Embed Size (px)
Citation preview

Indowordnet Workshop: IIT Bombay
Opening Remarks
Pushpak BhattacharyyaCSE Dept., IIT Bombay
1st January, 2012

Gloss
study
Hyponymy
Hyponymy
Dwelling,abode
bedroom
kitchen
house,home
A place that serves as the living quarters of one or mor efamilies
guestroom
veranda
bckyard
hermitage cottage
Meronymy
Hyponymy
Meronymy
Hypernymy
WordNet Sub-Graph

Hindi Wordnet
Dravidian Language Wordnet
North East Language Wordnet
Marathi Wordnet
Sanskrit Wordnet
EnglishWordnet
Bengali Wordnet
Punjabi Wordnet
KonkaniWordnet
UrduWordnet
INDOWORDNET
Gujarati Wordnet
Oriya Wordnet
Kashmiri Wordnet

Workshop goals To review the methodology of wordnet
construction To review progress: quantitative and
qualitative To clearly describe the process and to
identify lacunae To do knowledge and idea sharing To discuss challenges

Goals of Indowordnet effort 25000 synsets linked with Hindi
wordnet Synsets to satisfy principles of:
Minimality Coverage Replaceability Correctness (no outlier) High quality gloss and examples Semantically and lexically linked

Categories of Synsets (1/2)
• Universal: Synsets which have an indigenous lexeme in all the languages (e.g. Sun ,Earth).
• Pan Indian: Synsets which have indigenous lexeme in all the Indian languages but no English equivalent (e.g. Paapad).
• In-Family: Synsets which have indigenous lexeme in the particular language family (e.g. the term for Bhatija in Dravidian languages).

Categories of Synsets (2/2)
• Language specific: Synsets which are unique to a language (e.g. Bihu in Assamese language)
• Rare: Synsets which express technical terms (e.g. ngram).
• Synthesized: Synsets created in the language due to influence of another language (e.g. Pizza).

Need for categorization To bring systematicity in the way
the wordnet synsets are linked UniversalPan IndianLanguage
FamilyLanguageSynthesisedRare
All members have finished the Universal and Pan Indian synsets

Categorization methodology
34378 Hindi synsets were sent to all Indo-wordnet groups in the tool, in which they had these options to categorize:
Yes No
Universal synsets:- The synsets which were categorized Yes and also have equivalent English words or synsets.
Pan-Indian :- The synsets which were categorized Yes and did not have equivalent English words or synsets.

Challenges of linking by expansion
Based on discussions at Goa PRSG and Workshop, 8-10
Aug, 2011

Expansion approach: linking is a subtle and difficult process
To link or not to link While linking:
face lexical and semantic chasms Syntactic divergences in the example
sentences Change of POS Copula drop (HindiBangla)

Case of kashmiri
Linking kinship relations and fine grained concepts
Relative
Uncle
Mama Chacha
पा�नी� direct आब
पा�नी� hypernym त्रेश

Important decision
TWO kinds of linkages Direct Hypernymy
Case of kashmiri
पा�नी� direct आब
पा�नी� hypernym त्रेश

How to express a concept not present in the language?

Transliteration: often employed Synset ID : 39 POS : adjective Synonyms : सनी�थ
, (sanaatha) Gloss : जि�सका� का�ई पा�लनी-पा�षण या� देखभा�ल कारनी वा�ल� हो�
(orphan) Example statement : "सनी�थ ब�लका� का� अनी�थ ब�लका�
का� मदेदे कारनी� चा�हिहोए (children who are looked after should help the ones who are orphans)/ स�धका प्रभा& का� हो� ��नी पार अनी�थ नीहो' रहोता�, सनी�थ हो� ��ता� हो)”
Transliterated and adopted by Bangla and Gujarati

Short phrase: often employed
Bangla
Urdu(meaningInauspicious)

