Embed Size (px)
Citation preview

This presentation will address the many different ways you can search of data in DB2 for z/OS. Its concentration will be on table and index design to support searching and scrolling, as well as various SQL coding techniques for search capabilities and indexing. We will focus significantly on performance of queries while trying to keep the number of indexes to a minimum. It will also look at the basic and advanced scroll techniques and choices for performance from a practical coding perspective based upon real-world experience.

© YL&A 1999 - 2011 2

Dan Luksetich is a senior DB2 DBA. He works as a DBA, application architect, presenter, author, and teacher. Dan has been in the information technology business for over 24 years, and has worked with DB2 for over 19 years. He has been a COBOL and BAL programmer, DB2 system programmer, DB2 DBA, and DB2 application architect. His experience includes major implementations on z/OS, AIX, and Linux environments.
Dan's experience includes:Dan s experience includes:
* Application design and architecture* Database administration* Complex SQL* SQL tuning* DB2 performance audits DB2 performance audits* Replication* Disaster recovery* Stored procedures, UDFs, and triggers
Dan works 8-16 hours a day, everyday, on some of the largest and most complex DB2 implementations in the world. He is a certified DB2 DBA and application developer, and the author of
© YL&A 1999 - 2011 3
p pp p ,several DB2 related articles as well as co-author of the DB2 9 for z/OS Certification Guide. He is very tired so please be nice to him.

No animals were harmed during testing
© YL&A 1999 - 2011 4

© YL&A 1999 - 2011 5

It seems that almost all of the time the majority of application performance problems have to do with searching and scrolling. After all, once you have found what you are looking for you can generally process it very quickly. With increased use of automated interfaces, frameworks, and generic coding techniques and tools, this problem seems magnified.
While changing programming techniques and customizing code is time consuming, it is a necessity if you want to save processing time and costs over the life of an application. Besides, you typically apply custom solutions as the exception, not the rule, when building an application.
I’ve been involved in quite a few application builds, and these techniques are based upon my experience in solving performance issues for searching and scrolling.
© YL&A 1999 - 2011 6

© YL&A 1999 - 2011 7

DB2 has some built-in support for improving searching and scrolling, some have been around a while but others very new or coming soon.
Some of these features will be covered in coming slides, but most of the performance you can get won’t come from using these features but from theperformance you can get won’t come from using these features, but from the proper coding of predicates, or by taking advantage of the flexibility of the SQL language, to get the desired performance.
Scrolling cursors are not necessarily a performance feature, but they do allow you to move forward and backward through a result set using relative
iti ipositioning.
Multi-row fetch is indeed a fantastic performance enhancement, and should be a part of any design that fetches more than a handful of rows per cursor. For random access multi-row fetch can be a great CPU saver, and we have seen 25% CPU reduction for random cursors fetching 20 rows. For
ti l b t h lti f t h h d h 60% CPUsequential batch cursors multi-row fetch has saved us as much as 60% CPU and elapsed time processing large result sets.
© YL&A 1999 - 2011 8

Backward index scan is possible with DB2 backwards scrolling cursors. While the actual scan process may not be more efficient than having both a forward and backward index, it can create an opportunity to eliminate that extra index that supports the backwards scroll. This is important in the overall performance scheme because indexes cost time and money to maintain, and the fewer indexes there are to maintain the more efficient overall performance can be achieved.
© YL&A 1999 - 2011 9

The soundex function has existed in DB2 for LUW for some time, but is new for DB2 9 for z/OS. This is a great enhancement to the database in that we have a name search assistance built in! We have used soundex quite extensively to aid our search processing in many different applications.
The soundex algorithm was invented in the early 20th century as a way to assist with the filing and searching of information based upon a name. The idea was to compensate for the more common misspelling of names. This algorithm converts a name into a four character code. The first character of the code is the first letter of the name. The remaining four characters are all numeric based upon the remainder of the name. Vowels are usually ignored, p y gas are repetitive consonants, but there are some exceptions.
Another important feature built into DB2 9 for z/OS is the ability to create an index key based upon an expression. This performance feature allows us to compensate for predicates that are built on column expressions, which are normally stage two predicates and not able to use an index. This is y g ppotentially a significant performance improvement for existing predicates and future designs.
© YL&A 1999 - 2011 10

