Embed Size (px)
Citation preview


Domain BackgroundThe ImplementationsExperimental Results
Outline
1 Domain BackgroundSpin GlassFrustration
2 The Implementations
3 Experimental ResultsPerformance ComparisonSimulation result
Y. Fang, S. Feng et al.

Domain BackgroundThe ImplementationsExperimental Results
Spin GlassFrustration
Edwards-Anderson Spin Glass model
L
3 Cubic Lattice
E = �X
<i,j>
S
i
J
ij
S
j
� h
X
i
S
i
S
i
: Spin, ±1J
ij
: Interaction, ±1J = �1Ferromagnetic OrderingJ = +1Antiferromagnetic OrderingJ = Random
Spin Glass
Y. Fang, S. Feng et al.

Domain BackgroundThe ImplementationsExperimental Results
Spin GlassFrustration
Edwards-Anderson Spin Glass model
L
3 Cubic Lattice
E = �X
<i,j>
S
i
J
ij
S
j
� h
X
i
S
i
S
i
: Spin, ±1J
ij
: Interaction, ±1
J = �1Ferromagnetic OrderingJ = +1Antiferromagnetic OrderingJ = Random
Spin Glass
Y. Fang, S. Feng et al.

Domain BackgroundThe ImplementationsExperimental Results
Spin GlassFrustration
Edwards-Anderson Spin Glass model
L
3 Cubic Lattice
E = �X
<i,j>
S
i
J
ij
S
j
� h
X
i
S
i
S
i
: Spin, ±1J
ij
: Interaction, ±1J = �1Ferromagnetic Ordering
J = +1Antiferromagnetic OrderingJ = Random
Spin Glass
Y. Fang, S. Feng et al.

Domain BackgroundThe ImplementationsExperimental Results
Spin GlassFrustration
Edwards-Anderson Spin Glass model
L
3 Cubic Lattice
E = �X
<i,j>
S
i
J
ij
S
j
� h
X
i
S
i
S
i
: Spin, ±1J
ij
: Interaction, ±1J = �1Ferromagnetic OrderingJ = +1Antiferromagnetic Ordering
J = Random
Spin Glass
Y. Fang, S. Feng et al.

Domain BackgroundThe ImplementationsExperimental Results
Spin GlassFrustration
Edwards-Anderson Spin Glass model
L
3 Cubic Lattice
E = �X
<i,j>
S
i
J
ij
S
j
� h
X
i
S
i
S
i
: Spin, ±1J
ij
: Interaction, ±1J = �1Ferromagnetic OrderingJ = +1Antiferromagnetic OrderingJ = Random
Spin Glass
Y. Fang, S. Feng et al.

Domain BackgroundThe ImplementationsExperimental Results
Spin GlassFrustration
Ising Model
Consider an Anti-Ferromagnetic Ising Model
E = �X
<i,j>
J
ij
S
i
S
j
� h
X
i
S
i
, J
ij
= �1, h = 0
Ground state is the configuration that minimizes the energy.
e.g. Two spins e.g. Four Spins
For both examples the total energy can be minimized byminimizing the energy of every bond.
Y. Fang, S. Feng et al.

Domain BackgroundThe ImplementationsExperimental Results
Spin GlassFrustration
Frustration
E = �X
<i,j>
J
ij
S
i
S
j
� h
X
i
S
i
, h = 0
J
ij
= �1 J
ij
=Random
Geometrical Frustration Frustration due to randomness
Y. Fang, S. Feng et al.

