Embed Size (px)
Citation preview

FutureGrid Status Report
Steven [email protected]
Joint project with Jon Crowcroft (CUCL), Tim Harris (CUCL), Ian Pratt (CUCL), Andrew Herbert (MSR), Andy Parker (CeSC)

Grid systems architecture
Common themes of self-organization and distribution
Four motivating application areas:
1. Massively-scalable middleware
2. Advanced resource location mechanisms
3. Automatic s/w replication and distribution
4. Global data storage and publishing
Experimental test beds (PlanetLab, UK eScience centres / access grid / JANET).

Common Techniques
P2P (DHT) layer for distribution: Using Bamboo routing substrate (Intel Research) for
passing messages between peers Provides a fault-tolerant and scalable overlay net Can route a message to any node in an n node network in
O(ln n) hops, with O(ln n) routing information at each node
Location/Distance Service: Basic idea: Euclidean co-ordinate space for the Internet Using PCA + lighthouse/virtual landmark Running PlanetLab measurements looking at sensitivity to
#dimensions, etc Building “plug in” service for Bamboo neighbour selection

1. P2P Group Communication
Built on Bamboo and location service: Use location service (co-ordinates) to get best forward route Use RPF (Scribe) algorithm to build tree Tree is max 2*delay of native IP multicast tree
Can build per source, or “centered” tree based on density of group, #senders, #receivers, …
Current status: General system deployed and under test on PlanetLab Whiteboard demo program works on top of this
Next steps: IP multicast tunnels across multicast incapable ‘chasms’ P2P overlay for vic/rat/access grid anticipated end ‘04
2. Distributed resource location
1. Determine machine locations and resource availability2. Translate to locations in a multi-dimensional search space3. Partition/replicate the search space 4. Queries select portions of the search space

Current Focus
Location-based resource co-allocation Wish to choose subset of available nodes according to
resource availability and location First filter set, then use heuristic to solve constrained
problems of the form far(near(S1,S2), near(S3,S4), C1)
System built around P2P spatial index Three phase algorithm
Find an approximate solution in terms of clusters Use simmulated annealing to minimize associated cost Select representative machine(s) for each cluster
Results close to ‘brute force’ (average 10% error)

3. P2P Computing
Attempt to use P2P communication principles to gain similar benefits for grid computing
Proceeding on three axes targeting core computation, bioinformatics and batch workloads
Algorithm-specific load tolerance: Want to allow decentralized independent load shedding Client submits parallel computation to M > N nodes s.t.
any N results suffice to produce ‘correct’ result General case intractable: focus on algorithm-specific solns Current focus on matrix operations using erasure codes Also considering sketches as approximation technique

P2P Computing (2)
Indexing genomic sequences (3 x 109) Based on using suffix array indexes; supports string
matching, motif deletion, sequence alignments, etc Smaller memory reqs than state of art suffix tree Distributed on-line construction using P2P overlay Caching issues (memory and swap) need investigation
Batch-aware ‘spread spectrum’ storage Observe many batches share considerable data Want to encourage client-driven distribution of data but
avoid centralized quotas and pathological storage use Use Palimpsest P2P storage system with ‘soft
guarantees’ Data discarded under load => need refresh to keep

