Embed Size (px)
Citation preview

J Sign Process SystDOI 10.1007/s11265-014-0877-0
GPU Acceleration of a Configurable N-Way MIMODetector for Wireless Systems
Michael Wu · Bei Yin · Guohui Wang ·Christoph Studer · Joseph R. Cavallaro
Received: 8 May 2013 / Revised: 12 December 2013 / Accepted: 17 February 2014© Springer Science+Business Media New York 2014
Abstract Multiple-input multiple-output (MIMO) wirelessis an enabling technology for high spectral efficiency andhas been adopted in many modern wireless communi-cation standards, such as 3GPP-LTE and IEEE 802.11n.However, (optimal) maximum a-posteriori (MAP) detectionsuffers from excessively high computational complexity,which prevents its deployment in practical systems. Hence,many algorithms have been proposed in the literature thattrade-off performance versus detection complexity. In thispaper, we propose a flexible N -Way MIMO detector thatachieves excellent error-rate performance and high through-put on graphics processing units (GPUs). The proposeddetector includes the required QR decomposition step anda tree-search detector, which exploits the massive paral-lelism available in GPUs. The proposed algorithm performsmultiple tree searches in parallel, which leads to excellenterror-rate performance at low computational complexityon different GPU architectures, such as Nvidia Fermi andKepler. We highlight the flexibility of the proposed detec-tor and demonstrate that it achieves higher throughput than
M. Wu (�) · B. Yin · G. Wang · J. R. CavallaroRice University, Houston, TX, 77005 USAe-mail: [email protected]
B. Yine-mail: [email protected]
G. Wange-mail: [email protected]
J. R. Cavallaroe-mail: [email protected]
C. StuderCornell University, Ithaca, NY, 14850 USAe-mail: [email protected]
existing GPU-based MIMO detectors while achieving thesame or better error-rate performance.
Keywords MIMO · GPU · Parallel processing · GPGPU ·Detectors · Maximum likelihood · Sphere detection · MAPdetection
1 Introduction
Multiple-input multiple-output (MIMO) wireless is a keytechnology used in many modern communication stan-dards, such as 3GPP-LTE, WiMAX, and IEEE 802.11n.The use of multiple antennas at both ends of the wirelesslink enables significant improvements (compared to single-antenna systems) in terms of spectral efficiency. Most stan-dards employing MIMO use spatial multiplexing, whichtransmits multiple independent data streams concurrentlyand within the same frequency band. The received sig-nal mixture (caused by multi-path propagation) necessitatesa MIMO detector, which separates the received mixtureof transmitted data streams. Traditionally, correspondingdetector solutions are implemented on ASICs or FPGAs,due to the excessive complexity of MIMO detection. In thispaper, we aim to utilize off-the-shelf graphical processingunits (GPUs) in order to perform high throughput MIMOdetection. The massive amount of computational power pro-vided by GPUs is particularly useful for platforms in need ofgreat flexibility, such as software defined radios, or to speedup MIMO system simulations.
1.1 MIMO Detection
Among different MIMO detection schemes, soft-outputmaximum a-posteriori (MAP) detection is the optimal

J Sign Process Syst
detection scheme in coded systems. This nonlinear detec-tor requires an exhaustive search over all candidate vectors,which results in prohibitive computational complexity, evenfor MIMO systems transmitting a few spatial streams. Con-sequently, exact MAP detection is impractical as wirelesssystems typically have stringent hardware constraints (sil-icon area and power consumption), as well as challengingthroughput and latency requirements. As a result, most prac-tical solutions to MIMO detection rely on suboptimal butlow complexity algorithms [2–4, 10, 11, 16, 18, 23].
Suboptimal detection algorithms can mainly be catego-rized into linear detection algorithms and non-linear tree-search-based methods. Although the complexity of lineardetection methods is very low, the associated error-rateperformance is rather poor in practical systems [4, 11,23]. Non-linear tree-search-based detection methods, how-ever, are capable of achieving excellent error-rate perfor-mance at low computational complexity. Such detectorscan mainly be divided into two categories: (i) depth-first tree-search algorithms, such as sphere decoding [3,16], and (ii) breadth-first search algorithms, such as theK-best algorithm [18]. For both approaches, the searchspace, i.e., the set of all possible transmit vectors, can berepresented as a tree. To reduce the computational com-plexity of data detection, these detectors use heuristics toeliminate useless branch extensions during the tree-searchprocess.
Depth-first sphere detectors traverse the tree from topto bottom recursively and prune branches with large par-tial distances during backtracking. As the traversal path isnot deterministic, parallel implementations of depth-firstsearch require load balancing to achieve high efficiency [8];this requires global synchronization which is inefficient onGPUs. In addition to the random runtime of depth-first tree-search algorithms, they usually evaluate a large and smallnumber of tree branches at low and high SNR, respectively.Breadth-first search algorithms, such as the K-best algo-rithm, reduce the complexity by pruning branches level bylevel. Although the K-best algorithm has a deterministicrun-time, the algorithm requires a global sort at each treelevel to find the best K nodes, which is the main bottleneckfor corresponding software implementations [7].
More recently, the authors in [10] proposed the selectivespanning with fast enumeration (SSFE) MIMO detectionalgorithm, which can be viewed as a sort-free approxi-mation to the K-best algorithm; related MIMO detectionalgorithms were also proposed in [2, 5]. The SSFE method,however, results in a substantial error-rate performance loss.In order to recover part of this performance loss, one canrun a small number of instances of SSFE in parallel, whereeach instance operates with a different permuted detec-tion order [13, 20]. Since these instances perform the sameset of operations but work on different input data, this
improved algorithm maps very well onto GPU architectures[14, 22].
1.2 Contributions
Our contributions are as follows. We propose a flexi-ble MIMO detector that achieves excellent error-rate per-formance and high throughput on GPUs. We show thatthe proposed design achieves a wide range of trade-offsbetween throughput and error-rate performance, and is ableto approach the error-rate performance of the optimal soft-output MAP detector within 0.25 dB. We then describeour complete implementation, including both the requiredQR decomposition and the MIMO detection algorithm. Weoptimize our QR decomposition kernel for processing onmany small dense matrices in parallel, which is differentfrom conventional decomposition methods, such as the onein [9]. In addition, we improve the throughput of our pre-vious work in [22] using a variety of optimizations. Wefurthermore characterize the achieved throughput of our ker-nel on both Fermi and Kepler GPUs. Finally, we show thatour implementation on Nvidia GPU achieves a substantiallyhigher throughput than existing soft-output MIMO detectorsimplemented on GPUs [14, 19].
1.3 Outline of the Paper
This paper is organized as follows. Section 2 introducesthe MIMO system model. Section 3 describes the pro-posed detection algorithm and its GPU implementation.Section 4 characterizes the performance and complexity ofthe detector. We conclude in Section 5.
