Embed Size (px)
Citation preview

Flash research report
Da Zhou
2009-7-4

Outline
• Query Processing Techniques for Solid State Drives (Research Paper)
• Join Processing for Flash SSDs: Remembering Past Lessons (DaMoN)
• Evaluating and Repairing Write Performance on Flash Devices (DaMoN)
• Lazy- Adaptive Tree: An Optimized Index Structure for Flash Devices (VLDB 2009)

Outline
• Query Processing Techniques for Solid State Drives (Research Paper)
• Join Processing for Flash SSDs: Remembering Past Lessons (DaMoN)
• Evaluating and Repairing Write Performance on Flash Devices (DaMoN)
• Lazy- Adaptive Tree: An Optimized Index Structure for Flash Devices (VLDB 2009)

Query Processing Techniques for Solid State Drives
• Dimitris Tsirogiannis – University of Toronto, Toronto, ON, Canada
• Stavros Harizopoulos, Mehul A. Shah, Janet L. Wiener, Goetz Graefe– HP Labs, Palo Alto, CA, USA

Motivation
• Although SSD may benefit applications that stress random reads immediately, they may not improve database applications, especially those running long data analysis queries.
• Database query processing engines have been designed around the speed mismatch between random and sequential I/O on hard disks and their algorithms currently emphasize sequential accesses for disk-resident data.

Contributions
• Column-based layout: PAX
• FlashScan
• FlashJoin
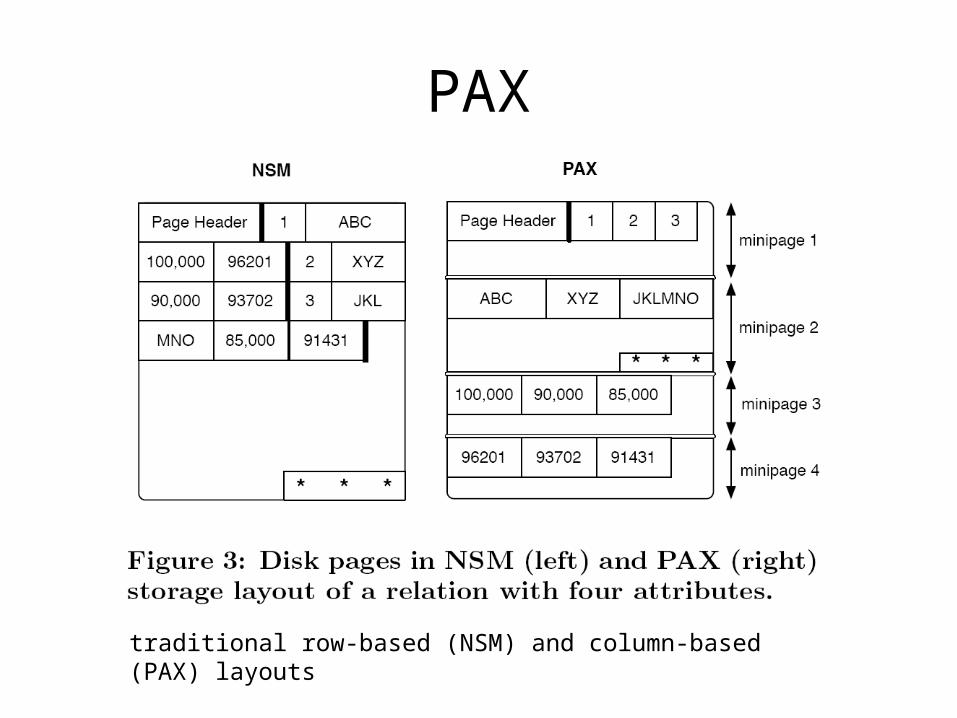
PAX
traditional row-based (NSM) and column-based (PAX) layouts

FlashScan
• FlashScan takes advantage of the small transfer unit of SSDs to read only the minipages of the attributes that it needs.

