Embed Size (px)
Citation preview

STUDIA SLAVICA, Ostravska Univerzita, Ostrava 2013
LINGWISTYCZNA ANALIZA FREKWENCYJNA
W BADANIACH SEMIOTYCZNYCH I RYNKOWYCH
Rafał Paprocki
Title: Linguistic frequency analysis in semiotic and market research
Abstract: The aim of this paper is to display a conceptual and methodological framework for
linguistic frequency research by drawing on the discipline of corpus linguistics accompanied
by the original proposal of the author’s solution within the field. Upon a critical review of
existing research conducted in Poland and in English speaking countries, the article suggests
the strong need for implementation of modern IT technologies in order to derive semantic
content from the Internet communication, as well as from traditional sources, such as books,
magazines, newspapers, etc. The text mining method proposed by the author is based upon the
combination of traditional frequency dictionaries linked with website browsers in order to
derive particular meanings of words from streams of everyday communication. The article
introduces the term freqsem, providing the thorough description of its use within the method
in question. By drawing on the ways the contemporary linguistic frequency analysis can be
used the paper addresses how language and daily communication can serve as a collection of
hidden and deeply interlacing, yet decodable meanings. The article attempts at presenting the
linguistic frequency technology as an innovative tool aimed at supporting semiotic and market
research.
Key words: corpus linguistics, pragmalinguistics, frequency analysis, semiotic research,
market research, freqsem
§1. Użytkownicy i badacze języka polskiego dysponują obecnie tylko jednym ogólnym
słownikiem frekwencyjnym, którego korpus pochodzi z lat 1963-1967 (Kurcz, Lewicki,
Sambor, Szafran, Woronczak 1990: VIII) i jak sami autorzy przyznali, reprezentatywność
materiałów źródłowych już według standardów obowiązujących w 1990 roku, czyli
w momencie wydania publikacji, pozostawiała wiele do życzenia (Kurcz, Lewicki, Sambor,
Szafran, Woronczak, ibid.: VIII-IX). Braki te wynikały z wieku pobranej próby oraz stopnia
aktualności jej korpusów składowych. Były one również pochodną ograniczeń technicznych,

które wynikały głównie z relatywnie skromnych możliwości indeksowania i przetwarzania
danych. Zwłaszcza postęp w dziedzinie pozyskiwania, gromadzenia i cyfrowej obróbki
danych poprawił sytuację dzisiejszego badacza w stopniu diametralnym.
Dla zobrazowania skali statystycznych badań językoznawczych prowadzonych obecnie
w Anglii i USA nad językiem angielskim, warto przytoczyć następujące dane:
- korpus współczesnej amerykańskiej angielszczyzny „COCA” składa się z 450 milionów
słów, zebranych w latach 1990-20121,
- korpus języka angielskiego „Oxford English Corpus” zawiera ponad 2 miliardy słów,
wybranych z zasobów tworzonych przez użytkowników tego języka na całym świecie2,
- „Google Books Interface” umożliwia selektywny dostęp do 155 miliardów słów w samej
tylko bazie danych dotyczących amerykańskiej angielszczyzny (dostępny jest tamże również
szereg innych baz danych leksykalnych)3.
Powyższe dane, podane skrótowo i w ogólnym zarysie, dotyczą wybranych systemów
frekwencyjnej obróbki tekstu pod kątem morfologiczno-leksykalnym. Systemy te traktują
słowa jako jednostki bilateralne, czyli jako formy będące nośnikiem określonych znaczeń.
Komunikowanie treści znaczeniowej odbywa się zarówno poprzez odniesienie do funkcji
jednostki w tekście (gramatyka), jak i rzeczywistości pozajęzykowej (semantyka).
Wzmiankowane systemy statystycznych badań językoznawczych umożliwiają m.in. takie
funkcje, jak: szeregowanie znajdujących się w rejestrach słów według części mowy,
identyfikowanie słów w towarzyszących im kontekstach, określanie najbardziej typowych
kolokacji, wyszukiwanie synonimów badanych słów, porównania sposobów użycia słów
w obrębie języka mówionego i pisanego, analiza frekwencyjna słów w obrębie gatunków
literackich oraz pod względem wycinka czasowego, w którym powstawały zgromadzone w
korpusach teksty.
§2. Rozwiązania proponowane w niniejszym opracowaniu podyktowane są chęcią
uzupełnienia instrumentarium mogącego służyć rozwojowi badań korpusowych w Polsce.
Jednocześnie, są one próbą wyjścia naprzeciw opinii, iż „w językoznawstwie polskim dość
szeroki jest konsensus co do potrzeby włączenia problematyki społeczno-kulturowego
podłoża międzyludzkiej komunikacji do centrum zainteresowań językoznawczych. Ów
konsensus sprowadza się do postulatu uczynienia przedmiotem badań językoznawczych
człowieka jako użytkownika języka, człowieka tworzącego społeczność komunikacyjną, która
1 [Online]. Protokół dostępu: http://corpus.byu.edu/coca/, [dostęp: 15.04.2013].
2 [Online]. Protokół dostępu: http://oxforddictionaries.com/words/about-the-oxford-english-corpus,
[dostęp: 15.04.2013]. 3 [Online]. Protokół dostępu: http://googlebooks.byu.edu/?x=3503486&c=us, [dostęp: 15.04.2013].

