Embed Size (px)
Citation preview

Oracleホワイト・ペーパー
20 10年1月
HadoopデータとOracle
パラレル処理の統合

HadoopデータとOracleパラレル処理の統合
1
はじめに
多種多様な業種において、ファイル・システムに保存されているデータが急増しています。一般的
に、このような莫大なデータには、重要度の低い大量の詳細データと、今後の分析やその他のデー
タソースの補完に役立つ多少の貴重なデータが含まれています。こういったデータがデータベース
の外部に保管されているにもかかわらず、データベース内に保管されているデータとの統合が求め
られる場合があります。このような統合における目標は、ビジネス・ユーザーにとって価値のある
情報を引き出すことです。
このホワイト・ペーパーでは、Hadoopクラスタに保管されたデータへOracleデータベースからアク
セスする方法について詳しく説明します。ここでは、HadoopとHDFSを例として取り上げています
が、その他の分散ストレージ・メカニズムに対しても、同じ方針を適用できます。このホワイト・
ペーパーでは各種のアクセス手法について説明するとともに、このような手法の具体的な実装例を
示します。

HadoopデータとOracleパラレル処理の統合
2
外部Hadoopデータに対するアクセス手法
ファイル・システム上の外部データや外部ファイルに対して、Oracleデータベース内からもっとも簡
単にアクセスするには外部表を使用します。外部表の概要については、こちらを参照してください。
外部表はファイル・システムに保管されたデータを表形式で表すものであり、SQL問合せにおいて透
過的に使用できます。したがって、外部表を使用して、Oracleデータベース内からHDFS(Hadoop File
System)に保管されたデータにアクセスすることも潜在的には可能です。ただし、残念ながら、外
部表のドライバが使用する通常のオペレーティング・システム・コールからHDFSファイルに直接ア
クセスすることはできません。このようなケースは、FUSE(File System in Userspace)プロジェクト
