Embed Size (px)
Citation preview

EfficientPerformance™ 1
High-PerformanceGPUClustering:GPUDirectRDMAover40GbEiWARP
TomReuConsultingApplicationsEngineerChelsioCommunicationstomreu@chelsio.com

EfficientPerformance™ 2
• Leading10/40GbEadaptersolutionproviderforserversandstoragesystems• ~800Kportsshipped
• Highperformanceprotocolengine• 80MPPS• 1.5μsec• ~5M+IOPs
• Featurerichsolution• Mediastreaminghardware/software• WANOptimization,Security,etc.
• CompanyFacts• Foundedin2000• 150strongstaff
• R&DOffices• USA–Sunnyvale• India–Bangalore• China-Shanghai
ChelsioCorporateSnapshotLeaderinHighSpeedConvergedEthernetAdapters
MarketCoverage
Manufacturing
OilandGas Finance
Service/Cloud
Storage
Media
HPC
Security
OEMSnapshot

EfficientPerformance™
• Directmemory-to-memorytransfer• Allprotocolprocessinghandlingbythe
NIC• Mustbeinhardware
• ProtectionhandledbytheNIC• Userspaceaccessrequiresbothlocal
andremoteenforcement• Asynchronouscommunicationmodel
• Reducedhostinvolvement• Performance
• Latency-polling• Throughput
• Efficiency• Zerocopy• Kernelbypass(userspaceI/O)• CPUbypass
RDMAOverview
Performanceandefficiencyinreturnfornewcommunicationparadigm
ChelsioT5RNICChelsioT5RNIC

EfficientPerformance™ 4
• ProvidestheabilitytodoRemoteDirectMemoryAccessoverEthernetusingTCP/IP
• UsesWell-KnownIBVerbs• InboxedinOFEDsince2008• RunsontopofTCP/IP
• ChelsioimplementsiWARP/TCP/IPstackinsilicon• Cut-throughsend• Cut-throughreceive
• Benefits• Engineeredtouse“typical”Ethernet• NoneedfortechnologieslikeDCBorQCN
• NativelyRoutable• Multi-pathsupportatLayer3(andLayer2)• ItrunsonTCP/IP• MatureandProven• GoeswhereTCP/IPgoes(everywhere)
iWARPWhatisit?

EfficientPerformance™ 5
• iWARPupdatesandenhancementsaredonebytheIETFSTORM(StorageMaintenance)workinggroup
• RFCs• RFC5040ARemoteDirectMemoryAccessProtocol
Specification• RFC5041DirectDataPlacementoverReliable
Transports• RFC5044MarkerPDUAlignedFramingforTCP
Specification• RFC6580IANARegistriesfortheRDDPProtocols• RFC6581EnhancedRDMAConnectionEstablishment• RFC7306RemoteDirectMemoryAccess(RDMA)
ProtocolExtensions• Supportfromseveralvendors,Chelsio,Intel,QLogic
iWARP

EfficientPerformance™ 6
• SomeUseCases• HighPerformanceComputing• SMBDirect• GPUDirectRDMA• NFSoverRDMA• FreeBSDiWARP• HadoopRDMA• LustreRDMA• NVMeoverRDMAfabrics
iWARPIncreasingInterestiniWARPasoflate

EfficientPerformance™ 7
• It’sEthernet• WellUnderstoodandAdministered• UsesTCP/IP• MatureandProven• Supportsrack,cluster,datacenter,LAN/MAN/WANandwireless
• CompatiblewithSSL/TLS• Donotneedtouseanybolt-ontechnologieslike• DCB• QCN
• Doesnotrequireatotallynewnetworkinfrastructure• ReducesTCOandOpEx
iWARPAdvantagesoverOtherRDMATransports

EfficientPerformance™
iWARPvsRoCE
iWARP RoCENative TCP/IP over Ethernet, no different from NFS or HTTP
Difficult to install and configure - “needs a team of experts” - Plug-and-Debug
Works with ANY Ethernet switches Requires DCB - expensive equipment upgrade
Works with ALL Ethernet equipment Poor interoperability - may not work with switches from different vendors
No need for special QoS or configuration - TRUE Plug-and-Play
Fixed QoS configuration - DCB must be setup identically across all switches
No need for special configuration, preserves network robustness
Easy to break - switch configuration can cause performance collapse
TCP/IP allows reach to Cloud scale Does not scale - requires PFC, limited to single subnet
No distance limitations. Ideal for remote communication and HA
Short distance - PFC range is limited to few hundred meters maximum
WAN routable, uses any IP infrastructure RoCEv1 not routable. RoCE v2 requires lossless IP infrastructure and restricts router configuration
Standard for whole stack has been stable for a decade
ROCEv2 incompatible with v1. More fixes to missing reliability and scalability layers required and expected
Transparent and open IETF standards process Incomplete specification and opaque process