zawsze odznacza się specyficznym porządkiem symbolicznym, przekładającym się na
określony porządek poznawczy” (Kajfosz 2009: 7). Pochodnym zainteresowaniom
językoznawców celem utylitarnym artykułu jest dostarczenie narzędzia wspomagającego
analizę zachowań komunikacyjnych do zastosowań w polu badań rynkowych,
w szczególności dotyczących zachowań konsumentów. Potrzeba takiego wykorzystania badań
lingwistycznych implikowana jest przez zmiany zachodzące obecnie w sferze działalności
gospodarczej, na której coraz silniejsze piętno wyciska zjawisko globalizacji. Wzory i wzorce
konsumpcji podlegają dynamicznej migracji i wymianie międzykulturowej, stąd chęć
zrozumienia specyfiki oddziałujących na siebie kultur właśnie przez pryzmat języka
i sposobów komunikacji rozumianych jako nośnik informacji kluczowych dla skutecznej
działalności gospodarczej.
„Podstawowa teza współczesnych teorii narracji sprowadza się do stwierdzenia, że
doświadczenie organizowane jest według tego samego systemu, którym kieruje się
fabularyzacja” (Kajfosz, ibid.: 9). Aby więc wydobyć struktury poznawcze, dzięki którym
światotwórcza rola języka odpowiada sposobom organizowania doświadczeń w wymiarze
typowym dla danej kultury czy środowiska, należy poddać badaniu teksty w odpowiadających
tymże doświadczeniom wymiarach. Jak zatem ludzkie doświadczenie cechuje różnorodność
pod względem okoliczności, w których ma ono miejsce, tak i relacje z owych doświadczeń
należy rozpatrywać pod kątem rozmaitych dyskursów, w obrębie których przebiega
komunikacja, odzwierciedlając i nadając światu oraz doświadczeniom określony sens.
Za punkt wyjścia do badań nad językiem jako zjawiskiem charakteryzującym strukturę
ludzkiego doświadczenia obrano głównie dane znajdujące się na stronach internetowych,
będące najobszerniejszym obecnie źródłem szerokodostępnej informacji. Internet jest
źródłem dużej ilości rozległej tematycznie informacji4 dostępnej badaczowi w jednym
miejscu (wysoka dostępność i dogodność). Poza tym, Internet jest źródłem danych
językowych (korpusem tekstów), które są aktualizowane na bieżąco. Przez to może on być,
zgodnie z założeniami proponowanego tutaj rozwiązania, użyty do monitorowania dynamiki
zmian dokonujących się w sferze zachowań językowych i odpowiadających im wzorów
zachowań (w tym konsumpcji). Pomimo istniejących ograniczeń dostępu do Internetu i różnej
aktywności jego użytkowników5 stanowi on okazję do wglądu w język en masse
6. Jako taki,
rozpatrywany jest on jako zbiór znaków, których wzajemne powiązania dają się poprzez
4 [Online]. Protokół dostępu: http://www.internetworldstats.com/stats.htm, [dostęp: 15.04.2013].
5 [Online]. Protokół dostępu: http://www.stat.gov.pl/cps/rde/xbcr/gus/PTS_Dwie_Polski_D_Batorski.pdf.
[dostęp: 15.04.2013]. 6 [Online]. Protokół dostępu: http://webhosting.pl/Co.sie.dzialo.w.Internecie.w.2010.roku. [dostęp: 15.04.2013].

wyszukiwarki i przeglądarki stron www zestawiać i jako relacje - identyfikować w szerokim
spektrum znaczeniowym. W przypadku eksploracji nieustrukturalizowanych źródeł
tekstowych należy brać pod uwagę problem dysambiguacji, dostępne są jednak narzędzia
umożliwiające choć częściowe jego rozwiązanie (Szymański, Błaszczyk, Chełmecki 2007:
1-6).
Źródłem informacji dla badaczy może być zresztą dowolny korpus danych językowych.
W przypadku komunikacji przebiegającej w obrębie sieci www, możliwa jest różnorodna
selekcja danych na bazie wyodrębnionych dyskursów (zawężenie analiz do takich rodzajów
komunikacji, jak fora tematyczne, grupy dyskusyjne, portale, serwisy społecznościowe, etc.),
segmentów (użytkownicy zamieszkujący określony region, poszczególne grupy wiekowe,
osoby z określonym wykształceniem, etc.) lub okresów (określone wycinki czasowe dla
zasygnalizowanych powyżej dyskursów lub segmentów). Rozpatrując bazy tekstów
istniejących w formie drukowanej (książek, czasopism), badaniu można poddać materiały
wydzielone pod kątem profili tematycznych lub zawartości (wydawnictwa poświęcone
określonej tematyce, publikacje na wybrany temat, etc.) lub autorstwa (teksty pochodzące od
określonych autorów, dzieła zebrane). Analogicznie do baz internetowych, publikacje
fizyczne można selekcjonować w przekroju czasowym oraz porównywać wybrane okresy,
roczniki, etc.
Chcąc więc uzyskać wgląd w strukturę frekwencyjną twórczości Szekspira, należałoby
zbadać powiązania interesujących analityka słów w zestawieniu z innymi słowami, które im
towarzyszą. Otwierając dyskusję na temat poruszanej tutaj problematyki można powiedzieć,
iż chcąc zbadać występujące u Szekspira słowo CZAS, należy w dziełach zebranych pisarza
wyodrębnić różnego rodzaju interesujące analityka powiązania pomiędzy „czasem”, a innymi
słowami, a następnie uporządkować uzyskane wyniki w odpowiedniej kolejności pod kątem
częstości ich występowania (np. w stosie malejącym). Tak uzyskana lista będzie wskazywać z
jednej strony na słowa, które w pracach wspomnianego autora najczęściej towarzyszą
„czasowi”. Z drugiej zaś strony, właśnie wskazanie na charakterystykę częstotliwość-
styczność wyodrębnionych powiązań być może pozwoli na wgląd w znaczenia, które zostały
nadane badanemu słowu w analizowanym tekście.
Za podstawę do stworzenia metody tak prowadzonych badań mogą posłużyć zbudowane na
podstawie słowników frekwencyjnych listy słów, które wskazują na częstotliwość
występowania określonego leksemu w danym (w tym przypadku- polskim i angielskim)

języku7. Słownik frekwencyjny jest „językowym odbiciem rzeczywistości(…)rodzajem
gigantycznego sondażu opinii publicznej, nie zawierającego wprawdzie odpowiedzi na
konkretne pytania, ale przedstawiającego obszernie pewną epokę historyczną i mentalność
konkretnej społeczności językowej(…)pokazującym konkretne społeczeństwa uwikłane w
konkretną sytuację polityczną, ideologiczną, materialną” (Pawłowski 1999: 82-83).
Relewantność słowników frekwencyjnych w proponowanym rozwiązaniu może być oceniana
m.in. pod kątem ich aktualności, gdyż „o ich (a)historyczności decyduje przede wszystkim
dobór badanych haseł czy grup tematycznych oraz przyjęta perspektywa badawcza”
(Pawłowski, ibid.: 83). ale również ze względu na wyżej wymienione aspekty przestrzenne i
środowiskowe. Ma to szczególne znaczenie w przypadku badań segmentacyjnych, w których
jednym z kryteriów miarodajności analizy jest zawężenie badanej grupy (społeczności
komunikacyjnej) w celu wyodrębnienia przez badacza interesującego go dyskursu.
Dyskursywne obrazy (świata, słowa, rynku, produktu) będą się różnić w zależności od
tworzących je i pozostających pod ich wpływem wspólnot komunikacyjnych.
Celowośc czerpania ze słowników frekwencyjnych wynika z potrzeby wyodrębnienia
elementów (słów) najbardziej typowych dla danego języka, co ma za zadanie zwiększyć
stopień reprezentatywności zgromadzonego zbioru danych względem zjawisk
przebiegających w obrębie danego języka naturalnego. Posiłkując się przykładem badań nad
językiem angielskim, operując na zbiorze 4000-5000 słów o najwyższej frekwencji jesteśmy
w stanie, w sensie ilościowym, odzwierciedlić 95% komunikacji przebiegającej na piśmie,
operowanie zaś leksykonem 1000 najczęściej używanych słów pozwala oddać 85% zjawisk
przebiegających w komunikacji ustnej (Davies 2006: VII). Takie zawężenie leksykonu
podyktowane jest zarówno możliwościami finansowymi, jak i technicznymi- sprawne
i szybkie gromadzenie interesujących badacza danych pociąga za sobą koszty proporcjonalne
zarówno do wielkości korpusu poddawanego analizie, jak i stopnia reprezentatywności
względem całości leksykonu danego języka. Pozyskiwanie i obróbka danych już na 85%
poziomie reprezentatywności w przypadku analiz wykonywanych ręcznie (nie maszynowo,
przy pomocy dedykowanego oprogramowania) jest przedsięwzięciem wystarczająco
mozolnym, aby istotnie angażować możliwości jednostkowego badacza.
§3. Problematyka społeczno-kulturowego podłoża komunikacji międzyludzkiej wymaga
odpowiedzi na pytanie, jak język łączy się ze światem ludzkiego doświadczenia. „Kultura
danej społeczności składa się z powszechnie respektowanych w owej społeczności przekonań
7 [Online:] Protokół dostępu: http://korpus.pwn.pl/stslow.php, [dostęp: 15.04.2013].

