Embed Size (px)
Citation preview

Graph Neural Networks
Alejandro RibeiroElectrical and Systems Engineering, University of Pennsylvania
Thanks: Joan Bruna, Luiz Chamon, Fernando Gama, Daniel Lee, Antonio Garcia Marques,Mark Eisen, Elvin Isufi, Vijay Kumar, Geert Leus, George Pappas, Jimmy Paulos,Luana Ruiz, Kate Tolstaya, Clark Zhang
Support: ARO W911NF1710438, Intel ISTC-WAS,NSF CCF 1717120, ARL DCIST CRA W911NF-17-2-0181
June 7, 2019
A. Ribeiro Graph Neural Networks 1/49

Machine Learning for Graph Signals
Machine Learning for Graph Signals
Authorship Attribution
Learning Decentralized Controllers in Distributed Systems
Learning Optimal Resource Allocations in Wireless Communications Networks
Invariance and Stability Properties of Graph Neural Networks
Concluding Remarks
A. Ribeiro Graph Neural Networks 2/49

Machine Learning for Everything
I The promise of Machine Learning is boundless. Should we use it to solve everything?
I Machine Learning (ML) is a set of tools for solving optimization problems with data
⇒ Other names for ML are regression, pattern recognition, or statistical signal processing
I Thus, the use of ML is justified when models are unavailable or inaccurate
I Or when they are too complex so we are better off using them as generators of simulated data
A. Ribeiro Graph Neural Networks 3/49

Machine Learning for Everything
I The promise of Machine Learning is boundless. Should we use it to solve everything?
A. Ribeiro Graph Neural Networks 4/49

Machine Learning for Everything
I The promise of Machine Learning is boundless. Can we use it to solve everything?
A. Ribeiro Graph Neural Networks 5/49

Machine Learning for Everything
I The promise of Machine Learning is boundless. Can we use it to solve everything?
I In 2019 Machine Learning ≡ Deep Learning ≡ Convolutional Neural Networks (CNNs)
⇒ If they rely on convolutions, we expect CNNs to work for Euclidean signals only (time, images)
⇒ Recent remarkable successes of Neural Networks are for image and speech processing, indeed
I Fully connected neural networks do not scale. They work for small scale problems only
I In fact, no ML method works in high dimensions if we can’t exploit signal structure
A. Ribeiro Graph Neural Networks 6/49

Machine Learning on Graphs
I Graphs are generic models of structure that can help to learn in several practical problems
I There is overwhelming empirical and theoretical justification to choose a neural network (NN)
I Challenge is we want to run a NN over this
I But one of the central purposes of graph signal processing is to generalize convolutions to graphs
⇒ Compose graph filters with pointwise nonlinearities ⇒ (convolutional) graph neural network (GNN)
A. Ribeiro Graph Neural Networks 7/49

Machine Learning on Graphs
I Graphs are generic models of structure that can help to learn in several practical problems
I There is overwhelming empirical and theoretical justification to choose a neural network (NN)
I Challenge is we want to run a NN over this I And we are good at running NNs over this
I But one of the central purposes of graph signal processing is to generalize convolutions to graphs
⇒ Compose graph filters with pointwise nonlinearities ⇒ (convolutional) graph neural network (GNN)
A. Ribeiro Graph Neural Networks 7/49

Machine Learning on Graphs
I Graphs are generic models of structure that can help to learn in several practical problems
I There is overwhelming empirical and theoretical justification to choose a neural network (NN)
I Challenge is we want to run a NN over this I And we are good at running NNs over this
I But one of the central purposes of graph signal processing is to generalize convolutions to graphs
⇒ Compose graph filters with pointwise nonlinearities ⇒ (convolutional) graph neural network (GNN)
A. Ribeiro Graph Neural Networks 7/49

Authorship Attribution
Machine Learning for Graph Signals
Authorship Attribution
Learning Decentralized Controllers in Distributed Systems
Learning Optimal Resource Allocations in Wireless Communications Networks
Invariance and Stability Properties of Graph Neural Networks
Concluding Remarks
A. Ribeiro Graph Neural Networks 8/49

