Embed Size (px)
Citation preview

Computers and Electrical Engineering xxx (2012) xxx–xxx
Contents lists available at SciVerse ScienceDirect
Computers and Electrical Engineering
journal homepage: www.elsevier .com/ locate/compeleceng
Focused crawling of tagged web resources using ontology q
Punam Bedi a, Anjali Thukral a,⇑, Hema Banati b
a Computer Science Department, University of Delhi, Delhi 110 007, Indiab Dyal Singh College, Computer Science Department, University of Delhi, Delhi, India
a r t i c l e i n f o
Article history:Available online xxxx
0045-7906/$ - see front matter � 2012 Elsevier Ltdhttp://dx.doi.org/10.1016/j.compeleceng.2012.09.00
q Reviews processed and recommended for public⇑ Corresponding author. Address: Keshav Mahavi
E-mail addresses: [email protected] (P. Bedi), ath
Please cite this article in press as: Bedi P et al.dx.doi.org/10.1016/j.compeleceng.2012.09.009
a b s t r a c t
Scrutinizing web resources of interest from a large number of search results is a tedious taskfor any web user. Fortunately, social sites such as Social Bookmarking Site (SBS) allow webusers to store their preferences and searched results of their interest in the form ofbookmarks. Such sites however contain lots of irrelevant data as noise and, predicting rel-evant URLs from the noise is a real challenge. With intent to overcome the challenge, thispaper proposes a focused crawler, FCHC that mimics a human cognitive search pattern tofind potentially relevant web resources from a SBS. The focused crawler utilizes domainspecific Concept Ontology to semantically expand a search topic and to determine SemanticRelevance of tags. The crawler is tested with different search patterns on the ‘database’domain and evaluated using a well established metric, harvest ratio. The performance ofFCHC is analyzed and compared with focused crawlers that crawl the WWW using ontologyand, without ontology.
� 2012 Elsevier Ltd. All rights reserved.
1. Introduction
The World Wide Web (WWW) is a huge collection of web pages where every second, a new piece of information is added.Searching and retrieving relevant web resources in such a vast collection is a protracted task and absence of any explicit/implicit feedback regarding the relevance of resources adds more intricacy to the process. The web crawlers of searchengines which provide a mechanism to generate indexes of resources available on the Web faces challenges of ever increas-ing volume of the WWW. With the passage of time, it is becoming difficult to crawl and update the complete Web in a shorttime. Focused crawling provides a better alternate to generic crawling especially when topic specific or personalized infor-mation is required [1]. A focused crawler is a topic-driven web crawler which selectively retrieves relevant web pages to apre-defined set of topics. It yields latest resources (web pages) relevant to the needs of individuals while utilizing minimumstorage space, time and network bandwidth [2]. Applications of the focused crawlers include business intelligence (to keeptrack of publically available information about their potential competitors) [3], generating Web based recommendations,constructing topic specific indexes of web pages to serve a generalized web search engine, retrieving domain/topic relevantlearning web resources/content [4], scientific paper repositories [5,6] and many more.
The selection of seed URLs, which consequently directs a focused crawler to identify a search area on the Web, is perhapsone of the major criteria which affect the results of a focused crawler. This feature of focused crawler motivated us to applythe focused crawl on a social site, where web users belonging to various communities with varied interests, across the globepool up web resources of their interest and bookmark them for later referral. Recommending semantically relevant webresources from a collection of manually annotated web resources is another source of motivation. A site consisting of such
. All rights reserved.9
ation to Editor-in-Chief Dr. Manu Malek by Guest Editor Dr. Sabu M. Thampi.dyalaya, University of Delhi, Delhi, India. Tel.: +91 9871975544; fax: +91 11 [email protected], [email protected] (A. Thukral), [email protected] (H. Banati).
Focused crawling of tagged web resources using ontology. Comput Electr Eng (2012), http://

2 P. Bedi et al. / Computers and Electrical Engineering xxx (2012) xxx–xxx
a collection, called a Social Bookmarking Site (SBS) is an online social network and a collaborative bookmarking system thatfacilitates web users to organize bookmarks of their interests.
Social networks have been analyzed for a couple of decades to find useful information related to web pages [1]. The webusers opt for relevant keywords to tag the web resources of their interest so that they could easily refer them later withoutthe repetitive searches on the Web. This information therefore can be used to find relevant web pages for other users as well.Finding relevant web resources on a topic from a structured folksonomy as compared to the complete hyperlinked Web canproduce better search results in lesser time. Using tags as the basis to decide which URLs fit best for a concept can make thedecision more fruitful. Research on social annotation [7] has shown promising results in this direction. Experimental results[8] have also shown that the tags based search algorithms yield improved results and faster recommendations, which con-sequently improves the effectiveness of a web search engine [9]. The main challenge in searching relevant resources in a SBSis to deal with the noise (irrelevant tags and bookmarks) that exist along with the relevant resources. In literature, this prob-lem has been discussed and approaches have been suggested to deal with it [10–12]. The existing approaches usually actupon the downloaded data from SBS; whereas our proposed approach FCHC act before downloading the data, so that onlypotentially relevant web resources could be retrieved leaving the noise behind at the initial level itself.
The other factor that may affect the results of a focused crawler is the selection of relevant terms by expanding the searchtopic. A particular topic or a concept can be represented with many different semantically related words. In Information Re-trieval the terms ‘related’ and ‘relevant’ possess a thin boundary of different interpretations [13], as the term could besemantically ‘related’ to a search topic but may not be necessarily ‘relevant’ to the topic. This is because the ‘relevance’ isusually considered a relative term, depending on a learner’s searching intent [14].
A focused crawler designed to retrieve web pages on a topic from natural language may use some pre-defined thesaurusor ontology. Ontology defines (specifies) the concepts, relationships, and other distinctions that are self explanatory for mod-eling a domain [15,16]. For the purpose of defining semantic relations among various terms or concepts, ontology providesan efficient solution. Applications like eLearning require various relations to be defined among different concepts for buildingthe knowledge base. Instead of using hypernyms, hyponyms, synonyms or antonyms from the WordNet which forms a tax-onomic hierarchy of natural language terms [17], the crawler rather uses conceptually related terms structured as a conceptmap, from manually created domain ontology. This is because the technical terms usually do not have synonyms, hyponyms,etc. rather they have sub concepts, super concepts and sibling concepts, which is more significant while extracting from thedomain ontology. For example, a user or a learner searching for a concept, say, ‘Data Manipulation Language’ (DML) from‘Database’ domain may find the required information in a web resource which might have been tagged with the keyword‘SQL’. This is because ‘DML’ is one of the language types of ‘SQL’. For such cases, a crawler must be aware of the semanticrelations that the concepts in a domain have. In addition, finding relevance ranking order among all the web resourcestagged with the same search concept also needs to be focused/also needs consideration.
These ontologies form the basis for determining semantic relation among various concepts and thus consequently used tocompute the empirical semantic distance (described in later section) between the pair of concepts. No doubt, they need to becarefully designed to represent a correct and factual relationship among different concepts. Although they are expensive tobuild, constructing ontology is a onetime process. These ontologies can be reused later in number of applications. In the com-ing years the semantic web [18] is expected to contain almost every topic of interest. At that time the topic expansion couldget processed using knowledge from the Giant Global Graph (GGG) [19]. Nevertheless, in the proposed system the ontologieshave been constructed as the combination of concept map and the taxonomic hierarchy for various concepts.
In this paper, we present how a focused crawler retrieves semantically relevant web resources for a given topic, from acollaboratively tagged bookmarks (folksonomy) site. The term ‘relevance’ has been given a special consideration from thesearcher’s perspective while semantically expanding the search topic. The paper also proposes a mechanism to compute So-cial Semantic Relevance of web pages with respect to a given topic. The system expands a search topic semantically usingdomain specific Concept Ontology and determines Semantic Relevance for each expanded term. These expanded topic termsare matched with the tagged bookmarks during SBS crawl using the Focused Crawling based on Human Cognition (FCHC)search pattern which reduces the noisy data from getting downloaded. The FCHC approach reflects on both the importantfactors, i.e. the Semantic Relevance of tags with the search topic and the popularity of web resources among the communityas well, unlike any other earlier similar works.
The rest of the paper is organized as follows – Section 2 presents the related work. The proposed ontology based SocialSemantic Focused Crawler is described in Section 3. This section also explains the design of the Concept Ontology and its useto determine the empirical Semantic Relevance of crawled web resources. Section 4 discusses the experimental methodologyemployed and the analysis of results. Section 5 concludes the paper.
