Embed Size (px)
Citation preview

Fusing supercomputing with an open, enterprise-standard framework

• Pattern Matching• Exploration• Relationship Discovery
• Data Processing & Exploration• Batch Processing• Data Mining• Fault-Tolerant• High-Throughput Storage (HDFS)
Hadoop®
Cray® Graph Engine
Spark™
• Data Exploration & Processing• Streaming Applications• Machine Learning• SQL Queries • Iterative Queries
Organizations today are looking for an information advantage in their big data — insights that can direct how they engage with customers and stakeholders, diversify business models, improve efficiencies and develop new opportunities. This is changing the fundamentals of insight and innovation, and it means that to not only survive — but to flourish — leveraging big data analytics is essential:
• Make immediate decisions
• Continuously pivot strategy and tactics
• Merge streams of inquiries into meaningful action
Collectively these represent high-frequency insights: the ultimate competitive edge. Successful companies use high-frequency insights to accelerate information advantage.
Only of companies extract full value from their information
Although big data analytics has paved the way to unimaginable possibilities, it has also opened a Pandora’s box of complexity. 43 percent of companies obtain little actual benefit from their information assets, and 36 percent lack the tools and skills they need to do so.
Source: “Seizing the information advantage,” PwC
Yet the sheer size and complexity of big data is overwhelming conventional enterprise systems. To unleash the promise of big data, only a supercomputing approach provides the agility and performance you need for high-frequency insights.
For businesses seeking an information advantage and grappling with the realities of big data, Cray has fused supercomputing with an open, standards-based framework to deliver the industry’s first agile analytics platform: the Cray® Urika®-GX system.
Seize your big data advantage with the Urika-GX platformThis agile platform has an unprecedented combination of versatility and speed to tackle your largest problems at super scale and uncover hidden patterns with a fast time to insight, up and running in days.
• A supercomputing approach delivers unmatched speed • A flexible open framework can run multiple workloads concurrently, including Hadoop®, Spark™ and graph• Pre-integrated, standards-based software and flexible system configurations can be running in days• Breakthrough insights with a system tuned for demanding workloads plus integrated graph analytics for pattern matching

