Embed Size (px)
Citation preview

Improving Rank Algorithm of Search Engine with
Ontology and Categorization
By
Qiaowei Dai
A thesis submitted for the degree of
Master of Science (Computer and Information Science)
School of Computer and Information Science
Division of Information Technology, Engineering and the Environment
Supervisor Dr. Jiuyong Li
1st June 2009
University of South Australia

2
Contents
INTRODUCTION ................................................................................................................................10
1.1 BACKGROUND ..............................................................................................................................10
1.2 MOTIVATION .................................................................................................................................13
1.3 RESEARCH AIM .............................................................................................................................13
1.4 SCOPE ...........................................................................................................................................14
1.5 THESIS ORGANIZATION .................................................................................................................14
TRADITIONAL LINK STRUCTURE-BASED RANK ALGORITHMS .......................................15
2.1 OBJECTIVE AND USAGE OF HYPERLINK EXISTING IN WEB............................................................15
2.2 PAGERANK ALGORITHM ...............................................................................................................16
2.2.1 Simplified PageRank Algorithm...........................................................................................18
2.2.2 Improved PageRank Algorithm ............................................................................................19
2.3 HITS ALGORITHM ........................................................................................................................21
2.3.1 Analysis of HITS Algorithm..................................................................................................22
2.3.2 Analysis of HITS Link...........................................................................................................23
3.4 SUMMARY.....................................................................................................................................25
LITERATURE REVIEW ....................................................................................................................26
3.1 RESEARCH ON TRADITIONAL RANK ALGORITHMS OF SEARCH ENGINES ......................................26
3.1.1 Problems and Improvements of PageRank Algorithm..........................................................26
3.1.2 Problems and Improvements of Hits Algorithm ...................................................................30
3.2 TRADITIONAL DOMAIN ONTOLOGY-BASED CONCEPT SEMANTIC SIMILARITY COMPUTATION ......33
3.2.1 Ontology...............................................................................................................................33
3.2.2 Three Main Semantic Similarity Computation Models ........................................................34
3.3 SUMMARY.....................................................................................................................................34
METHODOLOGY ...............................................................................................................................36
4.1 RESEARCH QUESTIONS .................................................................................................................36
4.2 RESEARCH STRATEGY...................................................................................................................36

3
4.3 EVALUATION TOOLS......................................................................................................................39
4.3.1 The Ontology Tool ................................................................................................................39
IMPROVE CONCEPT SEMANTIC SIMILARITY COMPUTATION MODEL..........................40
5.1 DISCUSSION ON TRADITIONAL COMPUTATION MODELS................................................................40
5.1.1 Distance-based Semantic Similarity Computation Model....................................................40
5.1.2 Content-based Semantic Similarity Computation Model .....................................................41
5.1.3 Attribute-based Semantic Similarity Computation Model....................................................41
5.2 DECISION FACTS OF SEMANTIC SIMILARITY COMPUTATION..........................................................42
5.2.1 Directed Edge Category.......................................................................................................43
5.2.2 Directed Edge Depth............................................................................................................44
5.2.3 Directed Edge Density .........................................................................................................45
5.2.4 Directed Edge Strength ........................................................................................................45
5.2.5 Concept Node Attribute of the Two Side of Directed Edge...................................................46
5.3 ESTABLISHMENT OF IMPROVED COMPUTATION MODEL ................................................................46
5.4 EVALUATION OF IMPROVED COMPUTATION MODEL......................................................................48
5.5 SUMMARY.....................................................................................................................................50
IMPROVE RANK ALGORITHM BASED ON CATEGORIZATION TECHNOLOGY .............51
6.1 COMBINATION OF CATEGORIZATION TECHNOLOGY AND LINK STRUCTURE BASED ALGORITHM ..51
6.2 BASIC IDEA OF CATEGORIZATION..................................................................................................54
6.2.1 Implementation of Categorization........................................................................................54
6.2.2 Pre-categorization Processes...............................................................................................55
6.2.2.1 Pre-categorization of Web Pages .......................................................................................... 55
6.2.2.2 Pre-categorization of Keywords ............................................................................................. 55
6.3 MODELING....................................................................................................................................58
6.3.1 Category Selective Mechanism ............................................................................................58
6.3.2 Integrating HITS Algorithm with Categorization.................................................................59
6.4 EVALUATION OF INTEGRATED ALGORITHM ...................................................................................61
6.4 SUMMARY.....................................................................................................................................62
CONCLUSION.....................................................................................................................................63
7.1 SUMMARY OF CONTRIBUTIONS......................................................................................................63
7.2 FUTURE WORK ..............................................................................................................................64
REFERENCES .....................................................................................................................................65

4
SEMANTIC RELATIONS ..................................................................................................................68
“LINEAR STRUCTURE” ONTOLOGY...........................................................................................71

5
List of Figures
Figure 1 Directed link graph G .........................................................................17
Figure 2 Simplified PageRank Algorithm...........................................................19
Figure 3 Improved PageRank Algorithm............................................................21
Figure 4 HITS algorithm on six-nodes graph .....................................................24
Figure 5 Function image of t .........................................................................33
Figure 6 Research strategy framework ...............................................................38
Figure 7 Main interface of Protégé 3.4 ...............................................................39
Figure 8 Ontology of linear structure..................................................................49
Figure 9 Screenshot of Linear Structure .............................................................49
Figure 10 Pre-categorization framework ............................................................57
Figure 11 Relation between authority value and hub value ................................59

6
List of Tables
Table 1 PageRank of each node in Figure 1........................................................21
Table 2 Semantic relations ..................................................................................43
Table 3 Experimental result.................................................................................49

7
Abstract
The appearance and rapid development of Internet has greatly changed the
environment of information retrieval. However, the rank algorithms for search engine
based on Internet are directly related to experiences in using when users perform
information retrievals in the new environment.
The existing rank algorithms for search engine are mainly based on the link structure
of web pages, and the two main representative algorithms are PageRank algorithm
and HITS algorithm. Many scholars and research institutions have made new
explorations and improvements based on these two algorithms, and some mature
integrated rank models suitable for search engines were generated.
In this paper, we study the shortcomings of search engines, and provide further
analysis on PageRank algorithm and Hits algorithm. Beside, we discuss the existing
improved algorithms based on link structure, and provide analysis on the
improvement ideas of existing search engine rank technology. Moreover, research on
traditional concept semantic similarity computation models based on domain ontology
is given as well.
According to the characteristics and shortcomings of existing models and algorithms,
we firstly propose an improved concept semantic similarity computation model. Then,
an improved rank algorithm which integrating categorization technology and
traditional link analysis algorithm based on it is given in this paper, which improves
HITS algorithm in two aspects, the pre-processing of Web pages and analysis on the
link structure of Web page. At last, the evaluations are provided as well.

8
Declaration
I declare that:
this thesis presents work carried out by myself and does not incorporate without
acknowledgment any material previously submitted for a degree or diploma in any
university;
to the best of my knowledge it does not contain any materials previously
published or written by another person except where due reference is made in the text;
and all substantive contributions by others to the work presented, including jointly
authored publications, is clearly acknowledged.
Qiaowei Dai
1st June 2009

9
Acknowledgements
I wish to express my sincere gratitude to my master thesis supervisor Dr. Jiuyong Li,
who is a Lecturer in the School of Computer and Information Science, for his helpful
suggestions, unreserved support, and encouragement throughout the research and
writing of this thesis. Besides this, I would also like to thank my course coordinator,
Dr. Stewart Von Itzstein for his encouragement and support. Last but not the least I
would like to express deepest thanks to my family for giving me the courage and their
support to study in Adelaide.

10
CHAPTER 1
Introduction
1.1 Background
Search engines have gradually become a high efficient and convenient way for data
query and information acquisition to people. With the continuous development of
search engine technology, the current mature commercial search engines have
experienced several generations of evolution. Meanwhile, Web information retrieval
technology, which is the essence of search engines, including commercial products
has come out for about 20 years. In this period of time, great progresses in the aspects
of retrieval key technology, system structure design, query algorithm and etc. are
made, and a lot of commercial search engine services are being used on Web.
Compare with these progresses, the rapid increment of data on Web weakens the
achievement obtained in the research field of Web search in some degree, the massive
data quantity and frequent update speed have brought a completely new challenge as
well. Currently, the shortcomings existing in Web information retrieval are mainly
shown in the following aspects according to my research:
· Low query quality
Low query quality is shown as when returning large amount of result pages,
however, the amount that really accords to users’ requirement is low. Moreover,
most of these relevant links don’t appear on the top of query results. Users have to
keep trying and turning pages in order to find valuable information, thus a lot of

11
time is consumed by this process. In the age that Web information amount is
increasing continuously, this problem has become particularly outstanding.
Improving Web query quality is the most critical subject of current intelligent
information retrieval research, after Web mining technology is integrated, the
query quality of search engines can obtain great improvement.
· Low query update speed
There are two reasons causing the low update speed of Web query results, one is
the low efficiency of the Crawler system of search engines, which the collection
period of documents is too long, after the index is completed, difference has
emerged between acquired content and the newest pages; the other one is the
update speed of Web documents has become faster and faster. Currently, many
Websites include dynamic pages, which are activated by the background database,
thus the change of database will directly cause these dynamic pages to be changed.
The update speed of part of static pages is increasing as well. When many Web
pages are continuously visited by Web Crawler by two times, the change times of
them will much higher than two times in the interval, so users can’t obtain the
content of these changes through query.
· Lack of effective information categorization
Currently, most of the query results of search engines are provided in the way of
list and paging, all the relevant and irrelevant links are put together without
association, which is quite inconvenient for users with explicit query objective,
because they have to keep jumping or selecting between various links.
Categorizing and clustering query pages is an effective way to improve the quality
of user navigation, which can make users select some category quickly and
ulteriorly refine query targets in this category. For example, if we input “mining”
into Vivisimo, several categories such as “data mining”, “gold” and “Mining and
Metallurgy” will emerge, and users can make further query in every category.

12
· Keyword-based Web query lacks understanding of user behavior
In the view of the development of Web retrieval technology, keyword-based query
will be the most important retrieval way in a quite long period from now on.
Keyword-based query is a complicated retrieval mechanism implemented by the
Boolean combination of keywords. However, the query functions provided by
current search engines are quite limited, which only the most basic Boolean
connections between keywords are provided by most search engines. For instance,
Yahoo only provides two logical operators, which are “AND” and “OR”, and
compulsory applies one logical operator to all keywords. In many cases, it is quite
difficult to construct an effective query combination.
On the other hand, even to the same keywords, the search objective of different
users maybe different, it is closely related to the facts such as users’ personal
preference, the environment of context of current search, the previous search
history and so on. After these parameters are fully considered, a search engine that
accords to users’ requirement can be designed based on it. In Lawrence and Lee
Guile’s (1998) paper, they proposed a context environment-based Web retrieval
and query correction method.
· Low index coverage rate of Web search engines
Currently, the coverage rate to Web of search engines is low than 50%, it is quite
difficult to completely index the whole Web because of resource restriction. In the
condition that the index coverage rate is low, when collecting documents, many
search services adopt same download priority for each page, which causes there
are many pages with low reference value remaining in index database, but some
relatively important pages are not indexed. In order to solve this problem,
discrimination of resource quality is needed in the process of Crawler traversing.
The pages with high quality should be downloaded in priority, and the index
database is constructed according to priority. In Chakrabarti, van den Berg and
Dom’s (1999) paper, they proposed an algorithm that analyzes Web document

13
quality in real time and determine download priority by means of focus crawling,
which makes up the shortcoming of low coverage rate in some degree.
1.2 Motivation
According to Intelligent Surfer Model, we can consider that the user behaviors in
browning Web page are not absolute random or blind, but related to topic. That is to
the numerous outbound links of each Web page, the outbound links which belong to
the same or similar Web page category will have the higher click rate.
No matter PageRank algorithm or HITS algorithm, they objectively describe the
essential characteristics between Web pages, but rarely consider about the topic
relativity of users’ surfer habit. Link structure-based algorithm can be integrated with
other technology very well in order to improve the algorithm adaptability.
Categorization technology can simulate user subject-related habit, so as to improve
this kind of link structure-based algorithm. Categorization technology overcomes the
unreliability brought by the assumption that the users’ behaviour of visiting Web
pages is absolute random, and distinguishes the direction relation between Web pages
according to category attributes, thus categorization technology can be regarded as an
important supplementary to traditional algorithms.
1.3 Research Aim
My research aim is to establish an improved rank algorithm for search engines based
on domain ontology and categorization technology in order to make rank algorithm
simulate the actual user behaviors in browsing Web pages more accurate. To achieve
this research aim, we have three objectives.
The first objective is to analyze the traditional link structure-based rank algorithms
for search engines in order to gain an insight into their principles and further studies.
Thought the research and analysis on traditional domain ontology-based concept

14
semantic similarity computation, we can gain a full understanding of the principles
and weaknesses of three common computation models. Therefore, our second
objective is to analyze and improve the decision facts of concept semantic similarity
computation, and then develop an improved concept semantic similarity computation
model in order to determine the relation between two categories in the categorization
process.
The third objective is, according to the study on category-integrated PageRank
algorithm, we firstly perform a pre-categorization process to Web pages and keywords
based on the improved concept semantic similarity computation model, and then
develop a category-based HITS algorithm to satisfy the final aim of this thesis.
1.4 Scope
This thesis will focus on researching the rank algorithm for search engines, which
needs to be able to adapt the link structure of network, and gives accurate feedback to
the information queried by user. A good rank algorithm should be able to filter the
content of Web pages, reject irrelevant Web pages, and displays the Web pages which
are most relevant and close to query condition to the top of the list. Meanwhile, the
waiting time of this kind of rank computation should be in user’s acceptable scope.
1.5 Thesis Organization
The thesis is structured as follow:
1 Chapter 2 (Traditional Link Structure-based Rank Algorithms)
2 Chapter 3 (Literature Review)
3 Chapter 4 (Methodology)
4 Chapter 5 (Improve Concept Semantic Similarity Computation Model)
5 Chapter 6 (Improve Rank Algorithm Based on Categorization Technology)
6 Chapter 7 (Conclusion)

15
CHAPTER 2
Traditional Link Structure-based Rank Algorithms
Hyperlink is a very important component of Web. Through the hyperlink in a page,
users can arbitrarily link from a page of any WWW server in the world to the page of
another WWW server. Hyperlink not only provides convenient information navigation,
but also is an information organization method, which includes help information that
is very rich and effective to Web information retrieval.
2.1 Objective and Usage of Hyperlink Existing in Web
In order to convenience users in intra-Website navigation, the internal hyperlinks of a
Web page can convenience users to jump between different Web pages freely, so as to
avoid to use the “back” button of Web browser. A well-designed Website should be
able to jump from an arbitrary page of the Website to the other pages of the Website
by multiple links. The main function of this kind of hyperlink is to assist users to
orderly visit the whole Website content.
Another kind of hyperlink is extra-Website hyperlink, which is the most important
hyperlink form in Web hyperlink mining research. Generally, extra-Website hyperlink
always represents the page creator’s attention and preference of some Website or
content, or say, some potential relations exist. For example, adding the hyperlink of
Yahoo to a page represents the author’s recommendation and preference of Yahoo;
adding the hyperlink of Kdnuggets, which is a famous data mining Website, to a page
represents that the page author is interested in data mining, as well as the page itself is

