Embed Size (px)
Citation preview

Go character encoding20 April 2013
Homin LeeGDG Korea Golang

Character encoding

Character encoding
문자 인코딩(⽂字―, 영어: character encoding) 또는 줄여서 인코딩은 문자나 기호들의 집합을 컴퓨터에서 저장하거나 통신에 사용할 목적으로 부호화하는 방법을 가리킨다.
문자 인코딩 in 위키백과 (http://ko.wikipedia.org/wiki/%EB%AC%B8%EC%9E%90_%EC%9D%B8%EC%BD%94%EB%94%A9)

Character encoding
type Raw []byte
func (r Raw) String() string { s := "[ " for _, c := range r { s += fmt.Sprintf("0x%02X ", c) } s += "]" return s}
func main() { s := "Hello 뽀로로" fmt.Println(s) fmt.Println(Raw(s))}
Run
Character encoding
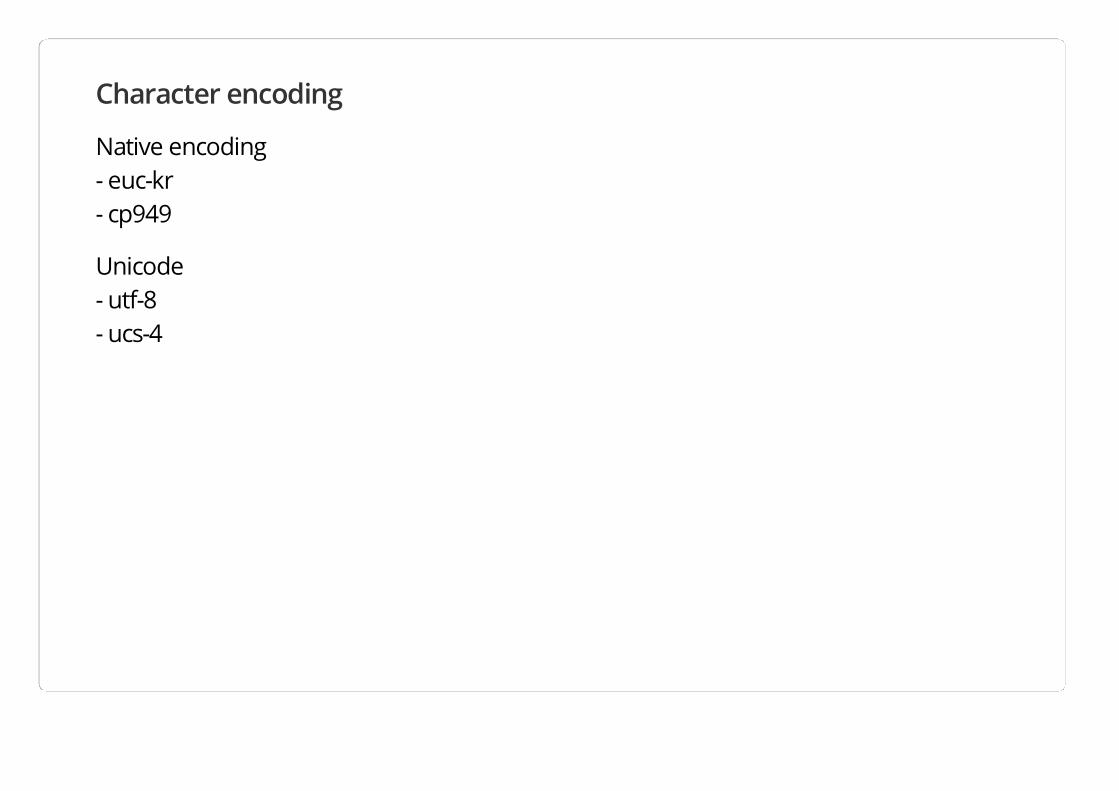
Native encoding - euc-kr - cp949
Unicode - utf-8 - ucs-4

Native encoding

It's bad because...
네이티브 인코딩은 한 나라에서 주로 쓰이는 문자셋 만을 포함한 인코딩 입니다.
네이티브 인코딩으로는 모든 국가의 모든 문자를 표현할 수 없다.
같은 바이트 열이 네이티브 인코딩에 따라 다른 글자로 표시됨.
어떤 네이티브 인코딩을 썼는지 알 수가 없음
한국어를 위한 네이티브 인코딩은 다음 두 가지가 살아 남았습니다.
euc-kr : 설믜문답[1]을 검색해 보세요
cp949 : euc-kr에 빠진 한글을 채워 넣은 인코딩 (한글 MS윈도 기본 인코딩)
[1]: 설믜문답 (http://blog.naver.com/onkai/90079680533)

Unicode

김똑딱
체크 남박이 똑딱이면 이상한가요?

