Embed Size (px)
Citation preview

INOM EXAMENSARBETE DATATEKNIK,GRUNDNIVÅ, 15 HP
, STOCKHOLM SVERIGE 2018
Improving Software Deployment and MaintenanceCase study: Container vs. Virtual Machine
OSCAR FALKMAN
MOA THORÉN
KTHSKOLAN FÖR ELEKTROTEKNIK OCH DATAVETENSKAP

i

ii
Abstract Setting up one's software environment and ensuring that all dependencies and settings are the same across the board when deploying an application, can nowadays be a time consuming and frustrating experience. To solve this, the industry has come up with an alternative deployment environment called software containers, or simply containers. These are supposed to help with eliminating the current troubles with virtual machines to create a more streamlined deployment experience. The aim of this study was to compare this deployment technique, containers, against the currently most popular method, virtual machines. This was done using a case study where an already developed application was migrated to a container and deployed online using a cloud provider’s services. Then the application could be deployed via the same cloud service but onto a virtual machine directly, enabling a comparison of the two techniques. During these processes, information was gathered concerning the usability of the two environments. To gain a broader perspective regarding the usability, an interview was conducted as well. Resulting in more well-founded conclusions. The conclusion is that containers are more efficient regarding the use of resources. This could improve the service provided to the customers by improving the quality of the service through more reliable uptimes and speed of service. However, containers also grant more freedom and transfers most of the responsibility over to the developers. This is not always a benefit in larger companies, where regulations must be followed, where a certain level of control over development processes is necessary and where quality control is very important. Further research could be done to see whether containers can be adapted to another company’s current environment. Moreover, how different cloud provider’s services differ. Keywords Docker; Kubernetes; Container; Virtual Machines; Cloud services; Deployment; Maintenance

iii
Förbättring av utplacering och underhåll av mjukvara Fallstudie: Containers vs. Virtuella maskiner
Abstrakt
Att sätta upp och konfigurera sin utvecklingsmiljö, samt att försäkra sig om att alla beroenden och inställningar är lika överallt när man distribuerar en applikation, kan numera vara en tidskrävande och frustrerande process. För att förbättra detta, har industrin utvecklat en alternativ distributionsmiljö som man kallar “software containers” eller helt enkelt “containers”. Dessa är ämnade att eliminera de nuvarande problemen med virtuella maskiner och skapa en mer strömlinjeformad distributionsupplevlese. Målet med denna studie var att jämföra denna nya distributionsteknik, containrar, med den mest använda tekniken i dagsläget, virtuella maskiner. Detta genomfördes med hjälp av en fallstudie, där en redan färdigutvecklad applikation migrerades till en container, och sedan distribuerades publikt genom en molnbaserad tjänst. Applikationen kunde sedan distribueras via samma molnbaserade tjänst men på en virtuell maskin istället, vilket möjliggjorde en jämförelse av de båda teknikerna. Under denna process, samlades även information in kring användbarheten av de båda teknikerna. För att få ett mer nyanserat perspektiv vad gäller användbarheten, så hölls även en intervju, vilket resulterade i något mer välgrundade slutsatser. Slutsatsen som nåddes var att containrar är mer effektiva resursmässigt. Detta kan förbättra den tjänst som erbjuds kunder genom att förbättra kvalitén på tjänsten genom pålitliga upp-tider och hastigheten av tjänsten. Däremot innebär en kontainerlösning att mer frihet, och därmed även mer ansvar, förflyttas till utvecklarna. Detta är inte alltid en fördel i större företag, där regler och begränsningar måste följas, en viss kontroll över utvecklingsprocesser är nödvändig och där det ofta är mycket viktigt med strikta kvalitetskontroller. Vidare forskning kan utföras för att undersöka huruvida containers kan anpassas till ett företags nuvarande utvecklingsmiljö. Olika molntjänster för distribuering av applikationer, samt skillnaderna mellan dessa, är också ett område där vidare undersökning kan bedrivas. Nyckelord Docker; Kubernetes; Container; Virtuella maskiner; Molntjänster; Utplacering; Underhåll

iv
Table of Contents 1 Introduction 1
1.1 Background 1
1.2 Problem 3
1.3 Purpose 4
1.4 Goal 4
1.5 Methods 5
1.6 Limitations and Delimitations 5
1.7 Outline 6
2 Containers and virtual machines as deployment techniques 7
2.1 Early Deployment Methods 7
2.2 Virtualization & Virtual Machines 7
2.3 Container Virtualization 10
2.4 Comparison Between (Docker) Containers and VMs 14
2.5 Literature and Related Work 15
3 Methodology 19
3.1 Research Approach 19
3.2 Outline of Research Process 22
3.3 Data Collection Methods 23
3.4 Tools 25
3.5 Project method 25
3.6 Documentation and modelling method 27
3.7 Evaluating Performance and Usability 27
4 Case study: Application Deployment 29
4.1 Phase 1: Container 29
4.2 Phase 2: Virtual Machine 38
5 Benefits and Drawbacks of Using Containers 43
5.1 Results from Performance Tests 43
5.2 Personal Observations and Usability 48
5.3 Interview 50
5.4 Theoretical Material 51
5.5 Conclusions 52
6 Discussion 55
6.1 Methods 55
6.2 Research Result Revisited 57
6.3 Ethical Aspects 58
6.4 Sustainability 59

v
6.5 Future Work/Research 59
Appendix A - Code 65
Appendix B - Interview (in Swedish) 69

1
1 Introduction
With the evolution of software, the software has become increasingly dependent on other resources, either from public repositories or other parts of one’s own software. As one includes more and more code from the outside, the deployment and maintenance complexity increases. This created the need to isolate the environment of each application in order to increase security and stability. Thus, virtual machines became an incredibly important part of software deployment. Nowadays however, with the rise of microservices and an increasing need of efficiency, virtual machines does not always fill all the needs of the providers. In the midst of this, software containers made an entrance, causing a lot of buzz in the industry because of their small size and minimal overhead. Is all the praise and hype really valid? Can containers help providers increase their efficiency? These are some questions which this thesis tries to answer.
1.1 Background
1.1.1 Software Deployment and Maintenance
The configuration needed to set up one’s workspace before starting a project, is something most software developers would rather want to skip. It can be both time consuming, frustrating and not to mention repetitive, since one often has to repeat this process each time one starts a new project [1]. However, skipping that part has not been an option. With the introduction of container environments though, it changed. Now, developers can configure the workspace once and simply reuse that configuration when they start a new project, greatly increasing the time the developers can be productive [1]. Deployment is often a daunting task for larger companies, since it often means that it has to manage all different integrations at once and to make these cooperate. It could also mean that the release management has to write several build and configuration scripts that has to be bug free, or the company is going to have bugs in the production even though the software itself might be reasonably bug free. This is just one of many things that containers aim to solve. In medium to large scale companies, containers could have an even greater impact, since it could replace the need for huge deploy and build scripts, that are needed to run for each server instance [1]. Instead, one could configure the application/environment once and quickly push this to all servers at the same time, making the production flow greatly increased and even minimizing the amount of errors during deployment.

2
1.1.2 Software Containers
A container contains the software and everything that it needs to run, making the software both stand-alone and system independent [2]. This means that it can run on all platforms, system independent, and does not depend on any other program, stand-alone. One could label it as a miniature OS, but where it is only necessary to run the processes of a task rather than an entire OS (like in a virtual machine), making them smaller in size and less resource-hungry. It also helps to sandbox1 the software, making it easier to create a secure environment, not only from a security perspective [3] but from a developer’s perspective as well, since it is possible to isolate different releases from each other. These factors would suggest that containers are could be beneficial for scaling a program [1].
1.1.3 Kubernetes
Kubernetes2 is an orchestration manager, a tool for managing, scheduling and deploying clusters. A cluster is a collection of, in this case, containers, that either communicate with each other or work together. Kubernetes assists with controlling the containers, and provide various helper functions, e.g. restarting containers or keeping services running at all times. Kubernetes thus makes it possible to handle scalable services, even if the containers are not running on one’s own computer.
1.1.4 Tradedoubler - The Main Stakeholder
Tradedoubler is a pioneering affiliate marketing business, whose purpose is to simplify advertising on the Internet. Tradedoubler acts as a broker between advertisers and publishers to simplify their interaction.
They give advertisers the ability to create marketing campaigns and see detailed statistics on how, when and from where their sales were generated. Moreover, Tradedoubler give publishers the ability to use profitable advertisements on their sites, such as blogs, by using campaigns created by the advertisers in the network. Tradedoubler also handles the backend tasks, like invoicing advertisers and creating payments for the publishers, so that the transactions between these parties goes smoothly.
As Tradedoubler’s affiliate network technology has evolved over the years, it has resulted in a heterogeneous environment deployed across several servers. To create an isolated development environment, and then easily test and deploy changes, is becoming increasingly challenging. An isolated development environment is when the software or OS you are running does not interfere with any other software that is currently running. This ensures the software does not depend on anything unexpected, or that the developer is trying to solve bugs that exists within other software.
1 What does "sandbox" mean? 2 What is Kubernetes?

3
To make development and deployment easier, Tradedoubler has started to create applications within Docker containers.
1.2 Problem
1.2.1 Issues with Current Deployment Methods
One of the most used deployment technologies within the industry at the moment, is the use of virtual machines (VMs) along with scripts for deployment. While it is a working solution, it is an unnecessarily complicated and bug-ridden process. Virtual machines require servers to run a full OS, despite the fact that all features provided by a full OS might not be necessary. The OS has to be configured before being used as well [4, pp. 3–6]. Another matter of concern when using VMs, are the resources. A virtual machine will require the resources of an entire OS, even when running a single application. [5]. As an example, when using a VM on a server, the VM requires a fixed amount of RAM on the server (or all of it). RAM is crucial for complex calculations and tasks, but also for being able to run several processes at the same time, as well as to provide those processes with working memory [6]. The RAM that is allocated to the VM will be unavailable for the host, as well as for any other machines connected to it, making it troublesome to run several sandboxed environments at the same time (a common scenario due to security reasons). This forces one to either predict the maximum amount of RAM that the machines will utilize or add additional resources to account for worst case scenarios. The RAM allocation and management is not the only issue with VMs however, the storage memory is another problem since a modern OS can take up more than 32GB of storage [7]. Imagine running 4 VMs on the same machine, the fixed storage would take up an entire 128GB disk. This does not include any programs that might have to be installed on them. Disregarding the technical issues, there is also the need of configuring the environment for each server. They might have different software versions, minor changes, or even different operating systems that might require its unique configuration.
1.2.2 Containers as an Alternative
It is worth to explore whether containers are a valid alternative to the deployment process, and whether it improves the conditions of the current experience by minimizing the amount of configuration and resources needed. The question of when either deployment technique is suitable is also of interest, as well as what difference there is between VMs and containers regarding performance, and whether optimizations can be made in this field as well.

4
1.2.3 Research Questions
Given the potential of containers, we are interested in how these could be used to improve today's complicated deployment techniques and in what environments they’re suitable. Hence, the aim of this thesis is to uncover the benefits and drawbacks of using containers when deploying applications, both in a personal and in a business environment, and to present conclusions based these findings. Thus, leading us to the following research question: RQ: What are the benefits and drawbacks of using containers for software deployment and maintenance in personal and business environments?
1.3 Purpose
The purpose of the thesis is to disclose what benefits and potential drawbacks that container-based applications, deployed with Kubernetes, have over traditional application deployments on physical servers. The results will be able to help Tradedoubler decide whether they should invest in the use of containers together with Kubernetes for deployment. If containers should prove to be a good solution for big scale deployment, then this could potentially increase their effectivity and improve developer satisfaction. However, should the conclusion be that containers have significant drawbacks as well, it could prove to be a better solution to use the old-fashioned way instead, virtual machines and build scripts. The results could benefit others by helping them make more informed decisions concerning deployment when in the process of developing applications. Other companies might benefit from them as well, since they could be influenced to either use or not use containers in order to improve their efficiency. The results could also prove to be beneficial to individuals, even if there are issues for larger companies.
1.4 Goal
The goal is to provide information about application deployment with containers, with its pros and cons over deployment on virtual machines. Our intentions include to further extend the information given with statistics, wherever possible, to back up our conclusions. A case study is performed where a stateful sample application is created using Docker containers, which is then configured as a Kubernetes cluster locally using Minikube. The application is deployed in Google Cloud Platform’s Kubernetes Engine. The results of the application deployments, regarding the performance and usability, is documented, evaluated and discussed.

5
The report will also present the benefits and potential drawbacks of container-based applications deployed with Kubernetes in comparison to traditional scaled application deployment on physical servers.
1.5 Methods
To be able to reach the goals of the thesis and acquire the correct and necessary results, a strategy for how to carry out the project is needed. This strategy consists of methods that will ensure that the project is conducted in a successful manner. The research methods can be divided into two categories, qualitative methods and quantitative methods, although some methods can belong to both. This thesis will be conducted using qualitative research methods in order to fulfill its purpose and goals. A smaller set of data derived from a case study will be investigated and analyzed in order to formulate a theory, making a qualitative approach more suitable than a quantitative. To answer the research questions, several activities are conducted. A literature study is performed in order to provide sufficient background information for a deeper understanding of the relevant area. A case study, where an application is deployed using containers and VM’s, is also performed and analyzed with performance and usability in mind. An interview is conducted where an employee at Tradedoubler provide useful insights to the current solution.
1.6 Limitations and Delimitations
In the basis for the thesis, the option of using bare-metal as a deployment technique is disregarded, since the use case is not really comparable with the virtualization techniques. It is also the case that bare-metal provisioning is not of interest to Tradedoubler because of their growing nature. There are many different virtual machines, several different OS: s, different applications and container types. However, we have limited ourselves to using the most used or accessible in each field, thus using Docker for containers, Ubuntu Server for OS and a self-developed simple application [8], [9]. Using the simple application, we hope to show the minimal differences, but it’s of course not possible to capture all. We also have been limited to using Google Cloud platform, since cloud servers are expensive and thus we can only test the one Tradedoubler kindly lent us access to. We are also limiting ourselves to Kubernetes as an orchestration manager, since it is the one of interest to Tradedoubler and we lack resources to test another.

6
1.7 Outline
The remainder of the thesis is structured as below:
● Chapter 2 will define the background of the thesis and establish information necessary to be able to fully understand the rest of the thesis. Examples include, what a container is more thoroughly explained and how the processes for deployment looks.
● Chapter 3 gives an overview of the methods that were used during the project. This includes the research and practical methods used and discussions about why they were chosen.
● Chapter 4 describes the case study we performed. This includes the development of the Docker container, the Kubernetes and virtual machine deployment, both locally and online on the Google Cloud Platform, and the testing on both virtual machines and containers.
● Chapter 5 compiles the results, which consists of those from the testing, together with the replies to the interview.
● Chapter 6 is a discussion regarding the results and the information we
gained during the literature study. It also contains a summary of the conclusions we have reached and discusses directions for future research.

7
2 Containers and virtual machines as deployment techniques
This chapter will explain several of the biggest concepts mentioned in the text, that can be needed for a deeper understanding of what the project is about and what is happening.
2.1 Early Deployment Methods
In the beginning of the internet there was not especially much traffic. Back then, one could simply run the applications directly on the computer. As more and more people gained access to the internet, the number of servers needed increased, but the resources on each server was not fully utilized. This was very costly because of the cost of the hardware, when it is standing and using only a certain percentage of the full capacity. At the same time, the applications grew increasingly complex and dependent on other software as well. This could also cause issues between applications. Furthermore, hackers got more sophisticated and having the applications directly on the server could increase the potential damage done if a security issue was found. Searching for an answer to all of these troubles, led to the interest in virtualization.
2.2 Virtualization & Virtual Machines
Today, virtualization is one of the most used deployment technologies. Most of these are virtual machines together with deployment scripts. Virtualization is the act of abstracting a component or multiple component to simulate something real. In our case this refers to the simulation of components and resources of a computer, on top of existing hardware. Thus, making it possible to simulate multiple resources, such as processors or disks, with just a single resource. This means that one is able to run software not designed for the real system, without changing the software or system. [10, pp. 32 – 33] However, it is not only subsystems that can be virtualized, it is also possible to apply to an entire system, thus creating a virtual machine. These virtual machines make it possible to run different architectures and/or operating systems on a single machine. Virtual machines have grown very popular with the introduction of cloud platforms and scaling. By using virtual machines, it is possible to provide efficient and secure environments for each cloud user. [11] [10, p. 36]
2.2.1 VMM
The virtual machine monitor (VMM), also known as hypervisor [12, p. 68], is the virtualization software which emulates the interfaces and resources so that the guest operating system can interact with the hardware believing it is

8
running on the right hardware. There are two different types of hypervisors, type 1 and type 2. 2.2.1.1 Type 1 Hypervisor A type 1 hypervisor is the type of VMM that runs on bare metal, which means it runs directly on the hardware, there is no operating system or anything else in between. It then can run the guest operating system as a user process. When a kernel call is executed by the guest operating system, a trap to the kernel occurs. This enables the VMM to be able to inspect the issued code. If the code was issued by the guest kernel, then the code is forwarded to be run by the kernel. If it were a user process who issued the instruction, then the VMM emulates what the actual kernel would have done if the instruction were done in an installed operating system. [12, pp. 569–570] Type 1 hypervisors are fast, since they are very close to the hardware and can thus run the virtual OS in the same speed as an actual OS, and it does not need to share resources with an actual OS. 2.2.1.2 Type 2 Hypervisor Type 2 hypervisors runs, as opposed to type 1 hypervisors, as user processes on top of an operating system. User processes are run like normal processes, however before running code the hypervisor scans through the code and replaces all sensitive calls, such as kernel calls, with procedures of the hypervisor which can handle the calls. This is called binary translation. [12, p. 570] These hypervisors use a lot of optimizations and caching which enables them to execute on near bare metal performance for user programs. However, the system calls can actually outperform the type 1 hypervisor in the long run, because the trap calls ruins many of the caching features in the actual CPU. With binary translation these are all left alone. This has led to type 1 hypervisors using binary translations for some calls as well, in order to increase performance. [12, p. 570]
2.2.2 Usages
As mentioned earlier virtual machines enables efficient use of physical resources, by making it possible to divide the physical resources but still give the illusion of having access to the entire resource. This makes it possible to reduce the operating costs by reducing the amount of unused resources, thus making it possible to have less resources but offer the same performance for the company and/or cloud provider. It also improves the service provider’s experience, since this can be used to improve the application performance while still decreasing the costs for the service provider by allowing to allocate more resources when needed and then decrease the amount of resources when they are not needed. It is then possible to allocate more or reduce the amount of physical resources to a machine on the fly, or to migrate, move the virtual

9
machines between different physical machines, without shutting down the virtual machine. [11] This makes them excellent for use with cloud computing where migration and/or resource management is common, and where it otherwise can get quite costly. However, it can also improve the normal self-hosting as well, though one might not see as large benefits. Furthermore, virtual machines are used to provide secure sandboxing for each user, since each user gets access to a single system. If the user tries to do something unallowed or hack the system all they get access to is their own environment, so at worst they only destroy their own environment, while the other users are unaffected. It is also easier to place restrictions on the resource access on a virtual machine, making it harder for users to try to throttle the services by different means. [10, p. 36]
2.2.3 Issues with Virtual Machines
So, what are the issues with virtual machines? Although it’s a well-established, working solution, it is still a fairly bug-ridden process that is unnecessarily complicated. Virtual machines require servers to run a full OS, while it might not require the full features that an OS provides. Additionally, the OS has to be configured before being used. [4, pp. 3–6]. Furthermore, there is also an issue regarding resources when using VMs, since we also need to provide the resources of an entire OS, while there is only one application we need to run [5]. As an example, when using a VM on a server, the VM takes up a fixed amount of the Random-Access Memory (RAM) on the server or the whole amount. RAM is crucial for computers, since it is necessary for complex calculations and tasks, but also to be able to run several processes at the same time and provide those processes with working memory [6]. The issue with the VM taking up a fixed amount of RAM is, when the memory is taken, it becomes unavailable for the host and thus also the other machines. This makes it troublesome to run several different sandboxed environments at the same time, a common scenario for security reasons. Furthermore, it forces you to either predict the maximum amount of RAM that the machines will utilize or add additional resources to account for worst case scenarios. Not only is RAM allocation and management a trouble with VMs but the storage memory is as well, a modern OS can take up more than 32GB of storage [7]. Imagine running 4 VMs at the same machine, then the fixed storage would take up an entire 128GB disk. What is worse is that that memory is just for the OS, not including the programs that the company or developers want to use. Past the technical issues, there is also a hurdle of configuring the environment for each server, which all might have different versions, have some small changes, or even different OS: s, where each might require its own unique configuration. This lead to a search for something that could solve these problems, but still provide the flexibility of the virtual machines. Thus, came the containers.

