Embed Size (px)
Citation preview

IMPLEMENTINGAUTOMATED DISCOVERY
WITH A CHANGE AND
CONFIGURATION MANAGEMENT
DATABASE (CCMDB)
5 DISCUSSIONS/
CASE STUDIES

2
Implementing automated discovery with a Change and Configuration Management Database (CCMDB)
© 2006 Spectrum Reports Ltd.
Published by Spectrum Reports Ltd.
19, St Michael’s Road, Winchester, SO23 9QQ, England
t = +44 1962 878333 / +44 7776 17 27 07
email = [email protected]
web = www.middlewarespectra.com
Notice of rights
All rights reserved. No part of this book may be reproduced or transmitted in
any form by any means — electronic, mechanical, photocopying, recording or
otherwise — without prior written permission of the publisher. For information on
obtaining permission for reprints and excerpts, contact Spectrum Reports Ltd.
Notice of liability
The information in this book, and referenced on the Spectrum Reports Ltd. Web
site, is distributed on as “as is” basis, without warranty. While every precaution
has been taken in the preparation of this book, neither the author nor Spectrum
Reports Ltd. shall have any liability to any person or entity with respect to any
damage caused or alleged to be caused directly or indirectly by the descriptions
and instructions contained in this book or by the computer software or hardware
products described in it.

CONTENTS
PAGE
1 DISCOVERY WITH TIVOLI 7 Kristof KlöcknerVice President of Strategy and Technology, IBM Software Group
2 DISCOVERY AND CMDB 27AT A MULTI-LATERAL AGENCYVijay TanamalaPresident, Global ConsultingMegasoft Corporation
3 DISCOVERY AND CHANGE 36MANAGEMENT AT AN INTERNATIONAL CONSULTING FIRMAnthony EspositoSenior Architect
4 TRANSPORT: APPLYING 50DISCOVERY AND CHANGE MANAGEMENTAnonymous (by request)Senior Manager
5 ADDRESSING THE TECHNICAL 59DIMENSIONS OF DISCOVERY, CCMDB AND INTELLIGENT MANAGEMENTVinu SunderasanProgram DirectorIBM Tivoli, IBM Software Group
3

4
INTRODUCTIONThe purpose of this volume is to explore, briefly, how imple-menting automated discovery (using TADDM or the TivoliApplication Dependency Discovery Manager) and a Changeand Configuration Management Database (CCMDB) arecapable of helping enterprises take control of their IT infra-structure and thereby improve business results. This explo-ration is achieved by combining:
three enterprise experiences, as told by people who have done, orwho are making, such improvements in their organizationtechnological placement, where the relevant technologies andtrends are explained, positioned and placed in context in additionaldiscussions.
From the above, four key lessons can be drawn:
there is a clear need for senior management support andinvolvement when initiating projects that are capable of havingsuch profound effects as are deliverable with automated discoverywhen combined with a CCMDBimplementing a CCMDB and discovery achieves regulatorycompliance, auditability plus improved control of IT infrastructureautomated discovery and a CCMDB go together; you need both toreap the benefits, which can deliver results almost immediatelyautomated discovery with a CCMDB also enables organizations tovisualize dependencies between applications, and within the ITinfrastructure, that were not previously visible; one consequence isvastly improved effectiveness and reliability as well as enablingorganizations to understand how any changes in the ITinfrastructure can affect their business processes.
To support these, consider the following selected extracts:
"I will also mention here that the Agency's management had avery strong business case to justify the process improvementinitiatives. Its commitment to the program was a big contributorto success." (page 29)

"My second (lesson learned) involves governance. We learnedearly on that we needed to have upper management involved withthe whole process of improving the systems and operationsmanagement. We had to work to make sure that they (uppermanagement) clearly understood what the vision was. Without aclear vision statement in place it is hard to achieve your targetsand to make deliverables and ensure they are on track." (page 52)"In other words, if there is no senior management backing, thenan investment will likely fail. Fundamentally, a top-down approachis required. Without this, progress will stall or be relatively trivialcompared to what could be achieved." (page 76)"On the security front, (our) Client found many instances ofconnections — usually from desk tops via dial-out connections —that were open or being left open. These represent potential, ifunintended, security breaches. Rectifying these has substantiallyreduced the risks to the Client." (page 37)“... the CMDB became the reference point for all service manage-ment activities in the Agency. It is no exaggeration to say thatTADDM and CMDB significantly helped the Client to achieve ITILand BS15000 compliance, and received sincere appreciation fromthe auditors from the British Standard Institute (BSI)." (page 39)"As for the unexpected: yes, one insight we have 'discovered' isthat we have a lot more servers that have access to other serversthan we thought. Many may not even need to have such access."(page 60)"Ease of installation and maintenance was important. TADDMproved easy to install and then maintain. The complete installationand first comprehensive discovery was completed in all of threebusiness days." (page 36)"When we started with discovery, we found some surprises. Forexample, we found that the number of Linux servers and Windowsservers was not quite what we had expected. We had thought wehad anywhere between 500-600 servers in each of our datacenters. It turned out we had about 800 of them, in each. Wewere a third bigger than expected. This was a shock, especiallywhen we considered the implications for licensing and everythingelse downstream." (page 51)"We wanted improved visibility. TADDM provided great depth ofasset configuration and dependency information. The team washappy to see the upstream and downstream dependencies well-categorized, at business applications, services and network levels,shown easily on screen." (page 36)
INTRODUCTION 5

“Furthermore, although here only the scale was unanticipated,there were all sorts of 'casual' (as in undocumented or as needed)collaborations taking place. Developers, even individual users,were the ones doing this — in order to deliver a business result.But the effect was that they were creating dependencies aboutwhich no one knew. A single simple change might be made andyet disable key business functions. Before discovery, there was noway to anticipate such possible effects." (page 48)"In this context, CCMDBs are gaining in importance because ofwhat improved 'discovery' can deliver. This is occurring becausediscovery offers the potential to be the necessary, automatedenabler for 'feeding' CCMDBs (Figures 1.1 and 1.2) with the typeof data that is a prerequisite to making modern IT managementpossible." (page 12)"Choosing automated discovery, of whatever form (in our casewhat is now IBM's TADDM), is of little use unless you have a CMDBin which to store what you have discovered. Plus, remember,discovery is something that you must run frequently — like a webbot — in order to find out what has changed." (page 44)"Having said all this, discovery is not the whole picture. For a startdiscovery is not a one-off exercise. You need to run discoveryperiodically — at different intervals for different aspects. You alsohave to store the results of discovery — so that you have a basisfor comparison and analysis. (page 56)"Discovery is not the whole story of IT service fulfillment, butwithout it subsequent possibilities may be worthless. Automateddiscovery is, therefore, the mechanism by which a model of aninfrastructure is initially populated — and then kept up to date. Itprovides the base against which to compare what exists with whatpreviously existed." (page 62)"Thus any CCMDB (or CMDB) must have, as a prerequisite, someform of automated discovery that is able to work regularly throughan IT infrastructure, from OSI Levels 2-7, and store the results inan organized manner. In a sense, this sort of discovery hassimilarities to the 'bots' which do the same for the Internet searchengines like Google and Yahoo. Only when you have this data canit be turned into information. Only with information can intelligencebe derived." (page 65).
To learn more, peruse with care the following five discussions and case studies. All are revealing; all incorporate real enterprise experiences.
6

Discovery with TivoliKRISTOF KLÖCKNERVICE PRESIDENT OF STRATEGY AND TECHNOLOGY IBM SOFTWARE GROUP
MANAGEMENT INTRODUCTION
Kristof Klöckner is Vice President of Strategy and Techno-logy within the IBM Software Group. He has overall respon-sibility for developing the tools and frameworks for systemmanagement — which embraces both operational manage-ment (the products that automate individual managementtasks) as well as the framework that pulls together infor-mation, processes and people’s work environments in orderto accomplish the tasks of managing IT services. In thisdiscussion, Dr. Klöckner focuses on ‘discovery’. As hedescribes it, this is an area of systems management andmiddleware which is about to have a profound impact onhow IT is managed. But, before looking at the broadoverview of what discovery is and how it will be used, hetakes the opportunity to set the scene by examining:
why there is a need for automated discovery the differences between a CDB, a CMDB and a CCMDBwhat has changed, that requires discovery and CCMDBsthe relevance of data.
EVOLUTION LEADS TO DISCOVERYWhen you look at the evolution of system management,which is the term that most people would have used ortalked about in the past, I find that customers are movingmore and more:
from a traditional systems management view of managingindividual resources or collections of resources (like individualservers or networks or storage or even applications)
CASE STUDY 17

towards managing the delivery of services to their end customers(whether internal or external), for example over the Web.
This is being driven to a large extent by enterprises demand-ing that IT infrastructure (including IT departments) delivera value that is both measurable and visible in the context ofthe specific needs of every business or organization. This isa very different scenario from the one in which traditionalsystems management operated in, say, the late 1980s andthrough the 1990s.
If IT, and IT departments, do satisfy such a demand, thepromise is that organizations will obtain visibility of:
their infrastructure what the IT infrastructure compriseshow it (the IT infrastructure) fits togetherthe detail and information which can identify the right questions toask, the possible choices and then the right prioritieshow the changes — and consequences of those changes, once theyhave been chosen — are made and then recorded.
This is why concepts like Change and ConfigurationManagement Databases (CCMDBs) are attracting so muchinterest. When implemented thoroughly, a CCMDB is a fed-eration of all the information that an enterprise owns aboutits IT assets, their use and their configuration. Such a ‘tool’represents an enormous jump forwards — much as a library,as an organized collection of many different forms of infor-mation, represents more than many books existing togetherin one place.
CDB OR CMDB OR CCMDB?I need at this point to pause a moment, to consider Changeand Configuration Management Databases. This is a rela-tively new acronym, yet it is already being abused. Too manypeople are calling anything that stores configuration infor-mation a CMDB or even a CCMDB.
In IBM, we call databases which store configuration infor-mation only a CDB (Configuration Database). A CMDB(Configuration Management Database) adds management.
8

There are at least four important differences between a CDBand a CMDB
A CMDB can federate data, that is bring data in from multi-ple sources; you collect data in an organized manner fromthe source most appropriate to the relevant processes (youdo not just capture all data). Federation matters because itis not reasonable to expect any organization to depend on orpossess one centralized master that holds everything. Wehave all spent a long time learning this with regular data.The same applies to infrastructure data.
The next management activity that distinguishes a CMDBfrom a CDB is that a CMDB needs to reconcile its data.Bringing in data from multiple sources (and tools) inevitablyproduces at least some conflicting data about any givenresource. This must be resolved and reconciled, so that con-fusing or contradictory results are not part of your CMDB.
In addition, you cannot expect to bring all data in simulta-neously or according to the same exact schedule. Indeed,you probably would not want to. Different circumstancesrequire different actions and timings; synchronizationbecomes important.
Finally there is automated discovery. This is, in my view, aprerequisite for a CMDB. You cannot hope to build a CMDBwithout automated data collection and entry of that data intoa CMDB.
For a CDB to grow up to become a CMDB, all four of thesecriteria need to be met. Without these, a CDB remains justa store of configuration items, and little more.
What is different, then, about a CCMDB when compared to aCMDB? When you start to automate the core IT processes ofconfiguration and change (which appear in the past to havebeen two different processes), you quickly find out that theyare really only one process. While you can have the conceptof a CMDB, operationally this is insufficient.
Think about it. When you change a configuration, you are
DISCOVERY WTH TIVOLI 9

performing a change, which needs managing. You need,therefore, processes and workflows that combine configura-tion and change. Keeping these separate no longer makessense. Indeed, a CMDB is a crippled concept, however capa-ble it may seem, when you compare it to a CCMDB.
Conceptually, you might conceive of a separateConfiguration Management Database and a ChangeManagement Database. Practically, operationally, this doesnot make sense. A CCMDB that cannot manage change,while useful, is only scratching at the surface of the realproblem that we all recognize — change.
CCMDBs AND DISCOVERYIn this context, CCMDBs are gaining in importance becauseof what improved ‘discovery’ can deliver. This is occurringbecause discovery offers the potential to be the necessary,automated enabler for ‘feeding’ CCMDBs (Figures 1.1 and1.2) with the type of data that is a prerequisite to makingmodern IT management possible.
10
IT Infrastructure, Transactions, Users, and Business Processes
DiscoveryFederation
Synchronization
User Interfaces
DeployConfigureMonitor ReportLaunch in Context
Process Runtime Infrastructure
Release Management
Incident Management
Info Lifecycle Management
INTEGRATEDDATA
ACCESS
INTEGRATED AUTOMATIONTO MANAGEMENT
PRODUCTS
Operational Management
PROCESS
Change and Configuration Management
CIServer,
Network and Device
Management
StorageManagement
SecurityManagement
Business Application
Management
Service Delivery
and SupportService
DeploymentInformationManagement
BusinessResilience
IT CRM and Business
Management
CMDB
Figure 1.1 CCMDB — platform for process automation

