Embed Size (px)
Citation preview

Instituto Politécnico de Coimbra
Instituto Superior de Engenharia de Coimbra
Departamento de Engenharia Informática e de Sistemas
Ferramentas de Business Intelligence
Open Source para PMEs
Marco Tereso
Mestrado em Informática e Sistemas
Coimbra, Dezembro, 2011

Instituto Politécnico de Coimbra
Instituto Superior de Engenharia de Coimbra
Departamento de Engenharia Informática e de Sistemas
Mestrado em Informática e Sistemas Projecto Industrial
Relatório Final
Ferramentas de Business Intelligence
Open Source para PMEs
Marco Tereso
Orientador:
Dr. Jorge Bernardino
ISEC - DEIS
Coimbra, Dezembro, 2011

Agradecimentos
A conclusão desta dissertação é o culminar da realização de um grande objetivo. Este foi o maior desafio ao nível académico e só se tornou possível graças ao grupo de pessoas que diariamente me apoiaram e incentivaram. Como tal, deixo aqui os meus agradecimentos:
Ao Professor Doutor Jorge Rodrigues Bernardino que orientou e acompanhou de forma assídua o meu trabalho, tornando possível esta dissertação.
Aos meus pais, por todo o esforço que fazem diariamente e que sempre me incentivaram a estudar.
À minha irmã, que me incentivou a entrar no ensino superior.
A todos os professores e colegas do Mestrado que directa ou indirectamente contribuíram para a minha formação.
Ao Engº Jorge Vieira que se disponibilizou a apoiar o processo de implementação prática num caso real.
E a todos os amigos de longa data que são inúmeros e teria uma lista infindável para referir, sem esquecer as pessoas que mais de perto acompanharam todo este trajecto, que prestaram um apoio essencial, mesmo preferindo o anonimato.
"Se não puder se destacar pelo talento, vença pelo esforço." (Dave Weinbaum)

Ferramentas Open Source BI para PMEs Resumo
i
RESUMO Em época de contenção de despesas e oscilações constantes dos mercados, inovação e otimização devem ser os fatores chave para o desbloqueio da economia. A sustentabilidade e presença no mercado de pequenas e médias empresas é constantemente ameaçada face à concorrência e competitividade apresentadas pelas grandes empresas. Uma das soluções para o aumento da competitividade e rentabilidade das pequenas e média empresas é a aquisição de ferramentas de Business Intelligence. Face às dificuldades de investimento encontradas, por parte das empresas apresentamos no contexto do nosso trabalho um conjunto de ferramentas de Business Intelligence open source que garantidamente apresentam qualidade suficiente para servir interesses e necessidades de pequenas e médias empresas. O nosso trabalho contempla uma investigação em torno de ferramentas Business Intelligence open source, avaliando-as e comparando-as em diversos parâmetros. A nossa avaliação baseou-se inicialmente na descrição das ferramentas e posteriormente na implementação e exploração prática das mesmas. Os resultados preliminares são bastante atrativos e realçam a qualidade das ferramentas de Business Intelligence open source analisadas. Para valorizar o nosso trabalho recorremos à implementação de uma das ferramentas sobre um projeto numa PME, com o principal objetivo de demonstrarmos na prática que a implementação destas ferramentas é simples e é claramente viável. Em suma, as ferramentas de Business
Intelligence existentes no mercado constituem uma alternativa viável às soluções comerciais e não envolvem gastos acrescidos. As ferramentas analisadas apresentam alguma maturidade, e uma interface com o utilizador aceitável, traduzindo-se numa menor dificuldade de adaptação por parte do utilizador. Em suma as ferramentas de Business Intelligence open source representam uma solução alternativa viável perante as soluções comerciais, com a mais-valia de serem gratuitas e não implicarem custos de aquisição por parte das empresas.

Ferramentas Open Source BI para PMEs Resumo
ii
ABSTRACT In times of cost containment and constant fluctuations of markets, innovation and optimization should be the keys to unlocking the economy. The market for small and medium enterprises is constantly threatened in the face of competition and competitiveness made by large companies. One solution to increase the competitiveness and profitability of small and medium business is the acquisition of business intelligence tools. Given the difficulties of business investment, we present in our work a toolkit of open source Business Intelligence. It is guaranteed to have sufficient quality to serve the interests and needs of small and medium enterprises. Our work includes one research about open source Business Intelligence tools, evaluating them and comparing them on various parameters. Our assessment was initially based on the description of tools and later in implementation. Preliminary results are very attractive and allow highlight the quality of business intelligence tools open source analyzed. To enhance our work we resorted to implementing one of the tools on a real project in an SME, with the main objective to demonstrate in practice that the implementation of these tools is simple and is clearly feasible. In short, the business intelligence tools on the market are a viable alternative to commercial solutions and do not involve a big investment. The analyzed tools have some maturity, and a user interface acceptable, translating into lower difficulty of adaptation by the user. The open source Business Intelligence tools represent a viable alternative before the paid solutions, with the advantage of being free and do not involve acquisition costs, for companies.

Ferramentas Open Source BI para PMEs Palavras-Chave
i
Palavras-Chave Open Source Business Intelligence PMEs Data Warehousing
Keywords Open Source Business Intelligence SMEs Data Warehousing

Ferramentas Open Source BI para PMEs Símbolos e Abreviaturas
ii
ABREVIATURAS AGPL – Affero General Public License AJAX – Asynchronous Javascript and XML API – Application Programming Interface
BAM - Business Activities Monitoring BD – Base de Dados BI – Business Intelligence BIRT – Business intelligence Reporting Tools BPM - Business Process Management CE – Community Edition CRM – Customer Relationship Management CSS – Cascading Style Sheets CSV – Comma-Separated Values DBMS – Database Management System DFSG - Debian Free Software Guidelines DSP – Decision Studio Professional DW – Data Warehouse EJB – Enterprise Java Beans ERP – Enterprise Resource planning ETL - Extract, Transform, Load FSF - Free Software Foundation GEO – Geo-referenced GIS - Geographic Information System GPL – General Public License HTML – Hypertext Markup language IDE - Integrated Development Environment J2EE – Java 2 Enterprise Edition JDBC – Java Database Conectivity
JVM – Java Virtual Machine JOLAP – Java Online Analytical Processing JSP – Java Server Pages KPI – Key Performance Indicator MDX - Multidimensional Expressions ODBC – Open Data Base Connectivity OLAP – On-line Analytical Processing

Ferramentas Open Source BI para PMEs Símbolos e Abreviaturas
iii
OLTP – Online Transaction Processing OSI - Open Source Iniciative PDF – Portable Document Format PDI – Pentaho Data Integration PHP – Hypertext Preprocessor PMEs – Pequenas e médias empresas POJO – Plain Old Java Objects QBE - Query by Example RDBMS – Relational Database Management System ROI – Return On Investment SaaS – Software as a Service SGBD - Sistema de Gestão de Base de Dados SI – Sistemas de Informação SIG – Sistema de Informação Geográfica SQL – Structured Query Language SWF - Shockwave Flash TOS – Talend Open Studio UE – União Europeia XML - Extensible Markup Language XMLA – Extensible Markup Language for Analysis
WCAG - Web Content Accessibility Guidelines WEKA - Waikato Environment for Knowledge Analysis

i
ÍNDICE CAPÍTULO 1 - INTRODUÇÃO 1 CAPÍTULO 2 - ESTADO DA ARTE 5 CAPÍTULO 3 - BUSINESS INTELLIGENCE 9
3.1 - Descrição do conceito de Business Intelligence 9 3.1.1 - Benefícios e Objetivos 10 3.1.2 – Vantagens 11 3.1.3 – Desvantagens 12 3.1.4 - Fracassos de BI 13 3.1.5 - Arquitetura de BI 14
3.2 - Propriedades de BI 15 3.2.1 - Data Warehouse 15 3.2.2 - Data Marts 15 3.2.3 – Metadados 16 3.2.4 – ETL 17 3.2.5 - Cubos de dados 17 3.2.6 – OLAP 18 3.2.6.1 - Arquiteturas OLAP 19 3.2.6.2 - Elementos OLAP 20 3.2.7 – Dashboards 21 3.2.8 - Data Mining 21 3.2.9 - GEO/GIS 22 3.2.10 – KPIs 23 3.2.11 - Importação e Exportação de dados 23 3.2.12 – OLTP 23 3.2.13 – Relatórios 23
CAPÍTULO 4 – SOFTWARE OPEN SOURCE E PMES 25 4.1 - Vantagens do Software Open Source 26 4.2 - Desvantagens do Software Open Source 27 4.3 - Onde encontrar Software Open Source? 27 4.4 – Descrição de PME 30
CAPÍTULO 5 - FERRAMENTAS BI OPEN SOURCE 33 5.1 - Suites BI Open Source 33
5.1.1 – JasperSoft 33 5.1.2 – OpenI 36 5.1.3 – Palo 38 5.1.4 – Pentaho 40 5.1.5 – SpagoBI 42 5.1.6 – Vanilla 45
5.2 – Comparação entre as ferramentas Suite BI Open Source 47

ii
5.3 - Outras Ferramentas BI 50 5.3.1 – Eclipse BIRT 50 5.3.2 – Mondrian 51 5.3.3 – Kettle 52 5.3.4 – Jpivot 53 5.3.5 – Weka 53 5.3.6 - RapidMiner 54
CAPÍTULO 6 - AVALIAÇÃO PRÁTICA DAS FERRAMENTAS 57 6.1. – Instalação de requisitos comuns às quatro ferramentas 57 6.2 – Instalação de JasperSoft 59 6.3 – Instalação de Pentaho 60 6.4 – Instalação de SpagoBI 62 6.5 – Instalação de Vanilla 63 6.6 - Avaliação técnica das ferramentas 64 6.6 - Conclusão da avaliação 69
CAPÍTULO 7 - IMPLEMENTAÇÃO NUMA PME 71 7.1 - Instalação de Pentaho em Windows 71 7.2 - Construção da Data Warehouse 73
7.2.1 - Descrição do negócio 82 7.2.2 - Objectivo 82 7.2.3 - Desafio 82 7.2.4 - Estratégia 82 7.2.5 - Questões às quais a DW deve conseguir responder 82 7.2.6 - Granularidade 83 7.2.7 - Identificação de estrelas e dimensões 83 7.2.8 - Tabela de factos Factos_Energy 86 7.2.9 - Dimensão Park 86 7.2.10 - Dimensão Element 87 7.2.11 - Dimensão Time 87 7.2.12 - Tabela de factos Factos_Average 87 7.2.13 - Dimensão Incident 88 7.2.14 - Dimensão Responsability 89 7.2.15 - Gerar código MySQL para a construção da DW 89
7.3 - Processo de ETL 89 7.3.1 - Dimensão Park 90 7.3.2 - Dimensão Element 94 7.3.3 - Dimensão Responsability 97 7.3.4 - Dimensão Incident 99 7.3.5 - Dimensão Time 102 7.3.6 Tabela de factos Factos_Energy 103

iii
7.3.7 - Tabela de factos Factos_Average 106 7.4 - Construção de cubos OLAP 109
7.4.1 - Linguagem MDX 109 7.4.2 - PAT Analysis Tool 110
7.4.2.1 - Instalação de PAT Plugin 0.8 no Pentaho CE 3.8 111 7.4.2.2 - Criação de análises com PAT Analysis 111 7.4.2.3 - Exemplos práticos do projeto utilizando PAT Analysis 112
7.4.3 - Saiku 115 7.4.3.1 Instalação de Saiku 2.0 no Pentaho BI Server CE 3.8 115 7.4.3.2 - Exemplos práticos do projeto utilizando Saiku 115
7.4.4 - Pentaho Mondrian 117 7.5 - Criação de dashboards 119
7.5.1 - Instalação CDF-DE 120 7.6 - Criação de relatórios 125
CAPÍTULO 8 - CONCLUSÕES E TRABALHO FUTURO 131 REFERÊNCIAS 135 ANEXOS - A Open Source Business Intelligence tools for SMEs 139 ANEXOS - B Commercial or open source business intelligence tools? 147 ANEXOS - C Open Source CRM Systems for SMEs 153 ANEXOS - D
Top Busines Intelligence Software for Small and Medium Enterprises 167 ANEXOS - E Better Decisions With Open Source Business Intelligence Tools 171

iv
ÍNDICE DE FIGURAS Figura 3.1. Ilustração da pirâmide de processos de Business Intelligence 10 Figura 3.2. Arquitetura de processos de Business Intelligence 14 Figura 3.3. Cubo tridimensional com o total de vendas 18 Figura 4.1. Gráfico da percentagem dos tipos de empresas a nível Mundial 30 Figura 5.1. Arquitectura JasperSoft 36 Figura 5.2. Relatório JasperSoft 36 Figura 5.3. Arquitectura da aplicação OpenI 37 Figura 5.4. Elementos gráficos OpenI 38 Figura 5.5. Ambiente Microsoft Excel composto do separador Palo 39 Figura 5.6. Conjunto de funcionalidades Pentaho 41 Figura 5.7. Ilustração de funcionalidades GEO de Pentaho 42 Figura 5.8. Conjunto de funcionalidades SpagoBI 43 Figura 5.9. Painel de visualização SpagoBI 45 Figura 5.10. Painel de visualização Vanilla 46 Figura 5.11. Painel de visualização Vanilla 46 Figura 5.12. Versão de Vanilla a correr em dispositivos móveis 47 Figura 5.13. Ambiente de trabalho Eclipse BIRT 51 Figura 5.14. Ambiente de trabalho Mondrian 52 Figura 5.15. Ambiente de trabalho Pentaho Data Integration (PDI) 52 Figura 5.16. Representação de um cubo de dados e respetivo gráfico em JPivot 53 Figura 5.17. Ilustração de um exemplo de uma análise Weka 54 Figura 5.18. Análise de Data Mining 55 Figura 6.1. Percentagem de referências encontradas, relativamente a cada ferramenta 70 Figura 7.1. Configuração da variável JAVA_HOME 72 Figura 7.2. Configuração da variável JRE_HOME 72 Figura 7.3. Servidor Pentaho BI CE 3.8 instalado com sucesso 73 Figura 7.4. Opção de Reverse Engineer 74 Figura 7.5. Escolha do tipo de base de dados a converter 75 Figura 7.6. Selecção do script SQL da base de dados 76 Figura 7.7. Progresso da ação de Reverse Engineer 76 Figura 7.8. Modelo físico da base de dados 77 Figura 7.9. Opção de Seleção de tipo de base de dados actual e futuro 78 Figura 7.10. Seleção do tipo da nova base de dados 78 Figura 7.11. Seleção da opção para gerar a nova base de dados 79 Figura 7.12. Escolha de diretório e nome do ficheiro 79 Figura 7.13. Ficheiro gerado 80 Figura 7.14. Script base dados em Bloco de Notas 80 Figura 7.15. Ambiente de trabalho da ferramenta HeidiSQL 6.0 81

v
Figura 7.16. Modelo concetual da DW 84 Figura 7.17. Modelo físico da DW 85 Figura 7.18. Tabela de factos “Factos_Energy” 86 Figura 7.19. Dimensão Park 86 Figura 7.20. Dimensão Element 87 Figura 7.21. Dimensão Time 87 Figura 7.22. Tabela de factos, Factos_Average 88 Figura 7.23. Dimensão Incident 88 Figura 7.24. Dimensão Responsability 73 Figura 7.25. Esquema de ETL de carregamento da dimensão Park 90 Figura 7.26. Ilustração do elemento tMap_1 92 Figura 7.27. Constituição da dimensão Park da DW. 92 Figura 7.28. Ilustração dos dados visíveis através do visualizador de dados 93 Figura 7.29. Ficheiro Excel gerado pelo processo de ETL 93 Figura 7.30. Esquema do processo ETL da dimensão Element 94 Figura 7.31. Representação do elemento tMap_1 96 Figura 7.32. Dimensão Element 96 Figura 7.33. Processo de ETL para a dimensão responsability 97 Figura 7.34. Representação do elemento tMap_1 do processo de ETL 98 Figura 7.35. Dimensão Responsability 99 Figura 7.36. Modelo de ETL da dimensão Incident 99 Figura 7.37. Representação do elemento tMap_1 100 Figura 7.38. Definição de uma expressão para obter o valor da duração de tempo 101 Figura 7.39. Dimensão Incident 101 Figura 7.40. Processo de ETL da tabela de factos factos_energy 103 Figura 7.41. Representação do elemento tMap_2 105 Figura 7.42. Ilustração do elemento tMap_1 106 Figura 7.43. Tabela de factos “factos_energy” 106 Figura 7.44. Processo de ETL da tabela de factos factos_average 107 Figura 7.45. Representação do elemento tMap_2 107 Figura 7.46. Representação do elemento tMap_1 108 Figura 7.47. Tabela de factos factos_average 108 Figura 7.48. Visualização dos dados com o elemento tLogRow_1 109 Figura 7.49. Ícones do ambiente de trabalho de Pentaho 111 Figura 7.50. Ambiente de trabalho PAT Analysis 112 Figura 7.51. Cubo de dados por dia por hora 113 Figura 7.52. Valores de radiação solar por dia por hora 114 Figura 7.53. Quantidade de incidentes por estado 114 Figura 7.54. Ícone Saiku no ambiente de trabalho de Pentaho 115 Figura 7.55. Ambiente de trabalho Saiku 116

vi
Figura 7.56. Ícone New Analysis View no ambiente de trabalho de Pentaho 117 Figura 7.57. Janela para seleção de cubo de dados 118 Figura 7.58. representação OLAP com a ferramenta do servidor 3.8 118 Figura 7.59. Ambiente de trabalho Pentaho atualizado com a nova funcionalidade
CDE 121 Figura 7.60. Ambiente de trabalho de CDE. 121 Figura 7.61. Seleção de um Template existente disponível no plugin. 122 Figura 7.62. Separador Components 123 Figura 7.63. Representação do separador Data Sources. 123 Figura 7.64. Dashboards do caso prático. 124 Figura 7.65. Primeiro passo para a contrução de um relatório de dados 126 Figura 7.66. Segundo passo para a criação de um relatório 126 Figura 7.67. Terceiro passo para a criação de um relatório de dados. 127 Figura 7.68. Quarto passo para a criação de um relatório 128 Figura 7.69. Ilustração do relatório produzido no formato de HTML. 128 Figura 7.70. Ilustração do relatório produzido no formato PDF. 129

vii
ÍNDICE DE TABELAS Tabela 3.1. Demonstração elementos OLAP 19 Tabela 4.1. Características das PME 30 Tabela 5.1 Comparação de funcionalidades 47 Tabela 5.2. Comparação das ferramentas quanto à linguagem de programação
de desenvolvimento 48 Tabela 5.3. Tipo de sistemas operativos que suportam as ferramentas 48 Tabela 5.4. Comparação das ferramentas relativamente às suas versões disponíveis 49 Tabela 5.5. Informações relevantes de cada uma das ferramentas 49 Tabela 6.1. Avaliação das funcionalidades de BI e caraterísticas das ferramentas 64 Tabela 6.2. Distribuições e suporte 65 Tabela 6.3. Avaliação quanto aos tipos de base de dados suportados 65 Tabela 6.4. Funcionalidades OLAP 66 Tabela 6.5. Funcionalidades de Dashboards 67 Tabela 6.6. avaliação aos elementos de KPIs 67 Tabela 6.7. avaliação das caraterísticas dos relatórios 67 Tabela 6.8. Avaliação do portal quanto à internacionalização 68 Tabela 6.9. Classificação das ferramentas na escala de 1 a 5 68 Tabela 6.10. Classificação das ferramentas de 1 a 4 tendo em conta a preferência 69 Tabela 7.1. Arquitectura da DW a construir 83

CAPÍTULO 1
1
1. INTRODUÇÃO
Os graves problemas económicos que afetam atualmente a economia global, conduzem à instabilidade dos mercados. As tendências de oscilação da economia mundial são um entrave à inovação e ao desenvolvimento das empresas, face à incapacidade de investimento e à insegurança demonstrada relativamente à sua rentabilização. Os fatores condicionantes da estabilidade da economia obrigam todo o tecido empresarial a fazer esforços de contenção na despesa e à redução dos custos da atividade. Focando a nossa visão sobre o continente europeu, somos constantemente confrontados com informações que nos revelam o atual estado caótico da economia europeia. O crescimento económico caminha de mãos dadas com a produção e as exportações, na ausência destes dois fatores não existe crescimento económico.
Face aos elevados custos de produção, resultantes da atividade laboral diária das empresas, e face às várias medidas de austeridade que vigoram em alguns países da união europeia, torna-se difícil para as empresas produzirem em larga escala e a preços que permitam competir com os preços apresentados pelos produtos comercializados pelos mercados externos e pelas grandes empresas. A incapacidade de investimento por parte das pequenas e médias empresas (PMEs) na otimização dos seus processos de negócio, representa um grave problema. A produção em larga escala muitas vezes contrapõe-se com a necessidade de investir e inovar nos métodos de trabalho e de produção, é a estes investimentos que na generalidade as empresas não se expõem, faltando-lhes a capacidade para investir, otimizar e rentabilizar o seu negócio. Os fatores de fixação no mercado das PMEs bem como a sua rentabilidade, estão diretamente relacionados com a sua capacidade de produção em larga escala, e com a sua capacidade de resposta.
As grandes empresas de um modo geral não têm problemas de inovar e investir porque normalmente têm capacidade económica para o fazerem, mas, representam uma percentagem reduzida de todo o conjunto empresarial.
O contexto do nosso trabalho são as PMEs, focando-nos nas dificuldades apresentadas pelas PMEs em fixarem-se de forma sólida no mercado e em competir com as grandes empresas. Com isto, o nosso trabalho tem como principal objetivo apresentar soluções viáveis para PMEs, que representam 99,9 % do número total de empresas portuguesas, 98% da totalidade das empresas da União Europeia (UE a 27) (ECEI, 2010/2011) e mais de 98% das empresas à escala mundial (Global Alliance of SMEs, 2010). Atendendo a estes números é fácil perceber a importância das PMEs e qual o nosso interesse de solucionar medidas de rentabilidade e crescimento, tendo em conta alguns fatores

CAPÍTULO 1
2
especiais como a incapacidade destas empresas em investir, diminuir os custos resultantes da sua atividade de produção e aumentar os seus lucros.
Neste contexto pretendemos solucionar parte das dificuldades de otimização e melhoria dos processos de negócio das empresas. Para isto, sugerimos a adoção de práticas e ferramentas de Business Intelligence (BI). O conceito de BI não é novo, mas só nos últimos anos tem conhecido uma maior divulgação e aceitação junto das empresas. O recurso a práticas de BI subentende que existam dados provenientes da atividade empresarial, que se possam processar de forma a obter informação e conhecimento capazes de suportar o apoio a tomada de decisão por parte de gestores e analistas de negócio. Os dados resultantes da atividade empresarial são a matéria-prima de processos e ferramentas de BI. As ferramentas de BI têm como principal objetico o cruzamento dos dados da atividade económica e exibindo-os de forma gráfica. O recurso a ferramentas BI permite através do cruzamento de dados extrair informações relevantes (p.ex: no sector das energias renováveis, identificar qual a localização do parque eólico que produz mais energia), identificar problemas no processo de negócio (p.ex: identificar qual a marca de motores das torres eólicas que apresentam maior taxa de indisponibilidade), estes dois exemplos permitem gestores e analistas de negócio tomar decisões (p.ex: reforçar os parques que produzem mais; adquirir motores das marcas que apresentam maior taxa de atividade).
Tendo em conta o custo das ferramentas de BI comerciais, dificilmente suportados por PMEs, focaremos a nossa investigação essencialmente em ferramentas open source. As ferramentas open source são desenvolvidas por comunidades de programadores sem fins lucrativos, que se dedicam à produção de software seguindo um conjunto de regras estabelecidas pela OSI (Open Source Iniciative), de entre as quais a disponibilização de software de forma gratuita. A disponibilização do código para a comunidade por parte das comunidades de desenvolvimento open source permite solucionar em parte a capacidade de investimento por parte das PMEs. Apesar do foco do nosso trabalho ser essencialmente a divulgação de ferramentas de BI open source, existe no mercado inúmeras ferramentas que apresentam uma alternativa de qualidade às ferramentas comerciais (p.ex: Mozilla Firefox, MySQL, PHP, Open Office).
Após a investigação e a análise às ferramentas de BI open source existentes no mercado, iremos analisar e comparar um conjunto de ferramentas elegendo as melhores, mediante um plano de avaliação. Para justificarmos que as ferramentas de BI open source são viáveis iremos proceder à demonstração prática da utilização de uma ferramenta, Pentaho, num projeto empresarial de âmbito real. A nossa demonstração prática detalha todos os passos da implementação de uma ferramenta de BI, tais como: a construção de uma Data
Warehouse (DW); especificação de processos de ETL (Extract, Transform, Load); criação de cubos de dados OLAP (On-Line Analytical Processing); criação de dashboards; criação de relatórios de dados.

CAPÍTULO 1
3
A demonstração prática do nosso trabalho tem por base sustentar a nossa conclusão, de que as ferramentas de BI open source apresentam uma solução claramente viável e que permite a inovação, desenvolvimento e otimização dos processos de negócio das empresas. Se por um lado a aquisição de software BI open source não implica custos, a sua implementação e utilização podem significar alguns custos para as empresas, tendo em conta que as ferramentas requerem utilizadores que possuam conhecimentos base de informática, especialmente nas áreas de base de dados, Data Warehousing, ETL e OLAP. As comunidades de desenvolvimento de ferramentas BI open source ao longo dos últimos anos têm tentado acompanhar os desenvolvimentos das ferramentas comerciais. Destacamos que um dos maiores desenvolvimentos está relacionado com o aumento da facilidade de interação com o utilizador. As versões mais recentes apresentam uma interação com o utilizador mais amigável, incluindo funcionalidades de drag and drop em alguns processos. Face a este desenvolvimento reconhecido, prevemos que num curto período de tempo as ferramentas de BI open source, se tornem ainda mais fáceis de utilizar e estejam acessíveis a qualquer utilizador sem conhecimentos base de informática.
1.1. Principais Contribuições deste trabalho
O principal objetivo do nosso trabalho é contribuir para o avanço da ciência e do conhecimento. Neste contexto, identificámos um problema, a necessidade de rentabilizar e otimizar o processo de negócio das PMEs. Identificado o problema vamos tentar. De um modo geral as nossas principais contribuições do nosso trabalho são:
• Solucionar a redução de custos da atividade normal das PMEs.
• Identificar um problema que apresenta facilidade de retorno sobre o investimento.
• A divulgação da importância do conceito de BI.
• Divulgação de ferramentas open source como uma solução viável para o problema.
• A demonstração prática da utilização de ferramentas open source e consequentes avaliações.
• Comparação prática de várias ferramentas BI, e consequente avaliação.
• Apresentar um conjunto de elementos que suporte a escolha de ferramentas open source como uma opção de redução de custos.
• Ajudar na decisão do processo de aquisição.
• Apoiar os processos de implementação e desenvolvimento.
• Mostrar que as ferramentas BI open source são claramente uma solução alternativa às ferramentas comerciais.
De um modo geral são estas as contribuições que pretendemos acrescentar com o desenvolvimento desta investigação.

CAPÍTULO 1
4
1.2. Estrutura do relatório
Este trabalho encontra-se estruturado em oito capítulos. O capítulo atual, é o capítulo introdutório no qual procurámos descrever o problema, e apresentar a nossa solução para a resolução do mesmo.
O capítulo 2, estado da arte, tem como por base a divulgação de outros trabalhos desenvolvidos na área e que de certa forma suportaram (através da sua informação) e incentivaram o desenvolvimento do nosso trabalho, pretendendo dar a conhecer outros trabalhos relacionados.
O capítulo 3 apresenta uma descrição detalhada sobre o conceito de Business Intelligence e todas as suas propriedades. É feita ainda referência aos benefícios e objetivos da utilização de BI, vantagens, desvantagens e fracassos.
O capítulo 4 apresenta uma descrição base sobre software open source e sobre PMEs, que são o foco do nosso trabalho. Neste capítulo são apresentadas vantagens e desvantagens do software open source e ainda referência aos repositórios Web onde é possível adquirir software open source.
O capítulo 5 apresenta um estado da arte relativamente aos pacotes de soluções de BI open source, comparação das ferramentas e ainda uma secção de ferramentas auxiliares, especificas para determinados processos.
No capítulo 6 procede-se à descrição dos processos de instalação dos quatro melhores pacotes de ferramentas, consequente avaliação técnica e uma conclusão da avaliação da qual resulta a eleição da melhor ferramenta BI open source que será utilizada para implementação no caso prático.
O capítulo 7 apresenta todos os passos de implementação prática de uma ferramenta de BI open source numa PME. Este é o capítulo mais extenso e que descreve em detalhe a construção de uma DW, a implementação de processos de ETL, a construção de cubos de dados OLAP, a criação de relatórios e a utilização de plugins para os processos de criação de cubos de dados e dashboards.
Por fim, o capitulo 8, apresenta as conclusões a nível prático e teórico de todo o desenvolvimento do nosso trabalho.
De referir ainda a existência do capítulo 9 de referências e em anexo um conjunto de cinco artigos científicos desenvolvidos e publicados no âmbito do nosso trabalho de investigação.

CAPÍTULO 2
5
2. ESTADO DA ARTE
O trabalho desenvolvido em torno da área da nossa investigação é um pouco escasso, existindo poucas referências bibliográficas no contexto da nossa investigação.
Ainda assim destacamos alguns trabalhos nesta área de investigação. Num trabalho de investigação, Christian Thomsen e Torben Pedersen identificaram que se notava um aumento de empresas a procurarem soluções de BI open source, mas que a confiança sobre este tipo de ferramentas estava um pouco aquém, quando comparada com a aceitação registada em torno de ferramentas open source de outras áreas (Thomsen & Pedersen, 2008). A sua investigação procurou classificar as soluções de BI existentes no mercado, avaliando os seus aspetos técnicos e a mais-valia que estas representam. Nesta investigação foram comparadas dez ferramentas de ETL, seis sistemas de gestão de bases de dados (SGBD), dois servidores OLAP e sete ferramentas cliente OLAP.
Os mesmos autores desenvolveram uma investigação semelhante no ano 2005 e procuraram comparar a evolução das ferramentas durante esse período de tempo. Relativamente ao tipo de ferramentas em análise os autores definem os SGBDs como as ferramentas open source mais desenvolvidas e que maior número de funcionalidades adquiriram durante aquele período de tempo. Relativamente às ferramentas de ETL identificam a existência de uma evolução clara nas suas funcionalidades. Relativamente aos servidores OLAP identificam Mondrian como melhor ferramenta disponível, quanto às ferramentas cliente OLAP defendem que existe várias ferramentas no mercado ainda que se apresentem pouco desenvolvidas.
Numa publicação da Pentaho (Pentaho, 2008), a comunidade alerta para o facto de as empresas estarem a procurar a aquisição de ferramentas BI como solução para a rentabilização dos seus processos de negócio sem a certeza de se as ferramentas que estão a adquirir são as mais indicadas para os seus processos de negócio. O problema identificado pela comunidade é que, gestores de negócio se deixam levar pelas campanhas de marketing por parte das empresas que produzem ferramentas BI, sem avaliar se as caraterísticas das ferramentas suportam as suas necessidades, ação que muitas vezes se traduz em maus investimentos. Desta forma, Pentaho tenta alertar os mercados para o facto das soluções open source terem como vantagem o facto de poderem ser alteradas à medida do negócio e por outro lado a facilidade de mudar de ferramenta sempre que se justifique, sem que isso traduza perdas excessivas.
Por sua vez, Matteo Golfarelli desenvolveu uma investigação (Golfarelli, 2009), que identificou a desconfiança dos mercados perante a potencialidade das soluções de BI open
source como alternativa às ferramentas comerciais. O objetivo da sua investigação era avaliar quais as potencialidades das ferramentas de BI open source e quais os limites da sua adoção em projetos reais. Golfarelli procurou desta forma avaliar se o contexto de

CAPÍTULO 2
6
software open source representaria uma alternativa válida às plataformas comerciais na área de BI. Para fundamentar a sua investigação recorreu à análise de três pacotes de soluções de BI open source, sendo eles: JasperSoft, Pentaho e SpagoBI (versões disponíveis até dezembro de 2008). Golfarelli na sua investigação não procurou medir resultados de eficiência mas procurar uma resposta para o seu problema relativamente à viabilidade da sua aplicação em ambientes reais. As conclusões a que chegou foi que o principal defeito das soluções de BI open source é a ausência de uma camada de Metadados. Da comparação entre as ferramentas concluiu que face à versão comercial a versão open source de Pentaho poderia ser mais abrangente e que a versão SpagoBI open
source é idêntica à versão comercial das ferramentas Pentaho e SpagoBI. Num outro tipo de análise referiu que PMEs procuram cada vez mais a aquisição de software deste tipo para colmatar despesas. Identifica ainda que a prematuridade, permanência no mercado e evolução levantam dúvidas no mercado, defendendo que um 20 anos de conhecimento nesta área e a experiência poderão fazer a diferença no futuro.
Em (JasperSoft, 2009) é descrita uma análise interessante, sustentada por um estudo (Ventana Research, 2006) que concluiu que 48% dos inquiridos esperam que a implementação de ferramentas open source BI signifiquem um corte de 50% nas despesas, quando comparada com o custo das ferramentas comerciais. O mesmo estudo refere ainda que 25% dos inquiridos estimam que os custos dispendidos com os dois tipos de software sejam equivalentes. O estudo (JasperSoft, 2009) procura apresentar resultados relativamente aos custos ocultos da implementação de ferramentas de BI open source e comparar com os custos das ferramentas comerciais, verificando se as ferramentas open
source são uma alternativa viável. Deste estudo o autor conclui que a implementação de do conceito BI tem significado um grande investimento de alto retorno, considerando que os preços de software das versões comerciais se têm tornado um entrave para aquisição por parte das empresas. O autor conclui ainda que a implementação de ferramentas de BI open source em empresas constituídas por equipas ágeis e com conhecimentos poderão significar pouco investimento e um maior retorno sobre o investimento. A distribuição do código permite a empresas com conhecimentos na área de informática adaptarem o software tendo em conta as necessidades das empresas, construindo desta forma uma solução viável e funcional sem grandes investimentos.
No mesmo contexto, destacamos também (Damiani et al., 2009) que identificaram a ausência de documentação relativamente ao conjunto de soluções de BI no mercado, destacando que o trabalho de investigação existente na área se prendia com comparações das funcionalidades das ferramentas. Posto isto, os autores apresentam uma visão geral sobre as diversas ferramentas e frameworks relacionadas com a área de BI, descrevendo um caso prático, modelos de custo e o seu risco de adoção. No âmbito da sua investigação os autores referem que um dos principais problemas das versões comerciais para o cliente, prende-se com o facto de antes do cliente obter resultados já efetuou gastos dispendiosos com a aplicação, enquanto que ao implementar soluções open source pode

CAPÍTULO 2
7
controlar o seu investimento à medida que vai obtendo resultados. Os autores concluem que os fatores de risco relacionados com a implementação de soluções de BI open source, são o facto de não conterem trabalhadores com conhecimentos de informática na sua estrutura empresarial e o receio de que os projetos sejam desapoiados/abandonados.
É importante perceber quais os valores que pretendemos poupar na implementação de ferramentas open source que possam substituir ferramentas comerciais, em (Ferreita et al., 2010) é efetuada uma análise comparativa entre as principais ferramentas comerciais e open source mediante vários critérios, de entre os quais o valor dos custos de aquisição entre uma das principais ferramentas comercial, Microsoft e a ferramenta gratuita Pentaho. Segundo esse estudo, os custos com a ferramenta comercial rondam os 25.000 reais o que equivale a cerca de 10.000 euros. Uma quantia que pesa no orçamento de qualquer PME. A estes custos acrescem o valor das licenças anualmente, e uma restrição ao número de utilizadores.
O nosso trabalho de investigação foca-se essencialmente nas ferramentas de BI open
source, tendo em conta que a sua aquisição não implica custos. Os custos das ferramentas comerciais são bastante elevados, muitas vezes inflacionados pelos custos das licenças e renovação das mesmas dentro de um período de tempo. Face à fraca capacidade de investimento por parte das PMEs, neste tipo de ferramentas pretendemos solucionar o nosso problema com ferramentas gratuitas. Neste contexto existe algum trabalho já desenvolvido, ainda que se considere escasso. Já existe algum trabalho realizado relacionado com o estado da arte de ferramentas de BI open source e comparação das funcionalidades disponibilizadas pelas diversas ferramentas. Relativamente à comparação de custos da aplicação de ferramentas comerciais e ferramentas open source a informação é mais escassa. Quanto a informação relacionada com a comparação dos custos das ferramentas BI comerciais também não existe muita informação.

8

CAPÍTULO 3
9
3. BUSINESS INTELLIGENCE
No âmbito do nosso trabalho, pretendemos investigar de forma aprofundada o conceito de Business Intelligence (BI). Para melhor compreendermos o conceito de BI, iremos apresentar a sua definição, os seus benefícios e objetivos, as suas vantagens e desvantagens, os seus fracassos e a sua arquitetura. Numa segunda fase, descrevemos as propriedades e conceitos relacionados com a área de BI. Neste capítulo pretendemos apresentar a definição de todos os conceitos relacionados com o termo de BI de modo a facilitar a compreensão dos capítulos seguintes.
3.1. Descrição do conceito de Business Intelligence
O conceito de Business Intelligence foi definido em 1989 por Howard Dresner como: “concepts and methods to improve business decision making by using fact-based support systems” (Power, 2007), ou seja, conjunto de conceitos e métodos que pretendem melhorar a atividade de tomada de decisão de negócio por parte de gestores e analistas, apoiadas pelos sistemas de suporte à decisão. O conceito BI não tem a finalidade de decidir, apenas tem o objetivo de reunir elementos visuais capazes de suportar a tomada de decisões por parte de gestores e analistas de negócio. Como podemos constatar o conceito de BI não é recente, a sua definição surgiu há mais de duas décadas ainda assim, possui atualmente um maior reconhecimento, sendo classificado como um conceito de topo atualmente. O facto de o conceito não ser novo mas só ter atingido recentemente o reconhecimento das suas potencialidades, pode ser justificado com o facto da adoção tardia de sistemas de informação (SI), por parte das empresas (Varajão et al. 2011). Os sistemas de informação ganharam um relevo enorme na atividade das empresas, passando a ser essencial a sua utilização nas atividades laborais. Os sistemas de informação permitem auxiliar a atividade das empresas, através do registo de dados. Os dados registados e guardados num sistema de gestão de base de dados permitem gerar informação, é esta informação que permite após ser trabalhada, gerar métricas para a otimização do negócio. Foi com base na necessidade de implementar processos de análise de informação e a partir dela extrair conhecimento que nasceu o termo BI. O conceito de BI é mais vantajoso quanto maior for a quantidade de dados relacionados com a atividade empresarial disponíveis. Uma empresa que não possua dados da sua atividade de negócio não possui elementos que sustentem a instalação de ferramentas de BI.
Os dados são a matéria-prima das ferramentas de BI, quando agrupados originam informação. Por sua vez, um conjunto de informação origina conhecimento. É através do conhecimento extraído dos dados que se torna possível otimizar processos e métodos de trabalho.
As ferramentas BI existem para apoiar gestores e analistas de negócio. As ferramentas BI simplesmente ilustram o cruzamento de dados, não tomam decisões por si, apenas reúnem

CAPÍTULO 3
10
elementos capazes de suportar a tomada de decisão de gestores e analistas de negócio. A análise da informação proveniente dos aglomerados de dados permite aos analistas de negócio extraírem conhecimentos e por conseguinte: estabelecerem métricas e estratégias de negócio, estimar e prever oscilações de mercado e apoiar a tomada de decisão.
A Figura 3.1 ajuda a ilustrar o processo de BI, representado por uma pirâmide, em que o conjunto de dados representados na base da pirâmide suporta o conjunto de informações. Por sua vez, a informação sustenta o topo da pirâmide, que coincide com o processo de tomada de decisão.
Figura 3.1. Ilustração da pirâmide de processos de Business Intelligence
Uma ferramenta de BI deve apresentar funcionalidades que permitam:
• Obter e modelar dados provenientes de sistemas de gestão de base de dados (SGBDs);
• Extrair, transformar, efetuar limpeza e carregamento de dados;
• Visualizar análises de dados;
• Mostrar dados em forma de dashboards;
• Implementação de processos de Data Mining;
• Criação de relatórios de dados.
3.1.1. Benefícios e objetivos
O principal objetivo de um sistema de BI é promover o cruzamento de dados e facilitar a tomada de decisão. Os principais objetivos e benefícios da utilização de BI são (Rodrigues, 2006):
• Antecipar alterações de mercados;
• Antecipar ações dos competidores diretos;
• Descobrir novos ou potenciais agentes competidores;
• Aprender com os sucessos e falhas dos outros
• Conhecer melhor as capacidades próprias
Decisão
Informação
Dados

CAPÍTULO 3
11
• Conhecer novos conceitos e metodologias que causem impacto na atividade de negócio
• Conquistar novos mercados
• Avaliar e rever os processos de negócio
• Auxiliar na implementação de novas práticas de negócio
3.1.2. Vantagens
À medida que o conhecimento avança vão se verificando novos progressos, baseados na melhoria de práticas e costumes. O desenvolvimento de novas práticas e de novos conceitos, coincide com a necessidade de descobrir e desenvolver novas estratégias que facilitem e melhorem os processos existentes. Deste modo, o conceito de BI surge no âmbito de acrescentar vantagens aos métodos inicialmente existentes. Para melhor classificar as capacidades das ferramentas de BI, passamos a enumerar as vantagens da sua implementação, nas empresas e organizações (Rodrigues, 2006).
• Aumento da qualidade no planeamento operacional e estratégico: o conhecimento extraído dos resultados obtidos permite um planeamento mais sustentado.
• Agilização do processo de tomada de decisão: a monitorização dos dados através de representações gráficas torna os processos de tomada de decisão mais simples e menos morosos.
• Diminuição dos custos da atividade empresarial: cortes na atividade administrativa.
• Maior credibilidade na previsão de mudança de ações.
• Aumento da credibilidade sobre as ações e sobre a qualidade dos produtos.
• Aumento da competitividade: a redução dos custos da atividade empresarial conduz a um aumento da competitividade.
• Maior rentabilidade: a identificação de problemas e de fatores de sucesso permite rentabilizar os processos de negócio.
• Redução de custos operacionais: a implementação de ferramentas de BI permite diminuir gastos com agentes de decisão.
• Ampliação da carteira de clientes: o agrupamento de dados relativos aos clientes, permite traçar um perfil e conhecer as necessidades do cliente, ajudando a definir estratégias capazes de amealhar maior número de clientes.
• Aumento da lealdade dos clientes: a possibilidade de traçar um perfil dos clientes da empresa ajuda a identificar os grupos de clientes que maiores garantias de lealdade oferecem.
• Retorno sobre o investimento (ROI) mais rápido em projetos BI: a redução dos gastos com analistas de negócio e gestores, bem como a rentabilidade oferecida pela implementação de soluções de BI, acelera a recuperação do investimento.
• Maior controlo e menor percentagem de erro: fruto da segurança coordenada, com acesso restrito a dados mediante cada tipo de utilizador; garantia de qualidade da

CAPÍTULO 3
12
informação; cruzamento de dados diversos, provenientes de sistemas de informação (SI) e fontes de dados diversas.
• Partilha de informação entre grupos distintos: a monitorização dos problemas dos diferentes setores empresariais, numa única ferramenta facilita a partilha de informação.
• Melhor interação com os utilizadores: é possível obter respostas/análises em tempo real e proceder à realização de análises de setores de negócio distintos na mesma ferramenta.
• Informação on-line: possibilidade de decidir em qualquer lugar e a qualquer hora.
3.1.3. Desvantagens
Do conceito de Business Intelligence não advêm só vantagens, também existem algumas desvantagens resultantes da implementação de ferramentas de BI. De entre as desvantagens enumeramos:
• Custo: a aquisição de ferramentas BI tem um custo elevado, as ferramentas proprietárias são dispendiosas e as ferramentas open source não dispensam conhecimentos e formação base para a sua utilização; os sistemas que oferecem suporte a este tipo de ferramentas necessitam de hardware com boa capacidade de processamento e resposta. O processamento de grandes quantidades de dados pode representar um congestionamento das redes internas.
• Suporte: a utilização deste tipo de ferramentas requer algum conhecimento base, alguma documentação de suporte e/ou formação; aspetos relacionados com o suporte aos sistemas muitas vezes também representam uma desvantagem, tendo em conta que este tipo de ferramentas requer sistemas com uma boa capacidade de processamento.
• ROI: o retorno sobre o investimento pode levar algum tempo, tudo depende do volume de negócio e dos gastos dispendidos com a obtenção, configuração e assistência.
• Uso limitado: de um modo geral este tipo de soluções, nomeadamente as proprietárias, possui licenças restritas a um número de utilizadores ou computadores.
• Complexidade: a utilização de ferramentas de BI requer pessoas com conhecimentos básicos na área de informática para a sua utilização.
• Implementação morosa: o processo de construção de uma Data Warehouse, implementação de processos ETL (Extract, Transform, Load), construção de cubos de dados OLAP (On-line Analytical Processing) e posteriormente a construção de dashboards é um processo moroso.
• Acumulação de dados históricos: o conceito é mais viável quão maior for a quantidade de dados e o intervalo de tempo da sua recolha, isto representa um

CAPÍTULO 3
13
enorme avolumado de dados, que requer uma grande capacidade de processamento.
• A adoção deste tipo de ferramentas por parte das empresas e organizações ainda não atingiu a maioridade: tendo em conta fatores como o custo e a capacidade de investimento por parte das empresas.
• Fracassos de BI (descritos na secção seguinte).
3.1.4. Fracassos de BI
Com base num estudo desenvolvido pela Information Builders (empresa de desenvolvimento de soluções BI proprietárias), é possível verificar que o interesse pela adoção de ferramentas BI aumentou, mas que nem sempre a adoção de ferramentas BI é sinónimo de sucesso. Segundo esse estudo existe um enorme número de projetos BI que terminam em fracasso. No mesmo estudo são identificadas as principais razões que conduzem a esse fracasso (Pino, 2011).
Das dez razões expressas temos como principais responsáveis pelo fracasso:
• O processo de levantamento de requisitos pouco claro: é importante definir KPIs (Key Performace Indicators) de forma concisa e correta para que o processo de tomada de decisão seja o mais correto e coerente.
• Existência de dados incorretos ou incompletos: é vulgar a existência de dados desatualizados, incorretos ou inacessíveis. Este tipo de dados com pouca qualidade representa um problema nos projetos de BI.
• Envolvimento de utilizadores finais tardiamente: tal como noutros tipos de projetos é importante integrar utilizadores finais no desenvolvimento do projeto, de forma a precaver anomalias e tornar o projeto mais acessível e à medida do utilizador e dos seus processos normais de trabalho.
• Resultados finais num prazo médio de dois anos: nos casos em que o cliente não recebe versões provisórias do projeto para ir testando e avaliando o projeto, conhecendo apenas o projeto na sua parte final, pode representar um fracasso na abordagem e implementação de requisitos.
• Falta de gestão da mudança: é importante existir um grupo de pessoas responsável por acompanhar o desenvolvimento do projeto de modo a gerir atempadamente ajustes e mudanças. Da ausência de gestão de mudanças resultam custos adicionais e atrasos na entrega final do projeto.
• Cumprimento e segurança descuidados: muitas vezes as equipas de desenvolvimento não se preocupam com questões de segurança, este é um aspeto que deve ser tido em conta para sigilo de dados.
• Documentação pobre sobre o ambiente de trabalho da aplicação: é comum nas ferramentas de BI pouca documentação sobre a ferramenta que normalmente varia de versão para versão.

CAPÍTULO 3
14
• Recursos de hardware vezes é subestimada, resultando desse erro de cálculos
• Funcionários centrados no Excelutilizadores, tornandodo tempo, em que se familiarizaram
• Orçamentação inadequadainsatisfeitos.
3.1.5. Arquitetura de BI
Para uma melhor compreensão de todos os passos dos processos de BI vamos analisar a sua arquitetura. A Figura 3.
Figura 3.2. Arquitetura
A arquitetura de BI, ilustrada na Figura Passamos a descreve-los:
Passo 1 -
• Recolha de dados: os dados podem ser provenientes de bases de dadode informação diversos, ERP (Enterprise Resource planning), CRM (Customer Relationship Management)(normalmente ficheiros Excel e/ou CSV (Comma
Passo 2 -
• Processo de tratamenneste passo os dados são trabalhados, extraídos, transformados e carregados para uma DW, Data Marts ou necessidade de transformar dados para o
ardware estimados de forma incorreta: a capacidade necessária por vezes é subestimada, resultando desse erro de cálculos clientes insatisfeitos.
Funcionários centrados no Excel: a mudança de costumes é uma barreira para os utilizadores, tornando-se difícil abandonar hábitos que foram adquirindo ao longo
em que se familiarizaram com determinada aplicação.
ação inadequada: erros de orçamentação resultam sempre em clientes
3.1.5. Arquitetura de BI
Para uma melhor compreensão de todos os passos dos processos de BI vamos analisar a 3.2 ilustra a arquitetura de um processo de BI
Arquitetura de processos de Business Intelligence
, ilustrada na Figura 3.2, pode ser analisada em
: os dados podem ser provenientes de bases de dadode informação diversos, ERP (Enterprise Resource planning), CRM (Customer Relationship Management), ‘flat files’ ou de ficheiros de dados externos (normalmente ficheiros Excel e/ou CSV (Comma-Separated Values)).
Processo de tratamento de dados: processo de ETL (Extract, Transform, Load), neste passo os dados são trabalhados, extraídos, transformados e carregados para uma DW, Data Marts ou cubos de dados. Por vezes existe incoerência de dados ou necessidade de transformar dados para outro formato que não o original, este é o
: a capacidade necessária por clientes insatisfeitos.
a mudança de costumes é uma barreira para os se difícil abandonar hábitos que foram adquirindo ao longo
aplicação.
: erros de orçamentação resultam sempre em clientes
Para uma melhor compreensão de todos os passos dos processos de BI vamos analisar a o de BI.
Business Intelligence
pode ser analisada em cinco passos.
: os dados podem ser provenientes de bases de dados de sistemas de informação diversos, ERP (Enterprise Resource planning), CRM (Customer
ou de ficheiros de dados externos Separated Values)).
to de dados: processo de ETL (Extract, Transform, Load), neste passo os dados são trabalhados, extraídos, transformados e carregados para
. Por vezes existe incoerência de dados ou utro formato que não o original, este é o

CAPÍTULO 3
15
processo de ”Transformação”, (p. ex: transformar mês 1 em ‘janeiro’; Sim ou Não em ‘1’ e ‘0’ respetivamente, etc.).
Passo 3 -
• Carregamento de dados: após o passo 1 e 2, a última operação de ETL é o carregamento de dados, este carregamento de dados pode ser efetuado para DWs (Data Warehouses), Data Marts (DWs mais pequenas, normalmente associadas a um setor do negócio) e cubos de dados.
Passo 4 -
• Criação de elementos BI: após o carregamento dos dados é possível usufruir das várias funcionalidades das ferramentas de BI, nomeadamente, construção de relatórios, análises de Data Mining, consultas ad-hoc, consultas OLAP, criação de dashboards e análises geográficas.
Passo 5 -
• Monitorização e interação com o utilizador: o último passo é a apresentação de resultados ao utilizador, o utilizador tem a possibilidade de visualizar os resultados obtidos dos processos de cruzamento de dados e interagir com a ferramenta.
3.2. Propriedades de BI
Antes de avançarmos, e para percebermos melhor os conceitos presentes na Figura 3.2, que representa a arquitetura de BI, vamos conhecer melhor, de forma detalhada cada um dos elementos.
3.2.1. Data Warehouse
Data Warehouse é o termo que designa armazém de dados, na prática uma DW é um sistema de armazenamento de dados de grandes dimensões, desenvolvido para guardar grandes quantidades de dados de vários processos de negócio. A sua estrutura foi desenvolvida a pensar num acesso menos moroso aos dados, a sua arquitetura dispensa as normalizações conhecidas da arquitetura de bases de dados relacionais, aumentando o desempenho das consultas à base de dados. A estrutura de um Data Warehouse é constituída por dois tipos de elementos, tabelas de factos (guardam os valores resultantes da medição de negócio) e dimensões (elementos chave de um negócio ou de cada processo de negócio) (Wikipédia, Data Warehouse).
3.2.2. Data Marts
Os Data Marts são repositórios de dados que representam um subconjunto de dados de um Data warehouse. Habitualmente os Data Marts surgem associados a conceitos específicos ou processos de negócio próprios. Vendas, controlo de stocks, vendas

CAPÍTULO 3
16
semanais, são alguns exemplos do que é um Data Mart. Os Data Marts são atualmente estruturas bastante flexíveis, preferencialmente constituídas por dados atómicos.
3.2.3. Metadados
O conceito de metadados surgiu em 1969 e foi criado por Jack Myres (Pereira et al, 2005), designando os dados que descreviam registos de arquivos convencionais. Por outras palavras, metadados são dados utilizados para descrever outros dados, isto é, dados que guardam informação relativamente aos dados a que se referem.
Os metadados são utilizados como um dicionário de informação, neste contexto são metadados todas as informações relacionadas com (Wikipédia-Data Warehouse, 2011):
• Origem dos dados: informação que permite saber a proveniência dos dados.
• Fluxo de dados: os elementos de dados necessitam de ter identificado os fluxos nos quais sofrem transformações.
• Formato dos dados: todos os elementos possuem designação relativamente ao tipo e tamanho de dados.
• Nomes e ‘alias’: todos os elementos devem ser identificados por um nome. O nome pode ser da área de negócio ou um nome técnico, os alias também estão inseridos neste contexto.
• Definições de negócio: esta informação tem bastante importância, tendo em conta que especifica o tipo de negócio ou o processo de negócio.
• Regras de transformação: esta informação retrata as ações praticadas no processo de extração, transformação e limpeza dos dados.
• Atualização de dados: a referência temporal é importante para definir atualizações sobre os dados.
• Requisitos de teste: devem conter informação relativamente aos intervalos de valores corretos no preenchimento de dados.
• Indicadores de qualidade de dados: é possível integrar informação relativamente à qualidade dos dados, tendo em conta a sua origem e o número de processamentos efetuados sobre esse dado, por exemplo.
• Triggers automáticos: podem existir processos automáticos associados aos metadados definidos.
• Responsabilidade sobre a informação: deve ser identificado o responsável pelo registo dos dados e o responsável pelos processos de transformação sobre os mesmos.
• Acesso e segurança: restrição de utilizadores com acesso aos dados e informações relativamente à segurança são aspetos muito importantes.

