Embed Size (px)
Citation preview

Pattern Recognition 45 (2012) 2868–2883
Contents lists available at SciVerse ScienceDirect
Pattern Recognition
0031-32
doi:10.1
n Corr
E-m
journal homepage: www.elsevier.com/locate/pr
Incremental face recognition for large-scale social network services
Kwontaeg Choi a, Kar-Ann Toh b, Hyeran Byun a,n
a Department of Computer Science, Yonsei University, 134 Shinchon-dong, Seodaemun-gu, Seoul 120-749, Republic of Koreab School of Electrical & Electronic Engineering, Yonsei University, 134 Shinchon-dong, Seodaemun-gu, Seoul 120-749, Republic of Korea
a r t i c l e i n f o
Article history:
Received 13 April 2011
Received in revised form
25 December 2011
Accepted 2 February 2012Available online 16 February 2012
Keywords:
Face recognition
Social network service
Incremental learning
Gabor filter
Neural network
03/$ - see front matter & 2012 Elsevier Ltd. A
016/j.patcog.2012.02.002
esponding author. Tel.: þ82 2 2123 2719; fax
ail address: [email protected] (H. Byun).
a b s t r a c t
Due to the rapid growth of social network services such as Facebook and Twitter, incorporation of face
recognition in these large-scale web services is attracting much attention in both academia and
industry. The major problem in such applications is to deal efficiently with the growing number of
samples as well as local appearance variations caused by diverse environments for the millions of users
over time. In this paper, we focus on developing an incremental face recognition method for Twitter
application. Particularly, a data-independent feature extraction method is proposed via binarization of
a Gabor filter. Subsequently, the dimension of our Gabor representation is reduced considering various
orientations at different grid positions. Finally, an incremental neural network is applied to learn the
reduced Gabor features. We apply our method to a novel application which notifies new photograph
uploading to related users without having their ID being identified. Our extensive experiments show
that the proposed algorithm significantly outperforms several incremental face recognition methods
with a dramatic reduction in computational speed. This shows the suitability of the proposed method
for a large-scale web service with millions of users.
& 2012 Elsevier Ltd. All rights reserved.
1. Introduction
1.1. Background and motivation
In recent days, social network services (SNS) such as Twitter,Facebook and Blogger strongly affect our daily life, the industryand the academy. In order to understand and analyze this new lifestyle, new research fields emerged and several internationalworkshops have also been held in these various fields for years.These research fields include computational social science [1],computational social network analysis [2] and computationaljournalism [3]. Among these fields, social media data such associal blogs, wikis, podcasts, photographs and video is onlineresource which is shared and analyzed among members of SNS.
Among these social media data, photography analysis contain-ing faces is attracting attention from the academy and theindustry due to fact that facial photographs occupy a significantshare in SNS. Face images analysis such as detection, recognition,3D modeling and tracking have been studied extensively in thefields of computer vision, pattern recognition and machine learn-ing. Various commercial products and research methods havebeen proposed for the face recognition related applications.
For example, Face.com offers a platform for developers andpublishers to automatically detect and recognize faces in photos
ll rights reserved.
: þ82 2 363 2599.
using a robust, free, REST API. The ‘‘remembAR’’ App for Androidplatform allows a user to look up the Facebook account from hisFacebook friends with same event participants. Augmented IDprovided a new interface combining face recognition, tracking,augmented reality and SNS. Moreover, Google has acquiredNevenVision, Riya, and PittPatt and deployed face recognitioninto Picasa. Facebook has licensed Face.com to enable automatedtagging.
Several works on face recognition under social network servicehave been proposed recently [2,4–9]. Particularly, in [9], theauthors focused on the democratization of surveillance, faces asconduits between online and off-line data, the emergence ofpersonally predictable information, the rise of visual, facialsearches and the future of privacy in the world of augmentedreality. Thus, face recognition under SNS is a very challenging andyet useful application.
Unlike conventional face recognition under a rather con-strained environment, face recognition under SNS has to dealwith large appearance variations and computational complexityfor millions of users. To deal with the former problem, a fusionapproach using contextual information can be used [2,4,7]. Thelater is more critical for our application. For example, consider acertain algorithm which takes 5 s for learning. The test time is notunder consideration since it is usually very short compared to thelearning time. If 1000 users requests their learning processessimultaneously, it will take 5000 s to accomplish the entirerequests. This means that the first user will wait 5 s to finishhis learning process and the last user will wait 5000 s. Unlike
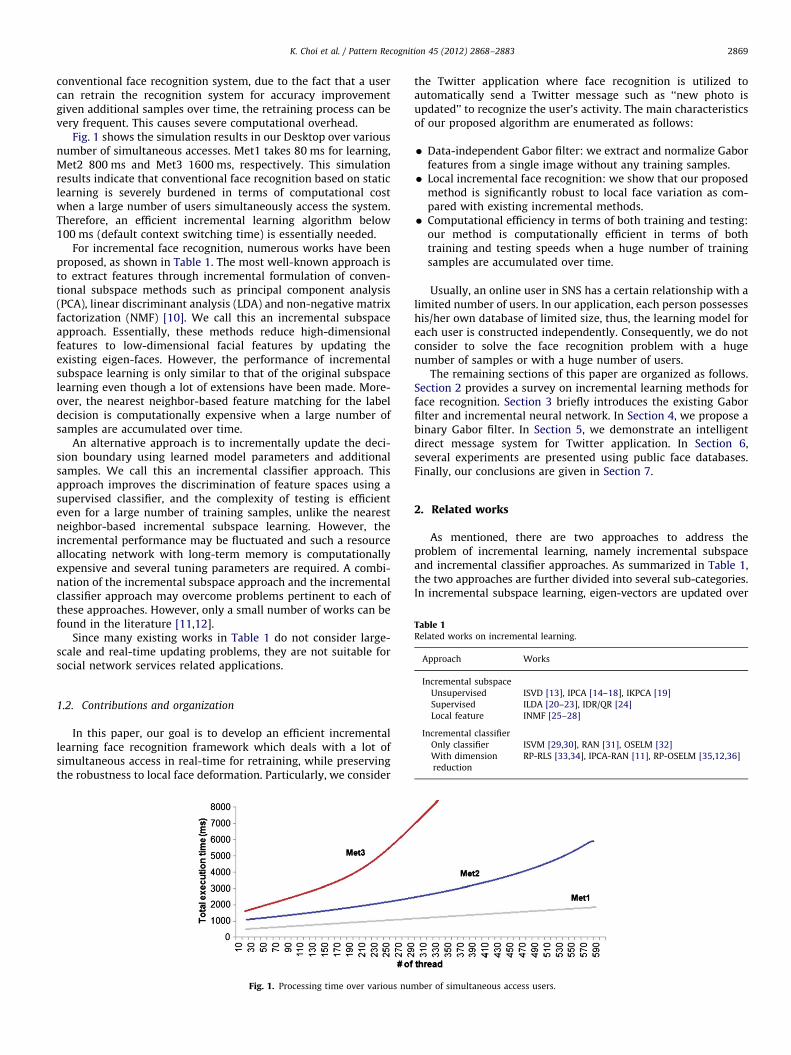
Table 1Related works on incremental learning.
Approach Works
K. Choi et al. / Pattern Recognition 45 (2012) 2868–2883 2869
conventional face recognition system, due to the fact that a usercan retrain the recognition system for accuracy improvementgiven additional samples over time, the retraining process can bevery frequent. This causes severe computational overhead.
Fig. 1 shows the simulation results in our Desktop over variousnumber of simultaneous accesses. Met1 takes 80 ms for learning,Met2 800 ms and Met3 1600 ms, respectively. This simulationresults indicate that conventional face recognition based on staticlearning is severely burdened in terms of computational costwhen a large number of users simultaneously access the system.Therefore, an efficient incremental learning algorithm below100 ms (default context switching time) is essentially needed.
For incremental face recognition, numerous works have beenproposed, as shown in Table 1. The most well-known approach isto extract features through incremental formulation of conven-tional subspace methods such as principal component analysis(PCA), linear discriminant analysis (LDA) and non-negative matrixfactorization (NMF) [10]. We call this an incremental subspaceapproach. Essentially, these methods reduce high-dimensionalfeatures to low-dimensional facial features by updating theexisting eigen-faces. However, the performance of incrementalsubspace learning is only similar to that of the original subspacelearning even though a lot of extensions have been made. More-over, the nearest neighbor-based feature matching for the labeldecision is computationally expensive when a large number ofsamples are accumulated over time.
An alternative approach is to incrementally update the deci-sion boundary using learned model parameters and additionalsamples. We call this an incremental classifier approach. Thisapproach improves the discrimination of feature spaces using asupervised classifier, and the complexity of testing is efficienteven for a large number of training samples, unlike the nearestneighbor-based incremental subspace learning. However, theincremental performance may be fluctuated and such a resourceallocating network with long-term memory is computationallyexpensive and several tuning parameters are required. A combi-nation of the incremental subspace approach and the incrementalclassifier approach may overcome problems pertinent to each ofthese approaches. However, only a small number of works can befound in the literature [11,12].
Since many existing works in Table 1 do not consider large-scale and real-time updating problems, they are not suitable forsocial network services related applications.
Incremental subspace
Unsupervised ISVD [13], IPCA [14–18], IKPCA [19]
Supervised ILDA [20–23], IDR/QR [24]
Local feature INMF [25–28]
Incremental classifier
Only classifier ISVM [29,30], RAN [31], OSELM [32]
With dimension
reduction
RP-RLS [33,34], IPCA-RAN [11], RP-OSELM [35,12,36]
1.2. Contributions and organization
In this paper, our goal is to develop an efficient incrementallearning face recognition framework which deals with a lot ofsimultaneous access in real-time for retraining, while preservingthe robustness to local face deformation. Particularly, we consider
Fig. 1. Processing time over various num
the Twitter application where face recognition is utilized toautomatically send a Twitter message such as ‘‘new photo isupdated’’ to recognize the user’s activity. The main characteristicsof our proposed algorithm are enumerated as follows:
�
be
Data-independent Gabor filter: we extract and normalize Gaborfeatures from a single image without any training samples.
� Local incremental face recognition: we show that our proposedmethod is significantly robust to local face variation as com-pared with existing incremental methods.
� Computational efficiency in terms of both training and testing:our method is computationally efficient in terms of bothtraining and testing speeds when a huge number of trainingsamples are accumulated over time.
Usually, an online user in SNS has a certain relationship with alimited number of users. In our application, each person possesseshis/her own database of limited size, thus, the learning model foreach user is constructed independently. Consequently, we do notconsider to solve the face recognition problem with a hugenumber of samples or with a huge number of users.
The remaining sections of this paper are organized as follows.Section 2 provides a survey on incremental learning methods forface recognition. Section 3 briefly introduces the existing Gaborfilter and incremental neural network. In Section 4, we propose abinary Gabor filter. In Section 5, we demonstrate an intelligentdirect message system for Twitter application. In Section 6,several experiments are presented using public face databases.Finally, our conclusions are given in Section 7.
2. Related works
As mentioned, there are two approaches to address theproblem of incremental learning, namely incremental subspaceand incremental classifier approaches. As summarized in Table 1,the two approaches are further divided into several sub-categories.In incremental subspace learning, eigen-vectors are updated over
r of simultaneous access users.

K. Choi et al. / Pattern Recognition 45 (2012) 2868–28832870
time for dimension reduction, while decision regions are updatedover time in the incremental classifier approach.
For the incremental subspace approach, dimension reductiontechniques such as incremental PCA (IPCA), incremental LDA(ILDA) and incremental NMF (INMF), have been proposed. Inthese methods, the current basis is updated using previous basisand new training samples. For example, [13] presented a theore-tical derivation of merging and splitting eigenspace models forincremental computation of an eigenspace model. The candidcovariance-free incremental principal component analysis(CCIPCA) method proposed in [15] incrementally computed theprincipal components of a sample sequence without estimatingthe covariance matrix. Ren and Dai [18] proposed the incrementalversion of bidirectional principal component analysis using con-cepts of tensor, k-mode unfolding and matricization. For non-linear feature extraction which overcomes the performancebarrier of liner IPCA, [19] proposed an approximated incrementalkernel PCA updating scheme which used the kernel trick. Insteadof processing the samples one-by-one, a chunk-by-chunk IPCAtechnique can be found in [17].
