Embed Size (px)
Citation preview

systems biology approach [1].These had longbeen examined by hypotheses-driven methods.We asked if we could uncover connectionsbetween seemingly unrelated physiologicalfunctions or pathways if we systematicallyobserved how cellular elements react whenthe core pathway is perturbed.The studydemonstrated a role for discovery science byconnecting cellular subsystems that were notapparent using the hypothesis driven method.
How does the ISB interact withpharmaceuticals and other areas ofmedical research?Proteomic tools like RNA or gene expressionanalysis potentially help in the early diagnosis ofcancer and other diseases. In drug development,we vary the structure by applying chemicalsynthesis to determine whether a new structureis more efficient? A defined molecular patternlets us see whether a drug might be toxic. It isexpected that genetics, genomics and proteomics
have a high quantitative impact to measurehow a drug is performing during developmentand that a systems biology approach will movedrug development away from trial and errorand random screening towards rational discoveryof druggable targets and rational drug design.
Reference1 Ideker T, et al. (2001) Integrated genomic and
proteomic analyses of a systematicallyperturbed metabolic network. Science 292,929–934
BIOSILICO Vol. 1, No. 2 May 2003
1478-5282/03/$ – see front matter ©2003 Elsevier Science Ltd. All rights reserved. PII: S1478-5282(03)02313-456 www.drugdiscoverytoday.com
UPDATE
INDUSTRY NEWS
Finding an oasis in the desert ofbioinformaticsJeffrey Thomas, Genstruct, 150 CambridgePark Drive, Cambridge, MA 01720, USA. David K. Stone, Flagship Ventures, 150 CambridgePark Drive,Cambridge, MA 01720, USA; e-mail: [email protected]
The market for bioinformatics is seeminglyvast, with sources from IBM Life Sciences(http://www.ibm.com/lifesciences) to WallStreet analysts estimating its current sizeand future potential in the billions of dollars [1]. Indeed, in the current era ofgenomics-driven discovery, scientists haveharnessed the industrial tools of automation and miniaturization to generatenew data at unprecedented rates.Thisexplosion of data far exceeds the capacity of the life-science industry for analysis,information extraction, and knowledgemanagement, creating huge unmet needs.However, in spite of the emergence of >150 bioinformatics start-ups, none has developed the technology and businessmodel on which to build a big company(Table 1).
Unmet needs in life sciencesinformaticsIn spite of the poor commercial success ofbioinformatics companies, life-sciencesresearchers face significant challenges in dataintegration, analysis and visualization, in silicobiology, and knowledge management.
Data integrationThe need for precise local management ofhigh-throughput data (e.g. microarray orhigh-throughout screening data) hasfrequently led to the creation of severaldifferent databases within a singleorganization. Both the administrative andopportunity costs of managing severaldatabases have led to a demand for systemsthat integrate these sources. Netgenics (nowLion Bioscience, http://www.lion-ag.de),IBM Life Sciences and Incellico (http://www.incellico.com) offer different approaches tothis important problem. It is unclearwhether major pharmaceutical companieswill choose to outsource in this business-critical area.
High-dimensional analysis and visualizationOverwhelmed by raw data, most analystsprefer to study high-dimensional datasetsusing tools that filter outliers and summarizetrends. Informax (http://www.informaxinc.com), Spotfire (http://www.spotfire.com) and AnVil (http://www.anvilinformatics.com) are bioinformatics companies that haveovercome non-trivial technical issues, such
as interoperability, client-server loading, anddynamic graphical rendering, and havesuccessfully marketed such data visualizationtools. Unfortunately, the development costsfor analysis and visualization tools oftenexceed their value when marketed assoftware.Thus, Informax has been sold,Spotfire is seeking lateral markets and AnVil has shifted to a partnership businessmodel.
In silico biology and chemistryGiven the low revenue potential forsoftware solutions in the life sciences,several informatics companies have adopted a discovery strategy.Their products typically predict optimal targets,markers or compounds. For example,Libraria (http://www.libraria.com) hasdeveloped a combined informatics–chemistry technology platform to identifycompounds appropriate for clinicaldevelopment. Given the serendipitousnature of drug discovery, as well as thelimited success of structure-based drugdesign, in silico discovery remains anunproven model.

