Embed Size (px)
Citation preview

Simulation Modelling Practice and Theory 15 (2007) 175–184
www.elsevier.com/locate/simpat
Improving the remote scheduling of distributed productionwith process statistics and AI techniques
Alessandra Orsoni a,*, Romeo Bandinelli b
a Senior Lecturer, Kingston University, School of Business Information Management, Kingston Hill, Kingston upon Thames,
Surrey KT2 7LB, UKb Research Associate, Universita’ di Firenze, Dipartimento di Energetica ‘‘Sergio Stecco’’, Sezione Impianti e Tecnologie Industriali,
Via Cesare Lombroso 6/17 quinto piano, 50134 Florence, Italy
Available online 2 November 2006
Abstract
Stochastic events, such as rush orders, stock-out events, and local failures have an important impact on the performanceof distributed production, but they are difficult to anticipate and account for when scheduling production activities. Processstatistics and artificial intelligence techniques can provide this knowledge to effectively time synchronization events amongthe simulation and scheduling federates of a same distributed architecture. Measurable benefits include reduced communi-cation delays and, thus, improved responsiveness of the system to changes in production and new scheduling needs, as theyarise. Comparative results on the productivity of actual industrial systems are proposed and discussed in the paper.� 2006 Elsevier B.V. All rights reserved.
Keywords: On-line production scheduling; Coordinated production processes; AI techniques; Modeling of failure events; XLA-RTIarchitecture
1. Introduction
Distributed simulation effectively supports the management of coordinated production processes. Industrialapplications show that a distributed approach significantly enhances the time-performance of simulation butintroduces the issue of effectively timing the transfer of status information among federates by means of suit-able synchronization events. These events need to be scheduled a-priori and are system-specific in that they areusually timed to reflect the completion of relevant production phases. In the context of re-configurable coor-dinated production plants, the occurrence of critical events, such as local failures, stock-out events, and rushorders, may introduce important simulation delays because these events are stochastic in nature and cannot bescheduled a-priori at the federation level. Component failures, for instance, are generated locally within thescope of a single simulation federate and are not communicated to the other federates until the next synchro-nization event is scheduled to occur. If the synchronization events are not scheduled to be frequent enough and
1569-190X/$ - see front matter � 2006 Elsevier B.V. All rights reserved.
doi:10.1016/j.simpat.2006.09.012
* Corresponding author.E-mail addresses: [email protected] (A. Orsoni), [email protected] (R. Bandinelli).

176 A. Orsoni, R. Bandinelli / Simulation Modelling Practice and Theory 15 (2007) 175–184
the federates have comparable computing loads, the occurrence of asynchronous events may invalidate thecomputation for the entire interval in between synchronization times, thus causing the waste of large batchesof simulated time. On the other hand, if communication is too frequent, the waste is reduced but time-perfor-mance still suffers because synchronization events are quite time-consuming in the economy of the simulationrun. A first objective of this research is to anticipate local component failures and use this information at theglobal level to customize the timing of synchronization events among the simulation and scheduling federatesof the same distributed architecture. By these means the researchers expect to reduce communication delaysand wasted computing time. Section 3 of the paper will describe in detail this approach and show the perfor-mance improvements that can be achieved at the simulation-scheduling level with reference to an industrialtest-case. A second objective of the research is to test if an improvement in the time-performance of distributedsimulation, generates measurable benefits in the remote scheduling of distributed production. Section 4 of thepaper will present an industrial case for the measurement of these performance benefits at the level of the phys-ical system: a reduction in lead time and in the percentage of late deliveries are examples of the observed ben-efits. A third objective of the research is to extend the applicability of the approach to the management ofcomplex production networks. Sections 5–7 will discuss the design and the use of AI techniques based on Arti-ficial Neural Networks (ANNs) to support the generation of customized synchronization events in complexapplication cases. Section 7 in particular will analyze the performance benefits of the AI-based approach atthe level of the physical system measuring improvements in the productivity of a supply chain. The paper out-lines the main steps of this research as follows. The current techniques for the remote scheduling of distributedproduction are presented and the relevant time-performance issues are discussed. A first approach based on theactual process statistics of component failures for the production system is proposed as means to customize thetiming of federation synchronization events in a way that is reflective of the characteristics of the simulatedprocesses. The results of its implementation and testing are presented as a starting point for further, and moreadvanced, developments involving Artificial Intelligence (AI) techniques. Specifically, the paper shows that, bymeans of AI techniques based on Artificial Neural Networks (ANNs) and distributed simulation, patterns offailure can be anticipated and that this knowledge can effectively be used to re-schedule production across thecoordinated plants. It also shows that by these means efficient production levels can be maintained throughoutthe entire production system, while coping with the effects of local failures. The paper discusses the implemen-tation of this methodology and its application to an industrial case.