Domain BackgroundThe ImplementationsExperimental Results
Spin GlassFrustration
Computational Challenges
Many aspects of this model are still poorly understood, despitethe intensive reseraches over the last few decades.
The randomness and frustration in the model lead to avery long equilibration time.We need to average over millions of disorder realizations.The simulation demands small memory but hugecomputations.
Y. Fang, S. Feng et al.
Domain BackgroundThe ImplementationsExperimental Results
Spin GlassFrustration
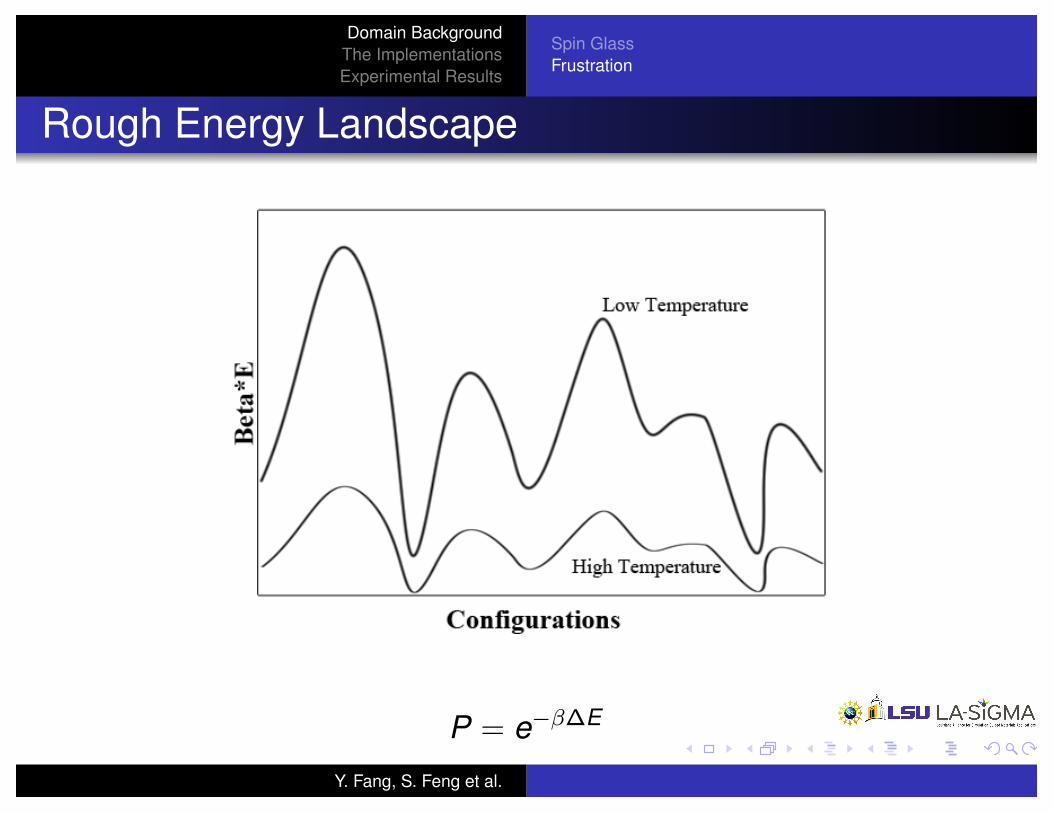
Rough Energy Landscape
P = e
���E
Y. Fang, S. Feng et al.
Domain BackgroundThe ImplementationsExperimental Results
Spin GlassFrustration
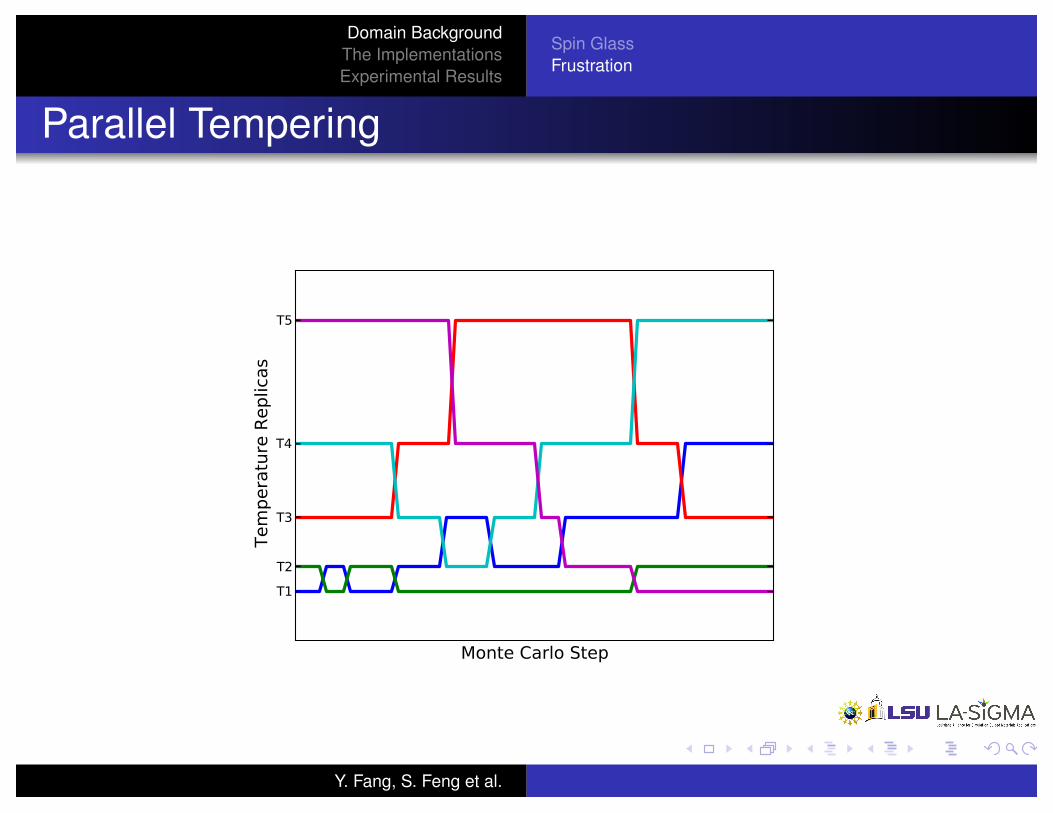
Parallel Tempering
Y. Fang, S. Feng et al.
Domain BackgroundThe ImplementationsExperimental Results
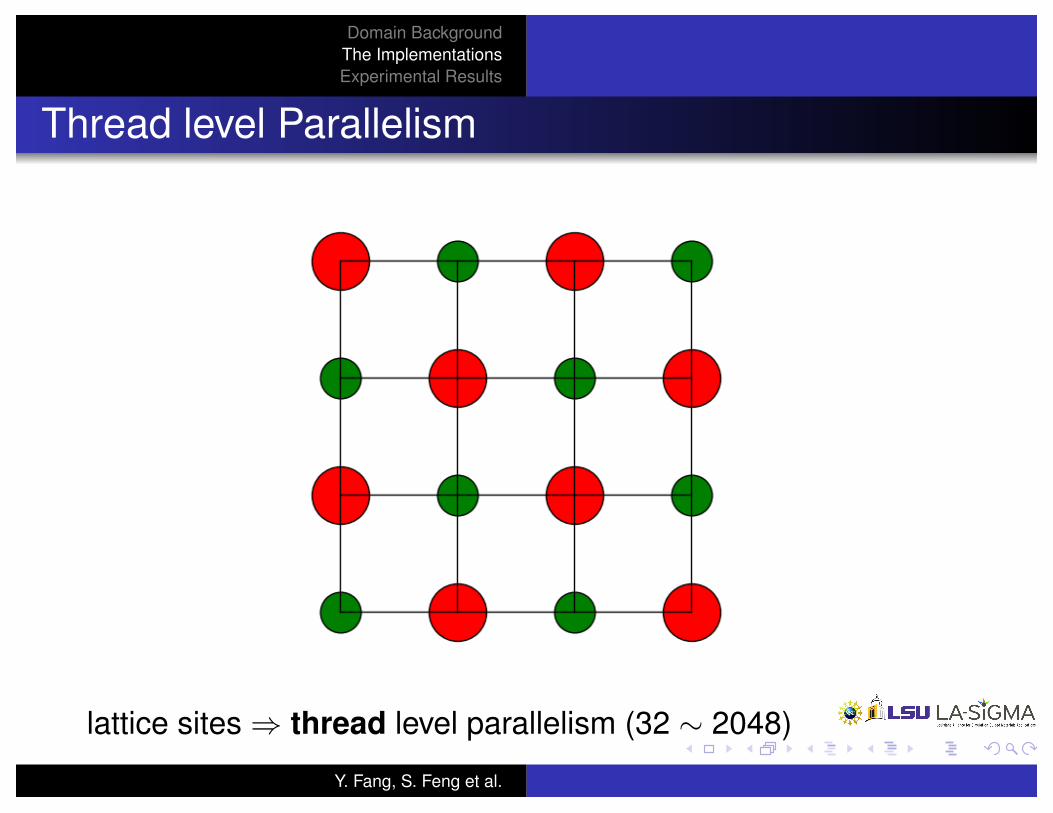
Thread level Parallelism
lattice sites ) thread level parallelism (32 ⇠ 2048)
Y. Fang, S. Feng et al.
Domain BackgroundThe ImplementationsExperimental Results
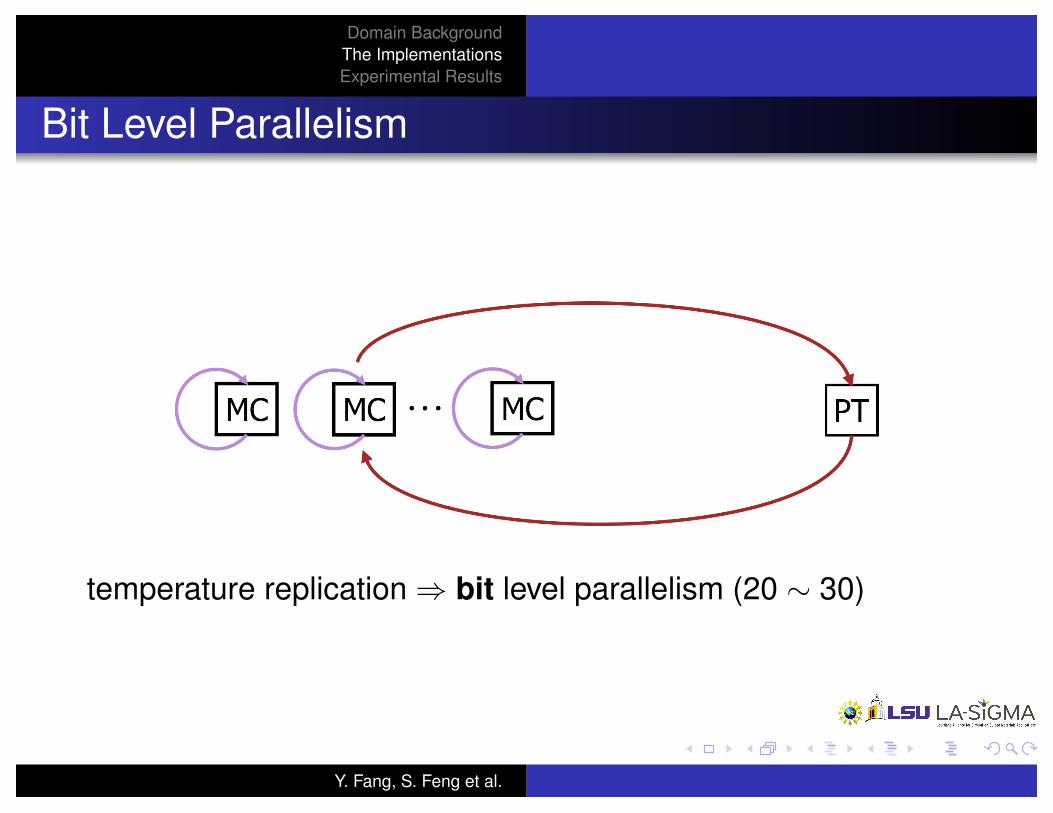
Bit Level Parallelism
temperature replication ) bit level parallelism (20 ⇠ 30)
Y. Fang, S. Feng et al.
Domain BackgroundThe ImplementationsExperimental Results