Imperative for agile analytics platforms
Big data analytics are a given in the enterprise, but using analytics effectively is a moving target. Analytics workflows are becoming increasingly sophisticated: Beyond Hadoop, businesses are integrating a breadth of analytics, like Spark and graph, with new tools emerging all the time. In this frenetic environment, data scientists must iterate quickly, and the platforms they use must not only perform at scale but also easily adapt to new and even concurrent workloads.
And just as important, an analytics platform must be easy to maintain and deliver insights at the pace of business. The Cray Urika-GX platform solves these challenges with a potent combination of system agility and pervasive speed needed to deliver high-frequency insights.
AgilityEasily adapt to changing needs with serious agility that starts with the ability to concurrently run multiple analytics workloads on a single platform, including Spark, Hadoop, graph and — for the first time in the industry — high performance computing as well.
Adding to that, the dynamic repurposing of analytics resources using Mesos™ orchestration lets you increase infrastructure utili-zation and reduce data silos, and empowers your data scientists to be more productive.
The open framework, with support for tools such as OpenStack, Kafka and Docker, enables you to customize for specific needs today and be ready to leverage future analytics tools. Agility also requires easy adoption and operation. That’s why the Urika-GX platform is based on pre-integrated, industry-standard software with intuitive management.
The standard datacenter format has three configurations that are easily extensible so you can grow the system as your needs change.
Pervasive speedGet the sheer horsepower you need to transform massive datasets into insights faster than ever before — so you can make decisions at the pace of your business.
The Urika-GX platform takes an architectural approach to speed and parallelization that leverages decades of expertise in supercomputing. It offers the performance of up to 1,728 cores cores per node on up to 48 nodes. A combination of 35-176 TB of PCIe SSD on-node memory and up to 22 TB DRAM for deep local memory hierarchy accelerates performance and the Cray-designed Aries™ interconnect enables large-scale, memory-intensive workloads. This means you can achieve blazing-fast results regardless of how small you start or how large your big data needs become.
Speed today also requires faster time to insight with systems that are running in days, not months. The Urika-GX system eliminates lengthy implementation work with the convenience of a pre-integrated and tested platform.
And because super-fast pattern matching is becoming so essential to finding hidden meaning in big data, we’ve integrated the Cray Graph Engine, pre-tuned to leverage the system’s serious parallelization and performance. The result is graph analytics that finds relationships faster than anything tested at high scale.
High-frequency insightsSee a whole new world of insights and discover new opportunities. The Cray Urika-GX platform gives businesses a way to achieve high-frequency insights with interactive and iterative analytics — from basic analysis to machine learning and dynamic analytics workflows that can adapt easily. Now you can move beyond limitations to uncover new opportunities faster, tackle your biggest challenges and have the freedom to evolve for whatever comes next. Unleash the value of your big data with the first agile analytics platform that fuses supercomputing with an open, enterprise framework for unprecedented versatility and speed that’s ready for high-frequency insights in days.
