Embed Size (px)
Citation preview

201428th International Conference on Supercomputing
München, 10-13 June
ICSC

Workshop Program 1
Conference Program 8
Map of Conference Sites 15
Restaurants 16
TUM and LRZ @ Garching 17
U-Bahn Map 18
1
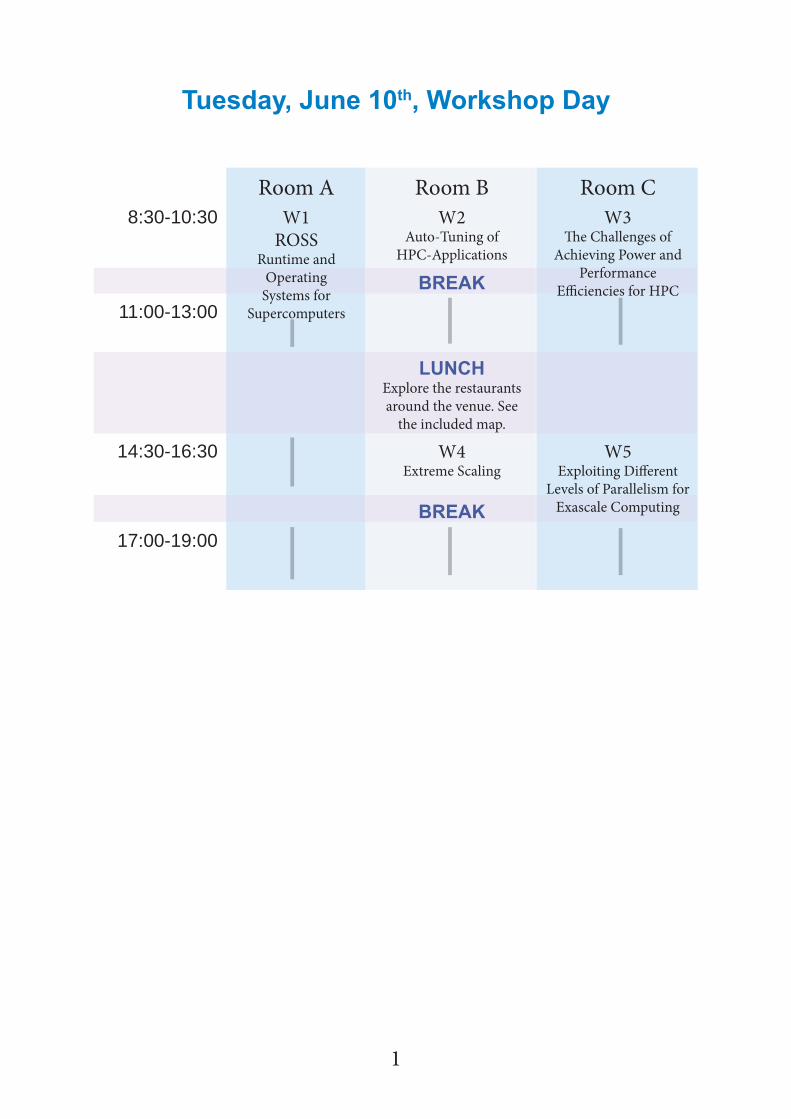
Tuesday, June 10th, Workshop Day
Room A Room B Room C8:30-10:30 W1
ROSSRuntime and
Operating Systems for
Supercomputers
W2Auto-Tuning of
HPC-Applications
W3Th e Challenges of
Achieving Power and Performance
Effi ciencies for HPCBREAK11:00-13:00
LUNCHExplore the restaurants around the venue. See
the included map.
14:30-16:30 W4Extreme Scaling
W5Exploiting Diff erent
Levels of Parallelism for Exascale ComputingBREAK
17:00-19:00

