Embed Size (px)
Citation preview

Indexing and Data Exchange Formats
Zachary G. IvesUniversity of Pennsylvania
CIS 455 / 555 – Internet and Web Systems
April 20, 2023

Reminders
Homework 1 Milestone 1 due tonight @ 11:59:59
2

3
Content Indexing: Unordered and Ordered Lists
Assume that we have entries such as:<keyword, #items, {occurrences}>
What does ordering buy us?
Assume that we adopt a model in which we use:<keyword, item><keyword, item>
Do we get any additional benefits?
How about:<keyword, {items}> where we fix the size
of thekeyword and the number
of items?

4
A Common Disk-Based Lookup Scheme: Tree-Based Indices
Trees have several benefits over lists: Potentially, logarithmic search time, as with
a well-designed sorted list, IF it’s balanced Ability to handle variable-length records
We’ve already seen how trees might make a natural way of distributing data, as well
How does a binary search tree fare? Cost of building? Cost of finding an item in it?
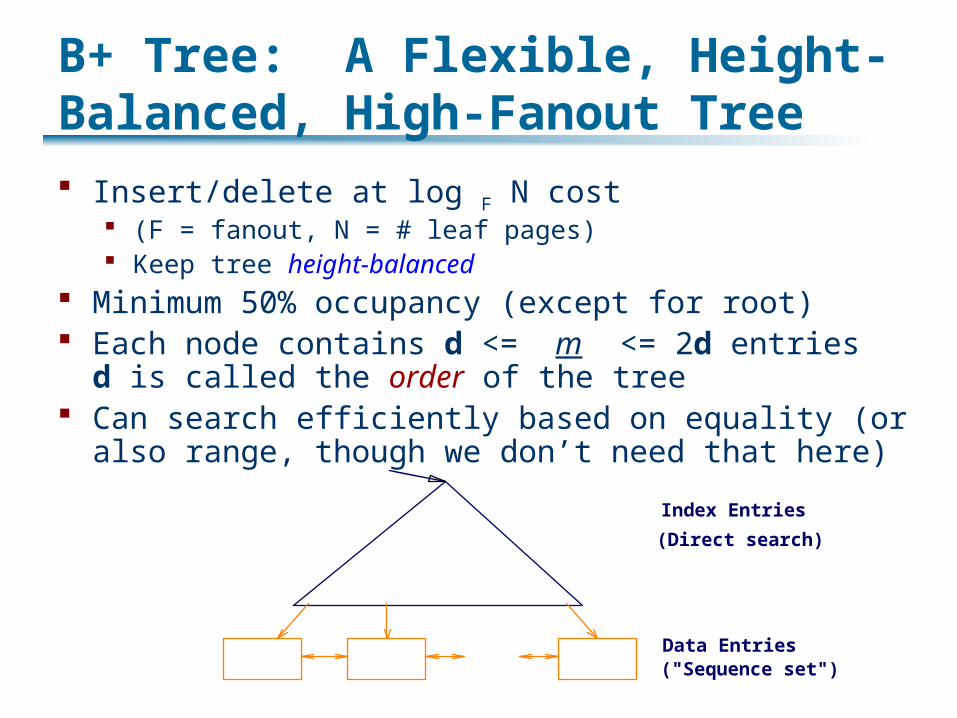
B+ Tree: A Flexible, Height-Balanced, High-Fanout Tree Insert/delete at log F N cost
(F = fanout, N = # leaf pages) Keep tree height-balanced
Minimum 50% occupancy (except for root) Each node contains d <= m <= 2d entries
d is called the order of the tree Can search efficiently based on equality (or also
range, though we don’t need that here)Index Entries
Data Entries("Sequence set")
(Direct search)