The incremental version of supervised learning-based LDAconsidered two updating processes for the within-class (Sw)and between-class (Sb) scatter matrices. The main difficulty forthis ILDA formulation [21] is that not all class data are presentat every incremental step. Pang et al. [21] provided an incre-mental calculation of Sw and Sb without updating the eigenspace.Ye et al. [24] adopted an QR-updating technique, however,information is lost during the first projection. Zhao and Yuen[22] incrementally reformulated the generalized singular valuedecomposition LDA in order to handle the inverse of Sw. Kim et al.[20] utilized a sufficient spanning set approximation in order tosignificantly reduce the computational complexity of the eigen-vectors of Sw and Sb. In [22,20], minor components were removedduring updating to reduce the computational cos. However, therewas a trade-off between accuracy and efficiency depending onhow many minor components were removed. Moreover, para-meter tuning was not easy [23]. Recently, [23] proposed efficientleast square-based LS-ILDA which calculated the exact leastsquare solution of batch LDA. This method was compared to[22] and achieved high accuracy with low CPU cost. However,LS-ILDA provided one-by-one updating formulation.
As an incremental version of local feature extraction, severalINMFs [25–28] have been proposed. Chen et al. [25] addressedboth the time-consuming and incremental learning aspects of theoriginal NMF by imposing supervised class information. Bucakand Gunsel [26] proposed an incremental subspace learningmethod via a weighted cost function which also allows control-ling the memory of factorization. Ref. [27] alleviated the require-ment to specify the number of base vectors in advance byassuming one new data sample at a time. Unlike these threemethods, [28] used both incremental and decremental non-negative matrix factorization to produce a better performancewith low computational cost.
For the incremental classifier approach, conventional classifierssuch as neural networks and support vector machines (SVM) havebeen reformulated into incremental form, in which the decisionboundaries are updated incrementally. For example, [29,30] pro-posed an incremental SVM (ISVM) which retained the Karush–Kuhn–Tucker conditions on all previously seen data while updat-ing the SVM upon inclusion or deletion of a support vector, given anew data sample. Ref. [31] proposed a resource allocation network(RAN) which had a similar structure to that of the radial basisfunction network but that used a sequential learning algorithmthat added and pruned hidden neurons so as to produce aparsimonious network. More recently, an extreme learningmachine (ELM) [37] based on single hidden layer feedforward
networks was proposed for fast training by means of a closed-form algorithm. In [32], the ELM was extended via a recursiveleast squares method for incremental learning. The experimentalresults in [32] had shown that the method was faster than othersequential algorithms and produced better generalization perfor-mances on many benchmark problems of regression, classifica-tion and time-series prediction. In [38], the ELM was extended forthe improvement of classification generalization via solving thetotal error rate minimization problem [39,40].
In order to reduce the computational cost for high-dimen-sional face images, a combination of dimension reduction and anincremental classifier has been proposed. For example, [36]proposed a face recognition system using neural networks withincremental learning ability where PCA and RAN were combined.In [11], an IPCA was combined with RAN. Also, a combination ofrandom projection and a recursive least squares-based classifiercan be found in [33,34]. These two works proposed an efficientincremental learning face recognition method for a large-scaleweb service. However, the recognition accuracy of these methodsis only comparable to that of the conventional PCA and they aresensitive to local face variations.
Although incremental learning alleviates the computationalcost compared to that of the batch-based approach, the existingincremental learning method, for face recognition suffers fromthe following difficulties:
�
Accuracy aspects:J The accuracy performances of the existing incrementalsubspace methods as shown in Table 1 are frequently seento be lower than those of batch-based state-of-the-artmethods. Particularly, the development of incrementalmethods has yet to follow up with the progress in batch-based methods.
J The accuracy performances of existing incremental sub-space methods (see Table 1) will degrade if old trainingsamples are not reprojected to new basis.
J The accuracy performances of many existing incrementalsubspace methods (except [19] in Table 1) will degrade ifthe features or distribution of features have non-linearstructure. This is because the kernel trick for non-linearfeature extraction is not applicable to existing incrementalformulations.
J Most existing works except INMF [25–28] are sensitive tolocal variations.
�
Computational aspects:J Those methods that adopt nearest neighbor-based incre-mental subspace learning get slower and require a largememory storage as the number of samples increasesover time.
J The updating cost of some implementations such as ISVM,ILDA and INMF is still computationally expensive.
J Some works provide only one-by-one updating rather thanchunk-by-chunk.
3. Preliminaries
In this section, we present some preliminaries for immediatereference. Particularly, Gabor filters and sequential feedforwardneural network will be introduced since these are two keyingredients of the proposed method.
3.1. Gabor features
It is well-known that a Gabor filter can capture salient visualproperties such as spatial localization, orientation selectivity and

K. Choi et al. / Pattern Recognition 45 (2012) 2868–2883 2871
spatial frequency characteristics [41]. In the 2D spatial domain, aGabor wavelet is a complex exponential modulated by a Gaussian,
gw,yðpx,pyÞ ¼1
2ps2exp �
x02þy02
2s2þ jwx0
� �ð1Þ
where x0 ¼ px cosðyÞþpy sinðyÞ, y0 ¼ �px sinðyÞþpy cosðyÞ, px andpy denote the pixel positions, w represents the center frequency, yrepresents the orientation of the Gabor wavelet, while s denotesthe standard deviation of the Gaussian function.
Usually, the Gabor features of a 2D image are extracted viaconvolution with several Gobor filters at different orientationsand scales. This process dramatically increases the featuredimension.
3.2. Sequential feedforward neural network
Given n samples xiARD and a correspond target yi, singlehidden-layer feedforward neural networks (SLFNs) with h hiddennodes and an activation function f can be mathematically mod-eled as
yi ¼Xh
j ¼ 1
bjf ðwjxiþbjÞ ð2Þ
where wj ¼ ½uj1,uj2, . . . ,ujD�T is the weight vector connecting the
jth hidden node to the input nodes, bj is the threshold of the jthhidden node and bjARh is the weight vector connecting the jthhidden node to the output nodes.
For a K-class problem, denote XARD�n as training samplesand Y¼ ½b1, . . . ,bK �ARh�K as the weight matrix, and YARn�K
as the indicator matrix. The n equations above can be writtencompactly as
HY¼ Y ð3Þ
where the hidden layer output matrix H is
H¼ f ðX,w,bÞ ¼
f ðw1x1þb1Þ � � � f ðwhx1þbhÞ
^ & ^
f ðw1xnþb1Þ � � � f ðwhxnþbhÞ
264
375 ð4Þ
The weight parameters Y can be estimated by minimizing theleast squares error, giving the solution [37]
Y¼ ðHT HÞ�1HT Y ð5Þ
Because SLFNs can work as universal approximators withadjustable hidden parameters, the hidden node parameters ofSLFNs can actually be randomly generated according to anycontinuous sampling distribution. This is seen in a random settingof w and b in the Extreme Learning Machine (ELM) [37]. Unliketraditional implementations, the ELM shows that the hiddennode parameters can be completely independent of the trainingdata. Moreover, for new data samples, the ELM can be retrained
Fig. 2. Our fusion framework which consists of various
efficiently using only those additional samples via a recursiveleast squares formulation. For this purpose, Huang [32] proposedan online sequential ELM (OSELM). When a new block of featuredata Htþ1 ¼ f ðXtþ1,w,bÞ and the corresponding indicator matrixYtþ1 are received, the parameter Ytþ1 can be estimated recur-sively as
Ytþ1 ¼YtþPtþ1HTtþ1ðYtþ1�Htþ1YtÞ ð6Þ
where
Ptþ1 ¼ Pt�PtHTtþ1ðIþHtþ1PtH
Ttþ1Þ
�1Htþ1Pt ð7Þ
OSELM is computationally efficient for high-dimensional faceimages and provides one-by-one and chunk-by-chunk updating.Unfortunately, OSELM suffers from an unstable least squaressolution due to a low rank problem.
4. The proposed binary Gabor-based incremental learningframework
In this section, we incorporate a binary Gabor filter into anincremental neural network in order to efficiently deal with theproblem of increasing samples over time in large-scale applications.
4.1. Overview
In this section,we provide an overview of the proposedmethod. As illustrated in Fig. 2, the two ingredients of our methodare binary Gabor filters and regularized OSELM. The formerextracts facial features without training samples and theextracted features are normalized using static min/max values.The later incrementally learns the normalized features. Therefore,the proposed method is computationally inexpensive at eachlearning step. In order to add robustness to local appearancevariations, we divide a 2D image into equally sized sub regionsand then our binary Gabor filters are applied at the center of eachsub region. Finally, a fusion method is adopted in order to coverthe entire sub regions.
4.2. Binary Gabor filter-based OSELM (BG-OSELM)
When the training samples are dynamic over time, a statictraining-based feature extraction cannot adopt efficiently. Thus,direct extraction of features without training is a more suitableapproach for such a system. Examples of such feature extractioninclude random projection (RP), discrete cosine transform (DCT)and Gabor filters. In this paper, we adopt a Gabor filtering methodwhich shows good performance in face recognition and textureclassification applications [42].
Usually, the Gabor features of a 2D image are extracted viaconvolution of the image with several Gobor filters at different
orientations and a fixed scale binary Gabor filter.
K. Choi et al. / Pattern Recognition 45 (2012) 2868–28832872
orientations and scales. Given training samples XARD�n and aGabor filter bank g with dy orientations and ds scales, totally dy �
ds filters, the hidden layer output matrix H in Eq. (4) can bewritten as follows:
H¼ fconvðX,gÞ
z,w,b
� �¼ f
convðX,gÞ�min
max�min,w,b
� �
ARn�h4Rn�ðD�dy �dsÞ ð8Þ
where convð�Þ is a convolution operation, and z is a normalizationfactor which is used in the activation function of neural networkswhose features are normalized to 0� 1. In this paper, we adopt amin–max normalization. Thus, min/max are minimum/maximumvalues of convðX,gÞ. Here, we refer to this binary Gabor-basedOSELM (BG-OSELM).
Unfortunately, Eq. (8) is computationally expensive due tonumerous convolutions over every image position at differentscales and rotations. Moreover, the estimation of min/max isunstable since sufficient initial training samples are not providedsufficiently in advance under an incremental learning framework.In addition, these normalization factors must be fixed in advancesince all samples most be re-normalize when these factors areupdated over time.