4. Global Data Storage
Global-scale distributed file system Mutability; shared directories; random access Data permanence, quotas Aggressive, localized caching in proportion to
demand While maintaining coherence
Storage Nodes Confederated, well connected, relatively stable Offer multiples of a unit of storage in return for
quota it can distribute amongst users Clients
Access via nearest Storage Node
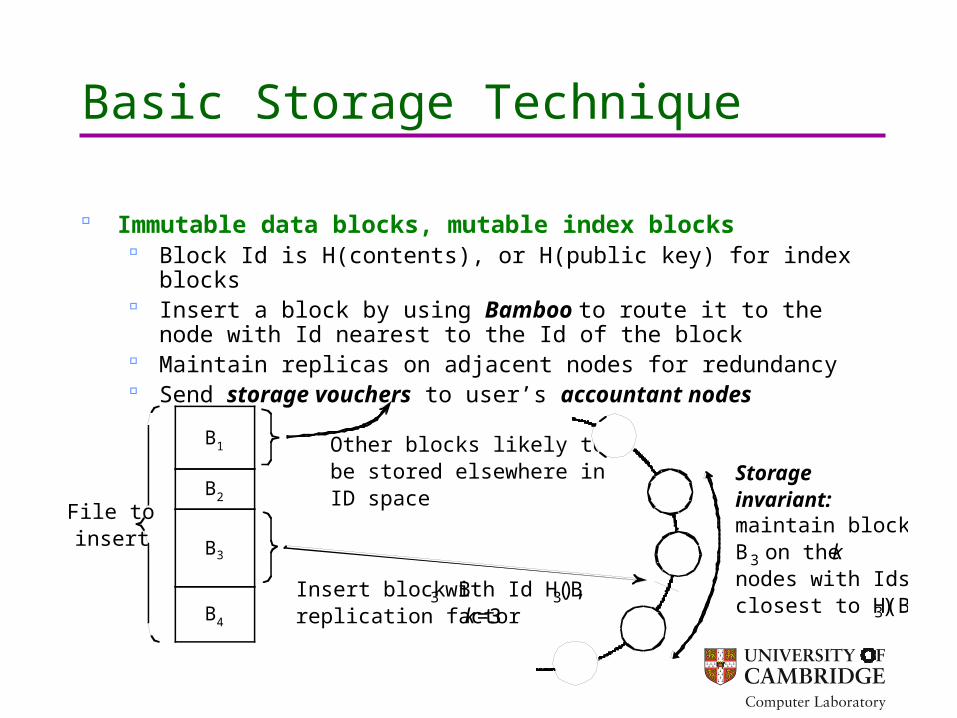
Basic Storage Technique
Immutable data blocks, mutable index blocks Block Id is H(contents), or H(public key) for index blocks Insert a block by using Bamboo to route it to the node with Id
nearest to the Id of the block Maintain replicas on adjacent nodes for redundancy Send storage vouchers to user’s accountant nodes
B2
B1
B3
B4
File to insert
Insert block B 3 with Id H(B 3),replication factor k=3
Storage invariant:maintain block B3 on the knodes with Ids closest to H(B 3)
Other blocks likely to be stored elsewhere in ID space
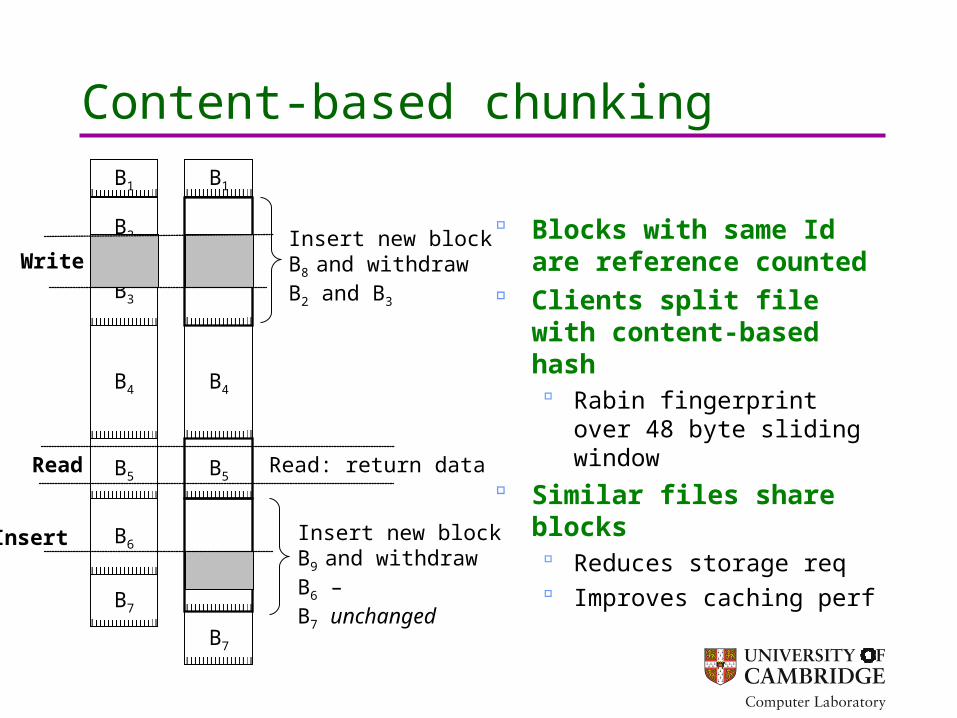
Content-based chunking
Blocks with same Id are reference counted
Clients split file with content-based hash Rabin fingerprint over 48
byte sliding window Similar files share
blocks Reduces storage req Improves caching perf
B2
B3
B4
B5
B6
B1
B7
B4
B5
B1
B7
Read: return data
Insert new block B8
and withdraw B2 and B3
Insert new block B9
and withdraw B6 – B7 unchanged
Read
Write
Insert