で回避できます。HDFSストアをマウントして通常のファイル・システムのように扱うことができる
FUSEドライバが多数提供されています。このようなドライバを使用してデータベース・インスタン
ス(RACデータベースの場合はすべてのインスタンス)にHDFSをマウントすると、外部表インフラ
ストラクチャを使用して、簡単にHDFSファイルにアクセスできます。
図1.データベース内のマップ・リデュースから外部表経由でのアクセス
図1では、この記事に説明されているとおり、Oracle Database 11gを利用してデータベース内のマップ・
リデュースが実装されています。Oracle Database 11gのパラレル実行フレームワークは、要求される
ほとんどの処理を外部表から直接パラレルで実行する能力を十分に備えています。
HadoopデータとOracleパラレル処理の統合
3
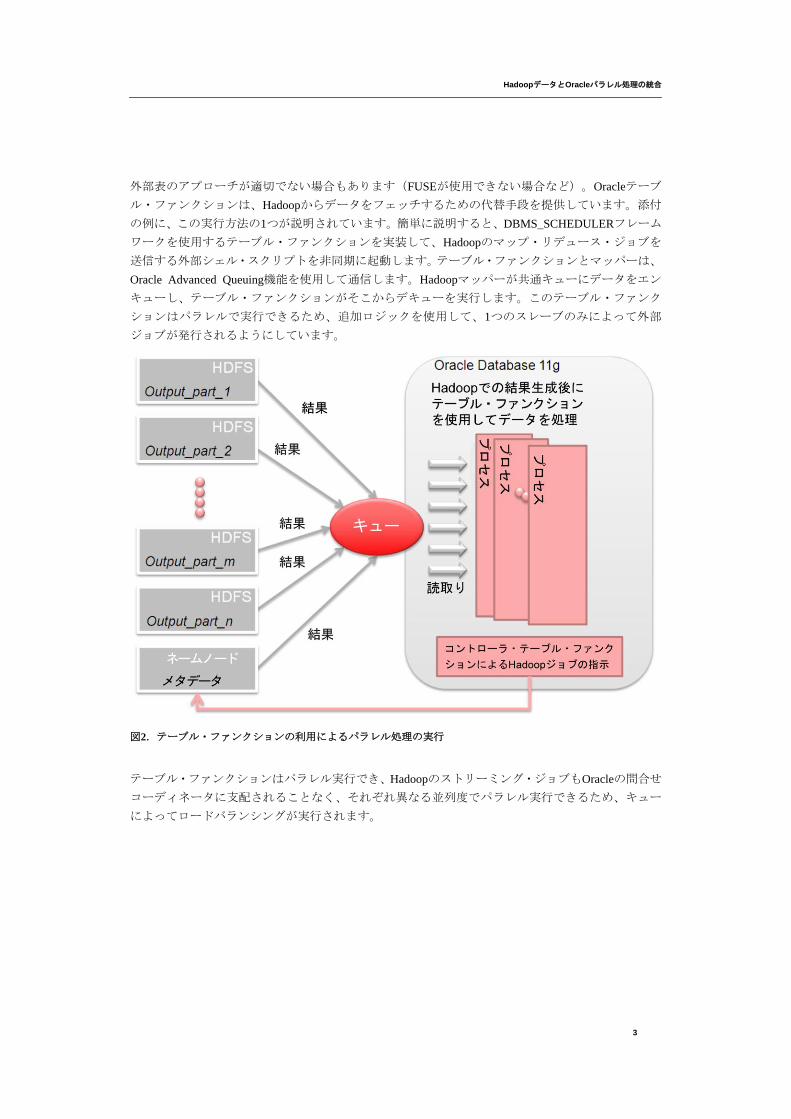
外部表のアプローチが適切でない場合もあります(FUSEが使用できない場合など)。Oracleテーブ
ル・ファンクションは、Hadoopからデータをフェッチするための代替手段を提供しています。添付
の例に、この実行方法の1つが説明されています。簡単に説明すると、DBMS_SCHEDULERフレーム
ワークを使用するテーブル・ファンクションを実装して、Hadoopのマップ・リデュース・ジョブを
送信する外部シェル・スクリプトを非同期に起動します。テーブル・ファンクションとマッパーは、
Oracle Advanced Queuing機能を使用して通信します。Hadoopマッパーが共通キューにデータをエン
キューし、テーブル・ファンクションがそこからデキューを実行します。このテーブル・ファンク
ションはパラレルで実行できるため、追加ロジックを使用して、1つのスレーブのみによって外部
ジョブが発行されるようにしています。
図2.テーブル・ファンクションの利用によるパラレル処理の実行
テーブル・ファンクションはパラレル実行でき、Hadoopのストリーミング・ジョブもOracleの問合せ
コーディネータに支配されることなく、それぞれ異なる並列度でパラレル実行できるため、キュー
によってロードバランシングが実行されます。