2. Related work
The focused web crawlers are designed to retrieve web pages based on the guidelines that identify relevant pages or/andpriority criterions to sequence the web pages to be crawled and add them to the local database. This database may then servedifferent application needs. Focused crawlers are grouped into two broad categories namely, the Classic Focused Crawler andthe Learning Focused Crawlers [2]. Both have their own variations depending on various algorithms [3] applied on them.However the main difference between the two is that the former follows the pre-defined and fixed guidelines or criteria
Please cite this article in press as: Bedi P et al. Focused crawling of tagged web resources using ontology. Comput Electr Eng (2012), http://dx.doi.org/10.1016/j.compeleceng.2012.09.009

P. Bedi et al. / Computers and Electrical Engineering xxx (2012) xxx–xxx 3
for crawling whereas the latter learns or adapts the crawling guidelines based on the dynamically updating training set.Learnable focused crawlers need comparatively more preprocessing time for building the training set, which usually involvesa generic crawl to fetch web pages, their manual segregation into good and bad web pages for every topic and then applyingsome learning technique to determine the relevance score of web pages [20,21]. Semantic crawler [22] and social semanticcrawler are the variations of the Classic Focused Crawler [23] which determines the web page relevance by utilizing theknowledge base. However, they may also be extended to Learning Focused Crawlers on the expense of preprocessing time.
There exist a few publications on focused crawlers that utilizes ontology for varied purposes viz. Luong et al. [24] has usedamphibian morphology ontology to retrieve web documents and the Support Vector Machine classifier to identify domainspecific documents; Kozanidis [25] has proposed a technique that automatically builds a training set consisting of relevantand non-relevant documents retrieved from the Web using domain ontology, based on which the focused crawler works; Liuet al. [26] has used similarity concept context graph constructed from concept lattice of seed page and a target page, whichare then used to generate the concept score and priority score; Yang [27] has proposed OntoCrawler that uses ontology sup-ported website model to perform focused crawling. By and large all focused crawlers need extra crawling efforts to buildeither a training-set or generating prerequisite data. Moreover, most of the existing focused crawlers are computationallyexpensive.
A Social Semantic Focused Crawler can utilize the Social Web and semantic knowledge to retrieve relevant web resources.The Web 2.0 which is considered as a Social Web comprises of various blogs, Social Bookmarking Sites, facebook, twitter,flicker, etc. where web users are allowed to share and organize their information and add their objects (text, images, videos,etc.) to the sites to represent their views. A single point of access to various social network systems [28] would give morebenefits, as the search area and number of users would get assimilated. However, at present the crawlers are designedfor the sites individually.
Collaborative web page tagging is one of the powerful means to build a folksonomy which may be consumed as implicitfeedback for determining web resource relevance. The use of collaborative social tagging information for searching relevantweb resources is comparatively a new area of research in Information Retrieval, especially educational content retrieval, withonly few published works. However, investigations on collaborative tagging systems, kind of tags, their distribution, suitabil-ity and usage for improving search have been done extensively. Bischoff et al. [7] have showed that most of the tags in acollaborative site can be used for search, and in most cases tagging behavior exhibits approximately the same characteristicsas the searching behavior. In another study by Valentin et al. [29] it was shown that the tagging distribution of heavilytagged resources tends to stabilize into power law distribution. This implies that the information driven by the taggingbehavior provides a collective consensus around the categorization.
Though much of the published literature has shown SBS as a vision and a promising solution for better search results, fewhave also raised some concerns over its limitations and complexities. For example, Pass et al. [30] noted an increase in noisewhile mapping tags and documents over a period of time. In fact a huge data provided by SBS needs a proper investigation.Researchers [10,31] have also suggested their view points in this regard. According to them, effective methods can be devel-oped to re-rank the search results using the tagging information from SBS.
Zanardi and Capra [11] have used the user similarity between the querying users and the users who have already createdtags using the topic terms in SBS, to rank the relevant resources. The word ‘query’ in their system resembles the search topicused in our approach. They used a two step model to find relevant tagged web resources from a SBS by finding user simi-larity. The first step was expanding the query term based on query tags chosen from a folksonomy. The second step ranksthe SBS resources by finding similarity between socially annotated tags and similar users. Xian et al. [12] derived semanticsstatistically from social annotations. They used probabilistic generative model to obtain semantics by analyzing occurrencesof web resources, tags and users. In another interesting work on Upper Tag Ontology (UTO) [32], the information on variousSBS are restructured into ontology which can be queried to determine varied relationships among users, tags and resources.However, the noise in social sites is one of the biggest constraints in building the knowledge base. The proposed design of thefocused crawler in our approach may efficiently be used to filter out this noise by downloading only those web resources thatare likely to be relevant.
The work by Bao et al. [10] used social similarity ranking and social page rank to rank relevant resources. The analysis isbased on web page annotations and web page annotators’ profile. However, they used keyword similarity method to asso-ciate query with annotations, where as relevance ranks have been computed by analyzing web pages and social annotationssolely. Our approach, instead, analyzes social annotations and the Semantic Relevance which is computed through theConcept Ontology.
Concept Ontology provides various concepts structured in a taxonomical hierarchy under a domain, quite similar toSimple Knowledge Organization System (SKOS) [33]. SKOS is one of the good examples that show the relations amongvarious concepts under a domain. Its use benefits the application areas like eLearning where educational concepts and theirtaxonomical relations need to be described [34]. They are simpler to build as compared to other expensive ontologies andmore expressive to describe relationships among contextual concepts. Besides this, the Concept Ontology also describes rela-tionships among concepts as in concept maps. Concept maps are graphical tools for organizing and representing knowledge[35]. They are sometimes also called semantic units. Concept maps are developed on the strong theoretical foundation whichprovides many benefits in the field of education [36]. The work on constructing ontology to concept maps [37] and vice versa[38] has been implemented in past, to serve different needs. The research in past [39] has shown best precision scores whena query term is expanded with its narrower concepts, associative concepts and synonyms.
Please cite this article in press as: Bedi P et al. Focused crawling of tagged web resources using ontology. Comput Electr Eng (2012), http://dx.doi.org/10.1016/j.compeleceng.2012.09.009

4 P. Bedi et al. / Computers and Electrical Engineering xxx (2012) xxx–xxx
One may argue that there exist many open educational resource systems like OER Commons [40] (Open Education Re-source) and other OER parallel initiatives like Connexions [41] which allows the authoring and retrieving learning content.Systems like EdShare [42] and Connexions are very good examples of collaborative learning systems. However, these sys-tems allow the sharing and reuse of the content created by the experts or its members. On the contrary our proposed ap-proach focuses on the retrieval of the existing available tagged web pages possibly containing learning content on them.In fact, the proposed social semantic crawler with modifications in page parsing logic can be used to retrieve semanticallyrelevant resources from web portals, even like Connexions, EdShare or any other digital library where tags are marked forevery resource.
In our understanding, we have not come across any work in the literature that implements a focused crawling approachon a Social Bookmarking Site to scrutinize potentially relevant web resources that mimics human cognition searching pat-tern, so as to reduce the noise. Our proposed approach, in addition utilizes ontology to determine the empirical SemanticRelevance of tagged web resources.
3. The proposed Social Semantic Focused Crawler: FCHC
Social Semantic Focused Crawlers utilize the Social Web and semantic knowledge to crawl relevant resources from theselected portions of the Web. In the proposed work, the search pattern used by the crawler mimics a pattern usually followedby human users while searching web pages of interest in a typical SBS. Hence the crawler is named FCHC which stands forFocused Crawling based on Human Cognition. Besides, the crawler utilizes social and semantic information to retrieve taggedweb pages, and therefore belongs to a Social Semantic Crawler category.
The searching pattern used to search relevant resources in SBS makes this crawler different from others. The frameworkfor the FCHC Crawler is illustrated in Fig. 1. Unlike other focused crawlers which parse every web page to calculate or predictrelevance of the web page or path to reach relevant resources, the proposed crawler makes use of the tags and the book-marks tagged by the SBS users. The crawler makes use of the Concept Ontology after initiating the search with seed URLstaken from the search results of a web search engine. The output generated by the crawler is a collection of possibly relevantbookmarks which are stored in a database for post processing.
Following subsections present the design of the Concept Ontology, search topic expansion, the design of FCHC crawler andthe evaluation methodology to determine topic relevance of crawled web resources.
3.1. Design of the Concept Ontology
The concept map, a well established tool for representing knowledge for learning purpose has been used as the basis toconstruct ontology for the proposed system. Besides the concept map, the taxonomic hierarchy for a given topic, as the oneexpressed in SKOS is also considered while building the ontology. The exact relation amongst the concepts can be expressedas the concept map, whereas the taxonomic structure among concepts can be defined in the form of super concepts and subconcepts.
Fig. 2 shows a small segment of Concept Ontology consisting of few properties, a class and a few individuals. It shows thatall individuals (DML, SQL, select and update) are of the type Concept which is a class. The properties hasSuperconcept andhasSubconcept have the domain and the range consisting of the class concept (only the range is shown in the figure). Theseproperties (relations) resemble the SKOS design which uses broader and narrower properties to relate the concepts. Further,the properties, hasSuperconcept and hasSubconcept acts as inverse to each other. They also exhibit transitivity, which isshown at the bottom of the figure as the owl:TransitiveProperty property.