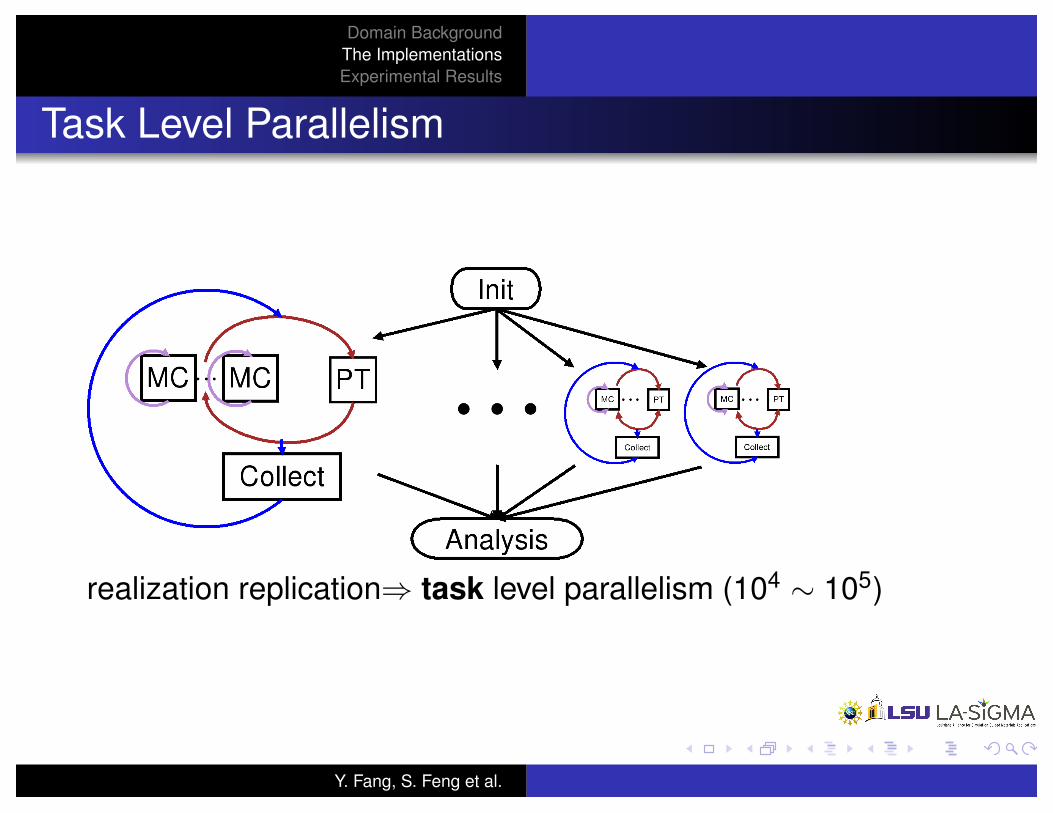
Task Level Parallelism
realization replication) task level parallelism (104 ⇠ 105)
Y. Fang, S. Feng et al.
Domain BackgroundThe ImplementationsExperimental Results
Memory Tiling
Y. Fang, S. Feng et al.
Domain BackgroundThe ImplementationsExperimental Results
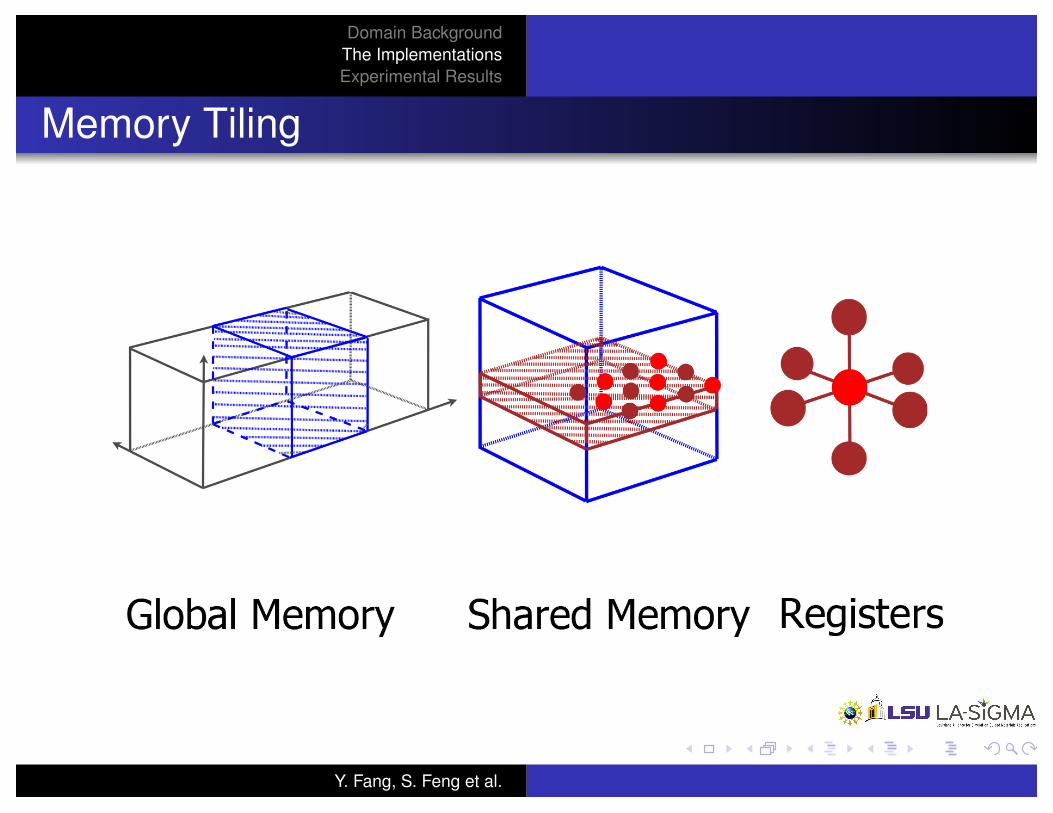
Memory Tiling
Y. Fang, S. Feng et al.
Domain BackgroundThe ImplementationsExperimental Results
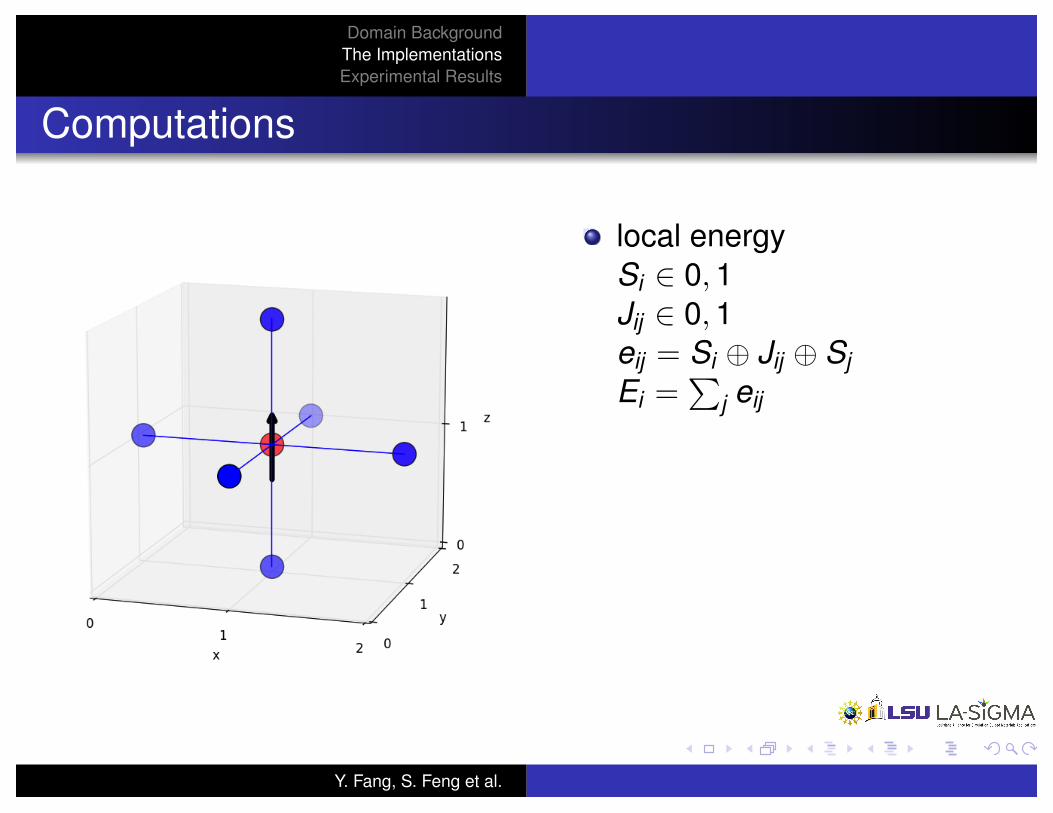
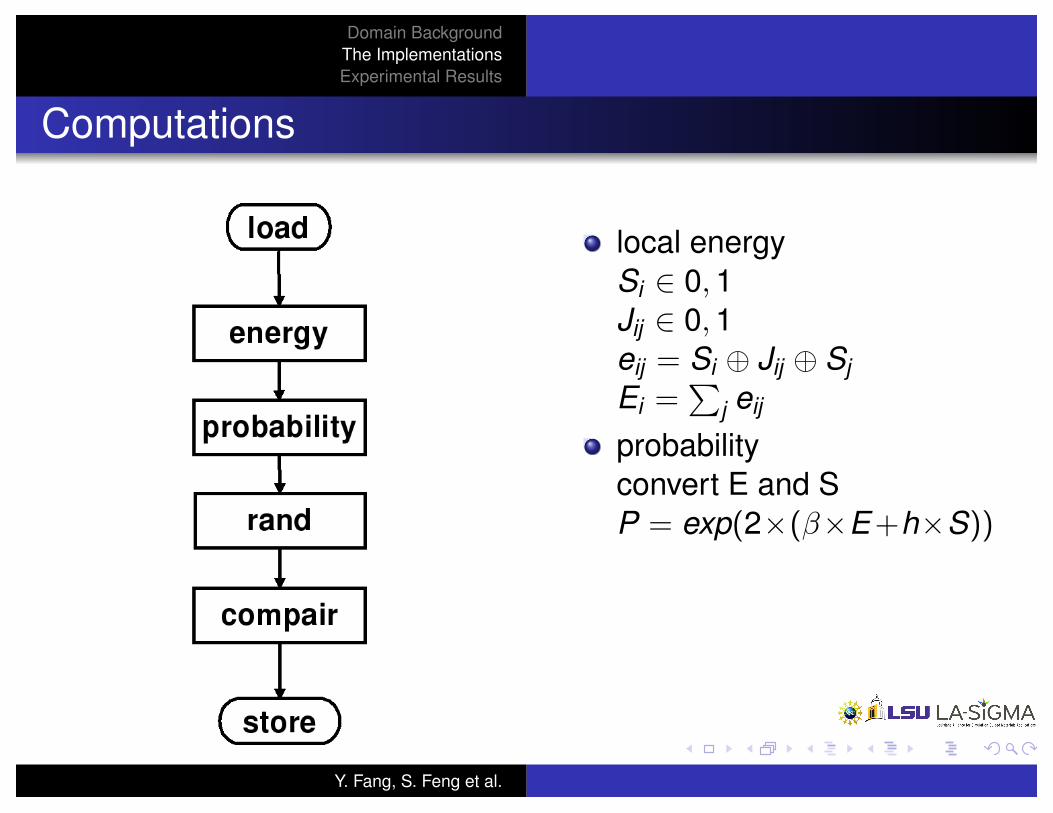
Computations
local energyS
i
2 0, 1J
ij
2 0, 1e
ij
= S
i
� J
ij
� S
j
E
i
=P
j
e
ij
probabilityconvert E and SP = exp(2⇥(�⇥E+h⇥S))
random numberR = rand()
updateflip = (R < P)
Y. Fang, S. Feng et al.
Domain BackgroundThe ImplementationsExperimental Results
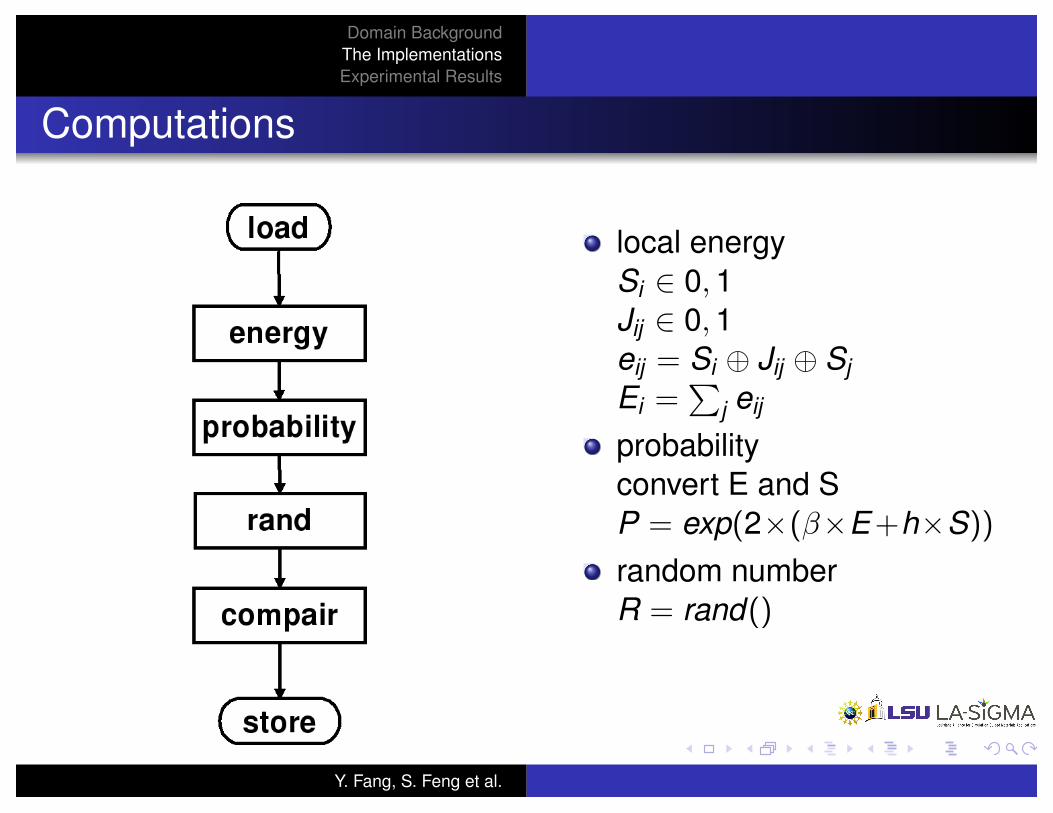
Computations
local energyS
i
2 0, 1J
ij
2 0, 1e
ij
= S
i
� J
ij
� S
j
E
i
=P
j
e
ij
probabilityconvert E and SP = exp(2⇥(�⇥E+h⇥S))
random numberR = rand()
updateflip = (R < P)
Y. Fang, S. Feng et al.
Domain BackgroundThe ImplementationsExperimental Results
Computations
local energyS
i
2 0, 1J
ij
2 0, 1e
ij
= S
i
� J
ij
� S
j
E
i
=P
j
e
ij
probabilityconvert E and SP = exp(2⇥(�⇥E+h⇥S))
random numberR = rand()
updateflip = (R < P)
Y. Fang, S. Feng et al.