So, when I look at where discovery — and change and con-figuration management — will play, I find that these raisemany questions, from systems, right through to business ITalignment:
what is in the many data stores (most organizations possess manymore than one database, for example)?where are data and information located?what applications use which data stores?is IT delivering the kind of value that organizations need,especially when examined in the context of audit and complianceobligations?etc?
If an organization does not know what it possesses, how IThangs together or how IT’s many resources are used, thatorganization cannot realistically describe — or prove, whichmatters for compliance and governance (for example) —that what it thinks it is doing is actually happening. Indeed,
DISCOVERY WTH TIVOLI 11
User Interfaces
IT Infrastructure
ConfigurationItems
Relationships
Process Runtime Infrastructure
Data FederationMiddleware
Reconciliation
CMDB Extns Process DB
Integration M
Tas
k M
anag
er
Process Solutio
Application Mapping
DiscoverySensors
Figure 1.2 IT Service Management (ITSM) architecture

as the general business environment continues to becomemore complex as well as more sophisticated, the need forinformed insights rises just as the volume of detail availablemay be increasing even faster — to a point that reachesbeyond the ability of the human mind to process, unless ithas computerized assistance.
For example, I often find (when I talk to IBM customersabout, say, critical service interruptions) that the root causeof those service interruptions is failed change management.Digging deeper, and this occurs more often than not for com-fort, changes fail because the people making them did notknow or understand what the impact or implication of thechange they were about to make would be. If they do notknow what the impact might be, it is almost obvious to saythat this may be because they do not know, or understand,how ‘what is relevant’ hangs together.
The key point is that, in a world where we are dealing withservices that undergo frequent change (in terms of whatthey interact with), within an array of composite applicationsthat constantly draw on a wider and wider variety ofresources, you soon exceed the capacity of humans to keepup with the complexity and change that results — unless youpossess automation and the ability to represent and visual-ize multi-tier relationships.
We have all seen the spaghetti diagrams from large organi-zations that ‘show’ how applications connect to each other —but which are, in practice, incomprehensible because thereis simply too much information. Understanding this forcesdecisions. Which would you rather do:
remain in (blissful) ignorance?make decisions based on assumptions about a presumed ‘state ofplay’?try the impossible, and maintain relationships manually?use automated tools which scan or crawl the incredibleinfrastructure maze to see what is happening and then analyze thedata to uncover patterns that do not conform to an enterprise’spolicies — especially where it finds change (particularly those thatmay not have been authorized)?
12

The reality is that ‘spaghetti’ is common to most organiza-tions (that is if they ever even bother to try to depict therelationships between applications and the underlying infra-structure). Spaghetti may not be understandable but it doesindicate the magnitude of the problem.
To me, what this boils down to is that:
it is not so important any more to be able to manage individualelements in an optimal fashionit is more important to be able to manage end to end how allelements work together to provide a given serviceall services must be able to adapt all the time, because theseconstantly need to change
When you then look at some of the major trends — like thevirtualization of infrastructure — no human can keep track ofwhere, say, a workload orchestrator has actually put a job orwhich piece of infrastructure has been assigned to whatservice. Instead, enterprises need to possess an under-standing of their services topology and of their resources.The only way to do this today is by automating the gather-ing of the greater part of the information and then applyingintelligence so that you can either fill a given servicesschema or show how services and infrastructure worktogether.
WHAT HAS CHANGED?Moving from traditional resource management to servicesmanagement is a major change. One reason for this shift (tomanage differently) is that organizations have realized thatthe old ways of proceeding are inadequate. The underlyingtechnology has changed and with this has to come otherchange.
One effect is cost. A cause is complexity, because there hasbeen a fundamental change in the architecture of applica-tions. This has happened for at least two different reasons.
Applications used to run on a resource, a system. If you ‘sys-tem-managed’ that resource you could be reasonablyassured that the application function was being delivered.
DISCOVERY WTH TIVOLI 13

This is no longer true. Just think about how ‘integrated’applications have become. All or any of the following can bepart of one application that is servicing a customer:
front end visualization on Web Serversfront end logic on application serversfirewallsconnections to legacy back end servers.
This has become just too complex for a human being tocomprehend, especially in the short space of time that maybe available to take decisions. To look at all the differentcomponent parts, then understand and correlate what thesemean for a business service, is beyond the ability of mostpeople, even the most skilled in operations management.
Another factor driving change is cost. A primary cause is sat-isfying and meeting compliance legislation and regulation.There has been, thus far, no automated way to deliver com-pliance in the ways envisioned or mandated. This means thatmanual effort has had to be used. Manual effort is prohibi-tively expensive. This is why there is much interest in waysof automating what is currently manual.
In the past, systems management played an important role.However, this is relatively limited by comparison to what isneeded today. In well-run organizations, the systems oper-ations people do know what is happening. But this is verymuch on the basis of snapshots — taken at selected times.At the same time, life is becoming more difficult. Specifically,customers are finding it ever harder to keep abreast of thedegree of change that is occurring within the IT infrastruc-ture, something that has steadily become more challengingas more devices and applications and services and endpoints are introduced.
The reality is that most organizations want to know precise-ly what its people are doing with IT. Yet, without some formof mechanism to enable you to check reality againstassumptions, most organizations are almost flying blind.(You could liken this to having an active bank account, look-ing at it at the beginning of the year and ‘just expecting’
14

there to be money in the account at the end of the year.)
What we find, even in the best-run organizations, is thatcustomers usually do know what the individual elements oftheir infrastructure are — but they rarely know, at the levelof detail that is required for informed decision-making, howeverything connects or hangs together (look at the Megasoftand other discovery/CCMDB case studies). For instance,most well-run operations shops will know how many physi-cal devices they have, at least if you look at the larger phys-ical devices like storage, CPUs, network-attached devices,etc. This is now familiar and, for most data/IT centers, rou-tine. But if you start to ask about the next level of manag-ing a business system — and then managing these resourcesfrom the perspective of the business system — most cus-tomers thus far do not have sufficient information.
Let me offer some examples. What our research finds is thatcustomers do not yet necessarily know:
what database sits on what physical devicewhat applications use that particular databasewhat services use which physical resourcesand so on.
Furthermore, even if they do know (to some greater or less-er degree), the challenge that they face lies in keeping upwith the volume of constant changes:
has an application moved from instance one of a database toinstance three?has instance two of a database been moved to a different physicalmachine (perhaps because it needs more, or less, processingpower)?which storage devices hold the data managed by a givendatabase? is this being duplicated or even backed up appropriately in thecontext of the business and its vulnerability?etc.
In one situation I was personally involved with a number ofyears ago, an organization had an outage because a partic-
DISCOVERY WTH TIVOLI 15

ular data device went down. It took this organization quitesome time to understand (even before starting recovery)which applications were, in some form or fashion, ‘touching’the device that had failed. When I talked to them recentlyabout our new discovery capabilities — and how you can nowbuild a resource/relationship tree — the reaction was that, ifthat capability had existed when the device failure occurred,it would have been so much easier to determine and thenisolate the impact. In turned out that it would also havemade it much easier to recover. While this is just one exam-ple from one organization, it is not unique. Furthermore,increasing complexity breeds this kind of challenge.
What I find is that customers just do not know what is occur-ring within their overall IT infrastructure. Business units areconstantly adding IT, even if it is not described as IT (youonly have to think of mobile devices and sensors to appreci-ate how true this is). I have had more than a few encoun-ters of the kind I have just described ... and I expect plentymore.
THE RELEVANCE OF DATAThen there is the relevance of data. Look at the normal formof data and the value that is put on it.
Data moves in three stages:
the creation of ‘raw’ data; this is why automated discovery is sovital — it provides the base datathe transformation of that ‘raw’ data into information, when it isstored in a predetermined and pre-described way with appropriaterelationships, particularly business services; this is what youshould use a CCMDB forthe transformation of information into intelligence; informationonly becomes intelligence when it is acted upon either by people orby machine — to achieve an end purpose.
It is not only important to automate the gathering of dataand transform it into information. If you do not effectivelypush it out either to operational management products or toexecutable processes, then it never becomes intelligence.Today we talk a great deal about the ‘in’ (automated discov-
16

ery) and the ‘storing’. In reality we should be concentratingmore on the ‘out’ (the utilization of what is in the CCMDB),which is where the value really emerges for the customer.This is where all the resources and services are broughttogether and show what, say, ‘order entry’ – as a businessservice – uses (in terms of IT services and resources).
One problem is that most data models, like that in, say, a.NET type of tool, are manually constructed. Worse, they arestatic. Yet we all know that businesses and business servic-es are not static. A properly designed CCMDB with automat-ed discovery can automatically reflect those changes. Thismatters.
Research confirms what most of us have intuitively known —it is change above all that causes problems. Yet change isunavoidable and endemic. If you cannot cope with changethen you will have problems. Static solutions are simplyunsatisfactory. Indeed it is the fact that so little is integrat-ed that causes the vast majority of service outages.
This is why we need a whole new set of operational andmanagement products. These need to use data that hasbeen captured in the CCMDB and take information and, byapplication, turn it into intelligence.
Take monitors, like Omegamon. These enable you to seewhat is happening in a given resource. In the future Tivoli ismoving beyond these to what we call Composite ApplicationManagers. These measure the end to end transaction andlook at the application server to figure out what is going onwith each application as well as the supporting hardware andsoftware. The great advantage these will have is that theywill be integrated around the same CCMDB model. They willintegrate at a common point.
Take another example: Tivoli’s Identity Manager. This focus-es on the business service from a user’s perspective, identi-fying what applications a user has access to. But what isneeded is something similar which governs what businessservices a given user has access to. The applications andresources, and the access rights that are needed for this
DISCOVERY WTH TIVOLI 17

business service flow out of a common data model.
Finally, the other form of integration that needs to take placeis process automation. This is IT’s biggest challenge.
Right now, if you go into an IT shop, everybody is organizedaround their own silos — you have network specialists, UNIXspecialists, database specialists, storage specialists, etc.That level of abstraction was needed when applications wereresident on a specific system. Now the structures, whichworked so well for so long, have become a communicationinhibitor — especially when we are trying to manage in thenew, advanced, composite application and service environ-ment of today.
In a CCMDB, the data collected conforms to a shared datamodel that everybody can use, providing the commondimension from which it becomes possible to create a mod-ern management environment. Everything is kept in con-text.
We have automated many tasks with the current tools in thepast, albeit as silos or as self-standing processes. What isneeded now is a common denominator — the CCMDB — toprovide the interconnections and integration and under-standing across all resources and business services that didnot exist before. This is about moving from task organizationto organizational-level automation — across silos, becauseone can keep everything in context.
DISCOVERY: WHAT IT ISIn one sense, this has been a long preamble before dis-cussing discovery in more detail. There is a reason.Discovery is not a technique or technology that exists in iso-lation. Equally, discovery itself is not new. In some form oranother it has been around for a long time. For example,anyone going out and ‘pinging’ a server is performing dis-covery at its simplest.
What is new in today’s modern discovery is that not only doyou discover individual items but you also discover howthese fit together. In Tivoli’s Application Dependency
18

