Embed Size (px)
Citation preview
![Page 1: [IEEE 2005 International Conference on Neural Networks and Brain - Beijing, China (13-15 Oct. 2005)] 2005 International Conference on Neural Networks and Brain - Speaker Identification](https://reader037.pdfslide.us/reader037/viewer/2022092810/5750a78b1a28abcf0cc1e088/html5/thumbnails/1.jpg)
Speaker Identification with Little Training Data
Based on Semiconductor NeurocomputerDewen Zhuang, Wenming Cao
Institute of Intelligent Information System,Zhejiang University of Technology,
Hangzhou, 310014E-mail: zdwen(zjut.edu.cn
Abstract-In this article we propose a novel speakeridentification method using semiconductor neurocomputer. Wealso give the multi-weight neuron training and recognitionalgorithm based on high dimensional feature space vertexcovering theory. The average distance of the frame between thetest sentence and the speaker covering region are used as ourdecision rule, then in the condition of little training data we canidentify all the speakers in the given test sets.
I. INTRODUCTION
Automatic speaker recognition (ASR) is based on featureparameters of the speaker's speech, which is extracted inadvance, so we can identify the speaker through theirspeeches. ASR includes speaker identification and speakerverification. Text-independent speaker identification isbased on the speakers' close-set, and then according to theprovided speaker's speech signal to identify the speakerwhose feature is the most similar. The main methods ofspeaker identification include vector-quantization (VQ)[1],Gaussian mixture model(GMM)[2], artificial neuralnetworks(ANN)[3] etc.. VQ method uses kNN clusteringalgorithm to get clustering centers, and then calculate theminimum distance between the test speech's feature vectorand the clustering center as the decision rule. GMM methodis based on statistic; it uses a number of Gauss probabilitydensity functions (pdf) to approximate arbitrary pdf.Obtaining the parameter model of the speaker throughsamples' learning, and we use the maximum posteriorprobability as the judgment evidence. Although GMM ismore popular in the text-independent speaker identificationfields, it needs a large number of training samples in orderto get a good performance. Based on BP-algorithm, MLP isalso used in speaker identification, but the optimal structurehas to be selected by trial-and-error procedures. When it isused in speaker identification and a new register is added in,it has to retrain the whole network.Aimed at the problems in the above, this article proposes
a novel method, which is based on high dimensional featurespace vertex covering theory[4,5,6]. It uses every speaker'straining speech and divides it into frames, then calculates
Shoujue WangInstitute of Semiconductors, Chinese Academy
of Science, Beijing 100083E-mail:wsjuegred.semi.ac.cn
every frame's feature parameters as the high dimensionalfeature space's point. Using semiconductor neurocomputerCASSANN_II[7] to cover these points of every speakerrespectively, we can get the corresponding covering range.And we can identify the speaker through calculating thedistance between the test speech's frames to every speaker'scovering region. Under the condition of little training data,the experimental results show that this method can identifyall speakers in the test set.
II SPEECH FEATURE EXTRACTION
Speaker identification system consists of featureextraction and identification, and the task of featureextraction is to draw out parameters that can represent thespeaker's characteristic from the speech signals. The featureof the speaker's speech can divide into two categories, oneis 'high-level' and the other is 'low-level'[8]. In decidingwhether the speaker can be identified or not, the high levelfeatures, such as clarity, roughness, rhythm etc., are thetimbre which can be apperceived, however, these featuresare not easy to be drew out by the automatic machine inspeaker identification. Therefore the low-level features aregenerally used as the speaker identification featureparameters. Short-Time Fourier Transform is the foundationof these features, among them MEL-Cepstrum is widelyused in speaker identification, and the experimental resultsalso show its validity[9]. In this article we use 16MEL-Cepstrum coefficient and one-order differentialcoefficient as the feature parameter of the speakeridentification, so every frame is a 32-dimension vector, andthe frame length is 32ms, frame shift is 16ms. For short wedenote training feature vector set as X ,X --}, x e
n = 32, and T is the number of the frames.
