Embed Size (px)
Citation preview

Image Processing With FPGAsImage Processing With FPGAs
Zach FuchsSarit Patel
EEL693514 April 2008

FPGA-Based Configurable Systolic FPGA-Based Configurable Systolic Architecture for Window-Based Architecture for Window-Based
Image ProcessingImage Processing
Authors:
César Torres-Huitzil
Miguel Arias-Estrada

IntroductionIntroduction
• Image processing is a fundamental step in modern machine vision systems.
• Many complex algorithms use lower level results to pursue higher level goals.– e.g.: edge detection to determine object
• Real time performance in video applications is usually required.

Difficulty Building SystemsDifficulty Building Systems
• Most computer vision applications are computationally intensive– Sequential nature of conventional processors slow
down performance
• Different computations in processing limits parallelization
• Real time performance is required

Sample ApplicationsSample Applications
• Robotics
• Multimedia
• Virtual reality
• Industrial inspection
• Medical engineering
• Autonomous navigation

Goals of PaperGoals of Paper
• Design 2D systolic architecture for window-based image processing
• Consider design issues:– Flexibility– Silicon area– Power consumption– Performance– Area

Window-Based Image ProcessingWindow-Based Image Processing
• Large number of repetitive neighbor operations over image data
• Area of w x w pixels extracted from image
• Transformed according to window mask and mathematical functions
• Produce single, new output according to transform

Windows-Based Image ProcessingWindows-Based Image Processing
1
2
3

Window-Based OperatorsWindow-Based Operators
• Same scalar function applied on a pixel by pixel basis
• Scalar functions– e.g.: relational, arithmetic, logical, look up tables
• Reduction functions– Reduce window of results from scalar function to
one output– e.g.: accumulation, maximum, absolute value

Computational RequirementsComputational Requirements
• Window-based operations are computationally expensive tasks
• Focusing on convolution– Convolution - the amount of overlap between f and
a reversed and translated version of g
• In general, complexity = O(w^2 x M x N)– w x w window mask– M x N image

Data Transfer RateData Transfer Rate
• Must transfer data between image acquisition module, memory, and processor
• Input Data Transfer Rate• Output Data Transfer Rate
– b = # of bits per pixel
– fF = processing rate of images per second
• Requires efficient use of communication bandwidth and parallel processing

Implementation Technology: FPGAImplementation Technology: FPGA
• Provides massive parallel structures and high density for logic arithmetic
• Tasks implemented by spatially rather than temporally
• Possible to control at bit level to build specialized data paths
• Offer more raw computational power compared to conventional processors
• Shorter design cycles than ASICs• Well suited for implementing parallel architectures.

Memory AccessesMemory Accesses
• Gap between processor speed and memory access speed– Memory access overhead critical issue
• Window-based operations are memory intensive; require new pixel in each step
• High potential for parallelism since independent operations are applied to large regions of image arrays

Memory AccessesMemory Accesses
• Pixels might not be stored as neighboring elements– Parallelism is hidden
• Windows usually overlap with neighboring windows
• Must create vectors of data elements and process them using parallel vectorization techniques.
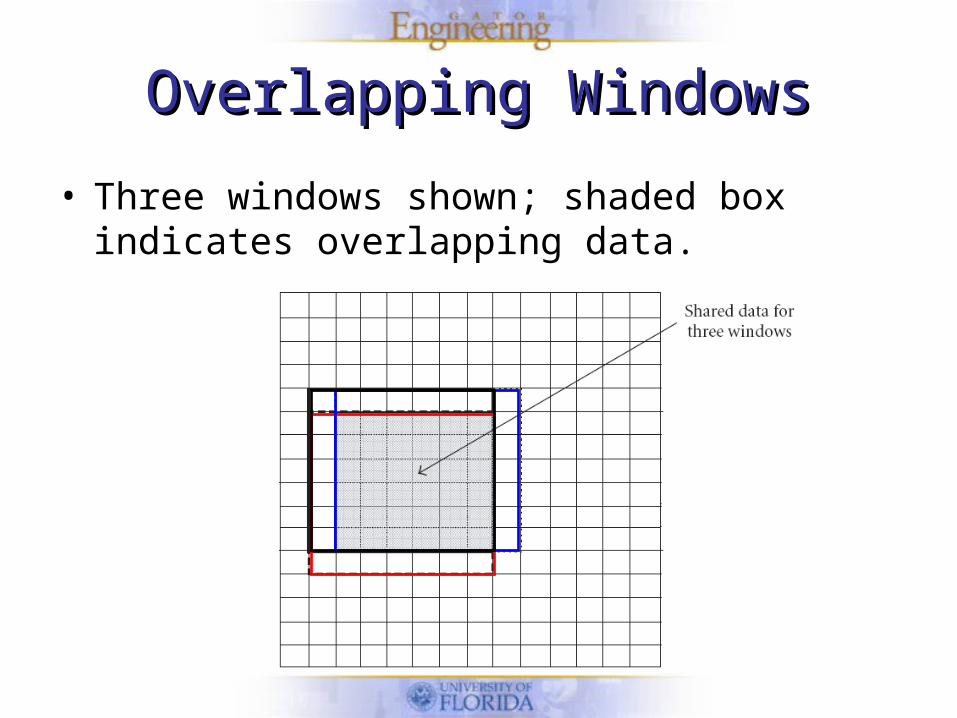
Overlapping WindowsOverlapping Windows
• Three windows shown; shaded box indicates overlapping data.