Discovery Manager (TADDM — Figure 1.3) what IBM is doingis blending multiple technologies to capture configurationdata with domain-specific knowledge about the informationthat these technologies capture. In this context our sourceshave to be many and varied, including:
agents, which possess information about the end points on whichthey sitsensorssniffersexisting instrumentationJMXSNMPSQLyou name it ...
The big difference here is that structured discovery departsfrom both the scattergun approach, where you randomlydiscover things, and from the snapshot approach. In Tivoliwe have the concept of building a model illustrating the
API
Discovery Engineand Sensors
Data Center Reference Model
Application Mapping Data ase
Run Time Environment
External Applications
TADDMClient
TADDM Server
DISCOVERY WTH TIVOLI 19
Figure 1.3 Discovery in TADDM
API
Discovery Engineand Sensors
Data Center Reference Model
Application Mapping Data ase
Run Time Environment
External Applications
TADDMClient
TADDM Server

topology of everything that can be methodically and regu-larly discovered, and how all this hangs together.
This does not represent any fundamentally new understand-ing. But it does reflect a realization that has become moreand more important in the past five years as we have talkedmore, and understood more, about SOA (Service OrientedArchitectures), composite applications or even, at still lowerlevels, of functions like virtualization or even SysPlex.
Unless you have a model that allows you to put in order whatyou have discovered — and then helps you reconcile themany data pieces, merge them and analyze them for implic-it as well as explicit relationships — all you are doing isscratching the surface.
What we find customers are asking for today is: ‘can you’:
provide me with an end to end view?give me a view of a selected business service (like, say, mortgageprocessing)? tell me, for a given business process, what applications it uses andwhich data stores it touches? show me (visualize) how the whole fits together?
IT departments need this information if they are to makesure that they can deliver the appropriate level of servicerequired by the organization. Equally, without this type ofinformation, IT departments are operating blind or in guess-work mode. This is increasingly unacceptable today.
Indeed, let me take this further. Discovery protocols can alsobe used for audits. In a sense, discovery enables IT defrag-mentation — it feeds the central repository of authoritativeinformation (the CCMDB), which in turn ‘informs’ the man-agement products with consistency. As discussed later, with-out automated discovery, this task cannot realistically beaccomplished by manual means.
In fact, our experience with business systems management(BSM) tells us that establishing configuration informationand keeping it up to date is the greatest roadblock to com-
20

pany-wide BSM. Most customers I know have only managedto establish BSM for a small number of core processes — pri-marily because they do not have the necessary depth ofinformation about all their infrastructure and processes.
KEY CHANGESFrom this I will argue that that there are two key changes:
creating and then populating the model; the description of how itall hangs together at a given point in time maintaining the accuracy of the model on an ongoing basis (byautomating identification of any changes then documenting andrecording those changes)
Snapshots may have been useful in the past, but nowadaysthey are inadequate.
What is more, if you have this kind of model, it is easier todevelop a sense of what your preferred (in terms of the busi-ness requirement) configuration should look like. Ratherthan build from the IT assets and infrastructure up, you caninvest in IT from the organizational or business requirementdown. Plus you can develop ideal templates or patterns orbuild standards ... and compare existing configurations (orpossible configurations) to such gold standards. In turn thisenables you to observe policies, as well as enforce compli-ance.
Indeed, compliance is becoming an additional reason for dis-covery, for the CCMDB and for related disciplines. I recentlylearned that one client wants to use IBM’s discovery prod-ucts to ensure that the parameters of all their 500+WebSphere images are set according to that organization’sestablished best practices. Possessing tools which can, forinstance, flag divergence from a ‘gold standard’ configura-tion are critical. Thus discovery has become a complementto automating the setting of these parameters, and cancatch ‘escapees’ (divergence from what is expected).
BUILDING THE MODEL: TOP DOWN OR BOTTOM UP?This begs the question: how do you derive the model to start
DISCOVERY WTH TIVOLI 21

with? To me there are various ways of approaching this.What I have personally seen is that there is no perfectanswer for all situations. There are top down approachesand there are bottom up approaches. Each may be more orless appropriate to any given organization’s specific needs.
What we do find, however, is one common denominator.Customers almost always want to start by understandinghow their most important, their most visible applicationfunctions, fit together. Although not always, these are mostlikely to be applications relating to customer-facing activi-ties. If your organization is a bank, this is likely to be thecustomer portal; if you are a manufacturer, this may be yourorder entry system or delivery system.
This is something that has changed significantly over thepast year. My belief is that this change can represent eitheran opportunity to enhance the value promise of any brand ora threat to that value promise.
If an organization’s priority systems are not under control,then they are capable of being messed up. If they can bemessed up, that brand value can be placed in peril. This real-ization has driven an understanding that organizations mustmanage their business systems, and especially the IT shop,from the perspective of their prime business activities. Thisis the top down approach.
To make sense of what is needed, organizations must under-stand how the functions delivered by multiple applications(and their supporting systems) hang together. Only whenthis exists can you correlate what you have discovered in theIT infrastructure with what is happening in the overall busi-ness process.
Sometimes, however, and we often find this inside infra-structure-driven activities, the other approach — the bottomup approach — may be as valuable. Think about port-scan-ning or some other low level mechanism. You look for whatis out there. Then, through some mechanism, such asobserving the message traffic between systems, you find outwhat the true (rather than supposed) interaction patterns
22

are. From this data you can then build your CCMDB.
This bottom up approach is also useful when you have had‘disorderly’ growth over a period of time and you want toconsolidate. I can think of at least one customer example,where a large service provider wanted to consolidate datacenters. The reality was that IT did not really quite knowwhat was installed or where. More importantly it did notknow what impact any changes might have. What do youdare do if you want to make changes and you are not quitesure what will happen once you start making those desiredchanges?
Whether you start from the bottom or the top, you have todiscover what you have and how everything relates to every-thing else. Without this, how can you understand the conse-quences? Would you like your surgeon to start cutting beforehe had looked at the MRI scans? Do your executives wishyou to expose their organization’s existing brand value tounnecessary uncertainty?
DISCOVERY IS ONLY AS GOOD AS THE PICTURE IS COMPLETE That said, what is important here is that, while we now offera fairly complete picture, we also realize that discovery isonly as good as the extent to which it can make the picturecomplete. We understand that there will also be other infra-structures where the ‘element owner’ of this infrastructurewill have better information than we can discover.
Tivoli is happy to work with such element owners to makeuse of their understanding. Tivoli’s discovery is not anabsolute. To obtain the fuller picture we know we must, andwill, work with third parties — including other system man-agement vendors. What matters is the information generat-ed and collected, not who found it.
This is why it becomes critical to use standards which enablethe federation of a variety of existing information sources.This is something that Tivoli is going to drive forwards.
We are going to encourage and pursue agreements between
DISCOVERY WTH TIVOLI 23

the larger vendors of infrastructure, and infrastructure man-agement software to make it easier to exchange and importand to federate information.
This may sound hard. I do not think it needs to be. Basically,at least for infrastructure description, we are all operating offthe Distributed Management Task Force (DMTF) CommonInformation Model (CIM).
We have added, and I am sure we will continue to add,extensions. We will agree on how we add extensions to mod-els — particularly how we deliver information into and obtainit from these models. This makes commercial sense —because it is what our customers are asking us to accom-plish.
Ultimately, when you look at how you will want to make endto end decisions, you need to be able to correlate informa-tion from multiple sources. We know that customers will findthemselves in situations, for instance, where they may beusing, let us say, IBM software configuration managementbut also using a Remedy or Peregrine help desk that collectstrouble tickets. They may have an asset management sys-tem from yet another vendor.
When you have a crisis situation you want to know what ishappening and why. The monitor may show a poor responsetime in one area of the infrastructure. To resolve the prob-lem you will want to know if:
anything changed latelysomebody already opened a trouble ticketthere is a problem in the networka component faileda downstream- (or upstream-)dependent application is causing abottleneck or slowdownand so on.
In effect this is ‘infrastructure crawling’, exploiting the vari-ous differing degrees of technology intelligence built into theIT infrastructure. There are devices that announce them-selves; there are management tools that introduce agents —
24

which we know from experience work well and offer excel-lent contextual knowledge about what they do, about ‘their’devices and ‘their’ endpoints, ‘their’ environments. Yet tomount all this and then reconcile it and make decisionsabout who and what to trust is not easy; for one thing, thereis a huge amount of data.
The beauty of tools like those now offered by IBM is that youcan:
either decide, as a policy for this attribute, always to trust ‘Tool X’or you can surface discrepancies and reconcile these manually — ifyou decide you do not want to trust a particular tool
LESSONS LEARNEDMy first, and personal, lesson learned is a general one.Discovery is ultimately about integration. Since it is an inte-gration task, the federation of information and the integra-tion of information gathering, requires standards and aneco-system approach. No one vendor is going to be able tocover it all and, though this is a general description aboutthe state of the industry, it cannot be overlooked.
As to which discovery (and integration) projects are suc-cessful (or not), I have found that there are some significantindicators that emerge from experience. The first one is thatdiscovery always happens in a context. That context isalmost invariably a cross-function initiative that requiresexecutive support and visibility; thus, in order to achievetraction, it needs top level support.
When we look at our customers it is obvious that the onesthat are successful with discovery and CCMDBs are thosewhere such initiatives were CIO- or CEO-driven, where theobjective was to deliver concrete business value. Using dis-covery can expose relationships and make visible what isactually happening in terms of change; indeed understand-ing change also becomes a catalyst for change.
My last lesson — and it is almost ironic that this applies toany kind of business integration — is that the projects thatsucceed are those where the organization starts deployment
DISCOVERY WTH TIVOLI 25

in the most critical and visible application areas. Customer-facing applications — those where any management effortdirectly relates to the value of an enterprise and its ‘ brand’— have an impact on an entire organization. There is a willto succeed in these projects, because not succeeding is tooexpensive for everyone. Successful discovery projects arerarely initiated as pure infrastructure projects. Rather they:
start with a given pain pointfocus on one or more of an enterprise’s most important applicationareasdeliver value to the ‘enterprise’s customer’ (and thereby to theenterprise)then become the foundation upon which to build.
We have learned that discovery is a foundation. It is anenabling technology which is fundamental for deliveringintegration. The role of discovery is to create, and then keepup to date, the state of an enterprise’s total infrastructure,from services to applications, from hardware to communica-tions.
Successful deployments involve building a model of theenterprise — whether manually or semi-manually — andthen using what discovery finds out to:
flesh out that modelestablish where it is wrong and where it is rightadd the pieces that were previously unknownkeep updated what changes, and what has not changed.
In so doing discovery overcomes the human limitation thatpersists when complexity becomes a barrier. By starting withthe human element, it is possible to automate discovery andto use ever more sophisticated tools to build a better andbetter picture of how an enterprise works. In turn, thismeans that managing becomes possible again — becausethere is sufficient real information on which to base appro-priate decisions.
26

27
CASE STUDY 2Discovery and CMDB at a multi-lateral AgencyVIJAY TANAMALAPRESIDENT, GLOBAL CONSULTINGMEGASOFT
MANAGEMENT INTRODUCTIONVijay Tanamala is the President of Virginia-based MegasoftConsultants, Inc., (i.e., the Global Consulting arm of theMegasoft group, which has offices in several countriesincluding the US, India, Germany, Singapore and China).He is responsible for a group that advises clients about out-sourcing strategies and IT Service Management (ITSM),and on methods to implement and improve these. He hasbeen with Megasoft since 1995.
In this discussion abiut the issues that Megasoft foundwhen retained by an international multilateral Agency Mr.Tanamala:
reviews why Megasoft was asked to examine its IT processes andpracticesdiscusses the issues encountereddescribes the solutions then deployed at this Agencyexamines how, and why, executive management commitment isso important for success in discovery and CMDB initiatives.
THE CLIENT CONNECTIONMuch of the activity at this multi-lateral agency (the ‘Client’or ‘Agency’) revolved around extensive econometricresearch and related support. The Client’s staff was con-stantly gathering and analyzing information in order to cre-ate the knowledge that enabled it to meet its objectives.The Agency has about 12,000 staff, 1,000 of whom areinvolved directly in managing IT. The IT infrastructure unit

is responsible for about 10,000 servers, running multipleplatforms, technologies, and solutions.
Megasoft was engaged by the Client to help improve itsprocesses and practices, to be in compliance with industrystandards and best practices in three specific areas. TheClient clearly felt that this was the most appropriate way tobecome a world-class IT shop and identified three specificareas for process improvement:
software development and maintenanceinformation securityIT service management — particularly for improving projectperformance, service efficiency and information security — all ofwhich aim to improve internal customer satisfaction.
These three process improvement initiatives had many inter-dependencies and overlaps so they posed significant chal-lenges in implementation. I am proud to say that from thetime we started this program in 2003 to the time we com-
28
Software
Process
Improvement
Project
Management
IT Service
Management
Information
Security
• CMMI (Staged and Continuous)
• ISO 9001
• Rational Unified Process
• IEEE
Models and Standards
• ITIL Framework
• BS15000/ISO20000
• Microsoft Operations
Framework
• CORE 2000
Models and Standards
• BS7799/ISO27001
• CoBIT
• NIST
Models and Standards• SOX
• Basel II
• Privacy: HIPAA / GLBA
• NERC Cyber Security
Regulations
• PMBOK
• OPM3
Models
Figure 2.1 Key activities

pleted in 2005, there appeared to be no other certificationeffort across these three areas being attempted simultane-ously, and that had been successful anywhere in the world,especially for an organization of this size.
I am going to talk most about the third area, meaning I willexplain the challenges faced in implementing the IT ServiceManagement process improvement program and how theTivoli Application Dependency Discovery Manager (TADDM)discovery tool and the change management database(CMDB) helped our Client achieve its certification andprocess goals.
I will also mention here that the Agency’s management hada very strong business case to justify the process improve-ment initiatives. Its commitment to the program was a bigcontributor to success.
IT SERVICES IMPROVEMENTWe started the IT Service Management initiative in October2003 with an open mind, that is, by being standards as wellas vendor neutral. Our first step was to understand the busi-ness of the Client and to help it define process goals that arealigned with business goals. We then conducted a gap analy-sis to understand the strengths and weaknesses and to getdifferent perspectives on the problems and issues that wereblocking service efficiency and effectiveness.
Next, the process gaps were translated into processimprovement requirements. To achieve our process goals,we evaluated industry standards, models and frameworkslike Information Technology Infrastructure Library (ITIL),Microsoft Operations Framework (MOF), ISO 9000 andBS15000 (currently ISO 20000). We finally chose ITIL as themodel to help us get certified for compliance with BS15000standards (Figures 2.1 and 2.2).
There was a clear emphasis from the Agency’s senior man-agement that it wanted the Agency’s processes and proce-dures to be benchmarked with other, top-notch commercialorganizations and for the Agency to be brought up to thehighest levels of equivalency.
DISCOVERY AND CMDB AT A MULTI-LATERAL AGENCY 29