Fig. 1. Framework for the FCHC crawler.
Please cite this article in press as: Bedi P et al. Focused crawling of tagged web resources using ontology. Comput Electr Eng (2012), http://dx.doi.org/10.1016/j.compeleceng.2012.09.009
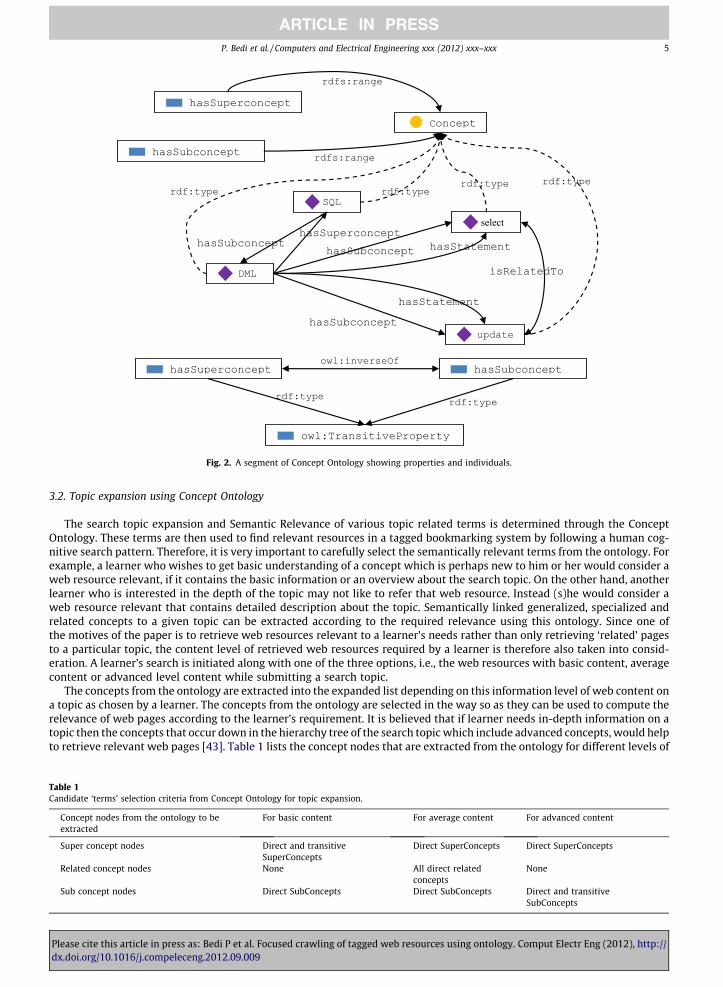
Fig. 2. A segment of Concept Ontology showing properties and individuals.
P. Bedi et al. / Computers and Electrical Engineering xxx (2012) xxx–xxx 5
3.2. Topic expansion using Concept Ontology
The search topic expansion and Semantic Relevance of various topic related terms is determined through the ConceptOntology. These terms are then used to find relevant resources in a tagged bookmarking system by following a human cog-nitive search pattern. Therefore, it is very important to carefully select the semantically relevant terms from the ontology. Forexample, a learner who wishes to get basic understanding of a concept which is perhaps new to him or her would consider aweb resource relevant, if it contains the basic information or an overview about the search topic. On the other hand, anotherlearner who is interested in the depth of the topic may not like to refer that web resource. Instead (s)he would consider aweb resource relevant that contains detailed description about the topic. Semantically linked generalized, specialized andrelated concepts to a given topic can be extracted according to the required relevance using this ontology. Since one ofthe motives of the paper is to retrieve web resources relevant to a learner’s needs rather than only retrieving ‘related’ pagesto a particular topic, the content level of retrieved web resources required by a learner is therefore also taken into consid-eration. A learner’s search is initiated along with one of the three options, i.e., the web resources with basic content, averagecontent or advanced level content while submitting a search topic.
The concepts from the ontology are extracted into the expanded list depending on this information level of web content ona topic as chosen by a learner. The concepts from the ontology are selected in the way so as they can be used to compute therelevance of web pages according to the learner’s requirement. It is believed that if learner needs in-depth information on atopic then the concepts that occur down in the hierarchy tree of the search topic which include advanced concepts, would helpto retrieve relevant web pages [43]. Table 1 lists the concept nodes that are extracted from the ontology for different levels of
Table 1Candidate ‘terms’ selection criteria from Concept Ontology for topic expansion.
Concept nodes from the ontology to beextracted
For basic content For average content For advanced content
Super concept nodes Direct and transitiveSuperConcepts
Direct SuperConcepts Direct SuperConcepts
Related concept nodes None All direct relatedconcepts
None
Sub concept nodes Direct SubConcepts Direct SubConcepts Direct and transitiveSubConcepts
Please cite this article in press as: Bedi P et al. Focused crawling of tagged web resources using ontology. Comput Electr Eng (2012), http://dx.doi.org/10.1016/j.compeleceng.2012.09.009

6 P. Bedi et al. / Computers and Electrical Engineering xxx (2012) xxx–xxx
content requirements. It shows that if the required web resources are expected to contain basic content related to a searchtopic by a learner, then the expanded list of the search topic must include all super concept nodes (i.e., all concepts thatare linked directly or transitively through the hasSuperconcept property from the search topic concept node), and conceptnodes linked down the hierarchy from the search topic concept node (i.e., directly linked through the hasSubconcept
property). However, for retrieving basic level of content on a search topic, the content nodes linked through isRelatedTo
property to the search topic concept nodes do not need to be considered. The reason to this is that isRelatedTo propertyexists between the sibling nodes in the ontology, and in ontology two terms are placed as sibling when they exhibit differentproperties. Therefore, the above argument infers that the sibling concepts do not contribute in providing basic informationabout a search topic concept. Nevertheless the sibling nodes are related to the search topic concept, they are not semanticallyrelevant to it, especially when the web resources consisting of basic content level are required. Similarly, the next two col-umns of Table 1 shows the extraction of the concept nodes from the ontology for the average content level web resourcesand the advanced level content web resources respectively. In this paper, we are limiting ourselves by focusing only on theretrieval of web resources consisting of basic content information. Based on this expanded list of a search topic, the crawlerdownloads web pages from a SBS that are tagged with words contained in the expanded list. These downloaded web resourcesare then computed for the Social Semantic Relevance using the Vector Space Model.
3.3. Retrieving tagged web resources relevant to the expanded topic
The crawler using a pattern based on human cognition explores the pages of SBS users who have bookmarked webresources with the semantically relevant tags. During the crawl, the crawler checks the resource relevance of web resourcesby analyzing tags given by the web users. However, the empirical relevance of web resources to a topic is computed later forranking purpose. This reduces the effective crawling time of the crawler. Subsequent sections explain the crawling designand relevance calculations carried out by the proposed crawler.
The proposed crawler FCHC is designed to crawl in a bookmarking web site to reuse the information which is tagged dailyby millions of web users. The information in SBS [44] is structurally perceived as a set of bookmarks, B, where each book-mark, b e B, is a set of triples: {ri, uj, tg1}, {ri, uj, tg2} . . . {ri, uj, tgk}. Thus a single triple consists of three data units, hri, uj, tgki,signifying a web resource ri being tagged by user uj with tag tgk. Each bookmark b represents a single web resource. The webresource is tagged by several users using various keywords as tags relevant to the resource content. It can further be noticedthat a web resource r which actually represents a URL on the WWW may or may not be tagged in a SBS. The proposed crawl-ing approach, FCHC is designed for the tagged web resources only. Web resources that are not bookmarked in the SBS cannotbe considered for determining resource relevance with FCHC technique at present. The FCHC technique retrieves (filters) tri-ples those are likely to be relevant. This process of retrieval avoids the unnecessary storage of voluminous irrelevant webresources and thus reduces the sparseness of data to some extent. In order to minimize the online connection duration whiledownloading the required data from SBS, the empirical semantic computation is postponed till the complete download. Dur-ing crawl, therefore, the Semantic Relevance of tagged resources is judged by comparing tags with the terms contained in theexpanded list of the search topic. It may be recalled here that the terms contained in the expanded list are semantically re-trieved terms from the domain ontology (see Section 3.1).
3.3.1. FCHC designSemantic Focused Crawler and Social Semantic Focused Crawler are the variations of a Classic Focused Crawler. The for-
mer uses the semantic knowledge and the latter uses social information in addition to the semantic knowledge in order todecide upon the crawling path. The FCHC crawler is a type of Social Semantic Focused Crawler as it makes use of the seman-tic and social information to crawl and to determine the relevance of web resources. Fig. 3 shows a general flow graph of afocused crawler. However, techniques used in the selection criteria vary from one variation of a focused crawler to the other.
In general, a crawler initiates with a set of pre-selected seed URLs. The crawler first fetches a page and then parses toextract its entire links on the page to check topic relevance of the page governed by ‘the page relevance criterion’.