Linking synsets across languages: Influence on Hindi Wordnet
Hindi wordnet has to add new synsets to accommodate language specific concepts, e.g., in Gujarati
ભૈ� રવજપ (bhairav jap)
ID :: 103040CAT :: NOUN CONCEPT :: मो�क्ष के� लि�ए जप केरते� हुए पर्व�ते पर से� अपने�
आप के� गि�र�ने� (Taking God’s name and throwing oneself from atop a mountain to attain liberation)
EXAMPLE :: गि�रने�र के� शि�खर पर से� या�गि�के भै�रर्वजप केरते� थे� एसे� मो�ने� ज�ते� है� । (it is thought that pilgrms used
to do bhairav jap atop Girnar mountain)SYNSET-HINDI :: भै�रर्वजप

Tools

Underlying Architecture

Basis Tools Developed
Synset making and linking tool Quantitative analysis tool Sense marking tool Indowordnet browser tools Morphology Analyser

Word SearchWord completion and Multi lingual search
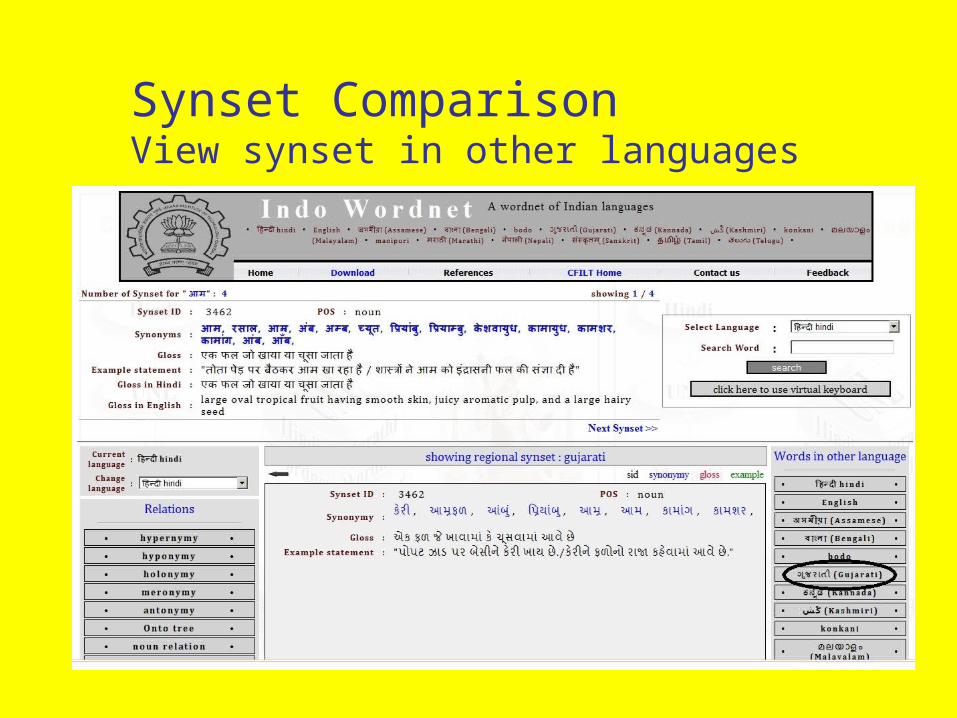
Synset ComparisonView synset in other languages