Find out more at www.cray.com/UrikaGX.
Certain Spark analytics workloads on the Urika-GX platform have been tested at over quadruple the speed as those running on Amazon EC2 instances
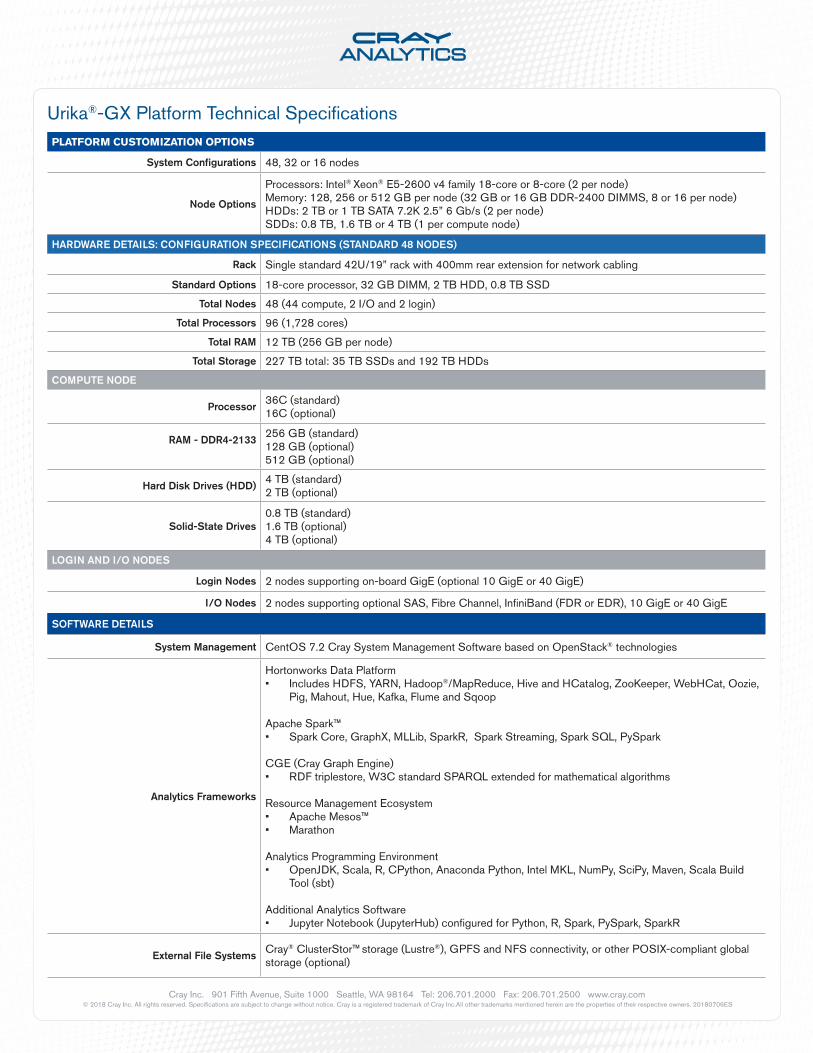
PLATFORM CUSTOMIZATION OPTIONS
System Configurations 48, 32 or 16 nodes
Node Options
Processors: Intel® Xeon® E5-2600 v4 family 18-core or 8-core (2 per node)Memory: 128, 256 or 512 GB per node (32 GB or 16 GB DDR-2400 DIMMS, 8 or 16 per node)HDDs: 2 TB or 1 TB SATA 7.2K 2.5” 6 Gb/s (2 per node)SDDs: 0.8 TB, 1.6 TB or 4 TB (1 per compute node)
HARDWARE DETAILS: CONFIGURATION SPECIFICATIONS (STANDARD 48 NODES)
Rack Single standard 42U/19” rack with 400mm rear extension for network cabling
Standard Options 18-core processor, 32 GB DIMM, 2 TB HDD, 0.8 TB SSD
Total Nodes 48 (44 compute, 2 I/O and 2 login)
Total Processors 96 (1,728 cores)
Total RAM 12 TB (256 GB per node)
Total Storage 227 TB total: 35 TB SSDs and 192 TB HDDs
COMPUTE NODE
Processor36C (standard)16C (optional)
RAM - DDR4-2133256 GB (standard)128 GB (optional)512 GB (optional)
Hard Disk Drives (HDD)4 TB (standard)2 TB (optional)
Solid-State Drives0.8 TB (standard)1.6 TB (optional)4 TB (optional)
LOGIN AND I/O NODES
Login Nodes 2 nodes supporting on-board GigE (optional 10 GigE or 40 GigE)
I/O Nodes 2 nodes supporting optional SAS, Fibre Channel, InfiniBand (FDR or EDR), 10 GigE or 40 GigE
SOFTWARE DETAILS
System Management CentOS 7.2 Cray System Management Software based on OpenStack® technologies
Analytics Frameworks
Hortonworks Data Platform • Includes HDFS, YARN, Hadoop®/MapReduce, Hive and HCatalog, ZooKeeper, WebHCat, Oozie,
Pig, Mahout, Hue, Kafka, Flume and Sqoop
Apache Spark™• Spark Core, GraphX, MLLib, SparkR, Spark Streaming, Spark SQL, PySpark
CGE (Cray Graph Engine)• RDF triplestore, W3C standard SPARQL extended for mathematical algorithms
Resource Management Ecosystem • Apache Mesos™• Marathon
Analytics Programming Environment • OpenJDK, Scala, R, CPython, Anaconda Python, Intel MKL, NumPy, SciPy, Maven, Scala Build
Tool (sbt)
Additional Analytics Software• Jupyter Notebook (JupyterHub) configured for Python, R, Spark, PySpark, SparkR
External File SystemsCray® ClusterStor™ storage (Lustre®), GPFS and NFS connectivity, or other POSIX-compliant global storage (optional)
Urika®-GX Platform Technical Specifications
© 2018 Cray Inc. All rights reserved. Specifications are subject to change without notice. Cray is a registered trademark of Cray Inc.All other trademarks mentioned herein are the properties of their respective owners. 20180706ESCray Inc. 901 Fifth Avenue, Suite 1000 Seattle, WA 98164 Tel: 206.701.2000 Fax: 206.701.2500 www.cray.com








![Endrich News Oktober 2017 dt+engl · Type C 2.5 W PERFORMANCE TYPE FUSING POWER [ FUSING TIME. ] ANCE FUSING PERFORMANCE FUSING PERFORMANCE Please note that this device](https://img.pdfslide.us/doc/110x75/5f68c7cca7d617432e4d41da/endrich-news-oktober-2017-dtengl-type-c-25-w-performance-type-fusing-power-fusing.jpg)








![Initiation Fusing[1]](https://img.pdfslide.us/doc/110x75/577ce0e11a28ab9e78b44e50/initiation-fusing1.jpg)