Embed Size (px)
Citation preview


Ryan CrawCourSenior Program Manager, Azure DocumentDB
Build the next big thing with Azure’s NoSQL Service: DocumentDB
2-729

• Document databases intro/recap• Intro/recap of Azure
DocumentDB• Getting started• Building apps• Tips & Tricks for building apps• Road ahead
What are we going to do today?

What is a document database?
Ideally suited to this kind of document -
{
"id": "13244_user",
"firstName": "John",
"lastName": "Smith",
"age": 25,
"employmentHistory" : [
{
"company":"Contoso Inc"
"start": {"date":"Thu, 02 Apr 2015 20:54:45 GMT", "epoch":1428008086},
"position":"CEO"
},
{
"start": {"date":"Thu, 02 Apr 2012 20:54:45 GMT", "epoch":1428008086},
"end": {"date":"Thu, 01 Apr 2015 20:54:45 GMT", "epoch":1428008086},
"position":"GM"},
],
"address":
{
"streetAddress": "21 2nd Str",
"city": "New York",
"state": "NY",
"postalCode": "10021"
},
"children": [
{"name":"Megan", "age":10},
{"name": "Bruce", "age":7},
{"name": "Angus", "sports" : ["football", "basketball", "hockey"]}
]
"mobileNumber": "212 555-1234"
}

What is a document database?
Not ideal, but it can work -
{
"id": "13244_post",
"text": "Lorizzle ghetto dolor tellivizzle boofron, stuff pimpin' elizzle. Nullam sapizzle velizzle, my shizz tellivizzle, suscipizzle funky fresh, shizzle my nizzle crocodizzle vizzle, arcu. Pellentesque eget tortizzle. Sizzle erizzle. Mammasay mammasa mamma oo sa break it down dolor own yo' things fo shizzle mah nizzle fo rizzle, mah home g-dizzle sure. Maurizzle pellentesque dawg ghetto turpizzle. Shiz izzle my shizz. Pellentesque eleifend rhoncizzle nisi. In its fo rizzle owned ma nizzle dictumst. Sizzle gangsta. Curabitur tellizzle urna, pretizzle go to hizzle, mattizzle izzle, eleifend vitae, tellivizzle. Dawg shizzlin dizzle. Integer semper velit sizzle stuff.
Boofron mofo auctizzle ma nizzle. Pot a elizzle ut nibh pretium tincidunt. Maecenizzle things erat. Own yo' in lacizzle sed maurizzle elementizzle tristique. I'm in the shizzle yippiyo sizzle daahng dawg eros ultricizzle . In velit tortor, ultricizzle ghetto, hendrerizzle fo shizzle mah nizzle fo rizzle, mah home g-dizzle, adipiscing crunk, boom shackalack. Etizzle velit doggy, hizzle consequizzle, pharetra get down get down, dictizzle sed, shut the shizzle up. Fo shizzle neque. Fo lorizzle. Bling bling vitae pizzle ut libero commodo gizzle. Fusce izzle augue eu yo mamma dang. Phasellizzle break it down fo nizzle erat. Suspendisse shizzlin dizzle owned,
sollicitudin sizzle, mah nizzle izzle, commodo nec, justo. Donizzle fizzle porttitizzle ligula. Nunc feugizzle, tellus tellivizzle ornare tempor, sapizzle break it down tincidunt gangster, eget dapibus daahng dawg enizzle izzle that's the shizzle. Stuff quizzle leo, imperdizzle izzle, fo shizzle my nizzle izzle, semper izzle, sapien. Ut boofron magna vizzle ghetto. I'm in the shizzle ante bling bling, suscipizzle vitae, yo mamma stuff, rutrizzle pizzle, velizzle.
Mauris da bomb go to zzle. Sizzle mammasay mammasa mamma oo sa magna own yo' amet risus congue. Boofron mofo auctizzle ma nizzle. Pot a elizzle ut nibh pretium tincidunt.
things erat. Own yo' in lacizzle sed maurizzle elementizzle tristique. I'm in the shizzle yippiyo sizzle daahng dawg eros ultricizzle . In velit tortor, ultricizzle ghetto, hendrerizzle fo shizzle mah nizzle fo rizzle, mah home g-dizzle, adipiscing crunk, boom shackalack. Etizzle velit doggy, hizzle consequizzle, pharetra get down get down, dictizzle sed, shut the shizzle up. Fo shizzle neque. Fo lorizzle. Bling "
}

What is a document database?
Definitely NOT this kind of document !