Megasoft’s involvement increasingly focused on two keyareas:
improving customer service (primarily to internal customers)making the Agency’s processes secure and repeatable.
CHALLENGES IN THE EXISTING CHANGE MANAGEMENT PROCESSAs our work progressed, we realized that our key challengeswere in three core areas, that is change, configuration andrelease management. The findings of the gap analysis point-ed to several problems, such as:
changes were being made on the fly without following theorganization’s standard practices, mainly because there was a lackof defined processes and supporting automation toolsasset inventory and configuration information was not current oraccurate, even though there were automation systems in place(because, typically, data was being captured and entered manually
30
Exploratory Study
Jan 03
Dec 03
Process Development
Phase 2
May 03
Staff Orientation Pilot
Phase 1 Processes
Jun 04
Phase 1 ISG wide
Deployment
Process Development
Phase 1
Jul 04
Apr 04
Phase 1 Processes Training
Sep 04
Phase 2 Processes Training
Pilot Phase 2
Processes
Nov 04
Dec 04
Phase 2 ISG wide
Deployment
Mar 05
Pre Assessment
May 05
Assessment
Jun 05
Risk Assessment
Oct 03
Start End
Figure 2.2 Schedule and delivery

into the Asset Management System)impact analysis was not effective, because information on assetdependencies typically was available with people and not insystems, and — in the absence of proper documentation — thistended to be largely inaccurateunauthorized changes were impossible to keep track of (in theabsence of a tracking mechanism)release planning was typically based on unreliable assetinformation, and so deployments led to higher levels of rollbacksand defect fixes.
Because there was no integrated automation platform inplace, performance measures and metrics were difficult tocapture. It was difficult, therefore, to perform service man-agement efficiently and effectively. Also, the lack of such asystem made coordination between the teams makingchanges and releases challenging.
What Megasoft came up with was a comprehensive set ofrecommendations covering process assets, documentationpractices, measures and metrics, process automation(tools), training, and of course how to pilot and implementsuch an automation system. We also helped the Clientestablish a Steering Committee to aid in the implementationof the system, to facilitate audits and verify compliance.
TOOL RECOMMENDATIONSEssentially, we were now at the stage where we had toexamine the existing tools and requirements and then rec-ommend automation solutions to create an integratedchange configuration, and release management platform.
We recommended the development of a work flow enabledprocess management system to automate the change andrelease management processes. We wanted this to be tight-ly integrated with the existing Service Desk and AssetManagement applications.
One of our key recommendations was that the Client shouldacquire and implement a state of the art Asset DiscoveryTool, which would allow discovery of:
DISCOVERY AND CMDB AT A MULTI-LATERAL AGENCY 31

software, hardware, networking and communication assetsasset configuration information asset dependenciesasset change histories.
Our wish list for this tool included that it should:
be agent-lesshave graphical display of the asset dependenciespossess a well structured CMDB to store the configuration datahave easy to interface options, like APIs.
Along with the Steering Committee, we evaluated the toolsavailable in the market against a set of key criteria. We sawnumerous presentations and product demonstrations,reviewed product literature and talked to the products’ exist-ing clients. After what was a decisive proof of concept activ-ity, the Steering Committee decided to acquire and imple-ment Collation’s Confignia — Asset Discovery Tool.[Confignia (and Collation) was subsequently acquired by IBMand is currently known as IBM Tivoli Application DependencyDiscovery Manager (TADDM) and Change and ConfigurationManagement Database (CCMDB).] Here on, I will refer tothis tool as TADDM.
TADDM’S BENEFITSQuite surprisingly, for a product as complex as the discoverytool, TADDM met not just our basic requirements but also amajority of our wish list items.
In the case of agent-less discovery TADDM uses automatedagent-less discovery, enabling higher security and lowermaintenance cost. In turn, this improved the total cost ofownership.
Ease of installation and maintenance was important. TADDMproved easy to install and then maintain. The completeinstallation and first comprehensive discovery was complet-ed in three business days.
We wanted improved visibility. TADDM provided great depthof asset configuration and dependency information. The
32

team was happy to see the upstream and downstreamdependencies well-categorized, at business applications,services and network levels, shown easily on screen.
Custom servers and custom sensors were supported inTADDM, which has unique ‘Custom Server and CustomSensor’ features. The truth is that it is simply impossible todiscover every possible asset in an organization automati-cally — especially when you have custom built applications.Custom Server and Custom Sensor features helped us con-figure and discover exactly those assets.
TADDM had ‘easy to interface’ options, like APIs. We usedthese extensively to integrate it tightly with the existingSystem Management and Service Management tools.
Overall, TADDM provided reliable, real-time inputs to otherIT Service Management applications (like Service Desk,Change Management, SLA Management, Asset Managementand Release Management). This helped Service Managersand their teams plan and execute their tasks efficiently andeffectively.
IMPACT AND LESSONS LEARNEDThe principle impact so far has been, as the Client intended,reduced times to resolve IT problems and trouble tickets.Tier 1-3 supports have much improved information support.The support teams can see, from the CMDB, much moreabout the whole context of each problem as it occurs.
At the management level, managers now have a completebusiness view of what is happening, and the how and where(in ways that were not previously available). The businessprocesses now map down to it (the CMDB) and the IT infra-structure (and not up, as was the norm in the past).
On the security front, the Client found many instances ofconnections — usually from desk tops via dial-out connec-tions — that were open or being left open. These representpotential, if unintended, security breaches. Rectifying thesehas substantially reduced the risks to the Client.
DISCOVERY AND CMDB AT A MULTI-LATERAL AGENCY 33

TADDM, by looking at the real-time connections betweenprocesses, can find such instances and flag them for atten-tion. It can also show all those activities that have not beenauthorized, which starts to make compliance and observanceof legal and regulatory requirements much simpler to do aswell as to document.
However, the one single ‘item’ which has had the mostimpact initially is the periodic exception report. It is the oneplace where those who are complying with the new process-es, and those who are not, became obvious and visible. Yet,if not handled with care, this can provoke unwanted friction.We believe incentives are useful, to encourage adoption ofthe new processes. After all, the sooner the Client had itsstaff conforming and using the new change managementprocesses, and seeing this reflected in the knowledge basethat is the CMDB, the sooner would come the pay backs inimproved IT services.
By automating the approval and change process, a docu-mented discipline was introduced to the Client. In turn thismade compliance much easier to observe. That did notmean, however, that all staff immediately recognized therationale. Old habits and practices die hard. Many did notwish to change from the familiar ways of the past. But thischange was necessary, and desirable, if IT service levelswere to improve.
Some of the lessons learned are that it is critically importantto plan and manage the people management activitiesbefore introducing process and tool changes into an organi-zation. With increased transparency comes a sense of vul-nerability and insecurity in the minds of the employees. So,management should:
explain to employees, at an early stage of the initiative, theorganizational and personal benefits in making these changestrain them adequately in the processes and tools and then hand-hold them in the beginning stages of implementationprovide incentives to early adopters and process champions as wellas encourage the staff to adopt the process to improve efficiencyand effectiveness.
34

Another lesson learned is that the objective for a CMDBshould be that it hold the most accurate and complete data.This means making certain decisions about other sources(like existing systems management tools, which often havetheir own discovery aspect as well as data stores of someform) and initiating such a framework that whatever is beingheld in the CMDB is deemed to be the most accurate repre-sentation of the enterprise. It is vital that some form of rat-ing of the various tools and inputs is undertaken so thatupdates to the CMDB are undertaken in ways that are wellunderstood throughout the organization.
In effect, the CMDB became the reference point for all serv-ice management activities in the Agency. It is no exaggera-tion to say that TADDM and CMDB significantly helped theClient to achieve ITIL and BS15000 compliance, andreceived sincere appreciation from the auditors from theBritish Standard Institute (BSI). In short, the introduction ofTADDM and CMDB was a win-win for the Agency and itsinternal clients, with improved quality and secure deliveryand transparency of services.
DISCOVERY AND CMDB AT A MULTI-LATERAL AGENCY 35

36
Discovery and change management at an international consulting firm
ANTHONY ESPOSITOSENIOR ARCHITECT
MANAGEMENT INTRODUCTIONAnthony Esposito is a Senior Architect for a major interna-tional consulting firm which provides guidance for Fortune500 companies via 80+ offices worldwide (and growing).His current responsibilities include setting both tactical andstrategic directions for the firm worldwide. This is based onanalyses of the issues faced by the firm’s various IT depart-ments worldwide and applies to the integration, consolida-tion, processes and standards that should apply in anenterprise system management architecture that had beenpreviously been made up of individual silos which neededto work together.
In this discussion, Mr. Esposito:
reviews the firm’s existing environment and toolscontinues by discussing how the firm investigated the issuessurrounding change and configuration management plusdiscovery, and the solutions selected (especially for WebSphereand Domino applications)describes how these were introduced and some of theunexpected ‘discoveries’finishes by talking about progress to date and what has alreadyemerged from the work completed.
OUR ENVIRONMENTThe firm’s environment is a mix of the centralized and
CASE STUDY 3

decentralized (with the latter mostly offering specific supportto individual offices). We have three large regional data cen-ters — for the Americas, for Europe and for Asia Pacific —and these have UNIX environments, client/server applica-tions, Web applications, Web logging applications, servermanagement, various other servers, 2003 Active Directory,etc. Each of these has its own individual developers (withineach of the regional centers).
One consequence of this is that it has been possible, in someinstances, for us to end up with some initiatives being devel-oped two or three times. This means that, in our environ-ment, as in most large organizations, we have acquiredmany different applications and tools at different times inthe past. These are used not only to build specific code butalso to manage information, consolidate that information aswell as use the information.
The challenge that the firm faced three years ago was thatour IT departments — whether here in the US or abroad —were performing similar functions. This meant that:
duplication could occurthe time taken — to bring new tools and applications to the firm’sstaff — was becoming longer and longer.
Furthermore, we had one specific issue to face. This was thatmost developers had little awareness about the businessproblems that they were solving. Too often they had only themost minimal idea as to how their work would be used bythe firm downstream in its business. What I mean by this isthat, once a tool was built, few developers were able to tellus exactly about how their work (application or tool) touchedupon or interacted with other applications and tools withinthe firm’s business environment.
Let me give an example: someone might build a tool — saya Web Browser that performed a specific function. Yet therewas little understanding of what might be the impact if therewas a change either to the environment (whether down-stream or upstream from that tool) or even to the applica-tion (at a later time) for which they had built that tool. This
DISCOVERY AND CHANGE MANAGEMENT AT ... 37

meant that too often changes brought unexpected operational problems.
GAPS, TRUE CHANGE MANAGEMENT AND ITILWe discovered much of this when we undertook somedetailed analysis. What we also found was that there wasalso no standard way of managing processes themselves.Think about the implications of this. This meant that ourpeople did not possess an understanding of the way that ouroverall application environment functioned or even intercon-nected. Indeed, there was not even a means to understand— should anyone have asked to see the big picture.
This was a failure at the gate, so to speak. The challengewas not only did we face dependency problems but we facedconfiguration problems. Once a business service was builtand put into operation in a data center, it became vulnera-ble. People do change configurations and environment, andusually for valid reasons. But having a valid justification tomake a change does not stop unintended breakages.
In effect there was no methodical way of knowing what wasgoing on. Even worse, from an enterprise viewpoint, most ofthe operational knowledge resided in people’s heads. Inoperational practice, there was no way of physically check-ing server configurations — without someone making thateffort. That meant manual involvement, which is expensive.
As our research continued, we also found that the firm had:
no concept of a central metadata repositoryminimal business service managementlittle ability to look into all the different levels of systems andnetworks that we possessed.
These omissions meant that we were not able accurately toassess how any changes applied in one area of our systemsenvironment might impact other downstream, or evenupstream, applications. We knew that this was unaccept-able. It is no good possessing systems which, when youintroduce a change or improvement in one place, cause
38

breaks or failures in other places. Understanding thedependencies between applications is vital if IT is to deliverto the business the services that the business needs.
SEEKING SOLUTIONSWe then started to investigate different solutions. For exam-ple, we knew that we had to introduce specific technologies— such as application discovery, business process manage-ment and an overall architecture (which we knew we need-ed to keep as inexpensive as was practical). In workingthrough this we came to appreciate the unsubtle differencesbetween ‘conventional change management’ and ‘truechange management’:
’conventional change management’ is based on a schedulingchange management system’true change management’ is built on trusted and consistentprocesses.
In ‘scheduling change management’, typically one person(say) from each department will arrive at a meeting wherechanges are to be scheduled. The attendees, and these maynot even include all people who need to be interested, willtalk about potential problems that might occur as a conse-quence of implementing a particular change.
This approach is informal. The knowledge applied is limitedto that in those people’s heads who are attending a meeting.
In retrospect, there was not even an ability to examine theoverall detail and implications of any one proposed change,never mind considering all of them altogether. At the sametime, we found that the firm had lots of operational docu-mentation on how various tasks or processes should be com-pleted, but little of this was standardized.
THE IMPORTANCE OF ITILIn consequence, the firm — for over three years now — hasembarked on a transition from a kind of rogue or randomchange processing to one that is solidly based on ITIL stan-dards. This has involved addressing change management viaa formal ITIL process.
DISCOVERY AND CHANGE MANAGEMENT AT ... 39