FlashScan(Opt)
• FlashScan can improve performance even further by reading only the minipages that contribute to the final result.
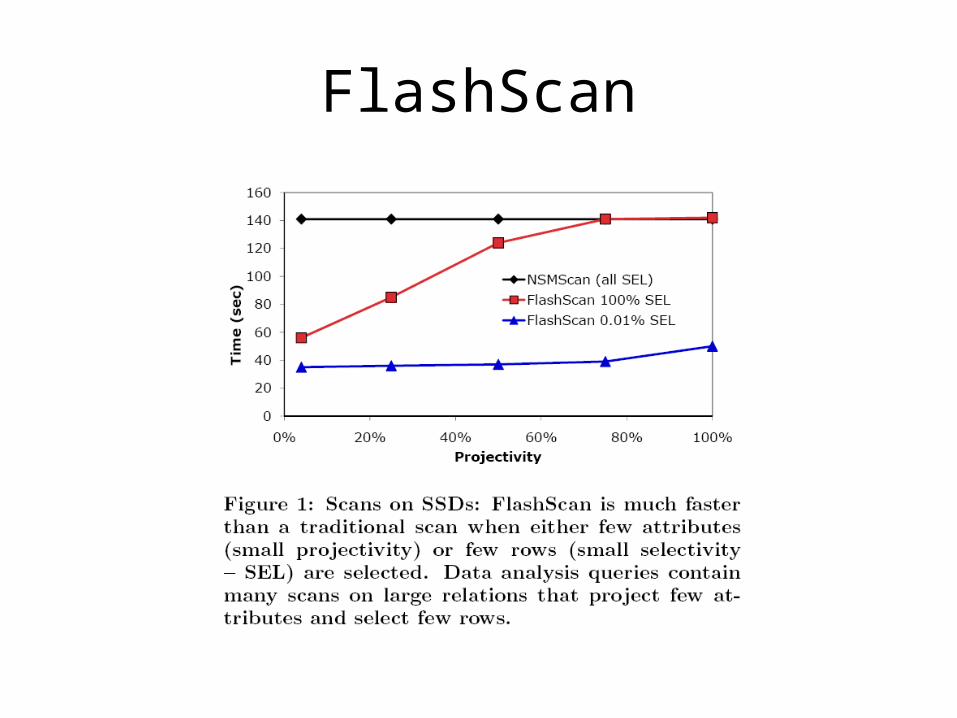
FlashScan
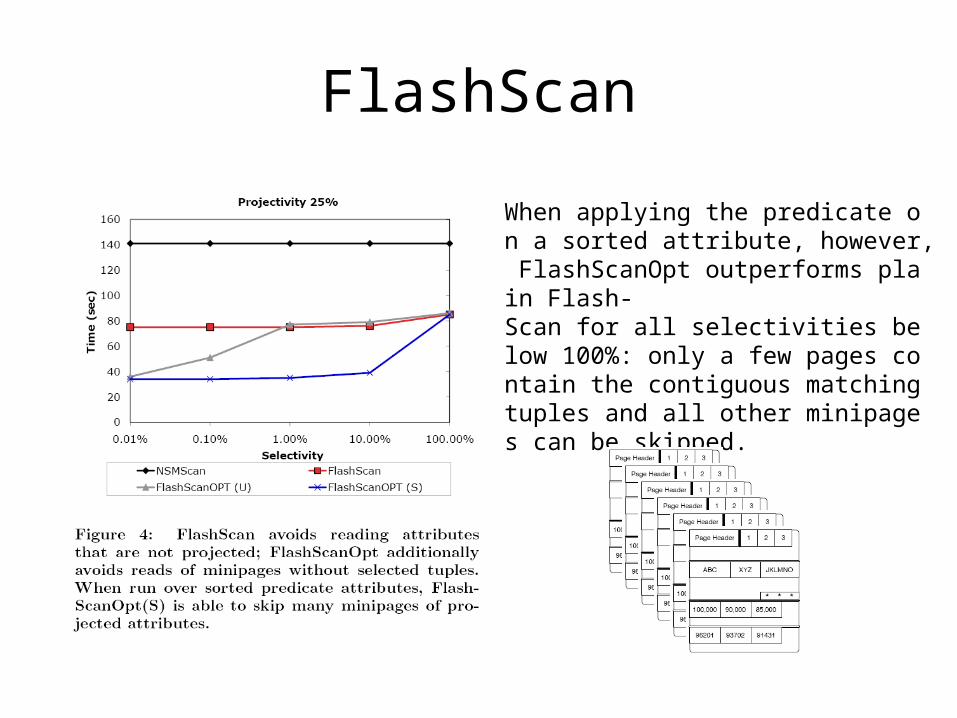
FlashScan
When applying the predicate on a sorted attribute, however, FlashScanOpt outperforms plain Flash-Scan for all selectivities below 100%: only a few pages contain the contiguous matching tuples and all other minipages can be skipped.