normatywnych, wyrażających pozytywne wartości-cele działań oraz z przekonań
dyrektywnych wskazujących działania wystarczające lub/i niezbędne (w określonych,
podawanych przez nie okolicznościach) dla realizacji owych celów. Przekonania owe
układają się tedy w sposób „naturalny” w pary typu: <przekonania normatywne, przekonania
dyrektywne> czy- krócej - <norma, dyrektywa>” (Kmita 1995: 271).
Kulturą danej społeczności może więc być nazwany „(…) układ szeregu powiązanych ze
sobą różnorakich kompleksów przekonań respektowanych (raczej milcząco niż świadomie
akceptowanych) powszechnie w owej społeczności i dających się wyrazić za pośrednictwem
zdań normatywnych oraz zdań dyrektywnych” (Kmita, ibid.: 94). Respektowane przez
poszczególne jednostki normy kulturowe „ukierunkowują” odpowiednie ich działania
(włączając operacje myślowe), a więc określają wartości-cele tych działań. Dyrektywy
kulturowe z kolei wskazują te działania, które powinny zostać podjęte jako środki realizacji
wyznaczonych celów (Kmita, ibid.: 94). Tak zdefiniowana kultura zawiera w sobie
obowiązujące jednostkę ramy (założenia) racjonalności. Są one spełnione (a jednostka
zachowuje status racjonalnej) w sytuacji, w której obrane przez jednostkę, zgodne z normą
kulturową cele osiągane są poprzez działania wyznaczone przez związane z tym celem
(przypisane mu) dyrektywy kulturowe (Kmita, ibid.: 97).
Istotnym dla badacza jest więc kwestia z jednej strony powiązania pomiędzy słowami,
a treściami, do których odsyłają. „Słowa- pamiętajmy, że idzie tu nie tyle o słowa literalnie,
ile o metaforycznie przez nie reprezentowane: pewne ich złożenia, zachowania werbalne, akty
mowy, język itd. – łączą się ze światem najpierw semantycznie” (Kmita, ibid.: 208-209).
Łączenie się <słów> ze światem uskuteczniające się za sprawą semantyki wewnętrznej języka
wspólnotowego (a taki rodzaj języka i semantyki rozważa niniejsze opracowanie)
przedstawiałoby się w sposób następujący: „Po pierwsze, jednostki ludzkie zdolne do
posługiwania się określonym językiem wspólnotowym <podkładają> pod pewne <słowa>
swoje <bezpośrednie dane>, które przy klasycznym rozumieniu ich można traktować jako
skutki czy inaczej rozumiane <reprezentacje> czegoś zwykle nie związanego z językiem,
(…)skutki pobudzeń zakończeń ludzkiego systemu nerwowego przez coś przeważnie
pozawerbalnego. Po drugie, pewne z założeń wewnątrz-semantycznych odniesień
przedmiotowych (potencjalnych czy stałych ich ośrodków) mają postać stwierdzeń
prawdopodobnych czy nawet praw – ustalających niekiedy związki przyczynowe pomiędzy
czymś pozawerbalnym a użyciem <słów>. Obydwie okoliczności stanowią niezłą podstawę
do tego, aby utrzymywać, że dyrektywy odniesienia przedmiotowego semantyki wewnętrznej
języka wspólnotowego łączą jednak nasze <słowa> z <całą resztą> świata, a nie tylko z

innymi naszymi <słowami>” (Kmita, ibid.: 209). „Łączą się one z nim (słowa ze światem,
przyp. autora) za pośrednictwem wypowiedzi zdaniowych (wyrażanych przez nie
przekonań), odpowiednio uzgodnionych ze sobą holistycznie, w sposób podyktowany przez
fizykalno-przyczynowe związki, dzięki którym wchodzą w interakcje z otoczeniem osób
wygłaszających te wypowiedzi; związki owe tak zostały obmyślone, aby ich aplikacja, w
szczególności do działań werbalnych, była użyteczna, między in. użyteczna technologicznie”
(Kmita, ibid.: 235).
§4. Określona wykładnia osadzenia języka w świecie - ze względu na charakter artykułu
wybiórcza i skrótowa - jest niezbędna, aby w ogóle móc wskazać płaszczyznę przełożenia
badań językoznawczych na praktykę, np. socjologiczną czy marketingową. Termin
„praktyka” odnosi się do próby zrozumienia manifestujących się w języku struktur
porządkujących rzeczywistość społeczną oraz zastosowania owej wiedzy, czy to w postaci
uporządkowanej wizji badanego wycinka świata, czy też np. w celu tworzenia strategii
i wdrażania kampanii społecznych czy rynkowych. Nie należy jednak zapominać, iż
płaszczyznę języka naturalnego cechuje wysoki poziomem ogólności. W związku z tym,
w przypadku określonych praktyk socjologicznych lub rynkowych konieczna może się okazać
pogłębiona specyfikacja określonych dysursów.
Z jednej strony więc, zidentyfikowaliśmy potrzebę badań nad językiem w określonym
kontekście (aktualność, potoczność, dyskurs) oraz zaproponowaliśmy wykładnię łączliwości
słów ze światem (kultura, doświadczenie). Z drugiej zaś strony- zasygnalizowaliśmy metodę
obróbki tekstów reprezentujących daną kulturę i dyskursów prowadzonych w jej obrębie
(reprezentacja przez frekwencję). Założenie proponowanej metody (wyrastające z ogólnej
tezy mówiącej, iż znaczenie słowa wynika z jego użycia w określonym kontekście) jest
następujące: miarą roli i znaczenia słowa w korpusie jest częstotliwość jego występowania
wraz z towarzyszącymi mu innymi, poszczególnymi słowami.
Tak więc to, co ważne w odniesieniu do danego słowa, co dane słowo charakteryzuje jest
tym, co najczęściej się w jego obecności pojawia i powtarza, wiąże się z nim zasadzie
współobecności (styczności). Istotą niniejszej analizy frekwencyjnej jest więc identyfikacja
(indeksowanie) częstości określonych relacji syntagmatycznych w taki sposób, aby poprzez
wydobycie najczęściej występujących połączeń słowa z innymi słowami wydobyć
zestawienia najpowszechniej dane słowo desygnujące. Należy jednak mieć na uwadze, iż tak
sformułowane kryterium identyfikowania znaczenia, czyli kryterium
powszechności/frekwencji, aby mogło być traktowane jako reprezentatywne względem
obranej społeczności językowej (dyskursu) wymagać może skali korpusu tekstu analogicznie