16
possibly related to data mining research. If the URL of some page is linked many
times in Web, it indicates that the quality of its content is high; on the contrary, the
important degree is lower. This kind of evaluation mechanism is similar to the
reference in scientific paper, the importance of the paper with more times being
referenced by other people is higher than it with less times being referenced. In Web
retrieval, besides the times being linked by other documents, the quality of source link
document is also a reference factor of evaluating the quality of linked documents,
which the document linked or recommended by the high-quality document always has
higher authority. Web can be considered as a graph structure in hyperlink analysis,
and analyze the link relations between nodes can help solve the difficult problem that
text content-based retrieval can’t achieve content quality evaluation.
Compare with the traditional search engines which use the rank algorithms based on
the query results of word frequency statistics, the advantage of hyperlink
analysis-based algorithm is that it provides an objective and cheat-proofing (Some
Web documents cheat traditional search engines by adding invisible strings) Web
resource evaluation method. Currently, link analysis algorithm is used in many Web
information acquisition fields, including rank search engine document, search related
document, arrange priority order of Web Crawler’s URL crawling, etc (Dean, J &
Henzinger, RM 1999). Recently, compared with the word frequency statistics-based
method used by traditional search engines, the Web retrieval algorithms based on
hyperlink analysis such as PageRank algorithm has great improvement in the aspect
of improving retrieval precious (Haveliwala, HT 1999).
2.2 PageRank Algorithm
PageRank is a global link analysis algorithm proposed by S. Brin and L. Page (Brin, S
& Page, L 1998). It performs statistics to the URL link condition of whole Web, and
calculates a weight, which is called as the PageRank value of this page, to every URL
according to the factors such as link times, etc. This PageRank value is fixed, not
changeable with the change of query keyword, which is different from the local link

17
analysis algorithm HITS.
Figure 1 Directed link graph G
For example, in Figure 1, page u includes a hyperlink referring to page v , there
exists ),( vulink . Here, the hyperlinks between pages compose a directed graph G .
To a node composing directed graph G in every page, if and only if when u
includes the hyperlink referring to page v , there exists directed edge ),( vu from u
to v .
To node v , nodes b , c , u have contributions to the weight value of v , because
these three nodes all exist directed edges to v . The more the directed edges referring
to some node, the higher the node (page) quality is. The main shortcoming of this
kind of algorithm is that only the link quantity is considered, which means all the
links are equivalent, but whether the quality of source node itself is high or low is not
considered. In fact, the high-quality page in Web always includes high-quality links,
to the effect of linked document quality evaluation, the impact of the quality of source
node is always high than the quantity. For example, the links appearing in Yahoo
always have certain reference value, because Yahoo itself is a relatively authoritative
Website, just as the papers issued in top publications always have higher academic
value.
PageRank algorithm is in recursive form, its value relies on the linked times and the
w
b
a
u
v c

18
PageRank value of source link (Brin, S & Page, L 1998).
2.2.1 Simplified PageRank Algorithm
Simplified PageRank algorithm implements the basic recursive procedure of link
times and source PageRank. Let the pages on Web as 1, 2 , …, m , )(iN is the
amount of the extra-Website links of page i , )(iB is the page set referring to page
i . Assume Web is a strong connected graph (actually it is impossible, this problem
will be discussed in the next section), then the PageRank value of page i can be
expressed by:
åÎ
=)( )(
)()(
iBj jNjr
ir
The expression above can be written as rAr T= , r is the vector of 1´m , the
arbitrary element in matrix A , which )(
1iN
aij = . If page i refers to j , then
0=ija . Thus, vector r is the eigenvector of matrix TA . Because Web is assumed to
be strong connected, the eigenvalue of TA is 1.
From the definition above, we can find that PageRank is accord with Random Surfer
Model (Page, L, Brin, S & Motwani, R 1998). We can consider Random Surfer Model
in this way: Assume a user visits Web page by means of randomly clicking hyperlinks,
moreover, he doesn’t use “back” function and keeps continuous clicking. The
PageRank of page i is essentially the probability of clicking page i in the process
that a user browses the whole Web by means of random surfer. Motwani, R &
Raghavan, P (1995) had made further research on RSM, these works can be also used
to analyze the Web link attributes.
The computation of simplified PageRank algorithm can use iterative method, after
several times of iteration, stop the iterative procedure when the PageRank value
converge to the condition that deviation is small enough. For example, in Figure 2, the

19
computation procedure is shown below:
1 Select arbitrary random vector s
2 sAr T ´=
3 If e<- || sr (e is the selected iterative threshold value), stop iteration. r is the
PangeRank vector
4 rs = , back to step 2
Figure 2 shows the computed rank value of every node in a small graph structure by
simplified PageRank algorithm. According to the RSM of PageRank, the sum of the
PageRank value of every node is 1.
Figure 2 Simplified PageRank Algorithm
2.2.2 Improved PageRank Algorithm
Simplified PageRank algorithm is only suitable for the ideal strong connected
environment, but in fact, Web is not a strong connected structure. Broder, A, Kumar,
R, & Maghoul, F’s (2000) paper shows there are only 28% pages on Web are strong
connected; 44% are one-way connected; and the remaining part forms Information
Isolated Island, which is neither linked by, nor links to other page. To simplify
PageRank algorithm, non strong connected Web exists two inextricable problems,
2
1 3
5 4
r2=0.286
r1=0.286 R3=0.143
r5=0.143 r4=0.143

20
which are rank sink and rank leak. Rank sink refers to some local strong connected
Web graph doesn’t include the link referring to outside. Rank leak refers to the page
that doesn’t include any external hyperlink. Actually, it is a special case of rank sink
when there is only one node in the strong connected graph. They will cause deviation
generating when analyzing graph structure. For example, if we discard the link from 5
to 1 in Figure 2, nodes 4 and 5 will form rank sink situation. If we use RSM to
simulate, we will fall into the dead circulation from 4 to 5 at last. Moreover, the rank
values of 1, 2 and 3 tend to 0, and the nodes 4 and 5 will share the rank, which the
total value is 1, of whole graph. If we remove 5 and its related links form figure 2,
node 4 will become a leak node. Because once this node is visited, the rank procedure
will stop here, thus, the rank values of all nodes will converge to 0. Therefore, Page
and Brin (Brin, S & Page, L 1998) proposed two methods, one is discarding all the
leak nodes which their outdegrees are 0, another one is introducing damping fact d
( 10 << d ) in simplified PageRank algorithm. The appearance of d makes
PageRank contribute to not only the node which it links to, but also the other pages on
Web. The expression of improved PageRank algorithm is shown below:
åÎ
-+=
)(
1)()(
*)(iBj m
djNjr
dir
m is the total node amount of Web subgraph that Web Crawler visits. As we can see
from the expression, the simplified PageRank algorithm is the special case when
1=d .
Figure 3 shows the computed PageRank value of every node after removing the
hyperlink from 5 to 1 by improved algorithm. Every node has been adjusted by
parameter d , which make their values all converge to a non 0 value.

21
Figure 3 Improved PageRank Algorithm
For example, in Figure 1, the PageRank value of each node is shown in the table
below ( 2.0=e ):
Table 1 PageRank of each node in Figure 1
Node a Node b Node c Node u Node v Node w
PageRank 0.060210 0.071004 0.094177 0.047534 0.097881 0.125839
PageRank can use iterative algorithm to complete recursion. To the PageRank of each
node in Figure 1, about 15 times iterations are needed. Generally, in actual
computation, 100 times iterations are enough to converge (Haveliwala, H.T 1999).
PageRank algorithm is currently applied by Google search engine, which provides
high-quality Web retrieval service.
2.3 HITS Algorithm
HITS (Hypertext Induced Topic Search) algorithm is a kind of rank algorithm that
analyzes Web resource based on local link, which is proposed by Kleinberg in 1998
(Kleinberg, J 1999). The difference between PageRank and HITS is that HITS is
related to query, and PageRank is a kind of query unrelated algorithm. As mentioned
2
1 3
5 4
r2=0.142
r1=0.154 R3=0.101
r5=0.290 r4=0.313

22
in the section above, PageRank algorithm gives each page a rank value which is
unique and unrelated to query keyword, but HITS algorithm gives each page two
values, which are Authority value and Hub value.
Authority page and Hub page are two important concepts in HITS algorithm, which
are the concepts all related to query keyword. Authority page refers to some page that
is most related to query keyword and combination (Kleinberg, J 1999). For example,
when querying “University of South Australia”, then the homepage of UniSA, which
is http://www.unisa.edu.au/, is the page with the highest Authority value in this query,
and the Authority value of other pages theoretically should be lower than it. Hub page
is the page that includes multiple Authority pages (Kleinberg, J 1999). Hub page itself
may not have direct relation to query content, but through it, the Authority page with
direct relation can be linked. For example, when inputting the query combination such
as “Australian university”, the homepage of Australian Education Network, which is
http://www.australian-universities.com/, is a Hub page, which includes the links
referring to each university in Australia. Hub page can be used as the auxiliary
reference when computing Authority page, and itself can be returned to user as query
result (Chakrabarti, B, Dom, B & Raghavan, P 1998).
2.3.1 Analysis of HITS Algorithm
The central idea of HITS algorithm is that: Firstly, use text-based retrieval algorithm
to obtain a Web subset, and the pages in this subset all have relativity to user query.
Then, HITS performs link analysis on this subset, and find out the Authority pages
and Hub pages related to query in the subset. The selection of subnet in HITS
algorithm is acquired by means of keyword matching. This subnet is defined as root
set R , then use link analysis to acquire set S from root set R , S is the page that
includes Authority page and ultimately meet the query requirement. The process from
R to S is called “Neighborhood Expand”, and the algorithm procedure for
computing S is shown below:
1 Use text keyword matching to acquire root set R , which includes thousands of URL or more;

23
2 Define S to R , that is S and R are equal;
3 To each page p in R , put the hyperlinks included by p into set S ; put the
pages referring to p into set S ;
4 S is the acquired expanded neighbourhood set.
HITS algorithm needs three parameters, which are query keyword, maximum
capability of root set R, and maximum capability of expanded neighborhood S . After
using the algorithm above, the pages in S will have more Authority pages and Hub
pages which meet the query keyword.
2.3.2 Analysis of HITS Link
The process of HITS link analysis takes advantage of the attribute that Authority and
Hub are interacting to identity them from expanded set S . Assume the pages in
expanded set S are respectively 1, 2, …, n. )(iB represents the page set referring
to page i , )(iF represents the page set referred by page i . HITS generates an
authority value ia and Hub value ih for each page in S . The initial value of
computing initial ia and ih can be an arbitrary value, similar to PageRank, HITS
can use iterative method to acquire convergence value. There are two steps in its
iterative procedure, which are step I and step O. In step I, the authority value of each
page is the sum of the Hub values of pages referring to it. In step O, the Hub value of
each page is the sum of the authority values of pages referring to it. That is:
I: åÎ
=)(iBj
ji ha
O: åÎ
=)(iFj
ji ah
The two steps, I and O, are based on the fact that one Authority page is always
referred by many Hub pages, and one Hub page includes many Authority pages. HITS
algorithm iteratively computes the two steps, I and O, till they converge. At last, ia
and ih are the Authority and Hub value of page i . The procedure is shown below:

24
1 Initialize ia , ih ;
2 Iterate procedure I, O; Perform iteration I; Perform iteration O; Normalize the value
of a and h , let 12 =åi
ia ; å =i
ih 12
3 Complete iteration
Figure 4 shows the application of HITS algorithm in a subgraph including 6 nodes.
Figure 4 HITS algorithm on six-nodes graph
As shown in Figure 4, the authority value of node 5 is equal to the Hub values of
nodes 1, 3 which refers to it, after normalization, the value is 0.816.
Assume mmA ´ is the matrix of subgraph, then the value of position ji, in matrix
A is equal to 1 (if page i refers to j ), or 0. Set a to be the authority value vector
],...,,[ 21 naaa , h to be the hub value vector ],...,,[ 21 nhhh , then the iteration I, O can
be expressed as Aha = , aAh T= . After completing the iteration, the values of
authority and hub respectively satisfy aAAca T1= , AhAch T
2= , which 1c and 2c
are constant in order to satisfy the normalization condition. Thus, vector a and
vector b respectively become the eigenvector of matrix TAA and matrix AAT .
2 1 3
5 4 6
h=0 a=0.408
h=0 a=0.816
h=0 a=0.408
h=0.408
h=0.816
h=0.408

25
This feature is similar to PageRank algorithm, their convergence speeds are decided
by eigenvector.
3.4 Summary
PageRank and HITS are currently the representations of Web retrieval algorithm
based on hyperlink mining. Through the analysis of Web hyperlink relation, we can
greatly improve the accuracy of Web retrieval, and overcome the disadvantage based
on context matching method. Currently, many search engine begin to use similar
algorithm to improve the query precious, for example, Google uses PageRank, Toema
and Altavista also adopt similar technology.
On the other hand, there are defects existing in both PageRank and HITS. PageRank
is independent to query, thus its computation amount is relatively small, but will lose
part of performance on content matching. Although HITS is query related, its link
analysis is only limited in the Web subgraph with thousands of nodes. It can’t reflect
the link condition of whole Web.