10
2.3 Container Virtualization
Containers is an alternative, or supplement, for virtual machines that offers lightweight sizes, are portable and have high performance. However, containers are different from virtual machines all together. The reason being that they take an entirely different approach to the way of virtualization, a graphical comparison can be seen in figure 1 and 2. Instead of the hardware (or para) virtualization, containers are virtualizing the processes, simply called process virtualization. As can be seen in figure 1, this means that instead of virtualizing the entire operating system, it is only the user processes that are virtualized, A, B and C, together with their dependencies, bins/libs. [13] [14]. This is possible due to the fact that the containers all run on top of the same kernel [15], the host OS’s kernel, unlike virtual machines who emulate the entire system including the kernel, guest OS. The containers can then interact with the underlying system via standard system calls, giving near native performance [16]. Since the kernel already is started with the underlying system, host OS, containers can have an almost instantaneous startup time (excluding the time taken to launch the developer’s own application) and allows for a significantly decreased overhead for both storage and the processes. [14]
Figure 1. The Docker structure when running applications. [17]
Figure 2. A VM structure when running applications. [17]
2.3.1 Docker
Docker has almost become a synonym to the container technology, but in fact there are several different technologies behind containers, Docker has however been the most successful in in terms of popularization and usage of containers. So, what is the difference between Docker and other container technologies? Docker is not a technology on its own, but rather it is built upon other container technologies such as LXC (a part of Linux containers), which has been developed since 2008. However what Docker did, and still does, differently is that it tries to simplify the management of these technologies, which on their own can be very hard to manage [2] [18]. By unifying these

11
technologies and providing a simple daemon for running the management tools, Docker has succeeded in bringing containers to the masses. 2.3.1.1 Technical Background By using LXC it is possible for Docker to integrate the containers in a separate environment with its own user groups, network device and virtual IP address. Together with the tools of cgroups, another component of LXC, Docker can gather metrics allowing constant monitoring, and thus be able handle the resource management of the containers. This makes it possible to run containers in its own environment, without the need to emulate a system. [2] Another difference is that Docker uses a layering filesystem, AUFS, which allows users to take previous containers as a base for their own application and then just add more onto it. Using this system, you can easily create images, where an image is the packaging of the application that includes everything needed to run. Together with their hub, a repository system not too unlike Github, it is easy to create new projects without having to start installing all dependencies from scratch. AUFS also helps with the downloading and updating of containers, since if a user already has installed an image that another application uses, then Docker can reuse that image instead of requiring the user to download it again. The layering also helps with the updating, as said, since only the differences are needed to be downloaded rather than the entire image. [2], [14] All of this ends up making the creation of containers as simple as creating a file, called a Dockerfile, where you write what to include, install and run. Moreover, each statement in this file is one layer in the AUFS system, thus making it easy to control how many or few layers you want to have in your application. [19] 2.3.1.2 Usages The nature of Docker makes it great for microservices, because of the lightweight containers and the separation of the content. Moving monolithic services to microservices can massively improve the service performance. [20] It is also possible to reduce costs by using Docker for deployment, something Docker advertises quite heavily, as well as providing a website for calculating the return on investments. [21] Another reason for using Docker containers is that you can move your service between different cloud providers without a hassle, since you only need to move the data. The application and all its dependencies are handled by the Docker application. By using Docker, all you need to do is start the application and then to provide the database data. [22] This also improves the update och patchibility of the web services. It only requires you to apply the updated images and then restart the cluster, something that takes a very short time, and is possible to accomplish while still having some servers running. Thus, decreasing the downtime of such updates. It also improves the data handling since the data is not part of the application, reducing risks of data corruption and other kinds of data issues.

12
Docker also massively improves the field for DevOps, since the development teams no longer work independently from the operations team, and vice versa [23]. This reduces many of the headaches that these two teams tend to have with each other, and also makes it possible to operate and evolve applications swiftly. This is because it is much simpler now to automate processes and, in addition, it decreases the amount of business layers and/or other teams that the application needs to go through. In some cases, it might even be possible to merge the two, developer and operations teams, together to a single DevOps team possibly reducing company costs and at the same time having the same or improved efficiency. [23] [24] Of course, these reasons can also be seen as negative for a larger company, however it is possible that this simply is due to the fact that companies are unwilling to cede that much control to developers. It is possible to then ask oneself whether this actually is a disadvantage or not, since it now is possible to have more direct influence in the development process and does not implicitly mean that the developers will do whatever they want.
2.3.2 Kubernetes
As previously introduced, Kubernetes is a portable, open-source platform for automating the deployment, management and scaling of containerized applications across clusters of hosts [25] [26]. It was designed to meet an extremely diverse range of workloads. Its building blocks are loosely coupled and extensible due to the Kubernetes API. The API is used by both internal components, extensions and containers. Kubernetes runs its components and workloads on a collection of nodes. A “node” refers to either a physical or a virtual machine that run Kubernetes. A collection of nodes and some other resources needed to run an application is referred to as a cluster. There are two kinds of nodes, master nodes and worker nodes. Every cluster has one master node and can have none or several worker nodes. A cluster that is “highly available”, meaning up and running and available for use under a longer period of time, have multiple master nodes [27] [28]. The master node operates as the brain of the cluster and is largely responsible for the centralized logic that is provided by Kubernetes. It exposes the API to clients, keeps track of the health of other nodes, is in charge of scheduling and manages communication between components [29] [26]. It’s the primary node of contact for the cluster. The worker nodes however, are responsible for running workloads, or containers, with the help of both local and external resources. Every node must therefore have a container runtime, like Docker, installed. The master node will distribute the workloads to the worker nodes, whom will create and destroy containers accordingly as well as handling route and forward traffic as necessary [29]. The basic operative unit in Kubernetes is called a “pod” and can be described as a collection of one or more, tightly coupled, containers that run in a shared

13
context. An illustration of a multi-container pod can be seen in figure 3, where one container implements a file puller and the other a web server. A pod may have one or multiple applications that run within and together implements a service. Usually, there is one container per application, although it is possible that the different containers are for just one application [26]. A pod provides a higher-level abstraction that simplifies the deployment and management of applications. This is where the scheduling, scaling and replication of containers is handled, automatically, instead of on individual container level [26] [27].
Figure 3. A multi-container pod with a volume for shared storage between the
containers. [28] A pod also provides automated sharing of resources. All containers within a pod share a network (IP and port space) and can locate and communicate with each other through “localhost”. This means that the usage of ports must be coordinated between the applications in a pod. Naturally, services that listen on the same port can’t be deployed within the same pod [27] [28] [26]. The containers within a pod also share volumes that can be mounted into an applications filesystem, as has been illustrated in figure 3. A volume is basically a directory that may or may not contain data. The aspects of a volume, such as content and the backing medium, is determined by the type of volume. A pod must specify what volumes exists in the pod and where these should be mounted within the containers. The abstraction of volumes solves, in addition to the sharing of files between containers, some issues concerning persistence of data. Files within a container are relatively short-lived, which could prove to be an inconvenience for non-trivial applications. When a container crashes, it’ll be restarted with a “clean slate”, meaning the files will be lost. Volumes will preserve the files, since the lifetime of a volume is consistent with the lifetime of the pod rather than the container. The volume will only cease to exist when the pod ceases to exist [28] [26]. Pods are also relatively short-lived entities. They will not withstand node and scheduling failures, nor other types of evictions that could occur because of node maintenance or lack of resources [28]. When a pod is created, it will be assigned a unique ID and then scheduled to a node where it will run until it is either terminated according to the present restart policy or deleted. A node,

14
here, refers to either a physical or virtual machine that runs Kubernetes. Should a node that has a pod scheduled to it, suddenly become unavailable for some reason, then the pod will be scheduled for deletion. It will not be rescheduled to a new functioning node, but an identical replication of the pod, with only a new UID, can replace it [28]. 2.3.2.1 Minikube Minikube3 is a tool for easily running a small instance of Kubernetes locally. A single-node Kubernetes cluster will be started inside a virtual machine on the local computer. It lets both inexperienced and experienced users try out Kubernetes or use for day-to-day development and testing without having to pay for a cloud provider [30].
2.4 Comparison Between (Docker) Containers and VMs
Before starting it is important to keep in mind what was mentioned earlier, that containers are not virtual machines. Docker [22] makes the comparison that virtual machines are like houses, they have all the necessary necessities needed in order to live there and provide protection from the outside. Containers on the other hand are like apartments, they also provide the protection and the basic necessities like the houses. However, the necessities such as water and electricity are all shared between all the apartments in the apartment complex. It is also possible to rent or buy all sorts of apartment sizes, everything from single room apartments, without kitchen, bedrooms and so on, to entire penthouse apartments. In a house however it can be very hard to find exactly what one want, one often has to make some sort of compromise. This is a good way of emphasizing one of the biggest differences between the two. A virtual machine will often consist of a full operating system onto which the developer has installed the application and possibly added, or removed, files, programs or dependencies. Whereas a container starts in the other direction, the developer only adds the application and the dependencies needed for it to run, possibly giving less overhead. One can take it one step further and claim that Docker is not a virtualization technology, it is an application delivery technology. What this means is that Docker containers are not used for virtualizing a system, where one takes everything an application uses and packages it in a system like if it were running on bare metal. Instead, a container on the other hand is each a part of the application and the data that the container might have is not part of the container, but rather sits directly on the disk. This means that if one needs to change the application architecture, backup or update the application, one does not need to do any pre-procedures at all, other than to back up the data volume. [22]
3 What is Minikube?

15
Virtual machines are more secure than containers by default, since it grants additional isolation. [31] In a virtual machine you are inside the contained environment whatever you do, but with containers you are still on top of the host system’s kernel, making it more likely for security breaches to occur. An example of this is that SELinux and other kernel modules are not part of the namespacing in the Docker containers. This means that if a Docker process manages to get access to one of these, it is accessing the actual host system [32]. Thus, making it important to treat privileged processes with care, as if they were running directly on the system. This does not mean that containers by definition are insecure, only that there is at least one less security measure available by default. Furthermore, Docker uses the Hub/Store for download and upload of the container images, even during runtime, which can lead to security issues. There are naturally several ways to contain this by e.g. downloading static images once, but the fact remains that these are conscious actions the developer has to take rather than default measures. [32] [33] In further comparison, Virtual machines are not as vulnerable to DDoS attacks and noisy neighbors as Docker containers [34, pp. 32 – 34]. Docker is more geared towards using several containers online at the same time, due to it being an application delivery technology. While the increased density of the application is favorable, this can cause additional troubles as well. With no restrictions this means that if one container is attacked, the whole network might be under heavy load and go down. This can be solved by using an orchestration manager such as Kubernetes, by limiting the max amount of resources each container can take and thus preventing starvation of the resources. Containers run on the kernel giving far faster startup times than an VM, since most of the system is already started for a container. All a container needs to do is basically launching the application the user wants. A VM on the other hand needs to launch the kernel, then the entire operating system and then, finally, the user application. However, it is not only the hardware efficiency which makes a case for containers, it is also the fact that Docker can be used with orchestration managers in order to create clusters which acts as a single machine. Using this one can make the service have high availability by using functions for automatic restarts, load balancing with others. It is possible to run containers on virtual machines in order to have the best of two worlds, the containment and isolation of the virtual machines, with the scalability and resource management of containers. So even with containers on the rise, virtual machines are not disappearing soon.
2.5 Literature and Related Work
2.5.1 Overview of Virtual Machine Resources
Table 1 shows the most substantial articles and resources which might be used by the interested reader for more in-depth learning concerning virtual
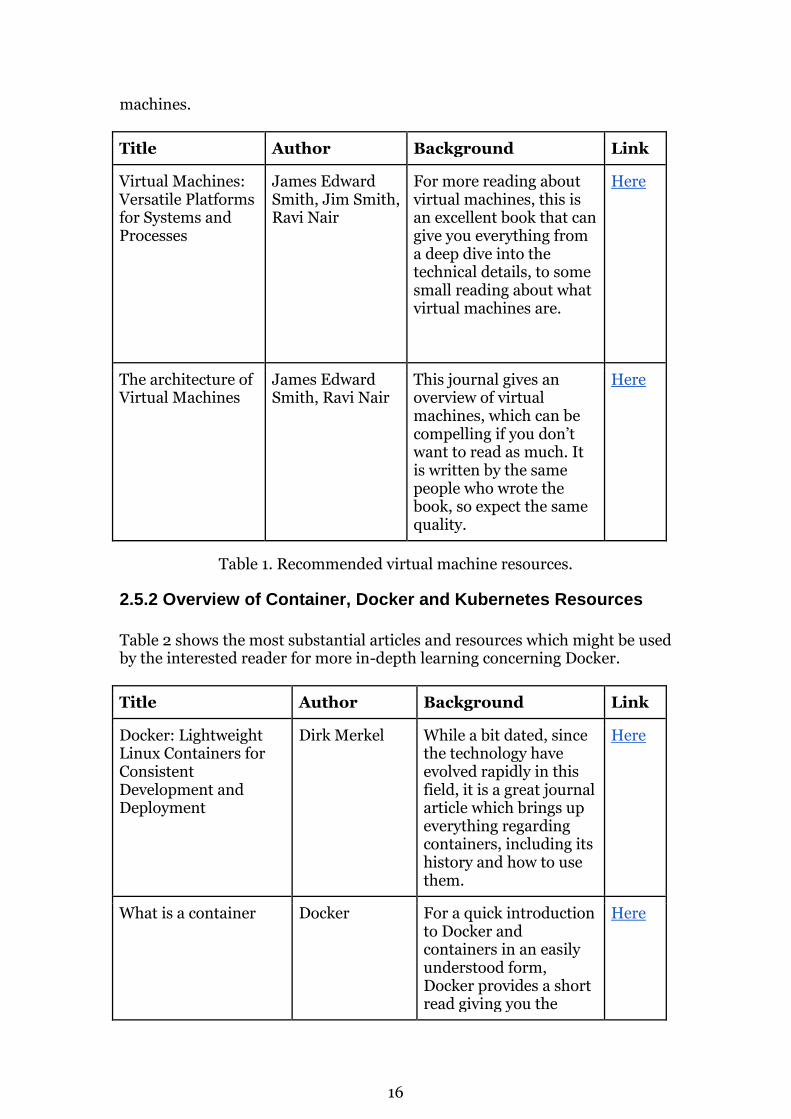
16
machines.
Title Author Background Link
Virtual Machines: Versatile Platforms for Systems and Processes
James Edward Smith, Jim Smith, Ravi Nair
For more reading about virtual machines, this is an excellent book that can give you everything from a deep dive into the technical details, to some small reading about what virtual machines are.
Here
The architecture of Virtual Machines
James Edward Smith, Ravi Nair
This journal gives an overview of virtual machines, which can be compelling if you don’t want to read as much. It is written by the same people who wrote the book, so expect the same quality.
Here
Table 1. Recommended virtual machine resources.
2.5.2 Overview of Container, Docker and Kubernetes Resources
Table 2 shows the most substantial articles and resources which might be used by the interested reader for more in-depth learning concerning Docker.
Title Author Background Link
Docker: Lightweight Linux Containers for Consistent Development and Deployment
Dirk Merkel While a bit dated, since the technology have evolved rapidly in this field, it is a great journal article which brings up everything regarding containers, including its history and how to use them.
Here
What is a container Docker For a quick introduction to Docker and containers in an easily understood form, Docker provides a short read giving you the
Here
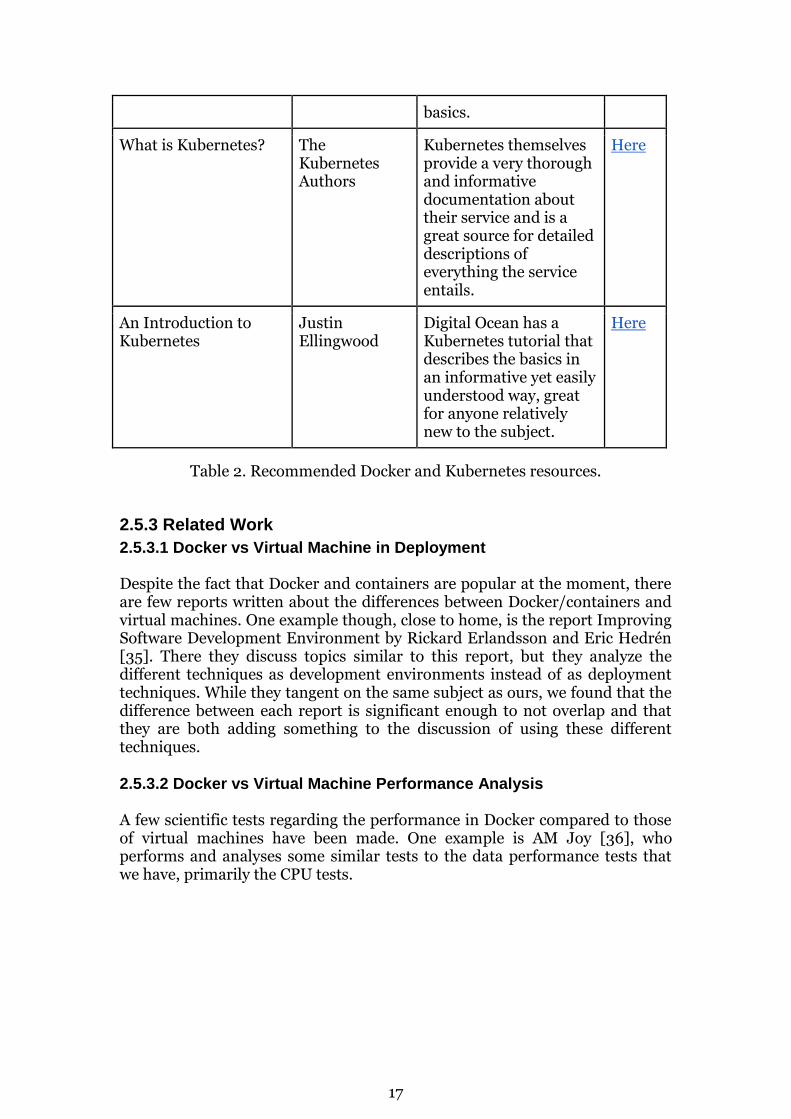
17
basics.
What is Kubernetes? The Kubernetes Authors
Kubernetes themselves provide a very thorough and informative documentation about their service and is a great source for detailed descriptions of everything the service entails.
Here
An Introduction to Kubernetes
Justin Ellingwood
Digital Ocean has a Kubernetes tutorial that describes the basics in an informative yet easily understood way, great for anyone relatively new to the subject.
Here
Table 2. Recommended Docker and Kubernetes resources.
2.5.3 Related Work
2.5.3.1 Docker vs Virtual Machine in Deployment Despite the fact that Docker and containers are popular at the moment, there are few reports written about the differences between Docker/containers and virtual machines. One example though, close to home, is the report Improving Software Development Environment by Rickard Erlandsson and Eric Hedrén [35]. There they discuss topics similar to this report, but they analyze the different techniques as development environments instead of as deployment techniques. While they tangent on the same subject as ours, we found that the difference between each report is significant enough to not overlap and that they are both adding something to the discussion of using these different techniques. 2.5.3.2 Docker vs Virtual Machine Performance Analysis A few scientific tests regarding the performance in Docker compared to those of virtual machines have been made. One example is AM Joy [36], who performs and analyses some similar tests to the data performance tests that we have, primarily the CPU tests.