CAPÍTULO 3
17
3.2.4. ETL
O conjunto de processos de ETL (Extract, Transform, Load) divide-se em três passos, Extração, Transformação e Carregamento. Este é um dos processos mais críticos de BI. No processo de extração é importante que se conheça a validade dos dados a fim de os transformar da melhor forma. O processo de transformação pode ser dispensável em alguns casos e bastante complexo noutros. No processo de transformação podem ocorrer diversos tipos de transformações, tais como (Kimball, 2008):
• Seleção de determinadas colunas de dados a carregar.
• Limpeza de dados (Transformação de “Masculino” da fonte de dados para “M” na Data Warehouse, por exemplo).
• Codificação de valores de forma livre (Transformar “Masculino” e “Sr.” Em “M”, por exemplo).
• Derivação de um novo valor calculado (Intervalo_tempo = data_final – data_inicial).
• Junção de dados, provenientes de fontes distintas.
• Resumo de várias linhas de dados (p. ex: a soma de totais de vendas por loja e por região).
• Gerar valores de chaves substitutas (Surrogate Keys).
• Transposição ou rotação (converter colunas em linhas e vice versa).
• Separação de uma coluna por várias colunas (p. ex: a separação de um campo data do tipo ‘aaaa-mm-dd’ em ‘aaaa’, ‘mm’ e ‘dd’).
Após a estruturação do modelo de ETL, procede-se ao último passo, que retrata o processo de carregamento dos dados para uma Data Warehouse ou Data Mart.
3.2.5. Cubos de dados
O cubo de dados é a representação de um formato lógico que permite modelar e visualizar dados em diversas perspetivas. O cubo de dados é constituído por dimensões e tabelas de factos.
As dimensões representam atributos do repositório de dados, apresentando as suas células os valores relativos às medidas de interesse registadas pelas tabelas de factos (Veras, 2009).
A Figura 3.3 ilustra um cubo tridimensional com o total de vendas de um produto num determinado mês numa região específica.

CAPÍTULO 3
18
Figura 3.3. Cubo tridimensional com o total de vendas
Na Figura 3.3 é possível visualizarmos um cubo de dados com três dimensões, a partir da representação do cubo é possível conhecer o total de vendas relativamente aos produtos (A, B, C, D, E e F), nos meses de (Janeiro, Fevereiro, Março, Abril, Maio e Junho), por região (Norte, Sul, Este e Oeste).
3.2.6. OLAP
O conceito OLAP (On-Line Analytical Processing) define o processamento analítico online dos dados. Permite a visualização de conjuntos de dados organizados em cubos multidimensionais. A sua finalidade é a de reunir conjuntos de dados de forma organizada e hierárquica fornecendo uma melhor organização dos dados, ajudando a uma melhor compreensão por parte dos utilizadores. Estes processos são extremamente importantes no auxílio à tomada de decisão (Anzanello, 2007).
Para uma melhor compreensão das caraterísticas das aplicações OLAP passamos a enumerá-las:
• Cubo de dados – é uma estrutura multidimensional que permite analisar dados de forma simples (elemento descrito anteriormente em 3.2.5).
• Dimensão – é uma unidade de análise que agrupa dados de negócio. As dimensões fazem parte dos cabeçalhos de linhas e colunas.
• Hierarquia – composta por todos os níveis de uma dimensão. Existem dois tipos de hierarquias, as balanceadas e as não balanceadas. Na hierarquia balanceada os níveis são equivalentes, nas hierarquias não balanceadas não existe equivalência de níveis. Como exemplo, olhemos para uma dimensão geográfica país, Portugal não possui estados enquanto que os Estados Unidos da América (EUA) possuem

CAPÍTULO 3
19
cinquenta estados. Este é um exemplo de hierarquia não balanceada em que Portugal não possui o subnível estado e os EUA possuem. Por outro lado, Portugal possui distritos enquanto que os EUA não.
• Membro – é um subconjunto de uma dimensão, a tabela seguinte ilustra um exemplo prático, apresentando o sub nível e os seus membros de uma dimensão geográfica.
Tabela 3.1. Demonstração elementos OLAP
Nível Membros Região Europa, América do Norte, Ásia
Países Portugal, Brasil, EUA
Estados/províncias Califórnia, Boston
• Medida – dimensão especial utilizada para fazer comparações. Esta dimensão surge associada a elementos como somas de totais, médias, custos, lucros, taxas, etc.
3.2.6.1. Arquiteturas OLAP
Mediante a forma de armazenamento de dados necessários a uma aplicação OLAP, deve-se procurar aplicar a arquitetura que melhor satisfaça as pretensões do utilizador/cliente. As arquiteturas OLAP de armazenamento são (Araújo, 2009):
• MOLAP – Multidimensional On-Line Analytical Processing, representa a arquitetura OLAP tradicional. Nesta arquitetura os dados são guardados em cubos multidimensionais e não na base de dados. O utilizador trabalha os dados do cubo e manipula-os diretamente no servidor. Esta arquitetura tem como vantagens o alto desempenho (os cubos são construídos previamente e no servidor) e a execução de cálculos complexos (todos os cálculos são gerados previamente aquando da criação do cubo de dados). Esta arquitetura tem como desvantagens a baixa escalabilidade (a vantagem de performance adquirida com a execução prévia de cálculos torna-a numa arquitetura limitada relativamente à quantidade de dados) e investimentos altos (esta arquitetura exige bastantes investimentos adicionais na projeção de cubos).
• ROLAP – Relational On-Line Analytical Processing, os dados são provenientes de bases de dados relacionais. A manipulação de dados da base de dados aparenta as operações de Slice/Dice (descritas em 3.2.6.2) e cada ação Slice/Dice equivale à junção de uma cláusula ‘WHERE’ em uma consulta SQL (Structured Query
Language). Esta arquitetura tem como vantagens a alta escalabilidade (utilizando esta arquitetura não existe limitação à quantidade de dados a serem analisados) e a possibilidade de recorrer a funcionalidades implícitas no próprio SGBD (Sistema de Gestão de Base de Dados). Esta arquitetura apresenta como desvantagens, o baixo desempenho (tendo em conta que cada relatório de dados representa pelo

CAPÍTULO 3
20
menos uma consulta SQL, estas consultas podem ser morosas nos casos em que a base de dados possua grandes quantidades de dados) e o facto de ser limitada pelas funcionalidades SQL (torna-se constrangedor executar cálculos complexos utilizando SQL).
• HOLAP – Hybrid On-Line Analytical Processing, tecnologia recente que tem por base a junção de MOLAP e ROLAP, oferecendo uma junção de performance existente no MOLAP e escalabilidade proveniente do ROLAP. HOLAP utiliza cubos de dados multidimensionais, em casos de necessidade de maior informação, esta arquitetura possibilita acesso à base de dados relacional. As vantagens são o alto desempenho (cubos de dados armazenam a síntese da informação) e a alta escalabilidade (a informação detalhada fica guardada na base de dados relacional). A desvantagem desta arquitetura é o seu custo, sendo a que detém o custo mais elevado de entre as arquiteturas OLAP.
• DOLAP – Desktop On-Line Analytical Processing, arquitetura que permite ao utilizador emitir uma consulta para o servidor obtendo o cubo de dados respetivo, posteriormente o cubo de dados será analisado na estação cliente. As vantagens desta arquitetura são o pouco tráfego na rede (o processamento OLAP é todo ele efetuado na estação cliente), ausência de sobrecarga do servidor de base de dados (tendo em conta que todo o processamento acontece na estação cliente) e a portabilidade de dados oferecida pela arquitetura. A desvantagem desta arquitetura é a limitação do tamanho do cubo de dados (caso o cubo de dados seja grande, a análise passa a ser morosa colocando até em causa a capacidade de suporte da estação cliente).
3.2.6.2. Elementos OLAP
As ferramentas OLAP permitem fazer várias ações sobre os cubos de dados. Para melhor conhecermos os conceitos vamos descreve-los:
• Consultas ad-hoc: o termo ad-hoc deriva do latim, e tem o significado de “para isto” ou “para esta finalidade”, que atribui um valor de especificidade por parte do termo. Este é um tipo de consultas geradas pelo utilizador da aplicação a dada altura, tendo em conta as suas necessidades, procedendo ao cruzamento de dados de forma espontânea e aplicando métodos que o conduzam à obtenção dos resultados pretendidos.
• Slice-and-Dice: funcionalidade que possibilita alteração de visão e perspetivas. Permite a alteração da posição dos dados e a troca de linhas por colunas, com o objetivo de facilitar a análise por parte dos utilizadores.
• Drill-down/up: funcionalidade que permite visualizar informação em maior detalhe (p. ex: na dimensão tempo a informação pode ir até ao detalhe hora, minuto, segundo).

CAPÍTULO 3
21
• Drill-Through: funcionalidade que permite realizar uma consulta SQL, associando as instruções SQL como filtros da consulta.
• Drill-across: processo de consultas combinadas a várias tabelas de factos, agrupando os resultados num único conjunto de dados. Um exemplo da utilização de este conceito é a criação de duas estrelas idênticas em que a primeira estrela guarda uma previsão de dados e a segunda estrela será composta por dados reais. Neste caso prático as duas estrelas devem ser compostas pelas mesmas dimensões de forma a ser possível a comparação entre dados previstos e dados reais (Thornthwaite, 2005).
Para além destas funcionalidades, as ferramentas de OLAP permitem normalmente visualizar gráficos ilustrativos dos dados representados nas dimensões do cubo (Anzanello, 2007).
3.2.7. Dashboards
O termo dashboard pode ser entendido como um painel de bordo. São responsáveis por demonstrar de forma ilustrada o desempenho dos processos de negócio de toda a organização (Wikipédia-Dashboards, 2011). Podem ser representados num painel virtual composto por uma ou mais camadas constituídas por instrumentos virtuais, como: Knobs (espécie de manómetros), mostradores e gráficos diversos (barras, colunas, bolhas, área, etc.), e tabelas.
Os dashboards relativamente à sua aplicação podem classificar-se como (Eckerson, 2006):
• Dashboards operacionais: Permitem a monitorização e acompanhamento dos processos de negócio, por parte de supervisores e trabalhadores.
• Dashboards táticos: voltados para o acompanhamento de processos departamentais. Este tipo de dashboards é destinado a gerentes e analistas de negócio.
• Dashboards estratégicos: permitem acompanhar a execução dos objetivos estratégicos delineados pelas empresas. Este tipo de dashboards é destinado a gestores, executivos e restante organização.
No conceito de BPM (Business Process Management) os dashboards devem ser o resultado final da fase de BAM (Business Activities Monitoring).
3.2.8. Data Mining
O conceito de Data Mining, ou prospeção de dados (traduzido para português), é o processo responsável pela exploração de grandes quantidades de dados. Este processo tem como principal objetivo a procura de padrões consistentes, como regras de associações ou sequências temporais. Estes padrões permitem detetar relacionamentos sistemáticos entre variáveis, em busca de subconjuntos de dados (Wikipédia-Data Mining, 2011).

CAPÍTULO 3
22
Os processos de Data Mining partem geralmente da seleção de algumas colunas de DWs ou Data Marts. Este conceito trabalha sobre sequências de dados, implementando técnicas das áreas de estatística, recuperação de informação através da área de inteligência artificial e reconhecimento de padrões. Vejamos um exemplo prático para uma melhor perceção das capacidades de Data Mining.
Sequência original: ABCXYABCZKABDKCABCTUABEWLABCWO
Após analisarmos atentamente a sequência acima, podemos verificar que:
• Existem sequências de dados que se repetem, “AB” e “ABC”.
• Existe segmentação de carateres tendo “AB” e “ABC” como prefixo.
"ABCXY" "ABCZK" "ABDKC" "ABCTU" "ABEWL" "ABCWO"
Atendendo aos dados representados acima, podemos descrever estes segmentos de dados recorrendo a representações genéricas.
"ABC??", "ABD??", "ABE??" e "AB???"
O carater ‘?’ representa qualquer letra. Pegando nesta representação podemos partir para um caso prático de exemplo. Suponhamos que ‘A’ representa a compra de um produto, (p. ex: pão), ‘B’ representa a aquisição de leite enquanto que ‘C’ possa indicar um tipo de leite (p. ex: meio gordo). Na prática com estes dados ficamos a saber que os clientes que compraram pão também compraram leite. Esta é uma das várias abordagens que o conceito Data Mining nos permite avaliar. Este tipo de informação permite tomar medidas de incentivo ao cliente. Normalmente as superfícies comerciais, tendem a expor este tipo de produtos lado a lado para facilitar a ação do cliente e ao mesmo tempo incentivar a sua compra.
Este é um dos conceitos BI recente mas que tem evoluído bastante nos últimos anos.
3.2.9. GEO/GIS
Um Sistema de Informação Geográfica (SIG), ou Geographic Information System (GIS), é um sistema composto de hardware, software, informação espacial e procedimentos computacionais. Estes procedimentos permitem uma melhor análise de forma simplificada, e uma melhor gestão ou representação do espaço e dos factos que nele

CAPÍTULO 3
23
ocorrem. Este tipo de sistemas é utilizado com o intuito de detetar e delinear acontecimentos no espaço físico.
Em BI, este tipo de sistemas é utilizado para análises no espaço, permitindo a utilização de mapas (p. ex: Google Maps) para especificar zonas com maior poder de compra, maior número de vendas, maior venda a nível de produtos, etc (Wikipédia-GEO, 2011).
3.2.10. KPIs
Os Key Performance Indicators (KPIs), são indicadores chave de desempenho, tem como principal objetivo medir quaisquer resultados das medidas implementadas. Nos dashboards é comum existirem várias referências de KPIs, servindo essencialmente para verificar se os resultados obtidos estão a superar ou a falhar as metas pretendidas. É uma funcionalidade bastante importante em BI, facilitando a visualização de resultados e comparando-os com as metas a alcançar.
3.2.11. Importação e Exportação de dados
O processo de importação de dados está relacionado com a introdução de dados no sistema provenientes de fontes externas. Estes dados podem ser provenientes de bases de dados externas ou ficheiros de dados.
A exportação de dados é o processo disponibilizado pelas aplicações de BI, que permite exportar dados para fontes externas, normalmente para suporte Excel, PDF (Portable
Document Format) e visualizações em HTML (Hypertext Markup Language), por exemplo.
3.2.12. OLTP
Online Transaction Processing (OLTP), termo que designa os sistemas de processamento de transações, isto é, são sistemas concebidos para registar todas as transações implícitas a uma determinada organização. No dia a dia utilizamos alguns sistemas deste tipo, como são os casos dos processos de transações bancárias que registam todas as atividades afetas a cada cliente, reservas on-line, utilização de cartões de crédito, etc. Também os sistemas ERP (Enterprise Resource Planning) se enquadram nesta categoria (Wikipédia-OLTP, 2011).
3.2.13. Relatórios
Relatórios BI são constituídos por um conjunto de elementos diversos de BI. Ilustram relatórios construídos à medida de uma necessidade, compostos de elementos distintos como: tabelas de dados, dashboards, cubos de dados, análises de Data Mining, análises de referenciação geográfica, KPIs etc. É possível configurar a sua construção de modo a obter relatórios relativos a períodos de tempo específicos (hora, dia, semana, mês, trimestre, semestre, ano, etc.) ou elementos exclusivos (nº de vendas de determinado

CAPÍTULO 3
24
produto, total de vendas de determinada loja, etc.). Os relatórios representam um dos elementos mais importantes de visualização dos processos de BI.

CAPÍTULO 4
25
4. SOFTWARE OPEN SOURCE E PMEs Neste capítulo abordamos os conceitos de software open source e apresentamos uma descrição sobre PMEs, definindo as suas caraterísticas.
O termo open source (código aberto) foi criado pela open source Iniciative (OSI) em 1988. De um modo geral, estamos perante um tipo de software que respeita as políticas de liberdade estipuladas pela Free Software Foundation (FSF), que são também partilhadas pelo projeto Debian Free Software Guidelines (DFSG).
Por vezes o software open source é vulgarizado por software gratuito, no entanto, existem algumas diferenças entre “software gratuito” e “software open source”; a principal diferença é que o software gratuito apesar de não implicar custos não é desenvolvido sobre as regras de software open source, estipuladas pela OSI (OSI, 2011), nem reconhecido como software open source por parte da OSI e FSF.
Uma aplicação Open Source deve, segundo a OSI, garantir as dez regras seguintes (OSI, 2011):
• Distribuição livre: a licença não deve restringir a venda ou distribuição gratuita do programa bem como a distribuição do software como componente de outro programa.
• Código fonte: o código fonte da aplicação deve estar incluído ou ter acesso gratuito. Deve ainda ser obtido de forma fácil e clara.
• Trabalhos derivados: as modificações e redistribuições têm de ser permitidas bem como a possibilidade de redistribuição do mesmo sobre a mesma licença.
• Integridade do autor do código fonte: a licença pode restringir a distribuição de código modificado se as mesmas licenças permitirem que as modificações sejam redistribuídas como patches (pequenas funcionalidades).
• Sem descriminação contra pessoas ou grupos: ninguém pode ser impedido de utilizar o software.
• Sem descriminações contra grupos de trabalho: A sua utilização não pode ser proibida em nenhuma atividade. Por exemplo, não se pode proibir que o software seja utilizado em qualquer empresa ou até para fins de pesquisas genéticas.
• Distribuição de licença: a licença que acompanha o software tem obrigatoriamente de suportar a totalidade do produto, evitando a necessidade de licenças adicionais.
• Licença não deve ser específica para um produto: a licença de um software não deve depender do facto deste fazer parte de uma distribuição particular de software.
• Licença não pode ser restrita a outro software: a licença não pode obrigar por exemplo, a que outro software com o qual é incluída, seja também ele open
source.

CAPÍTULO 4
26
• Licença deve ser tecnologicamente neutra: a licença não deve estabelecer uma tecnologia individual, estilo ou interface para ser aplicado no programa.
Todo o software que garanta as dez medidas acima enunciadas designa-se por software open source. O software gratuito não considerado open source, normalmente falha alguma (s) das regras mencionadas pela OSI, sendo desta forma considerado de software gratuito. Muitas vezes, este tipo de projetos surge associado a versões de demonstração de projetos comerciais, em que o cliente tem apenas acesso a parte das funcionalidades, sendo o acesso restrito a uma quantidade de espaço de alocação no caso de projetos Web; acesso a uma licença periódica que expira num curto período de tempo; ou que possibilita explorar o ambiente de trabalho mas não permite exportar ou guardar o trabalho produzido.
Tal como outros tipos de software, o open source tem vantagens mas também apresenta alguns inconvenientes (Martins e Oliveira, 2008), (open source, 2007). Para uma melhor perceção dos pontos fortes e fracos do software open source, iremos descrever nas secções seguintes as suas principais vantagens e desvantagens.
4.1. Vantagens do Software Open Source
Podemos afirmar que as principais vantagens da utilização de software open source são:
• Baixo custo: para além do software ser gratuito, os equipamentos de hardware necessários não são tão exigentes em termos de capacidade de processamento, quando comparados com os requisitos de hardware exigidos pelo software comercial, permitindo desta forma, reduzir o valor dispendido com os próprios dispositivos.
• Suporte da comunidade: o conceito de open source permite a troca de informação e esclarecimento de dúvidas perante a comunidade de desenvolvimento, bem como a contribuição na programação do software juntamente com a equipa de desenvolvimento. Normalmente existem fóruns de discussão associados a cada projeto.
• O software pode ser partilhado e utilizado para fins diversos.
• Acesso ao código fonte, permitindo por isso o seu estudo, alteração e implementação de novos módulos de funcionalidades.
• Possibilidade de adaptação às reais necessidades de cada organização, a disponibilização do código permite a adaptação do mesmo às pretensões de cada identidade.
• Constante atualização das versões através da contribuição da comunidade que o suporta.
• Possibilidade de experimentar o software sem que isso implique qualquer custo. Este factor contribui para a seleção do software que melhor se enquadre na real

CAPÍTULO 4
27
necessidade da instituição, evitando desperdício em aquisições de software que não satisfaça os requisitos pretendidos.
• Facilidade em aceder a software open source, nomeadamente acedendo aos repositórios específicos para download deste tipo de software (em 4.3 serão enumerados alguns repositórios de software open source).
4.2. Desvantagens do Software Open Source
De entre as desvantagens do software open source, destacamos as seguintes:
• Projetos em constante desenvolvimento: o que significa que os projetos podem ainda não ter atingido o grau de maturidade aceitável.
• Problemas no software: o facto de ser uma comunidade open source a desenvolver, por vezes suscita dúvidas relativamente à qualidade do produto final. Contudo, de um modo geral nos últimos anos assistimos a uma grande melhoria nos processos de teste das aplicações, mas ainda assim continuam a ser suscetíveis de conterem alguns bugs e falhas no seu desenvolvimento, o que por vezes também acontece em software comercial.
• Inexistência de informação: à exceção de uma minoria de projetos open source bem sucedidos, existe uma maioria de projetos open source que possuem pouca informação relativamente à instalação e ao suporte das aplicações.
• Continuidade dos projetos: esta nem sempre é assegurada, porque depende do tipo de aceitação por parte do mercado, e do objetivo da comunidade de o tornar um projeto comercial, estando o seu desenvolvimento condicionado pelo trabalho das equipas de voluntários.
Muitos são os projetos bem sucedidos do “mundo” open source que surgiram no mercado pelas comunidades de desenvolvimento e que posteriormente foram adquiridos por grandes empresas, patenteando e tornando-os software de licença comercial. Por exemplo, a Apple usa software open source como base do seu sistema operativo; o sistema operativo da Google para dispositivos móveis, o Android, é também open source; o Firefox e o Google Chrome, Web browsers open source, já são mais usados do que o Internet Explorer.
Existem muitos outros tipos de software que mantêm a sua licença open source para cativar o mercado e desenvolvem uma versão comercial com mais funcionalidades, de modo a financiar o desenvolvimento dos seus projetos.
4.3. Onde encontrar Software Open Source?
Nesta secção iremos apresentar uma lista de repositórios Web, onde é possível: adquirir software open source, aceder a informação de suporte, esclarecer dúvidas em blogues de discussão, participar no desenvolvimento de projetos entre outras opções.

CAPÍTULO 4
28
Existem repositórios específicos na Internet para disponibilizar projetos open source desenvolvidos pelas comunidades de desenvolvimento. A existência destes repositórios permite que as comunidades de desenvolvimento possam divulgar e alocar os seus projetos com maior facilidade, bem como, proporcionar aos utilizadores um acesso a software open source de forma simples.
Os repositórios de projetos open source, permitem proceder ao download e partilha de projetos, procurando desta forma angariar e divulgar novos projetos bem como despertar o interesse de possíveis colaboradores.
Alguns dos projetos open source detêm um repositório próprio pertencente à sua comunidade de desenvolvimento, que permite discussão e esclarecimento de dúvidas entre os membros da equipa de desenvolvimento e os utilizadores. Esta é uma forma de entender as dificuldades diversas dos utilizadores e de detetar eventuais bugs que necessitem de ser corrigidos nas versões futuras.
Com a exceção dos projetos indicados na secção anterior, a grande maioria dos projetos open source são alocados e partilhados em repositórios comuns, acessíveis a todo o tipo de público em geral. De seguida, iremos listar alguns dos repositórios de projetos Open
Source mais divulgados, indicando também o link respetivo da página Web onde pode ser efetuado o download do software (Martins e Oliveira, 2008):
• SourceForge (http://sourceforge.net/) - neste repositório é possível: colocar projetos desenvolvidos e em desenvolvimento; apresenta uma lista de projetos agrupados por mês de realização; permite visualizar estatísticas de downloads e colaboração; visualizar o número de downloads registados de cada projeto; contém browser, blogues e um separador de suporte no qual se encontra toda a documentação.
• Freshmeat (http://freshmeat.net/) – este repositório disponibiliza funcionalidades para: visualizar projetos e artigos inscritos mais recentemente; guardar também artigos; pesquisa de projetos associados a tags; disponibilizar informação acerca de cada projeto; discussões e esclarecimento de dúvidas em blogues.
• Hotscripts (http://www.hotscripts.com/) – este repositório permite: visualizar um conjunto de projetos agrupados por linguagem de programação; ter conhecimento relativamente ao top de projetos procurados; disponibiliza uma avaliação dos projetos mais populares; a utilização de fóruns e blogues diversos para a partilha de informação.
• RubyForge (http://rubyforge.org/) – este repositório oferece: suporte para projetos desenvolvidos na linguagem Ruby; uma listagem de projetos que necessitam de ajuda no desenvolvimento; apresenta valores estatísticos relativamente aos projetos mais ativos na semana corrente; exibe a lista dos projetos mais recentes; e mostra o top de projetos com maior número de downloads registado.

CAPÍTULO 4
29
• Savannah (http://savannah.gnu.org/) – este repositório disponibiliza aos utilizadores acesso às últimas notícias da comunidade; permite a consulta de projetos; apresenta valores estatísticos do repositório; exibe uma lista dos projetos que necessitam de colaboradores para o seu desenvolvimento; expõe o top de popularidade de cada projeto; mostra a lista de projetos alocados recentemente.
• CodeHaus (http://www.codehaus.org/) – neste repositório é possível: a pesquisa de projetos; aceder a um separador de projetos mais recentes; visualizar informação de suporte e das comunidades de desenvolvimento.
• Tigris (http://www.tigris.org/) – este repositório permite: visualizar projetos de forma ordenada por categorias; pesquisar projetos; filtrar projetos por nome e conteúdo; obter informação relativamente à utilização dos IDE de desenvolvimento, bem como acesso aos mesmos.
• OpenSymphony (http://www.opensymphony.com) – este repositório é o mais rudimentar de todos, quando comparado com os apresentados anteriormente. Este repositório apenas permite fazer downloads e aceder ao código fonte de cada projeto.
• Unesco (http://www.unesco.org/cgi-bin/webworld/portal_freesoftware/cgi/page. cgi?d=1) – neste repositório é possível: aceder à documentação de desenvolvimento dos projetos; obter informação relativa a cada projeto; ver uma listagem de projetos mais recentes; a pesquisa de projetos por palavras-chave; visualizar os diretórios criados mais recentemente e criar links para novos projetos.
• OSS4lib (http://www.oss4lib.org/) – neste repositório destacamos: a pesquisa de projetos por categoria e por linguagem de programação; a visualização de uma lista dos comentários mais recentes; o acesso aos protocolos e standards das normas de qualidade do desenvolvimento de projetos; a visualização de um grupo de artigos e sites recentes.
• TheOpenDisc (http://www.theopendisc.com/) – neste repositório é possível fazer download de uma aplicação que permite o download de projetos de várias categorias. O repositório é composto de wikis e fóruns para a partilha de conhecimento.
• OpenSourceWindows (http://www.opensourcewindows.org) – este repositório apresenta uma lista de projetos open source com link direto para as suas páginas oficiais.
O software open source oferece uma boa solução para colmatar quase todas as necessidades. De referir, que só o repositório SourceForge.net conta com mais de 300 mil projetos registados.

CAPÍTULO 4
30
4.4. Descrição de PME
Um foco importante do nosso trabalho de investigaçeuropeia, PME é toda a empresa qucinquenta trabalhadores efetivosmilhões de euros; e um balanço total menor ou igual a quarenta e três milhões de euros(EEN, 2011).
A Comissão Europeia adotcom a criação do conceito de microempresas, pequenas empresas e médias empresas. As microempresas são todas as empresas que possuam um número total de funcionários inferior a dez; um volume de negóciobalanço total que não ultrapasse também os dois milhõespequenas empresas, todas aquelas que tenham menos de cinquenta trabalhadores efetivosum volume de negócios e um balanço totTabela 4.1 permite analisar todos estes valores divididos pelas diferentes categorias.
Tabela 4.
Categoria
Média empresa
Pequena empresa
Microempresa
Como já fora referido, inicialmente na sena totalidade de todas as empresas tant4.1 ilustra um gráfico circular que nos ajuda a perceber qual a verdadeira importância das PMEs na economia europeia e mundial, segundo as referências (ECEI, 2010/2011) e (Global Alliance of SMEs, 2010empresas a nível nacional não foi produzido face à dificuldade de representação do valor mais baixo (0.01%) referente às grandes empresas
Figura 4.1. Gráfico da percenta
PMEs
Um foco importante do nosso trabalho de investigação são as PMEs. Segundo a definição europeia, PME é toda a empresa que possua um número total inferior a duzentos e cinquenta trabalhadores efetivos; um volume de negócio inferior ou igual a cinquenta
e um balanço total menor ou igual a quarenta e três milhões de euros
A Comissão Europeia adotou em maio de 2003 uma nova definição para as empresas, com a criação do conceito de microempresas, pequenas empresas e médias empresas. As microempresas são todas as empresas que possuam um número total de funcionários
um volume de negócios que não exceda os dois milhõesbalanço total que não ultrapasse também os dois milhões de euros. São consideradas pequenas empresas, todas aquelas que tenham menos de cinquenta trabalhadores efetivosum volume de negócios e um balanço total que não excedam os dez milhões de euros. A
permite analisar todos estes valores divididos pelas diferentes categorias.
Tabela 4.1. Caraterísticas das PME (EEN, 2011)
Efectivos Volume de Negócios Balanço total
Média empresa < 250 <= 50.000.000€ <= 43.000.000
Pequena empresa < 50 <= 10.000.000€ <= 10.000.000
Microempresa < 10 <= 2.000.000€ <= 2.000.000
Como já fora referido, inicialmente na secção introdutória, as PMEs têm um peso enorme na totalidade de todas as empresas tanto a nível nacional, europeu e Mundial. A Figura
ilustra um gráfico circular que nos ajuda a perceber qual a verdadeira importância das PMEs na economia europeia e mundial, segundo as referências (ECEI, 2010/2011) e Global Alliance of SMEs, 2010). O gráfico relativamente à percentagem de cada tipo de
empresas a nível nacional não foi produzido face à dificuldade de representação do valor referente às grandes empresas, tendo por base (ECEI, 2010/2011).
Gráfico da percentagem dos tipos de empresas a nível Mundial
98%
2%
Percentagem de PMEs a nível Mundial
PMEs Outras
Segundo a definição e possua um número total inferior a duzentos e
um volume de negócio inferior ou igual a cinquenta e um balanço total menor ou igual a quarenta e três milhões de euros
de 2003 uma nova definição para as empresas, com a criação do conceito de microempresas, pequenas empresas e médias empresas. As microempresas são todas as empresas que possuam um número total de funcionários
s que não exceda os dois milhões de euros; e um . São consideradas
pequenas empresas, todas aquelas que tenham menos de cinquenta trabalhadores efetivos; al que não excedam os dez milhões de euros. A
permite analisar todos estes valores divididos pelas diferentes categorias.
Balanço total
<= 43.000.000€
<= 10.000.000€
<= 2.000.000€
ção introdutória, as PMEs têm um peso enorme o a nível nacional, europeu e Mundial. A Figura
ilustra um gráfico circular que nos ajuda a perceber qual a verdadeira importância das PMEs na economia europeia e mundial, segundo as referências (ECEI, 2010/2011) e
áfico relativamente à percentagem de cada tipo de empresas a nível nacional não foi produzido face à dificuldade de representação do valor
, tendo por base (ECEI, 2010/2011).
a nível Mundial

CAPÍTULO 4
31
A representação da percentagem de PMEs é avassaladora, o que destaca a importância da nossa investigação, em querer solucionar um problema que abrange um enorme número de casos práticos.

32

CAPÍTULO 5
33
5. FERRAMENTAS BI OPEN SOURCE
Após uma primeira abordagem sobre os principais conceitos relacionados com a área de Business Intelligence, vamos começar a especificar em maior detalhe o nosso trabalho de investigação. O nosso trabalho de investigação tem como objetivo proceder ao levantamento do estado da arte relativamente a ferramentas open source de BI no intuito de as avaliar relativamente às suas funcionalidades de modo a encontrar as melhores soluções de integração para as PME´s. Após a avaliação das aplicações open source BI será escolhida a melhor solução que será implementada num projeto empresarial de âmbito real numa PME.
Os passos da investigação serão descritos nas próximas secções do nosso trabalho.
5.1. Suites BI Open Source
Inicialmente procedeu-se a um levantamento do estado da arte de todas as ferramentas open source relacionadas com a área de BI. Podemos constatar que existem bastantes ferramentas, algumas delas desenvolvidas exclusivamente para áreas especificas, isto é, processos de BI independentes (p. ex: processos de Data Mining, processos de ETL, OLAP, etc.). Inicialmente começamos por descrever as ferramentas que são consideradas ‘Suite’, este termo é usado para descrever ferramentas que agrupam um conjunto de funcionalidades BI. Como analisaremos ao longo da nossa investigação, algumas Suites de BI integram alguns projetos independentes, tornando-as mais funcionais e com maior ênfase de mercado.
Nesta secção iremos descrever sucintamente as principais Suites open source Business
Intelligence. As ferramentas analisadas são as seguintes: JasperSoft, OpenI, Palo, Pentaho, SpagoBI e Vanilla.
5.1.1. JasperSoft
Segundo a própria JasperSoft (JasperSoft, 2011), a empresa é uma líder em processos Business Intelligence. Atualmente com mais de 8.500 clientes comerciais distribuídos por 96 países. O nível de downloads da sua aplicação JasperSoft ultrapassa os 3.5 milhões. Estima-se que o software JasperSoft seja o software de BI mais utilizado em todo o mundo. JasperSoft é uma ferramenta open source que possui uma licença GNU GPL (General Public Licence).
Jaspersoft Business Intelligence Suite, inclui um servidor, Jasper Server, que permite: criar relatórios interativos, gráficos de diferentes tipos, consultas ad-hoc (possibilidade de consultas em tempo real, permite a utilizadores com poucos conhecimentos SQL, acederem a informação proveniente de bases de dados), interface de desenho de relatórios, análises OLAP, ferramentas de integração de dados ETL e recurso a bibliotecas java que permitem comunicação escalável.

CAPÍTULO 5
34
JasperSoft é uma aplicação fácil de implementar e que tem uma arquitetura incremental, isto torna-a uma aplicação robusta e capacitiva. Possibilita a analistas e profissionais, uma capacidade de conhecimento e observação mais aprofundadas.
JasperSoft permite a criação de relatórios e possui algumas propriedades interessantes na criação dos mesmos, permitindo:
• Facilidade na criação e parametrização de relatórios, sob o conceito de arrastar e soltar (drag-and-drop);
• Fazer consultas ad-hoc e criação de relatórios em tempo real;
• Formatação de relatórios de forma detalhada;
• Acesso a dados via XML (Extensible Markup Language), Hibernate, EJB (Enterprise Java Beans), POJO (Plain Old Java Object) ou tipos personalizados;
• Programação e distribuição automática de relatórios em diferentes formatos.
JasperSoft detém propriedades de criação de dashboards, das quais de destacam:
• A facilidade de manuseamento através das funcionalidades de arrastar e soltar;
• A possibilidade de realizar consultas ad-hoc e análises de dados em memória;
• A possibilidade de elaborar páginas com tabelas, crosstabs (processo que incide no cruzamento de dados de duas vistas de dados diferentes), gráficos, indicadores de entrada de parâmetros em tempo real e Mash-ups (combinação de dados entre duas ou mais fontes de dados).
As análises elaboradas em JasperSoft são baseadas em pradões ROLAP (Relational On
Line Analytical Processing), com acesso MDX padronizados para Web ou interface em folhas de cálculo Excel.
JasperSoft permite análises de dados em memória, possibilita configurações para processar dados em memória ou provenientes de uma base de dados relacional.
JasperSoft inclui mecanismos ETL para integração de dados. As funcionalidades ETL de JasperSoft são suportadas pela ferramenta Talend, que disponibiliza:
• Interface gráfico intuitivo para construção de modelos ETL;
• Alto desempenho e portabilidade na geração de código Java ou Perl;
• Monitorização de atividades para gestão de tarefas ETL.
A ferramenta JasperSoft possui um servidor (Jasper Server) de alta performance para relatórios. O servidor pode ser implementado como aplicação stand-alone ou integrado com outras aplicações. Permite consultas avançadas, análises de dados e criação de relatórios. O servidor possui:
• Conceito drag-and-drop, ad-hoc e query builder via comando de metadados;
• Painel de software drag-and-drop com tecnologia live-refresh e mash-up;

CAPÍTULO 5
35
• Análise de dados em memória;
• Construção de gráficos sobre a tecnologia flash;
• Conjunto de relatórios personalizados;
• Agendamento de relatórios e controlo de histórico de versões;
• Relatórios de segurança;
• Acesso a fontes de dados relacionais XML, Hibernate, EJB, POJO’s e fontes personalizadas;
• Segurança de dados por linha e coluna.
O servidor Jasper possui uma arquitetura escalável, sendo baseada em tecnologia Web de padrão aberto, com recurso a XML, JDBC (Java Database Connectivity), Hibernate, Java e Web Services. O servidor é totalmente integrado em Java.
O pacote de aplicação Jasper Server é constituído por MySQL, Apache Tomcat, Portal Liferay, abrangente para Web Services, Java e API’s HTML. O servidor contém ainda uma particularidade interessante, suporta serviços Web não Java, .NET(C#), C++ e PHP (Hypertext Preprocessor).
Jasper Server permite exportação de relatórios nos formatos de pdf, Html, xls, flash, doc, rtf e ods/odt.
Relatórios, consultas ad-hoc, dashboards e mash-up’s são baseados em tecnologia AJAX (Asynchronous Javascript And XML) e HTML de forma dinâmica.
JasperSoft permite a utilizadores sem conhecimentos técnicos sobre bases de dados ou linguagens de consulta a bases de dados criarem relatórios e consultas ad-hoc. Para isso, basta arrastar e soltar itens de visão empresarial definir filtros, parâmetros e gerar consultas sem dificuldades acrescidas.
A análise em memória funciona sobre a dinâmica de AJAX com HTML. Esta funcionalidade permite consultas ad-hoc, exploração de dados sobre o conceito multi-
dimensional data-pivoting, perfuração, corte, classificação e filtro de dados. Estes processos evitam sobrecarga de sistemas com criação de Data Warehouses e de consultas OLAP baseadas em MDX.
iReport é uma ferramenta concebida para desenho de relatórios, permite o controlo total sobre o seu conteúdo e aspeto. Esta funcionalidade é incluída no pacote JasperSoft.
A funcionalidade iReport permite:
• Criação de relatórios pixel-perfect;
• Pré-visualização de relatórios em diferentes formatos;
• Formatação do modelo de impressão;
• Upload e download de relatórios oriundos do repositório do servidor Jasper;

CAPÍTULO 5
36
• Personalizar e editar gráficos baseados em tecnologia flash;
• Construir gráficos de consultas SQL, MDX e domínios Jasper Server;
• Drill-Through;
• Girar texto.
JasperSoft inclui também funcionalidades GEO, a aplicação é constituída e auxiliada por centenas de mapas.
JasperSoft é uma aplicação robusta, confiável e atualizável, permite uma abordagem de integração faseada e pode ser adaptada consoante as necessidades do utilizador.
JasperSoft é um pacote BI apreciável, possui suporte para as funcionalidades principais de BI, apresenta apenas algumas lacunas, são elas a inexistência funcionalidades de Data
Mining e inexistência de KPIs.
Figura 5.1. Arquitetura JasperSoft e Figura 5.2. Relatório JasperSoft (JasperSoft, 2011)
A Figura 5.1 ilustra a arquitetura da ferramenta JasperSoft. É possível visualizar o conjunto de ferramentas que constitui a Suite JasperSoft. Na base da arquitetura surgem os processos de ETL a cargo da ferramenta Talend, Posteriormente e após os processos de ETL é possível utilizar iReports, JasperServer, JasperReports e JasperAnalysis, para os processos de criação de relatórios e análises. Na camada superior estão representados os elementos de visualização e interação do utilizador com a ferramenta.
A Figura 5.2 mostra um conjunto de elementos BI produzidos com auxílio de JasperSoft, em cima da esquerda para a direita é possível visualizarmos um gráfico de barras, um indicador de performance gráfico e um gráfico de progressão. Em baixo, da esquerda para a direita temos uma tabela de dados, uma listagem de dados e parte de um mapa de um sistema de informação geográfica.
5.1.2. OpenI
OpenI (OpenI, 2011) é uma ferramenta que suporta fontes de dados OLAP, bases de dados relacionais, modelos de dados estatísticos e modelos de Data Mining. Esta é uma ferramenta Web ideal para interagir com fontes de dados OLAP.

CAPÍTULO 5
37
A aplicação disponibiliza aos utilizadores componentes gráficas, tabelas Pivot, navegação e configurações. OpenI permite gerar relatórios OLAP, criar processos de Data Mining e Dashboards. A aplicação é desenvolvida sobre a linguagem de programação Java.
A ferramenta OpenI é auxiliada por alguns dispositivos de ligação, sendo a ligação entre a aplicação e as bases de dados relacionais estabelecida através de JDBC, para fontes de dados OLAP é utilizada a linguagem XMLA (Extensible Markup Language for Analysis), que é um protocolo de comunicaçãosuportado pelos servidores OLAP Microsoft Analysis Services e Mondrian. No caso de funcionalidades de Data Mining a ferramenta incorpora um aplicativo o RProject aplicativo open source que funciona sobre uma API (Application Programming Interface) nativa designada de RServe.
Os relatórios são suportados pela ferramenta JasperReports, tornando-se possível integrar nestes relatórios bases de dados relacionais, relatórios OLAP e conteúdos de Data Mining.
A interface é concebida para utilizadores distintos, com a finalidade de tornar acessível não só a pessoas ligadas ao desenvolvimento mas a toda a comunidade, oferecendo um interface amigável.
Em termos de segurança são regidas as especificações da tecnologia J2EE (Java 2
Enterprise Edition), após o login de utilizador, é possível aos utilizadores com permissões de administrador configurar aspetos visíveis por parte de utilizadores com permissões diferentes das de administrador.
Figura 5.3. Arquitetura da aplicação OpenI (OpenI, 2011)
A Figura 5.3 ilustra a arquitetura da aplicação OpenI, a aplicação é constituída pelas componentes de interface com o utilizador, definição do tipo de relatórios suportados pela aplicação, componentes de ligação entre funcionalidades internas da aplicação e servidores externos, nomeadamente servidores Olap, RDBMS (Relational Database
Management System) e Data Mining. A aplicação é suportada por um servidor J2EE.

CAPÍTULO 5
38
OpenI é um pacote de funcionalidades BI de valor, ainda assim peca numa primeira análise pela inexistência de um módulo de propriedades de ETL, pela impossibilidade de exportar dados e pela ausência do módulo de KPI.
Figura 5.4. Elementos gráficos de OpenI (OpenI, 2011)
A Figura 5.4 mostra o painel de visualizações da ferramenta OpenI, na figura surge representado tabelas de dados, gráficos de barras, gráficos circulares e gráficos de progressão.
5.1.3. Palo
Palo ou JPalo (Palo, 2011), é uma ferramenta OLAP desenvolvida pela empresa Jedox AG, cujo seu inicio de atividade remonta ao ano de 2002, sob alçada de Kristian Raue.
A Suite Palo engloba o grupo de funcionalidades Jedox, Palo OLAP Server, Palo Web, Palo ETL Server e Palo Para Excel.
OLAP é o processo chave da ferramenta Palo. O servidor de OLAP Palo fornece estabilidade, desempenho e algoritmos de lógica inovadores. O servidor permite multi-sessão em tempo real.
Palo Web concentra todas as componentes da aplicação num interface Web. Palo Web permite criar e fazer a gestão de relatórios OLAP e a visualização de processos ETL. A suite Palo permite acesso direto a utilizadores via Microsoft Excel e Open Office Calc.
Palo ETL Server é a componente de aquisição de dados na Web que permite extrair, transformar, carregar bases de dados de sistemas transacionais, bases de dados simples, DWs e outras fontes de dados externas.
A versão Palo concebida para suportes Microsoft Office Excel e Oppen Office Calc, permite resolver problemas relacionados com o limite de dados a processar e o seu tempo de processamento. Evita os habituais transtornos resultantes da necessidade de alteração das habituais folhas de cálculo para sistemas de gestão de dados mais complexos. Esta funcionalidade permite trabalhar sobre bases de dados de registos em folhas de cálculo.

CAPÍTULO 5
39
Palo para Excel inclui um servidor de base de dados OLAP robusto e disponibiliza os plugins Oppen Office Calc Add-in e Miccrosoft Excel Add-in. Para usufruir das funcionalidades destes plugins, basta instalá-los no Open Office Calc ou no Microsoft Excel. Após instalados aparecerá um novo separador de funcionalidades na ferramenta (Calc ou Excel), que permite construir um conjunto de elementos de BI.
No setor de análises, planeamentos e relatórios, Palo para Excel possui:
• Uma base de dados multidimensional em memória, disponível para todos os utilizadores;
• Suporte para processos básicos de BI, consolidação de dados em tempo real e propriedade write-back;
• Suporte para planeamentos, análises, criação de relatórios, consolidação na área das finanças e controlo de vendas.
Microsoft Office Excel Add-in e Oppen Office Calc Add-in, funcionam como um aplicativo adicional fácil de instalar, permite acesso às funcionalidades Palo OLAP Server a partir do Excel ou do Calc. Palo para Excel funciona nas versões Microsoft Office XP, 2003 e 2007, em alternativa funciona também no Oppen Office Calc.
Figura 5.5.Ambiente Microsoft Excel composto do separador Palo (Dashboardspy, 2011).
A Figura 5.5 ilustra o separador de funcionalidades Palo, instalado com recurso ao aplicativo Microsoft Office Excel Add-in.
A ferramenta Palo baseia-se em células, isto é, não se baseia nos registos mas nas próprias células das folhas de cálculo, daí a sua compatibilidade com as folhas de cálculo.
Resumidamente as caraterísticas de Palo são:
• Propriedade write-back (dados só serão escritos em memória principal, quando forçados a sair da memória cache);

CAPÍTULO 5
40
• Direitos de utilizador;
• Tecnologia de cálculo baseada em células;
• Multidimensional;
• Hierárquico;
• Baseado em memória e tempo real;
• Baseado em servidor;
• Subconjuntos;
• Regras.
Palo é uma plataforma baseada em folhas de cálculo, possibilita integração de dados provenientes de folhas de cálculo Microsoft Excel e de Open Office Calc. A integração de dados ETL e as consultas OLAP são as funcionalidades de maior relevo da plataforma. Os recursos para gerar gráficos e relatórios são os disponibilizados pelas aplicações de suporte (Microsoft Excel ou Open Office Calc).
5.1.4. Pentaho
Pentaho (Pentaho, 2011) é uma das ferramentas de Business Intelligence mais divulgadas e conceituadas. Pentaho é uma ferramenta de apoio à decisão composta por dois tipos de versões, Community que detém parte das funcionalidades totais da ferramenta sendo completamente gratuita (versão open source) e uma versão Enterprise que contém todas as funcionalidades (versão comercial).
As soluções Pentaho são soluções desenvolvidas com recurso à linguagem de programação Java e podem ser executadas a partir de uma JVM (Java Virtual Machine).
Pentaho incorpora a ferramenta Kettle para abordagens de ETL (também designada de pentaho Data Integration); para o cruzamento de dados OLAP incorpora as ferramentas Mondrian e Ramsetcube; possui funcionalidades próprias para criação de relatórios de dados; contém propriedades de Data Mining baseadas na aplicação Weka; e disponibiliza ainda propriedades relacionadas com a criação e visualização de dashboard.
A versão Community de demonstração online permite fazer análises através de um mecanismo próprio da Pentaho ou com recurso a xanalyzer, permite a criação e visualização de gráficos sendo possível a escolha de entre diversos tipos de gráficos existentes na plataforma.
É possível a criação de: relatórios, relatórios de análise e dashboards. A aplicação disponibiliza algumas livrarias Widget (componente de interface gráficas, p. ex: janelas, botões, menus, ícones, etc.) de Dashboards, são elas vistas de análise, KPIs e excertos de relatórios. Os relatórios podem ser visualizados e exportados nos formatos de Html, pdf, xls, csv, rtf e plain text.

CAPÍTULO 5
41
MDX (MultiDimensional eXpression) é a linguagem de consultas à base de dados integrada na ferramenta, é também ela a tecnologia que sustenta as funcionalidades OLAP da aplicação, as consultas podem ser exportadas em ficheiros pdf ou xls.
A ferramenta disponibiliza um WorkSpace que permite inserir e publicar elementos a serem analisados.
Figura 5.6. Conjunto de funcionalidades Pentaho (Pentaho, 2011)
A Figura 5.6 ilustra o conjunto de funcionalidades disponibilizadas pela aplicação Pentaho, apresentadas sob a forma de arquitetura. Surgem ilustrados 4 grupos de funcionalidades distintos: relatórios (produção, operação e ad-hoc), análises (Data
Mining, OLAP e Drill & Explode), dashboards (métricas, KPIs e alertas) e processos de gestão (integração, definição e execução).
Pentaho é um dos pacotes de BI open source mais poderosos do mercado.

CAPÍTULO 5
42
Figura 5.7. Ilustração de funcionalidades GEO de Pentaho (Dashboardinsight, 2011).
A Figura 5.7 ilustra uma representação das funcionalidades de GEO de Pentaho, com a utilização de informação e indicadores de performance gráficos.
5.1.5. SpagoBI
SpagoBI (SpagoBI, 2011) é uma aplicação desenvolvida pela SpagoWorld, fundada em 2006 e suportada por uma comunidade open-source. A ferramenta SpagoBI possui uma licença GNU LGPL (Lesser General Public Licence), que permite aos utilizadores usufruir da totalidade das funcionalidades da aplicação.
Esta ferramenta tem diversas funcionalidades, destacando-se: a criação e exportação de relatórios, a criação de gráficos, a integração de dados através de processos de ETL, a realização de análises através de processos OLAP, os processos de Data Mining, os processos de consultas simples a bases de dados, a criação de filtros de consulta e as propriedades geográficas. O conjunto de todas estas funcionalidades enumeradas torna a SpagoBI uma aplicação BI Suite.
O servidor de aplicação, SpagoBI Server, fornece e disponibiliza as funcionalidades da ferramenta, destacando-se: servidor de aplicação, serviço de login, criação de dashboard, processos de Data Mining, sistema de suporte a bases de dados DBMS (Database
Management System), ETL (Extract, Transform, Load), serviços de referenciação geográfica (GEO/GIS), agenda de tarefas, servidor OLAP (On-Line Analytical
Processing), criação de relatórios, realização de consultas a bases de dados e servidor Web. A Figura 5.8 ilustra o conjunto de funcionalidades existentes na Suite SpagoBI, acompanhadas pela informação relativamente às ferramentas que lhe oferecem suporte (ilustrada no canto superior direito de cada ícone).

CAPÍTULO 5
43
Figura 5.8. Conjunto de funcionalidades SpagoBI (SpagoBI, 2011)
Da análise à Figura 5.8 verificamos que SpagoBI permite a criação e visualização de relatórios estruturados com recurso a tabelas, gráficos e aglomerados de dados, estes relatórios têm a possibilidade de serem exportados em diferentes tipos de formatos, pdf, txt, xls, html, xml, csv e rtf. Esta funcionalidade utiliza como recurso de sustentação as ferramentas Eclipse BIRT, JasperReport e BusinessObject.
As propriedades OLAP disponibilizadas pela ferramenta permitem uma análise multidimensional efetuada com recurso às perspetivas de drill-down, drill-across, slice-
and-dice e drill-through (nome associado ao processo de mudança de uma dimensão para uma outra). Os processos de OLAP são suportados pelos motores OLAP, JPivot/Mondrian, JPalo/Mondrian, JPivot/XMLA Server.
As propriedades gráficas têm como suporte a ferramenta JFreeChart, esta funcionalidade permite o desenho de gráficos de diferentes tipos, barras, circulares, histogramas, etc.
A ferramenta disponibiliza mecanismos de Dashboard, permite a visualização de gráficos no formato SWF (Shockwave Flash), exibindo KPIs (Key Performance Indicators), estes KPIs são exibidos em tempo real. A ferramenta disponibiliza requisitos de criação, gestão e visualização de KPIs, permitindo aplicar diferentes especificações, entre elas, regras de cálculo, limites e regras de alarme, que condicionarão a ilustração do gráfico final.
SpagoBI detém uma funcionalidade para a elaboração de cockpits que permite a junção de diferentes documentos em apenas um, isto é, permite a elaboração de um documento capaz de conter elementos de OLAP, Dashboards, Data Mining entre outros.

