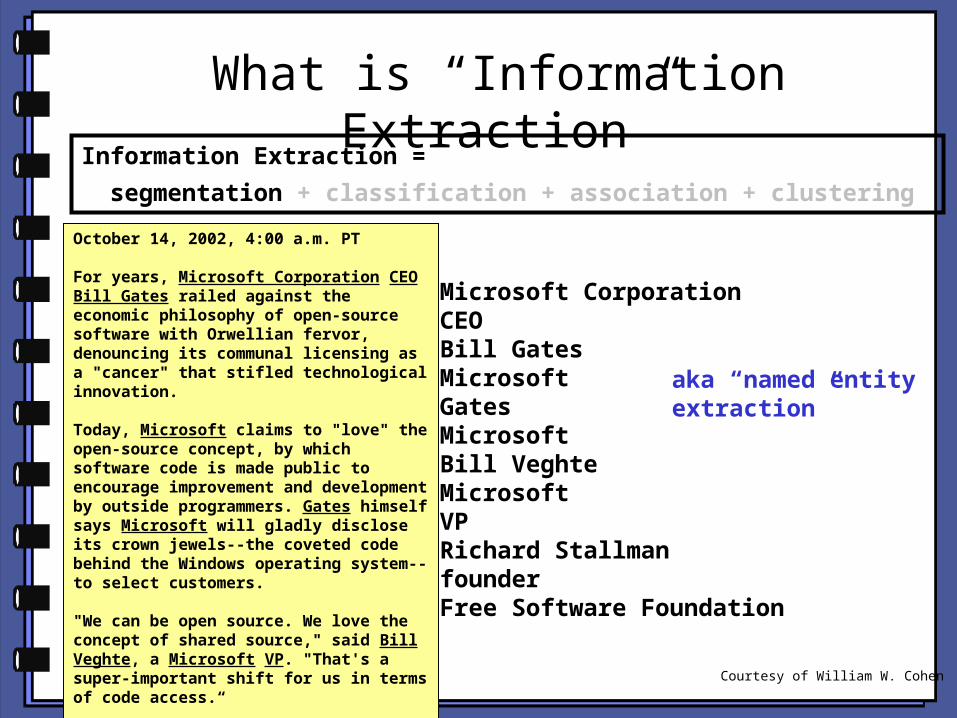
What is “Information Extraction”
Courtesy of William W. Cohen
Information Extraction =
segmentation + classification + association + clustering October 14, 2002, 4:00 a.m. PT
For years, Microsoft Corporation CEO Bill Gates railed against the economic philosophy of open-source software with Orwellian fervor, denouncing its communal licensing as a "cancer" that stifled technological innovation.
Today, Microsoft claims to "love" the open-source concept, by which software code is made public to encourage improvement and development by outside programmers. Gates himself says Microsoft will gladly disclose its crown jewels--the coveted code behind the Windows operating system--to select customers.
"We can be open source. We love the concept of shared source," said Bill Veghte, a Microsoft VP. "That's a super-important shift for us in terms of code access.“
Richard Stallman, founder of the Free Software Foundation, countered saying…
Microsoft CorporationCEOBill GatesMicrosoftGatesMicrosoftBill VeghteMicrosoftVPRichard StallmanfounderFree Software Foundation
aka “named entity extraction”
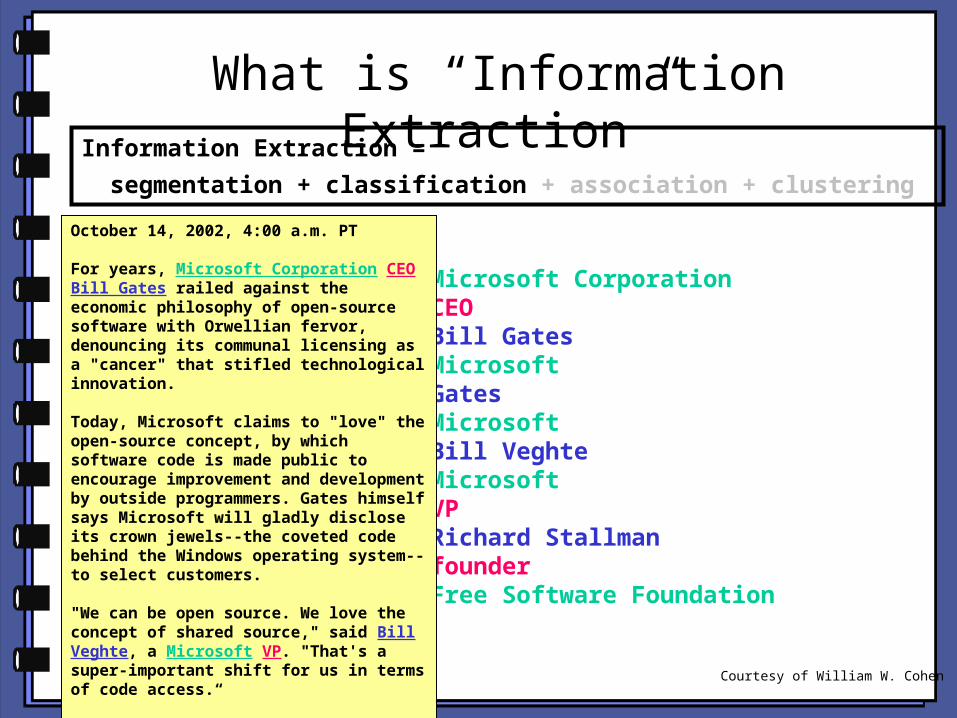
What is “Information Extraction”
Courtesy of William W. Cohen
Microsoft CorporationCEOBill GatesMicrosoftGatesMicrosoftBill VeghteMicrosoftVPRichard StallmanfounderFree Software Foundation
October 14, 2002, 4:00 a.m. PT
For years, Microsoft Corporation CEO Bill Gates railed against the economic philosophy of open-source software with Orwellian fervor, denouncing its communal licensing as a "cancer" that stifled technological innovation.
Today, Microsoft claims to "love" the open-source concept, by which software code is made public to encourage improvement and development by outside programmers. Gates himself says Microsoft will gladly disclose its crown jewels--the coveted code behind the Windows operating system--to select customers.
"We can be open source. We love the concept of shared source," said Bill Veghte, a Microsoft VP. "That's a super-important shift for us in terms of code access.“
Richard Stallman, founder of the Free Software Foundation, countered saying…
Information Extraction =
segmentation + classification + association + clustering
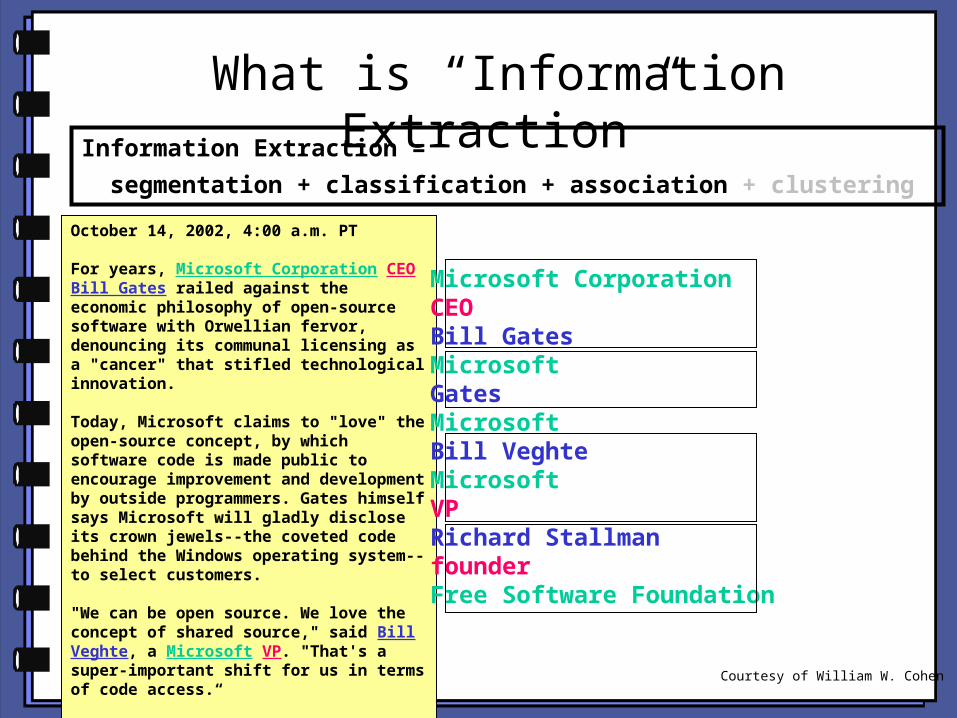
What is “Information Extraction”
Courtesy of William W. Cohen
October 14, 2002, 4:00 a.m. PT
For years, Microsoft Corporation CEO Bill Gates railed against the economic philosophy of open-source software with Orwellian fervor, denouncing its communal licensing as a "cancer" that stifled technological innovation.
Today, Microsoft claims to "love" the open-source concept, by which software code is made public to encourage improvement and development by outside programmers. Gates himself says Microsoft will gladly disclose its crown jewels--the coveted code behind the Windows operating system--to select customers.
"We can be open source. We love the concept of shared source," said Bill Veghte, a Microsoft VP. "That's a super-important shift for us in terms of code access.“
Richard Stallman, founder of the Free Software Foundation, countered saying…
Microsoft CorporationCEOBill GatesMicrosoftGatesMicrosoftBill VeghteMicrosoftVPRichard StallmanfounderFree Software Foundation
Information Extraction =
segmentation + classification + association + clustering