26
CHAPTER 3
Literature Review
3.1 Research on Traditional Rank Algorithms of Search
Engines
3.1.1 Problems and Improvements of PageRank Algorithm
The PageRank algorithm is more concerned about old pages, because the probability
of old pages being linked by other pages is much higher, but in fact that new pages
may contain information with better values.
Another problem it may cause is called ‘topic drift phenomenon”. The following
condition should be considered: The portal Websites on Web are always inclined to
make a clean sweep of all aspects of information, which presents as there exists
Website hyperlinks of various topics on their homepages. Meanwhile, many pages
will regard them as a guide for their further information reference, and then include
them in their own links. When searching some key words, if these portal Websites are
in the scope of consideration, there is no doubt that they will acquire the highest
authority, thereupon topic drift phenomenon generates. These portal Websites can be
always found on the top of the searching results, although they also contain the
information required by users, but usually the contents they contain are much
generalized than what the users expect, which is far from satisfactory. In contrast,
some professional Websites are more authoritative in describing these topics.
PageRank algorithm is not able to distinguish the hyperlinks in page being related to

27
its topic or not, that is to say, it is not able to judge the similarity of page content.
Thus, it is easy to cause topic drift problem, for example, Google and Yahoo are the
most popular Web pages on the Internet, and they have very high PageRank values.
Thus, when users input a query keyword, these Web pages will often appear in the
result set of this query, and occupy the very front positions. In fact, sometimes this
Web page is not even related to the users’ query topic.
In Kleinberg’s Hits algorithm paper (1999), he explicitly pointed that those links that
link back to the same Website cannot be counted in Web graph, instead, they should
be discarded. They are a kind of nepotistic links, obviously, not containing any
authority information. After the publication of Kleinberg’s paper, in Bharat and
Henzinger’s paper (1998), they pointed that there exists another nepotistic link, which
is the nepotistic link between two different Website, and this kind of links are trending
to increase rapidly. Moreover, this kind of nepotistic link may be generated in the
construction of Websites accidently. For instance, all the sub Websites of Yahoo have
links referring to main Website. The nepotistic link between two Websites will make
their authorities keep increasing in the iterative process, either for PageRank
algorithm or Hits algorithm.
In order to solving the problem that PageRank algorithm concerns old pages too much,
Ling & Fanyuan (2004) proposed an accelerated evaluation algorithm. This algorithm
make the valuable contents on network deliver in a faster speed, meanwhile, the
evaluation value of some pages containing old data will drop in a quicker speed. The
core idea of this algorithm is to predict the expected value of one certain URL in a
period of further time by analyzing the change condition of PageRank value based on
the time series, and regard it as the effective parameters of retieval service provided
by search engine. This algorithm defines a URL accelerated factor AR , which is
given by:
)(* DsizeofPRAR =

28
where )(Dsizeof is the document amount of the whole page set. The expression of
accelerated PageRank is:
last
last
M
BDARePRacclerat
+=
'
where lastAR is the AR value of URL in the latest time, B is the slope of the
quadratic fitting curve of the PageRank value of this URL in a period of time, D is
the day interval from the time that the page being downloaded in the latest time, and
lastM is the amount of the documents in the document set downloaded in the latest
time. When users retrieve, search engines will decide the URL position in the retieval
results according to the predicted PageRank value.
The WebGather search engine (Ming, L, Jianyong, W & Baojue, C 2001) developed
by Beijing University applied another way to overcome this weakness, which is to
give compensation to new Web pages. The clicking amount of linked LHN Web pages
can be divided into same Website link amount and different Website link amount.
Different Website link is called pure LHN, and gross LHN contains both. Only pure
LHN is considered here.
To new Web pages, they are not linked by other pages yet, so compensation is given.
st
st
TT(p) if ,0)(
TT(p) if ),)(log()log()(
£=>---=
PWLT
pTTTTPWLT nowstnow
where nowT is the current time, stT is the compensated limit time, and )( pT is the
time when Web pages are published.
After compensation weight being introduced, the new link weight is:
)()1)(log()(' pWLTpLHNPWL ++=

29
After standardization:
max
)(')(
WLpWL
pWL =
Haveliwala (2002) proposed a topic-sensitive PageRank algorithm in order to solving
the topic drift phenomenon. This algorithm considers that some pages are thought to
be important in some field, but it doesn’t represent that they are also important in
other fields. Therefore, the algorithm firstly lists 16 basic topic vectors according to
Open Directory (The Open Directory Project, which is a Web Directory for over 2.5
Million URLs), and then to every Web page, computing the PageRank values of these
basic topic vectors in offline condition. When users queries, according to the query
topic or query context inputted by users, the algorithm computes the similarity
between this topic and known basic topic, and chooses a closest topic from basic topic
set to replace the users’ query topic. The formal expression of the algorithm is shown
as follow:
PucuRcMuRMuR )1()()(')( -+´=´=
where Pu is the topic-sensitive vector of Web page u . This algorithm can
effectively avoid some obvious topic drift phenomenon, for example, when querying
“jaguar”, if the instruction of context is available, the algorithm can explicitly
distinguish whatever users tried to search:
1 jaguar car;
2 jaguar football team;
3 jaguar product;
4 jaguar, which is a kind of mammal,
thus, provide high-quality recommendation result set.

30
3.1.2 Problems and Improvements of Hits Algorithm
Multiple Websites posses some links that recursively refer to each other due to some
reason, which causes “faction attacks” emerge between these Websites. For instance,
some enterprise Websites are designed by the same Website design company for
different companies, it should be possible that there are friendly links between them.
The impact brought by faction attacks is similar to nepotistic links, but it is more
difficult to be detected than nepotistic links, because larger scope of Web graph needs
to be inspected. Another type of problem is called “mixed hub page phenomenon”,
which is a hub page simultaneously possesses links referring to several categories of
completely different topics. For example, a hub page related to a movie awards
usually includes a lot of links referring to movie companies. Mixed hub page is more
difficult to be detected by computers than faction attacks, furthermore, the probability
that it emerges is higher as well. It is possible for mixed hub page to mix the Web
pages with different topics together, especially in HITS algorithm, it is quite easy to
involve Web pages that are irrelevant to current topic in the process of constructing
extended set, and due to these Web pages have a large amount of links refer to pages
with higher authority, they cannot be discarded from results. In Google’s PageRank
algorithm, this impact can be reduced by adjusting the random surfer probability d .
In Hits algorithm, firstly a basic set is constructed, and then extended to extended set
through basic set, finally the whole Web graph is formed. The reason of doing this is
possibly that the result acquired by the information retrieval system in the first step
doesn’t include the pages that users really demand. For instance, when querying with
keyword “browser”, the pages returned by information retrieval system usually
doesn’t contain the pages of Netscape Navigator, Microsoft Internet Explorer, because
their pages will usually avoid using words such as “browser” to make product
promotion. Furthermore, usually some personal page will use words such as “best
viewed with a frames-capable browser…”, which causes the originally important
Netscape and Microsoft’s pages cannot be included in the results in the first step. This
problem can be solved by expended set, because the required Web pages can be

31
acquired through hub page. Due to this characteristic, HITS algorithm can be
impacted by the nepotistic links, faction attacks and mixed hub page mentioned above.
When constructing extended set, too many pages irrelevant to topic are involved, and
they are also with higher authority because of possessing links referring to each other.
If we restrict the radius when the extended set is constructed, it is possibly that we
can’t get enough pages. The really decent pages can be acquired only if the radius is
big enough when constructing extended set, but by then too many irrelevant pages
have been involved and causing “topic pollution phenomenon”.
Besides, similar to PageRank algorithm, Hits algorithm is also impacted by “topic
drift”. After including these portal Websites through extended set, Hits algorithm will
face the same difficulty as PageRank.
Bharat and Henzinger (1998) improved the computation method of authority weight
and hub weight by means of introducing relevance weight to hyperlinks, if the
relevance weight of hyperlink is smaller than certain threshold, then we consider the
impact of this hyperlink to page weight can be neglected, and this hyperlink will be
discarded from the subgraph. Besides, Chakrabarti, Dom and Gibson (1999) proposed
an idea that split big hub page into smaller units. A page always includes many links,
which possibly not relevant to the same topic. In this situation, in order to get a good
result, it is better to divide the hub page into continuous subsets and then make a
process, these subsets are called pagelet. The single pagelet refers to a topic more
concentrative than the whole hub page, so better retrieval results can be acquired by
computing weight for every pagelet. In the Clever system which is an application
example of HITS algorithm, the author computed the weight of hyperlink by means of
matching query keyword with the text around hyperlink and computing the word
frequency, and then replace the corresponding value in adjacency matrix with the
computed weight, thus achieves the objective of introducing semantic information
(Chakrabarti, B, Dom, B & Raghavan, P 1998).
Time parameter is introduced to improve HITS algorithm as well. To the reference of

32
a certain determined Web page, i.e., node P reference node Q , its application time,
to a great extend, reflects whether this referenced node is authoritative or not. In
reality, the visiting time of the authority pages which the users really want to visit
should be relatively long, and to those visits act as navigations occasionally or for
some other purposes, the visiting time is relatively short. In other words, if users’
visiting time to a certain page is relatively long, then we can consider this page as the
page that the users want to visit, which is target page. If this information is applied in
the computation of authority weight in HITS algorithm, the accuracy of HITS
algorithm can be greatly improved.
Xuelong, Xuemei and Xiangwei (2006) proposed a time parameter control model
which is described as follows: Define the hyperlink weight related to keyword K
which refers from page P to page Q is ),,,( TKQPW , this final value of W is
determined by three facts: the link referring from P to Q ; the emergence times of
query keyword in the hyperlink characters, which is K ; the visiting time that P
visits Q , which is T . In order to control the result more precisely, a coefficient is
introduced to control the proportion, which is in hyperlink weight, of semantic
information of the surrounding characters in K , and parameter t=T is
introduced to control the impact of visiting time to weight, then the weight control
model with time parameter is given by:
tkakTKQPW +F+F+= )(*)(1),,,(
where a can be adjusted according to different page sets, and the value of W will
continuously increase in the iterative procedure of computing authority weight, but we
only concern about the relative value between them, not the absolute value. t
reflects the non linear increment of its authority weight with the increment of visiting
time, and other function can be constructed to control the proportion of visiting time
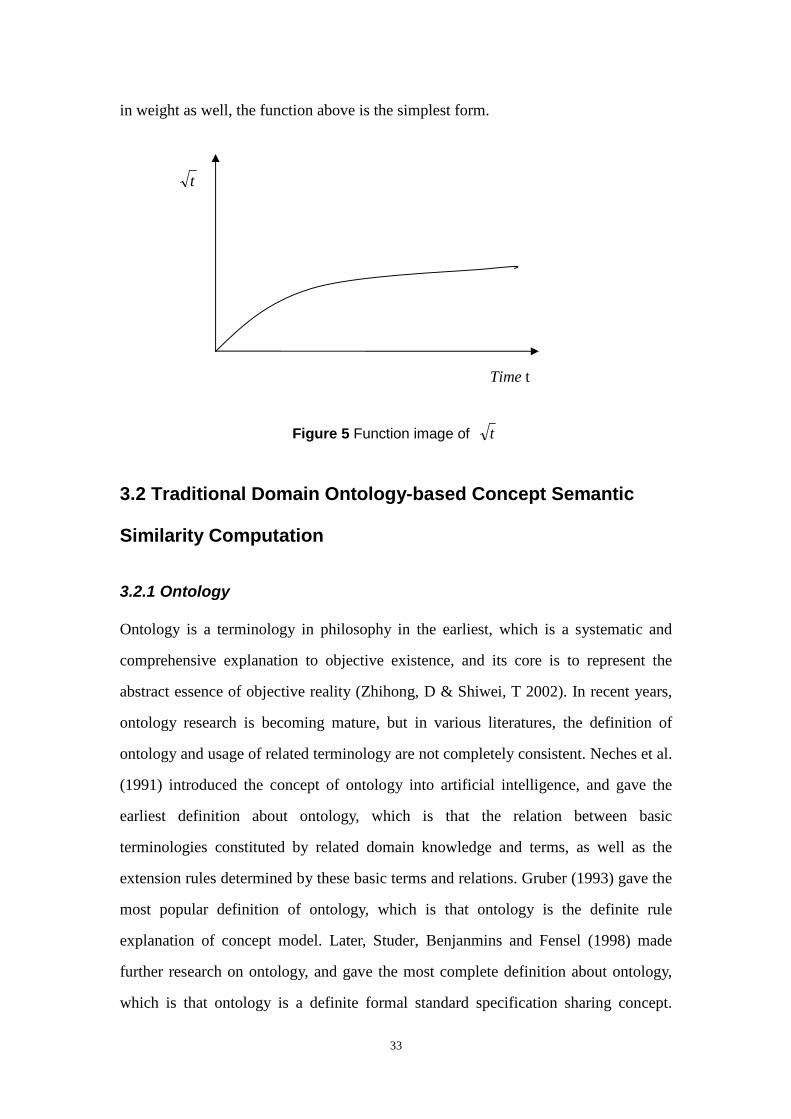
33
in weight as well, the function above is the simplest form.
Figure 5 Function image of t
3.2 Traditional Domain Ontology-based Concept Semantic
Similarity Computation
3.2.1 Ontology
Ontology is a terminology in philosophy in the earliest, which is a systematic and
comprehensive explanation to objective existence, and its core is to represent the
abstract essence of objective reality (Zhihong, D & Shiwei, T 2002). In recent years,
ontology research is becoming mature, but in various literatures, the definition of
ontology and usage of related terminology are not completely consistent. Neches et al.
(1991) introduced the concept of ontology into artificial intelligence, and gave the
earliest definition about ontology, which is that the relation between basic
terminologies constituted by related domain knowledge and terms, as well as the
extension rules determined by these basic terms and relations. Gruber (1993) gave the
most popular definition of ontology, which is that ontology is the definite rule
explanation of concept model. Later, Studer, Benjanmins and Fensel (1998) made
further research on ontology, and gave the most complete definition about ontology,
which is that ontology is a definite formal standard specification sharing concept.
t
tTime

34
There are four level meanings included here, which are concept model, explicit,
formalization and common sharing (BernersLee, T, Hendler, J, Lassila, O 2001).
3.2.2 Three Main Semantic Similarity Computation Models
Concept semantic similarity computation has wide application in the fields of
information retrieval, information recommendation and filtering, data mining and
machine translation, etc, which has become a hot point of current information
technology research (Sujian, L 2002). Currently, to the semantic similarity
computation between concepts, researches are performed mainly from three different
views. Leacock (2005) proposed a distance-based semantic similarity computation
model. This kind of computation model is simple and visual, but it extremely relies on
the ontology hierarchical network established in advance, and the network structure
directly influences semantic similarity computation. Lin (2000) proposed an
information content-based semantic similarity computation model. This kind of
computation model has more persuasion in theoretically, because when computing
concept semantic similarity, the related knowledge of information theory and
probability statistic theory are fully used. But this kind of computation model can only
grossly quantify the semantic similarity between concepts; it can’t distinguish each
concept semantic similarity more detailed. Tversky et al. (2004) proposed an
attribute-based semantic similarity computation model. This kind of model can
simulate people’s regular understanding and discrimination between things in real
world, but this method only considers a unique attribute fact, so to every attribute of
objective things, performing detailed and comprehensive description is required,
which is quite difficult.
3.3 Summary
In this chapter, we firstly analysis the problems of PageRank and HITS algorithm, and
some comparisons between them are made as well. Meanwhile, the ideas of several
improved methods of classical algorithms are given. Then, some basic information

35
about ontology and domain ontology-based concept similarity computation is
introduced, and the further research and analysis will be given in Chapter 5.