Authorship Attribution with Word Adjacency Networks
I Function words are those that don’t carry meaning
I Their use depends on the language’s grammar
I Different authors use slightly different grammar
I Capture with a word adjacency network (WAN)
⇒ How often pairs of works appear together
Segarra-Eisen-Ribeiro, Authorship Attribution through Function
Word Adjacency Networks, TSP 2015
abitcoupleaboardaboutaboveabsentaccordingaccordinglyacrossafteragainstaheadalbeitallalongalongside
althoughamidamidst
amongamongst
anandanother
anyan
ybod
y
anyo
ne
anyt
hing
arou
nd
asasid
e
astra
ddle
astri
de
ataway
bar
barr
ing
beca
use
befo
re
behi
nd
belo
wbe
neat
h
besi
debe
side
sbe
twee
nbe
yond
both
but
bycan
cert
ain
circ
acl
ose
conc
erni
ngco
nseq
uent
lyco
nsid
erin
gco
uld
dare
desp
itedo
wn
due
durin
gea
chei
ther
enou
ghev
ery
ever
ybod
yev
eryo
neev
eryt
hing
exce
ptex
clud
ing
failin
gfe
wfe
wer
follo
wing
for
from
given
heap
s
henc
e
howev
er
ifinspite
view
including
inside
instead
intoititsitselflesslikelittleloadslotsmanymaymightminusmoremostmuchmustnearneedneither nevertheless next no
nobody none nor nothing notwithstandingof off on once one onto opposite
or other oughtour out outside
over part past
pending
per pertaining
plenty
plusregarding
respecting
round
savesaving
several
shallshould
similar
sinceso som
esom
ebody
something
suchthanthatthethemthem
selvesthenthencethereforethesetheythisthothosethoughthroughthroughoutthrutillto tow
ardtow
ardsunder
underneath
unlessunlike
untilunto
upupon
usused
various
versus
viawanting
what
whatever
when
whenever
where
whereas
wherever
whether
which
whichever
whilewhilstwhowhoever
whomwhomever
whosewillwithwithinwithoutwouldyet
A. Ribeiro Graph Neural Networks 9/49

Authorship Attribution with Word Adjacency Networks
I Function words are those that don’t carry meaning
I Their use depends on the language’s grammar
I Different authors use slightly different grammar
I Capture with a word adjacency network (WAN)
⇒ How often pairs of works appear together
Segarra-Eisen-Ribeiro, Authorship Attribution through Function
Word Adjacency Networks, TSP 2015
a
aboard
about
all
and
anotherany
arou
ndas
at
awaybu
tbydesp
ite
eith
er
for
from
if
in
it
like
little
may
more
much
neither
no
nor
nothing
of
on
one
or
our
out
round shall so such
than
that
the
then
they
this
those
to
up
upon
us
what
will
with
yet
A. Ribeiro Graph Neural Networks 9/49

Authorship Attribution with Word Adjacency Networks
I Function words are those that don’t carry meaning
I Their use depends on the language’s grammar
I Different authors use slightly different grammar
I Capture with a word adjacency network (WAN)
⇒ How often pairs of works appear together
Segarra-Eisen-Ribeiro, Authorship Attribution through Function
Word Adjacency Networks, TSP 2015
a
aboard
aboutagainst
all
alongan
andanotherany
aroundas
asid
eat
awaybo
thbutbyca
ndesp
ite
dow
n
each
eith
er
enou
gh
for
from
henc
eif
in
into
itlik
elitt
le
man
y
may
might
more
most
much
must
neither
next
no
none
nor
nothing
of
on
onceone
orother our
outround shall should
so
some
such than that
the them
then
thence
therefore
these
they
this
thosethrough
to
untilunto
upupon
us
what
when
where
whether
which
while
will
with
would
yet
A. Ribeiro Graph Neural Networks 9/49

Henry the VI is a Collaborative Effort by Shakespeare and Marlowe
I Shakespeare’s and Marlowe’s WANs are sufficiently different to ascertain their collaboration in Henry VI
aaboutafteragainstallalong
amongamongstanand
anotheranyasasid
eatawayba
rbeca
use
befo
re
beyo
nd
bothbu
tbycanclos
e
cons
eque
ntly
dare
desp
ite
dow
n
due
each
eith
eren
ough
ever
yex
cept
few
for
from
heap
she
nce
how
ever
ifinspite
insi
dein
toit
its
like
little
lots
many
may
might
more
most
much
must
near
neither
next
nononenornothingofononceoneopposite or
other ourout
outside part past plenty regardinground saving
shall
should
since
so some
such
than
that
the them
themselves
thenthence
therefore
thesetheythisthosethroughthroughouttill
totow
ardtow
ardsunder
underneathunless
untilunto
upupon
usused
what
when
where
whether
which
while
who
whom
whose
willwithwithinwouldyet
aaboutafteragainstallalong
amongamongstanand
anotheranyasasid
eatawayba
rbeca
use
befo
re
beyo
nd
bothbu
tbycanclos
e
cons
eque
ntly
dare
desp
ite
dow
n
due
each
eith
eren
ough
ever
yex
cept
few
for
from
heap
she
nce
how
ever
ifinspite
insi
dein
toit
its
like
little
lots
many
may
might
more
most
much
must
near
neither
next
nononenornothingofononceoneopposite or
other ourout
outside part past plenty regardinground saving
shall
should
since
so some
such
than
that
the them
themselves
thenthence
therefore
thesetheythisthosethroughthroughouttill
totow
ardtow
ardsunder
underneathunless
untilunto
upupon
usused
what
when
where
whether
which
while
who
whom
whose
willwithwithinwouldyet
Segarra-Eisen-Egan-Ribeiro, Attributing the Authorship of the Henry VI Plays by Word Adjacency, Shakespeare Quarterly 2016
A. Ribeiro Graph Neural Networks 10/49