FlashJoin
The join kernel computes the join and outputs a join index. Each join index tuple consists of the join attributes as well as the row-ids (RIDs) of the participating rows from base relations.
The fetch kernel retrieves the needed attributes using the RIDs specied in the join index.

Outline
• Query Processing Techniques for Solid State Drives (Research Paper)
• Join Processing for Flash SSDs: Remembering Past Lessons (DaMoN)
• Evaluating and Repairing Write Performance on Flash Devices (DaMoN)
• Lazy- Adaptive Tree: An Optimized Index Structure for Flash Devices (VLDB 2009)

Join Processing for Flash SSDs: Remembering Past Lessons
• Jaeyoung Do, Jignesh M. Patel– Univ. of Wisconsin-Madison
• My current interests are: energy-efficient data processing, multi-core query processing, methods for searching and mining large graph and sequence/string data sets, and spatial data management.
• Towards Eco-friendly Database Management Systems, Willis Lang, Jignesh M. Patel, CIDR 2009
• Data Morphing: An Adaptive, Cache-Conscious Storage Technique, R. A. Hankins and J. M. Patel, VLDB 2003.
• Effect of Node Size on the Performance of Cache-Conscious B+-trees, R. A. Hankins and J. M. Patel, SIGMETRICS 2003.

Motivation
• We must carefully consider the lessons that we have learnt from over three decades of designing and tuning algorithms for magnetic HDD-based systems, so that we continue to reuse techniques that worked for magnetic HDDs and also work with flash SSDs.

Four classic ad hoc join algorithms
• Block Nested Loops Join– Block nested loops join first logically splits the smaller
relation R into same size chunks. For each chunk of R that is read, a hash table is built to efficiently find matching pairs of tuples. Then, all of S is scanned, and the hash table is probed with the tuples.
• Sort-Merge Join– Sort-merge join starts by producing sorted runs of eac
h R and S. After R and S are sorted into runs on disk, sort-merge join reads the runs of both relations and merges/joins them.

Four classic ad hoc join algorithms
• Grace Hash Join– Grace hash join has two phases. In the first phase, ha
shes tuples into buckets. – In the second phase, the first bucket of R is loaded int
o the buffer pool, and a hash table is built on it. Then, the corresponding bucket of S is read and used to probe the hash table.
• Hybrid Hash Join– Since a portion of the buffer pool is reserved for an in-
memory hash bucket for R– Furthermore, as S is read and hashed, tuples of S ma
tching with the in-memory R bucket can be joined immediately, and need not be written to disk.

Experimental Setup
• DB: SQLite3, Our experiments were performed on a Dual Core 3.2GHz Intel Pentium machine with 1 GB of RAM running Red HatEnterprise 5. For the comparison, we used a 5400 RPM TOSHIBA 320 GB external HDD and a OCZ Core Series60GB SATA II 2.5 inch flash SSD.
• As our test query, we used a primary/foreign key join between the TPC-H customer and the orders tables, generated with a scale factor of 30. The customer table contains 4,500,000 tuples (730 MB), and the orders table has 45,000,000 (5 GB).

