Embed Size (px)
Citation preview

Hardware Transactional Memory for GPU Architectures
Wilson W. L. FungInderpeet SinghAndrew BrownswordTor M. Aamodt
University of British ColumbiaIn Proc. 2011 ACM/IEEE Int’l Symp. Microarchitecture (MICRO-44)

Hardware TM for GPU Architectures 2
Motivation Lifetime of GPU Application Development
Time
Functionality Performance
Wilson Fung, Inderpeet Singh, Andrew Brownsword, Tor Aamodt
?
Time
Fine-Grained Locking
Time
Transactional Memory
E.g. N-Body with 5M bodies CUDA SDK: O(n2) – 1640 s (barrier)Barnes Hut: O(nLogn) – 5.2 s (locks)

Hardware TM for GPU Architectures 3Wilson Fung, Inderpeet Singh, Andrew Brownsword, Tor Aamodt Hardware TM for GPU Architectures 3
Are TM and GPUs Incompatible?
GPUs different from Multi-Core CPUs 1000s Concurrent Scalar Threads Challenges (from TM perspective)
Our Solution: KILO TM Hardware TM for GPUs

Hardware TM for GPU Architectures 4
T0 T1 T2 T3
Wilson Fung, Inderpeet Singh, Andrew Brownsword, Tor Aamodt Hardware TM for GPU Architectures 4
Hardware TM for GPUs Challenge #1: SIMD Hardware On GPUs, scalar threads in a warp/wavefront
execute in lockstep
...TxBeginLD r2,[B]ADD r2,r2,2ST r2,[A]TxCommit...
Committed
A Warp with 4 Scalar Threads
Aborted
Branch Divergence!
T0 T1 T2 T3
T0 T1 T2 T3

...TxBeginLD r2,[B]ADD r2,r2,2ST r2,[A]TxCommit...
Hardware TM for GPU Architectures 5Wilson Fung, Inderpeet Singh, Andrew Brownsword, Tor Aamodt Hardware TM for GPU Architectures 5
KILO TM – Solution to Challenge #1: SIMD Hardware Transaction Abort
Like a Loop Extend SIMT Stack
Abort

Hardware TM for GPU Architectures 6Wilson Fung, Inderpeet Singh, Andrew Brownsword, Tor Aamodt Hardware TM for GPU Architectures 6
Register File
CPU Core10s of
Registers
Hardware TM for GPUs Challenge #2: Transaction Rollback
Checkpoint Register File
@ TX Entry
@ TX Abort
Register File
GPU Core (SM)
32k RegistersWarpWarpWarpWarpWarpWarpWarpWarp
2MB TotalOn-Chip Storage
Checkpoint?

Hardware TM for GPU Architectures 7Wilson Fung, Inderpeet Singh, Andrew Brownsword, Tor Aamodt Hardware TM for GPU Architectures 7
KILO TM – Solution toChallenge #2: Transaction Rollback SW Register Checkpoint
Most TX: Registers overwritten at first use TX in Barnes Hut: Checkpoint 2 registers
TxBeginLD r2,[B]ADD r2,r2,2ST r2,[A]TxCommit
Abort
Overwritten

Hardware TM for GPU Architectures 8Wilson Fung, Inderpeet Singh, Andrew Brownsword, Tor Aamodt Hardware TM for GPU Architectures 8
Hardware TM for GPUs Challenge #3: Conflict Detection
Existing HTMs use Cache Coherence Protocol Not Available on GPUs No Private Data Cache per Thread
Signatures? 1024-bit / Thread 3.8MB / 30k Threads

Hardware TM for GPU Architectures 9
GPU Core (SM)
L1 Data CacheWarpWarpWarpWarpWarpWarpWarp
Wilson Fung, Inderpeet Singh, Andrew Brownsword, Tor Aamodt Hardware TM for GPU Architectures 9
Hardware TM for GPUs Challenge #4: Write Buffer
1024-1536 Threads Fermi’s L1 Data Cache (48kB)= 384 X 128B Lines
Problem: 384 lines / 1536 threads < 1 line per thread!