Henry the VI is a Collaborative Effort by Shakespeare and Marlowe
I Shakespeare’s and Marlowe’s WANs are sufficiently different to ascertain their collaboration in Henry VI
a
about
all
along
and
as
bar
but
by
clos
edesp
ite
dow
n
exce
pt
for
from
heap
s
henc
e
in
it
like
man
y
may
more
much
neither
no
none
nor
of
on
or
our
out
roundshall
so
such than that the themselves
then
thence
this
throughoutto
towards
underneathuntil
unto
upon
us
while
will
with
a
about
all
along
and
as
bar
but
by
clos
edesp
ite
dow
n
exce
pt
for
from
heap
s
henc
e
in
it
like
man
y
may
more
much
neither
no
none
nor
of
on
or
our
out
roundshall
so
such than that the themselves
then
thence
this
throughoutto
towards
underneathuntil
unto
upon
us
while
will
with
Segarra-Eisen-Egan-Ribeiro, Attributing the Authorship of the Henry VI Plays by Word Adjacency, Shakespeare Quarterly 2016
A. Ribeiro Graph Neural Networks 10/49
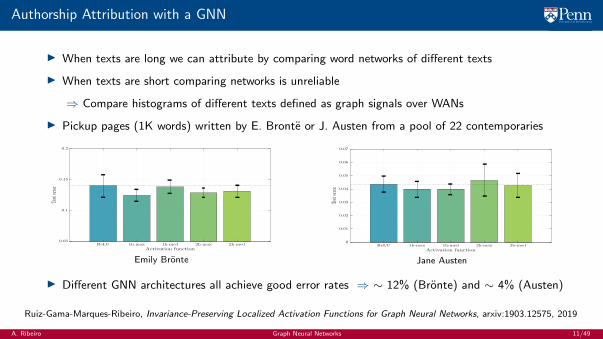
Authorship Attribution with a GNN
I When texts are long we can attribute by comparing word networks of different texts
I When texts are short comparing networks is unreliable
⇒ Compare histograms of different texts defined as graph signals over WANs
I Pickup pages (1K words) written by E. Bronte or J. Austen from a pool of 22 contemporaries
Emily Bronte Jane Austen
I Different GNN architectures all achieve good error rates ⇒ ∼ 12% (Bronte) and ∼ 4% (Austen)
Ruiz-Gama-Marques-Ribeiro, Invariance-Preserving Localized Activation Functions for Graph Neural Networks, arxiv:1903.12575, 2019
A. Ribeiro Graph Neural Networks 11/49

Learning Decentralized Controllers in Distributed Systems
Machine Learning for Graph Signals
Authorship Attribution
Learning Decentralized Controllers in Distributed Systems
Learning Optimal Resource Allocations in Wireless Communications Networks
Invariance and Stability Properties of Graph Neural Networks
Concluding Remarks
A. Ribeiro Graph Neural Networks 12/49

Decentralized Coordination of a Robot Swarm
I We want the team to coordinate on their individual velocities without colliding with each other
I This is a very easy problem to solve if we allow for centralized coordination ⇒ ui =∑N
i=1 vi
I But it is very difficult to solve if we do do not allow for centralized coordination ⇒ ui = . . .
A. Ribeiro Graph Neural Networks 13/49

Information Structure on Distributed Systems
I The challenge in designing behaviors for distributed systems is the partial information structure
xi(n)
I Node i has access to its own local information at time n ⇒ xi(n)
I
I
I
A. Ribeiro Graph Neural Networks 14/49

Information Structure on Distributed Systems
I The challenge in designing behaviors for distributed systems is the partial information structure
xi(n) xj(n−1) for j ∈ N 1i
I Node i has access to its own local information at time n ⇒ xi(n)
I And the information of its 1-hop neighbors at time n − 1 ⇒ xj(n−1) for all j ∈ N 1i
I
I
A. Ribeiro Graph Neural Networks 14/49