2 MIMO System Model
The considered MIMO system transmits Nt independentdata streams, and the destination receives signals on Nt
antennas. At the transmit-side, given a binary-valued vectorx = [x0, . . . , xL−1]T with L = Nt log2 M , the modulationfunction maps the vector x to s = [s0, . . . , sNt−1]T , wheresi is a complex number in a finite constellation alphabet �with cardinality M . For example, the constellation alphabetfor QPSK is {−1−j,−1+j, 1−j, 1+j} with M = 4. Thesource then transmits the modulated signal vector s over Nt
antennas. The received symbols can be modeled as
y = Hs + n, (1)
where y = [y0, . . . , yNt−1]T is the received symbol vector,H = [h0, . . . , hNt−1] is the Nt × Nt channel matrix. Weconsider a Rayleigh fading channel model, where each entryof H, denoted by hij , is modeled by an i.i.d. circularly sym-metric complex Gaussian (ZMCSCG) random variable with

J Sign Process Syst
variance σ 2h per complex dimension. Each element of the
additive noise vector, n = [n0, . . . , nNt−1]T , is assumed tobe i.i.d. ZMCSCG with variance σ 2
n per complex dimension.
2.1 Modified Real-Valued Decomposition
To perform MIMO detection in the real domain instead ofthe complex domain, we first perform a real-valued decom-position of the input-output relation (1). Specifically, werewrite (1) as(R(y)I(y)
)=
(R(H) −I(H)
I(H) R(H)
)(R(s)I(s)
)+
(R(n)I(n)
), (2)
where R(x) and I(x) denote the real and imaginary part ofthe complex variable x, respectively. In order to improve theerror-rate performance of the proposed detector, we deploythe modified real-valued decomposition (MRVD) put for-ward in [1]. In particular, we permute the vector and matrixelements such that the real and imaginary part of the samecomplex entry are adjacent to each other. With this, theresulting input-output relation is given by⎛⎜⎜⎜⎜⎜⎜⎜⎜⎜⎝
R(y0)
I(y0)
R(y1)
I(y1)...
R(yNR−1)
I(yNR−1)
⎞⎟⎟⎟⎟⎟⎟⎟⎟⎟⎠
= H
⎛⎜⎜⎜⎜⎜⎜⎜⎜⎜⎝
R(s0)
I(s0)
R(s1)
I(s1)...
R(sNR−1)
I(sNR−1)
⎞⎟⎟⎟⎟⎟⎟⎟⎟⎟⎠
+
⎛⎜⎜⎜⎜⎜⎜⎜⎜⎜⎝
R(n0)
I(n0)
R(n1)
I(n1)...
R(nNR−1)
I(nNR−1)
⎞⎟⎟⎟⎟⎟⎟⎟⎟⎟⎠
which we abbreviate by y = Hs+n.Compared to the original (complex-valued) system
model in (1), MRVD doubles the number of elements ineach vector and quadruples the dimensionality of H. Fur-thermore, each element of si is drawn from a smaller (real-valued) alphabet, �′, which has cardinality Q = √
M . Forexample, with QPSK, the MRVD-equivalent constellationalphabet is {−1,+1} with Q = 2.
2.2 Soft-Output MIMO Detection
Given the received vector after performing the MRVD, y,and the MRVD-equivalent channel matrix H, the soft-outputMIMO detector at the receiver computes the a-posterioriprobability log-likelihood (log-APP) ratio, Lk
D , for each bit.Assuming equally likely transmitted bits, the log-likelihoodratio (LLR) of the kth transmitted bit can be approximatedvia the max-log approximation [6]:
LkD ≈ 1
2σ 2n
(min
x∈Xk,0
∥∥y − Hs∥∥2− min
x∈Xk,1
∥∥y − Hs∥∥2
). (3)
Here, Xk,0 is the set of all binary-valued vectors with the kth
bit equals to 0, and Xk,1 is the set of all binary vectors with
the kth bit equal to 1. For the sake of brevity, the vector scorresponds to the modulated binary vector x. To reduce thecomplexity of Eq. 1, we can approximate Lk
D with a reducedset of transmit vectors, or a candidate list, L. This candidatelist, L, is generated by excluding transmit vectors with largeEuclidean distances. We then split L into two sublists forLk,0 and Lk,1. The list Lk,0 contains the candidates with thekth bit equal to 0 while the list Lk,1 contains the candidateswith the kth bit equal to 1. We then approximate Lk
D via (4),where the list Lk,0 is used for computing the 0-hypothesispart of the Lk
D , while the list Lk,+1 is used for computingthe 1-hypothesis part of the Lk
D .
LkD ≈ 1
2σ 2n
(min
x∈Lk,0
∥∥y − Hs∥∥2
︸ ︷︷ ︸0-hypothesis
− minx∈Lk,1
∥∥y − Hs∥∥2
︸ ︷︷ ︸1-hypothesis
). (4)
3 Soft-Output N-Way MIMO Detector on Nvidia GPU
Most wireless standards employ orthogonal frequency divi-sion multiplexing (OFDM), which simplifies equalizationby dividing the available bandwidth into multiple orthogo-nal subcarriers. With OFDM, each subcarrier corresponds toan independent MIMO detection problem. As a result, thereceiver needs to perform MIMO detection on every sub-carrier. Since many wireless standards use a large numberof subcarriers and GPUs consist of many independent pro-cessing cores, GPUs are very suitable for this applicationas hundreds of independent MIMO detection problems canrun in parallel on GPUs, which allows one to achieve highthroughput.
Since Nvidia GPUs can be viewed as multi-core SIMDprocessors, a suitable algorithm needs to be data parallel tomaximize the use of the available execution units. In addi-tion, the device memory latency is high on GPUs. To reducethe memory latency, a small amount of on-chip resources,such as registers and shared memory, can be used. As aresult, a good algorithm needs to have a memory footprintsmall enough to fit into the available on-chip memory toreduce the number of expensive device-memory accesses.
We implemented the soft-output N -way MIMO detectoron GPU using the CUDA C programming language.1 In thisprogramming model, the programmer specifies a kernel, ora set of computations. At runtime, threads execute the sameset of computations specified by the kernel on differentinput data to perform the task. The proposed MIMO detec-tor implementation consists of two kernels. The first kernelperforms a QR decomposition on the channel matrix. The
1We assume the reader is familiar with CUDA. A detailed descriptionand explanation can be found in [12].

J Sign Process Syst
second kernel searches for likely transmit vectors via a gen-erated candidate list. Then, the algorithm uses this candidatelist to compute soft-output information for each transmit-ted bit. In the following two sections, these two kernels aredescribed in detail.
3.1 QR Decomposition
To reduce the complexity of the candidate search, wefirst perform QR decomposition on H. With this, we canrewrite (4) as follows:
LkD ≈ 1
2σ 2n
⎛⎜⎜⎜⎜⎝ min
x∈Lk,0
∥∥y − Rs∥∥2
︸ ︷︷ ︸0-hypothesis
− minx∈Lk,1
∥∥y − Rs∥∥2
︸ ︷︷ ︸1-hypothesis
⎞⎟⎟⎟⎟⎠ . (5)
Here, R is the upper-triangular matrix obtained fromthe QR decomposition applied to H, and y is the effectivereceived vector obtained from QT y.
To achieve low computational complexity and goodnumerical stability, we implemented the Modified Gram-Schmidt QR factorization [17] on the GPU. Algorithm1 shows the pseudo-code for the modified Gram-SchmidtCUDA kernel function, which corresponds to a parallelimplementation of the modified Gram-Schmidt algorithm.At runtime, 2Nt threads execute the set of instructionsdefined in Algorithm 1 to perform one QR decomposi-tion. The kernel function can be summarized as follows.In the initialization part, 2Nt threads fetch the complex-
valued inputs, the received signals y and the channel H,from device memory. To perform MRVD, the threads usethe input data to construct a real-valued extended matrix,V = [H|y] = [v0, . . . , v2Nt ], in shared memory. The vectorvi is the i th column of V and the scalar vk,i is the kth entryof vi .