Effect of Varying the Buffer Pool Size
The block nested loops join whose I/O pattern is sequential reads shows the biggest performance improvement, with speedup factors between 1.59X to 1.73X.
Other join algorithms also performed better on the flash SSD compared to the magnetic HDD, with smaller speedup improvements than the block nested loops join. This is because the write transfer rate is slower than the read transfer rate on the flash SSD, and unexpected erase operations might degrade write performance further.
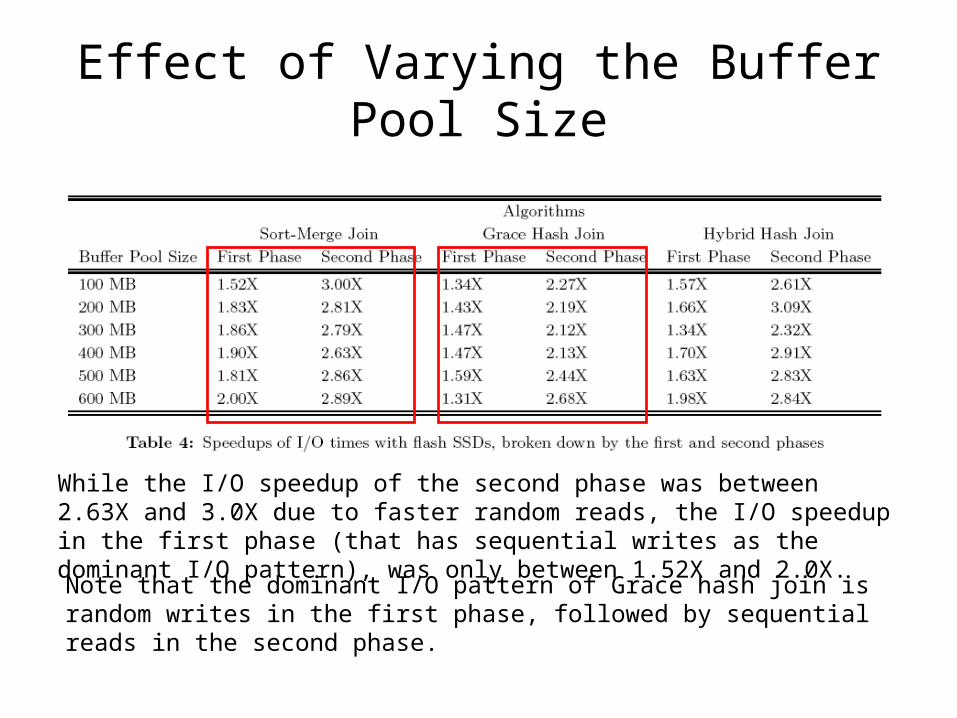
Effect of Varying the Buffer Pool Size
While the I/O speedup of the second phase was between 2.63X and 3.0X due to faster random reads, the I/O speedup in the first phase (that has sequential writes as the dominant I/O pattern), was only between 1.52X and 2.0X.
Note that the dominant I/O pattern of Grace hash join is random writes in the first phase, followed by sequential reads in the second phase.

