Embed Size (px)
Citation preview

Hsin-Hsi Chen 7-1
Chapter 7Text Operations
Hsin-Hsi Chen
Department of Computer Science and Information Engineering
National Taiwan University
Hsin-Hsi Chen 7-2
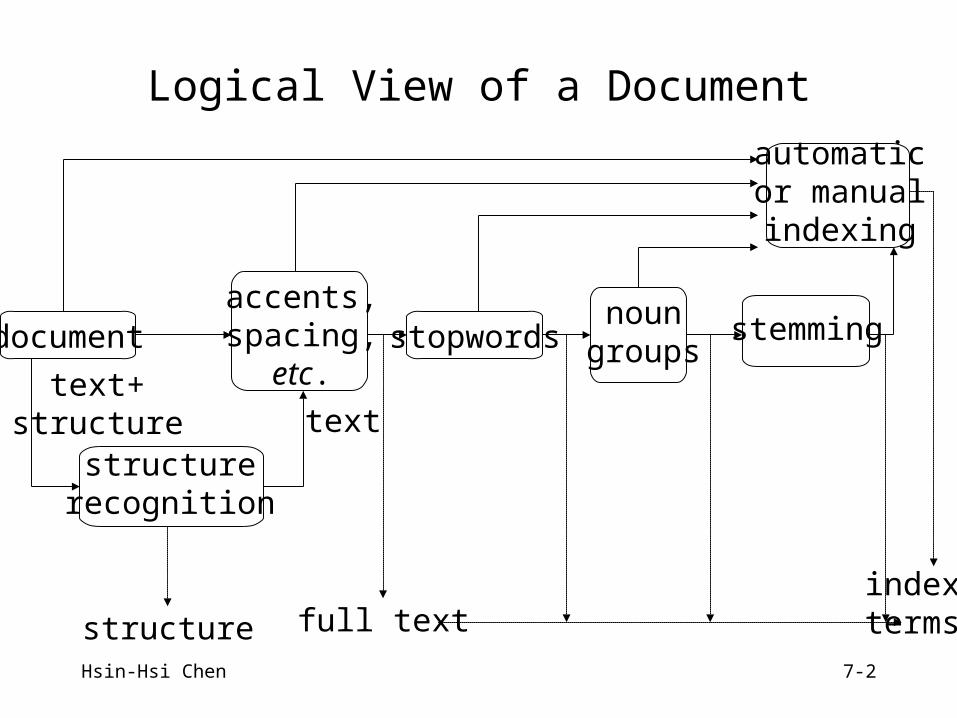
Logical View of a Document
document
structurerecognition
text+structure
accents,spacing,
etc.stopwords
noungroups
stemming
automaticor manualindexing
structure
text
full textindexterms

Hsin-Hsi Chen 7-3
Document Preprocessing
• Lexical analysis
• Elimination of stopwords
• Stemming of the remaining words
• Selection of index terms
• Construction of term categorization structures

Hsin-Hsi Chen 7-4
Lexical Analysis for Automatic Indexing
• Lexical AnalysisConvert an input stream of characters into stream words or token.
• What is a word or a token?Tokens consist of letters.– digits: Most numbers are not good index terms.
counterexamples: case numbers in a legal database, “B6” and “B12” in vitamin database.
– hyphens• break hyphenated words: state-of-the-art, state of the art• keep hyphenated words as a token: “Jean-Claude”, “F-16”

Hsin-Hsi Chen 7-5
Lexical Analysis for Automatic Indexing(Continued)
– punctuation marks: often used as parts of terms, e.g., OS/2, 510B.C.
– case: usually not significant in index terms
• Issues: recall and precision– breaking up hyphenated terms
increase recall but decrease precision– preserving case distinctions
enhance precision but decrease recall– commercial information systems
usually take recall enhancing approach(numbers and words containing digits are index terms, and all are case insensitive)

Hsin-Hsi Chen 7-6
Lexical Analysis for Query Processing
• Tasks– depend on the design strategies of the lexical analyzer
for automatic indexing (search terms must match index terms)
– distinguish operators like Boolean operators, stemming or truncating operators, and weighting functions
– distinguish grouping indicators like parentheses and brackets

Hsin-Hsi Chen 7-7
stoplist (negative dictionary)• Avoid retrieving almost every item in a database
regardless of its relevance.• Examples
– conservative approach (ORBIT Search Service): and, an, by, from, of, the, with
– (derived from Brown corpus): 425 wordsa, about, above, across, after, again, against, all, almost, alone, along, already, also, although, always, among, an, and, another, any, anybody, anyone, anything, anywhere, are, area, areas, around, as, ask, asked, asking, asks, at, away, b, back, backed, backing, backs, be, because, became, ...
• Articles, prepositions, conjunctions, …
Hsin-Hsi Chen 7-8
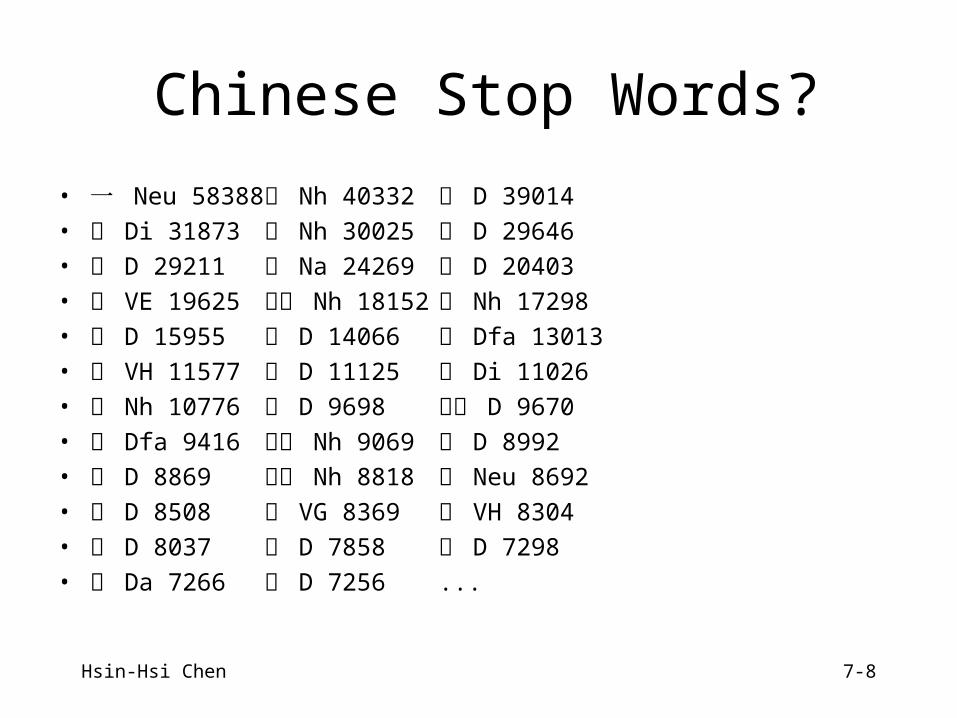
Chinese Stop Words?
• 一 Neu 58388 我 Nh 40332 不 D 39014
• 了 Di 31873 他 Nh 30025 也 D 29646
• 就 D 29211 人 Na 24269 都 D 20403
• 說 VE 19625 我們 Nh 18152 你 Nh 17298
• 要 D 15955 會 D 14066 很 Dfa 13013
• 大 VH 11577 能 D 11125 著 Di 11026
• 她 Nh 10776 還 D 9698 可以 D 9670
• 最 Dfa 9416 自己 Nh 9069 來 D 8992
• 所 D 8869 他們 Nh 8818 兩 Neu 8692
• 可 D 8508 為 VG 8369 好 VH 8304
• 又 D 8037 將 D 7858 更 D 7298
• 才 Da 7266 已 D 7256 ...