Here is an example of both the soundex function and index on expression. In the CREATE INDEX statement an index is actually built on the result of the soundex function for every row in the table. So, the first key value of the index is the soundex result.
The query shown here uses the soundex function against the column of a table to search for somebody with a soundex of “R300”. What normally would be a predicate that could not use an index now can.
© YL&A 1999 - 2011 11

© YL&A 1999 - 2011 12

The advancement of the SQL language now gives us many choices for doing things such as complex searches. In a situation in which we must search for multiple conditions or values we can choose a number of different ways to go at the data.
In this example we are search for two different names using three different techniques. The first uses a compound predicate which might get multi-index access at best. The second uses a UNION ALL to perform the search for each search condition, which has a better chance of two column index matching, but executes two query blocks. The third builds a search table using a common table expression and then relational division (a join) to g p ( j )perform the complex search.
I have used all three techniques with different results at different customer sites. It is best to try them all, EXPLAIN them, and benchmark test them.
© YL&A 1999 - 2011 13

This example is pretty typically of generic search criteria. A user is presented a screen with multiple search criteria they can enter. Many times this criteria is in the form of upper and lower values for a range search.
In this case of range predicates DB2 can only match on the first indexedIn this case of range predicates DB2 can only match on the first indexed column. At best it can do index screening on the other columns. The lower column matching can result in more of the index being accessed, especially for large tables with many rows of data.
© YL&A 1999 - 2011 14

In this example we take advantage of a non-correlated subquery and some code tables to generate a set of values to power the search. The access path (version 8) shows the access to the code tables first and 3 column matching index access for the table being searched.
So, we apply the range predicates to small code tables rather then the big table. So, the less efficient index (or table) access is against a small table instead of a big table. There is a Cartesian join between the code tables to provide all value combinations to the outer portion of the query.
© YL&A 1999 - 2011 15
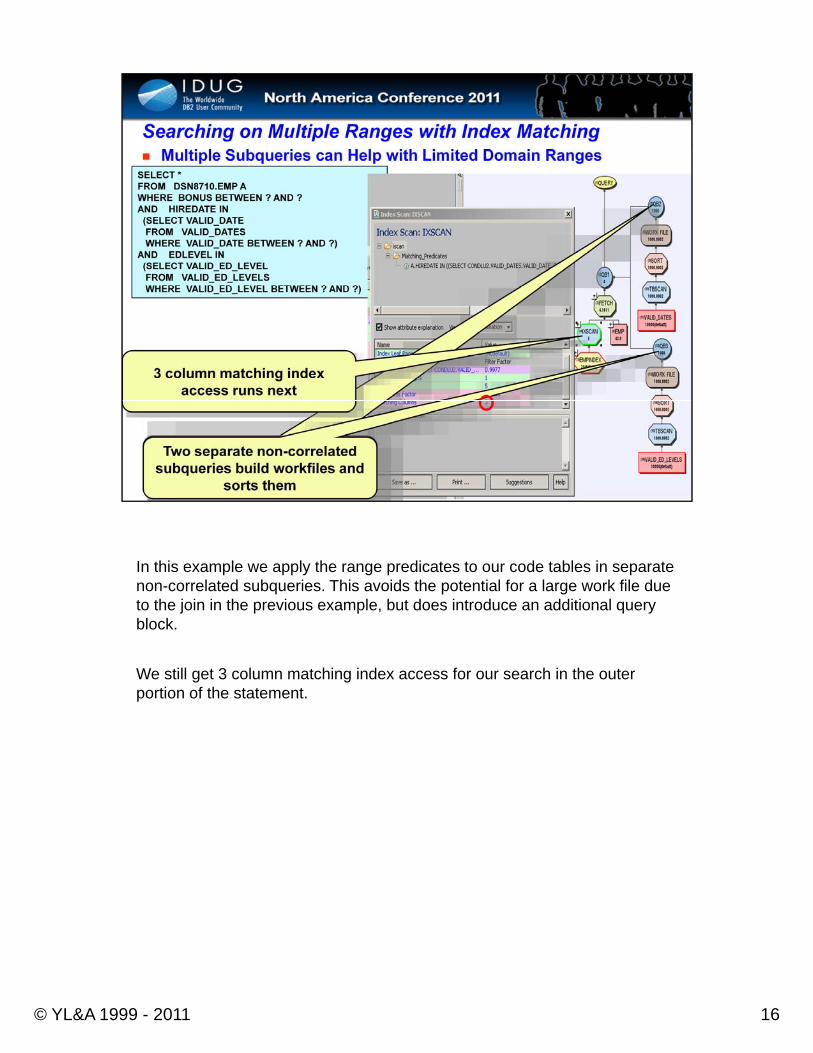
In this example we apply the range predicates to our code tables in separate non-correlated subqueries. This avoids the potential for a large work file due to the join in the previous example, but does introduce an additional query block.
We still get 3 column matching index access for our search in the outer portion of the statement.
© YL&A 1999 - 2011 16