2
W1: International Workshop on Runtime and Operating Systems for Supercomputers (ROSS)
Room A
8:45-9:00 Opening9:00-10:30 Keynote
Building Blocks for an Exa-Scale Operating SystemHermann Härtig
OS Architecture and ManycoremOS: An Architecture for Extreme-Scale Operating SystemsRobert W. Wisniewski, Todd Inglett, Pardo Keppel, Ravi Murty, and Rolf Riesen
BREAK11:00-13:00 Revisiting Virtual Memory for High Performance Computing on
Manycore Architectures: A Hybrid Segmentation Kernel ApproachYuki Soma, Balazs Gerofi , and Yutaka Ishikawa
VMM Emulation of Intel Hardware Transactional MemoryMaciej Święch, Kyle C. Hale, and Peter DindaRuntime Systems and Th readsPICS: A Performance-Analysis-Based Introspective Control System to Steer Parallel ApplicationsYanhua Sun, Jonathan Liffl ander, and Laxmikant V. Kalé
Hybrid MPI – A Case Study on Xeon Phi PlatformU. S. Wickramasinghe, Greg Bronevetsky, Andrew Lumsdaine, and Andrew Friedley
LUNCH

3
14:30-16:30 Automatic SMT Th reading for OpenMP Applications on the Intel Xeon Phi Co-processorWim Heirman, Trevor E. Carlson, Kenzo Van Craeynest, Ibrahim Hur, Aamer Jaleel, and Lieven Eeckhout
Exascale GossipAn Evaluation of BitTorrent’s Performance In HPC EnvironmentsMatthew G. F. Dosanjh, Patrick G. Bridges, Suzanne M. Kelly, James H. Laros III, and Courtenay T. Vaughan
Reduction of Operating System Jitter Caused by Page ReclaimYoshihiro Oyama, Shun Ishiguro, Jun Murakami, Shin Sasaki, Ryo Matsumi-ya, and Osamu Tatebe
Overhead of a Decentralized Gossip Algorithm on the Performance of HPC ApplicationsEly Levy, Amnon Barak, Amnon Shiloh, Matthias Lieber, Carsten Weinhold, and Hermann Härtig
16:30-16:40 Best Paper Award and Closing Remarks

4
W2: International Workshop on Auto-Tuning of HPC-Applications
Room B
8:30-9:30 Invited TalkAutotuning: Don‘t just search - learn!Markus Püschel, ETH Zürich, Switzerland
9:30-10:30 Th e European Autotune ProjectSiegfried Benkner, University of Vienna, Austria
CPU Frequency Tuning for Optimizing the Energy to SolutionDavid Brayford, Leibniz Supercomputing Centre, Germany
Implementation of a Model Based Tuning PluginEduardo César, Universitat Autònoma de Barcelona, Spain
Tuning of High-Level Pipeline Patterns for Heterogeneous SystemsEnes Bajrovic, University of Vienna, Austria
BREAK11:00-13:00 Automatic MPI-IO Tuning with the Periscope Tuning Framework
Weifeng Liu, Shandong University & Technische Universität München, Ger-many
Writing an Automatic Tuner with the Periscope Tuning FrameworkIsaias Compres, Technische Universität München, Germany
Integration and Synthesis for Automated Performance Tuning: Multi-target Autotuning and the SYNAPT ProjectAllen Malony, University of Oregon, USA
Flexible and Re-targetable Autotuning With Active HarmonyJeff Hollingsworth, University of Maryland, USA
Automated Program Analysis and Characterization for Performance Engineering and DebuggingPhil Roth, Oak Ridge National Laboratory, USA

5
W3: International Workshop on The Challenges of Achieving Power and
Performance Effi ciencies for HPCFrom Design-space Exploration to Dynamic Optimization
Room C
8:30-9:30 KeynoteNew Rules: Sustaining Performance Scaling in a Physical WorldSudhakar Yalamanchili, School of Electrical and Computer Engineering, Georgia Institute of Technology
9:30 -10:30 Session 1Performance and power models for optimal resource effi ciencyGeorg Hager, University of Erlangen, Germany
Over-provisioned Systems: Opportunity or Unmanageable Risk?Martin Schulz, Lawrence Livermore National Lab, USA
BREAK11:00-12:30 Session 2
Th e future of Interconnect and the road to Exascale?Gilad Shainer, Mellanox Technologies, USA
Dynamically steering power in large-scale systemsDarren J. Kerbyson, Kevin J. Barker, Adolfy Hoisie Pacifi c Northwest National Lab
TBA12:30-13:00 Panel
Achieving future power and performance effi ciencies
Closing Remarks