Relationship Comparison
In Gujarati
In Hindi
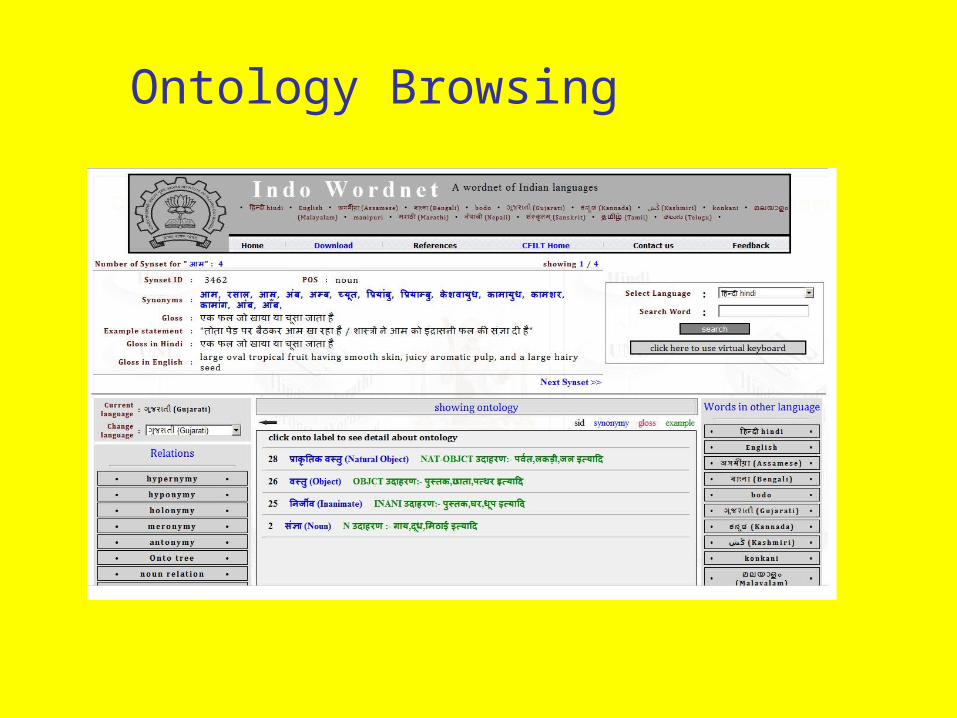
Ontology Browsing

Synsets for Ontology Node

Achievements so far Significant progress in the number and
quality of synsets of all languages Project on track
Deep insights obtained in the expansion approach
Platform created for multilingual WSD, Multilingual sense based dictionary Paving way for CLIR, MT
Students graduated/graduating (PhD, masters, bachelors)
Significant publications (LREC, GWC)

Number of linked synsets
Completely free for research purposes

Points from Goa Workshpp and PRSG, 8-10 Aug, 2011 (1/2)
Pre and post PRSG workshop are for clarifying many linguistic, computational and web interface points
Linguistic and computational issues will be documented in detail with specific committees being given the job
Discussion areas: Negative adjectives linkage, Language specific synsets

Points from Goa Workshop and PRSG, 8-10 Aug, 2011 (2/2)
Decision to open a google doc to share, vote on and filter language specific synsets
Decision to link by direct and hypernymy has solved quite a few problems in linkage.
PRSG: A detailed work plan, frequency of senses and frequency of words

Resource Constrained Multilingual WSD

WSD is costly!1
WordNets Princeton Wordnet: ~80000 synsets: 30 man
years Eurowordnet: 12 man years on the average for
12 languages Hindi wordnet: 24 man years
http://www.cfilt.iitb.ac.in/wordnet/webhwn/ Indowordnet: getting created; 15 languages; 4
people on the average; in 1 year close to 15000 synsets done
Scale of effort really huge Tricky too: when it comes to expanding from
one wordnet to another

WSD is costly!2
Sense Annotated corpora SemCor: ~200000 sense marked words SemEval/Senseval competition: to generate
sense marked corpora Sense marked corpora created at IIT Bombay
http://www.cfilt.iitb.ac.in/wsd/annotated_corpus
English: Tourism (~170000), Health (~150000)
Hindi: Tourism (~170000), Health (~80000) Marathi: Tourism (~120000), Health
(~50000) 12 man years for each <L,D> combination

This is the dream!spread from one <L,D> combination to others

Related Work (Not mentioning references, because they are too many)
Knowledge Based Approaches
Supervised Approaches
Unsupervised Approaches
Semi-supervised Approaches
Hybrid Approaches

No single existing solution to WSD completely meets our requirements of
multilinguality, high domain accuracy and good performance in the face of
limited annotation

Scenarios of language adaptation
• Scenario-1: Supervised• Large amount of annotated data available in a resource
rich language (say, L 1 ) • No annoated data available in the target language (say,
L 2 )
• Scenario-2: Supervised • Large amount of annotated data available in L1 • Small amount of annotated data available in L2
• Scenario-3: Unsupervised• Only unannotated data available in both L1 and L2
• Scenario-4: Semi-supervised• Small amount of seed annotated data and a large
amount of unannotated data are available in both L1 and L2

Why Project Parameters? for resource reuse
Wordnet-dependent parameters depend on the graph-based structure of wordnet
Corpus-dependent parameters depend on various statistics learnt from a sense marked corpora
Both the tasks, Constructing a wordnet from scratch Collecting sense marked corpora for multiple languages
are tedious and expensive
Can the effort required in constructing semantic graphs for multiple wordnets and collecting sense marked
corpora in multiple languages be avoided/lessened?