Unicode가 없었으면 김똑딱도 없었습니다.
한국 : 체크남방이 똑딱이면 이상한가요?
일본 : ちょっと⼈、点検のワイシャツが急なボタンを備えていることそれは奇妙である
か。
미국 : Hey guys, Is it strange that the check shirt has snap buttons?
중국간체 : 嘿⼈, 它是奇怪的, 检查衬⾐有短冷期按钮?
러시아 : Hey ванты, оно странно что рубашка проверки имеет щелчковые кнопки?
프랑스 : Hé des types, est-il étrange que la chemise de contrôle ait les boutonsinstantanés ?
독일 : He Kerle, ist es merkwürdig, daß das Überprüfung Hemd Schnelltasten hat?
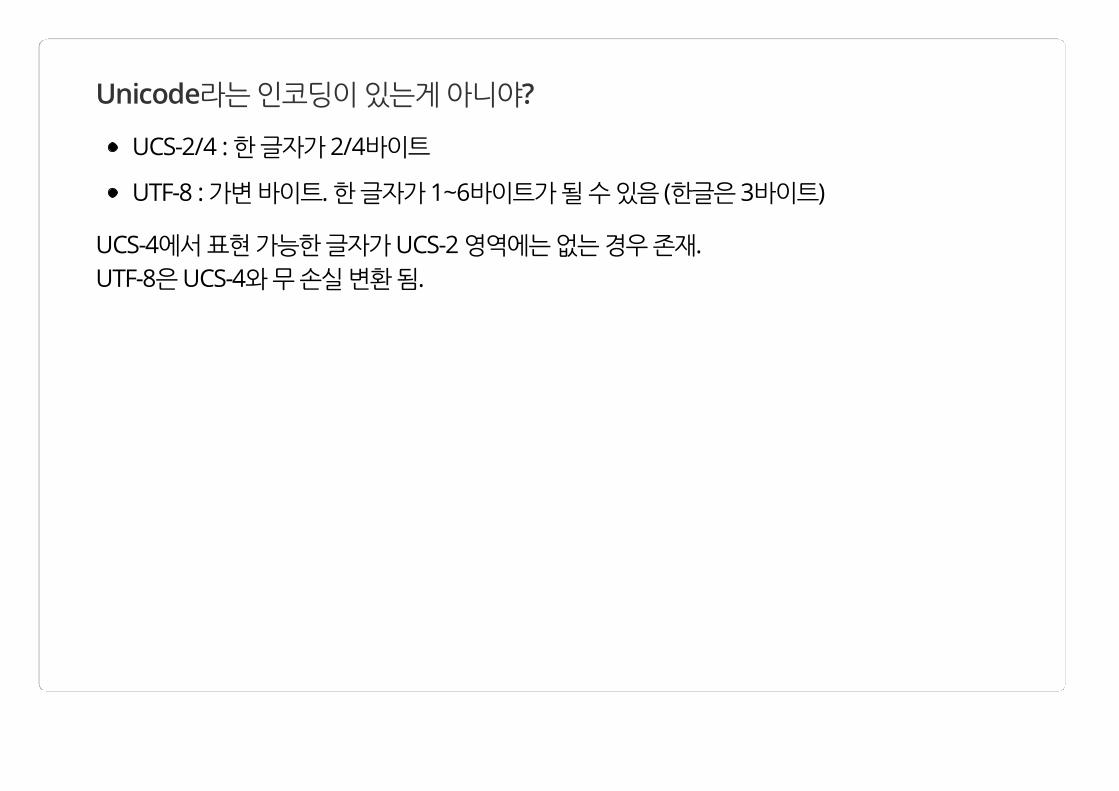
Unicode라는 인코딩이 있는게 아니야?