6
W4: Extreme-Scaling Workshop Room B
14:30-16:30 Overview: Th e Extreme Scaling Workshop@LRZ 2014Ferdinand Jamitzky
Extreme large scale computations with the Plasma-Simulation-Code (PSC) A modern framework for advanced Particle-in-Cell (PIC) simulations.Karl-Ulrich Bamberg
Achieving Petascale Performance with SeisSol on SuperMUCMichael Bader
Solving the Euler equations using implicit time-steppingPhilipp Edelmann
Anisotropic Diff usion Filtering Terabytes of Seismic Data in se-conds: Th e Power of the GPI-2 One-sided Communication Ap-proachMartin Kühn
BREAK17:00-19:00 Scaling of a Multigrid-like Solver for the Pressure Poisson Equation
in a CFD CodeJérôme Frisch, Ralf-Peter Mundani
Scaling of the hybrid MPI-OpenMP DNS code NSCOUETTE on SuperMUCMarkus Rampp
HPC in plasma astrophysics: Particle-in-Cell codesAndreas Kempf
Towards Petafl op capability of the VERTEX supernova codeTobias Melson

7
W5: Exploiting Different Levels of Parallelism for Exascale Computing
Room C
14:30-15:30 Keynote Fast Algorithms for the Evaluation for Volume Integral Equations on Hybrid ArchitecturesGeorge Biros, University of Texas at Austin
15:30-16:30 Breaking Global Communication -- Multi-level Parallelism for High-dimensional ProblemsDirk Pfl üger, University of Stuttgart
Domain Decomposition Methods -Towards Extreme Scalability using new Nonlinear ApproachesAxel Klawonn, University of Cologne
BREAK17:00-18:00 Building Blocks for Sparse Linear Algebra on Heterogeneous Hard-
wareGeorg Hager, Friedrich-Alexander Universität Erlangen-Nürnberg
Inter- and Intra-Solver Parallelism for Coupled Multi-Physics Simu-lationsBenjamin Uekermann, Technische Universität München
18:00-19:00 Open Discussion

8
Wednesday, June 11th
Room A8:30-9:00 Welcome
Prof. Dr. Karl-Heinz Hoff mannPresident of the Bavarian Academy of Sciences
Prof. Dr. Arndt BodeDirector of LRZCo-Chair of ICS 2014
Prof. Dr. Per StenströmChalmers UniversityProgram-Chair of ICS 2014
Prof. Dr. Michael GerndtTechnische Universität MünchenCo-Chair of ICS 2014
9:00-10:00 Keynote Session Chair: Arndt BodeHPC for the Human Brain ProjectTh omas Lippert
BREAK10:30-12:30 Programming Models Chair: Frank Müller
LAWS: Locality-Aware Work-Stealing for Multi-socket Multi-core ArchitecturesQuan Chen, Minyi Guo and Haibing Guan
Eff ective Automatic Computation Placement and Data allocation for Parallelization of Regular ProgramsChandan Reddy and Uday Bondhugula
On the Conditions for Effi cient Interoperability with Th reads: An Experience with PGAS Languages Using Cray Communication DomainsKhaled Ibrahim and Katherine Yelick
HOMR: A Hybrid Approach to Exploit Maximum Overlapping in MapReduce over High Performance InterconnectsMd Rahman, Xiaoyi Lu, Nusrat Islam and Dhabaleswar Panda
LUNCHExplore the restaurants around the venue. See the included map.

9
14:00-18:30 Tutorial: Hybrid PGAS, Room B14:00-16:00 Main Track, Room A
Memory Systems Chair: Josef WeidendorferDTail: A Flexible Approach to DRAM Refresh ManagementZehan Cui, Sally A. McKee, Zhongbin Zha, Yungang Bao and Mingyu Chen
Last-Level Cache DeduplicationYingying Tian, Samira Khan, Daniel Jiménez and Gabriel Loh
Block Value based Insertion Policy for High Performance Last-level CachesLingda Li, Junlin Lu and Xu Cheng
Multi-Stage Coordinated Prefetching for Present-day ProcessorsSanyam Mehta, Zhenman Fang, Antonia Zhai and Pen-Chung Yew
BREAK16:30-18:30 Applications and Algorithms Chair: Michael Bader
Evaluation of Methods to Integrate Analysis into a Large-Scale Shock Physics CodeRon Oldfi eld, Kenneth Moreland, Nathan Fabian and David Rogers
Input-adaptive Parallel Sparse Fast Fourier Transform for Stream ProcessingShuo Chen and Xiaoming Li
Th read-cooperative, bit-parallel computation of Levenshtein dis-tance on GPUAlejandro Chacón, Santiago Marco-Sola, Antonio Espinosa, Paolo Ribeca and Juan Carlos Moure
Load Balancing N-body Simulations with Highly Non-Uniform DensityOlga Pearce, Todd Gamblin, Bronis de Supinski, Tom Arsenlis and Nancy Amato
18:45-20:15 Guided Walking Tour MunichStarts at the entrance of the Academy of Sciences.