Summary
1. Joins on flash SSDs have a greater tendency to become CPU-bound (rather than I/O-bound), so ways to improve the CPU performance, such as better cache utilization, is of greater importance with flash SSDs.
2. Trading random reads for random writes is likely a good design choice for flash SSDs.
3. Compared to sequential writes, random writes produce more I/O variations with flash SSDs, which makes the join performance less predictable.
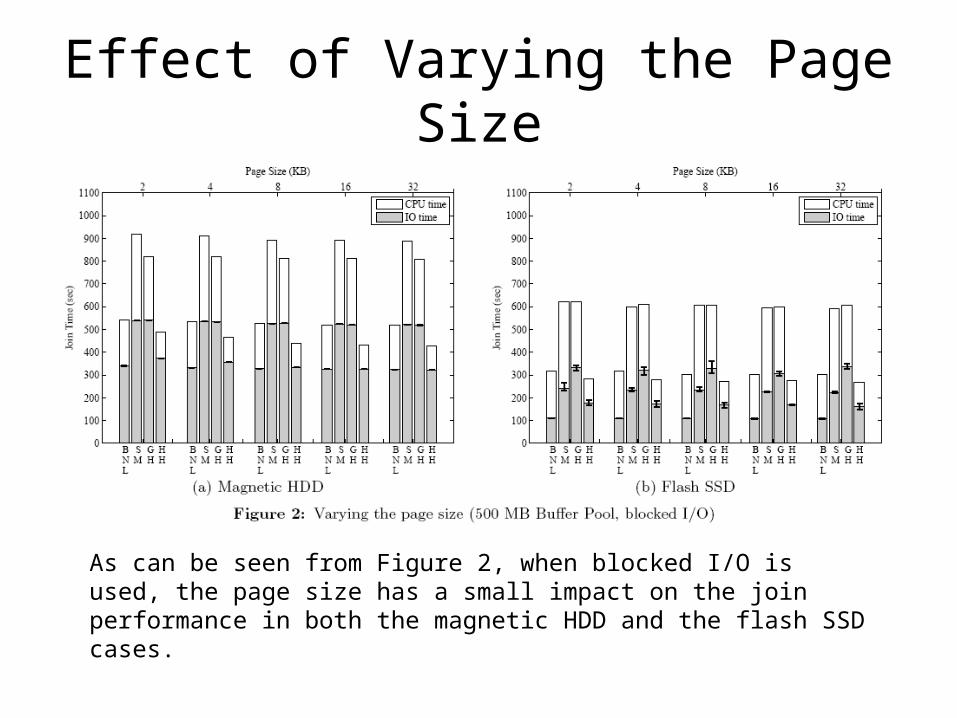
Effect of Varying the Page Size
As can be seen from Figure 2, when blocked I/O is used, the page size has a small impact on the join performance in both the magnetic HDD and the flash SSD cases.
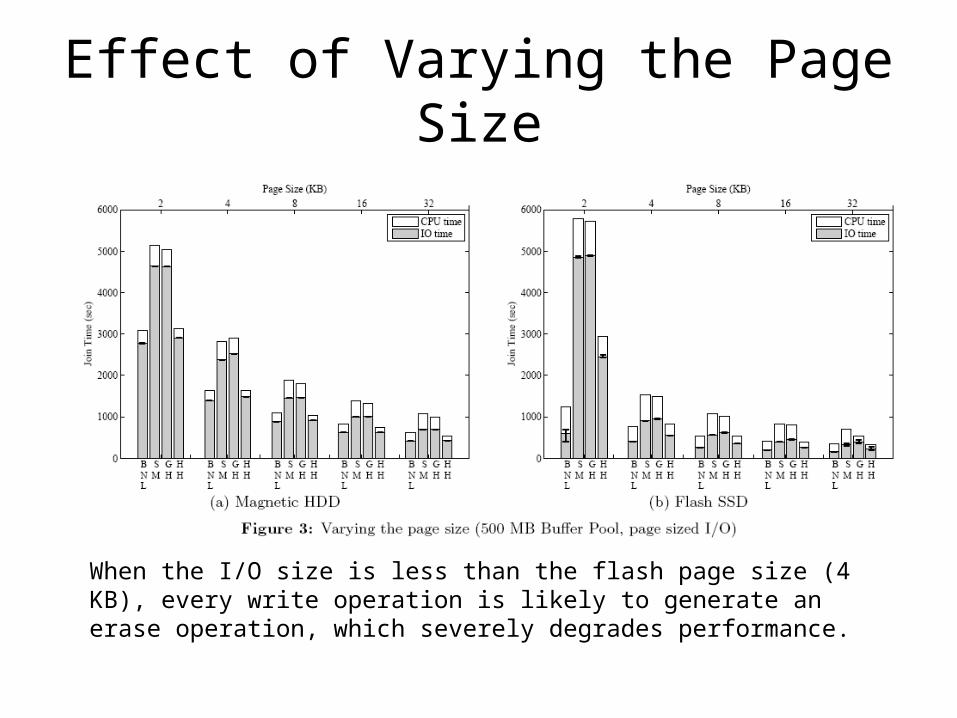
Effect of Varying the Page Size
When the I/O size is less than the flash page size (4 KB), every write operation is likely to generate an erase operation, which severely degrades performance.

Summary
1. Using blocked I/O significantly improves the join performance on flash SSDs over magnetic HDDs.
2. The I/O size should be a multiple of the flash page size.

Outline
• Query Processing Techniques for Solid State Drives (Research Paper)
• Join Processing for Flash SSDs: Remembering Past Lessons (DaMoN)
• Evaluating and Repairing Write Performance on Flash Devices (DaMoN)
• Lazy- Adaptive Tree: An Optimized Index Structure for Flash Devices (VLDB 2009)

Evaluating and Repairing Write Performance on Flash Devices
Anastasia Ailamaki• EPFL, VD, Switzerland• CMU, PA, USA• In 2001, she joined the Computer Science Department at
Carnegie Mellon University, where she is currently an Associate Professor. In February 2007, she joined EPFL as a visiting professor.
• S. Harizopoulos and A. Ailamaki. Improving instruction cache performance in OLTP. ACM Transactions on Database Systems, 31(3):887-920, 2006.

An Append and Pack Data Layout
• The layer always writes dirty pages, flushed by the buffer manager of the overlying DBMS, sequentially and in multiples of the erase block size.
• From a conceptual point of view, the physical database representation is an append-only structure.
• As a result, our writing mechanism benefits from optimal flash memory performance as long as enough space is available.