2. Remote scheduling of distributed production
Production management increasingly relies on the XLA-RTI architecture to remotely simulate and sche-dule complex production processes. Effective scheduling can be achieved by linking the simulation modelsof the physical system and suitable scheduling modules, as federates of this same architecture [1,2]. The sim-ulation models provide estimates for the state of the production plants at the time when the next batch is dueto be released for production; based on these estimates and on the current production plan the schedulingmodules dispatch the relevant production jobs to the different production plants. The estimated productioncapacity of each plant with respect to each production job/task is a function of the state of the individualmachines that constitute the plant [1–3]. Machine failures and downtimes are stochastic variables, whichare typically modeled at the individual plant level through their probability distributions: the Mean TimeBetween Failures (MTBF) and the Mean Time To Repair (MTTR), respectively. However, their consequencesat the level of the entire production system can be timely appreciated only when a suitable communicationpattern is established among the simulation federates [4]. Typically, the occurrence of a significant event atthe federate level cannot be reported to the other federates until an update of state variables is scheduledto occur, for instance when a given simulation phase is completed [5,6]. Because simulation phases are pro-cessed and executed in parallel by the different federates, delays in the communication of state changes amongfederates may invalidate large batches of simulated time and thus make the system less responsive to thescheduling needs of production [7,8]. Communication delays become a critical issue when the federation isused in the loop with the physical system to support on-line production scheduling [1,3]: estimates are valuableas long as they are available at the right time, and become useless after that. A first phase of this research haslooked at improving the time-performance of simulation federations by tailoring the timing of federation syn-

A. Orsoni, R. Bandinelli / Simulation Modelling Practice and Theory 15 (2007) 175–184 177
chronization events to the process statistics of otherwise asynchronous events [1]. This approach showed thatby introducing process-specific synchronization events, the average communication delay can be reduced by25–30%. Further work has also quantitatively shown how scheduling performance can benefit from thisimprovement at the communication level. Specifically a reduction in communication delays is shown to signif-icantly reduce the average number of unmet production deadlines (e.g. late product deliveries) as well as thecumulative delay on the ones that are not met [2]. Based on such results it was decided to analyze in furtherdetail the behavior of the production system with respect to random failure occurrences and see if suitablefailure patterns could be identified. Specifically, as part of a second research phase, an approach based onANNs has been devised to anticipate the impact of a local failure on the productivity of the coordinated pro-duction plants. The remainder of the paper will provide the details of the two approaches and discuss theirperformance impact as measured for reference industrial cases.
3. Synchronization based on process statistics
The research hypothesis that led the first phase of this work is that the performance of a distributed sim-ulation and scheduling tool based on the XLA-RTI architecture can be significantly improved if suitable pro-cess statistics are used to customize the timing of synchronization events for the federation [1,2]. Building fromthe failure characteristics of the critical process components, namely their Mean Time Between Failures(MTBF) distributions, for each one of the federate production plants, a methodology was devised to generatehistories of predicted failure events, which could be interspersed with the standard synchronization events, tomake the timing of communication among federates more responsive to the dynamic needs of productionscheduling [1]. In other words, the methodology statistically determines when component failures are likelyto occur for a particular production system and summarizes these statistics into additional synchronizationevents that capture the stochastic behaviour of the actual system as closely as deemed efficient for the appli-cation. There is a necessary trade-off in how closely the stochastic behaviour of the actual system should becaptured by the added-in synchronization events, as too fine a grain of communication among federatesmay actually stretch the duration of the simulation run beyond its efficient limits, and even outweigh the ben-efits of the corresponding reduction in wasted simulation time. The optimal customization of the synchroni-zation times, considering the added-in events of predicted failure, is case-specific as it depends on theparticular computational times and loads, which, in turn, depend on the number and on the nature of the sim-ulated processes. A customized history of synchronization events should be determined for each particular fed-eration as general rules would be quite difficult to produce, because of the diverse nature of the stochasticvariables involved in the simulated processes. A simple heuristic approach based on statistical inferencewas defined for the purpose of testing the research hypothesis. In order to appreciate the relevance of theapproach it should be observed that the failure behaviour of plant components is typically represented withinthe simulation federates by means of the random extraction of punctual values out of the relevant MTBF dis-tributions. A preliminary analysis of the production system, typically formalized as a fault analysis for eachproduction plant, may help isolate the components that are the most critical towards the smooth operation ofthe system and, thus, confine the scope of the predicted failure event generation process to those componentsonly. Once the critical components have been identified, for instance the ones whose failure have blocking con-sequences for an entire production line, series of random extractions are performed out of the correspondingMTBF distributions at time zero, when the simulation run is due to start. The component characterized by theminimum average MTBF at time zero is assumed to be the first one to fail. The time of this first failure event,indicated as tf1, can be estimated subtracting from the minimum average MTBF a fraction of the correspond-ing standard deviation. The procedure is then iterated to determine the time of the subsequent failure events(tf2..tfn) until the desired simulation horizon has been covered. This way a history of predicted failure events isgenerated, which can be scheduled a-priori as additional federation synchronization times. The generalizedformula to determine the (i + 1)th predicted failure time is given in Eq. (1).
tfðiþ1Þ ¼ tfi þMTBFi � f � ri ð1Þ
where tfi is the ith predicted failure time; MTBFi is the minimum average MTBF at the (i + 1)th iteration; f isthe designated fraction of the standard deviation; ri is the standard deviation corresponding to MTBFi.