do warunków, których spełnienie jest wymagane podczas tworzenie reprezentatywnych
słowników frekwencyjnych. Oznacza to, iż wyciąganie daleko idących wniosków
z wyrywkowych, niewielkich objętościowo próbek tekstu w przypadku proponowanej metody
nie jest możliwe.
Operując w obrębie danego korpusu, zestawienie słowa z innymi słowami i ich
frekwencyjne indeksowanie/porządkowanie ma więc na celu identyfikację kombinacji,
w których dane słowo występuje wraz z określeniem ich częstości występowania. Aby nadać
niniejszej analizie frekwencyjnej systematyczny charakter, badane słowo zestawiane jest
kolejno z listą słów zawierających się w określonym zbiorze, np. z wybranym zbiorem
zawierającym określoną część mowy. Kombinacji słowa z innym słowem (ewentualnie, słowa
ze zbiorem słów, tudzież określonego zbioru słów z innymi zbiorami słów), ze względu na
charakteryzującą jej tworzenie relację frekwencja-znaczenie, przydzielono termin: „freksem”.
„Freksem” jest pojęciem o tyle odmiennym od konwencjonalnie rozumianego związku
frazeologicznego, iż przypisany jest wyłącznie do określonego korpusu, w którym ponadto
daje się on wyodrębniać i klasyfikować na zasadach określonych przez badacza (bardziej
szczegółowa charakterystyka freksemu w dalszej części artykułu).
Prezentowaną metodę obrazuje poniższy przykład.
Słowo kluczowe: CZAS.
Zbiór dopełniający: lista frekwencyjna 100 najczęstszych rzeczowników w języku polskim.
(Kurcz, Lewicki, Sambor, Szafran, Woronczak, ibid.: 802-810)
Korpus źródłowy: katalog stron www zindeksowany wyszukiwarką Microsoft BING, język
wyszukiwania: polski, wyłączony filtr Safe Search (treści szkodliwe dla niepełnoletnich),
szerokość wyszukiwania: na stronie, otwarte kryterium wyszukiwania, format dokumentu:
dowolny.
Formy hasłowe: formy podstawowe leksemów, mianownik.
Raport z analizy: lista rangowa 30 najczęstszych freksemów.

Zaprezentowany przykład ma na celu przybliżenie charakterystyki metodologicznej
prowadzonej analizy frekwencyjnej, stąd widoczne uproszczenie formy badania. Aby
sprofilować analizę pod kątem okreslonych przez badacza kryteriów, tudzież dostosować jej
selektywność i reprezentatywność dla danego korpusu, słowo wyjściowe należałoby poddać
frekwencyjnemu skojarzeniu z elementami zbioru towarzyszącego w formach, w jakich
występuje ono w danym języku naturalnym. W powyższym przykładzie słowo CZAS
zestawiane mogłoby być osobno z każdym elementem zbioru dopełniającego kolejno
w formie odmienionej przez przypadki i liczbę. Analogicznie, gdyby słowem kluczowym był
przymiotnik, możliwa byłaby jego analiza frekwencyjna w formach wynikających z odmiany
przez przypadek, rodzaj i liczbę (ta sama zasada dotyczy elementów zbioru dopełniającego).
Korpus źródłowy mógłby zostać sprofilowany według obranych kryteriów, np. ściśle
określony stopień sąsiadowania wyszukiwanych wyrazów (szerokość odstępu, prawa/lewa
strona współwystępowania). Zbiór dopełniający może mieć sklad i być podzielony na
kategorie, których granice wyznacza zasób słów wystepujących w danym języku naturalnym
oraz liczba wyodrębnionych kategorii (gramatycznych, semantycznych, tematycznych, etc.).
Proponowana metoda analizy frekwencyjnej służyć może odpowiedzi na pytania
wynikające z potrzeby rozumienia znaczeń zawartych w pojęciach. Dotyczy to zarówno
poszukiwania znaczeń stojących za pojęciami, jak również wynika z chęci dotarcia do istoty
konwencji komunikacyjnych charakteryzujących wspólnoty tworzące określony tekst (język,
zbiór tekstów, dyskurs, etc.). Jest więc również próbą sformułowania językowego lub
dyskursywnego obrazu słowa, które w określonym kontekście łączy się z innymi słowami
w określony sposób i z określoną częstotliwością. Jest to więc, biorąc pod uwagę
sygnalizowaną wcześniej problematykę łączliwości słów ze światem, z jednej strony próba
odtworzenia struktury doświadczenia użytkowników języka (uczestników dyskursu)
w obrębie danej rzeczy lub pojęcia (słowo jako predykat), z drugiej zaś jest wglądem w
sposób funkcjonowania i przedstawiania owego pojęcia przez daną wspólnotę językową
(komunikacyjną). Tak, jak rozumienie jest zawsze kwestią relacji podmiotu do pojęcia
(świadomości do przedmiotu rozumienia, umysłu do fragmentu rzeczywistości; Czernawska
2002: 116), znaczenie pojęcia odzwierciedlone jest jego użyciem w określonym kontekście,
czyli relacją z innymi pojęciami. Należy więc zdawać sobie sprawę, iż jeśli językowa analiza
frekwencyjna wskazuje na znaczenie pojęcia poprzez rozkład rangowy zidentyfikowanych na
jego bazie freksemów, czyni to w sposób otwierający szerokie możliwości badawcze
i interpretacyjne. Teoretycznie, słowo kluczowe może być w danym korpusie analizowane
pod kątem jego łączliwości ze wszystkimi interesującymi badacza dziedzinami wiedzy