Overlapping WindowsOverlapping Windows
• Some pixels can be used in computation of all three windows
• Reduce memory accesses for those pixels by a factor of 3
• Large number of windows means less overlap
• Must compromise between data overlap and window count

Data ParallelismData Parallelism
• Can be combined with loop unrolling to diminish memory accesses for sequential accesses
• Process one window, then slide to the right and process next
• Unroll this loop so more windows are computed in parallel
• Authors use vertical unrolling– Can apply to horizontal unrolling equally

Data ParallelismData Parallelism
• Number of pixels read per column is directly dependent on number of rows processed in parallel
• Number of pixels read = w + NR – 1
– w = windows mask length/width
– NR = rows processed
• Number of Memory Accesses (MxN Image)

Data ParallelismData Parallelism

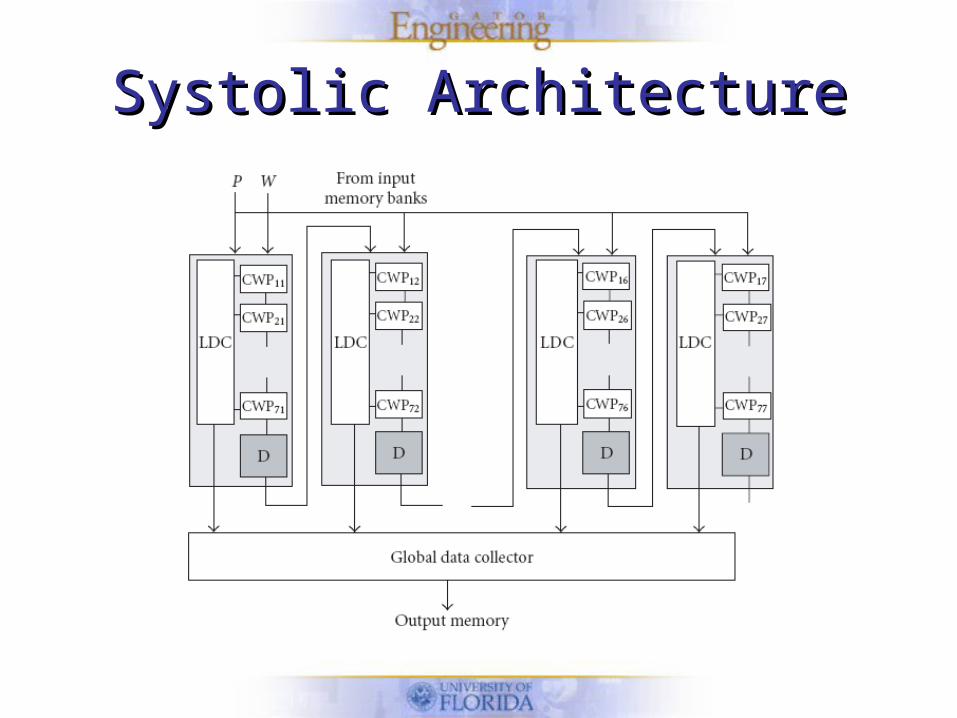
Systolic ArchitectureSystolic Architecture
• Configurable Window Processor (CWP)– Processing element in systolic arch.
• Architecture reads data from input memory– P = image pixel– W = window mask coefficients
• Transmitted to array of processing elements for computation

Array of CWPsArray of CWPs
• LDC = Local data collector– Collects results of CWPs
• CWP– Compute a window operator on same
column of input image
• D = Delay line / shift register– Used for synchronization purposes