UCS-2/4 : 한 글자가 2/4바이트
UTF-8 : 가변 바이트. 한 글자가 1~6바이트가 될 수 있음 (한글은 3바이트)
UCS-4에서 표현 가능한 글자가 UCS-2 영역에는 없는 경우 존재. UTF-8은 UCS-4와 무 손실 변환 됨.
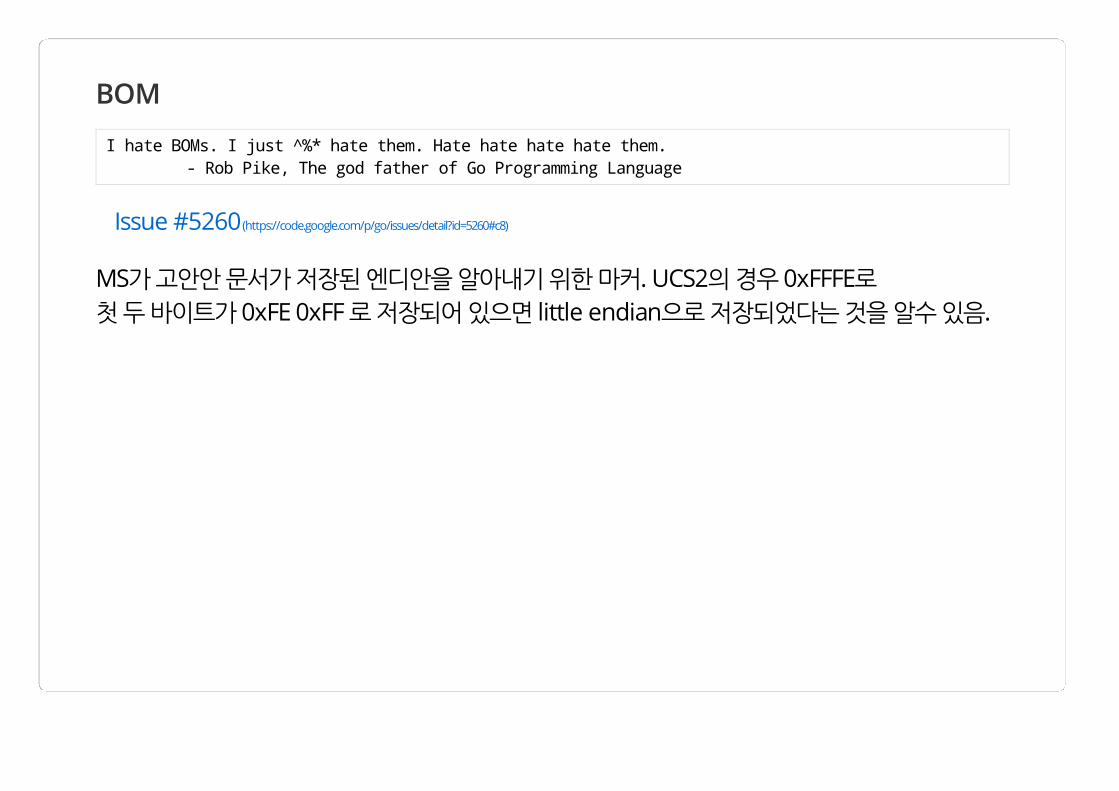
BOM
I hate BOMs. I just ̂%* hate them. Hate hate hate hate them. - Rob Pike, The god father of Go Programming Language
Issue #5260 (https://code.google.com/p/go/issues/detail?id=5260#c8)
MS가 고안안 문서가 저장된 엔디안을 알아내기 위한 마커. UCS2의 경우 0xFFFE로 첫 두 바이트가 0xFE 0xFF 로 저장되어 있으면 little endian으로 저장되었다는 것을 알수 있음.