CAPÍTULO 5
44
A ferramenta disponibiliza mecanismos geográficos, que permitem interligar dados em tempo real com dados provenientes de uma Data Warehouse, esta funcionalidade é suportada por duas aplicações, GEO e GIS.
O processo de Data Mining nesta ferramenta, é suportado pela aplicação Weka, esta ferramenta permite a extração de padrões e informação relevante de uma quantidade de dados considerável.
A ferramenta fornece um motor próprio de consultas, QBE (Query by Example), as consultas podem ser definidas pelos utilizadores de forma gráfica, esta funcionalidade permite ainda a elaboração de consultas, verificação de resultados, exportar dados, guardar consultas e criação de modelos de relatórios.
A opção Smart Filter permite criar formulários de consulta simples, utilizando a opção de filtragem de dados de forma a poder selecionar informação mais válida e específica.
No campo de acessibilidade de comunicação a ferramenta disponibiliza a opção de produzir relatórios tabulares, acessíveis tendo em conta a especificação WCAG (Web
Content Accessibility Guidelines).
A ferramenta possui um aplicativo designado de RT Console, que permite monitorizar dados em tempo real, monitorar processos de negócio e BAM (Business Activity
Monitoring), que é a monitorização da atividade de negócio.
As funcionalidades de ETL do SpagoBI integram a aplicação TOS (Talend Open Studio).
A aplicação permite a publicação de documentos nos formatos do Microsoft Office e Open Office.
SpagoBI disponibiliza ainda uma funcionalidade designada de dossiê, esta funcionalidade permite agrupar de forma organizada, elementos como relatórios, a esta informação podem ser adicionadas notas.
A ferramenta é disponibilizada nas versões, SpagoBI Studio (permite criar e modificar documentos de análise como relatórios, gráficos etc.), SpagoBI Meta (aplicação mais ligada à área de metadados) e SpagoBI SDK (serviço que agrupa as funcionalidades da aplicação suportadas pelo servidor).
SpagoBI é um pacote de funcionalidades de BI de grande dimensão. O seu conjunto de funcionalidades torna-a uma plataforma composta e com potencial, face a outras ferramentas apresenta um grande número de funcionalidades e disponibiliza-as numa única versão sem quaisquer custos. A incapacidade de realizar consultas ad-hoc, é o ponto frágil deste pacote de funcionalidades face a outros existentes no mercado.

CAPÍTULO 5
45
Figura 5.9. Painel de visualização SpagoBI (SpagoBI, 2011)
A Figura 5.9 ilustra algumas propriedades BI possíveis de execução por parte da ferramenta SpagoBI, nomeadamente a criação de gráficos de barras em 3D, tabelas de dados e gráficos de progressão em tempo real.
5.1.6. Vanilla
Segundo o site oficial, BPM Conceil é o grupo francês líder em soluções open source BI, é esta a organização responsável pelo desenvolvimento da plataforma Vanilla. A plataforma Vanilla é uma solução de BI completa, pois possui todas as funcionalidades de processos BI. A plataforma Vanilla permite efetuar: análises, criação de relatórios, representação de tabelas de dados, definição de KPIs e análises de Data Mining.
Das funcionalidades da plataforma Vanilla, destaca-se:
• A integração de metadados, com recurso às aplicações Birt e iReport;
• A inclusão de KPIs;
• Modalidade de Software as a Service (SaaS) habilitado, permite hospedagem de projetos diferentes, num único servidor;
• Pacote administrativo de gestão de servidores de auxílio à aplicação;
• Pacotes Java para criação e implantação de documentos de BI (sem manipulação de xml);
• Integração completa de dashboards, relatórios, cubos de dados, ETL e documentos;
• Portal com funções BI, relatórios de anotações, livros de histórico e relatórios;
• Caraterísticas de BI, conteúdo de colunas dinâmicas, fontes de dados alternativas, modo burst (para validação da politica de segurança);
• ETL integrado com suporte para SQL Server, OLAP, FreeMetrics &
FreeMetadata.

CAPÍTULO 5
46
A versão mais recente, versão V3.4 GA incute algumas novidades face às versões anteriores, para que a plataforma consiga acompanhar as tendências e necessidades de mercado. As novas funcionalidades são:
• A existência de um servidor de cluster e acompanhamento;
• Aumento de performance de dashboards, grelhas de dados (tipo Excel) inovadoras;
• Sistemas de gestão de conteúdos de indexação e segurança integrados;
• Consultas ad-hoc;
• Integração nos relatórios de tabelas cruzadas e gráficos.
A plataforma Vanilla encontra-se também disponível numa versão para sistemas operativos Android.
Vanilla é uma das plataformas de maior destaque atualmente, para além do suporte a todas as funcionalidades BI, a plataforma começa também a migrar para dispositivos de suporte móvel, o que a torna uma das plataformas com um maior índice de reconhecimento no momento.
Figuras 5.10 e 5.11. Painel de visualização Vanilla (Freeanalysis, 2011)
As Figuras 5.10 e 5.11 ilustram o ambiente de trabalho da ferramenta Vanilla, na Figura 5.10 surgem representados dois gráficos de progressão, enquanto que na Figura 5.11 é exibido um gráfico de área.
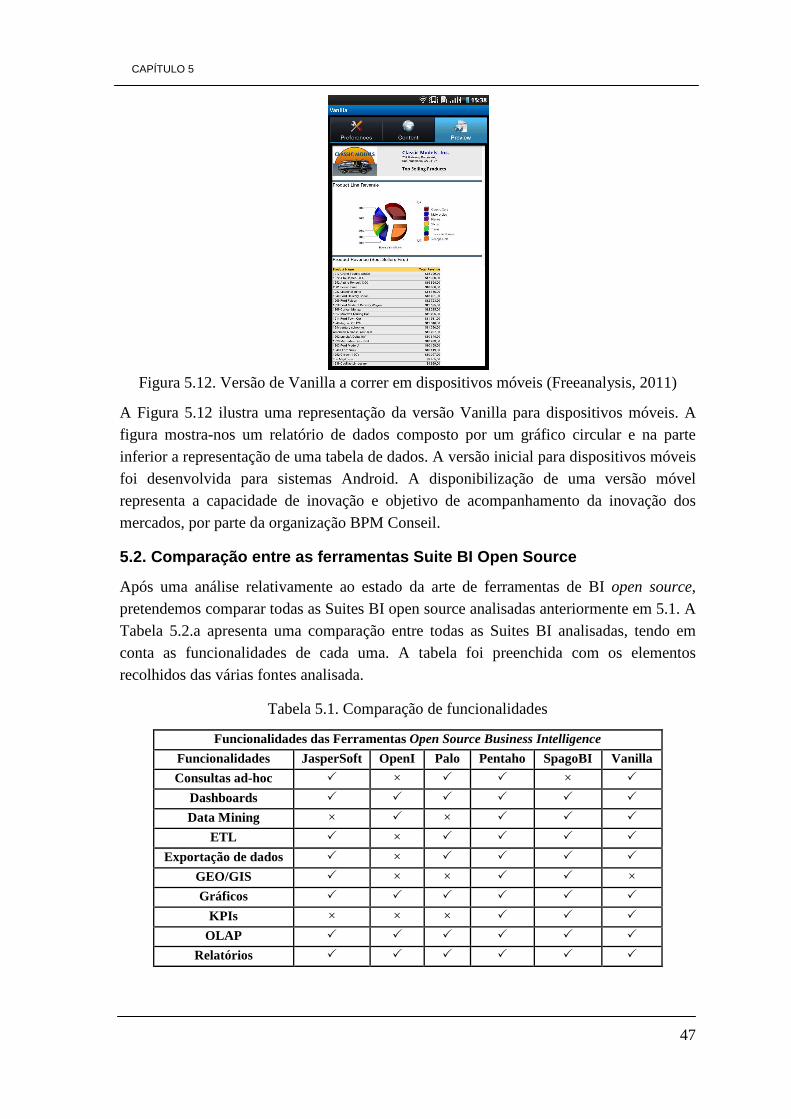
CAPÍTULO 5
47
Figura 5.12. Versão de Vanilla a correr em dispositivos móveis (Freeanalysis, 2011)
A Figura 5.12 ilustra uma representação da versão Vanilla para dispositivos móveis. A figura mostra-nos um relatório de dados composto por um gráfico circular e na parte inferior a representação de uma tabela de dados. A versão inicial para dispositivos móveis foi desenvolvida para sistemas Android. A disponibilização de uma versão móvel representa a capacidade de inovação e objetivo de acompanhamento da inovação dos mercados, por parte da organização BPM Conseil.
5.2. Comparação entre as ferramentas Suite BI Open Source
Após uma análise relativamente ao estado da arte de ferramentas de BI open source, pretendemos comparar todas as Suites BI open source analisadas anteriormente em 5.1. A Tabela 5.2.a apresenta uma comparação entre todas as Suites BI analisadas, tendo em conta as funcionalidades de cada uma. A tabela foi preenchida com os elementos recolhidos das várias fontes analisada.
Tabela 5.1. Comparação de funcionalidades
Funcionalidades das Ferramentas Open Source Business Intelligence
Funcionalidades JasperSoft OpenI Palo Pentaho SpagoBI Vanilla
Consultas ad-hoc � × � � × �
Dashboards � � � � � �
Data Mining × � × � � �
ETL � × � � � �
Exportação de dados � × � � � �
GEO/GIS � × × � � ×
Gráficos � � � � � �
KPIs × × × � � �
OLAP � � � � � �
Relatórios � � � � � �
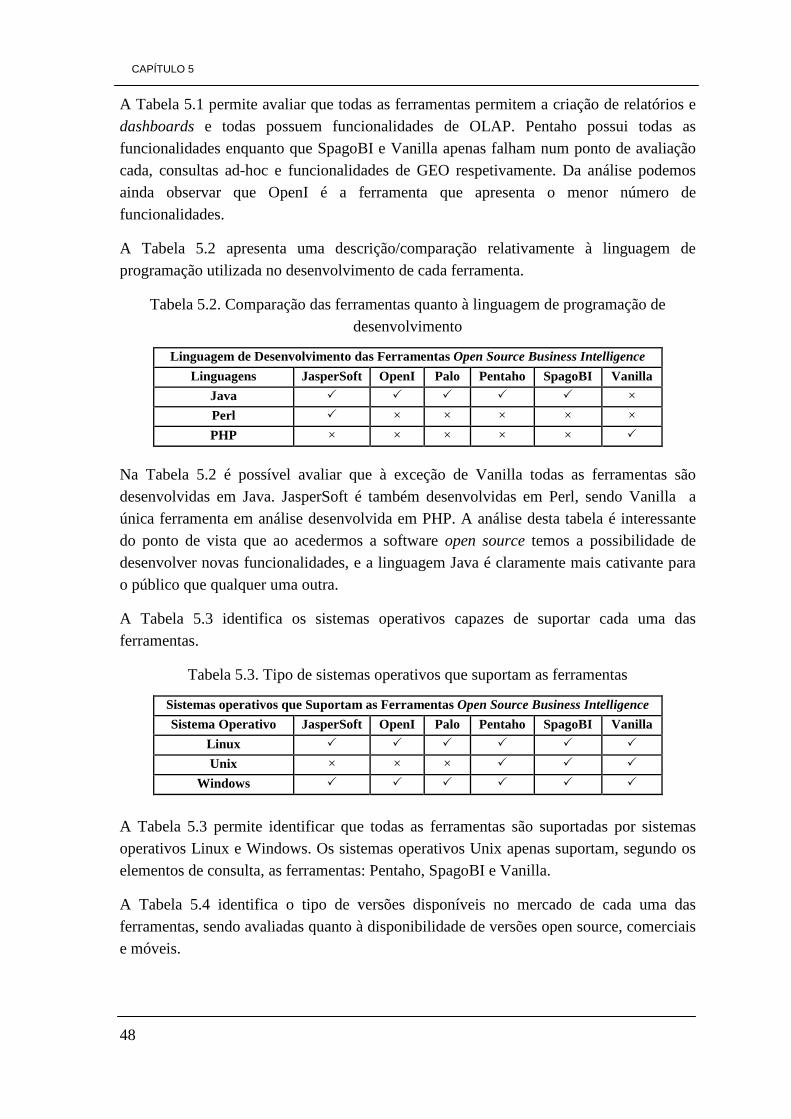
CAPÍTULO 5
48
A Tabela 5.1 permite avaliar que todas as ferramentas permitem a criação de relatórios e dashboards e todas possuem funcionalidades de OLAP. Pentaho possui todas as funcionalidades enquanto que SpagoBI e Vanilla apenas falham num ponto de avaliação cada, consultas ad-hoc e funcionalidades de GEO respetivamente. Da análise podemos ainda observar que OpenI é a ferramenta que apresenta o menor número de funcionalidades.
A Tabela 5.2 apresenta uma descrição/comparação relativamente à linguagem de programação utilizada no desenvolvimento de cada ferramenta.
Tabela 5.2. Comparação das ferramentas quanto à linguagem de programação de desenvolvimento
Linguagem de Desenvolvimento das Ferramentas Open Source Business Intelligence
Linguagens JasperSoft OpenI Palo Pentaho SpagoBI Vanilla
Java � � � � � ×
Perl � × × × × ×
PHP × × × × × �
Na Tabela 5.2 é possível avaliar que à exceção de Vanilla todas as ferramentas são desenvolvidas em Java. JasperSoft é também desenvolvidas em Perl, sendo Vanilla a única ferramenta em análise desenvolvida em PHP. A análise desta tabela é interessante do ponto de vista que ao acedermos a software open source temos a possibilidade de desenvolver novas funcionalidades, e a linguagem Java é claramente mais cativante para o público que qualquer uma outra.
A Tabela 5.3 identifica os sistemas operativos capazes de suportar cada uma das ferramentas.
Tabela 5.3. Tipo de sistemas operativos que suportam as ferramentas
Sistemas operativos que Suportam as Ferramentas Open Source Business Intelligence
Sistema Operativo JasperSoft OpenI Palo Pentaho SpagoBI Vanilla
Linux � � � � � �
Unix × × × � � �
Windows � � � � � �
A Tabela 5.3 permite identificar que todas as ferramentas são suportadas por sistemas operativos Linux e Windows. Os sistemas operativos Unix apenas suportam, segundo os elementos de consulta, as ferramentas: Pentaho, SpagoBI e Vanilla.
A Tabela 5.4 identifica o tipo de versões disponíveis no mercado de cada uma das ferramentas, sendo avaliadas quanto à disponibilidade de versões open source, comerciais e móveis.
CAPÍTULO 5
49
Tabela 5.4. Comparação das ferramentas relativamente às suas versões disponíveis
Versões das Ferramentas Open Source Business Intelligence
Versão JasperSoft OpenI Palo Pentaho SpagoBI Vanilla
Community � � � � � � Enterprise � � � � × ×
Mobile # × # # * �
# Apenas na versão paga. * Na versão analisada não possuía, atualmente já possui.
Mediante a análise à Tabela 5.4 é possível reter que apenas SpagoBI e Vanilla são verdadeiramente ferramentas open source, isto significa que não possuem versões comerciais. Outro aspeto importante que podemos reter da análise à Tabela 5.4 é o facto de que a comunidade de desenvolvimento de Vanilla foi pioneira na disponibilização de uma versão otimizada para dispositivos móveis (em versões open source).
A Tabela 5.5 contém elementos relativamente ao ano de desenvolvimento e ao tipo de licença que cada uma das ferramentas possui.
Tabela 5.5. Informações relevantes de cada uma das ferramentas. Outros aspetos das Ferramentas Open Source Business Intelligence
Aspetos JasperSoft OpenI Palo Pentaho SpagoBI Vanilla
Ano de desenvolvimento
2005 2005 2002 2004 2006 2010
Tipo Licença GNU GPL GNU GPL GNU GPL GNU GPL GNU GPL GNU GPL
Da análise à Tabela 5.5 podemos verificar que todas as ferramentas possuem uma licença do tipo GNU GPL. Vanilla é a ferramenta mais recente enquanto que Palo é uma das ferramentas open source pioneiras no mercado (não podemos considerar que tenha sido a pioneira porque existiram ao longo dos anos ferramentas que foram sendo descontinuadas, como o caso de BEE Project).
As principais conclusões que retiramos da análise a estas cinco tabelas, são que:
• A ferramenta Pentaho é a que disponibiliza mais funcionalidades.
• As ferramentas SpagoBI e Vanilla não suportam apenas uma funcionalidade cada, do conjunto de funcionalidades avaliadas.
• JasperSoft é uma ferramenta com potencial, falhando apenas em dois aspetos da avaliação.
• As ferramentas OpenI e Palo são as que disponibilizam menos funcionalidades.
• SpagoBI e Vanilla são das ferramentas analisadas as únicas que são verdadeiramente open source (apenas possuem uma única versão, community, que disponibiliza todas as funcionalidades disponibilizadas no pacote de soluções).
• Palo poderá ser uma solução viável em empresas que não possuam na sua estrutura alguém com conhecimentos base de informática nem possibilidades de

CAPÍTULO 5
50
contratar uma pessoa com essas caraterísticas. A ferramenta poderá ser viável tendo em conta que dispõem de um plugin para Calc e Excel, que normalmente são ambientes com os quais os recursos humanos das empresas se sentem mais familiarizados.
• Vanilla poderá ser uma opção difícil de incluir em empresas que os seus recursos humanos não estejam familiarizados com a linguagem de programação PHP, isto porque, normalmente Java oferece um maior ávontade aos utilizadores.
• Vanilla foi a ferramenta pioneira a desenvolver e disponibilizar uma versão para dispositivos móveis na versão open source. Recentemente SpagoBI também já disponibiliza uma versão para dispositivos móveis na sua nova versão 3.0.
Tendo por base estas conclusões e a análise às tabelas anteriores, consideramos que JasperSoft, Pentaho, SpagoBI e Vanilla são as melhores ferramentas open source existentes no mercado, sendo as que mais funcionalidades disponibilizam e maior confiança oferecem.
5.3. Outras Ferramentas
Para darmos a conhecer mais algumas ferramentas open source da área de BI, sem que constituam um pacote de soluções, iremos descrever sucintamente algumas ferramentas que compõem pacotes de soluções funcionando como módulos extra. As ferramentas aqui analisadas são as seguintes: Eclipse Birt, Mondrian, Kettle, Jpivot, Weka e RapidMiner.
5.3.1. Eclipse Birt
Em 2004 a Actuate Corporation juntamente com a fundação Eclipse iniciaram o projeto Eclipse BIRT (Business Intelligence Reporting Tools) (Eclipse BIRT, 2011). Birt é uma ferramenta open source flexível e de forte aceitação de mercado. BIRT funciona sobre o IDE Eclipse, funcionando como um plugin ideal para: conceção de relatórios, visualização de dados, análises e extrações de dados, acessos a bases de dados de diferentes tipos, transformação de dados, aplicar lógicas de negócio sobre dados, filtrar e formatar dados, a monitorização de resultados para o utilizador.
De um modo geral a ferramenta BIRT inclui:
• Extensão de acesso a dados;
• Personalização de dados;
• Reutilização de componentes/bibliotecas;
• Facilidade de integração;
• Internacionalização;
• Apresentação de dados de forma flexível;
• Múltiplas ferramentas de desenvolvimento e desenho.

CAPÍTULO 5
51
BIRT é uma ferramenta implementada em linguagem java, os seus resultados podem ser monitorizados através de funcionalidades Java, em aplicações stand-alone ou Java EE para vistas Web.
Os relatórios gerados por BIRT, são relatórios XML (Extensible Markup Language). BIRT permite acesso a bases de dados via Classic Models Inc. Simple Database, Flat File, JDBC, Scripted, Web Services e XML.
Figura 5.13. Ambiente de trabalho Eclipse BIRT (Wikipédia-BIRT, 2011)
A Figura 5.13 ilustra o ambiente de trabalho da aplicação Eclipse BIRT. Ao analisarmos a Figura 5.13 é possível verificar que se trata de um interface normal do IDE (Integrated
Development Environment) Eclipse. No topo da figura é possível visualizar os vários menus de opções, uma barra lateral do lado esquerdo com funcionalidades de desenho e indicação de diretórios. No centro da figura surge representada a área de desenho de gráficos acompanhada pelas suas opções de especificação de funcionalidades.
5.3.2. Mondrian
A aplicação Mondrian (Mondrian, 2011) é a ferramenta de servidor OLAP, que permite a construção de cubos de dados com várias perspetivas e dimensões. Esta ferramenta permite o cruzamento de dados entre diferentes estrelas de negócio. Esta ferramenta é desenvolvida com recurso à linguagem de programação Java e implementa as linguagens de modelação MDX, XML for Analysys e especificações JOLAP (Java Online Analytical
Processing ), recebe dados de várias fontes incluindo SQL Server.
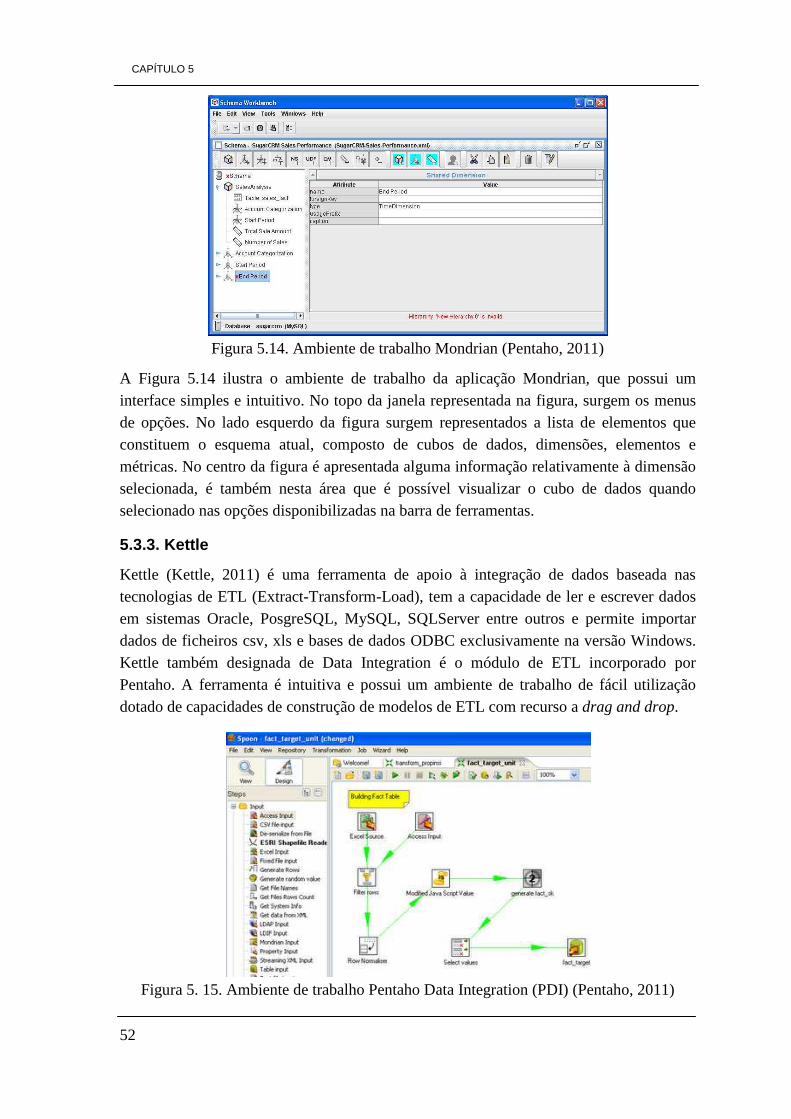
CAPÍTULO 5
52
Figura 5.14. Ambiente de trabalho Mondrian (Pentaho, 2011)
A Figura 5.14 ilustra o ambiente de trabalho da aplicação Mondrian, que possui um interface simples e intuitivo. No topo da janela representada na figura, surgem os menus de opções. No lado esquerdo da figura surgem representados a lista de elementos que constituem o esquema atual, composto de cubos de dados, dimensões, elementos e métricas. No centro da figura é apresentada alguma informação relativamente à dimensão selecionada, é também nesta área que é possível visualizar o cubo de dados quando selecionado nas opções disponibilizadas na barra de ferramentas.
5.3.3. Kettle
Kettle (Kettle, 2011) é uma ferramenta de apoio à integração de dados baseada nas tecnologias de ETL (Extract-Transform-Load), tem a capacidade de ler e escrever dados em sistemas Oracle, PosgreSQL, MySQL, SQLServer entre outros e permite importar dados de ficheiros csv, xls e bases de dados ODBC exclusivamente na versão Windows. Kettle também designada de Data Integration é o módulo de ETL incorporado por Pentaho. A ferramenta é intuitiva e possui um ambiente de trabalho de fácil utilização dotado de capacidades de construção de modelos de ETL com recurso a drag and drop.
Figura 5. 15. Ambiente de trabalho Pentaho Data Integration (PDI) (Pentaho, 2011)

CAPÍTULO 5
53
A Figura 5.15 mostra um esquema de ETL desenvolvido com recurso à utilização da ferramenta Kettle também designada por PDI (Pentaho Data Integration). O interface da ferramenta é simples e intuitivo, no topo da figura surgem os habituais menus de opções, do lado esquerdo da imagem o conjunto de funcionalidades de ETL, neste caso estão visíveis funcionalidades relativamente à entrada de dados. No centro da figura surge a área de trabalho do projeto, em que é possível visualizar um conjunto de processos interligados por setas que representam o sentido do fluxo de dados. No processo de ETL representado na Figura 5.15 as fontes de dados são um ficheiro Excel e uma base de dados Access que seguem várias etapas de transformação até ao carregamento dos dados numa tabela designada por”fact-target”.
5.3.4. JPivot
O JPivot (JPivot, 2011) é uma biblioteca JSP (Java Server Pages) que permite o desenho de gráficos e tabelas de dados OLAP, dispõe das opções de drill down e slice-and-dice. Mondrian e XMLA servem de suporte para os processos de OLAP.
Figura 5.16. Representação de um cubo de dados e respetivo gráfico em JPivot
(Bestanalytics, 2011)
Na Figura 5.16 é possível visualizar um cubo de dados representado por uma tabela, e o respetivo gráfico de barras representando os dados do cubo. JPivot utiliza consultas MDX para a construção dos seus cubos de dados. Mais à frente iremos descrever este tipo de consultas desenvolvido nesta linguagem (MDX).
5.3.5. Weka
Weka (Waikato Environment for Knowledge Analysis) (Weka, 2011) é uma ferramenta open source que permite agregar algoritmos da área de inteligência artificial. O objetivo desta ferramenta é permitir através do agregado de dados a extração de conhecimento indutivo e dedutivo. Esta ferramenta permite a análise computacional de dados e estatísticas aplicando conceitos de Data Mining, suportando processos de tomada de decisão (Wikipédia-Weka, 2011).

CAPÍTULO 5
54
A ferramenta Weka é desenvolvida na linguagem de programação Java, o que lhe concede um tipo de arquitetura flexível e portátil. A ferramenta é desenvolvida possui uma licença do tipo GPL.
Figura 5.17. Ilustração de um exemplo de uma análise Weka (Queensu, 2011)
A Figura 5.17 permite visualizar a representação de um conjunto de frações em grelha que delimitam conjuntos de pontos de várias cores (definindo-se por clusters em Data
Mining), a representação destes gráficos de dispersão permite extrair conhecimento relativamente à disposição de cada cluster e relativamente às diferentes cores que os constituem.
5.3.6. RapidMiner
RapidMiner (RapidMiner, 2011) é um software open source de Data Mining produzido sob licença AGPL (Affero General Public License) (GNU, 2011). RapidMiner é a continuação da versão do antigo software YALE (Yet Another Learning Environment), ambiente de análise de textos e dados. A versão inicial foi desenvolvida pela Unidade de Inteligência Artificial da Universidade de Dortmund, no ano de 2001. Segundo informação contida na página Web da Rapid-I (Rapid-I, 2011), RapidMiner é a solução open source de Data Mining líder. Estima-se que existam milhares de utilizadores da ferramenta, distribuídos por mais de 40 países.
RapidMiner é uma ferramenta stand-alone desenvolvida em linguagem Java, utilizada para investigação e realização de projetos. RapidMiner integra algoritmos e documentos da ferramenta WEKA.
RapidMiner disponibiliza:

CAPÍTULO 5
55
• Integração de dados de ETL;
• Análises OLAP;
• Construção de relatórios diversos;
• Interação com utilizador intuitiva e poderosa para análises de processos;
• Repositório para processos de manipulação de dados e metadados;
• Carregamento de dados, transformação e modelação de dados;
• Processos de DataMining.
RapidMiner funciona nas principais plataformas de BI e em todos os tipos de sistemas operativos. Os processos da aplicação são suportados por arquivos XML. A ferramenta possui linguagem de script para operações com dados provenientes de bases de dados. RapidMiner possibilita manipulação de dados provenientes de: folhas Excel, bases de dados Access, Oracle, IBM DB2, Microsoft SQL Server, Sybase, Ingres, MySQL, Postgres, SPSS, Dbase, arquivos de texto e outros.
RapidMiner é um pacote de funcionalidades estável, apresentando como mais valia os processos de Data Mining, ainda assim, permite integração de dados ETL, possibilita consultas OLAP, e permite a produção de relatórios e dashboards.
Figura 5.18. Análise de Data Mining (Amoldit, 2011)
A Figura 5.18 ilustra uma análise de Data Mining constituída com recurso à ferramenta RapidMiner. A ferramenta é composta por um menu de opções que oferece um conjunto de funcionalidades e por uma área de visualização que permite analisar processos de Data
Mining.

56

CAPÍTULO 6
57
6. AVALIAÇÃO PRÁTICA DAS FERRAMENTAS
Após a análise de todas as Suites BI na secção anterior, procedemos à escolha das quatro melhores ferramentas para proceder à sua instalação e avaliar aspetos mais técnicos de cada uma delas a fim de eleger a melhor solução para implementar num projeto real de uma PME.
A nossa escolha relativamente às quatro melhores Suites BI recaiu sobre JasperSoft, Pentaho, SpagoBI e Vanilla. A nossa escolha foi premeditada tendo em conta os resultados expressos nas tabelas 5.1 até 5.5.
Após identificadas as melhores ferramentas procedemos à sua instalação a fim de podermos avaliá-las quanto às suas funcionalidades e caraterísticas técnicas.
As quatro ferramentas foram instaladas numa máquina Virtual criada com a ferramenta Oracle VM VirtualBox Manager, na qual foi instalado o sistema operativo open source Ubuntu 10.10. As ferramentas foram instaladas em quatro máquinas virtuais, cada uma com uma ferramenta instalada, de forma a poder explorar cada ferramenta de forma mais eficaz. Este fator ajudou na avaliação da dificuldade da instalação de cada ferramenta, tendo em conta que para cada uma das ferramentas teve de se proceder à instalação de todos os componentes necessários (Java, MySQL, etc.).
A escolha do sistema operativo Ubuntu recaiu pelo facto de este ser o mais utilizado atualmente e por ser uma versão desenvolvida com base na versão Debian com a particularidade de ser atualizada semestralmente. Apesar da comunidade de desenvolvimento lançar uma nova versão Ubuntu semestralmente, têm a particularidade de prestar apoio de suporte a cada versão, durante os dezoito meses seguintes. Este fator foi importante porque permitia usufruir de apoio de suporte caso fosse necessário.
6.1. Instalação de requisitos comuns às quatro ferr amentas
As quatro ferramentas que pretendemos instalar, têm a necessidade da instalação prévia de alguns requisitos comuns. De modo a não repetir os mesmos passos na descrição dos passos de instalação das quatro ferramentas, procedemos à especificação dos passos de instalação comuns às quatro ferramentas. A instalação de todas as quatro ferramentas necessita das instalações prévias dos requisitos, explícitos nos próximos passos.
Os requisitos comuns às quatro ferramentas são, a instalação dos pacotes Java (sun), definição das variáveis de ambiente (JAVA_HOME e JRE_HOME) e a instalação de MySQL. Os próximos passos explicam os procedimentos a seguir para instalar os requisitos necessários (Ambiente Livre, 2011).
Passo 1 - Instalação do Java (Sun)

CAPÍTULO 6
58
• O primeiro passo é abrir uma janela do terminal com permissões de “root”.
• O segundo passo é atualizar as funcionalidades do repositório do Ubuntu, para isso, na janela do terminal deve digitar o seguinte código:
# sudo apt-get update
• De seguida é necessário digitar o comando que se segue para proceder ao download dos pacotes de Java.
# sudo apt-get install Sun-java6-jdk Sun-java6-jre
• Após a conclusão do download dos pacotes Java, surgirá uma mensagem relativamente aos termos da licença, deve ser aceite o acordo para proseguir com a instalação.
A instalação dos pacotes Java foi concluída com sucesso.
Passo 2 – Definir variáveis de ambiente
• Para um bom funcionamento das ferramentas, é necessário definir as variáveis de ambiente JAVA_HOME e JRE_HOME. Aceda ao diretório onde se encontra o link de Java, que normalmente se encontra em:
# cd /usr/lib/jvm
• O diretório deverá conter uma pasta relativamente à versão Java instalada e o link de Java. Deve abrir a pasta e digitalizar no terminal com permissões de “root” o seguinte comando:
# sudo gedit /etc/enviroment
• Ao ficheiro devem ser adicionadas as linhas:
JAVA_HOME=/usr/lib/jvm/java-6-sun
JRE_HOME=/usr/lib/jvm/java-6-sun
• Verifique se os diretórios e os ficheiros existem nos diretórios descritos.
• Caso não possua o ficheiro /etc/enviroment, configure as variáveis acedendo a /etc/profile inserindo as linhas:
export JAVA_HOME=/usr/lib/jvm/java-6-sun
export JRE_HOME=/usr/lib/jvm/java-6-sun
• Guarde as alterações efetuadas ao ficheiro e saia do editor.
• Para a atualização dos passos anteriores, deve reiniciar o sistema operativo.
Passo 3 – Instalar MySQL
• A instalação de MySQL é necessária para guardar as definições base das ferramentas, tal como dados de utilizador e códigos de acesso. Para proceder à

CAPÍTULO 6
59
instalação de MySQL aceda ao terminal. Proceda à instalação de MySQL Server e MySQL Client, digitalizando no terminal o seguinte comando:
# sudo apt-get install mysql-server-5.1 mysql-clien t-5.1
• Nova mensagem de termos e licença deverá aparecer, aceitando os termos de contrato deverá ainda digitar de seguida, a senha de “root” para MySQL.
• Para testar a instalação digite na janela do Terminal o seguinte comando:
# mysql –u root -p
• De seguida digite a senha de “root” definida anteriormente.
Se o processo de instalação for concluído com sucesso deverá aparecer a consola de MySQL.
Neste momento possuímos os requisitos base necessários para o funcionamento das ferramentas, para cada uma basta proceder ao download dos seus ficheiros de instalação e proceder com os passos de instalação mencionados nas próximas secções.
6.2. Instalação de JasperSoft
Para proceder à instalação de JasperSoft, deve garantir que efetuou os passos definidos em 6.1. Os passos de instalação da ferramenta JasperSoft são os seguintes:
Passo 1 - Criar diretório para instalar JasperServer
• O primeiro passo para a instalação da ferramenta JasperServer é a criação de um diretório para a sua instalação.
$ mkdir /home/<username>/jasperserver
Passo 2 - Obter ficheiro de instalação JasperServer
• O próximo passo é fazer o download do ficheiro de instalação da ferramenta JasperServer. Para obter o ficheiro de instalação (Jasperreports-server-cp-4.0.0-linux-installer.bin) basta aceder à página “http://jasperforge.org/website/ jasperserverwebsite/JSJA%20Website/js_download.html?header=project&target=jasperserver” e selecionar o ficheiro mediante o sistema operativo pretendido, no nosso caso Linux.
Passo 3 - Instalar JasperServer
• Após o download, o ficheiro .bin deve ser executado na pasta criada anteriormente no passo 1.
$ sudo sh jasperreports-server-cp-4.0.0-linux-inst aller.bin

CAPÍTULO 6
60
• Durante a instalação surgirá pedidos de confirmação relativamente aos componentes que o utilizador pretende instalar, surgirá a opção de instalar pacotes Java e MySQL, se seguiu 6.1. deve indicar que não os pretende instalar.
Passo 4 - Iniciar a ferramenta
• Após a instalação da ferramenta para iniciar a sua utilização deve inserir as instruções que se seguem no terminal de comando.
$ cd /home/<username>/jasperserver
$ jasperctl.sh start
Passo 5 – Login da aplicação
• A aplicação corre em http://localhost:8080/jasperserver .
• As credenciais de login na aplicação são:
Username: jasperadmin
Password: jasperadmin
6.3. Instalação de Pentaho
Para a instalação de Pentaho tomamos por base o tutorial de instalação (Ambiente Livre, 2011). Inicialmente deve proceder à realização dos passos descritos em 6.1.
A instalação de Pentaho BI Server 3.8 CE (Community Edition) segue os seguintes passos:
Passo 1 – Download da aplicação Pentaho BI Server 3.8 e consequente instalação
• O download da aplicação pode ser feito diretamente acedendo ao link “http://sourceforge.net/projects/pentaho/files/Business%20Intelligence%20Server/3.8.0-stable/biserver-ce-3.8.0-stable.tar.gz/download”
• Após a conclusão do download, deve descompactar o ficheiro descarregado. Para descompactar o arquivo digite o seguinte comando:
# tar xzvf .tar.gz
• Após descompactado o ficheiro, obtemos duas pastas, “administration-console” e “biserver-ce”
• De seguida vamos criar uma pasta para Pentaho no diretório /opt, diretório aconselhado por defeito. Para proceder à criação de uma pasta devemos digitar o seguinte código:
# sudo mkdir /opt/pentaho

CAPÍTULO 6
61
• Por fim, vamos transferir as pastas descompactadas para o novo diretório.
#mv administration-console /opt/pentaho
#mv biserver-ce /opt/pentaho
Passo 2 – Criar utilizadores de Pentaho no sistema operativo. Este é um passo opcional, mas oferece algumas vantagens relativamente a questões de acessibilidade de utilizadores.
• Para criar um grupo de utilizadores Pentaho execute o seguinte comando:
# sudo groupadd pentaho
• Para criar um utilizador de sistema para Pentaho execute o comando:
# sudo useradd –r –g pentaho pentaho
• Para atribuir permissões ao grupo e ao utilizador criados execute o seguinte comando:
# sudo chown –R pentaho:pentaho /opt/pentaho
Passo 3 – Iniciar a aplicação Pentaho BI Server 3.8
• Aceda ao diretório de instalação de Pentaho
# cd /opt/pentaho/
• De seguida é necessário atribuir permissões para a execução de arquivos com a extensão .sh no diretório, para efetuar esta ação execute os comandos seguintes:
# chmod 755 administration-console/*.sh
# chmod 755 biserver-ce/*.sh
# chmod 755 biserver-ce/tomcat/bin/*.sh
• Para inicializar o servidor Apache Tomcat de Pentaho digite o seguinte comando:
# sudo –u pentaho JAVA_HOME=/usr/lib/jvm/java-6-sun ./start-pentaho.sh
• Para testar Pentaho digite no browser o seguinte link:
http://localhost:8080/pentaho
• Para inicializar Pentaho Administrator console execute os seguintes comandos:
# cd /opt/pentaho/administration-console
# sudo ./start-pac.sh
• Para testar “Pentaho Administrator Console” aceda no browser a:
http://localhost:8099
• Para utilizar a aplicação, o utilizador por defeito é “admin” e a senha de validação é “password”.

CAPÍTULO 6
62
6.4. Instalação de SpagoBI
A instalação da ferramenta SpagoBI requer que sejam seguidos os passos descritos em 6.1. Posteriormente para proceder à instalação da ferramenta basta seguir os passos seguintes. Os passos que se seguem foram utilizados para instalação da versão 2.8.0 de SpagoBI.
Passo 1 – Download do ficheiro
• Acedendo à página “http://forge.ow2.org/project/download.php?group_id=204& file_id=17517” acede diretamente à página de download da versão 2.8.0 compacta. Esta versão contém todos os elementos instalados sobre o servidor Apache Tomcat, apenas necessita que descompacte os ficheiros.
Passo 2 – Criação de um diretório para a ferramenta
• Após o download do ficheiro deve proceder à criação de um diretório para descompactar o ficheiro. O comando que se segue permite criar um diretório “spagobi”
# sudo mkdir /opt/spagobi
Passo 3 – Descompactar ficheiros
• Tendo em conta que o ficheiro compactado tem a extensão .zip utilizamos o comando seguinte para o descompactar.
# unzip .zip
• Após descompactar ficamos com uma pasta com a extensão “All-In-One-SpagoBI-2.8.0-apache-tomcat-6.0.18-02252011”.
Passo 4 – Mover pasta descompactada para o diretório criado
• Devemos proceder à movimentação da pasta descompactada para o diretório criado, o comando que se segue permite efetuar esse passo.
#mv All-In-One-SpagoBI-2.8.0-apache-tomcat-6.0.18-0 2252011 /opt/spagobi
Passo 5 – Iniciar a aplicação
• Após a conclusão de todos os passos anteriores a aplicação encontra-se pronta para utilização. Para iniciar a aplicação deve executar os passos:
# sudo ./apache-tomcat-6.0.18/bin/startup.sh
# sudo ./apache-tomcat-6.0.18/bin/OOStart.sh
• Para testar a aplicação digite no seu browser o link abaixo.
http://localhost:8080/SpagoBI