Example B+ Tree
Data (inverted list ptrs) is at leaves; intermediate nodes have copies of search keys
Search begins at root, and key comparisons direct it to a leaf
Search for be↓, bobcat↓ ...
Based on the search for bobcat*, we know it is not in the tree!
Root
best but dog
a↓ am ↓ an↓ ant↓ art↓ be↓ best↓ bit↓ bob↓ but↓can↓cry↓ dog↓ dry↓ elf↓ fox↓
art

Inserting Data into a B+ Tree
Find correct leaf L Put data entry onto L
If L has enough space, done! Else, must split L (into L and a new node L2)
Redistribute entries evenly, copy up middle key Insert index entry pointing to L2 into parent of L
This can happen recursively To split index node, redistribute entries evenly, but push
up middle key. (Contrast with leaf splits.) Splits “grow” tree; root split increases height
Tree growth: gets wider or one level taller at top
8
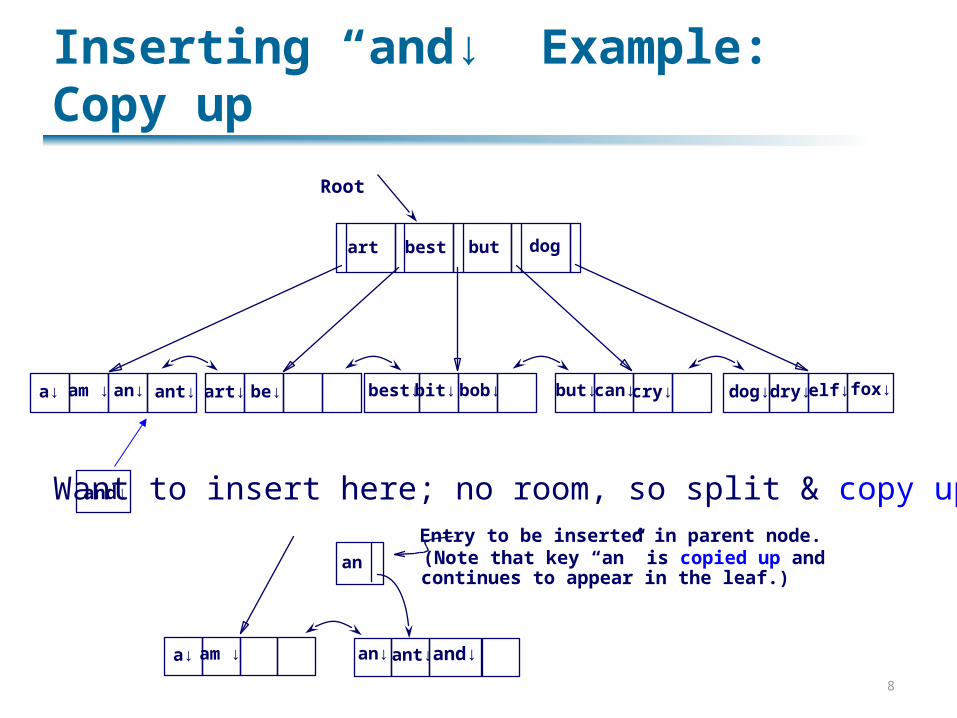