36
CHAPTER 4
Methodology
4.1 Research Questions
My main research objective is to improve rank algorithms in order to make them more
concerned about users’ surfer behaviors. To achieve this target and make my research
easier, some research questions are listed as follows:
· What facts will influence the relation between two concept nodes in the
hierarchical network structure in domain ontology?
· A web page maybe related to several topics, how to determine the category it
belongs to. If it is categorized into a certain category, how to make the other
categories it related to being considered as well.
· How to implement categorization to Web pages and keywords?
· Because the amount of Web pages and keywords are huge, do I need to introduce
any mechanism to reduce the unnecessary amount?
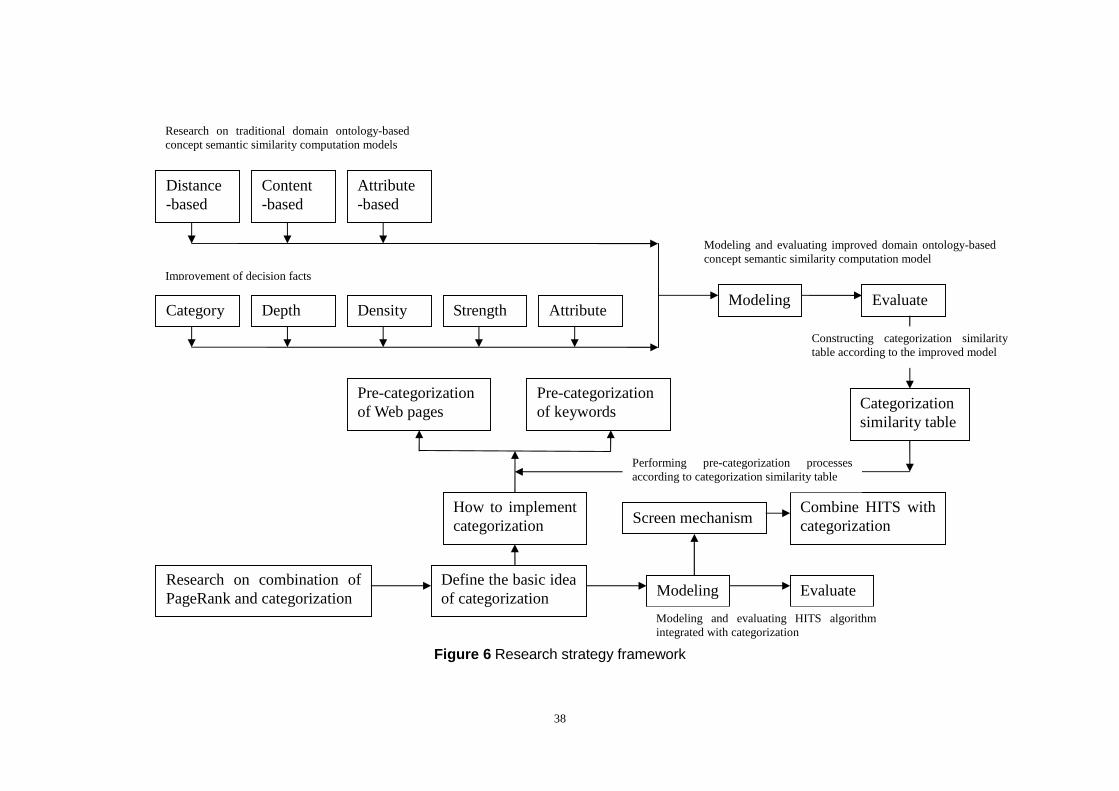
4.2 Research Strategy
The whole process of my research strategy is shown in Figure 6, which can be divided
in to two main steps, the first step is to model an improved domain ontology-based
concept similarity computation model, and the second step is to integrate rank
algorithm with categorization technology.
In the first step, firstly we will discuss the traditional three domain ontology-based

37
concept similarity computation models in order to get a full understanding about their
ideas, computing processes, advantages and disadvantages. Then, we will discuss and
improve the decision facts that have impact on directed edge weight in ontology
hierarchical network. At last, the improved domain ontology-based concept similarity
computation model including five decision facts will be modeled and evaluated.
In the second step, firstly we will discuss an existing categorization-integrated rank
algorithm, which combines PageRank with categorization technology in order to
provide a theoretical support. Secondly, the basic idea of categorization in this paper
is given, which will describe how categorization is implemented and the processes of
pre-categorization based on the improved model constructed in step one. Then, a
screen mechanism is introduced to filter the massive data amount. At last, the
improvement and evaluation of HITS algorithm integrated with categorization will be
provided.
38
Figure 6 Research strategy framework
Distance -based
Content -based
Attribute -based
Depth Category Density Strength Attribute Modeling Evaluate
Research on combination of PageRank and categorization
Define the basic idea of categorization Modeling Evaluate
How to implement categorization
Pre-categorization of Web pages
Pre-categorization of keywords Categorization
similarity table
Screen mechanism Combine HITS with categorization
Research on traditional domain ontology-based concept semantic similarity computation models
Improvement of decision facts
Modeling and evaluating improved domain ontology-based concept semantic similarity computation model
Constructing categorization similarity table according to the improved model
Performing pre-categorization processes according to categorization similarity table
Modeling and evaluating HITS algorithm integrated with categorization

39
4.3 Evaluation Tools
4.3.1 The Ontology Tool
The ontology tool adopted to evaluate the improved concept semantic similarity
computation model in this paper is Protégé 3.4, which is an ontology modeling tool.
Protégé is designed by Stanford University to edit instance and acquire knowledge,
which is currently the most popular ontology development tool. It shields the
shortcomings of many current ontology creation languages, and provides a friendly
GUI interface which is shown in Figure 7, which makes it much easier to edit class,
instance and attribute.
Figure 7 Main interface of Protégé 3.4

40
CHAPTER 5
Improve Concept Semantic Similarity Computation
Model
5.1 Discussion on Traditional Computation Models
5.1.1 Distance-based Semantic Similarity Computation Model
The basic idea of this computation model is to quantify the semantic distance between
concepts by using the geometric distance of two concepts in hierarchical network
(Qun, L & Sujian, L 2002). The easiest computation method is to consider the
distances of all directed edges in network as equal importance, denoted by 1. Thus,
the distance between two concepts is equal to the amount of directed edges
constituting shortest distance in hierarchical network of the node which these two
concepts corresponds to. According to this idea, a simple semantic similarity
computation model can be obtained:
)1(2min)1(2
)2,1(-´--´
=MaxLenth
MaxLenthwwsim
where MaxLenth is the maximum depth of network structure, Min is the amount
of directed edges of the shortest path between concept node 1w and 2w .
However, the above computation model is very rough in computing the semantic
similarity between concepts, which the difference between directed edges in network
structure is not considered. Then, Leacock (2005) performed an improvement to the
computation model based on it, and proposed an improved distance-based semantic
similarity computation model:
)],(,[)],(,[)2,1( 212211 wwAncwNwwAncwNwwDist linkslinks +=
max
)2,1(1log)2,1(
dwwDist
wwsim+
-=

41
where )2,1( wwAnc is the closest common ancestor node of concept nodes 1w and
2w in hierarchical network, )2,1( wwNlinks is the shortest distance of concept nodes
1w and 2w in hierarchical network, and maxd is the maximum depth of network.
5.1.2 Content-based Semantic Similarity Computation Model
The basic principle of content-based semantic similarity computation model is that if
the more information two concepts share, the higher semantic similarity between them;
contrarily, the less information two concepts share, the lower semantic similarity
between them (Xiaofeng, Z, Xinting, T & Yongsheng, Z 2006). In hierarchical
network, every concept can be considered to be the refinement to its ancestor node, so
it can be nearly interpreted as every child node includes the information contents of its
entire ancestor node. Thus, the semantic similarity of two concepts can be measured
by the information contents of their closest common ancestor node.
According to information theory, if the higher frequency a concept appears, the less
information amount it includes; contrarily, the lower frequency a concept appears, the
more information amount it includes. In hierarchical network, the computation
formula for quantifying the information amount of every concept node is:
)](log[)( wPwIC -=
material trainingofamount totalmaterial gin trainin appears concept w that times
)(the
thewP =
where )(wP is the probability that concept w appears in training material, )(wIC
is the information amount that concept w has.
Thus, according to the above quantization formula of concept information, the
semantic similarity computation model between arbitrary two concepts in hierarchical
network can be obtained.
)2()1()]2,1([2
)2,1(wICwICwwAncIC
wwsim+
´=
where )2,1( wwAnc is the closest common ancestor node of concept nodes 1w and
2w in hierarchical network.
5.1.3 Attribute-based Semantic Similarity Computation Model
In real world, the process that people distinguish and associate different things
generally by means of comparing the inherent attributes between things (Qianhong, P

42
& Ju, W 1999). If two things have many same attributes, it indicates that these two
thins are very similar; contrarily, it is opposite. Thus, the basic principle of
attribute-based semantic similarity computation model is to judge the similarity
degree of attribute set which the two concepts corresponding to. Tversky proposed an
attribute-based method for computing concept semantic similarity:
)()()(),( 12212121 wwfwwfwwfwwsim ----Ç= baq
which 21 ww Ç is the attribute set that concepts 1w and 2w commonly posses,
21 ww - is the attribute set that concept 1w possesses but concept 2w doesn’t
possess, 12 ww - is the attribute set that concept 2w possesses but concept 1w
doesn’t possess.
Besides, L. Rips proposed a multi-dimensional attribute-based semantic similarity
computation model: Set concept 1w and 2w respectively has n attributes, and the
attribute value respectively is },...,,{)1( 1,1,11,0 wnww AAAwAttr = ,
},...,,{)2( 2,2,12,0 wnww AAAwAttr = .
å=
-=n
kwkwk AAwwDist
0
22,1, )()2,1(
2)2,1()2,1(
wwDistwwsim
+=a
a
where a is adjustment factor.
5.2 Decision Facts of Semantic Similarity Computation
In a directed no-loop hierarchical network constituted by domain ontology, the
weights of directed edge may be different, that is to say the semantic similarity
between parent node and child node located in the two ends of different directed edge
is different. Thus, it indicates that the influence of weight needs to be considered
when computing the distance length between concepts. According to my research,
there are five main facts influence the weight of directed edge in ontology hierarchical
network:
· The category of directed edge between parent node and child node
· The depth of directed edge constituted by parent node and child node in
hierarchical network
· The density of parent node and child node in hierarchical network

43
· The strength of directed edge constituted by parent node and child node in
hierarchical network
· The attribute of concept node of the two ends of parent node and child node
5.2.1 Directed Edge Category
There are many categories of relations between concepts, which is shown in Table 2:
Table 2 Semantic relations
Seq.
No.
Semantic
relation
Extraction rule
1 ISA If CNP)NP2 SNP,(NP1NP2) be 1( ÎÎÙ® NPS
Then )2,1( NPNPISA
2 AKO If CNP)NP2 (NP1,NP2) be 1( ÎÙ® NPS
Then )2,1( NPNPAKO
3 Have If NP2 have/has 1NPS ®
Then )2,1( NPNPHave
4 Can If VPcan NPS ®
Then ),( VPNPCan
5 Is If ADJ be NPS ®
Then ),( ADJNPIs
6 Part-Of If NP2 of part/parts be[a] 1NPS ®
Then )2,1( NPNPOfPart -
7 Composed
-Of
If
NP1)) of composed be (NP2NP2) of part/parts be[a] 1(( Ú® NPSThen )1,2( NPNPOfComposed -
8 Belong-To If NP1)) tobelong (NP2NP2) include 1(( Ú® NPS
Then )1,2( NPNPToBelong -
9 Time If 0)21( >-TimeTime
Then )1,2( TimetimeBefore or )2,1( TimeTimeAfter
10 Position If NP2 PP be/locate 1NPS ®
Then )2,1( NPNPPPLocation -
11 Others If

44
To)-Belong
Of,-ComposedOf,-PartHave,AKO,(ISA,NP2) VP 1( ØÙ® NPS
Then )2,1( NPNPVPbase
However, in the hierarchical network constituted by domain ontology, only three main
relations are generally considered, which are inheritance relation, entirety-part relation
and synonymous relation, because these three relations have the highest proportion.
The weights that different directed edge categories corresponding to are different. To
synonymous relation, its nodes of two ends represent the same meaning, so the weight
of this edge should be bigger than it of the other two categories. Besides, the directed
edge weight of inheritance relation is generally considered to be bigger than it of
entirety-part relation. Thus, the relations about directed edge weight and their
categories can be obtained:
relation ),(*1 synonymouspctype =
µ),( pcweight relation tan),(*21
ceinheripctype =
relation ),(*31
partentiretypctype -=
where ),( pcweight is the weight of directed edge constituted by child node c and
its parent node p .
5.2.2 Directed Edge Depth
Domain ontology can be considered as hierarchy network graph. There is only one
ingress node in this graph, which is the maximum concept of this domain. The
second-level nodes are the partition of ingress node (first-level node), and the
third-level nodes are the further refinement based on second-level nodes, and so on.
Every level is the concept refinement of the level above. The meanings of concept are
concrete in lower level; contrarily, the meanings of concept are abstract in higher level.
Thus, the weight of directed edge is related to its depth in hierarchical network, so the
relation about directed edge weight and its depth can be obtained:
å=
- =+++µ)(
11)()( 2
1)
21
...2
12
1(),(
pdepth
nnpdepthpdepthpcweight
where )( pdepth is the depth of node p in hierarchical network.

45
5.2.3 Directed Edge Density
The overall density in domain ontology hierarchical network is a fixed value, but the
density in different place is different. If the node density of a certain local area in
hierarchical network is larger, it indicates that the refinement to concept is bigger here,
and the weight of corresponding edge is larger. Thus, the relation about directed edge
weight and its density can be obtained:
))(deg)(deg(*2)(deg)(deg)(deg)(deg
),(GreeinGreeout
creeoutpreeoutcreeinPreeinpcweight
++++
µ
where )(deg preein and )(deg creein are the ingress degree of parent node p and
child node c in hierarchical network, )(deg preeout and )(deg creeout
respectively represents the egress degree of parent node p and child node c in
hierarchical network, and )(deg Greein and )(deg Greeout represent the ingress
degree and egress degree of hierarchical network graph.
5.2.4 Directed Edge Strength
In the hierarchical network constituted by domain ontology, a parent node may have
multiple child nodes. If a child node is more important than the other nodes to this
domain, the weight of directed edge constituted by this child node and its parent node
should be bigger. Thus, if we use the condition proportion to quantify the strength of
directed edge, the following can be obtained:
)),(),,((tan)|()|( pclinkpclinktimporpcPpcP jiji ®>
where ()tan timpor represents the former is important than the latter
)()(
)|(pP
pcPpcP i
i
Ç=Q
and )()|( ii cPpcP =Q (In hierarchical network, the place that child node appears
can be nearly considered as parent node appearing as well.)
)()(
)|(pPcP
pcP ii =\
and )](log[)( wPwIC -=Q (According to the computation model based on
information content.)
|)()(|))(|)(log())|(log(),( iiii cICpICpPcPpcPpcLS -===\
where ),( pcLS i represents the strength of directed edge constituted by child node

46
and parent node.
a+µ\
),(),(
),(pcLS
pcLSpcweight
i
i
where a is adjustment factor.
5.2.5 Concept Node Attribute of the Two Side of Directed Edge
Domain ontology hierarchical network not only makes correct definition to the
concepts and their relations in the domain, but also makes detailed description to the
attribute of every concept. Thus, if the concept that the child node and parent node of
the two side of directed edge corresponds to possesses more same attributes, it
indicates that the relation between parent node and child node is closer, and the
weight of directed edge constituted by them is larger. Thus, the relation about directed
edge weight and its attribute can be obtained:
))()(())()((
),(pAttrcAttrcountpAttrcAttrcount
pcweightÈÇ
µ
where )(cAttr and )( pAttr is respectively the attribute set of concept c and
concept p , )()( pAttrcAttr Ç is the intersection attribute set of concept c and
concept p , )()( pAttrcAttr È is the union attribute set of concept c and concept
p , ()count is the amount of statistic attribute.
5.3 Establishment of Improved Computation Model
In this section, according to the special characteristic of domain ontology, we
establish an improved concept semantic similarity computation model by taking
advantage of the five influence facts about directed edge weight analysing in the
section 5.2. The procedure of establishment is described as follow:
1 The domain ontology completed by domain specialists can be considered as a hierarchical, directed and no-loop graph,
),( LNGG =
),...,,...,,( max21 nnnnN i=
)( ji ccL ®= max)j0 max,0( <<<< i
where N is the set of all the nodes in graph, and each node in represents the set of
concept and its attribute in domain, L is the set of all the directed edges in graph,
and each directed edge represents some kind of relation existing between nodes.