HadoopデータとOracleパラレル処理の統合
4
テーブル・ファンクションを利用した例
図2に示したアーキテクチャを実際の例に置き換えたものを次に示します。この例では、Hadoopに保
管されたデータへアクセスするためのテーブル・ファンクションを使用したテンプレートの実装の
みを示していることに注意してください。言うまでもなく、(より優れた)その他の実装方法も存
在します。
次の図は、図2に示した略図を技術的により正確かつ詳細に示した図であり、実際のコードをどこで、
どのように使用するかが説明されています。
図3.マッパー・ジョブの開始とデータの取得
ステップ1では、問合せコーディネータとなるものが特定されます。この例では、同じキー値を持つ
レコードを表に書き込むという単純な仕組みが使用されています。最初の挿入レコードが、プロセス
に対する問合せコーディネータ(QC)の役割を勝ち取ります。QCテーブル・ファンクションの呼出
しは、処理の役割も果たすことに注意してください。
ステップ2では、このテーブル・ファンクションの呼出し(QC)がdbms_scheduler(図3のジョブ・コ
ントローラ)を使用して、非同期ジョブを開始します。このジョブは、Hadoopクラスタ上で同期バッ
シュ・スクリプトを実行します。図3ではランチャーと呼ばれるこのバッシュ・スクリプトによって、
Hadoopクラスタでマッパー・プロセス(ステップ3)が開始されます。
HadoopデータとOracleパラレル処理の統合
5
マッパー・プロセスはデータを処理し、ステップ5でキューへの書込みを実行します。この例では、
クラスタ全体で使用できるキューが使用されています。ここでは、単純にすべての出力が直接キュー
に書き込まれていますが、出力をまとめてからキューに移動すると、より良いパフォーマンスが得
られます。言うまでもなく、パイプやリレーショナル表など、その他の各種配信メカニズムを使用
することもできます。
ステップ6は、データベース内で実行されているテーブル・ファンクションのパラレル呼出しによっ
て実行されるデキュー・プロセスです。これらのパラレル呼出しによってデータが処理されるたび
に、リクエスト元の問合せへとデータが返されます。テーブル・ファンクションはOracleデータと
キューから取得したデータの両方を利用して、2つのソースのデータを1つの結果セットに統合して
エンドユーザーに返します。
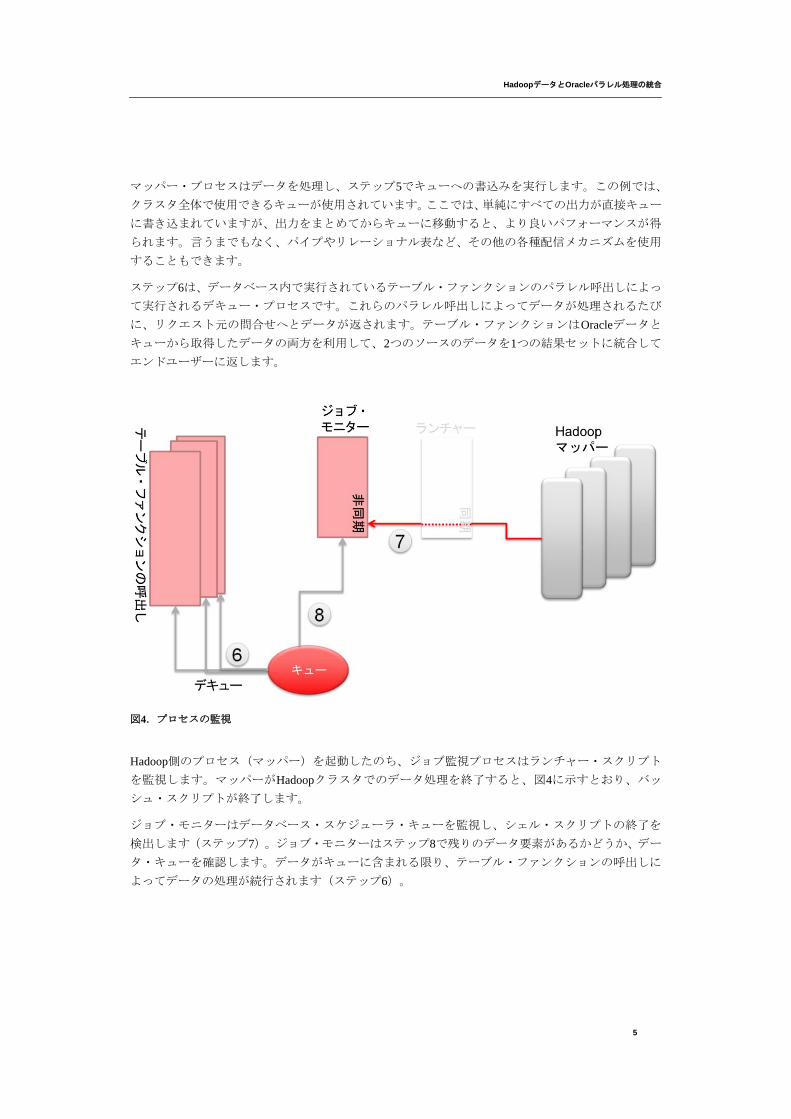
図4.プロセスの監視
Hadoop側のプロセス(マッパー)を起動したのち、ジョブ監視プロセスはランチャー・スクリプト
を監視します。マッパーがHadoopクラスタでのデータ処理を終了すると、図4に示すとおり、バッ
シュ・スクリプトが終了します。
ジョブ・モニターはデータベース・スケジューラ・キューを監視し、シェル・スクリプトの終了を
検出します(ステップ7)。ジョブ・モニターはステップ8で残りのデータ要素があるかどうか、デー
タ・キューを確認します。データがキューに含まれる限り、テーブル・ファンクションの呼出しに
よってデータの処理が続行されます(ステップ6)。