Inserting “and↓” Example: Copy up
Want to insert here; no room, so split & copy up:
a↓ am ↓ an↓ ant↓ and↓
an
Entry to be inserted in parent node.(Note that key “an” is copied up andcontinues to appear in the leaf.)
and↓
Root
best but dog
a↓ am ↓ an↓ ant↓ art↓ be↓ best↓ bit↓ bob↓ but↓can↓cry↓ dog↓ dry↓ elf↓ fox↓
art
9
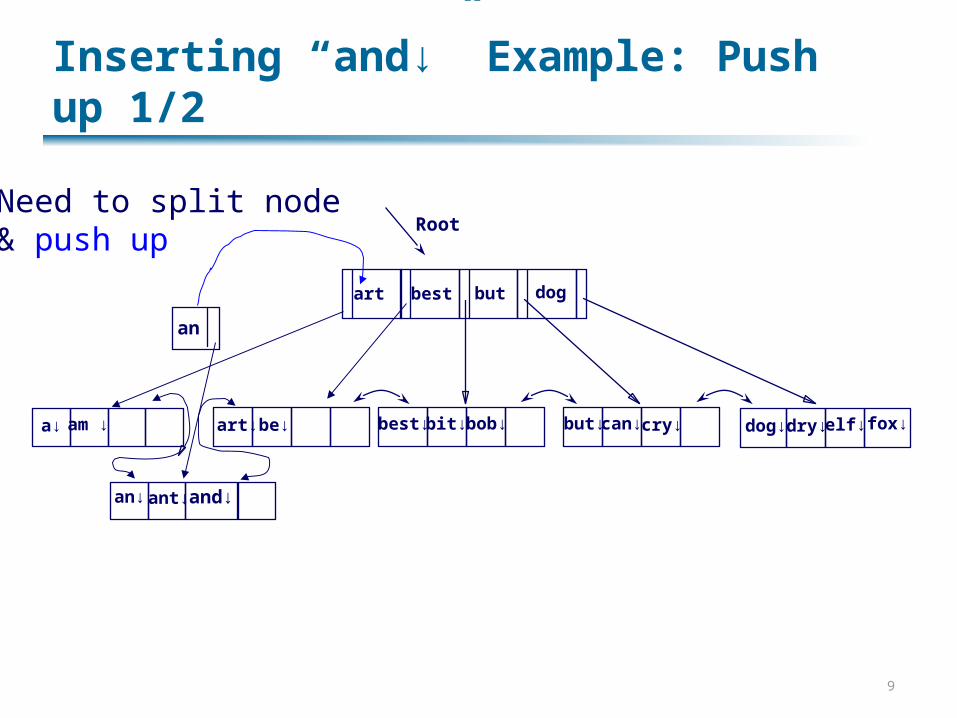
Inserting “and↓” Example: Push up 1/2
Root
art↓ be↓ best↓ bit↓ bob↓ but↓can↓ cry↓
an
Need to split node & push up
best but dogart
a↓ am ↓ dog↓ dry↓ elf↓ fox↓
an↓ ant↓ and↓
10
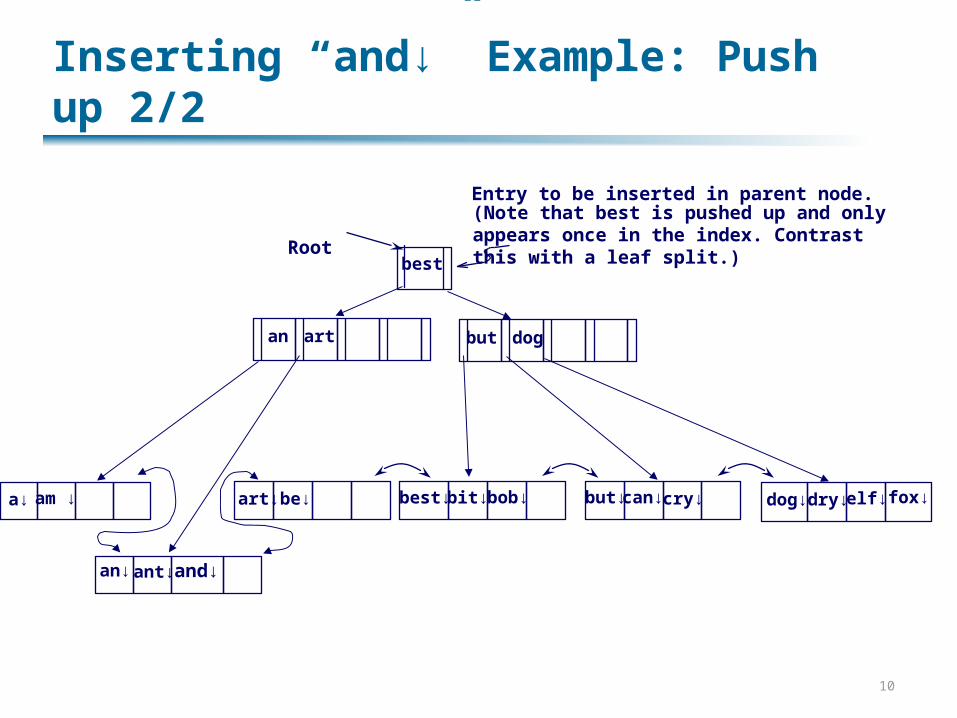
Inserting “and↓” Example: Push up 2/2
Root
art↓ be↓ best↓ bit↓ bob↓ but↓can↓ cry↓
an but dog
best
art
Entry to be inserted in parent node.(Note that best is pushed up and onlyappears once in the index. Contrastthis with a leaf split.)
a↓ am ↓ dog↓ dry↓ elf↓ fox↓
an↓ ant↓ and↓