47
2 As mentioned in section 5.2, the unit directed edge weight of hierarchical network
constituted by domain ontology is related to five facts, so, the facts influencing
weight need to be fully considered when qualifying the weight of directed edge.
Thus, the expression of directed edge weight should be:
attributeestrengthddensitycdepthbcategoryapcweight *****),( ++++µ
After substituting the relations between directed edge weight and category, depth,
density, strength and attribute analysing in section 5.2, we can obtain:
))()(())()((
*),(
),(*
))(deg)(deg(*2)(deg)(deg)(deg)(deg
*21
*),(*),()(
1
pAttrcAttrcountpAttrcAttrcount
epcLS
pcLSd
GreeinGreeoutcreeoutpreeoutcreeinPreein
cbpctypeapcweight
i
i
pdepth
nn
ÈÇ
++
++
+++
++= å=
a
where k is adjustment factor, ]1,0(Îk , 1=++++ edcba .
3 Because the length of unit directed edge is inversely proportional to the weight of
directed edge, the computation model of unit directed edge length can be obtained:
hh-=
),(),(
pcweightpcDist
where h is adjustable factor.
4 As the computation formula of unit directed edge length in ontology hierarchical
network is known, so the distance between any two concept nodes in hierarchical
network can be obtained (Here, we still use Leacock computation model to compute
the distance between two concepts in domain ontology):
)],(,[)],(,[)2,1( 212211 wwAncwNwwAncwNwwDist linkslinks +=
åÎ ))2,1(,1(
2111 ))(,())],(,(,[wwAncwpathn
links nparentnDistwwAncwAncwN
where ),( 21 wwAnc is the closest common ancestor node of node 1w and 2w ,
),( 21 wwpath is the set of all the nodes in the shortest path of node 1w and 2w in
hierarchical network.
5 As the distance between any two concepts in ontology hierarchical network is
known, the semantic similarity computation model of any two concepts can be
obtained:
+=
2)2,1()2,1(
wwDistwwsim
48
where q is amplification factor.
5.4 Evaluation of Improved Computation Model
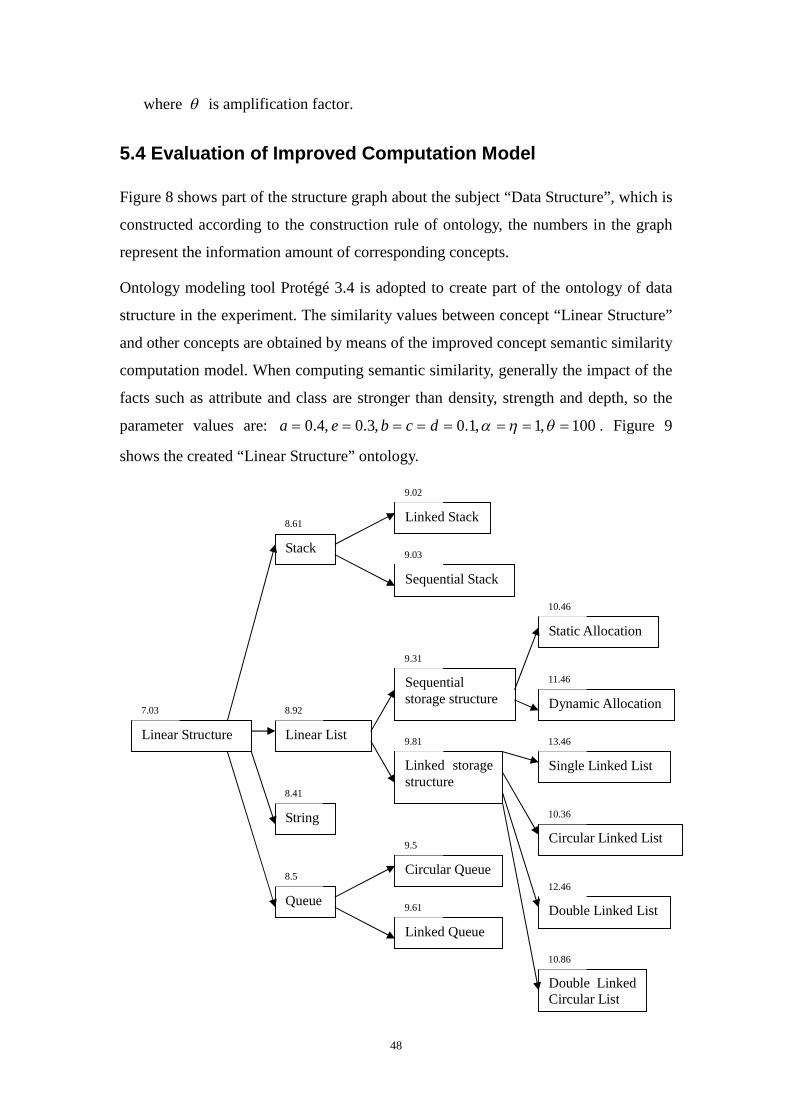
Figure 8 shows part of the structure graph about the subject “Data Structure”, which is
constructed according to the construction rule of ontology, the numbers in the graph
represent the information amount of corresponding concepts.
Ontology modeling tool Protégé 3.4 is adopted to create part of the ontology of data
structure in the experiment. The similarity values between concept “Linear Structure”
and other concepts are obtained by means of the improved concept semantic similarity
computation model. When computing semantic similarity, generally the impact of the
facts such as attribute and class are stronger than density, strength and depth, so the
parameter values are: 100 ,1 ,1.0 ,3.0 ,4.0 ======== qhadcbea . Figure 9
shows the created “Linear Structure” ontology.
Linear Structure Linear List
Stack
Sequential Stack
Linked Stack
Queue
Circular Queue
Linked Queue
Sequential storage structure
Linked storage structure
String
Static Allocation
Dynamic Allocation
Circular Linked List
Single Linked List
Double Linked List
Double Linked Circular List
7.03
9.02
8.92
8.41
8.5
8.61
9.03
9.31
9.81
9.5
9.61
10.46
11.46
13.46
10.36
12.46
10.86
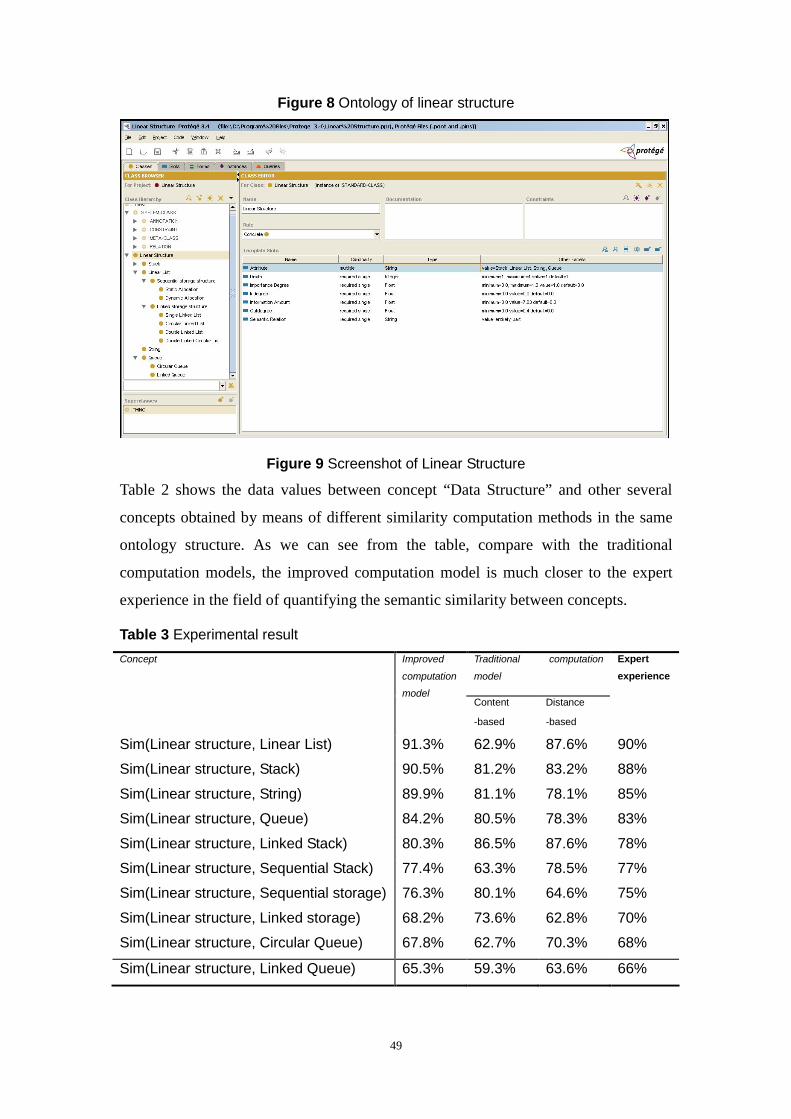
49
Figure 8 Ontology of linear structure
Figure 9 Screenshot of Linear Structure
Table 2 shows the data values between concept “Data Structure” and other several
concepts obtained by means of different similarity computation methods in the same
ontology structure. As we can see from the table, compare with the traditional
computation models, the improved computation model is much closer to the expert
experience in the field of quantifying the semantic similarity between concepts.
Table 3 Experimental result
Traditional computation
model
Concept Improved
computation
model Content
-based
Distance
-based
Expert
experience
Sim(Linear structure, Linear List) 91.3% 62.9% 87.6% 90%
Sim(Linear structure, Stack) 90.5% 81.2% 83.2% 88%
Sim(Linear structure, String) 89.9% 81.1% 78.1% 85%
Sim(Linear structure, Queue) 84.2% 80.5% 78.3% 83%
Sim(Linear structure, Linked Stack) 80.3% 86.5% 87.6% 78%
Sim(Linear structure, Sequential Stack) 77.4% 63.3% 78.5% 77%
Sim(Linear structure, Sequential storage) 76.3% 80.1% 64.6% 75%
Sim(Linear structure, Linked storage) 68.2% 73.6% 62.8% 70%
Sim(Linear structure, Circular Queue) 67.8% 62.7% 70.3% 68%
Sim(Linear structure, Linked Queue) 65.3% 59.3% 63.6% 66%

50
5.5 Summary
In this chapter, we perform analysis and explanation on the three traditional semantic
similarity computation models, and propose an improved domain ontology-based
concept similarity computation model according to the advantages and disadvantages
of these three computation models as well as the specific properties of domain
ontology. In this computation model, we firstly perform effective quantization to the
five facts which have impacts on the directed edge weight of ontology hierarchical
network according to the characteristic of ontology network, then make linear
weighted combination according to the impacts of these five categories of facts on
directed edge weights, so as to quantify the semantic similarity between the concept
nodes in ontology network more comprehensively.
As shown by the experimental result, this improved computation model can reflect the
semantic similarity between concepts with better accuracy, which provides an
effective quantization for the semantic relations between concepts.

51
CHAPTER 6
Improve Rank Algorithm Based on Categorization
Technology
The traditional rank algorithms for search engines are all based on the link structure
analysis of Web page. In traditional PageRank algorithm, the PageRank score
represents the probability that user browses a certain Web page, and the score of HITS
algorithm is based on the Authority and Hub of Web page. These algorithms are all
based on the assumption that the process of user browsing Web pages is absolute
random, but ignore the influence to link direction from the similarity of Web page
content, which makes them not able to fully reflect the difference in importance
degree of this Web page between different users. In this chapter, we design an
improved HITS algorithm based on categorization, which combines rank algorithm
with categorization technology.
6.1 Combination of Categorization Technology and Link
Structure Based Algorithm
In previous research works, some categorization technology-based improved
algorithms are already proposed. For example, CategoryRank Algorithm (Weizhu, C,
Ying, C & Yan, W 2005) is a kind of integrated rank algorithm that combines
PageRank with categorization technology
To any link from u to v , CategoryRank algorithm obtains a weight according to the
category that u and v belong to and the similarity degree between categories, adds
this weight value to )(/)( uCuPR , so as to modify the computation method of
PageRank, and forms single link-based CategoryRank computation. Because u and
v belong to the same or similar categories, but u and w belong to different

52
categories, so the link from u to v is obviously important than it from u to w ,
which represents in the wider width.
To each link referring from u to v , the algorithm will firstly use categorizer, which
regards the content of u and v as the input of categorizer. Assume in the
categorization results, u trends to category 1c more, and v trends to category 2c
more. Here, assume )1( cuP ® and )2( cuP ® respectively represents the
probability that u belongs to category 1c and 2c , then, in CategoryRank
algorithm, the similarity between u and v can be expressed as:
2))2()2(|2()2(|
1)()1()1(
|)1()1(|1(),( Sclc
cvPcuPcvPcuP
cvPcuPcvPcuP
vuP®+®®-®
-®+®®-®
-=
)21()21(
2CCsizeofCCsizeof
SclcÈÇ
=
where 2Sclc is the similarity degree between 1c and 2c , 1C and 2C
respectively represents the eigenvector of category 1c and 2c .
At last, normalization is need to ),( vuP in order to satisfy:
å =i
iuP 1),(
where the relation between u and i is iu ® , which there exists a link referring
from u to i . Make modification to PageRank formula, replace )( iTC with
category-related value ),( ATP i , then the computed CR value by means of
link-based CategoryRank algorithm is:
))(),(...)(),(()1()( 11 nn TPRATPTPRATPddACR *++*+-=
Besides considering the relation between Web pages, meanwhile, the different
appearances of single Web page in different categories need to be considered. For
example, a certain Web page A is possibly not important in category 1c , but very
important in category 2c . Thus, according to different catefories, Web page-based
CategoryRank algorithm will compute out different importance weight value. Assume
a system includes K categories in all, then each Web page will include K category
weight values according to categories. At last, the system will generate K
CategoryRank vectors according to different categories, which each vector is

53
corresponding to a category, and the vector element value is the category weight value
which each Web page belongs to in Web. Assume Web includes N pages in all, then
all the computation results can be expressed by a matrix M with KN * elements,
which icM is the element value of matrix, representing the category weight of Web
page i in category c .
When creating the vector of category c , several processes can be performed to icM .
For example, it can be combined with IDFTF * value which is used to compute
relativity, or PageRank value. Here, the algorithm directly combines icM into the
link-based CategoryRank computation formula mentioned above. We can consider
that when changing Category values by introducing category information into formula,
these values will eventually be transferred to rank score, so as to achieve the target
that introduce page categorization technology into ranking. Before modify the
link-based CategoryRank, the algorithm will firstly normalize icM in order to
satisfy:
å =i
ic NM
where i is Web page ID, c is the category ID, N is the total Web page amount of
in whole Web.
At last, according to each category c , a single CategoryRank vector need to be
created. Thus, the formula can be modified as :
))(*),(...)(*),(()1(),( 11 nnAC TPRATPTPRATPdMdcACR +++-=
The formula above considers not only the category similarity of links, but also the
category difference of Web pages. Finally, the category information of each Web page
is integrated into Category algorithm.
CategoryRank algorithm is based on the category information between two arbitrary
Web pages, and performs analysis and computation to link graph. Compared with
PageRank algorithm, this algorithm can simulate users’ habit in browsing Web pages
more accurate. Meanwhile, according to each Web page in Web, the algorithm
computes their category attributes, which directly reflects the importance degree of
this page to different users.