HadoopデータとOracleパラレル処理の統合
6
図5.プロセスの終了
テーブル・ファンクションのパラレル呼出しによってすべてのキューに対するデキューが完了する
と、ジョブ・モニターによってキューが終了され(図5のステップ9)、Oracleデータベースでのテー
ブル・ファンクション呼出しが停止します。この時点で、すべてのデータがリクエスト元の問合せ
に渡されています。

HadoopデータとOracleパラレル処理の統合
7
サンプル・コード
図3から図5で実装されたソリューションでは、次のコードが使用されました。すべてのコードは、
Oracle Database 11gと5ノードのHadoopクラスタを使用してテストされました。通常のホワイト・ペー
パーと同じように、これらのスクリプトをテキスト・エディタにコピーし、書式が正しいことを確
認してください。
データ処理向けのテーブル・ファンクション
このスクリプトには、セットアップ・コンポーネントが含まれています。たとえば、スクリプトの
最初の部分には、図3のステップ1に示した仲裁表の作成が含まれています。この例では、一般的な
OEスキーマが使用されています。
connect oe/oe
-- Table to use as locking mechanisim for the hdfs reader as
-- leveraged in Figure 3 step 1
DROP TABLE run_hdfs_read;
CREATE TABLE run_hdfs_read(pk_id number, status varchar2(100),
primary key (pk_id));
-- Object type used for AQ that receives the data
CREATE OR REPLACE TYPE hadoop_row_obj AS OBJECT (
a number,
b number);
/
connect / as sysdba
-- system job to launch external script
-- this job is used to eventually run the bash script
-- described in Figure 3 step 3
CREATE OR REPLACE PROCEDURE launch_hadoop_job_async(in_directory
IN VARCHAR2, id number) IS
cnt number;
BEGIN
begin DBMS_SCHEDULER.DROP_JOB ('ExtScript'||id, TRUE);

HadoopデータとOracleパラレル処理の統合
8
exception when others then null; end;
-- Run a script
DBMS_SCHEDULER.CREATE_JOB (
job_name => 'ExtScript' || id,
job_type => 'EXECUTABLE',
job_action => '/bin/bash',
number_of_arguments => 1
);
DBMS_SCHEDULER.SET_JOB_ARGUMENT_VALUE ('ExtScript' || id, 1,
in_directory);
DBMS_SCHEDULER.ENABLE('ExtScript' || id);
-- Wait till the job is done. This ensures the hadoop job is
completed
loop
select count(*) into cnt
from DBA_SCHEDULER_JOBS where job_name = 'EXTSCRIPT'||id;
dbms_output.put_line('Scheduler Count is '||cnt);
if (cnt = 0) then
exit;
else
dbms_lock.sleep(5);
end if;
end loop;
-- Wait till the queue is empty and then drop it
-- as shown in Figure 5
-- The TF will get an exception and it will finish quietly
loop