어떤 유니코드 인코딩을 써야 하나.
텍스트 파일은 utf-8을 사용하세요.
바이트 단위기 때문에 Little/Big endian 문제가 없습니다.
글자별 연산이 필요한 경우 ucs-4로 변환하면 편합니다.
문자열에 몇 글자가 있는지 확인하고 싶을때 등

고 언어에서 유니코드 다루기

What is rune type
고 언어에서 rune은 UCS-4 한 글자 나타내기 위한 타입.
package main
import ( "fmt")
func main() { s := "미지의세계"
fmt.Printf("type = %T, len = %d\n", s[0], len(s))
b := []byte(s) fmt.Printf("type = %T, len = %d\n", b[0], len(b))
r := []rune(s) fmt.Printf("type = %T, len = %d\n", r[0], len(r))} Run

For range with string
package main
import ( "fmt")
func main() { s := "bounce 바운스" for i, c := range s { fmt.Printf("i=%v, c=%c t=%T\n", i, c, c) }} Run

Packages
bytes
unicode/utf8

고 언어의 네이티브 인코딩 지원

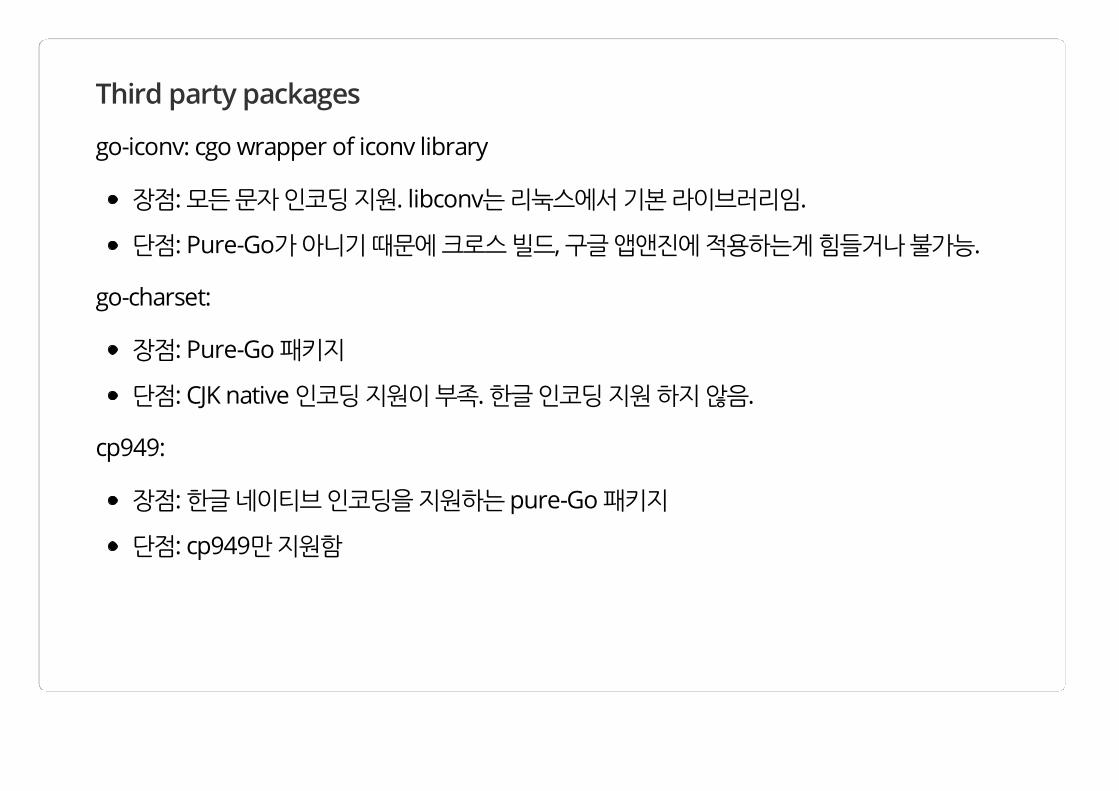
Third party packages
go-iconv: cgo wrapper of iconv library
장점: 모든 문자 인코딩 지원. libconv는 리눅스에서 기본 라이브러리임.
단점: Pure-Go가 아니기 때문에 크로스 빌드, 구글 앱앤진에 적용하는게 힘들거나 불가능.
go-charset:
장점: Pure-Go 패키지
단점: CJK native 인코딩 지원이 부족. 한글 인코딩 지원 하지 않음.
cp949:
장점: 한글 네이티브 인코딩을 지원하는 pure-Go 패키지
단점: cp949만 지원함

