Embed Size (px)
Citation preview

InfoMagnets: Making Sense of Corpus DataJaime Arguello
Language Technologies Institute

Topic Segmentation:Helping InfoMagnets Make Sense
of Corpus DataJaime Arguello
Language Technologies Institute

3
Outline
• InfoMagnets• Applications• Topic Segmentation
– Evaluation of 3 Algorithms
• Results• Conclusions• Q/A
4
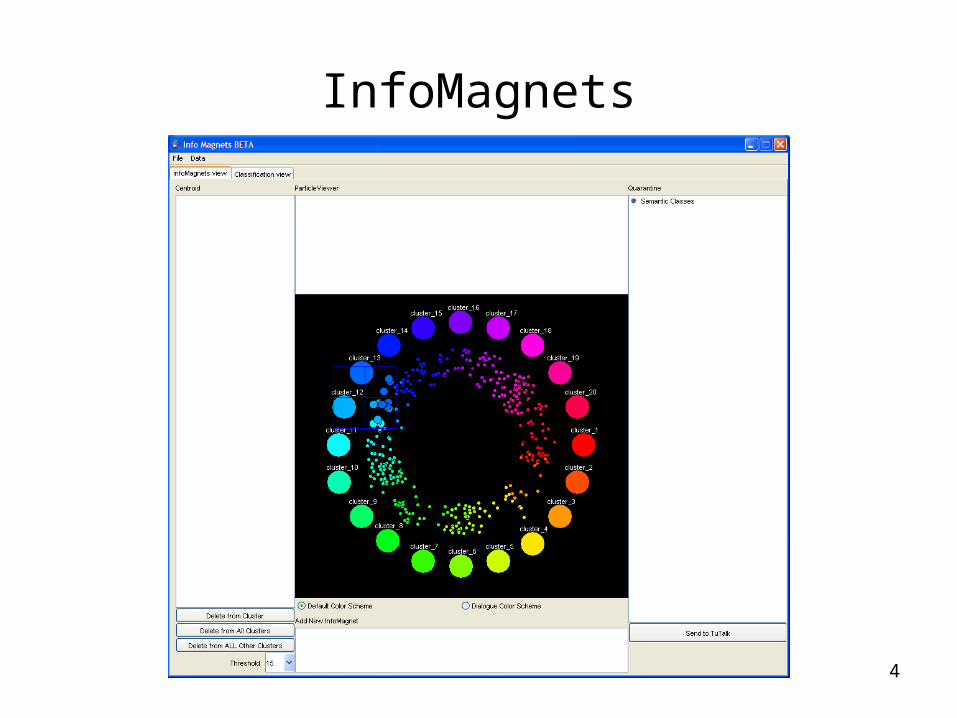
InfoMagnets