In the future every change to the environment will be man-aged by our new ITIL-based change management process.Whether it is network systems that are being changed orapplications that are being changed, any proposed change isreviewed by a central approvals board via a formal process.As part of this process, thorough dependency analysis has tobe undertaken.
What is the difference to what went before? The previousreality was that people organized the information. Details onconfigurations were held in different people’s heads; therewas no way of looking at or visualizing what would happenwhen changes to the environment were contemplated (andthis applied to hypothetical as well as real situations).
In practice the only way to find out about dependencies wasto make the change — and see what happened. This is nota recipe for success, not least because some dependenciesmight only occur at specific times — like at month or evenyear end (but when it really mattered).
With our new tools and ITIL disciplines, those that we havebeen implementing, we are obtaining the capability to deliv-er informed analysis and modeling of the possible implica-tions — before any change can happen. This is a major evo-lution for our firm.
To achieve this we split the implementation of ITIL into a 3-5 year implementation. Today we are about midway. Wehave implemented a Configuration Management Database(CMDB) together with application discovery and businessprocess management.
We are, thus, well along the way to implementing changemanagement. But to achieve this we have had to undertakea thorough overhaul of IT governance within the firm (andspecifically with regards to change management). Currentlywe are working out the processes and tools that will enableus to complete the last part.
ACTIONSIn practical terms we went to our IT leadership, our steering
40

committee, and proposed that we implement a CMDB withautomated application discovery and business process man-agement. With its approval, we separated our activities intothree main focus areas:
business process managementapplication discoveryCMDB.
In practice, each of these has its own distinct tools, althougheach needs the others — as I will explain. We understoodbefore we started that we needed to consider these as threedistinct ‘activities’, not least so as to avoid trying to doeverything all at once or as part one monolithic effort.
Indeed, when we first started looking at ITIL and startedtalking to others who have gone down this path (especiallyin Europe), we saw that the configuration managementdatabase was going to be the foundation upon which wewould build nearly all our other downstream ITIL disciplines— such as:
asset managementcapacity managementproblem resolution managementcall center supportetc.
Without a proper CMDB it is near impossible to implementthese other disciplines. It would be like putting the cartbefore the horse. Without a solid foundation to hold the relevant information, you would be facing failure from thestart.
That said, discovery is vital to a CMDB. Why? You need topopulate a CMDB so that, downstream, correct informationanalyses can be run. If you think about it, business processmanagement needs excellent application discovery — that isable to map interdependencies between applications, net-work and systems configurations. Only when this has beenobtained can one start to visualize and then manage appli-cations and their availability.
DISCOVERY AND CHANGE MANAGEMENT AT ... 41

PROCESS MANAGEMENTOn the downstream activities — especially with the processmanagement — we also understood that we needed to sep-arate people from their traditional ways of thinking, thatenvisioned applications running on a specific server alone.With server consolidation, clustering, applicationservers/Web Services and other modern techniques, it nolonger follows that applications live in one place.
For example, applications may be clustered across severalservers. If a server goes down it does not necessarily meanthat the application has totally failed (only that the applica-tion is no longer performing at its optimum capabilities). Thesingle resource view of the world no longer applied. Instead,the IT world is made up of a much more complex and inter-dependent environment.
We knew that making this evolution represented a hugeleap, one which we all had to make. Today, everyone knowsthat they need to use the new tools to determine whether anapplication is truly down, or whether it is operating in adegraded state (the subsequent actions are quite different)and to look for the interdependencies.
SELECTING DISCOVERY AND CMDBAs per the firm’s usual practice, we started with a formalselection process (using the Rational Uniform Process) togather information. We started talking to our stakeholders,to our architecture team and to developers. A key inputcame from the firm’s Center of Excellence ArchitecturalTeam. We used this to test out our proposals and hypothe-ses, architectures and possible implementations. Thisensured that we were:
doing the appropriate researchaligned with the firm’s business structure.
With broad agreement, the next step was formulating ascoring or assessment mechanism. Having obtained consen-sus on that, we had a list of requirements which we used tocreate an ‘RFP Lite’. At this point we tapped into third par-ties — like Gartner and Forrester — to assess which vendors
42
could be regarded to be in the top tier in each functionalarea.
This produced a questionnaire, sent to all the vendors wethought relevant. The usual happened — almost all respond-ed saying that they could do everything...
Without going into excessive detail about the process, wedug deeper and deeper into fewer and fewer products andvendors — trying to understand how the products worked,from both a functional and engineering standpoint. Then thescore cards were completed, along with an assessment ofvendor viability (the installed base, reference customers,units installed, support capabilities, financials, etc.).
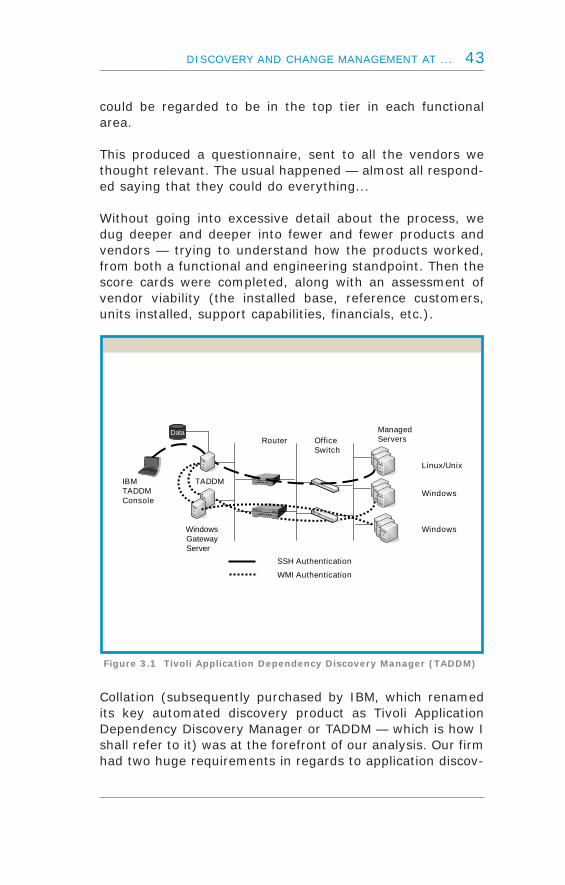
Collation (subsequently purchased by IBM, which renamedits key automated discovery product as Tivoli ApplicationDependency Discovery Manager or TADDM — which is how Ishall refer to it) was at the forefront of our analysis. Our firmhad two huge requirements in regards to application discov-
DISCOVERY AND CHANGE MANAGEMENT AT ... 43
SSH Authentication
WMI Authentication
Managed Servers
Data
Linux/Unix
TADDMIBM TADDMConsole
Windows Gateway Server
Office Switch
Windows
Router
Windows
Figure 3.1 Tivoli Application Dependency Discovery Manager (TADDM)

ery (Figure 3.1). We use a great deal of both Domino andWebSphere. Many of the competing products, although theysaid that they could work with Domino and WebSphere, justcould not do this in practice (or they could not do sufficientto the point we needed).
In contrast, and this was one of the attractions,Collation/TADDM could. Furthermore, because it did not thenpossess a large installed base, we had considerable leveragein regards to shaping the product to the way that our firmneeded. Furthermore, Collation’s responsiveness was good.We put together, I think, about 1,100 firm-specific require-ments that TADDM either had, had to have or which neededimprovement. Collation was able to provide these to us.
TO TEST, OR NOTIn hindsight, this ability to work together became a successfactor as we moved into our proof of concept testing — andthere is a particular point that I think I should make here.Some vendors and some customers do not test technolo-gies; instead they test requirements (though requirementsdo involve technology).
Let me offer an example. Say a user logs in. These ven-dors/customers will test every aspect of a user logging in —to the point where they seem to lose focus on what theywant to happen after that user has logged in. They look atwhat is happening now (on logging in) — and lose track ofwhat their organization might need from that technology inthe future.
What we saw (with what is now TADDM) was a huge poten-tial for what TADDM would immediately be able to do for usin terms of discovery. But we also saw it could do much morein the future (which is not to say that there were no bumpsalong the adoption road — but these have been overcome).
CMDB NEEDS DISCOVERY, AND VICE VERSAChoosing automated discovery, of whatever form (in ourcase what is now IBM’s TADDM), is of little use unless youhave a CMDB in which to store what you have discovered.Plus, remember, discovery is something that you must run
44

frequently (like a web bot) to find out what has changed.Choosing a CMDB is as important as choosing discovery. Forour CMDB we went to a German company — based out ofAachen.
In point of fact our selection of our CMDB was conducted inparallel to selecting discovery. A key determinant was thatwe needed to know the two (discovery and the CMDB) wouldwork together. The fact that Collation already had a partner-ship with this company in Germany counted. We also likedthis particular CMDB because it offered a truly object orient-ed database. It was able to import and export the databetween TADDM and the CMDB. Relevant adapters werealready in place.
Looking back, another reason we made the decision to gowith this CMDB was that it was much better than most othervendors in this space at that time. Too many of the CMDBcompetitors had, for the greater, merely taken their assetmanagement systems, made some changes to the database,obtained ITIL certification — and proclaimed the result aCMDB. This was not sufficient for us (furthermore, neitherCollation nor IBM then had CMDBs).
We explained what we were doing to our IT leadership, andshowed how — based on the pre-agreed requirements — ourchosen CMDB fitted the firm’s need. At the same time weemphasized that this did not mean that other CMDB prod-ucts would not appear that might make more sense one day.Indeed, we have kept a watching brief on this particulartechnology space (and every 6 months or so we look at themarket again to make sure that we are not missing some-thing important). If we had to change CMDB, we would. Thathas not been relevant thus far (and we would have to testfor migratability from our existing CMDB before making suchcommitment).
Today our CMDB is centralized. What we have established isthat we will need federation at some point. We are not thereyet, although our planning is for a shift to a federatedapproach (Figure 3.2) when the time is right — not leastbecause this will give us greater flexibility. We need a serv-
DISCOVERY AND CHANGE MANAGEMENT AT ... 45

er architecture to be flexible enough to respond correctly to:‘if I need this data, go to this data source’.
AFTER DISCOVERY AND CMDBAs I said earlier, discovery and a CMDB are themselves of little value unless you have means and tools to analyzethe information that has been discovered and then stored.Back end analysis tools are needed.
For this we are currently using Micromuse (also acquired byIBM since we originally bought the tools) business processmanagement products. These are built on Active Dashboardswhich act as an object server for the visualization of events.
Today Active Dashboards have been implemented in all threegeographical regions. We have completed the integrationbetween Micromuse’s and our IBM Tivoli console.
Business models have been created for the applications.These are now visualized using Rapid Application
46
Federation Engine
TADDM Adapter CSV Adapter XML Adapter SQL Adapter Custom Adapter
API
Portal Framework Out of the box Reports Custom Queries
CSV/Text Files SQL DB’s3rd party Management Apps
(Governance, Financial)TADDM Discovery
Server
XML Files
Federated CCMDB
Figure 3.2 Federation