In this example we use a common table expression and Cartesian join with our range predicates to build a set of values for the search. The table produced is then joined to the table we are searching. This can avoid the large work file creation and a sort of the search values. However, the optimize can choose the access path which may mean it does not access the code tables first.
In this example the code tables are accessed first. It is important to put the common table expression first in the join when coding the statement.
© YL&A 1999 - 2011 17

© YL&A 1999 - 2011 18

Multi-table searches can be expensive. This is because the optimizer has to pick what it thinks is the best access path, but only one path. So, if the input is variable and optional then the query may perform poorly if the values entered for predicates are not against the first table accessed in the join sequence.
There are many solutions to the generic search problem. Some include building the query on the fly, and providing dynamic literal values to the input. Such a solution could take advantage of DB2 distribution statistics. DB2 runtime optimization is also a possibility.
© YL&A 1999 - 2011 19

There is the possibility of a simple solution to the generic search if you know just a little bit about how your users enter their search queries. We have found in many cases that users typically have common search criteria that they enter most of the time. By simply coding two queries and a little programming logic you can dramatically improve overall performance of the generic search.
In this example a study of user activity showed that most of the time the users were given an employee number for input, and only a small amount of time they were given a different search value. With this knowledge the application can be built such that a search on only the employee table pp y p yhappens first. If the employee is then found the search is over. If the employee is not found then the normal generic search executes.
© YL&A 1999 - 2011 20

If two queries and application logic is not desired then you could potentially put your early out logic directly in a single query. The query in this example behaves just like the two queries and application logic in the previous example. It does this by taking advantage of a DB2 during join predicate.
DB2 join predicates are evaluated during the join operation, and the join is only performed if the join condition is true. So, if the join predicate is false the join does not happen. In this example if the employee number is found in the first join to just the employee table then the second table expression does not execute. So, if A.EMPNO has a value then the join does not happen.
© YL&A 1999 - 2011 21

This example also has early out logic built into the query via a COALESCE function. This function returns the first non-null value in a list of two or more values. Those values can actually be expression, and those expressions can actually be SQL statements.
The one drawback to this technique is that the COALESCE function can only return a scalar result.
We have used this technique quite effectively in several complex search operations that have variable input or search input against several tables
h ti i ti t blsuch as active versus inactive tables.
© YL&A 1999 - 2011 22

During performance testing of a legacy application accessing a DB2 database that was migrated from a flat file design it was determined that while performance of the name search query for less usual names was acceptable (sub second), the searches for more common names was not (up to 15 seconds). This was compounded by the fact that there could be a search of up to 60 consecutive months for one given name key.
This name key consisted of an improved Russell soundex value, the first four positions of the first name, year and month of birth. Common names during certain periods of time, such as Linda Smith July 1947 proved to be a challenge to performance, as that was the most popular name/date combination in history.
23

