Embed Size (px)
Citation preview

Improvement of CT Slice Image Reconstruction Speed Using
SIMD Technology
Xingxing Wu Yi Zhang
Instructor: Prof. Yu Hen Hu
Department of Electrical & Computer Engineering
University of Wisconsin, Madison

Motivation
CT Slice Image Reconstruction is a very important part which will affect the reconstructed image quality and scanning speed
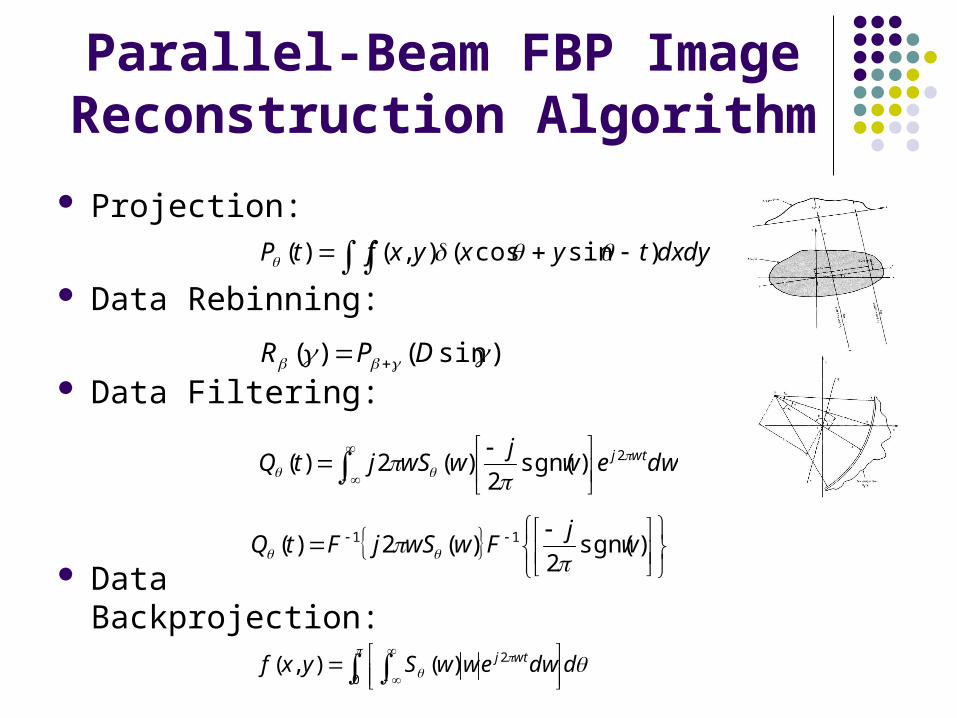
CT Slice Image Reconstruction is very time-consuming
Traditional methods for speedup: Specially designed hardware Parallel algorithm running on super computer
Explore a new method: SIMD implementation

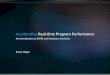
Parallel-Beam FBP Image Reconstruction Algorithm
The Algorithm consists on three parts: data rebinning:
data filtering
back-projection
Parallel-Beam FBP Image Reconstruction Algorithm
Projection:
Data Rebinning:
Data Filtering:
Data Backprojection:
dxdytyxyxftP )sincos(),()(
)sin()( DPR
dwewj
wwSjtQ wtj
2)sgn(2
)(2)(
)sgn(
2)(2)( 11 w
jFwwSjFtQ
ddwewwSyxf wtj
0
2)(),(
CT Slice Image Reconstruction Is Very Time Consuming
A Whole Head Spiral Scanning will generate several GB projection data

Function Profiling
0102030405060708090
time (s)
Data Rebinning Data Filtering DataBackprojection

Can FBP Algorithm Benefit from SIMD?
The Algorithm has the following features: Small, highly repetitive loops that operate on
sequential arrays of integers and floating-point values Frequent multiplies and accumulates Computation-intensive algorithms Inherently parallel operations Wide dynamic range, hence floating-point based Regular memory access patterns Data independent control flow

Analysis of Data Dynamic Range and Quantization Errors
Wide Dynamic Range
Relative Error Metric
32-Bit Single-Precision Floating Point and SSE2
N
i
DFPDFPi
DFPDFPi
N
ii
yy
yyxxRE
1
2
2
1
)(
)]()[(