Architecture FlowArchitecture Flow
• Pixel is broadcast to all CWPs
• At each clock cycle:– Each CWP receives a different window
coefficient
– New image pixel for all processing elements
• Each CWP multiplies and accumulates values until all pixels in a window are processed
• After short latency, the LDC will collect the data and send it to output memory
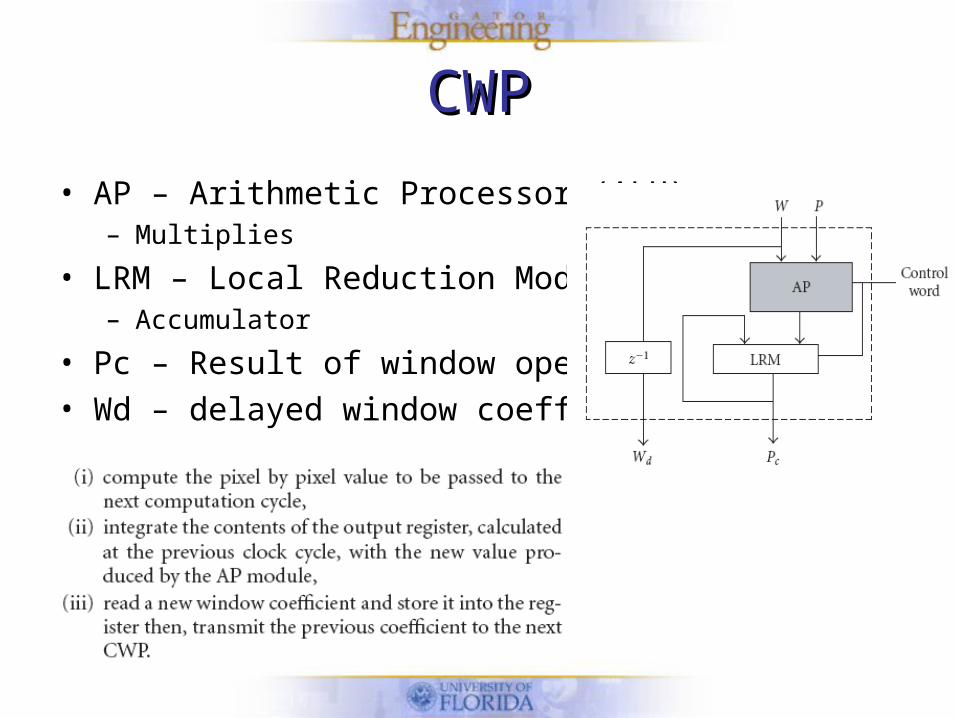
CWPCWP
• AP – Arithmetic Processor (ALU)– Multiplies
• LRM – Local Reduction Module– Accumulator
• Pc – Result of window operation
• Wd – delayed window coefficient
Systolic ArchitectureSystolic Architecture

Processing TimeProcessing Time
• Latency– Time required to start pipeline operation– Measured between activation of first CWP to last CWP
• Parallel processing time– Time when all CWPs are working in parallel– Addition of all times to process set of rows
• Performance compromised with number of rows processed– Directly reflects silicon resources allocated to architecture

ThroughputThroughput
• Number of elemental operations system can perform per second
• Only scalar function and local reduction function are considered

ImplementationImplementation
• Fully parameterizable VHDL description– Use generics to make design flexible
• Structural description used only elementary logic operations
• Design is platform, version, technology, and tool independent
• Used XCV2000E-6 VirtexE FPGA w/ 2 Million Gates