CAPÍTULO 6
63
• Para proceder ao login na aplicação utilize um dos pares utilizador/senha seguintes.
Administrador: biadmin/biadmin
Utilizador: biuser/biuser
Demonstração: bidemo/bidemo
6.5. Instalação de Vanilla
A instalação de Vanilla requer a instalação dos requisitos enumerados em 6.1. A versão de vanilla que pretendemos instalar é a versão 3.4 GA (GA significa que é uma versão estável de Vanilla).
Passo 1 – Download do ficheiro
• Acedendo à página “http://forge.bpm-conseil.com/frs/download.php/114/vanilla-tomcat-mysql-3.4.0_GA.zip” acede diretamente à página de download da versão 3.4 de Vanilla, esta versão é compacta. Esta versão contém todos os elementos instalados sobre o servidor Apache Tomcat, apenas necessita da descompactação dos seus ficheiros.
Passo 2 – Criação de um diretório para a ferramenta
• Após o download do ficheiro deve proceder à criação de um diretório para descompactar o ficheiro. O comando que se segue permite criar um diretório “vanilla”
# sudo mkdir /opt/vanilla
Passo 3 – Descompactar ficheiros
• Tendo em conta que o ficheiro compactado tem a extensão .zip utilizamos o comando seguinte para o descompactar.
# unzip .zip
• Após descompactar ficamos com uma pasta com a extensão vanilla-tomcat-mysql-3.4.0_GA.
Passo 4 – Mover pasta descompactada para o diretório criado
• Devemos proceder à movimentação da pasta descompactada para o diretório criado, o comando que se segue permite efetuar esse passo.
#mv vanilla-tomcat-mysql-3.4.0GA/opt/vanilla
Passo 5 – Iniciar aplicação
• Após a conclusão de todos os passos anteriores a aplicação encontra-se pronta para utilização. Para iniciar a aplicação deve executar os seguinte comando:
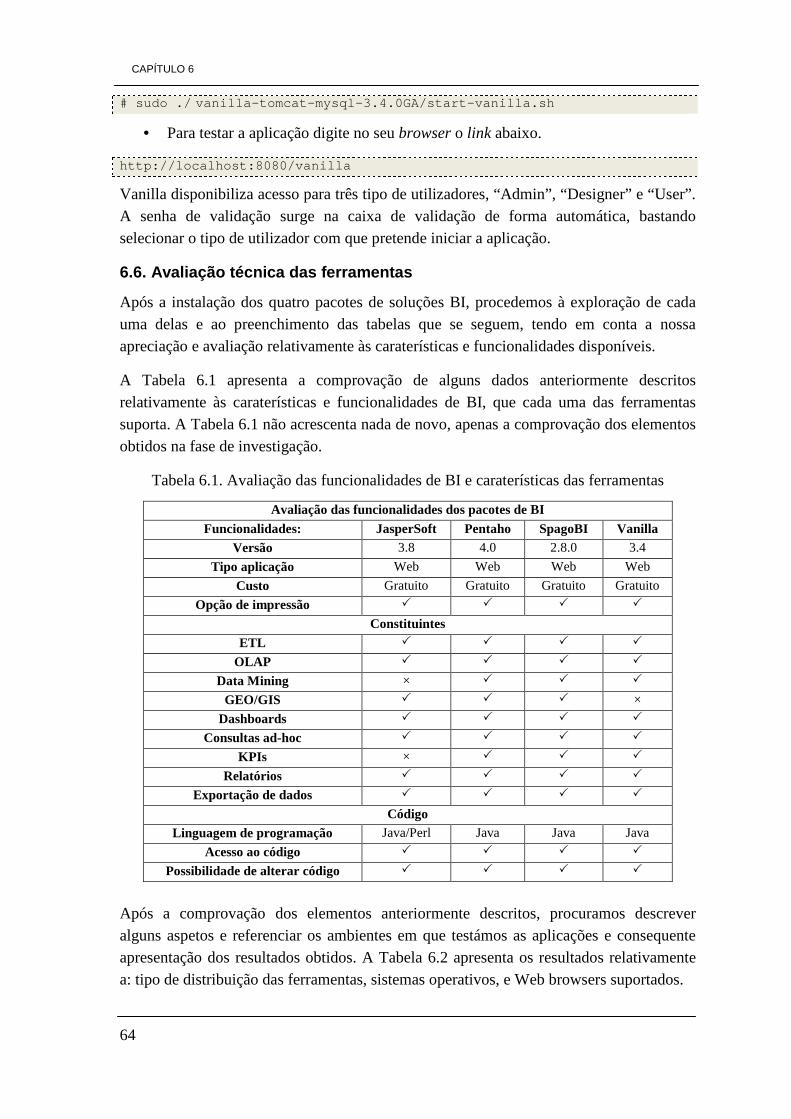
CAPÍTULO 6
64
# sudo ./ vanilla-tomcat-mysql-3.4.0GA/start-vanilla.sh
• Para testar a aplicação digite no seu browser o link abaixo.
http://localhost:8080/vanilla
Vanilla disponibiliza acesso para três tipo de utilizadores, “Admin”, “Designer” e “User”. A senha de validação surge na caixa de validação de forma automática, bastando selecionar o tipo de utilizador com que pretende iniciar a aplicação.
6.6. Avaliação técnica das ferramentas
Após a instalação dos quatro pacotes de soluções BI, procedemos à exploração de cada uma delas e ao preenchimento das tabelas que se seguem, tendo em conta a nossa apreciação e avaliação relativamente às caraterísticas e funcionalidades disponíveis.
A Tabela 6.1 apresenta a comprovação de alguns dados anteriormente descritos relativamente às caraterísticas e funcionalidades de BI, que cada uma das ferramentas suporta. A Tabela 6.1 não acrescenta nada de novo, apenas a comprovação dos elementos obtidos na fase de investigação.
Tabela 6.1. Avaliação das funcionalidades de BI e caraterísticas das ferramentas
Avaliação das funcionalidades dos pacotes de BI Funcionalidades: JasperSoft Pentaho SpagoBI Vanilla
Versão 3.8 4.0 2.8.0 3.4
Tipo aplicação Web Web Web Web
Custo Gratuito Gratuito Gratuito Gratuito
Opção de impressão � � � �
Constituintes ETL � � � �
OLAP � � � �
Data Mining × � � �
GEO/GIS � � � ×
Dashboards � � � �
Consultas ad-hoc � � � �
KPIs × � � �
Relatórios � � � �
Exportação de dados � � � �
Código Linguagem de programação Java/Perl Java Java Java
Acesso ao código � � � �
Possibilidade de alterar código � � � �
Após a comprovação dos elementos anteriormente descritos, procuramos descrever alguns aspetos e referenciar os ambientes em que testámos as aplicações e consequente apresentação dos resultados obtidos. A Tabela 6.2 apresenta os resultados relativamente a: tipo de distribuição das ferramentas, sistemas operativos, e Web browsers suportados.
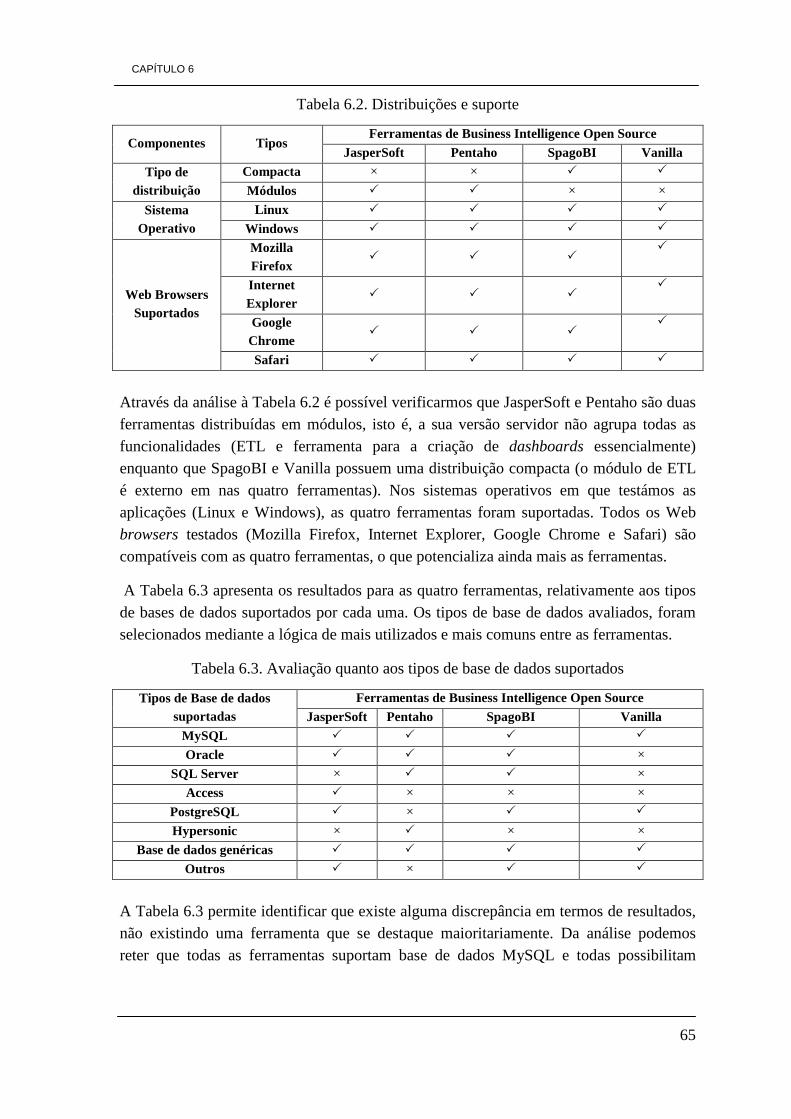
CAPÍTULO 6
65
Tabela 6.2. Distribuições e suporte
Componentes Tipos Ferramentas de Business Intelligence Open Source
JasperSoft Pentaho SpagoBI Vanilla
Tipo de distribuição
Compacta × × � �
Módulos � � × ×
Sistema Operativo
Linux � � � �
Windows � � � �
Web Browsers Suportados
Mozilla Firefox
� � � �
Internet Explorer
� � � �
Google Chrome
� � � �
Safari � � � �
Através da análise à Tabela 6.2 é possível verificarmos que JasperSoft e Pentaho são duas ferramentas distribuídas em módulos, isto é, a sua versão servidor não agrupa todas as funcionalidades (ETL e ferramenta para a criação de dashboards essencialmente) enquanto que SpagoBI e Vanilla possuem uma distribuição compacta (o módulo de ETL é externo em nas quatro ferramentas). Nos sistemas operativos em que testámos as aplicações (Linux e Windows), as quatro ferramentas foram suportadas. Todos os Web browsers testados (Mozilla Firefox, Internet Explorer, Google Chrome e Safari) são compatíveis com as quatro ferramentas, o que potencializa ainda mais as ferramentas.
A Tabela 6.3 apresenta os resultados para as quatro ferramentas, relativamente aos tipos de bases de dados suportados por cada uma. Os tipos de base de dados avaliados, foram selecionados mediante a lógica de mais utilizados e mais comuns entre as ferramentas.
Tabela 6.3. Avaliação quanto aos tipos de base de dados suportados
Tipos de Base de dados suportadas
Ferramentas de Business Intelligence Open Source JasperSoft Pentaho SpagoBI Vanilla
MySQL � � � �
Oracle � � � ×
SQL Server × � � ×
Access � × × ×
PostgreSQL � × � �
Hypersonic × � × ×
Base de dados genéricas � � � �
Outros � × � �
A Tabela 6.3 permite identificar que existe alguma discrepância em termos de resultados, não existindo uma ferramenta que se destaque maioritariamente. Da análise podemos reter que todas as ferramentas suportam base de dados MySQL e todas possibilitam
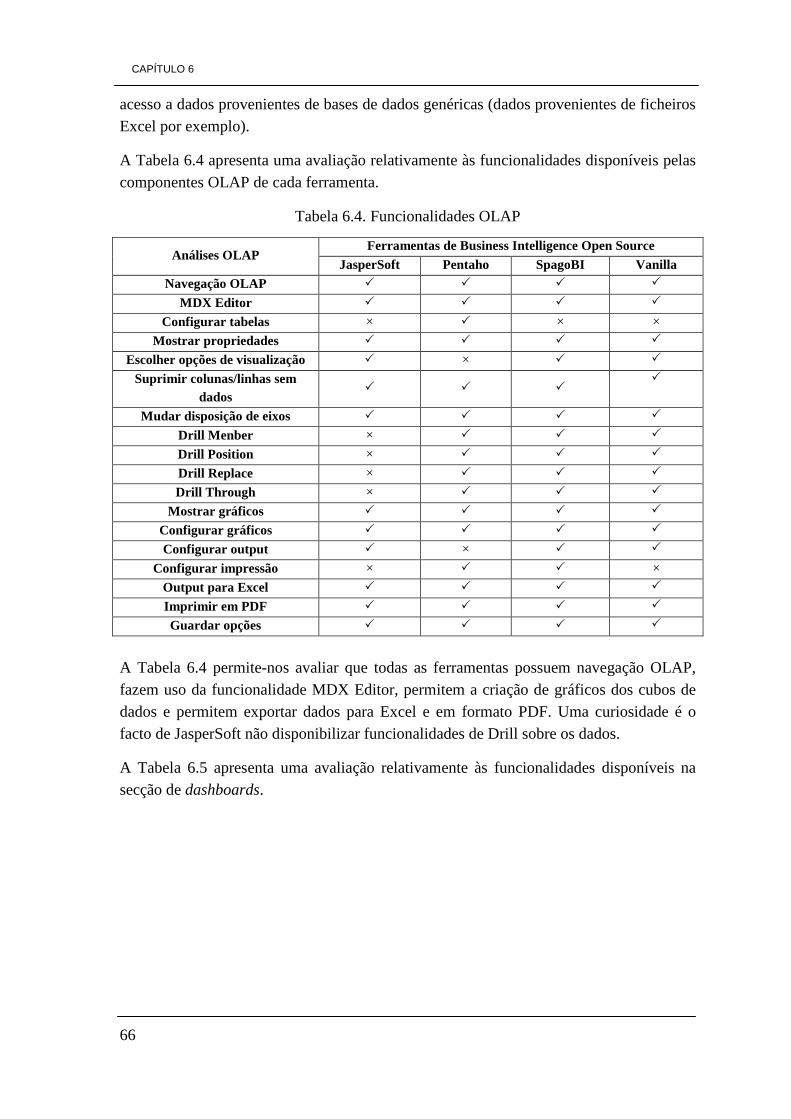
CAPÍTULO 6
66
acesso a dados provenientes de bases de dados genéricas (dados provenientes de ficheiros Excel por exemplo).
A Tabela 6.4 apresenta uma avaliação relativamente às funcionalidades disponíveis pelas componentes OLAP de cada ferramenta.
Tabela 6.4. Funcionalidades OLAP
Análises OLAP Ferramentas de Business Intelligence Open Source
JasperSoft Pentaho SpagoBI Vanilla Navegação OLAP � � � �
MDX Editor � � � �
Configurar tabelas × � × ×
Mostrar propriedades � � � �
Escolher opções de visualização � × � �
Suprimir colunas/linhas sem dados
� � � �
Mudar disposição de eixos � � � �
Drill Menber × � � �
Drill Position × � � �
Drill Replace × � � �
Drill Through × � � �
Mostrar gráficos � � � �
Configurar gráficos � � � �
Configurar output � × � �
Configurar impressão × � � ×
Output para Excel � � � �
Imprimir em PDF � � � �
Guardar opções � � � �
A Tabela 6.4 permite-nos avaliar que todas as ferramentas possuem navegação OLAP, fazem uso da funcionalidade MDX Editor, permitem a criação de gráficos dos cubos de dados e permitem exportar dados para Excel e em formato PDF. Uma curiosidade é o facto de JasperSoft não disponibilizar funcionalidades de Drill sobre os dados.
A Tabela 6.5 apresenta uma avaliação relativamente às funcionalidades disponíveis na secção de dashboards.
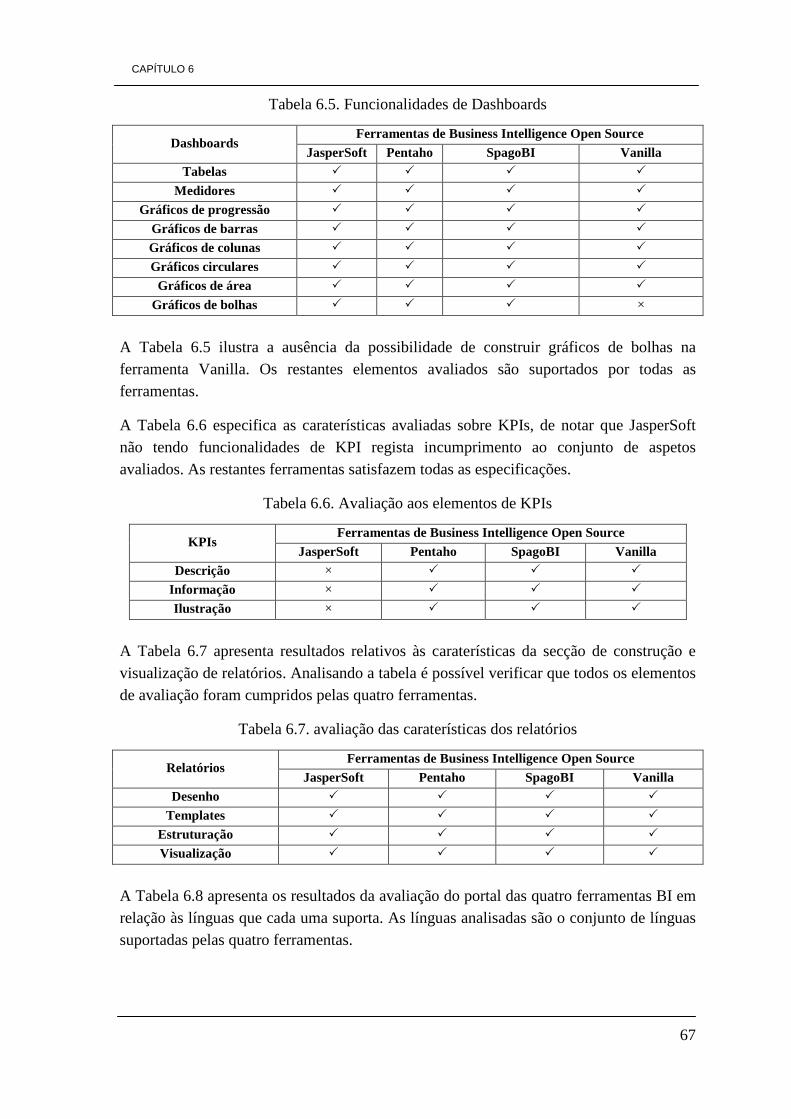
CAPÍTULO 6
67
Tabela 6.5. Funcionalidades de Dashboards
Dashboards Ferramentas de Business Intelligence Open Source
JasperSoft Pentaho SpagoBI Vanilla Tabelas � � � �
Medidores � � � �
Gráficos de progressão � � � �
Gráficos de barras � � � �
Gráficos de colunas � � � �
Gráficos circulares � � � � Gráficos de área � � � �
Gráficos de bolhas � � � ×
A Tabela 6.5 ilustra a ausência da possibilidade de construir gráficos de bolhas na ferramenta Vanilla. Os restantes elementos avaliados são suportados por todas as ferramentas.
A Tabela 6.6 especifica as caraterísticas avaliadas sobre KPIs, de notar que JasperSoft não tendo funcionalidades de KPI regista incumprimento ao conjunto de aspetos avaliados. As restantes ferramentas satisfazem todas as especificações.
Tabela 6.6. Avaliação aos elementos de KPIs
KPIs Ferramentas de Business Intelligence Open Source
JasperSoft Pentaho SpagoBI Vanilla Descrição × � � �
Informação × � � �
Ilustração × � � �
A Tabela 6.7 apresenta resultados relativos às caraterísticas da secção de construção e visualização de relatórios. Analisando a tabela é possível verificar que todos os elementos de avaliação foram cumpridos pelas quatro ferramentas.
Tabela 6.7. avaliação das caraterísticas dos relatórios
Relatórios Ferramentas de Business Intelligence Open Source
JasperSoft Pentaho SpagoBI Vanilla Desenho � � � �
Templates � � � �
Estruturação � � � �
Visualização � � � �
A Tabela 6.8 apresenta os resultados da avaliação do portal das quatro ferramentas BI em relação às línguas que cada uma suporta. As línguas analisadas são o conjunto de línguas suportadas pelas quatro ferramentas.
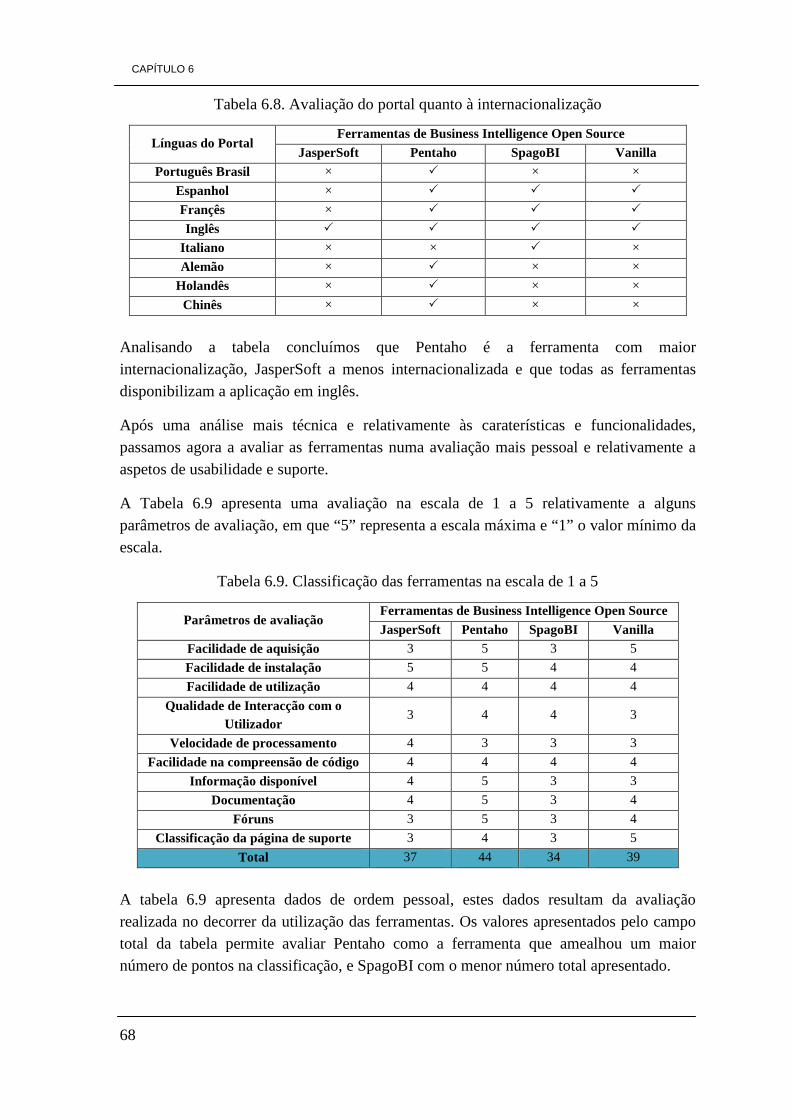
CAPÍTULO 6
68
Tabela 6.8. Avaliação do portal quanto à internacionalização
Línguas do Portal Ferramentas de Business Intelligence Open Source
JasperSoft Pentaho SpagoBI Vanilla Português Brasil × � × ×
Espanhol × � � �
Françês × � � �
Inglês � � � �
Italiano × × � ×
Alemão × � × ×
Holandês × � × ×
Chinês × � × ×
Analisando a tabela concluímos que Pentaho é a ferramenta com maior internacionalização, JasperSoft a menos internacionalizada e que todas as ferramentas disponibilizam a aplicação em inglês.
Após uma análise mais técnica e relativamente às caraterísticas e funcionalidades, passamos agora a avaliar as ferramentas numa avaliação mais pessoal e relativamente a aspetos de usabilidade e suporte.
A Tabela 6.9 apresenta uma avaliação na escala de 1 a 5 relativamente a alguns parâmetros de avaliação, em que “5” representa a escala máxima e “1” o valor mínimo da escala.
Tabela 6.9. Classificação das ferramentas na escala de 1 a 5
Parâmetros de avaliação Ferramentas de Business Intelligence Open Source JasperSoft Pentaho SpagoBI Vanilla
Facilidade de aquisição 3 5 3 5
Facilidade de instalação 5 5 4 4
Facilidade de utilização 4 4 4 4
Qualidade de Interacção com o Utilizador
3 4 4 3
Velocidade de processamento 4 3 3 3
Facilidade na compreensão de código 4 4 4 4
Informação disponível 4 5 3 3
Documentação 4 5 3 4
Fóruns 3 5 3 4
Classificação da página de suporte 3 4 3 5
Total 37 44 34 39
A tabela 6.9 apresenta dados de ordem pessoal, estes dados resultam da avaliação realizada no decorrer da utilização das ferramentas. Os valores apresentados pelo campo total da tabela permite avaliar Pentaho como a ferramenta que amealhou um maior número de pontos na classificação, e SpagoBI com o menor número total apresentado.
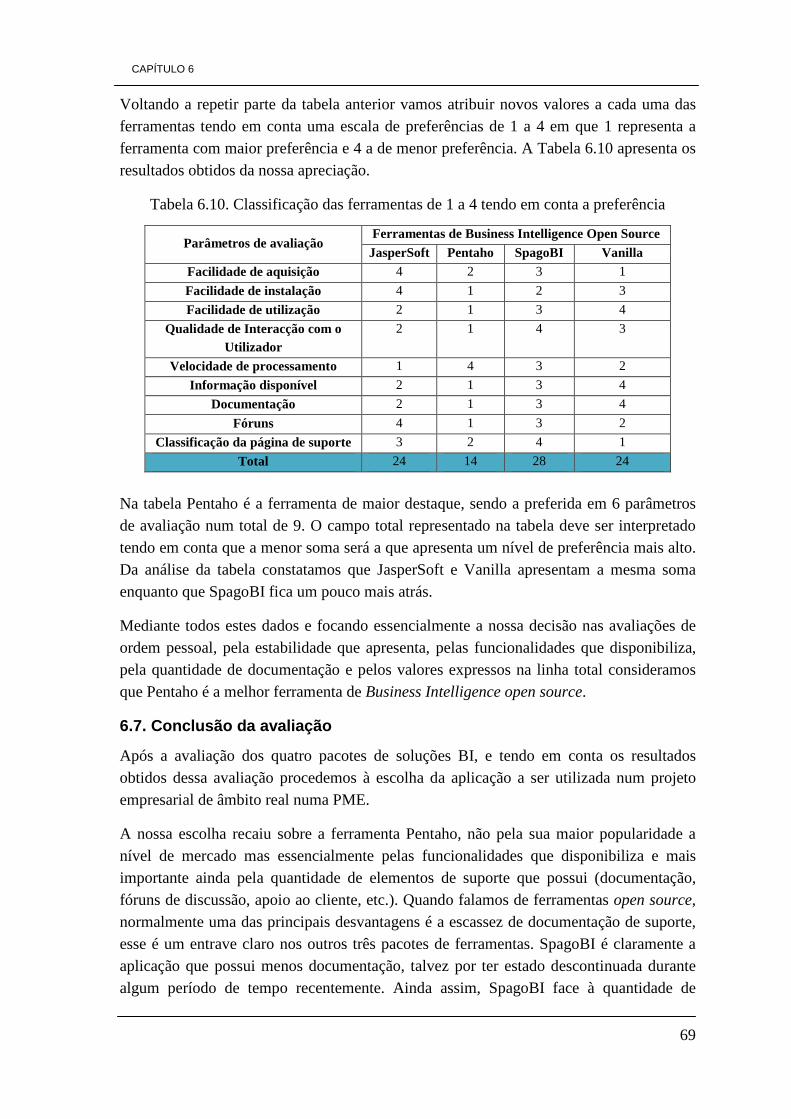
CAPÍTULO 6
69
Voltando a repetir parte da tabela anterior vamos atribuir novos valores a cada uma das ferramentas tendo em conta uma escala de preferências de 1 a 4 em que 1 representa a ferramenta com maior preferência e 4 a de menor preferência. A Tabela 6.10 apresenta os resultados obtidos da nossa apreciação.
Tabela 6.10. Classificação das ferramentas de 1 a 4 tendo em conta a preferência
Parâmetros de avaliação Ferramentas de Business Intelligence Open Source JasperSoft Pentaho SpagoBI Vanilla
Facilidade de aquisição 4 2 3 1
Facilidade de instalação 4 1 2 3
Facilidade de utilização 2 1 3 4
Qualidade de Interacção com o Utilizador
2 1 4 3
Velocidade de processamento 1 4 3 2
Informação disponível 2 1 3 4
Documentação 2 1 3 4
Fóruns 4 1 3 2
Classificação da página de suporte 3 2 4 1
Total 24 14 28 24
Na tabela Pentaho é a ferramenta de maior destaque, sendo a preferida em 6 parâmetros de avaliação num total de 9. O campo total representado na tabela deve ser interpretado tendo em conta que a menor soma será a que apresenta um nível de preferência mais alto. Da análise da tabela constatamos que JasperSoft e Vanilla apresentam a mesma soma enquanto que SpagoBI fica um pouco mais atrás.
Mediante todos estes dados e focando essencialmente a nossa decisão nas avaliações de ordem pessoal, pela estabilidade que apresenta, pelas funcionalidades que disponibiliza, pela quantidade de documentação e pelos valores expressos na linha total consideramos que Pentaho é a melhor ferramenta de Business Intelligence open source.
6.7. Conclusão da avaliação
Após a avaliação dos quatro pacotes de soluções BI, e tendo em conta os resultados obtidos dessa avaliação procedemos à escolha da aplicação a ser utilizada num projeto empresarial de âmbito real numa PME.
A nossa escolha recaiu sobre a ferramenta Pentaho, não pela sua maior popularidade a nível de mercado mas essencialmente pelas funcionalidades que disponibiliza e mais importante ainda pela quantidade de elementos de suporte que possui (documentação, fóruns de discussão, apoio ao cliente, etc.). Quando falamos de ferramentas open source, normalmente uma das principais desvantagens é a escassez de documentação de suporte, esse é um entrave claro nos outros três pacotes de ferramentas. SpagoBI é claramente a aplicação que possui menos documentação, talvez por ter estado descontinuada durante algum período de tempo recentemente. Ainda assim, SpagoBI face à quantidade de

CAPÍTULO 6
70
funcionalidades que apresenta esperava-se que possuísse maior número de elementos de suporte. Se recorrermos a um motor de busca Web (no nosso caso utilizámos o Google, que é o mais utilizado) e procurarmos pelo nome das quatro ferramentas podemos verificar e comparar a percentagem de documentação existente para cada ferramenta. O gráfico ilustrado na Figura 6.1, representa os valores em percentagem do número de referências a cada ferramenta encontrados na Internet.
Figura 6.1. Percentagem de referências encontradas, relativamente a cada ferramenta
Da análise à Figura 6.1 é possível verificar que JasperSoft possui a maior percentagem de referências, este fator pode dever-se ao facto de elementos JasperSoft suportarem outras ferramentas, nomeadamente, SpagoBI, Vanilla, Pentaho, ferramentas de CRM, etc. Um dos exemplos de utilização de ferramentas JasperSoft é a utilização dos módulos JasperReports para a criação de relatórios em várias outras ferramentas. Pentaho surge na segunda posição com aproximadamente um quarto da percentagem total, estes números são um pouco enganadores porque na prática Pentaho disponibiliza mais suporte e mais documentação, o que nos leva a justificar este facto com o célebre provérbio de que “Quantidade não é qualidade!”. SpagoBI surge com uma quota modesta de 16%, surgindo como a terceira ferramenta com mais documentação, este fator pode ser justificado tendo em conta que SpagoBI passou por um período em que esteve desativo, embora recentemente tenha sido novamente continuado. Por fim, Vanilla ocupa apenas 7% da totalidade dos registos de documentação, o facto de ser uma ferramenta recente pode incidir sobre os resultados apresentados.
JasperSoft
53%Pentaho
24%
SpagoBI
16%
Vanilla
7%

CAPÍTULO 7
71
7. IMPLEMENTAÇÃO NUMA PME
Após a análise das ferramentas e a consequente escolha de Pentaho como a melhor solução a aplicar na nossa demonstração prática, surgiu a oportunidade de envolvimento do nosso trabalho com um projeto empresarial de âmbito real numa PME. O projeto consiste na construção de uma Data Warehouse, partindo de um modelo de base de dados relacional de um sistema de controlo de parques de captura de energias renováveis (eólica e solar), fornecido por uma PME que apoiou o nosso projeto. Na nossa aplicação prática tivemos o cuidado de utilizar apenas software open source exceto: o Sistema Operativo, pelo simples facto de que no ambiente empresarial não se utilizar o Sistema Operativo Linux; e a ferramenta de arquitetura de Base de Dados, Power Designer 12.5, tendo em conta a necessidade de transformar a base de dados fornecida, SQL Server para MySQL.
De seguida apresentaremos de forma sucinta todos os passos abrangidos na implementação prática do nosso projeto.
7.1. Instalação de Pentaho em Windows
Anteriormente em 6.3 descrevemos os passos de instalação de Pentaho Server 3.8 no sistema operativo Ubuntu, mas tendo em conta que o projeto prático será implementado em sistemas operativos Windows procedemos à instalação do servidor Pentaho também em sistema operativo Windows.
De seguida apresentamos os passos de instalação da ferramenta no sistema operativo Windows (a versão utilizada foi o Windows XP).
Passo1 – Instalar Java (sun)
O primeiro passo para a instalação da ferramenta Pentaho é proceder à instalação do JDK (Java Development Kit) caso ainda não se encontre instalado.
• Para proceder ao download do ficheiro de instalação basta aceder em “http://www.oracle.com/technetwork/java/javase/downloads/index.html”, escolhendo a versão do JDK tendo em conta a arquitetura do computador (32/64 bits).
• Após o download deve proceder à instalação do JDK através da execução do ficheiro obtido.
Passo 2 – Definir as variáveis de sistema
A execução de Pentaho em Windows requer a configuração das variáveis JAVA_HOME e JRE_HOME.
• Para a configuração das variáveis basta aceder ao painel de controlo do computador, selecionar “sistemas”, em “sistemas” seleciona-se a aba de

CAPÍTULO 7
72
“configurações avançadas”, clicando-se de seguida em “variáveis de ambiente”. Para criar uma nova variável seleciona-se a opção “novo” em “variáveis de utilizador”.
• Surgirá uma janela como a representada nas figuras 7.1 e 7.2, que ilustram a nossa configuração das variáveis. O campo nome da variável deve ser preenchido com o nome de cada uma das variáveis enquanto que no valor da variável deve surgir informação relativamente ao diretório em que se encontram instaladas as componentes JDK e JRE do Java.
Figura 7.1. e 7.2. Configuração das variáveis JAVA_HOME e JRE_HOME
Passo 3 – Instalação de Pentaho BI Server 3.8
• Para proceder ao download do ficheiro de instalação de Pentaho BI Server CE 3.8 acedemos à página “http://sourceforge.net/projects/pentaho/files/Business%20 Intelligence%20Server/3.8.0-stable/”.
• Procedemos ao download da versão estável 3.8 (definida como stable) descarregando o ficheiro “biserver-ce-3.8.0-stable.zip”.
• Criamos um novo diretório pentaho e descompactamos o ficheiro biserver-ce-3.8.0-stable.zip
• O nosso diretório Pentaho contém dois diretórios, (“administration-console” e “biserver-ce”).
• Para iniciar o Pentaho execute o ficheiro start-pentaho.bat
• Digite o endereço http://localhost:8080/pentaho e verifique se funciona.

CAPÍTULO 7
73
Figura 7.3. Servidor Pentaho BI CE 3.8 instalado com sucesso
Os tipos de utilizador e as respetivas senhas, já se encontram atribuídas por defeito, basta selecionar o utilizador e o campo senha é preenchido automaticamente. Existem quatro tipos de utilizadores registados no Pentaho BI Server CE 3.8, sendo eles (Utilizadore Pentaho, 2011):
• Joe – Diretor executivo – este utilizador possui permissões de administrador, é lhe atribuída a possibilidade de utilizar todas as funcionalidades de Pentaho e permissão total sobre o Pentaho User Console.
• Suzy – Diretora de Tecnologia – este tipo de utilizador usufrui de permissões de utilizadores comuns, diretor de tecnologia e serviços de informação.
• Pat – Desenvolvedor – este utilizador pode usufruir das funcionalidades de utilizadores comuns (visualizar elementos) e ainda possui poder para desenvolver elementos.
• Tiffany – Gerente de desenvolvimento – este tipo de utilizador possui permissões de utilizador comum, desenvolvimento e gestão de desenvolvimento.
A senha de acesso para todos os tipos de utilizadores é “password”.
No nosso caso prático iremos utilizar o tipo de utilizador “Joe”, que nos permite usufruir de todas as funcionalidades disponibilizadas pelo servidor Pentaho.
7.2. Construção da Data Warehouse
A aplicação prática do nosso projeto tem por base implementar uma ferramenta de BI open source (neste caso Pentaho) sobre um sistema de controlo de parques de captura de energias renováveis (eólicos e solares). A nossa componente prática incide apenas sobre
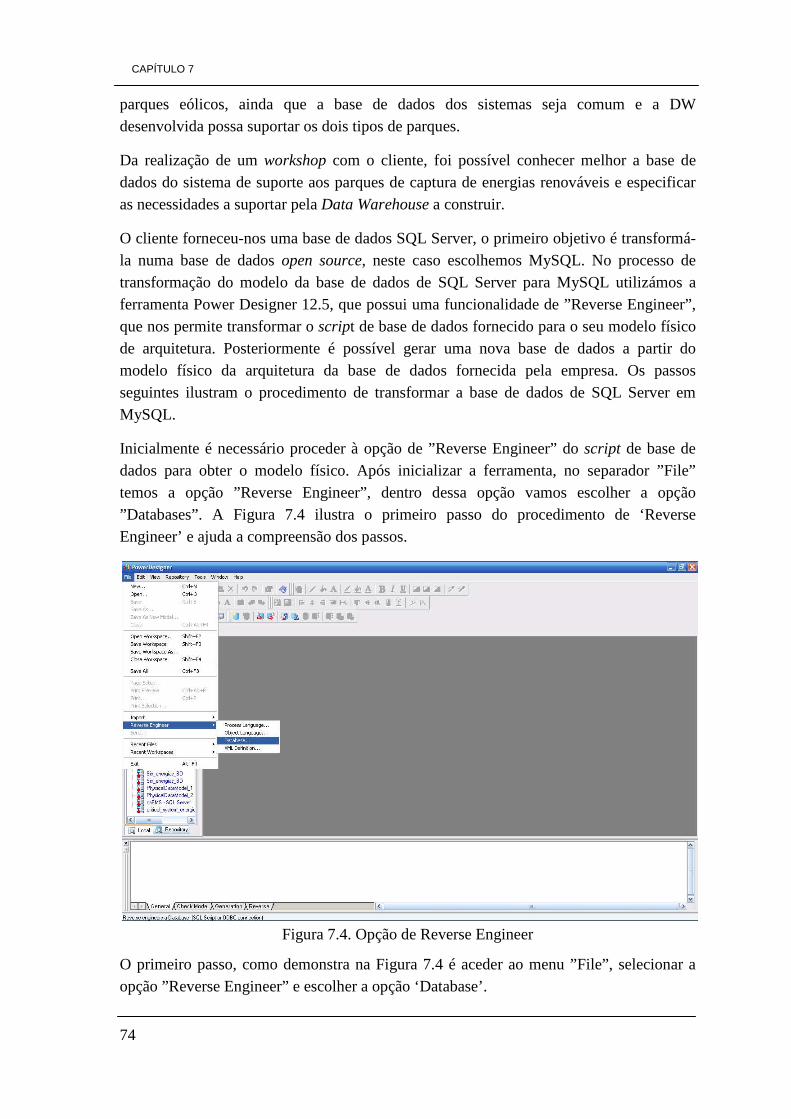
CAPÍTULO 7
74
parques eólicos, ainda que a base de dados dos sistemas seja comum e a DW desenvolvida possa suportar os dois tipos de parques.
Da realização de um workshop com o cliente, foi possível conhecer melhor a base de dados do sistema de suporte aos parques de captura de energias renováveis e especificar as necessidades a suportar pela Data Warehouse a construir.
O cliente forneceu-nos uma base de dados SQL Server, o primeiro objetivo é transformá-la numa base de dados open source, neste caso escolhemos MySQL. No processo de transformação do modelo da base de dados de SQL Server para MySQL utilizámos a ferramenta Power Designer 12.5, que possui uma funcionalidade de ”Reverse Engineer”, que nos permite transformar o script de base de dados fornecido para o seu modelo físico de arquitetura. Posteriormente é possível gerar uma nova base de dados a partir do modelo físico da arquitetura da base de dados fornecida pela empresa. Os passos seguintes ilustram o procedimento de transformar a base de dados de SQL Server em MySQL.
Inicialmente é necessário proceder à opção de ”Reverse Engineer” do script de base de dados para obter o modelo físico. Após inicializar a ferramenta, no separador ”File” temos a opção ”Reverse Engineer”, dentro dessa opção vamos escolher a opção ”Databases”. A Figura 7.4 ilustra o primeiro passo do procedimento de ‘Reverse Engineer’ e ajuda a compreensão dos passos.
Figura 7.4. Opção de Reverse Engineer
O primeiro passo, como demonstra na Figura 7.4 é aceder ao menu ”File”, selecionar a opção ”Reverse Engineer” e escolher a opção ‘Database’.
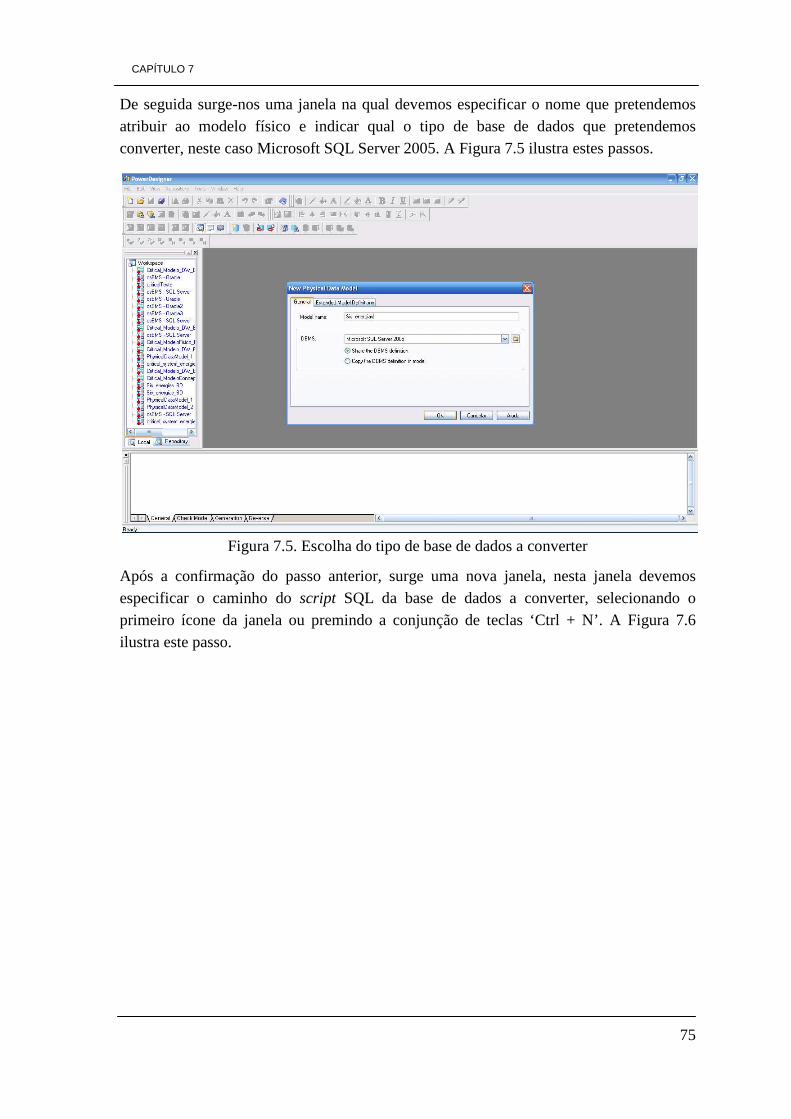
CAPÍTULO 7
75
De seguida surge-nos uma janela na qual devemos especificar o nome que pretendemos atribuir ao modelo físico e indicar qual o tipo de base de dados que pretendemos converter, neste caso Microsoft SQL Server 2005. A Figura 7.5 ilustra estes passos.
Figura 7.5. Escolha do tipo de base de dados a converter
Após a confirmação do passo anterior, surge uma nova janela, nesta janela devemos especificar o caminho do script SQL da base de dados a converter, selecionando o primeiro ícone da janela ou premindo a conjunção de teclas ‘Ctrl + N’. A Figura 7.6 ilustra este passo.
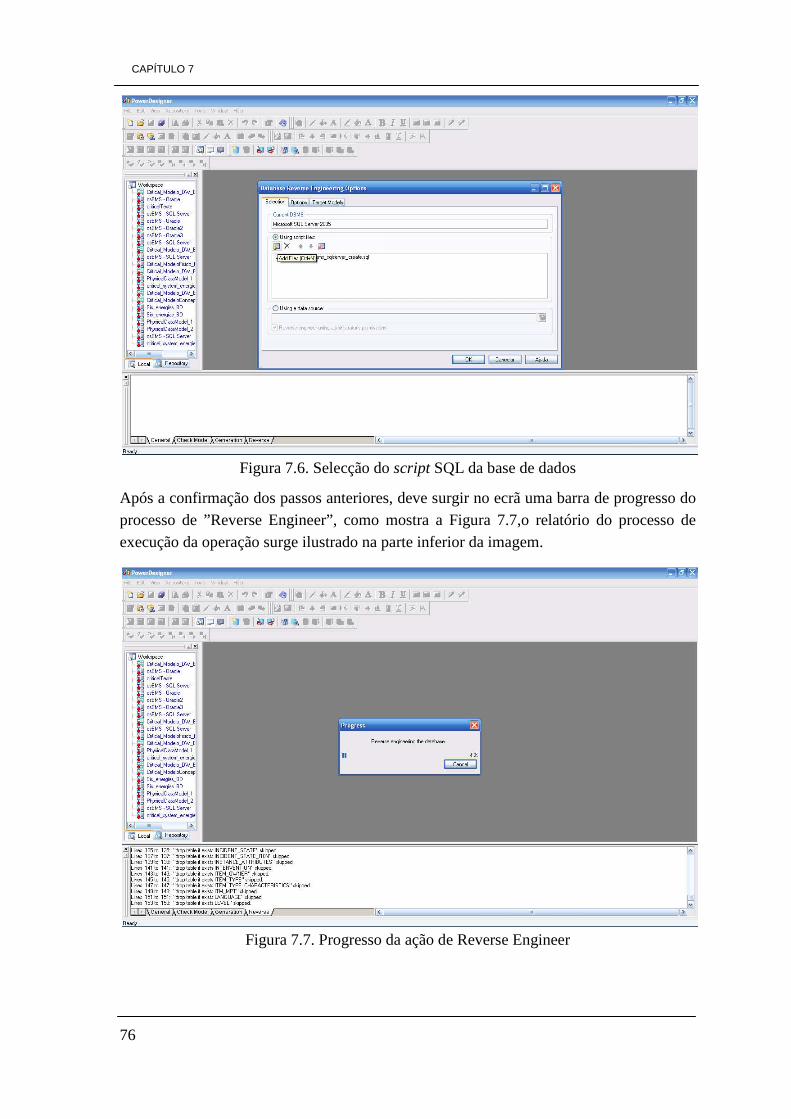
CAPÍTULO 7
76
Figura 7.6. Selecção do script SQL da base de dados
Após a confirmação dos passos anteriores, deve surgir no ecrã uma barra de progresso do processo de ”Reverse Engineer”, como mostra a Figura 7.7,o relatório do processo de execução da operação surge ilustrado na parte inferior da imagem.
Figura 7.7. Progresso da ação de Reverse Engineer

CAPÍTULO 7
77
Finalmente, temos o processo de ”Reverse Engineer” finalizado, e a arquitetura do modelo físico da base de dados gerada. A Figura 7.8 mostra parte da arquitetura do modelo físico da base de dados gerada nos passos anteriores.
Figura 7.8. Modelo físico da base de dados
Os próximos passos coincidem com a transformação do modelo físico atual para uma base de dados MySQL. Para continuar com o processo, primeiramente é necessário proceder à seleção do tipo de base de dados corrente e seleção do tipo de base de dados futura. Na ferramenta Power Designer 12.5 é necessário especificar antes de gerar novos elementos o tipo de base de dados corrente e o novo tipo de base de dados, caso seja diferente. No nosso caso, pretendemos transformar um modelo físico de uma base de dados SQL Server numa base de dados MySQL, o que obriga a este procedimento. No separador ”Database” devemos selecionar a primeira opção ”Change Current DBMS”, como demonstra na Figura 7.9.
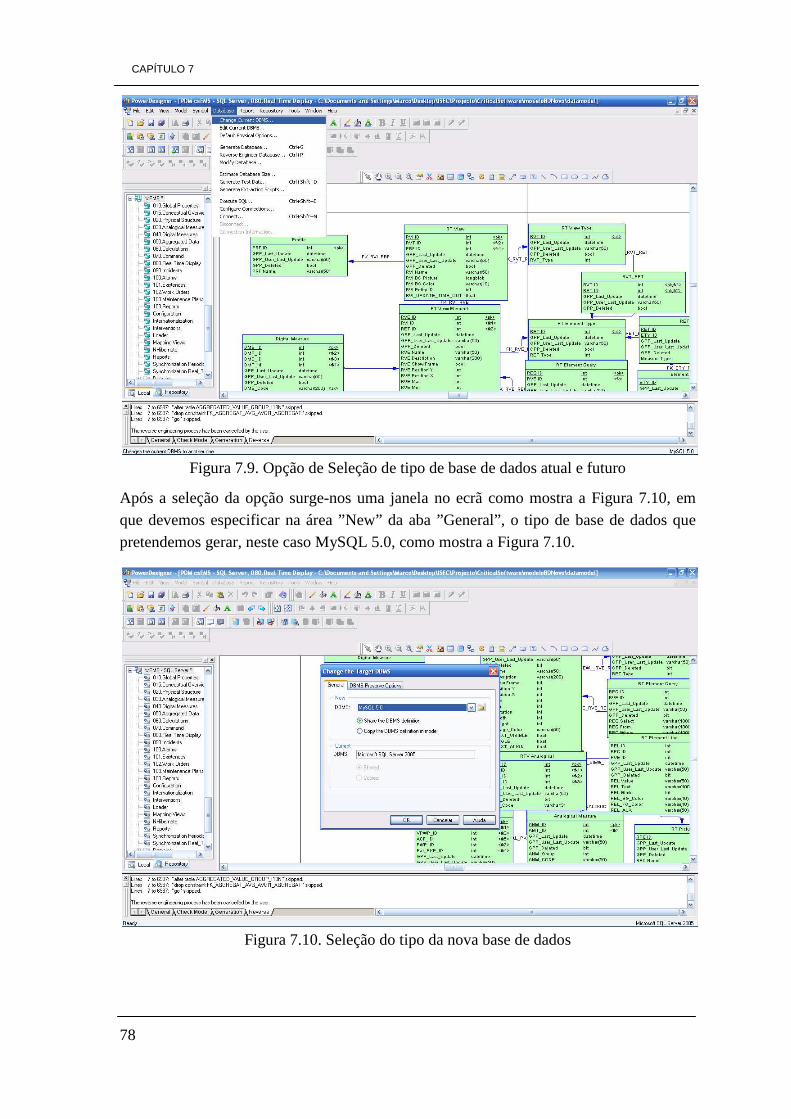
CAPÍTULO 7
78
Figura 7.9. Opção de Seleção de tipo de base de dados atual e futuro
Após a seleção da opção surge-nos uma janela no ecrã como mostra a Figura 7.10, em que devemos especificar na área ”New” da aba ”General”, o tipo de base de dados que pretendemos gerar, neste caso MySQL 5.0, como mostra a Figura 7.10.
Figura 7.10. Seleção do tipo da nova base de dados
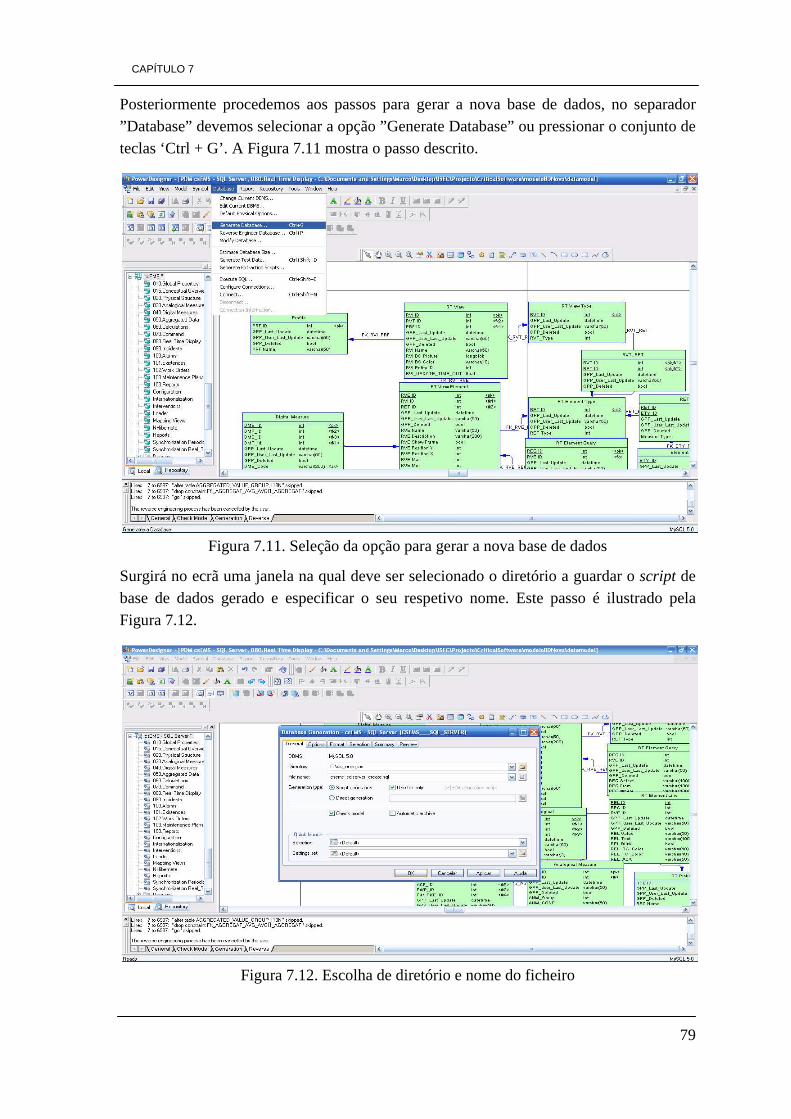
CAPÍTULO 7
79
Posteriormente procedemos aos passos para gerar a nova base de dados, no separador ”Database” devemos selecionar a opção ”Generate Database” ou pressionar o conjunto de teclas ‘Ctrl + G’. A Figura 7.11 mostra o passo descrito.
Figura 7.11. Seleção da opção para gerar a nova base de dados
Surgirá no ecrã uma janela na qual deve ser selecionado o diretório a guardar o script de base de dados gerado e especificar o seu respetivo nome. Este passo é ilustrado pela Figura 7.12.
Figura 7.12. Escolha de diretório e nome do ficheiro
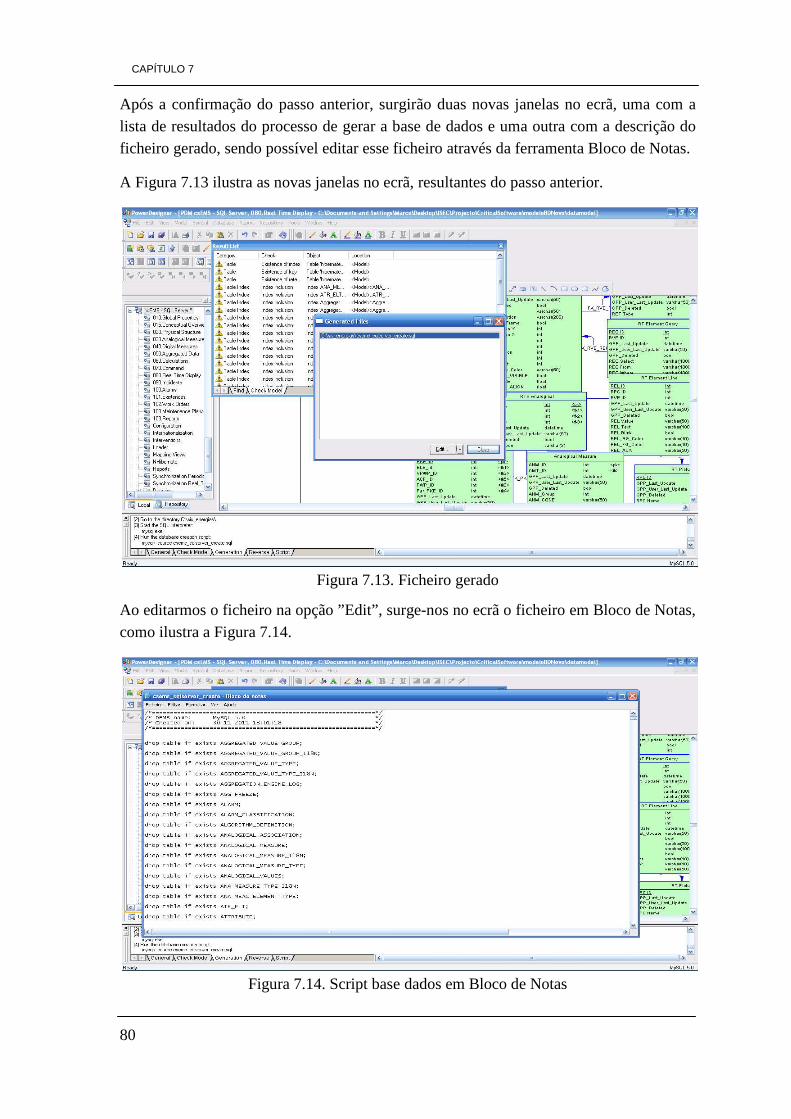
CAPÍTULO 7
80
Após a confirmação do passo anterior, surgirão duas novas janelas no ecrã, uma com a lista de resultados do processo de gerar a base de dados e uma outra com a descrição do ficheiro gerado, sendo possível editar esse ficheiro através da ferramenta Bloco de Notas.
A Figura 7.13 ilustra as novas janelas no ecrã, resultantes do passo anterior.
Figura 7.13. Ficheiro gerado
Ao editarmos o ficheiro na opção ”Edit”, surge-nos no ecrã o ficheiro em Bloco de Notas, como ilustra a Figura 7.14.
Figura 7.14. Script base dados em Bloco de Notas
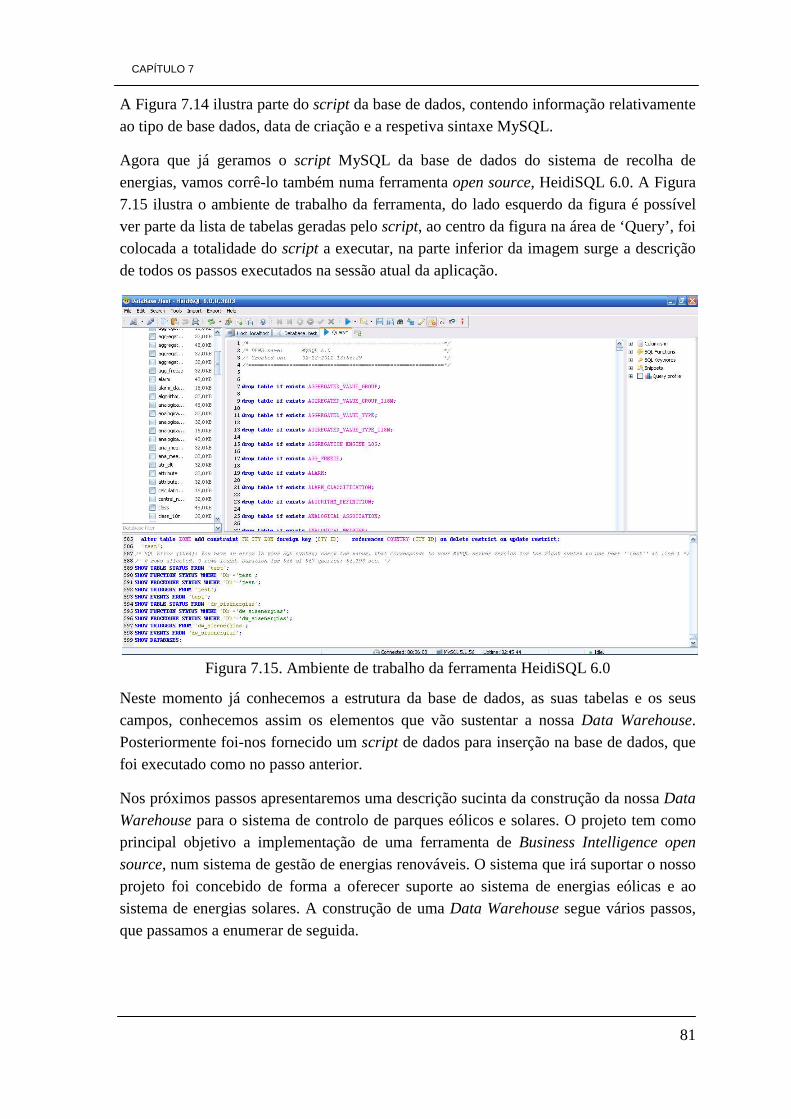
CAPÍTULO 7
81
A Figura 7.14 ilustra parte do script da base de dados, contendo informação relativamente ao tipo de base dados, data de criação e a respetiva sintaxe MySQL.
Agora que já geramos o script MySQL da base de dados do sistema de recolha de energias, vamos corrê-lo também numa ferramenta open source, HeidiSQL 6.0. A Figura 7.15 ilustra o ambiente de trabalho da ferramenta, do lado esquerdo da figura é possível ver parte da lista de tabelas geradas pelo script, ao centro da figura na área de ‘Query’, foi colocada a totalidade do script a executar, na parte inferior da imagem surge a descrição de todos os passos executados na sessão atual da aplicação.
Figura 7.15. Ambiente de trabalho da ferramenta HeidiSQL 6.0
Neste momento já conhecemos a estrutura da base de dados, as suas tabelas e os seus campos, conhecemos assim os elementos que vão sustentar a nossa Data Warehouse. Posteriormente foi-nos fornecido um script de dados para inserção na base de dados, que foi executado como no passo anterior.
Nos próximos passos apresentaremos uma descrição sucinta da construção da nossa Data
Warehouse para o sistema de controlo de parques eólicos e solares. O projeto tem como principal objetivo a implementação de uma ferramenta de Business Intelligence open
source, num sistema de gestão de energias renováveis. O sistema que irá suportar o nosso projeto foi concebido de forma a oferecer suporte ao sistema de energias eólicas e ao sistema de energias solares. A construção de uma Data Warehouse segue vários passos, que passamos a enumerar de seguida.

CAPÍTULO 7
82
7.2.1. Descrição do Negócio
O sistema de gestão de parques eólicos e solares, tem como principal objetivo controlar e registar as ações diárias dos diversos elementos que o constituem. É essencial o controlo dos diversos dados relacionados com o funcionamento dos diferentes elementos desses mesmos parques. Sucintamente a atividade de negócio prende-se com o controlo de todos os elementos constituintes de um parque de energias renováveis e a medição dos valores diários de energia capturados pelos elementos de cada parque.
7.2.2. Objetivo
O principal objetivo na construção da nossa Data Warehouse é controlar os diferentes elementos que constituem o sistema de captura de energias e monitorizar a sua rentabilidade, funcionamento e controlo de incidentes registados.
7.2.3. Desafio
Planeamento e construção de uma Data Warehouse que guarde a informação essencial do sistema de controlo de parques de energias renováveis, parques eólicos e solares.
7.2.4. Estratégia
A principal estratégia na construção da Data Warehouse é a construção de um modelo de arquitetura que suporte o sistema de gestão de energias eólicas e o sistema de gestão de energias solares.
7.2.5. Questões às quais a DW deve conseguir respon der
Quando se desenvolvemos uma DW é importante definir qual a estrutura que deve ter, fazendo uma seleção da informação que realmente é necessária para avaliar os processos de negócio. Posto isto, é importante que o cliente ou representante do cliente elabore uma descrição detalhada sobre o conjunto de métricas que pretende extrair do negócio. O desenvolvimento de uma DW tem o fundamento de tentar reunir a informação que suporte as necessidades exigidas pelo cliente. Desta forma, o cliente deve colocar as questões às quais quer obter resposta por parte da DW. Em seguida enumeramos um conjunto de questões que o cliente quer ver esclarecidas através da nossa implementação prática.
Qual o parque que produz mais energia? Qual o ramal que produz mais energia? Qual a torre por ramal que produz mais energia? Quais as condições climatéricas que contribuem para uma maior produção de energia? Qual a posição geográfica mais rentável na produção de energia? Qual a época do ano mais propicia à captura de energia? Qual o tipo de torres que detém melhores índices de rendimento? Qual o tipo de torres mais suscetíveis de avarias? Qual o tempo médio de reparação de avarias por tipo? Qual o tipo de reparação mais dispendiosa? Quais os valores médios de energia capturada por dia, por parque e por ramal?

