Embed Size (px)
Citation preview

Implementation of an OpenMulti-Ser viceRouter
FredKuhns,JohnDeHart,RalphKeller, JohnLockwood,PrashanthPappu,JyotiParwatikar, EdSpitznagel,David Richards,David Taylor, JonTurnerandKenWong
WUCS-01-20
August15,2001
Departmentof ComputerScienceCampusBox 1045WashingtonUniversityOneBrookingsDriveSt. Louis,MO 63130-4899
Abstract
This paper describesthe design, implementationand performanceof an open, high-performance,dynamicallyreconfigurableMulti-ServiceRouter(MSR) beingdevelopedatWashingtonUniversity in St. Louis. This routerprovides an experimentalplatform forresearchon protocols,routersoftwareandhardwaredesign,network management,qualityof serviceandadvancedapplications.TheMSR hasbeendesignedto beflexible, withoutsacrificingperformance.It supportsgigabit links andusesa scalablearchitecturesuitablefor supportinghundredsor even thousandsof links. The MSR’s flexibility makes it anideal platform for experimentalresearchon dynamicallyextensiblenetworks that imple-menthigherlevel functionsin directsupportof individual applicationsessions.
This work wassupportedin part by NSF grantsANI-0096052,ANI-9714698,ANI-9813723,ANI-9616754andDARPA grantN66001-98-C-8510.

Implementation of an Open Multi-Ser viceRouter
FredKuhns�, JohnDeHart
�, RalphKeller
�, JohnLockwood
�, PrashanthPappu
�,
JyotiParwatikar�, EdSpitznagel
�, David Richards� , David Taylor� , JonTurner
�andKenWong
��fredk,jdd,keller, lockwood,prashant,jp,ews1,wdr,det3,jst,kenw � @arl.wustl.edu�
Departmentof ComputerScienceandtheAppliedResearchLaboratory� Departmentof ElectricalEngineeringandtheApplied ResearchLaboratoryWashingtonUniversity, St. Louis,MO 63130,USA
1. Intr oduction
In the last decade,the Internethasundergonea fundamentaltransformation,from a small-scalenetwork servingacademicsandselecttechnologycompanies,to aglobalinfrastructureservingpeo-ple in all walks of life andall partsof the world. As the Internethasgrown, it hasbecomemorecomplex, makingit difficult for researchersandengineersto understandits behavior andthatof itsmany interactingcomponents.This increasesthechallengesfacedby thoseseekingto createnewprotocolsandtechnologiesthat canpotentiallyimprove the Internet’s reliability, functionalityandperformance.At thesametime, thegrowing importanceof the Internetis dramaticallyraisingthestakes.Evensmall improvementscanhave abig payoff.
In this context, experimentalstudiesaimedat understandinghow Internetroutersperforminrealistic network settings,are essentialto any seriousresearcheffort in Internet technologyde-velopment.Currently, academicresearchershave two mainalternativesfor experimentalresearchin commercialroutersand routing software. With commercialrouters,researchersaregenerallylimited to treatingthe routerasa black box with the only accessprovided by highly constrainedmanagementinterfaces.Theinternaldesignis largelyhidden,andnotsubjectto experimentalmod-ification.
Theotheralternative for academicresearchersis to useroutingsoftware,runningon standardcomputers.Opensourceoperatingsystems,suchasLinux andNetBSDhave madethis a popularchoice.This alternative hastheadvantagethat it providesdirectaccessto all of thesystem’s func-tionality andprovidescompleteextensibility. The growing performancedemandsof the Internethave madetheinternaldesignof high performanceroutersfar morecomplex. Routersnow supportlargenumbersof gigabit links andusededicatedhardwareto implementmany protocolprocessingfunctions. Functionalityis distributedamongthe line cardsthat interfaceto the links, thecontrolprocessorsthatprovidehigh level managementandtheinterconnectionnetwork thatmovespacketsfrom inputsto outputs.Thehighestperformancesystemsusemultistageinterconnectionnetworkscapableof supportinghundredsor even thousandsof 10 Gb/slinks. To understandhow suchsys-temsperform,onemustwork with systemsthathavethesamearchitecturalcharacteristics.A single
1

2
processorwith ahandfulof relatively low speedinterfaces,usesanarchitecturewhich is bothquan-titatively andqualitatively very different. Thekindsof issuesonefacesin systemsof this sortarevery different from the kinds of issuesfacedby designersof modernhigh performancerouters.If academicresearchis to be relevant to the designof suchsystems,it needsto be supportedbysystemsresearchusingcomparableexperimentalplatforms.
TheMulti-ServiceRouter(MSR) beingdevelopedat WashingtonUniversityprovidesan idealplatform for advancednetworking researchin the increasinglycomplex environment facing re-searchersand technologydevelopers. It is built arounda switch fabric that canbe scaledup tolargenumbersof ports.While typical researchsystemshavesmallportcounts,they dousethesameparallelarchitectureusedby muchlargersystems,requiringresearchersto addressin arealisticwaymany of theissuesthatarisein largersystems.TheMSR hasembedded,programmableprocessorsat every link interface,allowing packet processingat theseinterfacesto becompletelyflexible. Anextensionto theMSR architecture,which is now in progress,will enableall packet processingtobe implementedin hardware,allowing wire-speedforwardingat gigabit rates. The designof allsoftwareandhardwareusedin theMSRis beingplacedin thepublicdomain,allowing it to bestud-ied,modifiedandreusedby researchersanddevelopersinterestedin advancingthedevelopmentofopen,extensible,highperformanceInternetrouters.
Section2 describestheoverall systemarchitectureandsomenovel hardwarecomponents.Sec-tion 3 describesthe designandimplementationof system-level processingelementsandsomeofthedesignissuesrelatedto its distributedarchitecture.Section4 describesprocessingdoneat theport processors.Section5 describesperformancemeasurementsof our earlyprototypewhich usesa softwareimplementationof our packet forwardingengineandactive packet processor. Themea-surementsquantify the systemsability to forward packets and provide fair link access.Finally,Section6 closeswith final remarkson thecurrentstatusof thesystemandfutureextensions.
2. SystemOverview
Figure1: MSR HardwareConfiguration

