Embed Size (px)
Citation preview

INDEXING DATASPACESby Xin Dong & Alon Halevy
ITCS 6010FALL 2008
Presented by: VISHAL SHETH

AGENDA
• Background• Motivation• Problem Definition• Indexing Structure• Experimental Evaluation• Related Work• Conclusion• Future Work
2

Background• Indexing
– A technique used for faster execution of queries and result retrieval which can be created on one or more columns of DB table
– More indexes means faster query performance, but also longer transformation/load times
– Types of Indexes: B-Tree, Bitmap
• Dataspace– It is a data co-existence approach which forms a semantic web of inter-related /
similar things. E.g. Music Dataspace
• DS Indexing v/s DB Indexing
3
DB INDEXING DS INDEXINGIndexing on tables of Relational DB of same source
Indexing on dataspace having heterogeneous data sources
Data is structured Data may be structured or unstructured
Underlying DB Schema is very well defined (Relational)
Underlying schema may/may not be known (DB, XML, Doc, PPT)

Motivation
• Indexing of data from disparate data sources is a big problem and challenging
• To answer queries with keyword and structure efficiently
• Faster execution of queries on semantically different data
4

• Indexing Heterogeneous Data– Support queries over different “types” of data– Data may or may not be having semantic similarity– Data may be structured (XML/DB/Spreadsheet) or
(un/partially)structured files (PPT/DOC/Email/LaTex Files/WebPages)
– To extract associations / relationships between either structured or unstructured or both
5
Problem Definition
Inverted Lists
Querying HeterogeneousData
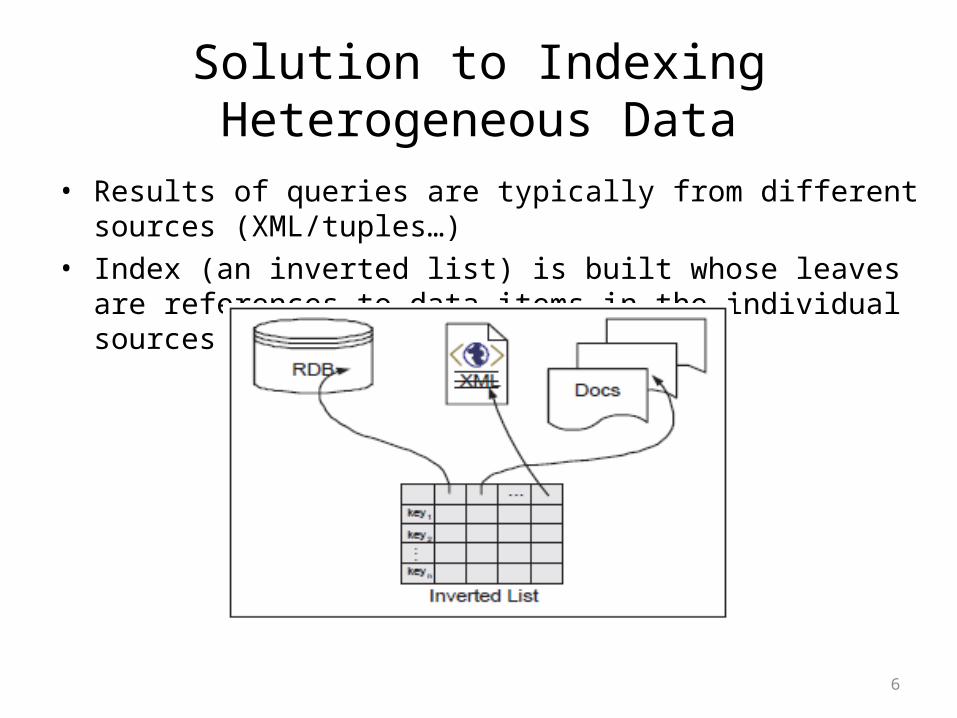
Solution to Indexing Heterogeneous Data
• Results of queries are typically from different sources (XML/tuples…) • Index (an inverted list) is built whose leaves are references to data
items in the individual sources
6