CAPÍTULO 7
83
7.2.6. Granularidade
Define-se por granularidade o grau de detalhe a que uma DW deve responder. A informação guardada numa DW poderá ter maior detalhe ou menor detalhe tendo em conta as exigências da avaliação estipulada pelo cliente. Se analisarmos uma dimensão “tempo” o nosso nível de granularidade pode repartir-se em (ano, semestre, trimestre, mês, semana, dia, hora, minuto, segundo), ou simplesmente (ano, mês, dia, hora).
Quantidade de energia produzida por parque, por ramal, por torre, por dia. Custos manutenção por tipo de avaria, por elemento, por tempo dispendido.
7.2.7. Identificação de estrelas e dimensões
Da reunião do conjunto de elementos descritos anteriormente, procedemos à identificação das estrelas, dimensões e tabelas de factos. Da nossa análise idealizámos a criação de um modelo arquitetónico de DW constituído por duas estrelas, uma estrela relacionada com os processos de recolha de energia e uma estrela para registo de avarias e incidentes.
A Tabela 7.1 apresenta as estrelas, as suas respetivas dimensões e as tabelas de factos.
Tabela 7.1. Arquitetura da DW a construir
Estrela Dimensões Factos
Captura de energia
Parque
Factos_energy Elemento
Tempo
Manutenção
Parque
Factos_average
Elemento
Tempo
Incidente
Responsabilidade
A partir das descrições presentes na Tabela 7.1. procedemos à criação do modelo concetual da Data Warehouse. Para a criação dos modelos, concetual e físico utilizámos também a ferramenta Power Designer 12.5. A Figura 7.1.7.a ilustra o modelo conceptual da arquitetura da DW.
Segundo a nossa perspetiva, vamos ter uma DW com duas estrelas, suportadas por duas tabelas de factos e cinco dimensões. A estrela relacionada com os processos de recolha de energia é composta pela tabela de factos (Factos_Energy) que guarda as métricas (activePower, reactivePower e solarRadiation) e interage com as dimensões (Park, Element e Time). A dimensão ”Park” guarda todos os dados relacionados com o parque eólico/solar. A dimensão ”Element” regista os dados relativamente a cada elemento de captura de energia que constitui o parque. A dimensão ”Time” é a dimensão responsável por associar cada registo ao momento em que acontece, registando dados de 15 em 15

CAPÍTULO 7
84
minutos, fazendo uma média dos resultados registados a cada intervalo de 15 minutos. Estas três dimensões também constituem a estrela de ocorrências de avarias composta pela tabela de factos (Factos_Average) que regista as métricas (power, duration e solarRadiation), que registarão o valor de ”power” a duração do incidente e os valores de radiação solar de modo a perceber a gravidade do problema tendo em conta a energia que não foi possível capturar nesse intervalo de tempo. Esta estrela é ainda composta pelas dimensões (Responsability e incident) que guardam o tipo de responsabilidade e dados relativamente ao incidente (descrição, duração e estado de resolução) respetivamente.
A Figura 7.16 que se segue ilustra a arquitetura do modelo concetual da DW construída.
Figura 7.16. Modelo concetual da DW.
No modelo concetual, as tabelas de factos (factos_energy e factos_average) apenas possuem os atributos que representam as métricas que se pretendem extrair. Todas as relações entre as tabelas são do tipo ”1:N” em que as dimensões estão do lado ”1” e as tabelas de factos do lado ”N”, de modo a que ao gerar o diagrama físico, as tabelas de factos tendo em conta a normalização, recebam todas as chaves primárias de cada uma das dimensões como chaves forasteiras, para que possuam toda a informação relativamente a cada registo.
Factos_Energy_Park Factos_Energy_Element Factos_Energy_Time
Factos_Average_Element
Factos_Average_Park Factos_Average_Time
Factos_Average_IncidentFactos_Average_Responsability
Element
ID_ElementnametypebrandmodelsoftwareVersionmanufactureDatediameterminimumUnavailabil ity
<pi> IntegerVariable characters (60)IntegerVariable characters (60)Variable characters (60)Variable characters (20)Variable characters (50)Variable characters (50)Variable characters (50)
<M>
Key_1 <pi>
Responsability
ID_Responsabilitytype
<pi> IntegerVariable characters (60)
<M>
Key_1 <pi>
Park
ID_Parknamecountryzoneclusterinstalled_power
<pi> IntegerVariable characters (60)Variable characters (60)Variable characters (60)Variable characters (60)Integer
<M>
Key_1 <pi>
Time
ID_Timeyearmothdayhour
<pi> IntegerIntegerVariable characters (10)IntegerVariable characters (8)
<M>
Key_1 <pi>
Factos_Energy
activePowerreactivePowersolarRadiation
FloatFloatFloat
Factos_Average
powerdurationsolarRadiation
IntegerFloatFloat
Incident
ID_IncidentdescriptionIncidentdurationIncidentstateIncident
<pi> IntegerVariable characters (60)Variable characters (60)Variable characters (60)
<M>
Key_1 <pi>

CAPÍTULO 7
85
A Figura 7.17 ilustra a arquitetura do modelo físico da DW, o modelo físico é o novo modelo que resulta da normalização definida no modelo conceptual, representado na Figura 7.16. No novo modelo gerado, as únicas diferenças surgem nas tabelas de factos (Factos_Energy e Factos_Average), que recebem como chaves forasteiras (foreign keys) os atributos chave primária (primary key) de cada uma das dimensões a si associadas. Os elementos ”ID” de cada dimensão vão permitir associar todos os registos guardados na DW e obter informação mais detalhada quando necessário.
O modelo físico é gerado automaticamente no Power Designer 12.5, selecionando a opção ”Generate Physical Data Model” no separador ”Tools” ou premindo o conjunto de teclas ‘Ctrl + Shift + P’.
Figura 7.17. Modelo físico da DW.
FK_FACTOS_ENERGY_PARK
FK_FACTOS_ENERGY_ELEMENT
FK_FACTOS_ENERGY_TIME
FK_FACTOS_AVERAGE_ELEMENT
FK_FACTOS_AVERAGE_PARK
FK_FACTOS_AVERAGE_TIME
FK_FACTOS_AVERAGE_INCIDENTFK_FACTOS_AVERAGE_RESPONSABILITY
Element
ID_ElementnametypebrandmodelsoftwareVersionmanufactureDatediameterminimumUnavailabil ity
intvarchar(60)intvarchar(60)varchar(60)varchar(20)varchar(50)varchar(50)varchar(50)
<pk>
Responsabili ty
ID_Responsabili tytype
intvarchar(60)
<pk>
Park
ID_Parknamecountryzoneclusterinstal led_power
intvarchar(60)varchar(60)varchar(60)varchar(60)int
<pk>
Time
ID_Timeyearmothdayhour
intintvarchar(10)intvarchar(8)
<pk>
Factos_Energy
ID_ParkID_ElementID_TimeactivePowerreactivePowersolarRadiation
intintintfloatfloatfloat
<fk1><fk2><fk3>
Factos_Average
ID_ElementID_ParkID_TimeID_IncidentID_Responsabil itypowerdurationsolarRadiation
intintintintintintfloatfloat
<fk1><fk2><fk3><fk4><fk5>
Incident
ID_IncidentdescriptionIncidentdurationIncidentstateIncident
intvarchar(60)varchar(60)varchar(60)
<pk>

CAPÍTULO 7
86
A Figura 7.17 ilustra a arquitetura do modelo físico que sustenta a nossa DW.
Para uma melhor perceção da estrutura da nossa DW, vejamos em detalhe a descrição de cada uma das tabelas (dimensões e factos) que constituem a arquitetura da DW.
7.2.8. Tabela de factos Factos_Eenrgy
A tabela “Factos_Energy” é a tabela de factos da estrela de produção de energia responsável por estabelecer a ligação com as dimensões que constituem a mesma estrela.
A Figura 7.18 ilustra a estrutura da tabela em análise.
Figura 7.18. Tabela de factos “Factos_Energy”
Os atributos da tabela ilustrada na Figura 7.18 são os atributos chave de cada uma das dimensões da estrela de captura de energia e as métricas “activePower” (mede o valor da potência ativa), “reactivePower” (mede o valor da potência reativa) e “solarRadiation” (que mede os valores da radiação solar).
7.2.9. Dimensão Park
A dimensão “Park” é responsável por guardar o registo de dados relacionados com cada parque de captura de energias renováveis.
A Figura 7.19 ilustra a estrutura da tabela da dimensão “Park”. A dimensão “Park” é partilhada também pela estrela de manutenção.
Figura 7.19. Dimensão Park
A dimensão “Park” é composta pelo atributo chave primária (ID_Park), atributos de informação relativamente ao parque como: nome (name); país de localização (country); zona de localização (zone); identificação do cluster (cluster); e o valor de potência instalada (installed_power).
Factos_Energy
ID_ParkID_ElementID_TimeactivePowerreactivePowersolarRadiation
intintintfloatfloatfloat
<fk1><fk2><fk3>
Park
ID_Parknamecountryzoneclusterinstalled_power
intvarchar(60)varchar(60)varchar(60)varchar(60)int
<pk>

CAPÍTULO 7
87
7.2.10. Dimensão Element
A dimensão “Element” é responsável por guardar informação relativamente a cada elemento constituinte do parque de captura de energias renováveis.
A Figura 7.20 ilustra a estrutura da tabela relativa à dimensão “Element”. A dimensão “Element” é partilhada também pela estrela de manutenção.
Figura 7.20. Dimensão Element
A tabela relativa à dimensão “Element” é composta pelo seu atributo chave primária (ID_Element), e por um conjunto de informação relativamente à descrição do elemento e suas caraterísticas. Os atributos que a completam são: descrição do elemento (name); tipo de elemento (type); marca do elemento (brand); modelo (model); versão do software instalado no elemento (softwareVersion); data de fabrico (manufactureDate); diâmetro (diameter); e indisponibilidade mínima (minimumUnavailability).
7.2.11. Dimensão Time
A dimensão “Time” é responsável por guardar dados relacionados com o tempo. A Figura 7.21 mostra a constituição da tabela. A dimensão “Time” é partilhada também pela estrela de manutenção.
Figura 7.21. Dimensão Time
A tabela da dimensão “Time” é constituída pelo seu atributo chave primária (ID_Time) e pelos atributos que guardam informação relativamente ao ano (year), mês (moth), dia (day) e hora (hour).
7.2.12. Tabela de factos Factos_Average
A tabela de factos “Factos_Average” é responsável por interligar as dimensões da estrela de manutenção. A sua estrutura é composta pelos atributos chave primária de cada uma
Element
ID_ElementnametypebrandmodelsoftwareVersionmanufactureDatediameterminimumUnavailabil i ty
intvarchar(60)intvarchar(60)varchar(60)varchar(20)varchar(50)varchar(50)varchar(50)
<pk>
Time
ID_Timeyearmothdayhour
intintvarchar(10)intvarchar(8)
<pk>

CAPÍTULO 7
88
das dimensões da estrela de manutenção e das suas métricas (“power”, “duration” e “solarRadiation”). A Figura 7.22 ilustra a estrutura da tabela.
Figura 7.22. Tabela de factos, Factos_Average
As métricas da tabela pretendem medir a capacidade do elemento danificado (power), a duração da avaria de modo a identificar os danos causados (duration) e a radiação solar que se fez sentir durante o período de tempo em que o equipamento esteve em fase de manutenção.
7.2.13. Dimensão Incident
A dimensão “Incident” tem como objetivo guardar os dados relativos aos incidentes ocorridos. A Figura 7.23 ilustra a estrutura da tabela.
Figura 7.23. Dimensão Incident
A dimensão “Incident” é composta pelo seu atributo chave primária (ID_Incident), pela informação descritiva do incidente (descriptionIncident), duração do incidente (durationIncident) e estado do incidente (stateIncident). O incidente pode ter sete estados diferentes, sendo eles:
• Restored 100%.
• Open.
• Closed.
• Pending.
• Locally Recognized.
• Recognized.
• Restored < 100%.
7.2.14. Dimensão Responsability
A dimensão “Responsability” é responsável por guardar informação relativamente ao tipo de responsabilidade dos agentes de manutenção sobre o incidente.
Factos_Average
ID_ElementID_ParkID_TimeID_IncidentID_Responsabil i typowerdurationsolarRadiation
intintintintintintfloatfloat
<fk1><fk2><fk3><fk4><fk5>
Incident
ID_IncidentdescriptionIncidentdurationIncidentstateIncident
intvarchar(60)varchar(60)varchar(60)
<pk>

CAPÍTULO 7
89
Figura 7.24. Dimensão Responsability
A Figura 7.24 ilustra a tabela da dimensão “Responsability”, que é composta pelo atributo chave primária (ID_Responsability) e pelo atributo que regista o tipo de responsabilidade (type).
7.2.15. Gerar código MySQL para a construção da DW
Os passos de criação do código MySQL para gerar a Data Warehouse construída nos passos anteriores, são os mesmos que foram seguidos em 7.1. Para a criação do código MySQL para gerar a DW recorrendo ao Power Designer 12.5, basta seguir os passos ilustrados pelas figuras 7.11, 7.12, 7.13, 7.14 e 7.15.
7.3. Processos de ETL
O processo de ETL é dos passos mais importantes para o preenchimento correto da nossa Data Warehouse. Aquando do desenvolvimento dos processos de ETL ainda estávamos numa fase de avaliação das quatro ferramentas (JasperSoft, Pentaho, SpagoBI e Vanilla), posto isto a ferramenta escolhida para o desenvolvimento dos processos de ETL foi Talend. Esta escolha deveu-se ao facto de Talend ser adotada por todas as ferramentas BI em análise, ainda que Pentaho possua um módulo específico (Pentaho Data Integration), para os processos de ETL. Posteriormente analisámos o Pentaho Data Integration e classificamo-lo como uma ótima solução fácil de usar e bastante apelativa. Esta escolha surgiu também para demonstrar que as ferramentas open source têm a particularidade de se tornarem compatíveis, sendo que a conciliação/utilização de ferramentas diferentes é possível, complementando-se umas às outras.
Após construída a Data Warehouse, e após a definição dos elementos chave da base de dados que seriam importantes analisar, procedemos ao inicio da construção do processo de ETL.
7.3.1. Dimensão Park
A dimensão “Park” é carregada através do processo de ETL ilustrado na Figura 7.25.
Responsabili ty
ID_Responsabili tytype
intvarchar(60)
<pk>

CAPÍTULO 7
90
Figura 7.25. Esquema de ETL de carregamento da dimensão Park
A Figura 7.25 representa o esquema de ETL que permite carregar os dados da dimensão “Park”. Na figura é possível identificar 5 elementos diferentes: fontes de dados, tabela de mapeamentos, visualização de dados transformados, exportação de dados para um ficheiro Excel e carregamento da dimensão Park da DW.
Os elementos “power_plant”, “zone”, “country”, “cluster” representam fontes de dados de entrada. O elemento “tMap_1” é responsável pelo mapeamento de dados das várias fontes de dados para a dimensão “park”, para o ficheiro de Excel “tFileOutputExcel_1” e para o visualizador de registos “tLogRow_1”.
Os dados a carregar para a dimensão “park” da DW provêm de várias tabelas da base de dados original, que suporta o sistema de energias renováveis. Para uma melhor perceção do processo de extração de dados procedemos à descrição das consultas MySQL de cada elemento de entrada de dados.
O elemento “country” segue a seguinte sintaxe MySQL de consulta.
"SELECT country.CTY_ID, country.CTY_NAME
FROM country"
O element “zone” contribui para o processo de transformação de dados com o resultado da consulta que se segue.
"SELECT zone.ZON_ID, zone.CTY_ID, zone.ZON_NAME
FROM zone"
O element “power_plant” fornece os dados resultantes da consulta seguinte.
"SELECT power_plant.PWP_ID,
power_plant.NOD_ID,
power_plant.ZON_ID,
power_plant.ITO_ID,
power_plant.CLUS_ID,
power_plant.GPP_LAST_UPDATE,
power_plant.GPP_USER_LAST_UPDATE,
power_plant.GPP_DELETED,

CAPÍTULO 7
91
power_plant.PWP_NAME,
power_plant.PWP_COMPANY,
power_plant.PWP_INSTALL_DATE,
power_plant.PWP_INSTALLED_POWER,
power_plant.PWP_LINK_POINT,
power_plant.PWP_CAN_BE_LIMITED,
power_plant.PWP_LIMITE_TYPE,
power_plant.PWP_APPARENT_POW_LIMIT_DOMAIN,
power_plant.PWP_POWER_FACTOR_DOMAIN,
power_plant.PWP_APPARENT_POWER_LIMIT,
power_plant.PWP_REACTIVE_POWER_LIMIT,
power_plant.PWP_TYPE,
power_plant.PWP_ASSIGNED_POWER,
power_plant.PWP_MAX_FEED_POWER,
power_plant.PWP_MAX_REACTIVE_POWER,
power_plant.PWP_NOMINAL_POWER
FROM power_plant"
Existem dois elementos “power_plant”, em que a consulta seguinte existe apenas para fornecer os dados necessários para a DW e o anterior é responsável por manter a relação com os atributos dos restantes elementos de entrada de dados.
"SELECT power_plant.PWP_ID,
power_plant.NOD_ID,
power_plant.ZON_ID,
power_plant.ITO_ID,
power_plant.CLUS_ID,
power_plant.PWP_NAME
FROM power_plant"
Por fim a fonte de dados “cluster”, que disponibiliza os dados resultantes da consulta que se segue.
"SELECT cluster.CLUS_NAME,
cluster.CLUS_ID
FROM cluster"
A Figura 7.26 ilustra o element tMap_1, responsável por suportar o processo de mapeamento de dados de tabelas para as respetivas fontes de destino, aplicando alguns processos de transformação.

CAPÍTULO 7
92
Figura 7.26. Ilustração do elemento tMap_1
Na Figura 7.26 é possível visualizar do lado esquerdo as fontes de dados, em que o atributo “PWP_INSTALLED_POWER” mapeia os seus dados para o atributo “INSTALLED_POWER” da dimensão “Park” e do ficheiro Excel. Do lado esquerdo da imagem estão representados os três elementos de saída de dados, a dimensão “Park” da DW (dimension_park), o ficheiro de Excel (park_data) e o visualizador de registos (tlr). Na zona inferior da imagem é possível visualizar o tipo de dados dos atributos de cada elemento e proceder à sua alteração bem como outras especificações (p.ex: tamanho dos campos). É possível inserir novos campos e proceder à eliminação de outros existentes em cada elemento de entrada e saída.
A Figura 7.27 ajuda a perceber melhor qual a relação de cada elemento com os atributos da dimensão “Park” da DW.
Figura 7.27. Constituição da dimensão Park da DW.
O elemento “tLogRow_1” ilustrado no processo de ETL da dimensão “Park”, foi utilizado com a finalidade de facilitar a visualização dos dados gerados pelo processo
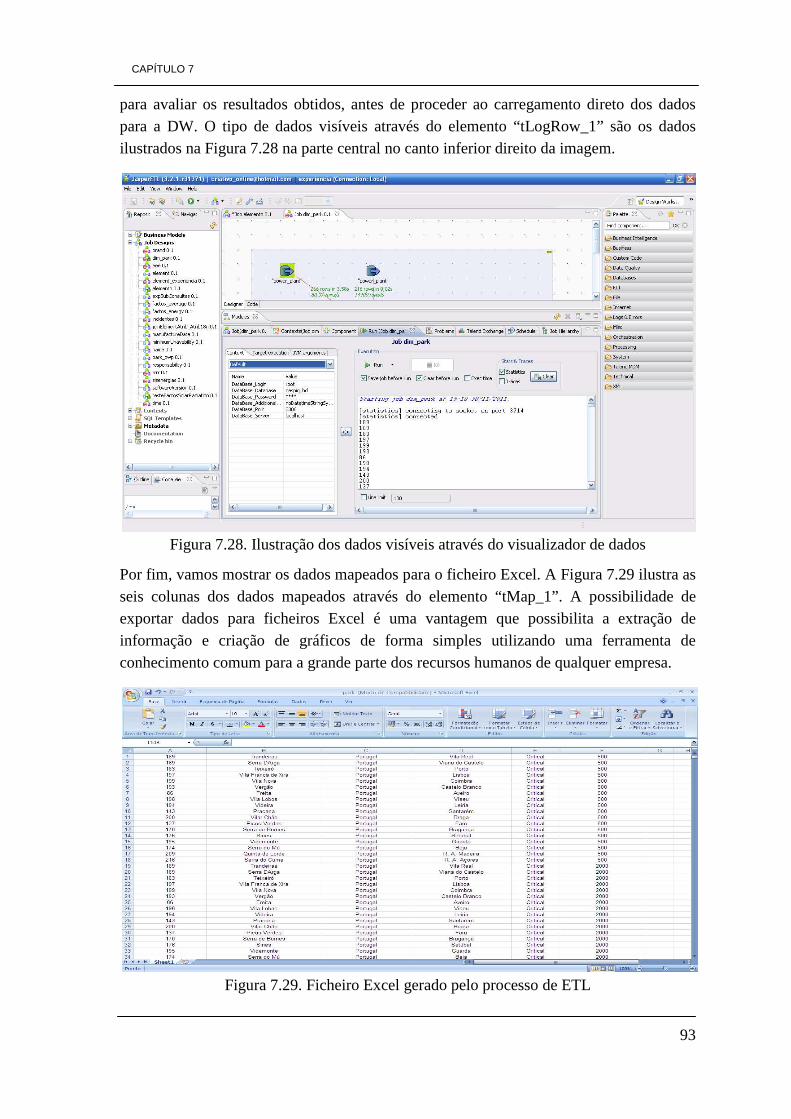
CAPÍTULO 7
93
para avaliar os resultados obtidos, antes de proceder ao carregamento direto dos dados para a DW. O tipo de dados visíveis através do elemento “tLogRow_1” são os dados ilustrados na Figura 7.28 na parte central no canto inferior direito da imagem.
Figura 7.28. Ilustração dos dados visíveis através do visualizador de dados
Por fim, vamos mostrar os dados mapeados para o ficheiro Excel. A Figura 7.29 ilustra as seis colunas dos dados mapeados através do elemento “tMap_1”. A possibilidade de exportar dados para ficheiros Excel é uma vantagem que possibilita a extração de informação e criação de gráficos de forma simples utilizando uma ferramenta de conhecimento comum para a grande parte dos recursos humanos de qualquer empresa.
Figura 7.29. Ficheiro Excel gerado pelo processo de ETL

CAPÍTULO 7
94
7.3.2. Dimensão Element
A dimensão “Element” tal como fora descrito anteriormente, tem como objetivo possuir informação diversa que permita identificar cada elemento de um parque de captura de energias renováveis. A Figura 7.30 mostra o esquema de ETL implementado.
Figura 7.30. Esquema do processo ETL da dimensão Element
A dimensão “element” é suportada pelos elementos de entrada (“element”, “manufacturedDate”, “minimumUnavability”, “brand”, “diameter”, “model”, “name”, “element_type” e “softwareVersion”), pelo elemento de mapeamento “tMap_1” e pelo elemento de saida “element”.
A fonte de dados “element” possui a seguinte sintaxe de consulta.
"SELECT element.ELE_ID,
element.ETY_ID,
element.GPP_LAST_UPDATE,
element.GPP_USER_LAST_UPDATE,
element.GPP_DELETED
FROM element"
Tendo em conta que a dimensão “Element” é constituída pela descrição de vários elementos independentes, e tendo em conta a arquitetura da base de dados do sistema de controlo dos parques, alguns atributos necessitam de consultas com recurso à inclusão da cláusula ‘WHERE’, o preenchimento do campo “manufacturedDate” requer uma consulta condicionada como descreve a sintaxe seguinte.
"SELECT b.ELE_ID, b.ELA_VALUE_STR
FROM attribute_i18n a, element_attributes b
WHERE ATI_NAME='Manufacture Date' and a.ATR_ID = b. ATR_ID;"
O elemento de entrada “minimumUnavability” fornece os dados provenientes da consulta que se segue, que também apresenta uma consulta condicionada.

CAPÍTULO 7
95
"SELECT b.ELE_ID, b.ELA_VALUE_STR
FROM attribute_i18n a, element_attributes b
WHERE ATI_NAME='Minimum Unavailability' and a.ATR_I D = b.ATR_ID;"
O elemento de entrada “brand” fornece os dados provenientes da seguinte consulta condicionada que se segue.
"SELECT b.ELE_ID, b.ELA_VALUE_STR
FROM attribute_i18n a, element_attributes b
WHERE ATI_NAME='Brand' and a.ATR_ID = b.ATR_ID;"
O elemento de entrada “diameter” retorna os dados provenientes da consulta condicionada que se segue.
"SELECT b.ELE_ID, b.ELA_VALUE_STR
FROM attribute_i18n a, element_attributes b
WHERE ATI_NAME='Diameter' and a.ATR_ID = b.ATR_ID;"
O elemento de entrada “model” disponibiliza o conjunto de dados provenientes da consulta condicionada:
"SELECT b.ELE_ID, b.ELA_VALUE_STR
FROM attribute_i18n a, element_attributes b
WHERE ATI_NAME='Model' and a.ATR_ID = b.ATR_ID;"
O elemento de entrada “name” fornece os dados provenientes da consulta que se segue, que também apresenta uma consulta condicionada.
"SELECT b.ELE_ID, b.ELA_VALUE_STR
FROM attribute_i18n a, element_attributes b
WHERE ATI_NAME='Name' and a.ATR_ID = b.ATR_ID;"
O elemento de entrada “element_type” apresenta os dados resultantes da consulta que se segue.
"SELECT element_type.ETY_ID,
element_type.GPP_LAST_UPDATE,
element_type.GPP_USER_LAST_UPDATE,
element_type.GPP_DELETED,
element_type.ETY_TYPE,
element_type.ETY_PWP_TYPE,
element_type.ETY_ALLOW_MULTIPLE
FROM element_type"
O element de entrada “softwareVersion” fornece os dados provenientes da consulta que se segue, que também apresenta uma consulta condicionada.
"select ELE_ID, ELA_VALUE_STR
From attribute_i18n a, element_attributes b
where ATI_NAME = 'Software Version' and a.ATR_ID = b.ATR_ID;"
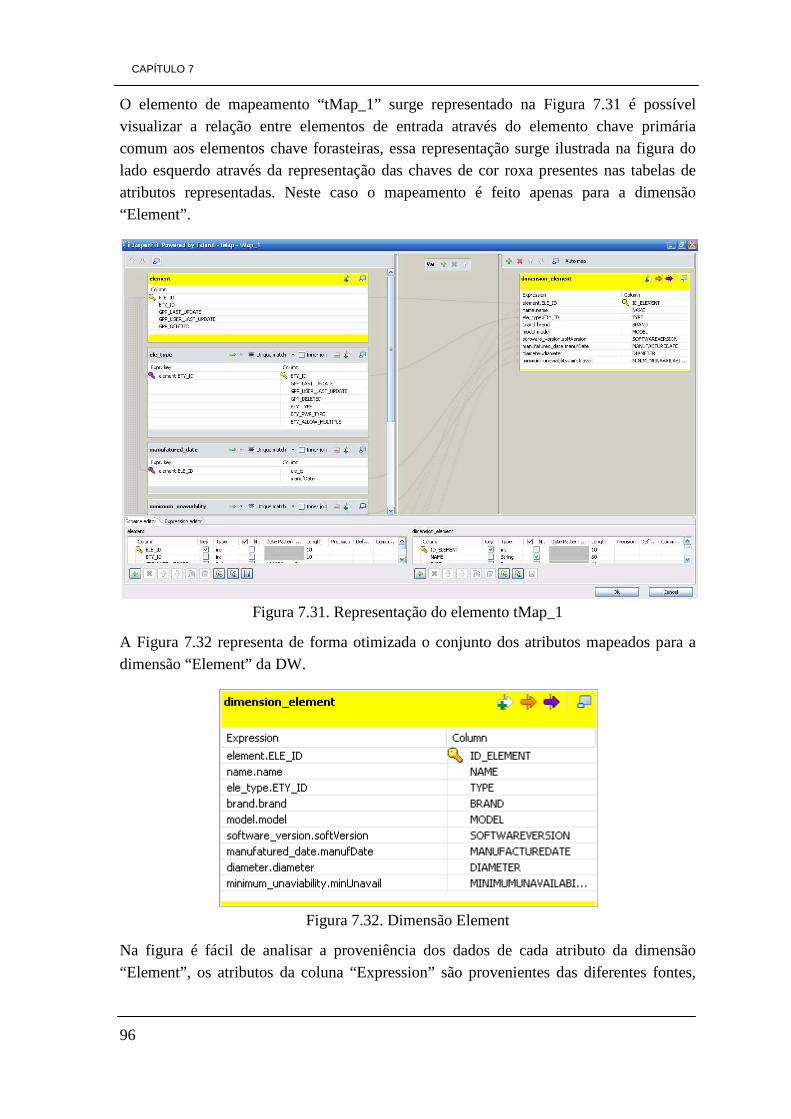
CAPÍTULO 7
96
O elemento de mapeamento “tMap_1” surge representado na Figura 7.31 é possível visualizar a relação entre elementos de entrada através do elemento chave primária comum aos elementos chave forasteiras, essa representação surge ilustrada na figura do lado esquerdo através da representação das chaves de cor roxa presentes nas tabelas de atributos representadas. Neste caso o mapeamento é feito apenas para a dimensão “Element”.
Figura 7.31. Representação do elemento tMap_1
A Figura 7.32 representa de forma otimizada o conjunto dos atributos mapeados para a dimensão “Element” da DW.
Figura 7.32. Dimensão Element
Na figura é fácil de analisar a proveniência dos dados de cada atributo da dimensão “Element”, os atributos da coluna “Expression” são provenientes das diferentes fontes,

CAPÍTULO 7
97
identificadas na primeira parte da descrição de cada atributo (fonte + . + atributo), enquanto que na coluna “Column” estão listados os atributos da dimensão “Element” da DW.
7.3.3. Dimensão Responsability
A dimensão “Responsability” tem como objetivo guardar os dados relativamente à responsabilidade pela manutenção dos equipamentos. O processo de ETL desenvolvido para o carregamento de dados na dimensão “responsability” é o que surge ilustrado na Figura 7.33.
Figura 7.33. Processo de ETL para a dimensão responsability
O processo de ETL apresentado na Figura 7.33, é composto pelas fontes de entrada de dados (“incident”, ”incident_cause” e “incident_cause_i18n”), pelo ficheiro Excel de saida “tFileoutputExcel_1”, pelo elemento de mapeamento “tMap_1” e pela dimensão “responsability” da DW.
Os dados fornecidos por cada elemento de entrada de dados são os que se fazem representar de seguida.
A fonte de dados “incident” retorna os valores obtidos através da consulta que se segue.
"SELECT incident.INC_ID,
incident.ICS_ID,
incident.ICL_ID,
incident.IMD_ID,
incident.PKE_ID,
incident.ICC_ID,
incident.IDS_ID,
incident.GPP_LAST_UPDATE,
incident.GPP_USER_LAST_UPDATE,
incident.GPP_DELETED,
incident.INC_CODE,
incident.INC_NOTES,
incident.INC_START_DATE,
incident.INC_END_DATE,
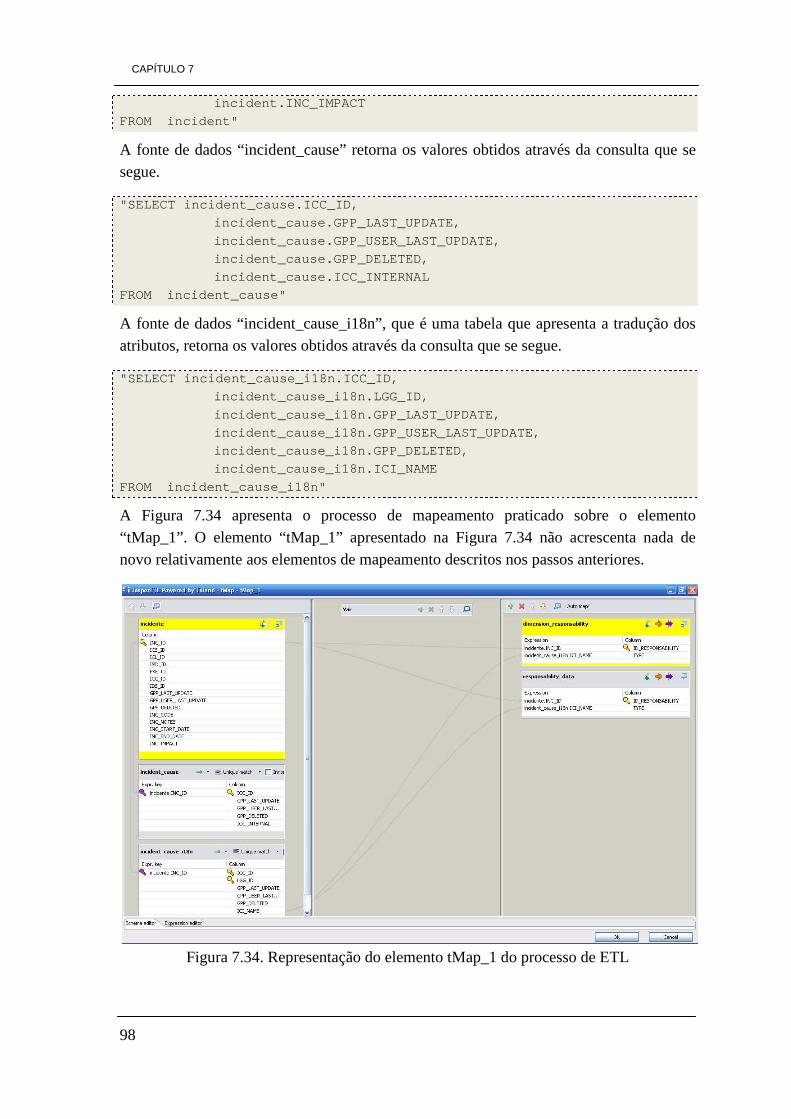
CAPÍTULO 7
98
incident.INC_IMPACT
FROM incident"
A fonte de dados “incident_cause” retorna os valores obtidos através da consulta que se segue.
"SELECT incident_cause.ICC_ID,
incident_cause.GPP_LAST_UPDATE,
incident_cause.GPP_USER_LAST_UPDATE,
incident_cause.GPP_DELETED,
incident_cause.ICC_INTERNAL
FROM incident_cause"
A fonte de dados “incident_cause_i18n”, que é uma tabela que apresenta a tradução dos atributos, retorna os valores obtidos através da consulta que se segue.
"SELECT incident_cause_i18n.ICC_ID,
incident_cause_i18n.LGG_ID,
incident_cause_i18n.GPP_LAST_UPDATE,
incident_cause_i18n.GPP_USER_LAST_UPDATE,
incident_cause_i18n.GPP_DELETED,
incident_cause_i18n.ICI_NAME
FROM incident_cause_i18n"
A Figura 7.34 apresenta o processo de mapeamento praticado sobre o elemento “tMap_1”. O elemento “tMap_1” apresentado na Figura 7.34 não acrescenta nada de novo relativamente aos elementos de mapeamento descritos nos passos anteriores.
Figura 7.34. Representação do elemento tMap_1 do processo de ETL

CAPÍTULO 7
99
A Figura 7.35 permite visualizar em maior detalhe a tabela de atributos que constituem a dimensão “Responsability” da DW.
Figura 7.35. Dimensão Responsability
7.3.4 Dimensão Incident
A dimensão “Incident” é responsável por guardar todos os dados que descrevam um incidente. O processo de ETL para o carregamento de dados da dimensão “Incident” da nossa DW, surge representado na Figura 7.36. Este processo é simples, apenas é apoiado por duas tabelas da base de dados, a tabela “incident” e a tabela que guarda os valores da tradução dos estados dos incidentes. O campo estado é preenchido com informação que permite descrever o estado de resolução/conhecimento do incidente. Para além dos elementos de entrada já descritos, o modelo é constituído ainda por um elemento de mapeamento de dados “tMap_1”, por um ficheiro Excel “tFileOutputExcel_1” e pela dimensão “incident” da DW.
Figura 7.36. Modelo de ETL da dimensão Incident
A tabela “incident” disponibiliza para mapeamento os dados resultantes da consulta que se segue.
"SELECT incident.INC_ID,
incident.ICS_ID,
incident.ICL_ID,
incident.IMD_ID,
incident.PKE_ID,
incident.ICC_ID,
incident.IDS_ID,
incident.GPP_LAST_UPDATE,
incident.GPP_USER_LAST_UPDATE,
incident.GPP_DELETED,
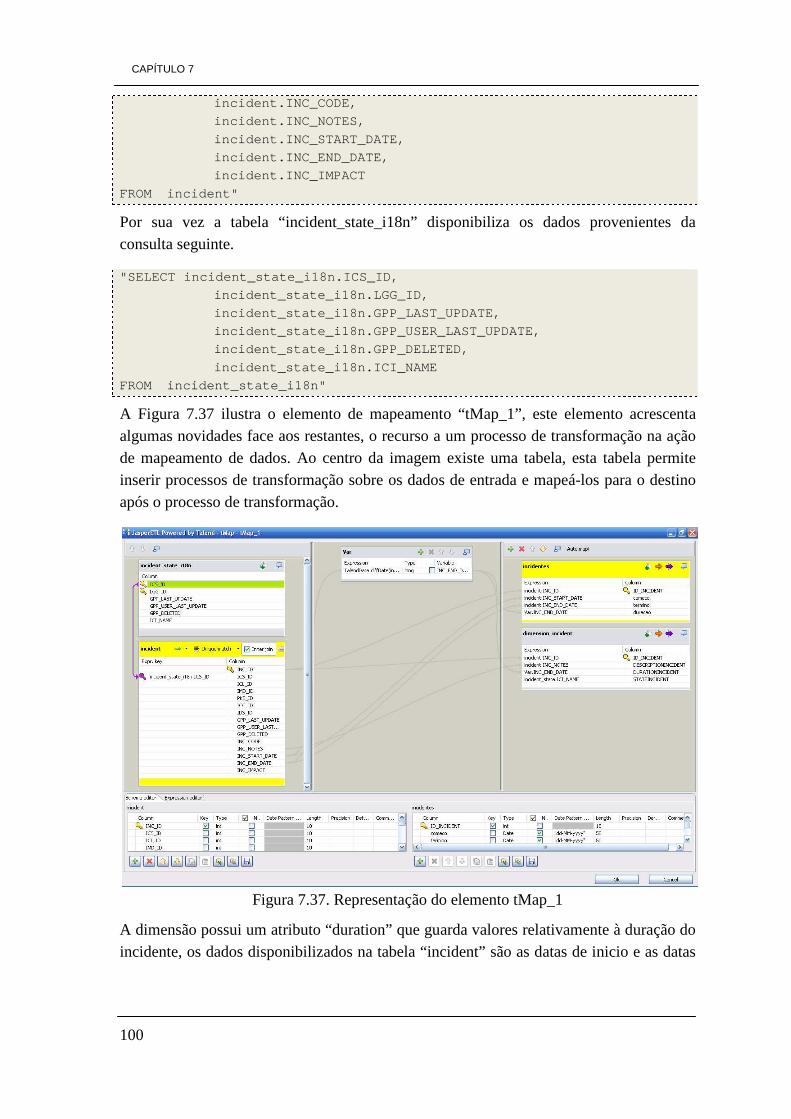
CAPÍTULO 7
100
incident.INC_CODE,
incident.INC_NOTES,
incident.INC_START_DATE,
incident.INC_END_DATE,
incident.INC_IMPACT
FROM incident"
Por sua vez a tabela “incident_state_i18n” disponibiliza os dados provenientes da consulta seguinte.
"SELECT incident_state_i18n.ICS_ID,
incident_state_i18n.LGG_ID,
incident_state_i18n.GPP_LAST_UPDATE,
incident_state_i18n.GPP_USER_LAST_UPDATE,
incident_state_i18n.GPP_DELETED,
incident_state_i18n.ICI_NAME
FROM incident_state_i18n"
A Figura 7.37 ilustra o elemento de mapeamento “tMap_1”, este elemento acrescenta algumas novidades face aos restantes, o recurso a um processo de transformação na ação de mapeamento de dados. Ao centro da imagem existe uma tabela, esta tabela permite inserir processos de transformação sobre os dados de entrada e mapeá-los para o destino após o processo de transformação.
Figura 7.37. Representação do elemento tMap_1
A dimensão possui um atributo “duration” que guarda valores relativamente à duração do incidente, os dados disponibilizados na tabela “incident” são as datas de inicio e as datas
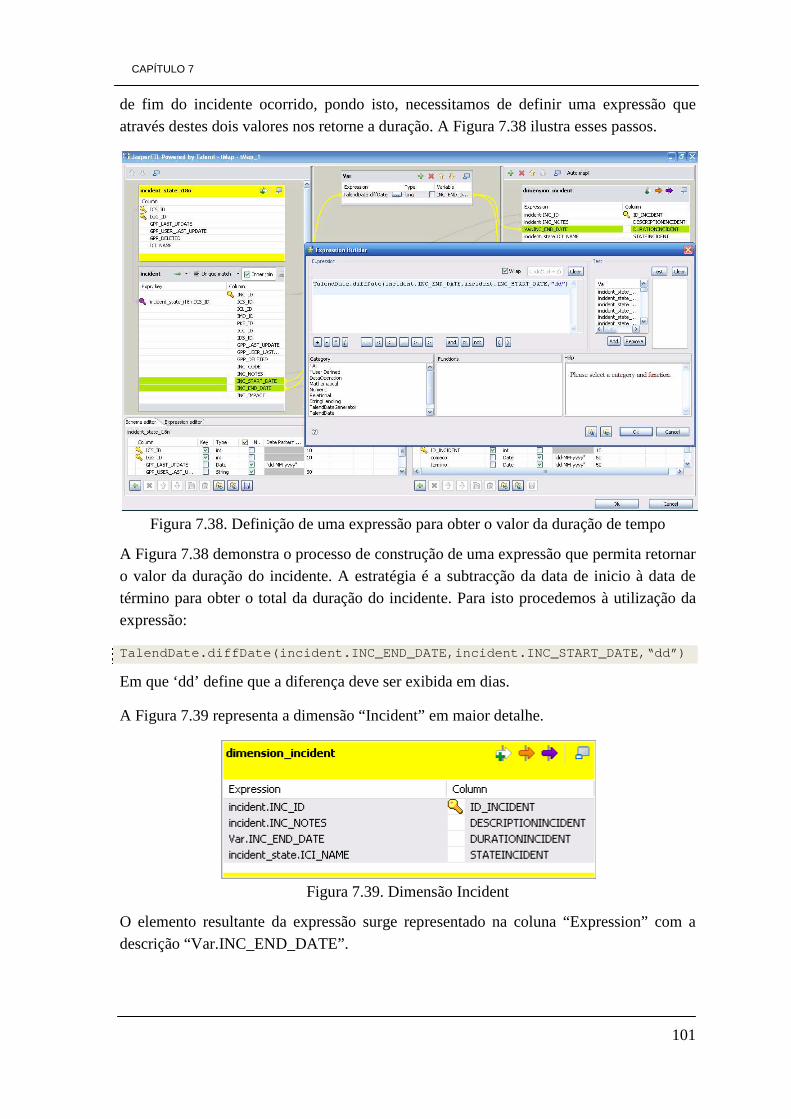
CAPÍTULO 7
101
de fim do incidente ocorrido, pondo isto, necessitamos de definir uma expressão que através destes dois valores nos retorne a duração. A Figura 7.38 ilustra esses passos.
Figura 7.38. Definição de uma expressão para obter o valor da duração de tempo
A Figura 7.38 demonstra o processo de construção de uma expressão que permita retornar o valor da duração do incidente. A estratégia é a subtracção da data de inicio à data de término para obter o total da duração do incidente. Para isto procedemos à utilização da expressão:
TalendDate.diffDate(incident.INC_END_DATE,incident. INC_START_DATE,“dd”)
Em que ‘dd’ define que a diferença deve ser exibida em dias.
A Figura 7.39 representa a dimensão “Incident” em maior detalhe.
Figura 7.39. Dimensão Incident
O elemento resultante da expressão surge representado na coluna “Expression” com a descrição “Var.INC_END_DATE”.

CAPÍTULO 7
102
7.3.5. Dimensão Time
A dimensão “Time” é uma exceção ao que tem sido descrito nos processos de ETL anteriores. Face à complexidade encontrada e à inexistência de documentação e funcionalidades específicas no Talend Open Studio 3.2 para o preenchimento de dimensões de tempo, o processo seguido no mapeamento de dados para a dimensão “Time” da DW foi diferente dos anteriores. A solução encontrada foi o desenvolvimento de um script em PHP (linguagem Web open source), que nos permitisse guardar dados para todos os meses em ficheiros diferentes e no final correr a totalidade do ficheiro no motor de base de dados de forma direta.
Inicialmente foi estipulado em conjunto com o cliente, que a dimensão “Time” deveria possuir dados a partir do ano de 2008 e com registos de tempo de quinze em quinze minutos. Pondo estes dados desenvolvemos o script PHP que se segue, não exigindo grande esforço de compreensão. De um modo geral os aspetos que mudam do atual script para os outros desenvolvidos é o nome do ficheiro, o valor de inicio da variável “$id”, o valor de “$ano”, o valor relativamente ao dia máximo do mês em “$dia<=?”, em que ‘?’ será o número total de dias de cada mês e a descrição do mês na cláusula de “VALUES”.
<?php $ficheiro = fopen("Janeiro.txt","w" ); $id = 1; $hora = 0; $ano = 2008; for($dia = 1;$dia <= 31;$dia++){ for($h = 0;$h < 24;$h++){ $r = 0; for($r = 0;$r < 4;$r++){ Switch($r){ case 0: $str="INSERT INTO timer (ID_TIME,ano, mes, dia, hora) VALUES (".$id."," .$ano.",' January ',".$dia.",'".$h.":00');"; fputs($ficheiro,$str); $id+=1; break; case 1: $str="INSERT INTO timer (ID_TIME,ano, mes, dia, hora) VALUES (".$id."," .$ano.",' January ',".$dia.",'".$h.":15');"; fputs($ficheiro,$str); $id+=1; break; case 2: $str="INSERT INTO timer (ID_TIME,ano, mes, dia, hora) VALUES (".$id."," .$ano.",' January ',".$dia.",'".$h.":30');"; fputs($ficheiro,$str); $id+=1; break;

CAPÍTULO 7
103
case 3: $str="INSERT INTO timer (ID_TIME,ano, mes, dia, hora) VALUES (".$id."," .$ano.",'January',".$dia.",'".$h.":45');"; fputs($ficheiro,$str); $id+=1; break; } } } } fclose($ficheiro); ?>
De um modo geral, nas primeiras linhas é especificado o nome do ficheiro a produzir, e os valores das variáveis descritas em cima. Inicia-se um ciclo que vai desde o primeiro dia do mês até ao último dia. Dentro deste ciclo existe um ciclo para cada hora do dia, que inicia nas 0h e se prolonga até às 24h, mas dentro deste ciclo existe ainda um novo ciclo que é repetido quatro vezes, de modo a registar dados de quinze em quinze minutos, ou seja, quatro vezes por hora. A cada quarto de hora será produzida a respetiva linha no ficheiro, esta linha de carateres tem a particularidade de ser a concatenação de elementos que originam instruções MySQL prontas a correr no editor de base de dados.
7.3.6. Tabela de factos Factos_Energy
As tabelas de factos são tabelas constituídas por chaves forasteiras de todas as dimensões da sua estrela e pelos atributos de medida. São compostas de algarismos e permitem aceder a toda a informação dos registos dos dados de cada dimensão. Após descritos todos os processos de ETL das dimensões vamos especificar agora os processos de ETL das tabelas de factos. A Figura 7.40 ilustra o processo de ETL da tabela de factos “factos_energy”.
Figura 7.40. Processo de ETL da tabela de factos factos_energy

CAPÍTULO 7
104
O processo de ETL é composto pelos elementos de entrada de dados (“park”, “element”, “activePower”, “reactivePower”, “SolarRadiation” e “timer”), os elementos de mapeamento “tMap_1” e “tMap_2”, visualizador de dados “tLogRow_1” e a tabela de factos da DW “factos_energy”.
Os elementos disponíveis por cada elemento de entrada, são os disponibilizados pelas consultas que se seguem.
A métrica “activePower” é satisfeita pela consulta que se segue, esta consulta recorre a uma cláusula “WHERE” para a seleção dos dados pretendidos, neste caso em que o atributo “ANM_ID” tenha o valor de 5001.
"SELEC Tanalogical_values.PKE_ID, analogical_values .ANV_VALUE
FROM analogical_values
WHERE analogical_values.ANM_ID = '5001';"
A métrica “reactivePower” é satisfeita pela consulta que se segue, esta consulta recorre a uma cláusula “WHERE” para a seleção dos dados pretendidos, neste caso em que o atributo “ANM_ID” tenha o valor de 5002.
"SELECTanalogical_values.PKE_ID, analogical_values. ANV_VALUE
FROM analogical_values
WHERE analogical_values.ANM_ID = '5002';"
A métrica “SolarRadiation” tendo em conta que é um valor instável durante todo o tempo, e tendo em conta que regista valores diferentes a cada quinze minutos, surgiu a necessidade de construir uma consulta complexa que nos permitisse guardar em cada quinze minutos o valor médio registado durante esse intervalo de tempo. A consulta que se segue representa essa operação.
"SELECT ID_TIME, YEAR(criticalsys.analogical_values .ANV_TIMESTAMP) as
\"ano2\",
MONTHNAME(criticalsys.analogical_values.ANV_TIMESTA MP) as mes2,
DAY(criticalsys.analogical_values.ANV_TIMESTAMP) as \"dia2\",
HOUR(criticalsys.analogical_values.ANV_TIMESTAMP) a s \"hora2\",
(SELECT CASE WHEN
MINUTE(criticalsys.analogical_values.ANV_TIMESTAMP) >=00 AND
MINUTE(criticalsys.analogical_values.ANV_TIMESTAMP) <15 then 00
WHEN MINUTE(criticalsys.analogical_values.ANV_TIMES TAMP)>=15 AND
MINUTE(criticalsys.analogical_values.ANV_TIMESTAMP) <30 then 15
WHEN MINUTE(criticalsys.analogical_values.ANV_TIMES TAMP)>=30 AND
MINUTE(criticalsys.analogical_values.ANV_TIMESTAMP) <45 then 30
ELSE 45 END) as \"Minuto\",
concat(HOUR(criticalsys.analogical_values.ANV_TIMES TAMP),':',
(SELECT CASE WHEN MINUTE(ANV_TIMESTAMP)>=00 AND MINUTE(ANV_TIMESTAMP)
<15 then '00'WHEN
MINUTE(criticalsys.analogical_values.ANV_TIMESTAMP) >=15 AND
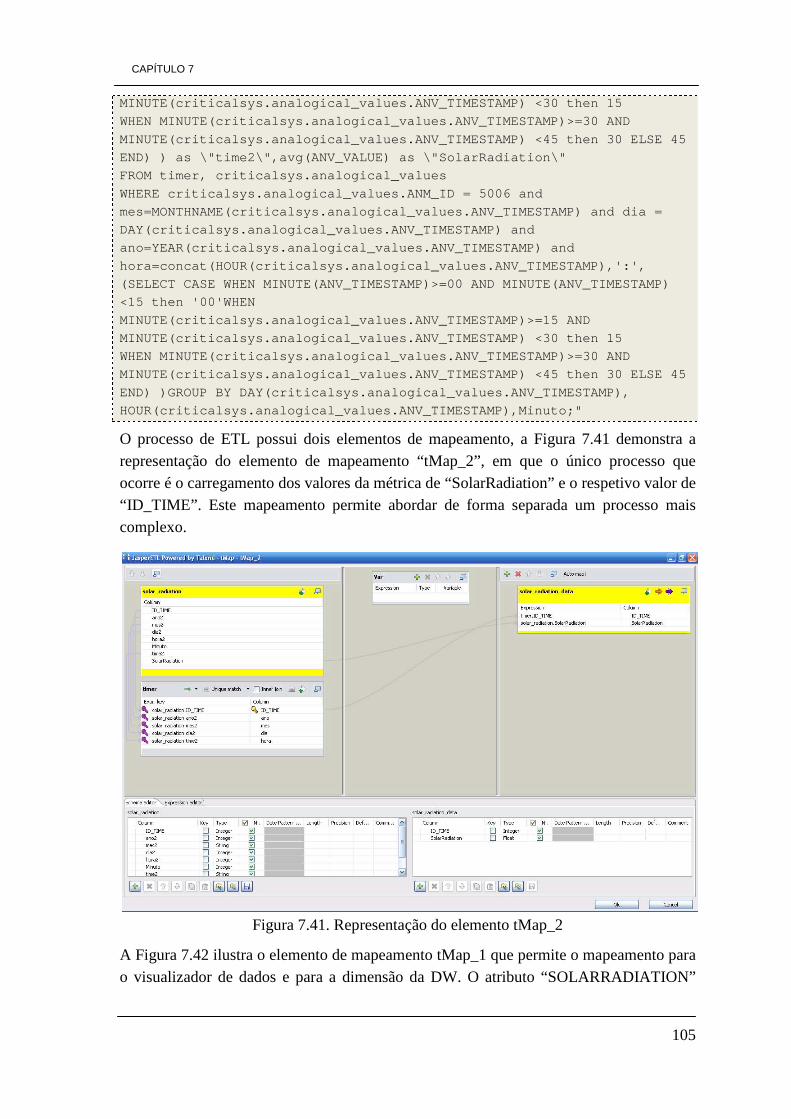
CAPÍTULO 7
105
MINUTE(criticalsys.analogical_values.ANV_TIMESTAMP) <30 then 15
WHEN MINUTE(criticalsys.analogical_values.ANV_TIMES TAMP)>=30 AND
MINUTE(criticalsys.analogical_values.ANV_TIMESTAMP) <45 then 30 ELSE 45
END) ) as \"time2\",avg(ANV_VALUE) as \"SolarRadiat ion\"
FROM timer, criticalsys.analogical_values
WHERE criticalsys.analogical_values.ANM_ID = 5006 a nd
mes=MONTHNAME(criticalsys.analogical_values.ANV_TIM ESTAMP) and dia =
DAY(criticalsys.analogical_values.ANV_TIMESTAMP) an d
ano=YEAR(criticalsys.analogical_values.ANV_TIMESTAM P) and
hora=concat(HOUR(criticalsys.analogical_values.ANV_ TIMESTAMP),':',
(SELECT CASE WHEN MINUTE(ANV_TIMESTAMP)>=00 AND MINUTE(ANV_TIMESTAMP)
<15 then '00'WHEN
MINUTE(criticalsys.analogical_values.ANV_TIMESTAMP) >=15 AND
MINUTE(criticalsys.analogical_values.ANV_TIMESTAMP) <30 then 15
WHEN MINUTE(criticalsys.analogical_values.ANV_TIMES TAMP)>=30 AND
MINUTE(criticalsys.analogical_values.ANV_TIMESTAMP) <45 then 30 ELSE 45
END) )GROUP BY DAY(criticalsys.analogical_values.AN V_TIMESTAMP),
HOUR(criticalsys.analogical_values.ANV_TIMESTAMP),M inuto;"
O processo de ETL possui dois elementos de mapeamento, a Figura 7.41 demonstra a representação do elemento de mapeamento “tMap_2”, em que o único processo que ocorre é o carregamento dos valores da métrica de “SolarRadiation” e o respetivo valor de “ID_TIME”. Este mapeamento permite abordar de forma separada um processo mais complexo.
Figura 7.41. Representação do elemento tMap_2
A Figura 7.42 ilustra o elemento de mapeamento tMap_1 que permite o mapeamento para o visualizador de dados e para a dimensão da DW. O atributo “SOLARRADIATION”

