Embed Size (px)
Citation preview

Handling non-determinism and incompleteness

Problems, Solutions, Success Measures:3 orthogonal dimensions
Incompleteness in the initial state Un (partial) observability of states Non-deterministic actions Uncertainty in state or effects Complex reward functions
(allowing degrees of satisfaction)
Conformant Plans: Don’t look—just do Sequences
Contingent/Conditional Plans: Look, and based on what you see, Do; look again Directed acyclic graphs
Policies: If in (belief) state S, do action a (belief) stateaction tables
Deterministic Success: Must reach goal-state with probability 1 Probabilistic Success: Must succeed with probability >= k
(0<=k<=1) Maximal Expected Reward: Maximize the expected reward (an
optimization problem)

11/8

Some specific cases
1.0 success conformant planning for domains with incomplete initial states
1.0 success conformant planning for domains with non-deterministic actions
1.0 success conditional plans for fully observable domains with incompletely specified init states, and deterministic actions
1.0 success conditional plans for fully observable domains with non-deterministic actions
1.0 success conditional plans for parially observable domains with non-deterministic actions
Probabilistic variants of all the ones on the left (where we want success probability to be >= k).

Paths to Perdition
Complexity of finding probability 1.0 success plans

Conformant Planning
Given an incomplete initial state, and a goal state, find a sequence of actions that when executed in any of the states consistent with the initial state, takes you to a goal state.
Belief State: is a set of states 2S
I as well as G are belief states (in classical planning, we already support partial goal state)
Issues: Representation of Belief States Generalizing “progression”, “regression” etc to belief states Generating effective heuristics for estimating reachability in the space of
belief states

Action Applicability Issue
Action applicability issue (what if a belief state has 100 states and an action is applicable to 90 of them?) Consider actions that are always applicable in any
state, but can leave many states unchanged. This involves modeling actions without executability
preconditions (they can have conditional effects). This ensures that the action is applicable everywhere

Generality of Belief State Rep

State Uncertainty and Actions
The size of a belief state B is the number of states in it. For a world with k fluents, the size of a belief state can be between 1 (no
uncertainty) and 2k (complete uncertainty). Actions applied to a belief state can both increase and reduce the
size of a belief state A non-deterministic action applied to a singleton belief state will lead to a
larger (more uncertain) belief state A deterministic action applied to a belief state can reduce its uncertainty
E.g. B={(pen-standing-on-table) (pen-on-ground)}; Action A is sweep the table. Effect is B’={(pen-on-ground)}
Often, a good heuristic in solving problems with large belief-state uncertainty is to do actions that reduce uncertainty
E.g. when you are blind-folded and left in the middle of a room, you try to reach the wall and then follow it to the door. Reaching the wall is a way of reducing your positional uncertainty

Progression and Regression with Belief States
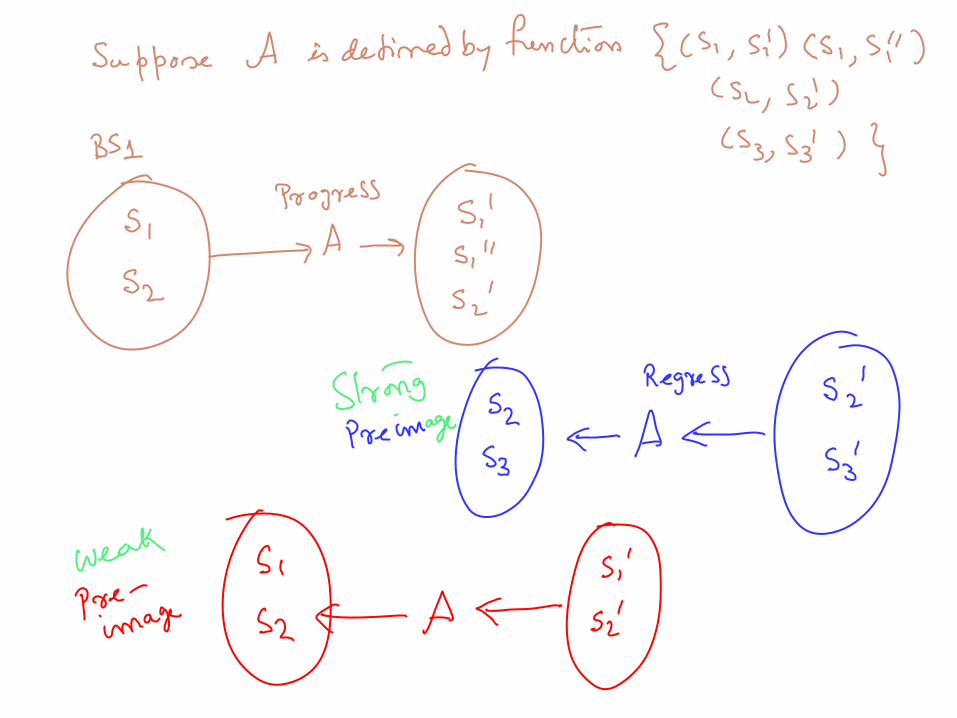
Given a belief state B, and an action a, progression of B over a is defined as long as a is applicable in every state s in B Progress(B,a) { progress(s,a) | s in B}
Given a belief state B, and an action a, regression of B over a is defined as long as a is regressable from every state s in B. Regress(B,a) { regress(s,a) | s in B} Non-deterministic actions complicate regression. Suppose an action a,
when applied to state s can take us to s1 or s2 non-deterministically. Then, what is the regression of s1 over a?
Strong and Weak pre-images: We consider B’ to be the strong pre-image of B w.r.t action a, if Progress(B’,a) is equal to B. We consider B’ to be a weak pre-image if Progress(B’,a) is a superset of B

