Embed Size (px)
Citation preview

Outline
• Introduction• Problems with existing systems• A modular approach
– Composable on-disk data structures– Application control of low-level primitives– Microbenchmarks
• The next steps– Library optimization during application compilation– Verification of application-specific extensions
• Conclusion

Introduction
• New applications introduce new demands for storage infrastructure– Database implementations eventually adapt
• Continuous queries, database file systems, XML, OLAP
– But not always• Web search, GMail, P2P
• Either way, custom storage solutions fill in the cracks– Expensive; little reuse of existing infrastructure– Subtle bugs lead to data corruption

Selective Reuse of Storage System Components
• Expose the RSS to allow greater reuse– Berkeley DB / Sleepy Cat– Layered Databases
• Proven real-world improvements in performance and code complexity
• Why not provide lower level interfaces?
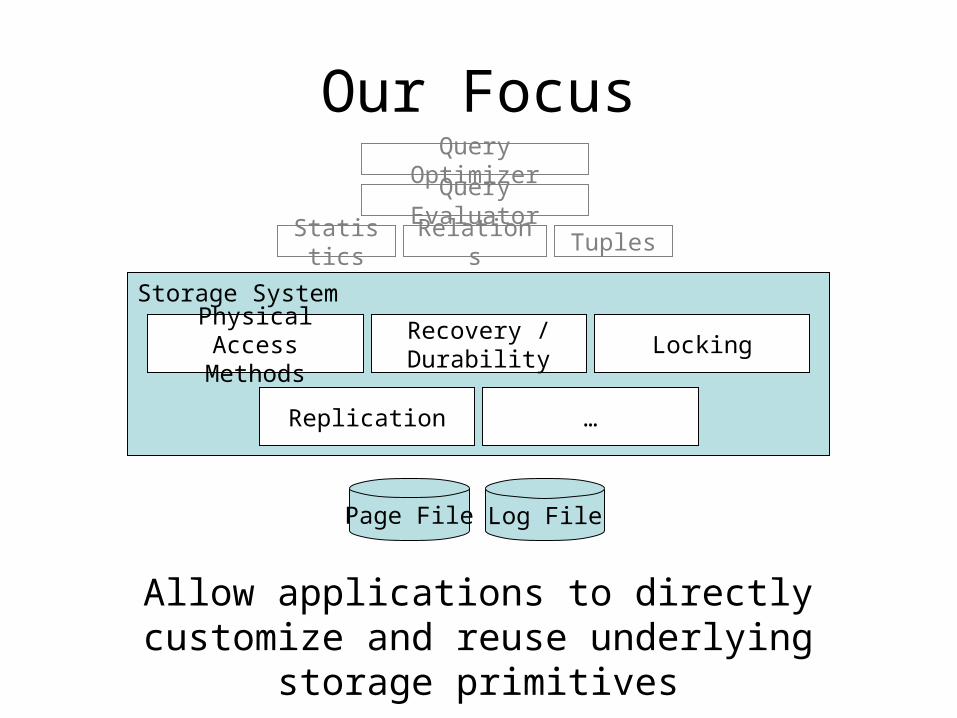
Storage System
Physical Access Methods
LockingRecovery / Durability
Replication …
Our Focus
Statistics TuplesRelations
Query Evaluator
Query Optimizer
Page File Log File
Allow applications to directly customize and reuse underlying storage primitives