What is “Information Extraction”
Courtesy of William W. Cohen
October 14, 2002, 4:00 a.m. PT
For years, Microsoft Corporation CEO Bill Gates railed against the economic philosophy of open-source software with Orwellian fervor, denouncing its communal licensing as a "cancer" that stifled technological innovation.
Today, Microsoft claims to "love" the open-source concept, by which software code is made public to encourage improvement and development by outside programmers. Gates himself says Microsoft will gladly disclose its crown jewels--the coveted code behind the Windows operating system--to select customers.
"We can be open source. We love the concept of shared source," said Bill Veghte, a Microsoft VP. "That's a super-important shift for us in terms of code access.“
Richard Stallman, founder of the Free Software Foundation, countered saying…
Information Extraction =
segmentation + classification + association + clustering
Microsoft CorporationCEOBill GatesMicrosoftGatesMicrosoftBill VeghteMicrosoftVPRichard StallmanfounderFree Software Foundation N
AME
TITLE ORGANIZATION
Bill Gates
CEO
Microsoft
Bill Veghte
VP
Microsoft
Richard Stallman
founder
Free Soft..
*
*
*
*
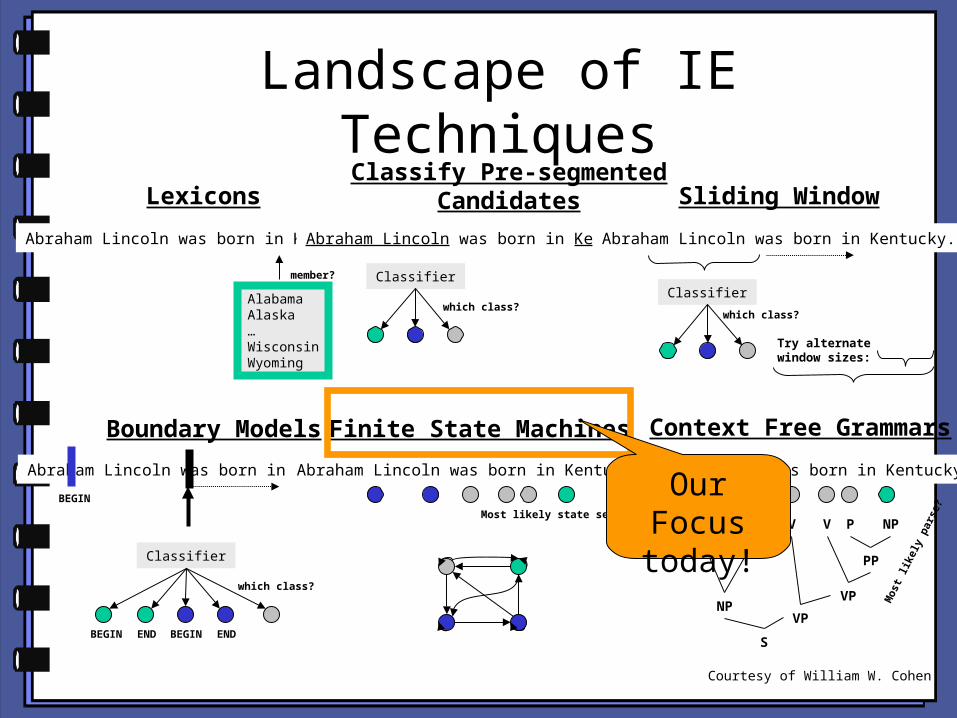
Landscape of IE Techniques
Courtesy of William W. Cohen
Lexicons
AlabamaAlaska…WisconsinWyoming
Abraham Lincoln was born in Kentucky.
member?
Classify Pre-segmentedCandidates
Abraham Lincoln was born in Kentucky.
Classifier
which class?
Sliding Window
Abraham Lincoln was born in Kentucky.
Classifier
which class?
Try alternatewindow sizes:
Boundary Models
Abraham Lincoln was born in Kentucky.
Classifier
which class?
BEGIN END BEGIN END
BEGIN
Context Free Grammars
Abraham Lincoln was born in Kentucky.
NNP V P NPVNNP
NP
PP
VP
VP
S
Mos
t lik
ely
pars
e?
Finite State Machines
Abraham Lincoln was born in Kentucky.
Most likely state sequence?
Our Focus today!
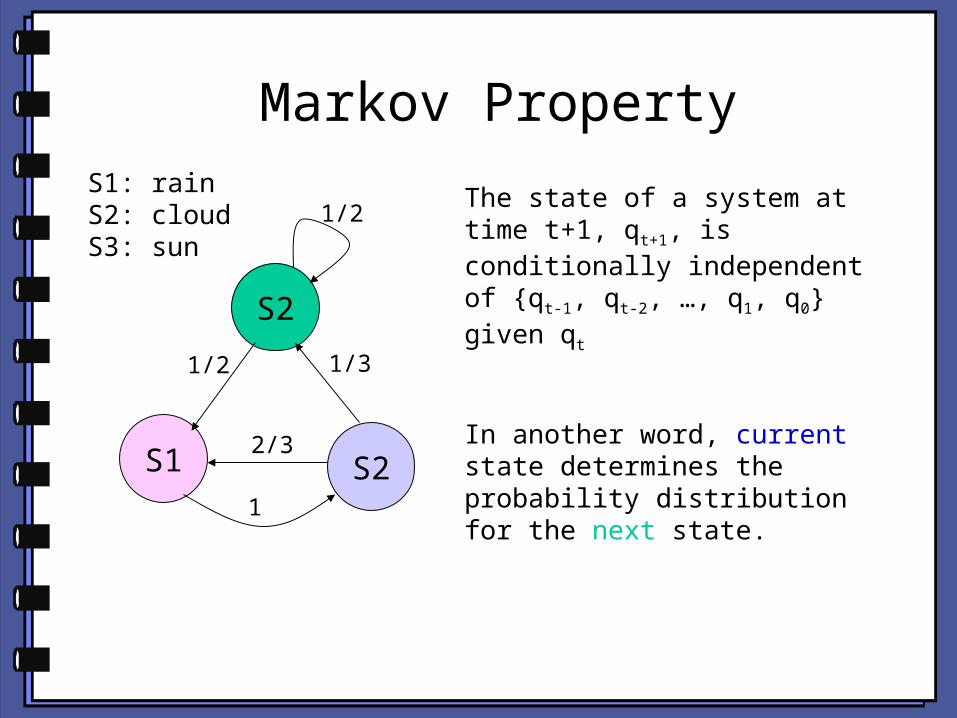
Markov Property
S2
S2S1
1/2
1/2 1/3
2/3
1
The state of a system at time t+1, qt+1, is conditionally independent of {qt-1, qt-2, …, q1, q0} given qt
In another word, current state determines the probability distribution for the next state.
S1: rainS2: cloudS3: sun
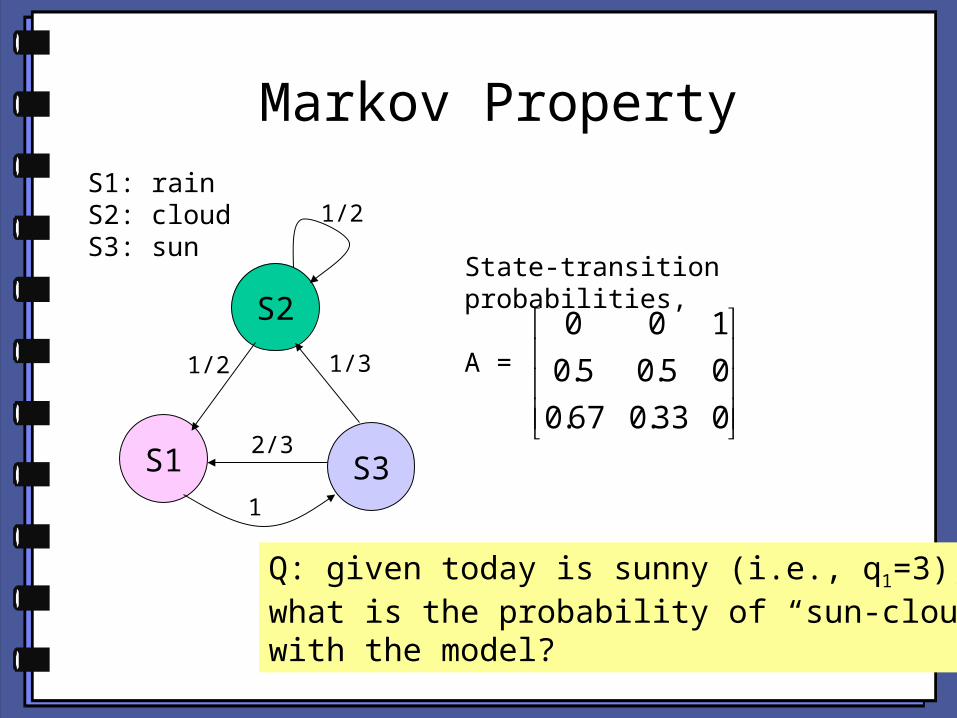
Markov Property
S2
S3S1
1/2
1/2 1/3
2/3
1
State-transition probabilities,
A =
S1: rainS2: cloudS3: sun
033.067.0
05.05.0
100
Q: given today is sunny (i.e., q1=3),what is the probability of “sun-cloud”with the model?
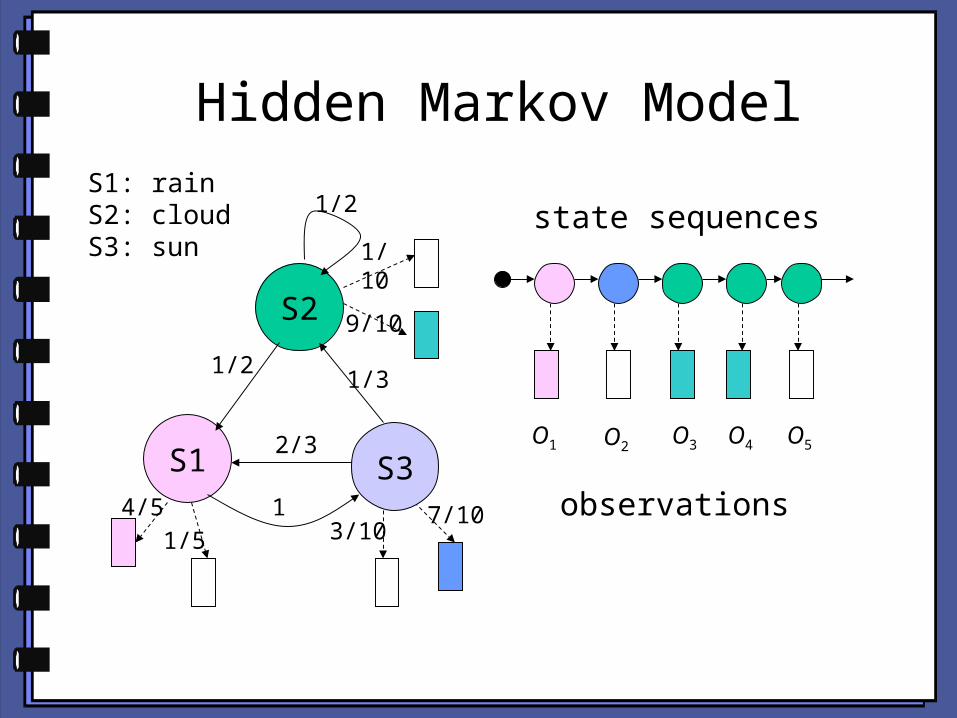
Hidden Markov ModelS1: rainS2: cloudS3: sun
S2
S3S1
1/2
1/21/3
2/3
14/5
1/10
7/101/5 3/10
9/10
observations
O1 O2 O3 O4 O5
state sequences