Summary and Future Work
Attempt to push towards a ‘Future GRID’ Four ‘strands’ with common themes and
(some) common infrastructure Group communication, resource co-allocation, load flexible
computing, global distributed storage
All four strands making progress: Early papers / tech reports in all cases Bamboo and location-service deployed & under test
Next steps include: Move PlanetLab experiments to UK eScience infrastructure Analysis and test of prototype designs/software
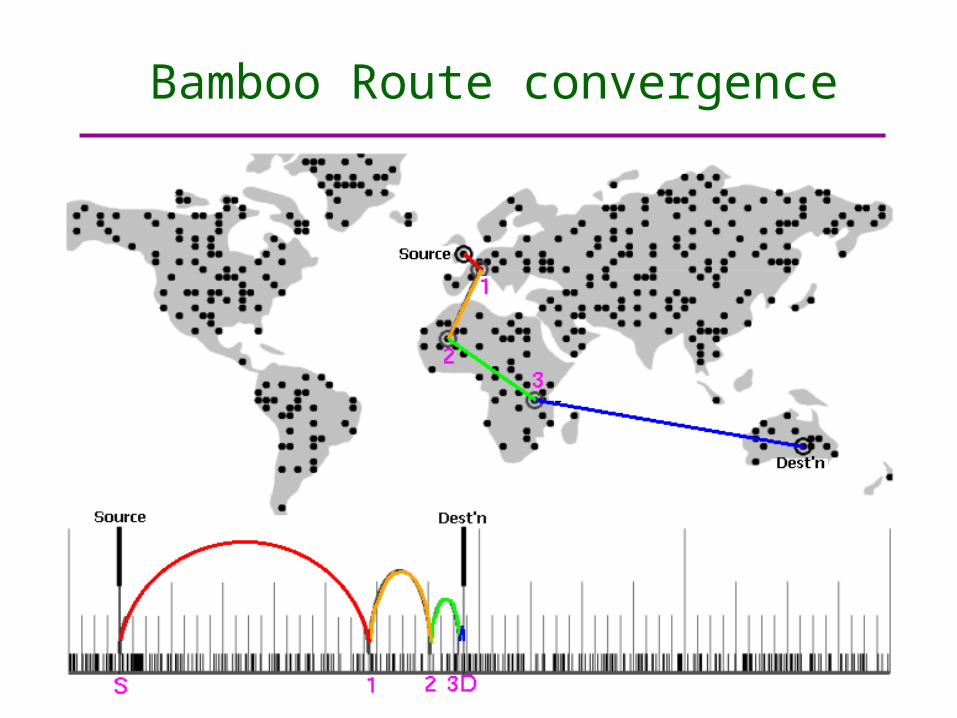
Bamboo Route convergence
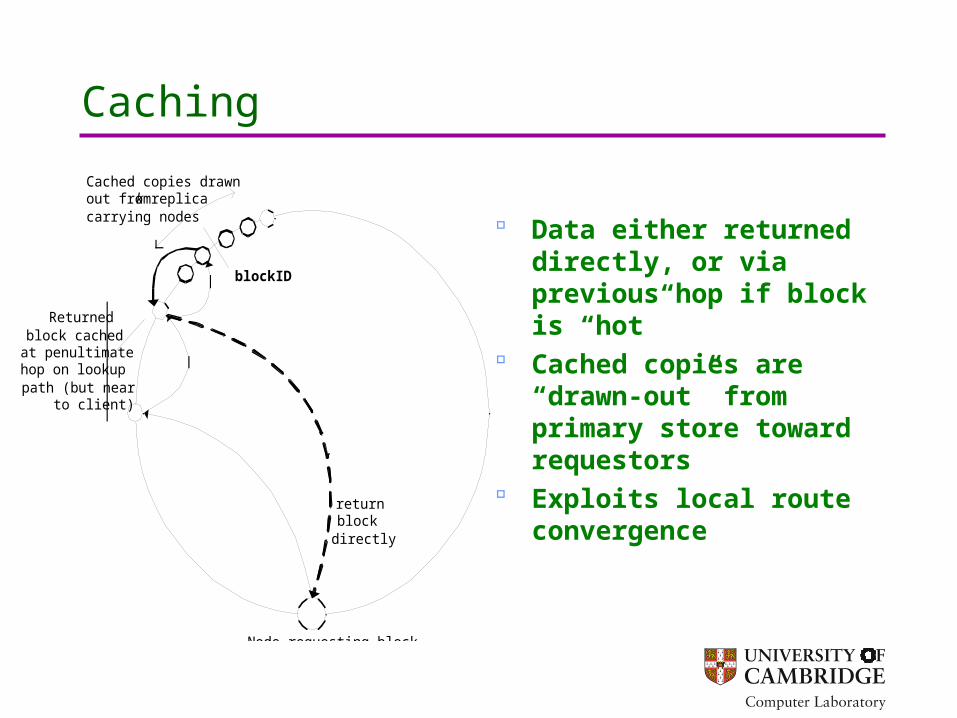
Caching
lookup(blockID) return
blockdirectly
Cached copies drawnout from k replicacarrying nodes
blockIDr et ur n
( bl ock)
Returnedblock cached
at penultimatehop on lookuppath (but near
to client)
Node requesting block(cache block for local use)
Data either returned directly, or via previous hop if block is “hot”
Cached copies are “drawn-out” from primary store toward requestors
Exploits local route convergence