Domain BackgroundThe ImplementationsExperimental Results
Computations
local energyS
i
2 0, 1J
ij
2 0, 1e
ij
= S
i
� J
ij
� S
j
E
i
=P
j
e
ij
probabilityconvert E and SP = exp(2⇥(�⇥E+h⇥S))
random numberR = rand()
updateflip = (R < P)
Y. Fang, S. Feng et al.
Domain BackgroundThe ImplementationsExperimental Results
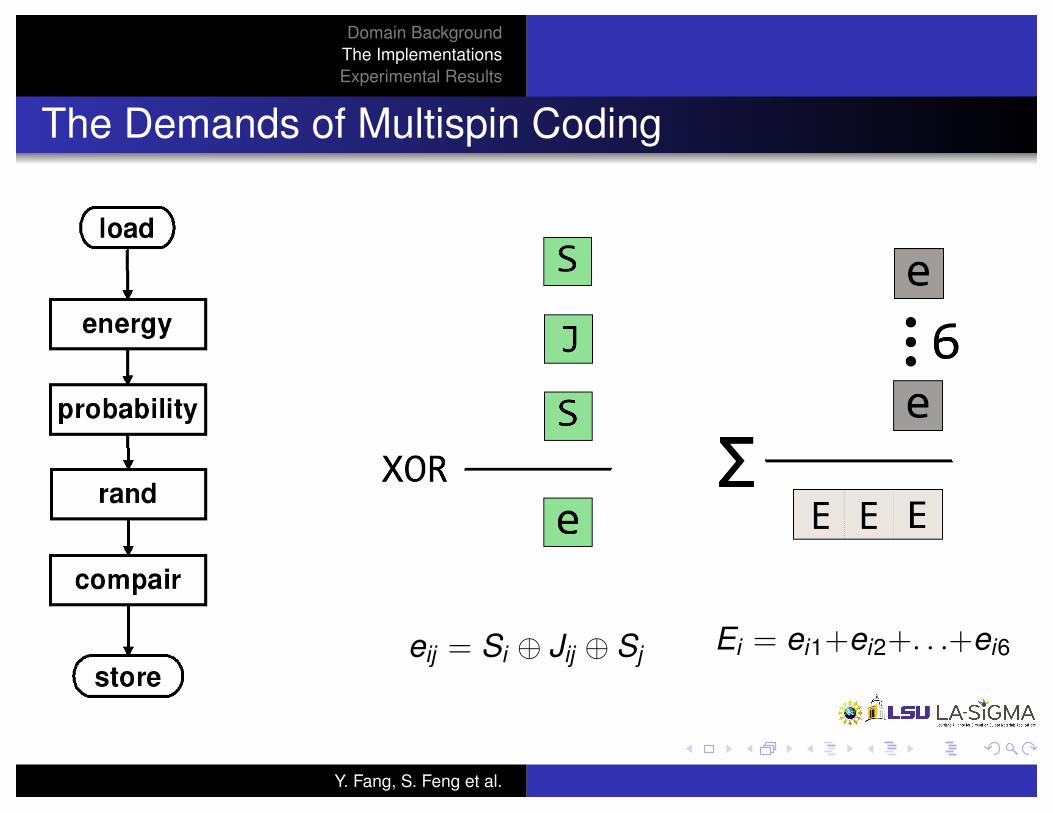
The Demands of Multispin Coding
e
ij
= S
i
� J
ij
� S
j
E
i
= e
i1+e
i2+. . .+e
i6
Y. Fang, S. Feng et al.
Domain BackgroundThe ImplementationsExperimental Results
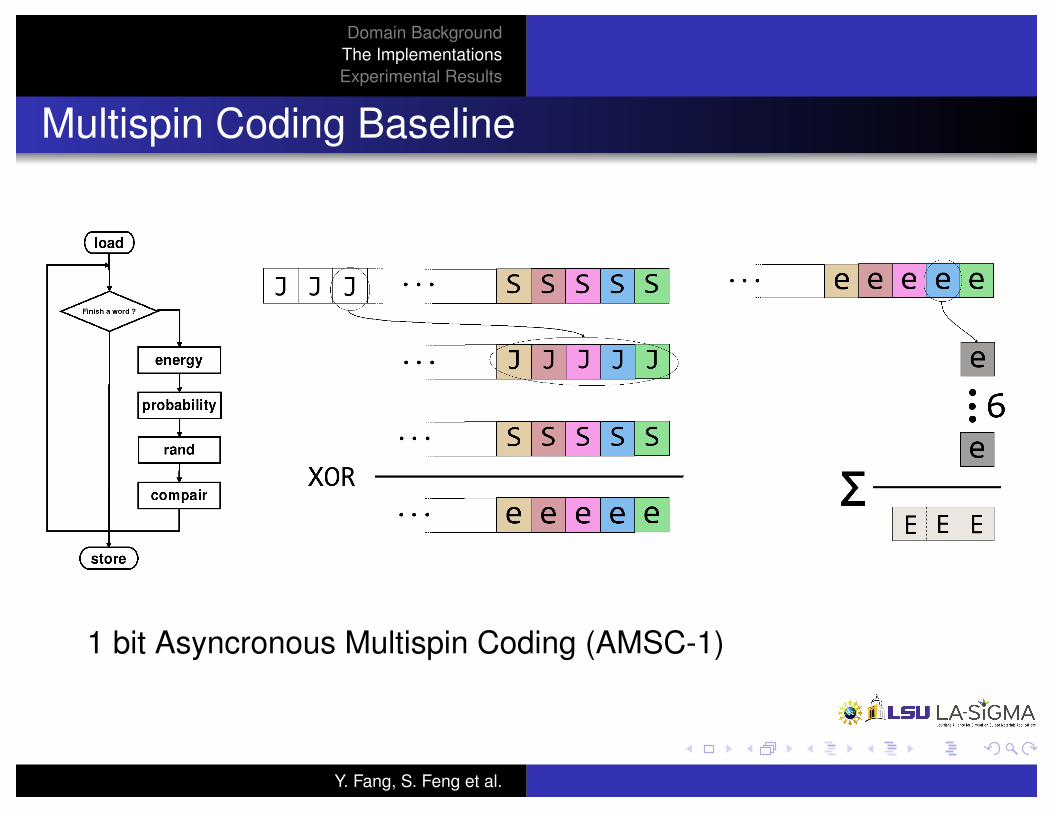
Multispin Coding Baseline
1 bit Asyncronous Multispin Coding (AMSC-1)
Y. Fang, S. Feng et al.
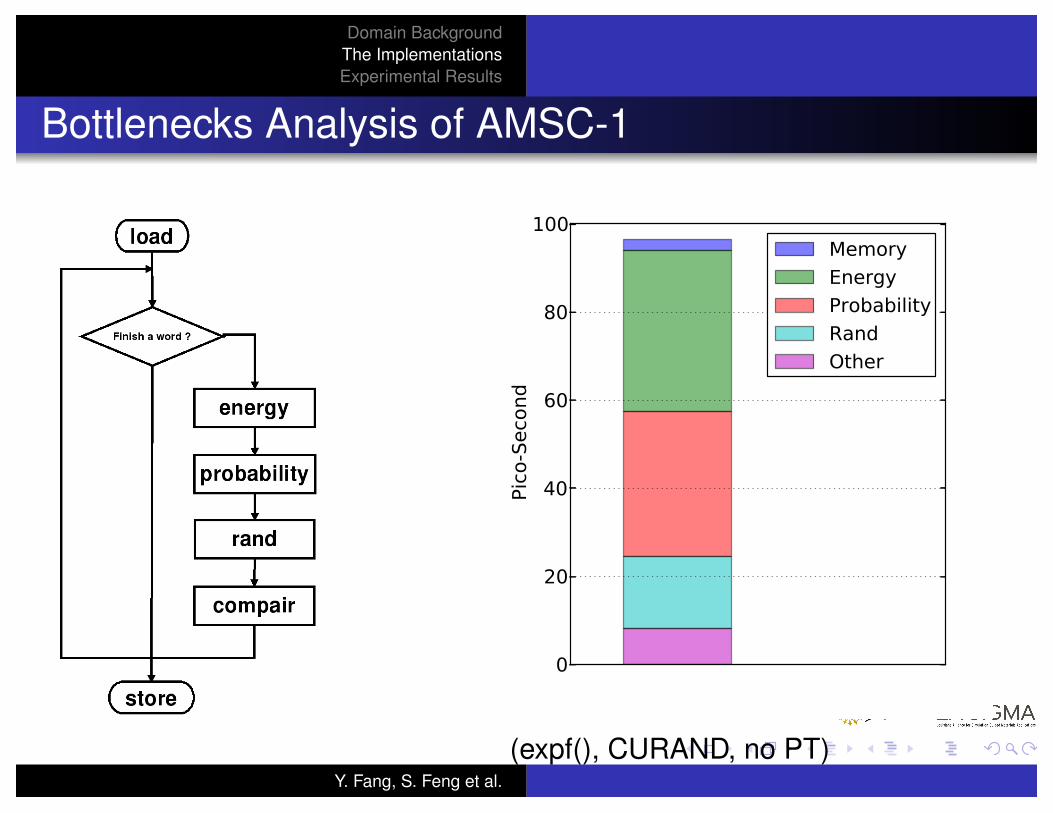