5
InfoMagnets Applications
• Behavioral Research 2 Publishable results (submitted to CHI)
• CycleTalk Project, LTI• Netscan Group, HCII
• Conversational Interfaces• Tutalk Gweon et al., (2005)
• Guide authoring using pre-processed human-human sample conversations
• Corpus organization makes authoring conversational agents less intimidating. Rose, Pai, & Arguello (2005)
6
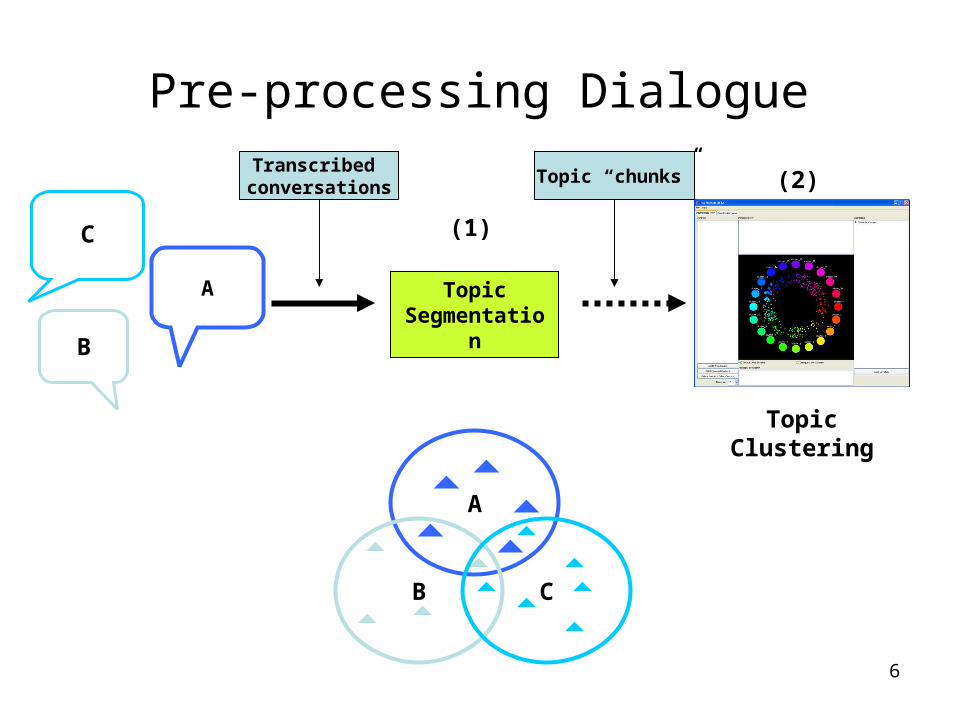
Pre-processing Dialogue
Topic Segmentation
A
C
A
B
Topic Clustering
(1)
(2)
B
C
Transcribed conversations
Topic “chunks”

7
Topic Segmentation
• Preprocess for InfoMagnets• Important computational linguistics
problem!• Previous Work:
– Marti Hearst’s TextTiling (1994)– Beeferman, Berger, and Lafferty (1997)– Barzilay and Lee (2004) NAACL best paper
award!– Many others
• But we are segmenting dialogue…

8
Topic Segmentation of Dialogue
• Dialogue is Different:– Very little training data– Linguistic Phenomena
• Ellipsis• Telegraphic content
- And, most importantly …
Coherence in dialogue is organized around a shared task, and not around a single flow of information!
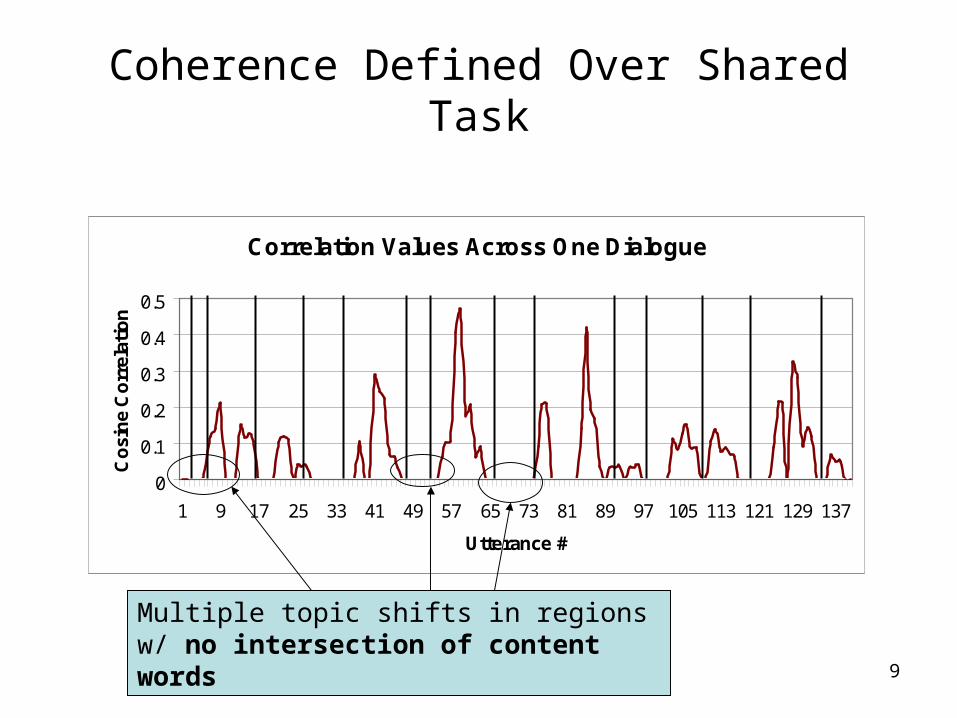
9
Correlation Values Across One Dialogue
0
0.1
0.2
0.3
0.4
0.5
1 9 17 25 33 41 49 57 65 73 81 89 97 105 113 121 129 137
Utterance #
Co
sin
e C
orr
elat
ion
Coherence Defined Over Shared Task
Multiple topic shifts in regions w/ no intersection of content words