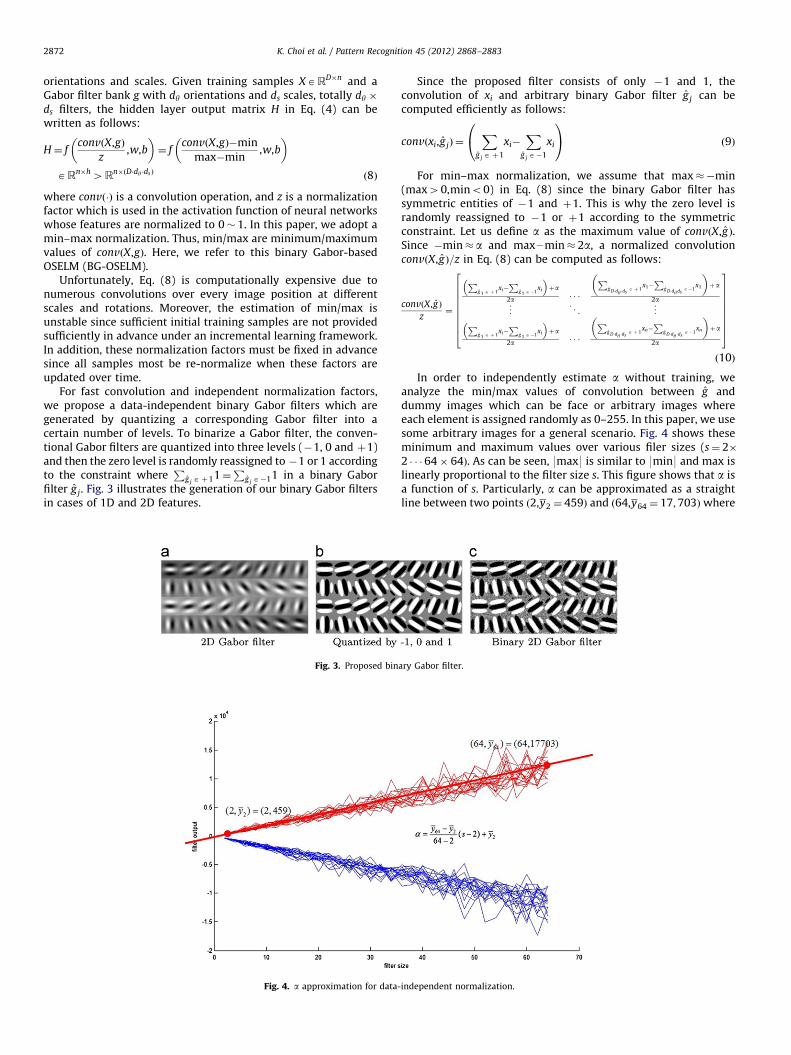
For fast convolution and independent normalization factors,we propose a data-independent binary Gabor filters which aregenerated by quantizing a corresponding Gabor filter into acertain number of levels. To binarize a Gabor filter, the conven-tional Gabor filters are quantized into three levels (�1, 0 and þ1)and then the zero level is randomly reassigned to �1 or 1 accordingto the constraint where
Pg j A þ11¼
Pg j A�11 in a binary Gabor
filter g j. Fig. 3 illustrates the generation of our binary Gabor filtersin cases of 1D and 2D features.
Fig. 3. Proposed bin
Fig. 4. a approximation for data-
Since the proposed filter consists of only �1 and 1, theconvolution of xi and arbitrary binary Gabor filter g j can becomputed efficiently as follows:
convðxi,g jÞ ¼X
g j A þ1
xi�X
g j A�1
xi
0@
1A ð9Þ
For min–max normalization, we assume that max��min(max40,mino0) in Eq. (8) since the binary Gabor filter hassymmetric entities of �1 and þ1. This is why the zero level israndomly reassigned to �1 or þ1 according to the symmetricconstraint. Let us define a as the maximum value of convðX,gÞ.Since �min� a and max2min� 2a, a normalized convolutionconvðX,gÞ=z in Eq. (8) can be computed as follows:
convðX,g Þ
z¼
Pg 1 A þ 1
xi�P
g 1 A�1xi
� �þa
2a � � �
Pg D�dy �ds
A þ 1x1�P
g D�dydsA�1
x1
� �þa
2a^ & ^
Pg 1 A þ 1
xi�P
g 1 A�1xi
� �þa
2a � � �
Pg D�dy �ds
A þ 1xn�P
g D�dy �dsA�1
xn
� �þa
2a
2666666664
3777777775ð10Þ
In order to independently estimate a without training, weanalyze the min/max values of convolution between g anddummy images which can be face or arbitrary images whereeach element is assigned randomly as 0–255. In this paper, we usesome arbitrary images for a general scenario. Fig. 4 shows theseminimum and maximum values over various filer sizes (s¼ 2�2 � � �64� 64Þ. As can be seen, 9max9 is similar to 9min9 and max islinearly proportional to the filter size s. This figure shows that a isa function of s. Particularly, a can be approximated as a straightline between two points ð2,y2 ¼ 459Þ and ð64,y64 ¼ 17;703Þwhere
ary Gabor filter.
independent normalization.

K. Choi et al. / Pattern Recognition 45 (2012) 2868–2883 2873
y2 and y64 are averages of the maximum values of convolutionbetween arbitrary images and g at specific filter sizes s¼2 ands¼64, respectively. The line equation y which passes throughðx1,y1Þ and ðx2,y2Þ is y¼ ððy2�y1Þ=ðx2�x1ÞÞðx�x1Þþy1. Thus, a canbe written as
a¼ y64�y2
64�2ðs�2Þþy2 ¼
17;703�459
64�2ðs�2Þþ459¼ 278s�97
ð11Þ
Given a binary Gabor filter bank g , a collection matrix oftraining samples Xt, the hidden layer output matrix Ht in theproposed BG-OSELM is
Ht ¼ fconvðXt ,gÞþ278s�97
2ð278s�97Þ,w,b
� �ð12Þ
For incremental learning of the new chunk set according toEq. (12), the two Eqs. (6) and (7) can be adopted, and the initialY0 and P�1
0 can be written as follows
Y0 ¼ P�10 HT
0Y0 ð13Þ
P�10 ¼ ðH
T0H0Þ
�1ð14Þ
where H0 is the hidden layout output matrix for initial trainingsamples according Eq. (12), and Y0 is the indicator matrix for theinitial training samples.
Unfortunately, HT0H0ARh�h in Eq. (14) is severely ill-posed
since the number of initial training samples in our incrementallearning problem is very small. Moreover, the number of hiddenunits h is larger than the feature dimension D � dy � ds. The inverseof unreliable and approximated zero singular values of ill-posedHT
0H0 are heavily weighted divided by approximated zero. Inorder to alleviate this problem, we adopt a regularization techni-que [38,43] as follows:
P�10 ¼ ðH
T0H0þlIÞ�1
ð15Þ
The inverse of singular values of HT HþlI is weighted dividedby l rather than approximated zero in the region of very smallsingular values. This leads to increased generalization capability.In this paper, we empirically fix l¼ 0:0001.
Our method is differentiated from the random projectionmethod as seen in [35], which was used for a mobile facerecognition application in which non-orthogonal local randombasis was generated to handle local face deformation and com-putational efficiency. Here, we adopt a normalization techniqueusing predefined binary Gabor filter instead of a randomlygenerated basis. Moreover, our method can be further extendedto other Gabor representations.
4.3. Handling orientations and scales of a binary Gabor filter
For Gabor feature extraction at various orientations and scales,convðx,gÞ usually produces higher-dimensional features thanthose in the original image. For example, given an image of32�32 pixels, the application of eight orientations and eightscales Gabor filters results in 8� 8�32�32¼65,536 features. Inorder to reduce the dimensionality of the Gabor features, variousmethods such as a feature selection [44] and dimension reduction[45] have been adopted. Unfortunately, these methods requiretraining samples in advance and are thus, not suitable for theincremental framework.
In order to reduce the high dimensionality of Gabor represen-tation without the need for training, we apply our filters withdifferent orientations dy and a single scale (ds¼1) at fixed singleposition (D¼1) instead of different orientations dy and differentscales ds at positions D. As such the feature dimensions ofconvðX,g Þ can be dramatically reduced from D� dy � ds to
1� dy � 1. These reduced Gabor features are trained by regular-ized OSELM. In order to define distinctive fixed positions withoutthe need for optimization and training, we divide a 2D image intoequally sized C number of sub regions (square type rectangle) andthen our binary filters are applied at the center of each sub region.Finally, a fusion method is adopted in order to cover the entiresub regions.
Here, we define each single hidden layer output matrix Hctþ1
for the cth sub region as follows:
Hctþ1 ¼ f
convðXctþ1,gÞ
z,wc ,bc
� �ð16Þ
where Xctþ1 is the pixel matrix of the cth sub region set of the
training images Xtþ1. And wc and bc are the cth random para-meters for each corresponding single hidden layer output matrixHc
tþ1. We note that the normalization factor z and binary Gaborfilter bank g are independent of the sub region c.
Each cth weight parameter Yc can be written as follows:
Yctþ1 ¼Yc
t þPctþ1ðH
ctþ1Þ
TðYtþ1�Hc
tþ1Yct Þ ð17Þ
where
Pctþ1 ¼ Pc
t�Pct ðH
ctþ1Þ
TðIþHc
tþ1Pct ðH
ctþ1Þ
T�1Hc
tþ1Pct ð18Þ
The class label of unseen sample x can be predicted usingvarious fusion methods. The sum rule-based prediction can bewritten as follows:
classðxÞ ¼ arg maxk
XC
c ¼ 1
f ðconvðxc ,g Þ=z,wc ,bcÞðYc
t Þk, k¼ 1, . . . ,K
ð19Þ
where ðYct Þk is kth column vector of Yc
t .One remaining problem for our method is the determination of
the number of sub regions C, the size of the binary Gabor filter s,the number of binary filters dy and the number of hidden units h
which affect both accuracy and computational cost are generallyestimated empirically. For example, when C is large, no structuralinformation can be extracted. Meanwhile, when C is very small,no local structural information can be extracted. Moreover, anempirical determination of the learning parameters of all net-works is a time consuming task.
Here, we set C¼16, which means that the output of our filter isa weighted sum of 1/16 of the entire region. When C is given, thecorresponding filter size is defined by the size of the sub region
s¼ffiffiffiffiffiffiffiffiffiD=C
pð20Þ
Since s� s pixels are sampled by a single binary filter, we set dyas follows:
dy ¼ s2 ¼D=C ð21Þ
and the number of hidden h is fixed empirically as follows:
h¼ 2dy ¼ 2D=C ð22Þ
Therefore, when the number of sub region C is defined (in ourexperiment, C¼16), others s,dy and h are determined independentto the database without tedious parameter tuning. Finally, thepseudo code of our algorithm is given in Algorithm 1.
Algorithm 1. The pseudo code of the proposed method
�
Binary Gabor filter set generationfor j¼1 to dy
Q’ðgj4dÞn1þðgjo�dÞn�1
N’lengthðQ Þ
IDXi’findðQ ¼ ¼ iÞ, where i¼�1;0,1
Ni’lengthðIDXiÞ, where i¼�1;0,1
g j’Q

TC
fo
Table 3
K. Choi et al. / Pattern Recognition 45 (2012) 2868–28832874
able 2omplex
r upda
Matrix
P�1
Y
YT x
distribution’½onesðN=2�N1,1Þ;�1nonesðN=2�N�1,1Þ�
Memory requirement. g jðIDXÞ’distributionðrandpermðN0ÞÞ�
Matrix OSELM E-OSELM Proposed BG-OSELM Normalized feature extraction for c¼1 to CP�1 D2 CD2CðD=CÞ2 ¼D2=C
Y DK CDK CðD=CÞK ¼DK
Xc¼
convðXc ,g Þþ278s�972ð278s�97Þ
�
Neural network training J initializationX0’ initial training images
Y0’ the corresponding labels for c¼1 to CHc0’f ðX
c
0,wc ,bcÞ
ðPc0Þ�1’ððHc
0ÞTðHc
0ÞþlIÞ�1
Yc0’ðP
c0Þ�1ðHc
0ÞT Y0
J updating
Xt’ additional training images Yt’ the corresponding labels for c¼1 to CHct’f ðX
c
t ,wc ,bcÞ
ðPct Þ�1’ðPc
t�1Þ�1�ðPc
t�1Þ�1ðHc
t ÞTðIþHc
t ðPct�1Þ
�1ðHct Þ
T�1Hc
t ðPct�1Þ
�1
Yct’Yc
t�1þðPct Þ�1ðHc
t ÞTðYt�Hc
tYct�1Þ
�
Prediction of an unknown image x’ an unknown image identified label ofx’arg maxk
PCc ¼ 1
f convðxc ,g Þþ278s�972ð278s�97Þ ,wc ,bc
� �ðYc
t Þ
k,k¼ 1, . . . ,K
(in case of sum rule)
4.4. Comparing the two OSELMs with the proposed BG-OSELM
In this section, we compare the original OSELM and anensemble of OSELM (E-OSELM) [46] with the proposed BG-OSELM. In the original OSELM, high-dimensional features ARD
without dimension reduction are used as input features of thehidden layer output matrix H. The E-OSELM combines C numberof OSELMs, indicating that the complexity is C times higher thanthat of the original OSELM. In the proposed BG-OSELM, a set ofreduced features ARD=C is used for H.