Next, 2Nt threads perform QR decomposition on theextended matrix V. The result is an extended upper trian-gular matrix E = [R|y] which is stored in device memory,where the scalar ek,i is the kth element of the i th column ofE. The whole process consumes 2Nt iterations. Each itera-tion consists of a set of serial operations and a set of paralleloperations.
The serial operations are summarized in Lines 4–7 ofAlgorithm 1, where we compute ‖vi‖2, the squared �2 normof the i th column of V, and the corresponding scaling factors. These serial computations are handled by one thread. Inour implementation, these serial computations are handledby the i th thread.2
Subsequent computations are done in parallel. In Line9, 2Nt threads compute the i th orthogonal projection, vi ,in parallel. In Lines 11–14, we assign one thread to eachcolumn of V and the number of columns (of V) updateddecreases by one after each iteration. For the i th iteration,only threads k ≥ i update the columns of V, which leadsto the condition k ≥ i in Line 11. Line 12 constructs theremaining elements in the i th row of E in parallel. In Line13, the matrix V is updated for subsequent iterations. Inthis instance, the kth thread updates vk+1 by subtracting theprojection of vk+1 on to the vi from vk+1.
The matrix V is stored in shared memory as elementsof V are accessed repeatedly. Storing V in shared memoryis much faster than storing the matrix in device memory.Storing the entire matrix in shared memory is possibleas the number of elements in the matrix V is small fortypical MIMO systems. Furthermore, the memory accesspattern of this kernel is very regular. A column-majorlayout for V results in bank-conflict-free shared memoryaccesses.
3.2 1-Way MIMO Detection
Given y and R, the MIMO detector computes LLR val-ues in two steps. The first step finds candidate vec-tors with small distances. The second step computes anLLR value for each transmitted bit using the candidatelist.
2The serial computations can be handled by any thread. For example,it is possible to always pick the 1st thread to compute the squared �2-norm.

J Sign Process Syst
3.2.1 Candidate Search
The search algorithm is essentially an SSFE MIMO detec-tor [2, 5, 10] operating in the real domain. The searchalgorithm attempts to find candidate vectors with small dis-tances in a greedy fashion. As R is an upper triangularmatrix, the search algorithm evaluates transmitted symbolsin reverse order, from antenna Nt − 1 to antenna 0. Theprocedure is equivalent to a tree traversal. For example, acomplete tree search for a 2 × 2 MIMO system using 16-QAM is shown in Fig. 1. This search keeps all branches ofantenna 1 by fully expanding the first two levels of the tree.For the subsequent tree levels, the branches of the tree arepruned by keeping the best outgoing paths. All survivingpaths at the end of the procedure are in our candidate listwhich in this example would be sixteen.
Let the kth path be pk =[pk
2Nt−1, . . . , pkt
], the set of
nodes along the path from the root node to pkt , a node on
level t . The best outgoing path can be found using Schnorr-Euchner enumeration [15]. The partial distance, the distancefrom pk
t to the i th node on level t − 1, w〈t−1〉k,i , can be
computed as
w〈t−1〉k,i = ||yt−1 −
t∑j=2Nt−1
rk,jpkj − rt−1,t−1si ||2, (6)
= ||bkt−1 − rt−1,t−1si ||2, (7)
where rk,i is the kth row of the i th column of R and yt isthe t th row of y. To expand this path, the best node in levelt − 1 that minimizes w〈t−1〉
k,i is simply the closest constella-
tion point in �′ to γ j = (rt−1,t−1)−1bkt−1, the zero-forcing
solution. If node i is the best node found at level t − 1, thekth distance can be updated by adding the partial distance,w〈t−1〉k,i , to the distance from the previous level t as follows:
dk = dk + w〈t−1〉k,i . (8)
The search algorithm is implemented with one kernel.The corresponding CUDA kernel function is shown inAlgorithm 2. At runtime, M threads execute the set ofinstructions defined in Algorithm 2 in parallel to performthe candidate search. Each thread is assigned to one mod-ulation point, where the kth thread is assigned to the kth
modulation point in the finite alphabet �. The first two lev-els of the tree are fully expanded as shown in Lines 3–4.For the subsequent levels, level 2Nt − 3 to level 0, thealgorithm first computes partial distances and then prunesoutgoing branches by keeping the best outgoing paths. Thepartial distance for the kth path is computed in Lines 6–9.Line 10 computes γk , which is used to find the best nodeat level i in lines 11–12. The best node is selected with asimple round function followed by a threshold function onγk . With the best node found, Line 13 updates the kth dis-tance by adding the partial distance of the best node. At theend of the loop, the path pk is a candidate in our candidatelist.
Figure 1 An example of thesearch process for a 2×216-QAM MIMO system.

J Sign Process Syst
3.2.2 0-Hypothesis and 1-Hypothesis Generation
With the candidate list, the 0-hypothesis and 1-hypothesis for each transmitted bit can be computed. Thecomputations for the kth thread are summarized in Algo-rithm 3. As shown in Line 1, the kth path, pk , is firstdemodulated into a binary vector bk which is then storedin shared memory. The corresponding distance for the kth
path, dk , is also stored in shared memory. We use Nt log(M)
threads, one thread per bit, to compute the 0-hypothesis andthe 1-hypothesis for each bit. In lines 5-11, the kth threadscans the binary vectors one by one to find the 0-hypothesis,h0k , and the 1-hypothesis, h1
k , for the kth bit. Finally, the LLRfor the kth bit is the difference between h0
k and h1k .
3.2.3 Optimizations
Beyond the above procedures, we also improve throughputin several ways.
1. We unroll the loops in both algorithms to reduce thetotal number of instructions.
2. As there are no data dependencies between the threadsin the search process, it is possible to store the pathhistory P in registers instead of using shared mem-ory to eliminate shared memory read/load instructionsand memory address computation. Storing path historyin registers also reduces the number of device mem-ory accesses as computation is carried out with on-chipresources.
3. On Nvidia GPUs, the SIMD instructions (or WARPinstructions) are 1024 bit wide, where each instructionoperates on 32 elements. At runtime, 32 threads sharethe same instruction. As a result, multiple MIMO detec-tions are packed into one thread block to ensure thateach thread block consists of an integer multiple of32 threads to improve efficiency. For example, for a4×4 MIMO 16-QAM system, QR decomposition uses
8 threads and MIMO detection uses 16 threads. We packat least 4 QR decompositions into one thread block andat least two 16-QAM detectors into one thread block toensure there are 32 threads within a thread block.
3.3 N-Way Parallel MIMO Detection
As described in the previous section, the soft-output SSFEdetector consists of a single QR decomposition, a singlecandidate search and a single LLR generator. However, theerror-rate performance of the soft-output SSFE detectionis significantly worse than that of the soft-output max-log-MAP detection, as shown in Section 4.1.