IE with Hidden Markov Model
SI/EECS 767 is held weekly at SIN2 .
SI/EECS 767 is held weekly at SIN2
Course name: SI/EECS 767
Given a sequence of observations:
and a trained HMM:
Find the most likely state sequence: (Viterbi)
Any words said to be generated by the designated “course name”state extract as a course name:
),(maxarg osPs
course name
location name
background
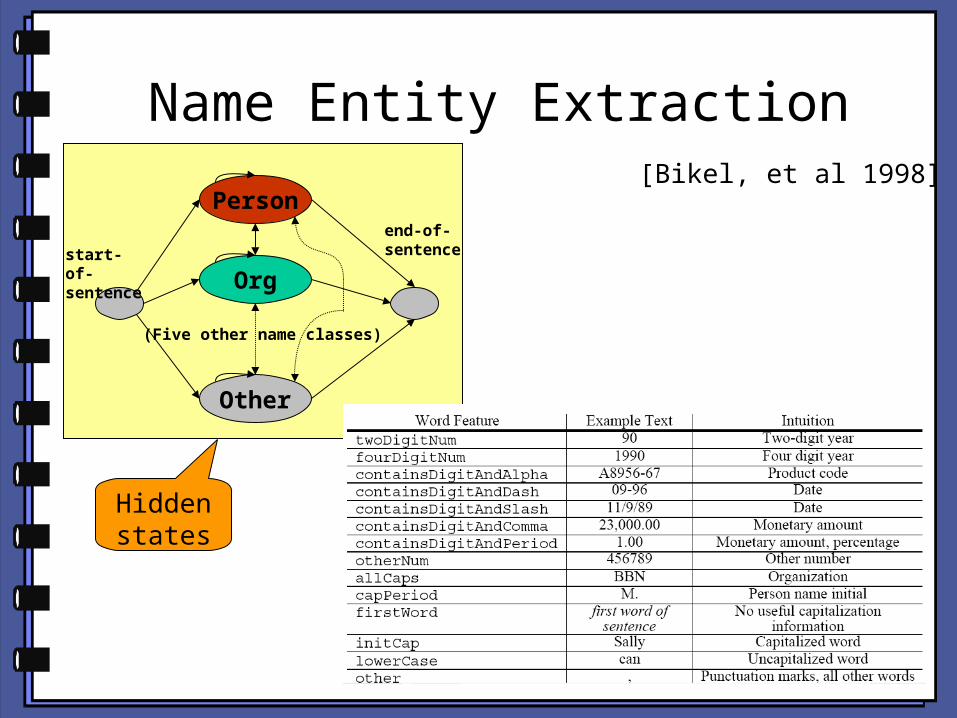
Name Entity Extraction[Bikel, et al 1998]
Person
Org
Other
(Five other name classes)
start-of-sentence
end-of-sentence
Hidden states