3
TheWashingtonUniversityMSRis designedto beascalable,high-performance,openplatformfor conductingnetwork research.It employshighly reconfigurabletechnology(programmablehard-wareanddynamicsoftwaremodules)to providehigh-speedprocessingof bothIP packets(with andwithout active processing)andATM cells. Figure1 shows theoverall architectureof theMSR andits maincomponents:ControlProcessor(CP),ATM switchcore,Field Programmableport eXten-ders(FPXs),SmartPortCards(SPCs)andLine Cards(LCs).
The main function of the router is to forward packets at a high speedfrom its input side toits outputside. Thesystemusesa multistageinterconnectionnetwork with dynamicroutingandasmall internalspeedadvantage(i.e., theinternaldatapathscanforwardpacketsat a fasterratethantheexternallinks) to connecttheinput sidePortProcessors(PPs)to theoutputsidePPs.A PPcanbeeithera Field Programmableport eXtender(FPX) and/ora SmartPortCard(SPC).An FPX is areprogrammablehardwaredevice, andanSPCis a general-purposeprocessor. ThesePPsperformpacket classification,routelookupandpacket scheduling.
Thesystememploys a numberof interestingtechniquesaimedat achieving high performanceandflexibility. A distributedqueueingalgorithmis usedto gainhighthroughputevenunderextremeoverload.ThePPsuseapacketclassificationalgorithmthatcanrunatwirespeedwhenimplementedin hardware.TheCPrunsopensourceroutedaemonsthatsupportstandardprotocolssuchasOSPFaswell as the MSR’s own flow-specificrouting protocol. Furthermore,the key router functionsareefficiently distributed amongits hardwarecomponentsby exploiting the high bandwidthandconnection-oriented circuitsprovidedby theATM switchcore.Theremainderof this sectiongivesanoverview of theMSR hardwarecomponents.
2.1.Control Processor
The Control Processor(CP) runssoftwarethat directly or indirectly controlsandmonitorsrouterfunctionssuchasport status,resourceusageandpacket classificationtablesusedin thePortPro-cessors(PPs).Someof thisprocessingis describedin Sections3 and4. TheCPis connectedto oneof theMSR’sportsandusesATM controlcellsto controlandmonitorPPactivity.
2.2.Switch Fabric and Line Cards
TheMSR’sATM switchcoreis aWashingtonUniversityGigabitATM Switch(WUGS)[1, 2]. ThecurrentWUGS haseight (8) portswith Line Cards(LCs) capableof operatingat ratesup to 2.4Gb/sandsupportsATM multicastingusinganovel cell recycling architecture.
EachLC providesconversionandencodingfunctionsrequiredfor thetargetphysicallayerde-vice. For example,anATM switchlink adapterprovidesparallel-to-serial,encoding,andoptical-to-electricalconversionsnecessaryfor datatransmissionover fiber usingoneof theoptical transmis-sionstandards,e.g.,SONET. CurrentLCs includea dual155Mb/s OC-3SONET[3] link adapter,a 622Mb/s OC-12SONETlink adapter, a 1.2Gb/sHewlett Packard(HP) G-Link [4] link adapter,andadual1.2Gb/sHP G-Link adapter. A gigabitethernetLC is currentlybeingdesigned.

4
SRAM
To/
Fro
m o
ther
net
wor
k po
rts
SelectMapProgramming
Interface
ccp
Four Port
Switch
EC EC
Control
VC
Error Check
Processor
Mod
ule
temp
Asynchronous
FPX
NIDFPGA
RAD FPGA
Cell
Switch
VC VC
VC
Mod
ule
Pentium
Switching
Use
r
FlowLookup
WUGS
Packet ProcessingSoftware−based
Three Port
APIC
Packet Processing
FIP
L
Circuit
Table
InterfaceSynchronous
Interface
Line
Car
d
SPC
Hardware−based
DataSRAM
DRAMEDO
BridgeSouthBridge
Data
SRAMData
North
Data
SDRAMSDRAM
RADProgram
Module
PCI Bus
PCI Interface
Intel Embedded
Figure2: An FPX/SPCPortProcessor

5
2.3.Port Processors
Commercialswitchesandroutersalreadyemploy complex queueingandpacket filtering mecha-nisms. However, this is usually accomplishedthroughspecializedintegratedcircuits. Figure 2shows how the MSR usesPPsmadeup of a general-purposeprocessor(the SPC)with a repro-grammablehardwaredevice(theFPX)to providethesemechanisms.Thisimplementationapproachtakesadvantageof thebenefitsof acooperativehardware/softwarecombination[5, 6]. AlthoughtheSPCis capableof performingall port functions,a high-speedconfigurationusesboththeFPX andSPC.TheFPX actsasa forwardingengine[7], andtheSPCactsasa network processorhandlingnon-standardprocessing(e.g.,active packet, IP options).
Field Programmable Port Extender (FPX): The FPX is a programmablehardwaredevice thatprocessespacketsasthey passbetweentheWUGSbackplaneandtheline card(shown in themid-dle of Figure2). All of thelogic on theFPX is implementedwith two FPGAdevices: theNetworkInterfaceDevice (NID) andtheReprogrammableApplicationDevice (RAD) [7]. TheFPX is im-plementedon a 20 cm � 10.5cm printedcircuit boardthatinterconnectstheFPGAswith multiplebanksof memory.
TheNetwork InterfaceDevice (NID) controlshow packetsareroutedto andfrom its modules.It alsoprovidesmechanismsto loadhardwaremodulesover thenetwork. Thesetwo featuresallowthe NID to dynamicallyload andunloadmoduleson theRAD without affecting the switchingofothertraffic flows or theprocessingof packetsby theothermodulesin thesystem[8].
As shown in thelower-centerof Figure2, theNID hasseveralcomponents,all of whichareim-plementedonaXilinx Virtex XCV-600EFPGAdevice. It contains:1) A four-portswitchto transferdatabetweenports;2) Flow look-up tableson eachport to selectively routeflows; 3) An on-chipControl Cell Processorto processcontrolcells thataretransmittedandreceivedover thenetwork;4) Logic to reprogramthe FPGA hardware on the RAD; and5) Synchronousandasynchronousinterfacesto thefour network portsthatsurroundtheNID.
A key featureof the FPX is that it allows the MSR to perform packet processingfunctionsin modularhardwarecomponents.As shown in the upper-centerof Figure2, thesemodulesareimplementedasregionsof FPGAlogic on theRAD. A standardinterfacehasbeendevelopedthatallows a moduleto processthestreamingdatain thepacketsasthey flow throughthemoduleandto interfacewith off-chip memory[9]. Eachmoduleon theRAD connectsto oneStaticRandomAccessMemory (SRAM) andto onewide SynchronousDynamicRAM (SDRAM). In total, themodulesimplementedon theRAD have full controlover four independentbanksof memory. TheSRAM is usedfor applicationsthatneedto implementtablelookupoperationssuchastheroutingtablefor theFastIP Lookup(FIPL) module.Theothermodulesin thesystemcanbeprogrammedover thenetwork to implementuser-definedfunctionality[10].
Smart Port Card (SPC): As shown in Fig. 3, theSmartPortCard(SPC)consistsof anembeddedIntel processormodule,64 MBytesof DRAM, an FPGAthatprovidessouthbridgefunctionality,and a WashingtonUniversity APIC ATM host-network interface [11]. The SPCruns a versionof the NetBSDoperatingsystem[12] that hasbeensubstantiallymodified to supportfastpacketforwarding,active network processingandnetwork management.
The Intel embeddedmodulecontainsa 166 MHz PentiumMMX processor, north bridge[13]andL2 cache.The“SystemFPGA” providesthefunctionalityof thesouthbridgechip[14] foundin