10
Thursday, June 12th
8:30-9:30 Keynote Session Chair: Per Stenström 21st Century Computer ArchitectureMarc D. Hill
9:30-10:00 Invited Session Chair: Per StenströmHigh-Performance Computing in Horizon 2020Panagiotis Tsarchopoulos, European Commission
BREAK10:30-12:30 MPI Chair: Martin Schulz
MT-MPI: Multithreaded MPI for Many-core EnvironmentsMin Si, Antonio Peña, Pavan Balaji, Masamichi Takagi and Yutaka Ishikawa
Implementing a Classic: Zero-copy All-to-all Communication with MPI datatypesJesper Larsson Träff , Antoine Rougier and Sascha Hunold
Value Infl uence Analysis for Message Passing ApplicationsPhilip Roth and Jeremy Meredith
Scalable Tracing of MPI Programs through Signature-Based Clustering AlgorithmsAmir Bahmani and Frank Mueller

11
12:30-14:00 LUNCH @ R Poster Session:Evaluation of student posters for best poster award.(*)An Optimal Distributed Load Balancing Algorithm for Homoge-nous Work Units (*)Akhil Langer
Addressing Bandwidth Contention in SMT Multicores Th rough Scheduling (*)Josué Feliu, Julio Sahuquillo, Salvador Petit and José Duato
Accelerating Cache Coherence Mechanism with Speculation (*)Jun Ohno and Kei Hiraki
Reducing Energy Consumption of NoC by Router Bypassing (*)Takahiro Naruko and Kei Hiraki
An Adaptive Cross-Architecture Combination Method for Graph TraversalYang You, Shuaiwen Song and Darren Kerbyson
Hardware-Assisted Scalable Flow Control of Shared Receive QueueTeruo Tanimoto, Takatsugu Ono, Kohta Nakashima and Takashi Miyoshi
Automating and Optimizing Data Transfers for Many-core Copro-cessorsBin Ren, Nishkam Ravi, Yi Yang, Min Feng, Gagan Agrawal and Srimat Chakradhar
14:00-16:00 I/O and NVRAM Chair: Michael GerndtRevealing Applications‘ Access Pattern in Collective I/O for Cache ManagementYin Lu, Yong Chen, Rob Latham and Yu Zhuang
Supporting Storage Confi guration for I/O Intensive Workfl owsLauro Beltrao Costa, Samer Al-Kiswany, Hao Yang and Matei Ripeanu
Understanding the Impact of Th reshold Voltage on MLC Flash Memory Performance and ReliabilityWei Wang, Tao Xie and Deng Zhou
DWC: Dynamic Write Consolidation for Phase Change Memory SystemsFei Xia, Dejun Jiang, Jin Xiong, Mingyu Chen, Lixin Zhang and Ninghui Sun
BREAK

12
16:30-18:30 Modeling and Optimization Chair: Philip RothPalm: Easing the Burden of Analytical Performance ModelingNathan Tallent and Adolfy Hoisie
An End-to-End Analysis of File System Features on Sparse Virtual DisksRuijin Zhou, Sankaran Sivathanu, Jinpyo Kim, Bing Tsai and Tao Li
Improving Performance by Matching Imbalanced Workloads with Heterogeneous PlatformsJie Shen, Henk Sips, Peng Zou, Yutong Lu and Ana Lucia Varbanescu
Long-Term Resource Fairness: Towards Economic Fairness on Pay-as-you-use Computing SystemsShanjiang Tang, Bu-Sung Lee, Bingsheng He and Haikun Liu
20:00-22:30 Conference Dinner @ AugustinerkellerAnnouncement of the Best Student Poster PriceHow to reach Augustinerkeller: Take any S-Bahn from Rosenhei-merplatz or Marienplatz to Hackerbrücke and enjoy the short walk from there.
22:00 Opening of Socker World Cup: Brazil - Croatia