Name Entity Extraction
Transitionprobabilities
Observationprobabilities
P(st | st-1, ot-1 ) P(ot | st , st-1 )
P(ot | st , ot-1 )or
(1) Generating first word of a name-class
(2) Generating the rest of words in the name-class
(3) Generating “+end+” in a name-class

Training: Estimating Probabilities

Back-Off“unknown words” and insufficient training data
P(st | st-1 )
P(st )
P(ot | st )
P(ot )
Transitionprobabilities
Observationprobabilities
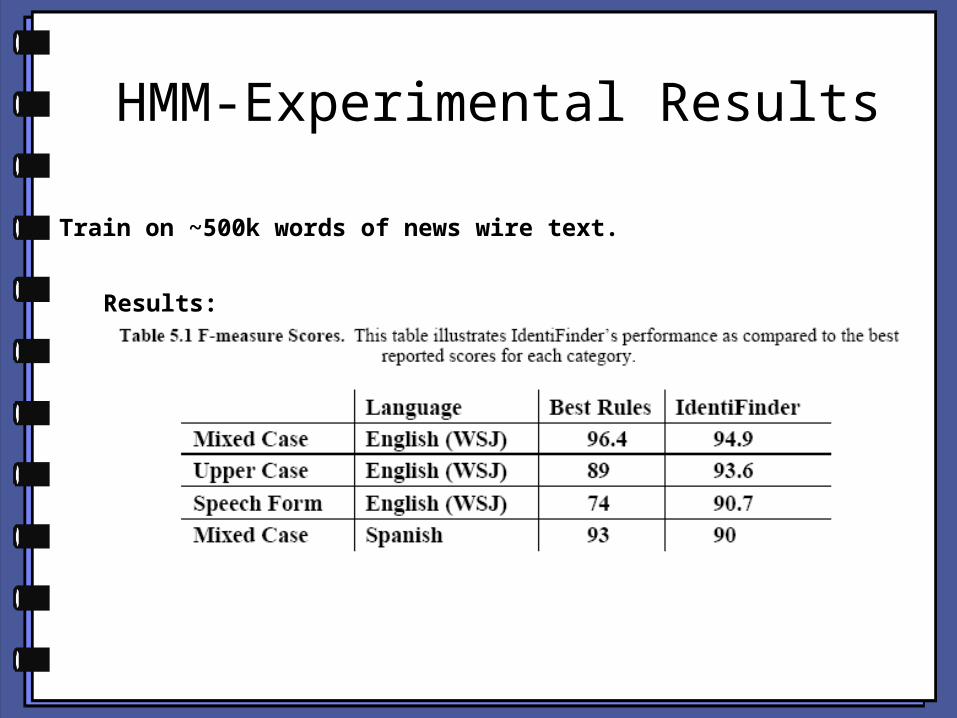
HMM-Experimental Results
Train on ~500k words of news wire text.
Results:
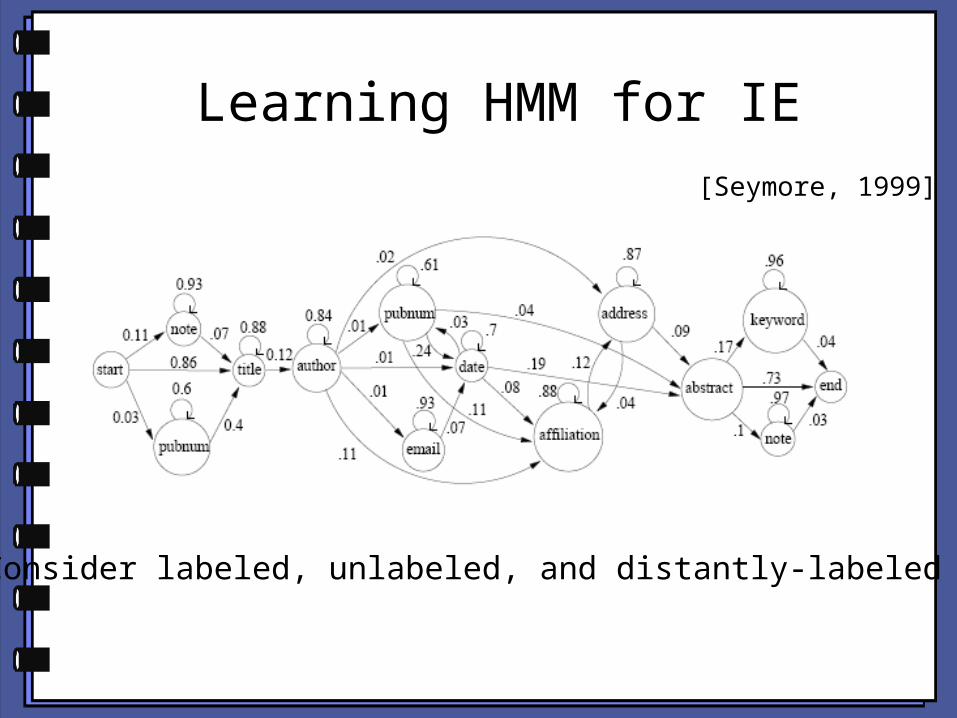
Learning HMM for IE[Seymore, 1999]
Consider labeled, unlabeled, and distantly-labeled data