6
Figure3: Block Diagramof theSmartPortCard(SPC)

7
anormalPentiumsystemandis implementedusingaXilinx XC4020XLA-08Field ProgrammableGateArray (FPGA) [15]. It containsa smallboot ROM, a ProgrammableInterval Timer (PIT), aProgrammableInterruptController(PIC),a dualUART interface,anda modifiedRealTimeClock(RTC’). See[16] for additionaldetails.
On the SPC,ATM cells are handledby the APIC [17, 18]. Eachof the ATM ports of theAPIC canbe independentlyoperatedat full duplex ratesrangingfrom 155Mb/s to 1.2 Gb/s. TheAPIC supportsAAL-5 andis capableof performingsegmentationandreassemblyat themaximumbus rate(1.05Gb/speakfor PCI-32). The APIC directly transfersATM framesto andfrom hostmemoryandcanbeprogrammedsothatcellsof selectedchannelspassdirectly from oneATM portto another.
WehavecustomizedNetBSDto useadisk imagestoredin mainmemory, aserialconsole,aselfconfiguringAPIC devicedriveranda“f ake” BIOS.ThefakeBIOSprogramactslikeabootloader:it performssomeof theactionswhicharenormallydoneby aPentiumBIOS andtheNetBSDbootloaderduringpower-up.
The above hardwareprovide the foundationfor implementingthe systemfunctionality to bedescribedin thefollowing two sections.
3. System-Level Processing
�����
� �� ��
��� �� �
��� �� �� �"! # $ % & ' ( )
*,+ - ./10 2 35416 7 8 9 6: ; < = >@?A B C D E F GH I J K L M N
O P,Q
R,S"T U V W X Y Z [\1] ^ _`1a b c5d,e f g h ei j k l m@n
o p q r s t uv w x y z { |} ~,�
�,�"� � � � � � � ��1� � ��1� � �5�,� � � � �� � � � �@�
� � � ¡ ¢ £¤ ¥ ¦ § ¨ © ª« ¬,
®,¯@° ± ² ³ ´ µ ¶ ·¸1¹ º »¼1½ ¾ ¿ÁÀ1Â Ã Ä Å ÂÆ Ç È É Ê1Ë
Ì Í Î Ï Ð Ñ ÒÓ Ô Õ Ö × Ø ÙÚ Û,Ü
ÝÞ ßà áâ
ãåäçæåèéëê5ìîíðï@êÁñóòôï@êöõ"÷çø,ø êöï
ùÁú û"ü,ý þÿ���� ������� �� �� � ������ ��� � ��� � � ��� � �� � ! " # $ % & ' (*) + ,- . /�0 1 2 3�4 5 6 1 . / 7�8 9�: ; <=�> ? @�A BCEDGFIH J�K L M N�OP�Q R S�T U V�W P�X
Y�Z [ \�]_^ ` ZGacb�d�b�e�Z ^
f*g h�ikj�l g ikh�mon p�q p�r p�l stvuxw y{zo|G} ~�� ������_� � �k��� � ��� ��� ��� �
� � � � � � � � � � � � � � � � �
Figure4: MSR LogicalView
Figure4 givesanalternative view of theMSR showing someof thefunctionsalongthecontrolanddatapaths. This sectiondescribesthe activities that involve the Control Processor(CP) andits interactionwith thePPs.The softwareframework runningon theCP supportssystemcontrol,resourcemanagement,routing,anddistributedqueueing.

8
3.1. Inter nal Communication
CommunicationbetweentheMSR’s distributedcomponentsis built on top of a setof ATM virtualcircuitsusingVCI (Virtual Circuit Identifier)allocationrulesthatsimplify their use.Also, theCPusesthe conceptof virtual interfacesto easilysegregatetraffic arriving from the PPs. The VCIspacepartitioningseparatespacketsinto threetraffic types:1) Control,2) IP, and3) Native ATM.
In addition,theVCI allocationrulesfor inter-PPcommunicationsimplifiestheidentificationofthesendingport. A VCI is treatedasa “tag” thatidentifiesthesendingport. For example,theMSRusesVCI (
��� �¢¡) to identify IP traffic transitingtheswitchfrom port
�(�
is between0 and7 sincethereare8 ports).Any outputPPknows thatall packetsfrom VCI (
��� �¢¡) is IP traffic from input
port�. Here,40 is thebaseVCI for IP traffic. Othertraffic typesusedifferentbaseVCIs.
In certainsituations,the CP will have to processa packet on behalf of a PP. For example,one implementationof traceroute sendsUDP packets to an unuseddestinationport[19] anddeterminescompletionwhen it receives a “port unreachable” responsemessagefrom thedestination.Whenthedestinationis an MSR interface,theMSR’s CP processestheUDP packet.TheMSR’svirtual interfaceconceptaccomplishesthiswithouttheneedto encapsulatetheincomingpacket beforesendingit to theCP. ThePPat theMSR interfacepassesthepacket to theCPusingits uniquevirtual interfaceVCI, andtheCP’s OSkernel“tags” thepacket uponarrival. Then,theCPsendstheappropriateICMP responseon thePP’sbehalf(thesourceIP addressis theIP addressof theinterface).In this fashion,anMSR port lookslike a logical interfaceof theCP.
3.2.SystemConfiguration
Systeminitialization setsup communicationpathsbetweenall processors(CP, PPs)andinitializesthePPswith instructionsanddata.This bootprocessis multi-tiered. First, it performsa low-levelinitialization sequenceso that theCP cancommunicatewith thePPs.Next, theprocessdiscoversthenumber, location,andtypesof computingresourcesandlinks ateachport.
Thefollowing sequenceis executed:
Configuration: The CP controls the operationof its PPsusing ATM control cells. Therefore,communicationmustbeestablishedbetweentheCPandits PPsevenbeforethediscovery stepcanbeperformed.TheCPsetsuppredefinedATM virtual circuits(VCs). TheseincludeVCsfor controlcells,for programloadingandfor forwardingIP packetsfrom input portsto outputports.
Discovery: TheCPdiscoversthelow-level configurationof a port by sendingcontrolcellsto eachpotentialprocessorat eachport usingtheVCIs in step1. Eachprocessorwill reportthecharacter-istics of theadjacentcardthat is further from the switch port. The responsesindicatethe type ofprocessorsat eachportandthelink rate.
SPCInitialization: TheCPdownloadsa NetBSDkernelandmemory-residentfilesystemto eachSPCusinga multicastVC andAAL5 framesandcompleteseachSPC’s identity by sendingthemtheirport locationusinganMSR controlmessage.
FPX Initialization: Initialization of an FPX follows a similar sequence.A programandconfig-uration is loadedinto the RAD reprogram memoryundercontrol of the NID usingcontrol cells.