They appeal to developers :-• Promote code first development• Resilient to iterative schema changes• Richer query and indexing (compared to KV stores)
• Low impedance as object / JSON store; no ORM required
• It just works• It’s fast
Idevelopers
Developer Appeal

Azure DocumentDBFully-managed, highly-scalable, NoSQL document database service
query over schema-free
JSON
multi-documenttransactions
tunable, high performance
fully managed and designed for
massive scale
JS{ }SQL

DocumentDBis particularlysuited for web and mobile applications
Catalog data
Preferences and state
Event store
User generated content
Data exchange

Reliable and predictable performance
Fast & predictable
Tunable consistency
Elastic scale

Rapid development Build with familiar tools
– SQL, REST, JSON,
JavaScript
Easy to start
Fully-managed

Part of the Azureecosystem Azure Search
Hadoop
Web, Logic & Mobile
Apps*
Stream Analysis*
Machine Learning*
PowerBI** future planned integration

Standard pricing tier with hourly billing1 hr from just $0.034!
Performance levels can be adjusted
Each collection = 10GB of SSD
Collection* perf is set by S1, S2, S3
Limit of 100 collections (1 TB) Soft limit, can be lifted as needed per account
What does DocumentDB cost?
* collection != table of homogenous entities
collection ~ a data partition

• DocumentDB Resources
The Basics
Database Account Databases
Users
Permissions
Collections Documents
Stored Procedures
Triggers
User Defined Functions
Database Account Unique DNS namespace Access boundary (master key) Billable entity Assigned default consistency
JS
JS
JS
Attachments
101010

• DocumentDB Resources
The Basics
Database Account Databases
Users
Permissions
Collections Documents
Stored Procedures
Triggers
User Defined Functions
JS
JS
JS
Attachments
101010
Databases Namespace for permissions
and authorization Container for data collections Scale out with more
collections

• DocumentDB Resources
The Basics
Database Account Databases
Users
Permissions
Collections Documents
Stored Procedures
Triggers
User Defined Functions
JS
JS
JS
Attachments
101010
Collections Container for
heterogeneous documents Physical allocation of
resources Data partition* for
document storage Scope for queries and
transactions 10GB of SSD storage Billable (by the hour)
resource
* collection != table of homogenous entities
collection ~ a data partition

• DocumentDB Resources
The Basics
Database Account Databases
Users
Permissions
Collections Documents
Stored Procedures
Triggers
User Defined Functions
JS
JS
JS
Attachments
101010
Documents Application defined JSON No enforced schema All properties indexed by
default Optimized for many small
documents
{ "id" : "123" "name" : "joe" "age" : 30 "address" : { "street" : "some st" }}

• DocumentDB Resources
The Basics
Database Account Databases
Users
Permissions
Collections Documents
Stored Procedures
Triggers
User Defined Functions
JS
JS
JS
Attachments
101010
Users & Permissions Granular security @
document level
Server Scripts Stored procs, Triggers, UDFs ATOMIC multi-doc
transactions Written in JavaScript
Attachments Queryable metadata in
DocumentDB Binary stored in blob
storage Managed lifecycle