We now describe a simple algorithm which improvesupon the error-rate performance of the SSFE detector. Weperform several tree searches with different antenna detec-tion orders in parallel to improve error-rate performance ofthe detector. This improves performance as multiple treesearches generate a larger candidate list which results inmore reliable LLRs. In our design, we run N parallel can-didate searches, where 1 ≤ N ≤ Nt , to generate N parallelcandidate lists, each with M candidates. We then gener-ate LLR values from the combined candidate list, whichconsists of MN candidates.
For example, the proposed algorithm for a 2×2 MIMO16-QAM system is shown in Fig. 2. The example consistsof two parallel detectors. The inputs consist of the receivedvector y and the channel matrix H. A different antennadetection order can be obtained by a simple circular rotationof columns of H. Each detector performs QR decomposi-tion followed by candidate search to generate a candidatelist. The results from the two detectors, two candidate lists,are then used to generate LLR values.
In our implementation, we spawn 2NNt threads for aninput pair H and y. Each set of 2Nt threads constructs a per-muted version of H in shared memory by reading the inputdata in a different order. Each set of 2Nt threads then per-forms QR decompositions on its permuted channel matrix.We then spawn MN threads to perform N parallel MIMOdetections and LLR generation. To reduce communicationamong cores on the GPU, all threads corresponding to aninstance of a MIMO detection problem reside within thesame thread block.
Figure 2 Proposed detector for a 2×2 MIMO System.

J Sign Process Syst
3.3.1 LLR Computation
The threads generate LLRs using the larger combined can-didate list, which consists of MN candidates. We can useone thread to scan through all MN candidates to findthe 0-hypothesis, h0
k , and 1-hypothesis, h1k , for the kth
bit. In this case, we use Nt log2(M) threads, one threadper transmitted bit, to compute LLRs for all transmittedbits.
Since our thread block consists of MN threads, wecan improve the efficiency of the LLR generator by par-allelizing the workload further. Instead of one thread pertransmitted bit, we split the workload of finding the h0
k
and h1k among N threads. Since there are N lists where
each list consists of M candidates, we assign one list toeach thread. Using the assigned list, each thread attemptsto find the 0-hypothesis and the 1-hypothesis. As a result,there is one set of N 0-hypotheses and one set of N
1-hypotheses per bit. To find the 0-hypothesis and the 1-hypothesis, we use two threads to scan through the N
0-hypotheses and N 1-hypotheses to find the minimum ofeach set. The two minimums correspond to the 0-hypothesisand 1-hypothesis respectively. The difference between thesevalues is Lk
D , the LLR for the kth bit. In total, we useNNt log2(M) threads to compute LLRs for all transmittedbits.
The complexity of the LLR generator is directly pro-portional to the number of candidates in the candidate list,which is MN . The parallel searches do not necessarily gen-erate unique candidates. As a result, there may be duplicatesin the candidate list. Since (4) consists of min(·) operators,duplications do not affect the result. Although it is possibleto reduce the complexity of the LLR generator by eliminat-ing duplications in the candidate list, the number of uniquecandidates is not fixed, which leads to indeterminate run-time. As a result, we do not eliminate duplicate candidatesin the list.
4 Performance
In this section, we first show the bit error rate (BER) per-formance simulation results of our proposed detector. Wethen investigate and analyze the detector’s throughput per-formance on Fermi and Kepler graphics cards for variousdifferent configurations. We then compare and show theadvantages of our detector to other GPU-based soft-outputMIMO detector implementations.
4.1 BER Performance
We compared the BER performance of the N -way par-allel MIMO detector against several other soft-output
detectors, including soft-output trellis-based MIMO detec-tor [19], fully parallel fixed complexity-sphere detec-tor (FPFSD) [14] and soft-output max-log-MAP detector.The soft-output max-log-MAP detector computes LLR val-ues using the set of all possible transmit vectors (i.e. adirect implementation of (4)) and serves as the performancebound.
In our BER simulation, we first generate a random binaryinformation vector which is then encoded by a rate 1/33GPP LTE turbo encoder where K = 6144. We then mod-ulate the coded binary vector onto MIMO symbols. Thesymbols are transmitted through a Rayleigh fading channelwith additive white Gaussian noise. The detector performsQR decomposition on the channel matrix and then per-forms soft-output detection once to generate LLRs. Thesoft-output of the detector is then fed to a 3GPP Turbodecoder [21] which performs up to 8 turbo decoding iter-ations. The detectors use an LLR clipping value of 8 forall the detector configurations with the exception of N = 4where LLR clipping is not required. An iterative detec-tion and decoding scheme is not considered in this paperas our implementation does not iteratively exchange LLRsbetween the MIMO detector and the channel decoder. Weperform soft-output MIMO detection once followed byturbo decoding.
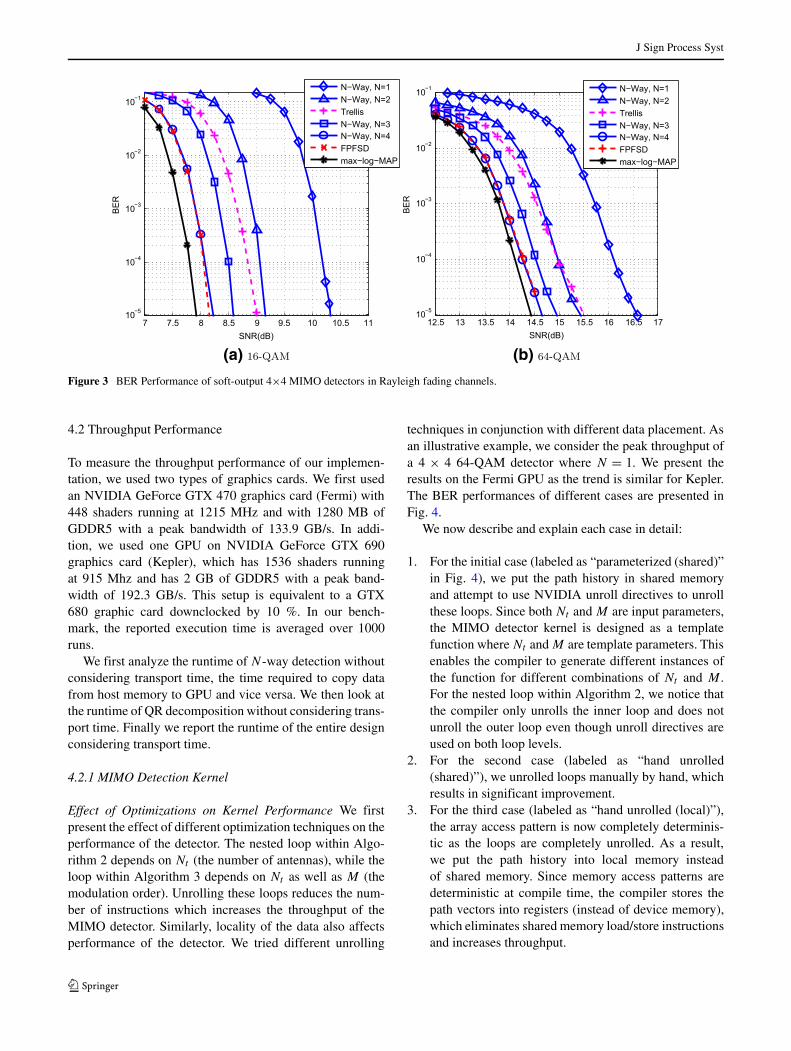
Figure 3 compares the BER performance of detectorsfor 16-QAM and 64-QAM. The trends are similar in bothplots. The N -way parallel MIMO detector is equivalent toSSFE when N = 1. For N = 1, the BER performance ofthe N -way MIMO detector is worse than that of the othersoft-output detectors. As we increase N , the performanceof the detector improves as a larger candidate list increasesthe probability of finding the smallest 0-hypothesis and thesmallest 1-hypothesis for each transmitted bit. For N = 4,the detector’s performance is within 0.25 dB of the soft-output max-log-MAP detector. We note that the compu-tational complexity difference between these two cases issignificant—the number of leaf nodes visited is NM forthe proposed algorithm compared to MN for the soft-outputmax-log-MAP detector.