10
Evaluation of 3 Algorithms
• 22 student-tutor pairs• Thermodynamics• Conversation via chat interface• One coder
• Results shown in terms of Pk Lafferty et al., 1999
• Significant tests: 2-tailed, t-tests

11
3 Baselines
• NONE: no topic boundaries
• ALL: every utterance marks topic boundary
• EVEN: every 13th utterance marks topic boundary– avg topic length = 13 utterances

12
1st Attempt: TextTiling
• Slide two adjacent “windows” down the text• Calculate cosine correlation at each step• Use correlation values to calculate “depth”• “Depth” values higher than a threshold
correspond to topic shifts
w1
w2
(Hearst, 1997)
13
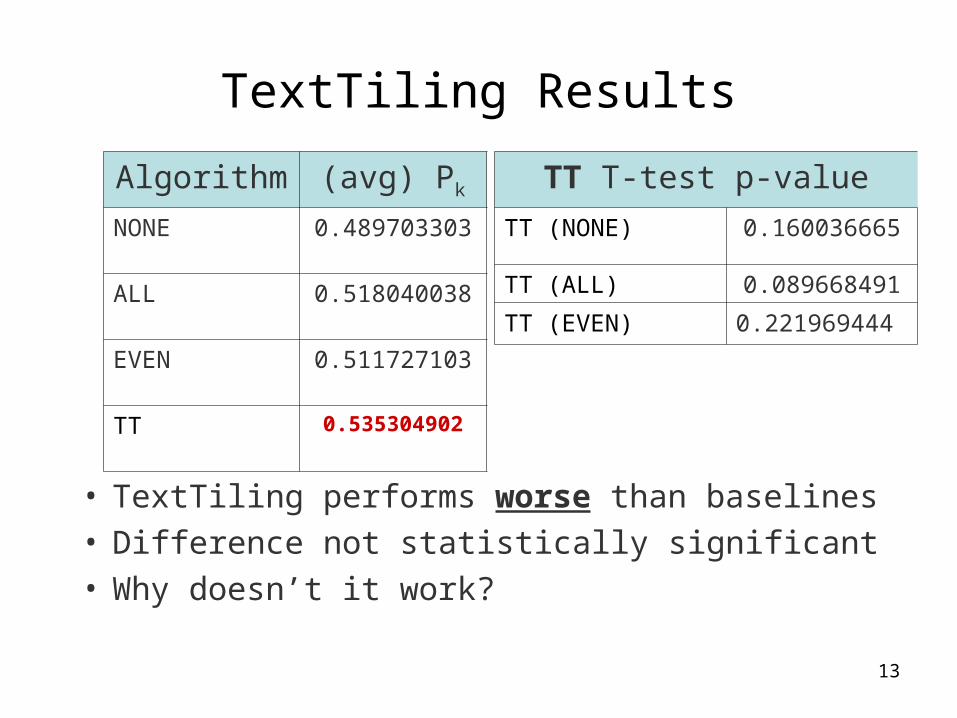
TextTiling Results
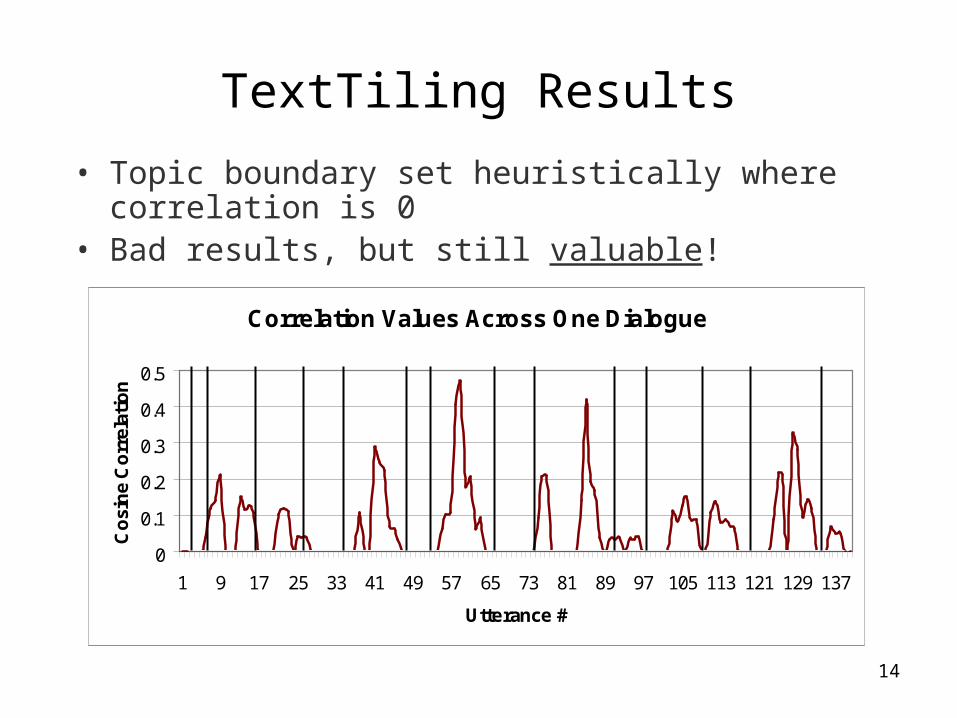
• TextTiling performs worse than baselines• Difference not statistically significant• Why doesn’t it work?
Algorithm (avg) Pk
NONE 0.489703303
ALL 0.518040038
EVEN 0.511727103
TT 0.535304902
TT T-test p-value
TT (NONE) 0.160036665
TT (ALL) 0.089668491
TT (EVEN) 0.221969444
14
• Topic boundary set heuristically where correlation is 0
• Bad results, but still valuable!
TextTiling Results
Correlation Values Across One Dialogue
0
0.1
0.2
0.3
0.4
0.5
1 9 17 25 33 41 49 57 65 73 81 89 97 105 113 121 129 137
Utterance #
Co
sin
e C
orr
elat
ion