Hsin-Hsi Chen 7-9
Implementing Stoplists
• approaches– examine lexical analyzer output and remove an
y stopwords• Every token must be looked up in the stoplist, and re
moved from further analysis if found
• A standard list searching problem
– remove stopwords as part of lexical analysis• best implementation of stoplist

Hsin-Hsi Chen 7-10
Stemming• stem
– Portion of a word which is left after the removal of its affixes– connect connected, connecting, connection, connections
• benefits of stemming?– Some favor the usage of stemming– Many Web search engines do not adopt any stemming
algorithm
• issues– correctness– retrieval performance– compression performance

Hsin-Hsi Chen 7-11
Stemmers• programs that relate morphologically similar indexing and
search terms• stem at indexing time
– advantage: efficiency and index file compression– disadvantage: information about the full terms is lost
• example (CATALOG system), stem at search timeLook for: system usersSearch Term: users Term Occurrences
1. user 152. users 13. used 34. using 2
Which terms (0=none, CR=all):
The user selects the terms he wants by numbers

Hsin-Hsi Chen 7-12
Conflation Methods• manual• automatic (stemmers)
– affix removallongest match vs. simple removal
– successor variety– table lookup– n-gram
• evaluation– correctness– retrieval effectiveness– compression performance
Term Stemengineering engineerengineered engineerengineer engineer

Hsin-Hsi Chen 7-13
Successor Variety
• Definition (successor variety of a string)the number of different characters that follow it in words in some body of text
• Examplea body of text: able, axle, accident, ape, aboutsuccessor variety of apple1st: 4 (b, x, c, p)2nd: 1 (e)

Hsin-Hsi Chen 7-14
Successor Variety (Continued)• IdeaThe successor variety of substrings of a term will decrease as more characters are added until a segment boundary is reached, i.e., the successor variety will sharply increase.
• ExampleTest word: READABLECorpus: ABLE, BEATABLE, FIXABLE, READS,
READABLE, READING, RED, ROPE, RIPEPrefix Successor Variety LettersR 3 E, O, IRE 2 A, DREA 1 DREAD 3 A, I, SREADA 1 BREADAB 1 LREADABL 1 EREADABLE 1 blank

Hsin-Hsi Chen 7-15
The successor variety stemming process
• Determine the successor variety for a word.• Use this information to segment the word.
– cutoff methoda boundary is identified whenever the cutoff value is reached
– peak and plateau methoda character whose successor variety exceeds that of the character immediately preceding it and the character immediately following it
– complete word methoda segment is a complete word
– entropy method
• Select one of the segments as the stem.

Hsin-Hsi Chen 7-16
n-gram stemmers
• diagrama pair of consecutive letters
• shared diagram methodassociation measures are calculated between pairs of terms
where A: the number of unique diagrams in the first word, B: the number of unique diagrams in the second, C: the number of unique diagrams shared by A and
B.
SC
A B
2

Hsin-Hsi Chen 7-17
n-gram stemmers (Continued)
• Examplestatistics => st ta at ti is st ti ic csunique diagrams => at cs ic is st ta tistatistical => st ta at ti is st ti ic ca alunique diagrams => al at ca ic is st ta ti
SC
A B
2 2 6
7 80 80
*.

Hsin-Hsi Chen 7-18
n-gram stemmers (Continued)
• similarity matrixdetermine the semantic measures for all pairs of terms in the database
word1 word2 word3 ... wordn-1
word1
word2 S21
word3 S31 S32
.
.wordn Sn1 Sn2 Sn3 … Sn(n-1)
• terms are clustered using a single link clustering method• more a term clustering procedure than a stemming one

Hsin-Hsi Chen 7-19
Affix Removal Stemmers
• procedureRemove suffixes and/or prefixes from terms leaving a stem, and transform the resultant stem. E.g., Porter algorithm
• example: plural formsIf a word ends in “ies” but not “eies” or “aies”
then “ies” --> “y”If a word ends in “es” but not “aes”, “ees”, or “oes”
then “es” --> “e”If a word ends in “s”, but not “us” or “ss”
then “s” --> NULL
• ambiguity

Hsin-Hsi Chen 7-20
Affix Removal Stemmers (Continued)
• longest match stemmerremove the longest possible string of characters from a word according to a set of rules
– recoding: AxC--> AyC, e.g., ki --> ky
– partial matching: only n initial characters of stems are used in comparing
• different versionsLovins, Slaton, Dawson, Porter, …Students can refer to the rules listed in appendix of the text book (pp. 433-436)

Hsin-Hsi Chen 7-21
Index Term Selection(see Chapter 2)

Hsin-Hsi Chen 7-22
Fast Statistical Parsing of Noun Phrases for Document Indexing
Chengxiang Zhai
Laboratory for Computational Linguistics
Carnegie Mellon University
(ANLP’97, pp. 312-319)

Hsin-Hsi Chen 7-23
Phrases for Document Indexing
• Indexing by single words– single words are often ambiguous and not specific
enough for accurate discrimination of documents
– bank terminology vs. terminology bank
• Indexing by phrases– Syntactic phrases are almost always more specific than
single words
• Indexing by single words and phrases

Hsin-Hsi Chen 7-24
No significant improvement?
• Fagan, Joel L., Experiments in Automatic Phrase Indexing for Document Retrieval: A Comparison of Syntactic and Non-syntactic methods, Ph.D. thesis, Cornel University, 1987.
• Lewis, D., Representation and Learning in Information Retrieval, Ph.D. thesis, University of Massachusetts, 1991.
• Many syntactic phrases have very low frequency and tend to be over-weighted by normal weighting method.

Hsin-Hsi Chen 7-25
author’s points
• A larger document collection may increase the frequency of most phrases, and thus alleviate the problem of low frequency.
• The phrases are used only to supplement, not replace the single words for indexing.
• The new issue is:how to parse gigabytes of text in practically feasible time.(133MH DEC alpha workstation, 8 hours/GB, 20 hours of training with 1GB text.)

Hsin-Hsi Chen 7-26
Experiment Design
• CLARIT commercial retrieval system• {original document set} ---->
CLARIT NP Extractor ---->{Raw Noun Phrases} ---->Statistical NP Parser, Phrase Extractor ---->{Indexing Term Set} ---->CLARIT Retrieval Engine

Hsin-Hsi Chen 7-27
Different Indexing Units
• example– [[[heavy construction] industry] group] (WSJ90)
• single words– heavy, construction, industry, group
• head modifier pairs– heavy construction, construction industry, industry group
• full noun phrases– heavy construction industry group

Hsin-Hsi Chen 7-28
Different Indexing Units (Continued)
• WD-SET– single word only (no phrases, baseline)
• WD-HM-SET– single word + head modifier pair
• WD-NP-SET– single word + full NP
• WD-HM-NP-SET– single word + head modifier + full NP

Hsin-Hsi Chen 7-29
Result Analysis
• Collection: Tipster Disk 2 (250MB)• Query: TREC-5 ad hoc topics (251-300)• relevance feedback: top 10 documents returned
from initial retrieval• evaluation
– total number of relevant documents retrieved
– highest level of precision over all the points of recall
– average precision

Hsin-Hsi Chen 7-30
Effects of phraseswith feedback and TREC-5
Experiments Recall Init Prec Avg Prec WD-SET 0.56(597) 0.4546 0.2208
WD-HM-SET Inc over WD-SET
0.60 (638) 7%
0. 5162 14%
0. 2402 9%
WD-NP-SET Inc over WD-SET
0.58 (613) 4%
0. 5373 18%
0. 2564 16%
WD-HM-NP-SET Inc over WD-SET
0.63 (666) 13%
0. 4747 (4%)
0. 2285 (3%)
Total relevant documents: 1064

Hsin-Hsi Chen 7-31
Summary
• When only one kind of phrase is used to supplement the single words, each can lead to a great improvement in precision.
• When we combine the two kinds of phrases, the effect is a greater improvement in recall rather than precision.
• How to combine and weight different phrases effectively becomes an important issue.

Hsin-Hsi Chen 7-32
Thesaurus Construction• IR thesaurus: coordinate indexing and retrieval
a list of terms (words or phrases) along with relationships among them physics, EE, electronics, computer and control
• INSPEC thesaurus (1979)
cesium ( 銫,Cs) USE caesium (the preferred form)
computer-aided instructionsee also education (cross-referenced terms) UF teaching machines (a set of alternatives)BT educational computing (broader terms, cf. NT)
TT computer applications (root node/top term)RT education (related terms) teachingCC C7810C (subject area)FC C7810Cf (subject area)
For indexer and searcher

Hsin-Hsi Chen 7-33
Roget thesaurus
• examplecowardly adjective ( 膽小的 )
Ignobly lacking in courage: cowardly turncoats
Syns: chicken (slang), chicken-hearted, craven,
dastardly, faint-hearted, gutless, lily-livered,
pusillanimous, unmanly, yellow (slang), yellow-
bellied (slang)

Hsin-Hsi Chen 7-34
Functions of thesauri
• Provide a standard vocabulary for indexing and searching
• Assist users with locating terms for proper query formulation
• Provide classified hierarchies that allow the broadening and narrowing of the current query request

Hsin-Hsi Chen 7-35
Usage
• IndexingSelect the most appropriate thesaurus entries for representing the document.
• SearchingDesign the most appropriate search strategy.
– If the search does not retrieve enough documents, the thesaurus can be used to expand the query.
– If the search retrieves too many items, the thesaurus can suggest more specific search vocabulary.