Domain BackgroundThe ImplementationsExperimental Results
Bottlenecks Analysis of AMSC-1
(expf(), CURAND, no PT)Y. Fang, S. Feng et al.
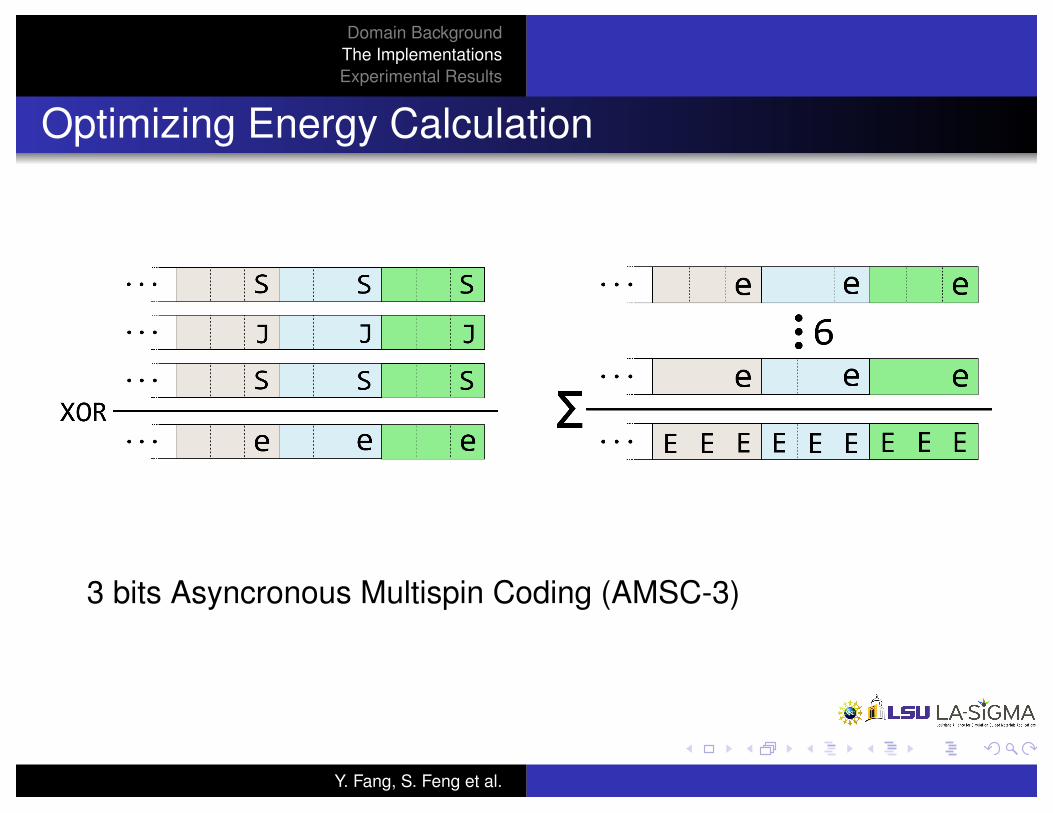
Domain BackgroundThe ImplementationsExperimental Results
Optimizing Energy Calculation
3 bits Asyncronous Multispin Coding (AMSC-3)
Y. Fang, S. Feng et al.
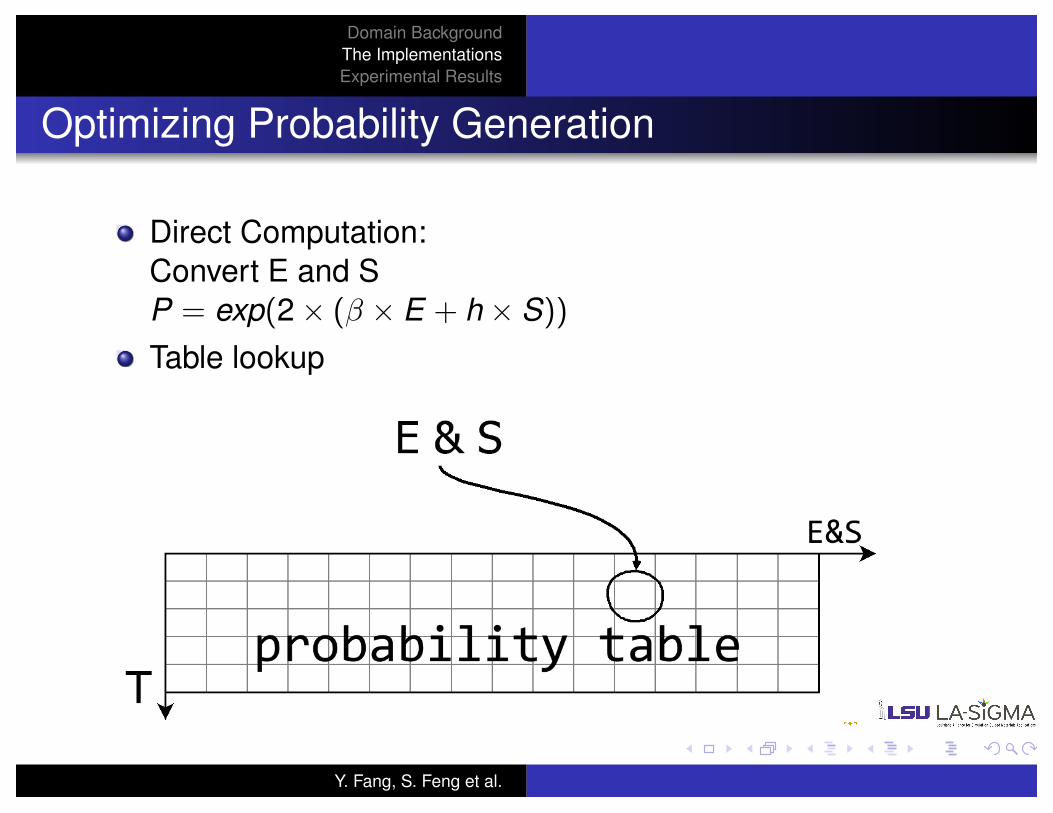
Domain BackgroundThe ImplementationsExperimental Results
Optimizing Probability Generation
Direct Computation:Convert E and SP = exp(2 ⇥ (� ⇥ E + h ⇥ S))
Table lookup
Y. Fang, S. Feng et al.
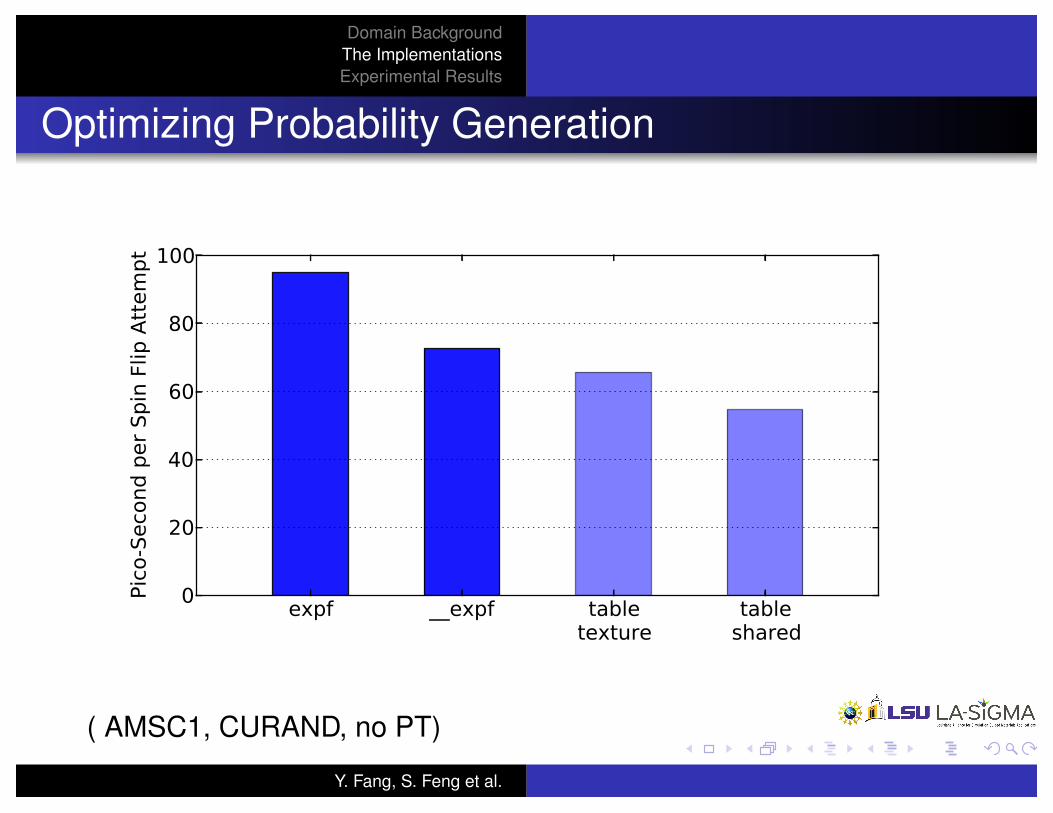
Domain BackgroundThe ImplementationsExperimental Results
Optimizing Probability Generation
( AMSC1, CURAND, no PT)
Y. Fang, S. Feng et al.