Name searches were quite simple, and based upon a simple key. The vast majority of searches in our database were very fast since many of the names are fairly unique. However, name searches for more common names were extremely slow, and did not meet our SLA.
24

A theory was established that if we can put only the “special names”, those being the most common names, into a denormalized table then the table could be relatively small and the index could contain all table columns. The name search query would read the special names table first, and return the names found. If the query would return nothing then the normal name search query would run.
A series of tests were conducted to determine which names qualified as special by means of extracting commonly occurring names, and putting the denormalized data into a test table. After this series of tests were concluded it was determined that acceptable performance could be achieved if only the data for names occurring 50 or more times per month was placed into the special names table. This represented approximately 600,000 keys, and 31 000 000 rows31,000,000 rows.
25
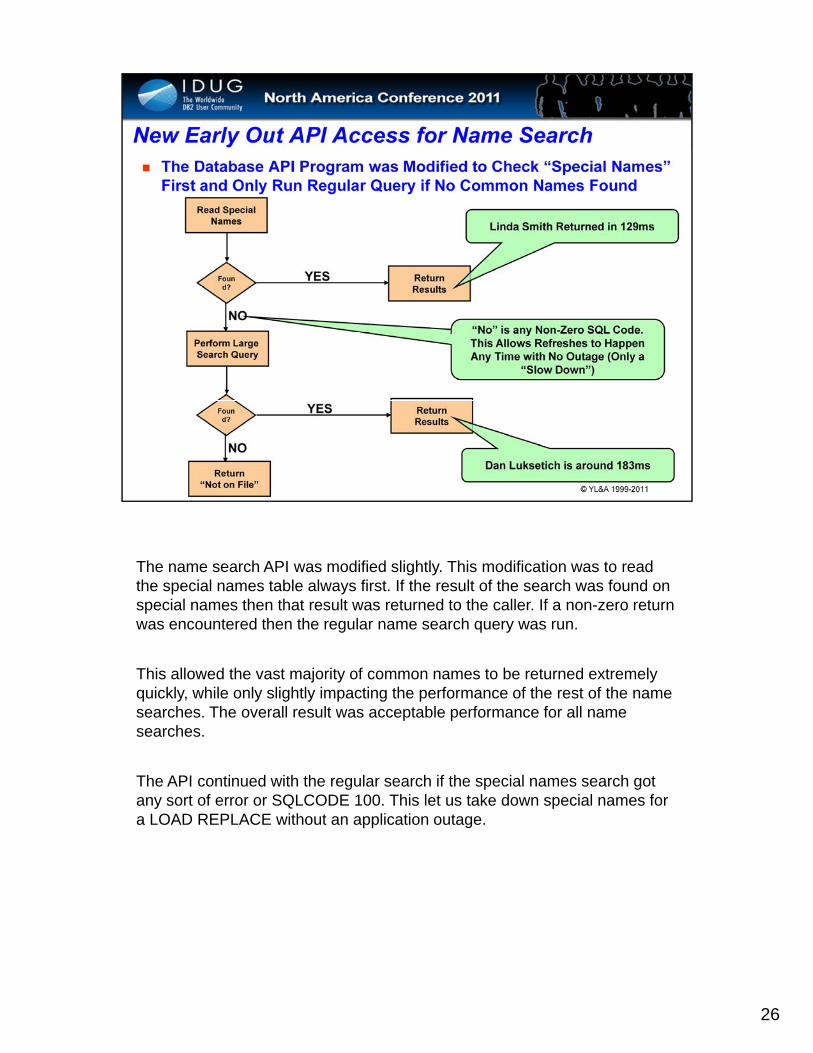
The name search API was modified slightly. This modification was to read the special names table always first. If the result of the search was found on special names then that result was returned to the caller. If a non-zero return was encountered then the regular name search query was run.
This allowed the vast majority of common names to be returned extremely quickly, while only slightly impacting the performance of the rest of the name searches. The overall result was acceptable performance for all name searches.
Th API ti d ith th l h if th i l h tThe API continued with the regular search if the special names search got any sort of error or SQLCODE 100. This let us take down special names for a LOAD REPLACE without an application outage.
26