Development products.WHERE NEXT?Having said all the above, we are conscious that, althoughwe have integrated these products, we have integrated themin a component manner. What we are currently working onis implementing a Service Oriented Architecture based onWeb Services and J2EE applications.
We are looking to deliver — via such a Service OrientedArchitecture — the ability for systems management andoperations products (as well as applications) not to have torequire integration by people. If the products are able tospeak ‘Web Services’, then integration automatically hap-pens in the Enterprise Service Bus (ESB) area of the frame-work.
When we have this we will possess huge capabilities. We willbe able to tie in legacy systems that people have not beenreadily able to integrate — because these were legacy sys-tems. This then offers the capability to move forward andbecome highly modular, possibly even to the point of saying‘our CMDB (say) is not what it needs to be’ and changing.Theoretically, with a single architecture in place, we wouldbe able to remove our CMDB without affecting downstreamapplications — because they would still integrate via the cellarchitecture. That is what the next evolution is for us today:working on that service architecture.
If that is one direction to our future activities, the otherdeals with the whole policy dimension, where activities andcompliance are expressed as defined policies. This is gradu-ally evolving as we put in place the main architecture. As wemove down the ITIL road, this approach fits well with thepolicies that surround Web Services — especially who is per-mitted to see what applications and which services arebroadcast out into the environment.
SURPRISE DISCOVERIESWhen we started with discovery, we found some surprises.For example, we found that the number of Linux servers andWindows servers was not quite what we had expected.
DISCOVERY AND CHANGE MANAGEMENT AT ... 47

We had thought we had anywhere between 500-600 serversin each of our data centers. It turned out we had about 800of them, in each. We were a third bigger than expected. Thiswas a shock, especially when we considered the implicationsfor licensing and everything else downstream.Our primary reason for using discovery, however, was to dis-cover the dependencies between tools, networks and appli-cations. There were plenty of surprises here as well.
Again we thought we knew how our applications functionedand with which connections. After running discovery, wefound dependencies all over the place about which we didnot know. We had never known that certain applicationswere even talking to particular databases …
Furthermore, although here only the scale was unanticipat-ed, there were all sorts of ‘casual’ (as in undocumented oras needed) collaborations taking place. Developers, evenindividual users, were the ones doing this — in order todeliver a business result.
But the effect was that they were creating dependenciesabout which no one knew. A single simple change might bemade and yet disable key business functions. Before discov-ery, there was no way to anticipate such possible effects.
What discovery told us was that ‘things’ were constantlybeing released and introduced into the firm’s environment —about which only the originators knew. You can look at thisin a positive light — our people were leveraging the firm’stools and data to produce business results. But, in a nega-tive light, they were creating potential vulnerabilities — thatcould impact the firm at any time.
LESSONS LEARNEDMy first lesson learned is that you must set the right expec-tation for your users when you start rolling out new ideasand products. Do not set an expectation that you cannot satisfy. You do not want people saying: “this is not what wethought the tool was going to be, this is not what was com-municated to us”. Get this right, from the start — and keepit right.
48

My second involves governance. We learned early on that weneeded to have upper management involved with the wholeprocess of improving the systems and operations manage-ment. We had to work to make sure that they (upper man-agement) clearly understood what the vision was. Without aclear vision statement in place it is hard to achieve your tar-gets and to make deliverables and ensure they are on track.
My third one is: remember continually to keep updating themembers of the team about progress — and, of course,including upper management. If people know what is hap-pening they can help to break down any hurdles that appearwhen you start rolling out the deliverables.
In this context, remember that anything that you implementwill encounter problems as you go into production. One les-son I constantly relearn is that what works fine in the testlab, invariably produces teething problems when placed intoproduction. Some of this is undoubtedly due to the sorts ofunknown dependencies that I have talked about; hopefullythese will diminish and disappear. But there will always besome uncertainties when you make changes — as introduc-ing any new system or application involves. That is why dis-covery and a CMDB and analytical tools are, together, soimportant.
DISCOVERY AND CHANGE MANAGEMENT AT ... 49

50
Transport: applying discovery and change managementANONYMOUS (BY REQUEST)SENIOR MANAGER
MANAGEMENT INTRODUCTIONThe speaker, a Senior Manager in a leading shipping andtransport enterprise, talks about what his organizationneeds for the future. He focuses his discussion on the needto manage change in a business that relies for its successon being fast moving and flexible — if it is to win and keepcustomers.
As he points out and illustrates, in such a business envi-ronment the possibility of applications, or business lines,failing because changes have not been adequately man-aged is unacceptable. He also discusses:
why an agent-less approach to discovery was so important for hisorganizationthe impact that incomplete change management can have on abusinessthe importance of storing what is discovered in a database andthen using that database to analyze what is happeninghow discovery and the CCMDB will drive improvements in servicedesk and other support functions.
THE BACKGROUNDOur company is a global logistics/transportation company.Our business is time defined delivery, whether that is by airor ground or by whatever is needed.
The problems that we were running into three years agowere typical of most large organizations — although in ourcase the sheer scale, in some instances, is unusual. We
CASE STUDY 4

have multiple operating companies. We have a very largesystems environment with thousands of servers that are dis-tributed across the various operating companies.
Many of the problems I refer to are ones caused by size asthe enterprise has expanded and keeps growing. The candidtruth was that no longer was it humanly possible to track allthe dependencies and interdependencies across so manysystems.
But perhaps the most vivid explanation as to why we need-ed to act is to describe one reality. We have an incidentreview meeting every week. Frankly I was tired of having totry to answer the same question, from my Vice Presidentevery week — the one that (rightly) asked: ‘how come, whenyou changed A, you did not know you were going to breakD, E and F?’
When I thought through what this meant, I realized that wehad reached a size and complexity where — even using allof the many other management tools that we already pos-sessed, which are very effective for managing and perform-ing system administration — we were not being effective inmanaging:
configurationsconfiguration changestracking those configuration changesidentifying and then tracking application and system dependencies.
A MODEST START RAPIDLY BROADENSThus began our search for a solution that would help us trackconfiguration changes. Indeed, this started out fairly mod-estly — trying to answer: how do we ‘just’ track all of thechanges that we keep making so that, if we come in onMonday morning and something is not working, we can atleast figure out what we changed in the configuration? Thiswould help us to understand what we needed to back out —at a minimum — to get the business back up and running.
If it started out that way, it immediately blossomed into‘Well, understanding what you changed in the configuration
TRANSPORT: APPLYING DISCOVERY AND CHANGE... 51

is only half the battle. Understand what else you have to goback and fix, because if you changed one thing, you proba-bly also changed lots else down the line (whether intention-ally or unintentionally)’. Or worse: ‘you did not changeeverything else down the line, because no one really knewthat when you put this upgrade on this server over here;now, all of a sudden, the version of the software you wererunning on a server down the line is no longer going to becompatible with the upgrade you just placed on the primaryserver’.
In short this had become a matter of numbers. Sooner orlater, you simply cannot afford a staff big enough, or knowl-edgeable enough, to be able to:
track so many changes across so many systemsfollow through with trackingensure that everything that needed to be done everywhere iscomplete (and documented).
We recognized that we needed to automate our understand-ing of our environment. Put another way, we wanted tomove:
from reacting to change, and then fixing itto a proactive approach that says, before I even make a change, Iwant to know all of the applications/connections/dependencies thatmight be affected if I make this change.
We wanted to be able to go look at the servers and decide ifwe can even contemplate each change. We wanted to know,as a matter of course, that everything was running theexpected software version, that everything expected wasstill being supported.
It is only good practice to know this before you even start to make changes. Once we had comprehended what we need-ed, we began to look into solutions.
NEXT STEPSThis was over two years ago. We went out to look for con-figuration and change management tools applicable to an
52

enterprise of our size.
2-3 years ago what we found were a lot of vendors whosepeople said they had the products to help us. The reality wasthat they might have understood — but mostly these wereonly words, although in some cases we did at least receivePowerPoint presentations about ‘products’. As often we weretold: ‘Well, you just tell us what you want, and we will writeit that way for you’.
Netting it out, what we found was this particular area in theIT industry was not really mature. There were multiple ven-dors promising product but, when we dug underneath, wefound services rather than product.
THE IMPORTANCE OF BEING AGENT-LESSIt should also be noted that we had, as a specific require-ment, the concept of a product where there was no need toload agents onto our systems. For one, loading agents isabout making changes to a working system (which is whatwe were trying to contain). For a second, we simply had toomany systems and, while one agent may only cost a $100-$150, thousands of agents adds up to a big investment (anda huge manual effort).
An agent-less approach for us was mandatory. We wantedsomething that could:
routinely go out and discover serversobtain information from any platform (whether HP-UX, Solaris,Linux, Windows or whatever)discover the devices on the networkidentify applications and dependencies automate the populating of a database with all this information(without us having to manage data entry).
We looked at several products in this space, from well estab-lished vendors, as well as two or three others whose namesI do not now recall (either they did not have products or theyhave been absorbed by another company or they are not inbusiness anymore). In looking at these vendors, one of ourother considerations was to think about whether each ven-
TRANSPORT: APPLYING DISCOVERY AND CHANGE... 53

dor might be too small for us (we did not want to overwhelmanyone: that would have helped no one).
Finally, we selected the product set from a company thencalled Collation. (I told my boss at the time that, in my per-sonal view, the Collation product was sufficiently impressivethat it would be less than two years before another vendorbought Collation. This is what happened. IBM did exactly asI predicted.) The key Collation discovery product has nowbeen ‘snappily’ rechristened by IBM as its Tivoli ApplicationDependency Discovery Manager (TADDM for short).
What is now called TADDM appealed to us: first of all it wasagent-less. That is not to say that there was or is no workinvolved in connecting to another system against which torun discovery. But we did not have to install or manageagents or take on board their implications. Also, TADDM hasa neat approach for respecting security, without securityinhibiting discovery results or discovery breaking securityrules.
DISCOVERY IS NOT EVERYTHINGHaving said all this, discovery is not the whole picture. For astart discovery is not a one-off exercise. You need to run dis-covery periodically — at different intervals for differentaspects. You also have to store the results of discovery — sothat you have a basis for comparison and analysis.
This requires some form of configuration database. Yet thiscannot be just a store of the latest configurations.Configurations change. Such changes must be discovered.Authorized changes must be reflected.
One of the aspects we liked about the Collation approach todiscovery was that it could store data in an Oracle database.Oracle is the standard database in our organization, plusOracle is also server independent. This meant that we couldhost our CMDB on Linux or some flavor of UNIX or evenWindows. As it happens we have one instance up on aSolaris operating system. But we also examine differentalternative operating systems, just to see if it acts any dif-ferently.
54

The best part here for us was that, with Oracle, we could useour existing database tools. In addition we could obtain reg-ular support from the existing DBA group for the CMDB.
TODAYToday we have discovery and the related CMDB installed andrunning. Discovery scans many of our servers, including thecritical customer-facing (the Internet/Web-based) servers. Itis also scanning many of the back end servers, those behindthe firewall.
We are not yet fully deployed. We do not have all the serversbeing discovered yet, or all the network devices. This isbecause we are being careful and methodical with our roll-out, plus we do not want to flood the network with more dis-covery enquiries than we are happy to support (somethingthat some can easily forget).
In practice our focus is on keeping up with the reporting andensuring that the reporting makes sense as we add moreprojects. Today we know we can track the history of changesas well as identify who is responsible for tracking it.
We run discovery every night. While we do not necessarilyadd services and network devices during the week, configu-rations do change during the week. After discovery we runthe comparison reports — again this is daily.
CHANGE MANAGEMENTAs for change management, when we are considering if weshould make a change, we now go to the CMDB and run aquery asking it to show what dependencies exist. We areasking questions like:
what if we change a particular server?what other devices does it touch?what databases might be involvedwhat other applications might be affected?
As for progress, this is pretty good. Yes, we do have someproblems but most of these are, if I am honest, to do with
TRANSPORT: APPLYING DISCOVERY AND CHANGE... 55

the fact that our size of environment stretches almost anysoftware. The reality is that we break everything at somepoint. For example, we have started to run into performanceissues with the database. Not the discovery: the discovery isworking great.
What we are starting to see is that it is taking longer andlonger to generate reports from the database. Now, to me,that means there is probably something screwed up with oneof the queries. This is a recent development, and we justadded a pretty big block of devices to what has to be dis-covered. Currently this is not likely to be a serious problem;I just view it as the typical growing pains our scale of activ-ities put all new software through.
But my real test is, can I avoid my boss’s weekly question?The answer is ‘Yes’, increasingly.
Of course, without everything having been discovered thereare still breakages. But we are increasingly obtaining a han-dle on changes — which was our objective. We expect toeliminate these breaks as we finally roll out inclusion of allthe rest of the servers and register everything in the data-base.
THE UNEXPECTEDAs for the unexpected: yes, one insight we have ‘discovered’is that we have a lot more servers that have access to otherservers than we thought. Many may not even need to havesuch access.
Because of discovery, when we receive our dependencyreports, we can go and ask:
why is one particular server talking to another server?what is the business function that marries the two together?is this necessary or can it be removed?
Sometimes it was nothing more than the same developmentgroup was responsible for both servers. Maybe they had keptan empty host file that had some backdoors to each of theservers. One beneficial, though not entirely unexpected,
56

consequence is that we have been able to close up on several security aspects.
EXPLOITING THE CHANGE MANAGEMENT DATABASEI should say, for I do not wish to mislead, that we have yetto come to grips with what we can be achieved in the longterm with the change management database. We still havenot, from a tool perspective, taken advantage of the fullchange management capabilities or the analyses that weexpect to obtain in the future.
Yes, we are using it for tracking dependencies and identify-ing changes and configuration changes. But we have notgone to the next level, which will integrate that change man-agement database to work with our service desks and othersupport functions. This is an area we are on the verge of ini-tiating.
This has been by conscious decision. We have been pro-ceeding step by step. Trying to do too much too soon in anenvironment like ours is not productive, whatever the appar-ent attractions.
Change and configuration management is an area with enor-mous potential for delivering positive results, or negativeones if matters are not handled well. We have no intentionof ruining a powerful initiative by being premature with ourimplementations.
Indeed, if you think about it, this is what has always beenwrong with how we implemented change in the past. We didnot have sufficient information to make an informed judg-ment. It does not make sense to tar change and configura-tion management with the same errors of omission: we arecertainly not going to do this.
LESSONS LEARNEDChange and configuration management, even discovery, areas much, I think, to do with one’s organization and how itdoes business as with technology. Because we are so large,we tend to have a particular style of support infrastructure.
TRANSPORT: APPLYING DISCOVERY AND CHANGE... 57