i doświadczenia. Dotyczy to zwłaszcza dużych korpusów danych językowych - wydobycie
frekwencyjnego obrazu słowa możliwe jest na tak wiele sposobów i przy pomocy tak różnych
heurystyk, że konkluzywne formułowanie zapytań jest głównie kwestią potrzeb i możliwości
badacza oraz stopnia uściślenia przedmiotu badań.
§5. Proponowana tutaj metoda analizy frekwencyjnej umożliwia realizację szeregu
potencjalnych celów. Obok zasygnalizowanego powyżej ogólnojęzykowego obrazu słowa,
warto wskazać na takie aspekty analiz, jak badania porównawcze w obrębie różnych języków
naturalnych oraz diachroniczny i dyskursywny wymiar słowa.
Badania porównawcze słowa CZAS/TIME dla dwóch języków naturalnych, polskiego
i angielskiego, po wyodrębnieniu zbiorów dopełniających (np. najczęstszych czasowników,
przymiotników, wybranych tematów typu: kolory, kształty, emocje, dyscypliny sportu, etc.)
i zestawieniu list rangowych powstałych freksemów dawać może wgląd w kolejność i stopień
łączliwości słowa kluczowego ze słowami ze zbiorów dopełniających. Ponadto, może
obrazować proporcje, w których słowo kluczowe występuje w zestawianych korpusach w
połączeniu ze wspólnie obranymi elementami (słowami) dopełniającymi.
0
500000000
1E+09
1,5E+09
2E+09
time + color
07.11.2012
0 1000000 2000000 3000000 4000000 5000000
czas + kolor
07.11.2012
Serie1

W powyższym przykładzie prostego porównawczego badania frekwencji istotna jest nie
tyle bezwzględna liczba zidentyfikowanych wystąpień freksemów (katalog stron www.
zapisanych w języku angielskim jest obszerniejszy, niż katalog stron w języku polskim, stąd
różnice w bezwzględnej liczbie wystąpień), co ich kolejność i proporcje liczbowe. Na
podstawie wykonanej próby można powiedzieć, że użytkowników języka angielskiego
cechuje podobny do użytkowników języka polskiego wzorzec łączliwości pomiędzy słowem
CZAS a kolorami: czarny, biały, czerwony i niebielski, częściej zaś łączą oni słowo CZAS z
kolorem zielonym, a użytkownicy języka polskiego z kolorem złotym (porównanie
freksemów na pozycji nr 4). Stosunkowo duże dysproporcje zachodzą pomiędzy częstością
freksemów „CZAS+CZARNY” i „CZAS+FIOLETOWY/PURPUROWY”; po
przeanalizowaniu szczegółowych danych liczbowych okazuje się, że dla języka angielskiego
jest to różnica odpowiednio ok. 5 i 10 razy częstszego udziału, podczas gdy dla języka
polskiego różnica jest o dwa rzędy wielkości większa (ok. 50 i 100 razy wyższa frekwencja
złożenia słowa kluczowego CZAS z dopełnieniem „czarny”, niż „fioletowy” i „purpurowy”).
Diachroniczny wymiar obrazu słowa jest pochodną zmian, jakim podlegają słowa
w obrębie każdego języka naturalnego będącego aktualnie w użytku. Na dzień dzisiejszy
trudno stwierdzić, jaka częstotliwość i głębia badań frekwencyjnych jest wskazana w
przypadku rekonstrukcji diachronicznego obrazu słowa. Jest to problem o tyle złożony, iż
uchwycenie prawidłowości (np. kowariancji) pomiędzy znajdującymi się w korpusie słowami
wymaga w przypadku katalogu stron www. cyklicznego przetwarzania dużych ilości danych,
skazując badacza bądź na wysokie koszty, lub też wymuszając określone przybliżenie
wynikające z wielkości (limitu) pobieranej próby.
Dyskursywny wymiar obrazu słowa uwidacznia się podczas analiz zbiorów freksemów
budowanych na podstawie dopełniających słowo kluczowe list tematycznych.
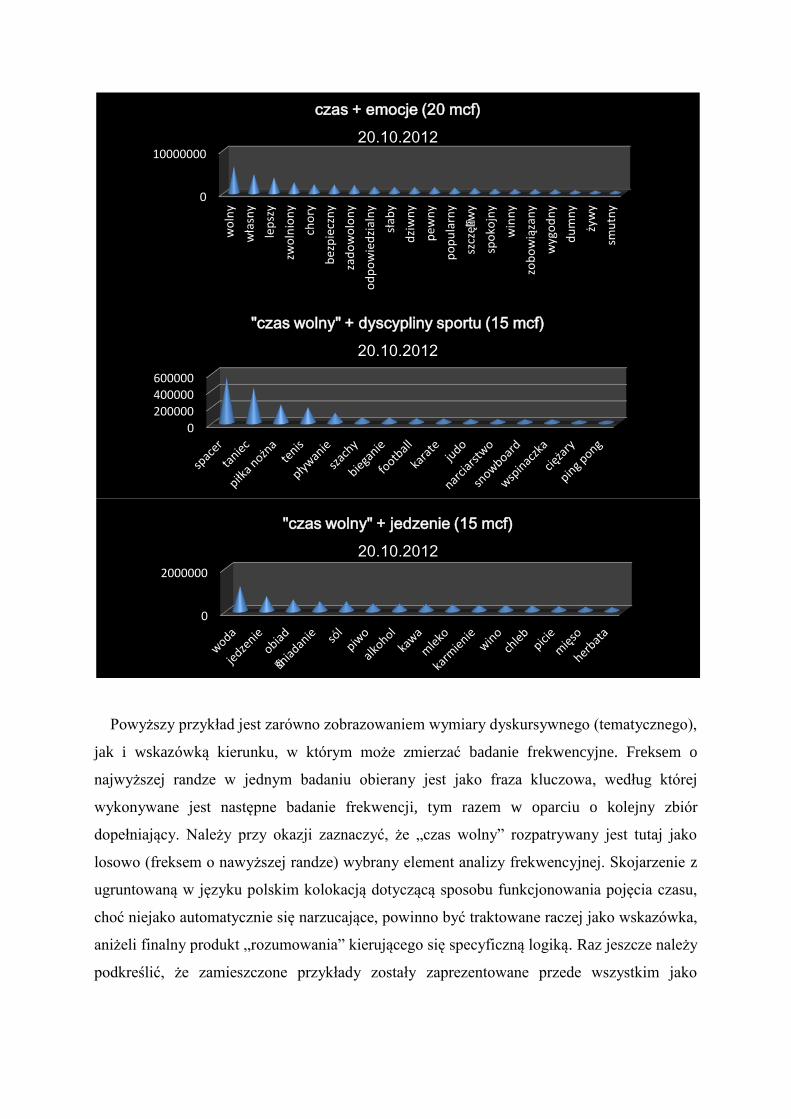
Powyższy przykład jest zarówno zobrazowaniem wymiary dyskursywnego (tematycznego),
jak i wskazówką kierunku, w którym może zmierzać badanie frekwencyjne. Freksem o
najwyższej randze w jednym badaniu obierany jest jako fraza kluczowa, według której
wykonywane jest następne badanie frekwencji, tym razem w oparciu o kolejny zbiór
dopełniający. Należy przy okazji zaznaczyć, że „czas wolny” rozpatrywany jest tutaj jako
losowo (freksem o nawyższej randze) wybrany element analizy frekwencyjnej. Skojarzenie z
ugruntowaną w języku polskim kolokacją dotyczącą sposobu funkcjonowania pojęcia czasu,
choć niejako automatycznie się narzucające, powinno być traktowane raczej jako wskazówka,
aniżeli finalny produkt „rozumowania” kierującego się specyficzną logiką. Raz jeszcze należy
podkreślić, że zamieszczone przykłady zostały zaprezentowane przede wszystkim jako
0
10000000
wo
lny
własn
y
lep
szy
zwo
lnio
ny
cho
ry
bez
pie
czn
y
zad
ow
olo
ny
od
po
wie
dzi
aln
y
słab
y
dzi
wn
y
pew
ny
po
pu
larn
y
szczę�liw
y
spo
kojn
y
win
ny
zobowiąza
ny
wyg
od
ny
du
mn
y
żywy
smu
tny
czas + emocje (20 mcf)
20.10.2012
0
200000
400000
600000
"czas wolny" + dyscypliny sportu (15 mcf)
20.10.2012
0
2000000
"czas wolny" + jedzenie (15 mcf)
20.10.2012