CAPÍTULO 7
106
presente na tabela de factos recebe os valores provenientes de tMap_2 associados com “ID_TIME”.
Figura 7.42. Ilustração do elemento tMap_1
A Figura 7.43 apresenta de forma mais visível os atributos e a origem dos dados da tabela de factos “factos_energy”.
Figura 7.43. Tabela de factos “factos_energy”
7.3.7. Tabela de factos Factos_Average
A tabela de factos “factos_average” guarda a informação necessária relativamente a todos os dados relativos a incidentes e manutenção.
O processo de ETL para o carregamento de dados nesta tabela de factos, é composto por seis fontes de dados de entrada (“park”, “element”, “SolarRadiation”, “timer”, “responsability” e “incident”), os elementos de mapeamento (“tMap_1” e “tMap2”) o visualizador de registos “tLogRow_1” e a tabela de factos “factos_average”.
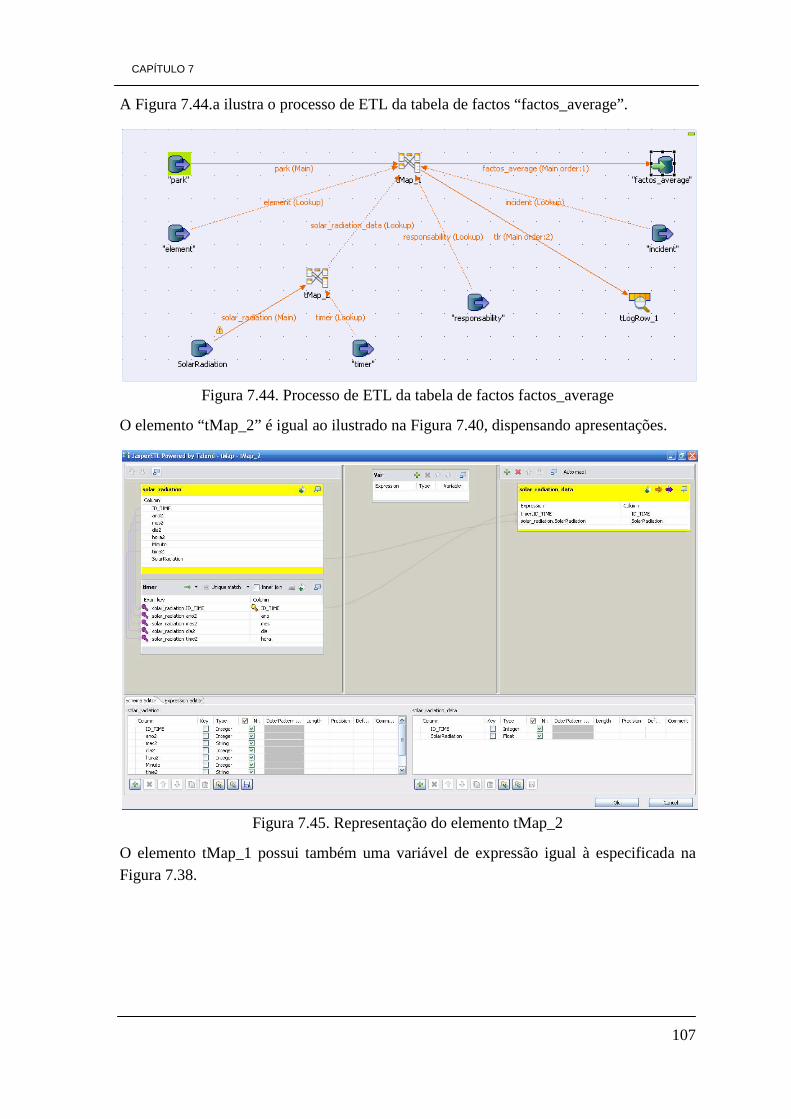
CAPÍTULO 7
107
A Figura 7.44.a ilustra o processo de ETL da tabela de factos “factos_average”.
Figura 7.44. Processo de ETL da tabela de factos factos_average
O elemento “tMap_2” é igual ao ilustrado na Figura 7.40, dispensando apresentações.
Figura 7.45. Representação do elemento tMap_2
O elemento tMap_1 possui também uma variável de expressão igual à especificada na Figura 7.38.
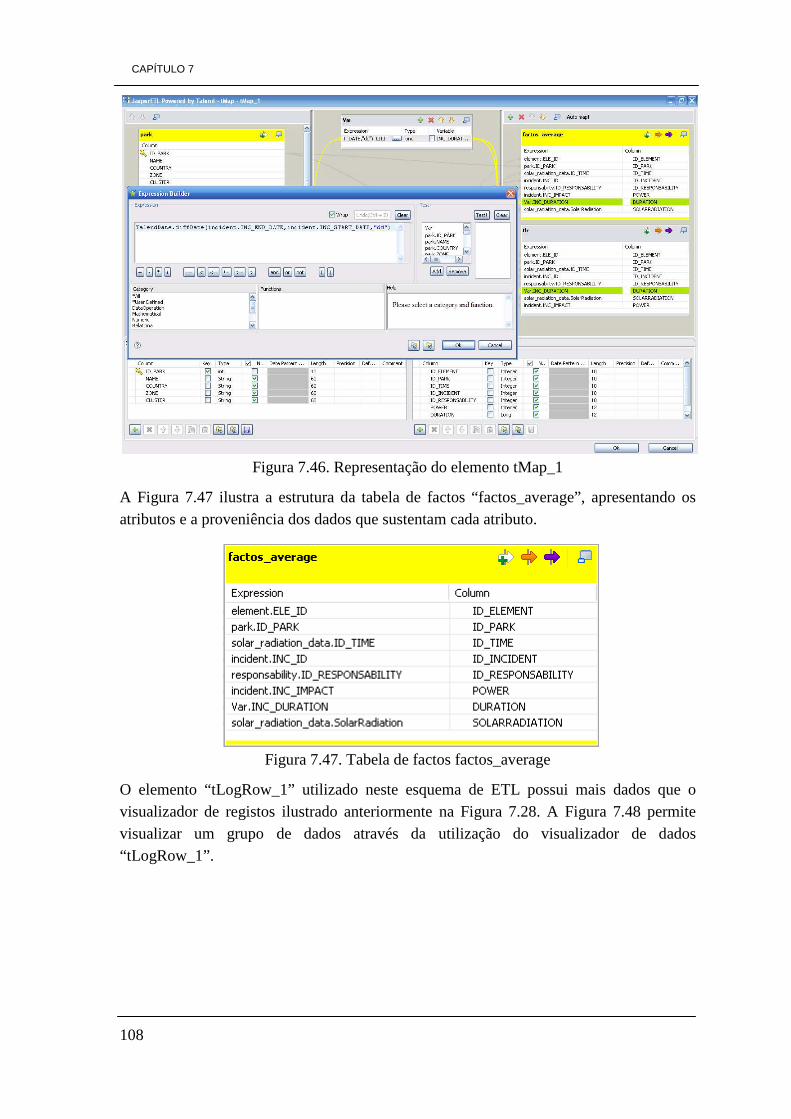
CAPÍTULO 7
108
Figura 7.46. Representação do elemento tMap_1
A Figura 7.47 ilustra a estrutura da tabela de factos “factos_average”, apresentando os atributos e a proveniência dos dados que sustentam cada atributo.
Figura 7.47. Tabela de factos factos_average
O elemento “tLogRow_1” utilizado neste esquema de ETL possui mais dados que o visualizador de registos ilustrado anteriormente na Figura 7.28. A Figura 7.48 permite visualizar um grupo de dados através da utilização do visualizador de dados “tLogRow_1”.
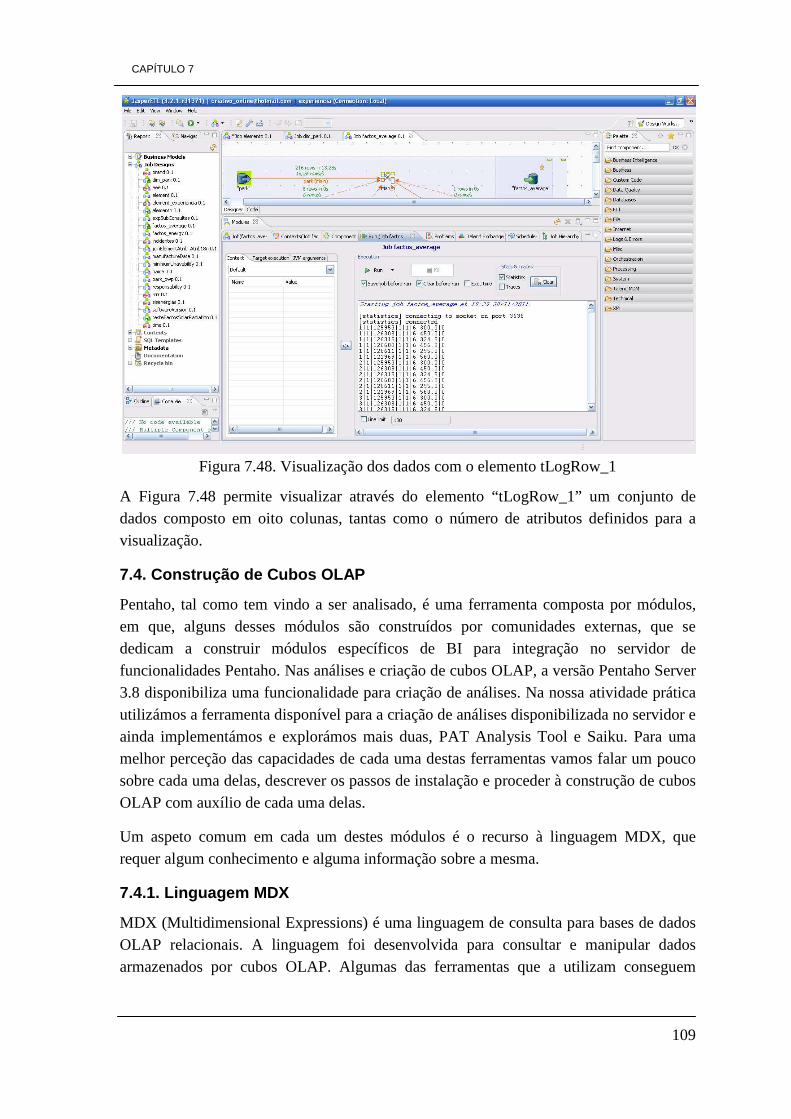
CAPÍTULO 7
109
Figura 7.48. Visualização dos dados com o elemento tLogRow_1
A Figura 7.48 permite visualizar através do elemento “tLogRow_1” um conjunto de dados composto em oito colunas, tantas como o número de atributos definidos para a visualização.
7.4. Construção de Cubos OLAP
Pentaho, tal como tem vindo a ser analisado, é uma ferramenta composta por módulos, em que, alguns desses módulos são construídos por comunidades externas, que se dedicam a construir módulos específicos de BI para integração no servidor de funcionalidades Pentaho. Nas análises e criação de cubos OLAP, a versão Pentaho Server 3.8 disponibiliza uma funcionalidade para criação de análises. Na nossa atividade prática utilizámos a ferramenta disponível para a criação de análises disponibilizada no servidor e ainda implementámos e explorámos mais duas, PAT Analysis Tool e Saiku. Para uma melhor perceção das capacidades de cada uma destas ferramentas vamos falar um pouco sobre cada uma delas, descrever os passos de instalação e proceder à construção de cubos OLAP com auxílio de cada uma delas.
Um aspeto comum em cada um destes módulos é o recurso à linguagem MDX, que requer algum conhecimento e alguma informação sobre a mesma.
7.4.1. Linguagem MDX
MDX (Multidimensional Expressions) é uma linguagem de consulta para bases de dados OLAP relacionais. A linguagem foi desenvolvida para consultar e manipular dados armazenados por cubos OLAP. Algumas das ferramentas que a utilizam conseguem

CAPÍTULO 7
110
converter sintaxe SQL para MDX ainda que não exista uma conversão base (Wikipédia- MDX, 2011).
A sintaxe de MDX possui seis tipos de dados distintos.
• Escalar: pode representar um número ou uma cadeia de carateres.
• Dimensão ou Hierarquia: representa a dimensão de um cubo. (p.ex: [Tempo])
• Nível: representa o nível de uma hierarquia de dimensão. (p.ex: [Tempo].[Ano].[Mês]).
• Membros: representa o membro de uma hierarquia de dimensão. (p.ex: [Tempo].[Mês].[dezembro 2011]).
• Tupla: representa um conjunto de dados agrupados. (p.ex: [Tempo].[Mês].[dezembro], [Clientes].[Zona].[All Clientes].[Coimbra], [Measures].[Sales]).
• Conjunto: representa um grupo de dados com a mesma dimensão ou hierarquia. (p.ex: {([Measures].[Sales], [Tempo].[Ano].[2006]), ([Measures].[Sales], [Tempo].[Ano].[2007])}).
Para uma melhor compreensão vamos descrever um exemplo prático.
SELECT
NON EMPTY {[Measures].[pc__sum(ACTIVEPOWER)],[Measu res].[pc__sum(
SOLARRADIATION)]} ON COLUMNS,
NON EMPTY {Hierarchize({Order({[pc__dia].[All pc__d ias].Children,
[pc__dia].[2].Children, [pc__dia].[5].Children, [pc __dia].[8].Children,
[pc__dia].[21].Children }, [pc__dia].CurrentMember. Name, ASC )
}) } ON ROWS FROM
[dw_sisenergias2]
A consulta acima apresenta no cubo de dados a soma das métricas (ACTIVEPOWER e SOLARRADIATION) por colunas e nas linhas do cubo os valores respetivos nos dias 2, 5, 8 e 21 de forma ascendente, com base na tabela dw_sisenergias2. Como podemos analisar a estrutura e a sintaxe é um pouco mais complexa que a linguagem SQL.
7.4.2. PAT Analysis Tool
PAT Analysis Tool é um módulo de OLAP desenvolvido pela organização Analytical Labs, liderada por Tom Barber e Paul Stoellberger que idealizaram a construção de uma ferramenta open source que suportasse a realização de análises completas. No futuro a ideia da organização é subdividir o atual projeto por vários módulos de forma a fornecer uma ferramenta mais estruturada e com maior número de funcionalidades.
PAT tem como objetivo apresentar os resultados de consultas à DW, através da representação de cubos de dados e gráficos ilustrativos das diferentes consultas.

CAPÍTULO 7
111
7.4.2.1. Instalação de PAT Plugin 0.8 no Pentaho
No nosso caso prático procedemos à instalação de uma versão PAT plugin que se instala com facilidade no servidor Pentaho BI Server CE 3.8 e em poucos passos torna-se funcional.
O primeiro passo a seguir para proceder à instalação da ferramenta PAT é aceder ao link “http://code.google.com/p/pentahoanalysistool/” e proceder ao download do ficheiro, no nosso caso ‘pat-plugin-0.8.zip’.
• Após o download da aplicação deve parar o servidor tomcat da aplicação Pentaho caso esteja a ser utilizado e posteriormente seguir os passos seguintes.
• Extrair o ficheiro .zip para o diretório de instalação de Pentaho para \pentaho\biserver-ce\pentaho-solutions\system.
• Iniciar o servidor Pentaho.
• Verificar a instalação acedendo em http://localhost:8080/pentaho/home.
• Verificar o novo ícone “New PAT Analysis”, como ilustra a Figura 7.49.
Figura 7.49. Ícones do ambiente de trabalho de Pentaho
• E está pronto a utilizar.
7.4.2.2. Criação de análises com PAT Analysis
Após a instalação da ferramenta é possível a criação de análises com PAT, os próximos passos vão explicar o processo de criação de análises com a ferramenta (Barber et. Al, 2010).
Inicialmente é necessário que o utilizador selecione o ícone “New PAT Analysis”, posteriormente aparece uma janela onde é possível criar e configurar ligações a bases de dados, selecionar cubos de dados já existentes no repositório ou procurar ajuda online relativamente à utilização da ferramenta. Aquando da seleção de um cubo de dados, a
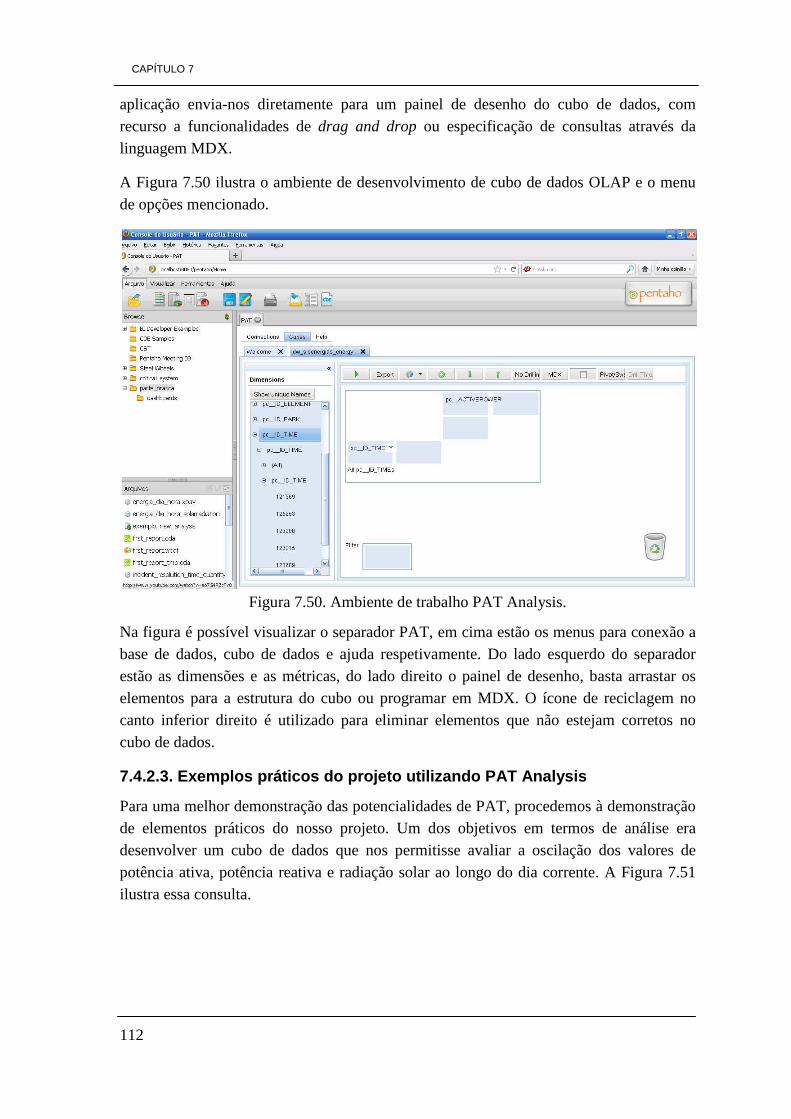
CAPÍTULO 7
112
aplicação envia-nos diretamente para um painel de desenho do cubo de dados, com recurso a funcionalidades de drag and drop ou especificação de consultas através da linguagem MDX.
A Figura 7.50 ilustra o ambiente de desenvolvimento de cubo de dados OLAP e o menu de opções mencionado.
Figura 7.50. Ambiente de trabalho PAT Analysis.
Na figura é possível visualizar o separador PAT, em cima estão os menus para conexão a base de dados, cubo de dados e ajuda respetivamente. Do lado esquerdo do separador estão as dimensões e as métricas, do lado direito o painel de desenho, basta arrastar os elementos para a estrutura do cubo ou programar em MDX. O ícone de reciclagem no canto inferior direito é utilizado para eliminar elementos que não estejam corretos no cubo de dados.
7.4.2.3. Exemplos práticos do projeto utilizando PA T Analysis
Para uma melhor demonstração das potencialidades de PAT, procedemos à demonstração de elementos práticos do nosso projeto. Um dos objetivos em termos de análise era desenvolver um cubo de dados que nos permitisse avaliar a oscilação dos valores de potência ativa, potência reativa e radiação solar ao longo do dia corrente. A Figura 7.51 ilustra essa consulta.
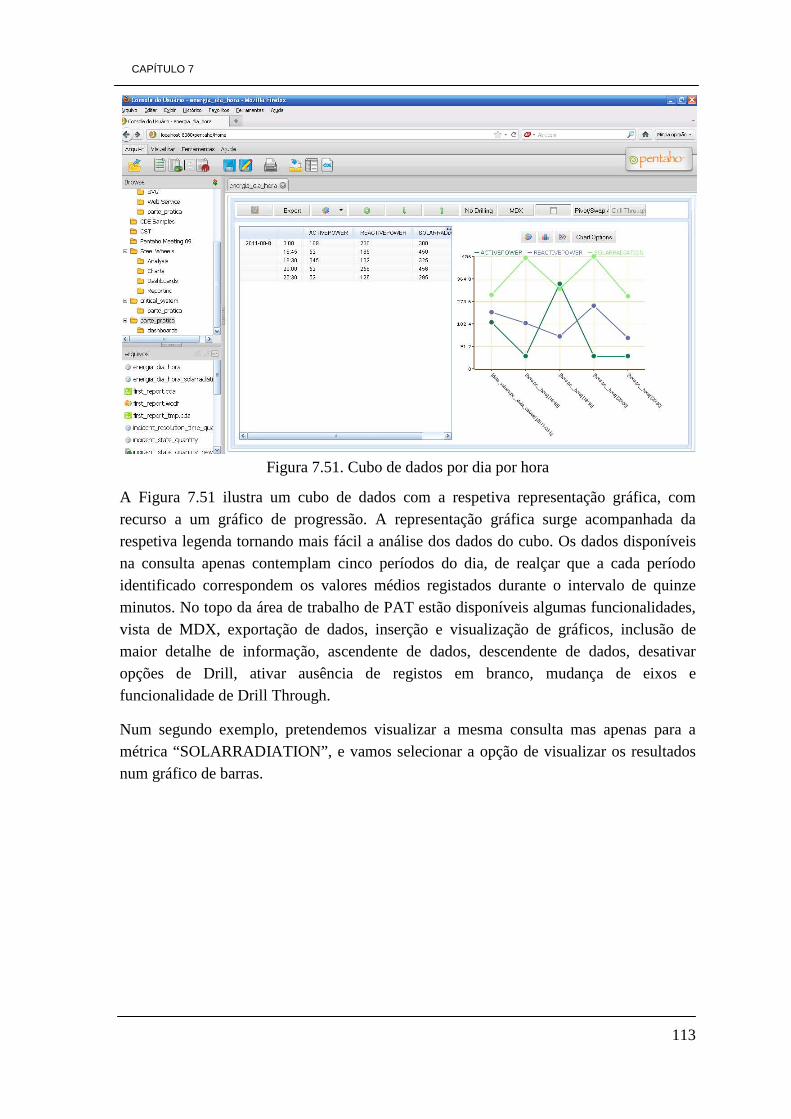
CAPÍTULO 7
113
Figura 7.51. Cubo de dados por dia por hora
A Figura 7.51 ilustra um cubo de dados com a respetiva representação gráfica, com recurso a um gráfico de progressão. A representação gráfica surge acompanhada da respetiva legenda tornando mais fácil a análise dos dados do cubo. Os dados disponíveis na consulta apenas contemplam cinco períodos do dia, de realçar que a cada período identificado correspondem os valores médios registados durante o intervalo de quinze minutos. No topo da área de trabalho de PAT estão disponíveis algumas funcionalidades, vista de MDX, exportação de dados, inserção e visualização de gráficos, inclusão de maior detalhe de informação, ascendente de dados, descendente de dados, desativar opções de Drill, ativar ausência de registos em branco, mudança de eixos e funcionalidade de Drill Through.
Num segundo exemplo, pretendemos visualizar a mesma consulta mas apenas para a métrica “SOLARRADIATION”, e vamos selecionar a opção de visualizar os resultados num gráfico de barras.
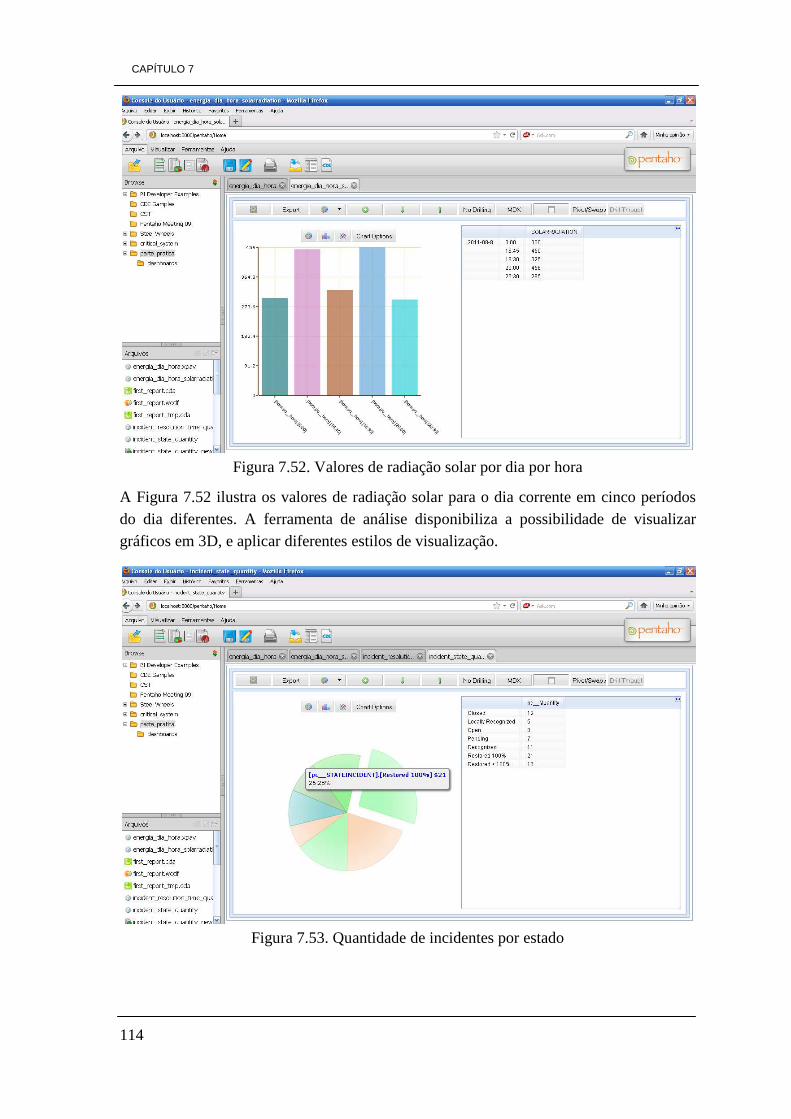
CAPÍTULO 7
114
Figura 7.52. Valores de radiação solar por dia por hora
A Figura 7.52 ilustra os valores de radiação solar para o dia corrente em cinco períodos do dia diferentes. A ferramenta de análise disponibiliza a possibilidade de visualizar gráficos em 3D, e aplicar diferentes estilos de visualização.
Figura 7.53. Quantidade de incidentes por estado

CAPÍTULO 7
115
A Figura 7.53 mostra uma consulta relativamente aos tipos de estado de incidentes e a quantidade de registos em cada estado de conclusão. Existe a representação de um gráfico circular.
7.4.3. Saiku
Saiku também desenvolvido pela organização Analytical Labs é uma ferramenta open
source modular de análises, e surgiu com o objetivo de simplificar o processo de análises de dados internos da aplicação.
7.4.3.1. Instalação de Saiku 2.0 no Pentaho BI Serv er CE 3.8
A ferramenta encontra-se disponível para download em “http://analytical-labs.com/” ou acedendo diretamente a “http://analytical-labs.com/downloads/saiku-plugin-2.0.zip”.
• Após o download da aplicação descompacta-se o ficheiro saiku-plugin-2.0-SNAPSHOT.zip.
• Termine a execução do servidor Pentaho caso esteja inicializado.
• Copie a pasta saiku para o diretório \pentaho\biserver-ce\pentaho-solutions\system.
• Reinicie o servidor Pentaho BI Server CE 3.8.
• Verificar o novo ícone “New Saiku Analytics”, como ilustra a Figura 7.54.
Figura 7.54. Ícone Saiku no ambiente de trabalho de Pentaho
• E está pronto a utilizar.
7.4.3.2. Exemplos práticos do projeto utilizando Sa iku
Após a instalação, para inicializar a construção de análises com recurso a Saiku basta clicar em “New Saiku Analytics” e logo de seguida será aberta a aplicação no ambiente de trabalho Pentaho. A Figura 7.55 ilustra o painel de desenvolvimento de Saiku.
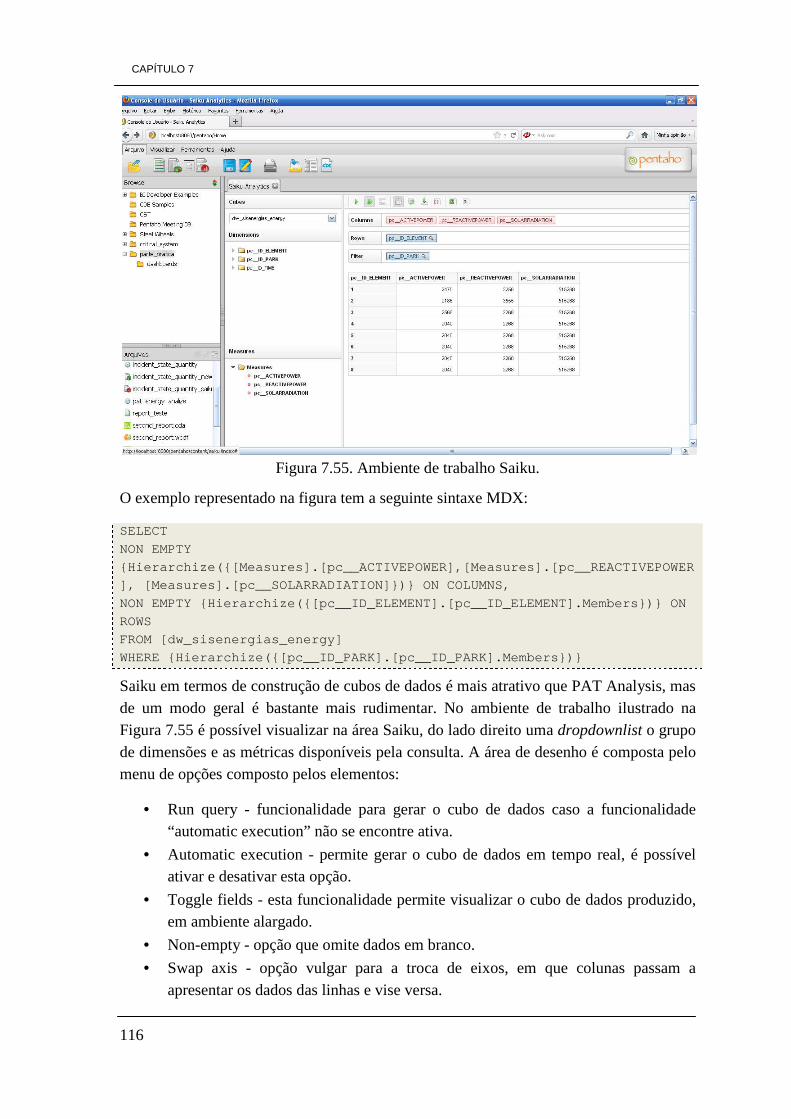
CAPÍTULO 7
116
Figura 7.55. Ambiente de trabalho Saiku.
O exemplo representado na figura tem a seguinte sintaxe MDX:
SELECT
NON EMPTY
{Hierarchize({[Measures].[pc__ACTIVEPOWER],[Measure s].[pc__REACTIVEPOWER
], [Measures].[pc__SOLARRADIATION]})} ON COLUMNS,
NON EMPTY {Hierarchize({[pc__ID_ELEMENT].[pc__ID_EL EMENT].Members})} ON
ROWS
FROM [dw_sisenergias_energy]
WHERE {Hierarchize({[pc__ID_PARK].[pc__ID_PARK].Mem bers})}
Saiku em termos de construção de cubos de dados é mais atrativo que PAT Analysis, mas de um modo geral é bastante mais rudimentar. No ambiente de trabalho ilustrado na Figura 7.55 é possível visualizar na área Saiku, do lado direito uma dropdownlist o grupo de dimensões e as métricas disponíveis pela consulta. A área de desenho é composta pelo menu de opções composto pelos elementos:
• Run query - funcionalidade para gerar o cubo de dados caso a funcionalidade “automatic execution” não se encontre ativa.
• Automatic execution - permite gerar o cubo de dados em tempo real, é possível ativar e desativar esta opção.
• Toggle fields - esta funcionalidade permite visualizar o cubo de dados produzido, em ambiente alargado.
• Non-empty - opção que omite dados em branco.
• Swap axis - opção vulgar para a troca de eixos, em que colunas passam a apresentar os dados das linhas e vise versa.

CAPÍTULO 7
117
• Drill Through current query – permite aplicar a função Drill Through no cubo de dados corrente.
• Show MDX - funcionalidade que permite aceder ao código de consulta MDX.
• Export XLS - Saiku permite extrair dados para Excel.
• Export CSV - exportação para ficheiros CSV também é suportada no Saiku.
Na área de desenho é possível construir o cubo de dados através de drag and drop, arrastando dimensões e métricas para os separadores:
• Columns – área restrita aos dados a visualizar nas colunas do cubo de dados.
• Rows – área de definição de dados a apresentar nas linhas do cubo.
• Filter – Saiku também permite filtrar dados relativamente a elementos específicos.
O cubo de dados é representado à medida que vai sendo construído, caso a opção “Automatic execution” esteja ativa. O plugin quando comparado com PAT Analysis torna-se mais rudimentar em termos de visualização, não disponibilizando opções para a criação de gráficos ilustrativos dos dados apresentados pelo cubo.
7.4.4. Pentaho Mondrian
O servidor Pentaho já possui uma funcionalidade para construção de cubos OLAP, o Mondrian. Essa funcionalidade encontra-se disponível no ambiente de trabalho Pentaho. Na Figura 7.56 é possível visualizar o ícone respetivo, acompanhado pela descrição “New Analysis View”.
Figura 7.56. Ícone New Analysis View no ambiente de trabalho de Pentaho
Após seleccionar a opção surge no ecrã uma nova janela, representada na Figura 7.57.
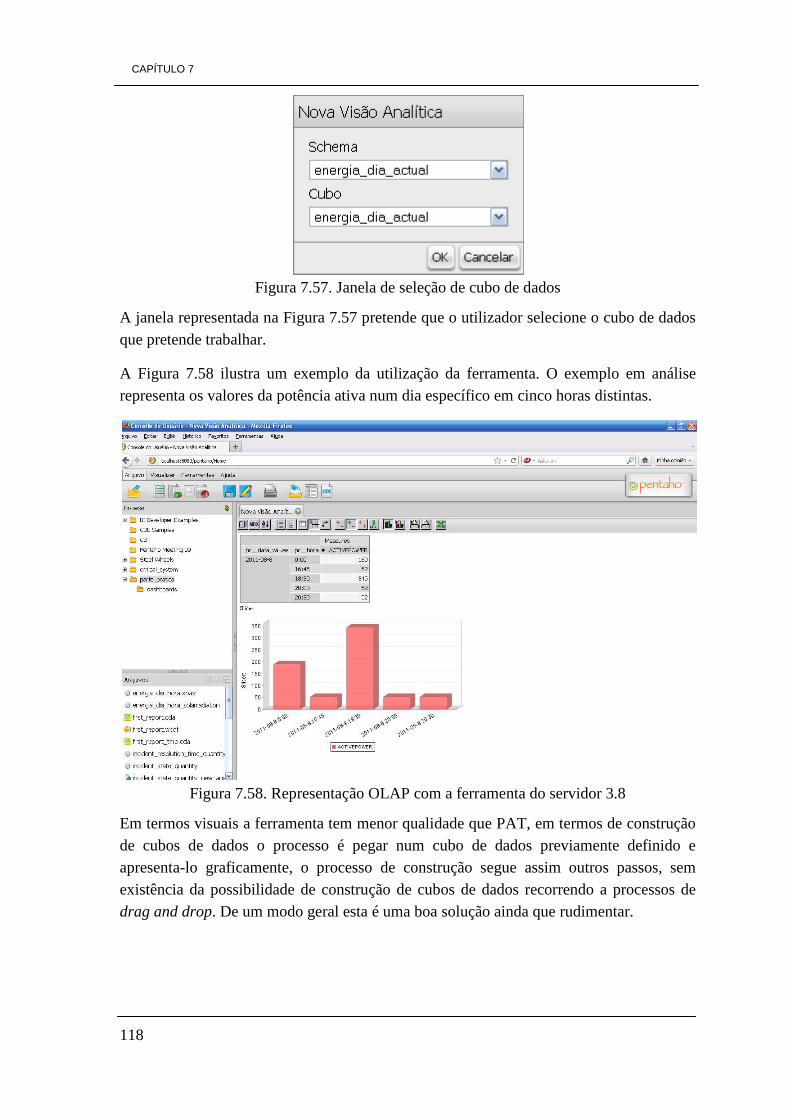
CAPÍTULO 7
118
Figura 7.57. Janela de seleção de cubo de dados
A janela representada na Figura 7.57 pretende que o utilizador selecione o cubo de dados que pretende trabalhar.
A Figura 7.58 ilustra um exemplo da utilização da ferramenta. O exemplo em análise representa os valores da potência ativa num dia específico em cinco horas distintas.
Figura 7.58. Representação OLAP com a ferramenta do servidor 3.8
Em termos visuais a ferramenta tem menor qualidade que PAT, em termos de construção de cubos de dados o processo é pegar num cubo de dados previamente definido e apresenta-lo graficamente, o processo de construção segue assim outros passos, sem existência da possibilidade de construção de cubos de dados recorrendo a processos de drag and drop. De um modo geral esta é uma boa solução ainda que rudimentar.

CAPÍTULO 7
119
7.5. Criação de Dashboards
Os dashboards são um dos elementos BI mais importantes, transformam conjuntos de dados em elementos gráficos. Existem algumas soluções Pentaho para a criação de dashboards, Pentaho é compatível com algumas ferramentas como JFree Charts ou Fusion Charts por exemplo, mas todas estas ferramentas são um pouco arcaicas e requerem bastantes conhecimentos técnicos de informática por parte dos seus utilizadores, nomeadamente conhecimentos da linguagem de programação Java. A maioria das ferramentas trabalham sobre o ambiente de Eclipse, que possibilita a criação de dashboards com recurso a programação de ficheiros que posteriormente sejam interpretados pelo servidor de Pentaho.
Para a criação dos nossos dashboards da atividade prática recorremos à utilização de uma Framework inovadora, CDF-DE (Community Dashboard Framework – Dashboard Editor).
Esta Framework de desenvolvimento de dashboards para a versão CE de Pentaho, foi desenvolvida por Pedro Alves e Klose Ingo, dois membros da comunidade de desenvolvimento de Pentaho.
Os dois membros da comunidade desenvolveram um plugin de fácil utilização e com alguns benefícios, nomeadamente (CDF, 2011):
• A criação de dashboards com necessidade de pouca/nenhuma utilização de javascript.
• Facilidade em definir objetos, painéis e variáveis.
• Carregamento automático de painéis em desenvolvimento.
• Atualização automática dos dashboards relativamente à alteração dos valores dos dados.
• Geração automática de elementos de navegação, caixas de texto selecionadores, etc.
• Separação de elementos de html e definição de componentes.
• Integração com OpenStreetmaps.
• Facilidade de integração com o servidor.
• Disponibilização de templates.
• Suporte a vários tipos de base de dados.
Possibilidade da criação de um ficheiro CSS (Cascading Style Sheets) que defina as formatações gerais do painel.
A quantidade de benefícios é clara, a facilidade de utilização da ferramenta é um fator crítico na nossa avaliação, procuramos solucionar um problema sem grandes investimentos, este é o plugin ideal tendo em conta que não exige grandes conhecimentos aprofundados de informática por parte dos utilizadores. Em seguida apresentamos um

CAPÍTULO 7
120
tutorial de instalação do plugin e alguns exeplos práticos de utilização do mesmo, no nosso caso prático.
7.5.1. Instalação CDF-DE
No nosso caso prático procedemos à instalação do plugin CDF-DE, a instalação do plugin é simples, tal como os plugins de análise de dados instalados e descritos em 7.3.2.1 e 7.3.3.1. Para a instalação apoiada do plugin basta seguir os passos seguintes.
Passo 1 – Download do plugin
• Inicialmente deve proceder ao download do ficheiro de instalação do plugin. O ficheiro pode ser encontrado em “http://code.google.com/p/cdf-de/downloads /list”.
• Ainda não existe uma versão estável do plugin ainda assim procedemos ao download do ficheiro mais atualizado atualmente o “CDE-bundle-1.0-RC3.tar.bz2”, as versões estáveis contêm a palavra “stable” na nomenclatura do ficheiro.
Passo 2 – Descompactar ficheiro
• Após efectuado o download deve proceder à descompactação do ficheiro “CDE-bundle-1.0-RC3.tar.bz2”.
• Após descompactado, o resultado deve ser o seguinte conjunto de diretórios:
/bi-developers
/cde_sample
/cdf
/CST
/system/
............../cda
............. /pentaho-cdf
............. /pentaho-cdf-dd
Passo 3 – Mover pastas descompactadas
• No diretório de instalação de Pentaho selecione as pastas “\biserver-ce\pentaho-solutions” e mova para a atual diretoria as seguintes pastas:
/bi-developers
/cde_sample
/cdf
/CST
/system/
…………/cda
…………/pentaho-cdf
…………pentaho-cdf-dd
CAPÍTULO 7
121
Figura 7.59. Ambiente de trabalho Pentaho atualizado com a nova funcionalidade CDE
A Figura 7.59. ilustra o ambiente de trabalho Pentaho com a nova Framework de dashboards instalada, “New CDE Dashboard”. O plugin está pronto a utilizar, ao selecionar “New CDE Dashboard” será iniciada a aplicação, a Figura 7.60 ilustra o ambiente de trabalho da aplicação. Para iniciar a utilização do plugin recomenda-se a visualização do tutorial acessível em:
“http://www.youtube.com/watch?v=cW8YzwC2uNU&feature=player_ embedded #!”
Figura 7.60. Ambiente de trabalho de CDE
O cabeçalho da aplicação CDE é composto por um menu composto pelas opções (criar novo dashboard, guardar dashboard, guardar como, atualizar dashboard e propriedades do dashboard). O menu da direita, é composto por separadores de opções técnicas.
No separador de “Layout” é possível estruturar a apresentação de dashboards, definindo blocos de instruções HTML, ficheiros de CSS e JavaScript. Esta estruturação pode ser feita de forma manual recorrendo aos ícones de construção presentes em “Layout Structure” (criar colunas, criar linhas, criar blocos de código HTML, etc.) ou selecionar um dos Templates já estruturados e disponíveis para utilização. A Figura 7.61 ilustra a seleção de um dos Template disponibilizados pelo plugin.
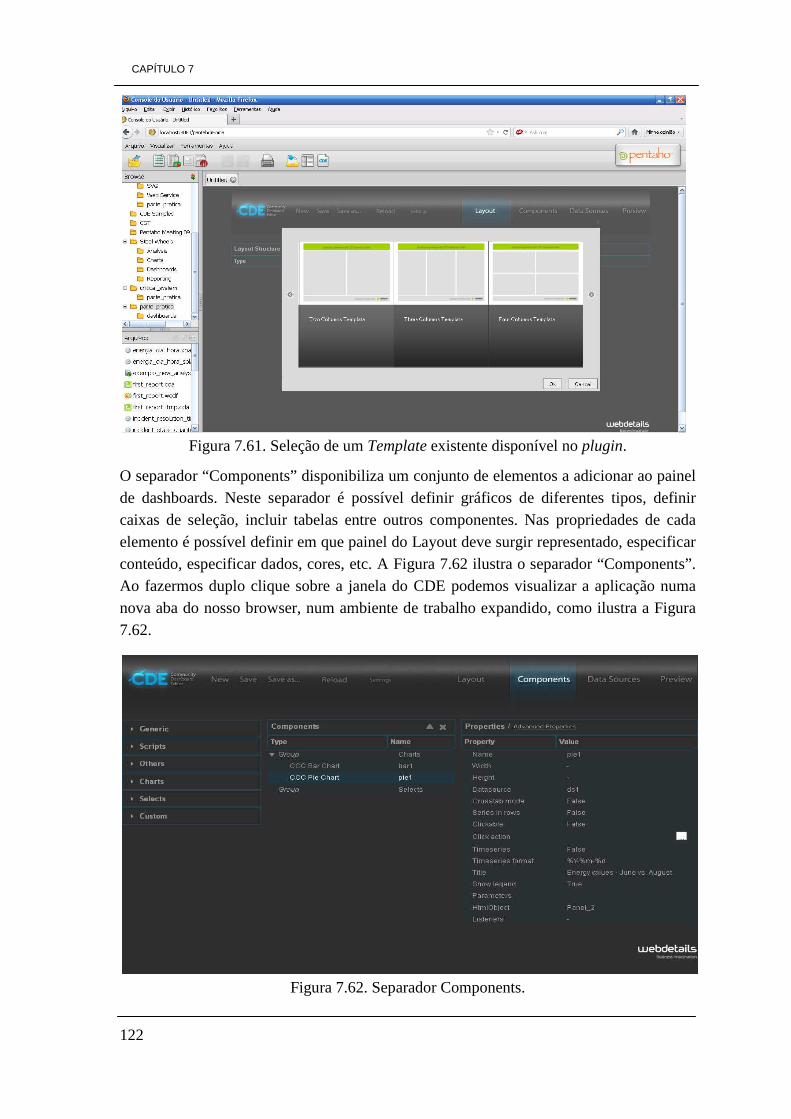
CAPÍTULO 7
122
Figura 7.61. Seleção de um Template existente disponível no plugin.
O separador “Components” disponibiliza um conjunto de elementos a adicionar ao painel de dashboards. Neste separador é possível definir gráficos de diferentes tipos, definir caixas de seleção, incluir tabelas entre outros componentes. Nas propriedades de cada elemento é possível definir em que painel do Layout deve surgir representado, especificar conteúdo, especificar dados, cores, etc. A Figura 7.62 ilustra o separador “Components”. Ao fazermos duplo clique sobre a janela do CDE podemos visualizar a aplicação numa nova aba do nosso browser, num ambiente de trabalho expandido, como ilustra a Figura 7.62.
Figura 7.62. Separador Components.

CAPÍTULO 7
123
No separador “Components” representado na Figura 7.62, surge a inserção de dois componentes do grupo de gráficos, um gráfico de barras “bar1” e um gráfico circular “pie1”. Na imagem é possível visualizar as propriedades do gráfico circular “pie1”.
O separador “Data Sources” é composto pelo conjunto de elementos relacionados com diferentes tipos de bases de dados e tipos de consultas. No nosso caso prático vamos necessitar apenas de utilizar consultas SQL via JDBC, mas a Figura 7.63, permite ter uma maior percepção do conjunto de componentes de base de dados disponíveis.
Figura 7.63. Representação do separador Data Sources.
A Figura 7.63 mostra as propriedades definidas para uma base de dados SQL designada de “ds1”. O acesso aos dados é feito com recurso a JDBC, e requer que nas propriedades da consulta seja definido o driver (com.mysql.jdbc.Driver) na segunda variável “Name” e o URL de acesso à base de dados, que neste caso é “jdbc:mysql://localhost:3306/ dw_sisenergias”.
Cada componente gráfica deve ser associada a um elemento “Data Source” de modo a representar os dados resultantes da sua consulta. A sintaxe SQL é definida na variável “Query” das propriedades da “Data Source”.
Por fim o separador “Preview”, este não é um separador de opções, funciona apenas como uma funcionalidade que tem como objetivo apresentar o resultado final.
A atividade prática que a empresa pretende visualizar em dashboard é uma representação dos valores de potência ativa agrupados por mês, no ano corrente. Na nossa base de dados apenas constam dados relativamente aos meses de junho e agosto.

