Embed Size (px)
Citation preview

Technical white paper
HP Reference Architecture for MapR M5 HP Converged Infrastructure with MapR M5 for Apache Hadoop
Table of contents Executive summary ...................................................................................................................................................................... 2 MapR overview ............................................................................................................................................................................... 3 Pre-deployment considerations ................................................................................................................................................ 5
Operating system ...................................................................................................................................................................... 5 Computation .............................................................................................................................................................................. 5 Memory ....................................................................................................................................................................................... 6 Storage ........................................................................................................................................................................................ 6 Network ....................................................................................................................................................................................... 7 Switches ...................................................................................................................................................................................... 7 Data movement into and out of the MapR cluster ............................................................................................................ 8
HP Insight Cluster Management utility ..................................................................................................................................... 9 Server selection ........................................................................................................................................................................... 10 Reference Architectures ............................................................................................................................................................ 12
Single Rack configuration ...................................................................................................................................................... 12 Medium Cluster configuration .............................................................................................................................................. 15 Large Cluster configuration .................................................................................................................................................. 19
Edge Nodes ................................................................................................................................................................................... 20 Summary ....................................................................................................................................................................................... 21 For more information ................................................................................................................................................................. 22

Technical white paper | HP Reference Architecture for MapR M5
2
Executive summary
HP and MapR allow you to derive new business insights from Big Data by providing a platform to store, manage and process data at scale. However, Apache Hadoop is complex to deploy, configure, manage and monitor. This HP converged infrastructure with MapR M5 for Hadoop white paper provides several performance optimized configurations for deploying MapR M5 distribution of Apache Hadoop clusters of varying sizes, on HP infrastructure. The reference architecture configurations for MapR M5 provide a significant reduction in complexity, faster time to value and an improvement in performance.
This white paper has been created to assist in the rapid design and deployment of MapR M5 software on HP infrastructure for clusters of various sizes. In addition, it is also intended to concretely identify the software and hardware components required in a solution in order to simplify the ordering process. The recommended HP Software, HP ProLiant servers and HP Networking switches and their respective configurations have been carefully tested with a variety of I/O, CPU, network and memory bound workloads to ensure the best designs possible.
HP Big Data solutions provide best-in-class performance and availability, with integrated software, services, infrastructure, and management – all delivered as one proven solution as described at hp.com/go/hadoop. In addition to the benefits described above, the solution in this white paper also includes the following features that are unique to HP:
• For networking, the HP 5830AF-48G 1GbE Top of Rack switch and the HP 5900AF-48XG-4QSFP Aggregation switch provide IRF Bonding and sFlow which simplifies the management, monitoring and resiliency of the customer’s Hadoop network. In addition, the HP 5830AF-48G delivers 1GB packet buffers to increase the Hadoop network performance by seamlessly handling burst scenarios such as Shuffle, Sort and Block Replication which are common in a Hadoop network.
• For management, HP Insight Cluster Management Utility (CMU) provides push-button scale out and provisioning with industry leading provisioning performance (deployment of 800 nodes in 30 minutes), reducing deployments from days to hours. In addition, CMU provides real-time and historical infrastructure and Hadoop monitoring with 3D visualizations allowing customers to easily characterize Hadoop workloads and cluster performance reducing complexity and improving system optimization leading to improved performance and reduced cost. HP Insight Management and HP Service Pack for ProLiant, allow for easy management of firmware and the server.
• For servers, the HP ProLiant DL380e provides:
– Up to 14 Large Form Factor disk drives, providing increased storage capacity and I/O performance for the MapR File System.
– The HP Smart Array P420 controller which provides increased1 I/O throughput performance resulting in a significant performance increase for I/O bound Hadoop workloads (a common use case) and the flexibility for the customer to choose the desired amount of resilience in the Hadoop Cluster with either JBOD or various RAID configurations.
– Two sockets with the fastest 6 core processors and the Intel® C600 Series Chipset, providing the performance required for fastest time to completion for CPU bound Hadoop workloads.
– The HP iLO Management Engine on the servers contains HP Integrated Lights-Out 4 (iLO 4) which features a complete set of embedded management features for HP Power/Cooling, Agentless Management, Active Health System, and Intelligent Provisioning which reduces node and cluster level administration costs for Hadoop.
All of these features reflect HP’s balanced building blocks of servers, storage and networking, along with integrated management software and bundled support.
Target audience: This document is intended for decision makers, system and solution architects, system administrators, and experienced users who are interested in reducing time to design or purchase an HP and MapR solution. An intermediate knowledge of Apache Hadoop and scale out infrastructure is recommended. Those already possessing expert knowledge about these topics may proceed directly to the Pre-deployment considerations section.
1 Compared to the previous generation of Smart Array controllers

Technical white paper | HP Reference Architecture for MapR M5
3
MapR overview
MapR makes Hadoop a reality for the enterprise. MapR's distribution for Hadoop is designed to not only meet core enterprise needs but also provide exceptional performance.
MapR provides these distinct advantages:
• Lights Out Data Center capability – MapR provides high availability across the entire stack including storage, MapReduce, NFS layers and more.
– In the storage layer, the No NameNode architecture provides high availability with self-healing and support for multiple, simultaneous failures, with no additional hardware whatsoever.
– In the MapReduce layer, MapR’s JobTracker HA makes JobTracker failures transparent to applications – the currently running tasks continue to execute during the failover process.
– In the NFS layer, MapR automatically manages virtual IP addresses and balances them between the nodes so that failures are transparent to clients that are reading and writing data via NFS.
– In addition, these capabilities are combined with both data protection (snapshots) and disaster recovery (mirroring) providing protection against user errors and enabling greater resiliency.
– Automated rolling upgrades on the other hand eliminate the need to bring the cluster down to move to the latest software release of MapR.
• Ease of Use – MapR provides the easiest interface to integrate other enterprise software with Hadoop.
– The NFS layer allows reading and writing directly to a file in the cluster, enabling near real-time streaming of data into a MapR cluster.
– Support for industry standard ODBC API facilitates seamless connection to SQL based systems.
– On the administration side, the MapR Control System provides a management console to set the frequency of the snapshots, number of replications, mirroring policies, and to better understand user defined cluster health criteria.
– Furthermore, with provision for logical partitioning of the physical cluster it is extremely easy to share the cluster across different users, groups and applications.
• Performance – MapR delivers faster performance with enterprise ready features such as snapshot and remote mirroring and is the only one that has near limitless scale-out capability.
The MapR Distribution for Hadoop includes almost all of the associated Apache projects (see picture below) and is 100% API compatible.