Domain BackgroundThe ImplementationsExperimental Results
Optimizing Probability Generation
Calculate table index more efficiently4 bits Asyncronous Multispin Coding (AMSC-4)
Y. Fang, S. Feng et al.
Domain BackgroundThe ImplementationsExperimental Results
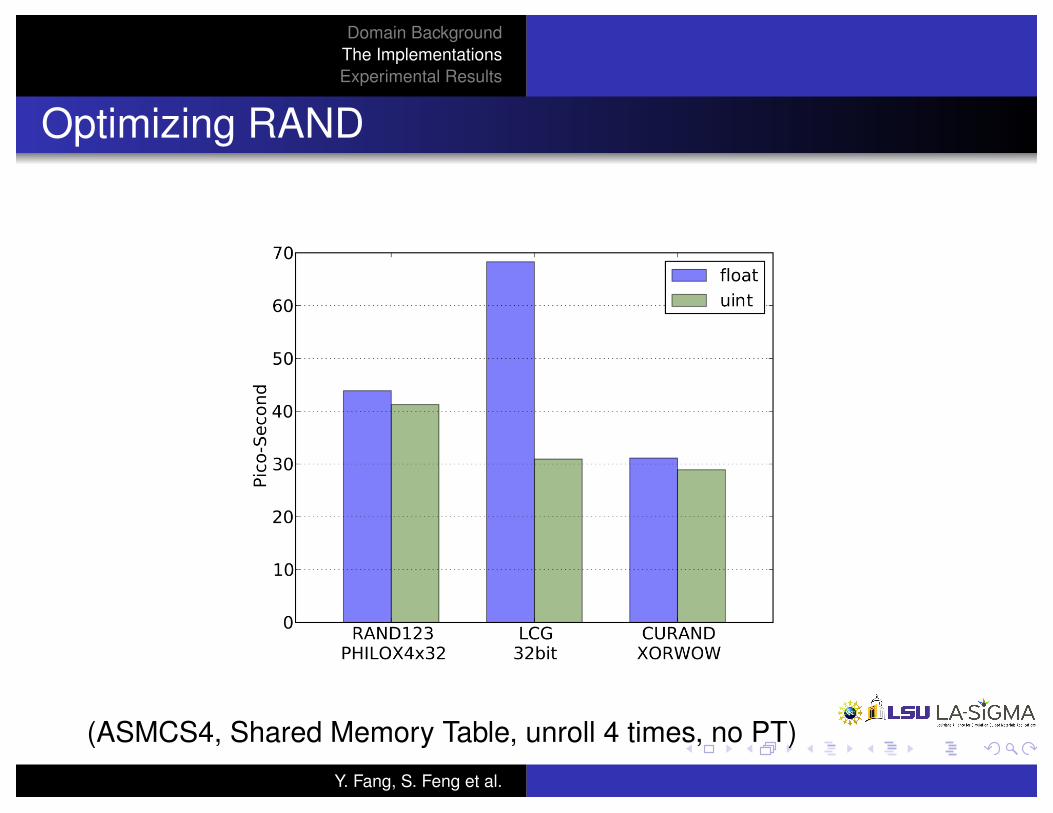
Optimizing RAND
(ASMCS4, Shared Memory Table, unroll 4 times, no PT)
Y. Fang, S. Feng et al.
Domain BackgroundThe ImplementationsExperimental Results
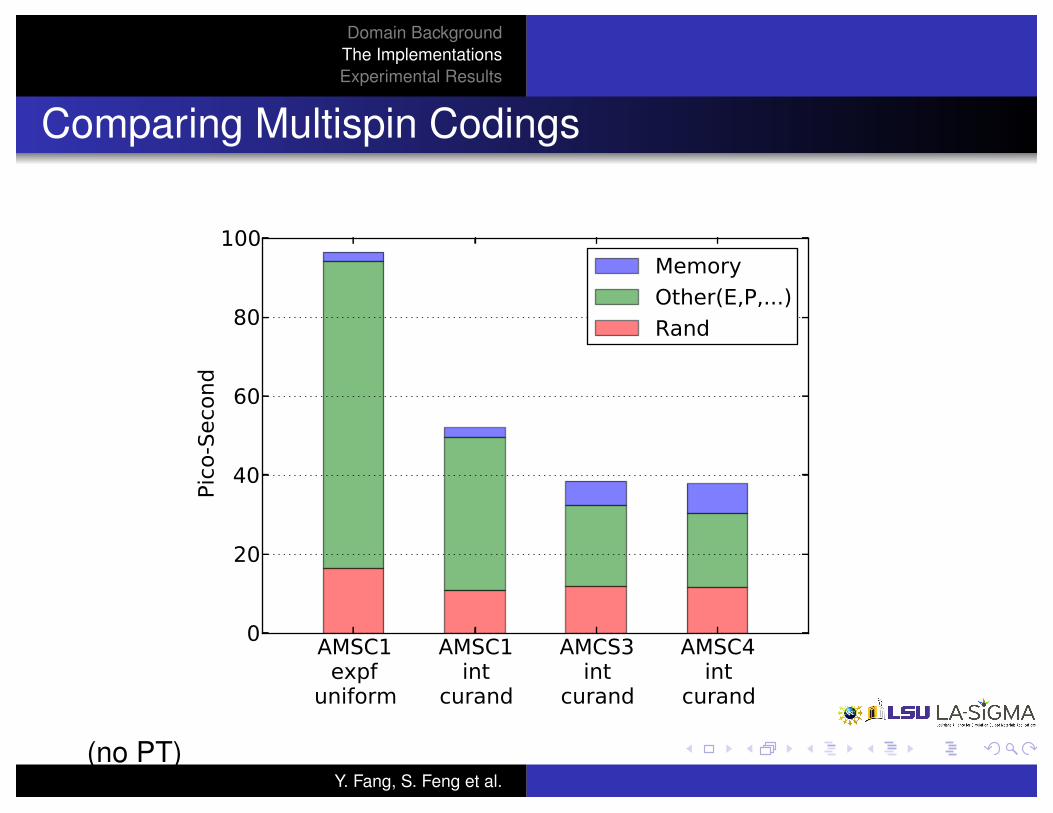
Comparing Multispin Codings
(no PT)Y. Fang, S. Feng et al.
Domain BackgroundThe ImplementationsExperimental Results
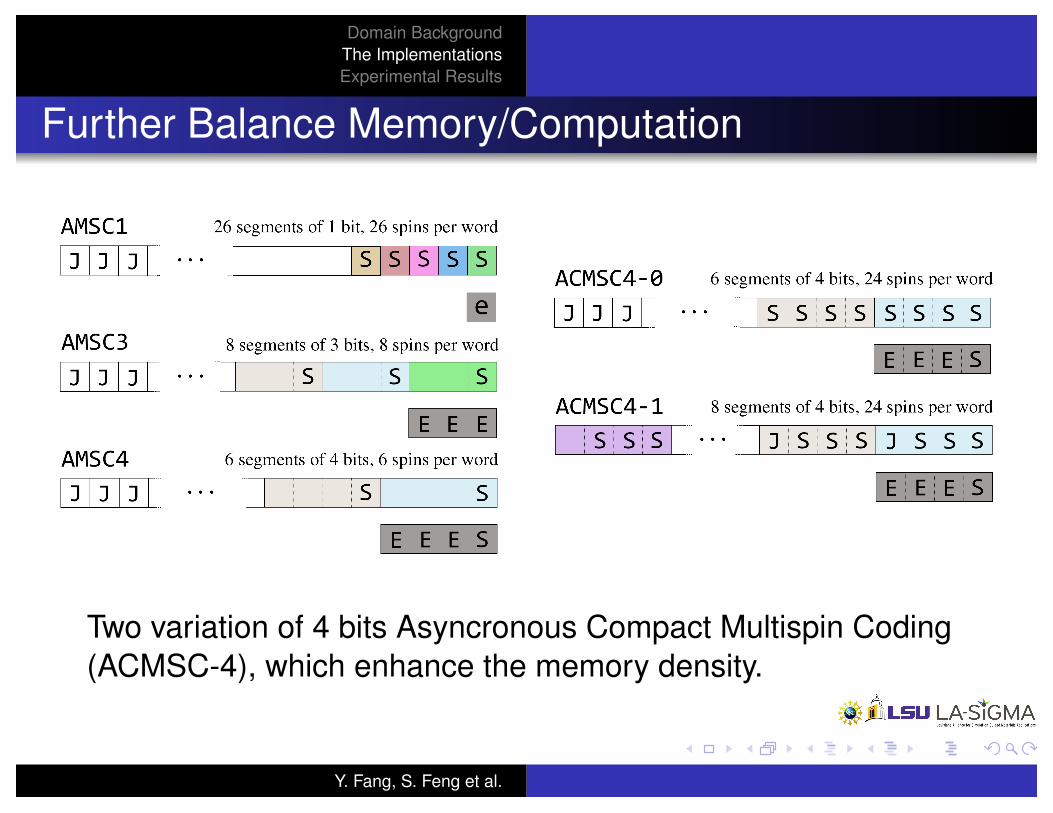
Further Balance Memory/Computation
Two variation of 4 bits Asyncronous Compact Multispin Coding(ACMSC-4), which enhance the memory density.
Y. Fang, S. Feng et al.
Domain BackgroundThe ImplementationsExperimental Results
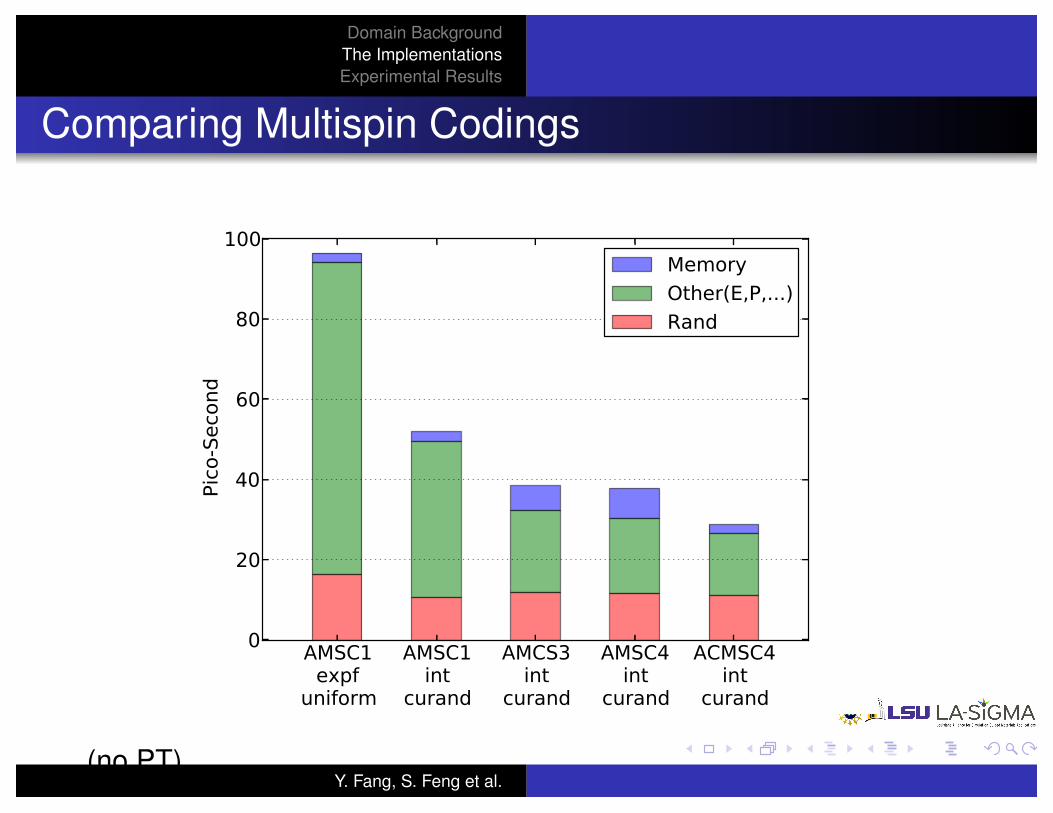
Comparing Multispin Codings
(no PT)Y. Fang, S. Feng et al.
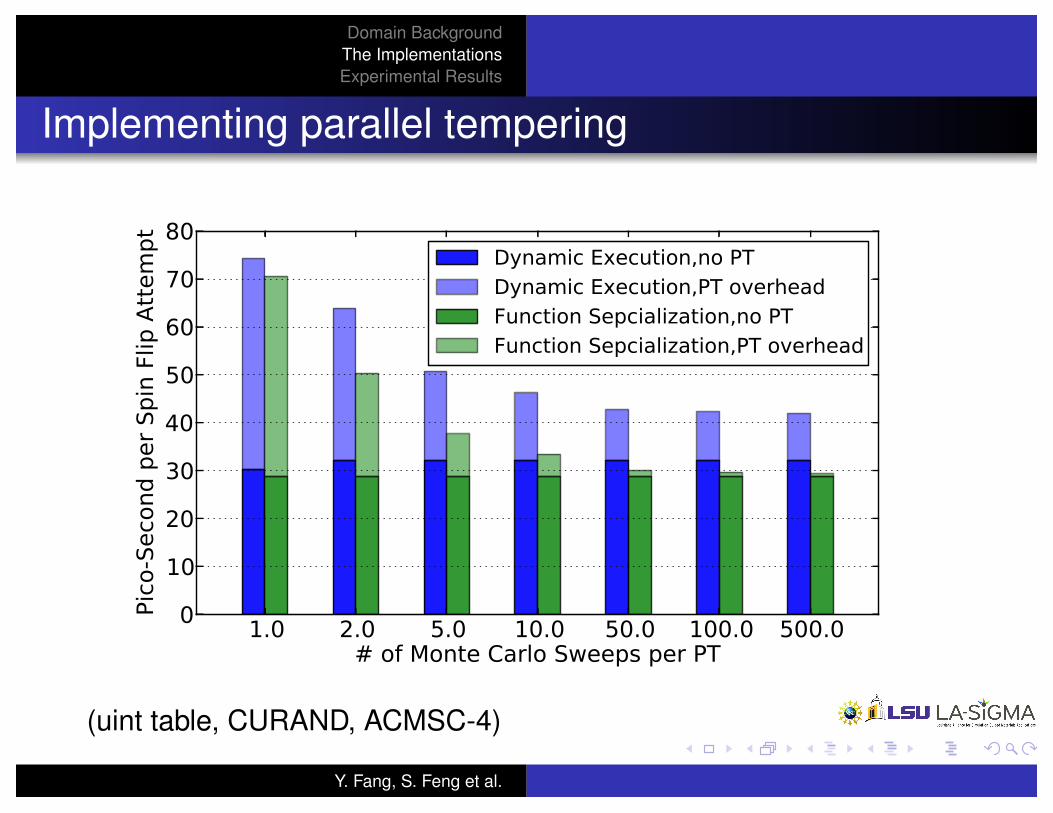
Domain BackgroundThe ImplementationsExperimental Results
Implementing parallel tempering
(uint table, CURAND, ACMSC-4)
Y. Fang, S. Feng et al.