13
Friday, June 13th
8:30-9:30 Keynote Session Chair: Lawrence RauchwergerTh e Future of SupercomputingMarc Snir
9:30-10:00 Invited Session Chair: Per StenströmHigh-Performance Computing in Horizon 2020Panagiotis Tsarchopoulos, European Commission
BREAK10:00-12:00 Accelerators Chair: Cosmin Oancea
Acceleration of Derivative Calculations with Application to Radial Basis Function – Finite-Diff erences on the Intel MIC ArchitectureGordon Erlebacher, Erik Saule, Natasha Flyer and Evan Bollig
An Effi cient Two-Dimensional Blocking Mechanism for Sparse Matrix-Vector Multiplication on GPUsArash Ashari, Naser Sedaghati, John Eisenlohr and P. Sadayappan
A Programming System for Xeon Phis with Runtime SIMD Paral-lelizationXin Huo, Bin Ren and Gagan Agrawal
Unifi ed On-chip Memory Allocation for SIMT ArchitectureAri Hayes and Eddy Z. Zhang
LUNCH @ R13:30-15:00 Interconnect and Microarchitecture Chair: Ronald Brightwell
Galaxy: A High-Performance Energy-Effi cient Multi-Chip Ar-chitecture Using Photonic InterconnectsYigit Demir, Yan Pan, Sukwoo Song, Nikos Hardavellas, Gokhan Memik and John Kim
A Performance Perspective on Energy Effi cient HPC LinksKarthikeyan P. Saravanan, Paul M. Carpenter and Alex Ramírez
Verifying Micro-architecture Simulators using Event TracesHui Meen Nyew, Nilufer Onder, Soner Onder and Zhenlin Wang
BREAK

14
15:30-17:00 Multi- and Many-core Systems Chair: Todd GamblinScaling Up Matrix Computations on Shared-Memory Manycore Systems with 1000 CPU CoresFengguang Song and Jack Dongarra
Collective Memory Transfers for Multi-Core ChipsGeorge Michelogiannakis, Samuel Williams, Alexander Williams and John Shalf
Scalable Analysis of Multicore Data Reuse and SharingMiquel Pericàs, Kenjiro Taura and Satoshi Matsuoka
15
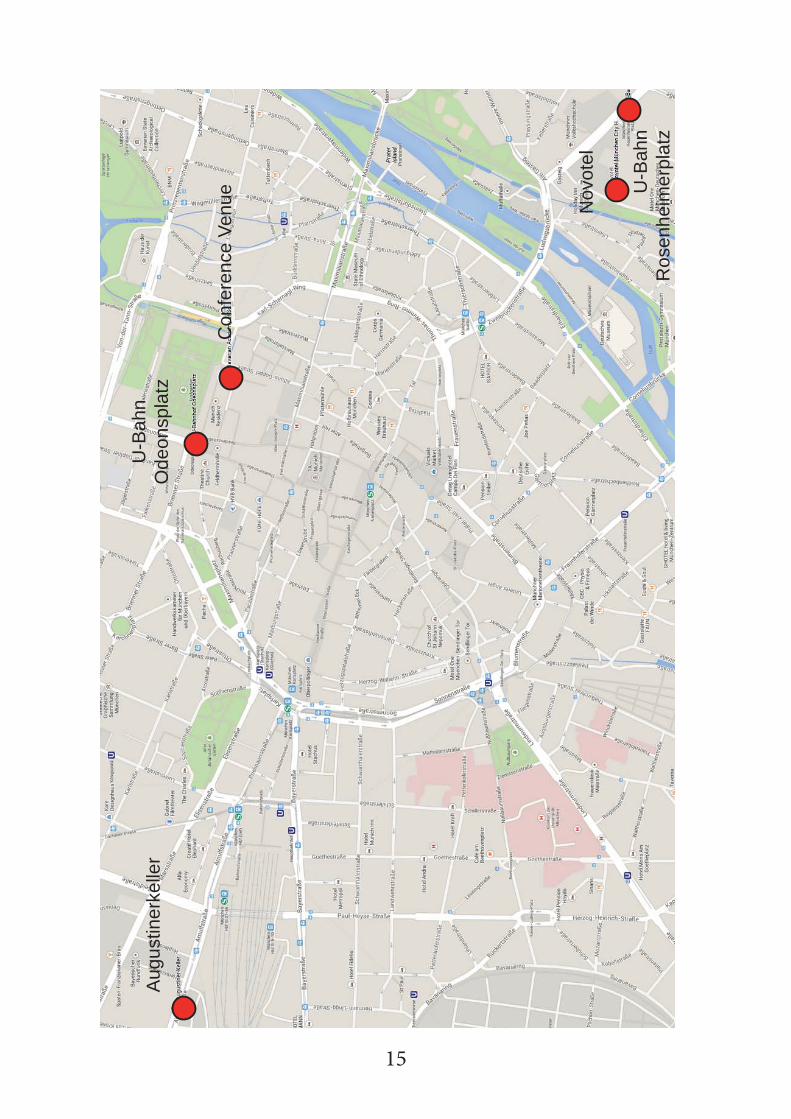
Augu
stin
erke
ller
U-B
ahn
Ode
onsp
latz
Con
fere
nce
Venu
e
Nov
otel
U-B
ahn
Ros
enhe
imer
plat
z