The original OSELM and the E-OSELM are computationallyefficient and accurate when the feature dimension is small.However, computation of P�1 can be inaccurate when the featuredimension is large and lack of initial training samples. Meanwhile,the computation of regularized P�1 using the reduced dimensionin our algorithm is efficient and produces a stable least squaressolution.
Table 2 shows the complexities of the OSELM, the E-OSELMand the proposed BG-OSELM. Here, we focus on P�1 and Y sincethe complexity of the classification, YT x, is linearly proportionalto the number of classifiers C, the image feature dimension D and
ity analysis: D (image feature dimension), n (number of training samples
ting), K (number of classes), C (number of classifiers).
OSELM E-OSELM Proposed BG-OSELM
D3n3 CD3n3 CðD=CÞ3n3 ¼D3n3=C2
D2nþnDK CD2nþCnDK CððD=CÞ2nþnD=CKÞ ¼D2n=CþnDK
DK CDK CðD=CÞK ¼DK
number of classes K. The computation of these three OSELMs ismainly determined by the original feature dimension D since n forchunk updating is usually small, and the complexity is linearlyproportional to C and K where the relationship of these computa-tional factors is ðD4K4C4nÞ. We note that the computation ofweight parameter Y requires computation of P�1. This meansthat the computational complexity of weight parameter Y isOðD3
þD2Þ. OSELM, E-OSELM and BG-OSELM have the same
complexities on feature dimension D. However, the computationof P�1 in the proposed method is C2 and C3 times more efficient ascompared to that of OSELM and E-OSELM, respectively.
Table 3 shows the memory requirements of the threecompared formulations of online ELMs (OSELM, E-OSELM andBG-OSELM). As can be seen, the proposed BG-OSELM requiresmuch less memory space than those of the OSELM and E-OSELM.
4.5. Comparing Haar, LBP and Gabor with the proposed BG-OSELM
Here, we compare the proposed binary Gabor with Haarwavelet, local binary pattern (LBP) and conventional Gabor inorder to study the differences among these texture descriptors.Table 4 summarizes the differences among those texture descrip-tors from several viewpoints.
The Haar wavelet is a certain sequence of rescaled ‘‘square-shaped’’ functions which together form a wavelet family or basis. Asshown in Fig. 5(a), Haar wavelet responses to vertical, horizontaland diagonal edges. Usually, wavelet transform is processed recur-sively by having half sized image, which produces a hierarchicalstructure. Several Haar wavelet based methods have been developedfor face recognition [47–49], where features are extracted usingHaar wavelet and PCA (or LDA) is applied for dimension reduction.There is a simplified Haar wavelet called Haar-like feature [50] forthe reduction of computational cost. Usually, these features are usedfor the detection rather than recognition.
A LBP operator [51] labels the pixels of an image by thresh-olding the 3�3-neighborhood of each pixel with the center valueand considering the result as a binary number. Consequently, thehistogram of the labels can be used as a texture descriptor. TheLBP operator is notated as LBPP,R where P is sampling points on acircle of radius of R. Fig. 5(b) shows the output of LBP transformover several (P, R) pairs. Usually, LBP operator is applied to subregions of the face image as efficient locality descriptor and eachregional histogram is concatenated to build a global description ofthe face. Since this descriptor is of high dimension, a dimensionreduction using methods such as PCA and LDA is adopted. TheLBP operator has been extended for detection and recognition. Forexample, [52] proposed a general LBP operator in order torepresent the missing information in the LBP style. Authorsshowed that the traditional LBP is equivalent to the sign operatorof the proposed LBP. Refs. [53,54] proposed a rotation invariantLBP. Heusch et al. [55] showed that the LBP representation issuitable when there is a strong mismatch in terms of illuminationconditions between the gallery and the probe image. Ref. [56]reported experiments using several LBP-based descriptors andproposed a set of novel texture descriptors for the representationof biomedical images. Differentiated from the above methodsin literature, our method focuses on locality of face and featurenormalization.

Table 4Summary of differences among several texture descriptors.
Comparison Haar wavelet Simplified Haar LBP Gabor Simplified Gabor Proposed
Operation Vertical, horizontal, diagonal – Sampling point, radius Scale, orientation Scale, orientation Scale, orientation
Element �1, 1, 0 �1, 1, 0 – Floating-point �1, 1, 0 �1, 1
Characteristic Transform Dot product Histogram Convolution Dot product Convolution
Purpose Effectiveness Efficiency Effectiveness Effectiveness Efficiency Normalization
Fig. 5. Comparison of several texture descriptors.
K. Choi et al. / Pattern Recognition 45 (2012) 2868–2883 2875
Unlike the Haar wavelet and LBP, Gabor filter responses tovarious orientation and scaling as shown in Fig. 5(c). Usually, a setof concatenated Gabor features have higher dimensionality thanthat of Haar wavelet and LBP. This means that a dimensionreduction or feature selection is essential. In order to reduce thecomputation cost, simplified Gabor filters have been proposedin [57]. The proposed binary Gabor filter seems to response toorientation as well as edge more than the original Gabor as shownin Fig. 5(d). Compared with the simplified Gabor, the proposedmethod considers feature normalization.
5. Application to intelligent photo notification
In this section, we apply the proposed incremental facerecognition framework for Twitter service where our scenario isto automatically send a direct message to online members whoappear within a photo image but who have not been identified.For example, after an user uploads an image using Twitter client,faces within the image are detected and identified using theproposed method. If this identification is successful, a notificationis then automatically sent to recognized users using Twitter API.Otherwise, the user manually annotates those incorrectly identi-fied faces and then training is performed to recognize those newface samples from the annotated labels.
The overview of our intelligent photo uploading notificationsystem is illustrated in Fig. 6. A conventional PHP on a Tomcatserver is used for server side programming. The core algorithm todetect and identify a face is written by C/Cþþ. The PHP scriptparses the URL parameter of the request command and calls theC/Cþþ object to detect and identify faces, then responds via anXML document to the client application. If the response XMLincludes the identified user names without error code, then aTwitter notification API is called to produce message regardingnew photo uploading to related users.
6. Experiment
In this section, we evaluate the recognition accuracies and execu-tion times on a desktop computer with 3.2 GHz CPU and 2.0 G RAMusing MATLAB 8.0 and Cþþ (for simultaneous access evaluation).
6.1. Benchmarking setup
�
Database: In the absence of a public SNS face database, weevaluate the performance of the proposed method usingselected public face recognition databases which containvarious appearance variations such as expression, illumina-tion, occlusion and time interval variations under controlledand real world conditions. Table 5 shows our evaluationdatabases and their characteristics.
� Preprocessing: Since automatic face alignment is yet anotheropen issue, we adopt a manual process to align and croprelevant face regions as the preprocessing step in order tofocus on the effectiveness of the proposed method for featureextraction as a separate issue. After cropping, the originalimages are resized to 32�32 in order to simulate the low-resolution images under the real world environment in whichhigh-frequency image regions can be blurred.
6.2. Evaluation protocol
We evaluate the identification accuracy (ratio of correctlyidentified samples in a test subset) and training/testing CPU timesof the several face recognition algorithms in order to show thegeneralization performance and computational efficiency of theproposed method.
We compare our method with several face recognition algorithmswhich can be grouped into four categories. The settings of thesemethods are shown in Table 6. In CCIPCA, IPCA and ILDA, the entiretraining set including old training samples is reprojected after eigen-vectors are updated in order to avoid performance degradation.
6.3. Comparison with incremental methods
In this section, we evaluate the recognition accuracies undervarious variations in imaging conditions. Table 7 shows thecomparison results.
6.3.1. Evaluation with various face variations (rows 1–7 in Table 7)
In this experiment, the recognition accuracy in the presence ofvariations in facial expression, illumination, occlusion and timeusing the AR database are evaluated. The first seven images (1–7)are used for training, and the remaining 19 images (8–13 and 15–26) are divided into six subsets according to the variationcategory. For the time-variation subset, all images of the firstsession (1–13) are used for training, and the remaining images(14–26) from the second session are used for testing. A total ofseven test subsets are thus, generated for the evaluation.
As can be seen in row 1–7 of Table 7, the proposed methodsignificantly outperforms all other methods in terms of recogni-tion accuracy rate for six subsets (nos. 1, 2, 4, 5, 6 and 7 rows).

Fig. 6. Our intelligent photo notification system for Twitter service.
Table 5Databases.
Database People Samples Characteristic
AR [58] 126 26 Various face variations, use only individuals
after removing impaired images
Extended
Yale B [59]
38 64 Various illumination variations
BioID [60] 22 25–150 Real world conditions
ETRI [61] 75 7–23 Indoor office
LFW [62] 153 10–150 Unconstrained real world
(collected from the web)
Table 6Evaluation protocol.
Method Setting
Baseline
PCA 20 to the maximum number of PCA bases
FDA Fisher LDA
Incremental subspace
CCIPCA [15] IPCA without estimating the covariance matrix,
reprojection after updating
IPCA [63] Chuck based IPCA, reprojection after updating
ILDA [20] ILDA using the sufficient spanning set
approximation, reprojection after updating
Incremental classifier
ISVM Modify public source code for multi-class
problem
OSELM With regularizer l¼ 0:0001
Incremental classifier
BG-OSELM(S) Sum rule-based fusion, C¼16
BG-OSELM(V) Voting-based fusion, C¼16
K. Choi et al. / Pattern Recognition 45 (2012) 2868–28832876
This shows that the proposed method can be robust to severelocal deformation, while the other compared methods appear tobe seriously impaired by local deformations.
Three major observations are made regrading the perfor-mances of the other compared methods. The first is that theCCIPCA does not work well compared to the batch-based PCA andIPCA, while the accuracy of ILDA is slightly better than that offisher discriminant Analysis (FDA). The second observation is thatISVM cannot operate without error throughout the datasets dueto lack of memory during training. The final observation is thatthere is difference between the two fusion methods, sum andvoting rules. The recognition accuracy of the sum rule showsbetter performances than those of the voting method in expres-sion, illumination and time interval subsets but worse perfor-mances in the Sunglass and Scarf subsets. In AR database, theSunglass and Scarf datasets contain severe local occlusionscompared to those of the expression, illumination and timeinterval subsets. This indicates that the voting rule is more robustto local deformation than that is the sum rule.
6.3.2. Evaluation under illumination variations (rows 8–10 in
Table 7)
In this experiment, the recognition accuracy under variousillumination conditions is evaluated using the EYALEB database.The images in EYALEB are divided into five subsets according to theangle of illumination. The first subset covers the angular range from01 to 51, the second subset covers 101 to 201, the third subset covers251 to 351, the fourth subset covers 501 to 701, and the remaining
images Z851 are not used. The images in subset 1 are selected fortraining, and the images in the other subsets are used for testing.The experiments are repeated ten times, and the average accuracy iscalculated. For all images in the EYALEB database, a histogramequalization is performed before feature extraction.
Rows 8–10 of Table 7 show the results of our method alongwith those of the conventional methods. When the angle ofillumination is small, the accuracies of all methods are fairly high.This means that the proposed approach has no advantage overthose conventional methods under small illumination angles.When the angle of illumination is increased, however, all methodsappear to be sensitive to illumination variations, and there is only aslight accuracy difference in BG-OSELM(S) and BG-OSELM(V).