Hsin-Hsi Chen 7-36
Features of Thesauri
• Coordination Level– pre-coordination: phrases
• phrases are available for indexing and retrieval• advantage: reducing ambiguity in indexing and searching• disadvantage: searcher has to be know the phrase formulation rules
– post-coordination: words• phrases are constructed while searching• advantage: users do not worry about the exact word ordering • disadvantage: the search precision may fall, e.g.,
library school vs. school library
– immediate level: phrases and single words• the higher the level of coordination, the greater the precision of the
vocabulary but the larger the vocabulary size
Construction of phrasesfrom individual terms
length of phrases?? Two or three words or more

Hsin-Hsi Chen 7-37
Features of Thesauri (Continued)
• Term Relationships– Aitchison and Gilchrist (1972)
• equivalence relationships– synonymy: trade names, popular and local usage, superseded t
erms– quasi-synonymy, e.g., harshness and tenderness
• hierarchical relationships, e.g., genus-species, BT vs. NT
• nonhierarchical relationships, e.g., thing-part (bus and seat), thing-attribute (rose and fragrance)
嚴肅 親切
dog-german shepherd

Hsin-Hsi Chen 7-38
Features of Thesauri (Continued)
– Wang, Vandendorpe, and Evens (1985)• parts-wholes, e.g., set-element, count-mass
• collocation relations: words that frequently co-occur in the same phrase or sentence
• paradigmatic relations: words that have the same semantic core, e.g., “moon” and “lunar”
• taxonomy and synonymy ( 分類與同義 )
• antonymy relations ( 反義 )

Hsin-Hsi Chen 7-39
Features of Thesauri (Continued)
• Number of entries for each term– homographs: words with multiple meanings
– each homograph entry is associated with its own set of relations
– problem: how to select between alternative meanings
• Specificity of vocabulary– the precision associated with the component terms
– a highly specific vocabulary promotes precision in retrieval (rules of phrase construction)

Hsin-Hsi Chen 7-40
Features of Thesauri (Continued)
• Control on term frequency of class members– for statistical thesaurus construction methods– terms included in the same thesaurus class have roughly equal
frequencies– the total frequency in each class should also be roughly similar
• Normalization of vocabulary– terms should be in noun form– noun phrases should avoid prepositions unless they are
commonly known– a limited number of adjectives should be used– singularity, ordering, spelling, capitalization, transliteration,
abbreviations, ...

Hsin-Hsi Chen 7-41
Thesaurus Construction
• manual thesaurus construction– define the boundaries of the subject area– collect the terms for each subarea
sources: indexes, encyclopedias, handbooks, textbooks, journal titles and abstracts, catalogues, relevant thesauri, vocabulary systems, ...
– organize the terms and their relationship into structures– review (and refine) the entire thesaurus for consistency
• automatic thesaurus construction– from a collection document items– by merging existing thesaurus

Hsin-Hsi Chen 7-42
Thesaurus Construction from Texts
1. Construction of vocabulary normalization and selection of terms phrase construction depending on the coordination level desired2. Similarity computations between terms identify the significant statistical associations between terms3. Organization of vocabulary organize the selected vocabulary into a hierarchy on the basis of the associations computed in step 2.

Hsin-Hsi Chen 7-43
Construction of Vocabulary
• Objectiveidentify the most informative terms (words and phrases)
• Procedure(1) Identify an appropriate document collection. The document collection should be sizable and representative of the subject area.(2) Determine the required specificity for the thesaurus.(3) Normalize the vocabulary terms. (a) Eliminate very trivial words such as prepositions and conjunctions. (b) Stem the vocabulary. (4) Select the most interesting stems, and create interesting phrases for a higher coordination level.

Hsin-Hsi Chen 7-44
Stem evaluation and selection
• selection by frequency of occurrence– each term may belong to category of high, medium or l
ow frequency
– terms in the mid-frequency range are the best for indexing and searching

Hsin-Hsi Chen 7-45
Stem evaluation and selection (Continued)
• selection by discrimination value (DV)– the more discriminating a term, the higher its value as an i
ndex term
– procedure• Compute the average inter-document similarity in the collection
• Remove the term K from the indexing vocabulary, and recompute the average similarity
• DV(K)=(average similarity without K)-(average similarity with k)
• The DV for good discriminators is positive.
由 retrieval 的角度來看,鑑別率越高的 terms 越好

Hsin-Hsi Chen 7-46
Phrase Construction
• Salton and McGill procedure1. Compute pairwise co-occurrence for high-frequency words.2. If this co-occurrence is lower than a threshold, then do not consider the pair any further.3. For pairs that qualify, compute the cohesion value. COHESION(ti, tj)= co-occurrence-frequency/(sqrt(frequency(ti)*frequency(tj))) COHESION(ti, tj)=size-factor* co-occurrence-frequency/(frequency(ti)*frequency(tj)) where size-factor is the size of thesaurus vocabulary 4. If cohesion is above a second threshold, retain the phrase
Decrease the frequency of high-frequency terms andincrease their value of retrieval
(vs. syntactic/semantic methods)

Hsin-Hsi Chen 7-47
Phrase Construction (Continued)
• Choueka Procedure1. Select the range of length allowed for each collocational expression. E.g., 2-6 wsords2. Build a list of all potential expressions from the collection with the prescribed length that have a minimum frequency.3. Delete sequences that begin or end with a trivial word (e.g., prepositions, pronouns, articles, conjunctions, etc.)
4. Delete expressions that contain high-frequency nontrivial words.5. Given an expression, evaluate any potential sub-expressions for relevance. Discard any that are not sufficiently relevant.6. Try to merge smaller expressions into larger and more meaningful ones. e.g, abcd abc and bcd

Hsin-Hsi Chen 7-48
Similarity Computation
• Cosinecompute the number of documents associated with both terms divided by the square root of the product of the number of documents associated with the first term and the number of documents associated with the second term.
• Dicecompute the number of documents associated with both terms divided by the sum of the number of documents associated with one term and the number associated with the other.
t
i
t
i
ii
t
i
ii
yx
yx
1 1
22
1
t
i
t
i
ii
t
i
ii
yx
yx
1 1
22
1
2

7-49
Vocabulary Organization
Assumptions: (1) high-frequency words have broad meaning, while low-frequency words have narrow meaning. (2) if the density functions of twoterms have the same shape, then the two words have similar meaning.1. Identify a set of frequency ranges.2. Group the vocabulary terms into different classes based on their frequencies and the ranges selected in step 1.3. The highest frequency class is assigned level 0, the next, level 1, and so on.4. Parent-child links are determined between adjacent levels as follows. For each term t in level i, compute similarity between t and every term in level i-1. Term t becomes the child of the most similar term in level i-1. If more than one term in level i-1 qualifies for this, then each becomes a parent of t. In other words, a term is allowed to have multiple parents.5. After all terms in level i have been linked to level i-1 terms, check level i-1terms and identify those that have no children. Propagate such terms to level i by creating an identical “dummy” term as its child.6. Perform steps 4 and 5 for each level starting with level.

Hsin-Hsi Chen 7-50
Merging Existing Thesauri
• simple mergelink hierarchies wherever they have terms in common
• complex merge– link terms from different hierarchies if they are similar
enough.
– similarity is a function of the number of parent and child terms in common