CAPÍTULO 7
124
A Figura 7.64 apresenta o resultado prático da nossa atividade prática, representado através de um gráfico de barras e um gráfico circular.
Figura 7.64. Dashboards do caso prático.
Da análise à Figura 7.64 podemos concluir que o mês de Agosto representa valores de potência ativa bastante mais elevados que o mês de Junho. A ferramenta permite a inserção de legendas de forma automática, inserção de valores nos eixos dos gráficos de barras e representação dos valores registados.
7.6. Criação de Relatórios
A criação de relatórios é uma possibilidade no Pentaho BI Server CE 3.8. Define-se por relatório de Business Intelligence a uma componente que permita apresentar um conjunto de dados, que se façam representar por diferentes tipos de elementos, nomeadamente análises, gráficos e tabelas.
O plugin CDF-DE também possibilita a construção de relatórios, compostos de um conjunto de dashboards, tendo como contrapartida o facto de os exibir apenas de forma gráfica, não tendo a possibilidade de os exportar para outro formato.
Como atividade prática foi-nos atribuída a tarefa de desenvolver um relatório tendo em conta a análise dos valores de potência ativa, potência reativa e irradiação solar registados no dia corrente ao longo dos períodos de tempo que possuam registos. No nosso caso prático vamos utilizar a ferramenta incluída no servidor Pentaho que se faz representar no ambiente de trabalho pelo ícone “New Report”.
A Figura 7.65 ilustra o ambiente de trabalho da ferramenta de criação de relatórios. A ferramenta é um pouco rudimentar, não permite a personalização dos relatórios em termos de cores e tipos de letra, estilos (CSS) apenas disponibiliza seis modelos de
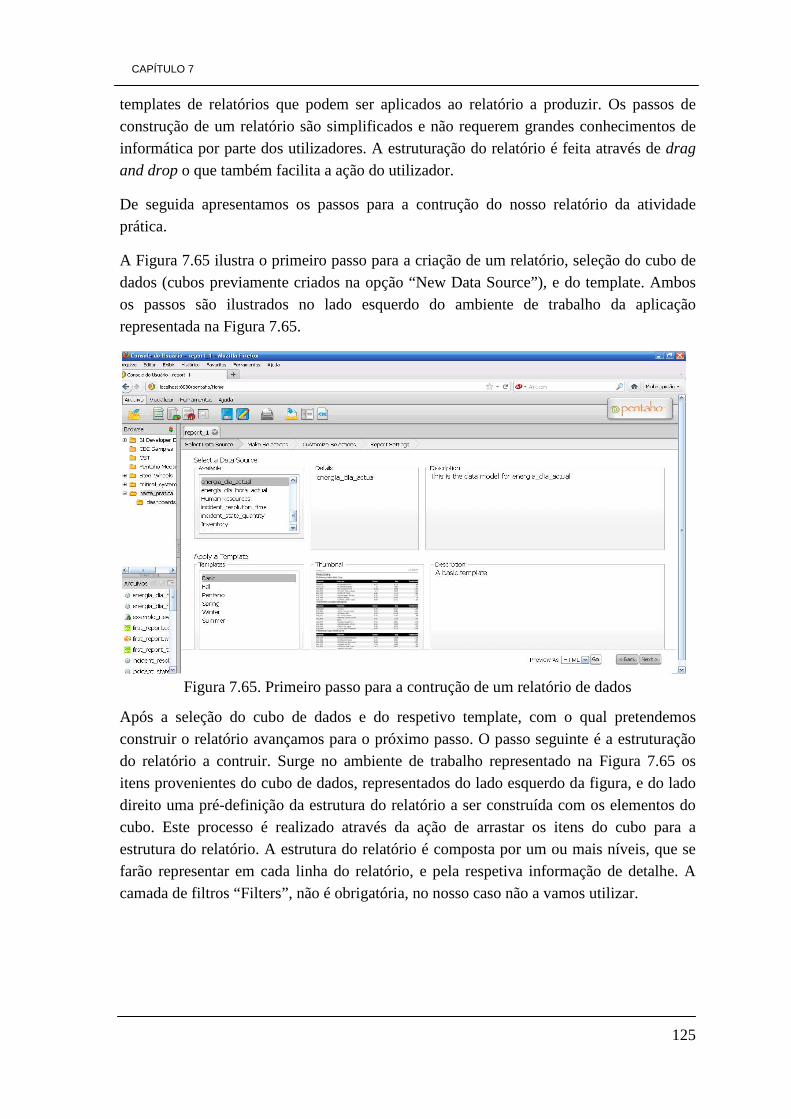
CAPÍTULO 7
125
templates de relatórios que podem ser aplicados ao relatório a produzir. Os passos de construção de um relatório são simplificados e não requerem grandes conhecimentos de informática por parte dos utilizadores. A estruturação do relatório é feita através de drag
and drop o que também facilita a ação do utilizador.
De seguida apresentamos os passos para a contrução do nosso relatório da atividade prática.
A Figura 7.65 ilustra o primeiro passo para a criação de um relatório, seleção do cubo de dados (cubos previamente criados na opção “New Data Source”), e do template. Ambos os passos são ilustrados no lado esquerdo do ambiente de trabalho da aplicação representada na Figura 7.65.
Figura 7.65. Primeiro passo para a contrução de um relatório de dados
Após a seleção do cubo de dados e do respetivo template, com o qual pretendemos construir o relatório avançamos para o próximo passo. O passo seguinte é a estruturação do relatório a contruir. Surge no ambiente de trabalho representado na Figura 7.65 os itens provenientes do cubo de dados, representados do lado esquerdo da figura, e do lado direito uma pré-definição da estrutura do relatório a ser construída com os elementos do cubo. Este processo é realizado através da ação de arrastar os itens do cubo para a estrutura do relatório. A estrutura do relatório é composta por um ou mais níveis, que se farão representar em cada linha do relatório, e pela respetiva informação de detalhe. A camada de filtros “Filters”, não é obrigatória, no nosso caso não a vamos utilizar.
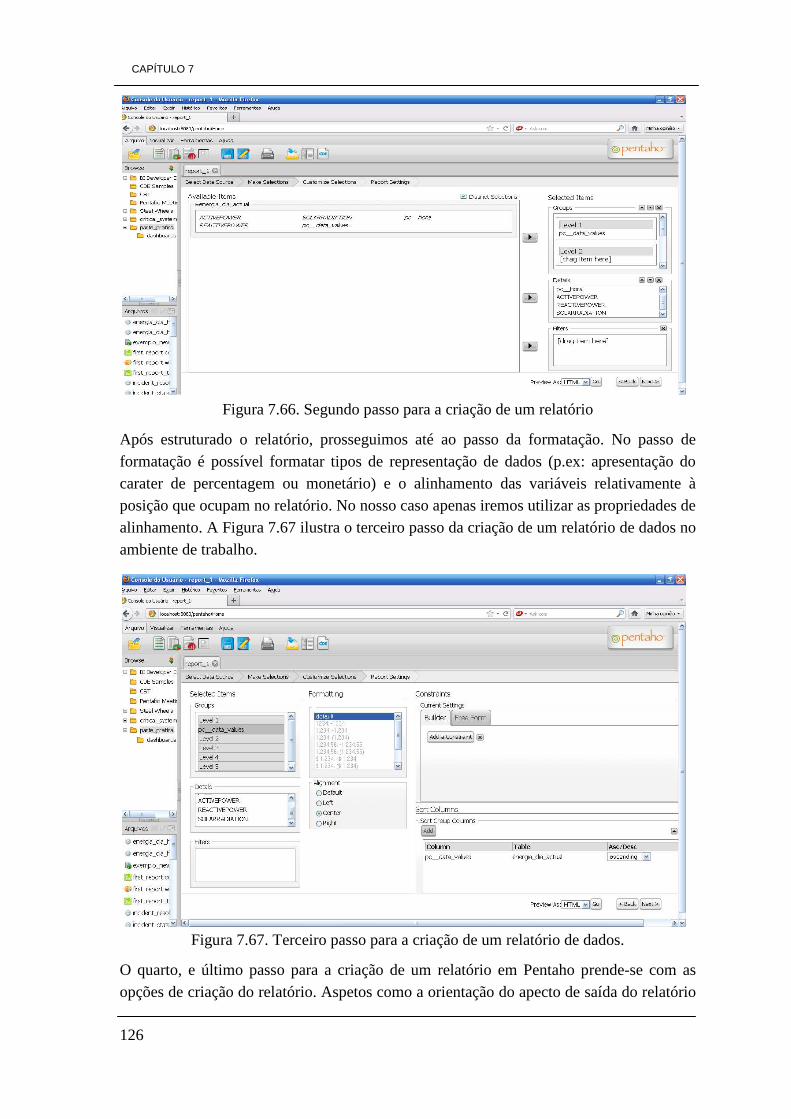
CAPÍTULO 7
126
Figura 7.66. Segundo passo para a criação de um relatório
Após estruturado o relatório, prosseguimos até ao passo da formatação. No passo de formatação é possível formatar tipos de representação de dados (p.ex: apresentação do carater de percentagem ou monetário) e o alinhamento das variáveis relativamente à posição que ocupam no relatório. No nosso caso apenas iremos utilizar as propriedades de alinhamento. A Figura 7.67 ilustra o terceiro passo da criação de um relatório de dados no ambiente de trabalho.
Figura 7.67. Terceiro passo para a criação de um relatório de dados.
O quarto, e último passo para a criação de um relatório em Pentaho prende-se com as opções de criação do relatório. Aspetos como a orientação do apecto de saída do relatório
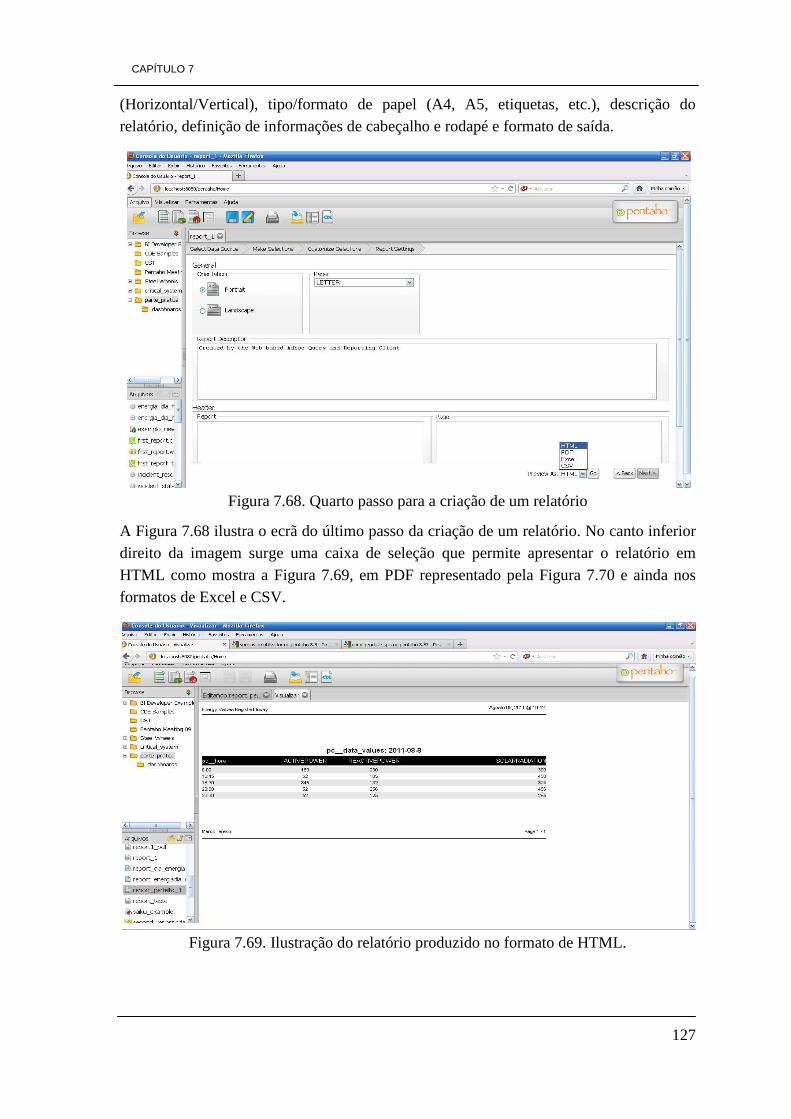
CAPÍTULO 7
127
(Horizontal/Vertical), tipo/formato de papel (A4, A5, etiquetas, etc.), descrição do relatório, definição de informações de cabeçalho e rodapé e formato de saída.
Figura 7.68. Quarto passo para a criação de um relatório
A Figura 7.68 ilustra o ecrã do último passo da criação de um relatório. No canto inferior direito da imagem surge uma caixa de seleção que permite apresentar o relatório em HTML como mostra a Figura 7.69, em PDF representado pela Figura 7.70 e ainda nos formatos de Excel e CSV.
Figura 7.69. Ilustração do relatório produzido no formato de HTML.

CAPÍTULO 7
128
Figura 7.70. Ilustração do relatório produzido no formato PDF.
Como podemos verificar a criação de relatórios em Pentaho não apresenta grandes dificuldades e é um processo rápido e simples. A possibilidade de exportar os relatórios produzidos em diferentes formatos é uma mais-valia.

CAPÍTULO 8
129
8. CONCLUSÕES E TRABALHO FUTURO
O nosso trabalho de investigação teve como objetivo procurar solucionar um problema, ajudar as PMEs a encontrar uma ferramenta de BI open source, capaz de servir as suas exigências, procurando reduzir os custos da sua atividade laboral e da mesma forma otimizar os seus processos de negócio. Na nossa investigação procurámos obter as melhores respostas e as melhores soluções para resolver o nosso mesmo problema. A relevância atribuída à descoberta da solução para um determinado problema é tão maior, quão maior for a necessidade de resolução do mesmo e quanto maior for a dimensão abrangida pelo problema. O facto das PMEs representarem uma percentagem acima dos 98% à escala mundial, confere-lhes uma importância tremenda no tecido económico de qualquer país, qualquer comunidade. Em época de oscilações constantes de mercado, o crescimento das PMEs, que representam 98% da economia mundial, poderá traduzir-se num fator de estabilidade económica. Vários são os problemas que afetam o dia a dia das PMEs, nomeadamente (Comissão Europeia, 2006):
• Dificuldade em aumentar a capacidade de produção
• Necessidade de criar uma equipa de apoio ao desenvolvimento da empresa
• Aquisição de mão de obra qualificada no mercado de trabalho
• Dificuldades no acesso a financiamento
• Burocracias sobre a livre importação de mercadorias estrangeiras, que apresentam um forte entrave ao escoamento das empresas nacionais.
• Dificuldades em se internacionalizarem, o aumento das exportações é o caminho a seguir, ainda que, seja difícil à grande maioria destas empresas se internacionalizarem.
• Dificuldade de se imporem no mercado face à forte concorrência
• A necessidade de investir na rentabilização das empresas Atendendo à lista de problemas enumerados, tendo em conta as respostas apresentadas na publicação (Comissão Europeia, 2006) podemos constatar que o âmbito do nosso trabalho permite solucionar quatro dos oito pontos descritos (dificuldade em aumentar a capacidade de produção; necessidade de criar uma equipa de apoio ao desenvolvimento da empresa; dificuldade de se imporem no mercado face à forte concorrência; necessidade de investir na rentabilização das empresas). Em tempos de grave crise económica e grande oferta e concorrência de mercado, indicamos a adoção de práticas de BI como uma solução de inovação e otimização dos processos de negócio das PMEs. A adoção de práticas de Business Intelligence por parte das PMEs, possibilita a resolução em parte, deste tipo de problemas. Para uma adoção completa ao conceito de BI é necessário que as empresas adquiram ferramentas informáticas que permitam agilizar processso e resultados. Mais uma vez convém referir que as ferramentas de Business

CAPÍTULO 8
130
Intelligence não têm capacidade de decidir por si, apenas reúnem um conjunto de elementos capazes de suportar a tomada de decisão de analistas e gestores de negócio. O conceito de BI torna-se mais preciso e rentável quanto maior for a quantidade de dados da atividade de negócio disponíveis para análise. O processo de BI tem mais possibilidades de sucesso quando o seu planeamento de negócio é bem definido por parte dos analistas e gestores. Tendo em conta o problema que procurámos resolver e todos estes aspetos relacionados com a adoção de práticas de BI identificámos as ferramentas de BI open source como uma solução viável de implementação por parte das PMEs. Após uma profunda análise relativamente ao estado da arte de ferramentas de BI existentes no mercado identificámos as ferramentas JasperSoft, Pentaho, SpagoBI e Vanilla como as melhores soluções de BI open source. Posteriormente procedemos a uma análise técnica das ferramentas, suportada pela instalação e exploração das funcionalidades disponibilizadas em cada um destes pacotes de BI. Da nossa análise elegemos Pentaho como a melhor ferramenta de BI open source da atualidade. A quantidade de documentação de suporte existente foi um dos fatores críticos da nossa avaliação, do qual reconhecemos que a ferramenta Pentaho será a que melhor suporte oferece. Após a análise e consequente eleição da melhor ferramenta, procurámos avaliar se Pentaho suportava as necesidades de uma PME. Para isso, recorremos à implementação da ferramenta sobre um sistema de produção de energia eólica, e verificámos que a ferramenta Pentaho na sua versão open source disponibiliza elementos suficientes de suporte à aplicação de técnicas de BI numa PME. Os resultados obtidos na nossa implementação prática permitem avaliar quais os parques de recolha de energias solar/eólicos produzem mais energia, quais os meses mais rentáveis, quais os elementos do parque estão sob processos de manutenção e qual a duração desses processos, etc. Da nossa análise consideramos que o processo de adoção a práticas de BI é normalmente moroso e requer pessoal especializado (com conhecimentos mínimos), nas áreas de base de dados, Data Warehousing, ETL e OLAP. O processo de estruturação de uma DW deve seguir alguma rigidez na sua construção e deve ser bem definido para que consiga dar resposta a todos os fatores que se pretendam medir. Este é um processo que envolve alguns custos caso as empresas não tenham na sua estrutura pessoal com conhecimentos nestas áreas. Na nossa investigação procuramos ao máximo reduzir na programação para avaliar a facilidade de interação cliente/aplicação. Do nosso trabalho de investigação podemos concluir que o mercado de ferramentas de BI open source, oferece boas soluções viáveis de aquisição por parte das PMEs. Todas as ferramentas analisadas têm potencial para satisfazer as reais necessidades das PMEs. De um modo geral, as versões open source das ferramentas OpenI e Palo apresentam algumas lacunas, relativamente à inexistência de várias funcionalidades de BI quando comparadas com restantes ferramentas analisada. Relativamente às ferramentas

CAPÍTULO 8
131
JasperSoft, Pentaho, SpagoBI e Vanilla, da nossa abordagem todas elas apresentam uma solução viável de implementação por parte das PMEs. JasperSoft é uma ferramenta evoluída, capaz de suportar as tarefas da área de BI, dispõe ainda de módulos de funcionalidades que são utilizados por outras ferramentas open
source como é o caso do JasperReports. A ferramenta Pentaho face à sua popularidade e à sua capacidade e desenvolvimento apresentado, é uma ferramenta que para além de ser muito utilizada cativa o desenvolvimento de plugins por parte de outras comunidades ou por elementos da própria comunidade. Ferramentas como as que exploramos na nossa demonstração prática são um claro exemplo disso. Apesar de ter sido a única ferramenta que utilizámos para o desenvolvimento do caso prático, permitie-nos avaliar que é uma ferramenta com bastante potencial, que dispõe de vários plugins fáceis de instalar e de fácil interação com o utilizador, disponibilizando funcionalidades de drag and drop em alguns dos seus módulos/plugins. Dos pacotes de ferramentas analisados é importante referir que apenas SpagoBI e Vanilla são verdadeiramente software open source, são as únicas ferramentas que não possuem versão comercial. É curioso que Vanilla sendo a aplicação mais recente de todas as analisadas, foi pioneira na disponibilização de uma versão para dispositivos móveis, o que nos perspetiva que seja uma ferramenta a ter em conta doravante. Da nossa implementação prática podemos concluir que a ferramenta utilizada, Pentaho, satisfez todas as necessidades exigidas pelo caso prático. O principal objetivo era desenvolver uma DW que permitisse guardar dados relativamente à produção de energia e dados relacionados com os aspetos de manutenção. Pentaho é claramente uma solução viável e alternativa às soluções comerciais. A aprendizagem e a adaptação à ferramenta não foi morosa, nem necessitou de grandes conhecimentos de informática, ainda que tenhamos tentado apresentar as soluções com interface mais acessível, exemplo disso é a simplicidade da utilização de todos os plugins que implementámos na versão servidor de Pentaho. Em suma, consideramos que as ferramentas de BI open source possuem capacidades suficientes para serem uma solução alternativa às ferramentas comerciais. A sua aquisição por parte das PMEs para além de não implicar custos, não tem condicionantes relacionados com licenças, taxas ou datas de validade do produto. Como trabalho futuro é importante acompanhar o desenvolvimento das ferramentas de BI open source. Seria importante proceder a uma avaliação relativamente aos custos médios da implementação de soluções de BI open source nas PMEs, no intuito de comparar a realidade dos custos dispendidos na aplicação de ferramentas comerciais com os custos da aplicação de ferramentas open source. Esta seria uma avaliação que teria maior credibilidade se ambos os tipos de ferramentas fossem aplicados na mesma PME e ao mesmo projeto. Por vezes a avaliação das ferramentas tem principal foco sobre as suas caraterísticas descritas pela comunidade de desenvolvimento e não numa avaliação

CAPÍTULO 8
132
profunda. Seria importante proceder à avaliação de ferramentas de forma mais profunda, contribuindo para uma avaliação mais crítica das ferramentas.

REFERÊNCIAS
133
REFERÊNCIAS BIBLIOGRÁFICAS
European Commission Enterprise and Industry (ECEI), (2010/2011). Ficha Informativa relative ao SBA Portugal. http://ec.europa.eu/enterprise/policies/sme/facts-figures-analysis/performance-review/pdf/2010_2011/portugal_pt.pdf
Global Alliance of SMEs, (2010). Global SME Expo 2010. http://www.globalsmes.org/html/index.php?func=expo2010&lan=en
Thomsen, C., Pedersen, T., B. (2008). A Survey of Open Source Tools for Business Intelligence.
Golfarelli, M. (2009). Open Source BI Platforms: a Funcional and Architectural Comparision.
Ferreira, M., Silva, R., Vieira, V., Guimarães, C., Carvalho, J. (2010). Um estudo de caso com análise comparativa entre ferramentas de BI livre e proprietária.
Lacy, M. K. O. (2010). SpagoBI – Plataforma BI livre e aberta. Revista Espírito Livvre. Varajão, J., Santana, D., Cunha, M., Castro, S. (2011). Adopção de sistemas CRM nas
grandes empresas portuguesas. http://www.computerworld.com.pt/media/2011/07/estudo_CRM.pdf
Rodrigues, G. L. (2006). Business intelligence. http://amigonerd.net/trabalho/33758-business-intelligence
Power, D. J. (2007). A Brief History of Decision Support Systems. http://dssresources.com/ history/dsshistory.html
Pereira, A. M., Júnior, D. I. R., Neves, G. L. C. (2005). Metadados para a Descrição de Recursos da Internet: As novas tecnologias desenvolvidas para o padrão Dublin Core e a sua utilização. revista.acbsc.org.br/index.php/racb/article/download/414/527
Thornthwaite, W., (2005). Design Tip #68 Simple Drill-Across in SQL. http://www.kimballgroup.com/html/designtipsPDF/DesignTips2005/DTKU68SimpleDrill-AcrossinSQL.pdf
Eckerson, W. W. Deploying Dashboards and Scorecards. TDWI Report, Vol. 22, 2006 Pentaho, (2008). Pentaho Open Source Business Intelligence Platform.
http://www.redhat.com/solutions/intelligence/collateral/pentaho_technical_whitepaper.pdf
JasperSoft, (2009). Open Source Business Intelligence Costs and Benefits. What You Need To Know.
Ventana Research, (2006). Open Source BI: A Ventana Research Primary Research Study. San Mateo, CA: Ventana Research, 2006.
Damiani, E., Fratil, F., Monteverdi, C., (2009). Open Source BI Adoption. Department of Information Technology, University of Milan – Italy.
Kimball, R. (2008). The Data Warehouse Lifecycle Toolkit. Pino, M. (2011). Dez razões mais frequentes para o fracasso do BI.
http://www.treinaweb.com.br/blog/2011/06/

REFERÊNCIAS
134
Wikipédia-Data Warehouse. http://pt.wikipedia.org/wiki/Armaz%C3%A9m_de_dados [Acedido em dezembro, 2011]
Veras, M. (2009). Cubos de Dados. http://gestaodati10.blogspot.com/2009/08/cubos-de-dados.html
Campos, R. A., (2005). Qualidade de dados em Data Warehouse. TCC (Graduação em Bacharelado em Sistemas de Informação). Centro de Ensino Superior de Juiz de Fora, Juiz de Fora.
Anzanello, C. A. (2007). OLAP Conceitos e Utilização. http://www.fag.edu.br/professores/limanzke/Administra%E7%E3o%20de%20Sistemas%20de%20Informa%E7%E3o/OLAP.pdf
Araújo, R. (2009). BI: Arquitecturas OLAP. http://rogerioaraujo.wordpress.com/2009/05/27/bi-arquiteturas-olap/
Barber, T., Selwood, W., Green, M. (2010). Pat User Guide the Definitive Edition Wikipédia-Dashboards. http://pt.wikipedia.org/wiki/Painel_de_bordo Wikipédia-Data Mining. [Acedido em dezembro, 2011]
http://pt.wikipedia.org/wiki/Minera%C3%A7%C3%A3o_de_dados Wikipédia-GEO. [Acedido em dezembro, 2011]
http://pt.wikipedia.org/wiki/Sistema_de_informa%C3%A7%C3%A3o_geogr%C3%A1fica [Acedido em dezembro, 2011]
Wikipédia-OLTP. http://pt.wikipedia.org/wiki/OLTP [Acedido em dezembro, 2011] Wikipédia-Weka. http://pt.wikipedia.org/wiki/Weka [Acedido em dezembro, 2011] Wikipédia-MDX. http://en.wikipedia.org/wiki/MultiDimensional_eXpressions [Acedido
em dezembro, 2011] Wikipédia-BIRT. http://en.wikipedia.org/wiki/File:Eclipse_BIRT_Report_Designer.png
[Acedido em dezembro, 2011] Dashboardspy, [Acedido em dezembro, 2011]
http://dashboardspy.com/dashboard-screenshot-MIS-cockpit-excel- palo.html Dashboardinsight, http://www.dashboardinsight.com/dashboards/screenshots/pentaho-
dashboards-one.aspx [Acedido em dezembro, 2011] Freeanalysis, http://freeanalysis.wordpress.com/page/2/?archives-list=1 [Acedido em
dezembro, 2011] Queensu, http://research.cs.queensu.ca/home/cisc333/tutorial/Weka.html [Acedido em
dezembro, 2011] Amoldit, http://arnoldit.com/wordpress/2009/04/11/rapidminer-open-source-data-mining/
[Acedido em dezembro, 2011] Bestanalytics, http://www.bestanalytics.net/2011/07/jpivot-ms-analysis-2000/ [Acedido
em dezembro, 2011] Open Source Initiative (OSI). (2011). http://www.opensource.org/ Martins, S. e Oliveira, L., (2008) "Software Open Source - o copo meio cheio ou meio
vazio?", http://nortebad.wordpress.com/2008/12/12/software-open-source-ocopo- meio-cheio-ou-meio-vazio/

REFERÊNCIAS
135
Open Source (2007), http://www.deei.fct.ualg.pt/~a28998/sie2007/OLPCfinal.pdf Enterprise Europe Network (EEN). (2011). Definição Europeia de PME. Decision Studio, http://decisionstudio.com/ [Acedido em outubro, 2011] JasperSoft, http://www.jaspersoft.com/ [Acedido em novembro, 2011] OpenI, http://openi.org/ [Acedido em setembro, 2011] Palo, http://www.jedox.com/ [Acedido em outubro, 2011] Pentaho, http://www.pentaho.com/[Acedido em dezembro, 2011] RapidMiner, http://rapid-i.com/content/view/181/190/ [Acedido em novembro, 2011] Rapid-I, http://rapid-i.com/ [Acedido em novembro, 2011] SpagoBI, http://www.spagoworld.org/xwiki/bin/view/SpagoWorld/ [Acedido em
novembro, 2011] Talend, http://www.talend.com/products-data-integration/talend-open-studio.php [Acedido em novembro, 2011] Vanilla, http://www.bpm-conseil.com/ [Acedido em novembro, 2011] R Project, http://www.r-project.org/ [Acedido em novembro, 2011] iReport, http://jasperforge.org/projects/ireport [Acedido em novembro, 2011] Kettle, http://kettle.pentaho.com/ [Acedido em novembro, 2011] Ramsetcube, http://www.ramsetcube.com/ [Acedido em novembro, 2011] GNU. (2011). http://www.gnu.org/licenses/agpl.html Weka, http://www.cs.waikato.ac.nz/ml/weka/ [Acedido em novembro, 2011] Eclipse BIRT, http://www.eclipse.org/birt/phoenix/ [Acedido em novembro, 2011] JPivot, http://jpivot.sourceforge.net/ [Acedido em novembro, 2011] Mondrian, http://en.wikipedia.org/wiki/Mondrian_OLAP_server [Acedido em Maio,
2011] Ambiente Livre. http://www.ambientelivre.com.br/tutoriais-pentaho-bi/131-instalacao-
do-pentaho-bi-server-no-ubuntu-server.html [Acedido em novembro, 2011] Utilizadores Pentaho, http://www.ambientelivre.com.br/tutoriais-pentaho-bi/221-senhas-
portas-urls-e-roles-padroes-no-pentaho-business-intelligence-ce.html [Acedido em novembro, 2011]
Comissão Europeia. (2006). Europa: uma oportunidade para as PMEs portuguesas. http://www.adrave.pt/ficheiros/docs/37-dossier%20PME%20na%20UE.pdf
Forrester Research, http://www.forrester.com/rb/research [Acedido em novembro, 2011] IDC, http://www.idc.com/ [Acedido em novembro, 2011] Bloor Research, http://www.bloorresearch.com/ [Acedido em novembro, 2011] SugarCRM, http://www.sugarcrm.com/crm/ [Acedido em novembro, 2011] Salesforce, http://www.salesforce.com/ [Acedido em novembro, 2011] SAP, http://www.sap.com/index.epx [Acedido em novembro, 2011] Actuate Corporation, http://www.actuate.com/home/ [Acedido em novembro, 2011] CDF, http://wiki.pentaho.com/display/COM/Community+Dashboard+Framework
[Acedido em Novembro, 2011]

REFERÊNCIAS
136

ANEXO A
137
Open Source Business Intelligence tools for SMEs
Marco Tereso Departamento Engenharia Informática e Sistemas
IPC – Instituto Superior de Engenharia de Coimbra Coimbra, Portugal
Jorge Bernardino Departamento de Engenharia Informática e de Sistemas
IPC – Instituto Superior de Engenharia de Coimbra Coimbra, Portugal
Abstract— In times of rapid change, intense competition, companies looking for innovations, new market segments and especially understand the time to act, the new market trends. To assist managers in making decisions, appeals to the business intelligence tools. In this work are evaluated and compared open source tools for Business Intelligence: SpagoBI, Open, Pentaho, JasperSoft, Palo and Vanilla. Thus, only free available solutions are analyzed for use by SMEs in order to maintain their competitive advantage in an increasingly global market.
Keywords- Business Intelligence; Open Source; PME’s.
Introdução A implementação de sistemas de apoio à decisão nas pequenas e médias empresas (PME’s) é uma necessidade, agravada pela concorrência e competitividade praticada pelas grandes empresas, o que obriga a esforços extra por parte das PME’s com o intuito de produzirem a preços de mercado competitivos. Atualmente, a generalidade das empresas possui sistemas de Tecnologias da Informação (TI), que permitem recolher, processar, transmitir e disseminar dados. Os sistemas de TI são concebidos para registar enormes quantidades de dados resultantes da atividade operacional das empresas. Os dados registados pelos sistemas de TI permitem aos gestores das empresas extrair informação e conhecimento do ramo de negócio e das tendências de mercado; este conhecimento é essencial para a tomada de decisões por parte dos responsáveis pela gestão empresarial. As maiores dificuldades das PMEs prendem-se com a colocação dos seus produtos no mercado a preços competitivos e a rentabilidade dos custos da sua
atividade. Face a estes problemas, este trabalho tem como finalidade efetuar um levantamento do estado da arte de ferramentas open source de Business
Intelligence (BI). As ferramentas BI permitem agrupar grandes quantidades de dados e organizá-los de forma a reunir informação relevante no apoio à tomada de decisão. Este tipo de ferramentas permite gerar gráficos, tabelas, relatórios e estatísticas, permitindo aos gestores visualizar irregularidades e tendências de negócio relevantes. Os processos de BI são também bastante importantes na área das vendas e de marketing.
Neste trabalho apresentamos soluções exequíveis de ferramentas open source BI para as PME’s, Estas soluções podem também ser aplicadas em grandes empresas, embora o nosso foco seja nas PMEs, que representam 98% da totalidade das empresas na União Europeia, e que atravessam maiores dificuldades para contenção das suas despesas. O nosso objetivo é apresentar uma lista de ferramentas BI gratuitas existentes no mercado e efetuar a comparação e análise destas ferramentas. O estudo realizado contemplou apenas ferramentas open
source, tendo em conta que o principal objetivo é reduzir as despesas nas PME’s e aumentar os seus lucros.
Este artigo está estruturado da seguinte forma: na secção II é apresentado o estado de arte de ferramentas open source Business Intelligence, na

ANEXO A
138
secção III é efectuada a comparação entre as ferramentas em análise. Por último, na secção IV são apresentadas as conclusões e uma descrição do trabalho futuro.
Ferramentas Open Source Business Intelligence
A área de Business Intelligence (BI) [1] está em grande evolução do ponto de vista científico e tecnológico, contudo não existem muitos artigos publicados sobre a avaliação ou comparação de ferramentas open-source BI; apenas podemos destacar os trabalhos de Thomsen e Pedersen [2], Golfarelli [3] e Ferreira et al. [4].
O nosso trabalho resulta da necessidade do aumento da competitividade e da redução de custos por parte das pequenas e médias empresas, oferecendo: um levantamento de soluções de mercado BI sem custos; capacidade de estruturar e melhorar os seus processos de negócio; apoio nas tomadas de decisão; capacidade de competição com empresas mais consolidadas. Nesta secção apresentaremos o estado da arte relativamente às seis ferramentas BI analisadas: SpagoBI [5], OpenI [6], Pentaho [7], JasperSoft [8], Palo [9] e Vanilla [10].
SpagoBI SpagoBI [5] é uma aplicação desenvolvida pela SpagoWorld, fundada em 2006 e suportada por uma comunidade open source. A ferramenta SpagoBI possui uma licença GNU LGPL (Lesser General Public Licence), que permite aos utilizadores usufruir da totalidade das suas funcionalidades. A ferramenta SpagoBI é desenvolvida em linguagem Java e disponibilizada unicamente na versão Community., isto é, completamente gratuita.
A ferramenta SpagoBI contém diversas funcionalidades, destacando-se: a criação e
exportação de relatórios, a criação de gráficos, a integração de dados através de processos ETL, a análise através de processos OLAP, os processos de Data Mining, os processos de consultas simples a bases de dados, a criação de filtros de consulta e as propriedades georreferenciadas..O servidor SpagoBI fornece e disponibiliza as funcionalidades da ferramenta: servidor de aplicação, serviço de login, Dashboard, Data Mining, sistema de suporte a bases de dados, ETL (Extract, Transform, Load), serviços de referenciação geográfica (GEO/GIS), agenda de tarefas, servidor OLAP, criação de relatórios, consultas a bases de dados e servidor Web. A Figura 1 ilustra as diversas funcionalidades existentes na Suite SpagoBI.
Figura 1: Conjunto de funcionalidades SpagoBI [5]
Para a criação e visualização de relatórios são utilizadas as ferramentas Eclipse BIRT, JasperReport e BusinessObject. O serviço de OLAP é suportado pelos motores JPivot/Mondrian, JPalo/Mondrian e JPivot/XMLA Server. A SpagoBI disponibiliza mecanismos de Dashboard, permitindo a visualização de gráficos no formato swf e exibindo KPIs (Key Performance Indicators) em tempo real. Este conjunto de funcionalidades torna-a uma ferramenta robusta e com elevado potencial, face a

ANEXO A
139
outras ferramentas. De salientar que SpagoBI é um pacote de soluções BI completo e que disponibiliza o seu conjunto de funcionalidades numa única versão e sem custos para o utilizador.
OpenI OpenI [6] é uma ferramenta em constante
desenvolvimento desde 2002, que possui também ela uma licença GNU GPL, sendo desenvolvida em linguagem Java. A ferramenta OpenI encontra-se disponível em duas versões, Community que detém parte das funcionalidades da ferramenta sendo completamente gratuita e Enterprise que contém todas as funcionalidades disponíveis pela solução, sendo esta versão paga.
A aplicação disponibiliza um leque de aplicativos de BI: elaboração de gráficos, criação de tabelas Pivot, geração de relatórios OLAP e processos de Data Mining. A interface da aplicação é apelativa e não oferece dificuldades acrescidas na sua utilização para qualquer tipo de utilizador. Para um melhor enquadramento com a estrutura da aplicação mostra-se na Figura 2 uma ilustração da arquitetura da ferramenta.
Figura 2: Arquitetura da aplicação OpenI [11]
A Figura 2 ilustra a arquitetura da ferramenta OpenI, que é constituída por: camada de interação com o utilizador, na qual se reúnem as
funcionalidades de BI disponíveis para o utilizador; camada de definição do conjunto de relatórios, disponibilizados pela aplicação; camada de componentes de ligação entre funcionalidades internas da aplicação e servidores externos, nomeadamente servidores OLAP, RDBMS (Relational Database Management System) e Data
Mining; camada de segurança e servidor de aplicação J2EE.
A ferramenta OpenI apresenta um conjunto de funcionalidades BI de qualidade, ainda assim peca numa primeira análise pela inexistência de um módulo de ETL, pela impossibilidade de exportar dados e pela ausência de um módulo de KPIs.
Pentaho A Pentaho [7] foi fundada no ano de 2004 por um grupo de colaboradores com grande experiência na área de Business Intelligence. A ferramenta Pentaho é desenvolvida em linguagem Java, possui uma licença GNU GPL, e é disponibilizada em duas versões, Community que detém parte das funcionalidades da ferramenta sendo completamente gratuita e Enterprise que contém todas as funcionalidades disponíveis pela solução, mas com custos para o utilizador. A versão Community de demonstração online permite realizar análises através de um mecanismo próprio da Pentaho ou recorrendo ao Xanalyzer e à criação e visualização de gráficos de diferentes tipos. A Pentaho possibilita a criação de relatórios simples, relatórios de análise e Dashboards. A ferramenta disponibiliza algumas bibliotecas Widget de Dashboards que funcionam como vistas de análise e KPIs. O cruzamento de dados OLAP é suportado pelas aplicações Mondrian e Ramsetcube, sendo as propriedades de Data Mining suportadas pelo módulo Weka.

ANEXO A
140
A Figura 3 ilustra o conjunto de funcionalidades disponibilizadas pela aplicação Pentaho, que surgem representadas sob a forma de arquitetura por camadas. Surgem ilustrados quatro grupos de funcionalidades: relatórios (produção, operação e ad-hoc), análises (Data Mining, OLAP e Drill &
Explode), Dashboards (métricas, KPIs e alertas) e processos de gestão (integração, definição e execução).
Figura 3: Conjunto de funcionalidades Pentaho [12]
Pentaho é um dos pacotes de BI open source mais poderosos, muito equivalente à ferramenta SpagoBI; a diferença é que, a Pentaho não suporta funcionalidades de georreferenciação GEO/GIS na sua versão Community.
JasperSoft JasperSoft surgiu em 2001, inicialmente designada por Panscopic, posteriormente Teodor Danciu (fundador do JasperReports) juntou-se à equipa Panscopic e em 2004 surgiu a JasperSoft. Esta é uma ferramenta open source desenvolvida em Perl e Java, possuindo uma licença GNU GPL. JasperSoft é disponibilizada nas versões Community e Enterprise. A versão Community de JasperSoft BI é disponibilizada em três produtos individuais: servidor JasperReports, JasperSoft OLAP e ETL JasperSoft.
Jaspersoft BI Suite, é incorporada por um servidor (Jasper Server) que permite: criação de relatórios interactivos, criação de diferentes tipos de gráficos, consultas ad-hoc (possibilidade de consultas em tempo real, permitindo a utilizadores com poucos conhecimentos de SQL acederem a informação proveniente de bases de dados), desenho e estruturação de relatórios, análises OLAP, integração de processos de ETL e disponibilidade da funcionalidade query builder. JasperSoft é uma ferramenta fácil de implementar e possui uma arquitetura incremental. JasperSoft permite aos utilizadores sem conhecimentos técnicos sobre bases de dados ou linguagens de consulta a bases de dados, criarem relatórios e consultas ad-hoc, recorrendo às propriedades de drag-and-drop, definir itens de visão empresarial, definir filtros de dados, especificar parâmetros e gerar consultas sem dificuldades acrescidas. JasperSoft inclui também funcionalidades de georreferenciação, a aplicação é constituída e auxiliada por centenas de mapas de escala mundial. JasperSoft é uma aplicação robusta, confiável e actualizável, permitindo uma abordagem de integração por fases que pode ser adaptada consoante as necessidades.
JasperSoft é um pacote BI aceitável que possui suporte para as principais funcionalidades de BI. Contudo, apresenta algumas lacunas nomeadamente a inexistência de um módulo de Data Mining e a inexistência de funcionalidades de KPIs.
Palo Palo [9] ou JPalo (Java Palo), é uma ferramenta desenvolvida pela empresa Jedox AG, que iniciou a sua atividade no ano de 2002. A ferramenta Palo possui uma licença GNU GPL e é desenvolvida em Java, disponível nas versões Enterprise e Community. A Suite Palo é constituída pelo grupo de funcionalidades Jedox: Palo OLAP Server, Palo

ANEXO A
141
Web, Palo ETL Server e Palo para Excel. Os processos de OLAP são os que maior destaque merecem na aplicação. Palo OLAP Server fornece estabilidade, desempenho, algoritmos de lógica inovadores e permite trabalhar num ambiente multi-sessão em tempo real. Palo Web é um interface Web que permite criar e gerir relatórios OLAP e visualizar processos de ETL.
A versão Palo é concebida para suportes Microsoft Office Excel e Open Office Calc. Palo para Excel inclui um servidor de base de dados OLAP e a componente Microsoft Excel Add-in/Open Office Calc Add-in, que permite adicionar um separador de funcionalidades de BI no ambiente da aplicação (Excel ou Calc), este separador possui um leque de funcionalidades que permitem trabalhar os dados registados nas folhas de cálculo.
Resumidamente, Palo é uma ferramenta baseada em folhas de cálculo que possibilita a integração de dados provenientes de folhas de cálculo Excel e Calc. A integração de dados ETL e as consultas OLAP são as funcionalidades de maior relevo da ferramenta. Os recursos para gerar gráficos e relatórios são os disponibilizados pela aplicação de suporte (Microsoft Excel ou Open Office Calc).
Vanilla BPM Conceil [10] é um grupo francês de soluções open source BI, sendo esta a organização responsável pelo desenvolvimento da ferramenta Vanilla. Esta ferramenta distingue-se de todas as outras por ser desenvolvida em linguagem PHP, mas a par das restantes também possui uma licença GNU GPL. A ferramenta Vanilla permite: efetuar análises de dados, construir relatórios, gerar e analisar tabelas de dados, criar gráficos, definir KPIs e empregar processos de Data Mining. Vanilla recorre às ferramentas BIRT e iReports com o intuito de fornecer capacidade de integração de
metadados. Vanilla tem a capacidade de alocar diferentes projetos num único servidor e disponibiliza no seu portal acesso aos diferentes relatórios e a um livro de histórico. A ferramenta Vanilla também está disponível numa versão para sistemas operativos Android. Das ferramentas analisadas, Vanilla é a única ferramenta open
source BI que disponibiliza uma versão do seu software para dispositivos móveis.
Vanilla é uma das ferramentas de maior destaque atualmente, para além do suporte a todas as funcionalidades BI, a ferramenta começa também a migrar para dispositivos de suporte móvel, tornando-a uma das ferramentas com elevadas perspectivas de progressão.
Comparação das Ferramentas Após o trabalho de estudo relativamente ao estado de arte de ferramentas open source BI, nesta secção faremos uma comparação relativamente às funcionalidades de cada ferramenta. A Tabela 1 apresenta uma comparação das ferramentas em análise tendo em conta as suas funcionalidades, características e os sistemas operativos que as suportam.
TABELA 1. COMPARAÇÃO DE FERRAMENTAS OPEN SOURCE BUSINESS INTELLIGENCE
Funcionalidades
Ferramentas Open Source Business Intelligence
Spa
goB
I
Ope
nI
Pen
taho
Jasp
erS
oft
Pal
o
Van
illa
Relatórios
Gráficos
Dashboards
OLAP
ETL
Data Mining
KPIs
Exportação de dados
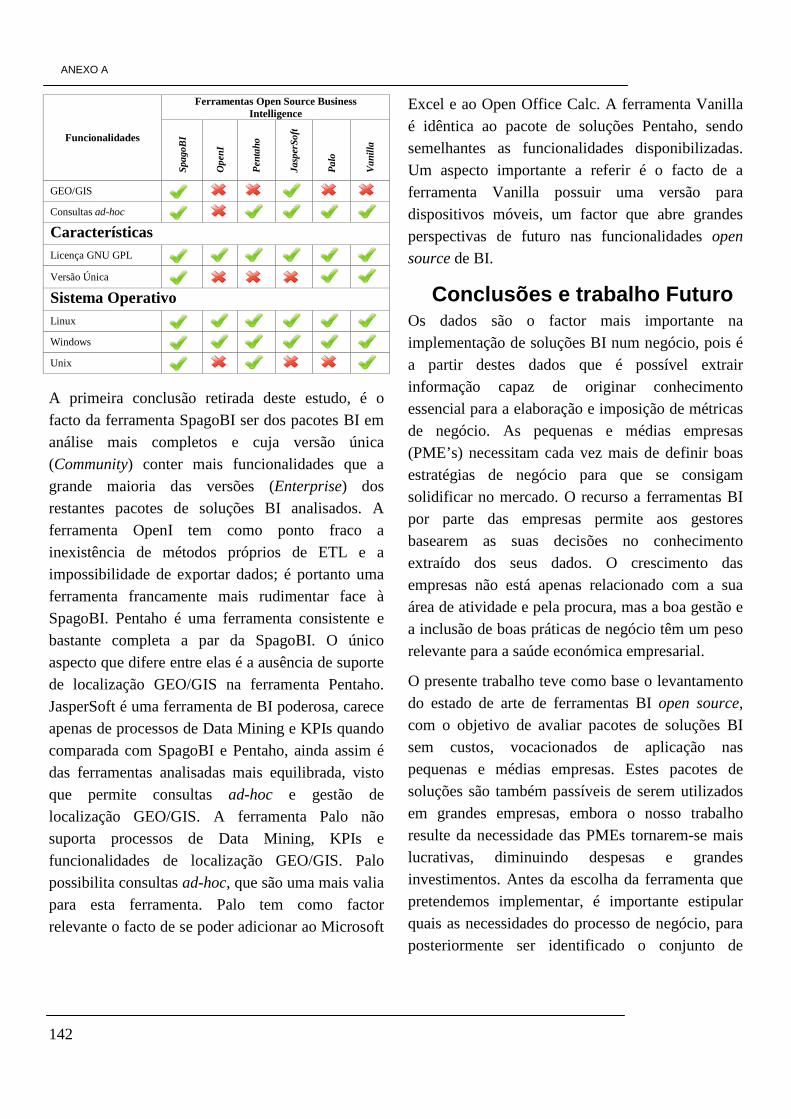
ANEXO A
142
Funcionalidades
Ferramentas Open Source Business Intelligence
Spa
goB
I
Ope
nI
Pen
taho
Jasp
erS
oft
Pal
o
Van
illa
GEO/GIS
Consultas ad-hoc
Características Licença GNU GPL
Versão Única Sistema Operativo Linux
Windows
Unix
A primeira conclusão retirada deste estudo, é o facto da ferramenta SpagoBI ser dos pacotes BI em análise mais completos e cuja versão única (Community) conter mais funcionalidades que a grande maioria das versões (Enterprise) dos restantes pacotes de soluções BI analisados. A ferramenta OpenI tem como ponto fraco a inexistência de métodos próprios de ETL e a impossibilidade de exportar dados; é portanto uma ferramenta francamente mais rudimentar face à SpagoBI. Pentaho é uma ferramenta consistente e bastante completa a par da SpagoBI. O único aspecto que difere entre elas é a ausência de suporte de localização GEO/GIS na ferramenta Pentaho. JasperSoft é uma ferramenta de BI poderosa, carece apenas de processos de Data Mining e KPIs quando comparada com SpagoBI e Pentaho, ainda assim é das ferramentas analisadas mais equilibrada, visto que permite consultas ad-hoc e gestão de localização GEO/GIS. A ferramenta Palo não suporta processos de Data Mining, KPIs e funcionalidades de localização GEO/GIS. Palo possibilita consultas ad-hoc, que são uma mais valia para esta ferramenta. Palo tem como factor relevante o facto de se poder adicionar ao Microsoft
Excel e ao Open Office Calc. A ferramenta Vanilla é idêntica ao pacote de soluções Pentaho, sendo semelhantes as funcionalidades disponibilizadas. Um aspecto importante a referir é o facto de a ferramenta Vanilla possuir uma versão para dispositivos móveis, um factor que abre grandes perspectivas de futuro nas funcionalidades open
source de BI.
Conclusões e trabalho Futuro Os dados são o factor mais importante na implementação de soluções BI num negócio, pois é a partir destes dados que é possível extrair informação capaz de originar conhecimento essencial para a elaboração e imposição de métricas de negócio. As pequenas e médias empresas (PME’s) necessitam cada vez mais de definir boas estratégias de negócio para que se consigam solidificar no mercado. O recurso a ferramentas BI por parte das empresas permite aos gestores basearem as suas decisões no conhecimento extraído dos seus dados. O crescimento das empresas não está apenas relacionado com a sua área de atividade e pela procura, mas a boa gestão e a inclusão de boas práticas de negócio têm um peso relevante para a saúde económica empresarial.
O presente trabalho teve como base o levantamento do estado de arte de ferramentas BI open source, com o objetivo de avaliar pacotes de soluções BI sem custos, vocacionados de aplicação nas pequenas e médias empresas. Estes pacotes de soluções são também passíveis de serem utilizados em grandes empresas, embora o nosso trabalho resulte da necessidade das PMEs tornarem-se mais lucrativas, diminuindo despesas e grandes investimentos. Antes da escolha da ferramenta que pretendemos implementar, é importante estipular quais as necessidades do processo de negócio, para posteriormente ser identificado o conjunto de

ANEXO A
143
soluções válidas e adequadas às suas reais necessidades.
Como trabalho futuro pretendemos prosseguir a análise das ferramentas, com o objetivo de avaliar outros aspetos de ordem técnica e de usabilidade. Posteriormente iremos proceder à implementação das ferramentas em ambiente empresarial usando um caso real.
Referências
[1] D. J. Power (2007-03-10). "A Brief History of Decision Support Systems, version 4.0". DSSResources.COM. World Wide Web, http://DSSResources.COM/history/dsshistory.html, version 4.0, March 10, 2007.
[2] Christian Thomsen e Torben Bach Pedersen "A Survey of Open Source Tools for Business Intelligence", International Journal of Data Warehousing and Mining, Volume 5, nº3, 2009, pp.56-75.
[3] Matteo Golfarelli, "Open Source BI Platforms: a Functional and Architectural Comparison", Proceedings of the 11th International Conference, DaWaK 2009, Linz, Austria, pp.287-297.
[4] Manuele Ferreira, Robson Silva, Vaninha Vieira, Carina Guimarães e Juliana Carvalho, "Um estudo de caso com ánalise comparativa entre ferramentas de BI livre e proprietária", UDESC, VI Escola Regional de Banco de Dados, Joinville, Brasil, Abril 2010.
[5] Miguel Koren O'Brien de Lacy, "SpagoBI - Plataforma BI livre e aberta", Revista Espírito Livre, Junho de 2010 .
[6] http://openi.org/, 6-02-2011
[7] http://www.pentaho.com/ , 7-02-2011
[8] http://www.jaspersoft.com/ , 8-02-2011
[9] http://www.jpalo.com/en/ , 8-02-2011
[10] http://vanilla-bi.com/ , 9-02-2011
[11] http://openi.sourceforge.net/openi_product.html , 6-02-2011
[12] http://www.crunchbase.com/company/pentaho , 7-02-2011