18

19
3 Methodology
This chapter describes the research approach, the outline of the research process, the data collection methods, the tools used during the case study and the general project method that has been adopted.
3.1 Research Approach
3.1.1 Quantitative and Qualitative Methods
When a scientific research is conducted, it’s important to apply appropriate methods that will steer the work in the direction of correct and proper results. Methods can generally be divided into two categories, quantitative methods and qualitative methods. Quantitative research methods are more aligned with measurable data like numbers and percentages. Mathematical, computational and statistical techniques and experiments are used to investigate an observable phenomenon. Large sets of hard data are analyzed, forming statistics that can be used for drawing conclusions and verifying or falsifying theories and hypothesis [37]. Qualitative research methods on the other hand, are more aligned with soft data and information that is not really measurable. A particular case is studied more closely, often through observations and interviews, for a deeper understanding. Smaller sets of data are analyzed in order to form hypothesis and theories [37]. Which type of methods that is best suited for a project or research, can be difficult to determine. A good place to start is to identify whether the project is about proving a phenomenon by large sets of data or experiments, or if it’s to investigate a phenomenon or small sets of data to build theories by exploring the environment [37]. If it’s the first, then quantitative research methods would be appropriate and if it’s the latter, qualitative research methods. Once a type has been chosen, the methods of the other type should not be used.
3.1.2 Inductive, Deductive and Abductive Methods
There are three, more commonly used, research approaches: inductive, deductive and abductive approaches. The inductive approach means that theories, with different explanations from observations, are created. Qualitative methods are used for collecting data, which is then analyzed for better understanding and for formulating different views of the observed phenomenon. There must be enough data to be able to explain why something is happening and for building a theory. [37] The deductive approach means that theories or hypotheses are investigated and tested in order to falsify or verify them. Quantitative methods with large

20
sets of data are used for testing the theories or hypotheses. The theory that is supposed to be tested, must be expressed in terms and variables that are measurable. The expected outcome that is to be achieved must be stated as well. [37]
3.1.3 Case Study
A case study is a research strategy and it consists of an empirical study. This study is a way of harnessing information by investigating the difference between real life and the theories. The data is harnessed by conducting an exhaustive examination of one specific case in the study, as well as its related contextual data. The case study can then be used as a basis from which one can draw conclusions about the specific context with a large data set as evidence. [37, p. 5]
3.1.4 Interview
An interview is a qualitative research method which can be divided into three underlying types: structured, semi-structured and unstructured. Structured interviews are a sort of verbal survey, which relies on a questionnaire where predetermined questions are written down. They don’t allow for much variation and response questions but are instead more focused on amassing more data in a shorter time. Semi-structured interviews consist of a few questions which structure the area to talk about but allows the researcher to ask follow up questions to get further details or explanations. This type is used to get concrete data but allows to get more elaborative answers from the interviewed subjects. Unstructured interviews have no predetermined questions, other than the possible starting question. The rest of the interview continues on from the answer to that initial question with questions made up on the fly for the area of interest. These are used when you want to study the subject in depth but can also be somewhat challenging for the interviewed subjects to answer. [37] [38]
3.1.5 Bunge’s Scientific Method for Technology
Bunge’s method for conducting scientific research, has ten ordered cognitive operations, where the next step is based on the outcome of previous work. The method can however be applied to all types of inquiries, like technological or humanistic, and not just inquiries of scientific nature. [39, pp. 253 – 254] 1. Identify a problem. 2. State the problem clearly. 3. Search for information, methods or instruments.

21
4. Try to solve the problem with the help of the means collected in the previous step. 5. Invent new ideas, produce new empirical data, design new artifacts. 6. Obtain a solution. 7. Derive the consequences. 8. Check the solution. 9. Correct possibly incorrect solution. 10. Examine the impact.
3.1.6 Adopted Research
This thesis is conducted using qualitative research methods. A smaller set of data derived from a case study is investigated and analyzed in order to formulate a theory, which made a qualitative approach more suitable rather than a quantitative. The other method we used in this project, is Bunge’s method. However, we have made certain changes in order to align it with the method in our project.
22
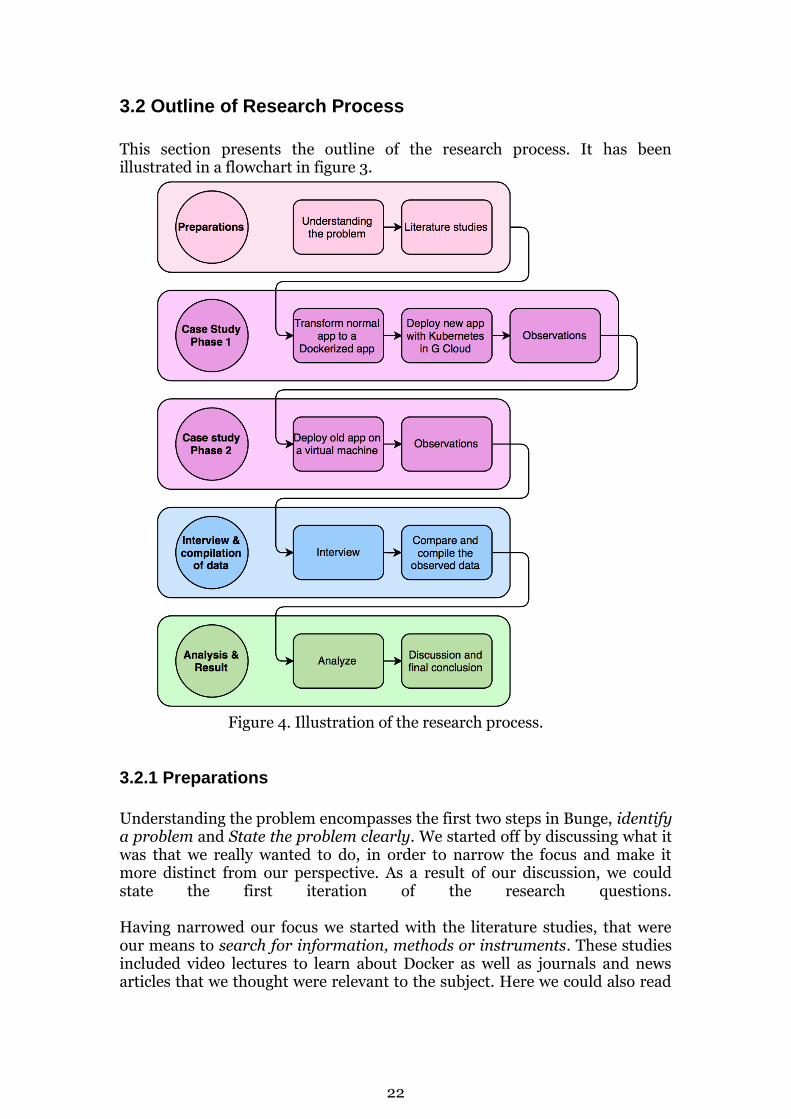
3.2 Outline of Research Process
This section presents the outline of the research process. It has been illustrated in a flowchart in figure 3.
Figure 4. Illustration of the research process.
3.2.1 Preparations
Understanding the problem encompasses the first two steps in Bunge, identify a problem and State the problem clearly. We started off by discussing what it was that we really wanted to do, in order to narrow the focus and make it more distinct from our perspective. As a result of our discussion, we could state the first iteration of the research questions. Having narrowed our focus we started with the literature studies, that were our means to search for information, methods or instruments. These studies included video lectures to learn about Docker as well as journals and news articles that we thought were relevant to the subject. Here we could also read

23
articles that would highlight some of the differences between the personal and business environments requirements on software.
3.2.2 Case Study: Phase 1
Next, in accordance with Bunge’s step 4 and 5, we conducted a case study that we divided into two phases. Phase 1 involved transforming a normal application into a containerized application using Docker containers. Here, the literature study was essential in order to succeed, because of the prerequisites required. Once the application had been containerized, we deployed the application in Google Cloud with the help of Kubernetes. Finally, we observed the results, in regard to performance and usability, and documented these.
3.2.3 Case Study: Phase 2
After phase 1 of the case study, we quickly moved on to phase 2. This involved deploying the same application, as non-containerized, on a virtual machine. The results were observed, once again with regards to performance and usability, and documented.
3.2.4 Interview
After the case study had been performed, an interview was conducted and documented in order to provide us with valuable insights from the development team at Tradedoubler. The goal of the interview was to discover in what way the subjects perceived that containers could help the business as a whole, and if they thought they could make use of containers themselves when developing. We used a semi-structured format in our interview, in order to find answers to the questions we had formulated but were able to steer the interview according to the subject’s answers.
3.2.5 Analysis and Result The results from both the interview and the case study were then compiled, allowing us to make a more informed comparison between the different deployment techniques. Our findings were then analyzed with the help of the information gathered during the literature study. A final conclusion was then drawn regarding the benefits and drawbacks of using containers for deployment and maintenance in the different environments.
3.3 Data Collection Methods
This section outlines the different methods used to collect data, a very important component in this project. During this project we used data from three different data sets: a literature study which was used as the foundation for our theories, two case studies giving us data to examine and an interview backing our assumptions about the current developer environment.

24
3.3.1 Literature Study
As mentioned earlier, a literature study is performed in order to provide sufficient background information for a deeper understanding of the relevant area of interest. This was especially true in this case, since we did not know much about Docker and the subject at first, though we found it interesting. After this study however, we felt proficient enough to be able to reach a conclusion regarding the usability of Docker and containers. During the first stage of the study we went through video lectures from Udemy, called Docker Mastery: The Complete Toolset From a Docker Captain, one of the top IT & Development courses at the time. We also learned Kubernetes using the interactive tutorials given at the official Kubernetes site. From these courses we learned about Docker and Kubernetes well enough to complete phase 1 in the case study. We then used KTH Primo [40], ScienceDirect [41] and Google Scholar [42] to find relevant books, journals, articles and other papers, in order to find more specific knowledge regarding Docker and virtual machines. We also read up on the different methodologies using the paper given by the school and read through other project reports to get an overlook over how the report should be formed.
3.3.2 Case Study Observations
Observation is to collect data by studying a phenomena and recording data about said phenomena. The observations are made as the last step of each phase in the case study, meaning after the deployment using containers and Kubernetes as well as after the deployment using a virtual machine. The observations are essential for the comparison between the different deployment techniques. The findings from the observations are arranged and presented in suitable form.
3.3.3 Interview
After having finished the literature- and case studies, we still did not have enough information about what people really thought about the current developer environment. If the technology is improved, but everyone is already content with the current environment, a change could be an unnecessarily burden to some. We wanted to find out if containers could solve some problems developers face today, so what could be better than asking them directly? Using their answers, we found it easier to argue for what the containers really could be used for in the current environment. We held one interview. The interview was conducted together with a developer from one of the three development groups within Tradedoubler, he was part of the database group. This was the group which had neither fully adapted containers but did use them to some degree. The interview questions can be seen in appendix B. The answers were then gathered, organized and

25
presented. Using these answers, we can easier back up our claims, with the feelings of one of those who work with this on a daily basis.
3.4 Tools
During this project we used a Lenovo Ideapad U330P with Ubuntu 18.04 LTS and a MacBook Pro (2013) with MacOS 10.13.4 (High Sierra). Visual Studio Code were used for all code editing, with the majority of the work oriented towards developing the Dockerfile and Kubernetes files. Docker were used to create the environments implemented in the research, Kubernetes were used as an orchestration manager for the Docker containers, together with Minikube on the local machines. When deploying the application online we used the Google Cloud Platform. For creating the flowcharts in this thesis Draw.io were used.
3.5 Project method
3.5.1 Goals
The goal of this project can be divided into three different sub goals, as defined by Eklund [43]. Effect Goal Effect goals are the goals considering the why of the project. This means in what way the project can be of use. This thesis is about two of the different deployment options that exists, how they compare to each other and what their strengths and weaknesses are. The goal of this thesis is to improve the current development structure. By informing the industry of the strengths and weaknesses of the two different deployment options, we hope to help improve their current development environment. Project Goal The project goal is the reason why we are doing this project and producing this thesis. The project is the final examination of our time at KTH, with the goal of testing whether we can apply our knowledge and deepen our understanding of the subjects learned during the course of our education, without being in the school environment for constant support [44]. Another part of this goal is to be able to provide Tradedoubler with some sort of research and result that could help them decide on their deployment methods in the future. Result Goal This is the goal that is the expected result of the project. In our case that is a scientific thesis containing the result of our research and its conclusions.

26
3.5.2 Applied Methods
Project Management Triangle During our project we used the project management triangle, or simply “project triangle”, as defined by Sven Eklund [43]. As can be seen in figure 4, the 3 different vertices illustrate the 3 different core principles that is required in a project: cost, time and function. In order to be able to have a margin for error, one of the corners should be flexible. We decided to let the function vertex be the flexible one, using the MoSCoW method.
Figure 5. The Project Triangle [45]
The MoSCoW Method One of the ways to introduce flexibility to the function vertex is by using the MoSCoW method. The MoSCoW method is a way to prioritize the requirement specification, by dividing the requirements into a few categories [43]. The Must, Should, Could and Won’t categories which contains the requirements that must be done in time, requirements that should be done but can be done a bit later than the must, requirements that would be nice to complete but are not necessary to complete the project and requirements that does not need to be done during this project respectively. Using this method, we came up with the following prioritizations: Must have
● We must reach the requirements set by the school. This is done by completing a thesis in which we show that we can understand and apply scientific methods for conducting a larger research project.
● We also must have answered the research question which we set in this
thesis. Should have
● An interview which can help us provide valid opinions from developers regarding our subject.

27
Could have
● Deployment of several different cloud providers and a comparison of their services.
Won’t have
● Several different application tests, regarding the different application types.
● Discuss other alternatives than containers and virtual machines. Buddy System The buddy system is an alternative to pair programming, where you don’t sit at one workstation but instead each has their own. [46] You don’t work on exactly the same code all the time, but rather work together towards a common goal or feature. This means that if there is some problem that one is experiencing, the other is already ready in that context and can help as soon as possible. It is also easier to learn since one can work at one's own pace, but still get help and feel that the other person learns with you. This was applied in this project during the development of the Dockerfiles, Docker compose files and Kubernetes config files in order to increase productivity.
3.6 Documentation and modelling method
This report has been written based upon the templates provided by our school, KTH, however we have adapted it to fit to our project to increase readability. We’ve also been inspired by other theses when structuring our own. The key findings of our work will be presented to Tradedoubler in form of a short oral presentation. They will also receive the finished report for documentation of the performance and usability metrics. The metrics are organized and presented in the form of graphs and tables.
3.7 Evaluating Performance and Usability
To be able to evaluate the deployment techniques with regards to performance and usability, relevant metrics had to be collected and analyzed. This section presents theses metrics and describes how they should be evaluated.
3.7.1 Performance Metrics
In order to evaluate the performance, certain aspects had to be measured, like how much RAM and CPU is required. Google Cloud Platform provide users with different ways of measuring these and several other aspects. We decided to take the following metrics into consideration:

28
Metrics that needs to be tested:
● RAM: How much RAM is used ● CPU: How much CPU is used ● Disk: How much disk space is needed ● Network: How many packet/second can be sent
Further metrics, considered when writing:
● Back-up speed: How quickly the application and/or its data can be backed-up
● Restoration: How quickly the application and its data can be restored ● Deployment: How easily the application can be deployed ● Security: How secure the application is
3.7.2 Taking Measurements
We needed to measure the performance data reliably and accurately, so that we don’t get extremities that we then base our thesis on. The measurements were taken using the Stackdriver Monitoring feature of the Google Cloud Platform on the cloud devices. On the local devices we used the resource managers of each device, both on the virtual machine and on the host machine. On the host machines we ensured that only the application was running and nothing else, in order to get as non-interfered data as possible. In order to get as reliable measurements as possible we redeployed the applications before testing to ensure that all instances had the same starting point. We also tested the applications locally on several computers, in order to see the local performances and to see if the metrics had about the same performance differences.
3.7.3 Data Analysis
To analyze the results, we compared the collected data with each other. In order to see if the data seemed trustworthy, we analyzed the data with the help of the findings from the literature study. Following those investigations, we analyzed whether the results were within the range of what could be expected according to other sources and within reason.