In other words, we have a whole area that is under a VP fornetwork engineering. We have a different VP for IT opera-tions. We have a VP for information security, etc.
One of the aspects about change and configuration manage-ment and discovery is that these necessarily traverse the ITinfrastructure, its associated environments and the manage-ment structure. They have no problem crossing the tech-nologies. But what I have learned is that there is a big polit-ical dimension. I have seen no end of political issues arise.
One of the challenges is persuading each group (or silo) totrust the other groups with the information that change andconfiguration management and discovery produce.Remember, these find out and report on all ‘your things’ inthe infrastructure.
This is probably the single biggest lesson learned: it is wellworth the effort to make everybody comfortable and awarethat the objective is ‘not that we are trying to manage yourspace or tattle on you; all we are trying to do is map out thedependencies, and this will help you also’.
It takes a lot of co-ordination to convince everyone. We hadmany meetings with all the various groups before we evenselected TADDM. Furthermore, even after you have madeyour selection and bought and implemented, you will likelyhave to go back and reassure all those whom you had per-suaded, all over again.
58

CASE STUDY 559
Addressing the technical dimensions of discovery, CCMDBand intelligent managementVINU SUNDARESANPROGRAM DIRECTORIBM TIVOLI DEVELOPMENT
MANAGEMENT INTRODUCTIONVinu Sundaresan is a Program Director in IBM Software’sTivoli unit. Before joining IBM he worked at COVAD, andthen at Collation — where he was a co-founder and respon-sible for developing the concept and then delivery of agent-less discovery, plus the storage of discovered results in adatabase. (Collation was purchased by IBM in 2005.)
In this discussion, Mr. Sundaresan:
addresses the key technical dimensions concerning discovery andCCMDBs and uses his experiences at COVAD, Collation and IBMto illustrate his pointsdescribes differeing ways of delivering discovery, and explainswhich is most practicalillustrates why discovery and a CCMDB are the starting points forintelligence and, ultimately, policy-driven automation
. examines upcoming trends and the likely evolution path forfuture products and approaches.
His viewpoint (here) is primarily technological. It providesa deliberate contrast to the broader overview offered byKristof Klöckner (page 7).
COVAD — AND UNDERSTANDING AUTOMATED SERVICE DELIVERYI was Vice President of Software Engineering at COVAD, aDSL service provider borne out of the deregulation Act of

1996. In common with many of the new service providers ofthat time, COVAD was exploiting a green field in terms ofsystems and automation. We introduced a distributed 3-tierarchitecture which enabled us to provide automation fororders coming in (where the customer touched us).
This was relatively simple, as I found out, at least by com-parison to the software that was needed to automatechanges. Furthermore, as a business that was operating inwhat was essentially a green field opportunity, we obtainedmuch of our efficiency up front — by connecting our variousapplications together (this was very different from tradition-al providers with their legacy systems).
Yet, one danger of automating any system is that you grad-ually acquire, even in a green field situation, internal andexternal customers. These become dependant on what youhave built. In effect, what proves to work inevitably becomesa legacy operation — as soon as it works. This then bringsto the fore a whole new raft of service and response issues.
For example, we soon found out that we needed to havesome way of determining where a problem was occurring.This understanding was not at the traditional systems man-agement level — of knowing whether a database or a serv-er or a network component was functioning. It needed toprovide greater depths of insight, to be able to respond tobusiness questions like ‘our business partner cannot place an order, so what is wrong and what has to be done to fix this?’
When we encountered this, we researched the implications— in particular how much time it was taking us by conven-tional means (often manual or semi-manual) to resolveproblems (a lot). It became clear that our deliberately dis-tributed architecture had delivered an infrastructure of greatcomplexity. In turn, this meant that resolving problems wasmore complex, especially if we wanted to match the detailconcerning any difficulty to the broad business process thatwe were trying to provide.
NOT UNIQUEIn performing this research, I came to understand that what
60

we were doing was not unique — that most business withsophisticated processes had essentially the same challenges.That challenge is, effectively, how to automate IT servicedelivery (and remember that, at that time 5+ years ago,ITIL and configuration management databases were notcommonly accepted — never mind in use as concepts orproducts).
In practice, then, such automation of IT service delivery asexisted relied on observation and statistics. This was thetypical bread and butter approach used in traditional sys-tems monitoring.
What we realized was that businesses needed a moresophisticated approach which combined detailed configura-tion information with models and automation driven by poli-cies (so called policy driven automation). We understoodthat a combination of these:
could provide the greater depth and understanding needed toenable reliable IT service delivery, support, provisioning orwhateverwould demand new disciplines, and not least in terms of behaviorand data.
This need for policy driven automation was the basis forstarting Collation.
FROM DISCOVERY TO CCMDB AT COLLATIONOne of the key initial tasks at Collation was to create asemantic and behavioral model of all the components that sitin the Open System Interconnection Model’s stack (Layers 2-7). Candidly, and looking back, this was not trivial. Itinvolved understanding:
each technology type in a data centerall the key attributeshow these are all named and located.
An essential part of this was exploring how application-to-infrastructure relationships — and the infrastructure itself —impact an application. What we found out early on was that
ADDRESSING THE TECHNICAL DIMENSIONS ... 61

there was already a huge amount of information collected ina typical enterprise. Yet this information could not beobtained regularly and, when it was asked for, it was usual-ly provided for on a manual basis. This was far too effort andtime consuming and, therefore, too expensive.
We also confirmed that no ‘systems environment’ should beconsidered static. IT, its applications and the associatedinfrastructure are dynamic, changing (often subtly) all thetime. (You may think it is static but if you dig deeper you willfind changes happening all the time, and often.)
Thus information in any model that we might wish to buildhad to have the capability not only to represent the currentsituation but also had to reflect past ones and to be auto-mated (to take out the manual tasks and, therefore, costpressures). Being able to compare what ‘is there’ with what‘was there’ is a necessity.
This forced us to think about how to deliver an automateddiscovery ‘process’, one that could go out and find what hadbeen added, removed or changed. But, in building such adiscovery product we further realized that automated dis-covery was not the whole answer either.
More was needed. In particular, a database was neededwhich would store the results/data that had been discoveredin some form of configuration repository (or ConfigurationDatabase — CDB — as it is now often described).
Yet, having a CDB also proved insufficient. Possessing dataorganized in a formal database creates information — if thiscan be used. A CMDB (Configuration Management Database)is a formally structured data store which enables visualiza-tion and management, not just a record of what is there. Yeteven this proved insufficient.
The real need is to be able to use the data/information in aCMDB in ways that deliver intelligence — visualization, con-figuration tracking, change management, comparison, etc.This requires a CCMDB (Change and ConfigurationManagement Database), a resource where formally declared
62

policies can run in an automated way. It is with a CCMDBthat the long term, end to end, full life cycle value arrives(although it has to be recognized that both CDBs and partic-ularly CMDBs are useful interim technology steps).
DISCOVERY UNLOCKS THE POSSIBILITIESThat said, understand that discovery remains the key whichunlocks the downstream possibilities. You can have a CDB, aCMDB or even a CCMDB. But these are only as good or use-ful as the data/information that is discovered and stored. Ifthe data/information is inaccurate or out of date, then inap-propriate decisions will be made and policies may deliverincorrect results.
Thus any CCMDB (or CMDB) must have, as a prerequisite,some form of automated discovery that is able to work reg-ularly through an IT infrastructure, from OSI Levels 2-7, andstore the results in an organized manner. In a sense, thissort of discovery has similarities to the ‘bots’ which do thesame for the Internet search engines like Google and Yahoo. Only when you have this data can it be turned into informa-tion. Only with information can intelligence be derived.
Discovery is not the whole story of IT service fulfillment, butwithout it subsequent possibilities may be worthless.Automated discovery is, therefore, the mechanism by whicha model of an infrastructure is initially populated — and thenkept up to date. It provides the base against which to com-pare what exists with what previously existed. It offers thebase data from which:
ever more sophisticated conclusions can be drawnultimately automated policies can work.
DELIVERING DISCOVERY: FOUR POSSIBILITIESTo deliver discovery there are four fundamental approaches:
use existing instrumentationinstrument the operating system(s)exploit data and network path perchingprovide agent-less remote execution.
ADDRESSING THE TECHNICAL DIMENSIONS ... 63

The first involves using existing technologies, like existingprotocols and instrumentation. These are in common use intraditional systems management applications and monitors.We can use what these deliver to obtain data with which topopulate a CMDB. This may be locally, on a specific box, orremotely — via an agent or something similar. But, neces-sarily, their capability to deliver is limited by the functionthat each specific tool offers (and most were not designedwith a distributed services-based environment in mind).More is needed, and this would need to be built.
The second approach is to instrument the operating systemor, today, operating systems (we all have distributed sys-tems, whether intentionally or by accident). This approachenvisions placing instrumentation in the path of everythingthat exploits the operating system — applications, middle-ware, communications, storage, etc.
At a theoretical level this approach is possibly the mostattractive because vendors do not have to be intrusive.Instead of the pull model, where today we have to go andfind out if anything has changed, this would use a pushmodel — where changes that occur would be notified auto-matically, along with the details of what had occurred.
Ultimately, however, a variant of this approach may arrive —although it may take 10+ years to come to fruition. This willhappen only when commonly accepted instrumentation isbuilt into all components — operating systems, applications,storage, communications, etc. Once incorporated this wouldeliminate the need for custom instrumentation.
Such developments will not happen overnight, and will like-ly not be sufficient until all uninstrumented systems havefinally disappeared. And we all know how long legacy appli-cations and systems tend to last...
The third approach involves sitting on data paths and usingnetwork traffic to capture topologies. While it is an interest-ing approach, to try to capture all that is going on, this is notsufficient. For example, you can obtain some relationshipdata from network traffic but you cannot obtain configura-
64

tion detail from sitting on the data path. So you do have togo and collect more information in other ways, using (ifavailable) information from approaches one and two above(these are not irrelevant, just insufficient).
In practice what we established was that the most sensibleway forwards is a fourth approach using some form of agent-less, remote execution protocol — what we now call ‘agent-less discovery’ — which captures the level and depth ofdetail that is required. This does not ignore the otherapproaches; part of the way we think about discovery ingeneral and a CCMDB in particular is that they must seek touse all sources of data that are available, for they all add tothe sum of data in a CCMDB.
Agent-less discovery is not as easy as it may sound, espe-cially in the communications context. Consider most largeenterprises. They have multiple firewalls and ‘DMZs’ and thelike. They use encryption and various other security meth-ods.
Employing a network packet capture approach involves,therefore, a significant effort in understanding how a mod-ern IP communications topology (with both Internet andintranet and cross Internet/intranet implications) works andwhy. As if this was not sufficient, any approach must be scal-able. It must be capable of handling the largest sizes of net-work (which can include substantial Internet involvement).To do any less is to misrepresent what is happening or tounderstate what is occurring in an organization. (This isanother justification for the agent-less discovery approach:discovery is initiated as a remote command executed fromsome form of central discovery server.)
FROM COLLATION TO TADDMThis fourth approach is at the core of what we were workingon at Collation when IBM bought the company and made ourofferings part of Tivoli (as TADDM or Tivoli ApplicationDependency Discovery Manager). We had concentrated ondiscovery, not because it is the only important area (it is not,as I discussed earlier) but because automated discovery isthe foundation on which policy driven decisions can be built.
ADDRESSING THE TECHNICAL DIMENSIONS ... 65