Solution Contd…
7
• Data is modeled as a set of triples called as triple base which can take form of (instance, attribute, value) or (instance, association, instance)
• Instance is a real world object described by multi-valued attributes.
• Association is a directional relationship between two instances (two directions of a particular association are named differently)
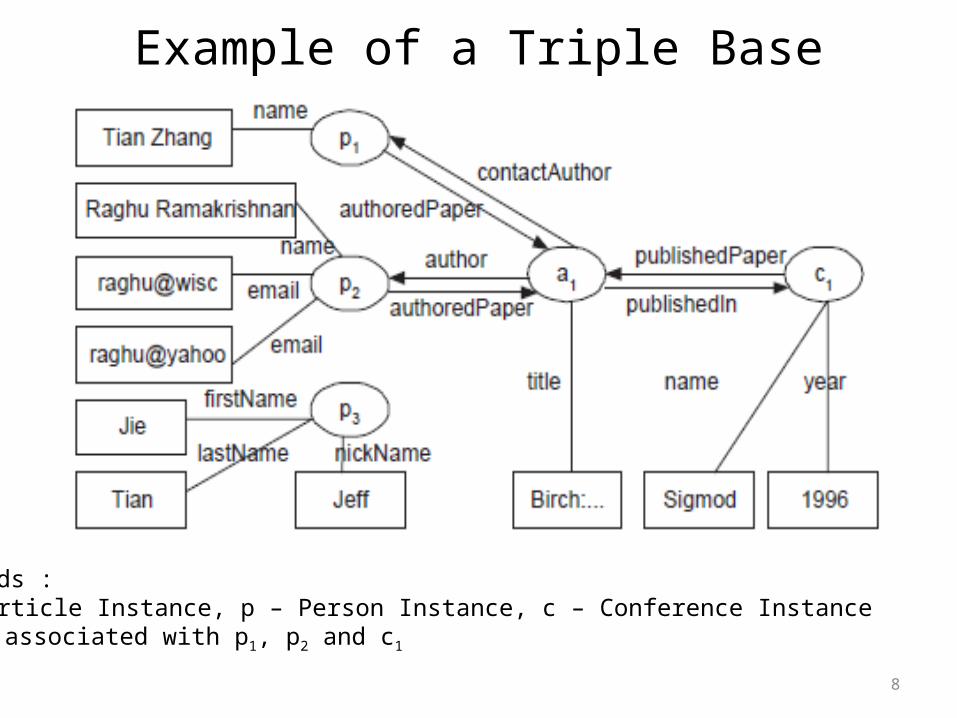
Example of a Triple Base
8
Legends :a – Article Instance, p – Person Instance, c – Conference Instancea1 is associated with p1, p2 and c1

9
• Querying Heterogeneous Data– Support queries over user independent data source structure– Support queries that enable users to specify structure, or none at
all
Problem Definition
Inverted ListsIndexing
HeterogeneousData

Solution…• Two types of query proposed• Predicate Queries
o Describes the desired instances by a set of predicateso Each predicate specifies an attribute value or an associated instanceo Example – “Raghu’s Birch paper in Sigmod 1996”o Three predicates – (“title ‘Birch’”), (“author ‘Raghu’”), (“publishedIn ‘1996
Sigmod’”)o Definition of a predicate query :
Each predicate is of the form (v, {K1, . . . ,Kn}). v (verb - attribute / association) and K1, . . . ,Kn (keywords)
v = attribute attribute predicate and v = association association predicate Returned instances need to satisfy at least one predicate in the query. An instance satisfies an attribute predicate if it contains at least one of {K1,. . . ,Kn}
in the values of attribute v or sub-attributes of v. An instance o satisfies an association predicate if there exists i, 1<=i<=n, such that
o has an association v or sub-association of v with an instance o that has an attribute value Ki. 10

• Neighborhood Keyword Querieso Extends keyword search by considering associationo A neighborhood keyword query is a set of keywords, K1, . . . ,Kn
o Definition of a Neighborhood Keyword query:• An instance satisfies a neighborhood keyword query if:
It contains at least one of {K1, . . . ,Kn} in attribute values. (relevant instance)
OR The instance is associated (in either direction) with a relevant
instance (associated instance)
11