11
Copying vs. Splitting, Summarized
Every keyword (search key) appears in at most one intermediate node Hence, in splitting an intermediate node, we push
up
Every inverted list entry must appear in the leaf We may also need it in an intermediate node to
define a partition point in the tree We must copy up the key of this entry
Note that B+ trees easily accommodate multiple occurrences of a keyword

Virtues of the B+ Tree
B+ tree and other indices are quite efficient: Height-balanced; logF N cost to search High fanout (F) means depth rarely more than 3 or 4 Almost always better than maintaining a sorted file Typically, 67% occupancy on average
A very similar structure: ISAM trees (big difference on updates)
Berkeley DB library (C, C++, Java; Oracle) is a toolkit for B+ trees that you will be using later in the semester: Interface: open B+ Tree; get and put items based on key Handles concurrency, caching, etc.

13
How Do We Distribute a B+ Tree?A Simple Method
We need to host the root at one machine and distribute the rest
What are the implications for scalability? Consider building the
index as well as searching

14
Eliminating the Root
Sometimes we don’t want a tree-structured system because the higher levels can be a central point of congestion or failure
Two strategies: Modified tree structure (e.g., BATON, Jagadish
et al.) Non-hierarchical structure (distributed hash
table, discussed in a couple of weeks)

Kinds of Content
Keyword search and inverted indices are great for locating text documents
… But what if we want to index and/or share other kinds of content? Spreadsheets Maps Purchase records Objects etc.
Let’s talk about structured data representation and transport, then later indexing and retrieval…
15

16
Sending Data
How do we send data within a program? What is the implicit model? How does this change when we need to make
the data persistent?
What happens when we are coupling systems? How do we send data between programs on
the same machine? Between different machines?

17
Marshalling
Converting from an in-memory data structure to something that can be sent elsewhere
Pointers -> something else Specific byte orderings Metadata
Note that the same logical data gets a different physical encoding A specific case of Codd’s idea of logical-physical
separation “Data model” vs. “data”

18
Communication and Streams
When storing data to disk, we have a combination of sequential and random access
When sending data on “the wire”, data is only sequential “Stream-based communication” based on packets
What are the implications here? Pipelining, incremental evaluation, …