178 A. Orsoni, R. Bandinelli / Simulation Modelling Practice and Theory 15 (2007) 175–184
Both the number of punctual extractions required at each iteration step and the fraction of the standarddeviation to be subtracted from the minimum average MTBF are the object of system-specific optimization,as their optimal values are relative to the actual speed of simulation.
In order to test the time-performance benefits of the methodology in terms of its ability to reduce wastedsimulation time, a simple industrial application case was studied. The physical system of reference for thestudy is a flexible manufacturing plant consisted of eight work centres, two for each machining job/operation.The modeling of machine failure events for this system is achieved using the corresponding MTBF and MTTRdistributions, as discussed in earlier sections of this paper. Referring to Eq. (1), the number of random extrac-tions out of the MTBF distributions to be performed at each iteration was experimentally determined to be 16and by the same rationale the fraction of the standard deviation to be subtracted from the average MTBF ateach iteration was identified as approximately 0.4. The methodology was tested referring to a standard feder-ation (with standard synchronization events) as baseline approach for the purpose of assessing the time-per-formance of the improved federation (with customized synchronization times). The time-performance measureused to determine if the improved federation actually reduces the percentage of wasted simulation time overthe duration of a simulation run is the percentage change in communication delays. For the purposes of thisanalysis communication delays are defined as the absolute difference in time between the occurrence of a crit-ical event and the next synchronization event when such an occurrence is actually communicated to the othersimulation federates. In order to avoid multiple counting, only the largest difference is accounted for in eachinterval between synchronization times. In other words, multiple critical events may occur during each intervalbut only the one contributing the longest communication delay counts towards the summary statistics on com-munication delays. Eq. (2) shows how the summary statistics is computed. This statistics represents the per-centage average reduction in wasted simulation time.
PKi¼1ðDtiÞst �
PNj¼1ðDtjÞimp
PKi¼1ðDtiÞst
� 100 ð2Þ
where K is the total number of synchronization events for the standard federation; N P K, is the number ofsynchronization events for the improved federation; (Dti)st is the communication delay corresponding to theith interval between synchronization times for the standard federation; (Dtj)imp is the communication delaycorresponding to the jth interval between synchronization times for the improved federation.
For the industrial application case described above the percentage average reduction in wasted simulationtime was estimated to be approximately 31.5%. A 95% confidence interval was built around this estimatedvalue to account for the variability in the communication delays that were actually observed in a sample of35 simulation runs. This sample size was chosen to be above 30 so that it could be statistically handled asa large sample. The resulting confidence interval is approximately 31.5 ± 3.5%, thus identified a range ofpotential simulation time savings of 28–35%.
The actual duration of synchronization events, is driven by the time required for the communication of theupdated status parameters among federates. This duration is specific to the federation, and communicationtimes can be assumed to be of very similar length for all of the synchronization events of a given federation.Therefore, a first estimate of the percentage increase in communication time due to the addition of new syn-chronization events in correspondence of predicted failure events can be obtained as indicated in Eq. (3).
N � KK� 100 ð3Þ
with N and K defined as above.The percentage increase in communication times can well exceed the value of 50% in common simulation
applications if the average MTBF of the critical components is shorter than the corresponding duration of thesimulated production phases. An increase of 50% indicates that on average one predicted failure event isexpected to occur in between standard synchronization times. Referring to the same sample of 35 simulationruns, the increase in communication time for the industrial application discussed above leads to a 95% con-fidence interval estimate of approximately 37 ± 4.5%. This type of result does not outweigh the effect of areduction in wasted simulation time on the time-performance of simulation, as the duration of communication
A. Orsoni, R. Bandinelli / Simulation Modelling Practice and Theory 15 (2007) 175–184 179
events is typically shorter in order of magnitude than the corresponding duration of the simulated productionphases.
Because an improvement in the time-performance of distributed simulation is valuable as long as its impactis reflected in the production performance of the physical system, further experimentation is required to assesswhether the customization of federation synchronization events is worth pursuing in the context of the remotescheduling of distributed production. The next section of the paper provides some quantitative results on theproduction performance impact of customized synchronization events pertaining to the remote scheduling ofthe manufacturing and installation of railways switch point assemblies.