9
Oncethelastcell hasbeensuccessfullyloaded,theCPsendsacontrolcell to theNID to initiate thereprogrammingof theRAD usingthecontentsof thereprogrammemory.
3.3.Route Management
The MSR maintainsinformation aboutother routersin the network by running Zebra [20], anopen-sourceroutingframework distributedundertheGNU license.Zebrasupportsvariousinterior(OSPFv3,RIPv2,RIPng)andexterior (BGP-4)routingprotocols.Eachindividual routingprotocolcontributesroutesto a commonrouting tablemanagedby theCP. Basedon this routing table,theCPcomputesa forwardingtablefor eachport, which it keepssynchronizedwith theroutingtable.As routingprotocolsreceiveupdatesfrom neighboringroutersthatmodify theroutingtable,theCPcontinuouslyrecomputestheforwardingtablesandpropagatesthechangesto eachport.
The forwardingtablesstoredin theFPXsandSPCsusea treebitmapstructurefor fastpacketclassificationwith efficient memoryusage[21]. The treebitmapalgorithmemploys multibit triedatastructuresthatareideally suitedfor fasthardwareimplementation[7].
Whenthe CP receivesa routeupdatefrom anotherrouterto addor deletea path, it createsanew internaltreebitmapstructurethat reflectsthemodifiedforwardingtable. Then,it sendsATMcontrolcells to theFastIP Lookupcomponentsin theSPCor FPX representingthemodificationsto themultibit trie structure.
3.4.Signaling and ResourceManagement
TheCPalsohandlesvarioussignalingprotocols(e.g.,RSVP, MPLS)andsupportsactivenetworkingfunctionality. Thesignallingprotocolsallow applicationsto make bandwidthreservationsrequiredfor QoSguarantees.Whena bandwidthreservationrequestarrivesat theCP, theCPfirst performsadmissioncontrol by checkingfor sufficient resources.If admissioncontrol succeeds,theCP re-servestherequiredbandwidthonboththeinputandoutputportsandreturnsasignalingmessagetograntthereservation.
The MSR signalingsystemalsosupportsprotocolsthat establishflow-specificroutes. Flow-specificroutesmight beusedby applicationsrequiringspecificQoSguaranteesor flows thatneedto transitspecificnetwork nodesin agivenorderfor active processing.
Flow-specificroutesarehandledby performingtherouting lookupusinga combinationof thedestinationIP address,sourceIP address,destinationport, sourceport, andprotocolfields. In thisway, asinglelongest-matching-prefix lookupwill handleboththenormalIP routesandflow-specificroutes.
In addition,theMSR providesflow-specificprocessingof datastreams.An active flow is ex-plicitly setupusingsignalingmechanismswhichspecifythesetof functionswhichwill berequiredfor processingthedatastream.In thecontext of theMSR,pluginsarecodemodulesthatprovide aspecificprocessingfunctionandcanbedynamicallyloadedandconfiguredateachport.
If anactivesignalingrequestreferencesapluginthathasnotbeendeployedontherouter, theCPretrievestheplugincodefrom aremotecodeserver, checksits digital signature,andthendownloads

10
it to a PPwhereit is configuredusingATM control cells. Oncethe plugin hasbeensuccessfullyloadedandconfigured,theCPinstallsafilter in theport’s forwardingtablesothatmatchingpacketswill beroutedto theplugin.
3.5.CongestionAvoidanceand Distrib uted Queueing
Undersustainedoverload,theinternallinks of theWUGScanbecomecongestedleadingto substan-tially reducedthroughput.Our DistributedQueueing(DQ) algorithmallows theMSR to performlikeanoutputqueueingsystem(switchfabricandoutputqueuesoperateat theaggregateinput rate)but with a switchfabricandoutputqueuesthatrunneartherateof asingleinput link [22].
Mechanism: TheDQ algorithmemploysacoarseschedulingapproachin whichinputsperiodicallybroadcastinformationabouttheir own backlogto eachoutput,andoutputsperiodicallybroadcastinformationabouttheir queuelengthandoutputrateback. TheMSR usesVirtual OutputQueue-ing [23, 24, 25] to avoid head-of-the-lineblocking. Eachinput maintainsseparatequeuesfor eachoutputallowing inputsto regulatetheflow of traffic to eachof theoutputssoasto keepdatamovingto theoutputqueuesin a timely fashion,while avoiding internallink overload.
In our implementation,eachbroadcastcontainsbothinputandoutputinformationsinceasinglePPhandlesboth input andoutput traffic. Eachinput port
�usesthe informationto computenew
input-to-outputflow rates£c¤�¥ for eachoutputport ¦ . Our currenttestbedhaseight portsandusesonly SPCsasPPs.The SPCusesa differentVCI to transmitpacketsto eachoutputport andcansettheoutputrateon a perVCI basisusingtheAPIC’s pacingfacility. After eachflow rateupdateperiod,eachSPCupdatestheAPIC pacingrateaccordingly.
Algorithm: At every updateperiod(currently100 § sec),eachinput port�
recalculatestherate £¨¤ª© ¥atwhich it cansendtraffic to output ¦ , using:
£¨¤ª© ¥¬«® �°¯²± ³ ¥µ´¶¤ª© ¥´·¥ �¹¸»º ´ º © ¥½¼
¾ ´¶¤ª© ¥¸»º ´ ¤�© ºÀ¿
where ³ ¥ is the link bandwidthat output ¦ , ´Á¥ is the backlogat output ¦ , ´¶¤ª© ¥ is the total trafficqueuedat input
�destinedto output ¦ and
¾is the internalspeedof theswitchingfabric. Thefirst
termsharestheoutputbandwidthproportionallybetweentheinputsandoutput ¦ . By includingtheoutputbacklog( ´·¥ ) in the denominator, traffic will be directedat outputswith smallerbacklogs.Thesecondterm sharestheswitch fabric bandwidthproportionallybetweenthe inputs. Themin-imum over the two expressionsinsuresthat inputscanalwayssendat their assignedrateswithoutoverloadingtheswitchfabric;i.e.,
±°¸ º £ ¤�© ºÃ ¾ ¿ .
4. Port-Level Processing
4.1. IP Processing
ThissectiondescribesIP packetprocessingandtheprogrammablenetwork environmentin theSPC.WhentheSPCis the only PPat a port, it musthandleall input andoutputprocessing.Although