54
Compared with traditional RankRank algorithm, CategoryRank algorithm has added
category parameters ),( 1 ATP and ACM computation.
6.2 Basic Idea of Categorization
6.2.1 Implementation of Categorization
In order to implement categorization, we proposed two assumptions:
1 Every Web page is categorize-able, and can be marked with a main category, denoted by C.
2 There is relation at different degree between every category, expressed by category
similarity degree S .
To every Web page, there is always a related content topic, which is subordinated to a
certain category of knowledge, or has a certain category of feature. These categories
can be also subdivided into more professional and specific subcategories. The
category division is according to the content topic of Web page, not the properties. For
example, the homepage of Google Website can be divided to the search engine
subclass of network technology; a news class can be divided to the related class of this
news topic.
To the same Web page, its topic may be related to category A , as well as related to
category B and category C at different degree. This relativity can be divided into:
· Directly topic-related
The content of a Web page may also include several categories of topic, so there is
a directly topic-related relation between this Web page and related topics. For
example, the homepage of msn includes many different aspects of class, so this
Web page is directly related to these topics. The direct relativity between a Web
page and each topic can be expressed by vector
group )1,...,,0...}( , , ,{ ££ cbacbaRd .
· Indirectly topic-related
There are relations existing between categories. If Web page W is determined to
be related to category A , and the relativity between category A and category B is
very high, then W can be considered to have indirect topic relativity to
category B as well. Its relativity to B is determined jointly by both the relativity
between category A and category B and the relativity between Web page and

55
category A . The indirect relativity between a Web page and each topic can be
expressed by vector group ...} , , ,{ cbaRid .
The vector sum of direct and indirect topic category of Web page topic is the topic
category vector of Web page:
...} c, b, ,{R...} c, b, ,{R...} c, b,, { id aaaR +=
6.2.2 Pre-categorization Processes
6.2.2.1 Pre-categorization of Web Pages
When search engines store data, they compute the category of Web pages, and save
the category information of Web pages. This process is called the pre-categorization
of Web pages.
Firstly, determine the main category of a Web page, which is to extract Web page
topic according to the Web page contents, and compute the direct category vector of
Web page. Then, input the direct category vector, and compute the indirect category
vector according to category similarity table. At last, combine the direct category
vector with indirect category vector, and obtain the topic category vector of Web page.
The category similarity table is based on the inherent attribute of knowledge
categories. Its establishment can follow the domain ontology-based semantic
similarity computation model established in Chapter 5. The subcategories in the same
main category have higher similarity, and the similarity between different categories is
relatively lower.
6.2.2.2 Pre-categorization of Keywords
The process corresponding to the pre-categorization of Web pages is the
pre-categorization of keywords. When user input a keyword and retrieval Web pages
according to this keyword, according to the categories that the meaning of this
keyword belongs to, the categories that the search Web page belongs to will be
screened. Then, make screen to the Web pages according to chosen category. This
kind of two-level screen process composes the pre-processing model that implements
categorization technology.
The pre-categorization model of keywords is same as it of Web pages. Firstly, obtain
the main category of keyword according to keyword categorizer. Then, compute the

56
indirect topic category according to category similarity table. At last, obtain the
weight value of keyword in all category by adding direct and indirect topic categories.
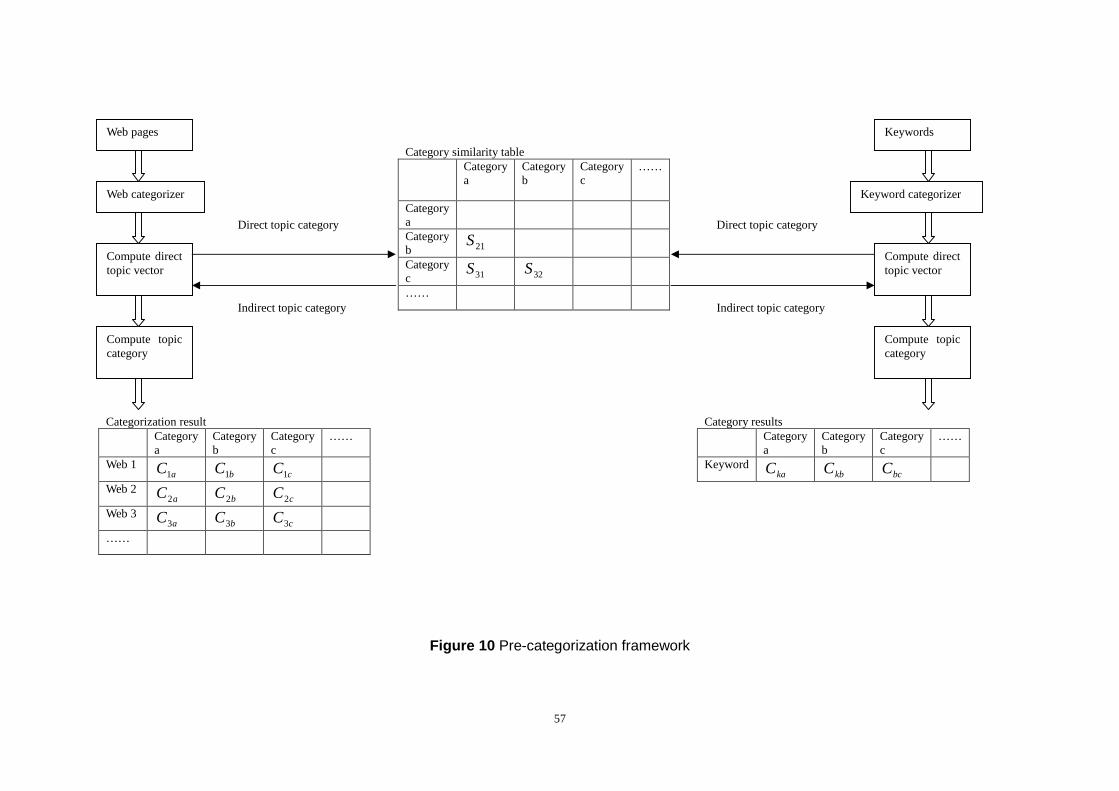
57
Figure 10 Pre-categorization framework
Category similarity table Category
a Category b
Category c
……
Category a
Category b 21S
Category c 31S 32S
……
Web pages
Web categorizer
Compute direct topic vector
Compute topic category
Categorization result Category
a Category b
Category c
……
Web 1 aC1 bC1 cC1
Web 2 aC2 bC2 cC2
Web 3 aC3 bC3 cC3
……
Category results Category
a Category b
Category c
……
Keyword kaC kbC bcC
Keywords
Keyword categorizer
Compute direct topic vector
Compute topic category
Direct topic category Direct topic category
Indirect topic category Indirect topic category

58
6.3 Modeling
6.3.1 Category Selective Mechanism
Because the amount of Web pages is huge and increasing explosively, the
pre-processing for searching process is particularly important. If the selection for
searching results can reduce the scope before searching all Web pages, it is helpful to
improve retrieval efficiency.
The process of selective mechanism is described as follow: Select the keyword
similarity coefficient 1k , category similarity coefficient 2k )10( 21 <<< kk . When
users retrieval keyword, search engines firstly select the categories with the similarity
between 1k to 1 according to the category vector of retrieval keyword. Then, search
engines select the Web pages with the category similarity between 2k to 1
according to the category vector of Web pages.
Though two-level categorization selective mechanism, after compare searching scope
with the category similarity of Web page according to keywords, the Web pages with
great difference in category are discarded. Because users are hardly concerned about
the information with low rank when browsing the result returned by search engines,
the pre-processed Web pages will not influence the searching performance in users’
view. And the amount of Web pages is greatly reduced, so the overhead of iterative
operation is reduced as well when computing rank
The selection of 1k : When the value of 1k tends to 1, the similarity of keyword
category is the highest, and only the direct topic category should be chosen to make
Web page selection. When the value of 1k tends to 0, it is equal to not make category
selection.
The selection of 2k : When the value of 2k tends to 1, the similarity between Web
page category and keyword category is required to be the highest, and only the Web
pages with the same category are retrieval. Thus, the coverage rate of retrieval Web

59
page is relatively low, and it is easy to cause missing important information. When the
value of 2k tends to 0 , the similarity between Web page category and keyword
category is required to be the lowest, all the Web pages are retrieval, and degenerate
to a selective mechanism without pre-categorization.
6.3.2 Integrating HITS Algorithm with Categorization
The basic principle of Hits algorithm is that how many links that exterior refers to a
Web page represents the authority degree that this Web page has, which can be
measured by authority value a ; how many links that a Web page refers to exterior
represents how much information that this Web page can provide as an information
center, which is the hub degree of this Web page, measured by hub value h .
The relation between the authority value and hub value of Web page is shown in
Figure 10.
Figure 11 Relation between authority value and hub value
)()()()( 321 uhuhuhva ++= )()()()( 321 vavavauh ++=
By several iterative computations according to the link structure of Web page, the
authority value and hub value of Web page can be obtained.
Consider the relating degree between the links of Web page and topic categories,
which the links with the target belonging to same or similar topic category are
considered to be more important.
Let the differential sum of Web pages ju and v on each category vector as the
difference degree of the two Web page categories.
Compute the difference degree between the category attribute of all the Web pages
·1u
·2u
·1u
v·
1v·
2v·
3v·
·u

60
ju , which referring to Authority Web page v , with v , expressed by juD
å=
-=
-++-+-+-=n
ivvu
vvuvvuvvuvvuu
iiji
nnjnjjjj
CCC
CCCCCCCCCCCCD
1
/||
/||.../||/||/||333222111
in the above formula, n is the total category amount, ||iji vu CC - is the difference
degree between Web pages ju , which referring to Authority Web page v , and Web
page v on category component i . iiji vvu CCC /|| - is the percentage of difference
degree. å=
-n
ivvu iiji
CCC1
/|| is the summation of difference degree ratio on each
category component, so as to obtain the difference degree on all categories.
Compute the difference degree between the category attribute of all the Web pages
jv , which referred by Hub Web page u , with u , expressed by jvD
å=
-=
-++-+-+-=n
iuuv
uuvuuvuuvuuvv
iiji
nnjnjjjj
CCC
CCCCCCCCCCCCD
1
/||
/||.../||/||/||333222111
in the above formula, n is the total category amount, ||njn uv CC - is the difference
degree between Web pages jv , which referred by Hub Web page u , and Web page
u on category component i . nnjn uuv CCC /|| - is the percentage of difference
degree. å=
-n
iuuv iiji
CCC1
/|| is the summation of difference degree ratio on each
category component, so as to obtain the difference degree on all categories.
Where jiuC and
jivC is respectively the vector attribute of Web page ju and jv
on category i , ivC and
iuC is respectively the vector attribute of Web page v and
u on category i . The values of jiuC ,
jivC , ivC ,
iuC are generated in the
pre-categorization process of Web pages.
After normalizations:

61
å =j
u jD 1
å =j
v jD 1
According to the category difference degrees, compute the category similarities of
Web pages referred by links:
jj uu DC -=1
jj vv DC -=1
According to the formula above, modify the formulas of Authority value and Hub
value in HITS algorithm to:
å=++++=
juj
unuuu
j
n
Cuh
CuhCuhCuhCuhva
)(
*)(...*)(*)(*)()(321 321
å=++++=
jvj
vnvvv
j
n
Cva
CvaCvaCvaCvavh
)(
*)(...*)(*)(*)()(321 321
6.4 Evaluation of Integrated Algorithm
The formula above integrates the category information of each Web page into HITS
algorithm, and the category relativity of link is considered while computing the link
structure of Web pages. Through this kind of method, the shortcoming that each link
between Web pages is treated equally in traditional HITS algorithm is overcome.
Combine the category information of Web pages themselves with link information,
and let it as the modified parameter of computation, thus, the accuracy of HITS
algorithm is improved.
In the aspect of computation complex degree, the application of categorization
information modifies the basic set of HITS algorithm by means of the
pre-categorization mechanism. Because HITS algorithm itself needs perform iterative
computation, the use of pre-categorization can greatly reduce computation overhead
by reducing Web page amounts, so as to improve the performance of HITS algorithm.

62
Meanwhile, the computation overhead of categorization process is )(nO , n is the
total category amount. Because the magnitude of n is always smaller than it of Web
page amount, the improved categorization-based HITS algorithm is better than HITS
algorithm on the complex degree of algorithms.
6.4 Summary
In this chapter, we perform improvement to HITS algorithm from two aspects, which
are the Web page pre-processing and analyzing the link structure of Web page, and
provide completive and detailed mathematics expression. After completive algorithm
expression and application, it shows that according to category information, more
accurate rank results can be obtained. The shortcoming caused by analysis and
computation only based on the link structure of Web page in HITS algorithm is
overcome, and the advantage that let Web pages in similar or same category have
higher relativity is obtained, so as to make rank algorithm simulate user habits when
browsing page in real time more accurate.

63
CHAPTER 7
Conclusion
In this paper, through the research and analysis on classical link structure-based
algorithms and their related improvements, we propose an improved HITS algorithm
based on categorization technology.
7.1 Summary of contributions
· Improve domain ontology-based concept similarity computation based on five
decision factors.
We perform effective quantization to the five facts which have impacts on the
directed edge weight of ontology hierarchical network according to the characteristic
of ontology network, then make linear weighted combination according to the impacts
of these five categories of facts on directed edge weights, so as to quantify the
semantic similarity between the concept nodes in ontology network more
comprehensively.
· Improve HITS algorithm based on categorization technology.
We integrate the category information of each Web page into HITS algorithm, and the
category relativity of links is considered when computing the link structure of Web
pages. Though this method, the shortcoming of traditional HITS algorithm is
overcome, which is each link between Web pages is treated equally. We combine the
category information of Web pages themselves with link information, and let it as the
corrected parameter of computation, so as to enhance the accuracy of HITS algorithm.

64
Besides, through the pre-categorization mechanism of category, the usage of
categorization information modifies the basic set of HITS algorithm. Because HITS
algorithm itself need perform iterative computation, the usage of pre-categorization
can greatly reduce computation overhead, and improve the performance of HITS
algorithm.
7.2 Future work
In this paper, we mainly discuss the theoretical researches and improvements of rank
algorithms for search engines, link structure-based algorithm is still the most common
rank technology being used now, which is relatively mature in the application of
commercial search engines.
With the passage of time, the personalized user-oriented search engine will certainly
take the place of the mainstream search engine using currently. However, the
personalized search engine need perform a long-period study in the aspects of
analyzing users’ habit in using search engines, the interesting topics, as well as some
other use characteristics, including the habits of choosing keywords, choosing results
from the returning set of query, the characteristics of query content and so on, so as to
become a personalized search engine accord to use habit which is a special
customization for users. In this paper, we only make limited exploration in the field of
user habit, which is also a general character, and the analysis and improved model
aiming at single user is not involved. Thus, the simulation of user behaviors is
relatively rough. In the field of researching personalized search engines, we need
obtain large amount of feedbacks and statistics data of users in a long period of time,
which can be accumulated and carried out in the further work.

