Embed Size (px)
Citation preview

Hadoop as a Service
Boston Azure / Microsoft DevBoston07-Feb-2012
Copyright (c) 2011, Bill Wilder – Use allowed under Creative Commons license http://creativecommons.org/licenses/by-nc-sa/3.0/
Boston Azure User Grouphttp://www.bostonazure.org@bostonazure
Bill Wilderhttp://blog.codingoutloud.com@codingoutloud
Big Data tools for the Windows Azure cloud platform
Windows Azure MVP
Windows Azure Consultant
Boston Azure User Group Founder
Cloud Architecture Patterns book (due 2012)
Bill Wilder

We will consider…
1. How might we build a simple Word Frequency Counter?
2. What are Map and Reduce?3. How do we scale our Word Frequency
Counter?– Hint: we might use Hadoop
4. How does Windows Azure make Hadoop easier with “Hadoop as a Service”
– CTP

Five exabytes of data created
every two days- Eric Schmidt
(CEO Google at the time)
As much as from the dawn of civilization up until 2003

Three Vs• Volume lots of it already• Velocity more of it every day• Variety many sources, many formats
“Big Data” Challenge

Short History of Hadoop //////
1. Inspired by:• Google Map/Reduce paper
– http://research.google.com/archive/mapreduce.html • Google File System (GFS)
– Goals: distributed, fault tolerant, fast enough
2. Born in: Lucene Nutch project• Built in Java• Hadoop cluster appears as single über-
machine

Hadoop: batch processing, big data
• Batch, not real-time or transactional• Scale out with commodity hardware• Big customers like LinkedIn and Yahoo!
– Clusters with 10s of Petabytes • (pssst… these fail… daily)
• Import data from Azure Blob, Data Market , S3– Or from files, like we will do in our example

Word Frequency Counter – how?
• The “hello world” of Hadoop / MapReduce– But we start without Hadoop / MapReduce
• Input: large corpus– Wikipedia extract for example – Can handle into PB
• Output: list of words, ordered by frequencythe 31415 be 9265 to 3589 of 793 and 238 … …

Simple Word Frequency Counter
const string file = @"e:\dev\azure\hadoop\wordcount\davinci.txt";var text = File.ReadAllText(file);
var matches = Regex.Matches(text, @"\b[\w]*\b");var words = (from m in matches.Cast<Match>() where !string.IsNullOrEmpty(m.Value) orderby m.Value.ToLower() select m.Value.ToLower()).ToArray();
var wordCounts = new Dictionary<string, int>();foreach (var word in words){ if (wordCounts.ContainsKey(word)) wordCounts[word]++; else wordCounts.Add(word, 1);}
foreach (var wc in wordCounts) Console.WriteLine(wc.Key + " : " + wc.Value);
Read in all text
Parse out words
Normalize & Sort
How many times does each word appear
aware : 7away : 99
awning : 2awoke : 1axes : 16
axil : 3axiom : 2
Output REDUCEMAP

Map
“Apply a function to each element in this list and return a new list”
Reduce
“Apply a function collectively to all elements in this list and return the final answer.”

Map Example 1square(x) { return x*x }{ 1, 2, 3, 4 } { 1, 4, 9, 16 }
Reduce Example 1
sum(x, y) { return x + y }{ 1, 2, 3, 4 } 10

Map Example 1square(x) { return x*x }{ 1, 2, 3, 4 } { 1, 4, 9, 16 }{ square(1), square(2), square(3), square(4) }
Reduce Example 1
sum(x, y) { return x + y }{ 1, 2, 3, 4 } 10sum(sum(sum(1,2),3),4)

Map Example 2
strlen(s) { return s.Length }{ “Celtics”, “Bruins” } { 7, 6 }
Reduce Example 2
strlen_sum(x, y) { return x.Length + y.Length }{ “Celtics”, “Bruins” } 13

Map Example 3 (the fancy one)
fancy_mapper(s) { if (s == “SkipMe”) return null; return ToLower(s) + “, “ + s.Length; }
{ “Will”, “Dan”, “SkipMe”, “Kevin”, “T.J.” } { “will, 4”, “dan, 3”, “kevin, 5”, “t.j., 4” }

Problems with Word Counter?
What happens if our data is…• 1 GB, 1 TB, 1 PB, …
What happens if our data is…• Images, videos, tweets, Facebook updates, …
What happens if our processing is…• Complex, multiple steps, …

Simplified Example
• Word Frequency Counter• Which word appears most frequently, and
how many times?