The page relevance criterion is similar to the classifier [1], which evaluates the relevance of hypertext document. All theparsed URLs are enqueued in the priority queue if the page is considered relevant according to the page relevance criterion.The priority of the page is further governed by the page priority criterion, which resembles the distiller. The distilleridentifies hypertext nodes that have good access points to many relevant pages within few links. If a page is considerednon-relevant then the links on that page are not added to the queue i.e. it is not crawled further. This is where it differs froma generic crawler used by search engines. After checking termination condition, which could be the number of URLs to becrawled, time limit or the empty queue, it decides to either dequeue a top priority URL from the queue to repeat the crawlprocess or to stop. The important selection criterions for FCHC from the design of Classic Focused Crawler’s (Fig. 3) perspec-tive are detailed below.
3.3.1.1. Seed selection criterion. Seed URLs are picked from the search results of a web search engine by querying on a searchtopic. Top N URLs are considered as seeds to initiate the crawl on the Web’s select portion. A good selection of the topicrelevant URLs and the number of seed URLs, certainly effect the results of a crawler. A large number of seed URLs enablea crawler to spawn a wider surface on the Web. However, in a controlled area like SBS, where the web resources are
Please cite this article in press as: Bedi P et al. Focused crawling of tagged web resources using ontology. Comput Electr Eng (2012), http://dx.doi.org/10.1016/j.compeleceng.2012.09.009

Fig. 3. Selection criteria and the flow graph for the FCHC crawler.
P. Bedi et al. / Computers and Electrical Engineering xxx (2012) xxx–xxx 7
accessible through many linked points like users, tags and URLs, it becomes feasible to reach more number of resources evenwith a small set of seed URLs.
3.3.1.2. Provide the area for crawling. Any bookmarking site or a portal where the resources have been tagged so as they depicttheir inside content, can be used as an area for crawling. However, this requires designing the crawling pattern according tothe structure of the portal. In the FCHC design, a well structured SBS, delicious.com has been used for crawling purpose.
3.3.1.3. Parse the page. The SBS pages are parsed for extracting bookmarks which are considered relevant by the crawler. Dur-ing parsing, the information related to resource and tags is extracted and stored in the local database.
3.3.1.4. Page relevance criterion. During the crawl, the crawler checks the relevance of a page by matching the tags of the re-source with the expanded topic terms. Later, after the complete crawl empirical Social Semantic Relevance of each resourceis computed (explained in Section 4) using the Vector Space Model.
3.3.1.5. Page priority criterion. A systematic search pattern motivated by human cognition is used as the priority criterion forthe crawler. This is illustrated in Fig. 4. Based on the SBS design of a SBS the pages can be crawled using two types of pattern:Breadth first pattern (BFP) and depth first pattern (DFP). In a BFP the crawler enqueue all users who have tagged URLs thatare similar to the seed URLs. Then from the queue one by one the tags page of each user is parsed to reach to the resources oftheir interest. All these potentially relevant web resources are then added to the queue to be parsed further.
In general it has been noticed that a crawler hardly uses DFP, but in particular case like crawling in SBS (a controlled areaof the Web), DFP has also shown promising results. In this pattern, the crawler first reaches the relevant resources of the firstuser using first seed URL and enqueue all of them. It then iterates the process for all users of the same seed URL. It similarlyworks upon all other seed URLs one by one. The difference between BFP and DFP is that the latter completes retrieval of rel-evant tagged resources of the user one by one, whereas the former first queue up all related users and then moves to theirtagged pages one by one. The Social Semantic Focused Crawler, FCHC uses DFP to crawl to different levels of the SBS asshown in Fig. 4. One level represents single iteration of resource retrieval by looking up the users and tags of the existinglist of resources (for the first level these resources are the seed URLs). For subsequent levels, the crawler iterates the processusing the list of resources retrieved from the previous level.
Please cite this article in press as: Bedi P et al. Focused crawling of tagged web resources using ontology. Comput Electr Eng (2012), http://dx.doi.org/10.1016/j.compeleceng.2012.09.009

Fig. 4. The crawling pattern FCHC-DFP for L1 and L2 inside the SBS.
8 P. Bedi et al. / Computers and Electrical Engineering xxx (2012) xxx–xxx
3.3.1.6. Termination criterion. If number of URLs to be crawled is specified then the crawler uses it as a termination criterionotherwise when the priority queue becomes empty, the crawler stops.
3.4. Computing social semantic similarity of tagged resources
As discussed earlier, the word ‘relevance’ is highly related to a learner’s information needs and to the resource content aswell. Besides this, ‘relevance’ is dynamic (relevance of a particular resource changes for single user with time) which changesdepending on a learner’s prior knowledge regarding the search topic and the intent with which (s)he seeks information. Con-sidering both aspects, relevance of crawled resources to a search topic is computed in the paper by combining Semantic Rel-evance of resource to the search topic and the relevance information provided by the learner for his/her information needs.For the purpose, a learner’s information needs is assumed to be categorized in any one of the three levels of content require-ment, i.e., basic content, average content, or advanced content related to a given search topic. The relevance of a web re-source can then be computed accordingly based on one of these requirements (discussed in Section 3.4.2). The first partof the relevance computation, Semantic Relevance of a web resource to a search topic is computed in effect to the secondpart which is the level of content required by a learner. Technically, the initial step, topic expansion expands the topic fromthe Concept Ontology depending on the content depth as expected by a learner. Semantic Relevance of a web page is thencomputed based on this expanded list. This is how both of the aspects of relevance are incorporated while computing theweb page relevance to a search topic, for a learner.
The steps to compute Social Semantic Relevance of a web resource to a given search topic, including other factors likepopularity of resources among community web users and the learner’s choice for the depth of web page content are pre-sented in subsequent sections.
3.4.1. Semantic Relevance between two conceptsSemantic Relevance in [45] is defined as the inverse of semantic distance, where semantic distance refers to the absolute
difference of levels between two nodes representing concepts in ontology. However, using this definition, if we compute theSemantic Relevance of a concept with itself then it comes to zero as there does not exist any distance; which is logicallyincorrect. Therefore, Semantic Relevance with modifications is presented as follows. The Semantic Relevance betweentwo concepts, Ci, Cj Dd (domain d), can be defined as:
Pleasedx.doi
SRCi ;Cj¼ 1jdjCi ;Cj
þ 1ð1Þ
where |d| is the number of minimum edges between concepts Ci and Cj in Concept Ontology.Fig. 5 shows few concepts from the Concept Ontology arranged in a hierarchal form. The Semantic Relevance between two
concepts say, DML and other concepts is computed using Eq. (1). The distance between any two concepts is measured asnumber of edges the two concepts are apart in Concept Ontology. This distance is taken as absolute quantity. The exemplifiedsearch topic, ‘DML’ is expanded with the assumed learner’s intent of retrieving resources that contains basic information rel-evant to the concept. The concept terms are extracted from the Concept Ontology to a vector T by following the rules of topicexpansion (Table 1)
T ¼ fðDML;0Þ; ðSQL;1Þ; ðDBMS;2Þ; ðdatabase;3Þ; ðselect;1Þ; ðupdate;1Þ; ðdelete;1Þ; ðinsert;1Þg ð2Þ
cite this article in press as: Bedi P et al. Focused crawling of tagged web resources using ontology. Comput Electr Eng (2012), http://.org/10.1016/j.compeleceng.2012.09.009

Fig. 5. Semantic Relevance between concepts of Concept Ontology.
P. Bedi et al. / Computers and Electrical Engineering xxx (2012) xxx–xxx 9
The structure T along with the expanded list of terms also contains the distance of each concept node from the concept nodeof the search topic. Semantic weight of each term of the expanded topic list corresponding to a search topic is computedusing the above calculated Semantic Relevance.
3.4.2. Semantic similarity based on the Vector Space ModelResearch on Information Retrieval presents many approaches that use Vector Space Model (VSM) for determining simi-
larity between documents and a search topic [46]. Among them, the most commonly used is Salton’s VSM [47] that assignweights to the terms by considering local or/and global information about terms (keywords) from individual document or/and collection of documents respectively. The VSM also known as ‘Term Vector Model’ uses term frequency, documentfrequency and inverse document frequency to measure weights of a query and document terms. These weights are then usedto compute similarity between the documents and the query vectors using VSM. The results obtained by this method arepromising, but it fails in cases where the query term has more than one context or senses. In such scenarios, the relevanceof terms is defined semantically and the relevance of documents is defined by these terms. As a consequence, semantics fromthe Concept Ontology are embraced as a basic building block in the Vector Space Model. The term weights, in this process arecomputed by measuring their semantic distance from the Concept Ontology. The method to determine semantic similarityusing VSM, which is called here as SS-VSM (semantic similarity using VSM), is explained below.