19
Why Data Interchange Is Hard
Need to be able to understand: Data encoding (physical data model)
May have syntactic heterogeneity Endian-ness, marshalling issues Impedance mismatches
Data representation (logical data model) May have semantic heterogeneity Imprecise and ambiguous values/descriptions
20
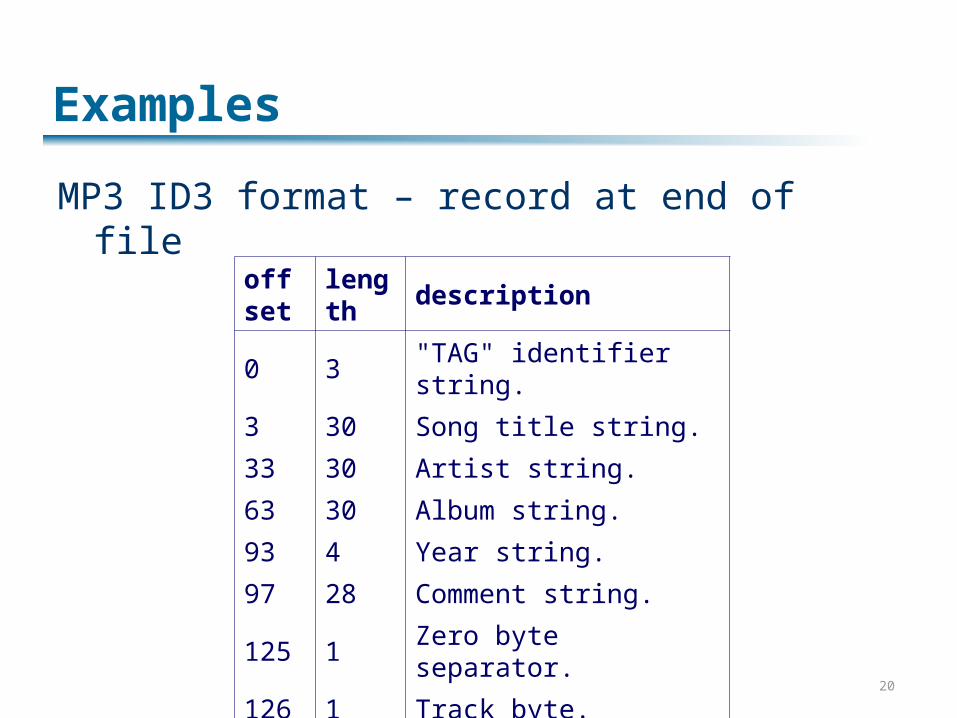
Examples
MP3 ID3 format – record at end of file
offset
length description
0 3 "TAG" identifier string.
3 30 Song title string.
33 30 Artist string.
63 30 Album string.
93 4 Year string.
97 28 Comment string.
125 1 Zero byte separator.
126 1 Track byte.
127 1 Genre byte.

21
ExamplesJPEG “JFIF” header:
Start of Image (SOI) marker -- two bytes (FFD8) JFIF marker (FFE0) length -- two bytes identifier -- five bytes: 4A, 46, 49, 46, 00
(the ASCII code equivalent of a zero terminated "JFIF" string) version -- two bytes: often 01, 02
the most significant byte is used for major revisions the least significant byte for minor revisions
units -- one byte: Units for the X and Y densities 0 => no units, X and Y specify the pixel aspect ratio 1 => X and Y are dots per inch 2 => X and Y are dots per cm
Xdensity -- two bytes Ydensity -- two bytes Xthumbnail -- one byte: 0 = no thumbnail Ythumbnail -- one byte: 0 = no thumbnail (RGB)n -- 3n bytes: packed (24-bit) RGB values for the
thumbnail pixels, n = Xthumbnail * Ythumbnail

22
Finding File Formats
http://www.wikipedia.org/ http://www.wotsit.org/ etc.

23
The Problem
You need to look into a manual to find file formats (At best, e.g., MS .DOC file format)
The Web is about making data exchange easier… Maybe we can do better! “The mother of all file formats”

24
Desiderata for Data Interchange
Ability to represent many kinds of information
Different data structures
Hardware-independent encodingEndian-ness, UTF vs. ASCII vs. EBCDIC
Standard tools and interfaces Ability to define “shape” of expected data
With forwards- and backwards-compatibility!
That’s XML…

25
Consumers of XML
A myriad of tools and interfaces, including: DOM – document object model
Standard OO representation of an XML tree
SAX – simple API for XML An event-driven parser interface for XML
startElement, endElement, etc.
Ant – Java-based “make” tool with XML “makefile”
XPath, XQuery, XSL, XSLT Web service standards Anything AJAX (“mash-ups”)