4. Performance impact of customized synchronization
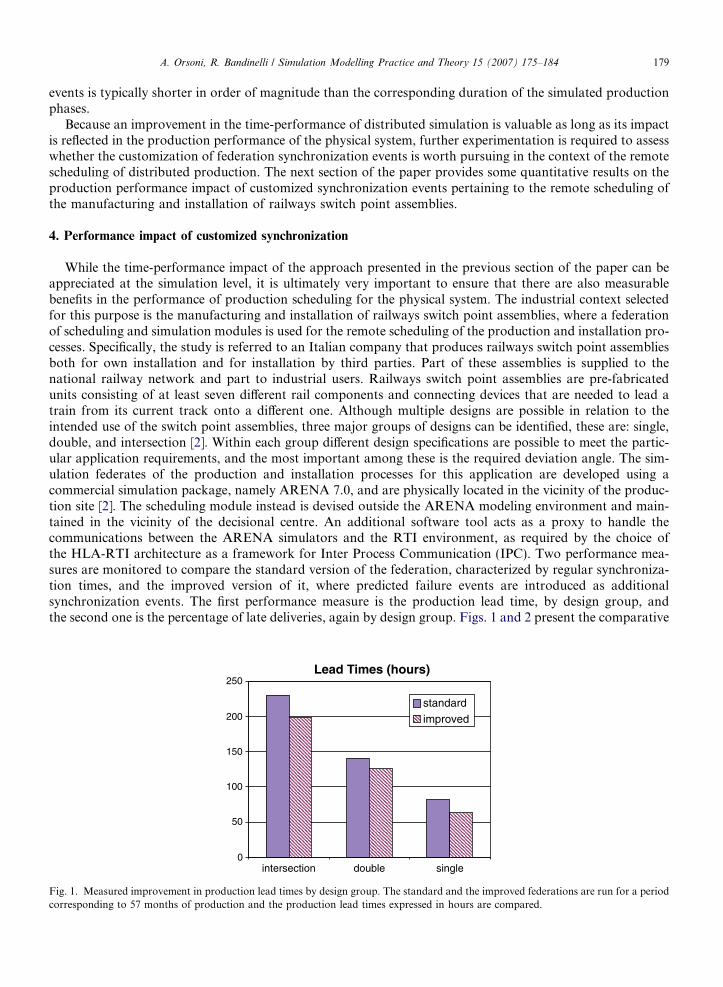
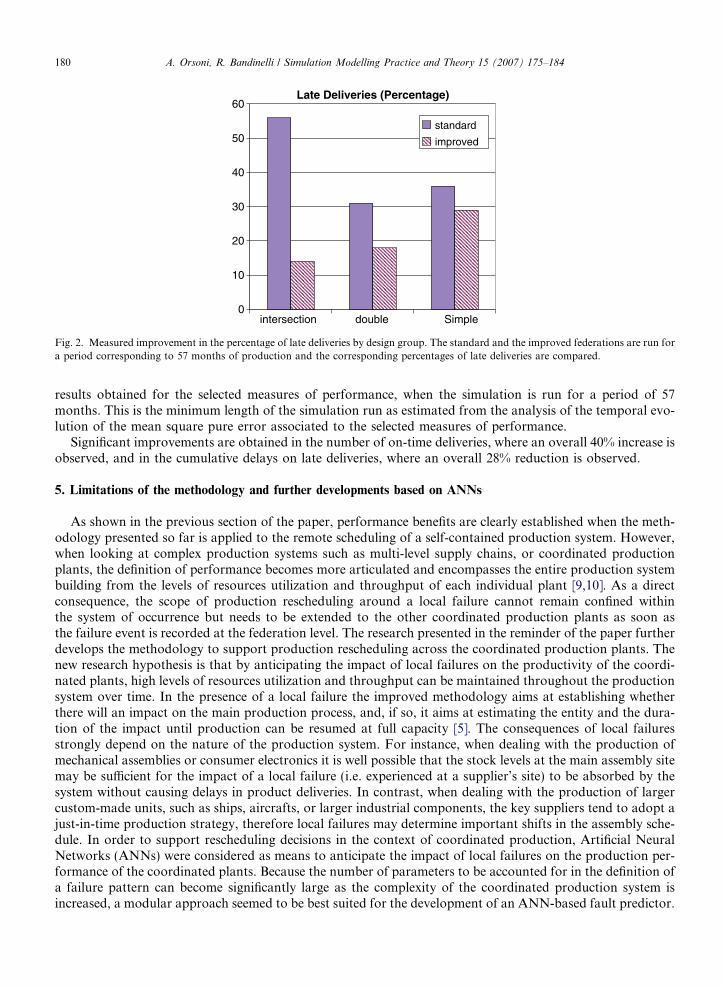
While the time-performance impact of the approach presented in the previous section of the paper can beappreciated at the simulation level, it is ultimately very important to ensure that there are also measurablebenefits in the performance of production scheduling for the physical system. The industrial context selectedfor this purpose is the manufacturing and installation of railways switch point assemblies, where a federationof scheduling and simulation modules is used for the remote scheduling of the production and installation pro-cesses. Specifically, the study is referred to an Italian company that produces railways switch point assembliesboth for own installation and for installation by third parties. Part of these assemblies is supplied to thenational railway network and part to industrial users. Railways switch point assemblies are pre-fabricatedunits consisting of at least seven different rail components and connecting devices that are needed to lead atrain from its current track onto a different one. Although multiple designs are possible in relation to theintended use of the switch point assemblies, three major groups of designs can be identified, these are: single,double, and intersection [2]. Within each group different design specifications are possible to meet the partic-ular application requirements, and the most important among these is the required deviation angle. The sim-ulation federates of the production and installation processes for this application are developed using acommercial simulation package, namely ARENA 7.0, and are physically located in the vicinity of the produc-tion site [2]. The scheduling module instead is devised outside the ARENA modeling environment and main-tained in the vicinity of the decisional centre. An additional software tool acts as a proxy to handle thecommunications between the ARENA simulators and the RTI environment, as required by the choice ofthe HLA-RTI architecture as a framework for Inter Process Communication (IPC). Two performance mea-sures are monitored to compare the standard version of the federation, characterized by regular synchroniza-tion times, and the improved version of it, where predicted failure events are introduced as additionalsynchronization events. The first performance measure is the production lead time, by design group, andthe second one is the percentage of late deliveries, again by design group. Figs. 1 and 2 present the comparative
Lead Times (hours)
0
50
100
150
200
250
intersection double single
standardimproved
Fig. 1. Measured improvement in production lead times by design group. The standard and the improved federations are run for a periodcorresponding to 57 months of production and the production lead times expressed in hours are compared.