Hsin-Hsi Chen 7-51
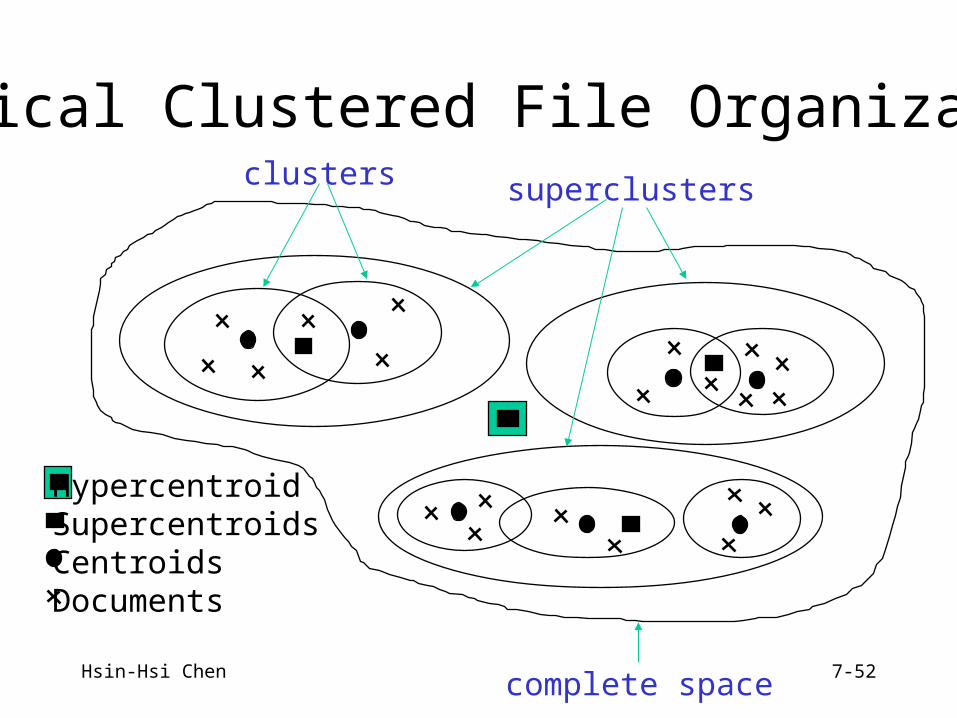
Document Clustering
• Searching vs. Browsing• Disadvantages in using inverted index files
– information pertaining to a document is scattered among many different inverted-term lists
– information relating to different documents with similar term assignment is not in close proximity in the file system
• Approaches– inverted-index files (for searching) +
clustered document collection (for browsing)– clustered file organization (for searching and browsing)
Hsin-Hsi Chen 7-52
HypercentroidSupercentroidsCentroidsDocuments
Typical Clustered File Organization
complete space
superclustersclusters
Hsin-Hsi Chen 7-53
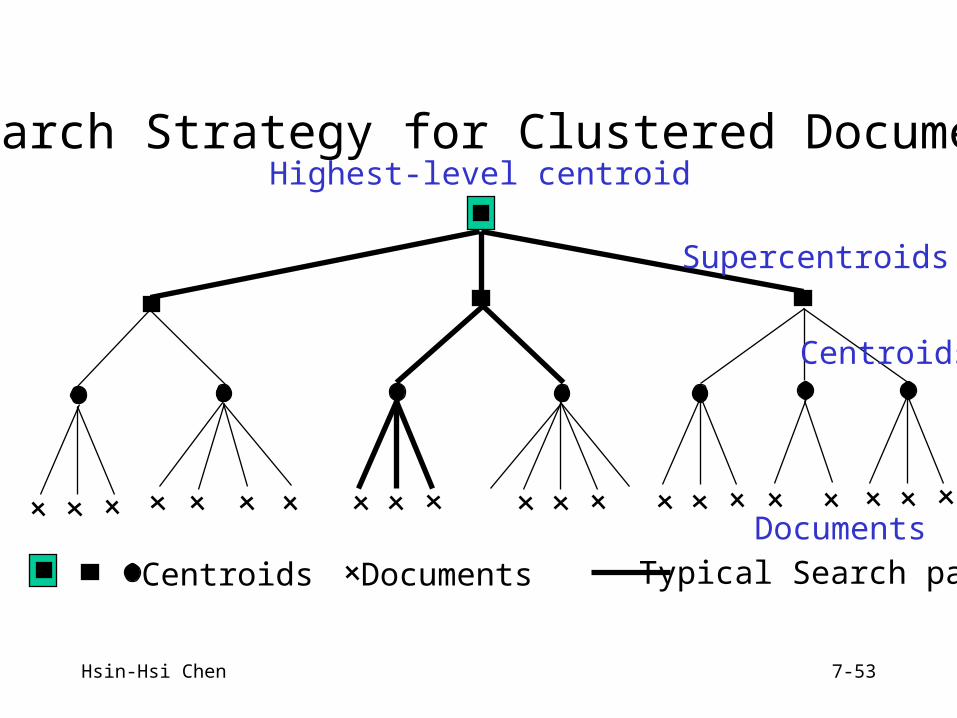
Search Strategy for Clustered Documents
Centroids Documents Typical Search path
Highest-level centroid
Supercentroids
Centroids
Documents

Hsin-Hsi Chen 7-54
Cluster Generation VS Cluster Search
• Cluster structure is generated only once.• Cluster maintenance can be carried out at
relatively infrequent intervals.• Cluster generation process may be slower and
more expensive.• Cluster search operations may have to be
performed continually.• Cluster search operations must be carried out
efficiently.

Hsin-Hsi Chen 7-55
Hierarchical Cluster Generation• Two strategies
– pairwise item similarities– heuristic methods
• Models– Divisive Clustering (top down)
• The complete collection is assumed to represent one complete cluster.
• Then the collection is subsequently broken down into smaller pieces.
– Agglomerative Clustering (bottom up)• Individual item similarities are used as a starting point.• A gluing operation collects similar items, or groups, into larger grou
p.

Hsin-Hsi Chen 7-56
ntnn
t
t
n
t
aaa
aaa
aaa
D
D
D
A
TTTT
L
MMMM
L
L
M
21
22221
11211
2
1
321
Term clustering: from column viewpointDocument clustering: from row viewpoint

Hsin-Hsi Chen 7-57
A Naive Program for Hierarchical Agglomerative Clustering
1. Compute all pairwise document-document similarity coefficients. (N(N-1)/2 coefficients)2. Place each of N documents into a class of its own.3. Form a new cluster by combining the most similar pair of current clusters i and j; update similarity matrix by deleting the rows and columns corresponding to i and j; calculate the entries in the row corresponding to the new cluster i+j.4. Repeat step 3 if the number of clusters left is great than 1.

Hsin-Hsi Chen 7-58
How to Combine Clusters?• Single-link clustering
– Each document must have a similarity exceeding a stated threshold value with at least one other document in the same class.
– similarity between a pair of clusters is taken to be the similarity between the most similar pair of items
– each cluster member will be more similar to at least one member in that same cluster than to any member of another cluster
e11
e12 e13e21
e22e23
e24
Let (e13,e21) be the most similar pair between c1 and c2, and its distance
be dist (e13,e21). pc1(c2), qc1(c2), pq such that dist(p,q)<dist (e13,e21)
c1 c2
距離最短
因為 dist (e13,e21) 是最短距離,所以當 dist(p,q)<dist (e13,e21) 時, dist(p,q) 也小於 dist(p,r), 所有 rc2(rq )

Hsin-Hsi Chen 7-59
How to Combine Clusters? (Continued)
• Complete-link Clustering– Each document has a similarity to all other documents
in the same class that exceeds the threshold value.
– similarity between the least similar pair of items from the two clusters is used as the cluster similarity
– each cluster member is more similar to the most dissimilar member of that cluster than to the most dissimilar member of any other cluster
e11
e12
e13 e21e22e23 e24
c1 c2
Let (e12,e24) be the least similar pair between c1 and c2, and its distance
be dist (e12,e24). pc1(c2), let q be the most dissimilar member of p in c1, i.e.,
dist(p,q)>dist(p,r) rc1(r q). Because dist(p,q)<dist(e12,e24), dist(p,r) <dist(e12,e24)
距離最長