11
ideally every port shouldhave bothanFPX to handlethetypical case(e.g.,no active processingoroptions)andanSPCto handlespecialcases(e.g.,active processing),it is desirableto have anSPCthathasfull port functionallity for severalreasons:
Ä RapidPrototyping: A prototypeMSRtestbedcanbeconstructedeventhoughtheFPXis stillunderdevelopment.
Ä LowerCost: A lowercost(but slower) MSR canbeconstructedusingonly SPCPPs.
Ä MeasurementandExperienceBase: Experiencewith theSPCmaybefruitful in thedevelop-mentof theFPX,andexperimentalfeaturescanbeexaminedusingtheSPCasa preliminarystepto commitingto hardware. Furthermore,theaccelerationbenefitsof usingtheFPX canbequantified.
In orderto reduceoverhead,theIP datapathandbasicresourcemanagementfunctionshave beencompletelyincorporatedinto theAPIC interrupthandler. Exceptionsincludetheallocationof MSRspecificmemoryobjectsfor buffersandtheschedulingof periodictasks.
Figure5: IP Processingon theSPC
Themainareasof improvementare:
Ä IP datapathselection(input versusoutputprocessing);
Ä Receive andsendpacket buffer management;
Ä APIC descriptorchainprocessing;and
Ä Interactionwith theAPIC hardware(reading/writingacrossthePCIbus).

12
Figure5 showsthedatapathsthroughtheSPCkernelasit forwardsIP packets(inputandoutputside),processesdistributedqueuingupdatesor respondsto controlcellsfrom theCP.
CodePath Selection:As indicatedin Section3.1,VCIs areusedasdemultiplexing keysfor incom-ing packets. TheVCI of an incomingpacket indicatesto thekernelwhetherit is from a previoushoprouter, theCPor oneof theconnectedMSR input ports. If received from a previoushop, thepacket is sentto theinput port processingcode:basicIP processing,IP lookupandthenoneof theMSR’svirtual outputqueues.If receivedfrom aninput port, thepacket canbeimmediatelysenttothenext hoprouteror endsystem1.
APIC Processingand Buffer Management: The operationof an APIC reducesthe load on theSPCby asynchronouslyperformingsequencesof read/writeoperationsdescribedby descriptorchains. An APIC descriptoris a 16-bytestructurethatdescribesthedatabuffer to bewritten to forreceive,or readfrom transmit.During initialization a contiguouschunkof memoryis allocatedforthedescriptors(half for TX (transmit)andhalf for RX (receive)). Thedriver andAPIC hardwarethenuseabaseaddressandindex to accessaparticulardescriptor.
During initialization, anothercontiguousregion of memoryis allocatedfor IP packet buffers.Eachbuffer is 2 KB, andthereareanidenticalnumberof buffersandRX descriptors.Eachbufferis boundto anRX descriptorsuchthattheir indexesarethesame.Consequently, givenadescriptoraddressor index, the correspondingRX buffer can be locatedsimply and quickly. The reverseoperationfrom buffer to descriptoris equallyfast.This techniquemakesbuffer managementtrivial,leaving only themanagementof theRX descriptorpoolasanon-trivial task.
Sincetherearethesamenumberof TX descriptorsasRX descriptors,wearealwaysguaranteedto beableto senda packet onceit is received. Notethatwhensendinga packet, thereceive bufferis boundto theTX descriptor. ThecorrespondingRX descriptoris not availablefor reuseuntil thesendoperationcompletes.This hastheniceeffect that theSPCwill stopreceiving duringextremeoverloadandavoid unnecessaryPCIandmemorytraffic andreceiver livelock.
4.2.ProgrammableNetworks Envir onment
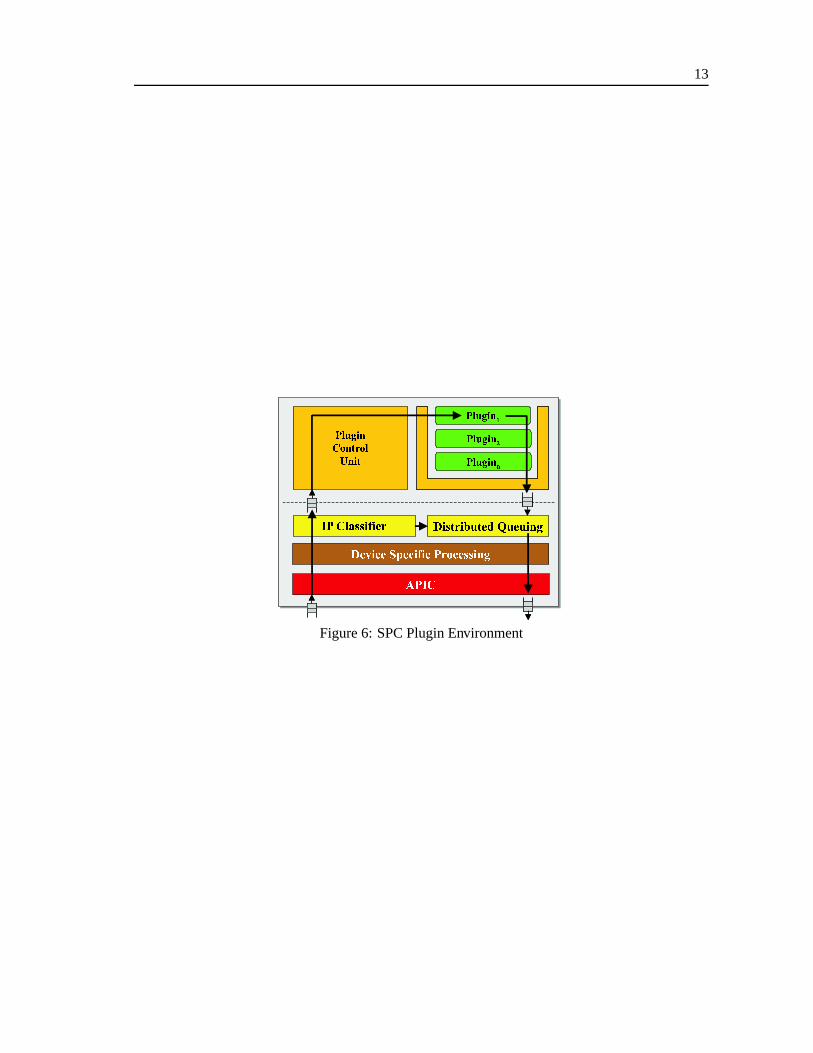
On eachport of theMSR, theSPCrunsa modifiedNetBSDkernelthatprovidesa programmable(plugin)environmentfor packetprocessing(Figure6). TheSPCenvironmentincludesfunctionalityto supportbothtraditionalIP forwardingaswell asflow-specificprocessing.
TraditionalIP forwardingincludescontrollingtheAPIC hardware,packetclassificationandfairoutputqueuingwhich runsat thehardwareinterruptlevel. Active packet processingis handledatthelower priority softwareinterruptlevel. Therefore,active processingcanbepreemptedby APICdevice interruptsassociatedwith packet arrivals,guaranteeingthatpacketscanbeimmediatelysentandreceivedfrom thehardware.
If anMSRport is equippedwith anFPX,packetsareclassifiedusingthehardwareimplementa-tion of theFastIP Lookup(FIPL) algorithmandsentto theSPConaspecialVCI, signalingtheSPC
1Currently the MSR only supportsonedirectly connecteddevice. However we plan to extend this to somefinitenumberof connectedhostsandrouters.
13
Å¨Æ Ç{È�É ÊËÍÌIÎÐÏ�Ñ�ÌvÒÓÕÔxÖ ×
بÙ�ÚÜÛ�Ý�ÞÜßà¨á�âÜã�ä�å�æç¨è é{ê�ë ìÐí
îðïEñ�òóðô�õµö_÷Iôùø¨úûôI÷vö*ü�ö_÷½ýÍþ�ÿ{÷ ô ��� ö����
��� ����������������� �������! "�$#&%'�!(�)�*+%&(�%'��,�-
Figure6: SPCPluginEnvironment