Domain BackgroundThe ImplementationsExperimental Results
Conclusion on Optimizations
Minimize communications and maximize the kernel spanLattice sites ) thread level parallelism (32 ⇠ 2048)Temperature replicas ) bit level parallelism (20 ⇠ 30)Disorder realizations) task level parallelism (104 ⇠ 105)
Memory architecture awarenessEnable sub-word SIMDlization via proper data-typesTranslate time consuming computation to table lookup
Y. Fang, S. Feng et al.

Domain BackgroundThe ImplementationsExperimental Results
Conclusion on Optimizations
Minimize communications and maximize the kernel spanLattice sites ) thread level parallelism (32 ⇠ 2048)Temperature replicas ) bit level parallelism (20 ⇠ 30)Disorder realizations) task level parallelism (104 ⇠ 105)
Memory architecture awarenessEnable sub-word SIMDlization via proper data-typesTranslate time consuming computation to table lookup
Y. Fang, S. Feng et al.
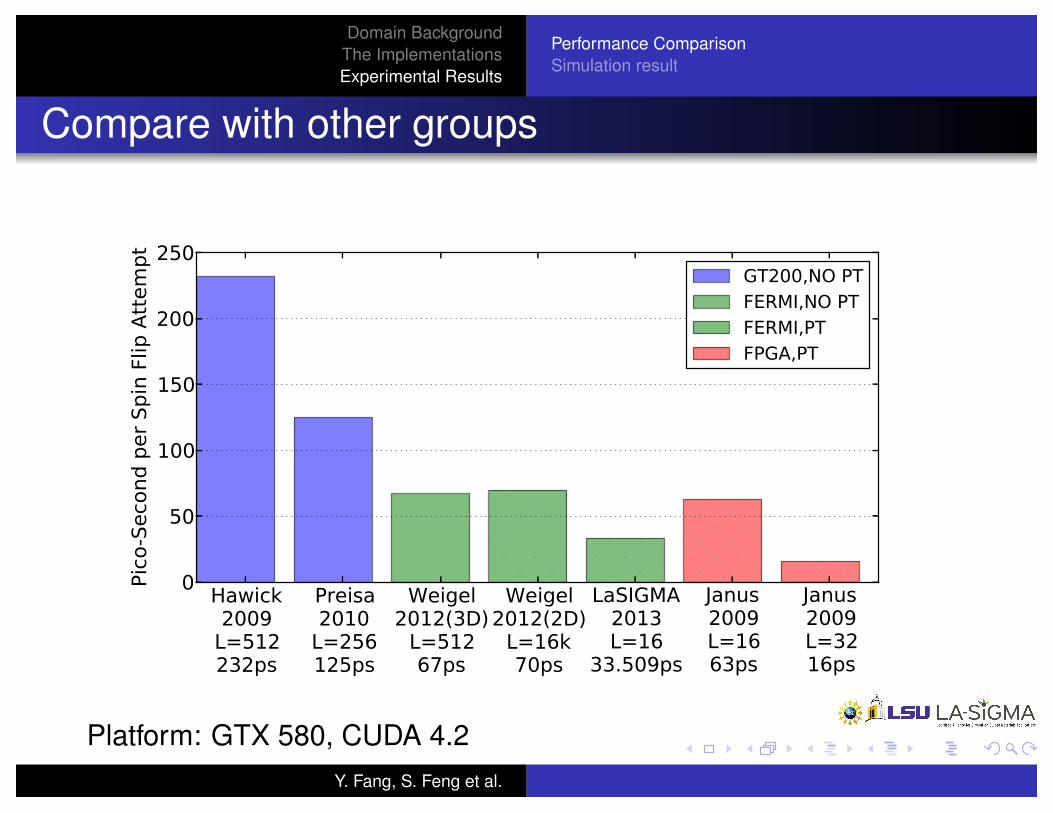
Domain BackgroundThe ImplementationsExperimental Results
Performance ComparisonSimulation result
Compare with other groups
Platform: GTX 580, CUDA 4.2Y. Fang, S. Feng et al.
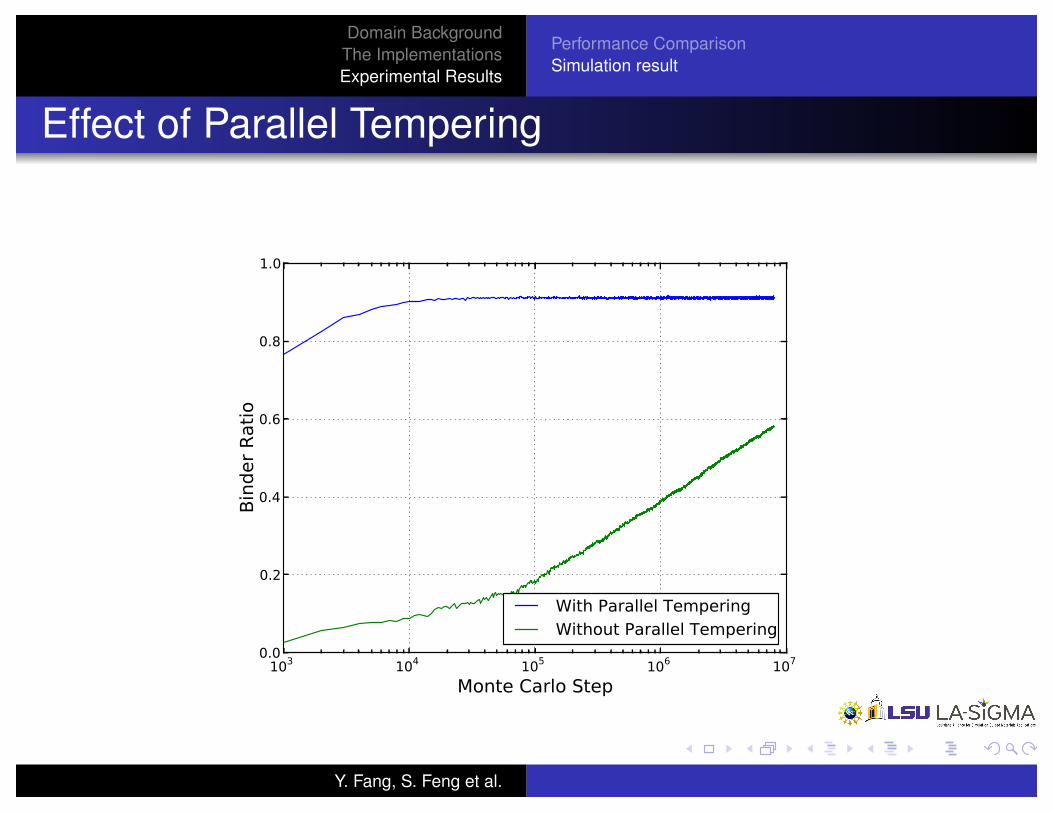
Domain BackgroundThe ImplementationsExperimental Results
Performance ComparisonSimulation result
Effect of Parallel Tempering
Y. Fang, S. Feng et al.
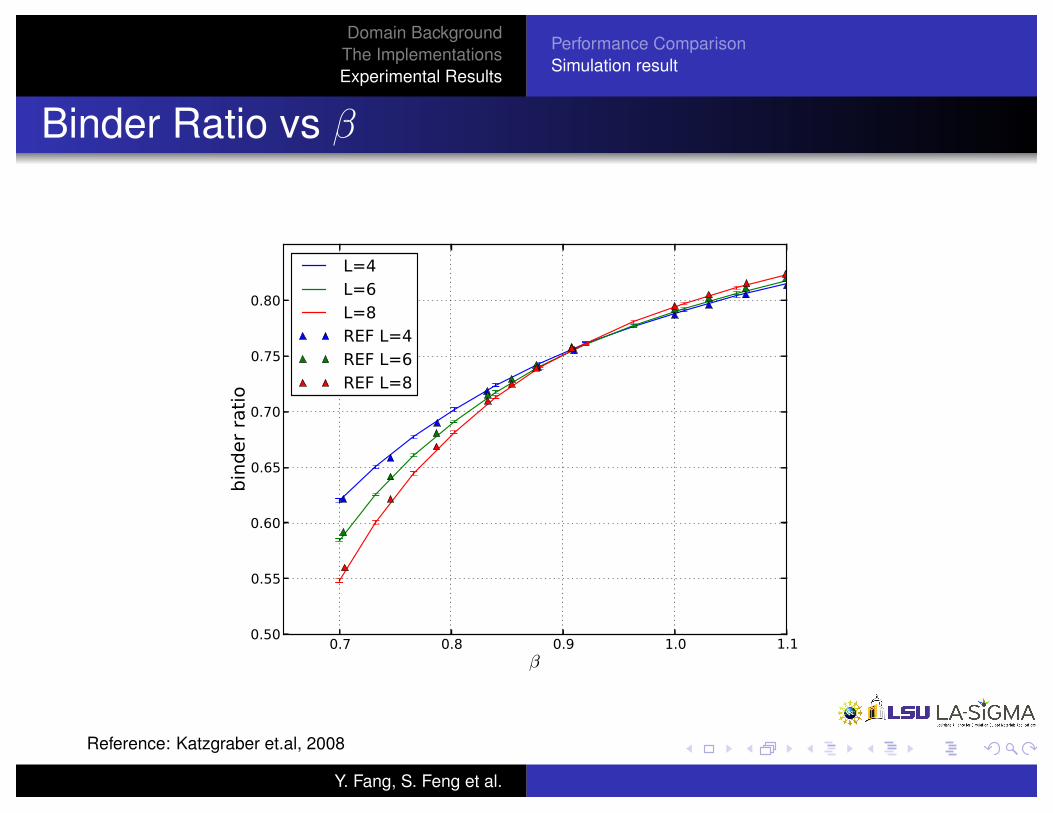
Domain BackgroundThe ImplementationsExperimental Results
Performance ComparisonSimulation result
Binder Ratio vs �
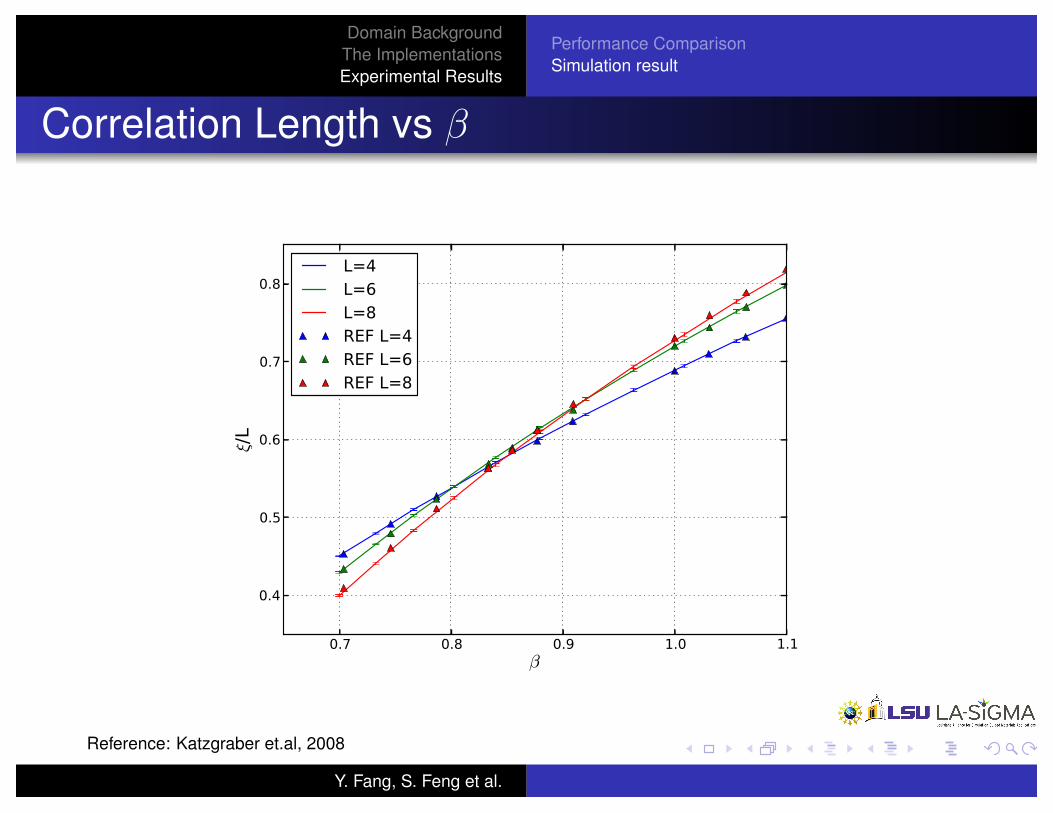
Reference: Katzgraber et.al, 2008
Y. Fang, S. Feng et al.
Domain BackgroundThe ImplementationsExperimental Results
Performance ComparisonSimulation result
Correlation Length vs �
Reference: Katzgraber et.al, 2008
Y. Fang, S. Feng et al.