Design Goals
• Let applications build upon or replace modules– Allocation strategies– Page layout – On disk data structures– Concurrency control– Log (format, durability and reordering)– Recovery
• Improved usability and performance – Application specific data structure organization– Program specific optimizations
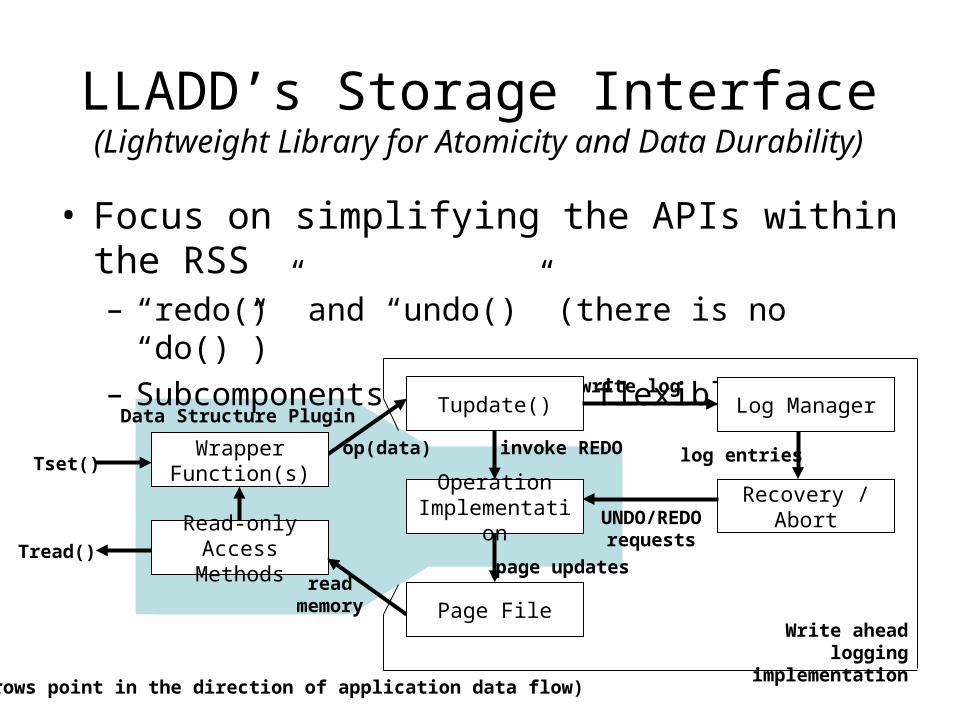
LLADD’s Storage Interface(Lightweight Library for Atomicity and Data Durability)
• Focus on simplifying the APIs within the RSS– “redo()” and “undo()” (there is no “do()”)– Subcomponents implement flexible APIs
Tset()op(data) invoke REDO
write log
UNDO/REDO requests
page updates
Data Structure Plugin
read memory
Read-only Access Methods
Operation Implementation
Tupdate()
Recovery / Abort
Log Manager
Tread()
log entries
(Arrows point in the direction of application data flow)
Write ahead logging implementation
Wrapper Function(s)
Page File
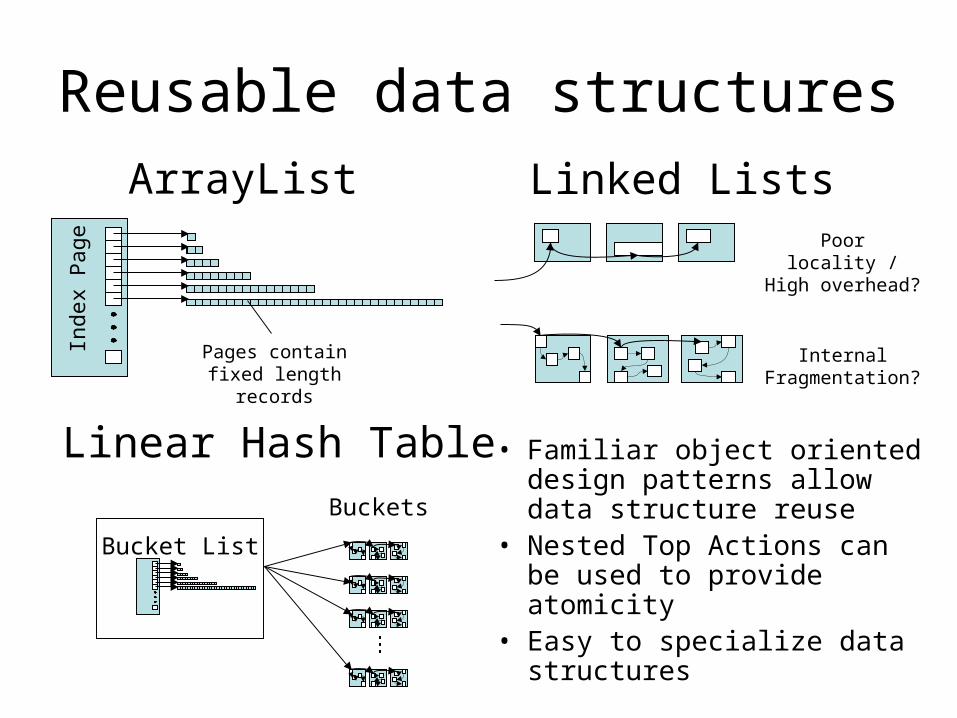
Reusable data structures
• Familiar object oriented design patterns allow data structure reuse
• Nested Top Actions can be used to provide atomicity
• Easy to specialize data structures
ArrayList Linked Lists
Inde
x P
age
Pages contain fixed length records
Poor locality / High overhead?
Internal Fragmentation?
Bucket List
Linear Hash TableBuckets