15
• Cluster utterances• Treat each cluster as a “state”• Construct HMM
– Emissions: state-specific language models– Transitions: based on location and cluster-
membership of the utterances
• Viterbi re-estimation until convergence
2nd Attempt: Barzilay and Lee (2004)
16
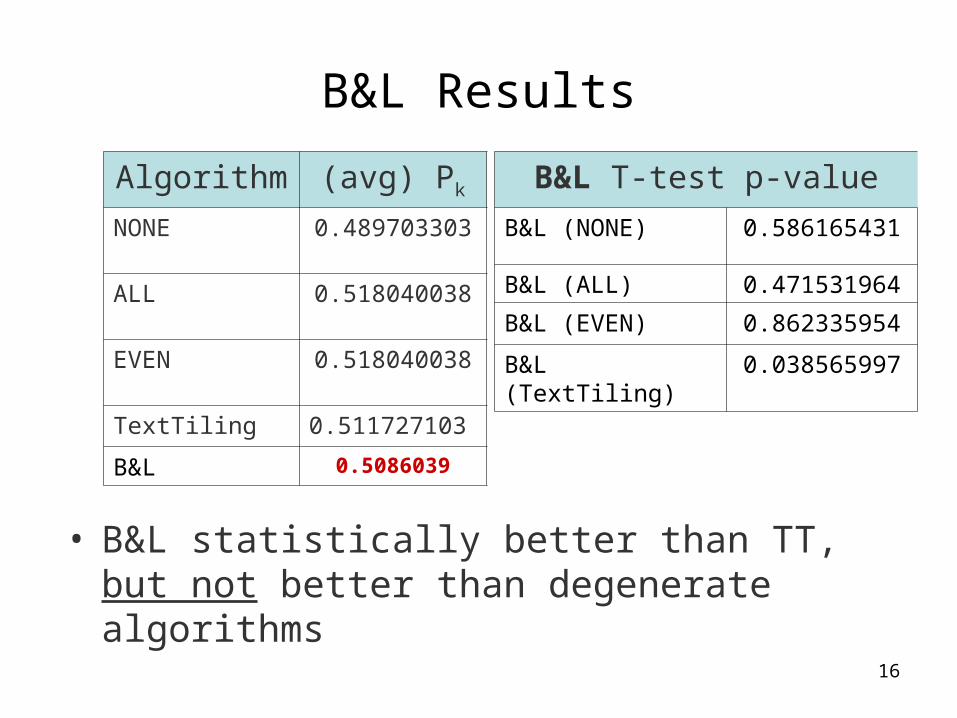
• B&L statistically better than TT, but not better than degenerate algorithms
B&L Results
Algorithm (avg) Pk
NONE 0.489703303
ALL 0.518040038
EVEN 0.518040038
TextTiling 0.511727103
B&L 0.5086039
B&L T-test p-value
B&L (NONE) 0.586165431
B&L (ALL) 0.471531964
B&L (EVEN) 0.862335954
B&L (TextTiling) 0.038565997