How to facilitate parameter projection

Synset based Multilingual DictionaryRajat Mohanty, Pushpak Bhattacharyya, Prabhakar Pande, Shraddha Kalele, Mitesh Khapra and
Aditya Sharma. 2008. Synset Based Multilingual Dictionary: Insights, Applications and Challenges. Global Wordnet Conference, Szeged, Hungary, January 22-25.
Link synsets and then link the synset word
Hindi is used as the central language – the synsets of all languages link to the corresponding Hindi synset.
39
Advantage: The synsets in a particular column automatically inherit the various semantic relations of the Hindi wordnet– the wordnet based parameters thus
get projected
Concepts L1 (English) L2 (Hindi) L3 (Marathi)
04321: a youthful male person
{malechild, boy}
{लड़का� ladkaa, ब�लका baalak, बच्चा� bachchaa}
{म&लगा� mulgaa, पा�रगा� porgaa, पा�र por}
CFILT
- IITB

Solving the lexical choice by word level linkage
40
म&लगा� /MW1
mulagaa,
पा�रगा� /MW2
poragaa,
पा�र /MW3 pora
लड़का� /HW1
ladakaa,
ब�लका /HW2 baalak,
बच्चा� /HW3 bachcha,
छो�र� /HW4 choraa
male-child /HW1,
boy /HW2
Marathi SynsetHindi Synset
English Synset
CFILT
- IITB

Data

#Polysemous words (tokens)
#monosemous words
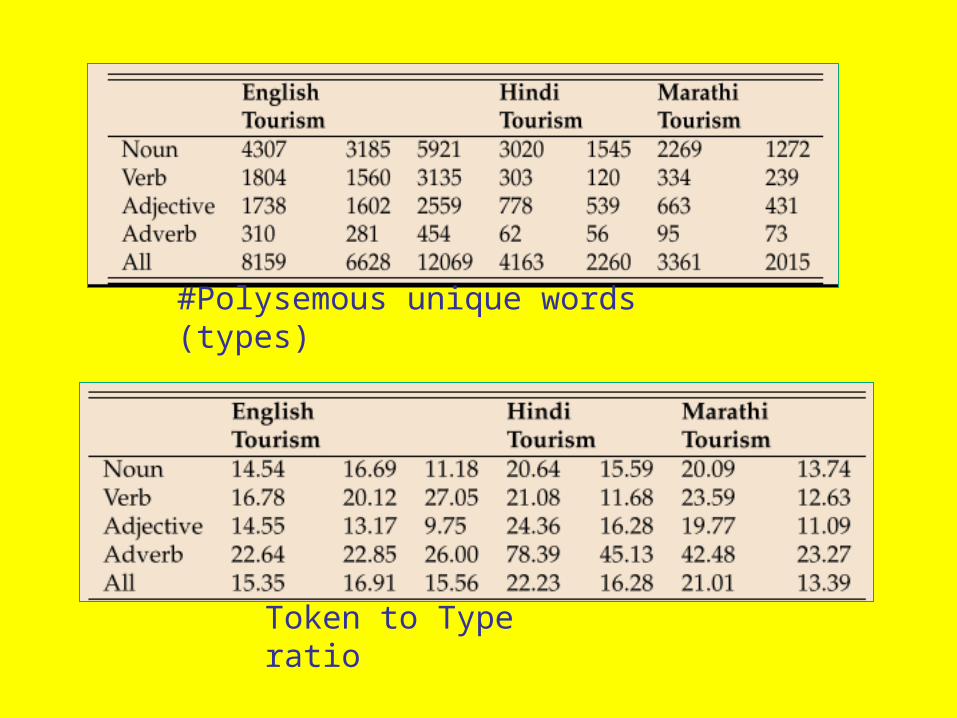
#Polysemous unique words (types)
Token to Type ratio

Average degree of WN polysemy
Average degree of and corpus polysemy
H S H H
H H HS

A look at monolingual WSD performance
Is IWSD good?