6.3.3. Evaluation in an uncontrolled indoor office (rows 11–12 of
Table 7)
Apart from AR and EYALEB which were captured in a con-trolled studio environment, we adopt the BioID and ETRI data-bases which were captured in a real indoor offices in order to
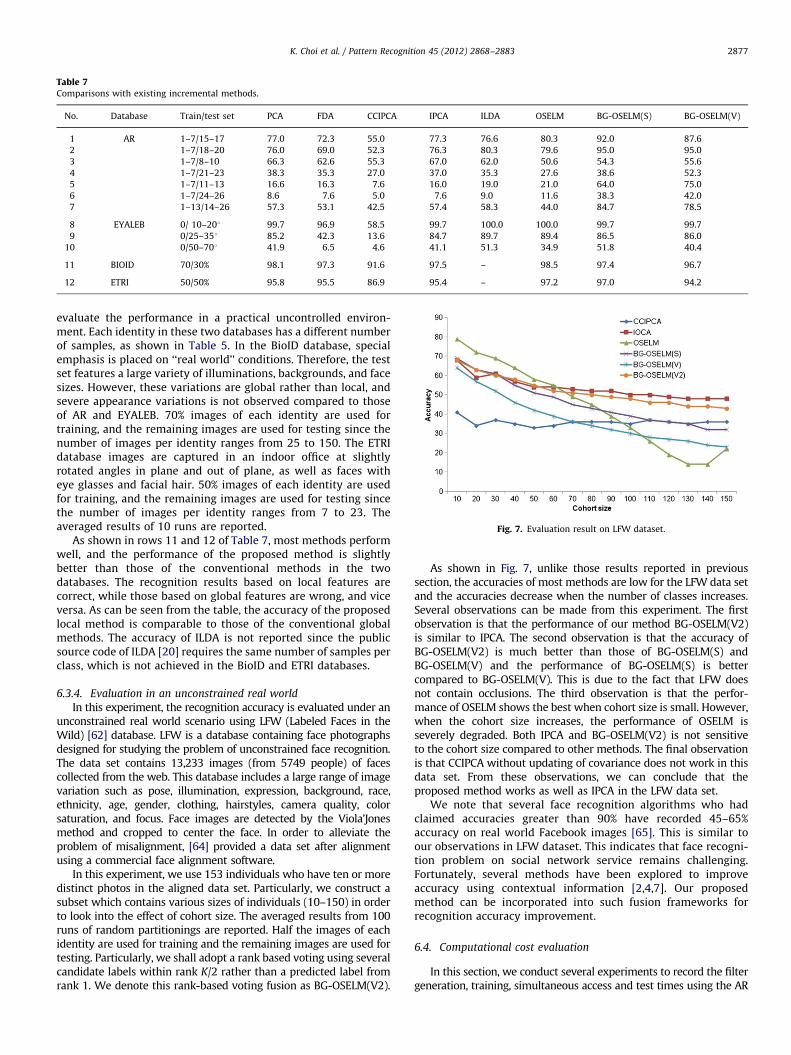
Table 7Comparisons with existing incremental methods.
No. Database Train/test set PCA FDA CCIPCA IPCA ILDA OSELM BG-OSELM(S) BG-OSELM(V)
1 AR 1–7/15–17 77.0 72.3 55.0 77.3 76.6 80.3 92.0 87.6
2 1–7/18–20 76.0 69.0 52.3 76.3 80.3 79.6 95.0 95.0
3 1–7/8–10 66.3 62.6 55.3 67.0 62.0 50.6 54.3 55.6
4 1–7/21–23 38.3 35.3 27.0 37.0 35.3 27.6 38.6 52.3
5 1–7/11–13 16.6 16.3 7.6 16.0 19.0 21.0 64.0 75.0
6 1–7/24–26 8.6 7.6 5.0 7.6 9.0 11.6 38.3 42.0
7 1–13/14–26 57.3 53.1 42.5 57.4 58.3 44.0 84.7 78.5
8 EYALEB 0/ 10–201 99.7 96.9 58.5 99.7 100.0 100.0 99.7 99.7
9 0/25–351 85.2 42.3 13.6 84.7 89.7 89.4 86.5 86.0
10 0/50–701 41.9 6.5 4.6 41.1 51.3 34.9 51.8 40.4
11 BIOID 70/30% 98.1 97.3 91.6 97.5 – 98.5 97.4 96.7
12 ETRI 50/50% 95.8 95.5 86.9 95.4 – 97.2 97.0 94.2
Fig. 7. Evaluation result on LFW dataset.
K. Choi et al. / Pattern Recognition 45 (2012) 2868–2883 2877
evaluate the performance in a practical uncontrolled environ-ment. Each identity in these two databases has a different numberof samples, as shown in Table 5. In the BioID database, specialemphasis is placed on ‘‘real world’’ conditions. Therefore, the testset features a large variety of illuminations, backgrounds, and facesizes. However, these variations are global rather than local, andsevere appearance variations is not observed compared to thoseof AR and EYALEB. 70% images of each identity are used fortraining, and the remaining images are used for testing since thenumber of images per identity ranges from 25 to 150. The ETRIdatabase images are captured in an indoor office at slightlyrotated angles in plane and out of plane, as well as faces witheye glasses and facial hair. 50% images of each identity are usedfor training, and the remaining images are used for testing sincethe number of images per identity ranges from 7 to 23. Theaveraged results of 10 runs are reported.
As shown in rows 11 and 12 of Table 7, most methods performwell, and the performance of the proposed method is slightlybetter than those of the conventional methods in the twodatabases. The recognition results based on local features arecorrect, while those based on global features are wrong, and viceversa. As can be seen from the table, the accuracy of the proposedlocal method is comparable to those of the conventional globalmethods. The accuracy of ILDA is not reported since the publicsource code of ILDA [20] requires the same number of samples perclass, which is not achieved in the BioID and ETRI databases.
6.3.4. Evaluation in an unconstrained real world
In this experiment, the recognition accuracy is evaluated under anunconstrained real world scenario using LFW (Labeled Faces in theWild) [62] database. LFW is a database containing face photographsdesigned for studying the problem of unconstrained face recognition.The data set contains 13,233 images (from 5749 people) of facescollected from the web. This database includes a large range of imagevariation such as pose, illumination, expression, background, race,ethnicity, age, gender, clothing, hairstyles, camera quality, colorsaturation, and focus. Face images are detected by the Viola’Jonesmethod and cropped to center the face. In order to alleviate theproblem of misalignment, [64] provided a data set after alignmentusing a commercial face alignment software.
In this experiment, we use 153 individuals who have ten or moredistinct photos in the aligned data set. Particularly, we construct asubset which contains various sizes of individuals (10–150) in orderto look into the effect of cohort size. The averaged results from 100runs of random partitionings are reported. Half the images of eachidentity are used for training and the remaining images are used fortesting. Particularly, we shall adopt a rank based voting using severalcandidate labels within rank K/2 rather than a predicted label fromrank 1. We denote this rank-based voting fusion as BG-OSELM(V2).
As shown in Fig. 7, unlike those results reported in previoussection, the accuracies of most methods are low for the LFW data setand the accuracies decrease when the number of classes increases.Several observations can be made from this experiment. The firstobservation is that the performance of our method BG-OSELM(V2)is similar to IPCA. The second observation is that the accuracy ofBG-OSELM(V2) is much better than those of BG-OSELM(S) andBG-OSELM(V) and the performance of BG-OSELM(S) is bettercompared to BG-OSELM(V). This is due to the fact that LFW doesnot contain occlusions. The third observation is that the perfor-mance of OSELM shows the best when cohort size is small. However,when the cohort size increases, the performance of OSELM isseverely degraded. Both IPCA and BG-OSELM(V2) is not sensitiveto the cohort size compared to other methods. The final observationis that CCIPCA without updating of covariance does not work in thisdata set. From these observations, we can conclude that theproposed method works as well as IPCA in the LFW data set.
We note that several face recognition algorithms who hadclaimed accuracies greater than 90% have recorded 45–65%accuracy on real world Facebook images [65]. This is similar toour observations in LFW dataset. This indicates that face recogni-tion problem on social network service remains challenging.Fortunately, several methods have been explored to improveaccuracy using contextual information [2,4,7]. Our proposedmethod can be incorporated into such fusion frameworks forrecognition accuracy improvement.
6.4. Computational cost evaluation
In this section, we conduct several experiments to record the filtergeneration, training, simultaneous access and test times using the AR
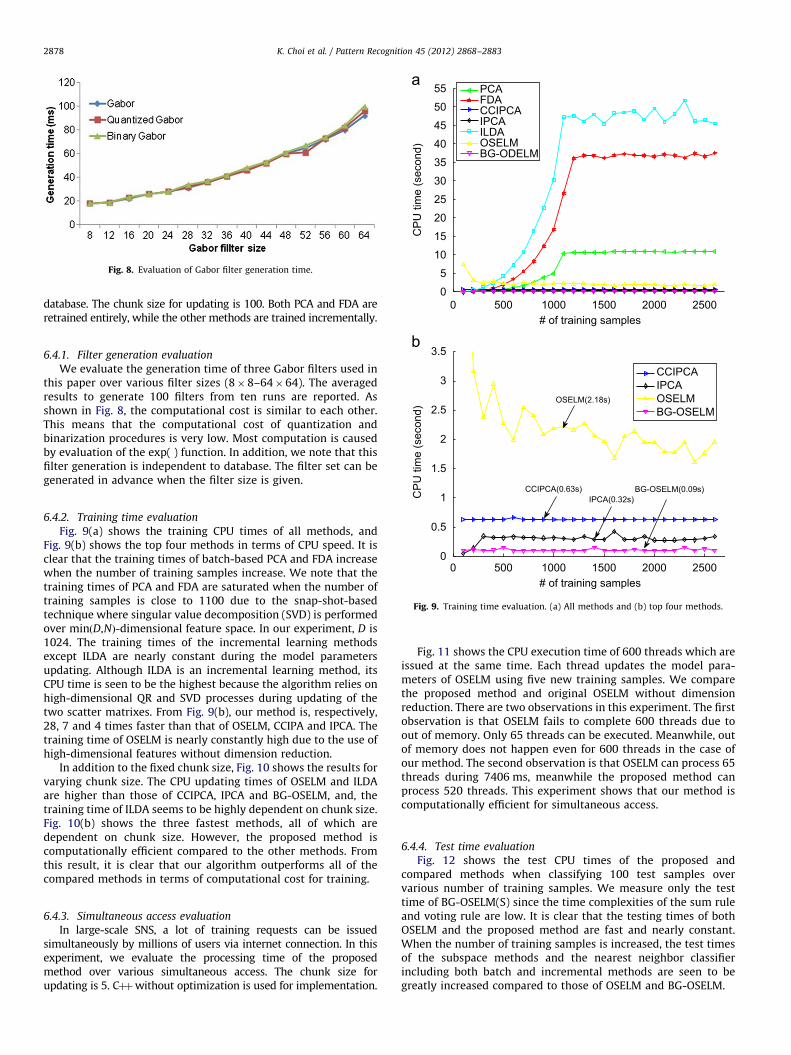
Fig. 8. Evaluation of Gabor filter generation time.
0 500 1000 1500 2000 25000
5
10
15
20
25
30
35
40
45
50
55
# of training samples
CP
U ti
me
(sec
ond)
PCAFDACCIPCAIPCAILDAOSELMBG-ODELM
K. Choi et al. / Pattern Recognition 45 (2012) 2868–28832878
database. The chunk size for updating is 100. Both PCA and FDA areretrained entirely, while the other methods are trained incrementally.
1.5
2
2.5
3
3.5
U ti
me
(sec
ond)
CCIPCAIPCAOSELMOSELM(2.18s)BG-OSELM
6.4.1. Filter generation evaluation
We evaluate the generation time of three Gabor filters used inthis paper over various filter sizes (8�8–64�64). The averagedresults to generate 100 filters from ten runs are reported. Asshown in Fig. 8, the computational cost is similar to each other.This means that the computational cost of quantization andbinarization procedures is very low. Most computation is causedby evaluation of the exp( ) function. In addition, we note that thisfilter generation is independent to database. The filter set can begenerated in advance when the filter size is given.
0 500 1000 1500 2000 2500# of training samples
0
0.5
1CP CCIPCA(0.63s)
IPCA(0.32s)BG-OSELM(0.09s)
Fig. 9. Training time evaluation. (a) All methods and (b) top four methods.
6.4.2. Training time evaluation
Fig. 9(a) shows the training CPU times of all methods, andFig. 9(b) shows the top four methods in terms of CPU speed. It isclear that the training times of batch-based PCA and FDA increasewhen the number of training samples increase. We note that thetraining times of PCA and FDA are saturated when the number oftraining samples is close to 1100 due to the snap-shot-basedtechnique where singular value decomposition (SVD) is performedover minðD,NÞ-dimensional feature space. In our experiment, D is1024. The training times of the incremental learning methodsexcept ILDA are nearly constant during the model parametersupdating. Although ILDA is an incremental learning method, itsCPU time is seen to be the highest because the algorithm relies onhigh-dimensional QR and SVD processes during updating of thetwo scatter matrixes. From Fig. 9(b), our method is, respectively,28, 7 and 4 times faster than that of OSELM, CCIPA and IPCA. Thetraining time of OSELM is nearly constantly high due to the use ofhigh-dimensional features without dimension reduction.