niekonkluzywna pragmalingwistycznie egzemplifikacja podstawowych aspektów obranej
metody badań.
§6. Wobec zawartych jak dotąd rozważań, szereg istotnych uwag na temat pojęcia
„freksemu”. Jako podstawową jednostkę proponowanej metody analizy frekwencyjnej,
freksem charakteryzują implikowane przez metodę własności. Wyróżnić można m.in. takie
cechy freksemu, jak: pochodzenie, ranga, reprezentatywność, zwartość, synchro-
i diachroniczność oraz trend.
Pochodzenie freksemu wynika z korpusu tekstu, w którym jest on identyfikowany.
Podczas, gdy ogólne słowniki frekwencyjne wskazują na popularność słowa w danym języku
naturalnym, dane freksemu zależą wyłącznie od zawartości badanego tekstu. Tekst ten równie
dobrze może być zamkniętym zbiorem słów reprezentatywnych dla danego języka, jak
również stanowić pochodną otwartego na zmiany w procesie komunikacji, bardziej
szczegółowo wyodrębnionego dyskursu prowadzonego w obrębie określonej grupy
uczestników. Może on pochodzić z publikacji istniejących fizycznie (książki, czasopisma,
gazety, etc.), jak i ze źródeł internetowych (katalog www. stron ogólnych, ale też wszelkich
wyodrębnionych formalnie, tudzież poddających się segmentacji dyskursów typu: grupy i fora
dyskusyjne, portale informacyjne, podzbiory przypisane określonym adresom www., portale
społecznościowe, etc.). Tekst stanowiący o pochodzeniu freksemu może istnieć w formie
pisemnej, bądź ustnej. Wreszcie, może on być profilowany terytorialnie (segment przypisany
do określonej przestrzeni/regionu).
Ranga (powszechność) odpowiada miejscu freksemu na rangowej (uporządkowanej w
stosie malejącym/rosnącym) liście frekwencyjnej i bezpośrednio wynika z porównania liczby
wystąpień danego freksemu z częstością innych, należących do odpowiadającej mu kategorii
freksemów. Reprezentatywność freksemu jest pojęciem o pewnym stopniu umowności i jest
kwestią miar przyjętych przez badacza. Jeżeli przyjmie się poczynione na początku artykułu
założenia o skali reprezentatywności leksykonu o określonej objętości dla komunikacji
przebiegającej w danym języku naturalnym, freksem mający źródło w zbiorze dopełniającym
składającym się ze 100 przymiotników będzie się cechował inną reprezentatywnością, niż
freksem określany na podstawie zbioru 1000 przymiotników; ten drugi będzie po prostu
bardziej reprezentatywny dla danego tekstu (choć w istocie może się zdarzyć, że w danym
korpusie jego obecność nie zostanie zidentyfikowana, co jednak również może być dla
badacza konkretną informacją).
Zwartość freksemu wynika z bliskości słowa kluczowego z elementami zbioru
dopełniającego. „Freksem ścisły” będzie złożeniem, w którym sąsiedztwo poszukiwanych

połączeń jest nierozdzielone innym słowem, „luźny” zaś w przypadku braku bezpośredniej
styczności. Zwartość freksemu jest więc kwestią stopnia i miary, ale przede wszystkim
potrzeb badacza, który decydując o poziomie zwartości poszukiwać może różnego rodzaju
relacji syntagmatycznych; wszak treści komunikowane wokół danego pojęcia mogą być w
tekście rozproszone w stopniu początkowo trudnym do przewidzenia, a zatem poszukiwanie
wyłącznie freksemów ścisłych (na podobieństwo kolokacji) może pomijać znajdujące się w
tekście relacje. Duże korpusy tekstów (np. liczone w milionach czy miliardach stron katalogi
stron www.) mogą umożliwiać statystycznie wartościowe porównania freksemów złożonych
z tych samych elementów (słów), jednak o różnej zwartości.
Synchro- i diachroniczność freksemu to charakteryzujący go parametr dynamiki czasowej.
„Freksem synchroniczny” opisuje relacje łączliwości występujące w korpusie w momencie
pobierania próby frekwencji. Analogicznie, „freksem diachroniczny” to jednostka analizy
frekwencyjnej o powtarzalnym, cyklicznym charakterze; ma to znaczenie w przypadku, kiedy
badacza interesuje zmienność występowania danego freksemu w czasie. Jest to szczególnie
interesujące biorąc pod uwagę zjawisko „starzenia się” i „odradzania” języka, któremu
towarzyszą rozmaite zmiany formalne, następuje zanik użycia wybranych form leksykalnych
i zastępowanie ich przez dotychczas rzadziej używane słowa, a także pojawianie się zupełnie
nowych słów. Wymiar diachroniczny jest ważny również w obliczu dynamicznego przyrostu
wolumenu treści komunikacji przebiegającej w Internecie. Chęć śledzenia wybranych zjawisk
komunikacyjnych oraz dyskursów mających miejsce w obrębie określonych grup społecznych
pod kątem ich zmienności również implikuje potrzebę diachronicznego spojrzenia na
omawianą problematykę.
Trend freksemu jest bezpośrednią pochodną wymiary diachronicznego; porównanie
częstości wystapień freksemu w odniesieniu do źródłowego zbioru dopełniającego słowo
kluczowe pozwala „kreślić” linię popularności określonych relacji leksykalnych w badanym
korpusie/dyskursie. Trend będzie więc cechować względny wzrost, spadek lub równowaga.
§7. Na koniec rozważań na temat autorskiej propozycji językowej analizy frekwencyjnej
kilka refleksji skierowanych w stronę badań rynkowych. „Ażeby odkryć związki jakiegoś
przedmiotu z innymi przedmiotami musimy mieć o nim ogólne pojęcie i rozważać go
z różnych punktów widzenia. Musimy go umiejscowić i określić jego położenie w ogólnym
układzie.” (Cassirer 1998: 98). Aby więc odkryć świadomość związków danego przedmiotu
z innymi przedmiotami, musimy go umiejscowić i określić jego położenie w układzie
będącym środowiskiem owej świadomości. Środowiskiem tym jest dla człowieka język
i mowa, czyli system komunikacji. Przedmiotowi zaś odpowiada nazwa, której daje się