Hsin-Hsi Chen 7-60
How to Combine Clusters? (Continued)
• Group-average clustering– a compromise between the extremes of single-
link and complete-link systems– each cluster member has a greater average
similarity to the remaining members of that cluster than it does to all members of any other cluster
Hsin-Hsi Chen 7-61
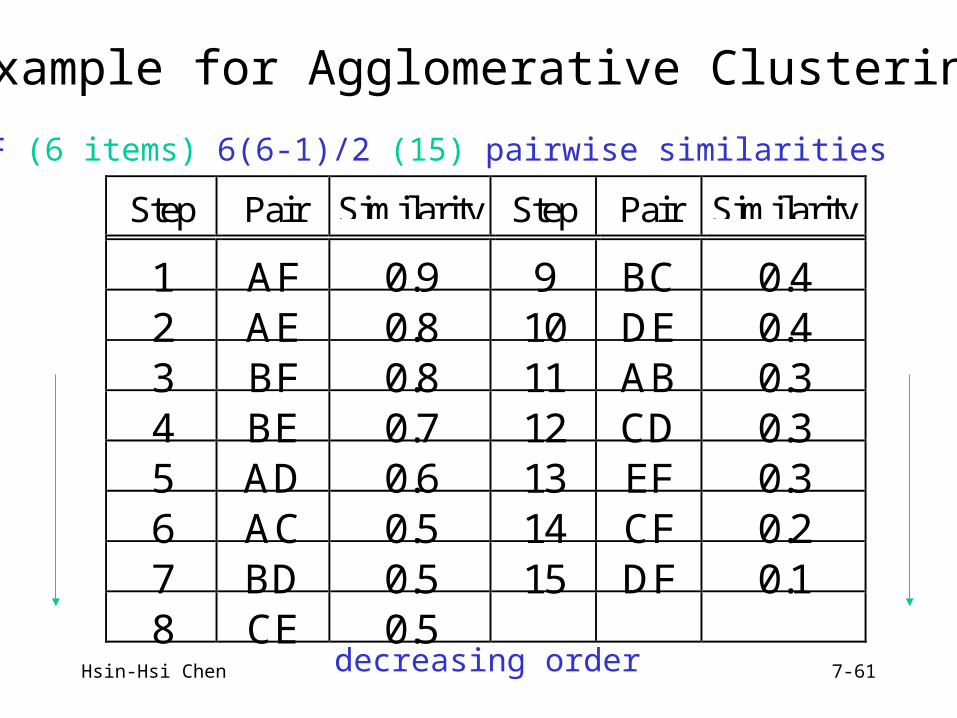
Example for Agglomerative Clustering
Step Pair Similarity Step Pair Similarity
1 AF 0.9 9 BC 0.42 AE 0.8 10 DE 0.43 BF 0.8 11 AB 0.34 BE 0.7 12 CD 0.35 AD 0.6 13 EF 0.36 AC 0.5 14 CF 0.27 BD 0.5 15 DF 0.18 CE 0.5
A-F (6 items) 6(6-1)/2 (15) pairwise similarities
decreasing order
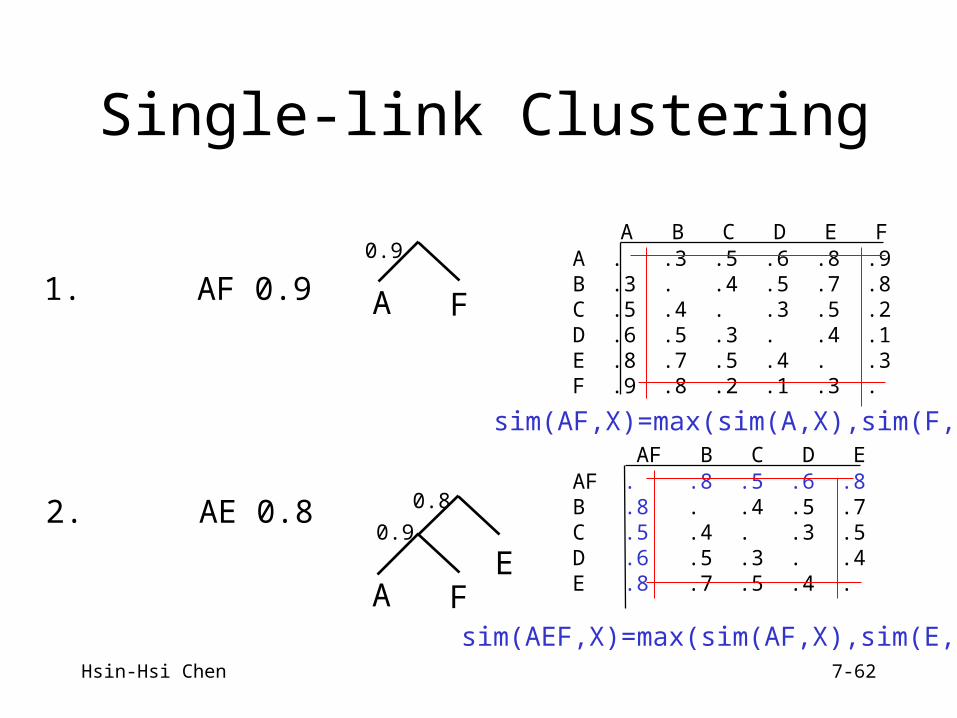
Hsin-Hsi Chen 7-62
1. AF 0.9 A F
A B C D E FA . .3 .5 .6 .8 .9B .3 . .4 .5 .7 .8C .5 .4 . .3 .5 .2D .6 .5 .3 . .4 .1E .8 .7 .5 .4 . .3F .9 .8 .2 .1 .3 .
2. AE 0.8
A F
AF B C D E AF . .8 .5 .6 .8 B .8 . .4 .5 .7 C .5 .4 . .3 .5 D .6 .5 .3 . .4 E .8 .7 .5 .4 .
E
0.9
0.9
0.8
Single-link Clustering
sim(AF,X)=max(sim(A,X),sim(F,X))
sim(AEF,X)=max(sim(AF,X),sim(E,X))
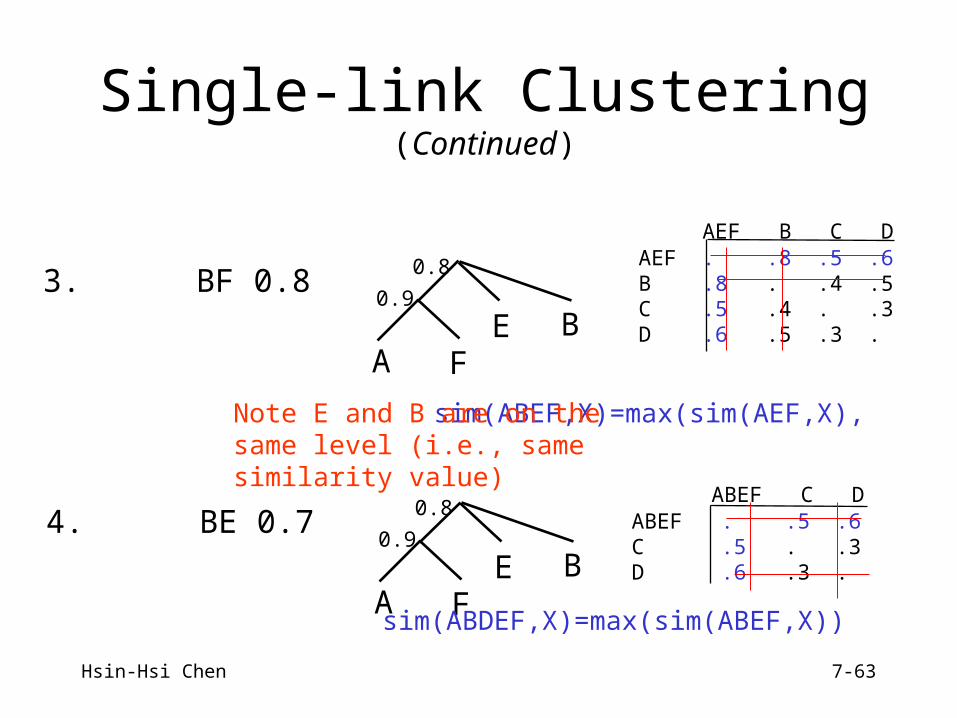
Hsin-Hsi Chen 7-63
Single-link Clustering(Continued)
3. BF 0.8
A F
AEF B C D AEF . .8 .5 .6 B .8 . .4 .5 C .5 .4 . .3 D .6 .5 .3 . E
0.9
0.8
B
4. BE 0.7
A FE
0.9
0.8
B
ABEF C D ABEF . .5 .6 C .5 . .3 D .6 .3 .
sim(ABEF,X)=max(sim(AEF,X), sim(B,X))
Note E and B are on thesame level (i.e., samesimilarity value)
sim(ABDEF,X)=max(sim(ABEF,X)) sim(D,X))
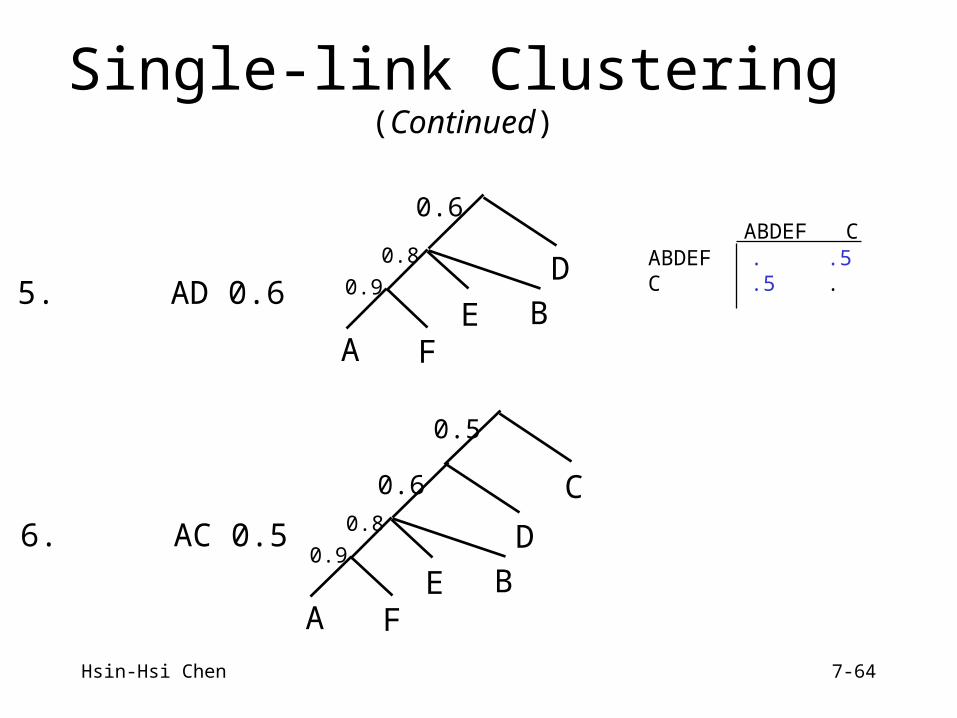
Hsin-Hsi Chen 7-64
Single-link Clustering (Continued)
5. AD 0.6
A FE
0.9
0.8
B
D
6. AC 0.5
A F
ABDEF C ABDEF . .5 C .5 .
E0.9
0.8
B
D
C
0.6
0.6
0.5