Ill. TRAINING AND P P-COGNITION ALGORITHM
A. Multi-Weight Neuron
CASSANN_II is a double-weight general-proposed
0-7803-9422-4/05/$20.00 02005 IEEE1523
![Page 2: [IEEE 2005 International Conference on Neural Networks and Brain - Beijing, China (13-15 Oct. 2005)] 2005 International Conference on Neural Networks and Brain - Speaker Identification](https://reader037.pdfslide.us/reader037/viewer/2022092810/5750a78b1a28abcf0cc1e088/html5/thumbnails/2.jpg)
neurocomputer, and the formula is as follows:y=[Wii(Xi Z)i) lX- P_0(1
where Y is the output of neuron i, f is the nonlinearfunction, 9 is the threshold, w, and z are input vector
j's direction weight and kernel weight ofneuron i separately,n is the dimension of the input space, s is the parameterthat decides the monomial sign, and it can choose 0 or 1,p is the power parameter. Through straightforwardverifying, we can know that the combination of the neuronparameter not only can simulate the hyperplane of the BPnetwork, but also can simulate the hypersphere of the RBFnetwork or the closed hypersurface of more complex highdimensional space.
According to the high dimensional space vertexcovering theory, the training of the sample is just as highdimensional space's complex geometry body covering. Inorder to get a proper covering of the given sample set, weusually use multi-weight neuron, which is composed of anumber of double-weight neurons; the formula of themulti-weight neuron is as follows:
Y=f [(o(X,WI ...,Wm)-Th] (2)xis the input vector, wi,...,w are m weight vectors, This the threshold, here we use triple-weight neurons, namedpSi3 neuron, it is composed of five double-weight neurons,where (X,W,,w3=px,I=I1x-_I, 0 represents the finite
space which is formed by three vertexes w,,W2,W3:0=JZJZ=O: [qW+(1-6q)]+(l-0)W3,o E[Ql],Oi C=[0Q1] (3)
PXO represents the distance from X to 0 , while
O(X, w,W2, W3) - Th < o represents the topology product ofthe finite space which is formed by three vertexes w,X W2 X W3and the hypersphere with a radius of Th. We can simplychoosef as follows:
1, x.<Th (4)-1, x>Th
From the pSi3 neuron we can determine whether the pointX locates the neuron's covering region or not.
B. Training Algorithm
Stepl: Suppose a speaker's training sample points set isX={Xl' IXT} XiERn n=32, T is the number of thesample points. We can calculate the distances of these points,then find the minimum distance of the two points, denote asB,, andB,2- Calculate the sum of the distances from the otherpoints to these two points, determine the point that make thissum minimum, and it is not collinear with B, and B2 ,denoteit as B these three points constitute the first plane triangle,
denotes it as 0S,use a pSi3 neuron to cover the region P1,which is the topology product of 9, and the hypersphere with aradius of Th , then suppose i equals 1.
Step2: Find out the point which is out of the covering area,and make sure the sum of the distance between this pointtoBI,B12B,3 is minimum, and denotes it as B2,, hien mark thetwo points of B,,gB,2,B,3which are closer to B2, as B2, and
B23, the three points A,, B23 and B2, form the second planetriangle B2,B22B23, denote it as o2' likewise we use a pSi3neuron to cover the region P2, then suppose i equals 2.
Step3: Find out the point with a minimum sum of distanceto the triangle i in the sample sets beyond the total i pSi3neuron covering regions, and similarly find out the two closestpoints of the triangle i to the very point, let i = i + 1, these threepoints denote as B,, B'X B'i and form i plane triangle BBigB3denote it as o , also use a pSi3 neuron to cover the region Pi,.
Step4: Do the Step3 until all samples in the training set aredealt with.
Finally it will totally produce m pSi3 neurons, and thenthe speaker's covering region is the union of these neurons'covering regions:
(5)m
P=Up.J= J
Similarly to other speakers, we can tien get all speaker models(suppose the number of speakers is n):
m,
I =UpI -U=
i=...n (6)
C. Identification Algorithm
We use the same feature extracting procedure as training todeal with the test speaker's speech, and get the test pointsset: y={y YL } , where L is the frame numbers of the test
speech. Suppose the speaker i 's training points arecovered with mi pSi3 neurons. Using the semiconductorneurocomputer we can calculate the minimum distance fromeach frame Yk to the covering region:
==Mn IY -PjIIAPi <j<--
Calculate the average distance:L
dp LdL
i
(7)
(8)
To other speaker model, we can get the average distancebetween the test speech y and speakeri's the coveringregion, namely we will get
dy i = 1, ...,n (9)Then the final identification results are:
i = arg mindy (10)l iSn
1524
![Page 3: [IEEE 2005 International Conference on Neural Networks and Brain - Beijing, China (13-15 Oct. 2005)] 2005 International Conference on Neural Networks and Brain - Speaker Identification](https://reader037.pdfslide.us/reader037/viewer/2022092810/5750a78b1a28abcf0cc1e088/html5/thumbnails/3.jpg)
IV. EXPERIMENT AND RESULTS
and therefore they will all be identified correctly.