przypisać adekwatny obraz oraz określoną definicję. Tak przedstawiona nazwa, czy to pod
postacią słowa mówionego lub też pisanego, jest nośnikiem określonej wiązki znaczeń. Jeżeli
więc słowo desygnuje odpowiadający sobie przedmiot, a znaczenia z nim związane są kwestią
kulturowo, a więc i językowo uwarunkowanej konwencji, wgląd w znaczenie opisywanego
przez słowo przedmiotu stanowi jednocześnie przesłankę wglądu w postawy użytkowników
danego języka (uczestników danego dyskursu) względem tego przedmiotu. Będzie to wgląd
uśredniony i umasowiony, wydobywający wspólny mianownik rozumienia przedmiotu przez
„omawiających” go rozmówców (stereotyp). Wydobycie treści akcentowanych przez
zaangażowanych w komunikację stoi w samym centrum uwagi badacza zachowań
konsumentów - jego celem jest wszak identyfikacja najczęściej manifestujących się postaw,
a więc również potrzeb i preferencji związanych z rynkowo rozumianym przedmiotem, czyli
z produktem.
Model zachowań konsumenta czerpiący z powyższych założeń względem kultury bierze
więc pod uwagę aspekt językowy, gdyż zjawisko konsumpcji, której częścią jest proces
decyzyjny, zawiera w sobie wymiar normatywny (wartości) oraz dyrektywny (instrukcje),
które z kolei znajdują swoje reprezentacje w sferze komunikacji. Zarówno zmiany
systemowe i obyczajowe, jak też postęp technologiczny oraz transfer i dyfuzja innowacji
wymuszają na podmiotach rynkowych specyficzne dostosowania do obowiązujących
uwarunkowań kulturowych (Mooij, Hofstede 2010: 85). W związku z tym coraz ważniejsze
okazują się próby zrozumienia kultury jako czynnika determinującego zachowania
konsumentów. Problematyka ta jest o tyle istotna, o ile przewidywana w związku z
globalizacją homogenizacja potrzeb, gustów i preferencji konsumentów ściera się z tendencją
do przejawiania przez nich zachowań typowych dla specyficznie ukształtowanych, lokalnych
wzorów kulturowych (Mooij 2010: 103). W związku z powyższym, językowe badania
frekwencyjne wykorzystane być mogą do identyfikacji tych cech przedmiotu/produktu, które
są werbalizowane w tekstach kultury oraz wyrażane (często wprost i spontanicznie, np.
w dyskusjach internetowych) przez samych konsumentów. Pośrednio dotyka to też kwestii:
co same produkty oraz w jaki sposób „mówią” o sobie (np. reklama, opisy charakterystyki lub
funkcji, etc.). Zagadnieniem mogącym przybliżyć odpowiedzi na powyższe pytania jest
pochodna problematyce kategoryzacji naturalnej kwestia identyfikowania prototypów
(Kardela 1990: 27; por.: Kajfosz 2001: 40-41).
Potrzeba wydobycia (odtworzenia) prototypu w badaniach nad zachowaniami
konsumentów odpowiada sposobowi postrzegania przez konsumenta przedmiotów, czyli
w tym przypadku produktów znajdujących się na rynku. Konsument podejmuje swoje decyzje

w dużej mierze w oparciu o kategoryzację naturalną i znaczeniowy obraz słowa (Tokarski
1999: 10). Wynika to z dostępu konsumentów głównie do potocznego, a nie naukowego
obrazu świata. Rzecz jasna, kategorie logiczne również są obecne i brane pod uwagę
w procesie konsumpcji, jednakże trudno większości konsumentów przypisywać tendencję do
poszukiwania informacji o produktach i ich definiowania w sposób naukowy (Falkowski,
Tyszka 2006: 115-121; por.: Maison 2010: 37). W związku z tym, kompetencje służące
podejmowaniu konkretnych decyzji oparte są o wartości co najwyżej przybliżone, nabyte
w procesie asymilacji wiedzy potocznej, z czym związana jest z tym m.in. kwestia wartości
symbolicznej produktów, wynikająca z określonego kontekstu kulturowego (Paprocki 2011:
64-65). Wynika to z aksjologicznego charakteru językowego obrazu świata (Kajfosz 2001:
45), czyli faktu, iż świat/rynek jest dla konsumenta przeniknięty określonymi wartościami,
a znajdujące się w nim przedmioty/produkty nie są mu obojętne. Można więc mówić
o emocjonalnym komponencie towarzyszącym kontaktom konsumentów z produktami.
Komponent ten poprzedzałby więc zawsze fazę konsumpcji w sensie przedteoretycznego
(względem poszczególnych konsumentów) porządku znaczeniowego, typowego dla danego
obszaru kultury i języka. Nie w pełni uświadomiony charakter „językowego obrazu rynku”
i „językowego obrazu produktu” z jednej strony stanowiłby o sile kształtującej jego normy
i wartości oraz towarzyszące im dyrektywy. Z drugiej strony zaś, dla badaczy rynku owa
aksjologiczna specyfika byłaby wyzwaniem, którego podjęcie w postaci identyfikacji cech
szczególnych przedmiotów przybliżałoby możliwość modelowania produktów w oparciu
o ich kulturowo uwarunkowane prototypy. W tym przypadku, należałoby podjąć badania
segmentacyjne uwzględniające LAF (lingwistyczną analizę frekwencyjną) jako narzędzie
diagnostyczne służące rekonstrukcji wzorów i wzorców konspmpcji w obrębie grup
konsumentów rozumianych jako wyodrębnione dyskursy i grupy komunikacyjne.
§8. Zmiana w polu znaczenia jednego słowa może mieć wymierne skutki: może wpływać na
znaczenie innego słowa. To z kolei pociągnie za sobą zmianę w znaczeniu słowa, lub słów
pozostających w bezpośrednim związku ze słowem (tudzież będących w mniej ścisłej z nim
relacji styczności), którego semantyczna transformacja zapoczątkowała łańcuch przemian.
Przemianom tym mogą odpowiadać rozmaite zmiany w świecie fizycznym, tudzież mogą być
one pochodną zmian w sferze kultury, świecie aktywności naukowej, twórczości artystycznej,
wierzeń religijnych, rzeczywistości rynkowej, etc. Opisane zjawiska przebiegać mogą na
zasadzie efektu motyla, bądź też prostych związków przyczynowo-skutkowych. Mogą być
również efektem trudnych do zlokalizowania i zidentyfikowania sprzężeń w wymienionych
sferach. Prędzej czy później jednak, niezależnie od przyczyn i kierunku ich przebiegu,