FPGA Technical DataFPGA Technical Data
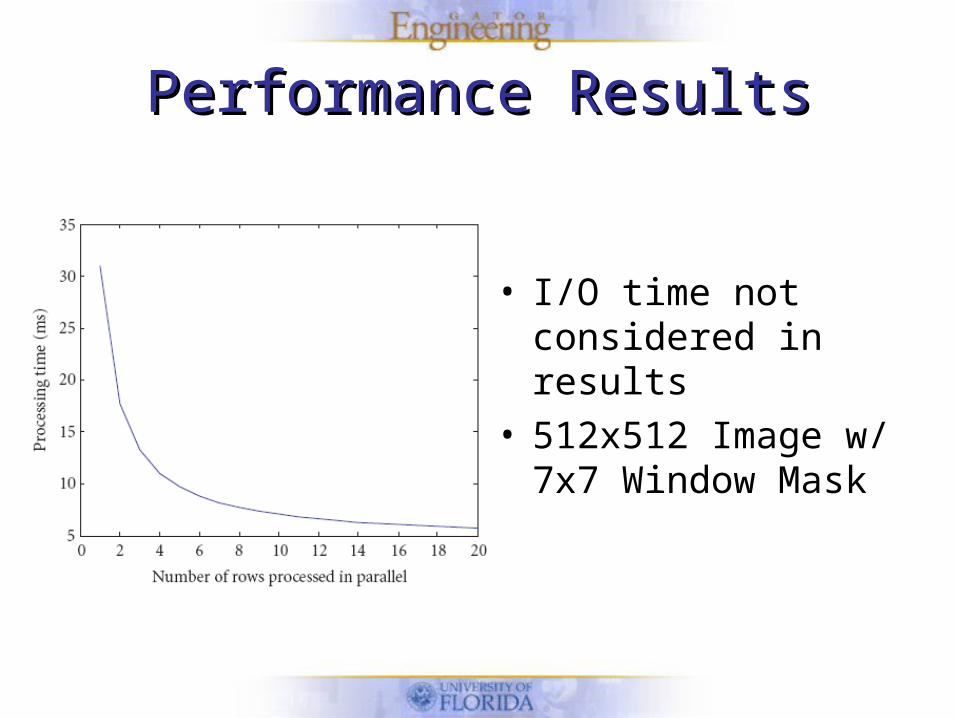
Performance ResultsPerformance Results
• I/O time not considered in results
• 512x512 Image w/ 7x7 Window Mask

Performance ResultsPerformance Results
• Image processing time for 7x7 window mask is 8.35 ms
• Leaves enough time for image acquisition
• 30ms required for real-time constraints
• Post-processing also possible
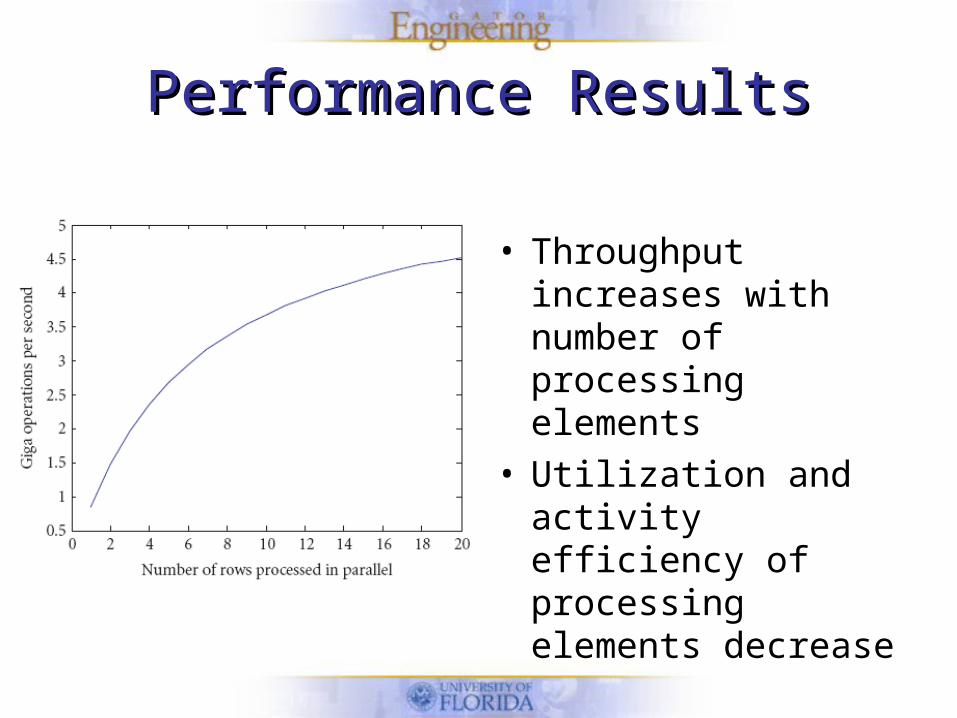
Performance ResultsPerformance Results
• Throughput increases with number of processing elements
• Utilization and activity efficiency of processing elements decrease

