Embed Size (px)
Citation preview

Industrial Project (234313)Final Presentation
“App Analyzer”Deliver the right apps users want!
(VMware)
Students: Edward Khachatryan & Elina ZharikovSupervisors: Yoel Calderon, Yan Aksenfeld
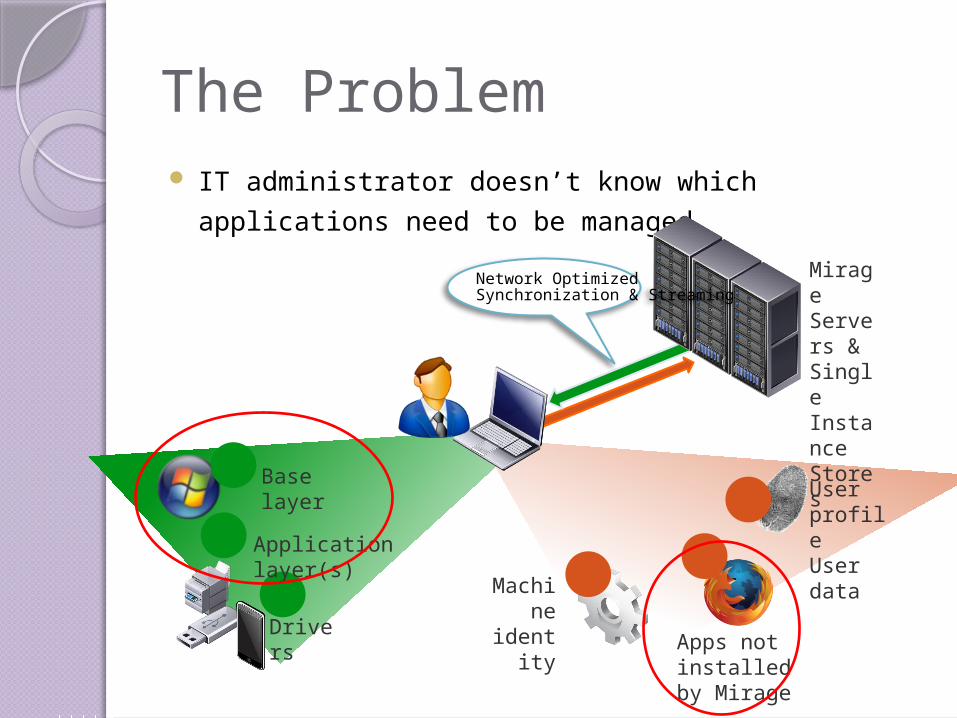
The Problem IT administrator doesn’t know which applications
need to be managed
Apps not installed by Mirage
User profileUser data
Machine