Mutable index blocks May describe an arbitrary
file hierarchy Index block has
associated keypair (eFS, dFS)
Insert index block using hash of public key as Id
Authenticate update by signing insertion voucher using private key
May link to other index blocks Merge contents
Organise according to access/update patterns
<folder name=“tim” <file name=“hello.txt”> <blocklist> <block o=“234”> …id… </block> </blocklist> </file> <folder name =“bar” <file name=“hello2.txt”> <blocklist> …id… </blocklist> </file></folder><overlay> <index path=.> …id… <\index> </overlay>
Voucher: H(blk), repl_factor, eFS dFS
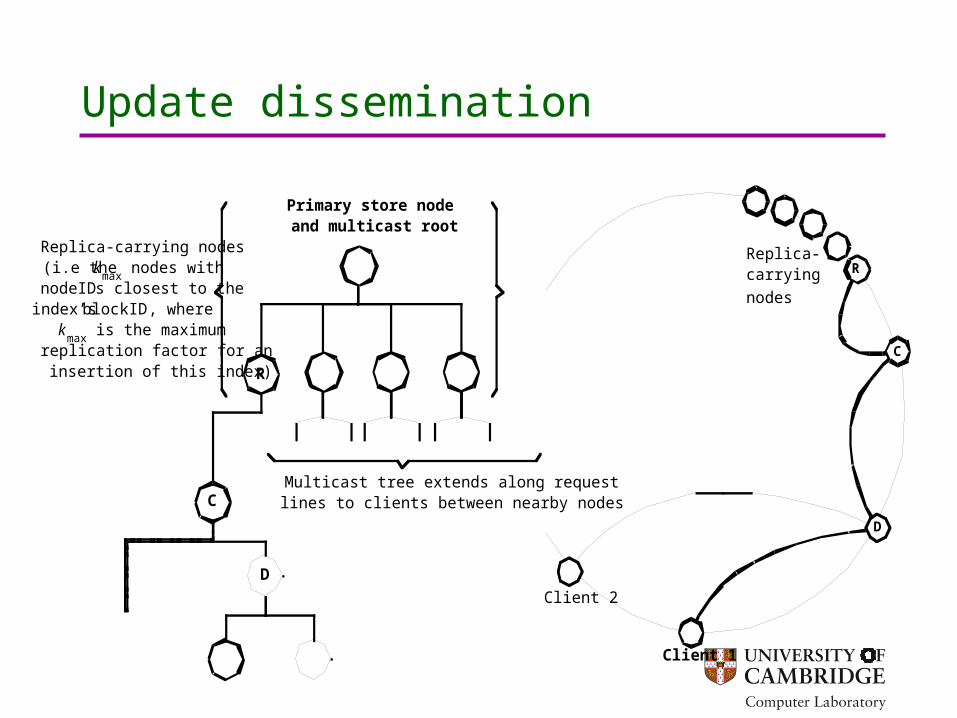
Update dissemination
Multicast tree extends along requestlines to clients between nearby nodes
