Embed Size (px)
Citation preview

GEOINFO 2006
Utilização da biblioteca TerraLib para algoritmos de agrupamento em Sistemas de Informações Geográficas
Mauricio P. Guidini
Carlos H. C. Ribeiro Nov 2006
Supervisor
Use of the TerraLib library for clustering algorithms in Geographic Information
Systems

25/10/2004
“... 3000 unregistered flights, with origin and destiny unkown by authorities, invaded the Brazilian airspace in the first ten months of this year. The Air Force calculates that about 30% of these flights were related to drug dealing ...
Translated from note from

3
Data Mining in GIS
Objetive
To present the integration of a Data Mining algorithm (k-means) to TerraLib/TerraView, forming a Geographic Information System for Unknown Air Traffic analysis (GisTAD).

4
SummaryData Mining
Clustering Algorithms
Air Traffic
K-means Implementation
Results
Aplication
Data Mining in GIS

5
Data Mining Definition:
“A non-trivial process of identification of valid, new, useful standards implicitly present in large volumes of data”
Knowledge Discovery in Database (KDD) - Fayyad et al. (1996)
Data Mining in GIS
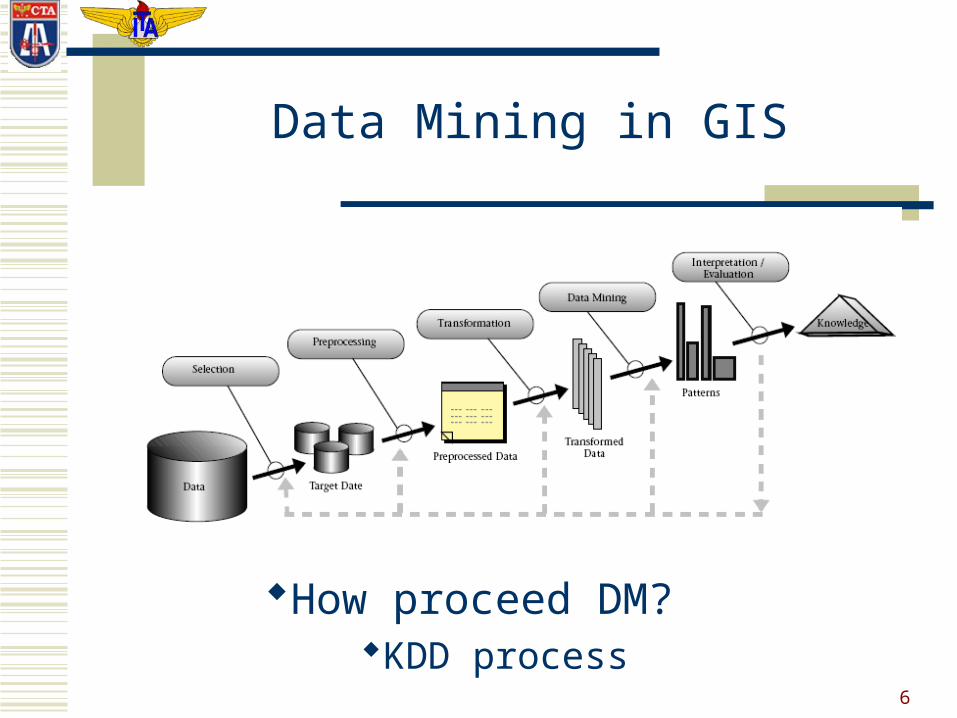
6
How proceed DM?KDD process
Data Mining in GIS

7
Clustering Algorithms
The clustering process tries to grouping the data into groups that have highly similar features, helping the understanding of the information that they hold.
A good clustering algorithm is characterized by the production of high level classes, where the intraclass similarity is high, and the interclass similarity is low. [Han & Kamber 2001]
Data Mining in GIS

8
Data Mining in GIS
Major Categories Partitioning – k-means, k-medoids Hierarchical – CURE, BIRCH Density-based – DBSCAN, OPTICS Grid-based – STING Model-based
Others ANN – Kohonen network Incremental - Leader

9
Data Mining in GIS
Air TrafficMovement of aircraft, national or foreign, that fly over national territory.
Unkown Air TrafficTo unidentified airplanes (flight plan), two lines of action can be taken[Bernabeu 2004]:
1.Intercept; or
2.Generate an Unkown Air Traffic Report

10
Traffic RepresentationLine segments
Latitude (decimal degrees)Longitude (decimal degrees)Distance (miles)Heading
RestrictionsAcceptable deviations
Data Mining in GIS

11
K-means algorithm
Data Mining in GIS
Precondition: set max deviation values to coordinates, distance and routeBegin: K=0 While criterion condition not satisfied (deviation in clusters) Increase K Arbitrarily choose K centers (among data objects) While centers change (k-means) (re)assign routes in cluster based on weights update centers values end movement intergroups deviation in groups ok Save resultsEnd

12
Distance Measure
Data Mining in GIS
2222** mimimimi prprdistdistlonglongpesolatlatpeso
Minimize deviationsImprove cluster quality
coordmi paramlatlat coordmi paramlonglong and

13
GIS Integration
TerraLib
TerraView
k-means
Data Mining in GIS

14
Data preparation
8000 records
looking for information (what?)
Data Mining in GIS
Search space restrictionsSearch space restrictions