HadoopデータとOracleパラレル処理の統合
9
select sum(c) into cnt
from
(
select enqueued_msgs - dequeued_msgs c
from gv$persistent_queues where queue_name =
'HADOOP_MR_QUEUE'
union all
select num_msgs+spill_msgs c
from gv$buffered_queues where queue_name =
'HADOOP_MR_QUEUE'
union all
select 0 c from dual
);
if (cnt = 0) then
-- Queue is done. stop it.
DBMS_AQADM.STOP_QUEUE ('HADOOP_MR_QUEUE');
DBMS_AQADM.DROP_QUEUE ('HADOOP_MR_QUEUE');
return;
else
-- Wait for a while
dbms_lock.sleep(5);
end if;
end loop;
END;
/
-- Grants needed to make hadoop reader package work
grant execute on launch_hadoop_job_async to oe;

HadoopデータとOracleパラレル処理の統合
10
grant select on v_$session to oe;
grant select on v_$instance to oe;
grant select on v_$px_process to oe;
grant execute on dbms_aqadm to oe;
grant execute on dbms_aq to oe;
connect oe/oe
-- Simple reader package to read a file containing two numbers
CREATE OR REPLACE PACKAGE hdfs_reader IS
-- Return type of pl/sql table function
TYPE return_rows_t IS TABLE OF hadoop_row_obj;
-- Checks if current invocation is serial
FUNCTION is_serial RETURN BOOLEAN;
-- Function to actually launch a Hadoop job
FUNCTION launch_hadoop_job(in_directory IN VARCHAR2, id in out
number) RETURN BOOLEAN;
-- Tf to read from Hadoop
-- This is the main processing code reading from the queue in
-- Figure 3 step 6. It also contains the code to insert into
-- the table in Figure 3 step 1
FUNCTION read_from_hdfs_file(pcur IN SYS_REFCURSOR, in_directory
IN VARCHAR2) RETURN return_rows_t
PIPELINED PARALLEL_ENABLE(PARTITION pcur BY ANY);
END;
/

HadoopデータとOracleパラレル処理の統合
11
CREATE OR REPLACE PACKAGE BODY hdfs_reader IS
-- Checks if current process is a px_process
FUNCTION is_serial RETURN BOOLEAN IS
c NUMBER;
BEGIN
SELECT COUNT (*) into c FROM v$px_process WHERE sid =
SYS_CONTEXT('USERENV','SESSIONID');
IF c <> 0 THEN
RETURN false;
ELSE
RETURN true;
END IF;
exception when others then
RAISE;
END;
FUNCTION launch_hadoop_job(in_directory IN VARCHAR2, id IN OUT
NUMBER) RETURN BOOLEAN IS
PRAGMA AUTONOMOUS_TRANSACTION;
instance_id NUMBER;
jname varchar2(4000);
BEGIN
if is_serial then
-- Get id by mixing instance # and session id
id := SYS_CONTEXT('USERENV', 'SESSIONID');
SELECT instance_number INTO instance_id FROM v$instance;
id := instance_id * 100000 + id;
else
-- Get id of the QC

HadoopデータとOracleパラレル処理の統合
12
SELECT ownerid into id from v$session where sid =
SYS_CONTEXT('USERENV', 'SESSIONID');
end if;
-- Create a row to 'lock' it so only one person does the job
-- schedule. Everyone else will get an exception
-- This is in Figure 3 step 1
INSERT INTO run_hdfs_read VALUES(id, 'RUNNING');
jname := 'Launch_hadoop_job_async';
-- Launch a job to start the hadoop job
DBMS_SCHEDULER.CREATE_JOB (
job_name => jname,
job_type => 'STORED_PROCEDURE',
job_action => 'sys.launch_hadoop_job_async',
number_of_arguments => 2
);
DBMS_SCHEDULER.SET_JOB_ARGUMENT_VALUE (jname, 1, in_directory);
DBMS_SCHEDULER.SET_JOB_ARGUMENT_VALUE (jname, 2, CAST (id AS
VARCHAR2));
DBMS_SCHEDULER.ENABLE('Launch_hadoop_job_async');
COMMIT;
RETURN true;
EXCEPTION
-- one of my siblings launched the job. Get out quitely
WHEN dup_val_on_index THEN
dbms_output.put_line('dup value exception');
RETURN false;
WHEN OTHERs THEN
RAISE;
END;