Domain BackgroundThe ImplementationsExperimental Results
Performance ComparisonSimulation result
Summary
GPU is suitable for Monte Carlo Simulation with paralleltempering for frustrated spin systems, in particular for Isingspin systems.Employing various optimization algorithms and techniquesto solve communication/memory/computation bottlenecks,our program has achieved world leading performance.The program is ideal for systems which have extremesluggish dynamics even for relatively small system sizes,e.g. Edwards-Anderson model in an external field; and thestudy of long time non-equilibrium dynamics.
Y. Fang, S. Feng et al.
Domain BackgroundThe ImplementationsExperimental Results
Performance ComparisonSimulation result
Acknowledgement
Portions of this research were conducted with highperformance computational resources provided by LouisianaState University (http://www.hpc.lsu.edu) supported in part bythe NSF EPSCoR LA-SiGMA grant EPS-1003897. Part of thiswork is done on Oakley, Ohio Supercomputing Center.
Y. Fang, S. Feng et al.
Domain BackgroundThe ImplementationsExperimental Results
Performance ComparisonSimulation result
Thank you!
Y. Fang, S. Feng et al.

Domain BackgroundThe ImplementationsExperimental Results
Performance ComparisonSimulation result
Backup Slides
Y. Fang, S. Feng et al.

Domain BackgroundThe ImplementationsExperimental Results
Performance ComparisonSimulation result
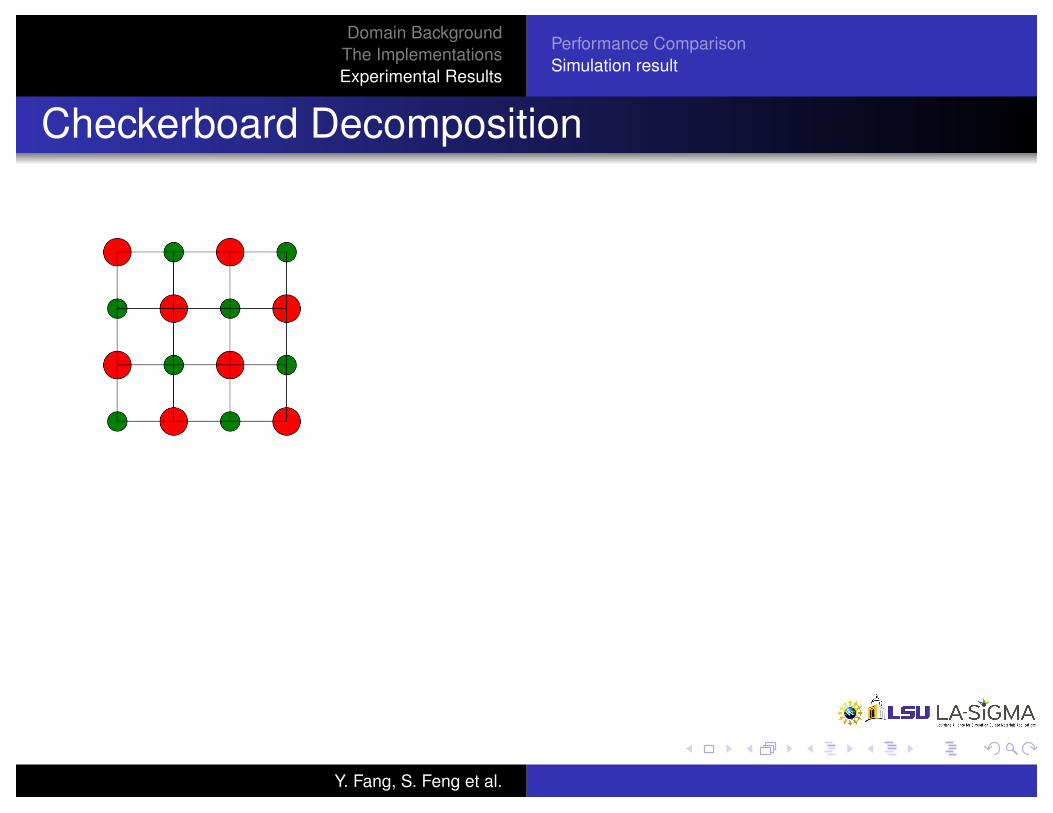
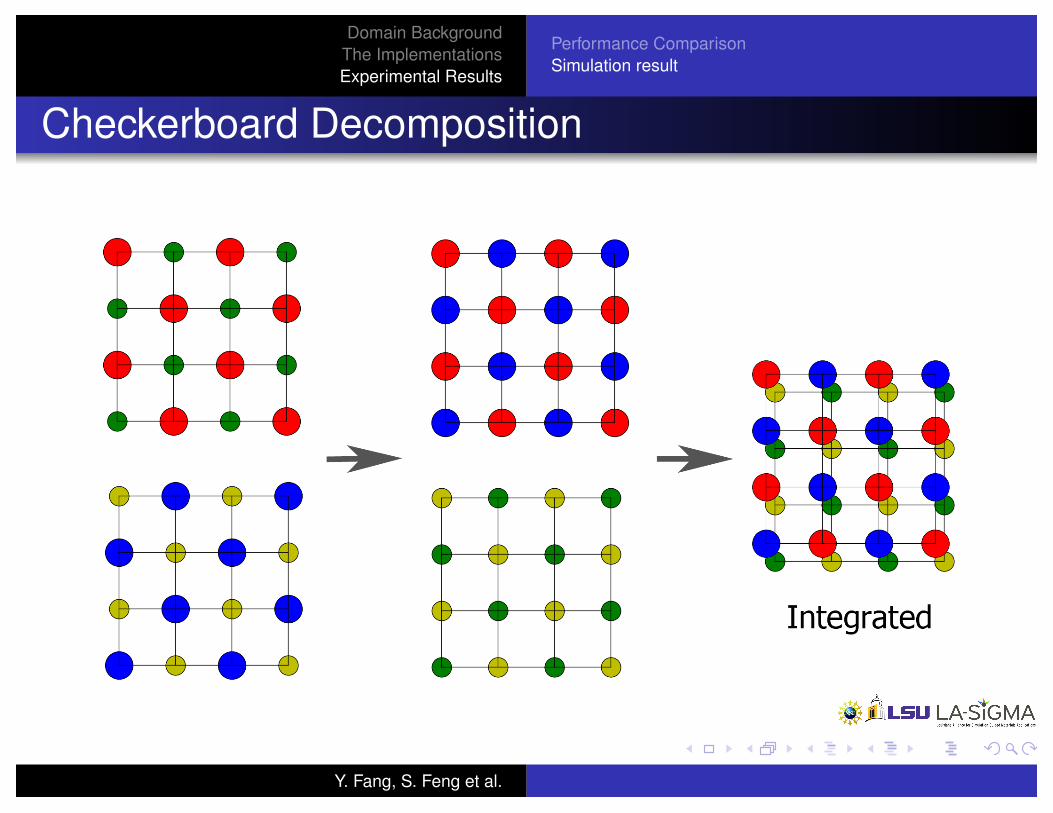
Checkerboard Decomposition
Figure : Shared
Figure : Separate
Y. Fang, S. Feng et al.

Domain BackgroundThe ImplementationsExperimental Results
Performance ComparisonSimulation result
Checkerboard Decomposition
Figure : Shared Figure : Separate
Y. Fang, S. Feng et al.
Domain BackgroundThe ImplementationsExperimental Results
Performance ComparisonSimulation result
Checkerboard Decomposition
Y. Fang, S. Feng et al.

Domain BackgroundThe ImplementationsExperimental Results
Performance ComparisonSimulation result
Checkerboard Decomposition
Y. Fang, S. Feng et al.

Domain BackgroundThe ImplementationsExperimental Results
Performance ComparisonSimulation result
Checkerboard Decomposition
Y. Fang, S. Feng et al.
Domain BackgroundThe ImplementationsExperimental Results
Performance ComparisonSimulation result
Checkerboard Decomposition
Y. Fang, S. Feng et al.
Domain BackgroundThe ImplementationsExperimental Results
Performance ComparisonSimulation result
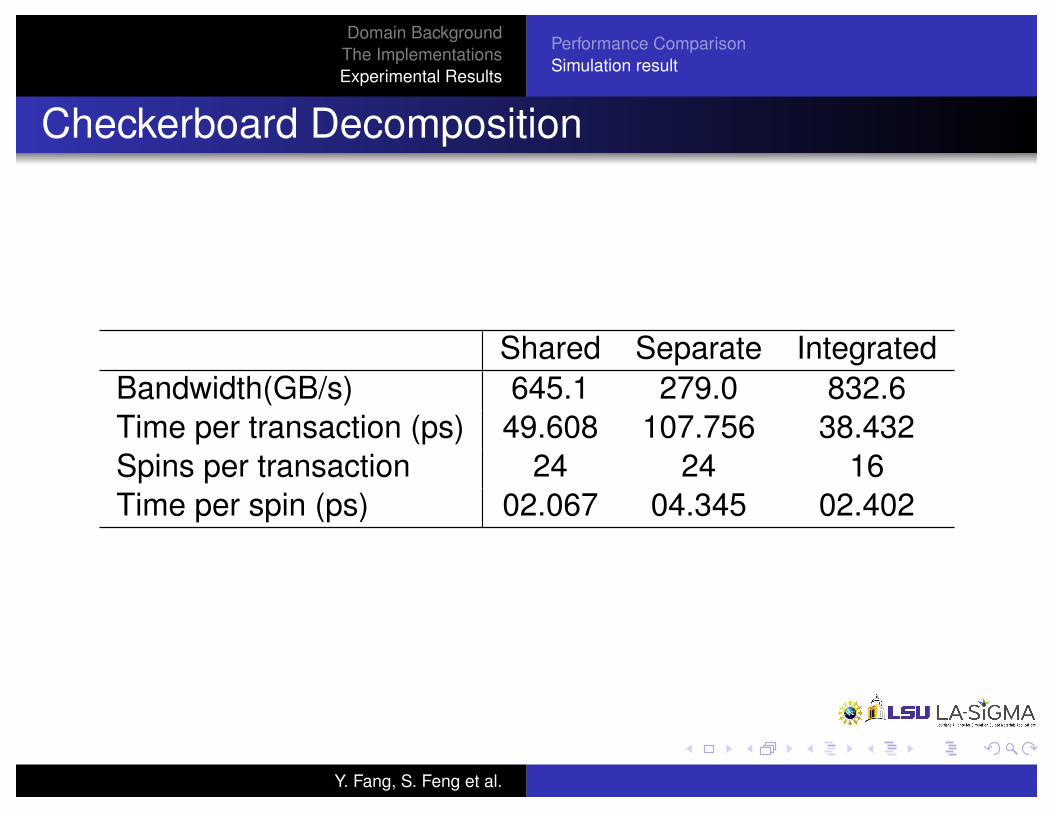
Checkerboard Decomposition
Shared Separate IntegratedBandwidth(GB/s) 645.1 279.0 832.6Time per transaction (ps) 49.608 107.756 38.432Spins per transaction 24 24 16Time per spin (ps) 02.067 04.345 02.402
Y. Fang, S. Feng et al.





