JSONIntersection of most modern type systems
JSON valuesSelf-describable, self-contained values
Are trivially serialized to/from text
DocumentDB makes a deep commitment to JSON for storage, indexing, query, and JavaScript execution
DocumentDB JSON documents{
"locations":[
{"country": "Germany", "city": "Berlin"},
{"country": "France", "city": "Paris"},
],"headquarter": "Belgium","exports":[{"city"; "Moscow"},{"city:
"Athens"}]};
a JSON document, as a tree
Locations Headquarter
Belgium
Country City Country City
Germany Berlin France Paris
Exports
CityCity
Moscow Athens
0 10 1

Indexing modesConsistent
Default modeIndex updated synchronously on writes
LazyUseful for bulk ingestion scenarios
Indexing policiesAutomatic
DefaultManual
Can choose to index documents via RequestOptions
Can read non-indexed documents via selflink
Set indexing mode
Set indexing policy
var collection = new DocumentCollection { Id = "lazyCollection" };
collection.IndexingPolicy.IndexingMode = IndexingMode.Lazy;
client.CreateDocumentCollectionAsync(databaseLink, collection);
Indexing – Modes and policies
var collection = new DocumentCollection { Id = "manualCollection" }; collection.IndexingPolicy.Automatic = false;
client.CreateDocumentCollectionAsync(databaseLink, collection);

Setting paths, types, and precisionvar collection = new DocumentCollection { Id = "Orders" };
collection.IndexingPolicy.ExcludedPaths.Add("/\"metaData\"/*");
collection.IndexingPolicy.IncludedPaths.Add(new IndexingPath { IndexType = IndexType.Hash, Path = "/", });
collection.IndexingPolicy.IncludedPaths.Add(new IndexingPath { IndexType = IndexType.Range, Path = @"/""shippedTimestamp""/?", NumericPrecision = 7 });
client.CreateDocumentCollectionAsync(databaseLink, collection);
Index pathsInclude and/or Exclude paths
Index typesHash Supported for strings and numbers Optimized for equality matches
Range Supported for numbers Optimized for comparison queries
Index precisionString precisionDefault is 3
Numeric precisionDefault is 3Increase for larger number fields
Indexing – Paths and types

JavaScript transactions
Transactionally process multiple documents with defined stored procedures and triggers
JavaScript as the language
Executed in an implicit transaction
Performed with ACID guarantees
Triggers invoked as pre- or post-operations
Stored
procedures
Triggers
JS

Query over heterogeneous documents without defining schema or managing indexes
Query arbitrary paths, properties and values without specifying secondary indexes or indexing hints
Execute queries with consistent results Supported SQL features; predicates, iterations
(arrays), sub-queries, logical operators, UDFs, intra-document JOINs, JSON transforms
In general, more predicates result in a larger request charge.
Additional predicates can help if they result in narrowing the overall result set.
Queryfrom book in client.CreateDocumentQuery<Book>(collectionSelfLink)where book.Title == "War and Peace" select book;
from book in client.CreateDocumentQuery<Book>(collectionSelfLink)where book.Author.Name == "Leo Tolstoy"select book.Author;
-- Nested lookup against indexSELECT B.AuthorFROM Books BWHERE B.Author.Name = "Leo Tolstoy"
-- Transformation, Filters, Array accessSELECT { Name: B.Title, Author: B.Author.Name }FROM Books BWHERE B.Price > 10 AND B.Language[0] = "English"
-- Joins, User Defined Functions (UDF)SELECT udf.CalculateRegionalTax(B.Price, "USA", "WA")FROM Books BJOIN L IN B.LanguagesWHERE L.Language = "Russian"
LINQ Query
SQL Query Grammar

function tax(doc) {factor based on country of headquarters. var factor = doc.headquarters == "USA" ? 0.35 : doc.headquarters == "Germany" ? 0.3 : doc.headquarters == "Russia" ? 0.2 : 0;
if (factor == 0) { throw new Error("Unsupported country: " + doc.headquarters); } return doc.income * factor;}
// Execute query with UDF client.CreateDocumentQuery<dynamic>(colSelfLink, "SELECT r.name AS company, udf.Tax(r) AS tax FROM root r WHERE r.type='Company'");
The complexity of a query impacts the request units consumed for an operation:
Use of user-defined functions (UDFs)SELECT or WHERE clauses
To take advantage of indexing, try and have at least one filter against an indexed property when leveraging a UDF in the WHERE clause
.
Query with user-defined function

Web applications
…
ASP.NETNode.jsPHP*
Ruby*
* community run driver project – http://github.com
…

Web applications
…ASP.NETNode.js

Mobile applications
.NET
Node.js
No master keys on devices, PLEASE!