Improving PerformanceImproving Performance
• Optimize design mapped on the FPGA
• Apply timing restrictions for increased speed
• Use better FPGA
• Note that performance requirement for real-time operation is still met with lower FPGA
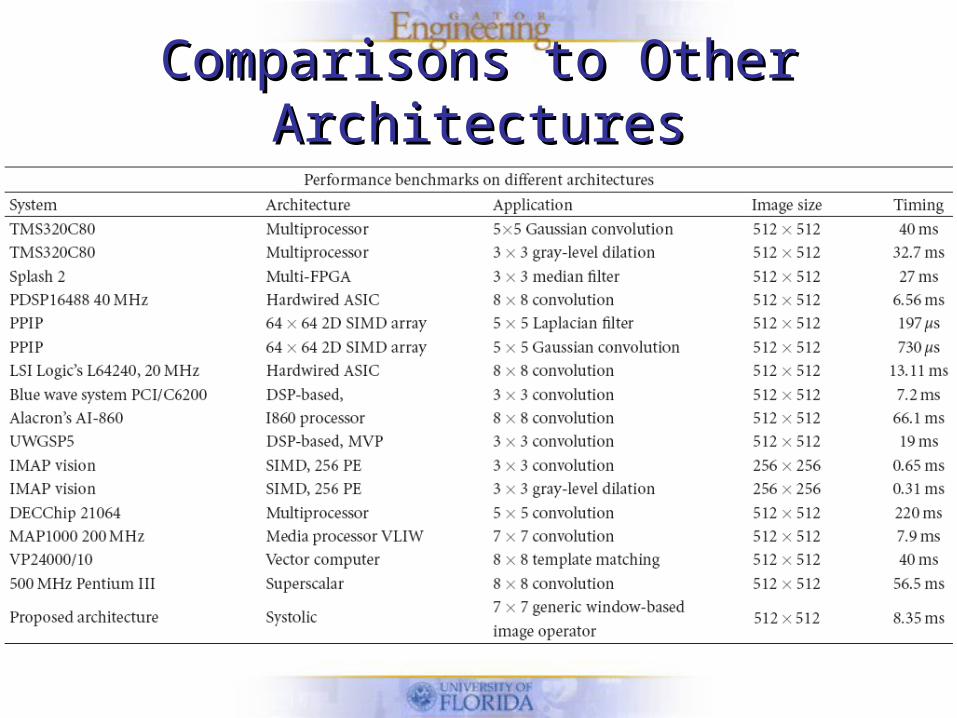
Comparisons to Other ArchitecturesComparisons to Other Architectures

Area/Performance TradeoffsArea/Performance Tradeoffs
• Low resource utilization allows implementation in compact mobile apps
• High computational density due to small area usage
• Can reduce hardware or clock frequency– Reduces power– Still meets timing requirements

ReconfigurabilityReconfigurability
• Flexible enough to support different window-based image operators
• Allows different image-based applications on a SoC

ConclusionConclusion
• Easy to exploit SIMD for parallelism in image processing
• FPGAs allow reconfigurability and flexibility
• Real-time constraints can be met with high performance and low area usage
• All Images and Graphs from:
Torres-Huitzil, Cesar, and Miguel Arias-Estrada. "FPGA-Based Configurable Systolic Architecture for Window-Based Image Processing." EURASIP Journal on Applied Signal Processing 7(2005): 1024-1034.

Hardware, Design and Hardware, Design and Implementation Issues on a FPGA-Implementation Issues on a FPGA-
Based Smart CameraBased Smart CameraFabio Dias, Francois Berry, Jocelyn Serot,
Francois Marmoiton

Summary of PaperSummary of Paper
• Describe the hardware architecture of a FPGA-based Smart Camera research platform and some of the hardware design issues.
• Propose a architectural design methodology based on pre-programmed processing elements.
• Provide a low level image processing example.
• Present an embedded tracking application to show the camera’s utilization.

What is a Smart Camera?What is a Smart Camera?
• Smart cameras utilize embedded processing to relieve some of the low level computational burden of the interfacing system.
• Reduce communication flow and overhead.• Processing resources consist of FPGA devices,
medi/streaming processors, DSP’s, etc.

Why FPGA devices?Why FPGA devices?
• Reconfigurability– Allows the camera to adapt to a wide range of applications.
• Parallelism– Take advantage of independence of many computational
tasks in order to meet time restraints.
• Hardware Flexibility– Capable of interfacing with a wide range of external
devices such as memory or ASICs.