© YL&A 1999 - 2011 27

This is an example of a classic search for the most recent data when history is maintained in a separate table. From a logical point of view the account table is accessed first for a given account and then joined to the history table. A correlated subquery is used to get the most recent status date for the history table. This means that if there are many history rows then the history table inside the correlated subquery will be accessed many times. Sorting could be avoided with an index on the history table (account id, status date).
This query could be an efficient choice if you are accessing one or few accounts with limited history.y
© YL&A 1999 - 2011 28

This query produces the same result as the previous query, but accesses the database in a much different way. This particular coding technique forces DB2 to access the account table first and then the history table using a correlated reference for each qualifying account row. This can cause the history table expression to be executed multiple times if you select multiple accounts. Each time the account history table expression is executed so is the ORDER BY. Thus, if an index does not prevent a sort, then the query could sort multiple times.
This query, like the previous example, is good for a small number of qualifying accounts with a relatively small amount of history.q y g y y
© YL&A 1999 - 2011 29

This query does indeed return results identical to the previous two queries, but it’s behavior is quite different. This query has no repeated access to obtain the most recent status. It does, however, require the programmer to enter redundant information in the form of the account number. A sort can be avoided dependent upon indexes. Table access sequence is also not guaranteed, which may be a good thing in that the optimizer should choose the most efficient.
This query may be better if lots of accounts are processed at once. Of course you would have to code two IN-Lists.
© YL&A 1999 - 2011 30

From a table management perspective it is generally a good idea to separate your current data from your historical data. It can also be a smart performance move if your applications rarely require historical data. Maintaining separate tables can also vastly improve the performance of backups and REORGs.
The best performing queries against current and historical data are those that read the tables individually. Need current data only then read the current table. Need history only then read only the history table. This may be impractical however for generic applications or situations in which you don’t know where the data you need resides. In these situations you can read y yfrom a UNION to probe both the current and history tables to return only the data you need in one SQL statement.
We use this design quite extensively in our high performance and large databases.
© YL&A 1999 - 2011 31

The multi-table history design can be more complicated than storing both current and history in the same table. This is because the application must maintain more tables, and move the data between the tables. This additional application logic, however, can be encapsulated in DB2 triggers. In this way changes to history are recorded automatically by the database when the application makes updates to the current data This is the preferredapplication makes updates to the current data. This is the preferred technique for updating the history information in that it is located within the database. This removes dependency on the application to properly maintain history, and also offers improved performance because the application does not have to make separate database calls to update both the current data and maintain the history information.
Q i d t b th t t hi t t b li t dQuerying a database that stores history separate can be more complicated. Instead of one query against one table you could instead have up to three queries; one for current, one for history, and one for both. There is no really simple solution to this issue, and you generally have to do the extra development work on your queries. You can however, establish database views over queries similar to the one on the previous slide to get both current and historical as one apparent table access. This could diminish performance but reduced the required application programmingperformance, but reduced the required application programming.
© YL&A 1999 - 2011 32

DB2 10 system-maintained temporal tables automate the current and history table design highlighted in the last few slides. With this built-in temporal design you build a current table and a history table, and then tell DB2 that the two tables are related in that manner. DB2 then takes responsibility for moving data from the current table to the history table whenever there is a change to data in the current table. DB2 also automatically provides the capability of querying data based upon a timestamp. It will use a UNION ALL, much like in our “homegrown” design, to pull the data requested based upon a supplied timestamp.
While this automated way of storing history and current may not be a high y g y y gperformance solution, it certainly does relieve the application and the DBA from a lot of extra work.
© YL&A 1999 - 2011 33

A temporal relationship is quite easily defined by creating both a base table and a history table. The base table contains automated timestamp columns to designate the range of the active data. The history table is related to the current table by specifying versioning as an attribute of the history table definition, which identifies the current table as the source of the data. Then, whenever a change is made to the current table the information for the active period is sent to the history table.
© YL&A 1999 - 2011 34