29
4 Case study: Application Deployment
This chapter describes the implementation process of the conducted case study. All the necessary steps taken, from start to finish, will be explained in more detail. The case study was divided into two phases. The first phase consists of deploying our application using containers, while the second phase consists of deploying it using a virtual machine.
4.1 Phase 1: Container
4.1.1 Migration of a Java Application to a Container
The first phase of the case study was to deploy an application using Docker containers and the orchestration manager Kubernetes. We used an already existing Java application that provides a currency converter, developed during a previous course at KTH. The first step was therefore to migrate this application to a container. In order to accomplish this, we started with creating a Dockerfile. 4.1.1.1 Dockerfile A Dockerfile is a script with commands and instructions that will be executed automatically and in descending order within the Docker environment, in order to build an image [19]. Our Dockerfile contains six different basic commands (and 7 in total), as can be seen in code block 2, which will be executed one by one when the command for building the image is called. The command we used to build our image can be seen in code block 1.
$ docker build -t osyx/static-currency-converter .
Code Block 1. Build command
FROM payara/server-full
RUN git clone https://github.com/Osyx/CurrConv.git --branch dockerino --single-
branch
WORKDIR CurrConv
USER root
RUN apt-get update && apt-get install -y maven \
&& mvn package
ENTRYPOINT ${PAYARA_PATH}/generate_deploy_commands.sh && \
echo 'create-jdbc-connection-pool --datasourceclassname
com.mysql.jdbc.jdbc2.optional.MysqlDataSource --restype javax.sql.DataSource --property
user=admin:password=kiwi:DatabaseName=currconv:ServerName=mysql:port=3306
currconv_pool\ncreate-jdbc-resource --connectionpoolid currconv_pool jdbc/currconv\ndeploy
/opt/payara5/CurrConv/target/CurrConv.war' > mycommands.asadmin && \
cat ${DEPLOY_COMMANDS} >> mycommands.asadmin && \
${PAYARA_PATH}/bin/asadmin start-domain -v --postbootcommandfile mycommands.asadmin

30
${PAYARA_DOMAIN}
Code Block 2. Dockerfile A valid Dockerfile must always begin with a FROM instruction, as can be seen in code block 2 above. It specifies an image that the new image will be based on [19]. Usually, this will be an image that is pulled from a public repository. The application we migrated uses a Payara server, so we chose our base image to be the image from Payaras public repository. The RUN command will execute a command in a new layer on top of the base image. In our case, we cloned the GitHub repository, where the files of our application reside, into the current directory. The WORKDIR command that came next, changes (or creates a new, if non-existent) the current directory for any subsequent instructions. We changed the directory to “CurrConv”, the main directory of our application. To set the username that should be used when running the image and for any subsequent instructions, the USER command can be executed. We set our username to “root”. The RUN commands that follow in our Dockerfile installs Maven and finally packages the compiled code into a distributable form, in our case a WAR-file. Finally, the ENTRYPOINT command is used to configure the container when it is run as an executable. What our ENTRYPOINT command does, is first to create the default deploy commands for Payara. Then the “echo” command will copy the following lines of text into an asadmin file. The default deploy commands is then also copied into this file. Lastly, the commands in the asadmin file are run after having started the domain. 4.1.1.2 Docker-compose Once we had the Dockerfile, the next step was to create a Docker-compose file. Compose is a tool for defining and running multi-container applications. The compose file is a yaml file, which defines services, networks and volumes, in other words how the containers should behave in production, which can be seen in code block 3 [47] [48].
version: '3.1'
services:
currconv:
image: osyx/static-currency-converter
ports:
- '8080:8080'
- '4848:4848'
depends_on:
- mysql

31
networks:
- currconv_net
mysql:
image: mysql
environment:
MYSQL_ROOT_PASSWORD: supersafepassword
MYSQL_DATABASE: currconv
MYSQL_USER: admin
MYSQL_PASSWORD: kiwi
volumes:
- ./mysql-data:/var/lib/mysql
networks:
- currconv_net
networks:
currconv_net:
Code Block 3. Docker-Compose File
The first line of code concerning version, tells which version of compose file format that is used, namely 3.1 in our case. Depending on which version is being used, the instructions that are supported vary. Services refers to the different parts of an application. Basically, a service is a container that has been taken into production and runs only one image [48]. Our application is run by two containers, one that has the server and one containing the database. For each service, we can define what image, ports, networks etc. that should be used. For the first service, we’ve set the image to our server image. Then we specified the ports (in host:container format) 8080, where the website can be reached and 4848, where the admin interface can be reached. Then we define dependencies between the services, by stating that the server depends on the MySQL database. This means that the database will be started before the server. Then we define the network, stating that we are using “currconv_net”. This is just a name of the current network that we define at the very end of the file. However, we have not made any network configurations, because the default settings were sufficient. By doing that, we could state that the two services should use the same network. For the second service, we set the image to be that of the database image. Then we define some environment variables: root password, name of database and database login credentials. Then we specified a path on the host, relative to the compose file, for the volume where the database contents will be located. As mentioned in the previous paragraph, we also specify the name of the network used, which is the same as for the server.
4.1.2 Kubernetes

32
Having created the compose files, we used a CLI program called Kompose (not to be confused with compose) [49], by simply entering the command shown in code block 4, Kompose creates the Kubernetes configuration files from the compose files in the folder. Making it very simple to go from testing only with Docker and compose, to start testing with Kubernetes and Minikube.
$ kompose convert
Code Block 4. Kompose command for conversion. 4.1.2.1 Minikube Having created the configuration files, we wanted to test if the program worked locally on our devices. This was done using Minikube. First, we started the Minikube virtual machine on our device, seen in code block 5.
$ minikube start
Code Block 5. Start the Minikube virtual machine. Then we wanted to start the Kubernetes deployment with its services and storage claims, as seen in code block 6, by running the files created by Kompose.
$ kubectl create -f mysql-claim0-
persistentvolumeclaim.yaml,mysql-service.yaml,currconv-
service.yaml,mysql-deployment.yaml,currconv-deployment.yaml
persistentvolumeclaim "mysql-claim0" created
service "mysql" created
service "currconv" created
deployment.extensions "mysql" created
deployment.extensions "currconv" created
Code Block 6. Start the application using Kubernetes. Having launched the Kubernetes deployment, we ran the command to assign an IP to the Kubernetes currconv service on the Minikube virtual machine, seen in code block 7. The reason being to get the Kubernetes service assigned an external IP.
$ minikube service currconv
Code Block 7. Assign an IP to the Kubernetes service.
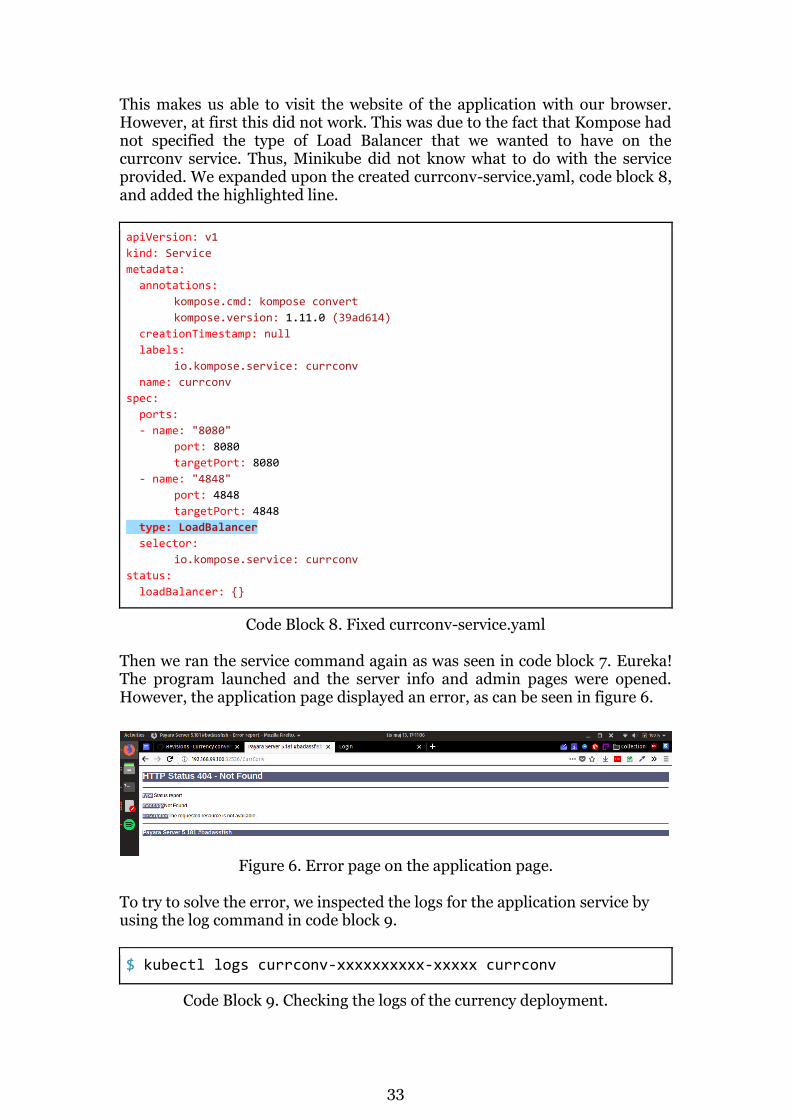
33
This makes us able to visit the website of the application with our browser. However, at first this did not work. This was due to the fact that Kompose had not specified the type of Load Balancer that we wanted to have on the currconv service. Thus, Minikube did not know what to do with the service provided. We expanded upon the created currconv-service.yaml, code block 8, and added the highlighted line.
apiVersion: v1
kind: Service
metadata:
annotations:
kompose.cmd: kompose convert
kompose.version: 1.11.0 (39ad614)
creationTimestamp: null
labels:
io.kompose.service: currconv
name: currconv
spec:
ports:
- name: "8080"
port: 8080
targetPort: 8080
- name: "4848"
port: 4848
targetPort: 4848
type: LoadBalancer
selector:
io.kompose.service: currconv
status:
loadBalancer: {}
Code Block 8. Fixed currconv-service.yaml Then we ran the service command again as was seen in code block 7. Eureka! The program launched and the server info and admin pages were opened. However, the application page displayed an error, as can be seen in figure 6.
Figure 6. Error page on the application page.
To try to solve the error, we inspected the logs for the application service by using the log command in code block 9.
$ kubectl logs currconv-xxxxxxxxxx-xxxxx currconv
Code Block 9. Checking the logs of the currency deployment.

34
In the log there were quite a few errors, but they all seemed to be caused by some problem with the database. So, the next step was to look in the logs for the database:
$ kubectl logs mysql-xxxxxxxxxx-xxxxx mysql
Code Block 10. Checking the logs of the mysql deployment. The error messages told us that the folder wasn’t empty, so changing to another folder seemed to be a likely solution to the issue. Having changed the mysql-deployment.yaml file so that it simply used the user position instead, see the right side of code block 11, we tried running the application again.
volumeMounts: - mountPath: /var/lib/mysql-data name: mysql-claim0
volumeMounts:
- mountPath: mysql-data
name: mysql-claim0
Code Block 11. Extract of the mysql-deployment.yaml.
Restarting the deployment using the new edit, we had no errors and the application ran as expected, as can be seen in figure 7.
Figure 7. The application. 4.1.2.2 Google Cloud Platform Having successfully deployed the application locally, it was time to deploy it online using Google cloud. We started by uploading the working Kubernetes configuration files to a gist. Then we created a Google Cloud Project and a Kubernetes cluster. A part of this process is visible in figure 8.
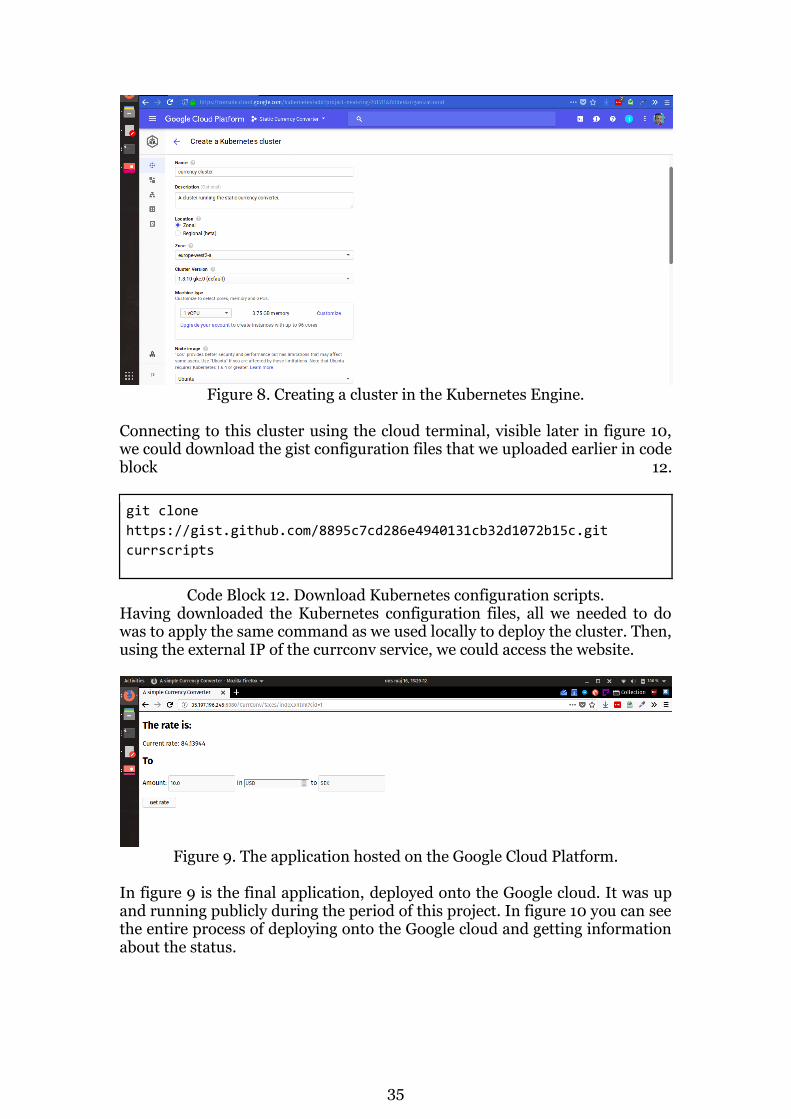
35
Figure 8. Creating a cluster in the Kubernetes Engine.
Connecting to this cluster using the cloud terminal, visible later in figure 10, we could download the gist configuration files that we uploaded earlier in code block 12.
git clone
https://gist.github.com/8895c7cd286e4940131cb32d1072b15c.git
currscripts
Code Block 12. Download Kubernetes configuration scripts. Having downloaded the Kubernetes configuration files, all we needed to do was to apply the same command as we used locally to deploy the cluster. Then, using the external IP of the currconv service, we could access the website.
Figure 9. The application hosted on the Google Cloud Platform.
In figure 9 is the final application, deployed onto the Google cloud. It was up and running publicly during the period of this project. In figure 10 you can see the entire process of deploying onto the Google cloud and getting information about the status.