15
Numeric Tests
to 500 records
GisTAD Tests
319 records 73 groups
Aprox. time = 40 sec.
Data Mining in GIS

16
TerraView

17
TerraView
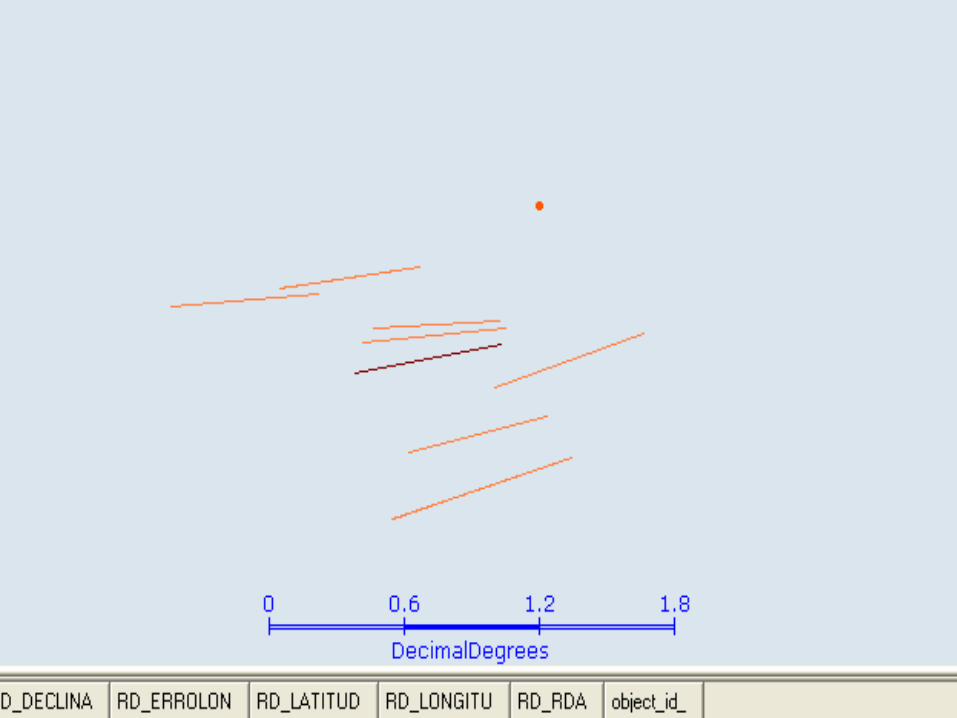
18

19
Applications
Air Operations
Improper use of air space
Data Mining in GIS
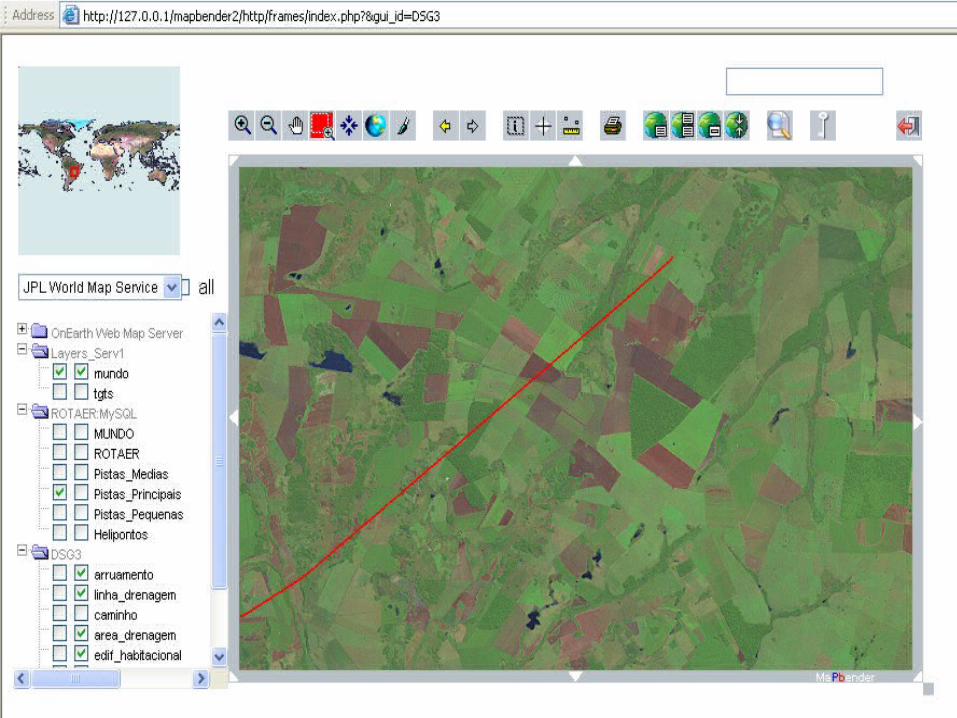
20

21
Data Mining in GIS
Conclusion
Considering the problem proposed, the k-means algorithm is applicable, and returned a good set of clusters.
However, the number of records that must be clustered can make the application of the algorithm very time consuming.

22
Future Work
Other partitioning algorithms should be implemented, to verify which one is the most efficient for the problem in analysis, considering any size of records to be clustered.
The algorithms to be tested are:
Kohonen neural network;
Leader algorithm.





