Updated Algorithm to Fit SIMD
Update the algorithm to eliminate some conditional branches
Reduce the on-the-fly calculations which are not suitable for the SIMD implementation

Parallel Implementation of Data Filtering In SIMD
A0 A1 A2 A3 A4 A5 A6 A7
B0 B1 B2 B3 B4 B5 B6 B7
Rebinned Data
Weight
A0*B0+A4*B4 A1*B1+A5*B5 A2*B2+A6*B6 A3*B3+A7*B7 Filtered Data
* * * * * * * *
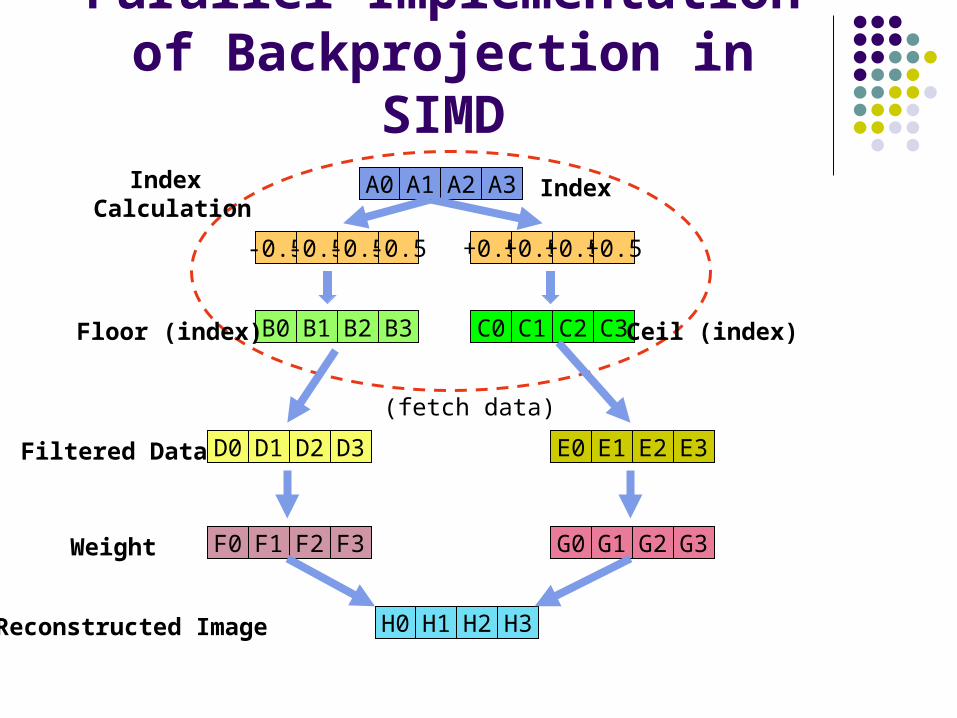
Parallel Implementation of Backprojection in SIMD
A0 A1 A2 A3
+0.5+0.5+0.5+0.5-0.5-0.5-0.5-0.5
B0 B1 B2 B3 C0 C1 C2 C3
D0 D1 D2 D3 E0 E1 E2 E3
F0 F1 F2 F3 G0 G1 G2 G3
H0 H1 H2 H3
Index Calculation
Index
Ceil (index)Floor (index)
Filtered Data
Weight
Reconstructed Image
(fetch data)

Optimization of The Implementation
Optimize Memory Access Ensure proper alignment to prevent data split across cache line
boundary: data alignment, stack alignment, code alignment Observe store-forwarding constraints Optimize data structure layout and data locality to ensure efficient
use of 64-byte cache line size and also reduce the frequency of memory loading and storing
Use prefetching cacheability instructions control appropriately Minimize bus latency by segmenting the reads and writes into
phases Replace Branches with Logic Operations Optimize Instruction Scheduling Optimize the Parallelism
Loop Unrolling Break dependence chains

Optimization of The Implementation
Optimize Instruction Selection avoid longer latency instruction avoid instructions that unnecessarily introduce dependence-related stalls
Optimize the Floating-point Performance avoid exceeding the representable range avoid change floating-point control/status register enable flush-to-zero and DAZ mode

Improvement of Performance
0102030405060708090
time (s)
Data Rebinning Data Filtering DataBackprojection
C Implementation
SIMD Implementation
The differences of the reconstructed image pixel values between C implementation and SIMD implementation are less than 0.01