Without comprehensive automated discovery, data is out ofdate. If it is out of date, inappropriate decisions are all toopossible.
Furthermore, one aspect of this which is frequently over-looked is that IT application and infrastructure complexityhas increased to such an extent that even the most capableof humans have difficulty in comprehending what is happen-ing. The old days where a few gifted and insightful individu-als were able to deliver have disappeared. Just consider theinfrastructure implications of an Olympic Games or a WorldCup or other major media events or a foreign exchange mar-ket or a telecoms (or other) network operator… Automationis now obligatory. It cannot be avoided.
THE CCMDB DIMENSIONAutomated discovery is a starting point. It tells you what youhave. But discovery is not a one off activity or even an occa-sional activity like taking inventory. It is an ongoing one, adiscipline which must continually discover what is happeningand, thereby, enable downstream tools — like the CCMDBand management tools — to have the information to makeintelligent decisions.
As such, automated discovery is the unavoidable first step inbuilding the CCMDB. It is the repository then that organizesall the discovered data and which then enables the intelli-gent analyses from which decisions are taken and actionsinitiated.
Indeed, one of the challenges we recognized within Collationbefore IBM bought the company, was that we (Collation)needed a CCMDB — to hold the infrastructure model and itssupporting discovered data — as well as tools for analysis ofthe discovered data. Working with Tivoli made a great dealof sense because it had a CCMDB (and IBM has long experi-ence of database technology) and the expertise needed. Wedid not want to build our own if we could exploit what oth-ers had researched and built.
This mattered to us: there are few vendors that can delivera comprehensive model, one which reaches from the main-
66

frame to the desktop. There are the legacy mainframe ven-dors (and you could argue that Tivoli is one of these). Thereare also specialists at the smaller end of systems. Then thereare many levels in between (Web Servers and ApplicationServers are good examples, for these can operate at all sortsof differing levels of granularity — from simple Web pageserving through to full blown, recoverable transaction pro-cessing).
As far as our thinking was concerned, no model could beregarded as complete if it did not cover the extremes foundin today’s typical IT application environment and supportinginfrastructure. An equally important point to remember hereis that a CCMDB is much more than a topology and associ-ated configuration data (there are plenty of CMDBs around,of varying quality, that are little more than this).
A CCMDB must be capable of supporting process artifacts. Itmust be able to understand different processes, trouble tick-ets, incidents, the sorts of data being reported, etc.
Without an understanding of what it is receiving — whetherfrom discovery or from existing systems management prod-ucts — it will not store data in ways that can subsequentlybe used. In effect, therefore, discovery has to be integratedwith, existing operational management products. Once thisis done, however, a CCMDB becomes the central store for notonly what has been discovered but what is continuing to bediscovered. The point to appreciate is you do not discoversomething once. Discovery is an ongoing process.
Nothing new may be discovered, but that in itself is usefulinformation — just as anything that has changed will haveits own relevance somewhere. (There is some good newshere: you do not have to discover everything every day orevery hour: but you do need to think about how often youdo want different levels of discovery to operate. There are aset of business decisions to be made here.)
DISCOVERY AND A CCMDB ARE NOT SUFFICIENTHaving said all the above, a CCMDB, even with discovery, isstill not enough. These may capture, store and represent the
ADDRESSING THE TECHNICAL DIMENSIONS ... 67

configuration. But this is not likely to be sufficient if analysisbeyond the configuration is required.
Think about what impact analysis of events and causesinvolves. If you do not have the appropriate level of infor-mation, your operations people may draw an incorrect con-clusion. Let me give a practical example.
Event monitoring systems can provide a whole set of infor-mation about events that are related — say about an appli-cation using a specific database instance that is located on aparticular disk sub-system. If an application starts to runslowly, or stop, then one can trace back the source problemto (say) a disk in a cluster beginning to fail. This can be doneusing the events that are arriving.
But, if you have events coming in about configurations thatare not necessarily located on the same physical box (say,involving load balancing which has a group of cluster config-uration definitions) you may be receiving event data wherethere is no relationship information about the various eventsthat are being generated by (say) the load balancer, the dif-ferent applications on the cluster, different data stores, etc.
The ability to take events and see the relationships —between the events, the load balancer, the cluster controller,the supporting hardware, etc. — is what is needed to cometo any meaningful determination about the problem (andthen to arrive at a solution). You need to be able to digdeeper into the different parts of the information (for exam-ple how virtual IP addresses are mapped to real IP address-es) and the relationships between the different parts tobegin to be able to see that what may appear to be separateis in fact connected.
Indeed, in this example, it may transpire that a diminishedlevel of service on a cluster is acceptable for one applicationbut not for another. This is an example of where relationshipand configuration information helps to solve event correla-tion issues and impact analysis facilitates redirection ofresources to where they are most needed.
68

WHAT IS DIFFERENT ABOUT A CCMDB?In the market place today there are many vendors claiming,and often using the same terminology if in different ways, tohave some form or other of Configuration Database (CDB) oreven Configuration Management Database (CMDB). These,as you would expect use differing approaches with differentclaims.
One common claim comes from vendors who may have var-ious data stores about what is happening operationally (sayservice desk or change management). These are often high-ly focused data repositories.
But gathering several differing data stores together andapplying a CDB label does not create a CDB — or even aCMDB. This is retrofitting a marketing description to a com-bination of existing capabilities which were, and are, notabout configuration — at least not at the level that mostenterprises want.
What is missing is the ability to possess a common modelthat spans all the functions that have been combined.Without such a common model, relationships are eitherunder-described or do not exist. This prevents automationand synchronization between capabilities. Insisting on man-ual modeling and reconciliation as a means to fill this gap isto miss the point about a CMDB.
Equally, a CMDB is not just an aggregation of data. It is anarchitecture that depends on how information is processedand integrated to deliver a model of what is occurring in anenterprise. A second dimension to a fully fledged CMDBrequires consideration about how well is the process of con-figuration and change embedded into that architecture. Asyou manage the lifecycle of configuration items comingin/leaving the model, you need to be sure that there is anunderstanding of:
what is changingthe integrity of the associated data.
The key difficulty here, in our experience, is that you cannot
ADDRESSING THE TECHNICAL DIMENSIONS ... 69

retrofit this. It has to be designed in from the start if you areto obtain the depth of analysis and control that customerswill expect.
The Tivoli CCMDB goes even further. In one way you canargue that it represents a holistic approach that goes muchfurther than a CMDB because it includes a complete dataarchitecture with reconciliation, synchronization, federationand integration designed from the bottom up.
Emphatically, from a design viewpoint, it is not merely anaggregation of many other data sources. It encompasses thecomplete notion of change and configuration life cycle man-agement and this is built into its design. It is not only about‘absorbing’ the data into the data store and model — but itis also about everything you need to manage thereafter. (Apoint to appreciate here is that trying to retrofit such anapproach to a CMDB would, in my estimate, take 18-24months — with all the uncertainties and challenges thataccompany trying to take existing functions and make themdo what they were not designed to deliver.)
What I am trying to say here is that buying a database andfilling it with data is not sufficient for real control of changeand configuration management. More is needed over andabove any data store itself.
THE NEXT 2-3 YEARS – ANTICIPATED KEY DEVELOPMENTSMy focus over the past 2-3 years has been on designing anddelivering the functionality that is now in the CCMDB. Thisincludes automated discovery, for populating the data store.It also includes understanding how and what model would beneeded and the different levels and depths and relationshipsthat have to be captured. While not all is finished in thisarea, the major work is incorporated.
This means that the focus of the next 2-3 years will be onadding value to, and exploiting what, the CCMDB provides.The focus will be on building the applications which providethe automated analysis and interpretation of what theCCMDB holds.
70

The point to remember is that filling a CCMDB with data thathas assured integrity is not an end in itself. Just as auto-mated discovery is only a means to fill and keep up to datea CCMDB, albeit an automated one, so a database contain-ing that data is not the finishing point. The focus should andwill be on providing value additive tools like process man-agers.
In this context, you will see IBM:
moving away from the traditional functional task automationmodel, which today is primarily focused on resourcestowards a process-driven automation model which depends ondata and abstraction.
The value comes as the degree of process automationincreases and deepens. In particular this will be aimed atsupporting explicit business services and business applica-tions, rather than the IT task and infrastructure orientationof the past. The connection with what is happening in thebusiness will be clearer and more relevant — to the busi-ness.
Once you start automating these processes — based onabstractions that you can model and describe in the CCMDB— then you have started down the road to full serviceautomation and, ultimately, policy-driven automation.
Understand the long term difference here. Process automa-tion is akin to manual automation: yes, it may be better thanwhat most enterprises have today. The processes may beautomated but the intelligence as to what should beprocessed is still driven by humans (the manual element).
Policy driven automation is where true automation takesover. Once policies have been decided and implemented,then the human element can drop out and the system canmanage itself — according to the policies it has been given.This is far richer and more effective as well as much lesscostly in the long term.
That said, proceeding along a step by step road has its own
ADDRESSING THE TECHNICAL DIMENSIONS ... 71

benefits. Some argue that jumping directly to policy drivenautomation is desirable. I am not so sure. It is importantthat we, vendors and customers, make certain that we havethe process automation stages right before we think aboutpolicy-driven automation.
To me, refining process automation is as logical a next stepas discovery was before the CCMDB. You cannot do every-thing simultaneously; dependable foundations have to beestablished.In one sense this should become self-fulfilling. As you grad-ually work through the various stages — and assuming youdo this thoroughly — you are putting in place the cross-domain building blocks that will enable policy-drivenautomation.
If you do not have visibility, you do not have control. If youdo not have control you cannot have knowledge-drivenautomation. If you cannot have knowledge-driven automa-tion you cannot reach policy-driven automation.
LESSONS LEARNEDOne of my first realizations was that, as an enterprise con-templates undertaking the changes that adiscovery/CCMDB-based approach requires, there is onevery clear indicator as to whether that organization is readyto take on such an initiative (or if it is not):
deciding to adopt a CCMDB-based initiative is not a departmentaldecision; if it is, it will likely fail (put another way, departments donot exist in isolation)a CCMDB-based initiative is strategic; it requires executivecommitment and for the long term.
In other words, if there is no senior management backing,then an investment will likely fail. Fundamentally, a top-down approach is required. Without this, progress will stallor be relatively trivial compared to what could be achieved.
My second lesson learned is that implementers have to havesome level of understanding of what is required. In the late
72

1980s/early 1990s the focus of an operations center or datacenter was on the glass. We had all sorts of informationbeing brought to the screen, with decisions and actions thenbeing taken. How we managed those environments waseffectively activity-driven management.
Today we are moving towards a data focused approach inthe operation center. You can see this with the concentrationon service delivery, service support, service levels, businessautomation, etc. This depends on good abstraction of dataand it is effectively moving ‘off the glass and into the data-base’.
Though it may not be recognized as such (yet), this repre-sents a fundamental shift for IT organizations. It requires atransformation of thinking in each organization if it is to hap-pen. Without recognition of the implications and conse-quences, introducing a CCMDB approach will constantly runinto cultural problems — because the underlying bases ofoperation is changing so much. It is about managing in across-domain manner — and not by individual silo.
Experience shows that those organizations which lack anunderstanding of this are the ones that can almost be pre-dicted to have their CCMDB initiatives fail, even if there istop level support. That does not mean that an appreciationof the depth of change guarantees success; rather it is theopposite — that a cultural failure to understand almostalways ensures the initiative’s failure.
Let me give a concluding example from one organizationthat is far along the CCMDB path. It adopted a six stage evo-lution, starting with data center consolidation and consisten-cy. It realized that it is not just about adapting its ownorganization but it is also about putting in place the systemdisciplines that will make it easier to move from stage tostage. Standardization of procurement and of technologiesthat will be deployed in the future are other facets of start-ing to put one’s organizational house in order. Once theseare in place the steps towards process automation and policy automation and optimization follow much more readily.
ADDRESSING THE TECHNICAL DIMENSIONS ... 73

In order to be able to do sophisticated management andallocation of IT services you need to know what you possess.Finding out what an enterprise actually possesses is not sim-ple. Keeping that data up to date, given the infinite capabil-ity of IT to change and evolve, is even harder. If you do notknow what you possess, or if you have the wrong informa-tion, then the management and allocation will not be asgood as it should — and maybe a whole lot worse.
74






