Information Structure on Distributed Systems
I The challenge in designing behaviors for distributed systems is the partial information structure
xi(n) xj(n−1) for j ∈ N 1i xj(n−2) for j ∈ N 2
i
I Node i has access to its own local information at time n ⇒ xi(n)
I And the information of its 1-hop neighbors at time n − 1 ⇒ xj(n−1) for all j ∈ N 1i
I And the information of its 2-hop neighbors at time n − 2 ⇒ xj(n−2) for all j ∈ N 2i
I
A. Ribeiro Graph Neural Networks 14/49

Information Structure on Distributed Systems
I The challenge in designing behaviors for distributed systems is the partial information structure
xi(n) xj(n−1) for j ∈ N 1i xj(n−2) for j ∈ N 2
i xj(n−3) for j ∈ N 3i
I Node i has access to its own local information at time n ⇒ xi(n)
I And the information of its 1-hop neighbors at time n − 1 ⇒ xj(n−1) for all j ∈ N 1i
I And the information of its 2-hop neighbors at time n − 2 ⇒ xj(n−2) for all j ∈ N 2i
I And the information of its 3-hop neighbors at time n − 3 ⇒ xj(n−3) for all j ∈ N 3i
A. Ribeiro Graph Neural Networks 14/49

Learning to Imitate the Centralized Solution
I Control actions can only depend on information history ⇒ Hin =K−1⋃k=0
{xj(n−k) : j ∈ N k
i
}I Optimal controller is famously difficult to find. Even for very simple linear systems
⇒ Witsenhausen, H. “A counterexample in stochastic optimum control” (February 1968)
I When optimal solutions are out of reach we resort to heuristics ⇒ data driven heuristics
I The centralized optimal control policy π∗(xn) can be computed during training time
I Introduce parametrization and learn decentralized policy that imitates centralized policy
H∗ = argminH
Eπ∗[L(π(Hin,H
),π∗(xn)
)]I Need parametrization H adapted to the information structure Hin ⇒ Aggregation GNN
A. Ribeiro Graph Neural Networks 15/49

The Aggregation Sequence (Diffusion Sequence)
y0n = xn y1n = Sy0(n−1) y2n = Sy1(n−2) y3n = Sy2(n−3)
I Aggregate information at nodes through successive averaging with graph adjacency S
ykn = Sy(k−1)(n−1) ⇒[
ykn
]i
=[
Syk−1(n−1)
]i
=∑
j=1,j∈Nin
[S]ij
[yk−1n−1
]j
I Computed with local operations that respect information structure of distributed system
A. Ribeiro Graph Neural Networks 16/49

Aggregation Graph Neural Networks
y0n = xn y1n = Sy0(n−1) y2n = Sy1(n−2) y3n = Sy2(n−3)
CNNzin uin
I Aggregation sequence zin =[[
y0n
]i;[y1n
]i; . . . ;
[y(K−1)n
]i
]has a temporal structure
I Having a temporal structure it can be processed with a regular CNN
Gama-Marques-Leus-Ribeiro, Convolutional Neural Network Architectures for Signals Supported on Graphs, TSP, 2019
A. Ribeiro Graph Neural Networks 17/49

Permutation Covariance
I The Aggregation Graph Neural Network is defined by a filter tensor H
I This tensor is shared by all the nodes in the graph = agents in the system
⇒ If two agents observe the same input
⇒ Their K -hop neighbors observe the same inputs
⇒ And the local structures of the graph are the same
⇒ The output of the control policy it the same. As it should. Or not.
I Aggregation GNN is permutation covariant ⇒ Permute graph and input = permute output
I Permutation covariance is not a choice. It is a necessity for offline training
A. Ribeiro Graph Neural Networks 18/49

Offline Training vs Online Execution
I If we want to train offline and execute online we can’t assume the graph is the same
I Train online on a graph like this
I
I
I
I
A. Ribeiro Graph Neural Networks 19/49

Offline Training vs Online Execution
I If we want to train offline and execute online we can’t assume the graph is the same
I Train online on a graph like this I And execute offline on a graph like this
I
I
I
I
A. Ribeiro Graph Neural Networks 19/49

Offline Training vs Online Execution
I If we want to train offline and execute online we can’t assume the graph is the same
I Train online on a graph like this I And execute offline on a graph like this
I CNN runs on aggregation sequence ⇒ It can be ran independently of graph’s structure.
I Permutation covariance says that if graphs are similar CNN outputs will be similar.
I Thereby producing similar policies and ensuring generalization across different graphs
I
A. Ribeiro Graph Neural Networks 19/49

Offline Training vs Online Execution
I If we want to train offline and execute online we can’t assume the graph is the same
I Train online on a graph like this I And execute offline on a graph like this
I CNN runs on aggregation sequence ⇒ It can be ran independently of graph’s structure.
I Permutation covariance says that if graphs are similar CNN outputs will be similar.
I Thereby producing similar policies and ensuring generalization across different graphs
I Aggregation sequence is the only linear processing that generates permutation covariance.
A. Ribeiro Graph Neural Networks 19/49