Some Issues with HMM
• Need to enumerate all possible observation sequences
• Not practical to represent multiple interacting features or long-range dependencies of the observations
• Very strict independence assumptions on the observations
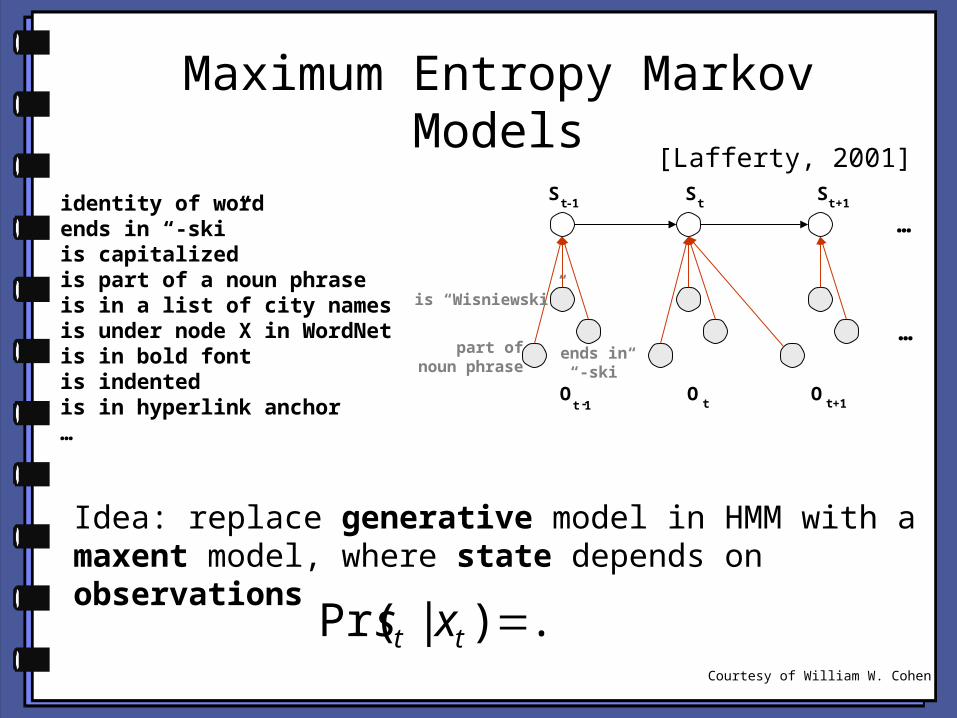
Maximum Entropy Markov Models
St -1
St
Ot
St+1
Ot +1
Ot -1
identity of wordends in “-ski”is capitalizedis part of a noun phraseis in a list of city namesis under node X in WordNetis in bold fontis indentedis in hyperlink anchor…
…
…part of
noun phrase
is “Wisniewski”
ends in “-ski”
Idea: replace generative model in HMM with a maxent model, where state depends on observations
...)|Pr( tt xsCourtesy of William W. Cohen
[Lafferty, 2001]
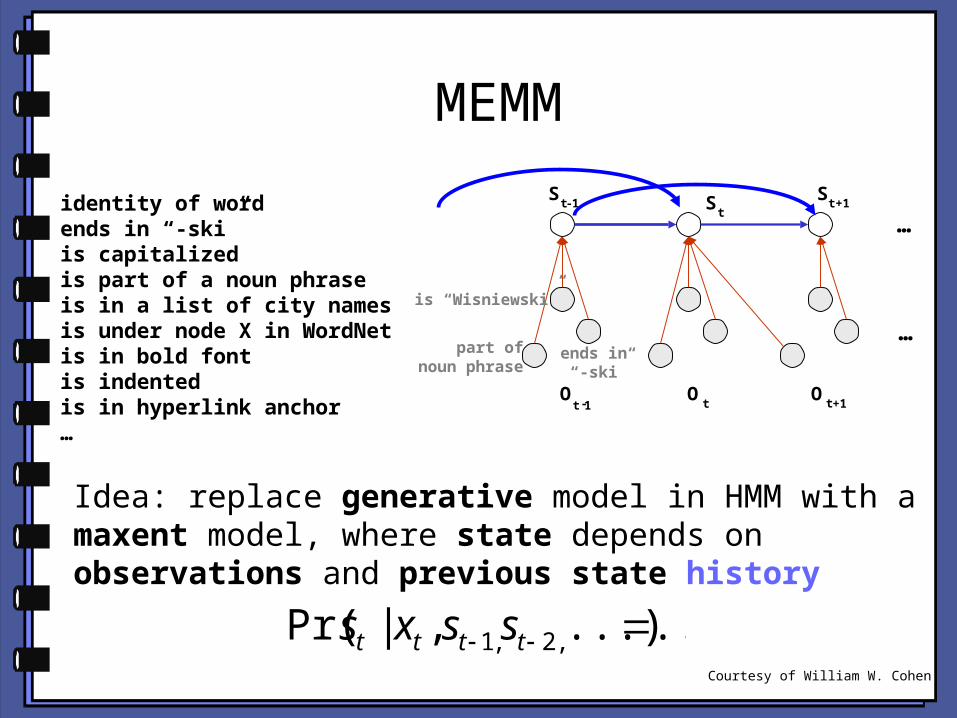
MEMM
St -1 S
t
Ot
St+1
Ot +1
Ot -1
identity of wordends in “-ski”is capitalizedis part of a noun phraseis in a list of city namesis under node X in WordNetis in bold fontis indentedis in hyperlink anchor…
…
…part of
noun phrase
is “Wisniewski”
ends in “-ski”
Idea: replace generative model in HMM with a maxent model, where state depends on observations and previous state history
......),|Pr( ,2,1 tttt ssxsCourtesy of William W. Cohen
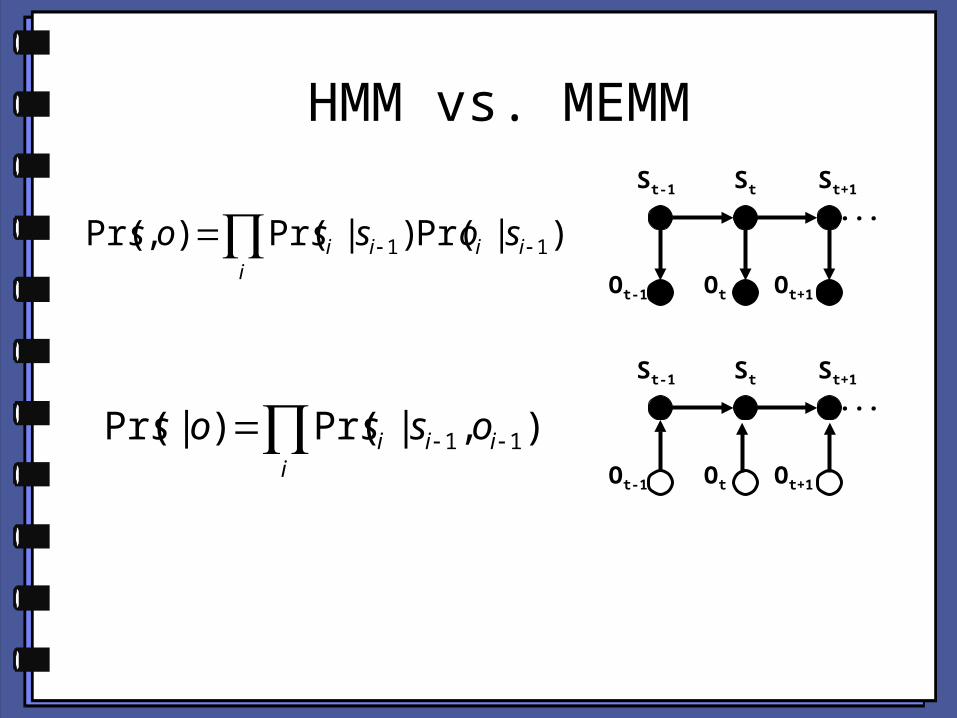
HMM vs. MEMMSt-1 St
Ot
St+1
Ot+1Ot-1
...
i
iiii sossos )|Pr()|Pr(),Pr( 11
St-1 St
Ot
St+1
Ot+1Ot-1
...
i
iii ossos ),|Pr()|Pr( 11