14
thatthepacket is alreadyclassified.If no FPX is presentat aport, thepacket arrivesat thestandardVCI andtheSPCperformsthelookupitself usingasoftwareimplementationof theIP classifier.
Regardlessof how thepacket is identifiedasrequiringactive processing,it is enqueuedinto theactive processingqueueandcontrolis givento thePluginControlUnit (PCU).
ThePCUprovidesanenvironmentfor loading,configuring,instantiatingandexecutingplugins.Pluginsare dynamically loadableNetBSD kernel moduleswhich residein the kernel’s addressspace.Sincenocontext switchingis required,theexecutionof pluginsis highly efficient.
For thedesignof plugins,we follow anobject-orientedapproach.A plugin classspecifiesthegeneralbehavior of apluginanddefineshow it is initialized,configuredandhow packetsneedto beprocessed.A plugin instanceis a runtimeconfigurationof apluginclassboundto aspecificflow. Itis desirableto havemultipleconfigurationsof aplugin,eachprocessingits specificflow andhavingits own datasegmentthatincludestheinternalstate.Multiple plugin instancescanbeboundto oneflow, andmultiple flowscanbeboundto asingleinstance.
Throughavirtual functiontable,eachpluginclassrespondsto astandardizedsetof methodstoinitialize, configureandprocessplugins. All codefor initialization, configurationandprocessingis encapsulatedin the plugin itself. Therefore,the PCU is not requiredto know anything aboutaplugin’s internaldetails.
WhenthePCUis in control,it decideswhich packet needsto beschedulednext for processingin orderto meeteachflow’s QoSdelayguarantees.Suitableexecutionschedulingalgorithmshavebeendiscussedin severalreferences[26, 27].
Oncea packet hasbeendequeuedfrom the active processingqueue,the plugin environmentinvokestheprocessingfunctionof thecorrespondingplugin instance,passingit a referenceto thepacket to be processed.Theprocessingmight alter thepacket payloadaswell astheheader. If apacket’s destinationaddresshasbeenmodified,thepacket needsto bereclassifiedsincetheoutputportmight have changedbeforethepacket is finally forwarded.
5. MeasurementExperiments
In this sectionwe focuson the routerthroughputwhenusingSPCsasboth input andoutputportprocessors.In particular, we measurethepacket forwardingrateanddatathroughputfor differentIP packet sizes.
5.1.Experimental Setup
Figure7 shows theexperimentalsetupusedfor our tests.TheconfigurationincludesanMSR withCPandonePCon port P4actingasa traffic source.TheATM switchcoreis aneight-portWUGSconfiguredwith an SPCon eachport. TheCP andtraffic sourceareboth 600MHz PentiumPCswith APIC NICs.
The experimentsuse four key featuresof the WUGS: input port cell counters,a calibratedinternalswitchclock,andATM multicastandcell recycling. TheCPreadsthecell counterfrom the

15
Figure7: ExperimentalSetup
switchinput portsandusestheswitchcell clock to calculatea cell rate.Thepacket ratecaneasilybe derived from the cell ratesincethe numberof cells per packet is a constantfor an individualexperiment.
Themulticastandrecycling featuresof theWUGSwereusedto amplify thetraffic volumeforsingle-cellIP packets.Cell traffic canbeamplifiedby .�/ by copying andrecycling cellsthrough̄VCIs beforedirectingthecellsto a targetport. However, this featurecannot beusedfor multi-cellIP packetssincetheATM switchcoredoesnotpreventtheinterleaving of cellsfrom two packets.
The SPCson portsP2 andP3 wereconfiguredto operateasIP packet forwarders.Port P2 isusedastheinput portandport P3astheoutputport. All otherSPCsaredisabledsothattraffic willpassthroughthemunaffected.
Typically, hostsor other routerswould be connectedto eachport of an MSR. However, tofacilitatedatacollectionwehavedirectlyconnectedtheoutputof portP1to theinputof portP2andtheoutputof port P3to theinputof P7.Ourdatasourceis connectedto portP4.Thuswecanuse:
Ä Thecell countersatport P4to measurethesendingrate;
Ä Thecell countersat port P2to measurethetraffic forwardedby theinput sidePPat port P2;and
Ä Thecell countersatportP7to measurethetraffic forwardedby theoutputsidePPatportP3.
IP traffic is generatedby usinga programthat sendsspecificpacket sizesat a prescribedrate.Packet sendingratesare controlledusing two mechanisms:1) logic within the traffic generatorprogram,and2) for high rates,theAPIC’s pacingfacility. Thesetwo mechanismsproducedbothhighandconsistentsendingrates.