Knowledge managementKnowledge derived from cutting-edgetechnologies is typically captured in atraditional form: the laboratory notebook.Some large companies use enterprisecontent-management systems, such as thatfrom Documentum (http://www.documentum.com), but these systems relyon users to interpret and operate on theknowledge. Some new companies, such asGenstruct (http://www.genstruct.com), areworking to replace traditional knowledge-management systems by using semanticallyrich knowledge representations to enablecomputer-aided reasoning across broadknowledge domains.
Where informatics has yieldedbreakthroughsUnprecedented levels of competition,commercialization, venture funding andpublic awareness have accompanied the‘genomics revolution’. Perhaps it is notsurprising then that expectations were setunrealistically high. Nevertheless, severalhighly successful bioinformatics applicationshave emerged.
Genome assembly and analysisThe assembly of three billion base pairs (bp)of sequence from segments of <1000 bp isan accomplishment that is unprecedented.Built on over two decades of advances insequence analysis (e.g. GCG, BLAST, PHREDand PHRAP), the success of both the public(http://www.ornl.gov/hgmis/) and private(http://www.celera.com/genomics/academic/home.cfm) genome assembly effortshighlights the importance of computation inthe life sciences.
MEDLINELittle heralded, yet central to life-sciencesresearch, is MEDLINE, the National Libraryof Medicine’s database of >10 millionabstracts from life sciences journals. PubMed(http://www.ncbi.nlm.nih.gov/PubMed), thecontemporary user interface to MEDLINE,is widely used for literature-based researchand as an aid in data interpretation andhypothesis development. Keys to the successof PubMed include its broad availability andits high level of curation, both by authors ofthe abstracts as well as the standardizedMedical Index Subject Heading (MeSH)
annotation performed by PubMedpersonnel.
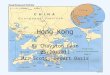
Microarray analysis systemsIn the late 1990s, the rapid growth ofmicroarray techniques to measure geneactivity created an urgent need for analysisand visualization tools. Several groups notonly created tools, but also invented newparadigms for visualization. Most notable isthe work of Eisen et al. [2] and Weinsteinet al. [3]. Spotfire, Rosetta Inpharmatics(http://www.rii.com) and AnVil (Fig. 1) haveall had commercial success in this area andare well positioned to serve the emergingfield of systems biology.
Quest for a sustainable businessmodelDeveloping an informatics technology thatsolves a problem in life sciences is notoverly difficult.A handful of entrepreneurswith almost no capital can create a ‘solution’in less than a year.The difficult part is findingenough customers whose problem is thesame.Thus, a software package that sells forUS$5000 per seat has to reach a population
BIOSILICO Vol. 1, No. 2 May 2003
57www.drugdiscoverytoday.com
UPDATE
INDUSTRY NEWS
Table 1. The high mortality rate of concentrated bioinformatics companiesa
Company URL Business model Status
Compugen http://www.cgen.com Software and drug discovery Public, US$35 million market capitalization
DoubleTwist Application service provider (ASP) DefuncteBioinformatics http://www.entigen.com ASP and software Renamed Entigen sold to BiosiftGenomica http://www.genomica.com Software and services Sold to ExelixisInformax Software Sold to InvitrogenLion Bioscience http://www.lion-ag.de Software and drug discovery Public, US$60 million market
capitalization, discovery stoppedMolecular Mining http://www.molecularmining.com Software and services DefunctNeomorphic http://www.neomorphic.com Software Sold to AffymetrixNetgenics http://www.netgenics.com Software Sold to Lion BiosciencesOxford Molecular http://www.oxmol.co.uk Software Software division sold to PharmacopeiaParacel http://www.paracel.com Software and hardware Sold to CeleraSilicon Genetics http://www.sigenetics.com Software PrivateSpotFire http://www.spotfire.com Software PrivateStructural http://www.strubix.com Content and drug discovery Private BioinformaticsTimeLogic http://www.timelogic.com Hardware and software Private
aThis list of concentrated bioinformatics companies was taken from a March 2000 analyst report [1]. Of the 15 companies listed, over half have been sold or havegone out of business.