For N ≥ 3, the N -way MIMO detector outperformsthe soft-output trellis-based MIMO detector. The FPFSDMIMO detector is similar to the N = 4 case except that theFPFSD MIMO detector performs detection in the complexdomain. In addition, the PFSD detector uses column-normreordering preprocessing to improve performance. Never-theless, we found the FPFSD detector performs similarly tothe N = 4 N -way detector despite their differences.3
3The column-norm reordering processing, however, is an effective wayof improving the N = 1 case. Nevertheless, the BER performance ofthe N = 1 case with column norm reordering preprocessing is stillworse than that of the N = 2 case without column-norm reordering.
J Sign Process Syst
(a) (b)
Figure 3 BER Performance of soft-output 4×4 MIMO detectors in Rayleigh fading channels.
4.2 Throughput Performance
To measure the throughput performance of our implemen-tation, we used two types of graphics cards. We first usedan NVIDIA GeForce GTX 470 graphics card (Fermi) with448 shaders running at 1215 MHz and with 1280 MB ofGDDR5 with a peak bandwidth of 133.9 GB/s. In addi-tion, we used one GPU on NVIDIA GeForce GTX 690graphics card (Kepler), which has 1536 shaders runningat 915 Mhz and has 2 GB of GDDR5 with a peak band-width of 192.3 GB/s. This setup is equivalent to a GTX680 graphic card downclocked by 10 %. In our bench-mark, the reported execution time is averaged over 1000runs.
We first analyze the runtime of N -way detection withoutconsidering transport time, the time required to copy datafrom host memory to GPU and vice versa. We then look atthe runtime of QR decomposition without considering trans-port time. Finally we report the runtime of the entire designconsidering transport time.
4.2.1 MIMO Detection Kernel
Effect of Optimizations on Kernel Performance We firstpresent the effect of different optimization techniques on theperformance of the detector. The nested loop within Algo-rithm 2 depends on Nt (the number of antennas), while theloop within Algorithm 3 depends on Nt as well as M (themodulation order). Unrolling these loops reduces the num-ber of instructions which increases the throughput of theMIMO detector. Similarly, locality of the data also affectsperformance of the detector. We tried different unrolling
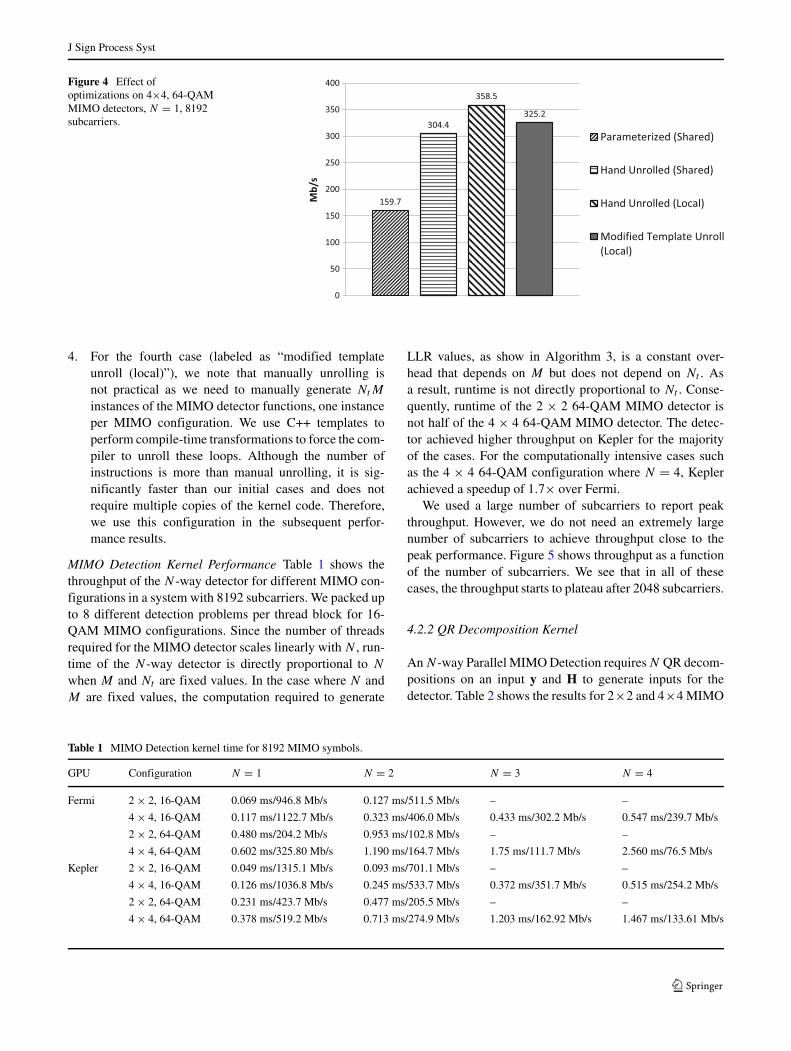
techniques in conjunction with different data placement. Asan illustrative example, we consider the peak throughput ofa 4 × 4 64-QAM detector where N = 1. We present theresults on the Fermi GPU as the trend is similar for Kepler.The BER performances of different cases are presented inFig. 4.
We now describe and explain each case in detail:
1. For the initial case (labeled as “parameterized (shared)”in Fig. 4), we put the path history in shared memoryand attempt to use NVIDIA unroll directives to unrollthese loops. Since both Nt and M are input parameters,the MIMO detector kernel is designed as a templatefunction where Nt and M are template parameters. Thisenables the compiler to generate different instances ofthe function for different combinations of Nt and M .For the nested loop within Algorithm 2, we notice thatthe compiler only unrolls the inner loop and does notunroll the outer loop even though unroll directives areused on both loop levels.
2. For the second case (labeled as “hand unrolled(shared)”), we unrolled loops manually by hand, whichresults in significant improvement.
3. For the third case (labeled as “hand unrolled (local)”),the array access pattern is now completely determinis-tic as the loops are completely unrolled. As a result,we put the path history into local memory insteadof shared memory. Since memory access patterns aredeterministic at compile time, the compiler stores thepath vectors into registers (instead of device memory),which eliminates shared memory load/store instructionsand increases throughput.
J Sign Process Syst
Figure 4 Effect ofoptimizations on 4×4, 64-QAMMIMO detectors, N = 1, 8192subcarriers.
4. For the fourth case (labeled as “modified templateunroll (local)”), we note that manually unrolling isnot practical as we need to manually generate NtM
instances of the MIMO detector functions, one instanceper MIMO configuration. We use C++ templates toperform compile-time transformations to force the com-piler to unroll these loops. Although the number ofinstructions is more than manual unrolling, it is sig-nificantly faster than our initial cases and does notrequire multiple copies of the kernel code. Therefore,we use this configuration in the subsequent perfor-mance results.