You can choose how to read the temporally related tables. Like with our home-grown design you can read the current table for the current data, and the history table for all historical queries. If you want to read data “as of” a given time, or for a range of time, you can query the current table and specify a system time predicate in the query. DB2 will return the data from both the current and history tables relative to the time or period you requested. It does this by rewriting the query as a UNION ALL in a way very similar to what we do in our home-grown design.
© YL&A 1999 - 2011 35

© YL&A 1999 - 2011 36

Many times with cursors that are used for scrolling or restart the queries are coded with compound predicates that facilitate the scrolling based upon multiple columns. The problem with these types of compound predicates is that they typically lack Boolean term predicates. DB2 needs Boolean term predicates to efficiently utilize indexes for queries. If your query lacks Boolean term predicates than the best index access you are going to get (as of DB2 9) is multi-index access or non-matching index access. This can cause a lot of anxiety as you wait for what appears to be a simple scrolling cursor as it scans through an entire index before returning the few rows you require to fill a screen.
So, it is important to code Boolean term predicates. You can do this by maintaining separate search, scroll, and restart queries. You can also added Boolean term predicates, as is sown here.
© YL&A 1999 - 2011 37

This is an example where a batch scrolling cursor is processing a range of data based upon two leading columns of an index. However, there are no Boolean term predicates and the result is a non-matching index scan.
© YL&A 1999 - 2011 38

This is the same query as the previous slide, but the predicates have been change such that they are Boolean term. The result is a single column match on the first key column.
© YL&A 1999 - 2011 39

This example is again the same query, but combines the search positioning/restart with our technique of building keys we discussed in the search portion of this presentation. Here a code tables that contains all values for SEG and SUBSEG is accessed in a non-correlated subquery, where the range of values desired is applied. The result of the non-correlated subquery is then evaluated in a row expression to get 2 matching index column access.
This works only if the code table you build is relatively small. The code table in this example contained 200 rows of data while the main table had about 500 million.
© YL&A 1999 - 2011 40

© YL&A 1999 - 2011 41

One major issue with search and scroll is when it involves complex queries that access several tables and can return large quantities of data. You want to minimize the amount of work that the database is doing, and many times DB2 can do this for you. DB2 will do its best to avoid sorting or materializing the result in any way such that you only return the data needed to fill a screen. However, if DB2 does have to materialize the result then the query could process a lot of data only to have the application through most of it away when it gets control.
When this happens you should try to write a query that eliminates the materialization, but this is not always possible. If materialization is y punavoidable then you may be better off materializing the smallest amount of data in one query, and then going back to the database for the rest of the data later.
© YL&A 1999 - 2011 42

This is an extremely simple example for what is actually a problem with extremely large and complex queries used to fills screens with data. If we can’t avoid materialization then perhaps we can minimize it. What the applications will do is to read only the data required to avoid or reduce the materialization. Then they do with that data what is best:
•Send only one screen’s worth back using a programmatic join to get other table data•Save the results in an array with key values to retrieve related data on subsequent screen viewsG t l t d d t i h t i I Li t d th idi l t•Get related data in our shot using In-Lists and thus avoiding large sorts
•And many more…
© YL&A 1999 - 2011 43

© YL&A 1999 - 2011 44

Dan Luksetich is a senior DB2 DBA consultant. He works as a DBA, application architect, presenter, author, and teacher. Dan has been in the information technology business for over 26 years, and has worked with DB2 for over 21 years. He has been a COBOL and BAL programmer, DB2 system programmer, DB2 DBA, and DB2 application architect. His experience includes major implementations on z/OS, AIX, i Series, and Linux environments.
Dan's experience includes:
A li ti d i d hit tApplication design and architectureDatabase administrationComplex SQLSQL tuningDB2 performance auditsReplicationReplicationDisaster recoveryStored procedures, UDFs, and triggers
Dan works everyday on some of the largest and most complex DB2 implementations in the world. He is a certified DB2 DBA, system





