17
B&L Results
• Too fine grained topic boundaries• Fixed expressions (“ok”, “yeah”, “sure” )
• Remember: cohesion based on shared task
• State-based language models sufficiently different?

18
Adding Dialogue Dynamics
• Dialogue Act coding scheme– Developed for discourse analysis of human-
tutor dialogues
• 4 main dimensions:– Action– Depth– Focus – Control
• Dialogue Exchange (Sinclair and Coulthart, 1975)

19
• X- dimensional learning (Donmez et al., 2004)
• Use estimated labels on some dimensions to learn other dimensions
• 3 types of Features:– Text (discourse cues)– Lexical coherence (binary)– Dialogue Acts labels
• 10-fold cross-validation• Topic Boundaries learned on estimated
labels, not hand coded ones!
3rd Attempt: Cross-Dimensional Learning
20
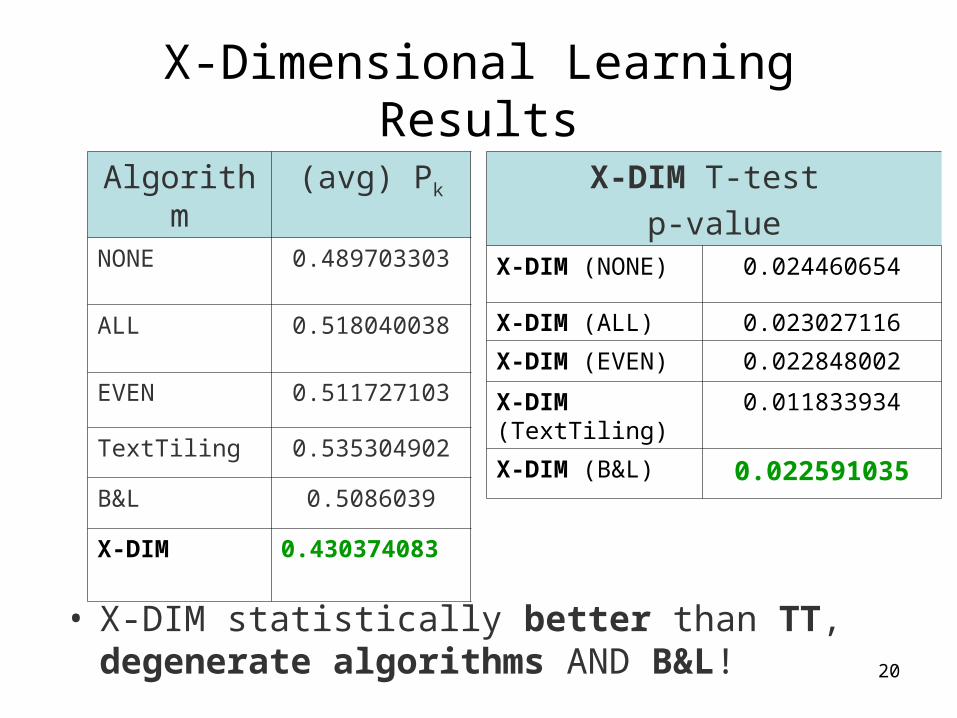
X-Dimensional Learning Results
• X-DIM statistically better than TT, degenerate algorithms AND B&L!