Late Deliveries (Percentage)
0
10
20
30
40
50
60
intersection double Simple
standard
improved
Fig. 2. Measured improvement in the percentage of late deliveries by design group. The standard and the improved federations are run fora period corresponding to 57 months of production and the corresponding percentages of late deliveries are compared.
180 A. Orsoni, R. Bandinelli / Simulation Modelling Practice and Theory 15 (2007) 175–184
results obtained for the selected measures of performance, when the simulation is run for a period of 57months. This is the minimum length of the simulation run as estimated from the analysis of the temporal evo-lution of the mean square pure error associated to the selected measures of performance.
Significant improvements are obtained in the number of on-time deliveries, where an overall 40% increase isobserved, and in the cumulative delays on late deliveries, where an overall 28% reduction is observed.
5. Limitations of the methodology and further developments based on ANNs
As shown in the previous section of the paper, performance benefits are clearly established when the meth-odology presented so far is applied to the remote scheduling of a self-contained production system. However,when looking at complex production systems such as multi-level supply chains, or coordinated productionplants, the definition of performance becomes more articulated and encompasses the entire production systembuilding from the levels of resources utilization and throughput of each individual plant [9,10]. As a directconsequence, the scope of production rescheduling around a local failure cannot remain confined withinthe system of occurrence but needs to be extended to the other coordinated production plants as soon asthe failure event is recorded at the federation level. The research presented in the reminder of the paper furtherdevelops the methodology to support production rescheduling across the coordinated production plants. Thenew research hypothesis is that by anticipating the impact of local failures on the productivity of the coordi-nated plants, high levels of resources utilization and throughput can be maintained throughout the productionsystem over time. In the presence of a local failure the improved methodology aims at establishing whetherthere will an impact on the main production process, and, if so, it aims at estimating the entity and the dura-tion of the impact until production can be resumed at full capacity [5]. The consequences of local failuresstrongly depend on the nature of the production system. For instance, when dealing with the production ofmechanical assemblies or consumer electronics it is well possible that the stock levels at the main assembly sitemay be sufficient for the impact of a local failure (i.e. experienced at a supplier’s site) to be absorbed by thesystem without causing delays in product deliveries. In contrast, when dealing with the production of largercustom-made units, such as ships, aircrafts, or larger industrial components, the key suppliers tend to adopt ajust-in-time production strategy, therefore local failures may determine important shifts in the assembly sche-dule. In order to support rescheduling decisions in the context of coordinated production, Artificial NeuralNetworks (ANNs) were considered as means to anticipate the impact of local failures on the production per-formance of the coordinated plants. Because the number of parameters to be accounted for in the definition ofa failure pattern can become significantly large as the complexity of the coordinated production system isincreased, a modular approach seemed to be best suited for the development of an ANN-based fault predictor.

A. Orsoni, R. Bandinelli / Simulation Modelling Practice and Theory 15 (2007) 175–184 181
In order to make the tool more responsive to changes in the physical systems and more efficient in terms ofmaintenance, the modular structure was devised so that each ANN module would track the failure behavior ofone of the federate production plants, and establish a correlation between the failure modes of one particularproduction plant and the productivity of the main production process. A first advantage of the modularapproach can be appreciated at the development level, as both the design and the training of each ANN unitbecome simpler and less time-consuming. Another important advantage can be identified in the maintenanceand upgrade of the fault predictor. If any important change occurs in either the design or the operation one ofthe federate production plants, only the relevant ANN module needs to be modified (i.e. re-design or re-train-ing on new data sets), while leaving all the others virtually unchanged. Input to each ANN module includesthe identifier of the component that is failing, the current stock level at the main production site, and the cur-rent production stage. The output of each ANN module includes the duration of the period until productionat the main production site is resumed to full capacity and the estimated production capacity, expressed as apercentage of the full capacity, during that period. It is important to observe that the duration of such a perioddoes not normally coincide with the Mean Time To Repair (MTTR) of the component because of the lag inthe response of the main production process to sudden variations of the supply of parts and components fromthe coordinated production plants. This lag is a function of lead times, WIP and existing stock levels at thetime of failure [11]. The next section will provide a detailed description of the design, training and testingof each ANN module.