identity
Drivers
Base layer
Network OptimizedSynchronization & Streaming
Application layer(s)
Mirage Servers & Single Instance Stores
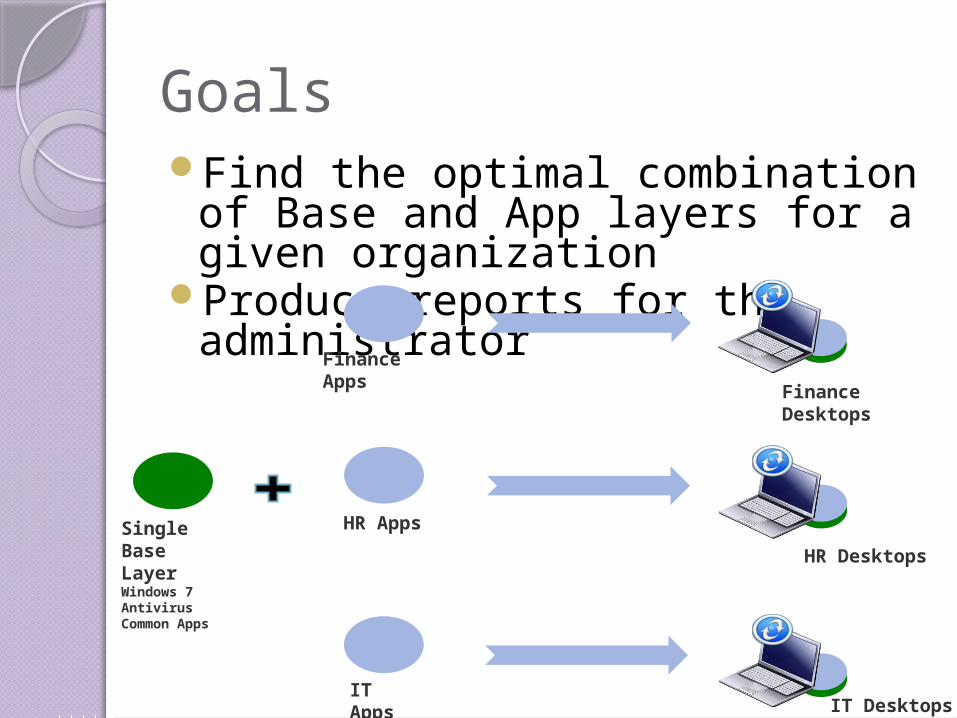
GoalsFind the optimal combination of
Base and App layers for a given organization
Produce reports for the administrator
HR Desktops
IT Desktops
Finance Apps
HR Apps
IT Apps
Finance Desktops
SingleBase LayerWindows 7AntivirusCommon Apps