HadoopデータとOracleパラレル処理の統合
13
FUNCTION read_from_hdfs_file(pcur IN SYS_REFCURSOR, in_directory
IN VARCHAR2) RETURN return_rows_t
PIPELINED PARALLEL_ENABLE(PARTITION pcur BY ANY)
IS
PRAGMA AUTONOMOUS_TRANSACTION;
cleanup BOOLEAN;
payload hadoop_row_obj;
id NUMBER;
dopt dbms_aq.dequeue_options_t;
mprop dbms_aq.message_properties_t;
msgid raw(100);
BEGIN
-- Launch a job to kick off the hadoop job
cleanup := launch_hadoop_job(in_directory, id);
dopt.visibility := DBMS_AQ.IMMEDIATE;
dopt.delivery_mode := DBMS_AQ.BUFFERED;
loop
payload := NULL;
-- Get next row
DBMS_AQ.DEQUEUE('HADOOP_MR_QUEUE', dopt, mprop, payload,
msgid);
commit;
pipe row(payload);
end loop;
exception when others then
if cleanup then
delete run_hdfs_read where pk_id = id;
commit;
end if;

HadoopデータとOracleパラレル処理の統合
14
END;
END;
/
バッシュ・スクリプト
この短いスクリプトは、図3のステップ3および4に示したとおり、データベース外のコントローラです。
これは、Hadoopマッパーが実行されている限りシステム上に残る同期ステップです。
#!/bin/bash
cd -HADOOP_HOME-
A="/net/scratch/java/jdk1.6.0_16/bin/java -classpath
/home/hadoop:/home/hadoop/ojdbc6.jar StreamingEq"
bin/hadoop fs -rmr output
bin/hadoop jar ./contrib/streaming/hadoop-0.20.0-streaming.jar -
input input/nolist.txt -output output -mapper "$A" -jobconf
mapred.reduce.tasks=0
Javaマッパー・スクリプト
この例では、Hadoopクラスタ上で実行されるマッパー・プロセスとして、小さく単純なプロセスを
作成していますが、もちろん、より総合的なマッパーを作成することも可能です。このプロセスは
文字列を2つの数字に変換し、これらの数字を1行ごとにキューに書込みます。
// Simplified mapper example for Hadoop cluster
import java.sql.*;
//import oracle.jdbc.*;
//import oracle.sql.*;
import oracle.jdbc.pool.*;
//import java.util.Arrays;
//import oracle.sql.ARRAY;
//import oracle.sql.ArrayDescriptor;

HadoopデータとOracleパラレル処理の統合
15
public class StreamingEq {
public static void main (String args[]) throws Exception
{
// connect through driver
OracleDataSource ods = new OracleDataSource();
Connection conn = null;
Statement stmt = null;
ResultSet rset = null;
java.io.BufferedReader stdin;
String line;
int countArr = 0, i;
oracle.sql.ARRAY sqlArray;
oracle.sql.ArrayDescriptor arrDesc;
try {
ods.setURL("jdbc:oracle:thin:oe/oe@$ORACLE_INSTANCE
");
conn = ods.getConnection();
}
catch (Exception e){
System.out.println("Got exception " + e);
iif (rset != null) rset.close();
iif (conn != null) conn.close();
System.exit(0);
return ;
}
System.out.println("connection works conn " + conn);
stdin = new java.io.BufferedReader(new
java.io.InputStreamReader(System.in));