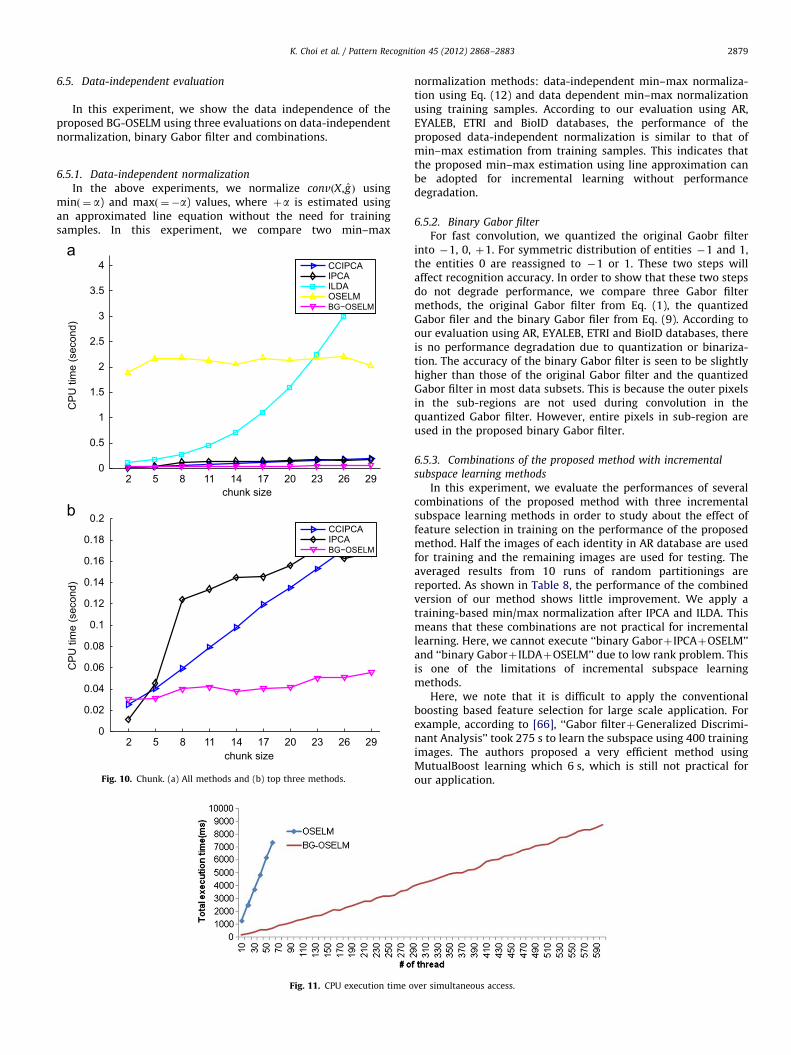
In addition to the fixed chunk size, Fig. 10 shows the results forvarying chunk size. The CPU updating times of OSELM and ILDAare higher than those of CCIPCA, IPCA and BG-OSELM, and, thetraining time of ILDA seems to be highly dependent on chunk size.Fig. 10(b) shows the three fastest methods, all of which aredependent on chunk size. However, the proposed method iscomputationally efficient compared to the other methods. Fromthis result, it is clear that our algorithm outperforms all of thecompared methods in terms of computational cost for training.
6.4.3. Simultaneous access evaluation
In large-scale SNS, a lot of training requests can be issuedsimultaneously by millions of users via internet connection. In thisexperiment, we evaluate the processing time of the proposedmethod over various simultaneous access. The chunk size forupdating is 5. Cþþwithout optimization is used for implementation.
Fig. 11 shows the CPU execution time of 600 threads which areissued at the same time. Each thread updates the model para-meters of OSELM using five new training samples. We comparethe proposed method and original OSELM without dimensionreduction. There are two observations in this experiment. The firstobservation is that OSELM fails to complete 600 threads due toout of memory. Only 65 threads can be executed. Meanwhile, outof memory does not happen even for 600 threads in the case ofour method. The second observation is that OSELM can process 65threads during 7406 ms, meanwhile the proposed method canprocess 520 threads. This experiment shows that our method iscomputationally efficient for simultaneous access.
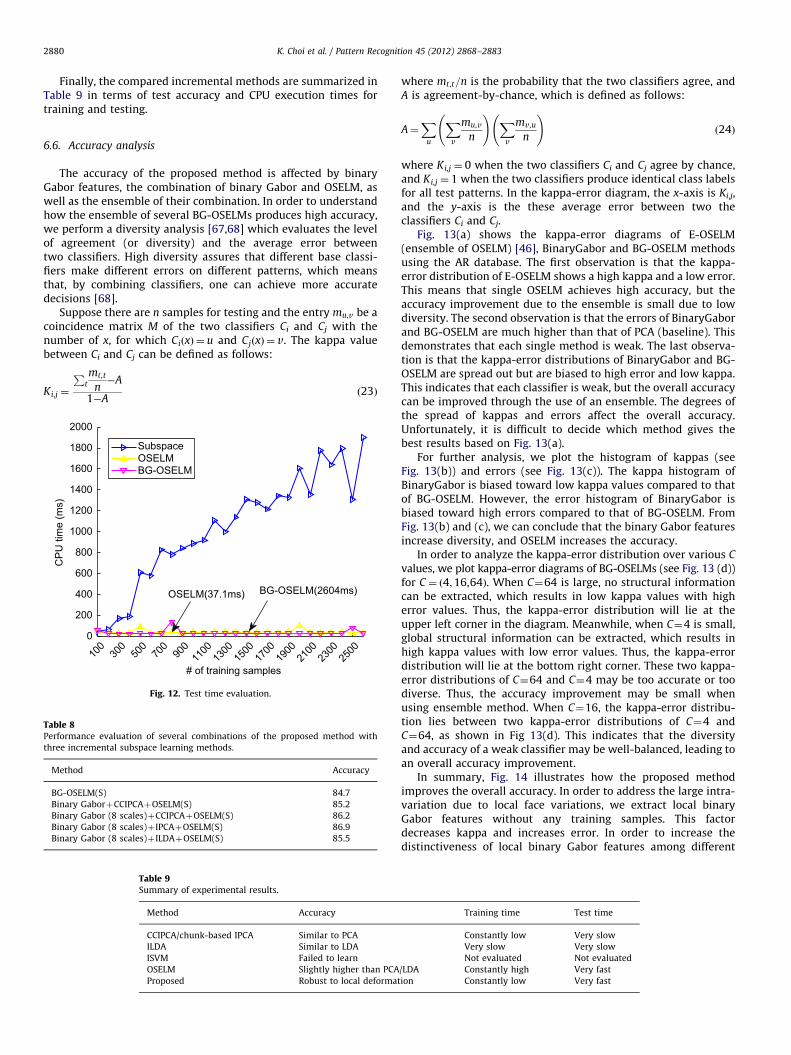
6.4.4. Test time evaluation
Fig. 12 shows the test CPU times of the proposed andcompared methods when classifying 100 test samples overvarious number of training samples. We measure only the testtime of BG-OSELM(S) since the time complexities of the sum ruleand voting rule are low. It is clear that the testing times of bothOSELM and the proposed method are fast and nearly constant.When the number of training samples is increased, the test timesof the subspace methods and the nearest neighbor classifierincluding both batch and incremental methods are seen to begreatly increased compared to those of OSELM and BG-OSELM.
K. Choi et al. / Pattern Recognition 45 (2012) 2868–2883 2879
6.5. Data-independent evaluation
In this experiment, we show the data independence of theproposed BG-OSELM using three evaluations on data-independentnormalization, binary Gabor filter and combinations.
6.5.1. Data-independent normalization
In the above experiments, we normalize convðX,gÞ usingminð ¼ a) and maxð ¼�a) values, where þa is estimated usingan approximated line equation without the need for trainingsamples. In this experiment, we compare two min–max
2 5 8 11 14 17 20 23 26 290
0.5
1
1.5
2
2.5
3
3.5
4
chunk size
CP
U ti
me
(sec
ond)
CCIPCAIPCAILDAOSELM
2 5 8 11 14 17 20 23 26 290
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
0.18
0.2
chunk size
CP
U ti
me
(sec
ond)
CCIPCAIPCA
Fig. 10. Chunk. (a) All methods and (b) top three methods.
Fig. 11. CPU execution time o
normalization methods: data-independent min–max normaliza-tion using Eq. (12) and data dependent min–max normalizationusing training samples. According to our evaluation using AR,EYALEB, ETRI and BioID databases, the performance of theproposed data-independent normalization is similar to that ofmin–max estimation from training samples. This indicates thatthe proposed min–max estimation using line approximation canbe adopted for incremental learning without performancedegradation.
6.5.2. Binary Gabor filter
For fast convolution, we quantized the original Gaobr filterinto �1, 0, þ1. For symmetric distribution of entities �1 and 1,the entities 0 are reassigned to �1 or 1. These two steps willaffect recognition accuracy. In order to show that these two stepsdo not degrade performance, we compare three Gabor filtermethods, the original Gabor filter from Eq. (1), the quantizedGabor filer and the binary Gabor filer from Eq. (9). According toour evaluation using AR, EYALEB, ETRI and BioID databases, thereis no performance degradation due to quantization or binariza-tion. The accuracy of the binary Gabor filter is seen to be slightlyhigher than those of the original Gabor filter and the quantizedGabor filter in most data subsets. This is because the outer pixelsin the sub-regions are not used during convolution in thequantized Gabor filter. However, entire pixels in sub-region areused in the proposed binary Gabor filter.
6.5.3. Combinations of the proposed method with incremental
subspace learning methods
In this experiment, we evaluate the performances of severalcombinations of the proposed method with three incrementalsubspace learning methods in order to study about the effect offeature selection in training on the performance of the proposedmethod. Half the images of each identity in AR database are usedfor training and the remaining images are used for testing. Theaveraged results from 10 runs of random partitionings arereported. As shown in Table 8, the performance of the combinedversion of our method shows little improvement. We apply atraining-based min/max normalization after IPCA and ILDA. Thismeans that these combinations are not practical for incrementallearning. Here, we cannot execute ‘‘binary Gaborþ IPCAþOSELM’’and ‘‘binary Gaborþ ILDAþOSELM’’ due to low rank problem. Thisis one of the limitations of incremental subspace learningmethods.
Here, we note that it is difficult to apply the conventionalboosting based feature selection for large scale application. Forexample, according to [66], ‘‘Gabor filterþGeneralized Discrimi-nant Analysis’’ took 275 s to learn the subspace using 400 trainingimages. The authors proposed a very efficient method usingMutualBoost learning which 6 s, which is still not practical forour application.
ver simultaneous access.
K. Choi et al. / Pattern Recognition 45 (2012) 2868–28832880
Finally, the compared incremental methods are summarized inTable 9 in terms of test accuracy and CPU execution times fortraining and testing.
6.6. Accuracy analysis
The accuracy of the proposed method is affected by binaryGabor features, the combination of binary Gabor and OSELM, aswell as the ensemble of their combination. In order to understandhow the ensemble of several BG-OSELMs produces high accuracy,we perform a diversity analysis [67,68] which evaluates the levelof agreement (or diversity) and the average error betweentwo classifiers. High diversity assures that different base classi-fiers make different errors on different patterns, which meansthat, by combining classifiers, one can achieve more accuratedecisions [68].
Suppose there are n samples for testing and the entry mu,v be acoincidence matrix M of the two classifiers Ci and Cj with thenumber of x, for which CiðxÞ ¼ u and CjðxÞ ¼ v. The kappa valuebetween Ci and Cj can be defined as follows:
Ki,j ¼
Pt
mt,t
n�A
1�Að23Þ
100
300
500
700
900
1100
1300
1500
1700
1900
2100
2300
2500
0
200
400
600
800
1000
1200
1400
1600
1800
2000
# of training samples
CP
U ti
me
(ms)
SubspaceOSELM
OSELM(37.1ms) BG-OSELM(2604ms)
BG-OSELM
Fig. 12. Test time evaluation.