6. ANN design, training, and testing
The design of an ANN structure for a particular application involves the specification of the ANN archi-tecture (i.e. the number and composition of the ANN’s layers) and the choice of an efficient learning algorithmwith the aim of achieving a suitable trade-off among precision, learning time, and generalization ability [13,14].As indicated in the literature [13,15,16] and directly experienced in other industrial applications [14,17–19]feed-forward, fully-connected networks with two hidden layers of neurons (i.e. intermediate layers of neuronsplaced between the input layer and the output layer), provide high generalization ability [17,18,20]. The com-position of each hidden layer typically depends on the size of the training data sets, on the complexity of theproblem, and on the modelling scope (i.e. width of the input variability ranges) [13,17,19]. Although no expli-cit correlations exist among these parameters to determine the exact composition of each layer, previous expe-rience on a wide range of industrial applications, led to the specification of the hidden layers as follows: 9neurons in the first hidden layer and 5 neurons in the second one. A direct correspondence was establishedbetween the number of neurons in the input/output layers and the actual number of input/output parameters(i.e. 3 neurons in the input layer, and 2 in the output layer.) Back Propagation [13,14,19] was chosen as learn-ing algorithm because it is easily implemented and provides good trade-offs between precision levels and learn-ing times [13,17,20].
ANN training and testing phases require the availability of large numbers of paired sets of input and outputrecords. Because suitably large sets of data are not usually available through historical records, nor can theybe experimentally obtained within typical time and budget constraints, simulation experiments were con-ducted to produce the data required for the study. An existing federation of simulation models reproducingthe final assembly stages of an aircraft manufacturing process, as well as the coordinated production of air-craft engines and landing gear, provided the required data sets. The federation was customized under thehypothesis that the engine and landing gear suppliers were subsidiaries of the main contractor, however itwas assumed that on average only 15% of the engines and 8% of the landing gear production would feed intothe main contractor’s assembly process so that the remaining of their production would be intended for thirdparties. As part of earlier verification and statistical validation of the federation the evolution of the meansquare pure error was plotted over time to establish the minimum length of the simulation run compatible withthe stochastic variability associated to the simulated processes (e.g. incoming orders, component failure andrepair rates for each production plant) [10,12]. Because the main assembly process produces on average 3 air-crafts per month, a relatively long period of simulation was required to observe the system in its steady oper-ation regime: the minimum length of the simulation run was then found to be equal to 26 months ofproduction. In order to generate suitable sets of training and test data, it was decided to run the federation

182 A. Orsoni, R. Bandinelli / Simulation Modelling Practice and Theory 15 (2007) 175–184
for a much longer period corresponding to 10 years of production and the experimental phase involved 10replications, for a total of 100 years of production. During the course of each simulation the following vari-ables were tracked and recorded: each failure, by location (plant identifier) and component (machine identi-fier), the time of occurrence, the current stage of assembly, and the number of aircrafts produced during eachmonth. The stock levels on the engines and landing gear are always assumed to be zero because these compo-nents are produced on order for each individual aircraft. By monitoring the monthly production of aircraftassemblies after the occurrence each local failure (whether in one of the coordinated production plants orin the main assembly process) it is possible to establish the impact of the failure on the aircraft assembly ratesand the duration of this impact, which are the two designated output for the ANN system. Upon completionof the 10 simulation replications the data was split by failure location so as to obtain separate data sets foreach ANN module. A total of 84 failure events were recorded for the engine production plant, a total of134 failure events were recorded for the landing gear production plant and a total of 98 failure events wererecorded for the assembly process. Minor failures leading to production delays of the order of a few hourswere not accounted for at this stage. Three quarters of these data points were used for ANN training, whilethe remaining one quarter was used for testing purposes. The number of learning iterations for each ANNmodule was adjusted so as to obtain comparable levels of precision and generalization ability across modules.The output error measured on the training data set was used as an indicator of the ANN’s precision, while theoutput error measured on the test data set was used as an indicator of the ANNs generalization ability. Net-work training aimed at maintaining the error measures on training data within a maximum of 5% and those ontest data within a maximum of 10%. The same ANN structure was maintained for the three modules becausethe type of correlation to be learned was the same and also the numbers of data points available for learningand testing in all three cases were of the same order.