MethodologyResearch clustering algorithmsConnect to Mirage Database on
SQL ServerParse UTF encoded XML dataProcess and analyze the dataBuild custom reports

MethodologyResearch and choose the right
set of tools◦Python libraries:
scikit-learn for clustering algorithms lxml for parsing UTF encoded XML SQLAlchemy for SQL interaction pandas for gluing it all together
◦Microsoft SQL Report Builder for custom reports
◦VMWare Mirage web interface for GUI

AchievementsQuick and efficient data analysis:
the desired results can be generated in just a few minutes
User friendly experience: a variety of reports can be produced in a matter of few clicks
Integration with the existing VMWare Mirage platform
A variety of parameters to customize the output
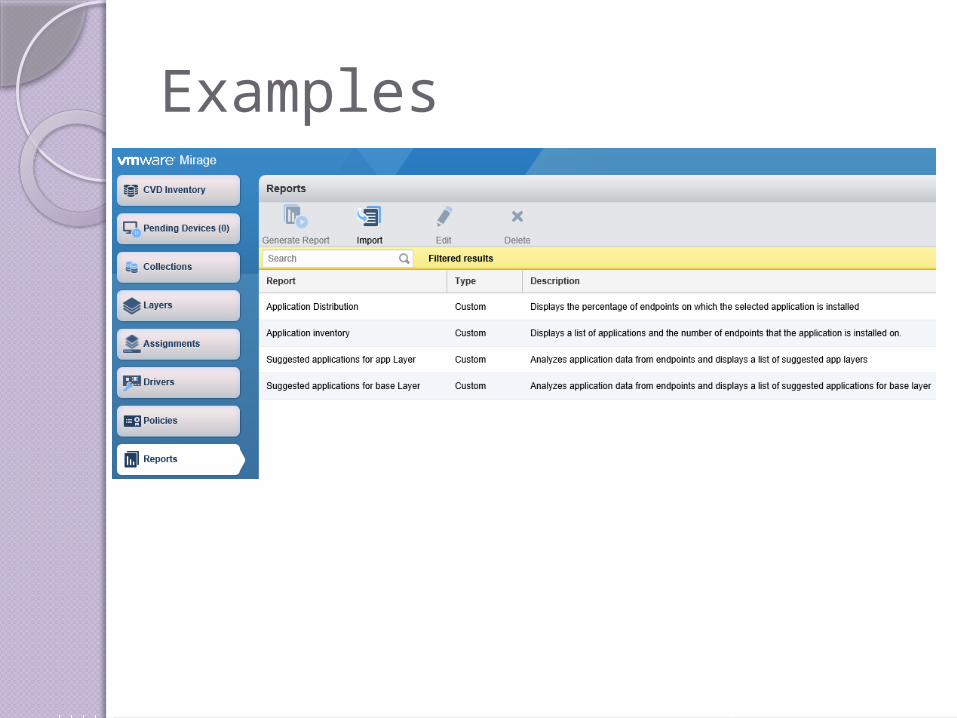
Examples
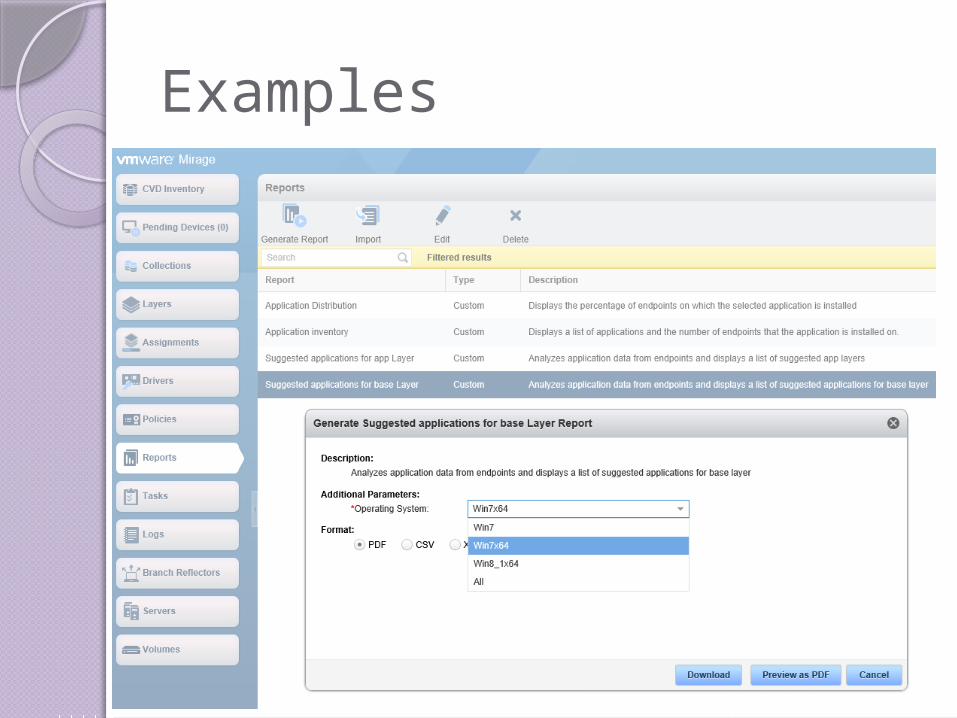
Examples