Technical white paper | HP Reference Architecture for MapR M5
4
Figure 1. MapR’s software overview
Note MapR provides the aforementioned features via services that run on nodes throughout the cluster. Services that manage the cluster and coordinate the jobs (“control services”) run on a small number of nodes that the user can designate; the services responsible for the actual execution of work (“worker services”) run on most or all nodes in the cluster. The Reference Architectures we provide in this document are prescriptive as to which nodes the control and worker services are deployed to. By mapping the services onto specific nodes within the HP infrastructure for clusters of varying sizes we have simplified your deployment.
Table 1. Control Services Summary
Service Package Recommended Number of Instances
Container Location Database (CLDB) mapr-cldb 1-6
Web Server mapr-webserver 1 or more
ZooKeeper mapr-zookeeper 3, 5
JobTracker mapr-jobtracker 1-3
HBase Master mapr-hbase-master 1-3

Technical white paper | HP Reference Architecture for MapR M5
5
Table 2. Worker Services Summary
Service Package Distribution across nodes
FileServer mapr-fileserver Most or all nodes
TaskTracker mapr-tasktracker Most or all nodes
NFS mapr-nfs Most or all nodes
HBase RegionServer mapr-hbase-regionserver Varies
Pre-deployment considerations
There are a number of key factors one should consider prior to designing and deploying a Hadoop Cluster. The following subsections articulate the design decisions in creating the baseline configurations for the reference architectures. The rationale provided includes the necessary information for one to take the configurations and modify them to suit a particular custom scenario.
Table 3. Overview of Functional Components and Configurable Value
Functional Component Value
Operating System Improves Availability and Reliability
Computation Ability to balance Price with Performance
Memory Ability to balance Price with Capacity and Performance
Storage Ability to balance Price with Capacity and Performance
Network Ability to balance Price with Performance
Operating system MapR supports 64-bit Red Hat Enterprise Linux (RHEL), CentOS 5.4 or higher and 64-bit Ubuntu 9.04 or higher as choices for the operating system.
MapR Benefit A 64-bit operating system is required for MapR deployment. 64-bit Red Hat Enterprise Linux 5.4 or greater is recommended due to better ecosystem support, more comprehensive functionality for components such as RAID controllers and compatibility with HP Insight CMU. The Reference Architectures listed in this document were tested with 64-bit Red Hat Enterprise Linux 6.2.
Computation Map/Reduce slots are configured on a per server basis. Employing Hyper-Threading increases your effective core count, allowing you to configure more Map/Reduce slots. Refer to the Storage section to see how I/O performance issues arise from sub-optimal disk to core ratios (too many slots and too few disks). For CPU bound workloads we recommend buying processors with faster clock speeds to remove the bottleneck.
MapR Benefit To remove the bottleneck for CPU bound workloads, for the best cost/performance tradeoff, we recommend buying 6 core processors with faster clock speeds as opposed to buying 8 core processors.

Technical white paper | HP Reference Architecture for MapR M5
6
The default number of slots per node in a MapR cluster is set to the following values:
• Map Slots = (Total Hyper-Threaded cores per server * 0.75)
• Reduce Slots = (Total Hyper-Threaded cores per server * 0.5)
Since the server in each of our configurations in the Reference Architectures section below is a dual socket system with a total of 12 cores with Hyper-Threading enabled for 24 logical processors, this gives a default of 18 Map Slots and 12 Reduce Slots per server. Some application mixes may do better with either more or fewer slots per node.
Memory Use of Error Correcting Memory (ECC) should be used with MapR clusters and is standard on all HP ProLiant servers. Memory requirements differ between the control services and the worker services. For the worker services, sufficient memory is needed to manage the TaskTracker and FileServer services in addition to the sum of all the memory assigned to each of the Map/Reduce slots. If you have a memory bound Map/Reduce Job we recommend that you increase the amount of memory on all the nodes running worker services.
MapR Benefit When increasing memory, one should always attempt to populate all the memory channels available to ensure optimum performance. For instance, if one had 6 memory channels total per server, one could begin by populating the channels with 4GB DIMMs resulting in 24GB RAM for the server. If that became insufficient, one could replace all the 4GB DIMMs with 8GB DIMMs resulting in 48GB of RAM for the server.
In addition, the MapR M5 cluster can also be used for HBase which is very memory intensive, which is why we recommend more RAM per server. The ProLiant DL380e Gen8 server has a baseline of 48GB memory and can be easily upgraded to higher memory capacity if all memory channels are populated. The Reference Architectures section details how to constrain the amount of Map/Reduce slots on nodes that are running control services to avoid the services competing for resources.
Storage Fundamentally, MapR is designed to achieve performance and scalability by moving the compute activity to the data. It does this by distributing the Hadoop jobs to nodes close to their data, ideally running the tasks against data on local disks.
MapR Benefit Given the architecture of MapR, the data storage requirements for the worker nodes are best met by direct attached storage (DAS) in a Just a Bunch of Disks (JBOD) configuration and not as DAS with RAID or Network Attached Storage (NAS).
There are several factors to consider and balance when determining the number of disks a node requires.
• Storage capacity – The number of disks and their corresponding storage capacity determines the total amount of the FileServer storage capacity for your cluster. We recommend Large Form Factor (3.5”) disks due to their lower cost and larger storage capacity compared with the Small Form Factor (2.5”) disks.
• Redundancy – MapR ensures that a certain number of block copies are consistently available. This number is configurable as a volume property, and is typically set to three. If a MapR node goes down, MapR will replicate the blocks that had been on that server onto other servers in the cluster to maintain the consistency of the number of block copies. For example, if a server with 12 TB of data fails, that 12 TB of data will be replicated onto other servers, generating 12 TB of traffic within the cluster. The failure of a non-redundant TOR (Top of Rack) switch will generate even more replication traffic. Make sure your network, whether 1GbE or 10GbE, has the capacity to handle block replication for your server configurations in case of failure.
• I/O performance – Each node has a certain number of Map/Reduce slots available for processing Hadoop tasks. Each slot operates on one block of data at a time. The more disks you have, the less likely it is that you will have multiple tasks accessing a given disk at the same time. This avoids thrashing the disk heads and incurring the resulting I/O performance degradation.