Belief State Search
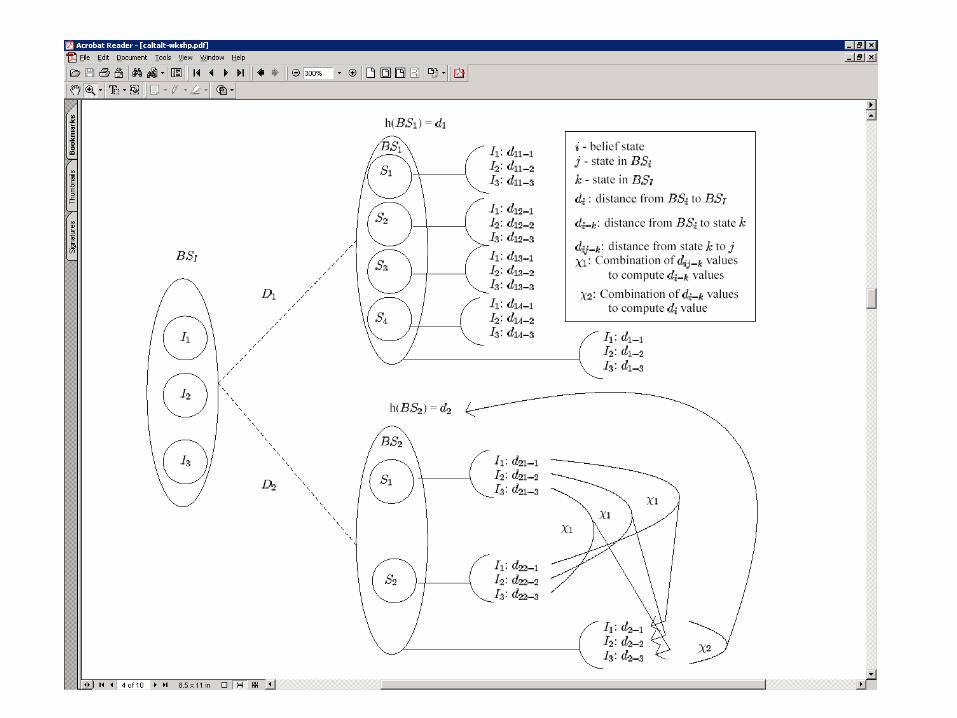
Planning problem: initial belief state BI and goal state BG and a set of actions ai – the objective is to find a sequence of actions [a1…ak] that when executed in the initial belief state takes the agent to some state in BG The plan is strong if every execution leads to a state in BG [probability of
success is 1] The plan is weak if some of the executions lead to a state in BG [probability
of success > 0 ] If we have stochastic actions, we can also talk about the “degree” of strength
of the plan [ 0 <= p <= 1] We will focus on STRONG plans
Search: Start with the initial belief state, BI and do progression or regression until you find a belief state B’ s.t. B’ is a subset of BG