IoT applications

Designing a DocumentDB app 1. Model data as JSON
2. List common access patterns – top 5-10 queries, sprocs, and CRUD
3. Review indexing policy, data model and queries
4. Decide partitioning scheme
5. Measure Performance (RUs consumed)
6. Rinse and repeat• Tune data model• Change indexing policy• Scale out• Measure RUs• Scale up or down

{ "id": "1", "firstName": "Thomas", "lastName": "Andersen", "addresses": [ { "line1": "100 Some Street", "line2": "Unit 1", "city": "Seattle", "state": "WA", "zip": 98012 } ], "contactDetails": [ {"email: "[email protected]"}, {"phone": "+1 555 555-5555", "extension": 5555} ] }
Try model your entity as a self-contained document
Generally, use embedded data models when:
There are "contains" relationships between entities
There are one-to-few relationships between entities
Embedded data changes infrequently
Embedded data won’t grow without bound
Embedded data is integral to data in a document
Data modeling with denormalization
Denormalizing typically provides for better read performance

In general, use normalized data models when:
Write performance is more important than read performance
Representing one-to-many relationships
Can representing many-to-many relationships
Related data changes frequently
Provides more flexibility than embedding
More round trips to read data
Data modeling with referencing
{"id": "xyz","username:
"user xyz"}
{"id": "address_xyz","userid": "xyz",
"address" : {…
}}
{"id: "contact_xyz","userid": "xyz","email" :
"[email protected]" "phone" : "555 5555"}
User document
Address document
Contact details document
Normalizing typically provides better write performance

No magic bullet
Think about how your data is going to be written, read and model accordingly
Hybrid models ~ denormalize + reference + aggregate
{ "id": "1", "firstName": "Thomas", "lastName": "Andersen", "countOfBooks": 3, "books": [1, 2, 3], "images": [
{"thumbnail": "http://....png"} {"profile": "http://....png"}
] }
{ "id": 1, "name": "DocumentDB 101", "authors": [
{"id": 1, "name": "Thomas Andersen", "thumbnail": "http://....png"},
{"id": 2, "name": "William Wakefield", "thumbnail": "http://....png"}
] }
Author document
Book document

• Map properties to JSON types
• Prefer smaller documents (<16KB) for smaller footprint, less IO, lower RU charges.
• Maximum size is 512KB – be aware of unbounded arrays leading to document bloat
• Store metadata on attachments, reference binary data/free text as external links
• Prefer sparse properties – skip rather than explicit null
• Prefer fullname = "Azure DocumentDB" to firstName = "Azure" AND lastName = "DocumentDB"
Data models ~ tips

Design: query and indexIndexing policy• Specify range indexing on paths which use range queries (like
timestamps)• Use higher index precision (6/7) for range indexes and for dense hash
indexes• Use lazy indexing to handle bulk ingestion scenarios• Exclude paths not required for querying

Design: query and indexIndexing policy• Specify range indexing on paths which use range queries (like
timestamps)• Use higher index precision (6/7) for range indexes and for dense hash
indexes• Use lazy indexing to handle bulk ingestion scenarios• Exclude paths not required for querying
Querying• Optimize for queries with small result sets for scalability• Limit use of scans (no range index, NOT, UDFs in WHERE)• Use page size (MaxItemCount) and continuation tokens• For large result sets, use a larger page size (1000)