Coordinating a Robot Swarm
I The GNN learns to imitate the central policy. Outperforms existing distributed control methods
Tolstaya-Gama-Paulos-Pappas-Kumar-Ribeiro, Learning Decentralized Controllers for Robot Swarms with Graph Neural
Networks, arxiv:1903.10527, 2019
A. Ribeiro Graph Neural Networks 20/49

Learning Optimal Resource Allocations in Wireless Communications Networks
Machine Learning for Graph Signals
Authorship Attribution
Learning Decentralized Controllers in Distributed Systems
Learning Optimal Resource Allocations in Wireless Communications Networks
Invariance and Stability Properties of Graph Neural Networks
Concluding Remarks
A. Ribeiro Graph Neural Networks 21/49

Interference Channel
I Groups of communicating pairs from infrastructure base stations to mobile user terminals
A. Ribeiro Graph Neural Networks 22/49

Interference Channel
I Groups of communicating pairs from infrastructure base stations to mobile user terminals
I There is interference crosstalk from other communicating pairs that we can describe with a graph
A. Ribeiro Graph Neural Networks 23/49

Interference Channel
I Pairs communicate over a time varying fading channel. Pair i is interfered by neighboring pairs j
⇒ Channel is hi for communicating pair i . Transmitter allocates power pi (h). h = [h1; . . . ; hn]
⇒ Channel crosstalk from pair j to receiver of pair i is hji . Nonzero when j ∈ n(i)
I We want to select a power allocation that maximizes communication rates in some sense
p∗(h) = argmaxp(h)
Eh
[∑i
log
(1 +
hipi (h)
1 +∑
j∈n(i) hijpj(h)
)]I This is a problem we know well. We can’t solve it exactly but we can approximate it (WMMSE)
A. Ribeiro Graph Neural Networks 24/49

Model Uncertainty and Model Complexity
I There are two drawbacks to the use of WMMSE and other model based solutions
⇒ We can model the rate function but there is a mismatch between reality and model
ci = log
(1 +
hipi (h)
1 +∑
j∈n(i) hijpj(h)
)+ f (h, p(h))
⇒ We modularize design but in reality we can have ∼ 103 base stations with ∼ 105 active users
I To some extent, both drawbacks can be ameliorated with an ML parametrization
⇒ The function f is unknown but it is possible to probe the environment to evaluate f (x, u)
⇒ The optimization problem is too difficult (large scale). The parametrization may make it easier
I ML parametrizations are justified in large scale wireless communications with uncertain models
A. Ribeiro Graph Neural Networks 25/49

Interference Channel as a Statistical Learning Problem
I Unsupervised statistical learning data to actions that minimize and expected loss
u∗(x) = argminu(x)
Ex
[f(
x, u(x)) ]
I Given fading channel we search for a power allocation that maximizes expected sum rates
p∗(h) = argmaxp(h)
Eh
[∑i
log
(1 +
hipi (h)
1 +∑
j∈n(i) hijpj(h)
)]I Fading channel ∼ Data. Power allocation ∼ classifier. Capacity function ∼ loss.
I Parametrize with a Neural Network. Or parametrize with a Graph Neural Network. Either way
θ∗ = argmaxθ
Eh
[∑i
log
(1 +
hipi (h,θ)
1 +∑
j∈n(i) hijpj(h,θ)
)]
Eisen-Zhang-Chamon-Lee-Ribeiro, Learning Optimal Resource Allocations in Wireless Systems, TSP, 2019
A. Ribeiro Graph Neural Networks 26/49

Learning at Scale with Graph Neural Networks
Fully connected neural network ⇒ 8 pairs
0 2 4 6 8 10104
0.5
1
1.5
2
2.5
3
Graph Neural Network ⇒ 50 pairs
0 0.5 1 1.5 2 2.5 3 3.5 4104
0
0.5
1
1.5
2
2.5
3
3.5
I A GNN parametrized resource allocation scales to large networks ⇒ The only solution that scales
Eisen-Ribeiro, Large Scale Wireless Power Allocation with Graph Neural Networks, SPAWC 2019
A. Ribeiro Graph Neural Networks 27/49