Technical white paper | HP Reference Architecture for MapR M5
7
MapR Benefit Customers can choose to use SATA or SAS Midline (MDL) disks in a MapR Cluster. SAS MDL disks are preferred by customers who are looking for disks that are more efficient at driving higher I/O throughput across a larger amount of disks delivering to customers a higher performing cluster. SAS MDL disks are recommended over SAS Enterprise (ENT) disks in a MapR cluster because the SAS ENT disks deliver only marginally higher performance at a higher cost with lower storage capacity.
Network Configuring only a single Top of Rack (TOR) switch per rack introduces a single point of failure for each rack. In a multi-rack system such a failure will result in a large amount of network traffic as Hadoop re-replicates data, and in a single-rack system such a failure will bring down the whole cluster. Consequently, configuring two TOR switches per rack is recommended for all production configurations as it provides an additional measure of redundancy. This can be further improved by configuring link aggregation between the switches.
MapR Benefit In order to balance network bandwidth against disk I/O bandwidth. MapR recommends 2-4 1GbE NICs per node or 1-2 10GbE NICs per node to satisfy the disk throughput requirements. MapR auto detects multiple NICs per node and enables application layer bonding for maximum throughput.
Larger clusters with three or more racks will benefit from having TOR switches connected by 10GbE uplinks to core aggregation switches. During the map phase of Hadoop jobs that utilize the FileServer, the majority of tasks reference data on the server that executes the task (node-local). For those tasks that must access data remotely, the data is usually on other servers in the same rack (rack-local). Only a small percentage of tasks need to access data from remote racks. The shuffle and reduce phases, in contrast, can drive very high levels of network traffic for some kinds of workloads.
MapR Benefit TOR switches with deep buffering are recommended to minimize the effects of switch congestion during periods of high network traffic. In particular, it is important to avoid lost packets since this will cause servers to decrease their TCP window sizes leading to lower throughput.
Switches MapR clusters contain two types of switches, namely Aggregation switches and Top of Rack switches. Top of Rack switches route the traffic between the nodes in each rack and Aggregation switches route the traffic between the racks.
Aggregation switches The HP 5900AF-48XG-4QSFP switch is an ideal aggregation switch as it offers exceptional scalability for Hadoop cluster expansion with its 10GbE ports. For more information on the HP 5900AF-48XG-4QSFP, please see http://h17007.www1.hp.com/us/en/products/switches/HP_5900_Switch_Series/index.aspx or 5900AF QuickSpecs.
The configuration for the HP 5900AF-48XG-4QSFP switch is provided below.
Figure 2. HP 5900AF-48XG-4QSFP Aggregation switch

Technical white paper | HP Reference Architecture for MapR M5
8
Table 4. HP 5900AF-48XG-4QSFP Single Aggregation Switch options
Qty Description
1 HP 5900AF-48XG-4QSFP Switch
2 HP 58x0AF 650W AC Power Supply
2 HP 58x0AF Front (port-side) to Back (power-side) Airflow Fan Tray
4 HP X140 40G QSFP MPO SR4 Transceiver
48 HP X130 10G SFP+ LC SR Transceiver
48 HP X240 40G QSFP 5m Direct Attach Copper Cable
Top of Rack (TOR) switches The HP 5830AF-48G is an ideal TOR switch and has a 1 GB buffer size for very deep buffering, better HA support, two 10GbE uplinks, forty-eight 1GbE ports and the option for adding two more 10GbE ports. A dedicated management switch for iLO traffic is not required as the ProLiant DL380e servers are able to share iLO traffic over the first NIC. The volume of iLO traffic is minimal and does not degrade performance over that port. For more information on the HP 5830AF-48G switch, please see http://h17007.www1.hp.com/us/en/products/switches/HP_5830_Switch_Series/index.aspx or 5830AF QuickSpecs.
This switch is rear-facing, in that the cables for the switch are connected on the same side of the rack as the cables that are connected to the NICs at the back of the DL380e servers.
Figure 3. HP 5830AF-48G Top of Rack (TOR) switch
The configuration for the HP 5830AF-48G switch is provided below.
Table 5. HP 5830AF-48G Switch options
Qty Description
1 HP 5830AF-48G Switch with 1 Interface Slot
2 HP 58x0AF 650W AC Power Supply
1 HP 5500/5120 2-port 10GbE SFP+ Module
1 HP 5830AF-48G Back(power)-Front(prt) Fan Tray
Data movement into and out of the MapR cluster It is best to isolate the MapR M5 cluster on its own private network in order to ensure that external network traffic does not collide with that of the MapR network. However, one still needs to ensure that data can be moved into and out of the MapR cluster from external networks. MapR can be mounted by another system as a network file share (NFS). In order to enable the import and export of data to and from a MapR cluster, we recommend configuring the aggregation switches to allow NFS traffic from external networks.