36
Figure 10. Deploying the application on the Google Cloud Platform.
4.1.3 Testing Performance Having deployed the application, it was time to start the testing of performance. During the test, we considered the following metrics:
● RAM: How much RAM is used ● CPU: How much CPU is used ● Disk: How much disk space is needed ● Network: How many packets/second can be sent
To start the performance testing, we first needed to install measurement tools on the virtual machine. The reason being that we wanted to use Stackdriver to get the performance details. The process of registering the Stackdriver was simple. All we needed to do was to run a script and then it installed the right tools. Having installed the tools, we could now access the performance values we wanted. The tool we used to simulate all different clients were Locust [50], a tool used to just simulate a lot of clients and stress test web applications. We wrote a simple file, appendix A - code block A, which told the clients what they should do. Then we could start Locust from the command line, with a parameter with the host server. Now we got to a screen, which can be seen in figure 11, which asked us to enter the number of users we wanted to simulate.
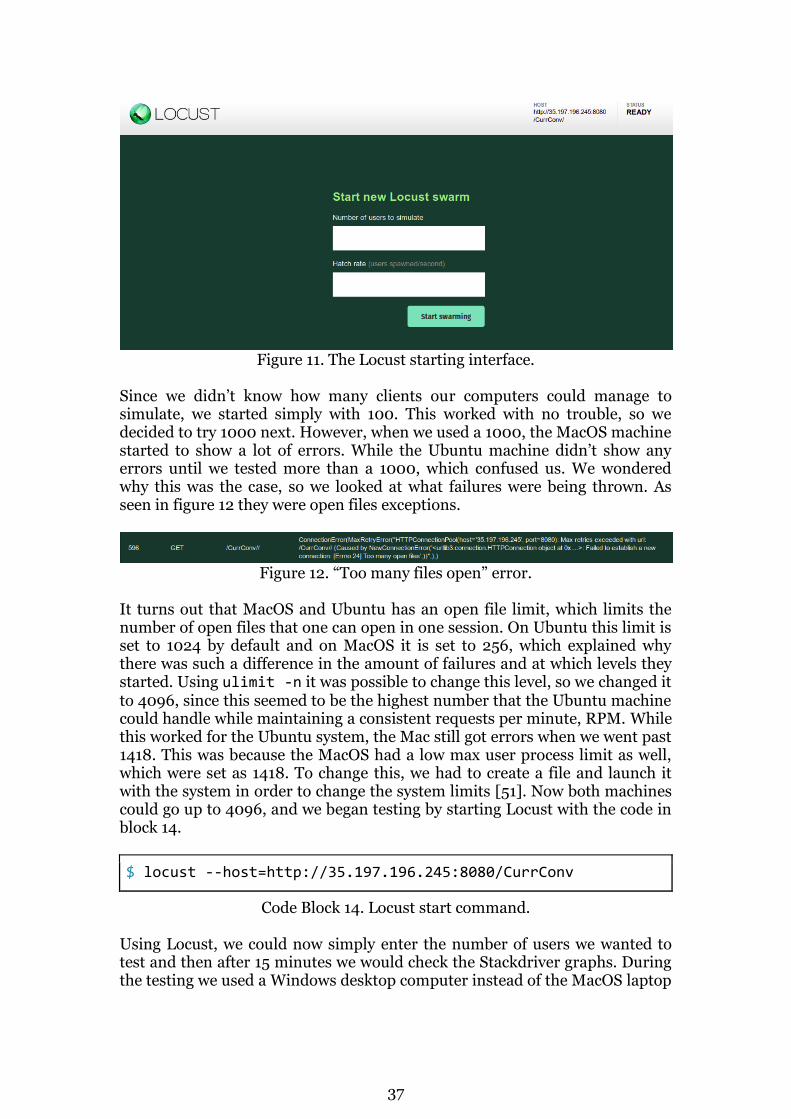
37
Figure 11. The Locust starting interface.
Since we didn’t know how many clients our computers could manage to simulate, we started simply with 100. This worked with no trouble, so we decided to try 1000 next. However, when we used a 1000, the MacOS machine started to show a lot of errors. While the Ubuntu machine didn’t show any errors until we tested more than a 1000, which confused us. We wondered why this was the case, so we looked at what failures were being thrown. As seen in figure 12 they were open files exceptions.
Figure 12. “Too many files open” error.
It turns out that MacOS and Ubuntu has an open file limit, which limits the number of open files that one can open in one session. On Ubuntu this limit is set to 1024 by default and on MacOS it is set to 256, which explained why there was such a difference in the amount of failures and at which levels they started. Using ulimit -n it was possible to change this level, so we changed it to 4096, since this seemed to be the highest number that the Ubuntu machine could handle while maintaining a consistent requests per minute, RPM. While this worked for the Ubuntu system, the Mac still got errors when we went past 1418. This was because the MacOS had a low max user process limit as well, which were set as 1418. To change this, we had to create a file and launch it with the system in order to change the system limits [51]. Now both machines could go up to 4096, and we began testing by starting Locust with the code in block 14.
$ locust --host=http://35.197.196.245:8080/CurrConv
Code Block 14. Locust start command. Using Locust, we could now simply enter the number of users we wanted to test and then after 15 minutes we would check the Stackdriver graphs. During the testing we used a Windows desktop computer instead of the MacOS laptop

38
to test the values, because it could handle more users and kept a steady requests per minute, RPM, value.
4.2 Phase 2: Virtual Machine
4.2.1 Installing the Application on the Virtual Machine
The second phase of the case study was to deploy an application using a virtual machine. The first steps were to create the virtual machine and set it up and then deploy the same Java application as we used for the container. After that we began testing the virtual machine. 4.2.1.1 Setting Up the Virtual machine To set up the virtual machine, we used Google Cloud Platform’s Compute Engine to create an instance, which is a virtual machine hosted on Google’s infrastructure [52]. It allowed us to create a custom instance, where we could choose machine properties such as how many virtual CPU’s, how much disk space, and what operating system to be used etc. We chose the same settings as the instance used to run the container had. Then we had to make some installations that our application needs in order to run. We started by installing the Payara server. We downloaded the zip file and renamed it with the command in code block 15. Then, using the command in code block 16, we unzipped the file and moved its contents to a root folder to install the Payara server.
$ wget https://search.maven.org/remotecontent?filepath=fish/
payara/distributions/payara/5.181/payara-5.181.zip -O
payara.zip
Code Block 15. Download Payara zip.
$ sudo unzip payara.zip -d /opt/
Code Block 16. Unzipping the payara files. Once we had done that, we needed to enable secure remote access to the Glassfish Admin page [53]. This was done by first adding an admin password (that was previously unset). So, we navigated to opt/payara5/bin and ran the command in code block 17. Having set a new password, we used the command in code block 18 to enable the remote access.
$ ./asadmin --host localhost --port 4848 change-admin-password
Code Block 17. Change admin password.

39
$ ./asadmin --host localhost --port 4848 enable-secure-admin
Code Block 18. Enable secure remote access
The next step was to install MySQL for our application’s database, code block 19, and download a MySQL connector for connecting the server and the database, code block 20. Having downloaded the connector, we unzipped it and moved it to the Payara libraries using the code in code block 21.
$ sudo apt install mysql-server-5.7
Code Block 19. Install the MySQL Server.
$ wget https://dev.mysql.com/get/Downloads/Connector-J/mysql
-connector-java-5.1.46.zip
Code Block 20. Download the Java MySQL connector.
$ sudo mv mysql-connector.java.5.1.46.jar
/opt/payara5/glassfish/domains/domain1/lib
Code Block 21. Move the connector to the Payara server libraries. Then, we cloned our git repository, code block 22, and installed Maven using the command in code block 23.
$ git clone https://github.com/Osyx/CurrConv --branch
dockerino --single-branch
Code Block 22. Clone the application.
$ sudo apt install maven
Code Block 23. Install Maven. Before we could package the application, we had to replace the certificate signing method [54]. Then we navigated into the CurrConv directory and ran the command for building the project.
$ mvn package
Code Block 24. Package the application to a WAR file. Once the project had been built, we could navigate to /opt/payara5/bin where we logged into the mysql admin, created the database and started the server, as can be seen in code block 25. This concluded the setup of the virtual machine.
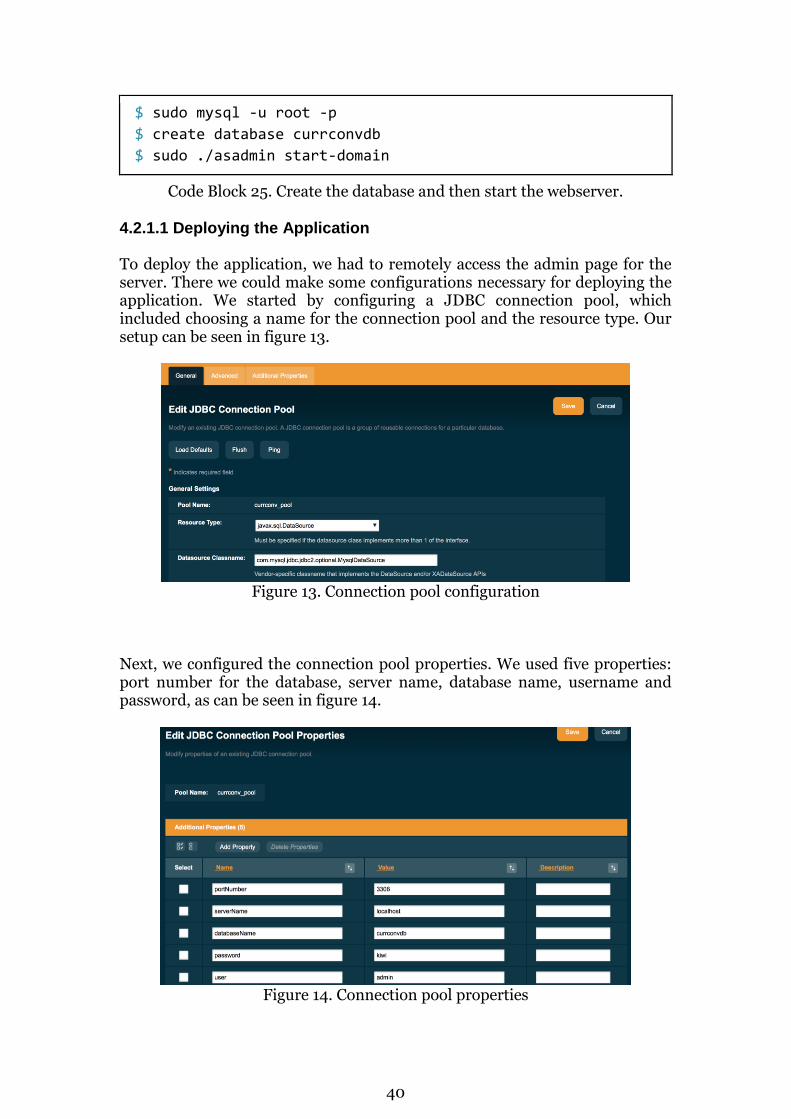
40
$ sudo mysql -u root -p
$ create database currconvdb
$ sudo ./asadmin start-domain
Code Block 25. Create the database and then start the webserver. 4.2.1.1 Deploying the Application To deploy the application, we had to remotely access the admin page for the server. There we could make some configurations necessary for deploying the application. We started by configuring a JDBC connection pool, which included choosing a name for the connection pool and the resource type. Our setup can be seen in figure 13.
Figure 13. Connection pool configuration
Next, we configured the connection pool properties. We used five properties: port number for the database, server name, database name, username and password, as can be seen in figure 14.
Figure 14. Connection pool properties

41
Then we had to edit the JDBC Resource, as can be seen in figure 15, which only consisted of selecting the connection pool that we had just created as the one that should be used from the dropdown menu.
Figure 15. JDBC Resource configuration
Finally, we could deploy the application rather easily by uploading the WAR file and launching it. The web application could then be reached at the external IP address with port 8080 and the folder/Currconv.
Figure 16. Application deployment
4.2.2 Testing Performance
Now with the application deployed we could use the same testing tool, Locust, as we did with the container. However, the monitoring tool we used to get Stackdriver to gather memory and disk data was not available for Ubuntu 18.04 LTS when not used in a container. Thus, we had to do it the old fashion way and log onto the computer to monitor it ourselves. For logging the memory, we used the command in code block 26 and to check how much disk space the VM took, we used the command in code block 27.
$ sudo du -sh /
Code Block 26. Check the amount of space taken by the system.
$ watch -n 1 free -m
Code Block 27. Monitor the amount of memory used.

42
43
5 Benefits and Drawbacks of Using Containers
This chapter outlines the results we collected during the course of this project. Including the performance tests, we have made, the interview and our own observations during the development and deployment of the application. It then mentions the conclusions we drew from this and tries to answer the research questions.
5.1 Results from Performance Tests
5.1.1 Collected Data
The results from the performance tests that were carried out, are presented in the form of both tables and graphs. The first table, table 3, holds the results of the tests performed on the virtual machine instance and the second table, table 4, holds the results of the tests performed on the container instance. As previously mentioned, the performance metrics that were measured were CPU usage, RAM usage, network usage and disk space usage. Multiple tests were performed, and the metrics presented in the tables and graphs are calculated mean values for all tests. The graphs show the differences between the deployment techniques, for each metric, more clearly. All graphs have the same color scheme for each deployment technique, to avoid any confusion.
Clients/avg. RPS4 CPU (ms/s) RAM (MB) Network
100/10 77.0 1328 in: 3.11 KB/s out: 13.55 KB/s
1000/100 283.7 1343 in: 28.78 KB/s out: 135.6 KB/s
4000/400 775.4 1348 in: 112.62 KB/s out: 542.07 KB/s
8000/800 984.3 1358 in: 207.37 KB/s out: 1010.0 KB/s
12000/1000 987.3 1364 in: 304.11 KB/s out: 1440,0 KB/s
Table 3. VM performance metrics.
4 RPS, Requests Per Second, how many requests that were sent to the application per second.
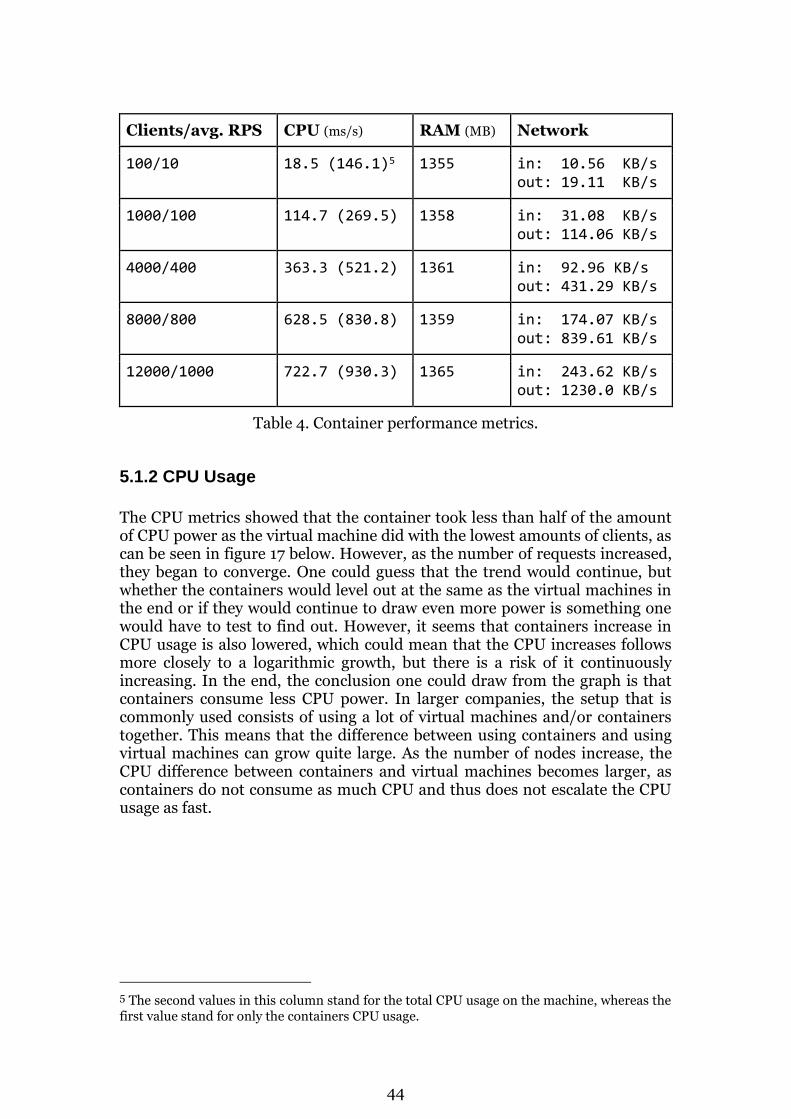
44
Clients/avg. RPS CPU (ms/s) RAM (MB) Network
100/10 18.5 (146.1)5 1355 in: 10.56 KB/s out: 19.11 KB/s
1000/100 114.7 (269.5) 1358 in: 31.08 KB/s out: 114.06 KB/s
4000/400 363.3 (521.2) 1361 in: 92.96 KB/s out: 431.29 KB/s
8000/800 628.5 (830.8) 1359 in: 174.07 KB/s out: 839.61 KB/s
12000/1000 722.7 (930.3) 1365 in: 243.62 KB/s out: 1230.0 KB/s
Table 4. Container performance metrics.
5.1.2 CPU Usage
The CPU metrics showed that the container took less than half of the amount of CPU power as the virtual machine did with the lowest amounts of clients, as can be seen in figure 17 below. However, as the number of requests increased, they began to converge. One could guess that the trend would continue, but whether the containers would level out at the same as the virtual machines in the end or if they would continue to draw even more power is something one would have to test to find out. However, it seems that containers increase in CPU usage is also lowered, which could mean that the CPU increases follows more closely to a logarithmic growth, but there is a risk of it continuously increasing. In the end, the conclusion one could draw from the graph is that containers consume less CPU power. In larger companies, the setup that is commonly used consists of using a lot of virtual machines and/or containers together. This means that the difference between using containers and using virtual machines can grow quite large. As the number of nodes increase, the CPU difference between containers and virtual machines becomes larger, as containers do not consume as much CPU and thus does not escalate the CPU usage as fast.
5 The second values in this column stand for the total CPU usage on the machine, whereas the first value stand for only the containers CPU usage.
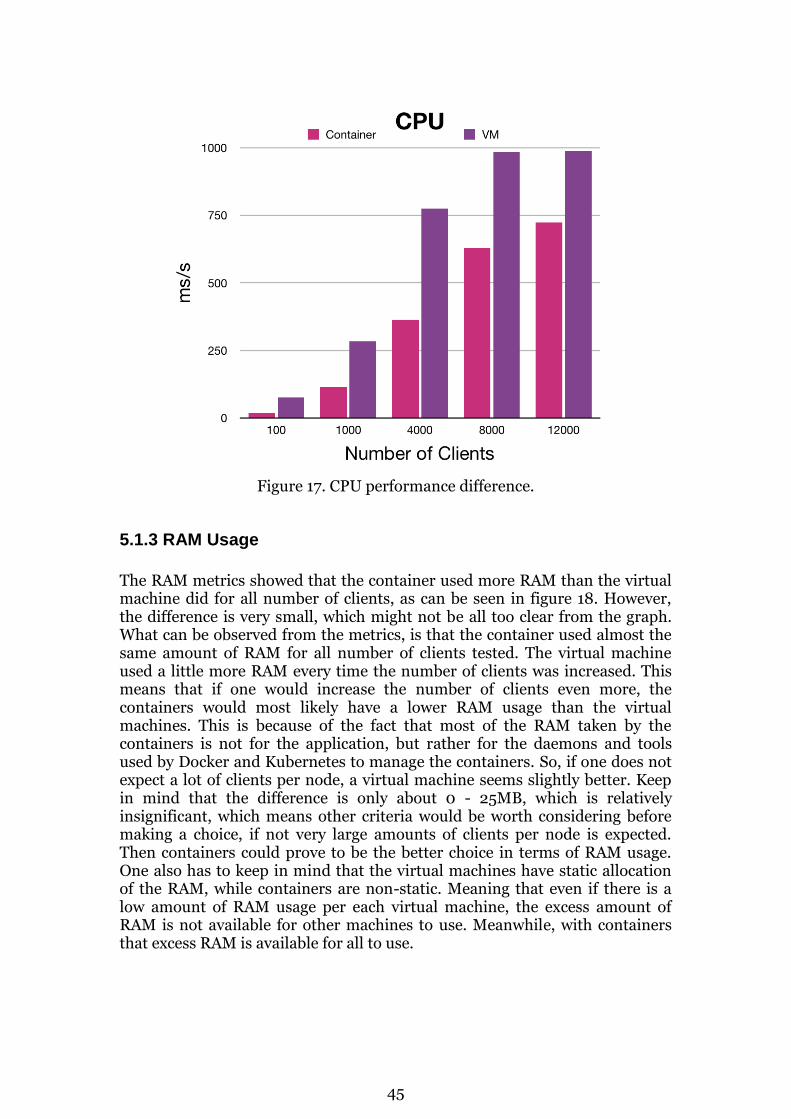
45
Figure 17. CPU performance difference.
5.1.3 RAM Usage
The RAM metrics showed that the container used more RAM than the virtual machine did for all number of clients, as can be seen in figure 18. However, the difference is very small, which might not be all too clear from the graph. What can be observed from the metrics, is that the container used almost the same amount of RAM for all number of clients tested. The virtual machine used a little more RAM every time the number of clients was increased. This means that if one would increase the number of clients even more, the containers would most likely have a lower RAM usage than the virtual machines. This is because of the fact that most of the RAM taken by the containers is not for the application, but rather for the daemons and tools used by Docker and Kubernetes to manage the containers. So, if one does not expect a lot of clients per node, a virtual machine seems slightly better. Keep in mind that the difference is only about 0 - 25MB, which is relatively insignificant, which means other criteria would be worth considering before making a choice, if not very large amounts of clients per node is expected. Then containers could prove to be the better choice in terms of RAM usage. One also has to keep in mind that the virtual machines have static allocation of the RAM, while containers are non-static. Meaning that even if there is a low amount of RAM usage per each virtual machine, the excess amount of RAM is not available for other machines to use. Meanwhile, with containers that excess RAM is available for all to use.
46
Figure 18. RAM difference.
5.1.4 Network Usage
Both of the network metrics, figure 19 and 20, showed pretty much the same result where containers had a slightly lower result than the virtual machine, except for the smallest results. The differences are not significant enough to make a distinction, especially in the case of the incoming traffic where it is at max 60 KB. This could easily be within the margin of error, but since others have reached the same type of results [55] and the differences are fairly consistent, it is deemed reasonable. A fair assumption about this discrepancy would be that the container needs to virtualize a bridge and its own internal network. Thus, it performs a bit slower than the virtual machine which only needs to virtualize the bridge.
47
Figure 19. Network incoming traffic difference.
Figure 20. Network outgoing traffic difference.
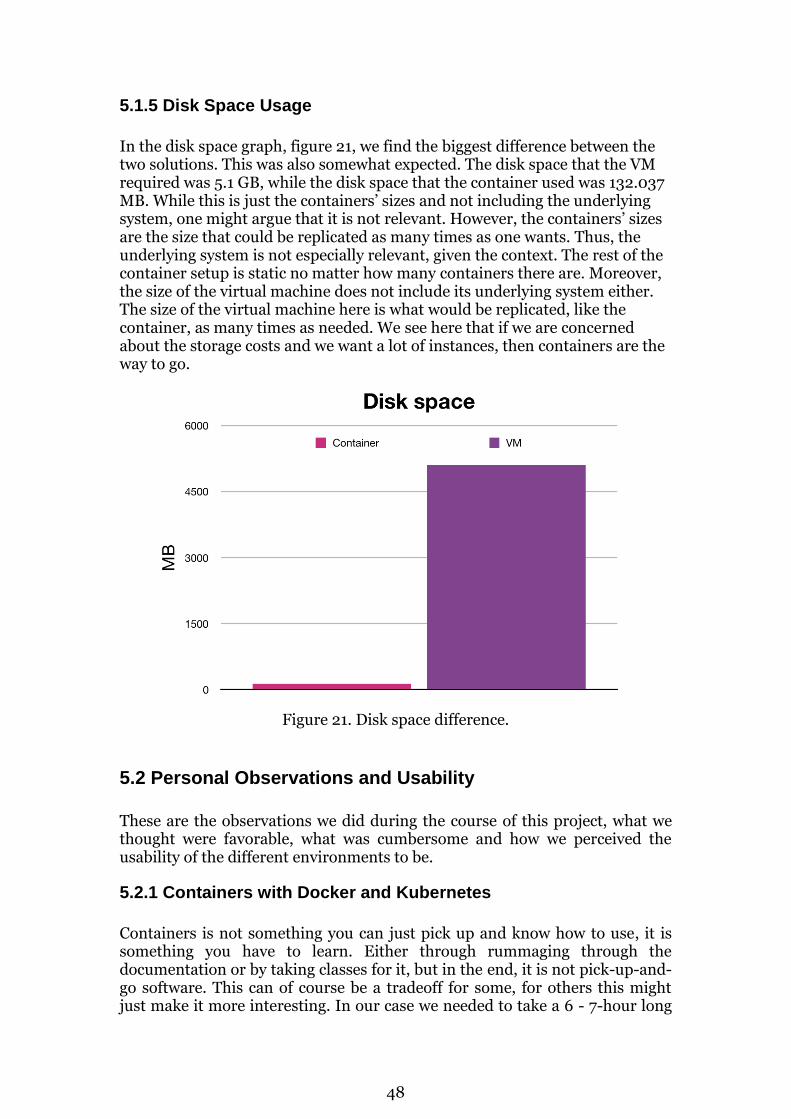
48
5.1.5 Disk Space Usage
In the disk space graph, figure 21, we find the biggest difference between the two solutions. This was also somewhat expected. The disk space that the VM required was 5.1 GB, while the disk space that the container used was 132.037 MB. While this is just the containers’ sizes and not including the underlying system, one might argue that it is not relevant. However, the containers’ sizes are the size that could be replicated as many times as one wants. Thus, the underlying system is not especially relevant, given the context. The rest of the container setup is static no matter how many containers there are. Moreover, the size of the virtual machine does not include its underlying system either. The size of the virtual machine here is what would be replicated, like the container, as many times as needed. We see here that if we are concerned about the storage costs and we want a lot of instances, then containers are the way to go.
Figure 21. Disk space difference.
5.2 Personal Observations and Usability
These are the observations we did during the course of this project, what we thought were favorable, what was cumbersome and how we perceived the usability of the different environments to be.
5.2.1 Containers with Docker and Kubernetes
Containers is not something you can just pick up and know how to use, it is something you have to learn. Either through rummaging through the documentation or by taking classes for it, but in the end, it is not pick-up-and-go software. This can of course be a tradeoff for some, for others this might just make it more interesting. In our case we needed to take a 6 - 7-hour long