Examples
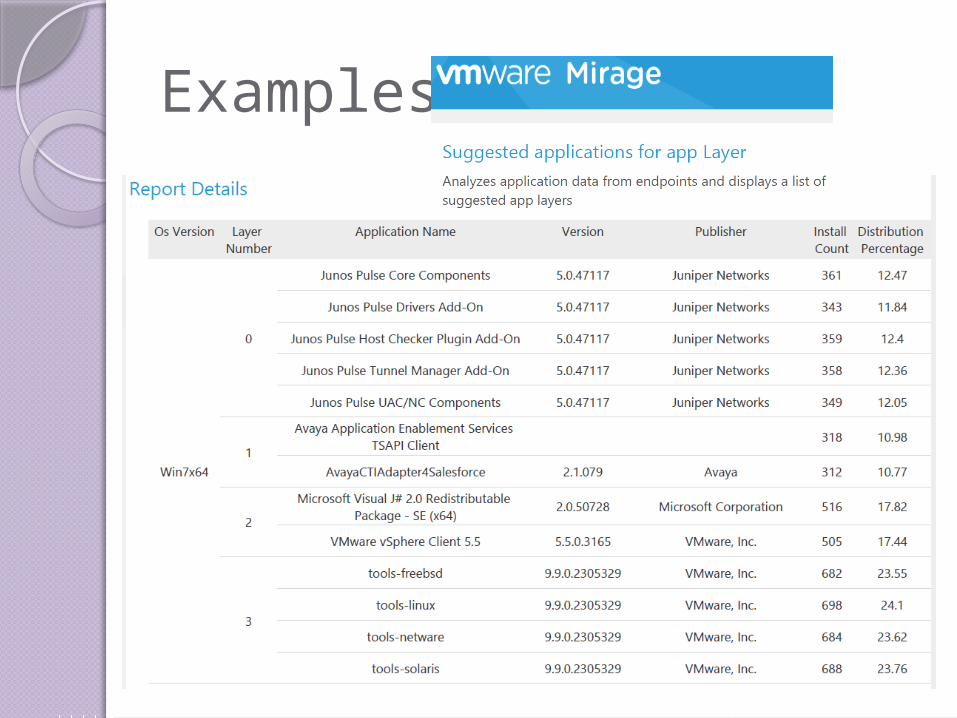
Examples
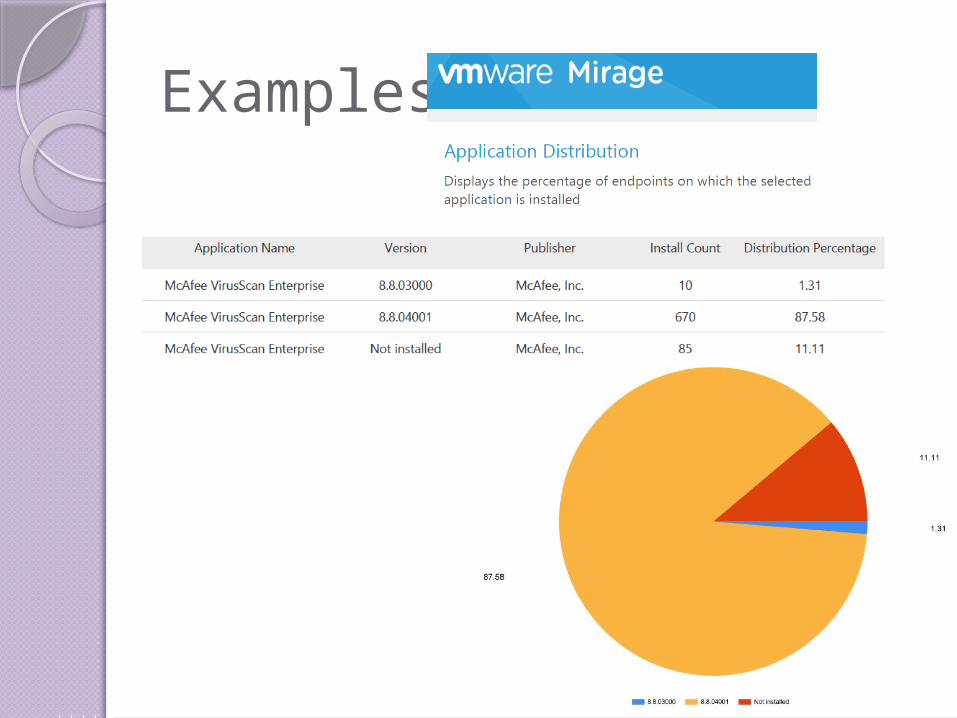
Examples