Hash Table Bulk Load Time
• Layered version’s performance is competitive• Also benchmarked optimized version
– No nested top actions Temporary inconsistency– Saves log bandwidth, roughly doubles throughput– Complex, monolithic code
0
5
10
15
20
25
30
35
40
45
0 50000 100000 150000 200000 250000
Insertions
Sec
on
ds
Berkeley DB
Modular / Nested Top Actions
Monolithic / Well ordered writes

Object serialization
• Persistent objects are often triple buffered
• Turning off OS cache removes one copy
• We can remove a second copy
System Memory
Disk
File system cache DB page cache Application Data(Live objects)

The Problem with the Page Cache
• Approach #1: Reduce the number of live objects– Need to repeatedly serialize and deserialize objects– CPU intensive
• Approach #2: Reduce the size of the page cache– Object updates force a write to the page cache– Two extra disk accesses (1 read, 1 write) to update
an object in cache!

Specialized Page Caching
• Defer page update until object is evicted from application memory– Issue log writes immediately– Application cache manipulates page cache
directly

Object serialization performance
0
1000
2000
3000
4000
5000
6000
7000
0 10 20 30 40 50 60 70 80 90 100
Percentage of Object that Changed
Up
dat
es/S
eco
nd
LLADD+deltaLLADD+update/flushLLADDBerkeley DBMySQL - In process / InnoDB
Roughly doubled throughput while reducing memory requirements.
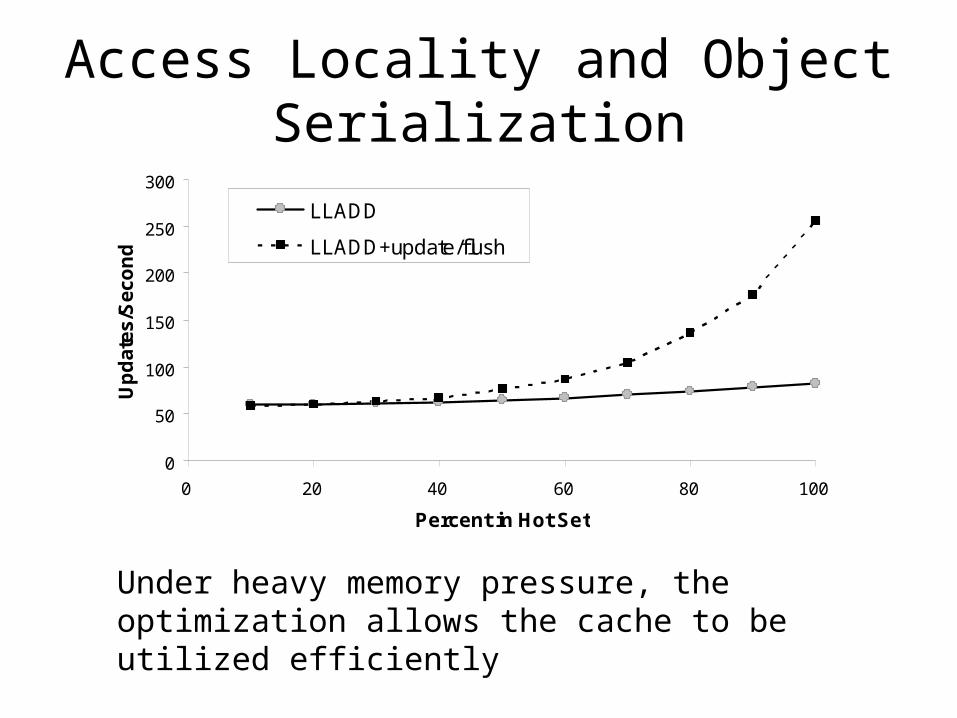
Access Locality and Object Serialization
0
50
100
150
200
250
300
0 20 40 60 80 100
Percent in Hot Set
Up
dat
es/S
eco
nd
LLADD
LLADD+update/flush
Under heavy memory pressure, the optimization allows the cache to be utilized efficiently

Language Based Tools
• Modern programming techniques provide some interesting opportunities– Software verification– Optimization
• High level interfaces make it difficult to take advantage of some of these tools
• How much do we gain by moving to lower level interfaces?