Technical white paper | HP Reference Architecture for MapR M5
9
HP Insight Cluster Management utility
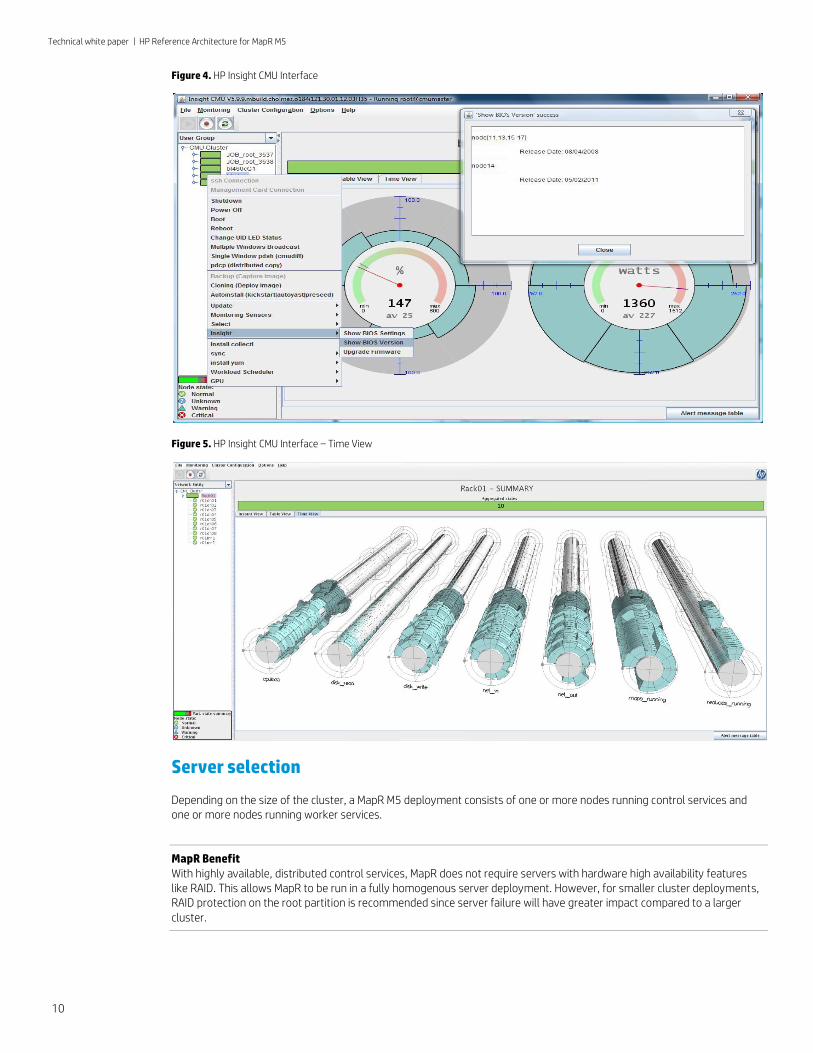
HP Insight Cluster Management Utility (CMU) is an efficient and robust hyperscale cluster lifecycle management framework and suite of tools for large Linux clusters such as those found in High Performance Computing (HPC) and Big Data environments. A simple graphical interface enables an ‘at-a-glance’ view of the entire cluster across multiple metrics, provides frictionless scalable remote management and analysis, and allows rapid provisioning of software to all the nodes of the system. Insight CMU makes the management of a cluster more user friendly, efficient, and error free than if it were being managed by scripts, or on a node-by-node basis. Insight CMU offers full support for iLO 2, iLO 3, iLO 4 and LO100i adapters on all HP ProLiant servers in the cluster.
MapR Benefit HP Insight CMU allows you to easily correlate MapR metrics with cluster infrastructure metrics, such as CPU Utilization, Network Transmit/Receive, Memory Utilization and I/O Read/Write. This allows you to characterize your MapR workloads and optimize the system thereby improving the performance of the MapR Cluster. CMU TimeView Metric Visualizations will help you understand, based on your workloads, whether your cluster needs more memory, a faster network or processors with faster clock speeds. In addition, Insight CMU also greatly simplifies the deployment of MapR, with its ability to create a Golden Image from a Node and then deploy that image to up to 4000 nodes. Insight CMU is able to deploy 800 nodes in 30 minutes.
Insight CMU is highly flexible and customizable, offers both GUI and CLI interfaces, and is being used to deploy a range of software environments, from simple compute farms to highly customized, application-specific configurations. Insight CMU is available for HP ProLiant and HP BladeSystem servers, with Linux operating systems, including Red Hat Enterprise Linux, SUSE Linux Enterprise, CentOS, and Ubuntu. Insight CMU also includes options for monitoring Graphical Processing Units (GPUs) and for installing GPU drivers and software.
For more information, please see hp.com/go/cmu.
Table 6. HP Insight CMU options
Qty Description
1 HP Insight CMU 1yr 24x7 Flex Lic
1 HP Insight CMU 1yr 24x7 Flex E-LTU
1 HP Insight CMU 3yr 24x7 Flex Lic
1 HP Insight CMU 3yr 24x7 Flex E-LTU
1 HP Insight CMU Media
Technical white paper | HP Reference Architecture for MapR M5
10
Figure 4. HP Insight CMU Interface
Figure 5. HP Insight CMU Interface – Time View
Server selection
Depending on the size of the cluster, a MapR M5 deployment consists of one or more nodes running control services and one or more nodes running worker services.
MapR Benefit With highly available, distributed control services, MapR does not require servers with hardware high availability features like RAID. This allows MapR to be run in a fully homogenous server deployment. However, for smaller cluster deployments, RAID protection on the root partition is recommended since server failure will have greater impact compared to a larger cluster.

Technical white paper | HP Reference Architecture for MapR M5
11
This section specifies which server to use and the rationale behind it. The Reference Architectures section will provide topologies for the deployment of control and worker services across the nodes for clusters of varying sizes.
Processor configuration MapR manages the amount of work each server is able to undertake via the amount of Map/Reduce slots configured for that server. The more cores available to the server, the more Map/Reduce slots can be configured for the server (see the Computation section for more detail). We recommend 6 core processors for a good balance of price and performance. We recommend that Hyper-Threading is turned on.
Drive configuration Redundancy is built into the MapR architecture and thus there is no need for RAID or additional hardware components to improve redundancy on the server as it is all coordinated and managed in the MapR software.
MapR Benefit Drives should use a Just a Bunch of Disks (JBOD) configuration, which can be achieved with the HP P420 RAID controller by configuring each individual disk as a separate RAID 0 volume. We recommend disabling array acceleration on the controller to better handle large block I/Os in the Hadoop environment.
Lastly, servers should provide a large amount of storage capacity which increases the total capacity of the distributed file system and provide that capacity by using at least twelve 2TB Large Form Factor drives for optimum I/O performance. The DL380e supports 14 Large Form Factor (LFF) drives, which allows one to either use all 14 drives for data or use 12 drives for data and the additional 2 for mirroring the operating system and MapR runtime. Hot pluggable drives are recommended so that drives can be replaced without restarting the server.
Memory configuration Servers running the node processes should have sufficient memory for either HBase or for the amount of Map/Reduce Slots configured on the server. A server with larger RAM configuration will deliver optimum performance for both HBase and Map/Reduce. To ensure optimal memory performance and bandwidth, we recommend using 8GB or 16GB DIMMs to populate each of the 6 memory channels as needed.
Network configuration The DL380e includes four 1GbE NICs onboard. MapR automatically identifies the available NICs on the server and bonds them via the MapR software to increase throughput.
MapR Benefit Each of the reference architecture configurations below specifies an additional Top of Rack Switch for redundancy. To best make use of this, we recommend cabling the ProLiant DL380e Worker Nodes so that NIC 1 is cabled to Switch 1 and NIC 2 is cabled to Switch 2, repeating the same process for NICs 3 and 4. Each NIC in the server should have its own IP subnet instead of sharing the same subnet with other NICs.
HP ProLiant DL380e Gen8 The HP ProLiant DL380e Gen8 (2U) is an excellent choice as the server platform for the worker nodes.
Figure 6. HP ProLiant DL380e Gen8 Server