HadoopデータとOracleパラレル処理の統合
16
String query = "declare dopt
dbms_aq.enqueue_options_t; mprop dbms_aq.message_properties_t;
msgid raw(100); begin dopt.visibility := DBMS_AQ.IMMEDIATE;
dopt.delivery_mode := DBMS_AQ.BUFFERED;
dbms_Aq.enqueue('HADOOP_MR_QUEUE', dopt, mprop, hadoop_row_obj(?,
?), msgid); commit; end;";
CallableStatement pstmt = null;
try {
pstmt = conn.prepareCall(query);
}
catch (Exception e){
System.out.println("Got exception " + e);
if (rset != null) rset.close();
if (conn != null) conn.close();
}
while ((line = stdin.readLine()) != null) {
if (line.replaceAll(" ", "").length() < 2)
continue;
String [] data = line.split(",");
if (data.length != 2)
continue;
countArr++;
pstmt.setInt(1, Integer.parseInt(data[0]));
pstmt.setInt(2, Integer.parseInt(data[1]));
pstmt.executeUpdate();
}
if (conn != null) conn.close();
System.exit(0);
return;
}

HadoopデータとOracleパラレル処理の統合
17
}
データ要求問合せ
テーブル・ファンクション処理を利用した上述のシステムでselectを実行する例を次に示します。
-- Set up phase for the data queue
execute DBMS_AQADM.CREATE_QUEUE_TABLE('HADOOP_MR_QUEUE',
'HADOOP_ROW_OBJ');
execute DBMS_AQADM.CREATE_QUEUE('HADOOP_MR_QUEUE',
'HADOOP_MR_QUEUE');
execute DBMS_AQADM.START_QUEUE ('HADOOP_MR_QUEUE');
-- Query being executed by an end user or BI tool
-- Note the hint is not a real hint, but a comment
-- to clarify why we use the cursor
select max(a), avg(b)
from table(hdfs_reader.read_from_hdfs_file
(cursor
(select /*+ FAKE cursor to kick start parallelism */ *
from orders), '/home/hadoop/eq_test4.sh'));

HadoopデータとOracleパラレル処理の統合
18
結論
このホワイト・ペーパーでは簡単な例を使用して、HadoopシステムとOracle Database 11gの統合が簡
単に実行できることを示しました。
本書で説明したアプローチを採用すると、HadoopからOracle問合せに対してデータを直接ストリーミ
ングできます。これによって、ローカル・ファイル・システムへのデータ・フェッチとOracle表への
マテリアライズを実行することなく、SQL問合せにアクセスすることが可能になります。

HadoopデータとOracle
パラレル処理の統合
2010年1月
著者:Shinkanth Shanker、Alan Choi、
Jean-Pierre Dijcks
Oracle Corporation
World Headquarters
500 Oracle Parkway
Redwood Shores, CA 94065
U.S.A.
海外からのお問い合わせ窓口:
電話:+1.650.506.7000
ファクシミリ:+1.650.506.7200
oracle.com
Copyright © 2010, Oracle and/or its affiliates. All rights reserved.
本文書は情報提供のみを目的として提供されており、ここに記載される内容は予告なく変更されることがあります。本文書は一切間違
いがないことを保証するものではなく、さらに、口述による明示または法律による黙示を問わず、特定の目的に対する商品性もしくは
適合性についての黙示的な保証を含み、いかなる他の保証や条件も提供するものではありません。オラクルは本文書に関するいかなる
法的責任も明確に否認し、本文書によって直接的または間接的に確立される契約義務はないものとします。本文書はオラクル社の書面
による許可を前もって得ることなく、いかなる目的のためにも、電子または印刷を含むいかなる形式や手段によっても再作成または送
信することはできません。
Oracleは米国Oracle Corporationおよびその子会社、関連会社の登録商標です。その他の名称はそれぞれの会社の商標です。
0109


![サンプル版 初めての TableauはじめてのTableau 5 [データ ソース] ページが開きます。 左側のペインに Tableau Desktop が接続しているデータの詳細が表示されます。](https://img.pdfslide.us/doc/110x75/5e7124e28ec64c70e92b2b99/fffc-tableau-tableau-5-ff-f.jpg)


