49
course to start this project, but one could probably take less if one just wanted to start with containers and then learn along the way. Having learnt Docker through the courses, we found Docker very simple to use. All one needed to do at first was simply to create a file with some commands and the app launched. If we would have wanted, we could simply have created the WAR file for the application and then simply ran a Payara and MySQL server, configured the connection and deployed the war through the web interface. This would then have been pretty similar to the second part of the deployment on the virtual machine. However, we figured that we wanted to use the full capacity of the containers and make our container be able to self-setup, thus increasing the complexity. Had we had a larger application, we believe this step to be the one which can be quite a bit more complex. Our application was a simple one, without many dependencies. A larger one, with more dependencies and/or configuration, can probably create an increasingly complex Dockerfile. On the other hand, while the process in itself might be long, it is often something that the developers have created themselves which they want to deploy. Thus, it does not necessarily mean that it is harder with a larger application, rather that it just takes a lot of time to complete and that a larger amount of small errors can occur. Kubernetes was very simple to use when utilized together with Kompose, simply because you did not really have to create your own Kubernetes configurations at all. In our case we had to configure the database service further, had one not had any use for further configuration then Kubernetes could essentially be used as a plug and play service. In general, we think the troubles we had was more due to not having worked with Docker and Kubernetes before. Having learned during the course of this project made us believe it to be a lot simpler to repeat or create new projects using these technologies.
5.2.2 Virtual Machines
We found virtual machines to be simpler to start with than Docker, since it is pretty much just installing an operating system, when done locally, so most people already possess this experience. If one is using a hosting service it is even easier, since the service configures most of the things for you. You basically just follow through an instructional webpage and then it is done and configured. The process of installing an application on the system was something we found a lot harder than Docker however, since the dependencies for Maven in the system recently had changed. While it can be seen as bad luck, it highlights one of the issues that containers solve. When installing on a virtual machine you manually have to make sure that all dependencies are satisfied and then updating, and reconfiguring can be some you can be quite reluctant about. This could potentially create security issues and such, a trouble quite common within larger companies. However, back to our experiences, we had to take quite a detour in order to fix this. This detour was most likely the

50
biggest problem we faced during this project. Furthermore, in the virtual machine we had to manually fetch and install both MySQL and Payara as well, which sometimes could cause us to have to type in extremely long URLs into the console. These problems are usually solved after one time, since normally one creates a script for the deployment after having tested the process the first time. However, the procedure of finding this process can be a lot more demanding than it might initially seem, especially if one has to cater to several different providers, operating systems, etc.
5.3 Interview
The interview was conducted with one of the employees at Tradedoubler, Göran Paues. Göran is part of one of the three development teams within the company, specifically the database team. The interview lasted a little over 30 minutes, this section covers the most important topics brought up during our conversation with Göran. Göran is currently using Docker within the company, at a smaller scale. At the moment, he is using Docker in order to get a developer environment for the database. The reason for doing this, Göran says, is that there are many concerns when setting up an Oracle database, such as going through all configurations and the costs for getting an instance etc. However, if you use the license personally at home/work, it’s possible to just download it, so it was a very good use case for Docker. Oracle has uploaded a Docker image on Docker Hub as well, making it easier for him to use the standard configurations to begin with. Having a local developer environment is great, and with Docker it became simple due to the fact that he could just download it again and thus get a clean starting slate. These were a few of the reasons why he chose Docker, but when asked why it was specifically Docker he used, there were a few more reason mentioned. Docker is very lightweight compared to other alternatives, such as different Vagrant configurations or VirtualBox, making it simpler to manage when at home or when using several versions. Göran also mentioned that he uses Flyway, as a tool for release management of the database, making database development much simpler. Flyway can also be used with Docker, making it possible to easily connect to the database when used in Docker as well. This will spare the developer some headaches, as the developer environment uses the same code and configuration as the live environment. Göran also remarked that he had planned to use Kubernetes, to manage these two instances, however he abandoned that idea. This was due to the fact that it seemed like a too heavy investment with, in this case, small returns. The negatives, according to Göran, was largely dependent on the fact that Docker has not fully matured yet which makes it hard to interact with the underlying disk system. This is very important since the database heavily relies on good access to the disk volumes. In most companies, the database is critical in order for the company’s services, and thus one must be sure that it

51
performs as well and as stable as possible. Göran does not feel like Docker is there just yet. “This is the biggest reason as to why we don’t use Docker more in our team” says Göran, “Because of the fact that Docker is in a start-up process, there is a lot of new features and bugs being introduced and fixed/reverted. At the time, when considering Docker, there was still much that was unstable, which did not feel right to incorporate into a production environment. While it has gotten a lot better, it does not feel quite ready for production in the team just yet.” When we previously asked him whether Tradedoubler uses virtual machines at the moment he became a bit confounded. This is because virtual machines are meant to operate invisibly to the user, thus making it hard to separate whether one uses bare metal or virtual machines, since they should act the same. This makes virtual machines easy to work with, since it feels like working on a local machine or bare metal server. In Docker, it is hard to not notice that one is using it, since one is writing configuration files specifically made for these containers. These files are made in order to not need to interact with the device itself, creating a whole other approach to working, which might not suit everyone and at every occasion. We also asked Göran about the deployment techniques they use, how they are chosen and how he feels they impact the developers. Göran said that since his team is so small in size, two persons, he could make the decision himself to use Docker, without having to introduce it to an entire team of several developers. As previously mentioned, developers get more responsibility with Docker and DevOps in general. We asked Göran what he thought about this. He said that he thought it was quite positive since he thought that the developers get a better overview of the system, it also gives greater security since automated processes minimizes the number of manual mistakes that can be made. However, he wanted to highlight that the scripts still need to be developed and maintained, so time will have to be allocated to this. So, while minimizing some parts of the process, it introduces more work in others. In the case of Docker, someone still needs to write the Dockerfiles, even if there no longer is a need to write deployment and installation scripts. As a final note, Göran said that he feels like we are going towards a better world for developers in general, by having all these tools available. He feels like it is mostly better nowadays since many processes that used to be tedious and time consuming, have been made much simpler. The difficulties of older tools, compared to the more recent development tools, are easily forgotten when memories begin to fade, and nostalgia sets in.
5.4 Theoretical Material
The most relevant findings from the theoretical research are presented below, to give a simple yet informative overview by listing the key differences. Further information regarding each finding, can be found in the theoretical background.

52
Docker + Container: Positive:
+ Microservices + Simple migration + Simple updates + DevOps + Fast startup time + Easier uptime management
Negative: - DevOps - Container OS dependent - Storage management
Virtual Machine: Positive:
+ Secure Sandboxing + Explicit resource management + Replicate entire state + Full OS + Less vulnerable to internet attacks by default
Negative: - Fixed memory - Fixed storage - Full OS
5.5 Conclusions
Revisiting the research questions, we sought to find out, what the benefits and drawbacks of using containers for software deployment and maintenance in personal and business environments. In other words, what did we learn during the course of this project? In the performance tests, we found that containers had an advantage over virtual machines in CPU and storage, but not in network or memory. This makes Docker seem like a good choice if performance is a concern, which it probably is since higher performance machines equals higher costs, regardless of whether we use cloud services or our own hardware. However, the memory usage could prove to show benefits as well with more demanding applications and with higher number of clients. This because, as we could see in figure 18, the RAM usage of Docker basically does not change. This is probably due to the fact that our application is so small, with larger applications the initial difference in RAM usage is minimal, if not almost non-existent. This due to the fact that the differences are already extremely small in the context. With a larger number of clients, the differences might even turn in favor of containers. The performance benefits from Docker depends on what kind of application one provides, as well. If one has one application which simply consists of one

53
part, then using a single container might not provide as much of benefits as an application which consists of several parts and is to be provided as a microservice. For microservices we think using Docker is an almost obvious choice, for single applications it is more a question of preference and context. As an individual or smaller company that wants to provide a microservice, containers probably are the better choice. Simply because it improves the deployment process immensely when working as a smaller team, where it often can be hard to have someone focus simply on deployment of the applications. If a company already uses DevOps, the switch to using Docker instead of the current platform should not be too much of a hassle, with pretty large benefits over time. In large companies with a strict hierarchy Docker could prove to provide less benefits at a higher price because of the responsibility put upon the shoulders of the developers rather than the executives/product owners, and it might be a better choice to stick with the current environment. Security is also an issue with containers that could mean a lot in larger companies, but also in smaller and personal businesses as well, where providing reliable and secure services is often a huge part of the services that these companies focuses on. A possible solution for this is to use containers inside of virtual machines in order to get the best of the two worlds. This could provide better isolation and might help with security by narrowing the areas of attack and also limiting the amount of systems that can be affected by a single attack. We also found Dockerfiles to be simpler to create, once learned, than deployment scripts for virtual machines. This because there is a lot more to take into consideration, regarding different compatibility issues, etc. with different virtual machines. Another plus for Docker in regard to using different machines is that it is possible to change cloud provider and/or servers very easily, because all you have to do is backup the data and then the rest of the application is in the container which simply needs to be used on the new service/server. This can often be done with just a few commands. With virtual machines it is easier to get tied to a specific provider, because it can be a considerably time-consuming process to reinstall all the applications, dependencies and data, on the new service/servers which might support different versions etc. What we gathered from the interview with Göran, was that Docker and containers can be very beneficial, at this moment in time, when used on a smaller scale. As mentioned, Göran used containers to get a developer environment for a database. By using Oracles docker image, he could use their standard configurations instead of setting everything up from scratch. Another advantage he mentioned, was that Docker is very lightweight compared to other alternatives, making it simpler to manage when at home or when using several versions. The disadvantage, according to Göran, is that Docker is not fully mature yet. Docker is still in a start-up phase where new features are being added and bugs are being introduced and fixed. He does not feel that it’s ready to use in a production environment just yet, even if it’s improved a lot during recent time.

54
When asked about virtual machines, he mentioned the advantage that virtual machines are basically invisible to the user, giving the user the illusion of working in a local environment. Docker containers require config files specifically made for them, in order to remove the need to interact directly with a device, which is an entirely different way to work when compared to using virtual machines. Göran’s thoughts about developers getting more responsibility with Docker and containers, were of positive nature. He thinks developers will gain a better overview of the system and automated processes will increase security by reducing the amount of manual errors. However, he highlighted the fact that while some processes might be simpler when using containers, other processes will require more work instead. In conclusion, we think that switching to containers is something most companies could benefit from, while the drawbacks of using containers relates to the high initial investment, the returns from it are received indefinitely. We do however understand that this is not something all companies feel confident in doing, at the time. A solution for this would be to use the containers internally in small projects to begin with, to get a taste of how it can improve the current deployments and developer environment. We believe that just using containers internally for development, testing and to test deployment might be something that could improve the current development environment immensely within a company.

55
6 Discussion
This chapter will discuss the methods used in order to answer the research question, as well as the results gathered during this research. The reliability and validity of methods will be discussed, and the research question will be answered.
6.1 Methods
The purpose of the introductory literature study was to provide us with sufficient background knowledge before any other activities took place. We had very little knowledge of the container technology before initiating this research, so we had to start at the very beginning. The online course on Udemy proved to be very useful for learning the basics and for creating the various Docker files needed when conducting the case study. We’ve also relied on a lot of documentation from Docker and Kubernetes. It proved to be a bit more of a challenge to find relevant peer reviewed articles and journals though. The container technology is still fairly new, and it did not appear to be a lot of research where the differences between containers and virtual machines were investigated. The Kubernetes service was rarely mentioned at all. The case study had its challenges as well, although most of the problems we encountered, were most likely due to the fact that we lacked any previous experience with containers or the Kubernetes service. The application we used was rather simple, but it was deemed to be sufficient for the purpose of our research. The case study was essential in order to investigate the differences between the two deployment techniques, with regards to performance and usability, and ultimately to answer the research question. The case study was however limited to only testing Google Cloud Platform’s Kubernetes service, since it was not deemed to be possible, within the given time frame of the project, to test any similar services by other cloud providers. The interview was designed to capture information that was not, or could not, be gathered during the theoretical research or the case study. We wanted to know what the developers at Tradedoubler thought about the current developer environment, and whether containers could solve some of the problems that they might be facing today. The answers that Göran offered, made it easier for us to draw conclusions about the benefits and drawbacks of containers in a business environment.