26
XML as a Data Model
XML “information set” includes 7 types of nodes: Document (root) Element Attribute Processing instruction Text (content) Namespace: Comment
XML data model includes this, plus typing info, plus order info and a few other things

27
Example XML Document<?xml version="1.0" encoding="ISO-8859-1" ?> <dblp> <mastersthesis mdate="2002-01-03" key="ms/Brown92"> <author>Kurt P. Brown</author> <title>PRPL: A Database Workload Specification Language</title> <year>1992</year> <school>Univ. of Wisconsin-Madison</school> </mastersthesis> <article mdate="2002-01-03" key="tr/dec/SRC1997-018"> <editor>Paul R. McJones</editor> <title>The 1995 SQL Reunion</title> <journal>Digital System Research Center Report</journal> <volume>SRC1997-018</volume> <year>1997</year> <ee>db/labs/dec/SRC1997-018.html</ee> <ee>http://www.mcjones.org/System_R/SQL_Reunion_95/</ee> </article>
Processing Instr.
Element
Attribute
Close-tag
Open-tag

28
XML Data Model Visualized(~ Document Object Model)
Root
?xml dblp
mastersthesis article
mdate key
author title year school editor title yearjournal volume eeee
mdatekey
2002…
ms/Brown92
Kurt P….
PRPL…
1992
Univ….
2002…
tr/dec/…
Paul R.
The…
Digital…
SRC…
1997
db/labs/dec
http://www.
attributeroot
p-i element
text

29
A Few Common Uses of XML
Serves as an extensible HTML Allows custom tags (e.g., used by MS Word,
openoffice) Supplement it with stylesheets (XSL) to define
formatting
Provides an exchange format for data (still need to agree on terminology) Tables, objects, etc.
Format for marshalling and unmarshalling data in Web Services

30
XML as a Super-HTML(MS Word)
<h1 class="Section1"><a name="_top“ />CIS 550: Database and Information Systems</h1><h2 class="Section1">Fall 2003</h2><p class="MsoNormal">
<place>311 Towne</place>, Tuesday/Thursday<time Hour="13" Minute="30">1:30PM –
3:00PM</time></p>

31
XML Easily Encodes Relations
id course
grade
1 330-f03
B
23 455-s04
A<student-course-grade>
<tuple><sid>1</sid><course>330-f03</
course><grade>B</grade></tuple><tuple>
<sid>23</sid><course>455-s04</course><grade>A</grade></tuple>
</student-course-grade>
Student-course-grade

32
It Also Encodes Objects (with Pointers Represented as IDs)
<projects> <project class=“cse455” >
<type>Programming</type><memberList>
<teamMember>Joan</teamMember><teamMember>Jill</teamMember>
</memberList><codeURL>www….</codeURL><incorporatesProjectFrom class=“cse330” />
</project>…

33
XML and Code
Web Services (.NET, Java web service toolkits) are using XML to pass parameters and make function calls – marshalling as part of remote procedure calls SOAP + WSDL Why?
Easy to be forwards-compatible Easy to read over and validate (?) Generally firewall-compatible
Drawbacks? XML is a verbose and inefficient encoding! But if the calls are only sending a few 100s of bytes, who
cares?

34
XML When Tags Are Used by Different Sources
Namespaces allow us to specify a context for different tags
Two parts: Binding of namespace to URI Qualified names
<tag xmlns:myns=http://www.fictitious.com/mypath xmlns=“http://www.default/mypath”><thistag>is in default namespace</thistag><myns:thistag>this a different tag</myns:thistag></tag>

35
XML Isn’t Enough on Its Own
It’s too unconstrained for many cases! How will we know when we’re getting
garbage? How will we query? How will we understand what we got?





