Transferring for Scale
I GNN built for 50 pairs generalizes to larger networks
⇒ No need for retraining ⇒ exploits permutation invariance of graph convolution
⇒ Performance of GNN trained with 50 nodes (top) to one trained for larger network (bottom)
Sum-rate0 1 2 3 4 5 6 7 8 9 10
0
0.02
0.04
0.06
0.08
0.1
REGNN - 50
Sum-rate0 1 2 3 4 5 6 7 8 9 10
0
0.02
0.04
0.06
0.08
0.1
REGNN - 75
Sum-rate0 5 10 15
0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
REGNN - 50
Sum-rate0 5 10 15
0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
0.1
REGNN - 100
Figure: (left) 75 and (right) 100 pairs
A. Ribeiro Graph Neural Networks 28/49

Transferring for Scale
I GNN built for 50 pairs generalizes to larger networks
⇒ No need for retraining ⇒ exploits permutation invariance of graph convolution
50 100 150 200 250 300 350 400 450 5000
5
10
15
20
25
A. Ribeiro Graph Neural Networks 29/49

Invariance and Stability Properties of Graph Neural Networks
Machine Learning for Graph Signals
Authorship Attribution
Learning Decentralized Controllers in Distributed Systems
Learning Optimal Resource Allocations in Wireless Communications Networks
Invariance and Stability Properties of Graph Neural Networks
Concluding Remarks
A. Ribeiro Graph Neural Networks 30/49
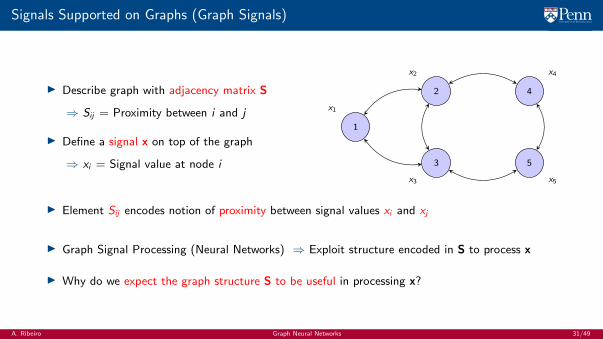
Signals Supported on Graphs (Graph Signals)
I Describe graph with adjacency matrix S
⇒ Sij = Proximity between i and j
I Define a signal x on top of the graph
⇒ xi = Signal value at node i
2
3
1
4
5
x1
x2
x3
x4
x5
I Element Sij encodes notion of proximity between signal values xi and xj
I Graph Signal Processing (Neural Networks) ⇒ Exploit structure encoded in S to process x
I Why do we expect the graph structure S to be useful in processing x?
A. Ribeiro Graph Neural Networks 31/49

The importance of signal structure in time
I Signal and Information Processing is always about exploiting the structure of the signal
⇒ We don’t always make it explicit. But it is always implicit
I Discrete time described by cyclic graph
⇒ Time n follows time n − 1
⇒ Signal value xn similar to xn−1
I Formalized with the notion of frequency
1
2
3
4
5
6
x1
x2
x3
x4
x5
x6
A. Ribeiro Graph Neural Networks 32/49

Exploiting Time Structure in Machine Learning
I Given a training set of input-output example pairs T {(x, y)}
I Find the best arbitrary linear regressor for some loss function f ⇒ H∗ = argminH
∑(x,y)∈T
f(
Hx, y)
I Or, find the best convolution (linear) regressor for same loss f ⇒ h∗ = argminh
∑(x,y)∈T
f(
h ∗ x, y)
where h ∗ x means a signal with components zn =∑
k hhxn−k
I The linear regressor is better than the convolution by definition. Both are linear. One is generic
⇒ This is true in the test set. In reality, the convolution does better. It generalizes.
A. Ribeiro Graph Neural Networks 33/49

Convolutional Neural Networks (CNN)
I The convolution is covariant to time shifts ⇒ S(h ∗ x) = h ∗ S(x) .
⇒ It respects and exploits the internal symmetries of the input signal
I What should we do if we want a nonlinear processing architecture?
⇒ Compose convolution with a pointwise nonlinearity
I And if we want a more ddescriptive architecture?
I Stack layers composing pointwise nonlinearities with convolutional filters (input x0 = x, outputy = xL)
x1 = σ1
(h1 ∗ x
), . . . , x` = σ`
(h` ∗ x`−1
), . . . , xL = σL
(hL ∗ xL−1
)I This is a CNN. It is covariant to time shifts
A. Ribeiro Graph Neural Networks 34/49

Graph Convolutions
I Interpret the graph adjacency or Laplacian as a shift operator S
I Define graph convolution as a polynomial on the shift operator
y = h1S0x + h1S1x + h2S2x + . . .+ hLSLx =K−1∑k=0
hkSkx := h ∗S x
I Generalizes regular (time) convolution ⇒ It’s recovered if we use the adjacency of a cycle graph
A. Ribeiro Graph Neural Networks 35/49