Hsin-Hsi Chen 7-65
Single-Link Clusters
• Similarity level 0.7 (i.e., similarity threshold)
• Similarity level 0.5 (i.e., similarity threshold)
E A F B E.8 .9 .8 .7
C D
E A F B E.8 .9 .8 .7
D
C
.5
.6Small number of large, poorly linked clusters

Hsin-Hsi Chen 7-66
Complete-link cluster generation
1. AF 0.9
A F
A B C D E FA . .3 .5 .6 .8 .9B .3 . .4 .5 .7 .8C .5 .4 . .3 .5 .2D .6 .5 .3 . .4 .1E .8 .7 .5 .4 . .3F .9 .8 .2 .1 .3 .
0.9
2. AE 0.8 (A,E)(A,F)
new
checkEF
3. BF 0.8 checkAB
(A,E)(A,F)(B,F)
StepNumber
CheckOperations
SimilarityPair
CompleteLink Structure &
Pairs Covered
Similarity Matrix
sim(AF,X)=min(sim(A,X), sim(F,X))

Hsin-Hsi Chen 7-67
Complete-link cluster generation (Continued)
4. BE 0.7 new
B E
0.7 AF B C D E AF . .3 .2 .1 .3 B .3 . .4 .5 .7 C .2 .4 . .3 .5 D .1 .5 .3 . .4 E .3 .7 .5 .4 .
5. AD 0.6 checkDF
(A,D)(A,E)(A,F)(B,E)(B,F)
6. AC 0.6 checkCF
(A,C)(A,D)(A,E)(A,F)(B,E)(B,F)
7. BD 0.5 checkDE
(A,C)(A,D)(A,E)(A,F)(B,D)(B,E)(B,F)
StepNumber
SimilarityPair
CheckOperations
CompleteLink Structure &
Pairs Covered
Similarity Matrix
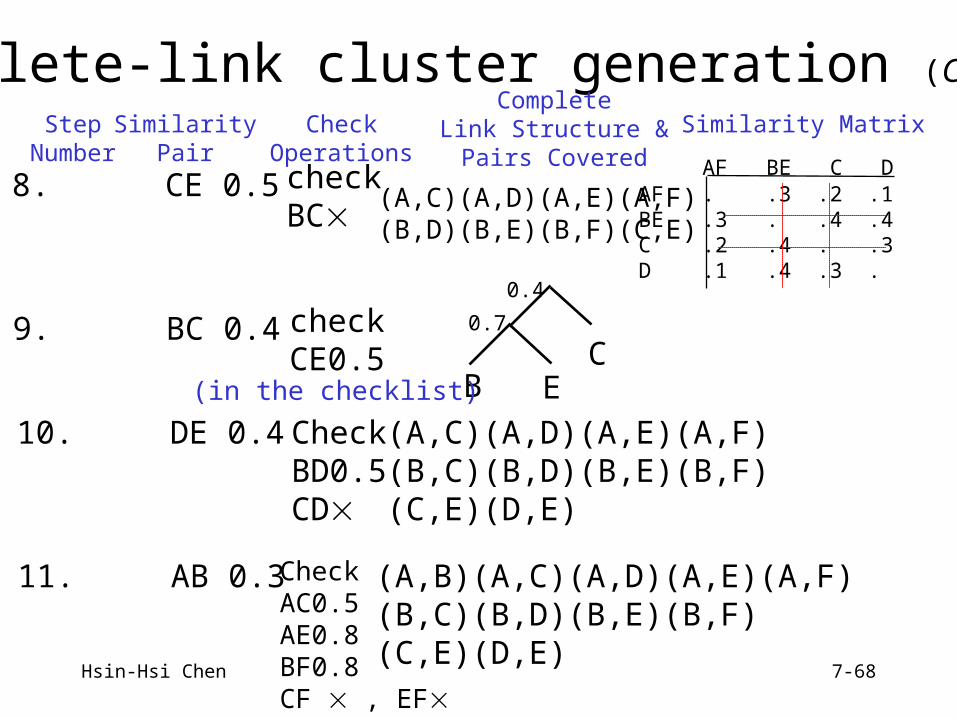
Hsin-Hsi Chen 7-68
Complete-link cluster generation (Continued)
8. CE 0.5
B EC
0.7
0.4
checkBC
AF BE C D AF . .3 .2 .1 BE .3 . .4 .4 C .2 .4 . .3 D .1 .4 .3 .
9. BC 0.4 checkCE0.5
10. DE 0.4 CheckBD0.5CD
(A,C)(A,D)(A,E)(A,F)(B,C)(B,D)(B,E)(B,F)(C,E)(D,E)
11. AB 0.3 CheckAC0.5AE0.8BF0.8CF , EF
(A,B)(A,C)(A,D)(A,E)(A,F)(B,C)(B,D)(B,E)(B,F)(C,E)(D,E)
StepNumber
SimilarityPair
CheckOperations
CompleteLink Structure &
Pairs Covered
Similarity Matrix
(A,C)(A,D)(A,E)(A,F)(B,D)(B,E)(B,F)(C,E)
(in the checklist)
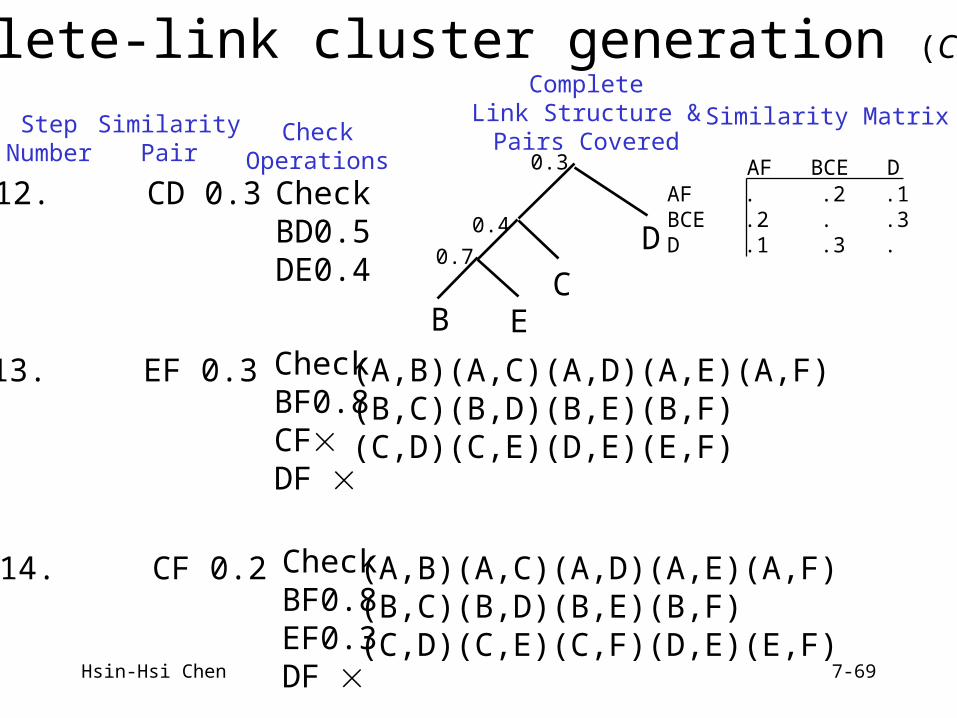
Hsin-Hsi Chen 7-69
Complete-link cluster generation (Continued)
B EC
0.7
0.4 D
0.3 AF BCE D AF . .2 .1 BCE .2 . .3 D .1 .3 .
12. CD 0.3 CheckBD0.5DE0.4
13. EF 0.3 CheckBF0.8CFDF
(A,B)(A,C)(A,D)(A,E)(A,F)(B,C)(B,D)(B,E)(B,F)(C,D)(C,E)(D,E)(E,F)
14. CF 0.2 CheckBF0.8EF0.3DF
(A,B)(A,C)(A,D)(A,E)(A,F)(B,C)(B,D)(B,E)(B,F)(C,D)(C,E)(C,F)(D,E)(E,F)
StepNumber
SimilarityPair
CheckOperations
CompleteLink Structure &
Pairs CoveredSimilarity Matrix
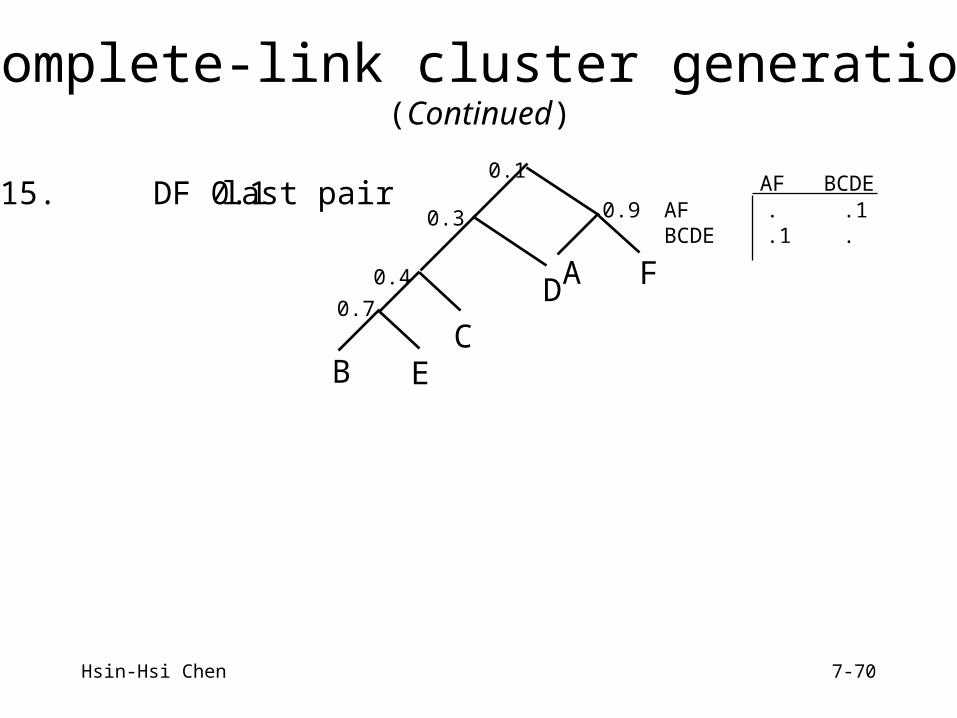
Hsin-Hsi Chen 7-70
Complete-link cluster generation(Continued)
B EC
0.7
0.4 D
AF BCDE AF . .1 BCDE .1 .
A F
0.3
0.1
0.915. DF 0.1 last pair
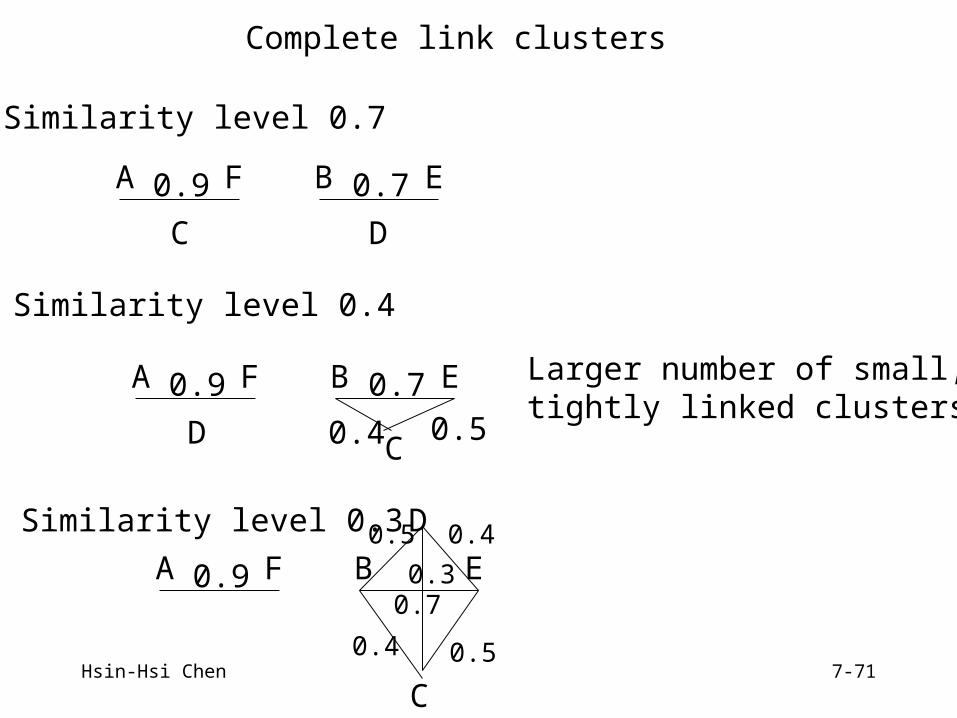
Hsin-Hsi Chen 7-71
Complete link clusters
Similarity level 0.7
A F0.9 B E0.7
C D
Similarity level 0.4
A F0.9 B E0.7
D C0.4 0.5
Similarity level 0.3
A F0.9 B E
D
C
0.5 0.4
0.30.7
0.4 0.5
Larger number of small,tightly linked clusters