Smart Camera Hardware ArchitectureSmart Camera Hardware Architecture
• ALTERA Stratix EP1S60F1020C7
• 4Mpixels LUPA-400 image sensor
• (2) 2d accelerometers
• (3) gyroscopes
• 10Mb SRAM
• 64Mb SDRAM
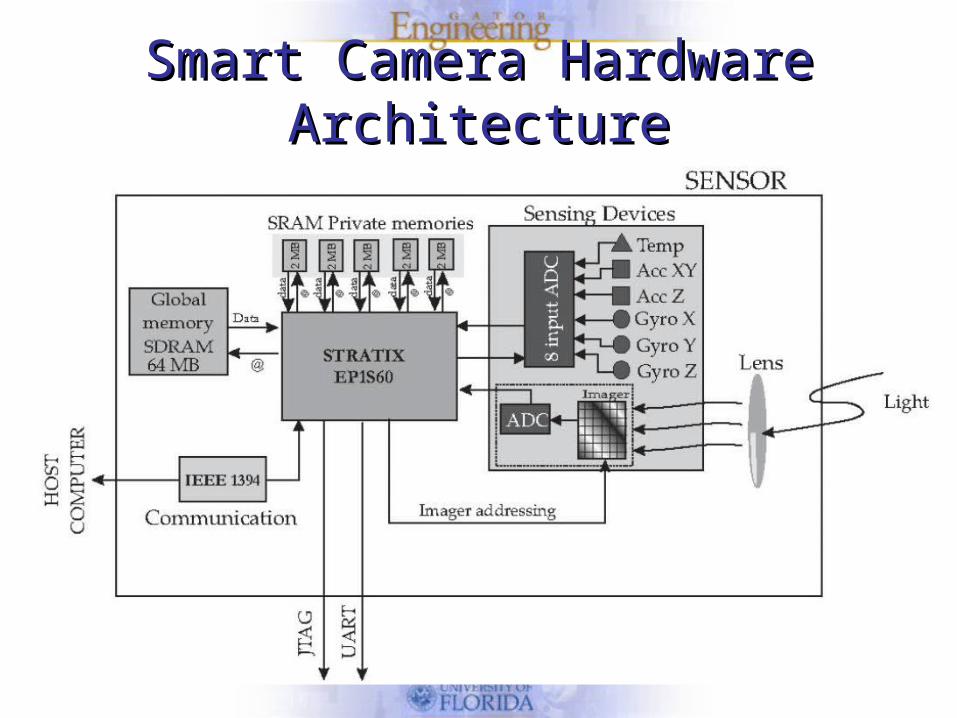
Smart Camera Hardware ArchitectureSmart Camera Hardware Architecture

Design MethodologyDesign Methodology
• Centralized around reconfiguration of the FPGA.– Set of Pre-designed configurable data processing
elements (PE’s).– Programmable Control Module
• System supervisor, communicating with the PE’s through registers and hand-shake signals
• Configures and synchronizes different PE’s
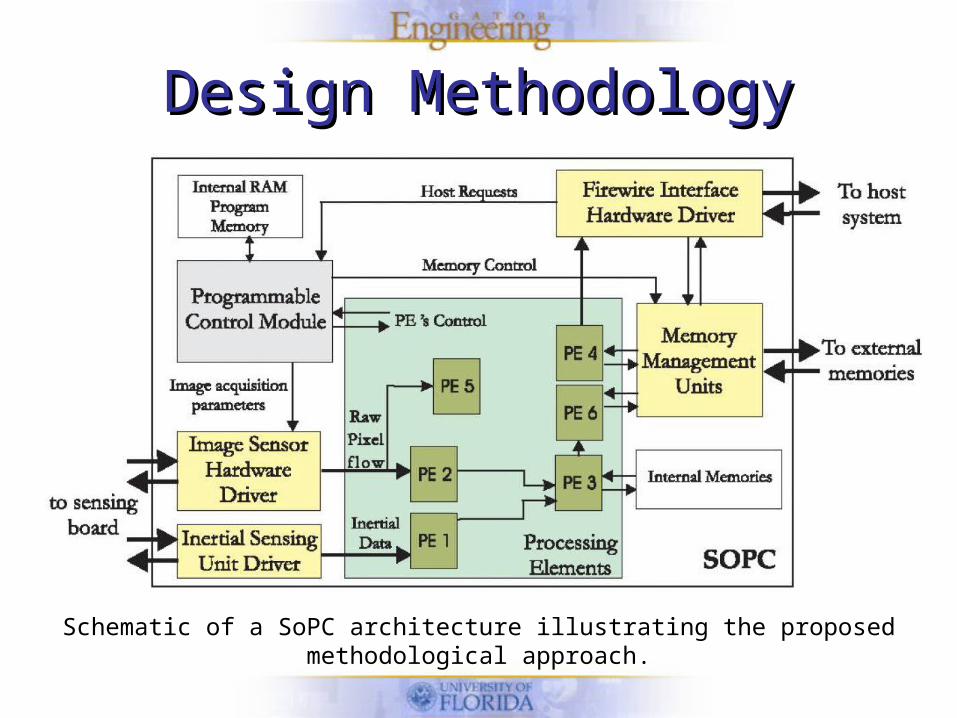
Design MethodologyDesign Methodology
Schematic of a SoPC architecture illustrating the proposed methodological approach.