Label Bias Problem with MEMM
Consider this MEMM
Pr(12|ro) = Pr(2|1,ro)Pr(1,ro) = Pr(2| 1,o)Pr(1,r)
Pr(2|1,o) = Pr(2|1,r) = 1
Pr(12|ri) = Pr(2|1,ri)Pr(1,ri) = Pr(2| 1,i)Pr(1,r)
Pr(12|ro) = Pr(12|ri)
But it should be Pr(12|ro) < Pr(12|ri)!

Solve the Label Bias Problem
• Change the state-transition structure of the model
– Not always practical to change the set of states
• Start with a fully-connected model and let the training procedure figure out a good structure– Prelude the use of prior, which is very valuable (e.g.
in information extraction)
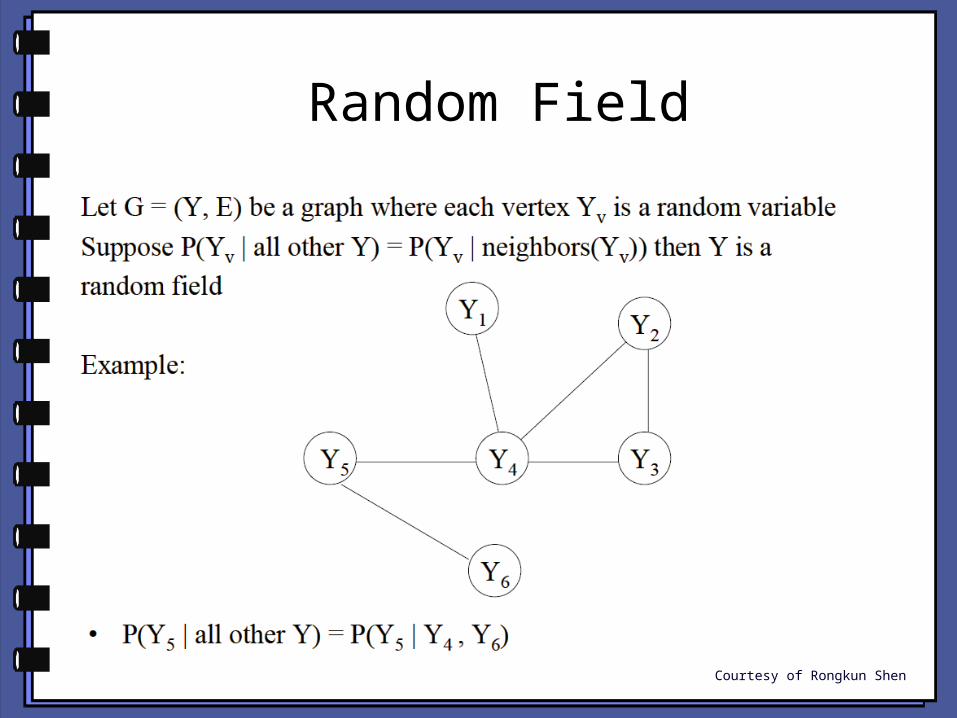
Random Field
Courtesy of Rongkun Shen

Conditional Random Field
Courtesy of Rongkun Shen

Conditional Distribution
1 2 1 2( , , , ; , , , ); andn n k k
x is a data sequencey is a label sequence v is a vertex from vertex set V = set of label random variablese is an edge from edge set E over Vfk and gk are given and fixed. gk is a Boolean vertex feature; fk
is a Boolean edge featurek is the number of features
are parameters to be estimated
y|e is the set of components of y defined by edge ey|v is the set of components of y defined by vertex v
If the graph G = (V, E) of Y is a tree, the conditional distribution over the label sequence Y = y, given X = x, by fundamental theorem of random fields is:
(y | x) exp ( , y | , x) ( , y | , x)
k k e k k v
e E,k v V ,k
p f e g v