Hsin-Hsi Chen 7-72
The Behavior of Single-Link Cluster
• The single-link process tends to produce a small number of large clusters that are characterized by a chaining effect.
• Each element is usually attached to only one other member of the same cluster at each similarity level.
• It is sufficient to remember the list of previously clustered single items.

Hsin-Hsi Chen 7-73
The Behavior of Complete-Link Cluster
• Complete-link process produces a much larger number of small, tightly linked groupings.
• Each item in a complete-link cluster is guaranteed to resemble all other items in that cluster at the stated similarity level.
• It is necessary to remember the list of all item pairs previously considered in the clustering process.

Hsin-Hsi Chen 7-74
The Behavior of Complete-Link Cluster(Continued)
• The complete-link clustering system may be better adapted to retrieval than the single-link clusters.
• A complete-link cluster generation is more expensive to perform than a comparable single-link process.

Hsin-Hsi Chen 7-75
How to Generate Similarity
Di=(di1, di2, ..., dit) document vector for Di
Lj=(lj1, lj2, ..., ljnj) inverted list for term Tj
lji denotes document identifier of ith document listed under term Tj
nj denote number of postings for term Tj
for j=1 to t (for each of t possible terms) for i=1 to nj (for all nj entries on the jth list) compute sim(Dlji,Dlj,i+k) i+1<=k<=nj end for end for
number of documents containing term Tj

Hsin-Hsi Chen 7-76
Similarity without Recomputation
for j=1 to N (for each document in collection) set S(j)=0, 1<=j<=N for k=1 to nj (for each term in document) take up inverted list Lk
for i=1 to nk (for each document identifier on list) if i<j or if Sji=1 take up next document Di
else compute sim(Dj,Di) set Sji=1 end for end forend for

Hsin-Hsi Chen 7-77
Heuristic Clustering Methods
• Hierarchical clustering strategies– use all pairwise similarities between items– the clustering-generation are relatively expensive– produce a unique set of well-formed clusters for each se
t of data, regardless of the order in which the similarity pairs are introduced into the clustering process
• Heuristic clustering methods– produce rough cluster arrangements at relatively little e
xpense

Hsin-Hsi Chen 7-78
Single-Pass Heuristic Clustering Methods
• Item 1 is first taken and placed into a cluster of its own.• Each subsequent item is then compared against all existing
clusters.• It is placed in a previously existing cluster whenever it is si
milar to any existing cluster.– Compute the similarities between all existing centroids and the ne
w incoming item.– When an item is added to an existing cluster, the corresponding ce
ntroid must then be appropriately updated.
• If a new item is not sufficiently similar to any existing cluster, the new item forms a cluster of its own.