Technical white paper | HP Reference Architecture for MapR M5
12
The recommended DL380e configuration includes:
• Dual Six-Core Intel Xeon® E5-2440 2.4 GHz Processors with 15M L3 Cache and Hyper-Threading enabled
• Twelve 2TB 7.2K LFF (3.5 inch) SATA MDL or SAS MDL disks (24 TB for Data)
• Two 500GB SATA 7.2K LFF MDL (Mirrored OS and Runtime)
• 1 x Smart Array P420 Controller
• 48 GB (6 x HP 8GB DDR3) Memory
• 4 x 1GbE NICs
MapR Benefit The DL380e has 12 hot swappable drives in the front of the server and 2 at the back of the server. The description above reflects a server that has the front 12 drives allocated for data in a JBOD configuration and the 2 drives at the back used to mirror the operating system and MapR runtime. This provides a very low cost approach to increase the resiliency of each of the worker nodes. Customers also have the option of not mirroring the OS and MapR runtime and leveraging all 14 of the drives for data. In addition, customers have the option of purchasing a second power supply and fans for additional power redundancy.
The Bill of Materials (BOM) for the server is provided below.
Table 7. The MapR DL380e server configuration
Qty Description
1 HP ProLiant DL380e Gen8 12LFF CTO Base Server
1 HP 2U LFF BB Rail Gen8 Kit
1 Intel Xeon E5-2440 (2.4GHz/6-core/15MB/95W) FIO Kit - CPU
1 Intel Xeon E5-2440 (2.4GHz/6-core/15MB/95W) – Additional CPU
1 HP DL380e Gen8 CPU1 Riser Kit
6 HP 8GB 2Rx4 PC3L-10600R-9 (1333MHz) - Memory
1 HP 2U Gen8 Rear 2LFF Kit
2 HP 500GB 6G SATA 7.2k 3.5in SC MDL HDD
1 HP Ethernet 1Gb 4-port 331T Adapter
1 HP Smart Array P420/1GB FBWC Controller
2 HP 750W CS Gold Ht Plg Pwr Supply Kit
1 HP DL380eGen8 HP Fan Kit
12 HP 2TB 6G SATA 7.2k 3.5in SC MDL HDD
Reference Architectures
This section provides a progression of configurations from single rack to full scale out MapR cluster configurations. Best practices for each of the components within the configurations specified have been articulated earlier in this document.
Single Rack configuration The Single Rack MapR M5 configuration provides a starting point for a MapR M5 cluster configuration. The configuration reflects the following components.

Technical white paper | HP Reference Architecture for MapR M5
13
Rack enclosure The rack contains nineteen HP ProLiant DL380e servers and two HP 5830AF-48G switches within a 42U rack enclosure. This leaves 2U open for an additional 2U DL380e server or a 1U KVM switch.
Network As previously described in the Switches section, two HP 5830AF-48G switches are specified for performance and redundancy. The HP 5830AF-48G includes up to four 10GbE uplinks which can be used to connect the switches in the rack into the desired network.
MapR nodes The ProLiant servers in the rack act as nodes in the MapR cluster and are divided up into nodes that run control services and nodes that run exclusively worker services. In the diagram for this configuration (see Figure 8 below), the nodes that run control services are specified with a number, thereby denoting Node 1, Node 2, and Node 3. It is worth noting that the nodes that run the worker services and control services can be placed on any nodes in the rack and cluster.
Nodes running control services To provide high availability (HA), it is recommended to configure multiple control services in the rack. One should have at least 3 ZooKeeper, 2 to 3 CLDB, 2 to 3 JobTracker, and 2 Web Server services for the Single Rack configuration. We recommend configuring them as follows:
Node 1 runs the following control services:
• Container Location Database (CLDB)
• JobTracker (or HBaseMaster)
• Web Server
• ZooKeeper
Node 2 runs the following control services:
• Container Location Database (CLDB)
• JobTracker (or HBaseMaster)
• Web Server
• ZooKeeper
Node 3 runs the following control services:
• Container Location Database(CLDB)
• JobTracker (or HBaseMaster)
• ZooKeeper
• HP Insight CMU
In addition, each of the nodes listed above run the following worker services:
• FileServer
• Network File Share (NFS)
• TaskTracker (or HBaseRegionServer if you are using HBase)
MapR Benefit In order to ensure that the worker services do not consume the resources required for the control services we recommend you limit the amount of configured Map/Reduce slots (see the Computation section) to half on the nodes running the control services. This would require one to reduce the Map Slots percentage in total number of cores from 75% to 50% and reduce slots from 50% to 25%, namely, 12 map slots and 6 reduce slots.