Generic Window-Based Generic Window-Based Processing ElementProcessing Element
• Applied over a small defined over a small defined portion of the input image.
• Deal with large amounts of data because they are often applied over the entire image.
• Examples– Convolution– Correlation estimation– Morphological transformations
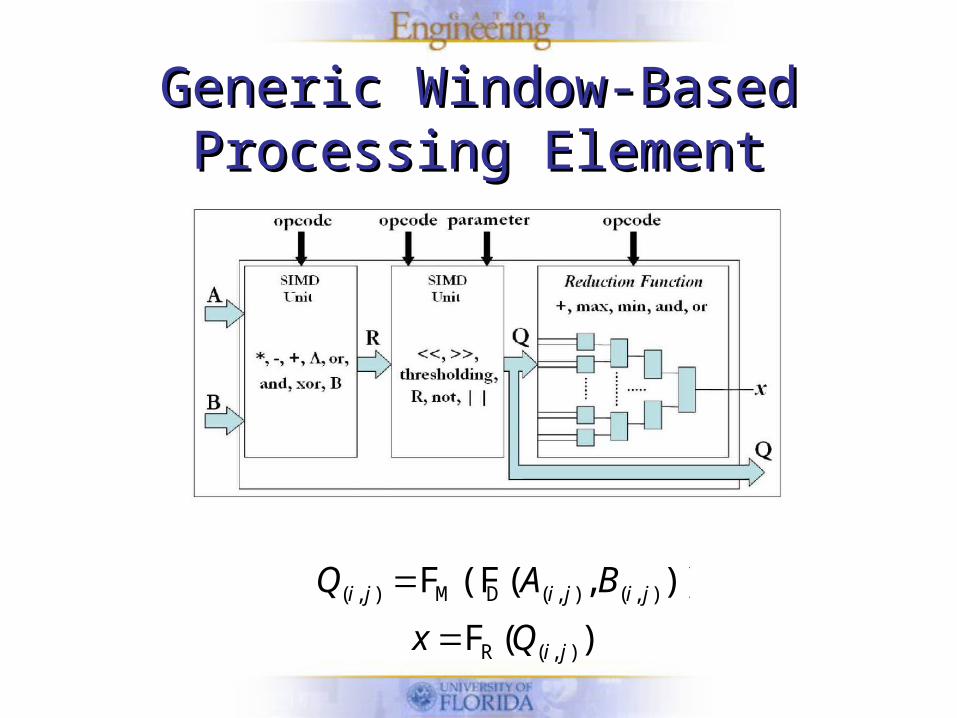
Generic Window-BasedGeneric Window-BasedProcessing ElementProcessing Element
)(F
)),((FF
),(R
),(),(DM),(
ji
jijiji
Qx
BAQ