7. Performance impact of the ANN-based approach
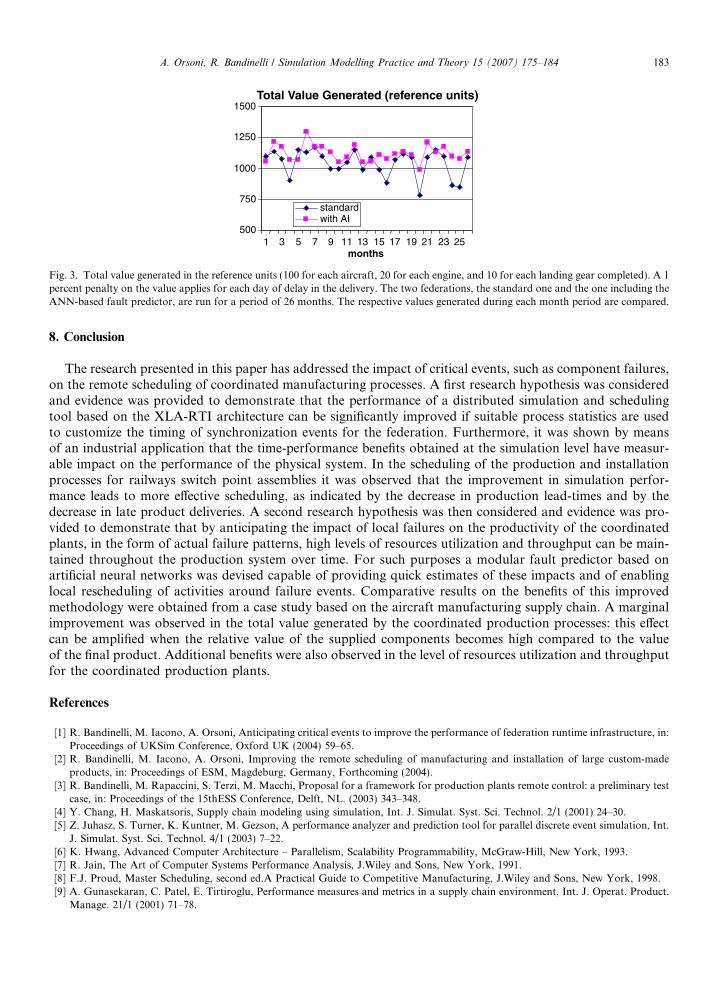
The implemented ANN modules were integrated in the federation of simulation and scheduling tools tosupport both the off-line generation of histories of predicted failure events and the dynamic rescheduling ofproduction in the coordinated production plants. When running the federation, predicted failure events areused as reference to time the federation synchronization events around the process characteristics of the fed-erate plants. The dynamic role of the ANN module is further explained in the following. Whenever a localfailure is recorded and communicated to the federation, the identifier of the failing component and the currentstage of aircraft assembly are passed to the relevant ANN module; the corresponding stock level on the sup-plier’s product is always zero because production is carried out on a just-in-time basis. The ANN moduledetermines the expected impact (entity and duration) on the assembly process, which is passed to the localscheduling, at the federate plant level, to determine whether the production plan should proceed unchangedor not: if the incident has determined sufficient slack time, a third-party request may be sent to production,prior to fulfilling the current order of the main aircraft assembly. In order to assess the performance improve-ments induced by the methodology, the federation was run over a period of 26 months with and without thescheduling support of the ANN infrastructure. Because of confidentiality agreements the actual performancefigures could not be either used or disclosed. Therefore, a simple scoring system was defined for each process: avalue of 100 was assigned to each aircraft completed on time. Similarly a value of 20 was assigned to eachengine set delivered on time (whether for internal assembly or for third party). A value of 10 was assignedto each landing gear whether for internal assembly or not. A 1 percent penalty on the value of each item (air-craft, engine, or landing gear) was applied for each day of delay in the delivery. Fig. 3 compares the total valuegenerated over the 26 month period with and without the support of the ANN-based fault predictor,respectively.
A marginal improvement can be observed in the overall system performance, as the availability of detailedinformation on the impact of local failures provides access to the benefits of rescheduling at the local level.These marginal benefits can reach higher proportions in applications where the relative importance of the sup-plier products, with respect to the final assembly, becomes higher. In addition, by enabling the more efficientrescheduling of production to account for local failures, the variability in the monthly production levels is alsoreduced which reflects a more consistent level of resources utilization over time.
Total Value Generated (reference units)
500
750
1000
1250
1500
1 3 5 7 9 11 13 15 17 19 21 23 25months
standardwith AI
Fig. 3. Total value generated in the reference units (100 for each aircraft, 20 for each engine, and 10 for each landing gear completed). A 1percent penalty on the value applies for each day of delay in the delivery. The two federations, the standard one and the one including theANN-based fault predictor, are run for a period of 26 months. The respective values generated during each month period are compared.