Algorithm (avg) Pk
NONE 0.489703303
ALL 0.518040038
EVEN 0.511727103
TextTiling 0.535304902
B&L 0.5086039
X-DIM 0.430374083
X-DIM T-test p-value
X-DIM (NONE) 0.024460654
X-DIM (ALL) 0.023027116
X-DIM (EVEN) 0.022848002
X-DIM (TextTiling)
0.011833934
X-DIM (B&L) 0.022591035
21
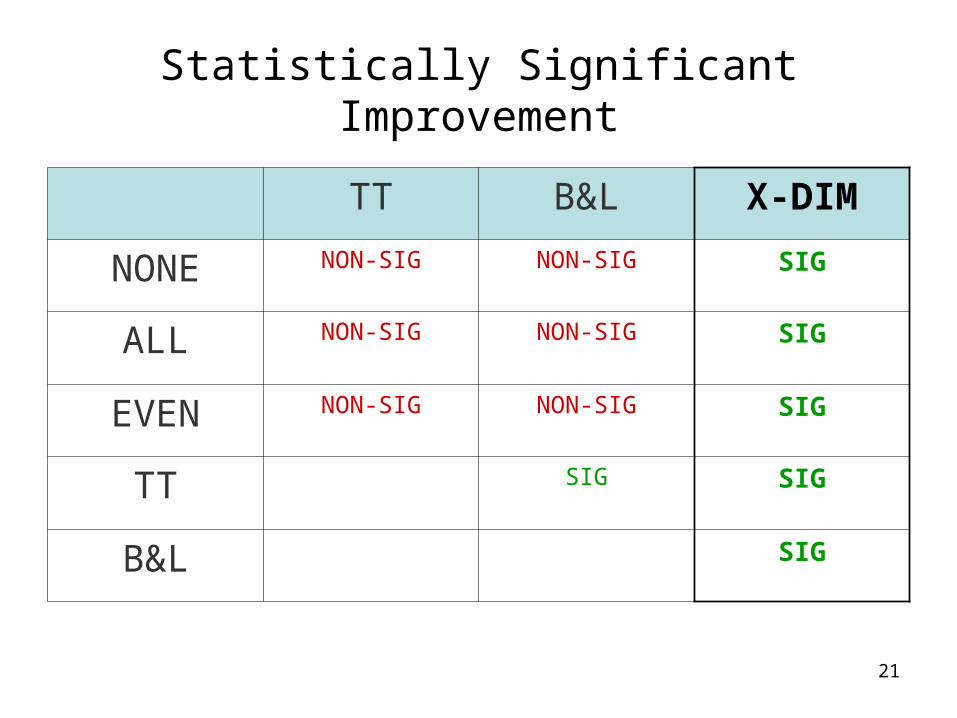
Statistically Significant Improvement
TT B&L X-DIM
NONE NON-SIG NON-SIG SIG
ALL NON-SIG NON-SIG SIG
EVEN NON-SIG NON-SIG SIG
TT SIG SIG
B&L SIG

22
Future Directions
• Merge cross-dimensional learning (w/ dialogue act features) with B&L content modeling HMM approach.
• Explore other work in topic segmentation of dialogue

23
Summary
• Introduction to InfoMagnets• Applications• Need for topic segmentation• Evaluation of other algorithms• Novel algorithm using X-dimensional
learning w/statistically significant improvement

24
Q/A
Thank you!





