65
References
Berners Lee, T, Hendler, J, Lassila, O 2001, ‘The semantic web’, Scientific American,
284(5)34-43.
Bharat, MK & Henzinger, R 1998, ‘Improved Algorithm for Topic Distillation in a
Hyperlinked Environment’, In Proceeding of {SIGIR}-98, 21st {ACM} International
Conference on Research and Development in Information Retrieval.
Brin, S & Page, L 1998, ‘The anatomy of a large-scale hypertexual web search
engine’, In Proceeding of the WWW7 Conference, page 107-117.
Broder, A, Kumar, R, & Maghoul, F 2000, ‘Graph structure in the web: experiments
and models.’ In Proceeding of the Ninth International World-Wide Web Conferecne.
Itsky AB & Hirst, G 2004, ‘Evaluating word net-based measures of lexical semantic
relatedness’, Computational Linguistics, 1(1);1-49.
Chakrabarti, S, Dom, B & Gibson, D 1999, ‘Mining the Link Stucture of the World
Wide Web’, IEEE Computer, 32(8).
Chakrabarti, S, Dom, B & Raghavan, P 1998, ‘Automatic resource compilation by
analyzing hyperlink structure and associated text’, In Proceeding of the Seventh
International World-Wide Web Conference.
Chakrabarti, S, van den Berg, M & Dom, B 1999, ‘Focused crawling: A new
approach to topic-specific web resource discovery’, In Proceedings of the Eighth
International World-Wide Web Conference.

66
Dean, J & Henzinger, RM 1999, ‘Finding related pages on the Web’, In Proceeding of
the WWW8 Conference, page 389-401.
Gan, KW & Wong, PW 2000, ‘Annotation information structures in Chinese texts
using how net’, Hong Kong: Second Chinese Language Processing Work shop, 85-92.
Gruber, T 1993, ‘Ontolingua: A translation approach to portable ontology
specification’, Knowledge Acquisition 5(2), pp.199-200.
Haveliwala, HT 1999, ‘Efficient computing of PageRank’, Stanford Database Group
Technical Report.
Haveliwala HT 2002, ‘Topic-sensitive PageRank’, Proceedings of the Eleventh
International World Wide Web Conference.
Kleinberg, J 1999, ‘Authoritative sources in a hyperlinked environment’, Jouranl of
the ACM, 46(5):604-632.
Lawrence, S & Lee Guiles, C 1998, ‘Context and page Analysis for Improved Web
Search.’, IEEE Internet Computing, page38-46.
Ling, Z & Fanyuan, M 2004, ‘Accelerated evaluation algorithm: a new method to
improve Web structure mining quality’, Computer Research and Development,
41(1):98-103.
Mendelzon, OA & Rafiei, D 2000, ‘What do the neighbors think? Computing web
page reputations’, IEEE Data Engineering Bulletin, Page 9-16.
Ming, L, Jianyong, W & Baojue, C 2001, ‘Improved Relevance Ranking in
WebGather’, J. Cimput. Sci. & Technol. Vol.16 No.5.
Motwani, R & Raghavan, P 1995, ‘Randomized Alogrithms’, Cambridge University
Press.
Neches, R, Fikes, R, Finin, T, Gruber, T, Patil, R, Senator, T & Swartout, WR 1991,
‘Enabling technology for knowledge sharing’, AI Magazine 12(3), pp.36-56
Page, L, Brin, S & Motwani, R 1998, ‘The PageRank citation ranking: Bringing order

67
to the Web’ Technical report, Computer Science Department, Stanford University.
Qianhong, P & Ju, W 1999, ‘Attribute theory-based text similarity computation’,
Computer Journal, 22(6):651-655.
Qun, L & Sujian, L 2002, ‘CNKI-based word semantic similarity computation’,
Computer Linguistics and Chinese Information Processing, 2002(7):59-76
Steichen, O & Daniel-Le, C 2005, ‘Bozec. Computation of semantic similarity within
an ontology of breast pathology to assist inter-observer consensus’, Computers in
Biology and Medicine, (4):l-21.
Studer, R, Benjanmins, VR & Fensel, D 1998, ‘Knowledge engineering: principles
and methods’, Data and knowledge engineering 25, pp.161-197.
Sujian, L 2002, ‘Research on semantic computation-based sentence similarity’,
Computer Engineering and Application, 38(7):75-76.
Weizhu, C, Ying, C & Yan, W 2005, ‘Categorization technology-based rank
algorithm for search engine – Category Rank’, Computer Application, 2005(5).
Xiaofeng, Z, Xinting, T & Yongsheng, Z 2006, ‘Ontology technology-based Internet
intelligent search research’, Computer Engineering and Design, 27(7):1194-1197.
Xuelong, W, Xuemei Z & Xiangwei L 2006, ‘Application and improvement of time
parameter in Hits algorithm’, Modern Computer.
Zhihong, D & Shiwei, T 2002, ‘Ontology research review’, Beijing University
Journal (Natual Science Edition), (5):730-738

68
APPENDIX A
Semantic Relations
In table 2, S represents sentence, NP represents noun phrase, SNP represents
individual noun phrase, CNP represents category noun phrase, VP represents verb
phrase, VPbase represents original verb phrase, and PP represents prepositional
phrase. All the verb forms in rules include various kinds of deformations of their
verbs.
Seq.
No.
Semantic
relation
Extraction rule
1 ISA If CNP)NP2 SNP,(NP1NP2) be 1( ÎÎÙ® NPS
Then )2,1( NPNPISA
2 AKO If CNP)NP2 (NP1,NP2) be 1( ÎÙ® NPS
Then )2,1( NPNPAKO
3 Have If NP2 have/has 1NPS ®
Then )2,1( NPNPHave
4 Can If VPcan NPS ®
Then ),( VPNPCan
5 Is If ADJ be NPS ®
Then ),( ADJNPIs
6 Part-Of If NP2 of part/parts be[a] 1NPS ®

69
Then )2,1( NPNPOfPart -
7 Composed
-Of
If
NP1)) of composed be (NP2NP2) of part/parts be[a] 1(( Ú® NPS
Then )1,2( NPNPOfComposed -
8 Belong-To If NP1)) tobelong (NP2NP2) include 1(( Ú® NPS
Then )1,2( NPNPToBelong -
9 Time If 0)21( >-TimeTime
Then )1,2( TimetimeBefore or )2,1( TimeTimeAfter
10 Position If NP2 PP be/locate 1NPS ®
Then )2,1( NPNPPPLocation -
11 Others If
To)-Belong
Of,-ComposedOf,-PartHave,AKO,(ISA,NP2) VP 1( ØÙ® NPS
Then )2,1( NPNPVPbase
Explanations:
Rule 1: If sentence S can be expressed in form of NP2 be 1NP , and 1NP is an
individual noun phrase, NP2 is a category noun phrase, then the semantic relation can
be extracted as )2,1( NPNPISA .
Rule 2: If sentence S can be expressed in form of NP2 be 2NP , and 1NP is a
category noun phrase, as well as 2NP , then the semantic relation can be extracted
as )2,1( NPNPAKO .
Rule 3: If sentence S can be expressed in form of NP2 have/has 1NP , then the
semantic relation can be extracted as )2,1( NPNPHave .
Rule 4: If sentence S can be expressed in form of VPcan NP , then the semantic
relation can be extracted as ),( VPNPCan .