Technical white paper | HP Reference Architecture for MapR M5
14
Nodes running worker services After the nodes running the control services are configured, there are up to 16 nodes in the rack that can be configured to run worker services. Keep in mind that it is not mandatory to fully populate the rack with nodes running worker services; however, both performance and storage capacity will improve the more you add. The following worker services run on the remaining nodes:
• FileServer
• Network File Share (NFS)
• TaskTracker (or HBaseRegionServer if you are using HBase)
Figure 7. Single Rack MapR M5 Configuration
Technical white paper | HP Reference Architecture for MapR M5
15
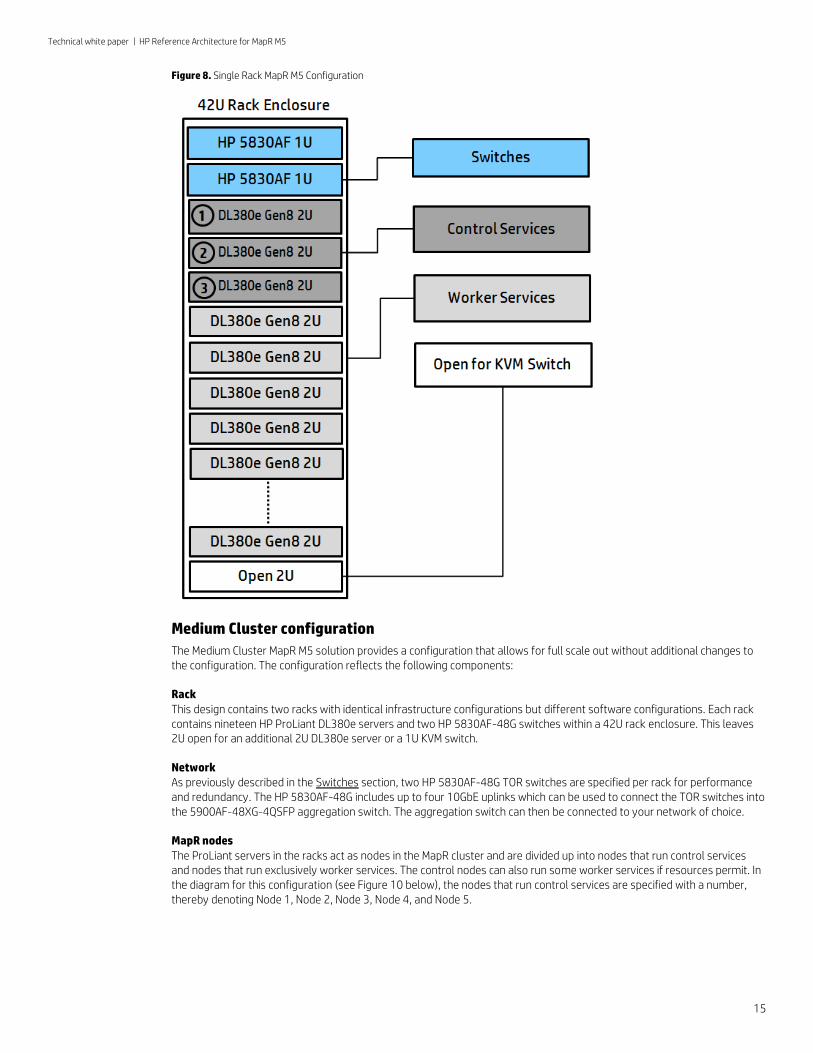
Figure 8. Single Rack MapR M5 Configuration
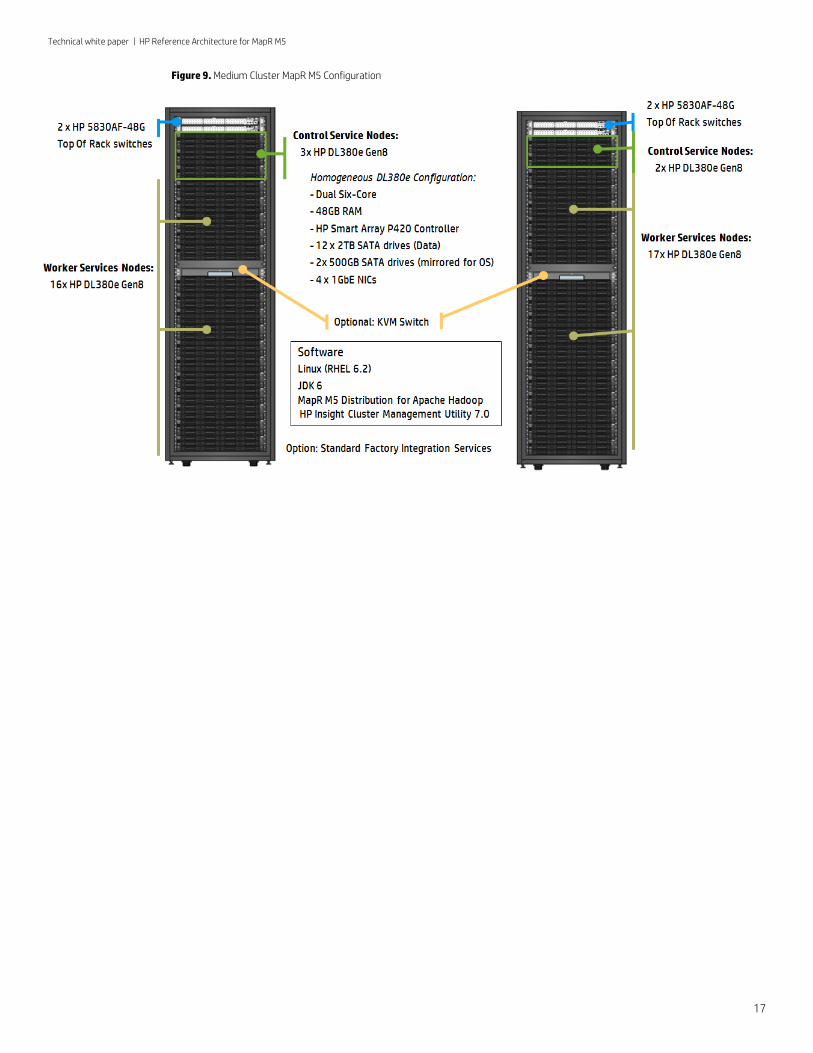
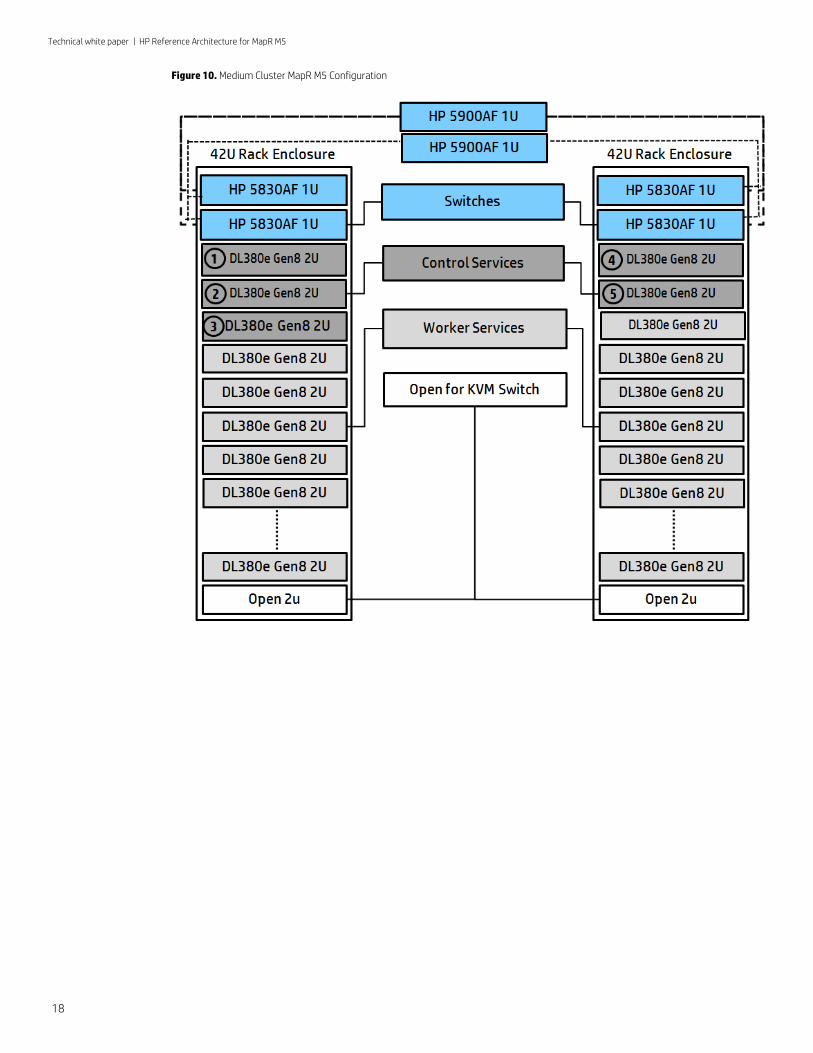
Medium Cluster configuration The Medium Cluster MapR M5 solution provides a configuration that allows for full scale out without additional changes to the configuration. The configuration reflects the following components:
Rack This design contains two racks with identical infrastructure configurations but different software configurations. Each rack contains nineteen HP ProLiant DL380e servers and two HP 5830AF-48G switches within a 42U rack enclosure. This leaves 2U open for an additional 2U DL380e server or a 1U KVM switch.
Network As previously described in the Switches section, two HP 5830AF-48G TOR switches are specified per rack for performance and redundancy. The HP 5830AF-48G includes up to four 10GbE uplinks which can be used to connect the TOR switches into the 5900AF-48XG-4QSFP aggregation switch. The aggregation switch can then be connected to your network of choice.
MapR nodes The ProLiant servers in the racks act as nodes in the MapR cluster and are divided up into nodes that run control services and nodes that run exclusively worker services. The control nodes can also run some worker services if resources permit. In the diagram for this configuration (see Figure 10 below), the nodes that run control services are specified with a number, thereby denoting Node 1, Node 2, Node 3, Node 4, and Node 5.