Hardware TM for GPU Architectures 10Wilson Fung, Inderpeet Singh, Andrew Brownsword, Tor Aamodt Hardware TM for GPU Architectures 10
TX2atomic
{A=B+2}
Private Memory
Read-Log
Write-Log
KILO TM: Value-Based Conflict Detection
TX1atomic
{B=A+1}
Private Memory
Read-Log
Write-Log
GlobalMemory
A=1
B=2
TxBeginLD r1,[A]ADD r1,r1,1ST r1,[B]TxCommit
A=1
B=0
A=1
B=0
A=2
B=2
B=2
Self-Validation + Abort: Only detects existence of conflict (not identity)
TxBeginLD r2,[B]ADD r2,r2,2ST r2,[A]TxCommit

TX1atomic
{B=A+1}
TX2atomic
{A=B+2}
Private Memory
Read-Log
Write-Log
Hardware TM for GPU Architectures 11Wilson Fung, Inderpeet Singh, Andrew Brownsword, Tor Aamodt Hardware TM for GPU Architectures 11
Parallel Validation?
Private Memory
Read-Log
Write-Log
GlobalMemory
A=1
B=2
A=1
B=0
A=1
B=0
A=2
B=0
B=2
A=2
Tx1 then Tx2:
A=4,B=2
Tx2 then Tx1:A=2,B=3
OR
Data Race!?!

Hardware TM for GPU Architectures 12Wilson Fung, Inderpeet Singh, Andrew Brownsword, Tor Aamodt Hardware TM for GPU Architectures 12
Serialize Validation?
GlobalMemory
CommitUnit
Benefit #1: No Data Race Benefit #2: No Live Lock Drawback: Serializes Non-Conflicting Transactions
(“collateral damage”)
TX1 TX2V + C Stall
Tim
e
V + C
V = ValidationC = Commit
Hardware TM for GPU Architectures 13
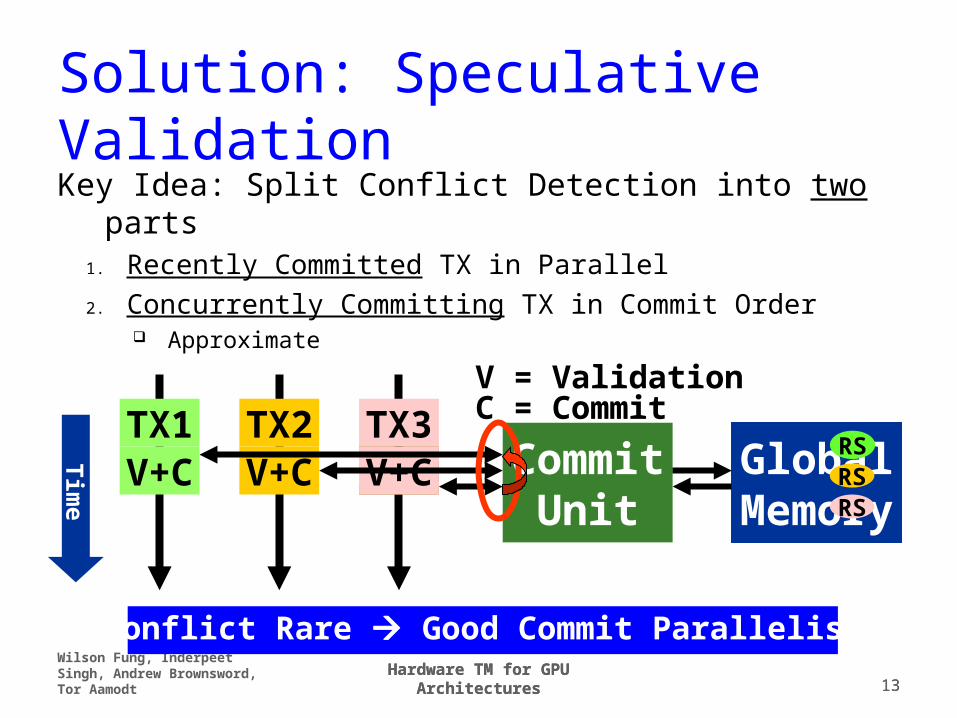
Solution: Speculative Validation
Wilson Fung, Inderpeet Singh, Andrew Brownsword, Tor Aamodt Hardware TM for GPU Architectures 13
GlobalMemory
CommitUnit
TX3TX1V+C Stall
Tim
e
V+CTX2V+C
Key Idea: Split Conflict Detection into two parts1. Recently Committed TX in Parallel
2. Concurrently Committing TX in Commit Order Approximate
RSRSRS
Conflict Rare Good Commit Parallelism
V = ValidationC = Commit