A. Orsoni, R. Bandinelli / Simulation Modelling Practice and Theory 15 (2007) 175–184 183
8. Conclusion
The research presented in this paper has addressed the impact of critical events, such as component failures,on the remote scheduling of coordinated manufacturing processes. A first research hypothesis was consideredand evidence was provided to demonstrate that the performance of a distributed simulation and schedulingtool based on the XLA-RTI architecture can be significantly improved if suitable process statistics are usedto customize the timing of synchronization events for the federation. Furthermore, it was shown by meansof an industrial application that the time-performance benefits obtained at the simulation level have measur-able impact on the performance of the physical system. In the scheduling of the production and installationprocesses for railways switch point assemblies it was observed that the improvement in simulation perfor-mance leads to more effective scheduling, as indicated by the decrease in production lead-times and by thedecrease in late product deliveries. A second research hypothesis was then considered and evidence was pro-vided to demonstrate that by anticipating the impact of local failures on the productivity of the coordinatedplants, in the form of actual failure patterns, high levels of resources utilization and throughput can be main-tained throughout the production system over time. For such purposes a modular fault predictor based onartificial neural networks was devised capable of providing quick estimates of these impacts and of enablinglocal rescheduling of activities around failure events. Comparative results on the benefits of this improvedmethodology were obtained from a case study based on the aircraft manufacturing supply chain. A marginalimprovement was observed in the total value generated by the coordinated production processes: this effectcan be amplified when the relative value of the supplied components becomes high compared to the valueof the final product. Additional benefits were also observed in the level of resources utilization and throughputfor the coordinated production plants.
References
[1] R. Bandinelli, M. Iacono, A. Orsoni, Anticipating critical events to improve the performance of federation runtime infrastructure, in:Proceedings of UKSim Conference, Oxford UK (2004) 59–65.
[2] R. Bandinelli, M. Iacono, A. Orsoni, Improving the remote scheduling of manufacturing and installation of large custom-madeproducts, in: Proceedings of ESM, Magdeburg, Germany, Forthcoming (2004).
[3] R. Bandinelli, M. Rapaccini, S. Terzi, M. Macchi, Proposal for a framework for production plants remote control: a preliminary testcase, in: Proceedings of the 15thESS Conference, Delft, NL. (2003) 343–348.
[4] Y. Chang, H. Maskatsoris, Supply chain modeling using simulation, Int. J. Simulat. Syst. Sci. Technol. 2/1 (2001) 24–30.[5] Z. Juhasz, S. Turner, K. Kuntner, M. Gezson, A performance analyzer and prediction tool for parallel discrete event simulation, Int.
J. Simulat. Syst. Sci. Technol. 4/1 (2003) 7–22.[6] K. Hwang, Advanced Computer Architecture – Parallelism, Scalability Programmability, McGraw-Hill, New York, 1993.[7] R. Jain, The Art of Computer Systems Performance Analysis, J.Wiley and Sons, New York, 1991.[8] F.J. Proud, Master Scheduling, second ed.A Practical Guide to Competitive Manufacturing, J.Wiley and Sons, New York, 1998.[9] A. Gunasekaran, C. Patel, E. Tirtiroglu, Performance measures and metrics in a supply chain environment, Int. J. Operat. Product.
Manage. 21/1 (2001) 71–78.

184 A. Orsoni, R. Bandinelli / Simulation Modelling Practice and Theory 15 (2007) 175–184
[10] A. Orsoni, A. Bruzzone, R. Revetria, Framework development for web-based simulation applied to supply chain management, Int. J.Simulat. Syst., Sci. Technol. 4/1 (2003) 1–6.
[11] E.J. Williams, R. Narayannaswamy, Application of simulation to scheduling, sequencing, and material handling, in: Proceedings ofWinter Simulation Conference, IEEE, Piscataway, NJ, (1999) 861–865.
[12] R.J. Sargent, Validation and verification of simulation models, in: Proceedings of Winter Simulation Conference Piscataway, NJ,(1999) 39–48.
[13] R. Mosca, P. Giribone, A.G. Bruzzone, A. Orsoni, S. Sadowski, Evaluation and analysis by simulation of a production line modelbuilt with back-propagation neural networks, Int. J. Model. Simulat. 17/2 (1997) 72–77.
[14] S.E. Fahlmann, An empirical study to of learning speed in back-propagation networks, CMU Technical Report, CMU-CS88, 1998.[15] J. Anderson, Rosenfeled E Neurocomputing – Foundation of Research, MIT Press, Cambridge, MA, 1998.[16] D.W. Hillis, The Connection Machine, MIT Press, Cambridge, MA, 1989.[17] P. Giribone, A.G. Bruzzone, Artificial neural networks as adaptive support for the thermal control of industrial buildings, Int. J.
Power Energ. Syst. 19 (1) (1999) 75–78.[18] P. Giribone, A.G. Bruzzone, Design of a study to use neural networks and fuzzy logic in maintenance planning, in: Proceedings of
IEEE – The Institute of Electrical and Electronics Engineering Conference on Systems, Man, and Cybernetics, Atlanta, GA, (1997)98–103.
[19] A.G. Bruzzone, A. Orsoni AI and simulation-based techniques for the assessment of supply chain logistic performance’’, in:Proceedings of the IEEE Annual Simulation Symposium (ANSS 2003), Orlando, FL, (2003) 154–164.
[20] D.E. Rumelhart, G.E. Hinton, R.J. Williams, Learning representations by back-propagating errors, Nature 323 (9) (1986) 533–536.





