Technical white paper | HP Reference Architecture for MapR M5
16
Nodes running control services A minimum of three control nodes are required to provide HA, hence the multi-rack configuration to ensure that the services will stay available in the event that an entire rack goes offline. It is recommended to have 3 ZooKeeper, 3 CLDB, 2 JobTracker, and 2 Web Server services in the Medium Cluster configuration. Rack 1 contains two nodes that run control services and Rack 2 contains three nodes that run control services. We recommend configuring these nodes as follows:
Node 1 runs the following control services:
• Container Location Database (CLDB)
• Web Server
Node 2 runs the following control services:
• Container Location Database (CLDB)
• Web Server
• ZooKeeper
Node 3 runs the following control services:
• Container Location Database (CLDB)
• Web Server
Node 4 runs the following control services:
• JobTracker (or HBaseMaster)
• ZooKeeper
• HP Insight CMU
Node 5 runs the following control services:
• JobTracker (or HBaseMaster)
• ZooKeeper
In addition, each of the nodes listed above run the following worker services:
• FileServer
• Network File Share (NFS)
• TaskTracker (or HBaseRegionServer if you are using HBase
MapR Benefit In order to ensure that the worker services do not consume the resources required for the control services we recommend you limit the amount of configured Map/Reduce slots (see the Computation section) to half on the nodes running the control services. This would require one to reduce the Map Slots percentage in total number of cores from 75% to 50% and reduce slots from 50% to 25%, namely, 12 map slots and 6 reduce slots.
Nodes running worker services The rest of the nodes in the rack that are not running control services exclusively run worker services. Keep in mind that it is not mandatory to fully populate the rack with nodes running worker services; however, both performance and storage capacity will improve the more you have. The following worker services run on the remaining nodes:
• FileServer
• Network File Share (NFS)
• TaskTracker (or HBaseRegionServer if you are using HBase)
Technical white paper | HP Reference Architecture for MapR M5
17
Figure 9. Medium Cluster MapR M5 Configuration
Technical white paper | HP Reference Architecture for MapR M5
18
Figure 10. Medium Cluster MapR M5 Configuration