Representing Belief States

Belief State Rep (cont) Belief space planners have to search in the space of full
propositional formulas!! In contrast, classical state-space planners search in the
space of interpretations (since states for classical planning were interpretations).
Several headaches: Progression/Regression will have to be done over all states
consistent with the formula (could be exponential number). Checking for repeated search states will now involve checking the
equivalence of logical formulas (aaugh..!) To handle this problem, we have to convert the belief states into some
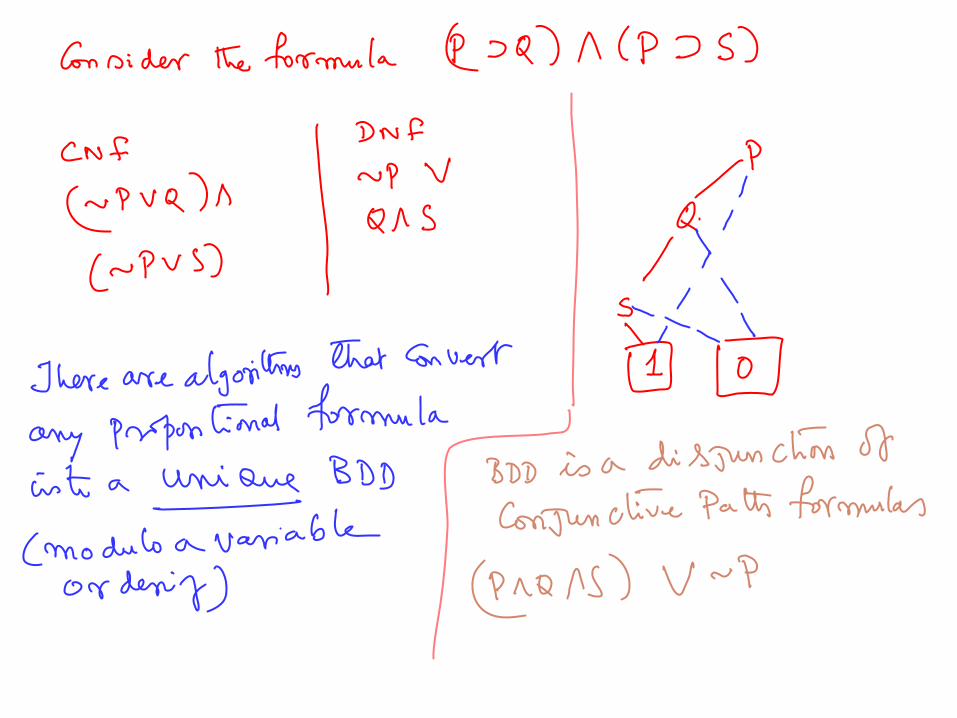
canonical representation. We already know the CNF and DNF representations. There is another one, called Ordered Binary Decision Diagrams that is both canonical and compact
OBDD can be thought of as a compact representation of the DNF version of the logical formula

Doing Progression/Regresssion Efficiently
Progression/Regression will have to be done over all states consistent with the formula (could be exponential number). One way of handling this is to restrict the type of uncertainty allowed.
For example, we may insist that every fluent must either be true, false or unknown. This will give us just the space of conjunctive logical formulas (only 3n space).
Flip side is that we may not be able to represent all forms of uncertainty (e.g. how do we say that either P or Q is true in the initial state?)
Another idea is to directly manipulate the logical formulas during progression/regression (without expanding them into states…)
Tricky… connected to “Symbolic model checking”

Effective representations of logical formulas
Checking for repeated search states will now involve checking the equivalence of logical formulas (aaugh..!) To handle this problem, we have to convert the belief states into
some canonical representation. We already know the CNF and DNF representations. These are
normal forms but are not canonical Same formula may have multiple equivalent CNF/DNF representations
There is another one, called Reduced Ordered Binary Decision Diagrams that is both canonical and compact
ROBDD can be thought of as a compact representation of the DNF version of the logical formula

Symbolic model checking: The bird’s eye view
Belief states can be represented as logical formulas (and “implemented” as BDDs )
Transition functions can be represented as 2-stage logical formulas (and implemented as BDDs)
The operation of progressing a belief state through a transition function can be done entirely (and efficiently) in terms of operations on BDDs
Read Appendix C before next class (emphasize C.5; C.6)

Conformant Planning: Efficiency Issues
Graphplan (CGP) and SAT-compilation approaches have also been tried for conformant planning Idea is to make plan in one world, and try to extend it as
needed to make it work in other worlds Planning graph based heuristics for conformant
planning have been investigated. Interesting issues involving multiple planning graphs
Deriving Heuristics? – relaxed plans that work in multiple graphs Compact representation? – Label graphs

KACMBP and Uncertainty reducing actions