56
6.1.1 Reliability of Methods
In the context of a qualitative research, the term “reliability” refers to the trustworthiness and quality of the conducted research, rather than the replicability of results and observations, as in the context of a quantitative research [56]. The theoretical material used for the background research, is deemed to be trustworthy. The documentation provided by Docker and Kubernetes has only been used for deeper understanding of these technologies. The material is perceived to be of an objective nature and we’ve seen no reason to question the accuracy of the contents. Criticism could however be directed towards the fact that not all articles that have been used for reference, has been peer reviewed. However, the container technology is still fairly new, and it’s reasonable to expect that not all material has existed long enough to be peer reviewed. The material has been deemed trustworthy even so, since other sources and documentation from Docker and Kubernetes can support the information found in these articles. The case study has been thoroughly documented, where each step of the process, along with the problems and how they were solved, has been explained. This was to ensure the transparency and trustworthiness of our work, so that others can learn from it and use it for reference, should they want to perform a similar study. One could direct criticism towards the fact that only Google Cloud’s Kubernetes was tested in the case study. It was, however, deemed to be outside the scope of the project to test other cloud providers as well, we direct this to future research. One could also argue that tests could have been performed locally as well, for comparison with the cloud-based services. The interview could be subject to some criticism as well. Only one person was interviewed, which could be problematic in the sense that it’s possible that this person could be biased and perhaps favor one of the techniques. Therefore, it would have been better to interview several different subjects, to ensure a variety of perspectives. However, due to time constraints, this part had to be shortened. On the other hand, Göran reflected on both pros and cons of each technique. He gave elaborate answers as well, e.g. when he thought one technique would be more suitable than the other. This made it easier to understand what a developer takes into account, and it provided insight into how a part of the community thinks regarding the choices available. The results have been deemed trustworthy, based on the fact that our findings from the literature study supports the results of the conducted case study and seem reasonable. The performance metrics of the two techniques did differ a bit, but the differences were not so large that they raised any suspicion about any incorrectness. The fact that they are relatively close to each other, only speaks to their accuracy. We also ran the same tests multiple times and calculated mean values in order to get representative numbers for all metrics. The testing was done during only one day, so one could question if they should

57
have been done with more time in between each test, to make sure that there were no network problems or similar, that could have affected the results. The tests were performed using only one cloud instance of a VM and a Kubernetes cluster, both with specific settings, for each of the deployment techniques. Perhaps it would have been beneficial to test several instances with a variety of settings, like the number of virtual CPUs that should be used, to see whether it would have made any difference to the results. However, this had to be excluded because of time constraints.
6.1.2 Validity of Methods
The term validity, in the context of a qualitative research, refers to the appropriateness of the applied methods used to examine a phenomenon, and whether the results that have been generated from the study, are apt to answer the research question [56]. The literature study served the purpose of providing sufficient background knowledge and a theoretical perspective of the technologies. It also enabled us to verify that the results from the case study is consistent with the information found in the literature. The purpose of the case study was to measure performance metrics and highlight some usability aspects of both deployment techniques. The results would in turn, allow us to make comparisons between VMs and containers, to ultimately identify the benefits and drawbacks of each strategy. The interview was conducted in order to gain some additional insights from developers at Tradedoubler. Göran’s input complemented the results of the theoretical research and case study and put more weight behind our arguments.
6.2 Research Result Revisited
The aim of this thesis was to investigate the benefits and drawbacks of using containers when deploying, both in a personal and in a business environment. The research question was as follows: RQ: What are the benefits and drawbacks of using containers for software deployment and maintenance in personal and business environments? The results found, show that containers provide many benefits in the area of performance. Judging by our performance results, and by applying the knowledge gained from the literature study, we can hypothesize that it is close to bare metal performance, excluding the RAM usage. However, we found containers to have an advantage there as well, since containers have non-static memory allocation. Furthermore, the difference in terms of memory was not especially large to begin with and might turn in favor for containers, in case of larger applications with more usage. This is something we can see have a positive impact on both personal and business environments.

58
We found containers to be simpler to deploy, partly because Dockerfiles were easier to write than the deployment scripts for virtual machines, but more importantly due to the nature of Docker. Containers means that you only have to worry about installation once. When using containers, you simply install the app inside of the container and then it acts uniformly no matter where you deploy it subsequently. This can improve the current deployment phase in both personal and business environments. However, this brings us to the biggest difference between personal and business environments. Depending on how adaptable the company’s hierarchy is, containers can sometimes lead to more problems than they solve, due to the shift of power over deployment, to the developers. In larger businesses it could also prove to be disadvantageous to use containers due to the lack of knowledge in the field of containers. This would mean that all developer and operation teams would need to undergo education regarding the new environment. This might not be optimal since it could prove to be quite costly, and even if the returns might ultimately make it a worthwhile investment, it might not be something all companies has a budget for in the short term. Furthermore, older businesses might have trouble to switch to containers because of their hardware not supporting this new technology. In that case, the cost of investing in all new hardware, might be something that could impact even the largest companies. Security is also something that could prove to be a downside of using containers in business, however using containers together with virtual machines notably diminishes this issue, while still introducing possible improvements. Göran did however argue that automated processes could increase security by reducing the amount of manual errors that developers might make. The conclusion is that containers are more efficient in resources. This could improve the service provided to the customers by improving the quality of the service through more reliable uptimes and speed of service. However, containers also provide more freedom and transfers most of the responsibility over to the developers. This is not always a benefit in larger companies, where regulations must be followed, where a certain level of control over development processes is necessary and where quality control is a crucial aspect. It might also be a good idea to use containers together with virtual machines in order to increase security even more in larger businesses.
6.3 Ethical Aspects
As Seth Payne mentions in his article about the ethics of cloud computing [57], businesses have an obligation to keep their systems up 24/7 if they are providing a business-critical service. A failure in doing so, can lead to ethical concerns regarding the security policy and development of the provided service. This is due to the fact that if the business knows that there are better options available for keeping the service up and running at all times, but does not use these because of an unwillingness due to e.g. budget constraints and/or laziness, then is that a morally right decision to make?

59
Containers themselves provide strong assurances that the application will run the same everywhere, so one does not have to worry about dependency issues. Furthermore, it is possible to configure the containers, together with an orchestration manager such as Kubernetes, to keep the service running at all times. There are several options here: e.g. health-check based restarts, switching to other containers if one goes down, monitoring and live updates without any impact on the users. Together with containers there are also more options available in order to provide a more consistent service, such as packet managers for your clusters [58]. So, if it is possible to use containers in one’s company without unreasonable downsides, is it really ethical to not use them in order to provide a better service for one’s customers?
6.4 Sustainability
Sustainability can be divided into three main goals: environmental, economic and social. [59] Environmental sustainability focuses on improving the welfare by limiting the impact on the environments resources, economical sustainability focuses on the ability to limit the amount of money flowing out of one’s capital and social sustainability focuses on keeping the humans in good social health and thus improving the community. [60] [61] A good deployment technique can increase the productivity of a company by enabling them to create and manage deployments more quickly but with the same quality as longer deployments. This creates a healthier environment within the company and thus helps the social sustainability. Since containers have lower resource usage/can perform more with less than virtual machines, containers can create a better environmental sustainability by allowing to lower the company’s energy consumption. This also help the companies with their economical sustainability by allowing them to pay less in cooling resources and power consumption.
6.5 Future Work/Research
Some areas in need of further research, has been identified during the course of this project. Firstly, this thesis only investigates one container orchestration manager, Google Cloud’s Kubernetes service, but there are other companies and solutions as well who provide the same type of service. These services and providers could be evaluated as well, and a comparison between them could potentially reveal some interesting differences and findings. Secondly, this thesis does not take any financial aspects into consideration. There have been no attempts to calculate what the costs would be for a

60
company to use either deployment technique. There are many aspects that would have to be considered in order to make such calculations, and it was deemed to be outside the scope of this project. Further research about the financial costs, would perhaps be of most interest to companies like Tradedoubler, whom are considering a transition to container-based deployments. Lastly, specific research could be conducted in order to investigate whether containers can be adapted to other companies’ current environment.

61
References
[1] C. Anderson, “Docker [Software engineering],” IEEE Softw., vol. 32, no. 3, pp. 102–c3, 2015.
[2] D. Merkel, “Docker: lightweight Linux containers for consistent development and deployment,” Linux J., vol. 2014, no. 239, 2014.
[3] S. Hog, “Software Containers: Used More Frequently than Most Realize,” Network World, vol. 26, 2014.
[4] J. E. Smith and R. Nair, Virtual Machines: Versatile Platforms for Systems and Processes. Elsevier, 2005.
[5] “Docker: a software as a service, operating system-level virtualization framework,” Code4Lib Journal, vol. 25, no. 29, 2014.
[6] D. Gupta et al., “Difference engine,” Commun. ACM, vol. 53, no. 10, p. 85, 2010. [7] Microsoft, “System Requirements,” Microsoft Docs, 17-Oct-2017. [Online].
Available: https://docs.microsoft.com/en-us/windows-server/get-started/system-requirements. [Accessed: 10-Mar-2018].
[8] Rightscale, “State of the Cloud Report,” 2017. [9] M. Gelbmann, “Ubuntu became the most popular Linux distribution for web
servers,” W3Techs, 02-May-2016. [Online]. Available: https://w3techs.com/blog/entry/ubuntu_became_the_most_popular_linux_distribution_for_web_servers. [Accessed: 10-Mar-2018].
[10] J. E. Smith and R. Nair, “The architecture of virtual machines,” Computer , vol. 38, no. 5, pp. 32–38, 2005.
[11] N. Fonseca and R. Boutaba, Cloud Services, Networking, and Management. John Wiley & Sons, 2015.
[12] A. S. Tanenbaum and H. Bos, Modern Operating Systems. Pearson, 2014. [13] Docker, “Containers and virtual machines,” Get Started, Part 1: Orientation and
setup. [Online]. Available: https://docs.docker.com/get-started/#containers-and-virtual-machines. [Accessed: 23-Apr-2018].
[14] R. Rosen, “Linux Containers and the Future Cloud,” Linux J., vol. 2014, no. 240, pp. 86–95, Jun. 2014.
[15] B. I. Ismail et al., “Evaluation of Docker as Edge computing platform,” in 2015 IEEE Conference on Open Systems (ICOS), 2015.
[16] A. Tosatto, P. Ruiu, and A. Attanasio, “Container-Based Orchestration in Cloud: State of the Art and Challenges,” in 2015 Ninth International Conference on Complex, Intelligent, and Software Intensive Systems, 2015.
[17] Docker, “What is a container,” Docker. [Online]. Available: https://www.docker.com/what-container. [Accessed: 02-May-2018].
[18] Linuxcontainers.org, “LXC - Linux Containers,” Github. [Online]. Available: https://github.com/lxc/lxc. [Accessed: 23-Apr-2018].
[19] Docker, “Dockerfile reference,” docker docks. [Online]. Available: https://docs.docker.com/engine/reference/builder/. [Accessed: 23-Apr-2018].
[20] V. Singh and S. K. Peddoju, “Container-based microservice architecture for cloud applications,” in 2017 International Conference on Computing, Communication and Automation (ICCCA), 2017.
[21] Docker, “The Docker ROI Calculator,” Docker. [Online]. Available: https://www.docker.com/roicalculator-result. [Accessed: 27-Apr-2018].
[22] Docker, Docker for the Virtualization Admin. Docker, 2016. [23] Amazon, “What is DevOps?,” Amazon Web Services. [Online]. Available:
https://aws.amazon.com/devops/what-is-devops/. [Accessed: 27-Apr-2018]. [24] M. Stillwell and J. G. F. Coutinho, “A DevOps approach to integration of software
components in an EU research project,” in Proceedings of the 1st International Workshop on Quality-Aware DevOps - QUDOS 2015, 2015.
[25] KubernetesAuthors, “What is Kubernetes?,” Kubernetes. [Online]. Available: https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/. [Accessed:

62
08-May-2018]. [26] V. Medel, O. Rana, J. Á. Bañares, and U. Arronategui, “Modelling performance &
resource management in kubernetes,” in Proceedings of the 9th International Conference on Utility and Cloud Computing - UCC ’16, 2016.
[27] D. Vohra, Kubernetes Microservices with Docker. 2016. [28] KubernetesAuthors, “Pods,” Kubernetes. [Online]. Available:
https://kubernetes.io/docs/concepts/workloads/pods/pod/. [Accessed: 08-May-2018].
[29] J. Ellingwood, “An Introduction to Kubernetes,” Digital Ocean. [Online]. Available: https://www.digitalocean.com/community/tutorials/an-introduction-to-kubernetes. [Accessed: 08-May-2018].
[30] KubernetesAuthors, “Running Kubernetes Locally via Minikube,” Kubernetes. [Online]. Available: https://kubernetes.io/docs/getting-started-guides/minikube/#minikube-features. [Accessed: 08-May-2018].
[31] A. Martin, S. Raponi, T. Combe, and R. Di Pietro, “Docker ecosystem – Vulnerability Analysis,” Comput. Commun., vol. 122, pp. 30–43, 2018.
[32] T. Combe, A. Martin, and R. Di Pietro, “To Docker or Not to Docker: A Security Perspective,” IEEE Cloud Computing, vol. 3, no. 5, pp. 54–62, 2016.
[33] D. Walsh (Red Hat), “Are Docker containers really secure?,” opensource.com, 22-Jul-2014. [Online]. Available: https://opensource.com/business/14/7/docker-security-selinux. [Accessed: 04-May-2018].
[34] B. Scholl, T. Swanson, and D. Fernandez, Microservices with Docker on Microsoft Azure (includes Content Update Program). Addison-Wesley Professional, 2016.
[35] R. Erlandsson and E. Hedrén, “Improving Software Development Environment: Docker vs Virtual Machines,” KTH, 2017.
[36] A. M. Joy, “Performance comparison between Linux containers and virtual machines,” in 2015 International Conference on Advances in Computer Engineering and Applications, 2015.
[37] A. Håkansson, “Portal of Research Methods and Methodologies for Research Projects and Degree Projects,” presented at the WORLD COMP’13 - Proceedings of the International Conference on Frontiers in Education: Computer Science and Computer Engineering FECS 13, 2013, pp. 67–73.
[38] P. Gill, K. Stewart, E. Treasure, and B. Chadwick, “Methods of data collection in qualitative research: interviews and focus groups,” Br. Dent. J., vol. 204, no. 6, pp. 291–295, 2008.
[39] M. Bunge, Epistemology & Methodology I:: Exploring the World. Springer Science & Business Media, 1983.
[40] KTH, “KTH Primo,” KTH Library. [Online]. Available: https://www.kth.se/en/kthb. [Accessed: 08-May-2018].
[41] ScienceDirect, “ScienceDirect.com,” ScienceDirect. [Online]. Available: https://www.sciencedirect.com/. [Accessed: 08-May-2018].
[42] Google, “Google Scholar,” Google Scholar. [Online]. Available: https://scholar.google.se/. [Accessed: 08-May-2018].
[43] S. Eklund, Arbeta i Projekt, 4th ed. Studentlitteratur, 2011. [44] KTH, “II142X Examensarbete inom datateknik, grundnivå 15,0 hp,” kth.se.
[Online]. Available: https://www.kth.se/student/kurser/kurs/II142X. [Accessed: 08-May-2018].
[45] Smartsheet, “The Triple Constraint: The Project Management Triangle of Scope, Time, and Cost,” Smartsheet. [Online]. Available: https://www.smartsheet.com/triple-constraint-triangle-theory. [Accessed: 13-May-2018].
[46] J. Boutelle, “The buddy system: an alternative to pair programming,” LinkedIn Engineering, 28-Nov-2011. [Online]. Available:

63
https://engineering.linkedin.com/slideshare/buddy-system-alternative-pair-programming. [Accessed: 08-May-2018].
[47] Docker, “Compose file version 3 reference,” Docker. [Online]. Available: https://docs.docker.com/compose/compose-file/. [Accessed: 16-May-2018].
[48] Docker, “Get Started, Part 3: Services,” Docker Docs. [Online]. Available: https://docs.docker.com/get-started/part3/#your-first-docker-composeyml-file. [Accessed: 17-May-2018].
[49] KubernetesAuthors, “kubernetes/kompose: Go from Docker Compose to Kubernetes,” Github. [Online]. Available: https://github.com/kubernetes/kompose. [Accessed: 22-Apr-2018].
[50] Locust, “Locust - A modern load testing framework,” Locust. [Online]. Available: https://locust.io/. [Accessed: 17-May-2018].
[51] S. C. Pong, “How to persistently control maximum system resource consumption on Mac?,” Unix & Linux Stack Exchange, 08-Aug-2015. [Online]. Available: https://unix.stackexchange.com/a/221988. [Accessed: 18-May-2018].
[52] G. Cloud, “Virtual Machine Instances,” Google Cloud. [Online]. Available: https://cloud.google.com/compute/docs/instances/. [Accessed: 09-May-2018].
[53] User:filip, “Glassfish enable secure admin,” Java Tutorial Netwrok. [Online]. Available: https://javatutorial.net/glassfish-enable-secure-admin. [Accessed: 18-May-2018].
[54] M. Gueck, “Error - trustAnchors parameter must be non-empty,” Stack Overflow, 30-Apr-2018. [Online]. Available: https://stackoverflow.com/a/50103533. [Accessed: 23-May-2018].
[55] Z. Li, M. Kihl, Q. Lu, and J. A. Andersson, “Performance Overhead Comparison between Hypervisor and Container Based Virtualization,” in 2017 IEEE 31st International Conference on Advanced Information Networking and Applications (AINA), 2017.
[56] N. Golafshani, “Understandning reliability and validity in qualitative research,” The Qualitative Report, vol. 8, no. 4, pp. 597–606, 2003.
[57] S. Payne, “The Ethics of Cloud Computing – Part 2,” Skytap, 19-Dec-2014. [Online]. Available: https://www.skytap.com/blog/the-ethics-of-cloud-computing-part-2/. [Accessed: 31-May-2018].
[58] B. Burns, “Kubernetes in action: How orchestration and containers can increase uptime and resiliency,” Microsoft Azure, 24-May-2017. [Online]. Available: https://azure.microsoft.com/en-us/blog/kubernetes-in-action-how-orchestration-and-containers-can-increase-uptime-and-resiliency/. [Accessed: 31-May-2018].
[59] T. Kuhlman and J. Farrington, “What is Sustainability?,” Sustain. Sci. Pract. Policy, vol. 2, no. 11, pp. 3436–3448, 2010.
[60] R. Goodland and H. Daly, “Environmental Sustainability: Universal and Non-Negotiable,” Ecol. Appl., vol. 6, no. 4, pp. 1002–1017, 1996.
[61] “The concept of environmental sustainability,” in Economic Growth and Environmental Sustainability, 1999.