Inverted Lists
• It is a 2-D table with indexed keyword (as rows) and instances (as columns)
• Concept:– ith row represents indexed keyword Ki
– jth column represents instance Ij
– Cell (Ki, Ij) records no. of occurrences (called as occurrence count) of keyword Ki in the attributes of Ij
– Non zero cell value Instance Ij is indexed on Ki
– Keywords are sorted and arranged in an alphabetical order in the list– Instances are ordered by their identifiers– No structural information present– Stored as sorted array or a prefix B-Tree
12
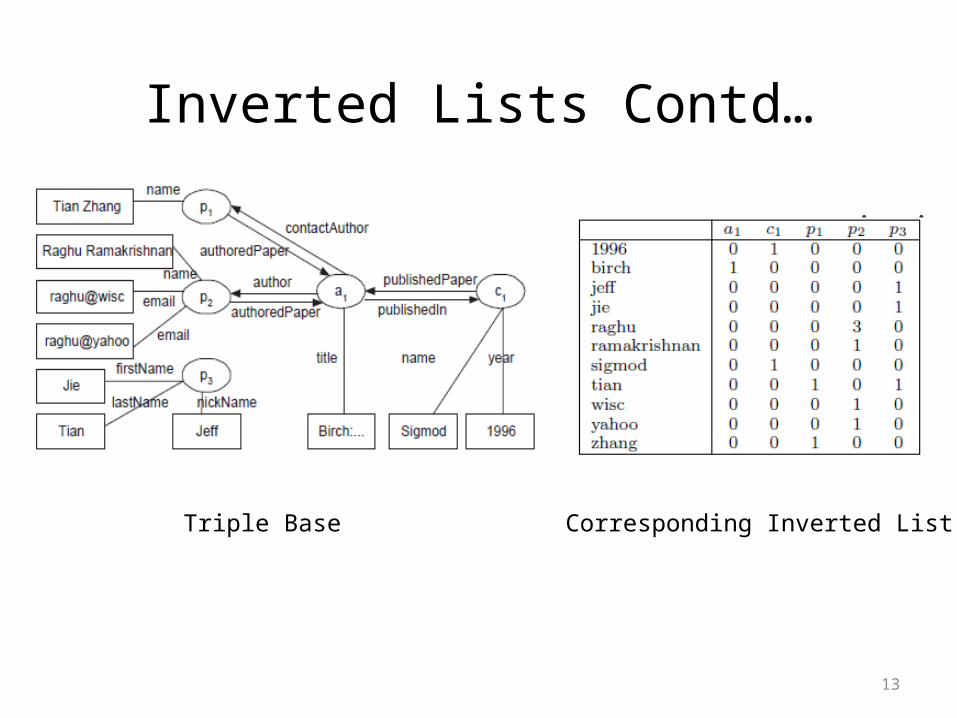
13
Triple Base Corresponding Inverted List
Inverted Lists Contd…

Indexing Structure
• It is an extension to Inverted List addressing some of the issues (structural information). E.g. Tian = Last Name or First Name ?
• It describes how attributes and association are indexed to support predicate queries
• Two ways:– Indexing Attribute ATtribute Inverted List (ATIL)– Indexing Associations Attribute-Association Inverted List (AAIL)
14

Indexing Attribute• Indexing each attribute (excessive overhead)• Specify the attribute name in the cells of IL (complex query answering)• ATIL (k-Keyword, a-attribute, I-Instance)
– There is a row in IL for k//a//, when k appears in the value of a– The cell (k//a//, I) records occurrence count– E.g. Attribute Predicate = (“LastName, ‘Tian’”)
• Query converted to Keyword query as “Tian//LastName//”• Search yields p3 and not p1
15
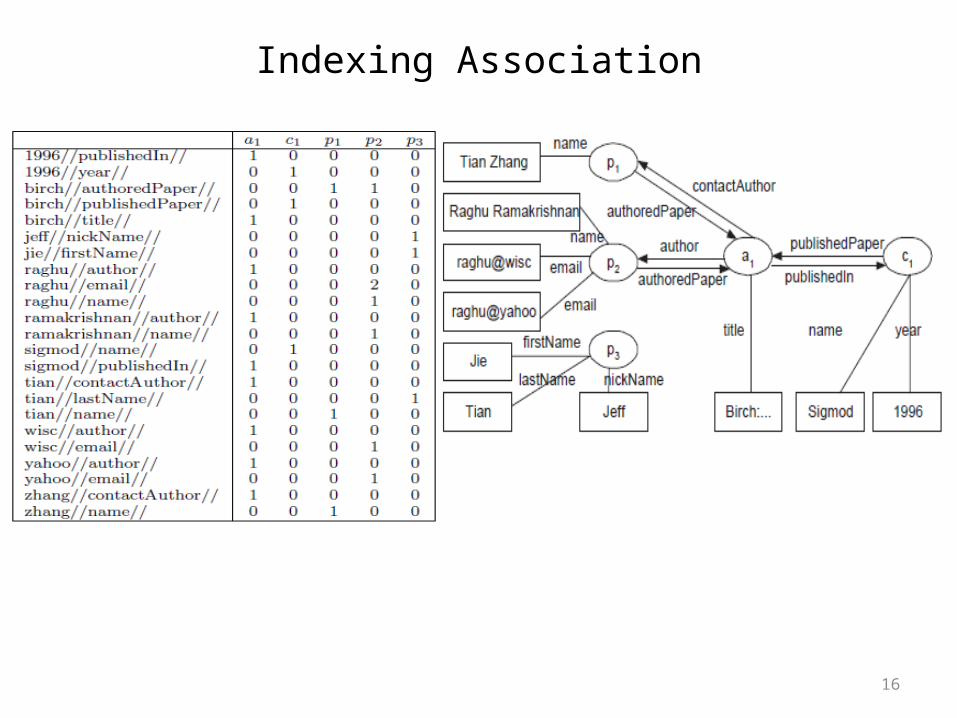
Indexing Association
• Perform keyword search on keywords, find a set of instances that contain these keywords and find associated instances for each instance (very expensive)
• AAIL (k-Keyword, r-association, I-Instance, a-attribute)– There is a row in IL for k//r//, when k appears in the value of a– The cell (k//r//, I) records occurrence count– E.g. Query = “Raghu’s Paper”
• It has an association predicate = “author ‘Raghu’” and keyword = “raghu//author//”• Search yields a1
– ATIL + association information Slightly slow in answering attribute predicates but speeds up answering association predicates
16