SS-VSM is based on the VSM model where the term weights are computed using the semantic distance between ontologyconcepts. In VSM any object or reference is considered as a vector, and a vector is a quantity with direction and magnitude. InSS-VSM, we can compute the expanded topic list, T from the search topic, t0, and the possibly relevant retrieved resourcesset, R = {r1, . . . ,RN+a} as vectors, to determine the similarity between query and each document/resource ri. Since the topicand the resource have nothing to do with direction, therefore in Information Retrieval the magnitude of the vectors is usedin computation. Here, we first explain the method to determine similarity between vectors in a two-dimensional space andthen include semantics to build the vectors. Secondly we will expand it to n-dimensional space to incorporate the weights ofall known semantically extracted terms.
Let T, r1, r2 be the vectors (refer Fig. 6) in two-dimension space (for simplicity) representing the topic and the tworesources respectively, originating from the origin O(0, 0). Here each dimension represents a term; therefore, n terms in avector create n dimensional space. However, for a simplified explanation, we limit ourselves to two-dimension space whichin any case, can be expanded for n dimensions later. The magnitude or length of each vector can be measured by usingEuclidian Distance. Therefore, the vector length is determined by computing distance between the origin and each pointin space. This gives us the topic length,
Pleasedx.doi
dOT ¼ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiðx0 � 0Þ2 þ ðy0 � 0Þ2
q¼
ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffix2
0 þ y20
q
cite this article in press as: Bedi P et al. Focused crawling of tagged web resources using ontology. Comput Electr Eng (2012), http://.org/10.1016/j.compeleceng.2012.09.009

Fig. 6. Semantic similarity between search topic and resource vectors.
10 P. Bedi et al. / Computers and Electrical Engineering xxx (2012) xxx–xxx
Similarly, distance from origin to each resource, r1 and r2 is, dOr1 ¼ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffix2
1 þ y21
qand, dOr2 ¼
ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffix2
2 þ y22
qresp., where x0, y0 corre-
sponds to the query terms, x1, y1 terms to represent resource r1 and x2, y2 terms to represent resource r2. Since O being atthe center (0, 0), vectors, T, r1 and r2 can be represented as absolute magnitudes (Garcia, Cosine Similarity and Term Weight2006), signifying: dOT = |T|, dOr1 ¼ jr1j and, dOr2 ¼ jr2j. The cosine angle formed between vectors signifies the similarity be-tween them. The angle between T and r1, can be used as the quantitative similarity between them. The cosine angle betweenthese vectors is defined by the ratio,
Pleasedx.doi
cos h ¼ T � rjTj � jrj ð3Þ
where T � r is the dot product, and |T|, |r| represent the magnitudes or length of the vectors T and r respectively. In this way,we can measure the similarity between the topic and each of the retrieved web resource. The values of the ratio lies between1 and 0, representing similarity and complete dissimilarity respectively, i.e. cos(0) = 1 = similar and cos(1) = 0 = unrelated. Itmay similarly be expanded to n dimensional space. In the context of determining Semantic Relevance of a resource with agiven topic, the n dimensional space represents n terms semantically associated to the given topic from the Concept Ontol-ogy under the defined specifications (axioms in ontology). Below we describe how this model has been used to integratesemantics in it and transforming it to n dimensional space.
3.4.3. Topic vector computationThe weight for each term (i.e., each dimension of the vector) in the topic vector can be computed using the Semantic Rel-
evance, which is inversely proportional to the semantic distance between two concepts of Concept Ontology. Formalizing theweight Wtt0 ;tq for each term tq e T, (0 6 q 6 n), w.r.t the search topic t0, using Eq. (1), we get
Wtt0 ;tq ¼SRt0 ;tqPnq¼0SRt0 ;tq
ð4Þ
The topic vector length |T| is then computed using the following function:
jTj ¼
ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiXn
q¼0
Wt2t0 ;tq
vuut ð5Þ
Consider Fig. 5 again, and the vector T, we derived in Eq. (2) by using the concept ‘DML’ example. Semantic Relevance ofeach term in T is calculated using the semantic distance between two concepts. For instance the weight of concept ‘SQL’ withrespect to the search topic ‘DML’ and vector T can be calculated using Eq. (4) as below,
WtðDML;SQLÞ ¼ 0:5=ð0:2448þ 0:1224þ 0:0816þ 0:0612þ 0:1224þ 0:1224þ 0:1224þ 0:1224Þ
Similarly, weight for each term in the expanded vector T can be computed. By doing so and using Eq. (5) the Topic vector, |T|comes out to be 0.3812.
The resource vectors for each resource retrieved by the crawler FCHC can be computed in the similar manner. Other fac-tors like tags and popularity count of the resource is considered to compute web resource vector besides the semantic weightcomputation. The next section describes the computational steps.
3.4.4. Web resource vector computationSemantic Relevance of SBS resources (downloaded by the crawler) is computed here. Every tag given to a resource by web
users in a SBS is treated as one word concept, and each resource can be seen as a set of tags. The web resource vector com-putation is achieved by the following three steps.
cite this article in press as: Bedi P et al. Focused crawling of tagged web resources using ontology. Comput Electr Eng (2012), http://.org/10.1016/j.compeleceng.2012.09.009

P. Bedi et al. / Computers and Electrical Engineering xxx (2012) xxx–xxx 11
3.4.4.1. Semantic Relevance of tags. To compute Semantic Relevance, SR of each unique and relevant tag, tgk of a resource, ri
w.r.t. a topic term, t0, we first calculate the Semantic Relevance between t0 and tgk by using Eq. (1). Thus, we get,
Pleasedx.doi
SRt0 ;tgk¼ 1jdjt0 ;tgk
þ 1ð6Þ
It may further be noted that the SR of all relevant terms have already been calculated during the topic vector computation.Therefore, the same can be used here without any re-computation.
3.4.4.2. Tags weight based on their social impact. The information related to that a resource has been bookmarked and that byhow many users is drawn from the SBS to infer the social impact on a resource. This is obtained by the count of similar termstagged by SBS users for the resource. Tag weight represents the popularity of associated resource and thus measures its use-fulness. It is proportional to the number of times a resource has been tagged with the same term by different users. Thus ifmore the number of users have visited and tagged a resource then more will be the weight of that tag. Incorporating thisinformation to the Semantic Relevance we obtain Social Semantic Relevance (S2R) of each tag w.r.t. the search topic. In otherwords, if Counttgk
is the number of times tgk has been used as tag for resource ri by all users who have tagged ri, then weightWtðriÞt0 ;tgk
, of tag tgk associated with resource ri is determined by using Eq. (6), as
S2RðriÞt0 ;tgk¼ SRðriÞt0 ;tgk
� Counttgkð7Þ
Finally, the tag weight with respect to each resource is obtained by normalizing Social Semantic Relevance of each tag.After normalizing all m tags within 0 and 1 by using Eq. (7), the generalized tag weight, WtðriÞt0tgk
can be represented as:
WtðriÞt0 ;tgk¼
S2RðriÞt0 ;tgkPmk¼1S2RðriÞt0 ;tgk
ð8Þ
The tag weight formulated above does not only determine quantitative measure of usefulness for a resource but alsoquantitatively determines the Semantic Relevance of tags with the weighted feedback.
3.4.4.3. Resource vector length. To compute the resource vector length, |ri|, we take square root of sum of squares of relevanttag weights computed using Eq. (8), therefore,
jrij ¼ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiWtðriÞ2t0 ;tg1
þWtðriÞ2t0 ;tg2þ � � � þWtðriÞ2t0 ;tgk
þ � � �WtðriÞ2t0 ;tgm
q) jrij ¼
ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiXm
k¼0
WtðriÞ2t0 ;tgk
vuut ð9Þ
The resource vectors are computed using Eq. (9) for all crawled potentially relevant resources that exist in the databasegenerated by the crawler. Further to recall, a resource is considered relevant to a search topic concept if it contains one ormore relevant tags.
3.4.5. Social Semantic Relevance of crawled web resourcesThe angular distance is measured between each resource vector length and the topic vector length, using SS-VSM. This
determines the resource relevance to the search topic. Now expanding Eq. (3) to n dimensions, where each dimension cor-responds to the semantically relevant term and using Eqs. (5) and (9), we obtain the following formula that computes thesocial semantic similarity between the search topic t0 and each resource ri.
cos ht0 ;ri¼
Ptq¼tgk
ðWtt0 ;tq �WtðriÞt0 ;tgkÞffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiPn
q¼0Wt2t0 ;tq
q�
ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiPmk¼0WtðriÞ2t0 ;tgk
q ð10Þ
4. Experimental results
The experimental study was conducted on Intel core 2 Duo processor, 2.4 GHz, 2 GB RAM, 32-bit OS. The crawlers wereimplemented in Java and MySql. Initially the domain specific Concept Ontology, consisting of semantically organized con-cepts were developed using Protégé editor whereas the modules related to semantic term expansion and semantic distancecomputation were programmed using protégé-OWL API and Jena model. Although the crawlers were implemented on threesearch topics from different domains, the presented results however are shown for the search topic ‘Data ManipulationLanguage’ (DML), a database concept, so as it could be easily related to the exemplifiers given throughout the paper. Theseresults for other experiments were nearly same.