Memoization
• Servicing a cache hit is expensive compared to a pointer traversal
• Programs typically access the same page repeatedly
• Simple solution: Keep a pointer to the last value returned by the page cache
• Problem: Unrelated, interleaved calls– Multi-threaded code – Layered APIs

Example• Consider this application code:
for(int i = 0; i < len; i++) {value = hash_lookup(recordid, key[i]);
}
• hash_lookup() probably looks something like this:
hash_lookup(…) { Page * p = pin(recordid.page); // Read hashtable header unpin(recordid.page); … // pin and unpin bucket, data pages}
• Memoize header by storing values in the application’s stack frame

Dynamic Checks
• Insert memoization logic into application code, and store memoized values on the stack.– Preserves access locality within each thread– Handles “special cases” (B-Tree roots, iterators, etc)– Simplifies application/library source code
• Implemented using CIL, a C source to source transformation library.
• ~2x speedup on read-only CPU-bound hash table workload

Static analysis (work in progress)
• Dynamic checks are expensive• Use BLAST to remove redundant checks
at compile time– Tentatively remove check and call to pin()– Ask BLAST to prove the memoized value is
correct at pin()’s call site.
• Assumed the original program is “well behaved” C by removing problematic constructs

Verification of Invariants (future work)
• Extensions to the library must follow a number of invariants– Using nested top actions correctly– Updating the LSN of altered pages– Not relying upon transient data in redo()/undo()– and so on
• Want to check application code’s adherence to invariants
• Hopefully, this will allow us to guarantee high level properties are met
• Similar in spirit to the use of SLAM to verify Windows drivers

Conclusion
• Presented a simple storage architecture that supports a wide variety of applications
• The architecture brings up a number of interesting research questions
• A preliminary implementation is available– Ready for researchers, not for important data– http://lladd.sourceforge.net/
Acknowledgements
Eric Brewer
Jimmy Kittiyachavalit
Jim Blomo
Jason Bayer
Mike Demmer
Bowei Du
Gilad Arnold
Amir Kamil
Colleen Lewis

Backup Slides

Database Systems Take Control Away from Developers
• Great solution for established classes of applications
• Leads to serious problems in unanticipated situations
• A DBMS implementation can only support a finite set of semantics and must make decisions regarding– Data layout / programming model– Concurrency / consistency– Recovery / durability– Replication / scalability

One Solution
• Give application developers more choices– Relational / Cube / XML data models– Optimistic / pessimistic concurrency control– Serializable / Repeatable Read / Read Committed /
Read Uncommitted– Disable media recovery, partial logging, no logging– 2PC, merge replication, master / slave, partitioning– and so on…
• Leads to complex DBMS implementations• It takes a long time to get this right!

Editing DBMS Source Code is Difficult
• Requires knowledge of complex DB internals• Easy to get the extensions wrong• Difficult to test or debug• Breaks existing functionality• Leads to incompatible DB versions.
Are these all just artifacts of conventional database design?

Challenges
• It must be easy to add new extensions, and hard to (accidentally) break existing ones.
• Low level changes should not alter high level functionality in unexpected ways
• Bugs in recovery logic should be obvious
• In ‘interesting’ cases, should see ‘significant’ performance improvement.

Multiple page formats
• Record id’s are of the form: (page, slot, length) • ‘slot’ is interpreted by the appropriate page format
implementation; ‘length’ is for the application’s benefit.• Page Type 0 is reserved (allows lazy page initialization)
Page type specific
LSN Page Type LSN Fixed Length Data
Length Record Count
1 2 …
Generic page layout: Fixed length record layout:

Dynamic Check ExampleOriginal Code
foo(int i, record r) { Page *p; while(i--) { r->slot++; p = pin(r.page);
… unpin(p); if(...) { r.page++; r.slot = 0; } }
}
Optimized Code
foo(int i, record r) { Page *p = null; while(i--) { r.slot++;
if(!p || p->page != r.page) { unpin(p); p = pin(r.page);
} … if(...) { r.page++; r.slot = 0; }
} if(p) unpin(p);}

Static Analysis ExampleOriginal Code + Dynamic Checks
foo(int i, record r) { Page *p = pin(r.page); … while(i--) { r.slot++;
if(!p || p->page != r.page) { unpin(p); p = pin(r.page); } } unpin(p);}
Optimized Code
foo(int i, record r) { Page *p = pin(r.page); … while(i--) { r.slot++;
}unpin(p);
}

Potential applications
• Tool for future database research
• Improved performance from better compiler / language based optimization
• New programming language primitives seek to abstract SQL away. In some cases legacy declarative interfaces may simply be getting in the way

Lock Manager API
• Page level locking can be supported by the buffer manager, but requires solid error handling.
• Record level / index locking is tricky– Needs to understand built in and third party
extensions– Plan to implement Hierarchical 2PL in a way
that allows reuse by index implementations– Index implementations can simply lock the
entire index if performance is not an issue.