Indexing Hierarchies• Answering predicate queries having hierarchical structure • E.g. Query = (“Name, ‘Tian’”) Results = p1 and p3
• Find all the descendants of an attribute (FirstName, LastName and NickName)
• Expand the scope of query by adding above attributes• E.g. “Tian//Name//” OR “Tian//FirstName//” and so on• This incurs multiple index lookups and hence expensive• Solution
– Attribute IL with duplication (Dup-ATIL)– Attribute IL with Hierarchies (Hier-ATIL)– Hybrid Attribute IL (Hybrid-ATIL)
17

Index With Duplication
• Duplicate a row with attribute name for each of its ancestors• Dup-ATIL (k-Keyword, a0-attribute, a-ancestor of a0, I-Instance)
– There is a row in IL for k//a//– The cell (k//a//, I) records occurrence count of k in values of a of I– E.g. Query = “Name ‘Tian’” Results retrieved = p1 and p3
– Extensive index size (long hierarchy) problem?– Appropriate when k occurs in many a0 with common ancestors
18
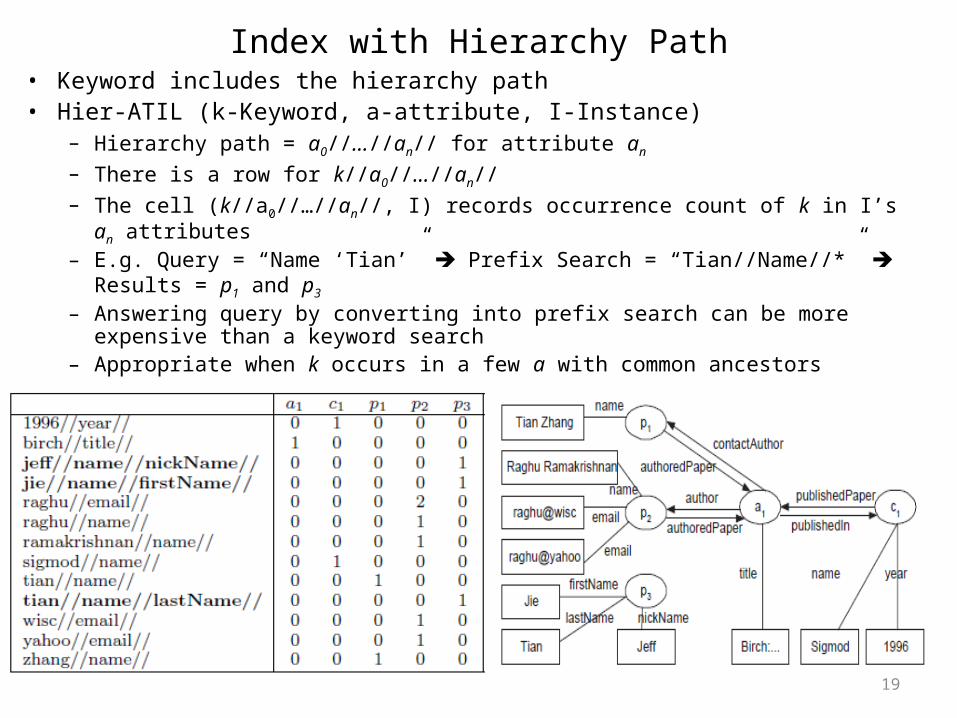
Index with Hierarchy Path• Keyword includes the hierarchy path• Hier-ATIL (k-Keyword, a-attribute, I-Instance)
– Hierarchy path = a0//…//an// for attribute an
– There is a row for k//a0//…//an//– The cell (k//a0//…//an//, I) records occurrence count of k in I’s an attributes– E.g. Query = “Name ‘Tian’” Prefix Search = “Tian//Name//*” Results = p1 and p3
– Answering query by converting into prefix search can be more expensive than a keyword search
– Appropriate when k occurs in a few a with common ancestors
19