Technical white paper | HP Reference Architecture for MapR M5
19
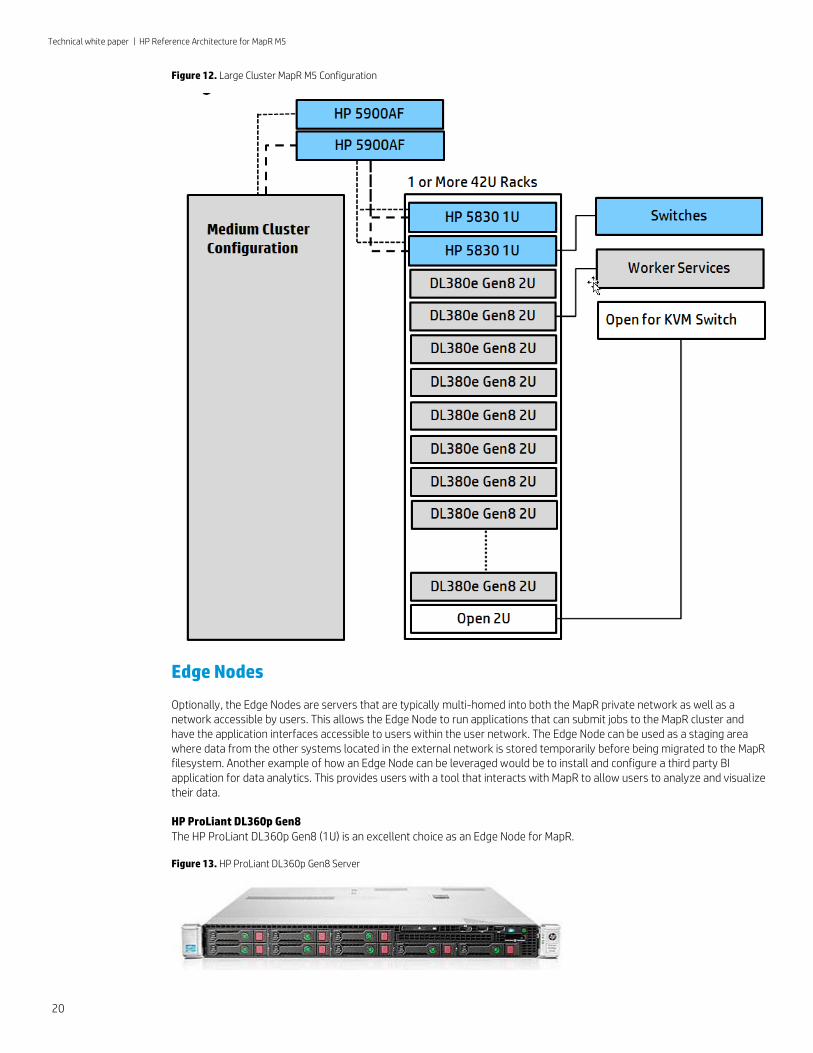
Large Cluster configuration The Large Cluster design assumes the Medium Cluster design is already in place and extends its scalability. The Medium Cluster design ensures the required amount of control services are in place for large scale out. For large clusters, one simply adds more racks of the configuration provided below to the Medium Cluster design. This section reflects the design of those racks.
Rack enclosure The rack contains nineteen HP ProLiant DL380e servers and two HP 5830AF-48G switches within a 42U rack enclosure. This leaves 2U open for an additional 2U DL380e server or a 1U KVM switch.
Network As previously described in the Switches section, two HP 5830AF-48G switches are specified for performance and redundancy. The HP 5830AF-48G includes up to four 10GbE uplinks which can be used to connect the switches in the rack into an aggregation switch such as the HP 5900AF-48XG-4QSFP and the desired network.
MapR nodes The ProLiant servers in the rack act as nodes in the MapR cluster. Since the Medium Cluster configuration already has the required control services in place, one needs only worker services on the additional nodes. These are:
• FileServer
• Network File Share (NFS)
• TaskTracker (or HBaseRegionServer if you are using HBase)
Figure 11. Large Cluster MapR M5 Configuration
Technical white paper | HP Reference Architecture for MapR M5
20
Figure 12. Large Cluster MapR M5 Configuration
Edge Nodes
Optionally, the Edge Nodes are servers that are typically multi-homed into both the MapR private network as well as a network accessible by users. This allows the Edge Node to run applications that can submit jobs to the MapR cluster and have the application interfaces accessible to users within the user network. The Edge Node can be used as a staging area where data from the other systems located in the external network is stored temporarily before being migrated to the MapR filesystem. Another example of how an Edge Node can be leveraged would be to install and configure a third party BI application for data analytics. This provides users with a tool that interacts with MapR to allow users to analyze and visualize their data.
HP ProLiant DL360p Gen8 The HP ProLiant DL360p Gen8 (1U) is an excellent choice as an Edge Node for MapR.
Figure 13. HP ProLiant DL360p Gen8 Server

Technical white paper | HP Reference Architecture for MapR M5
21
The following base configuration is popular for Edge Nodes:
• Dual Six-Core Intel E5-2667 2.9 GHz Processors
• Smart Array P420i Controller
• Eight 900GB SFF SAS 10K RPM disks
• 64 GB DDR3 Memory
• 4 x 1GbE FlexibleLOM NICs
Bill of materials Table 8. The HP ProLiant DL360p Gen8 Server Configuration
Qty Description
1 HP DL360p Gen8 8-SFF CTO Chassis
1 HP DL360p Gen8 E5-2667 FIO Kit
1 HP DL360p Gen8 E5-2667 Kit
8 HP 8GB 1Rx4 PC3-12800R-11 Kit
8 HP 900GB 6G SAS 10K 2.5in SC ENT HDD
1 HP Ethernet 1GbE 4P 331FLR FIO Adapter
1 HP 512MB FBWC for P-Series Smart Array
2 HP 460W CS Gold Hot Plug Power Supply Kit
1 HP 1U SFF BB Gen8 Rail Kit
1 ProLiant DL36x(p) HW Support
Summary
HP and MapR allow one to derive new business insights from Big Data by providing a platform to store, manage and process data at scale. However, designing and ordering Hadoop Clusters can be both complex and time consuming. This white paper provides several reference configurations for deploying clusters of varying sizes on MapR’s M5 distribution of Apache Hadoop and HP infrastructure. These configurations leverage HP’s balanced building blocks of servers, storage and networking, along with integrated management software and bundled support. In addition, this white paper has been created in order to assist in the rapid design and deployment of MapR M5 software on HP infrastructure for clusters of various sizes.

For more information
MapR, mapr.com
Hadoop on HP, hp.com/go/hadoop
HP Insight Cluster Management Utility (CMU), hp.com/go/cmu
HP ProLiant DL380e Gen8, hp.com/servers/dl380e
HP ProLiant servers, hp.com/go/proliant
HP Enterprise Software, hp.com/go/software
HP Networking, hp.com/go/networking
HP Integrated Lights-Out (iLO) Advanced, hp.com/servers/ilo
HP Product Bulletin (QuickSpecs), hp.com/go/quickspecs
HP Services, hp.com/go/services
HP Support and Drivers, hp.com/go/support
HP Systems Insight Manager (HP SIM), hp.com/go/hpsim
To help us improve our documents, please provide feedback at hp.com/solutions/feedback.
Sign up for updates hp.com/go/getupdated
© Copyright 2012, 2013 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice. The only warranties for HP products and services are set forth in the express warranty statements accompanying such products and services. Nothing herein should be construed as constituting an additional warranty. HP shall not be liable for technical or editorial errors or omissions contained herein.
Intel and Xeon are trademarks of Intel Corporation in the U.S. and other countries.
4AA4-2434ENW, January 2013, Rev. 1





