Hsin-Hsi Chen 7-79
Single-Pass Heuristic Clustering Methods(Continued)
• Produce uneven cluster structures.
• Solutions
– cluster splitting: cluster sizes
– variable similarity thresholds: the number of clusters, and the overlap among clusters
• Produce cluster arrangements that vary according to the order of individual items.
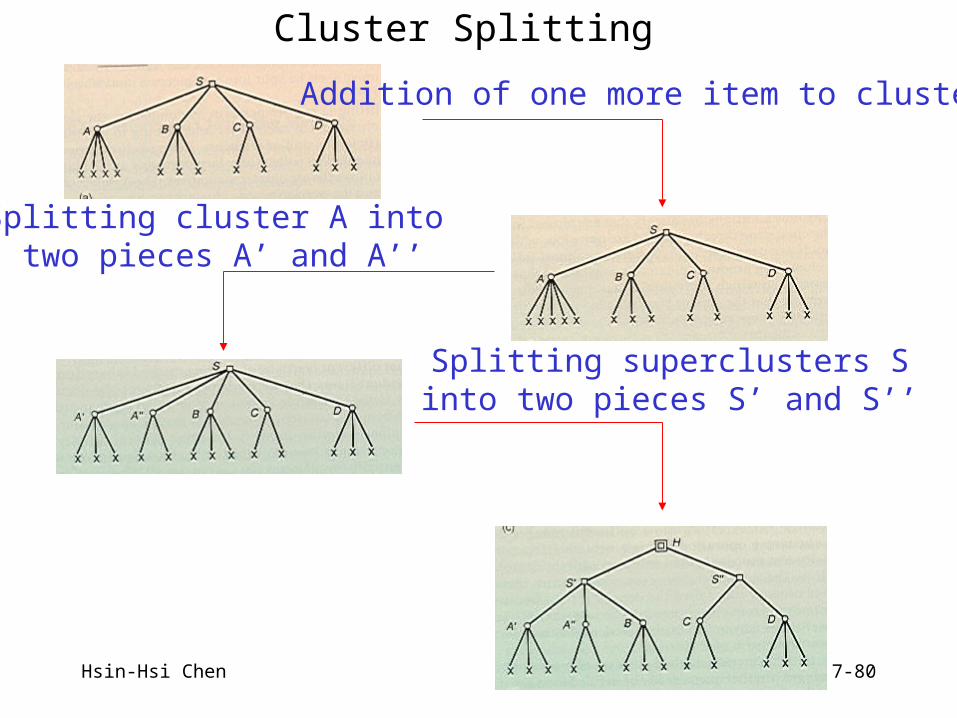
Hsin-Hsi Chen 7-80
Cluster Splitting
Addition of one more item to cluster A
Splitting cluster A into two pieces A’ and A’’
Splitting superclusters Sinto two pieces S’ and S’’

Hsin-Hsi Chen 7-81
Cluster Searching
• Cluster centroidthe average vector of all the documents in a given cluster
• strategies– top down
the query is first compared with the highest-level centroids
– bottom uponly the lowest-level centroids are stored, the higher-level cluster structure is disregarded

Hsin-Hsi Chen 7-82
Top-down entire-clustering search
1. Initialized by adding top item to active node list;
2. Take centroid with highest-query similarity from active node list;
if the number of singleton items in subtree headed by that
centroid is not larger than number of items wanted,
then retrieve these singleton items and eliminate the
centroid from active node list;
else eliminate the centroid with highest query similarity
from active node list and add its sons to active node
list;
3. if number of retrieved number wanted then stop
else repeat step 2
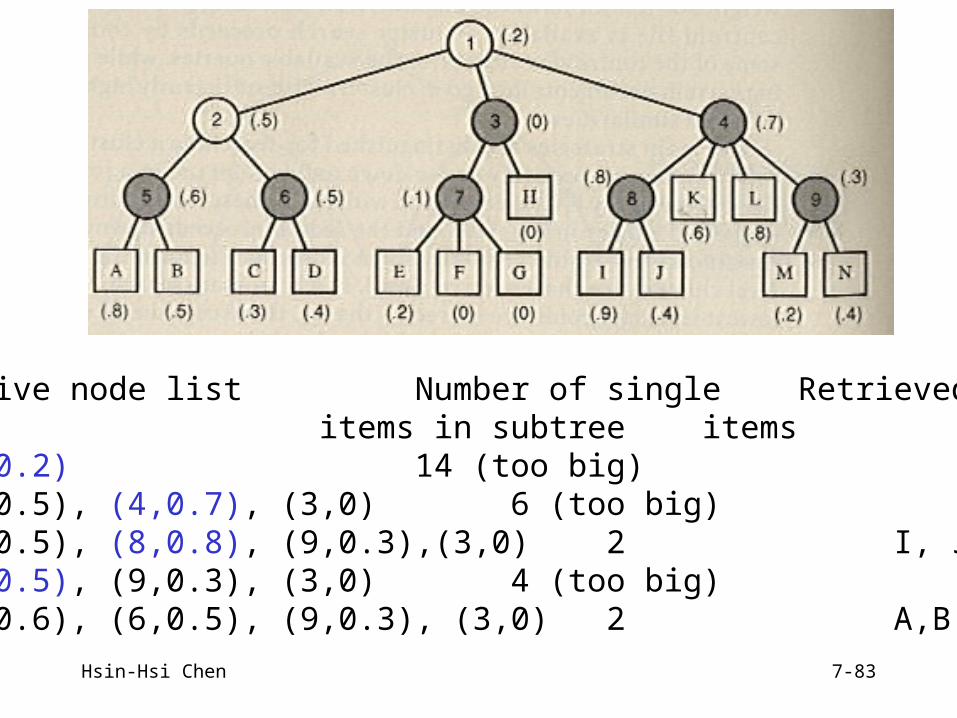
Hsin-Hsi Chen 7-83
Active node list Number of single Retrieveditems in subtree items
(1,0.2) 14 (too big)(2,0.5), (4,0.7), (3,0) 6 (too big)(2,0.5), (8,0.8), (9,0.3),(3,0) 2 I, J(2,0.5), (9,0.3), (3,0) 4 (too big)(5,0.6), (6,0.5), (9,0.3), (3,0) 2 A,B

Hsin-Hsi Chen 7-84
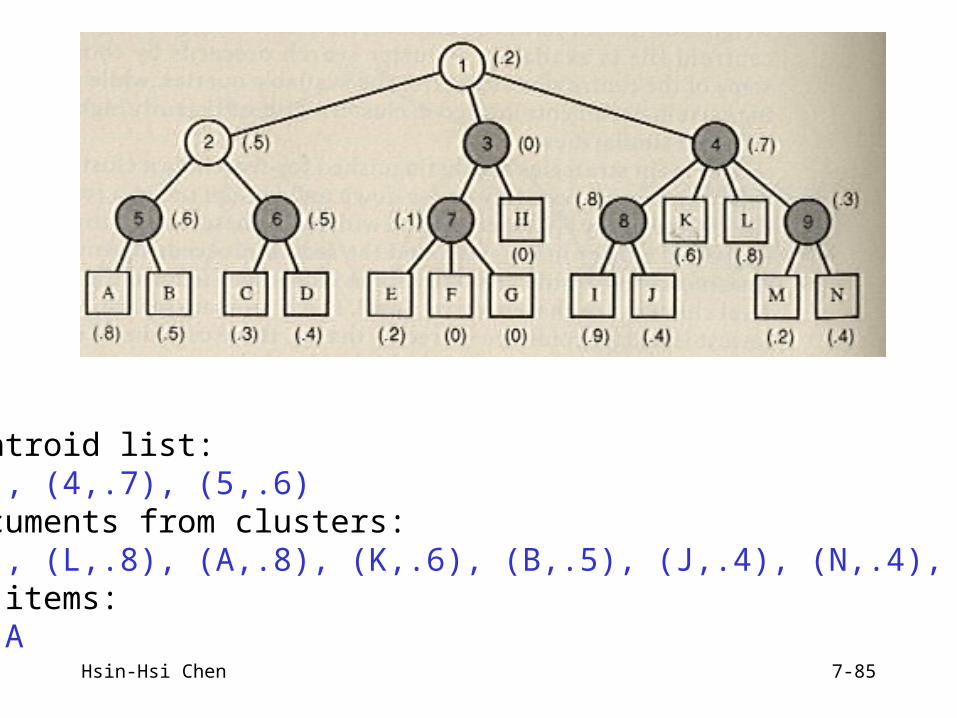
Bottom-up Individual-Cluster Search
Take a specified number of low-level centroids if there are enough singleton items in those clusters to equal the number of items wanted, then retrieve the number of items wanted in ranked order; else add additional low-level centroids to list and repeat test
Hsin-Hsi Chen 7-85
Active centroid list: (8,.8), (4,.7), (5,.6)Ranked documents from clusters: (I,.9), (L,.8), (A,.8), (K,.6), (B,.5), (J,.4), (N,.4), (M,.2)Retrieved items: I, L, A





