70
Rule 5: If sentence S can be expressed in form of ADJ be NP , then the semantic
relation can be extracted as ),( ADJNPIs .
Rule 6: If sentence S can be expressed in form of NP2 of part/parts [a] be 1NP , then
the semantic relation can be extracted as )2,1( NPNPOfPart - .
Rule 7: If sentence S can be expressed in form of
NP2 of part/parts be[a] 1NP or NP1 of composed be 2NP , then the semantic relation
can be extracted as )1,2( NPNPOfComposed - .
Rule 8: If sentence S can be expressed in form of
NP2 include 1NP or NP1 tobelong 2NP , then the semantic relation can be extracted
as )1,2( NPNPToBelong - .
Rule 9: If sentence S can be expressed in form of 0Time2-Time1 > , then the
semantic relation can be extracted as )1,2( TimetimeBefore or )2,1( TimeTimeAfter .
Rule 10: If sentence S can be expressed in form of NP2 PP be/locate NP1 , then the
semantic relation can be extracted as )2,1( NPNPPPLocation - .
Rule 11: If sentence S can be expressed in form of NP2 VP NP1 , and
not ToBelongOfCompsedOfPartHaveAKOISa --- ,,,,, , then the semantic
relation can be extracted as )2,1( NPNPVPbase .
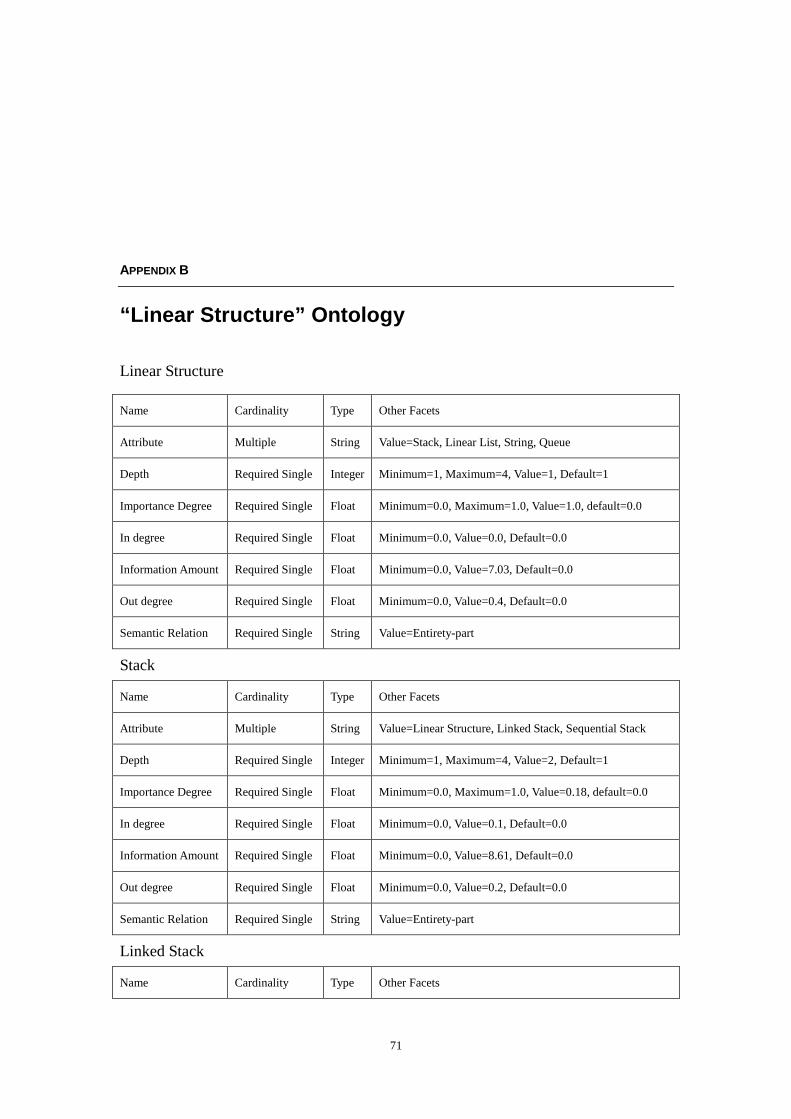
71
APPENDIX B
“Linear Structure” Ontology
Linear Structure
Name Cardinality Type Other Facets
Attribute Multiple String Value=Stack, Linear List, String, Queue
Depth Required Single Integer Minimum=1, Maximum=4, Value=1, Default=1
Importance Degree Required Single Float Minimum=0.0, Maximum=1.0, Value=1.0, default=0.0
In degree Required Single Float Minimum=0.0, Value=0.0, Default=0.0
Information Amount Required Single Float Minimum=0.0, Value=7.03, Default=0.0
Out degree Required Single Float Minimum=0.0, Value=0.4, Default=0.0
Semantic Relation Required Single String Value=Entirety-part
Stack
Name Cardinality Type Other Facets
Attribute Multiple String Value=Linear Structure, Linked Stack, Sequential Stack
Depth Required Single Integer Minimum=1, Maximum=4, Value=2, Default=1
Importance Degree Required Single Float Minimum=0.0, Maximum=1.0, Value=0.18, default=0.0
In degree Required Single Float Minimum=0.0, Value=0.1, Default=0.0
Information Amount Required Single Float Minimum=0.0, Value=8.61, Default=0.0
Out degree Required Single Float Minimum=0.0, Value=0.2, Default=0.0
Semantic Relation Required Single String Value=Entirety-part
Linked Stack
Name Cardinality Type Other Facets
72
Attribute Multiple String Value=Stack
Depth Required Single Integer Minimum=1, Maximum=4, Value=3, Default=1
Importance Degree Required Single Float Minimum=0.0, Maximum=1.0, Value=0.12, default=0.0
In degree Required Single Float Minimum=0.0, Value=0.1, Default=0.0
Information Amount Required Single Float Minimum=0.0, Value=9.02, Default=0.0
Out degree Required Single Float Minimum=0.0, Value=0.0, Default=0.0
Semantic Relation Required Single String Value=Entirety-part
Sequential Stack
Name Cardinality Type Other Facets
Attribute Multiple String Value=Stack
Depth Required Single Integer Minimum=1, Maximum=4, Value=3, Default=1
Importance Degree Required Single Float Minimum=0.0, Maximum=1.0, Value=0.12, default=0.0
In degree Required Single Float Minimum=0.0, Value=0.1, Default=0.0
Information Amount Required Single Float Minimum=0.0, Value=9.03, Default=0.0
Out degree Required Single Float Minimum=0.0, Value=0.0, Default=0.0
Semantic Relation Required Single String Value=Entirety-part
Linear List
Name Cardinality Type Other Facets
Attribute Multiple String Value=Linear Structure, Sequential storage structure, Linked
storage structure
Depth Required Single Integer Minimum=1, Maximum=4, Value=2, Default=1
Importance Degree Required Single Float Minimum=0.0, Maximum=1.0, Value=0.53, default=0.0
In degree Required Single Float Minimum=0.0, Value=0.1, Default=0.0
Information Amount Required Single Float Minimum=0.0, Value=8.92, Default=0.0
Out degree Required Single Float Minimum=0.0, Value=0.2, Default=0.0
Semantic Relation Required Single String Value=Entirety-part
Sequential storage structure
Name Cardinality Type Other Facets
Attribute Multiple String Value=Linear List, Static Allocation, Dynamic Allocation
73
Depth Required Single Integer Minimum=1, Maximum=4, Value=3, Default=1
Importance Degree Required Single Float Minimum=0.0, Maximum=1.0, Value=0.24, default=0.0
In degree Required Single Float Minimum=0.0, Value=0.1, Default=0.0
Information Amount Required Single Float Minimum=0.0, Value=9.31, Default=0.0
Out degree Required Single Float Minimum=0.0, Value=0.2, Default=0.0
Semantic Relation Required Single String Value=Entirety-part
Static Allocation
Name Cardinality Type Other Facets
Attribute Multiple String Value=Sequential storage structure
Depth Required Single Integer Minimum=1, Maximum=4, Value=4, Default=1
Importance Degree Required Single Float Minimum=0.0, Maximum=1.0, Value=0.18, default=0.0
In degree Required Single Float Minimum=0.0, Value=0.1, Default=0.0
Information Amount Required Single Float Minimum=0.0, Value=10.46, Default=0.0
Out degree Required Single Float Minimum=0.0, Value=0.0, Default=0.0
Semantic Relation Required Single String Value=Entirety-part
Dynamic Allocation
Name Cardinality Type Other Facets
Attribute Multiple String Value=Sequential storage structure
Depth Required Single Integer Minimum=1, Maximum=4, Value=4, Default=1
Importance Degree Required Single Float Minimum=0.0, Maximum=1.0, Value=0.18, default=0.0
In degree Required Single Float Minimum=0.0, Value=0.1, Default=0.0
Information Amount Required Single Float Minimum=0.0, Value=11.46, Default=0.0
Out degree Required Single Float Minimum=0.0, Value=0.0, Default=0.0
Semantic Relation Required Single String Value=Entirety-part
Linked storage structure
Name Cardinality Type Other Facets
Attribute Multiple String Value=Linear list, Single linked list, Circular linked list,
Double linked list, Double linked circular list
Depth Required Single Integer Minimum=1, Maximum=4, Value=3, Default=1
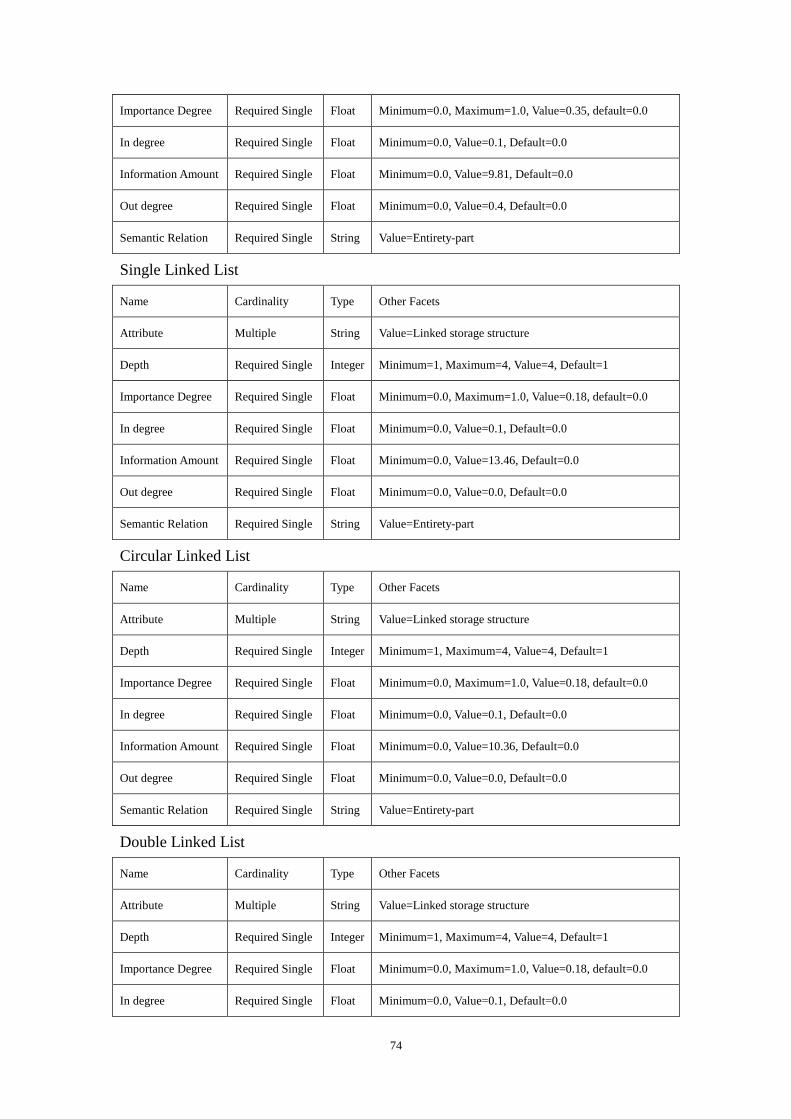
74
Importance Degree Required Single Float Minimum=0.0, Maximum=1.0, Value=0.35, default=0.0
In degree Required Single Float Minimum=0.0, Value=0.1, Default=0.0
Information Amount Required Single Float Minimum=0.0, Value=9.81, Default=0.0
Out degree Required Single Float Minimum=0.0, Value=0.4, Default=0.0
Semantic Relation Required Single String Value=Entirety-part
Single Linked List
Name Cardinality Type Other Facets
Attribute Multiple String Value=Linked storage structure
Depth Required Single Integer Minimum=1, Maximum=4, Value=4, Default=1
Importance Degree Required Single Float Minimum=0.0, Maximum=1.0, Value=0.18, default=0.0
In degree Required Single Float Minimum=0.0, Value=0.1, Default=0.0
Information Amount Required Single Float Minimum=0.0, Value=13.46, Default=0.0
Out degree Required Single Float Minimum=0.0, Value=0.0, Default=0.0
Semantic Relation Required Single String Value=Entirety-part
Circular Linked List
Name Cardinality Type Other Facets
Attribute Multiple String Value=Linked storage structure
Depth Required Single Integer Minimum=1, Maximum=4, Value=4, Default=1
Importance Degree Required Single Float Minimum=0.0, Maximum=1.0, Value=0.18, default=0.0
In degree Required Single Float Minimum=0.0, Value=0.1, Default=0.0
Information Amount Required Single Float Minimum=0.0, Value=10.36, Default=0.0
Out degree Required Single Float Minimum=0.0, Value=0.0, Default=0.0
Semantic Relation Required Single String Value=Entirety-part
Double Linked List
Name Cardinality Type Other Facets
Attribute Multiple String Value=Linked storage structure
Depth Required Single Integer Minimum=1, Maximum=4, Value=4, Default=1
Importance Degree Required Single Float Minimum=0.0, Maximum=1.0, Value=0.18, default=0.0
In degree Required Single Float Minimum=0.0, Value=0.1, Default=0.0
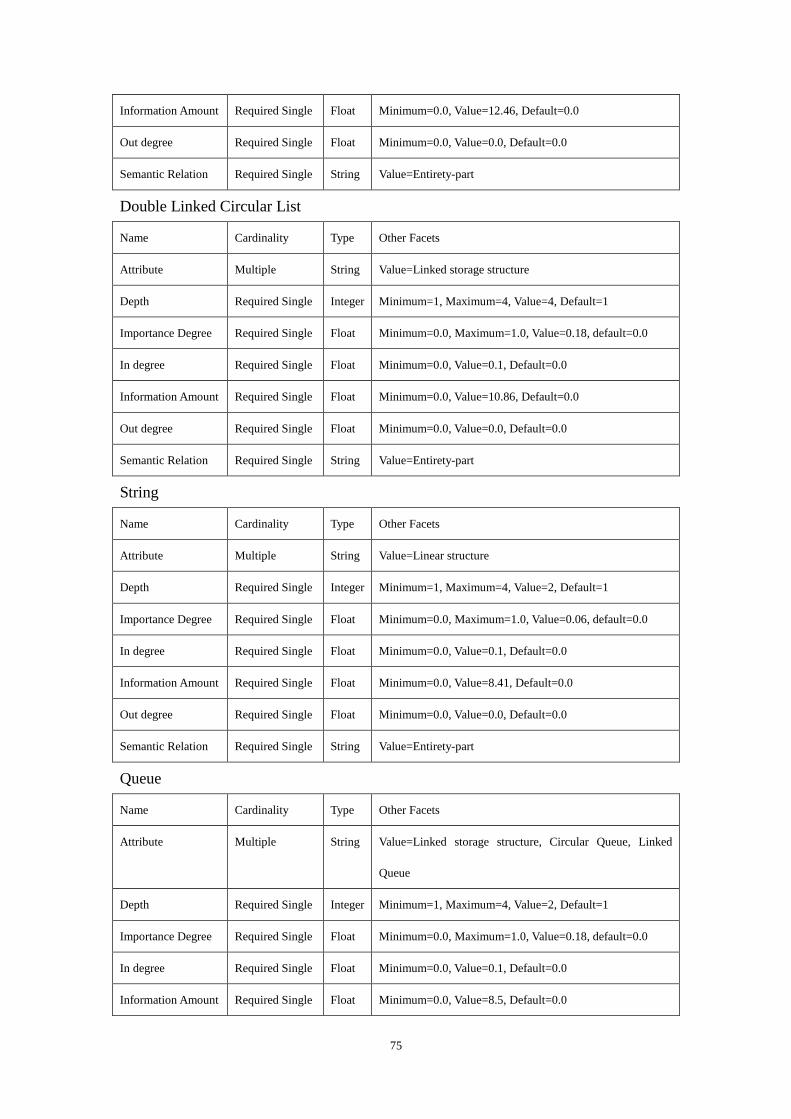
75
Information Amount Required Single Float Minimum=0.0, Value=12.46, Default=0.0
Out degree Required Single Float Minimum=0.0, Value=0.0, Default=0.0
Semantic Relation Required Single String Value=Entirety-part
Double Linked Circular List
Name Cardinality Type Other Facets
Attribute Multiple String Value=Linked storage structure
Depth Required Single Integer Minimum=1, Maximum=4, Value=4, Default=1
Importance Degree Required Single Float Minimum=0.0, Maximum=1.0, Value=0.18, default=0.0
In degree Required Single Float Minimum=0.0, Value=0.1, Default=0.0
Information Amount Required Single Float Minimum=0.0, Value=10.86, Default=0.0
Out degree Required Single Float Minimum=0.0, Value=0.0, Default=0.0
Semantic Relation Required Single String Value=Entirety-part
String
Name Cardinality Type Other Facets
Attribute Multiple String Value=Linear structure
Depth Required Single Integer Minimum=1, Maximum=4, Value=2, Default=1
Importance Degree Required Single Float Minimum=0.0, Maximum=1.0, Value=0.06, default=0.0
In degree Required Single Float Minimum=0.0, Value=0.1, Default=0.0
Information Amount Required Single Float Minimum=0.0, Value=8.41, Default=0.0
Out degree Required Single Float Minimum=0.0, Value=0.0, Default=0.0
Semantic Relation Required Single String Value=Entirety-part
Queue
Name Cardinality Type Other Facets
Attribute Multiple String Value=Linked storage structure, Circular Queue, Linked
Queue
Depth Required Single Integer Minimum=1, Maximum=4, Value=2, Default=1
Importance Degree Required Single Float Minimum=0.0, Maximum=1.0, Value=0.18, default=0.0
In degree Required Single Float Minimum=0.0, Value=0.1, Default=0.0
Information Amount Required Single Float Minimum=0.0, Value=8.5, Default=0.0
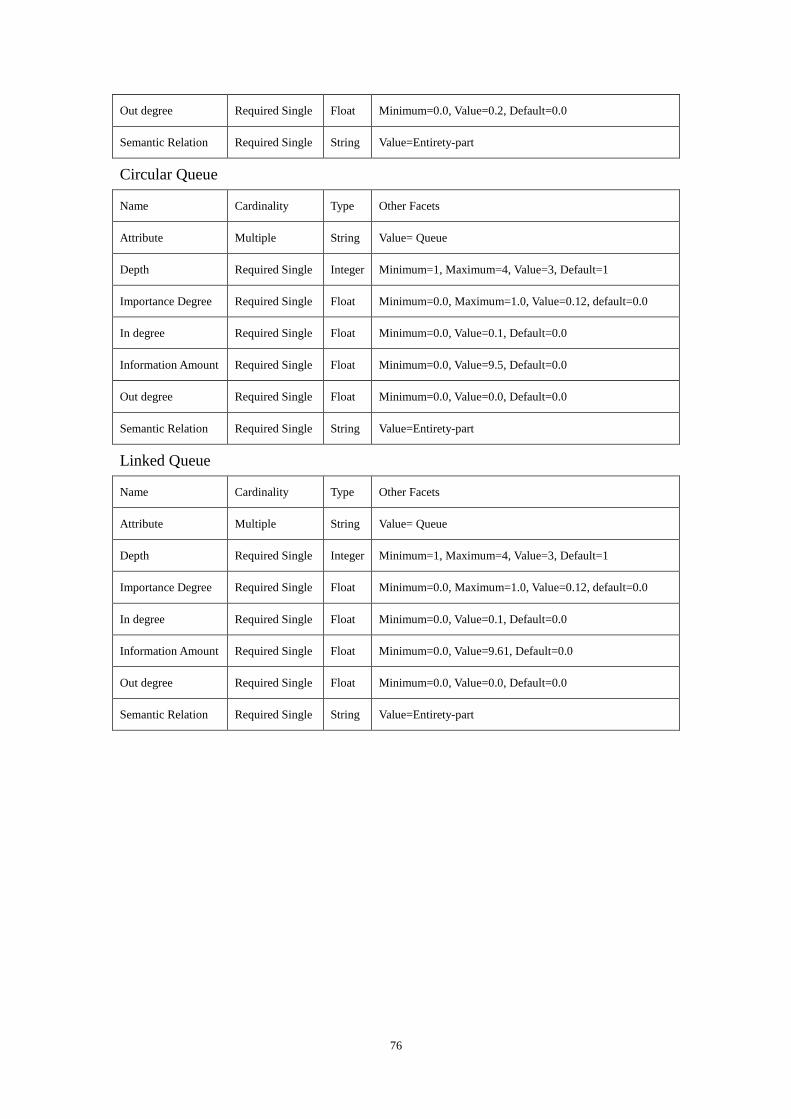
76
Out degree Required Single Float Minimum=0.0, Value=0.2, Default=0.0
Semantic Relation Required Single String Value=Entirety-part
Circular Queue
Name Cardinality Type Other Facets
Attribute Multiple String Value= Queue
Depth Required Single Integer Minimum=1, Maximum=4, Value=3, Default=1
Importance Degree Required Single Float Minimum=0.0, Maximum=1.0, Value=0.12, default=0.0
In degree Required Single Float Minimum=0.0, Value=0.1, Default=0.0
Information Amount Required Single Float Minimum=0.0, Value=9.5, Default=0.0
Out degree Required Single Float Minimum=0.0, Value=0.0, Default=0.0
Semantic Relation Required Single String Value=Entirety-part
Linked Queue
Name Cardinality Type Other Facets
Attribute Multiple String Value= Queue
Depth Required Single Integer Minimum=1, Maximum=4, Value=3, Default=1
Importance Degree Required Single Float Minimum=0.0, Maximum=1.0, Value=0.12, default=0.0
In degree Required Single Float Minimum=0.0, Value=0.1, Default=0.0
Information Amount Required Single Float Minimum=0.0, Value=9.61, Default=0.0
Out degree Required Single Float Minimum=0.0, Value=0.0, Default=0.0
Semantic Relation Required Single String Value=Entirety-part

