20
Hybrid Index• Combination of Dup-ATIL and Hier-ATIL• Hybrid-ATIL (k-Keyword, a0-attribute, a-ancestor of a0, I-Instance)
– Build an IL that answer’s prefix-search query with rows < threshold (t)– Hierarchy path = a0//…//an// for attribute an
– p = k//a0//…//an// is an indexed keyword
– The cell (p//, I) records occurrence count of k in I’s an attributes
– E.g. Query = “Name ‘Jeff’” Prefix Search = “Jeff//Name//*” Result = p3
– E.g. Query = “Name ‘Tian’” Prefix Search = “Tian//Name//*” Result = p1 and p3
20t = 1
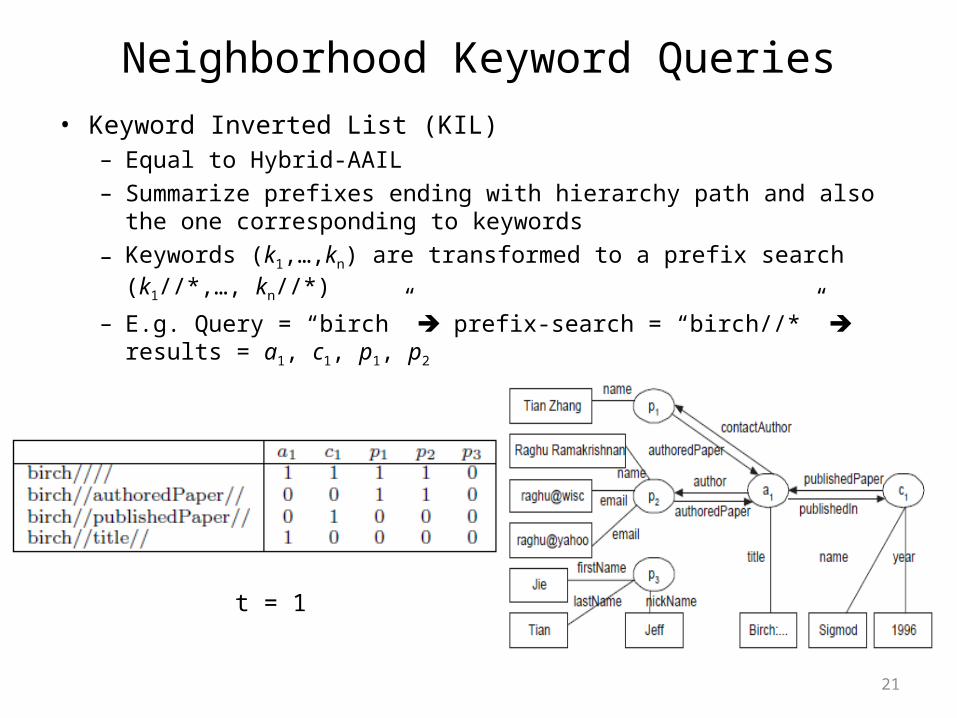
Neighborhood Keyword Queries• Keyword Inverted List (KIL)
– Equal to Hybrid-AAIL– Summarize prefixes ending with hierarchy path and also the one
corresponding to keywords– Keywords (k1,…,kn) are transformed to a prefix search (k1//*,…, kn//*)
– E.g. Query = “birch” prefix-search = “birch//*” results = a1, c1, p1, p2
21
t = 1