Two sets of comparisons were studied during the experiment. In the first set we compared three variations of the pro-posed FCHC crawlers based on differences in their crawling search patterns. The social information for these crawlers wascomputed from the SBS combined with the semantic knowledge from the domain based Concept Ontology. As already men-tioned these crawlers were made to crawl in the SBS. Each of these FCHC crawlers used one of the three patterns viz. Breadthfirst pattern (BFP), depth first pattern (DFP) up to level 1 and DFP up to level 2. Their results have been analyzed and
cite this article in press as: Bedi P et al. Focused crawling of tagged web resources using ontology. Comput Electr Eng (2012), http://.org/10.1016/j.compeleceng.2012.09.009
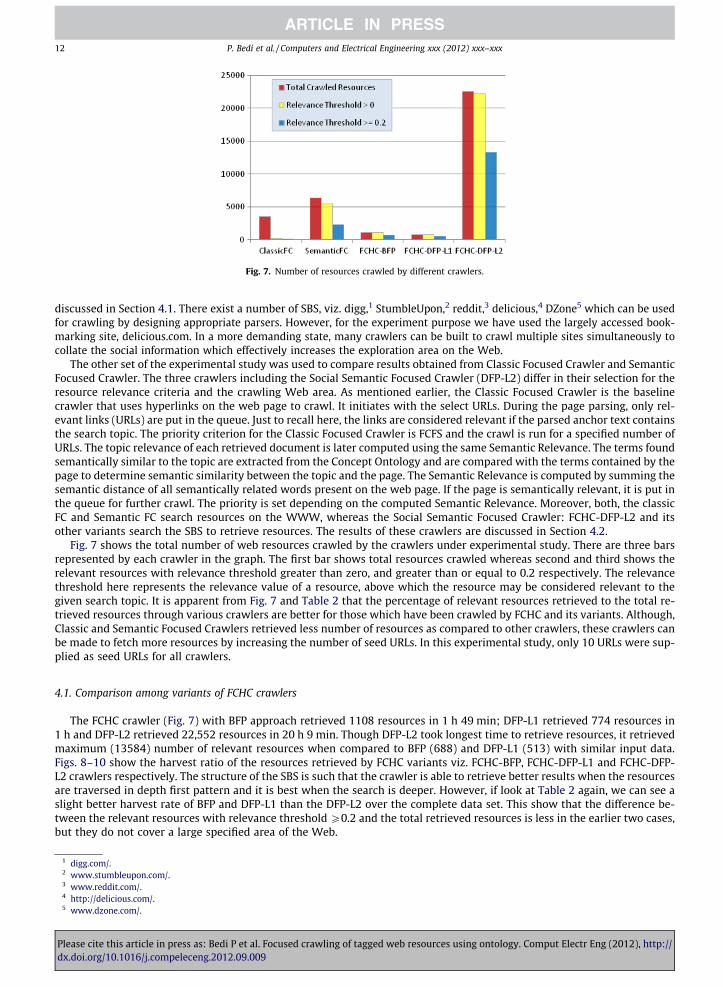
Fig. 7. Number of resources crawled by different crawlers.
12 P. Bedi et al. / Computers and Electrical Engineering xxx (2012) xxx–xxx
discussed in Section 4.1. There exist a number of SBS, viz. digg,1 StumbleUpon,2 reddit,3 delicious,4 DZone5 which can be usedfor crawling by designing appropriate parsers. However, for the experiment purpose we have used the largely accessed book-marking site, delicious.com. In a more demanding state, many crawlers can be built to crawl multiple sites simultaneously tocollate the social information which effectively increases the exploration area on the Web.
The other set of the experimental study was used to compare results obtained from Classic Focused Crawler and SemanticFocused Crawler. The three crawlers including the Social Semantic Focused Crawler (DFP-L2) differ in their selection for theresource relevance criteria and the crawling Web area. As mentioned earlier, the Classic Focused Crawler is the baselinecrawler that uses hyperlinks on the web page to crawl. It initiates with the select URLs. During the page parsing, only rel-evant links (URLs) are put in the queue. Just to recall here, the links are considered relevant if the parsed anchor text containsthe search topic. The priority criterion for the Classic Focused Crawler is FCFS and the crawl is run for a specified number ofURLs. The topic relevance of each retrieved document is later computed using the same Semantic Relevance. The terms foundsemantically similar to the topic are extracted from the Concept Ontology and are compared with the terms contained by thepage to determine semantic similarity between the topic and the page. The Semantic Relevance is computed by summing thesemantic distance of all semantically related words present on the web page. If the page is semantically relevant, it is put inthe queue for further crawl. The priority is set depending on the computed Semantic Relevance. Moreover, both, the classicFC and Semantic FC search resources on the WWW, whereas the Social Semantic Focused Crawler: FCHC-DFP-L2 and itsother variants search the SBS to retrieve resources. The results of these crawlers are discussed in Section 4.2.
Fig. 7 shows the total number of web resources crawled by the crawlers under experimental study. There are three barsrepresented by each crawler in the graph. The first bar shows total resources crawled whereas second and third shows therelevant resources with relevance threshold greater than zero, and greater than or equal to 0.2 respectively. The relevancethreshold here represents the relevance value of a resource, above which the resource may be considered relevant to thegiven search topic. It is apparent from Fig. 7 and Table 2 that the percentage of relevant resources retrieved to the total re-trieved resources through various crawlers are better for those which have been crawled by FCHC and its variants. Although,Classic and Semantic Focused Crawlers retrieved less number of resources as compared to other crawlers, these crawlers canbe made to fetch more resources by increasing the number of seed URLs. In this experimental study, only 10 URLs were sup-plied as seed URLs for all crawlers.
4.1. Comparison among variants of FCHC crawlers
The FCHC crawler (Fig. 7) with BFP approach retrieved 1108 resources in 1 h 49 min; DFP-L1 retrieved 774 resources in1 h and DFP-L2 retrieved 22,552 resources in 20 h 9 min. Though DFP-L2 took longest time to retrieve resources, it retrievedmaximum (13584) number of relevant resources when compared to BFP (688) and DFP-L1 (513) with similar input data.Figs. 8–10 show the harvest ratio of the resources retrieved by FCHC variants viz. FCHC-BFP, FCHC-DFP-L1 and FCHC-DFP-L2 crawlers respectively. The structure of the SBS is such that the crawler is able to retrieve better results when the resourcesare traversed in depth first pattern and it is best when the search is deeper. However, if look at Table 2 again, we can see aslight better harvest rate of BFP and DFP-L1 than the DFP-L2 over the complete data set. This show that the difference be-tween the relevant resources with relevance threshold P0.2 and the total retrieved resources is less in the earlier two cases,but they do not cover a large specified area of the Web.
1 digg.com/.2 www.stumbleupon.com/.3 www.reddit.com/.4 http://delicious.com/.5 www.dzone.com/.
Please cite this article in press as: Bedi P et al. Focused crawling of tagged web resources using ontology. Comput Electr Eng (2012), http://dx.doi.org/10.1016/j.compeleceng.2012.09.009
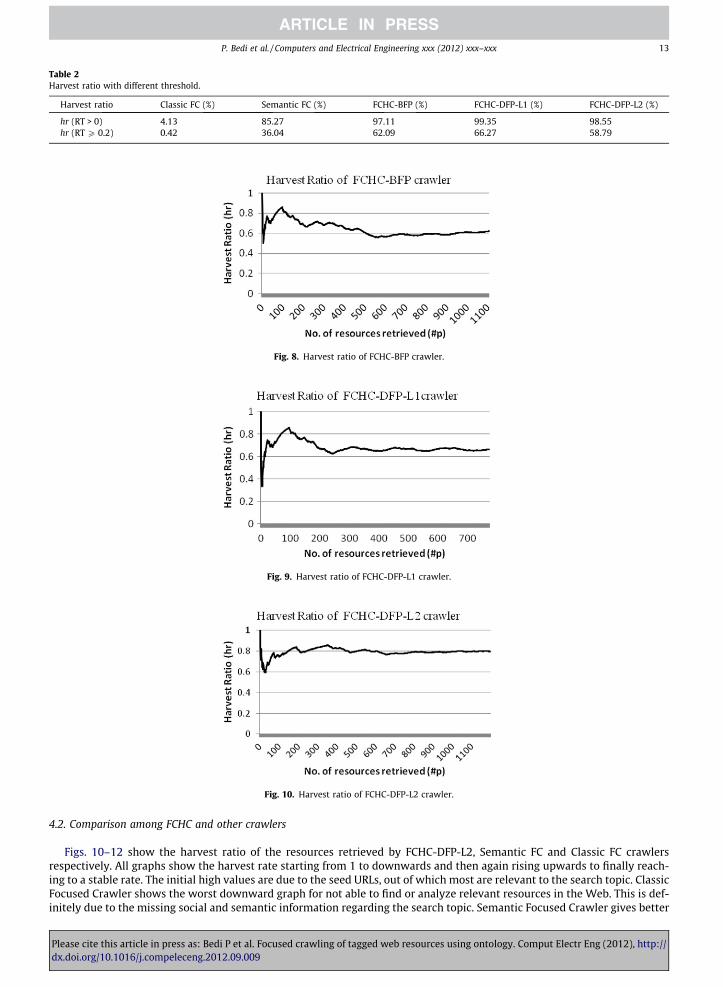
Table 2Harvest ratio with different threshold.