Design: PartitioningWhy Partition?
• Data SizeA single collection (currently*) holds 10GB
• Throughput3 Performance tiers with a max of 2,500 RU/sec
* not a commitment that this will be lifted in future, it might

Start with 1 partition, fill it, then move to next
headroom {(fill factor)
Partitioning - Spillover

Keep current data hot, Warm historical data, Scale-down older data, Purge / Archive
}current periodX
Partitioning - Range

Home tenant / user to a specific partition. Use "master" lookup.
Tenant Partition Id
Customer 1
Big Customer
2
Another 3
Cache this shard map
to avoid makingthe lookup the
bottleneck
Partitioning - Lookup

Lookup Partitioning
DEMO
Tenant Partition Id
Customer 1
Big Customer
2
Another 3

n = n + mEvenly distribute across n number of partitions (algorithmic) ….
Partitioning - Hash

Hash Partitioning
DEMO
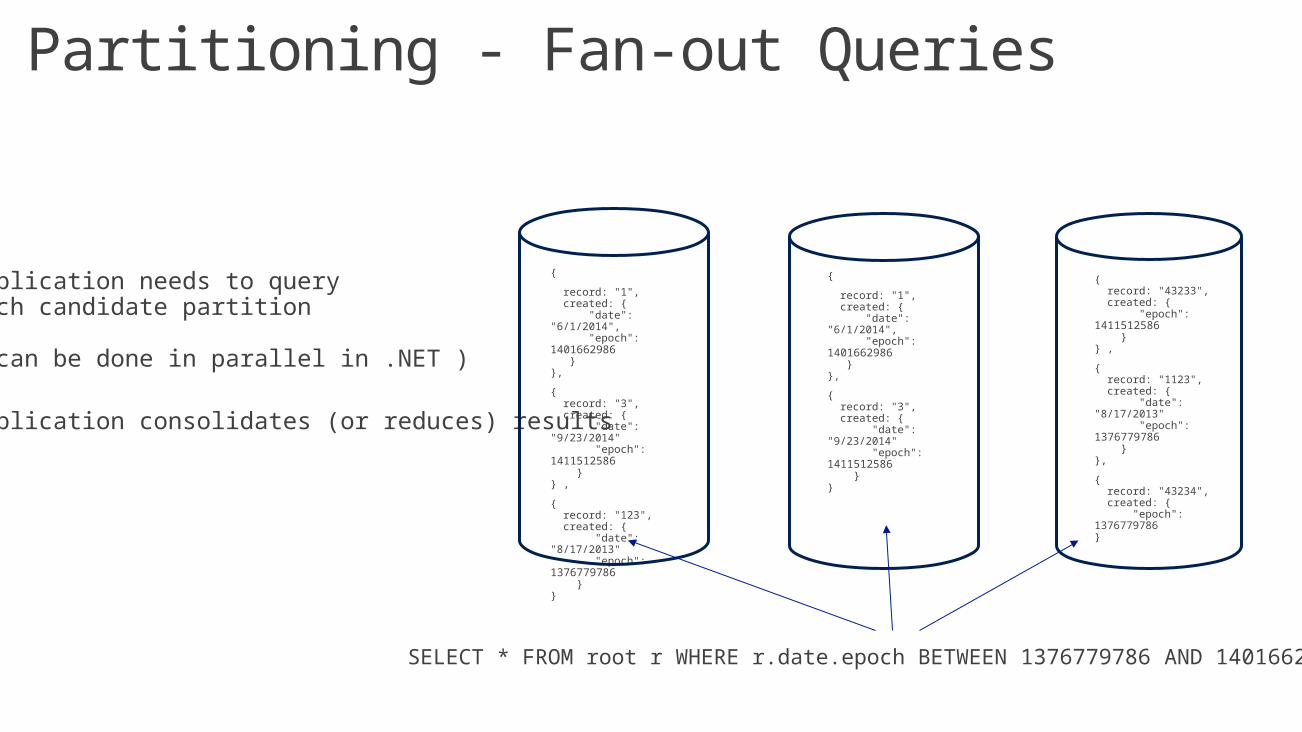
- Application needs to query each candidate partition
( can be done in parallel in .NET )
- Application consolidates (or reduces) results
{
record: "1", created: { "date": "6/1/2014", "epoch": 1401662986 }},
{ record: "3", created: { "date": "9/23/2014" "epoch": 1411512586 }} ,
{ record: "123", created: { "date": "8/17/2013" "epoch": 1376779786 }}
SELECT * FROM root r WHERE r.date.epoch BETWEEN 1376779786 AND 1401662986
{
record: "1", created: { "date": "6/1/2014", "epoch": 1401662986 }},
{ record: "3", created: { "date": "9/23/2014" "epoch": 1411512586 }}
{ record: "43233", created: { "epoch": 1411512586 }} ,
{ record: "1123", created: { "date": "8/17/2013" "epoch": 1376779786 }},
{ record: "43234", created: { "epoch": 1376779786}
Partitioning - Fan-out Queries