Experimental Evaluation• Indexing structure + text improves performance in answering both the
type of queries• Data set = personal data on desktop + some external sources• Extracted associations and relationships from disparate items are stored in
RDF file managed by Jena• RDF : Resource Description Framework• Jena : Java framework supporting Semantic Web applications• RDF file had 105,320 object instances; 300,354 attribute values; 468,402
association instances; file size = 52.4 MB• Four types of queries –
– PQAS: Predicate Queries with Attribute (no sub-attributes)– PQAC: Predicate Queries with Attribute (with sub-attributes)– PQR: Predicate Queries with association– NKQ: Neighborhood Keyword Queries
• Hardware – 4 CPU’s (with 3.2 GHz Processor and 1 MB Cache memory)– 1 GB memory (RAM)
22
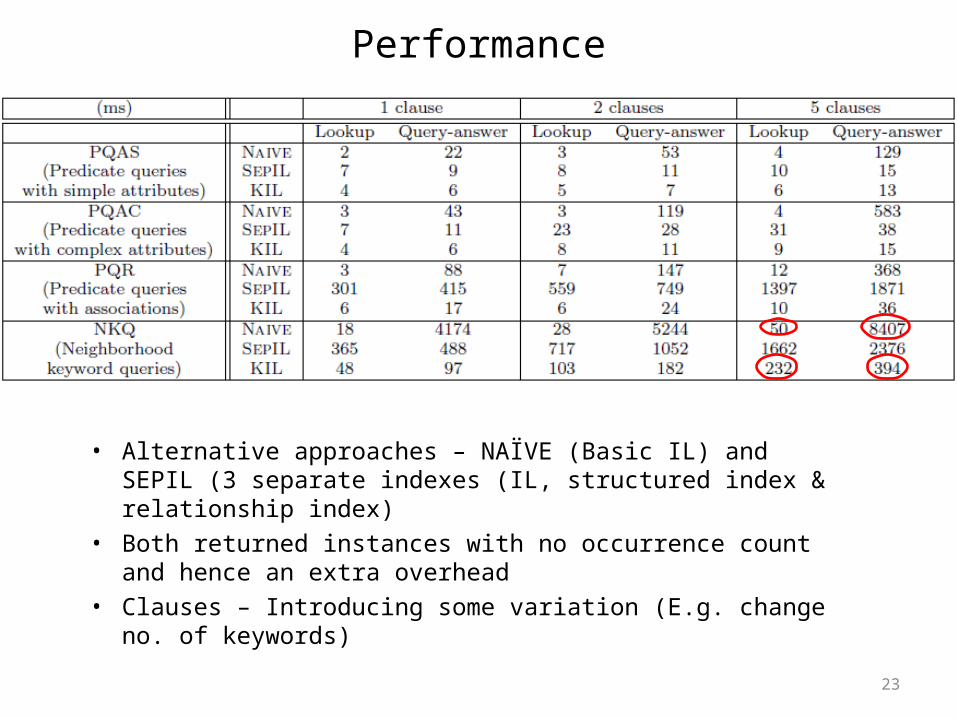
Performance
23
• Alternative approaches – NAÏVE (Basic IL) and SEPIL (3 separate indexes (IL, structured index & relationship index)
• Both returned instances with no occurrence count and hence an extra overhead
• Clauses – Introducing some variation (E.g. change no. of keywords)

Performance Contd…
• Compare efficiency of ATIL with a technique that creates separate index for each attribute
• ATIL reduces indexing time by 63 % and keyword-lookup time by 33 %
24

Related Work• Indexing XML– Indexing on Structure
• Schema-driven queries (list all book authors) • Does not index text values
– Indexing on Value• Indexes text values and encodes parent-child/ancestor-
descendant relation– Indexing on both
• Combines indexes on structure and on text• Indexing keyword queries in R-DB– DISCOVER, DBXplorer and BANKS require join-network at
run-time which is expensive
25

Conclusion
• Novel indexing approach to support flexible querying over dataspaces
• Inverted list are used for creating indexes• IL captures the structure including attributes
of instances, relationships between instances and hierarchies of schema elements.
• The experimental results shows that IL speeds up query answering
26

Future Work
• Extend indexes to support heterogeneous (attribute) values
• Appropriate ranking algorithms
27





