Algorithms IWSD: Our algorithm EGS: the exhaustive graph search algorithm
described PPR: a state of the art knowledge based
approach SVM based McCarthy et al. 2007: a state of the art
unsupervised approach RB: randomly selects one of the senses of the
word from the Wordnet WFS: assigns the first sense of the word from the
Wordnet MFS: assigns the most frequent sense of the
word as obtained from an annotated corpus.

Performance of different algorithms: monolingual WSD

Upcoming Global Wordnet Conference

Basic Facts Venue: Matsue, Japan Dates: Jan 9-13, 2012 #papers: 57 #Invited Talks: 2
Prof. Makoto Nagao: Amendment of Copyright Law and Natural Language Processing
Prof. Naoyuki Ono: Eventiveness and Argument Selection in Nominals

Topics WN Creation WN Augmentation WN Evaluation Tools Sense Tagging Applications Sentiment Analysis

Papers from India (1/2) Tanuja Ajotikar, Malhar Kulkarni and Pushpak
Bhattacharyya: Verbs in Sanskrit wordnet Sanghamitra Mohanty and Das Adhikary:
Ontology of Sanskrit Wordnet: Nouns and Verbs
Balamurali A R, Subhabrata Mukherjee, Akshat Malu and Pushpak Bhattacharyya: Leveraging Sentiment to Compute Word Similarity
Brijesh Bhatt, C Bhensdadia, Pushpak Bhattacharyya, Dinesh Chauhan and Kirit Patel: Introduction to Gujarati wordnet

Papers from India (2/2) Shikhar Kr. Sarma, Utpal Saikia, Mayashree
Mahanta and Himadri Bharali: ASSAMESE VOCABULARY AND ASSAMESE WORDNET BUILDING: ANALYSIS
Panchanan Mohanty: NOUNS IN ODIA: AN ONTOLOGICAL PERSPECTIVE
Arindam Chatterjee, Salil Joshi, Pushpak Bhattacharyya, Diptesh Kanojia and Akhlesh Meena: A Study of the Sense Annotation Process: Man v/s Machine
Arindam Roy, Sunita Sarkar and Bipul Shyam Purkayastha: A Proposed Nepali Synset Entry and Extraction Tool

This workshop program
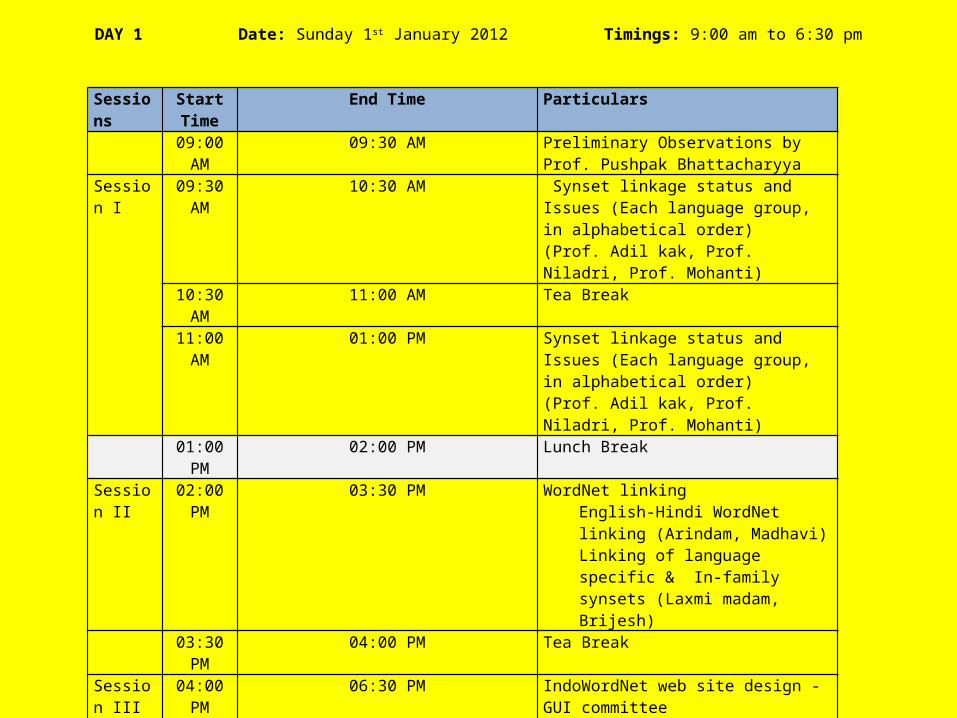
Sessions Start Time
End Time Particulars
09:00 AM
09:30 AM Preliminary Observations by Prof. Pushpak Bhattacharyya
Session I 09:30 AM
10:30 AM Synset linkage status and Issues (Each language group, in alphabetical order)(Prof. Adil kak, Prof. Niladri, Prof. Mohanti)
10:30 AM
11:00 AM Tea Break
11:00 AM
01:00 PM Synset linkage status and Issues (Each language group, in alphabetical order)(Prof. Adil kak, Prof. Niladri, Prof. Mohanti)
01:00 PM 02:00 PM Lunch Break
Session II 02:00 PM 03:30 PM WordNet linking English-Hindi WordNet linking
(Arindam, Madhavi) Linking of language specific & In-
family synsets (Laxmi madam, Brijesh)
03:30 PM 04:00 PM Tea Break
Session III
04:00 PM 06:30 PM IndoWordNet web site design -GUI committee User friendliness of interface Computational challanges (Dr. Jyoti, Prof. CKB, Dr. Bhattacharyya)
DAY 1 Date: Sunday 1st January 2012 Timings: 9:00 am to 6:30 pm