64

65
Appendix A - Code
from locust import HttpLocust, TaskSet, task
class MyTaskSet(TaskSet):
@task(1)
def index(self):
self.client.get("/")
class MyLocust(HttpLocust):
task_set = MyTaskSet
min_wait = 5000
max_wait = 15000
Code Block A. locustfile.py
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
annotations:
kompose.cmd: kompose convert
kompose.version: 1.11.0 (39ad614)
creationTimestamp: null
labels:
io.kompose.service: currconv
name: currconv
spec:
replicas: 1
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
io.kompose.service: currconv
spec:
containers:
- image: osyx/static-currency-converter
name: currconv
ports:
- containerPort: 8080
- containerPort: 4848
resources: {}
restartPolicy: Always
status: {}
Code Block B. currconv-deployment.yaml
apiVersion: v1
kind: Service

66
metadata:
annotations:
kompose.cmd: kompose convert
kompose.version: 1.11.0 (39ad614)
creationTimestamp: null
labels:
io.kompose.service: currconv
name: currconv
spec:
ports:
- name: "8080"
port: 8080
targetPort: 8080
- name: "4848"
port: 4848
targetPort: 4848
selector:
io.kompose.service: currconv
status:
loadBalancer: {}
Code Block C. currconv-service-yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
creationTimestamp: null
labels:
io.kompose.service: mysql-claim0
name: mysql-claim0
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Mi
status: {}
Code Block D. mysql-claim0-persistentvolumeclaim.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
annotations:
kompose.cmd: kompose convert
kompose.version: 1.11.0 (39ad614)
creationTimestamp: null
labels:
io.kompose.service: mysql
name: mysql

67
spec:
replicas: 1
strategy:
type: Recreate
template:
metadata:
creationTimestamp: null
labels:
io.kompose.service: mysql
spec:
containers:
- env:
- name: MYSQL_DATABASE
value: currconv
- name: MYSQL_PASSWORD
value: kiwi
- name: MYSQL_ROOT_PASSWORD
value: supersafepassword
- name: MYSQL_USER
value: admin
image: mysql
name: mysql
resources: {}
volumeMounts:
- mountPath: /var/lib/mysql
name: mysql-claim0
restartPolicy: Always
volumes:
- name: mysql-claim0
persistentVolumeClaim:
claimName: mysql-claim0
status: {}
Code Block E. mysql-deployment.yaml
apiVersion: v1
kind: Service
metadata:
annotations:
kompose.cmd: kompose convert
kompose.version: 1.11.0 (39ad614)
creationTimestamp: null
labels:
io.kompose.service: mysql
name: mysql
spec:
clusterIP: None
ports:
- name: headless
port: 55555
targetPort: 0
selector:
io.kompose.service: mysql
status:
loadBalancer: {}
Code Block F. mysql-service.yaml

68

69
Appendix B - Interview (in Swedish)
Du har använt dig utav Docker förut inom företaget?
Ja, jag använder Docker för att få en utvecklingsmiljö för vår databas. Just för att det är ett
problem som jag har haft många andra problem, så när jag sätter upp en Oracle insats så är
det jobbigt, kostar pengar och sätter man upp en databas någonstans så vill Oracle ha betalt.
Licensen är så att om man använder den för personlig utveckling så kan man bara ladda ner
den, så det var ett väldigt bra use case för Docker och Oracle själva har laddat upp en
version för Docker, så då kunde jag använda den konfigurationen som de lagt upp.
Det är just jättebra att kunna ha en lokal utvecklarversion så att säga, det är det jag använder
det till. Om det blir något konfigurations problem eller om man har en missat något, så är det
bara att ta bort allt och så köra allt igen, så installeras allt om igen som en bas.
Vad var det som fick dig att välja Docker jämfört med andra?
De är största på marknaden och just den här färdiga konfigurationen uppe också. De hade ju
också kunnat haft någon Vagrant konfiguration, som det finns VirtualBox versioner av också,
men allt blir ju mycket tyngre. Allt blir lätt viktigare med Docker känns det som. Plus att jag har
också konfigurerat Flyway vilket gör att man har koll på vad som är installerat i databasen.
Gör man konfigurationer med Flyway skrift så får man en slags versionshantering utav dess
kod. Så då kan jag integrerat det med en Flyway Docker instans också. Då kollar den om
databasen har den senaste versionen, har den inte den så uppdaterar den versionen i
databasen. Vilket gör det jätteskönt, då man innan inte kunde veta riktigt vad som var
installerat på databasen, vilken gör så att om man följer processen så har man koll på vad
som gjorts. Detta går ju också att göra utan Docker, men Docker gjorde det lättare då man
kunde köra dessa två olika instanser. Så då kan man bara ladda ner Docker avbilden och sen
automatiskt använda sig utav Flyway för att kontrollera att versionen den senaste.
Jag var även inne på att använda Kubernetes där med Flyway och Docker, men det övergav
jag då jag inte kände att det kändes riktigt nödvändigt i det här fallet. Det gör att man blir lite
mer avslappnad då man vet att det man har på live miljön har man kört själv på
utvecklingsmiljön.
Har du märkt några nackdelar med det här systemet?
Det man gärna hade velat gjort är att köra hela proceduren med Docker hela vägen ut, så att
man bara kunde pusha ut de man gjort när man är klar. Men det går inte riktigt här då det är
mycket som fortfarande är beroende utav hårdvaran under, för en databas. Jag har ju läst lite
om det där, det verkar vara svårt för Docker att ha disk systemet under som utvecklas i
samma takt. Om man har Docker images så vet man inte riktigt vad som finns under. Just
databasmiljöer är väldigt beroende utav att ha bra tillgång till diskaccess. Den leverantören
ser till att man inte har noisy neighbors, i moln är det lätt hänt att om man tar den billigaste, så
delar man med flera andra men sen så när man skalar så kanske det är en spik precis då,
och då kan det ta ett tag innan man får det man sökte om. Men det är många som erbjuder
bare-metal, dvs man erbjuder direkt hårdvara. Det är sånt man måste tänka på då databasen
är en trottel. Det är många som med Kubernetes just sätter upp allt förutom databasen. Det
går ju med DB också, men jag är osäker på om det är riktigt moget där än att använda det. Så
vi använder det endast lokalt för utvecklingsmiljön. Det hade ju varit kul och tagit miljön, för
drömmen vore, att ha exakt samma produktionsmiljö som utvecklar så man bara kan pusha
de direkt. Men där känner jag inte att Docker är riktigt än.
När tycker du är det ideala scenariot att använda virtuella maskiner?
Det är ju just det att jag var ju osäker när ni frågade tidigare om vi hade virtuella maskiner
idag. Grejen med virtuella maskiner är ju att man inte riktigt man har de. Som vi har det idag

70
så loggar vi ju in som vanligt, och då märker man inte riktigt om det är virtuella maskiner eller
om det är fysiska servrar. Det är ju det som är bra med VMs, med Docker märker man ju att
man använder de. Det som är den stora skillnaden, med Docker så sitter man inte och hackar
direkt i miljön, utan det bygger ju på att skriva dessa Dockerfiles som sätter upp hela miljön.
Så det är ju ett helt annat sätt att jobba, på virtuella maskiner så sitter man ju och konfigurerar
som på en vanlig maskin, det är en mer komplett miljö. Mer likt hur man brukar göra.
När ni valde de deployment techniques som ni har, vad för faktorer ni tänkte på?
Vi är ju så pass små, så att det här med Docker kunde jag ju bara välja att använda själv. Vi
har ju vissa grejer i Amazon, så vår front-end som samlar in vad folk klickar på och så, den
går ju via Amazon. Där är fördelen att det är geografiskt spritt, så vi har vår front-end cache
runt om hela världen så att folk kan vara var som helst när de klickar utan att märka någon
skillnad. Det är just vår back-end som vi har hos Evry, i Kista. Vi hade planer för några år sen
att lokalisera ut delar av vår back-end till Amazon också, men det blev inte riktigt av då vi
valde mer att fokusera på vår core business som är här i Europa. Det är ju mer komplext med
en global back-end, för det man vill undvika är ju att det finns olika versioner av sanningen.
För de finns ju en del bolag där de haft problem med att folk ser olika versioner utav data.
Men i fall som företag som Twitter och liknande så spelar det ju ingen större roll om folk ser
exakt samma sak samtidigt eller om någon kanske får ett tweet någon sekund senare. Men i
fallet för oss om folk så skulle se olika siffror i back-end:en är ju inte bra, för de har ju hand
om betalningar och liknande. Där vill man att allt ska ske samtidigt. I ett globaliserings
scenario blir det svårare att lösa. Det finns arkitekturer där man skriver till en centraliserad
databas och sen replikerar ut till flera andra databaser, så att man har en master som
replikerar ut data till de andra, via något replikerings verktyg och sen om man behöver någon
omvandling så kan man ha en transportprocess som gör det. Men allt det där måste ju göras
och det är ju dyr. Så vi ändrade strategi då att fokusera på vår centrala core business här i
Europa istället. Docker osv är ju jättekul men det är ju en startupprocess, och det händer ju
saker där hela tiden just nu. Ändå ganska mycket som var instabila som man inte ville gå ut i
produktion med. Som utvecklare så är det ju jättekul att testa, men som driftare känns det
skönt att veta att man har stabilitet.
Känner du att det är något som kan bli bättre med tiden?
Ja absolut det är ju en mognadsprocess i alla produkter. Det som är skönt när man vet att det
är stora företag bakom, när en open sourceprodukt backas upp av stora spelare som Google,
Facebook m.fl., det blir det en helt annan trygghet. Då man vet att det finns stora spelare som
har intresse utav att hålla produkten vid liv, se till att den mognar och som lägger ner de
resurser som behövs. Risken annars med många open sourceprojekt är att det sitter en
eldsjäl som driver projektet framåt. Sen när den slutar för att den inte orkar eller vill göra
något annat, för det är ju oftast gratis arbete, så sitter man där med en produkt som inte
utvecklas längre. Så kommer något säkerhetshål och det är ingen som patchar produkten, så
då måste man själv fixa det, vilket kan bli lite mycket om man har ett annat jobb själv. Med en
produkt som har support och liknande så blir det oftast inte alls samma bekymmer. Det är
därför det oftast är sådana här open sourceprojekt som backas upp av de stora spelarna.
T.ex. React och Angular, då de är dessa stora företag bakom, så blir det de som folk vågar
satsa på och därmed blir de mest populära. Så det är ju lite samma med Docker, så det är ju
väldigt väl känt nu. Men nu känns det som det har börjat nått en ganska mogen nivå, för bara
några år sedan så funkade inte grejor riktigt som man förväntade sig och var lite buggigt. Men
nu så verkar det mesta funka bra.
Hur tycker du att deployment delen utav era projekt påverkar det som ni gör?
Det blir ju mer och mer tid som går åt till DevOps och liknande. Sätta upp Jenkins och sätta
upp våra automatiska tester. Det är ju väldigt bra för att det gör produkten mer stabil, men det

71
gör ju även så att mer tid går åt till underhåll. När man gör något nytt så kanske testerna blir
utdaterade och då måste man utveckla nya och liknande. I slutändan så tjänar man ändå tid,
tror jag, men det finns ju nackdelar med allt. Men förhoppningsvis så leder det till en bättre
slutprodukt. Det är ju väldigt bra om någon checkar in någonting och helt plötsligt så kraschar
bygget direkt, och man kan lätt åtgärda. På vissa företag jag jobbat tidigare så är det någon
sån där kod apa som passerat och helt plötsligt så kraschar allt senare och det är ganska
svårt att veta vad som hänt. Ju tidigare man upptäcker felen, desto billigare blir det för alla.
Som utvecklare så blir man ju mer och mer inblandad i de här som varit på driftsidan tidigare.
Där det tidigare var så att driftpersonerna kanske var lite utanför ens egen process så man
visste inte vad de gjorde riktigt, utan det verkade vara ganska komplext. Men nuförtiden så
kan man sätta upp en driftmiljö själv, så utvecklarna får mer koll på driftmiljön och
driftpersonerna mer på själva bryggan eller produkten. Vi har ingen egen driftgrupp här utan
det är Evry som har våra servrar som sköter den biten. Men på tidigare jobb så hade man
kommit väldigt långt med DevOps, så där var det automatiserat nästan hela vägen ut till
produktion, förutom att man hade en review innan det gick ut. Men jag tyckte även att
konfigurations verktygen är väldigt bra, men även där är det ju skript som måste underhållas.
Det låter ju magiskt med DevOps där allt bara rullas ut men allt det måste ju också skapas
och underhållas. Man uppdaterar någon miljö och så pajar något skript som man måste fixa
osv.
Hur känner du inför att utvecklare själva börjar ta en större del i driftprocessen?
Jag tycker att det är bra för att det ökar helhets förståelsen för miljön, det ger också större
trygghet om man har skript och liknande att andelen manuella misstag blir färre. Som när jag
använder Flyway så kan jag ändå känna trygghet i att det här jag har gjort kommer funka
även i produktionsmiljön då det är exakt samma som det jag testat i testmiljön och det är inget
som kommer emellan. Det gör ändå att man känner en helt annan trygghet än tidigare då
man kunde oroa sig för om det var en annorlunda konfiguration eller liknande. Det är främst
det jag tycker de här DevOps verktygen gör, att det gör att allt blir mer konsekvent så att man
kan vara mer säker på att det är samma procedur som tillämpas varje gång, så att den
sortens misstag minskar.
Ser du några nackdelar med att utvecklarna tar med ansvar med DevOps?
Underhållsbiten nämnde jag tidigare, det blir mer underhåll och mer tid som går till det. Man
kan ju sitta och scripta upp allting men det tar ju tid att skriva alla skript och sen ska de
underhållas. Så slutar personen som skrivit skripten, så “jaha vad gjorde det här?” så är det
ingen som vet. Men o andra sidan så innan DevOps var ett begrepp, så var det ju så att om
någon utav driftpersonerna blev sjuka eller slutade så var det ingen som hade någon aning
om vad som gjordes. Men görs det med DevOps skript så blir det lite mer öppet vilket är
positivt såklart. Det gäller också att inte glömma bort hårdvaran när man håller på med
DevOps, det är något som annars är väldigt lätt att glömma. Det är ju ändå den tillslut som
ska göra allt jobbet och då gäller det att komma ihåg den. DevOps är så pass mjukvara
fokuserat att det kan vara lätt att glömma den delen. Sen är det lätt att “hypen” blir för stor
med DevOps så man sitter och utvecklar massor med nya saker hela tiden och fokuserar inte
på att få en mogen produkt. Så blir det någon drift-stackare som får sitta där sen och fixa alla
buggar och liknande. Så det gäller att ha en klar strategi när man börjar utveckla, så att man
sen väl är redo när man kommer till driften, även om den inte alltid är lika sexig och rolig att
prata om på konferenser och liknande. Då det ändå är driften som sker dagligen hela tiden.
Vilken teknik föredrar du?
Jo Docker var ju väldigt rolig med att man får en redo miljö direkt. När man själv sitter hemma
och ska installera Oracle DB t.ex. så känner man sig trött redan innan man börjar med alla

72
installations skärmar och konfigurationer. Med Docker så är det bara att hämta direkt, vilken
för mig iallafall är en revolution. Drömmen med Docker och Kubernetes är ju att man bara kan
utveckla det och sen bara ta hela paketet och lägga ut där man vill ha det direkt. Allt sådant
har känts väldigt krångligt tidigare, men det känns lättare nu. I alla fall i drömmen, vi har ju
inte riktigt det här än.
Hur lång tid brukar era processer ta när ni har bestämt er för att byta teknik(er)?
Jag började här för 1,5 år sen, och då såg jag möjligheten att använda Flyway för att få ut
releaser mer pålitligt mm, traditionellt annars så har det ju varit skript och då är det lätt med
misstag där man skrivit något fel, kopierat en extra fil eller bara testat i någon annan miljö etc.
etc. Att få in det i den här processen är fortfarande inte riktigt klart, det har varit något man
har tagit in steg för steg. Så nu har vi så att vi kör alla våra releaser med det här migrations
verktyget, Flyway. Men vi har ju fortfarande inte uppdaterat alla våra procedurer i Git, vilken
Flyway hämtar ifrån. Nackdelen med databas procedurer är att det är så himla lätt, man ser
källkoden i databasen, och sen är det bara att trycka compile och så kan man göra det på en
gång. Så att när jag började så var koden som fanns i Git inte pålitlig helt enkelt, utan man
fick hämta koden direkt ifrån produktionsdatabasen istället, för annars fanns det en jätterisk
att man kanske skrev över någonting. Det känns mycket tryggare nu med vårt
produktionsverktyg är att jag vet att det som finns i Git, det är det som gäller. Det blir en
process på ett annat sätt som gör att det blir lättare att inte göra misstag. Men då gäller det
också att man håller på de här processerna, annars är man ju tillbaka där man började eller
ännu värre. Så nu när någon ny börjar så måste man lära de alla de här nya reglerna. Det
bästa är helt enkelt att man bestämmer sig för någonting och sen följer det. Så ska man köra
DevOps eller liknande så gäller det att man följer den process man hittar på, annars kan det
göra mer skada än gott.
Hur stor del tycker du att du haft när ni bestämmer er för dessa tekniker?
Just de här databasbitarna har jag haft stor del, vi är ju bara ett team på två personer så det
har ju blivit lätt då. I de andra teamen däremot har jag inte varit särskilt inblandad alls.
Något du vill nämna innan vi avslutar?
Överlag så känns det som en mycket bättre värld, att ha alla de här verktygen tillgängliga. Så
jag tycker det mesta bättre, och jag vill inte tillbaka till hur det var tidigare.

TRITA EECS-EX-2018:130
www.kth.se





