Harvest ratio Classic FC (%) Semantic FC (%) FCHC-BFP (%) FCHC-DFP-L1 (%) FCHC-DFP-L2 (%)
hr (RT > 0) 4.13 85.27 97.11 99.35 98.55hr (RT P 0.2) 0.42 36.04 62.09 66.27 58.79
Fig. 8. Harvest ratio of FCHC-BFP crawler.
Fig. 9. Harvest ratio of FCHC-DFP-L1 crawler.
Fig. 10. Harvest ratio of FCHC-DFP-L2 crawler.
P. Bedi et al. / Computers and Electrical Engineering xxx (2012) xxx–xxx 13
4.2. Comparison among FCHC and other crawlers
Figs. 10–12 show the harvest ratio of the resources retrieved by FCHC-DFP-L2, Semantic FC and Classic FC crawlersrespectively. All graphs show the harvest rate starting from 1 to downwards and then again rising upwards to finally reach-ing to a stable rate. The initial high values are due to the seed URLs, out of which most are relevant to the search topic. ClassicFocused Crawler shows the worst downward graph for not able to find or analyze relevant resources in the Web. This is def-initely due to the missing social and semantic information regarding the search topic. Semantic Focused Crawler gives better
Please cite this article in press as: Bedi P et al. Focused crawling of tagged web resources using ontology. Comput Electr Eng (2012), http://dx.doi.org/10.1016/j.compeleceng.2012.09.009
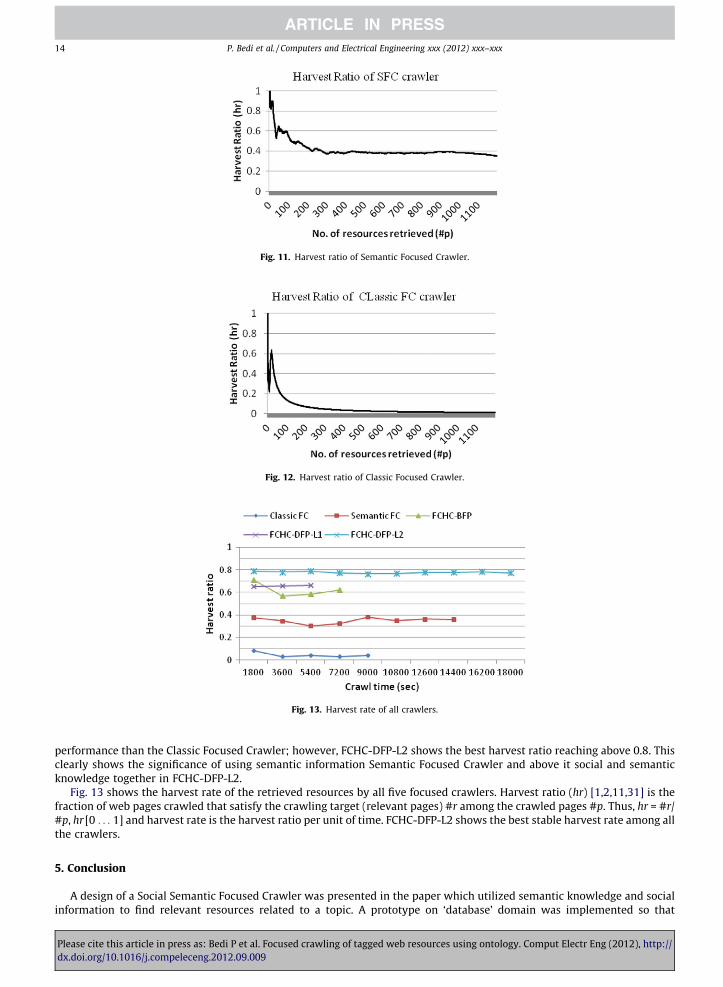
Fig. 11. Harvest ratio of Semantic Focused Crawler.
Fig. 12. Harvest ratio of Classic Focused Crawler.
Fig. 13. Harvest rate of all crawlers.
14 P. Bedi et al. / Computers and Electrical Engineering xxx (2012) xxx–xxx
performance than the Classic Focused Crawler; however, FCHC-DFP-L2 shows the best harvest ratio reaching above 0.8. Thisclearly shows the significance of using semantic information Semantic Focused Crawler and above it social and semanticknowledge together in FCHC-DFP-L2.
Fig. 13 shows the harvest rate of the retrieved resources by all five focused crawlers. Harvest ratio (hr) [1,2,11,31] is thefraction of web pages crawled that satisfy the crawling target (relevant pages) #r among the crawled pages #p. Thus, hr = #r/#p, hr [0 . . . 1] and harvest rate is the harvest ratio per unit of time. FCHC-DFP-L2 shows the best stable harvest rate among allthe crawlers.
5. Conclusion
A design of a Social Semantic Focused Crawler was presented in the paper which utilized semantic knowledge and socialinformation to find relevant resources related to a topic. A prototype on ‘database’ domain was implemented so that
Please cite this article in press as: Bedi P et al. Focused crawling of tagged web resources using ontology. Comput Electr Eng (2012), http://dx.doi.org/10.1016/j.compeleceng.2012.09.009

Table A1Seed URLs fed to the crawlers in the experimental study.
http://en.wikipedia.org/wiki/Data_Manipulation_Language
http://www.tomjewett.com/dbdesign/dbdesign.php?page=ddldml.php
http://www.geekinterview.com/question_details/12782
http://www.orafaq.com/faq/what_are_the_difference_between_ddl_dml_and_dcl_commands
http://www.dmlgroup.in/mdsdesk.html
http://www.dml.co.in
http://www.directmylink.com
http://dmlbuild.sourceforge.net
http://en.wikipedia.org/w/index.php?title=Data_Manipulation_Language&action=edit
http://www.dotnetuncle.com/SQL/What-are-DML-commands-Select-Insert-Update-Delete.aspx
P. Bedi et al. / Computers and Electrical Engineering xxx (2012) xxx–xxx 15
semantically relevant resources under the domain could be made available to the learners. For this purpose, various conceptsunder the domain were structured semantically in the Concept Ontology, a part of the proposed system.
The results retrieved by the Social Semantic Focused Crawlers were analyzed and compared with other focused crawlers,viz. Classic Focused Crawler which was taken as baseline focused crawler, did not use any semantic or social informationduring crawling, and Semantic Focused Crawler used only semantic information during crawling. Both these crawlers, ClassicFocused Crawler and Semantic Focused Crawler fetched resources (or URLs) from the WWW whereas the variants of SocialSemantic Focused Crawler (FCHC-BFP, FCHC-DFP-L1 and FCHC-DFP-L2), as proposed in the paper were designed to retrieveresources from the SBS based on different searching patterns.
All crawlers under experimental study were evaluated on the computed Semantic Relevance of crawled web resourcesusing the well known performance metric, harvest rate. In spite of a large number of retrieved resources, FCHC-DFP-L2 re-sulted in harvest rate of 98.5% and comparatively much lesser number of retrieved resources, FCHC-DFP-L1 gave 99.3%;FCHC-BFP showed 97.1%, all with relevance threshold greater that zero.
Overall all three variants of Social Semantic Focused Crawler showed better performances over Semantic and Classic Fo-cused Crawlers. It was apparent from the experimental study that crawling SBS for relevant resources yields better results ascompared to the Web crawling. However there may exist some relevant web pages that had not been bookmarked or taggedby any user, those web pages could not be retrieved through the FCHC crawler.
Appendix A
See Table A1.
References
[1] Chakrabarti S, van den Berg M, Dom B. Focused crawling: a new approach to topic-specific web resource discovery. Comput Netw 1999;31(11–16):1623–40.