16
5.2.Small-Packet Forwarding Rate
In orderto determinetheperpacket processingoverhead,we measuredtheforwardingrateof 40-byteIP packets(1 ATM cell each)at theinput andoutputports.Single-cellpacket ratesashigh as907KPps(KiloPacketspersecond)weregeneratedby usingtheATM multicastandcell recyclingfeaturesof theswitchto multiply theincomingtraffic by a factorof 8.
0
20
40
60
80
100
120
140
160
0 200 400 600 800 1000
Source Packet Rate (KPPS)
Pack
et F
orw
ardi
ng R
ate
(KPP
S)
Input Port Out Port
Figure8: Packet ForwardingRatefor 40-ByteIP Packets
Figure8 shows thepacket forwardingratefor 40-byteIP packets.Theline labeled“Input Port”representsthepacket forwardingratefor anSPCoperatingasaninputPP. Similarly, theline labeled“Output Port” is thecorrespondingrateon theoutputside.
The maximumforwardingrateat an input port PPis about140 KPps. As expected,the out-put port PPhasa higherforwardingratesinceit doesnot performIP destinationaddresslookup.Furthermore,140KPpsis sustainedevenfor a sourcerateashigh as900KPps.This ratestabilityat high loadsis a consequenceof our receiver livelock avoidancescheme.The throughputcanbeobtainedfrom Figure8 by multiplying thepacket forwardingrateby thepacket size(40 bytes).Acalculationwould show that140KPpscorrespondsto a maximumforwardingdatarateof around45 Mbpsandto apacket processingtimeof approximately7.1 § sec.
5.3.Throughput Effectsof Packet Size
We next measuredtheeffect of thepacket sizeon thepacket forwardingrate. BecauseIP packetslarger than40 bytesrequiremorethanonecell (thereis 8 bytesof overhead),we no longerusedATM multicastwith cell recycling to amplify the traffic. We useda singlehostto generatetrafficusingpacket sizesrangingfrom 40 bytesto 1912bytes.
Figure9 shows thepacket forwardingrateasa functionof the input packet ratefor a rangeofpacket sizes.A straightline with aslopeof 1 correspondsto thecasewhentherearenobottlenecksalongthepaththroughtherouter. For all packet sizes,the forwardingratestartsout asa line withslope1 until finally akneeoccursendingin ahorizontalline. Thehorizontalportionof aforwarding

17
0
20
40
60
80
100
120
140
160
0 50 100 150 200
Source Packet Rate (KPps)
Out
put P
acke
t Rat
e (K
Pps)
40 B/pkt136 B/pkt232 B/pkt520 B/pkt760 B/pkt1192 B/pkt1480 B/pkt1912 B/pkt
Figure9: Packet ForwardingRatefor VariousIP Packet Sizes

18
0.00
50.00
100.00
150.00
200.00
250.00
0.00 100.00 200.00 300.00 400.00 500.00 600.00 700.00
Source Data Rate (Mbps)
Outp
ut D
ata
Rate
(Mbps)
40 B/pkt136 B/pkt232 B/pkt520 B/pkt760 B/pkt1192 B/pkt1480 B/pkt1912 B/pkt
Figure10: RouterThroughputfor VariousIP Packet Sizes
ratecurve is an indicationof CPU, PCI bus andmemorysystembottlenecks.Saturationoccursearlier(smallerpacket sourcerate)for largerpacketssincemorememoryandPCIbusbandwidthisbeingconsumed.
Figure10 shows the outputdataratewhich canbe derived from Figure9 by multiplying thepacket forwardingrateby thepacket size.
5.4.Analysis of Results
In analyzingourperformanceresults,we consideredthreepotentialbottlenecks:
Ä PCIBus(33MHz, 32bit)
Ä SPCMemoryBus(66MHz EDO DRAM)
Ä Processor(166MHz PentiumMMX)
Eachof thesecomesinto playatdifferentpointsin thepacket forwardingoperation.
Ourstudiesof thePCIbusoperationsthattakeplaceto forwardapacket indicatethatthereare3PCIreadoperationsand5PCIwriteoperationswhichtogetherconsume60buscycles.Additionally,underheavy load,wecanexpect64wait cyclesto beintroduced.Thusatotalof 124buscycles(30.3nspercycleon a33 MHz bus)or 3.72 § secareconsumedby PCI busoperationsin theforwardingof a packet.
Theaveragesoftwareprocessingtime for performingthesimpleIP lookupschemeutilized inour testcaseshasbeenmeasuredto be3.76 § sec.This,combinedwith thePCIbustimecalculated

19
above givesusaperpacket forwardingtimeof 7.48 § sec.This is very closeto thetime of 7.1 § secfor thesmallpacket forwardingrateof 140KPpsshown in Figure8.
Oneof theproblemsthatwe have to overcomewith theSPCis a bug in theAPIC chip. Thisbug causesthe received word orderon an Intel platform to be incorrect. In orderto work aroundthis, theAPIC driver mustperforma word swap on all received data. Thus,eachreceived packetmaycrossthememorybus4 times:
Ä APIC writespacket to memory
Ä CPUreadspacket duringwordswapping
Ä CPUwritespacket duringwordswapping
Ä APIC readspacket from memory
Wehavedemonstratedtheimpactof thewordswappingby eliminatingmostof it from asimpletestusing1912-bytepackets. In this test,we only performedtheword swapon the20 bytesof theIP headerso thatwe couldperformour IP lookupoperation.In this testcase,our forwardingrateincreasedfrom about14KPpsto 22KPps,a50%increase.Thecorrespondingthroughputincreasedfrom 212Mbpsto 336Mbps.
6. Concluding Remarks
Additional performancemeasurementsof theMSR arein progress,anda numberof developmentsand extensionsare underway. First, the integration of the FPX with the currentMSR configu-ration will sooncommence.The Fast IP Lookup (FIPL) algorithmhasbeenimplementedin re-programmablehardwareusingthe FPX, andsimulationshave demonstrateda speedof over ninemillion lookupspersecondmaybe possibleon eachport. In addition,otherapplicationsarecur-rently beingportedto theFPX. Second,SPCII is underdevelopmentwith availability plannedfortheendof 2001.It will haveafasterprocessor(500MHz to 1 GHzPIII), muchhighermainmemorybandwidth(SDRAM), anda largermemory(256MB). Third, a Gigabit Ethernetline card is beingdesignedaroundthe PMC-SierraPM3386S/UNI-2xGEDual Gigabit EthernetControllerchipsetwith plansfor availability in early 2002. This will allow us to interfacethe MSR to routersandhoststhathaveGigabitEthernetinterfaces.Fourth,many CPsoftwarecomponentsarein theirearlyprototypingstage.Someof thesecomponentsinclude: 1) Automaticmulti-level bootprocessthatstartswith discoveryandendswith acompletelyconfigured,runningrouter;2) Network monitoringcomponentsbasedonactive,extensibleswitchandPPMIBs andprobesprovidesamulti-level viewof theMSR router;and3) theZebra-basedroutingframework.
The WashingtonUniversity MSR providesan open,flexible, high-performanceroutertestbedfor advancednetworking research.Its parallelarchitecturewill allow researchersto dealwith manyof the samereal designissuesfacedby moderncommercialdesigners.Finally, its reprogramma-bility in combinationwith its opendesignand implementationwill make it an ideal prototypingenvironmentfor exploring advancednetworking features.