In memory vs. on disk semantics
• Holy grail: Application data acts like persistent data– But we still want a bunch of database features
• One solution: Map a custom declarative interface into SQL.– Don’t we still need an optimizer, etc for the in memory
data?– Transactional pages look a lot like RAM, especially if
you provide a library of persistent data structures that match the ones the application uses

Sample Operation Implementation (1/3)
// Operation Implementation// p is the bufferPool’s current copy of the page.int operateIncrement(int xid, Page *p, lsn_t lsn,
recordid rid, const void * d) { inc_dec_t * arg = (inc_dec_t*)d; int i; latchRecord(p, rid); readRecord(xid, p, rid, &i); // read current value i += arg->amount; // write new value, update LSN writeRecord(xid, p, lsn, rid, &i); unlatchRecord(p, rid); return 0; // no error}

Sample Operation Implementation (2/3)
// register the operation
ops[OP_INCREMENT].implementation= &operateIncrement;
ops[OP_INCREMENT].argumentSize = sizeof(inc_dec_t);
// set the REDO to be the same as normal operation
ops[OP_INCREMENT].redoOperation = OP_INCREMENT;
// UNDO is the inverse of REDO
ops[OP_INCREMENT].undoOperation = OP_DECREMENT;
// Define inc_dec_t
typedef struct {int amount } inc_dec_t;

Sample Operation Implementation (3/3)
// User friendly wrapper functionint Tincrement(int xid, recordid rid, int amount) { // rec will be serialized to the log int_dec_t rec; rec.amount = amount;
// write a log entry, then execute it Tupdate(xid, rid, &rec, OP_INCREMENT); // return the incremented value int new_value // wrappers can call other wrappers Tread(xid, rid, &new_value); return new_value;}

What if the database is missing a crucial feature?
• An application could use the database anyway– Convoluted data and/or programming model– Performance problems
• Or it could implement what it needs from scratch– Reinventing the wheel– Subtle problems with data loss and corruption
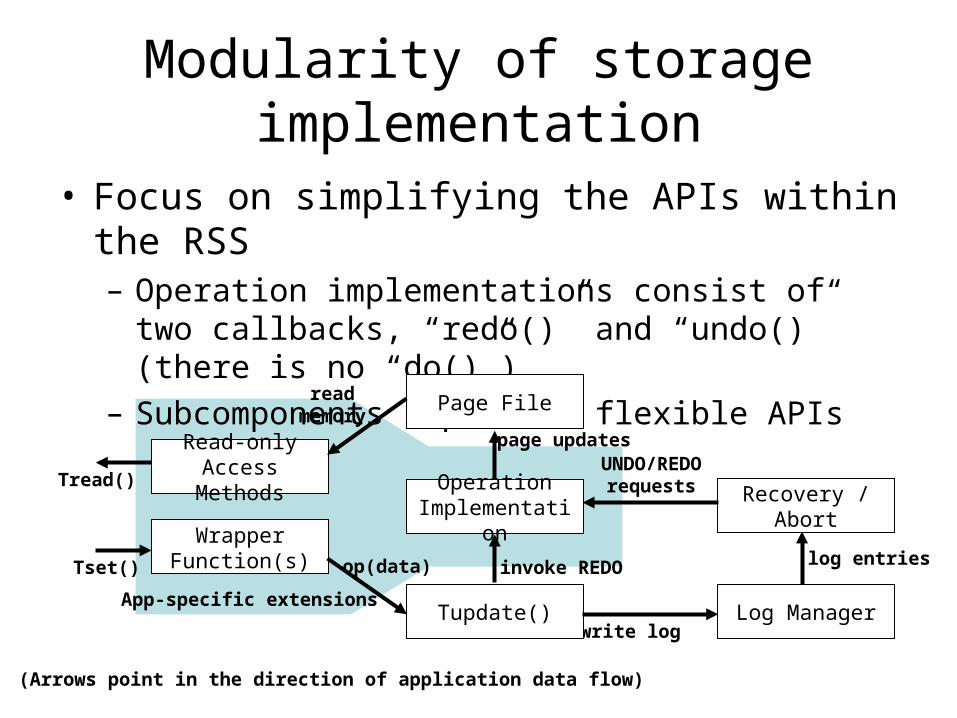
Modularity of storage implementation
• Focus on simplifying the APIs within the RSS– Operation implementations consist of two callbacks,
“redo()” and “undo()” (there is no “do()”)– Subcomponents implement flexible APIs
Tset() op(data) invoke REDO
write log
UNDO/REDO requests
page updates
App-specific extensions
read memory
Read-only Access Methods
Wrapper Function(s)
Page File
Operation Implementation
Tupdate()
Recovery / Abort
Log Manager
Tread()
log entries
(Arrows point in the direction of application data flow)