The corpus of this article is composed of 10 people, fivemen and five women, the youngest is 9 years old and theoldest is 74 years old. The training set is formed of everyspeaker with three eight-digits; it is about 5 to 9 secondslong; the test set is constituted of every speaker with fiveeight-digits. The speeches are all spoken out smoothly, andrecorded in different environments, the sampling rate is 8kHz, 16-bit quantization, and the silence segments areremoved in training and identification.
B. Experiment Results
Table I: number of neurons, threshold and number of the training sample-oints of everv speaker
speaker's 1 2 3 4 5 6 7 8 9 10type
number ofthe 204 172 178 141 115 187 133 186 119 166neuronsftreshold 200 120 180 200 160 130 180 180 180 180
number of
1h 341 404 605 400 459 431 326 408 550 417
points
The training parameters of theCASSANN_II are showed in the table 1.
350,
. 300 2
1294250
200-
150-
100
so
,IH-1
neurocomputer
Table II: the average distance from the test sentences toother speakers' covering range
testsentences
sentence sentence2 sentence3 sentence4 sentenceStypeof thcspeatker
l 1.4868 1.2456 1.2743 1.284 1.28532 1.2362 1.3043 1.3471 1.2624 1.25563 1.1591 1.2066 1.1954 1.1526 1.11724 1.1067 1.2056 1.2013 1.1973 1.14815 1.241 1.307 1.2584 1.1977 1.16066 1.2084 1.2976 1.2562 1.2058 1.19117 1.096 1.089 1.1309 1.1859 1.20528 1.1644 1.1242 1.1909 1.1464 1.12719 1.1755 1.2344 1.2384 1.2023 1 .202410 1.2318 1.2047 1.2028 1.176 1.1583
V. CONCLUSION
This article is based on high dimensional feature spacevertex covering theory; it uses semiconductorneurocomputer to deal with the text-independent speakeridentification. It proposes a new speaker model, which can
be used in the little training data, and identification allcorrect is obtained to the test set. The research on largerspeaker set and the condition of training set un-match testset will be the content of our next research.
REFERENCE
10
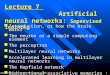
Figure 1: the average frame distance of a speaker's five sentences to everyspeaker's covering range
Fig. 1 shows an example of number 2 speaker'sidentification results of five sentences.
In order to get clearer, let the average distance from thetest speech to one's own is 1. Table 2 gives out the averagedistance from every test speech to other speakers' coveringregion. Just as table 2 shows, 10 speakers with 5 testsentences everyone, the distance to one's own is minimal,
[I]T.F.Quatieri, Discrete-Time Speech Signal Processing: Principles andPractice. Electron Industry Press, No. 1, 2004.8
[2]D. A. Reynolds, T. F. Quatieri, and R. B. Dunn, Speaker verificationusing adapted Gaussian mixture models, Digital Signal Processing,2000.10(1), pp. 19-41
[3]S. Hykin, The principle of neural networks. Mechanism industry Press,No.1, 2004.1
[4] Wang ShouJue, A new development on ANN in China - Biomimeticpattern recognition and multi weight vector neurons, LECTURE NOTESINARTIFICLAL INTELLIGENCE 2639: 35-43 2003
[5]Wang Shoujue, etc., Multi Camera Human Face Personal IdentificationSystem Based on Biomimetic pattern recognition, Acta ElectronicaSinica 2003,31(1): 1-3
[6]Wenming Cao, Xiaoxia Pan, and Shoujue Wang, Continuous SpeechResearch Based on Two-Weight Neural Network. ISSN 2005, LNCS3497,pp. 345_350,2005. Springer_Verlag Berlin Heidelberg
[7]Wang Shoujue, etc., Discussion on the basic mathematical models ofNeurons in General purpose Neurocomputer, Acta Electronica Sinica2001, 29(5): 577-580
[8] J. P. Campbell, D. A. Reynolds, and R. B. Dunn, Fusing high- andlow-level features for speaker recognition, in Proceedings ofEurospeech, 2003, pp. 2665-2668.
[9]Bimbot, F., etc., A tutorial on text-independent speaker verification,EURASIP JASP 2004:4 (2004) 430-451
1525
A. Corpus
u,