20
References
[1] T. Chaney andA. FingerhutandM. Flucke andJ. S. Turner, “Design of a Gigabit ATM Switch,” inIEEEINFOCOM’97, (Kobe,Japan),IEEEComputerSocietyPress,April 1997.
[2] J. S. TurnerandA. Staff, “A gigabit local atmtestbedfor multimediaapplications,” Tech.Rep.ARL-94-11,AppliedResearchLaboratory, WashingtonUniversityin St.Louis,1994.
[3] A. T1.106-1988,Telecommunications- Digital Hierarchy Optical Interface Specifications: SingleMode, 1988.
[4] H.-P. Corporation,“Hdmp-1022transmitter/hdmp-1024receiverdatasheet,” 1997.
[5] S.Choi,J.Dehart,R.Keller, J.W. Lockwood,J.Turner, andT. Wolf, “Designof aflexibleopenplatformfor high performanceactivenetworks,” in AllertonConference, (Champaign,IL), 1999.
[6] D. S. Alexander, M. W. Hicks, P. Kakkar, A. D. Keromytis,M. Shaw, J. T. Moore, C. A. Gunter,J.Trevor, S.M. Nettles,andJ.M. Smithin The1998ACM SIGPLANWorkshopon ML / InternationalConferenceon FunctionalProgramming(ICFP), 1998.
[7] J. W. Lockwood, J. S. Turner, and D. E. Taylor, “Field programmableport extender(FPX) for dis-tributedroutingandqueuing,” in ACM InternationalSymposiumon Field ProgrammableGateArrays(FPGA’2000), (Monterey, CA, USA), pp.137–144,Feb. 2000.
[8] J. W. Lockwood, N. Naufel, J. S. Turner, andD. E. Taylor, “ReprogrammableNetwork Packet Pro-cessingon theField ProgrammablePortExtender(FPX),” in ACM InternationalSymposiumon FieldProgrammableGateArrays(FPGA’2001), (Monterey, CA, USA), pp.87–93,Feb. 2001.
[9] D. E. Taylor, J.W. Lockwood,andN. Naufel,“GeneralizedRAD ModuleInterfaceSpecificationof theField-programmablePort eXtender(FPX),” tech.rep.,WUCS-01-15,WashingtonUniversity, Depart-mentof ComputerScience,July2001.
[10] J.W. Lockwood,“Evolvableinternethardwareplatforms,” in TheThird NASA/DoDWorkshoponEvolv-ableHardware (EH’2001), pp.271–279,July2001.
[11] Z. D. Dittia, “ATM PortInterconnectChip.” www.arl.wustl.edu/apic.html.
[12] “NetBSD.” http://www.netbsd.org.
[13] Intel Corporation,Intel 430HXPCISET82439HXSystemController (TXC)Data Sheet. Mt. Prospect,IL, 1997.
[14] Intel Corporation,822371FP(PIIX) and 82371SB(PIIX3) PCI ISA IDE Xcelerator Data Sheet. SanJose,CA, 1997.
[15] Xilinx, Inc., Xilinx 1999DataBook. SanJose,CA, 1999.
[16] J. D. DeHart,W. D. Richard,E. W. Spitznagel,andD. E. Taylor, “The SmartPort Card: An Embed-dedUnix ProcessorArchitecturefor Network ManagementandActive Networking,” DepartmentofComputerScience,TechnicalReportWUCS-01-18,WashingtonUniversity, St.Louis,2001.
[17] Z. D. Dittia, J. R. Cox, Jr., and G. M. Parulkar, “Design of the APIC: A High PerformanceATMHost-Network InterfaceChip,” in IEEE INFOCOM’95, (Boston,USA), pp.179–187,IEEE ComputerSocietyPress,April 1995.
[18] Z. D. Dittia, G. M. Parulkar, andJ. R. Cox, Jr., “The APIC Approachto High PerformanceNetworkInterfaceDesign: ProtectedDMA andOtherTechniques,” in Proceedingsof INFOCOM ’97, (Kobe,Japan),pp.179–187,IEEE,April 1997.
[19] W. R. Stevens,TCP/IPIllustrated,Volume1. Reading,Massachusetts:AddisonWesley, 1993.
[20] TheZebraOrganization,“GNU Zebra.” http://www.zebra.org.
[21] W. Eatherton,“Hardware-BasedInternetProtocolPrefix Lookups,” Master’s thesis,DepartmentofElectricalEngineering,WashingtonUniversityin St.Louis,1998.

21
[22] E. Leonardi,M. Mellia, F. Neri, andM. A. Marsan,“On the stability of input-queuedswitcheswithspeed-up,” IEEE Trans.on Networking, vol. 9, pp.104–118,Feb2001.
[23] T. Anderson,S. Owicki, J. Saxe, andC. Thacker, “High speedswitch schedulingfor local areanet-works,” ACM Trans.on ComputerSystems, vol. 11,pp.319–352,Nov 1993.
[24] N. McKeown,V. Anantharam,andJ.Walrand,“Achieving 100input-queuedswitch,” IEEETrans.Com-munication, vol. 47,pp.1260–1267,1999.
[25] N. McKeown, M. Izzard, A. Mekkittikul, W. Ellersick, andM. Horowitz, “The tiny tera: A packetswitchcore,” in Hot Interconnects, 1996.
[26] T. Wolf and D. Decasper, “CPU Schedulingfor Active Processingusing FeedbackDeficit RoundRobin,” in Allerton Conferenceon Communication,Control, and Computing, (Monticello, Illinois),September1999.
[27] P. PappuandT. Wolf, “Schedulingprocessingresourcesin porgrammablerouters,” Submittedto IEEEInfocom2002.





