16
Restaurants around Conference Venue
On Tuesday and Wednesday you may explore the many restaurants of Munich during lunch time. Please also have a look at the conference web site.

17
TUM Faculty of Informatics
in Garching
LRZ in Garching
SuperMUC in the LRZ Compute Cube
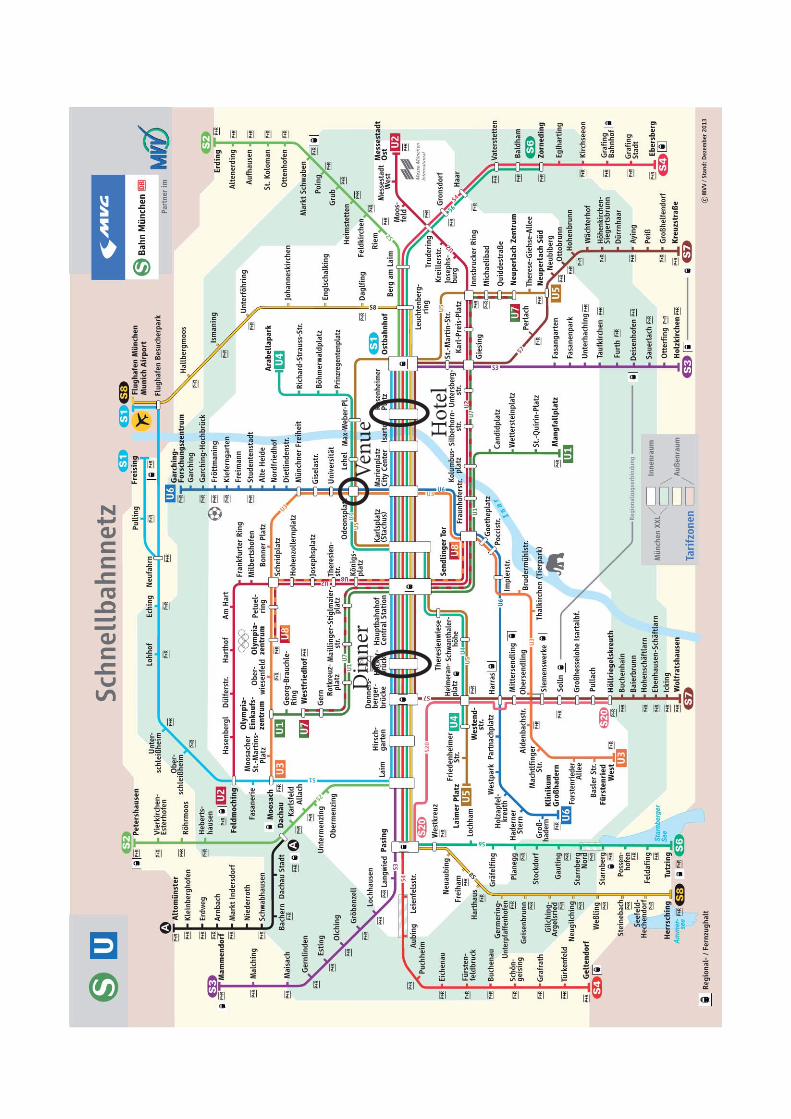
Hot
el
Din
ner
Venu
e





