Smart Camera ApplicationSmart Camera ApplicationTemplate Tracking System
• VGA images sent to host computer to be displayed.
• The user selects frame of interest for tracking.
• A search window is acquired and stored into memory.
• A sliding window SAD algorithm is applied.
• The portion with the best correlation score is considered the as being the new template location.
• A null acceleration model is employed in order to predict displacement in the next frame.
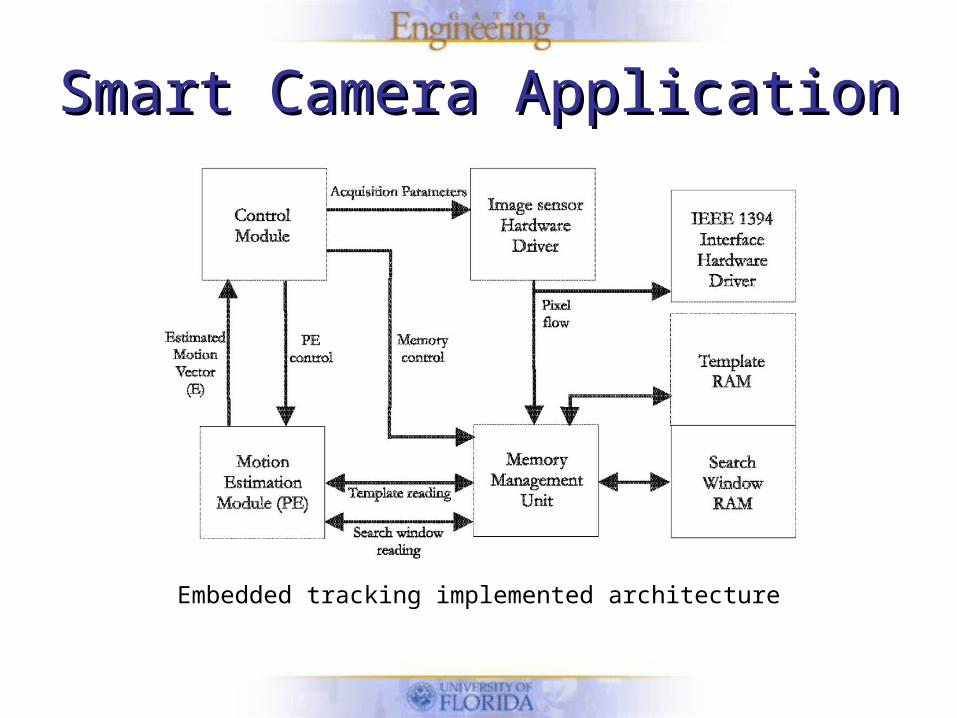
Smart Camera ApplicationSmart Camera Application
Embedded tracking implemented architecture
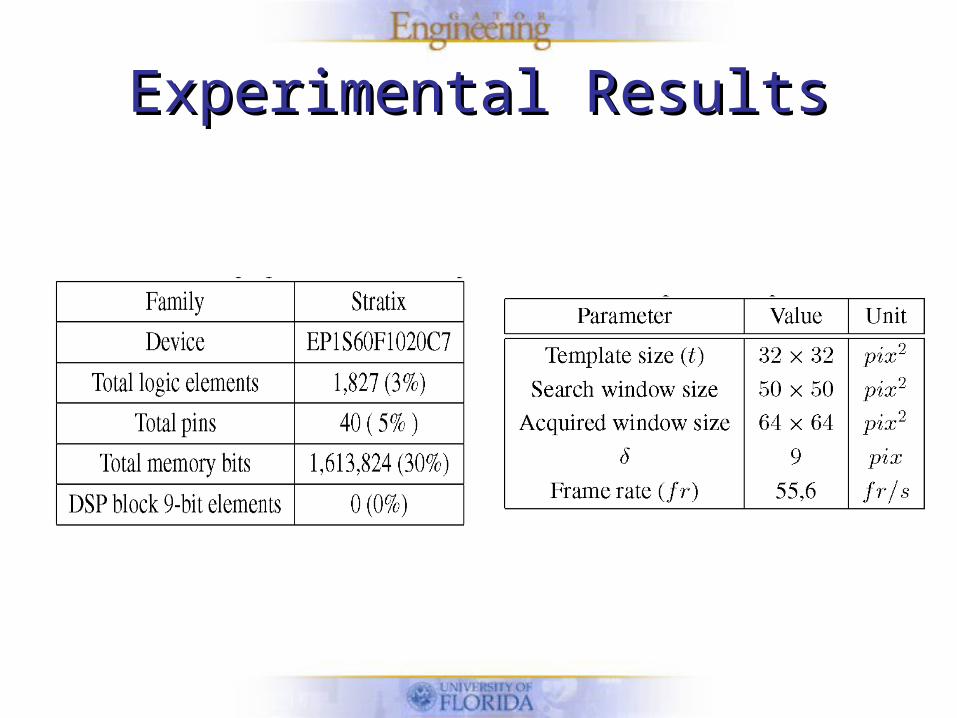
Experimental ResultsExperimental Results

ConclusionConclusion
• Generic window-based processing element successfully implemented in an FPGA.
• An image tracking algorithm utilizing the described design methodology successfully implemented with adequate performance.
• A flexible FPGA base smart camera research platform created for future research.
All Images and Graphs from:
Dias, Fabio, Francois Berry, Jocelyn Serot, and Francois Marmoiton, "HARDWARE, DESIGN AND IMPLEMENTATION ISSUES ON A FPGA-BASED SMART CAMERA." IEEE 1-4244-1354-0/07(2007): 20-26.





