Language Based Optimization
• Applications often use storage libraries in limited, predictable ways
• Storage infrastructure must support all legal access patterns
• Could add calls to the API to optimize special cases– Difficult to use correctly– Library contains multiple implementations of
each function

Longer Introduction
• Conventional databases are not appropriate for some applications– It takes time to add support for new classes of
applications– Niche applications may not warrant added complexity– Sometimes declarative interfaces are overkill
• Low level API’s can be difficult to use– Expose intricately connected subsystems– Bugs in recovery logic– Applications must implement high-level functionality
• Modern programming techniques can address these problems

…
• Relational databases force some decisions upon application developers:– Data model / layout– Concurrency model– Consistency model– Recovery and durability semantics– Replication system– Declarative programming models– and so on…
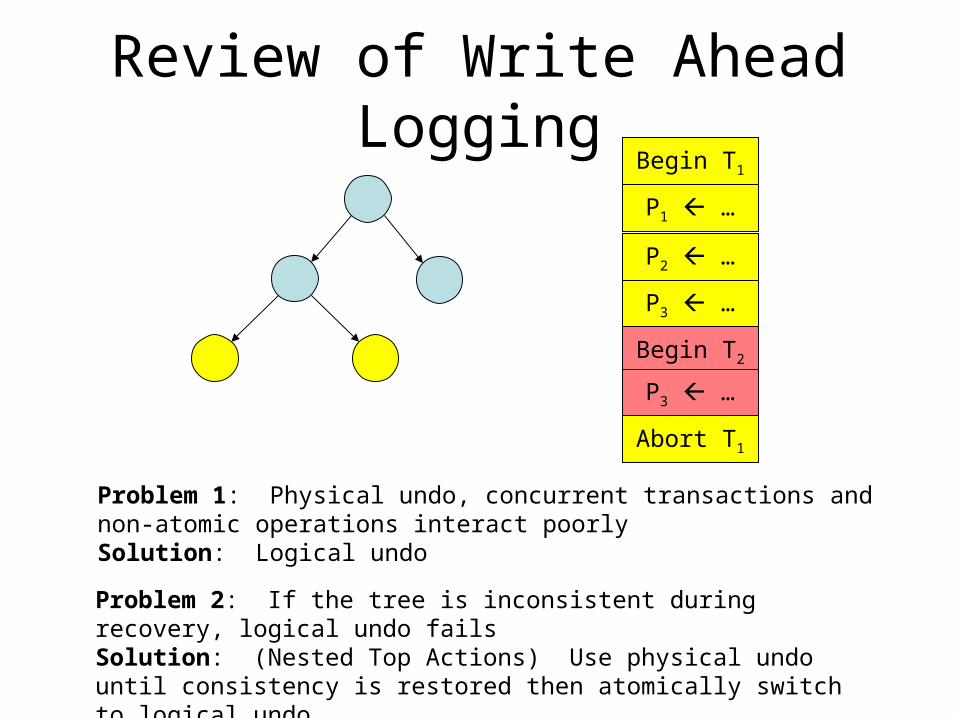
Review of Write Ahead LoggingBegin T1
P1 …
Abort T1P2 …
P3 …
Begin T2
P3 …
Abort T1
Problem 1: Physical undo, concurrent transactions and non-atomic operations interact poorlySolution: Logical undo
Problem 2: If the tree is inconsistent during recovery, logical undo failsSolution: (Nested Top Actions) Use physical undo until consistency is restored then atomically switch to logical undo






