cp949 practice
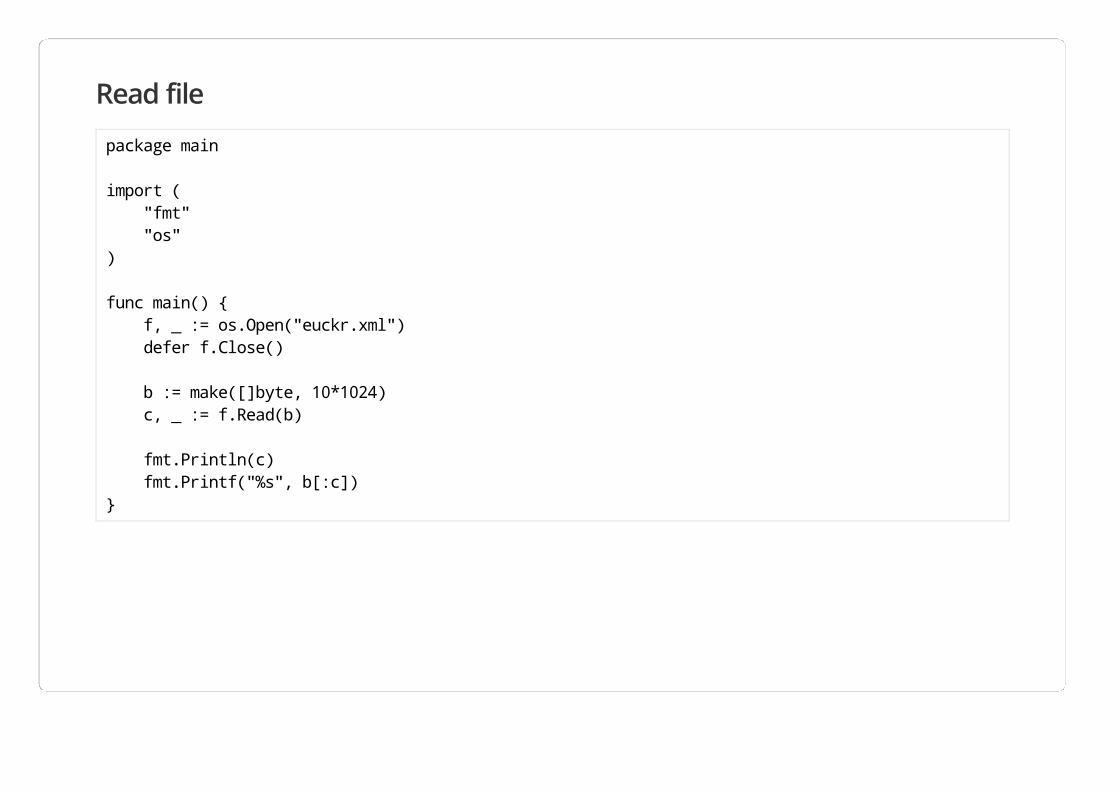
Read file
package main
import ( "fmt" "os")
func main() { f, _ := os.Open("euckr.xml") defer f.Close()
b := make([]byte, 10*1024) c, _ := f.Read(b)
fmt.Println(c) fmt.Printf("%s", b[:c])}

Using cp949.Reader
package main
import ( "fmt" "github.com/suapapa/go_hangul/encoding/cp949" "os")
func main() { f, _ := os.Open("euckr.xml") defer f.Close()
r, _ := cp949.NewReader(f)
b := make([]byte, 10*1024) c, _ := r.Read(b)
fmt.Println(c) fmt.Printf("%s", b[:c])}

Unmarshal non-UTF8 xml
func unmarshalCp949XML(data []byte, v interface{}) error { d := xml.NewDecoder(bytes.NewBuffer(data)) d.CharsetReader = func(c string, i io.Reader) (io.Reader, error) { if c != "cp949" && c != "euc-kr" { return nil, errors.New("unexpect charset: " + c) }
r, err := cp949.NewReader(i) if err != nil { return nil, err }
return r, nil }
return d.Decode(v)}

















![Legendes Normandes - livros01.livrosgratis.com.brlivros01.livrosgratis.com.br/gu011036.pdfRelease Date: February 11, 2004 [EBook #11036] Language: French Character set encoding: ISO](https://img.pdfslide.us/doc/110x75/5ab7bdae7f8b9a28468bf61f/legendes-normandes-date-february-11-2004-ebook-11036-language-french-character.jpg)
![[MS-UCODEREF]: Windows Protocols Unicode … character set (DBCS): A character encoding in which the codepoints can be either one or two bytes. For example, the DBCS is used to encode](https://img.pdfslide.us/doc/110x75/5ab5c2d97f8b9ab7638d24e9/ms-ucoderef-windows-protocols-unicode-character-set-dbcs-a-character-encoding.jpg)