MIMO Detection Kernel Performance Table 1 shows thethroughput of the N -way detector for different MIMO con-figurations in a system with 8192 subcarriers. We packed upto 8 different detection problems per thread block for 16-QAM MIMO configurations. Since the number of threadsrequired for the MIMO detector scales linearly with N , run-time of the N -way detector is directly proportional to N
when M and Nt are fixed values. In the case where N andM are fixed values, the computation required to generate
LLR values, as show in Algorithm 3, is a constant over-head that depends on M but does not depend on Nt . Asa result, runtime is not directly proportional to Nt . Conse-quently, runtime of the 2 × 2 64-QAM MIMO detector isnot half of the 4 × 4 64-QAM MIMO detector. The detec-tor achieved higher throughput on Kepler for the majorityof the cases. For the computationally intensive cases suchas the 4 × 4 64-QAM configuration where N = 4, Keplerachieved a speedup of 1.7× over Fermi.
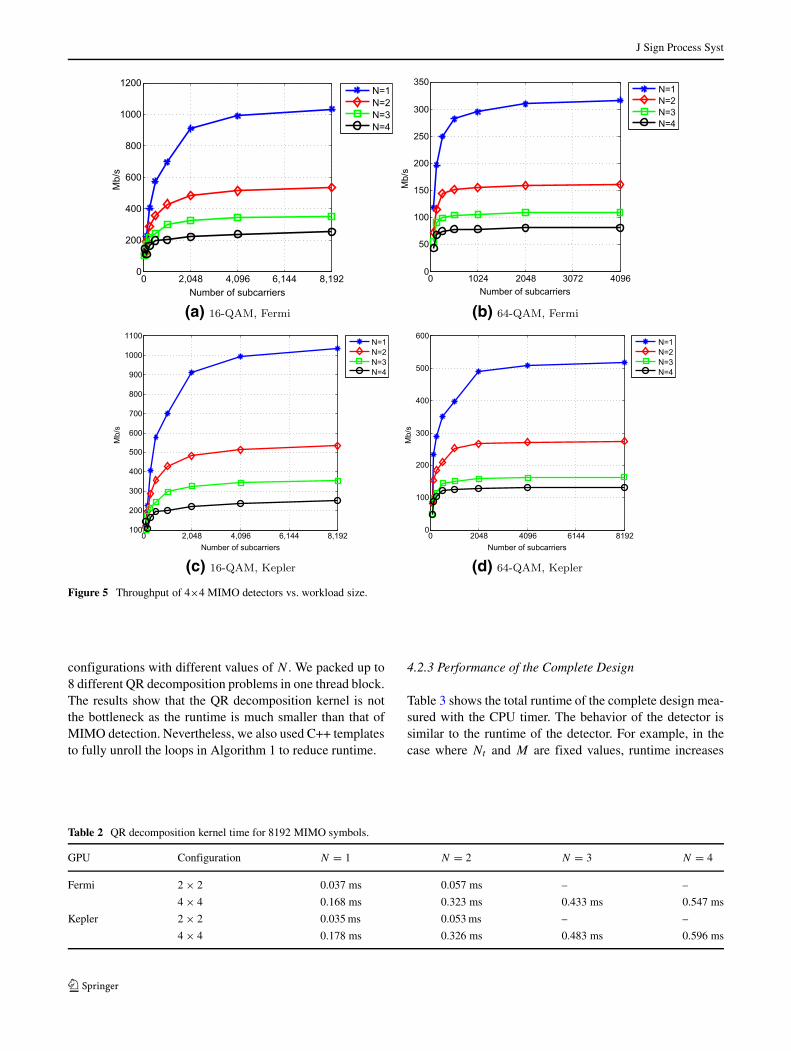
We used a large number of subcarriers to report peakthroughput. However, we do not need an extremely largenumber of subcarriers to achieve throughput close to thepeak performance. Figure 5 shows throughput as a functionof the number of subcarriers. We see that in all of thesecases, the throughput starts to plateau after 2048 subcarriers.
4.2.2 QR Decomposition Kernel
An N -way Parallel MIMO Detection requiresN QR decom-positions on an input y and H to generate inputs for thedetector. Table 2 shows the results for 2×2 and 4×4 MIMO
Table 1 MIMO Detection kernel time for 8192 MIMO symbols.
GPU Configuration N = 1 N = 2 N = 3 N = 4
Fermi 2 × 2, 16-QAM 0.069 ms/946.8 Mb/s 0.127 ms/511.5 Mb/s – –
4 × 4, 16-QAM 0.117 ms/1122.7 Mb/s 0.323 ms/406.0 Mb/s 0.433 ms/302.2 Mb/s 0.547 ms/239.7 Mb/s
2 × 2, 64-QAM 0.480 ms/204.2 Mb/s 0.953 ms/102.8 Mb/s – –
4 × 4, 64-QAM 0.602 ms/325.80 Mb/s 1.190 ms/164.7 Mb/s 1.75 ms/111.7 Mb/s 2.560 ms/76.5 Mb/s
Kepler 2 × 2, 16-QAM 0.049 ms/1315.1 Mb/s 0.093 ms/701.1 Mb/s – –
4 × 4, 16-QAM 0.126 ms/1036.8 Mb/s 0.245 ms/533.7 Mb/s 0.372 ms/351.7 Mb/s 0.515 ms/254.2 Mb/s
2 × 2, 64-QAM 0.231 ms/423.7 Mb/s 0.477 ms/205.5 Mb/s – –
4 × 4, 64-QAM 0.378 ms/519.2 Mb/s 0.713 ms/274.9 Mb/s 1.203 ms/162.92 Mb/s 1.467 ms/133.61 Mb/s
J Sign Process Syst
(a) (b)
(c) (d)
Figure 5 Throughput of 4×4 MIMO detectors vs. workload size.
configurations with different values of N . We packed up to8 different QR decomposition problems in one thread block.The results show that the QR decomposition kernel is notthe bottleneck as the runtime is much smaller than that ofMIMO detection. Nevertheless, we also used C++ templatesto fully unroll the loops in Algorithm 1 to reduce runtime.
4.2.3 Performance of the Complete Design
Table 3 shows the total runtime of the complete design mea-sured with the CPU timer. The behavior of the detector issimilar to the runtime of the detector. For example, in thecase where Nt and M are fixed values, runtime increases
Table 2 QR decomposition kernel time for 8192 MIMO symbols.
GPU Configuration N = 1 N = 2 N = 3 N = 4
Fermi 2 × 2 0.037 ms 0.057 ms – –
4 × 4 0.168 ms 0.323 ms 0.433 ms 0.547 ms
Kepler 2 × 2 0.035 ms 0.053 ms – –
4 × 4 0.178 ms 0.326 ms 0.483 ms 0.596 ms
J Sign Process Syst
Table 3 Total runtime for 8192 MIMO symbols including data transport time.