R
C
D
Replica-carrying nodes(i.e the k
max nodes with
nodeIDs closest to theindex’s blockID, where
kmax
is the maximumreplication factor for aninsertion of this index)
Client 1 Client 2
Primary store nodeand multicast root
Replica-carrying
nodes
Client 1
Client 2
R
C
D
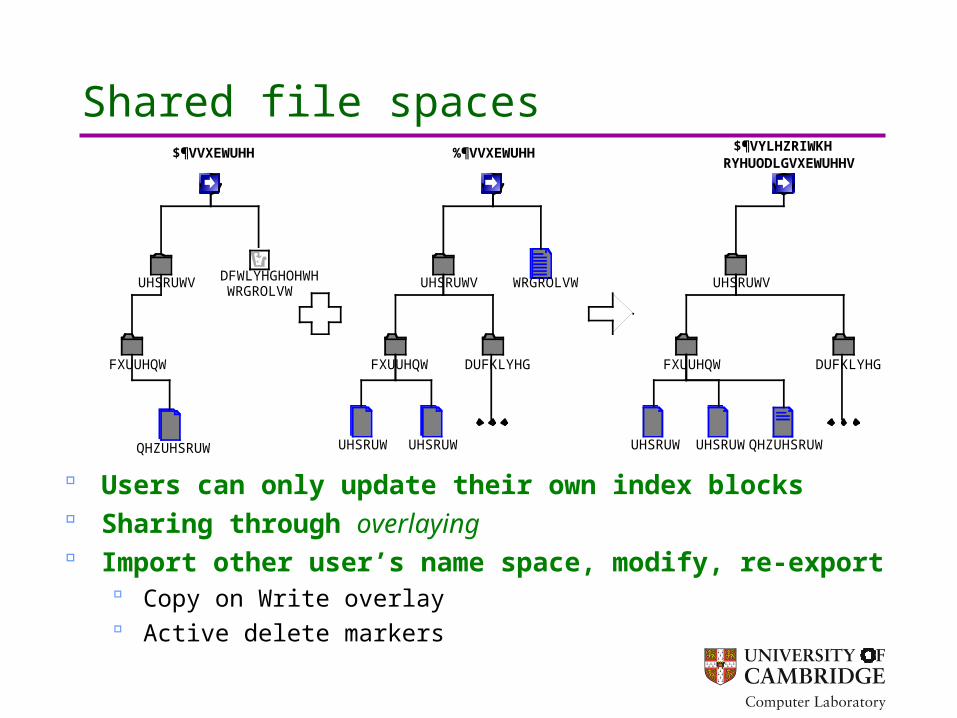
Shared file spaces
UHSRUW UHSRUW
FXUUHQW DUFKLYHG
WRGROLVWUHSRUWV
UHSRUW UHSRUW
FXUUHQW DUFKLYHG
UHSRUWV
QHZUHSRUWQHZUHSRUW
FXUUHQW
DFWLYHGHOHWHWRGROLVW
UHSRUWV
$¶VVXEWUHH %¶VVXEWUHH $¶VYLHZRIWKHRYHUODLGVXEWUHHV
Users can only update their own index blocks Sharing through overlaying Import other user’s name space, modify, re-export
Copy on Write overlay Active delete markers





