Conditional Distribution
• CRFs use the observation-dependent normalization Z(x) for the conditional distributions:
Z(x) is a normalization over the data sequence x
(y | x) exp ( , y | , x) ( , y |1
(x), x)
k k e k k v
e E,k v V ,k
p f e g vZ
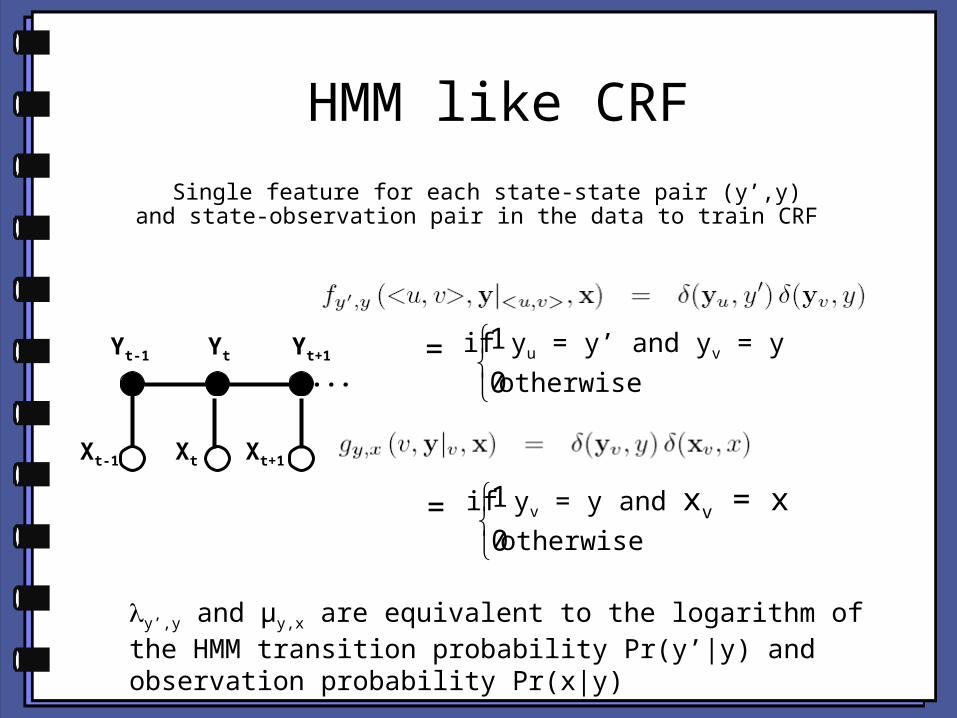
HMM like CRF
Single feature for each state-state pair (y’,y) and state-observation pair in the data to train CRF
Yt-1 Yt
Xt
Yt+1
Xt+1Xt-1
...=
0
1 if yu = y’ and yv = y
otherwise
= 0
1 if yv = y and xv = xotherwise
y’,y and µy,x are equivalent to the logarithm of the HMM transition probability Pr(y’|y) and observation probability Pr(x|y)

HMM like CRF
For a chain structure, the conditional probability of a label sequence can be expressed in matrix form.
For each position i in the observed sequence x, define matrix
Where ei is the edge with label (yi-1, yi) and vi is the vertex with label yi

HMM like CRF
The normalization function is the (start, stop) entry of the productof these matrices
The conditional probability of label sequence y is:
where, y0 = start and yn+1 = stop

Parameter EstimationThe problem: determine the parameters From training data with empirical distribution
The goal: maximize the log-likelihood objective function

Parameter Estimation – Iterative Scaling Algorithms
Update the weights as and for Appropriately chosen
for edge feature fk is the solution of
T(x, y) is a global property of (x,y) and efficiently computing the Right-hand sides of the above equation is a problem

Algorithm S
Define slack feature:
For each index i = 0, …, n+1 we define forward vectors
And backward vectors
p y y( ' , )

Algorithm S
=
= p x p y y x f e y xx n
n
k i e y yy y
i
( ) ( ' , , ) ( , | , )( ', )'1
p y y xy x M y y x y x
Z xi i i( ' , , )
( ' | ) ( ' , | ) ( | )
( ) 1
=

Algorithm S
The rate of convergence is governed by step size which is Inversely proportional to constant S, but S is generally quite large, resulting in slow convergence.

Algorithm TKeeps track of partial T total. It accumulates feature expectations into counters indexed by T(x)
Use forward-back ward recurrences to compute the expectationak,t of feature fk and bk,t of feature gk given that T(x) = t

Experiments
• Modeling label bias problem– 2000 training and 500 test samples generated by
HMM– CRF error is 4.6%– MEMM error is 42%
CRF solves label bias problem