Hardware TM for GPU Architectures 14Wilson Fung, Inderpeet Singh, Andrew Brownsword, Tor Aamodt Hardware TM for GPU Architectures 14
KILO TM Implementation
SIMT Core
ConstantCache
TextureCache
MemoryPort
L1 DataCache
SIMTStacksSIMT Core
ConstantCache
TextureCache
MemoryPort
L1 DataCache
SIMTStacks
Memory PartitionMemory Partition
CPUKernelLaunch
InterconnectionN
etwork
Memory Partition
Last-LevelCache Bank
Off-ChipDRAM Channel
Atomic Op.Unit
CommitUnit
SIMT Core
Thread Block
Thread Block
Shared
Mem
ory
ConstantCache
TextureCache
MemoryPort
RegisterF
ile
L1 DataCache
TXLogUnit
SIMTStacksSIMT
StacksCommit
UnitTXLogUnit
Minimal Modification to Existing GPU Arch.

Hardware TM for GPU Architectures 15Wilson Fung, Inderpeet Singh, Andrew Brownsword, Tor Aamodt Hardware TM for GPU Architectures 15
Evaluation Methodology
GPGPU-Sim 3.0 (BSD license) Detailed: IPC Correlation of 0.93 vs GT 200 KILO TM (Timing-Driven Memory Accesses)
GPU TM Applications Hash Table (HT-H, HT-L) Bank Account (ATM) Cloth Physics (CL) Barnes Hut (BH) CudaCuts (CC) Data Mining (AP)

Hardware TM for GPU Architectures 16Wilson Fung, Inderpeet Singh, Andrew Brownsword, Tor Aamodt Hardware TM for GPU Architectures 16
Serializing TX ≈ Coarse-Grained Locks
1.14
1.04
0
100
200
300
400
500
600
700
HT-H HT-L ATM CL BH CC AP AVG
Sp
eed
up
ove
r S
eria
lizi
ng
Tx
Ideal TM
FG Lock
Performance (vs. Serializing TX)
Higher is Better

0
1
2
3
HT-H HT-L ATM CL BH CC AP
No
rma
lize
d E
xec
. T
i me
Hardware TM for GPU Architectures 17Wilson Fung, Inderpeet Singh, Andrew Brownsword, Tor Aamodt Hardware TM for GPU Architectures 17
Performance (Exec. Time)
Captures 59% of FG Lock Performance
Ideal TM
KILO TM
FG Lock
Lower is Better

Hardware TM for GPU Architectures 18Wilson Fung, Inderpeet Singh, Andrew Brownsword, Tor Aamodt Hardware TM for GPU Architectures 18
Implementation Complexity
Logs in Private Memory @ L1 Data Cache Commit Unit
5kB Last Writer History Unit 19kB Transaction Status 32kB Read-Set and Write-Set Buffer
CACTI 5.3 @ 40nm 0.40mm2 x 6 Memory Partition 0.5% of 520mm2

Hardware TM for GPU Architectures 19Wilson Fung, Inderpeet Singh, Andrew Brownsword, Tor Aamodt Hardware TM for GPU Architectures 19
Summary
KILO TM: Hardware TM for GPUs 1000s of Concurrent Scalar TXs Handles Scalar TX Abort No cache coherence protocol dependency Word-level conflict detection Unbounded Transaction 59% Fine-Grained Locking Performance
128X Faster than Serializing TX Execution 0.5% Area Overhead
Question?

Hardware TM for GPU Architectures 20Wilson Fung, Inderpeet Singh, Andrew Brownsword, Tor Aamodt Hardware TM for GPU Architectures 20
Backup Slides

Hardware TM for GPU Architectures 21
ABA Problem?
Classic Example: Linked List Based Stack
Thread 0 – pop():while (true) { t = top; Next = t->Next;
// thread 2: pop A, pop B, push A
if (atomicCAS(&top, t, next) == t) break; // succeeds!
}
top ANext
BNext
CNext Null
top ANext
CNext Null
top BNext
CNext Null
top BNext
CNext Null
Next Bt A
top CNext Null
Wilson Fung, Inderpeet Singh, Andrew Brownsword, Tor Aamodt Hardware TM for GPU Architectures 21

Hardware TM for GPU Architectures 22
ABA Problem?
atomicCAS protects only a single word Only part of the data structure
Value-based conflict detection protects all relevant parts of the data structure
top ANext
BNext
CNext Null
while (true) { t = top; Next = t->Next; if (atomicCAS(&top, t, next) == t) break; // succeeds!}
Wilson Fung, Inderpeet Singh, Andrew Brownsword, Tor Aamodt Hardware TM for GPU Architectures 22





