Table 8Performance evaluation of several combinations of the proposed method with
three incremental subspace learning methods.
Method Accuracy
BG-OSELM(S) 84.7
Binary GaborþCCIPCAþOSELM(S) 85.2
Binary Gabor (8 scales)þCCIPCAþOSELM(S) 86.2
Binary Gabor (8 scales)þIPCAþOSELM(S) 86.9
Binary Gabor (8 scales)þILDAþOSELM(S) 85.5
Table 9Summary of experimental results.
Method Accuracy
CCIPCA/chunk-based IPCA Similar to PCA
ILDA Similar to LDA
ISVM Failed to learn
OSELM Slightly higher than PCA
Proposed Robust to local deformat
where mt,t=n is the probability that the two classifiers agree, andA is agreement-by-chance, which is defined as follows:
A¼X
u
Xv
mu,v
n
! Xv
mv,u
n
!ð24Þ
where Ki,j ¼ 0 when the two classifiers Ci and Cj agree by chance,and Ki,j ¼ 1 when the two classifiers produce identical class labelsfor all test patterns. In the kappa-error diagram, the x-axis is Ki,j,and the y-axis is the these average error between two theclassifiers Ci and Cj.
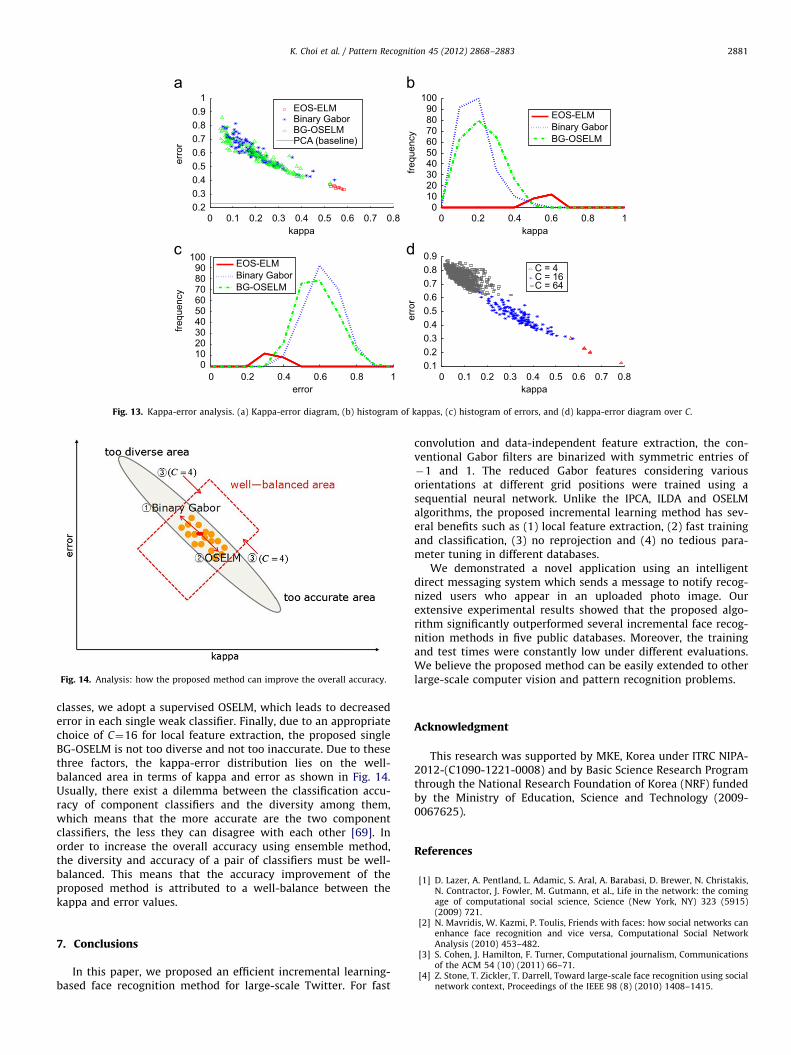
Fig. 13(a) shows the kappa-error diagrams of E-OSELM(ensemble of OSELM) [46], BinaryGabor and BG-OSELM methodsusing the AR database. The first observation is that the kappa-error distribution of E-OSELM shows a high kappa and a low error.This means that single OSELM achieves high accuracy, but theaccuracy improvement due to the ensemble is small due to lowdiversity. The second observation is that the errors of BinaryGaborand BG-OSELM are much higher than that of PCA (baseline). Thisdemonstrates that each single method is weak. The last observa-tion is that the kappa-error distributions of BinaryGabor and BG-OSELM are spread out but are biased to high error and low kappa.This indicates that each classifier is weak, but the overall accuracycan be improved through the use of an ensemble. The degrees ofthe spread of kappas and errors affect the overall accuracy.Unfortunately, it is difficult to decide which method gives thebest results based on Fig. 13(a).
For further analysis, we plot the histogram of kappas (seeFig. 13(b)) and errors (see Fig. 13(c)). The kappa histogram ofBinaryGabor is biased toward low kappa values compared to thatof BG-OSELM. However, the error histogram of BinaryGabor isbiased toward high errors compared to that of BG-OSELM. FromFig. 13(b) and (c), we can conclude that the binary Gabor featuresincrease diversity, and OSELM increases the accuracy.
In order to analyze the kappa-error distribution over various C
values, we plot kappa-error diagrams of BG-OSELMs (see Fig. 13 (d))for C ¼ ð4;16,64Þ. When C¼64 is large, no structural informationcan be extracted, which results in low kappa values with higherror values. Thus, the kappa-error distribution will lie at theupper left corner in the diagram. Meanwhile, when C¼4 is small,global structural information can be extracted, which results inhigh kappa values with low error values. Thus, the kappa-errordistribution will lie at the bottom right corner. These two kappa-error distributions of C¼64 and C¼4 may be too accurate or toodiverse. Thus, the accuracy improvement may be small whenusing ensemble method. When C¼16, the kappa-error distribu-tion lies between two kappa-error distributions of C¼4 andC¼64, as shown in Fig 13(d). This indicates that the diversityand accuracy of a weak classifier may be well-balanced, leading toan overall accuracy improvement.
In summary, Fig. 14 illustrates how the proposed methodimproves the overall accuracy. In order to address the large intra-variation due to local face variations, we extract local binaryGabor features without any training samples. This factordecreases kappa and increases error. In order to increase thedistinctiveness of local binary Gabor features among different
Training time Test time
Constantly low Very slow
Very slow Very slow
Not evaluated Not evaluated
/LDA Constantly high Very fast
ion Constantly low Very fast
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.80.20.30.40.50.60.70.80.9
1
kappa
erro
r
Binary Gabor
PCA (baseline)
0 0.2 0.4 0.6 0.8 10
102030405060708090
100
kappa
frequ
ency
Binary Gabor
0 0.2 0.4 0.6 0.8 10
102030405060708090
100
error
frequ
ency
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.80.10.20.30.40.50.60.70.80.9
kappa
erro
r
C = 4C = 16C = 64
EOS-ELM
BG-OSELMEOS-ELM
BG-OSELM
Binary GaborEOS-ELM
BG-OSELM
Fig. 13. Kappa-error analysis. (a) Kappa-error diagram, (b) histogram of kappas, (c) histogram of errors, and (d) kappa-error diagram over C.
Fig. 14. Analysis: how the proposed method can improve the overall accuracy.
K. Choi et al. / Pattern Recognition 45 (2012) 2868–2883 2881
classes, we adopt a supervised OSELM, which leads to decreasederror in each single weak classifier. Finally, due to an appropriatechoice of C¼16 for local feature extraction, the proposed singleBG-OSELM is not too diverse and not too inaccurate. Due to thesethree factors, the kappa-error distribution lies on the well-balanced area in terms of kappa and error as shown in Fig. 14.Usually, there exist a dilemma between the classification accu-racy of component classifiers and the diversity among them,which means that the more accurate are the two componentclassifiers, the less they can disagree with each other [69]. Inorder to increase the overall accuracy using ensemble method,the diversity and accuracy of a pair of classifiers must be well-balanced. This means that the accuracy improvement of theproposed method is attributed to a well-balance between thekappa and error values.
7. Conclusions
In this paper, we proposed an efficient incremental learning-based face recognition method for large-scale Twitter. For fast
convolution and data-independent feature extraction, the con-ventional Gabor filters are binarized with symmetric entries of�1 and 1. The reduced Gabor features considering variousorientations at different grid positions were trained using asequential neural network. Unlike the IPCA, ILDA and OSELMalgorithms, the proposed incremental learning method has sev-eral benefits such as (1) local feature extraction, (2) fast trainingand classification, (3) no reprojection and (4) no tedious para-meter tuning in different databases.
We demonstrated a novel application using an intelligentdirect messaging system which sends a message to notify recog-nized users who appear in an uploaded photo image. Ourextensive experimental results showed that the proposed algo-rithm significantly outperformed several incremental face recog-nition methods in five public databases. Moreover, the trainingand test times were constantly low under different evaluations.We believe the proposed method can be easily extended to otherlarge-scale computer vision and pattern recognition problems.
Acknowledgment
This research was supported by MKE, Korea under ITRC NIPA-2012-(C1090-1221-0008) and by Basic Science Research Programthrough the National Research Foundation of Korea (NRF) fundedby the Ministry of Education, Science and Technology (2009-0067625).
References
[1] D. Lazer, A. Pentland, L. Adamic, S. Aral, A. Barabasi, D. Brewer, N. Christakis,N. Contractor, J. Fowler, M. Gutmann, et al., Life in the network: the comingage of computational social science, Science (New York, NY) 323 (5915)(2009) 721.
[2] N. Mavridis, W. Kazmi, P. Toulis, Friends with faces: how social networks canenhance face recognition and vice versa, Computational Social NetworkAnalysis (2010) 453–482.
[3] S. Cohen, J. Hamilton, F. Turner, Computational journalism, Communicationsof the ACM 54 (10) (2011) 66–71.
[4] Z. Stone, T. Zickler, T. Darrell, Toward large-scale face recognition using socialnetwork context, Proceedings of the IEEE 98 (8) (2010) 1408–1415.

K. Choi et al. / Pattern Recognition 45 (2012) 2868–28832882
[5] M. Dantone, L. Bossard, T. Quack, L.V. Gool, Augmented faces, in: IEEEInternational Workshop on Mobile Vision (ICCV 2011), 2011.
[6] C. Tseng, M. Chen, Photo identity tag suggestion using only social networkcontext on large-scale web services, in: 2011 IEEE International Conferenceon Multimedia and Expo (ICME), IEEE, 2011, pp. 1–4.
[7] J. Choi, W. De Neve, K. Plataniotis, Y. Ro, Collaborative face recognition forimproved face annotation in personal photo collections shared on onlinesocial networks, IEEE Transactions on Multimedia 13 (1) (2011) 14–28.
[8] R. Poppe, Scalable face labeling in online social networks, in: 2011 IEEEInternational Conference on Automatic Face & Gesture Recognition andWorkshops (FG 2011), IEEE, 2011, pp. 566–571.
[9] A. Acquisti, R. Gross, F. Stutzman, Faces of Facebook: Privacy in the Age ofAugmented Reality, BlackHat USA, 2011.
[10] D. Lee, H. Seung, Learning the parts of objects by non-negative matrixfactorization, Nature 401 (6755) (1999) 788–791.
[11] S. Ozawa, S. Toh, S. Abe, S. Pang, N. Kasabov, Incremental learning of featurespace and classifier for face recognition, IEEE Transactions on Neural Net-works 18 (5–6) (2005) 575–584.
[12] Y. Ghassabeh, H. Moghaddam, A face recognition system using neuralnetworks with incremental learning ability, in: International Symposiumon Computational Intelligence in Robotics and Automation (CIRA), 2007,pp. 291–296.