of 50,000 users to create a market ofUS$25 million.An enterprise license mightcommand a US$1 million price tag, butgarnering 25 such customers is equallydifficult. Informax, for example, claimed 23 ofthe top 25 pharmaceutical companies amongits 2100 customers, yet expected sales ofunder US$20 million and a net loss of overUS$20 million in 2002 [4]. Selling specializedinfrastructure for life sciences via anapplication service provider (ASP) modelhas also proved problematic because mostlife sciences companies have opted topurchase their own equipment from majorhardware vendors. Content-orientatedcompanies, such as Celera Genomics (http://www.celera.com), GeneLogic (http://www.genelogic.com), Human Genome Sciences
(http://www.hgsi.com) and Incyte Genomics(http://www.incyte.com), have fared betterthan those selling software have. However,most such companies have shifted theirfocus to drug discovery to escape theeventual commoditization of their databaseproducts.
Finding a pathway for successIn spite of market challenges, there is abroad consensus that the most importantlife sciences innovations will come from theintersection of information technology andbiology; there are clear opportunities in this space.The most promising businessmodels today are knowledge-based contentand discovery partnerships.As life sciencesinformation technologies become
more-and-more powerful, presentingcomplex information in a manner accessibleto the human mind presents an ongoinginterpretive versus analytical challenge.Thisis because humans can only comprehendabout seven variables at once. Knowledge-based content companies can address thisproblem and offer the promise of anenterprise-wide application that spansmultiple disciplines and remains proprietaryand upgradeable year-after-year. Thediscovery partnership model is wellestablished in biotechnology but has onlyrecently emerged in bioinformatics. Entelos(http://www.entelos.com) and PhysiomeSciences (http://www.physiome.com) – bothin silico modeling companies – have achievedmomentum with this model, in spite of achallenging investor and customer climate.Most would agree that, in time, life scientistswill use computational technologies to‘perform’ rather than merely ‘facilitate’discovery.The opportunities for increasingR&D efficiency and making clinical medicinemore effective are both strong andpermanent drivers for life sciencesinformatics.
References1 Reed, J. (2000) Trends in commercial
bioinformatics. Oscar Gruss(http://www.oscargruss.com)
2 Eisen, M.B. et al. (1998) Cluster analysis anddisplay of genome-wide expression patterns.Proc. Natl. Acad. Sci. U. S. A. 95, 14863–14868
3 Weinstein, J.N. et al. (1997) An information-intensive approach to the molecularpharmacology of cancer. Science 275,343–349
4 Whiteley, A. (2002) InforMax reports secondquarter results. InforMax (http://www.informaxinc.com/about/IR/319284.html)
BIOSILICO Vol. 1, No. 2 May 2003
58 www.drugdiscoverytoday.com
UPDATE
INDUSTRY NEWS
Figure 1. AnVil’s radical visualization (http://www.anvilinformatics.com).This high-dimensionalanalysis and visualization tool reveals the compounds most effective in inhibiting growth ofdifferent cancer cell lines in this dataset from the National Cancer Institute. Compounds arearranged around the perimeter and the cancer cell lines are shown as coloured circles (green,melanoma; blue, leukemia; orange, other) within the large circle.
BioSilico
6306
84
1179
173661
40
6912
72
632855
671456
645976
650599659648
664316621888625133
634182
649900
641394
641395
6171
45
6643
11
6481
47
6301
286285
076562
39637229
46061642009
644902
690434
690432
602617
654236
658450
642061
670766
670762
686368
688027
618315
Leukemia
Melanoma
Other
BioMedNet Reviews
5000+ review articles including
Trends, Current Opinion and
Drug Discovery Today
Publications
Bookmark:
http://reviews.bmn.com/






![OASIS HOT SPRINGS MOBILEHOME AND RV PARK › app › uploads › 2020 › ... · [2] OASIS HOT SPRINGS MOBILEHOME AND RV PARK 69-530 Dillon Road Desert Edge, California 92241 Phone:](https://img.pdfslide.us/doc/110x75/5f0d5ff37e708231d43a0a0f/oasis-hot-springs-mobilehome-and-rv-park-a-app-a-uploads-a-2020-a-.jpg)

![CRAFT TRADITIONS OF THE DESERT, OASIS, AND SEA · 2020-01-16 · [ 6 6] CRAFT TRADITIONS OF THE DESERT, OASIS, AND SEA MARCIA STEGATH DORR AND NEIL RICHARDSON raft industries have](https://img.pdfslide.us/doc/110x75/5f1a96ab5e17ba03897bd8da/craft-traditions-of-the-desert-oasis-and-sea-2020-01-16-6-6-craft-traditions.jpg)