Sessions Start Time
End Time Particulars
Session I 09:00 AM 10:00 AM Issues related to sense marking (Arindam)
10:00 AM 11:00 AM Word Sense Disambiguation (Salil)
11:00 AM 11:30 AM Tea Break
Session II 11:30 AM 01:00 PM IndoWordNet Data base design – Data base committee Data base architecture Distributing database to language groups(Dr. Jyoti, Dr. Ramdas, Dr. Prateek)
01:00 PM 02:00 PM Lunch Break
Session III 02:00 PM 03:00 PM WordNet Tool Demonstration
03:00 PM 04:00 PM Talk on GWC papers
04:00 PM 05:00 PM WordNet validation plan and concluding remarks
DAY 2 Date: Monday 2nd January 2012 Timings: 9:00 AM to 5:00 PM

MWE Workshop: Chennai, 15-16, Dec, 2012

Conclusions (1/2) Wordnet: Great unifier of the India (similar to
Adi Shankaracharya, Bollywood films…) 15 major languages of India (50m to 500m
speaker population Getting linked with PWN; would like to link with
Eurowordnet Completely free lexical resource (GNU License) Language teaching: Hindi wordnet is already
being used for teaching Hindi to children Initiator of really gigantic applications like
translation and search Will influence Multilingual E-Commerce deeply

Hindi Wordnet
Dravidian Language Wordnet
North East Language Wordnet
Marathi Wordnet
Sanskrit Wordnet
EnglishWordnet
Bengali Wordnet
Punjabi Wordnet
KonkaniWordnet
UrduWordnet
INDOWORDNET
Gujarati Wordnet
Oriya Wordnet
Kashmiri Wordnet

Conclusions (2/2) WSD: Showed ways of resource reuse both
between languages and between domains Should prove useful for languages with
resource scarcity Closer study needed for familialy close
languages Another area of investigation is usage of
language specific properties, in particular, morphology
The projection idea can be used in other NLP problems like POS tagging and Parsing

Upcoming:
Computational Linguistics conference, COLING 2012
IIT BombayMumbai,
Dec, 8-15, 2012
July-7-2011: Deadline for paper submission

Coling12 Website getting ready…

URL for resources: http://www.cfilt.iitb.ac.in
URL for publicationshttp://www.cse.iitb.ac.in/~pb
Thank You





![Wordnet-Affect [IIT-Bombay]](https://img.pdfslide.us/doc/110x75/55503cebb4c90580748b4770/wordnet-affect-iit-bombay.jpg)