Experiments
• Modeling mixed order sources– CRF converge in 500 iterations– MEMM converge in 100 iterations
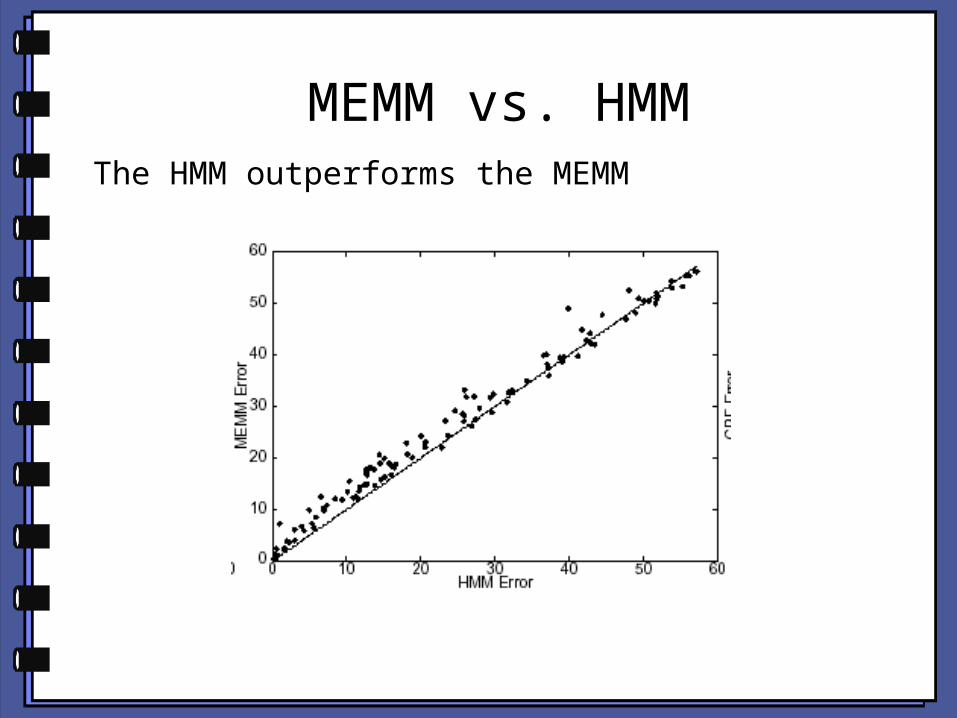
MEMM vs. HMMThe HMM outperforms the MEMM
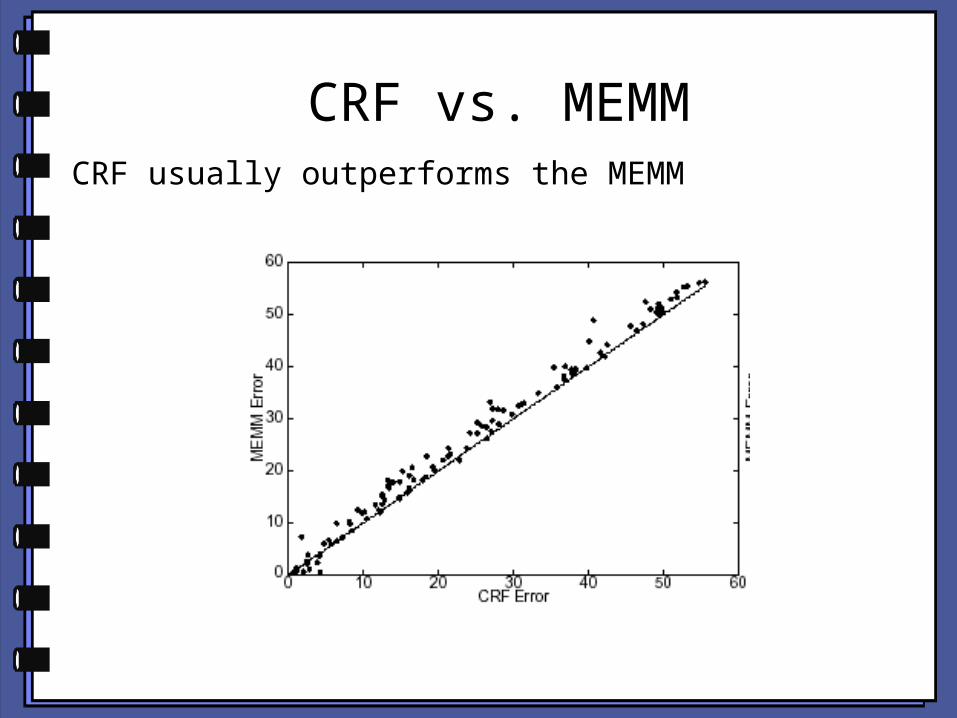
CRF vs. MEMMCRF usually outperforms the MEMM
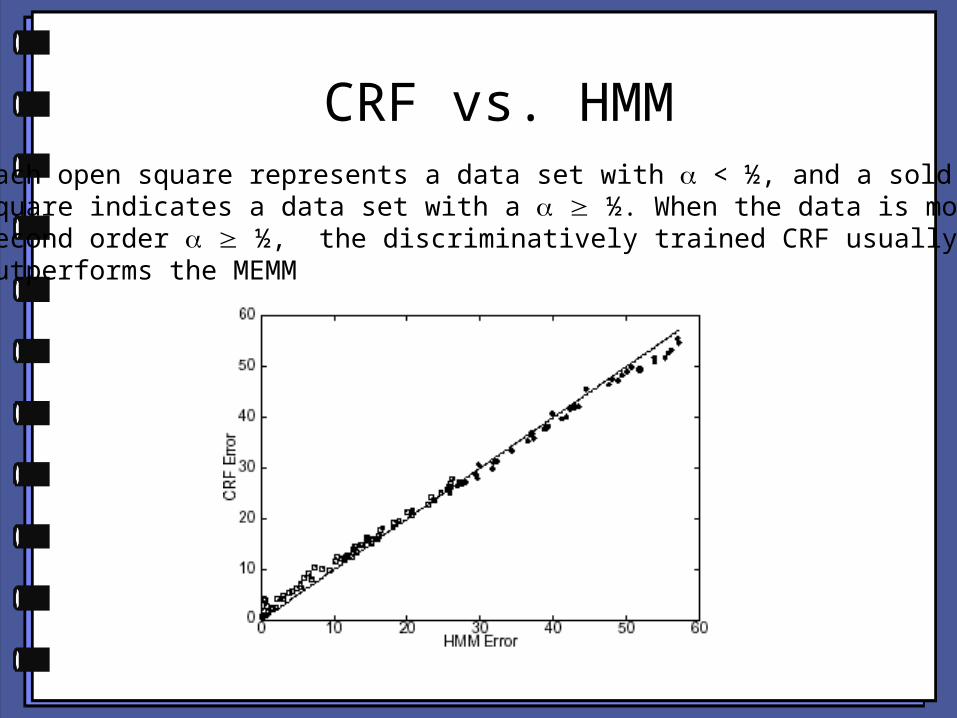
CRF vs. HMMEach open square represents a data set with < ½, and a sold square indicates a data set with a ½. When the data is mostly second order ½, the discriminatively trained CRF usually outperforms the MEMM

POS Tagging Experiments
• First-order HMM, MEMM and CRF model• Data set: Penn Tree bank• 50-50% test-train split
• Uses MEMM parameter vector as a starting point for training the corresponding CRF to accelerate convergence speed.

Interactive IE using CRF
Interactive parser updates IE results according to user’s changes. Color coding used to alert the ambiguity of IE.

Some IE tools Available
• MALLET (UMass) – statistical natural language processing, – document classification, – clustering, – information extraction
– other machine learning applications to text. • Sample Application:
GeneTaggerCRF: a gene-entity tagger based on MALLET (MAchine Learning for LanguagE Toolkit). It uses conditional random fields to find genes in a text file.

• http://minorthird.sourceforge.net/• “a collection of Java classes for storing
text, annotating text, and learning to extract entities and categorize text”
• Stored documents can be annotated in independent files using TextLabels (denoting, say, part-of-speech and semantic information)
MinorThird

GATE
• http://gate.ac.uk/ie/annie.html
• leading toolkit for Text Mining • distributed with an Information Extraction
component set called ANNIE (demo)• Used in many research projects
– Long list can be found on its website– Under integration of IBM UIMA

Sunita Sarawagi's CRF package
• http://crf.sourceforge.net/• A Java implementation of conditional
random fields for sequential labeling.

UIMA (IBM)
• Unstructured Information Management Architecture.– A platform for unstructured
information management solutions from combinations of semantic analysis (IE) and search components.

Some Interesting Website based on IE
• ZoomInfo• CiteSeer.org (some of us using it everyday!)
• Google Local, Google Scholar• and many more…


















![767 INDEX [] · 767 INDEX ... index](https://img.pdfslide.us/doc/110x75/5e6407d785e377181b6fee19/767-index-767-index-index-.jpg)