GPU Configuration N = 1 N = 2 N = 3 N = 4
Fermi 2 × 2, 16-QAM 0.340 ms/191.1 Mb/s 0.440 ms/147.7 Mb/s – –
4 × 4, 16-QAM 0.890 ms/147.2 Mb/s 1.130 ms/115.9 Mb/s 1.360 ms/ 96.3 Mb/s 1.640 ms/79.9 Mb/s
2 × 2, 64-QAM 0.820 ms/119.5 Mb/s 1.350 ms/72.6 Mb/s – –
4 × 4, 64-QAM 1.560 ms/125.6 Mb/s 2.180 ms/89.9 Mb/s 2.950 ms/66.4 Mb/s 3.870 ms/0.6 Mb/s
Kepler 2 × 2, 16-QAM 0.290 ms/224.3 Mb/s 0.220 ms/145.3 Mb/s – –
4 × 4, 16-QAM 0.698 ms/188.0 Mb/s 0.925 ms/141.6 Mb/s 1.209 ms/108.3 Mb/s 1.460 ms/89.7 Mb/s
2 × 2, 64-QAM 0.489 ms/200.5 Mb/s 0.779 ms/125.8 Mb/s – –
4 × 4, 64-QAM 0.986 ms/198.9 Mb/s 1.432 ms/136.9 Mb/s 2.068 ms/ 94.8 Mb/s 2.460 ms/79.6 Mb/s
as N increases. However, due to constant overhead such astransport time, runtime is no longer linearly proportional toN . We note that the total runtime results are pessimistic.Using CUDA streams, data transfers can be overlapped withcomputation to further increase the throughput.
4.2.4 Comparison with Existing Work
We compare the kernel time of our MIMO detector withthe kernel times of other soft-output MIMO detectionimplementations in Table 4.
We compared the N = 4 case against the soft-outputtrellis-based MIMO detector [19] and the fully parallelfixed complexity-sphere detector (FPFSD) [14]. As shownin Section 4.1, the error-rate performance of the N = 4case is better than the BER performance of soft-outputtrellis MIMO detector and is similar to the BER perfor-mance of FPFSD. To compare these detectors, we alsoprovided throughput normalized by core count and corefrequency.
Compared to N -way MIMO detection, trellis basedMIMO detection [19] requires more instructions. For trellisbased MIMO detection, the number of instructions requiredto find the best path out of M possible paths scales with
modulation order M . By comparison, N -way detection usesa round and threshold function to find the best outgo-ing path. As a result, the number of instructions requiredto find the best outgoing path is constant and does notdepend on M . Consequently, particularly for higher mod-ulation orders, the N -way MIMO detector achieves highernormalized throughput than that of the trellis-based MIMOdetector.
The work that is the most similar to ours is the FPFSDin [14], which uses a similar detector on the same GPU.We emphasize, however, that the throughput of FPFSD islower than that of our work. In our design, we performdetection in the real domain through RVD, while FPFSDperforms MIMO detection in the complex domain. Wedo not expect this to cause a large throughput difference,as RVD does not reduce the computation complexity. Webelieve there are two key differences between our detec-tor and the FPFSD. First, in our design, we store thecandidate list in registers to reduce the number of devicememory accesses. For FPFSD, the candidate list is storedin device memory which increases the number of slowdevice memory accesses. Second, we reduce the numberof instructions by aggressively unrolling loops in our ker-nels. This is not straightforward; we used C++ templates
Table 4 Throughput comparison of the MIMO detection kernel with other GPU MIMO detectors.
Detector type GPU Configuration Throughput Normalized throughput
[Mb/s] [(Mb/s)/(Core×GHz)]
Trellis-based [19] Telsa C1060 4 × 4, 16-QAM 122.03 0.422
4 × 4, 64-QAM 12.05 0.042
FPFSD [14] Tesla C2070 4 × 4, 16-QAM 92.39 0.179
4 × 4, 64-QAM 17.20 0.033
N-way, N = 4 GTX 470 4 × 4, 16-QAM 239.7 0.440
4 × 4, 64-QAM 76.50 0.141

J Sign Process Syst
to automatically unroll loops for different MIMO detec-tor configurations (see Section 4.2.1). These optimizationswere not done for the FPFSD detector. As a result, weachieved higher normalized throughput than that of theFPFSD detector.
5 Conclusion
In this paper, we have presented a novel parallel highthroughput MIMO detector algorithm that maps well ontoNvidia GPU architectures. We have implemented the pro-posed N-way MIMO detector on both the NVIDIA Fermiand Kepler GPUs, and have shown that our proposeddetector outperforms existing GPU-based MIMO detectorsin terms of detection throughput. Furthermore, we haveshown that by changing the number of parallel candidatesearches, our MIMO detector provides a wide range ofdetection options: from a design that provides excellenterror-rate performance (within 0.25 dB of the soft-outputmax-log-MAP detector) to an extreme high-throughputdesign that achieves several hundred Mb/s to Gb/s detectionthroughput.
Acknowledgments This work was supported in part by RenesasMobile, Texas Instruments, Xilinx, Samsung, Huawei, and by theUS National Science Foundation under grants CNS-1265332, ECCS-1232274, EECS-0925942 and CNS-0923479.
References
1. Amiri, K., Cavallaro, J.R., Dick, C., Rao, R.M. (2011). A highthroughput configurable SDR detector for multi-user MIMO wire-less systems. Journal of Signal Processing Systems, 62, 233–245.
2. Barbero, L.G., & Thompson, J.S. (2006). A fixed-complexityMIMO detector based on the complex sphere decoder. In: IEEEinternational workshop on signal processing advances in wirelesscommunications (SPAWC). IEEE.
3. Burg, A., Borgmann, M., Wenk, M., Zellweger, M., Fichtner,W., Bolcskei, H. (2005). VLSI implementation of MIMO detec-tion using the sphere decoding algorithm. Journal of Solid-StateCircuits, 40, 1566–1577.
4. Burg, A., Haene, S., Perels, D., Luethi, P., Felber, N., Fichtner, W.(2006). Algorithm and VLSI architecture for linear MMSE detec-tion in MIMO-OFDM systems. In: IEEE international symposiumon circuits and systems (ISCAS) (pp. 4012–4105). IEEE.
5. Hess, C., Wenk, M., Burg, A., Luethi, P., Studer, C., Felber, N.,Fichtner, W. (2007). Reduced-complexity MIMO detector withclose-to ML error rate performance. In: Proceedings of the 17thACM great lakes symposium on VLSI (pp. 200–203).
6. Hochwald, B., & ten Brink, S. (2003). Achieving near-capacity ona multiple-antenna channel. IEEE Transactions on Communica-tions, 51, 389–399.
7. Janhunen, J., Silven, O., Juntti, M., Myllyla, M. (2008). Soft-ware defined radio implementation of K-best list sphere detectoralgorithm. In: International conference on embedded computersystems: Architectures, modeling, and simulation (SAMOS) (pp.100–107).
8. Karypis, G., & Kumar, V. (1994). Unstructured tree search onSIMD parallel computers. IEEE Transactions on Parallel andDistributed Systems, 5(10), 1057–1072.
9. Kerr, A., Campbell, D., Richards, M. (2009). QR decompositionon GPUs. In: Proceedings of 2nd workshop on GPGPU (pp. 71–78). ACM.
10. Li, M., Bougard, B., Lopez, E., Bourdoux, A., Novo, D., Van DerPerre, L., Catthoor, F. (2008). Selective spanning with fast enu-meration: A near maximum-likelihood MIMO detector designedfor parallel programmable baseband architectures. In: IEEE inter-national conference on communications (ICC) (pp. 737–741).IEEE.