An Append and Pack Data Layout
• The proposed layer consolidates the least recently updated logical pages, starting from the head of the append structure, packs them together, then writes them back sequentially to the tail.
• We append them to the write-cold dataset because pages which reach the beginning of the hot dataset have gone the longest without being updated and are therefore likely to be write-cold.
• We read data from the head of the cold log structure and write them to the end

Outline
• Query Processing Techniques for Solid State Drives (Research Paper)
• Join Processing for Flash SSDs: Remembering Past Lessons (DaMoN)
• Evaluating and Repairing Write Performance on Flash Devices (DaMoN)
• Lazy- Adaptive Tree: An Optimized Index Structure for Flash Devices (VLDB 2009)

Lazy- Adaptive Tree: An Optimized Index Structure for Flash Devices
• Yanlei Diao
• Department of Computer Science
• University of Massachusetts Amherst

Motivation
• They present significant challenges in designing tree indexes due to their fundamentally different read and write characteristics in comparison to magnetic disks.

Key Features
• Cascaded Buffers
• Adaptive Buffering

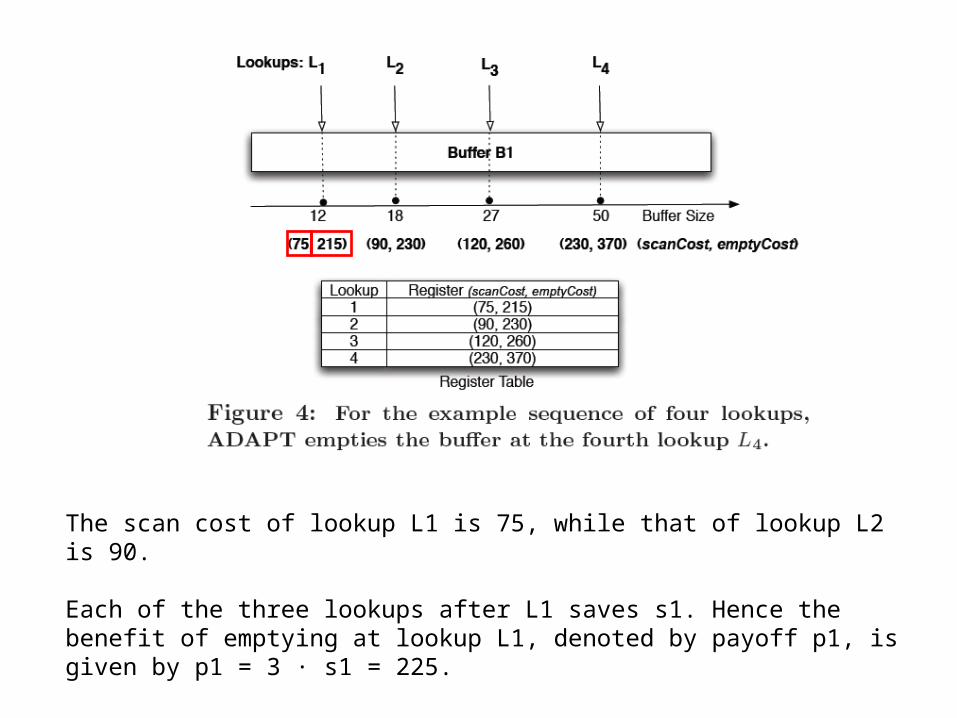
The scan cost of lookup L1 is 75, while that of lookup L2 is 90.
Each of the three lookups after L1 saves s1. Hence the benefit of emptying at lookup L1, denoted by payoff p1, is given by p1 = 3 · s1 = 225.
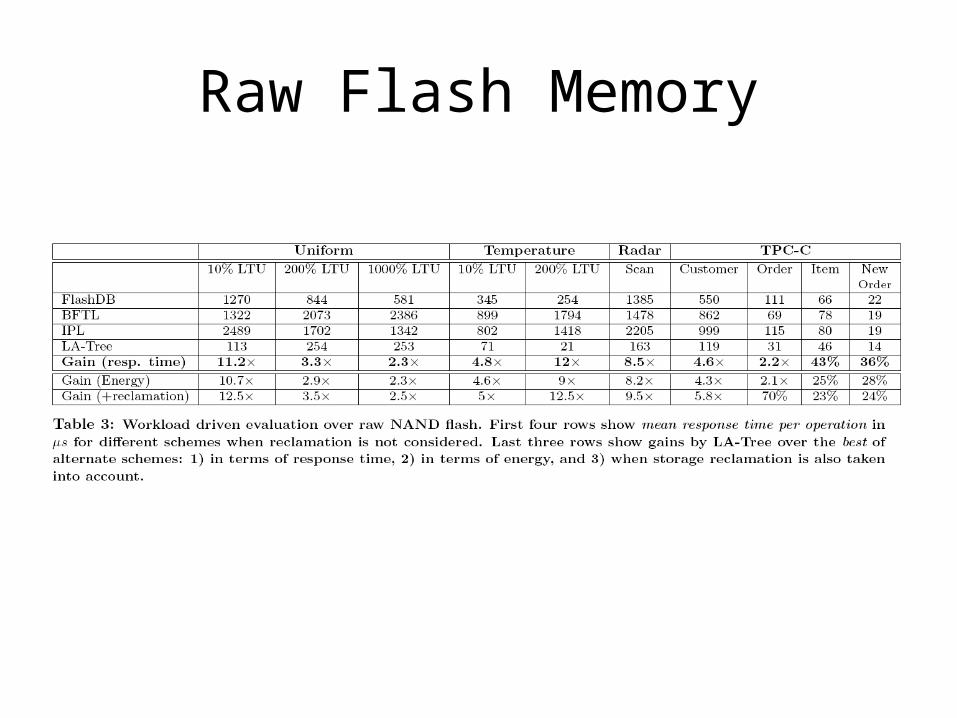
Raw Flash Memory
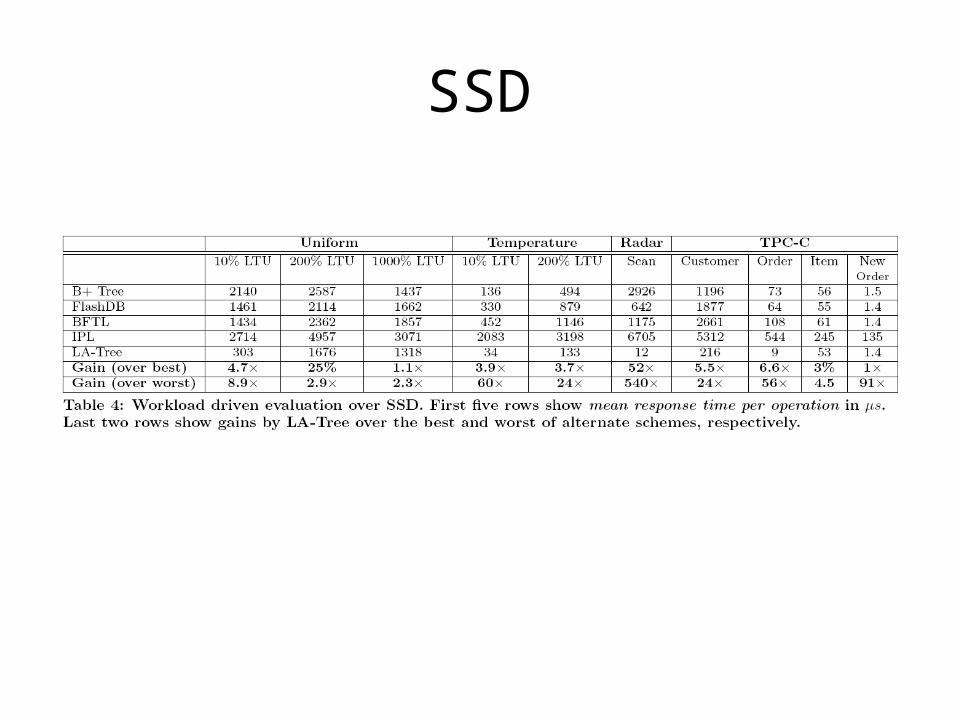
SSD

Outline
• Query Processing Techniques for Solid State Drives (Research Paper)
• Join Processing for Flash SSDs: Remembering Past Lessons (DaMoN)
• Evaluating and Repairing Write Performance on Flash Devices (DaMoN)
• Lazy- Adaptive Tree: An Optimized Index Structure for Flash Devices (VLDB 2009)

Thank You





