ExamplesLive demonstration…

ConclusionsDBSCAN is a fast clustering algorithm.
It’s scalable for large datasets and works well with Boolean vectors data.
Instead of the usual Euclidian distance, it’s better to work with metrics intended for boolean-valued vector spaces, such as Jaccard, Sokal-Sneath or Dice.
Using open source libraries saves a lot of valuable time.
Microsoft SQL Report Builder is a great WYSIWYG tool for building custom reports
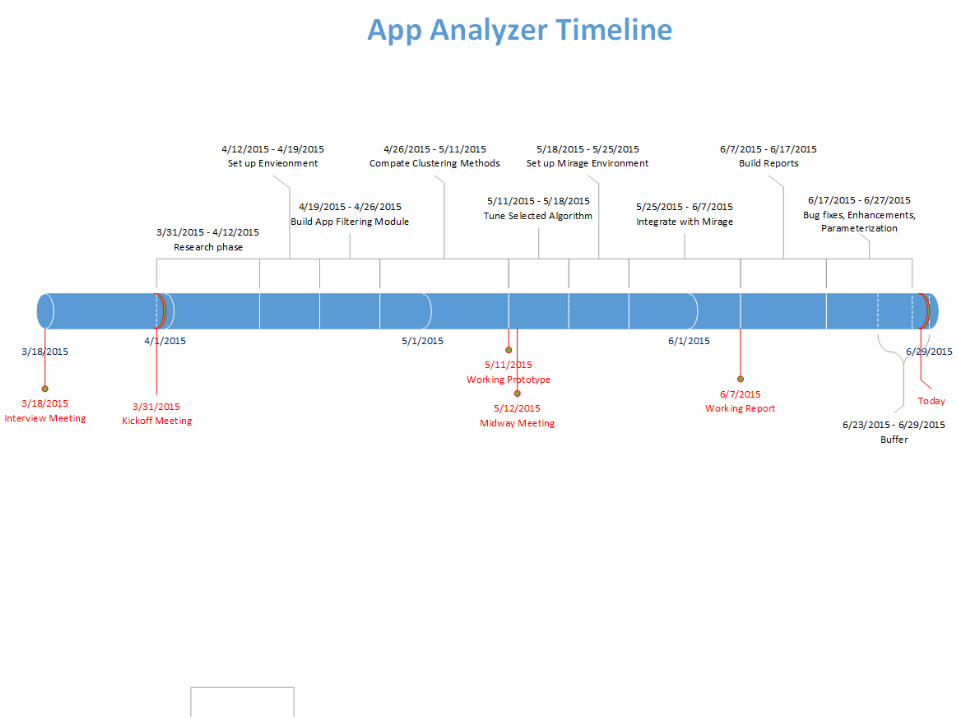

Progress Recap31.3 – Kickoff Meeting31.3-12.4 – Research period: reading
materials on clustering algorithms.12.4-19.4 – Installing Microsoft SQL
Server, restoring a VMWare Mirage database, querying and parsing the data from the database.
19.4-26.4 – Creating a filtering module to clean up the raw application list: uniting applications by their name, product ID or upgrade code, filtering out unimportant applications. Finalizing the criteria for Base Layer apps.

Progress Recap26.4-11.5 – Focusing on 4 clustering
algorithms (K-Means, Agglomerative, DBSCAN, Birch), testing various parameters and metrics on different databases.
12.5 – Midway meeting12.5-19.5 – Continuing the
aforementioned tests, focusing strictly on DBSCAN.
19.5-25.5 – Setting up and configuring a virtual machine running Windows Server with VMWare Mirage and Microsoft SQL Server Reporting Services.

Progress Recap 25.5-7.6
◦ Learning to use Microsoft SSRS, the Report Builder tool and Mirage web interface.
◦ Moving the Python IDE and SQL databases to the virtual machine.
◦ Actually exporting our results to SQL instead of CSV and text files.
◦ Building a sample report. 7.6-17.6 – Building custom reports
according to the given guidelines. 18.6-27.6 – Improving reports’
appearance, fixing bugs, parameterizing the Python code.




