11. Michalke, C., Zimmermann, E., Fettweis, G. (2006). LinearMIMO receivers vs. tree search detection: A performancecomparison overview. In: International symposium on personal,indoor and mobile radio communications (PIMRC).IEEE.
12. NVIDIA Corporation (2008). CUDA compute unified devicearchitecture programming guide. http://www.nvidia.com/object/cuda develop.html.
13. Qi, Q., & Chakrabarti, C. (2010). Parallel high throughput soft-output sphere decoder. In: IEEE workshop on signal processingsystems (SiPS) (pp. 50–55). IEEE.
14. Roger, S., Ramiro, C., Gonzalez, A., Almenar, V., Vidal, A.(2012). Fully parallel GPU implementation of a fixed-complexitysoft-output MIMO detector. IEEE Transactions on Vehicular Tech-nology, 61, 3796–3800.
15. Schnorr, C., & Euchner, M. (1993). Lattice basis reduction:Improved practical algorithms and solving subset sum problems.Mathematical Programming, 66, 181–191.
16. Studer, C., Burg, A., Bolcskei, H. (2005). Soft-output spheredecoding: Algorithms and VLSI implementation. IEEE Journalon Selected Areas in Communications, 26(2), 290–300.
17. Trefethen, L., & Bau, D. (1997). Numerical linear algebra. SIAM:Society for Industrial and Applied Mathematics.
18. Wong, K., Tsui, C., Cheng, R., Mow, W. (2002). A VLSI architec-ture of a K-best lattice decoding algorithm for MIMO channels.IEEE international symposium on circuits and systems (ISCAS),3, 273–276.
19. Wu, M., Sun, Y., Gupta, S., Cavallaro, J.R. (2011). Implementa-tion of a high throughput soft MIMO detector on GPU. Journal ofSignal Processing Systems, 64(1), 123–136.
20. Wu, M., Dick, C., Sun, Y., Cavallaro, J. (2011a). ImprovingMIMO sphere detection through antenna detection order schedul-ing. In: Software defined radio forum (SDR-WInnComm) (pp.280–284).
21. Wu, M., Sun, Y., Wang, G., Cavallaro, J. (2011b). Implementa-tion of a high throughput 3GPP turbo decoder on GPU. Journal ofSignal Processing Systems, 171–183.
22. Wu, M., Yin, B., Cavallaro, J.R. (2012). Flexible N-way MIMOdetector on GPU. In: IEEE workshop on signal processing systems(SiPS) (pp. 318–323). IEEE.
23. Wubben, D., Bohnke, R., Kuhn, V., Kammeyer, K.D. (2004).Near-maximum-likelihood detection of MIMO systemsusing MMSE-based lattice reduction. In: IEEE interna-tional conference on communications (vol. 2, pp. 798–802).IEEE.

J Sign Process Syst
Michael Wu received hisB.S. degree from Franklin W.Olin College of Engineeringin May of 2007 and his M.S.degree from Rice University inMay of 2010, both in Electri-cal and Computer Engineer-ing. He is currently a Ph.Dcandidate in the Department ofElectrical and Computer Engi-neering at Rice University,Houston, Texas. His researchinterests are wireless algo-rithms, software defined radioon GPGPU and other parallelarchitectures, and high perfor-mance wireless receiverdesigns.
Bei Yin received his B.S.degree in Electrical Engineer-ing from Beijing Universityof Technology, Beijing, China,in 2002, and his M.S. degreein Electrical Engineering fromRoyal Institute of Technol-ogy, Stockholm, Sweden, in2005. He is currently a Ph.D.student in the Department ofElectrical and Computer Engi-neering at Rice University,Houston, Texas. His researchinterests include VLSI sig-nal processing and wirelesscommunications.
Guohui Wang received theB.S. degree in electrical engi-neering from Peking Univer-sity, Beijing, China, and theM.S. degree in computer sci-ence from the Institute ofComputing Technology, Chi-nese Academy of Sciences,Beijing, China. Since 2008, hehas been working towards thePh.D. degree in Departmentof Electrical and ComputerEngineering, Rice University,Houston, Texas. His researchinterests include mobile com-puting, digital signal proces-sing, and VLSI architecturefor wireless communicationsystems.
Christoph Studer receivedhis Ph.D. degree in Informa-tion Technology and Electri-cal Engineering from ETHZurich in 2009. In 2005, hewas a Visiting Researcher withthe Smart Antennas ResearchGroup at Stanford University.From 2006 to 2009, he wasa Research Assistant in boththe Integrated Systems Lab-oratory and the Communica-tion Technology Laboratory atETH Zurich. From 2009 to2012, Dr. Studer was a Post-doctoral Researcher at CTL,
ETH Zurich, and the Digital Signal Processing Group at Rice Univer-sity. In 2013, he has held the position of Research Scientist at RiceUniversity. Since 2014, Dr. Studer is an Assistant Professor at CornellUniversity. Dr. Studer’s research interests include the design of digitalvery large-scale integration (VLSI) circuits and systems for wirelesscommunication systems, as well as signal and image processing, con-vex optimization, and compressive sensing. Dr. Studer received ETHMedals for his M.S. and Ph.D. theses, and he collected various acco-lades for academic achievement including several best paper and bestdemo awards. In addition, he received a two-year Swiss National Sci-ence Foundation fellowship for Advanced Researchers in 2011 andhe shared the Swisscom/ICTnet Innovations Award in both 2010 and2013.

J Sign Process Syst
Joseph R. Cavallaro recei-ved the B.S. degree fromthe University of Pennsylva-nia, Philadelphia, Pa, in 1981,the M.S. degree from Prince-ton University, Princeton, NJ,in 1982, and the Ph.D. degreefrom Cornell University, Itha-ca, NY, in 1988, all in electri-cal engineering. From 1981 to1983, he was with AT&T BellLaboratories, Holmdel, NJ. In1988, he joined the faculty ofRice University, Houston, TX,where he is currently a Profes-sor of electrical and computer
engineering. His research interests include computer arithmetic, andDSP, GPU, FPGA, and VLSI architectures for applications in wirelesscommunications. During the 1996–1997 academic year, he served atthe National Science Foundation as Director of the Prototyping Toolsand Methodology Program. He was a Nokia Foundation Fellow and aVisiting Professor at the University of Oulu, Finland in 2005 and con-tinues his affiliation there as an Adjunct Professor. He is currently theDirector of the Center for Multimedia Communication at Rice Univer-sity. He is a Senior Member of the IEEE and a Member of the IEEESPS TC on Design and Implementation of Signal Processing Systemsand the IEEE CAS TC on Circuits and Systems for Communications.He is currently an Associate Editor of the IEEE Transactions on Sig-nal Processing, the IEEE Signal Processing Letters, and the Journalof Signal Processing Systems. He was Co-chair of the 2004 SignalProcessing for Communications Symposium at the IEEE Global Com-munications Conference and General/Program Co-chair of the 2003,2004, and 2011 IEEE International Conference on Application- Spe-cific Systems, Architectures and Processors (ASAP), General/ProgramCo-chair for the 2012, 2014 ACM/IEEE GLSVLSI, and Finance Chairfor the 2013 IEEE GlobalSIP conference.





