[13] P. Hall, D. Marshall, R. Martin, Merging and splitting eigenspace models, IEEETransactions on Pattern Analysis and Machine Intelligence 22 (9) (2000)1042–1049.
[14] H. Zhao, P. Yuen, J. Kwok, A novel incremental principal component analysisand its application for face recognition, IEEE Transactions on Systems, Man,and Cybernetics, Part B 36 (4) (2006) 873–886.
[15] J. Weng, Y. Zhang, W. Hwang, Candid covariance-free incremental principalcomponent analysis, IEEE Transactions on Pattern Analysis and MachineIntelligence 25 (8) (2003) 1034–1040.
[16] S. Yan, X. Tang, Largest-eigenvalue-theory for incremental principal compo-nent analysis, in: IEEE International Conference on Image Processing (ICIP),2005., pp. I-1181-4.
[17] S. Ozawa, S. Pang, N. Kasabov, An incremental principal component analysisfor chunk data, in: International Conference on Fuzzy Systems, 2006,pp. 2278–2285.
[18] C. Ren, D. Dai, Incremental learning of bidirectional principal components forface recognition, Pattern Recognition 43 (1) (2010) 318–330.
[19] T. Chin, D. Suter, Incremental kernel PCA for efficient non-linear featureextraction, in: British Machine Vision Conference, 2006.
[20] T. Kim, S. Wong, B. Stenger, J. Kittler, R. Cipolla, Incremental linear dis-criminant analysis using sufficient spanning set approximations, in: Proceed-ings of Computer Vision and Pattern Recognition, 2007, pp. 1–8.
[21] S. Pang, S. Ozawa, N. Kasabov, Incremental linear discriminant analysis forclassification of data streams, IEEE Transactions on Systems, Man, andCybernetics, Part B 35 (5) (2005) 905–914.
[22] H. Zhao, P. Yuen, Incremental linear discriminant analysis for face recogni-tion, IEEE Transactions on Systems, Man, and Cybernetics, Part B 38 (1)(2008) 210–221.
[23] L. Liu, Y. Jiang, Z. Zhou, Least square incremental linear discriminant analysis,in: Ninth IEEE International Conference on Data Mining (ICDM), 2009,pp. 298–306.
[24] J. Ye, Q. Li, H. Xiong, H. Park, R. Janardan, V. Kumar, IDR/QR: an incrementaldimension reduction algorithm via QR decomposition, IEEE Transactions onKnowledge and Data Engineering 17 (9) (2005) 1208–1222.
[25] W. Chen, B. Pan, B. Fang, M. Li, J. Tang, Incremental nonnegative matrixfactorization for face recognition, Mathematical Problems in Engineering,2008.
[26] S. Bucak, B. Gunsel, Incremental subspace learning via non-negative matrixfactorization, Pattern Recognition 42 (5) (2009) 788–797.
[27] S. Rebhan, W. Sharif, J. Eggert, Incremental learning in the non-negativematrix factorization, Advances in Neuro-Information Processing 5507 (2009)960–969.
[28] H. Yang, G. He, Online face recognition algorithm via nonnegative matrixfactorization, Information Technology Journal 9 (8) (2010) 1719–1724.
[29] Z. Liang, Y. Li, Incremental support vector machine learning in the primal andapplications, Neurocomputing 72 (11) (2009) 2249–2258.
[30] G. Cauwenberghs, T. Poggio, Incremental and decremental support vectormachine learning, Advances in Neural Information Processing Systems 13(2009).
[31] J. Platt, A resource-allocating network for function interpolation, NeuralComputation 3 (2) (1991) 213–225.
[32] N. Liang, G. Huang, P. Saratchandran, N. Sundararajan, A fast and accurateonline sequential learning algorithm for feedforward networks, IEEE Trans-actions on Neural networks 17 (6) (2006) 1411–1423.
[33] K. Choi, H. Byun, K.-A. Toh, A collaborative face recognition framework on asocial network platform, in: Eighth International Conference on AutomatedFace and Gesture Recognition (AFGR), 2008, pp. 1–8.
[34] K. Choi, K. Toh, H. Byun, An efficient incremental face annotation for largescale web services, Telecommunication Systems, 2010 (published online).
[35] K. Choi, K.-A. Toh, H. Byun, Realtime training on mobile devices for facerecognition applications, Pattern Recognition 44 (2) (2011) 386–400.
[36] S. Toh, S. Ozawa, A face recognition system using neural networks withincremental learning ability, in: Eighth Australian and New Zealand Con-ference on Intelligent Information Systems, 2003, pp. 389–394.
[37] G. Huang, Q. Zhu, C. Siew, Extreme learning machine: theory and applica-tions, Neurocomputing 70 (1–3) (2006) 489–501.
[38] K. Toh, Deterministic neural classification, Neural Computation 20 (6) (2008)1565–1595.
[39] K. Toh, J. Kim, S. Lee, Biometric scores fusion based on total error rateminimization, Pattern Recognition 41 (3) (2008) 1066–1082.
[40] K. Toh, H. Eng, Between classification-error approximation and weightedleast-squares learning, IEEE Transactions on Pattern Analysis and MachineIntelligence 30 (4) (2008) 658–669.
[41] A. Serrano, I. de Diego, C. Conde, E. Cabello, Recent advances in facebiometrics with Gabor wavelets: a review, Pattern Recognition Letters 31(5) (2010) 372–381.
[42] S. Arivazhagan, L. Ganesan, S. Priyal, Texture classification using Gaborwavelets based rotation invariant features, Pattern Recognition Letters 27(16) (2006) 1976–1982.
[43] A. Hoerl, R. Kennard, Ridge regression: biased estimation for nonorthogonalproblems, Technometrics (1970) 55–67.
[44] P. Yang, S. Shan, W. Gao, S. Li, D. Zhang, Face recognition using ada-boostedGabor features, in: Sixth International Conference on Automated Face andGesture Recognition (AFGR), 2004, pp. 356–361.
[45] L. Nanni, D. Maio, Weighted sub-Gabor for face recognition, Pattern Recogni-tion Letters 28 (4) (2007) 487–492.
[46] Y. Lan, Y. Soh, G. Huang, Ensemble of online sequential extreme learningmachine, Neurocomputing 72 (13–15) (2009) 3391–3395.
[47] N. Nain, A. Kumar, A. Mohapatra, R. Das, A. Kumar, N. Singh, Face recognitionusing LDA with wavelet transform approach, International Journal of Infor-mation Technology 4 (2) (2011) 603–607.
[48] M. Alwakeel, Z. Shaahban, Face recognition based on haar wavelet transformand principal component analysis via Levenberg–Marquardt backpropaga-tion neural network, European Journal of Scientific Research (2010) 25–31.(ISSN).
[49] R. Kunte, R. Samuel, Wavelet descriptors for recognition of basic symbols inprinted Kannada text, International Journal of Wavelets Multiresolution andInformation Processing 5 (2) (2007) 351.
[50] P. Viola, M. Jones, Robust real-time object detection, International Journal ofComputer Vision 57 (2) (2001) 137–154.
[51] T. Ahonen, A. Hadid, M. Pietikainen, Face description with local binarypatterns: application to face recognition, IEEE Transactions on PatternAnalysis and Machine Intelligence 28 (12) (2006) 2037–2041.
[52] Z. Guo, L. Zhang, D. Zhang, A completed modeling of local binary patternoperator for texture classification, IEEE Transactions on Image Processing 19(6) (2010) 1657–1663.
[53] Z. Guo, L. Zhang, D. Zhang, Rotation invariant texture classification using LBPvariance (LBPV) with global matching, Pattern Recognition 43 (3) (2010)706–719.
[54] L. Nanni, S. Brahnam, A. Lumini, A study for selecting the best performingrotation invariant patterns in local binary/ternary patterns, in: Proceedings ofthe International Conference on Image Processing, Computer Vision, andPattern Recognition (IPCV’10), 2010.
[55] G. Heusch, Y. Rodriguez, S. Marcel, Local binary patterns as an image preproces-sing for face authentication, in: Seventh International Conference on AutomaticFace and Gesture Recognition, 2006 (FGR 2006), IEEE, 2006, p. 6.
[56] L. Nanni, A. Lumini, S. Brahnam, Local binary patterns variants as texturedescriptors for medical image analysis, Artificial Intelligence in Medicine 49(2) (2010) 117–125.
[57] W. Choi, S. Tse, K. Wong, K. Lam, Simplified Gabor wavelets for human facerecognition, Pattern Recognition 41 (3) (2008) 1186–1199.
[58] A. Martinez, R. Benavente, The AR Face Database, CVC Technical Report #24,1998.
[59] A. Georghiades, P. Belhumeur, D. Kriegman, From few to many: illuminationcone models for face recognition under variable lighting and pose, IEEETransactions on Pattern Analysis and Machine Intelligence 23 (6) (2001)643–660.
[60] BioID Face Database, URL /http://www.bioid.com/support/downloads/software/bioid-face-database.htmlS.
[61] S. Jung, J. Yoo, A robust eye detection method in facial region, ComputerVision/Computer Graphics Collaboration Techniques 4418 (2007) 596–606.
[62] G. Huang, M. Ramesh, T. Berg, E. Learned-Miller, Labeled Faces in the Wild: ADatabase for Studying Face Recognition in Unconstrained Environments,Technical Report, TR 07-49, 2007, University of Massachusetts.
[63] A. Levey, M. Lindenbaum, Sequential Karhunen–Loeve basis extraction andits application to images, IEEE Transactions on Image Processing 9 (8) (2000)1371–1374.
[64] Y. Taigman, L. Wolf, T. Hassner, Multiple one-shots for utilizing class labelinformation, in: British Machine Vision Conference (BMVC), 2009.
[65] B. Becker, E. Ortiz, Evaluation of face recognition techniques for applicationsto facebook, in: Eighth International Conference on Automated Face andGesture Recognition (AFGR), 2008.
[66] L. Shen, L. Bai, Mutualboost learning for selecting Gabor features for facerecognition, Pattern Recognition Letters 27 (15) (2006) 1758–1767.
[67] D. Margineantu, T. Dietterich, Pruning adaptive boosting, in: InternationalWorkshop and Conference on Machine Learning, 1997, pp. 211–218.
[68] Y. Zhu, J. Liu, S. Chen, Semi-random subspace method for face recognition,Image and Vision Computing 27 (9) (2009) 1358–1370.
[69] X. Li, L. Wang, E. Sung, AdaBoost with SVM-based component classifiers,Engineering Applications of Artificial Intelligence 21 (5) (2008) 785–795.

K. Choi et al. / Pattern Recognition 45 (2012) 2868–2883 2883
Kwontaeg Choi received the B.S. degree in computer science from Hallym Universit
y, Chooncheon, Korea, and the M.S. and Ph.D. degrees in computer science from YonseiUniversity, Seoul, Korea. His research interests include computer vision, pattern recognition, and face recognition.Kar-Ann Toh is a full professor in the School of Electrical and Electronic Engineering at Yonsei University, South Korea. He received the Ph.D. degree from NanyangTechnological University (NTU), Singapore. He had two years of work experience in the aerospace industry prior to his post-doctoral appointments at research centers inNTU from 1998 to 2002.
He was then affiliated with Institute for Infocomm Research in Singapore from 2002 to 2005 before his current appointment in Korea. His research interests includebiometrics, pattern classification, optimization and neural networks. He is a co-inventor of a US patent and has made several PCT filings related to biometric applications.Besides being an active member in publications, he has served as a member of technical program committee for international conferences related to biometrics andartificial intelligence. He has also served as a reviewer for international journals including several IEEE Transactions. He is a senior member of the IEEE.
Hyeran Byun received the B.S. and M.S. degrees in mathematics from Yonsei University, Seoul, Korea, and the Ph.D. degree in computer science from Purdue University,West Lafayette, IN. She was an assistant professor at Hallym University, Chooncheon, Korea, from 1994 to 1995. She is currently a professor of computer science at YonseiUniversity. Her research interests include computer vision, image and video processing, artificial intelligence, event recognition, gesture recognition, and patternrecognition.
