EfficientPerformance™ 9
• HighPerformancePurposeBuiltProtocolProcessor• Runsmultipleprotocols
• TCPwithStatelessOffloadandFullOffload• UDPwithStatelessOffload• iWARP• FCoEwithOffload• iSCSIwithOffload
• AlloftheseprotocolsrunonT5withaSINGLEFIRMWAREIMAGE• Noneedtoreinitializethecardfordifferentuses• Futureproofe.g.supportforNVMfyetpreserves
today’sinvestmentiniSCSI
Chelsio’sT5SingleASICdoesitall

EfficientPerformance™ 10
T5ASICArchitecture
▪ Singleprocessordata-flowpipelinedarchitecture
▪ Upto1Mconnections▪ ConcurrentMulti-Protocol
Operation
1G/10G/40GMAC
EmbeddedLayer2EthernetSwitch
Lookup,filteringandFirewallCut-ThroughRXMemory
Cut-ThroughTXMemory
Data-flowProtocolEngine
TrafficManager
ApplicationCo-ProcessorTX
ApplicationCo-ProcessorRX
DMAEn
gine
PCI-e
,X8,Gen
3
GeneralPurposeProcessor
OptionalexternalDDR3memory
1G/10G/40GMAC
100M/1G/10GMAC
100M/1G/10GMAC
On-ChipDRAMMemoryController
Singleconnectionat40Gb.LowLatency.
HighPerformancePurposeBuiltProtocolProcessor

EfficientPerformance™ 11
LeadingUnifiedWire™ArchitectureConvergedNetworkArchitecturewithall-in-oneAdapterandSoftware
Networking▪4x10GbE/2x40GbENIC▪FullProtocolOffload▪DataCenterBridging▪Hardwarefirewall▪WireAnalytics▪DPDK/netmap
HFT▪WireDirecttechnology▪Ultralowlatency▪Highestmessages/sec▪Wirerateclassification
Storage▪NVMe/Fabrics▪SMBDirect▪iSCSIandFCoEwithT10-DIX▪iSERandNFSoverRDMA▪pNFS(NFS4.1)andLustre▪NASOffload▪Disklessboot▪Replicationandfailover
Virtualization&Cloud▪Hypervisoroffload▪SR-IOVwithembeddedVEB▪VEPA,VN-TAGs▪VXLAN/NVGRE▪NFVandSDN▪OpenStackstorage▪HadoopRDMA
HPC▪iWARPRDMAoverEthernet▪GPUDirectRDMA▪LustreRDMA▪pNFS(NFS4.1)▪OpenMPI▪MVAPICH
MediaStreaming▪TrafficManagement▪VideosegmentationOffload▪Largestreamcapacity
SingleQualification–SingleSKUConcurrentMulti-ProtocolOperation

EfficientPerformance™
• IntroducedbyNVIDIAwiththeKeplerClassGPUs.AvailabletodayonTeslaandQuadroGPUsaswell.
• EnablesMultipleGPUs,3rdpartynetworkadapters,SSDsandotherdevicestoreadandwriteCUDAhostanddevicememory
• AvoidsunnecessarysystemmemorycopiesandassociatedCPUoverheadbycopyingdatadirectlytoandfrompinnedGPUmemory
• Onehardwarelimitation• TheGPUandtheNetworkdeviceMUSTsharethesame
upstreamPCIerootcomplex• AvailablewithInfiniband,RoCE,andnowiWARP
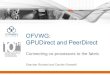
GPUDirectRDMA

EfficientPerformance™ 13
• Read/writeGPUmemorydirectlyfromnetworkadapter• Peer-to-peerPCIe
communication• BypasshostCPU• Bypasshostmemory
• Zerocopy• Ultralowlatency• Veryhighperformance• ScalableGPUpooling
• AnyEthernetnetworks
GPUDirectRDMAT5iWARPRDMAoverEthernetcertifiedwithNVIDIAGPUDirect
RNIC
LAN/Datacenter/WAN
Network
MEMORY MEMORY
PayloadNotifications
CPU
Payload
HostHost
CPU
Notifications
Packets Packets
GPU RNIC GPU

EfficientPerformance™
• ChelsioModules• cxgb4-Chelsioadapterdriver• iw_cxgb4-ChelsioiWARPdriver• rdma_ucm-RDMAUserSpaceConnectionManager
• NVIDIAModules• nvidia-NVIDIAdriver• nvidia_uvm-NVIDIAUnifiedMemory• nv_peer_mem-NVIDIAPeerMemory
ModulesrequiredforGPUDirectRMDAwithiWARP

CaseStudies

EfficientPerformance™ 16
• GeneralPurposeParticlesimulationtoolkit
• Standsfor:HighlyOptimizedObject-orientedMany-particleDynamics-BlueEdition
• RunningonGPUDirectRDMA-WITHNOCHANGESTOTHECODE-ATALL!
• MoreInfo:www.codeblue.umich.edu/hoomd-blue
HOOMD-blue