Graph Neural Networks (GNNs)
I The graph convolution is covariant to permutations (relabelings)
h ∗P(S) P(x) =K−1∑k=0
hk (PT SP)kPT x = PT
( K−1∑k=0
hkSkx
)= P(h ∗S x)
I Graph convolutions exploit the internal symmetry of the graph signal
I And if we want a more descriptive architecture?
I Stack layers composing pointwise nonlinearities with graph convolutional filters (input x0 = x andoutput y = xL)
x1 = σ1
(h1 ∗S x
), . . . , x` = σ`
(h` ∗S x`−1
), . . . , xL = σL
(hL ∗S xL−1
)I This is a GNN. It is covariant to permutations (relabelings)
A. Ribeiro Graph Neural Networks 36/49

Covariance to Permutations
I GNN output depends on input signal, graph shift, and filter tensor
Φ(x; S,H)= xL = σL
(hL ∗S xL−1
). . . , x1 = σ1
(h1 ∗S x
)Theorem (Gama, Ribeiro, Bruna)
For shift operators S′ = PTSP and graph signals x′ = PTx it holds
Φ(x′; S′,H) = PTΦ(x; S,H)
A. Ribeiro Graph Neural Networks 37/49

Covariance to Permutations is More Valuable than Apparent
I Invariance to node relabelings allows GNNs to exploit internal symmetries of graph signals
I Although different, signals on (a) and (b) are permutations of one other
⇒ Permutation invariance means that the GNN can learns to classify (b) from seeing (a)
1 2
3
45
6 7 10
8 9
12 11
1 2
3
45
6 7 10
8 9
12 11
11 12
7
89
10 3 6
4 5
2 1
(a) (b) (c)
A. Ribeiro Graph Neural Networks 38/49

Covariance to Permutations is a Property of Graph Filters
I Permutation covariance = property of graph convolutions inherited to GNNs
⇒ Q1: What is good about pointwise nonlinearities?
⇒ Q2: What is wrong with linear graph convolutions?
I A2: They can be unstable to perturbations of the graph if we push their discriminative power
I A1: They can be made stable to perturbations while retaining discriminability
I Beautifully, these questions can only be answered with an analysis in the GFT domain
A. Ribeiro Graph Neural Networks 39/49

Graph Convolutions in the Frequency Domain
I Graph convolution is a polynomial on the shift operator ⇒ y =K−1∑k=0
hkSkx
I Decompose operator as S = VHΛV to write the spectral representation of the graph convolution
VHy =K−1∑k=0
hk(VHSV)k VHx ⇒ y =K−1∑k=0
hkΛk x
I where we have used the graph Fourier transform (GFT) definitions x = VHx and y = VHy
I Graph convolution is a pointwise operation in the spectral domain
⇒ Determined by the (graph) frequency response ⇒K−1∑k=0
hkλkk
A. Ribeiro Graph Neural Networks 40/49

Graph Frequency Response
I We can reinterpret the frequency response as a polynomial on continuous λ ⇒ h(λ) =K−1∑k=0
hkλk
λ0 λ1 λk λn−1
I Frequency response is the same no matter the graph ⇒ It’s instantiated on its particular spectrum
A. Ribeiro Graph Neural Networks 41/49

Graph Frequency Response
I We can reinterpret the frequency response as a polynomial on continuous λ ⇒ h(λ) =K−1∑k=0
hkλk
λ0 λ1 λk λn−1
I Frequency response is the same no matter the graph ⇒ It’s instantiated on its particular spectrum
A. Ribeiro Graph Neural Networks 41/49

Graph Frequency Response
I We can reinterpret the frequency response as a polynomial on continuous λ ⇒ h(λ) =K−1∑k=0
hkλk
λ0 λ1 λk λn−1
I Frequency response is the same no matter the graph ⇒ It’s instantiated on its particular spectrum
A. Ribeiro Graph Neural Networks 41/49

Measuring Graph Perturbations
I To measure graph perturbations introduce a relative perturbation model ⇒ S′ = EHS + SE
I Since graphs S and S′ are identical if they are permutations of each other define the set
E ={
E : PTS′P = EHS + SE for some P ∈ P}
P = set of permutation matrices
I Smallest E matrix that maps S into a permutation of S′ is the relative distance between S and S′
d(S,S′) = minE∈E‖E‖
I This distance measures relative differences between graphs modulo permutations
⇒ In particular, it is small if the graphs are close to being permutations of each other
A. Ribeiro Graph Neural Networks 42/49