[2] Batsakisa S, Petrakisa EGM, Milios E. Improving the performance of focused web crawlers. Data Knowl Eng 2009;68(10):1001–13.[3] Pant G, Srinivasan P, Menczer F. Crawling the web. In: Levene M, Poulovassilis A, editors. Web dynamics: adapting to change in content, size, topology
and use. Springer-Verlag; 2004. p. 153–78.[4] Bedi P, Banati H, Thukral A. Social semantic retrieval and ranking of eResources. In 2nd Int conference on advances in recent technologies in
communication and computing. IEEE; 2010. p. 343–7.[5] Zhuang Z. What’s there and what’s not? Focused crawling. In: 5th ACM/IEEE-CS joint conference on digital libraries; 2005.[6] Moghaddam GG. Preserve scientific electronic journals: a study of archiving initiatives. Electron Libr 2008;26(1):83–96.[7] Bischoff K, Firan CS, Nejdl W, Paiu R. Can all tags be used for search? In 17th ACM conference on information and knowledge management. ACM, New
York; 2008. p. 193–202.[8] Firan CS, Nejdl W, Paiu R. The benefit of using tag-based profiles. In: The 2007 Latin American web conference – LA-WEB. IEEE Computer Society,
Santiago de Chile; 2007. p. 32–41.[9] Agrahri AK, Anand DTM, Riedl J. Can people collaborate to improve the relevance of search results? In: 2nd ACM international conference on
recommender systems. ACM; 2008. p. 283–6.[10] Bao S, Xue G, Wu X, Yu Y, Fei B, Su Z. Optimizing web search using social annotation. In: 16th International conference on World Wide Web. ACM;
2007. p. 501–10.[11] Zanardi V, Capra L. Social ranking: uncovering relevant content using tag-based recommender systems. In: RecSys ‘08 ACM conference on
recommender systems; 2008. p. 51–8.[12] Xian W, Zhang L, Yu Y. Exploring social annotations for the semantic web. In: 15th International conference on World Wide Web. ACM, NY, USA; 2006.
p. 417–26.[13] Ellis D. The dilemma of measurement in information retrieval research. J Am Soc Inform Sci – Spec Issue: Eval Inform Retr Syst 1996;47(1):23–36.[14] Wu J, Ilyas I, Weddell G. A study of ontology-based query expansion, technical report CS-2011-04; 2011.[15] Gruber TR. A translation approach to portable ontology specifications. Knowl Acquisit 1993;5(2):199–220.[16] Gruber TR. Toward principles for the design of ontologies used for knowledge sharing. Int J Hum–Comput Stud 1995;43(5–6):907–28.[17] WordNet: a lexical database for English. Princeton University. <http://wordnet.princeton.edu/>.[18] Devedzic V. Education and the semantic web. Int J Artif Intell Educ 2004;14:39–65 [IOS Press].[19] Berners-Lee T. Giant Global Graph. Blog submitted on Wednesday, 2007-11-21 18:45. Semantic Web Technologies. <http://dig.csail.mit.edu/
breadcrumbs/node/215>.[20] Zheng Hai-Tao, Kang Bo-Yeong, Kim Hong-Gee. An ontology-based approach to learnable focused crawling. Inform Sci 2008;178(23):4512–22
[Elsevier].
Please cite this article in press as: Bedi P et al. Focused crawling of tagged web resources using ontology. Comput Electr Eng (2012), http://dx.doi.org/10.1016/j.compeleceng.2012.09.009

16 P. Bedi et al. / Computers and Electrical Engineering xxx (2012) xxx–xxx
[21] Zheng Hai-Tao, Kang Bo-Yeong, Kim Hong-Gee. Learnable focused crawling based on ontology. In: Information retrieval technology, 4th Asiainformation retrieval symposium. LNCS, Springer; 2008. p. 264–75.
[22] Bedi P, Thukral A, Banati H, Behl A, Mendiratta V. A multithreaded semantic focused crawler. J Comput Sci Technol, in press [Springer].[23] Thukral A, Mendiratta V, Behl A, Banati H, Bedi P. FCHC: a social semantic focused crawler. In: Int conference on advances in computing and
communications. Part II. CCIS, vol. 191; 2011. p. 273–83.[24] Luong HP, Susan G, Qiang W. Ontology-based focused crawling. In: Int conference on information, process, and knowledge management. IEEE; 2009. p.
123–8.[25] Kozanidis L. An ontology-based focused crawler. In: LNCS 5039. Springer; 2008. p. 376–9.[26] Liu Z, Du Y, Zhao Y. Focused crawler based on domain ontology and FCA. J Inform Comput Sci 2011;8(10):1909–17.[27] Yang SY. OntoCrawler: a focused crawler with ontology-supported website models. Exp Syst Appl 2010;37(7):5381–9.[28] Chao W, Guo Y, Zhou B. Social networking federation. Comput Electric Eng 2012;38(2):306–29.[29] Valentin R, Halpin H, Shepherd H. Emergence of consensus and shared vocabularies in collaborative tagging systems. ACM Trans Web 2009;3(4):1–34.[30] Pass G, Chowdhury A, Torgeson C. A picture of search. In: 1st International conference on scalable information systems, article no. 1; 2006.[31] Chen S-Y, Zhang Y. Improve web search ranking with social tagging. In: 1st International Workshop on mining social media and 13th conference of the
Spanish association for artificial intelligence; 2009. p. 1–9.[32] Ding Y, Jacob EK, Fried M, Toma I, Yan E, Foo S. Upper tag ontology (UTO) for integrating social tagging data. J Am Soc Inform Sci Technol
2010;61(3):505–21.[33] SKOS: Simple Knowledge Organization System Primer. Antoine I, Summers E, editors. W3C working group note. <http://www.w3.org/TR/skos-primer>
[18.08.09].[34] Allemang D, Hendler J. Semantic web for the working ontologist. USA: Morgan Kaufmann, Elsevier; 2011.[35] Novak JD, Cañas AJ. The theory underlying concept maps and how to construct them. Technical report IHMC CmapTools 2006-01 Rev 01-2008. Florida
Institute for Human and Machine, Cognition; 2008.[36] Novak JD. Learning, creating, and using knowledge: concept maps as facilitative tools in schools and corporations. J e-Learning Knowl Soc
2010;6(3):21–30.[37] Graudina V, Grundspenkis J. Concept map generation from owl ontologies. In: 3rd Int conference on concept mapping, Tallinn, Estonia & Helsinki,
Finland; 2008. p. 1–8.[38] Simón A, Luigi C, Alejandro R. Generation of OWL ontologies from concept maps in shallow domains. In: CAEPIA, Springer; 2007. p. 259–67.[39] Kekalainen J, Jarvelin K. The impact of query structure and query expansion on retrieval performance. In: Croft WB, Moffat A, Van Rijsbergen CJ,
Wilkinson R, Zobel J, editors. 21st Annual international ACMSIGIR conference on research and development in information retrieval; 1998. p. 130–7.[40] OER Commons. A project created by ISKME. <http://www.oercommons.org/>.[41] Connexions. Supported by the William and Flora Hewlett Foundation, the Maxfield Foundation, and the Connexions Consortium. <http://cnx.org/
aboutus/>.[42] EdShare. University of Southampton. <http://www.edshare.soton.ac.uk/>.[43] Shute SJ, Smith PJ. Knowledge-based search tactics. Inform Process Manage 1993;29(1):29–45.[44] Chi EH, Mytkowicz T. Understanding the efficiency of social tagging systems using information theory. In: 19th ACM conference on hypertext and
hypermedia; 2008. p. 81–8K.[45] Rhee SK, Lee J, Park M. Ontology-based semantic relevance measure. In: 1st SWW workshop (ISWC); 2007.[46] Ali R, Beg MMS. An overview of Web search evaluation methods. Comput Electric Eng 2011;37(6):835–48.[47] Salton G, Buckley C. Term-weighting approaches in automatic text retrieval. Tech rep. Cornell University; 1987. p. 513–23.
Punam Bedi is an Associate Professor in the Department of Computer Science, University of Delhi, India. She has about 25 years of teaching and researchexperience with over 140 publications in National/International Journals/Conferences. She is also a member of AAAI, ACM, IEEE and Computer Society ofIndia. Her research interests include Web Intelligence, Soft Computing, Semantic Web, Multi-agent Systems, Intelligent Information Systems, IntelligentSoftware Engineering, Intelligent User Interfaces, Human Computer Interaction (HCI), Trust, Information Retrieval and Personalization.
Anjali Thukral is an Assistant professor in the Department of Computer Science at Keshav Mahavidyalaya, University of Delhi, India with an experience ofover 13 years of teaching to undergraduate and post-graduate students. She is also a research scholar and her research interests include InformationRetrieval, Knowledge Representation, Ontology, eLearning, Semantic Web and Multi Agent Systems.
Hema Banati is an Associate Professor in the Department of Computer Science, Dyal Singh College, University of Delhi, India. She has over 18 years ofteaching experience to both undergraduate and postgraduate classes. She received her Ph.D. in Computer Science from the University of Delhi in 2006. Shehas many national and international publications to her credit. Her research interests include Web engineering, Software Engineering, Human ComputerInteraction, Multi-agent Systems, E-commerce and E-learning.
Please cite this article in press as: Bedi P et al. Focused crawling of tagged web resources using ontology. Comput Electr Eng (2012), http://dx.doi.org/10.1016/j.compeleceng.2012.09.009





