Workflow
1.Setup2.Map
3. Shuffle4. Reduce
5.Celebrate
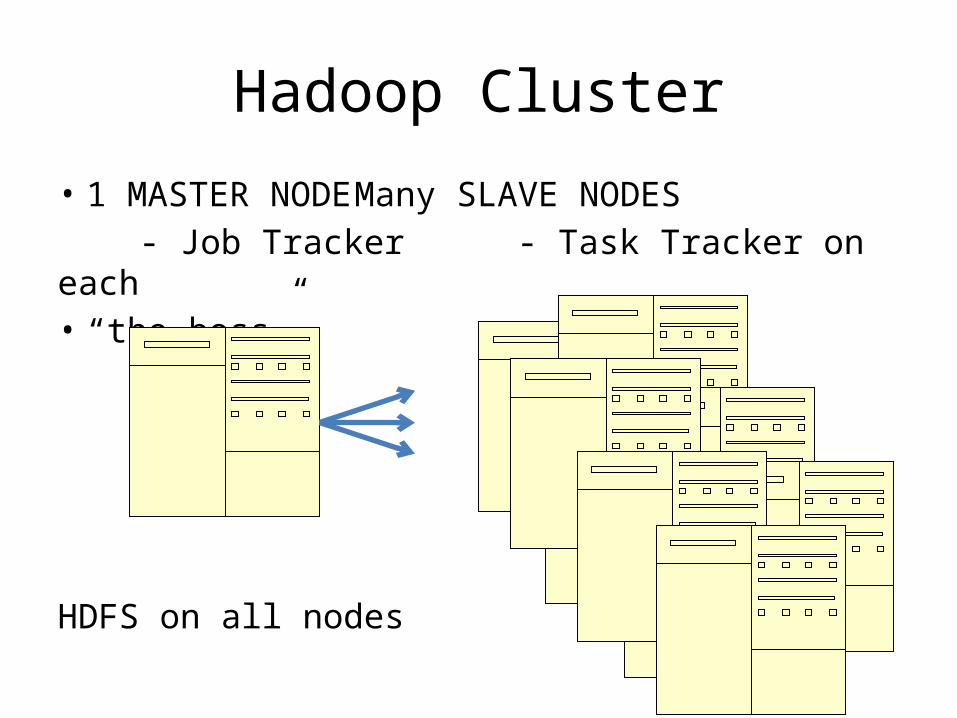
Hadoop Cluster
• 1 MASTER NODE Many SLAVE NODES - Job Tracker - Task Tracker on each• “the boss”
HDFS on all nodes

Step 1. Setup
(Assumes: you’ve installed Hadoop on a cluster of computers)
You supply:1. Map and Reduce logic
– This is “code” – packaged in a Java JAR file– Other language support exists, more coming
2. A big pile of input files– “Get the data here”– For Word Frequency Counter, we might use
Wikipedia or Project Gutenberg files
3. Go!

Step 2. Map
• Job Tracker distributes your Mapper and Reducer– To every node
• Job Tracker distributes your data– To some nodes (at least 3) in 64 MB chunks
• Task Tracker on each node calls Mapper– Repeatedly until done; lots of parallelism
• Job Tracker watches for problems– Manages retries, failures, optimistic attempts

Mapper’s Job is Simple*
• Read input, write output – that’s all– Function signature: Map(text) – Parses the text and returns { key, value }– Map(“a b a foo”) returns {a, 1}, {b, 1}, {a, 1}, {foo,
1}
* for Word Frequency Counter!

Actual Java Map Function
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException{ StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, “1”); }}

Step 3. Shuffle
• Shuffle collects all data from Map, organizes by key, and redistributes data to the nodes for Reduce

Step 3. Shuffle – example
• Mapper input:“the Bruins are the best in the NHL”
• Mapper output:{ the, 1 } { the, 1 } { the, 1 }{ Bruins, 1 } { best, 1 } { NHL, 1 }{ are, 1 } { in, 1 }
• Shuffle transforms this into Reducer input:{ are, [ 1 ] } { in, [ 1 ] } { Bruins,
[ 1 ] }{ best, [ 1 ] } { the, [ 1, 1, 1 ] } { NHL, [ 1 ] }

Step 4. Reduce
• Output from Step 3. Shuffle has been distributed to datanodes
• Your “Reducer” is called on local data– Repeatedly, until all complete– Tasks run in parallel on nodes
• This is very simple for Word Frequency Counter! – Function signature:
Reduce(key, values[]) – Adds up all the values and returns { key, sum }

Actual Java Reduce Functionpublic void reduce( Text key,
Iterable<IntWritable> values, Context context
) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); }}

Step 5. Celebrate!
• You are done – you have your output• In more complex scenario, might repeat
– Hadoop tool ecosystem knows how to do this• There are other projects in the Hadoop
ecosystem for …– Multi-step jobs– Managing a data warehouse – Supporting ad hoc querying – And more!

www.hadooponazure.com
demo

There’s a LOT MORE to the Hadoops…
• Hadoop streaming interface allows other languages– C#
• HIVE (HiveQL)• Pig (Pig Latin language)• Cascading.org• Commercial companies dedicated:
– HortonWorks

Questions?Comments?
More information?
?





