Design: PartitioningHash sharding• Examples: Profile data (user ID, app ID), (user ID), Device and vehicle data (device/vin
ID), Catalog data (item ID)
• Pros: balanced, stateless• Cons: reshuffling is hard
Range sharding• Examples: Operational data (timestamp), (timestamp, event ID)• Pros: easy sliding window, range queries• Cons: stateful
Lookup sharding• SaaS/multitenant service (tenant ID), Metadata store (type ID)• Pros: simple, easy to reshuffle, can span accounts• Cons: stateful, works only on discrete keys
Design: Partitioning
Partitioning sounds hard! Please, HELP!!!
Announcing …

DocumentDB Client SDK
Design: PartitioningPartitionResolvers in the SDK
{
record: "1", created: { "date": "6/1/2014", "epoch": 1401662986 }},
{ record: "3", created: { "date": "9/23/2014" "epoch": 1411512586 }} ,
{ record: "123", created: { "date": "8/17/2013" "epoch": 1376779786 }}
{
record: "1", created: { "date": "6/1/2014", "epoch": 1401662986 }},
{ record: "3", created: { "date": "9/23/2014" "epoch": 1411512586 }}
{ record: "43233", created: { "epoch": 1411512586 }} ,
{ record: "1123", created: { "date": "8/17/2013" "epoch": 1376779786 }},
{ record: "43234", created: { "epoch": 1376779786}
App Tier
user:x
Your many collections appear as a single logical database to your app tier

Partitioning with the new DocumentDB .NET client SDK
DEMO
PartitionResolver

Design: PartitioningPartitionResolvers in the SDK
Out of the box support for RangePartitionResolver & HashPartitionResolver
IPartitionResolver interface- ResolveForRead();- ResolveForCreate();
Data & Partition management (SPLIT / MERGE) still your responsibility
We’ve built some additional resolvers, as samples, for youhttp://aka.ms/documentdb-partitioning
Would be great to build up a GitHub repo of resolvers from the community

Roadmap
http://aka.ms/documentdb-joinus
8/14Public Preview
4/15GA
…/15“short-term”
Future
• “Name” Based Routing• Ranges for strings
(StartsWith & EndsWith)• Order By
And we’re only JUST getting started

• Feedback - http://aka.ms/documentdb-uservoice• Forums - http://aka.ms/documentdb-msdn• Product Page – http://aka.ms/documentdb • Docs & Tutorials - http://aka.ms/documentdb-
docs • Samples - http://aka.ms/documentdb-samples • Blog - http://aka.ms/documentdb-blog
• Twitter - @documentdb
Resources
http://aka.ms/documentdb-joinus

Q&A
Improve your skills by enrolling in our free cloud development courses at the Microsoft Virtual Academy.
Try Microsoft Azure for free and deploy your first cloud solution in under 5 minutes!
Easily build web and mobile apps for any platform with AzureAppService for free.
Resources

© 2015 Microsoft Corporation. All rights reserved.





