EfficientPerformance™ 17
• 4Nodes• [email protected]• 64GBRAM• ChelsioT580-CR40GbAdapter• NVIDIATeslaK80(2GPUspercard)• RHEL6.5• OpenMPI1.10.0• OFED3.18• CUDAToolkit6.5• HOOMD-bluev1.3.1-9• Chelsio-GDR-1.0.0.0• CommandLine:$MPI_HOME/bin/mpirun --allow-run-as-root -mca btl_openib_want_cuda_gdr
1 -np X -hostfile /root/hosts -mca btl openib,sm,self -mca btl_openib_if_include cxgb4_0:1 --mca btl_openib_cuda_rdma_limit 65538 -mca btl_openib_receive_queues P,131072,64 -x CUDA_VISIBILE_DEVICES=0,1 /root/hoomd-install/bin/hoomd ./bmark.py --mode=gpu|cpu
HOOMD-blueTestConfiguration

EfficientPerformance™ 18
• ClassicbenchmarkforgeneralpurposeMDsimulations.• RepresentativeoftheperformanceHOOMD-blueachievesforstraightpairpotentialsimulations
HOOMD-blueLennard-JonesLiquid64KParticlesBenchmark

EfficientPerformance™ 19
HOOMD-blueLennard-JonesLiquid64KParticlesBenchmarkResults
AverageTimestepsperSecond
Test1
Test2
Test3
0 450 900 1350 1800
1,771
1,403
1,230
1,089
503
488
214
88
26
CPU GPUw/oGPUDirectRDMAGPUw/GPUDirectRDMA
LongerisBetter
2 CPU Cores2 GPUs
2 GPUs
8 CPU Cores4 GPUs
4 GPUs
40 CPU Cores8 GPUs
8 GPUs

EfficientPerformance™ 20
HOOMD-blueLennard-JonesLiquid64KParticlesBenchmarkResults
Hourstocomplete10e6steps
Test1
Test2
Test3
0 30 60 90 120
1.5
1.7
2.2
2.5
5.5
6
13
32
108
CPU GPUw/oGPUDirectRDMAGPUw/GPUDirectRDMA
ShorterisBetter
2 CPU Cores
8 CPU Cores
40 CPU Cores
2 GPUs
4 GPUs
8 GPUs
2 GPUs
4 GPUs
8 GPUs

EfficientPerformance™ 21
• runsasystemofparticleswithanoscillatorypairpotentialthatformsaicosahedralquasicrystal• Thismodelisusedintheresearcharticle:EngelM,et.al.(2015)Computationalself-assemblyofaone-componenticosahedralquasicrystal,Naturematerials14(January),p.109-116.
HOOMD-blueQuasicrystalBenchmark

EfficientPerformance™ 22
HOOMD-blueQuasicrystalresults
AverageTimestepsperSecond
Test1
Test2
Test3
0 300 600 900 1200
1,158
728
407
915
656
308
31
43
11
CPU GPUw/oGPUDirectRDMAGPUw/GPUDirectRDMA
LongerisBetter
2 CPU Cores2 GPUs
2 GPUs
8 CPU Cores4 GPUs
4 GPUs
40 CPU Cores8 GPUs
8 GPUs

EfficientPerformance™ 23
HOOMD-blueQuasicrystalresults
Hourstocomplete10e6steps
Test1
Test2
Test3
0 75 150 225 300
2.4
3.5
7
3
4
9
86
63
264
CPU GPUw/oGPUDirectRDMAGPUw/GPUDirectRDMA
ShorterisBetter
2 CPU Cores
8 CPU Cores
40 CPU Cores
2 GPUs
4 GPUs
8 GPUs
2 GPUs
4 GPUs
8 GPUs

EfficientPerformance™
• OpensourceDeepLearningsoftwarefromBerkeleyVisionandLearningCenter
• UpdatedtoincludeCUDAsupporttoutilizeGPUs• StandardversiondoesNOTincludeMPIsupport• MPIimplementations
• mpi-caffe• Usedtotrainalargenetworkacrossaclusterofmachines• model-paralleldistributedapproach.
• caffe-parallel• Fasterframeworkfordeeplearning.• data-parallelviaMPI,splitsthetrainingdataacrossnodes
CaffeDeepLearningFramework

EfficientPerformance™ 25
• iWARPprovidesRDMACapabilitiestoaEthernetnetwork
• iWARPusestriedandtrueTCP/IPasitsunderlyingtransportmechanism
• UsingiWARPdoesnotrequireawholenewnetworkinfrastructureandthemanagementrequirementsthatcomealongwithit
• iWARPcanbeusedwithexistingsoftwarerunningonGPUDirectRDMAwhichNOCHANGESrequiredtothecode
• ApplicationsthatuseGPUDirectRDMAwillseehugeperformanceimprovements
• Chelsioprovides10/40GbiWARPTODAYwith25/50/100Gbonthehorizon
SummaryGPUDirectRDMAover40GbEiWARP

EfficientPerformance™ 26
• Visitourwebsite,www.chelsio.com,formoreWhitePapers,Benchmarks,etc.
• GPUDirectRDMAWhitePaper:http://www.chelsio.com/wp-content/uploads/resources/T5-40Gb-Linux-GPUDirect.pdf
• Webinar:https://www.brighttalk.com/webcast/13671/189427
• BetacodeforGPUDirectRDMAisavailableTODAYfromourdownloadsiteatservice.chelsio.com
• [email protected]• [email protected]
MoreinformationGPUDirectRDMAover40GbEiWARP

Questions?
27

ThankYou