zjawiska te znajdują odzwierciedlenie w postaci mniej lub bardziej subtelnych zmian w sferze
językowej. Zaprezentowana w artykule perspektywa językowych badań statystycznych,
uwzględniając postęp dokonujący się na polu technologii informacyjnej, ma na celu
strukturalne uporządkowanie zjawisk przebiegających w komunikacji językowej oraz
systematyczne monitorowanie zmian zachodzących w określonych wycinkach niezmiernie
złożonej sieci międzyludzkiej komunikacji.
RESUME
The article gives account of current developments in the field of corpus linguistics in Poland
in short comparison with contemporary research conducted in the following field both in
Britain and USA. Combining pragmalinguistic analysis of narrative text with frequency
dictionaries and IT technologies, the author presents the original model of semiotic and
market research. The aim of technology presented is to retrace communication habits and
derive stereotypes in order to reconstruct the linguistic view of the world. According to most
recent needs for inclusion of social-cultural context into the linguistic research, the emphasis
is placed on the discursive view of the world and further reconstruction of the discursive
views of words, brands and products. Communication behaviour displayed both in electronic
and traditional forms is traced down to support semiotic and market analysis, enabling
comparative research between and among users of different natural languages. The paper
introduces and explains a newly coined term freqsem, referred to as a basic unit in technology
of linguistic frequency analysis.

Literatura:
1. Batorski D., [Online].
www.stat.gov.pl/cps/rde/xbcr/gus/PTS_Dwie_Polski_D_Batorski.pdf. Protokół
dostępu: [15.04.2013],
2. Cassirer E., 1998, Esej o człowieku, Wstęp do filozofii kultury, Warszawa, s 98.
3. Czernawska M. M., 2002, Kilka uwag o pojęciu rozumienia. - Czynności tworzenia
i rozumienia wypowiedzi, red. J. Porayski-Pomsta, Warszawa, s 116.
4. Davies M., 2006, A frequency dictionary of Spanish, New York, s. VII.
5. http://corpus.byu.edu/coca/. [Online]. Protokół dostępu [15.04.2013].
6. http://googlebooks.byu.edu/?x=3503486&c=us. [Online]. Protokół dostępu:
[15.04.2013].
7. http://www.internetworldstats.com/stats.htm; [Online]. Protokół dostępu:
[15.04.2013].
8. http://korpus.pwn.pl/stslow.php, Lista 200 najczęstszych leksemów w języku polskim,
[Online]. Protokół dostępu: [15.04.2013].
9. http://oxforddictionaries.com/words/about-the-oxford-english-corpus. [Online].
Protokół dostępu [15.04.2013].
10. http://webhosting.pl/Co.sie.dzialo.w.Internecie.w.2010.roku. [Online]. Protokół
dostępu: [15.04.2013].
11. Falkowski A., Tyszka T., 2006, Psychologia zachowań konsumenckich, Gdańsk,
s 115-121.
12. Kajfosz J., 2001, Językowy obraz świata w etnokulturze Śląska Cieszyńskiego, Czeski
Cieszyn, s. 40-45.
13. Kajfosz J., 2009, Magia w potocznej narracji, Katowice, s. 7-9.
14. Kardela H., 1990, Ogdena i Richardsa trójkąt uzupełniony, czyli co bada gramatyka
kognitywna, - Językowy obraz świata, Lublin, s. 27.
15. Kmita J, 1995, Jak słowa łączą się ze światem, Poznań, s. 94-235.
16. Kurcz I, Lewicki A, Sambor J, Szafran K., Woronczak J., 1990, Słownik
frekwencyjny polszczyzny współczesnej, Kraków, s. VIII-810.
17. Maison D., 2010, Jakościowe metody badań marketingowych, Warszawa, s. 37.
18. Mooij de, M, 2010, The future is predictable for international marketers, -
International Marketing Review, Bradford, s. 103.
19. Mooij de, M., Hofstede G, 2010 The Hofstede model. Applications to global branding
and advertising strategy and research., - International Journal of Advertising,
Oxfordshire, s. 85.
20. Paprocki R., 2011, Badania Motywacyjne Ernesta Dichtera - geneza, istota,
aktualność, - Zeszyty Naukowe Towarzystwa Doktorantów UJ, 3, Kraków, s. 64-65.
21. Pawłowski A., 1999, Metodologiczne podstawy wykorzystania słowników
frekwencyjnych w badaniu językowego obrazu świata, - Przeszłość w językowym
obrazie świata, red. A. Pajdzińska, P. Krzyżanowski, Lublin, s. 82-83.
22. Szymański J., Błaszczyk K., Chełmecki A., 2007, Rozwiązywanie dysambiguacji za
pomocą lingwistycznej sieci semantycznych relacji leksykalnych na przykładzie
systemu WordNet, Toruń, s. 1-6.
23. Tokarski R., 1999, Przeszłość i współczesność w językowym obrazie świata.
Metodologiczne pytania i propozycje, - Przeszłość w językowym obrazie świata, red.
A. Pajdzińska, P. Krzyżanowski, Lublin, s. 10.










![The San Francisco Call (San Francisco) 1907-01-20 [p 1].8.899.683 pQBSAs, \u25a0 t2-73.>t&»Jstatistical " table.. BlnoeT they:average 100 cherries '-totho-ponad^only those; who can](https://img.pdfslide.us/doc/110x75/5f5feb4244543123d57973bd/the-san-francisco-call-san-francisco-1907-01-20-p-1-8899683-pqbsas-u25a0.jpg)


