Stablity of Integral Lipschitz Filters to Relative Perturbations
I Let h(λ) be the frequency response of filter h. We say h is integral Lipschitz if |λh′(λ)| ≤ C
TheoremConsider integral Lipschitz filter h and graphs S and S′. Their relative distance satisfies d(S,S′) ≤ ε/2and the matrix E that achieves minimum distance is such that ‖E/‖E‖ − I‖ ≤ ε. It holds that for allsignals x
‖h ∗S x− PTh ∗S′ x‖ ≤ Cε + O(ε2)
I Not all filters are stable to graph perturbations (more later). But integral Lipschitz filters are
I Requires validity of the structural perturbation constraint ‖E/‖E‖ − I‖ ≤ ε
Gama-Bruna-Ribeiro, Stability Properties of Graph Neural Networks, arxiv:1905.04497, 2019
A. Ribeiro Graph Neural Networks 43/49

Stability of Graph Neural Networks with Integral Lipschitz Filters
I The nonlinearity σ is said to be normalized Lipschitz if ⇒ ‖σ`(x)− σ(x′)‖ ≤ ‖x− x′‖
TheoremConsider a GNN with L layers having integral Lipschitz filter h` and normalized Lipschitz nonlinearitiesσ`. Graphs S and S′ are such that their relative distance satisfies d(S,S′) ≤ ε/2 and the matrix E thatachieves minimum distance satisfies ‖E/‖E‖ − I‖ ≤ ε. It holds that for all signals x
‖Φ(x′; S′,H)− PTΦ(x; S,H)‖ ≤ CLε + O(ε2)
I GNNs can be made stable to graph perturbations if filters are integral LIpschitz
Gama-Bruna-Ribeiro, Stability Properties of Graph Neural Networks, arxiv:1905.04497, 2019
A. Ribeiro Graph Neural Networks 44/49

Proof of Stability Theorems
I The theorems are elementary to prove for edge dilation ⇒ multiply edges by α ≈ 1
I Graph spectrum is dilated ⇒ If S = VΛVH then S′ = V(αΛ)VH
λ0 λ1 λk λn−1
I Small deformations may result in large filter variations for large λ
A. Ribeiro Graph Neural Networks 45/49

Proof of Stability Theorems
I The theorems are elementary to prove for edge dilation ⇒ multiply edges by α ≈ 1
I Graph spectrum is dilated ⇒ If S = VΛVH then S′ = V(αΛ)VH
λ0 λ1 λk λn−1
I Small deformations may result in large filter variations for large λ
A. Ribeiro Graph Neural Networks 45/49

Proof of Stability Theorems
I The theorems are elementary to prove for edge dilation ⇒ multiply edges by α ≈ 1
I Graph spectrum is dilated ⇒ If S = VΛVH then S′ = V(αΛ)VH
λ0 λ1 λk λn−1
I Small deformations may result in large filter variations for large λ
A. Ribeiro Graph Neural Networks 45/49

Discriminative Graph Filter Banks are Unstable
I Q2: What is wrong with linear graph convolutions?
I Graph convolutions can’t simultaneously be stable to deformations and discriminate features athigh frequencies
λ0 λ1 λk λn−1
I This limits their value in several machine learning problems
A. Ribeiro Graph Neural Networks 46/49

Nonlinearities Create Low Frequency Components
I Q1: What is good about pointwise nonlinearities?
I Preserves permutation covariance while generating low graph frequency components that we candiscriminate with stable filters
λ0 λ1 λk λn−1
I Showing spectrum of rectified graph signal ⇒ xrelu = max(x, 0)
⇒ Low frequency components are garbage. But stable garbage
A. Ribeiro Graph Neural Networks 47/49

Concluding Remarks
Machine Learning for Graph Signals
Authorship Attribution
Learning Decentralized Controllers in Distributed Systems
Learning Optimal Resource Allocations in Wireless Communications Networks
Invariance and Stability Properties of Graph Neural Networks
Concluding Remarks
A. Ribeiro Graph Neural Networks 48/49

Concluding Remarks
I Graph Neural Networks (GNN) generalize Convolutional Neural Networks (CNN) to graph signals
⇒ They leverage structure ⇒ Machine learning in high dimensions necessitates structure
I GNNs show particular promise in distributed collaborative intelligent systems
⇒ Data needed for their execution respects the information structure of distributed systems
I GNNs can be made discriminative and stable to deformations of the graph
⇒ A property that linear filters can’t have. Explains their better performance
⇒ Analogous to stability of CNNs versus instability of convolutional filters
A. Ribeiro Graph Neural Networks 49/49












![Deep Parametric Continuous Convolutional Neural Networks€¦ · Graph Neural Networks: Graph neural networks (GNNs) [25] are generalizations of neural networks to graph structured](https://img.pdfslide.us/doc/110x75/5f7096c356401635d36dbe30/deep-parametric-continuous-convolutional-neural-networks-graph-neural-networks.jpg)
