144

ANEXO B
145
Commercial or open source business intelligence tools?
Marco Tereso Departamento Engenharia Informática e de Sistemas IPC – Instituto Superior de Engenharia de Coimbra
Coimbra, Portugal [email protected]
Jorge Bernardino Departamento de Engenharia Informática e de Sistemas
IPC – Instituto Superior de Engenharia de Coimbra Coimbra, Portugal
Abstract— In order to stay competitive in a global world, the organizations must use business intelligence techniques for obtaining and processing relevant information quickly and cost effectively. These techniques include the activities of decision support systems, query and reporting, online analytical processing (OLAP), statistical analysis, text mining, data mining and visualization. Consequently, the importance of using business intelligence tools is crucial for the success of actual organizations. Yet, many organizations are learning that this no easy task to decide which business intelligence tool to choose to expand their business. In this way, this work will evaluate the characteristics and costs of eight major business intelligence tools: four commercial (IBM Cognos, Microsoft BI, MicroStrategy and Oracle BI) and four open source solutions (JasperSoft, Pentaho, SpagoBI and Vanilla). The main objective is to present the differences in functionality between the various platforms, estimating overall usability, helping decision managers to choose the best tool.
Keywords-Business Intelligence; Open Source BI Tools; Commercial BI Tools.
• INTRODUCTION
Business Intelligence (BI) is a broad category of applications and technologies for gathering, storing, analyzing, and providing access to data to help managers make better business decisions. Business Intelligence applications include the activities of decision support systems, query and reporting, online analytical processing (OLAP), statistical analysis, text mining, data mining and visualization [2].
The benefit from business intelligence platforms for organizations is extremely important. Business intelligence platforms allows managers and business analysts monitor data and statistics, make decisions, analyze market trends, study the insertion of new products and maintain profitable and long-lasting relationships with customers in order to stay competitive in a global world.
Currently, there are several known cases of success, from implementing business intelligence tools in various business segments. The resource to business intelligence platforms is extremely important in order to monitor market trends, technological innovation and make the most work activity of the company. The business intelligence tools are intended to
assist business managers in making decisions, drawing on data analysis and applying them to metrics that enable them to extract knowledge. The processes of business intelligence help make business more profitable and dynamic. When is time to choose one business intelligence platform is important that companies have some knowledge about existing platforms on the market. There are several tools in the business intelligence market with different types of licenses, which we can break up in two main groups: commercial and open source platforms. Before making a decision for the business intelligence platform to acquire, business managers must take into account the features of the tool to satisfy the needs of the organization, check whether the minimum requirements of the platform are supported by the company computer system. The implementation of business intelligence platforms in an organization requires some additional efforts. Some of the problems regarding the adoption of business intelligence for organizations is directly related to: acquisition of skilled human resources in the area of databases, changes in organizational structure forcing the inclusion of new employees, implementation of new standards of regulation and planning of new work methods. This study compares the features of four commercial business intelligence platforms: IBM Cognos [3], Microsoft BI [5], MicroStrategy [7] and Oracle BI [9], with four open source platforms: JasperSoft [11], Pentaho [13], SpagoBI [15] and Vanilla [17].
This article is structured as follows: section 2 analyzes the advantages and drawbacks of open source platforms and commercial platforms. In section 3 we describe the four major commercial tools, and section 4 the four major open source tools. In section 5 is presented a comparison between all tools. Finally, section 6 concludes the paper by summarizing the main conclusions of our research and pointing out directions for future work.
• COMMERCIAL OR OPEN SOURCE TOOLS?
Before we proceed with some of the business intelligence solutions in the market is important to establish some of the benefits and disadvantages of using open source or commercial tools. The most relevant aspect of open source tools is that they are free and allow access to the code, with the possible modification of the various modules. In contrast
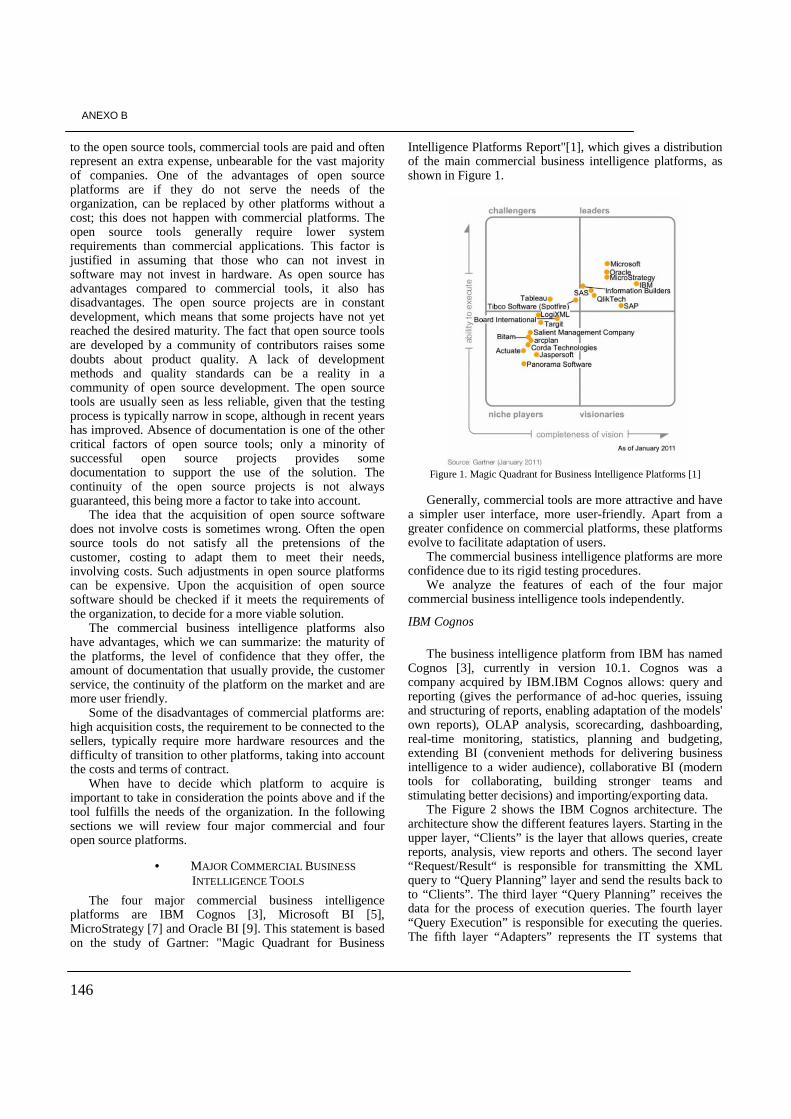
ANEXO B
146
to the open source tools, commercial tools are paid and often represent an extra expense, unbearable for the vast majority of companies. One of the advantages of open source platforms are if they do not serve the needs of the organization, can be replaced by other platforms without a cost; this does not happen with commercial platforms. The open source tools generally require lower system requirements than commercial applications. This factor is justified in assuming that those who can not invest in software may not invest in hardware. As open source has advantages compared to commercial tools, it also has disadvantages. The open source projects are in constant development, which means that some projects have not yet reached the desired maturity. The fact that open source tools are developed by a community of contributors raises some doubts about product quality. A lack of development methods and quality standards can be a reality in a community of open source development. The open source tools are usually seen as less reliable, given that the testing process is typically narrow in scope, although in recent years has improved. Absence of documentation is one of the other critical factors of open source tools; only a minority of successful open source projects provides some documentation to support the use of the solution. The continuity of the open source projects is not always guaranteed, this being more a factor to take into account.
The idea that the acquisition of open source software does not involve costs is sometimes wrong. Often the open source tools do not satisfy all the pretensions of the customer, costing to adapt them to meet their needs, involving costs. Such adjustments in open source platforms can be expensive. Upon the acquisition of open source software should be checked if it meets the requirements of the organization, to decide for a more viable solution.
The commercial business intelligence platforms also have advantages, which we can summarize: the maturity of the platforms, the level of confidence that they offer, the amount of documentation that usually provide, the customer service, the continuity of the platform on the market and are more user friendly.
Some of the disadvantages of commercial platforms are: high acquisition costs, the requirement to be connected to the sellers, typically require more hardware resources and the difficulty of transition to other platforms, taking into account the costs and terms of contract.
When have to decide which platform to acquire is important to take in consideration the points above and if the tool fulfills the needs of the organization. In the following sections we will review four major commercial and four open source platforms.
• MAJOR COMMERCIAL BUSINESS
INTELLIGENCE TOOLS
The four major commercial business intelligence platforms are IBM Cognos [3], Microsoft BI [5], MicroStrategy [7] and Oracle BI [9]. This statement is based on the study of Gartner: "Magic Quadrant for Business
Intelligence Platforms Report"[1], which gives a distribution of the main commercial business intelligence platforms, as shown in Figure 1.
Figure 1. Magic Quadrant for Business Intelligence Platforms [1]
Generally, commercial tools are more attractive and have a simpler user interface, more user-friendly. Apart from a greater confidence on commercial platforms, these platforms evolve to facilitate adaptation of users.
The commercial business intelligence platforms are more confidence due to its rigid testing procedures.
We analyze the features of each of the four major commercial business intelligence tools independently.
IBM Cognos
The business intelligence platform from IBM has named
Cognos [3], currently in version 10.1. Cognos was a company acquired by IBM.IBM Cognos allows: query and reporting (gives the performance of ad-hoc queries, issuing and structuring of reports, enabling adaptation of the models' own reports), OLAP analysis, scorecarding, dashboarding, real-time monitoring, statistics, planning and budgeting, extending BI (convenient methods for delivering business intelligence to a wider audience), collaborative BI (modern tools for collaborating, building stronger teams and stimulating better decisions) and importing/exporting data.
The Figure 2 shows the IBM Cognos architecture. The architecture show the different features layers. Starting in the upper layer, “Clients” is the layer that allows queries, create reports, analysis, view reports and others. The second layer “Request/Result“ is responsible for transmitting the XML query to “Query Planning” layer and send the results back to to “Clients”. The third layer “Query Planning” receives the data for the process of execution queries. The fourth layer “Query Execution” is responsible for executing the queries. The fifth layer “Adapters” represents the IT systems that

ANEXO B
147
make the link between data and users. Finally layer six “Data Sources” is the data layer, consisting of databases and data files.
Figure 2. IBM Cognos architecture [4]
Microsoft BI
According to Gartner [1], Microsoft emerged as the leading tool of business intelligence tools market.
In the business intelligence processes Microsoft [5] uses two of its solutions packages: Microsoft Office and Microsoft SQL Server. The features of Data Warehouse, Data Marts and Operational Data are supported by SQL Server; data integration by SQL Integration Services; data analysis by SQL Analysis Services and operations with reports served by SQL Reporting Services.
Excel supports the features of end-user analysis tool and the business intelligence portal uses Sharepoint. The business scorecards, analytics and planning tools are supported by PerformancePoint.
This platform allows: querying, analysis, reporting, data integration, synchronization, searches, cloud storage and importing/exporting data.
The Figure 3 shows the Microsoft Business Intelligence architecture. The architecture show the features supported by the Office and SQL Server, separated by different application layers.
Figure 3. Microsoft Business Intelligence architecture [6]
MicroStrategy
According to Gartner [1], Microstrategy [7] holds the third podium position of commercial business intelligence platforms market leaders.
Currently at version 9 and is available in optimized solutions for mobile environments, including iPad, iPhone and BlackBerry.
The main features of the MicroStrategy are: querying, reporting (allows the development and structuring of reports) OLAP analysis (allows the analysis and construction of an intelligent data cubes, MDX connection and incorporates a ROLAP server), dashboarding, data mining and importing/exporting data.
The Figure 4 shows MicroStrategy platform architecture. The physical layer of the application is made up of databases and operational databases for decision support. The logic layer enables the preparation of scorecards, dashboards, reports, OLAP cubes, advanced analysis, proactive alerts and notifications. The visual layer is composed of Web browsers, enterprise portals and Microsoft Office applications.
Figure 4. MicroStrategy architecture [8]
Oracle BI
According to Gartner [1], Oracle BI [9] holds the second podium position of commercial business intelligence platforms market leaders.
Oracle BI is available in the market as package, called Oracle Business Intelligence Enterprise Edition (OBIEE). The OBIEE offers a range of solutions necessary to create and view reports. OBIEE allows the development of several tests for the data.
In a more detailed OBIEE allows: to create interactive dashboards, reporting and publishing, answers (ad-hoc analysis), delivers (proactive detection and alerts), disconnected analytics, Microsoft Office Plug-in and a Web Services.

ANEXO B
148
The Figure 5 shows the OBIEE architecture. OBIEE architecture has three layers: physical, logic and application. The physical layer consists of databases, data warehouses, data files and business processes. The logic layer can work and display the data of: interactive dashboards, ad-hoc analysis, proactive detection, alerts, reporting, publishing and support to the Microsoft Office applications. The application layer represents the set of applications that can be used in the data: sales, services, contact center, marketing, order management, supply chain, financial and human resources.
FIGURE 5. OBIEE ARCHITECTURE [10]
• MAJOR OPEN SOURCE BUSINESS
INTELLIGENCE TOOLS
The communities of developing open source business intelligence solutions are required along with their employees to optimize their platforms, contributing to a steady development, making them more functional solutions.
In this section we present a brief description of the potential of JasperSoft [11], Pentaho [13], SpagoBI [15] and Vanilla [17] platforms. The analysis platforms have one feature in common, the fact that all have a GNU GPL license.
We analyze the features of each of the four major open source business intelligence platforms independently.
JasperSoft
JasperSoft [11] is an open source business intelligence platform developed in Java and Perl language. JasperSoft has two proprietary versions, Enterprise and Professional in addition to the Community version. The Community is a free version, this version is not available in a single package but in three individual modules: Jasper Reports Server, JasperSoft OLAP and ETL JasperSoft. The Jasper Reports Server module enables the creation, structuring and displaying BI reports; JasperSoft OLAP module is the tool that allows linking of data and parameterization of the different views of the data cube, ETL JasperSoft is the module that allows the tool creating the structure of production, processing and loading data.
The set of modules that make up the community version of the tool features available for creating and viewing reports, various graphics, dashboards, OLAP and ETL processes, analysis of geo-referencing, export data and ad-hoc queries. This platform was developed for Linux and Windows operating systems.
The Figure 6 shows JasperSoft architecture.
Figure 6. JasperSoft architecture [12]
Pentaho
Pentaho [13] is one of the most popular open source business intelligence platform, developed in Java, the tool is available in two versions, Community and Enterprise. Like other platforms, the Community version is free and the Enterprise version is a paid solution.Pentaho is a platform consisting of a set of integrated tools. Pentaho incorporates the Kettle application for ETL processes, Mondrian and Ramsetcube in OLAP processes, Weka for properties of data mining. Pentaho allows creating reports, creating charts, dashboards, data manipulation processes through ETL and OLAP, data mining processes, KPI's, exports of data and ad-hoc queries. Pentaho uses MDX to access and manipulate data from databases. The tool is available for Linux, Windows and Unix operating systems.
The Figure 7 shows Pentaho architecture layers.

ANEXO B
149
Figure 7. Pentaho architecture [14]
SpagoBI
SpagoBI [15] is an open source business intelligence platform developed in Java. SpagoBI is available in a single version, Community. This is the most comprehensive free platform, because has all the main features of business intelligence and provides them as a single release covering its users with a good solution that offers all its capabilities in a package completely free.
SpagoBI contains features for creating and exporting reports, charting several, development of dashboards, data integration using ETL processes, analyzes, processes using OLAP, data mining processes, implementation of filters in queries, export data, ad-hoc queries and features GEO/GIS. The tool is available for Linux, Windows and Unix operating systems.
The Figure 8 shows SpagoBI features.
Figure 7. SpagoBI features [16]
Vanilla
Vanilla [17] is an open source business intelligence platform developed in PHP language. Vanilla is available in a single version, community. Vanilla is a complete platform taking into account that integrates all main functionalities of business intelligence. The platform allows to create reports, perform analysis, generate and analyze data tables, charting several, dashboards, ad-hoc queries, integrate OLAP and ETL processes, define KPIs, data export and use of procedures of Data Mining.
Vanilla uses the tools BIRT and iReports for the purpose of metadata integration. Vanilla allows filing several separate projects, and an historical book.
The platform is available in a version for mobile operating system Android, highlighting the monitoring effort of innovation on the part of the development group. Vanilla is available for Linux, Windows and Unix operating systems.
The Figure 9 shows Vanilla architecture.
Figure 9. Vanilla architecture [17]
• COMPARISON BETWEEN COMERCIAL AND
OPEN SOURCE BUSINESS INTELLIGENCE TOOLS
In this section we intend to illustrate a comparative table of the different features offered by each platform. The results are related to the research work on the 8 platforms.
TABELA 1. COMPARISION BETWEEN OPEN SOURCE AND COMMERCIAL BUSINESS INTELLIGENCE

ANEXO B
150
Features
Business Intelligence Platforms Open Source Commercial
Jasp
erS
oft
Pen
taho
Spa
goB
I
Van
illa
IBM
Mic
roso
ft
Mic
roS
tra
teg
y
Ora
cle
Reports � � � � � � � �
Dashboards � � � � � � � �
OLAP � � � � � � � �
ETL � � � � � � � �
Data Mining � � � � � � �
KPIs � � � � � � �
Data export � � � � � � � �
GEO/GIS � � � � � � �
Ad-hoc queries � � � � � � � �
Linux � � � � � � �
Windows � � � � � � � �
Unix � � � � �
In open source platforms, Pentaho and SpagoBI are
identical platforms, having all the main features and are available for major operating systems. JasperSoft has neither Data Mining features nor KPI’s. JasperSoft does not support UNIX operating system. Vanilla just does not have GEO/GIS features. Microsoft Business Intelligence platform does not available to Linux and Unix, but if resort to Wine tool it is possible.
The commercial platforms are identical, processing all the features analyzed. Relatively to operating system, Oracle does not support Unix.
Pentaho and SpagoBI are equivalent to commercial platforms, being an alternative with lower acquisition costs.
• CONCLUSIONS AND FUTURE WORK
The importance of implementing business intelligence tools in an organization is unquestionable, given the recognized importance of use of such platforms, it is important when seeking to implement one that meets the needs, from a standpoint of cost / quality.
When choosing a platform, organizations should prevail their choice taking into account the advantages and disadvantages that we announced.
It is important to realize the capabilities of the organizational structure in terms of basic knowledge of business intelligence tools. Aspects such as knowledge of data modeling languages are sometimes essential and you must have qualified people with such knowledge in the organization.
The choice between open source or commercial tools should take into account the financial situation of the company or organization and their capacity for investement and maintenance.
The commercial adoption of evaluation tools have the advantage of providing interfaces easier to use and which do not require much knowledge of informatics by users, this is the main advantage that sometimes makes the difference in business without people with knowledge. As for open source tools, already have very large features common to commercial tools but in return are more difficult to use.
In our analysis, the open source BI tools with the greatest potential are clearly Pentaho and SpagoBI.
For the commercial platforms, we highlight the two platforms on top of market leadership, Microsoft BI and Oracle BI. This conclusion is partly motivated by the publication of Gartner [1].
As future work we intend to determine the average cost of maintaining two types of solutions and evaluate the need to have skilled labor in the organization to implement business intelligence processes.
REFERENCES
http://www.fdsystems.co.uk/files/Gartner%20BI%20Magic%20Quadrant%
20QlikView.pdf (accessed in 08-06-2011)
Business Intelligence Techniques: A Perspective from Accounting and Finance, Murugan Anandarajan, Asokan Anandarajan, Cadambi A. Srinivasan, Springer Verlag, 2004. (accessed in 08-06-2011)
http://www-01.ibm.com/software/data/businessintelligence/ (accessed in 08-06-2011)
http://www.ibm.com/developerworks/data/library/cognos/infrastructure/cognos_specific/page529.html (accessed in 08-06-2011)
http://www.microsoft.com/BI/en-us/pages/home.aspx (accessed in 08-06-2011)
http://www.collectiveintelligence.com/jahia/webdav/site/ciweb/shared/docs/Presentations/Microsoft%20Business%20Intelligence%20-%20Platform%20Overview.pdf (accessed in 08-06-2011)
http://www.microstrategy.com/Software/businessintelligence/index.asp (accessed in 08-06-2011)
http://www.microstrategy.com/QuickTours/HTML/CompIntel_Template/QuickTour/index.asp?vendor=SAS&page=21 (accessed in 08-06-2011)
http://www.oracle.com/technetwork/middleware/bi-enterprise-edition/overview/index.html (accessed in 08-06-2011)
http://www.analyticspartners.com/ProductsServices/obiee.aspx (accessed in 08-06-2011)
http://www.jaspersoft.com/ (accessed in 08-06-2011)
http://www.columnit.com/column-partners/jaspersoft/jaspersoft-business-intelligence.html (accessed in 08-06-2011)
http://www.pentaho.com/ (accessed in 08-06-2011)
http://www.crunchbase.com/company/pentaho (accessed in 08-06-2011)
http://www.spagoworld.org/xwiki/bin/view/SpagoBI/ (accessed in 08-06-2011)
http://todobi.blogspot.com/2010/11/webinars-gratuitos-de-spagobi.html (accessed in 08-06-2011)
http://www.bpm-conseil.com/ (accessed in 08-06-2011)

ANEXO C
151
OPEN SOURCE CRM SYSTEMS FOR SMES
Marco Tereso1 and Jorge Bernardino1
1 Polytechnic of Coimbra – ISEC, Coimbra, Portugal [email protected], [email protected]
� ABSTRACT Customer Relationship Management (CRM) systems are very common in large companies. However, CRM systems are not very common in Small and Medium Enterprises (SMEs). Most SMEs do not implement CRM systems due to several reasons, such as lack of knowledge about CRM or lack of financial resources to implement CRM systems. SMEs have to start implementing Information Systems (IS) technology into their business operations in order to improve business values and gain more competitive advantage over rivals. CRM system has the potential to help improve the business value and competitive capabilities of SMEs. Given the high fixed costs of normal activity of companies, we intend to promote free and viable solutions for small and medium businesses. In this paper, we explain the reasons why SMEs do not implement CRM system and the benefits of using open source CRM system in SMEs. We also describe the functionalities of top open source CRM systems, examining the applicability of these tools in fitting the needs of SMEs.
� KEYWORDS � CRM, Information Systems, Open Source, SMEs.
1. INTRODUCTION As companies face increasing competition, wider customer choice, and the challenges of doing e-Business in the 21st century, many have chosen to implement CRM solutions in response to their strategic imperative, and to improve the sales and marketing effectiveness and efficiency. A Customer Relationship Management (CRM) system is a software system designed to empower a company to maximize profits by reducing costs and increasing revenue; to increase competitive advantage by streamlining operations; and to achieve business goals. Most companies have been collecting information about their customers and trying to use this information to better understand and predict what customers might want next. Therefore, CRM is both information-based and technology based, and is about building customer loyalty by putting customers at the center of what a company does. CRM also applies to how customers experience a company, not just how a company looks at its customers [1].
To survive in the global market, focusing on the customer is becoming a key factor for big and small companies. It is known that it takes up to five times more money to acquire a new customer than to get an existing customer to make a new purchase [2]. Therefore, customer retention is in particular important to Small and Medium Enterprises (SMEs) because of their limited resources. A second aspect of CRM is that knowing the customer and his/her problems allows a company to acquire new customers more easily and facilitates targeted cross-selling [3].
The CRM is a set of processes and methodologies that has as main objective to bring together a wide range of information about customers and their consumption behaviour. This type of information allows companies to define groups of users, making possible some sales strategies and campaigns and promotions targeted at different types of customers.

ANEXO C
152
Open source software for CRM represents a great opportunity for SMEs as they can significantly impact their competiveness. Given the high fixed costs of normal activity of companies, we intend to promote open source solutions for small businesses. In this paper, we present viable solutions, describing the functionalities of top CRM tools, according to recent publications [4, 5]. We will describe each of these tools to assess their capabilities, their strengths and the aspects that differ between them, exploring the applicability of each of those tools in fitting the needs of SMEs.
This paper is structured as follows. In Section 2 we give a brief introduction about Information Systems (IS) and CRM, and presents the reasons why SMEs do not implement CRM systems. In Section 3 we list the advantages of open source software. In Section 4 we present CRM open source systems, with an overview of its features and Section 5 describes related works. Finally, in Section 6 we present our conclusions and point out future work.
2. INFORMATION SYSTEMS AND CRM Given the competitive market, companies must adopt strategies that allow them to remain active in the market and become increasingly competitive. The collection of data resulting from business activity is extremely important. This process allows data to work in different areas, in order to make business activity most profitable.
Data is one of the most important and valuable assets for companies and organizations. The grouped data when generating information is a very important role to reduce uncertainty. The recognition of the importance of information by business managers led to the development of information systems. Information systems may have different objectives, taking into account the type of information we have to process and the desirable results.
The focus of our work is in IS (Information Systems) area, primarily CRM (Customer Relationship Management) systems. IS are systems that present a set of elements that capture, store, process and communicate information. There are several types of IS, with each type designed for a particular purpose.
In this section we intend to specify the importance of collecting data, that later on turns information in knowledge. We will also explain the importance to implement information systems into companies and organizations.
We present CRM systems in greater detail, analyzing their characteristics and importance to companies and organizations to disseminate information regarding the advantages of their use.
2.1. Why SMEs do not implement CRM system
In this competitive market, the client must be regarded as the fundamental entity of an organization [6]. The importance of satisfying the customer must be seen as a priority. Given the importance that clients represent to the enterprises economy, especially in SMEs, organizations must adopt strategies that allow them to define the profile of its customers. It is in this context that the CRM software has great importance in collecting and recording data.
The data should be regarded as one the most important assets of an organization, that start in information and will be transformed in knowledge. The organizations have in their data, the possibility of its future growth. Later using a Decision Support System (DSS) is possible to identify strengths and areas for improvement in order to optimize business processes and customer relations. Given all these advantages we must ask why companies do not implement CRM systems?

ANEXO C
153
The current economic crisis leads companies to adopt strategies in order to fight against the difficulties. Known the swollen costs of normal business activity, it becomes difficult to SMEs to make extra investments. Lack of knowledge by SMEs of the existence of free solutions (open source) is one factor that determines why these tools are not acquired and implemented in the organizations. Our main goal is to disseminate to SMEs some viable solutions to implement a free CRM system to improve their business processes.
3. ADVANTAGES OF USING OPEN SOURCE SOFTWARE Before going further, it is essential answer an important question, that is, which is the advantage of using open source software?
Regarding the costs, the purchase of open source software is free and the hardware associated to these systems has lower costs. This is justified, taking into account that those which are looking for open source software are not available to purchase commercial software, and also usually don’t have financial resources to invest in more sophisticated equipment.
The open source software has a good quality, despite being developed by community. Nowadays the releases and the stable versions of software usually suffer an extended inspection and are exposed to various tests of software quality before being delivered.
Often the commercial software lacks some essential functionalities for organizations. The fact of commercial software does not provide the source code, not allows adding extra features. The open source software provides its source code, enabling organizations to develop new characteristics and integrating them into their applications.
The integration of other complementary software, is an additional possibility. The availability of the source code allows the integration of different tools. For example, it is possible the integration of open source databases, open source CRM systems, open source business intelligence tools, etc.
Simple license management, without license fees, without expired licenses date, etc. is a clear advantage of using open source software. Open source software usually has a support community, documentation, discussion forums and constant updates of its versions, updates, identify and resolve software glitches and bugs.
In summary, the main advantages of using open source software by companies are: free license, low cost maintenance, support community; the software can be shared and used for various purposes, access to source code and permission to study and amendment, ability to adapt to the real needs of each organization, constant updating of versions through the contribution of the community that supports it, possibility to try the software without any cost and ease of access to the specific open source repositories to download [25, 26].
For SMEs the main benefit of using open source CRM tools is the ability to adapt the software to business needs, with opportunity to add new modules developed accordingly to the company requirements. The possibility to access the code allows the company to benefit of the initially features available but also to configure the application taking into account their needs and environment.
Today it is very important that companies make cost containment. The SMEs has here good solutions that allow the evolution of business and reduce the expenses.
4. OPEN SOURCE CRM TOOLS

ANEXO C
154
In an era of financial crisis and expense reduction it is important that companies keep pace with changing technologies and markets, adopting strategies for tracking trends, but which are not expensive. SME’s need low cost CRM solutions that can easily adapt to their business model and IT structure, instead of having to adapt their business model and IT structure to the CRM software. In this section our main objective is to disclose open free solutions viable for implementation by SMEs.
In this particular case we rely on some recent sources of information, namely [4] and [5]. We will describe open source CRM systems to assess their capabilities, their strengths and the aspects that differ between them and exploring the applicability of each of those tools in fitting the needs of SMEs. The open source CRM systems that we analyze are: CiviCRM [7], OpenCRX [8], OpenTaps [9], SugarCRM [10], Vtiger [11] and Free CRM [12].
4.1. CiviCRM
CiviCRM [7] is an open source tool, based on relationship management solutions. This tool is web-based, multi-language, and intended to needs of advocacy, non-profit and non-governmental groups. CiviCRM allows recording data for the various constituents of an organization as volunteers, activists, donors, customers, employees, suppliers, etc.
The main strengths of the tool are: store information about individuals, organizations and households; the community of development work regularly in the growth and extension of system; ease of integration with other websites; CiviCRM integrates directly into the popular open source Content Management Systems – Drupal and Joomla; save the access history of each user, using the log record; CiviCRM was designed for use worldwide, allowing the many localized formats and supporting multi language, such as, French, Spanish, German, Dutch, Portuguese, etc.; licensed under the GNU AGPL allow a changes in code, add new features, etc. [7].
The advantages of the web-based applications are the possibility of linking several people at the same time in different locations, accessibility within and outside the corporate infrastructure, making communication between people practical and accessible.
CiviCRM has optional components that provide a better service of support to its users. The CiviCRM components are: CiviContribute – component that allows managing online donations and contributions to an organization; CiviCase – to manage interactions between people and organizations; CiviEvent – allows the creation and listing of paid and free events, allows to create events through the creation of Web pages specifically for this purpose; CiviMail – e-mail service that lets redirect to the lists and email contacts and various custom reports; CiviMember – to on-line registration and revalidation of the user account; CiviReport – module tool that allows to create reports on data that are intended to illustrate [7].
When associate with a CMS (Content Management System) CiviCRM allows a content management relatively to customers data. With the implementation of the CMS tool the visitors have the possibility to signing up for events, requesting email updates and donating money.
CiviCRM is a web tool that can be installed on a Web server or an internal server. The requirements for installing CiviCRM are open source tools, namely: Apache Server 2.0 (or higher), PHP 5.2.1 (or though PHP 5.3 is only supported from version 3.2 of CiviCRM), MySQL 5.1.x (or higher), Drupal 6.x ou 7.x/Joomla 1.5.x ou 1.6.x, Server Cronjobs and require 128 Mb of memory [7].
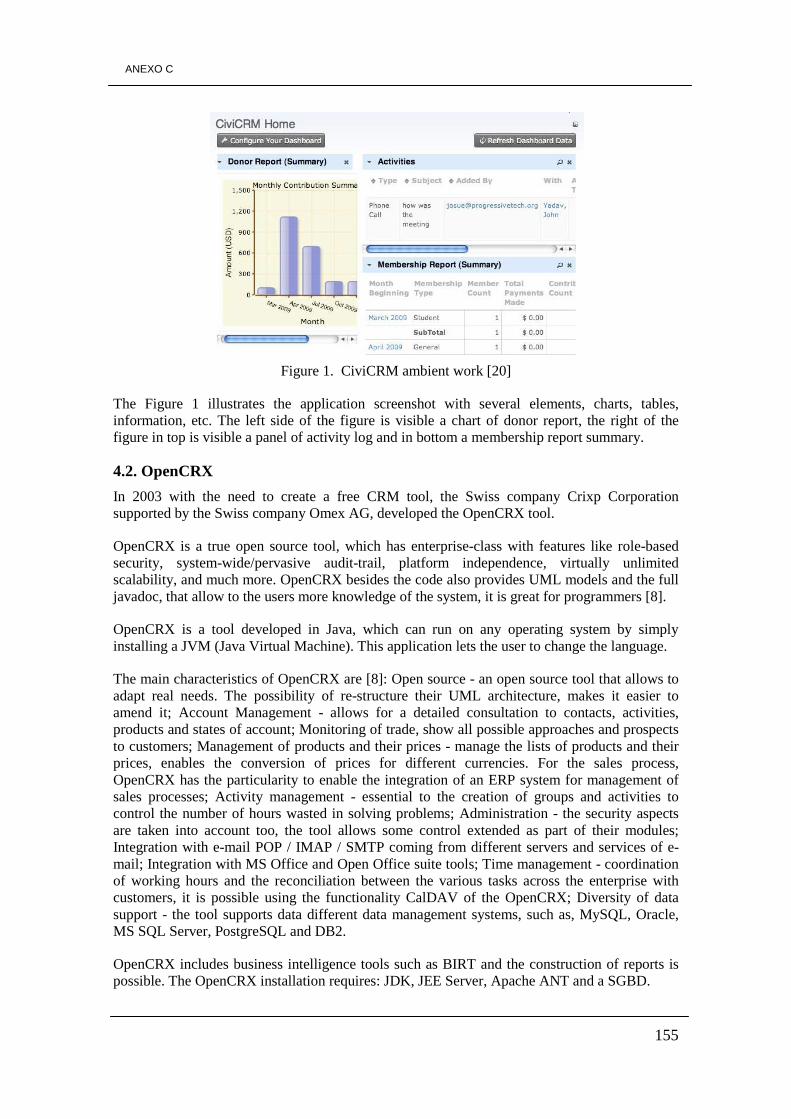
ANEXO C
155
Figure 1. CiviCRM ambient work [20]
The Figure 1 illustrates the application screenshot with several elements, charts, tables, information, etc. The left side of the figure is visible a chart of donor report, the right of the figure in top is visible a panel of activity log and in bottom a membership report summary.
4.2. OpenCRX
In 2003 with the need to create a free CRM tool, the Swiss company Crixp Corporation supported by the Swiss company Omex AG, developed the OpenCRX tool.
OpenCRX is a true open source tool, which has enterprise-class with features like role-based security, system-wide/pervasive audit-trail, platform independence, virtually unlimited scalability, and much more. OpenCRX besides the code also provides UML models and the full javadoc, that allow to the users more knowledge of the system, it is great for programmers [8].
OpenCRX is a tool developed in Java, which can run on any operating system by simply installing a JVM (Java Virtual Machine). This application lets the user to change the language.
The main characteristics of OpenCRX are [8]: Open source - an open source tool that allows to adapt real needs. The possibility of re-structure their UML architecture, makes it easier to amend it; Account Management - allows for a detailed consultation to contacts, activities, products and states of account; Monitoring of trade, show all possible approaches and prospects to customers; Management of products and their prices - manage the lists of products and their prices, enables the conversion of prices for different currencies. For the sales process, OpenCRX has the particularity to enable the integration of an ERP system for management of sales processes; Activity management - essential to the creation of groups and activities to control the number of hours wasted in solving problems; Administration - the security aspects are taken into account too, the tool allows some control extended as part of their modules; Integration with e-mail POP / IMAP / SMTP coming from different servers and services of e-mail; Integration with MS Office and Open Office suite tools; Time management - coordination of working hours and the reconciliation between the various tasks across the enterprise with customers, it is possible using the functionality CalDAV of the OpenCRX; Diversity of data support - the tool supports data different data management systems, such as, MySQL, Oracle, MS SQL Server, PostgreSQL and DB2.
OpenCRX includes business intelligence tools such as BIRT and the construction of reports is possible. The OpenCRX installation requires: JDK, JEE Server, Apache ANT and a SGBD.

ANEXO C
156
According to [8] OpenCRX is a tool that requires more learning time compared with other similar open source CRM tools. The fact that it is not a tool based on LAMP (Linux, Apache, MySQL, PHP) makes it more difficult to install compared with solutions of this type. The ANT (is a project of Apache Software Foundation, allows building automation software) technology becomes more complex to implement.
Figure 2. OpenCRX ambient work [21]
In Figure 2 is possible to visualize an application screenshot of OpenCRX. In the left it is a tool bar, in the right is visible the work ambient composed by tab options and content tables.
4.3. OpenTaps
OpenTaps [9] is an open source tool of CRM + ERP (Enterprise Resource Planning). OpenTaps was developed thinking in small and medium enterprises and had as its starting point the Apache Open for Business. OpenTaps was developed in Java language (JEE), which offers scalability of implementation.
OpenTaps has the following features [15]: eCommerce, Poin-of-sales, inventory, warehouse, order, customers management and general ledger. OpenTaps allows interconnection with business intelligence tools (iReport) and mobility integration with Microsoft Outlook, Google Calendar and mobile phones.
OpenTaps is many used by organizations that are linked to activities such: industrial machinery manufacturers, online good retailers, online content distributors, telecommunications companies, independent software vendors and hosted services providers. For these industries, OpenTaps is used for order management, customer service purchasing, production planning, inventory management, and manufacturing to shipping and accounting [9].
We enumerate some key features of the tool OpenTaps based on [15] and [16]: OpenTaps has a web based user interface; internationalization - multi language; integrate marketing and sales - customers services, warehouse, supply chain, online and physical stores, and accounting; marketing - support stores, catalogs, categories and products; promotion store - online promotion store; cross-sells (are suggested complementary products) and up-sells (update to sell any product or service) for products; price rules for customers or group-specific pricing; integration online and Point of Sales (POS); real-time accounting reports; manage the manufacturing process; plan and automate purchasing and manufacturing.
OpenTaps has also some additional modules namely: project management; human resources; fixed asset management; Outlook and mobile phone integration with Funambol; integration with

ANEXO C
157
eBay, Google base and Google check out; content management; Point of Sales (POS); integration eCommerce; Business Intelligence (integration with Pentaho and JasperReports).
The OpenTaps can be applied in systems with the following characteristics: operating systems - Windows, Mac OS X, Linux and Solaris; SGBDs - Oracle, Microsoft SQL Server, MySQL and PostgreSQL; Google Web Toolkit (GWT), allows an use more easy of the OpenTaps.
Figure 3. OpenTaps screenshot [22]
In Figure 3 is illustrated the work ambient of OpenTaps tool. In the left of the figure is visible a menu options, in top is visible some tabs of options. In the right of the figure is visible the user ‘home’ and in the bottom a table of pending activities.
4.4. SugarCRM
SugarCRM [10] is a software company based in California. SugarCRM includes some features, such as: sales-force automation, marketing campaigns, customer support, collaboration and reporting.
SugarCRM is one of the premier CRM solutions, which today has over 4 million of users. The open source version is developed in PHP, this project is growing rapidly and has an active developer community [30].
The main features of SugarCRM tool are [10]: scalability of pages to application; contacts management; relationship accounts; marketing campaigns; tasks and activities management; documental management; Web portal; occurrences management; processing emails.
The requirements to support the application are: operating systems - Linux, Windows or Unix; PHP 5.2.x (or higher); MySQL 4.1 (or higher) or MS SQL Server; Apache 1.3 (or higher), IIS 6 (or higher) or NGINX 1.x (or higher, with php-fpm); HD with 100MG; Around 64M of memory by user.

ANEXO C
158
Figure 4. SugarCRM work ambient [23]
The Figure 4 illustrates the work ambient of SugarCRM. On the left in the figure is visible a menu options, in top exists some tabs, on the right is illustrate a calendar and a chart, on centre is visible a table with upcoming appointments of user. In comparison with other tools, SugarCRM present a big amount of icons and tabs.
4.5. Vtiger
Vtiger [11] is an open source business-oriented solution, built on platforms LAMP/WAMP (Linux/Windows, Apache, MySQL and PHP).
Vtiger has been developed by the same development community of SugarCRM, with the intention of developing an open source CRM solution and providing similar functionality to SugarCRM and Salesforce.com.
Vtiger CRM has 15 modules: covering Marketing, Sales, Support, Inventory, and project Management functions. Vtiger is available in more than 15 different languages[11].
The main features of Vtiger are: sales automation; control support; Marketing automation; inventory management; support for multiple database systems; security control; product customization; integrated calendar; integration with email service; add-ons (plug-in for Outlook, MS Office, Thunderbird, customers portal and web forms).
Vtiger software needs the following requirements: operating system - Linux or Windows; Apache 2.0.40 or higher; MySQL 5.1.x or higher; PHP 5.0x or higher; Firefox or Internet Explorer; minimum of 200 MB free disk space; minimum of 256MB RAM.

ANEXO C
159
Figure 5. VtigerCRM screenshot [24]
The Figure 5 illustrating the appellative ambient of VtigerCRM tool. On the left in figure is visible a browser search, a list of last viewed, a time zone setting and a calculator. In top of figure is visible a set of option tabs. In centre of figure is visible the properties of email service.
4.6. Free CRM
Free CRM [12] is an open source CRM software, which is a Web based solution for customer relationship management and sales force automation. This is a software for up to 50 users that doesn´t require to download any software. In the open source version, Free CRM is somewhat limited with regard to storage capacity and security [25].
Free CRM is great for contact and lead tracking, sales and contact management, sales pipeline management and forecasting, customer services and business management [27].
The main features of FreeCRM are: contact and lead tracking; sales and pipeline management; support ticket & service management; advanced security & uptime; superior technical support; tasks; reports; calendar.
FreeCRM has some specifics available functionalities [12]:
� Calendar – schedule all of meetings and calls using the scheduler; track team member’s availability and schedule; set multi-user alerts that send notification emails to all members.
� Company – track calls, history, trouble tickets, and sales activities; introduce workflow and automation to sales campaigns, vendors and prospects; bridge contact management data with tasks, deals, calendar events, and more.
� Contact – import contact lists from any spreadsheet file; synchronize the new contacts and related information in real time; empower full sales potential with an interface that allows to get down to business with contacts database.
� Deal – create a complete view of your sales process; analyze the progress any given campaign, cycle or employee is doing; quantify your sales success over time.

ANEXO C
160
� Task – get the tasks priority; create custom tasks types specific for business; assign tasks to team members or employees; give workflow and status of the tasks; delegate workload across the team.
� Case – customize support issues with our custom fields; assign issues to one or multiple team members; track the cases so no customer issue falls through the cracks.
� Call – create call campaigns; automate calls; organize follow-up.
� Email – integration with the service of POP email.
� Doc – management documents.
� Form – give customer a quality feedback form; give your staff questionnaires and scripts; build custom surveys for sales, marketing, and customer satisfaction.
� Report – generate charts and graphs of company performance; generate hard numbers based on calls campaigns, email campaigns, tasks, deals, and much more; choose from over 70 pre-defined reports.
The requirements systems, necessary to run the application are [28]: Internet Explorer or Netscape.
Figure 6. FreeCRM screenshot [12]
In Figure 6 is visible the ambient of work of the FreeCRM tool. In the top of figure is visible the option tabs, on the left is possible view the options menu, in centre of figure is visible the list of tasks.
5. RELATED WORK According to a publication of Global Alliance of SMEs [31], SMEs represent over 98% of companies worldwide; based on this percentage we have focused our research into small firms with lower investment capacity. CRM systems are a necessity for companies and organizations to improve their competitiveness. However, there are not many papers focusing into open

ANEXO C
161
source CRM tools. For example [32] and [33], evaluate and present a review of the top 10 CRM open source solutions based on utility, business models and developer communities. In [32] they show a comparison between the top 10 CRM tools, containing a features table of each tool, helping to decide which is the best tool. In a white paper published by CRM Outsiders [34], an industry blog, and sponsored by SugarCRM is given a description about advantages and disadvantages of the use the CRM systems by SMEs. In [35] is presented the evaluation about the costs between open source and proprietary solutions. The choice of CRM tool is very important, such as, the knowledge of the importance its use, for this purpose, references [36] and [37] may be useful. In [38] is described an application for evaluating CRM open source systems. And [39] presents a description about a comparison about assessment methodologies between free and open source software. However, companies sponsor most of these works and there are not many research papers. In our work we presented an independent evaluation of open source CRM tools.
6. CONCLUSIONS AND FUTURE WORK Nowadays, the contact lists, the customers profile information and a basic knowledge about customers have a great importance for the enterprises and organizations. Data is the most important asset in any organization, from which it is possible to extract information and transform it into knowledge.
The main objective of this work was to promote some open source CRM solutions for small enterprises and organizations. The adoption of open source CRM tools has many advantages for SMEs, as the possibility of really trying the system, reduction of vendor lock-in, low licence cost and possibility of in-depth personalization. Taking into account the importance of data for enterprises and organizations, is essential the acquisition these tools by enterprises and organizations.
All the described tools, CiviCRM, OpenCRX, OpenTaps, SugarCRM, Vtiger and Free CRM, have the particularity of being open source, not entail any licence costs. Each CRM solutions analyzed here has its particularities, their advantages when compared with others, different features, different difficulties of using and differences in system requirement.
When choosing of the CRM tool to adopt, is important that the final customer evaluate the tool taking into account the requirements of the organization and evaluate the features of each tool. The easiness of adapting the tool is one of the aspects to consider.
It is often difficult to evaluate which the best solution CRM to implement in organizations, taking into account the best solution is also conditioned by the specific needs of each company. Taking into account the lack of related works, and how we do not implement in practice each of the tools, would not be fair to define which/what the best of these solutions. The sources [4] and [5] elect the same tools as the best open source CRM today. This is a good idea for a future work, examine in practice, what the top tree best CRM open source systems.
Overall, the CRM tools described here, have the potentiality for help small enterprises and organizations in their day to day, contributing for contacts management of customers, tasks management, save the customers data, and define customer profile. Among all the features the most important is the fact to be open source and without licence costs. From our evaluation, we conclude that we should not elect any of the tools as the winner. All analyzed tools have capacities that can be adopted by companies and organizations and all have quality to serve the needs and requirements of SMEs.

ANEXO C
162
We can conclude the world of open source tools has good solutions to be implemented in small and medium enterprises. This type of systems also allows the organizations to modernize and optimize their business processes at low costs.
REFERENCES [1] Melissa C. Lin A Study of Main stream Features of CRM System And Evaluation Criteria, , 2003
[2] Adrian Payne. Customer Relationship Management. www.crm2day.com, 2002.
[3] Hubert Baumeister, “Customer Relationship Management for SME’s “, Institut fur Informatik, Munchen, German, 2002
[4] Jun Auza “Best Free and Open Source CRM Software”, June 2010, http://www.junauza.com/2010/06/open-source-crm-software.html
[5] Sundheer Raju, “Top 7 Free/Open Source “CRM” tools”, January 2011. ToolsJournal, http://www.toolsjournal.com/tools-world/item/141-top-free-crm-tools
[6] Boon Loh, Khain Koo, Kee Ho and Rosnah Idrus, “A review of Customer Relationship Management System Benefits and Implementation in Small and Medium Enterprises”, http://www.wseas.us/e-library/conferences/2011/Brasov2/MCBANTA/MCBANTA-44.pdf
[7] CiviCRM, http://civicrm.org/
[8] OpenCRX, http://www.opencrx.org/index.html
[9] OpenTaps, http://www.opentaps.org/
[10] SugarCRM, http://www.sugarcrm.com/crm/
[11] Vtiger, http://www.vtiger.com
[12] FreeCRM, http://www.freecrm.com/
[13]http://www.opencrx.org/downloads/200705M30_Linux_Magazine_OpenCRX.pdf
[14]http://www.opencrx.org/downloads/200802M39_Linux_Magazine_OpenCRX.pdf
[15] http://en.wikipedia.org/wiki/Opentaps
[16] http://www.opentaps.org/about-opentaps
[17] http://en.wikipedia.org/wiki/SugarCRM
[18]http://sugarcrm.com.pt/item2_detail.php?lang=0&id_channel=11&id_page=4&id=1
[19] http://www.crmreview.org/Salesforce-CRM-Review.htm
[20] http://www.2020media.com/content/view/232/45/
[21] http://download.pmi.it/crm/0/335/opencrx.html
[22] http://ostatic.com/opentaps/screenshot/1
[23]http://www.swotti.com/tmp/swotti/cacheC3VNYXJJCM0=U29MDHDHCMUTU29MDHDHCMU=/imgSugarCRM2.jpg
[24]http://www.swotti.com/tmp/swotti/cacheDNRPZ2VYIGNYBQ==U29MDHDHCMUTU29MDHDHCMU=/imgvtiger%20CRM1.jpg
[25] http://www.smallwebusiness.com/free-crm-software .html
[26] http://savedelete.com/best-free-web-based-business-apps.html
[27] http://www.slideshare.net/catiabrito/open-source-449595
[28] http://open-source.gbdirect.co.uk/migration/benefit.html
[29] http://www.outsource2india.com/software/articles/open-source-software.asp

ANEXO C
163
[30] http://www.concentricsky.com/about/technology/sugarcrm/
[31] Global Alliance for SMEs, http://www.globalsmes.org/html/index.php?func=expo2010&lan=en, June, 2010
[32] Chris, “The top 10 Open Source CRM Systems”, http://crmsearch.com/top-10-open-source-crm-systems.php
[33] Fadi Amroush and A. Baderddeen Alkhoder, “Evaluation of Open Source CRM Systems”, 2008
[34] Chris Bucholtz, “CRM and Small Business: Smaller, Faster, Better”, 2011
[35] SugarCRM, “CRM Total Cost of Ownership: Comparing Open Source Solutions to Proprietary Solutions”, Business white paper, 2005.
[36] Michelle Murrain, “Open Source CRM”, Nonprofit Open Source Initiative, March 27, 2008
[37] Optaros, “Understanding Open Source CRM”, Optaros white paper, http://61.153.44.88/crm/optaros_wp_os_crm_20060316.pdf
[38] Lerina Aversano, Maria Tortorella, “Applying EFFORT for Evaluating CRM Open Source Systems”, Proceedings of Product-Focused Software Process Improvement - 12th International Conference, PROFES 2011, Torre Canne, Italy, June 20-22, 2011, pp. 202-216.
[39] J.C. Deprez, S. Alexandre, “Comparing Assessment methodologies for Free/Open Source: OpenBRR & QSOS”, Proceedings of Product-Focused Software Process Improvement, 9th International Conference, PROFES 2008, Monte Porzio Catone, Italy, June 23-25, 2008, pp. 189-203.
Authors
Short Biography
Jorge Bernardino is Coordinator Professor of the Department of Systems and Computer Engineering at the ISEC (Instituto Superior de Engenharia de Coimbra) of Polytechnic of Coimbra, Portugal. He was President of ISEC from 2005–2010 and President of Scientific Council during 2003–2005. He received his PhD Degree in Computer Engineering from the Computer Engineering Department of the University of Coimbra in 2002. He is member of Software and Systems Engineering (SSE) group of Centre for Informatics and Systems of the University of Coimbra (CISUC) research centre. His main research areas are Data Warehousing, Business Intelligence, database knowledge management, e-business and e-learning.
Marco Tereso studied Computer Science - Information Technology and Multimedia at ESTGOH (Escola Superior de Tecnologia e Gestão de Oliveira do Hospital) and attained his graduation in 2009. After completion of graduation joined the ISEC
(Instituto Superior de Engenharia de Coimbra) where attends the Master of Informatic and Systems - Software Development. At this moment is to finish the master's thesis on open source business intelligence tools under the orientation of Prof. Jorge Bernardino. His main research areas are Business Intelligence and open source systems.

164

ANEXO E
165
Top Business Intelligence Software for Small and Medium
Enterprises Jorge Bernardino1, Marco Tereso1
1 Polytechnic of Coimbra - ISEC, Coimbra, Portugal Email: {[email protected], [email protected]}
Abstract— Business Intelligence (BI) is one of the few forms of sustainable competitive advantage left. However, BI software are not very common in Small and Medium Enterprises (SMEs). Most SMEs do not implement BI tools due to several reasons, such as lack of knowledge about BI or lack of financial resources to implement BI. In this paper, we present top open source and commercial solutions, describing the functionalities of the top BI tools, examining the applicability of each of those tools in fitting the needs of SMEs. Finally, the future of BI is addressed to envision the potential of its growth. Index Terms—business intelligence, open source BI software, commercial BI software, SME’s
I. INTRODUCTION
The need to implement decision support systems in organizations is an unavoidable reality. Currently, the majority of organizations have Information Technology (IT) systems, designed to record and store massive amounts of data resulting from the operational activity. This data set has to be transformed in information and all that information will lead to knowledge useful for the organizations.
The concept of “business intelligence” and “analytics” include tools and techniques supporting a collection of user communities across an organization, as a result of collecting and organizing numerous (and diverse) data sets to support both management and decision making at operational, tactical, and strategic levels. Through data collection, aggregation, analysis, and presentation, business intelligence can be delivered to best serve a wide range of target users. Organizations that have matured their data warehousing programs allow those users to extract actionable knowledge from the corporate information asset and rapidly realize business value.
But while traditional data warehouse infrastructures support business analyst querying and canned reporting or senior management dashboards, a comprehensive program for information insight and intelligence can enhance decision-making process for all types of staff members in numerous strategic, tactical, and operational roles. Even better, integrating the relevant information within the immediate operational context becomes the
differentiating factor. Offline customer analysis providing general sales strategies is one thing, but real-time business intelligence can provide specific alternatives to the sales person talking to a specific customer based on that customer’s interaction history in ways that best serve the customer while simultaneously optimizing corporate profitability as well as the salesperson’s commission. Maximizing overall benefit to all of the parties involved ultimately improves sales, increases customer and employee satisfaction, and improves response rate while reducing the cost of goods sold – a true win-win for everyone.
Nevertheless small businesses generally don’t have the time, finances or employees that big businesses have. In a small business one will find a whole list of jobs to do which larger businesses have entire departments to work on. With resources in short supply, it is imperative to be careful about how time and money is spent. For many small and medium enterprises, this can mean eliminating business intelligence (BI) as this can be seen as an unnecessary expense or just downright confusing. However, BI is a vital exercise for any business, no matter what size.
In this paper we present the top BI tools, in view of ranking presented in [1], examining the applicability of each of those tools in fitting the needs of SMEs to see how we can make business intelligence work for small and medium enterprises, which represent more than 98% of worldwide companies [2]. We will analyze the top open-source tool Actuate BIRT [3]. Following, we evaluate the top commercial tool of the pure play vendors, Information Builders [4]. Pure play vendors are vendors focused primarily upon BI software and services that have typically been in business for more than 15 years.
This paper is structured as following: Section II gives details about the top open source tool and Section III describes the top commercial tool of the pure play vendors. Finally Section IV presents our conclusions and the future of BI is addressed to envision the potential of its growth.
II. OPEN SOURCE BUSINESS INTELLIGENCE TOOL
Many open source solutions related to business intelligence exists in the market. A number of tools are more focused on specific processes (ETL-Extract, Transform, Loading, OLAP-Online Analytical Processing, Data Mining, Reports, etc.) with others including a set of these features.
Given the difficulties and mandatory spending cuts in SMEs, this is a type of solution increasingly requested and that presents a vast number of successful cases. Taking into account the maturity recognized, the open source business intelligence tools are clearly a practicable solution for SMEs.
Based on the ranking presented in [1], we will examine the top open source tool: Actuate BIRT [3], which according to the study, have highest potential. Other open-source tools include: JasperSoft [7], Pentaho [8] and

ANEXO E
166
SpagoBI [9], but due space limitations are not analyzed in this paper.
• A. Actuate BIRT
Actuate founded and now co-leads the BIRT (Business Intelligence and Reporting Tools) open source project with the Eclipse Foundation, the home of the open source Eclipse Development Framework [3]. The BIRT project’s goal was to bring the web design metaphor to creating visualizations of structured data. Actuate is one of the first enterprise software companies to make a strategic commitment to open source for its core technology and the future of its product line and overall business.
BIRT offers features for design and deployment including: ad hoc queries and reporting tools, OLAP processes and dashboards. Innovative aspects of BI such as Executive Information Systems (EIS) statistical analysis, modelling capabilities, Data Mining tools, Data Warehouse Modelling Tools, ETL and Data Quality Tools, are also presented. BIRT makes use of Talend Open Studio [17] for ETL processes. Talend Open Studio is the open source tool, which run in the Eclipse ambient such as BIRT. The Figure 1 illustrates an ETL sample schema developed with Talend Open Studio.
Talend Open Studio ETL schema [17]
The Figure 2 shows the cylindrical column charts in the BIRT Report Viewer. In this figure is visible the options offered by BIRT to: navigate in different pages, save the chart, print document and export it to other formats, like Excel and PDF.
Charts in BIRT Report Viewer [18]
The Figure 3 illustrates a set of business intelligence elements with complex report that includes different graphs. The figure shows bar charts, pie charts, line charts, and elements of GIS (Geographic Information System).
BIRT Report [19]
Actuate BIRT also focuses on innovation and market trends. The investment in the market for mobile application is a reality. BIRT has developed applications for iPhone, iPod, iPad and Android.
The advantage of mobile version is that allows the user to make decisions anytime and anywhere. The BIRT Mobile Viewer apps present engaging BIRT reports, analytics and dashboards for the supported mobile devices.
The Figure 4 illustrates one screenshot of BIRT Mobile Viewer for iPad.

ANEXO E
167
BIRT Mobile Viewer for iPad [20]
In Figure 4 is visible several elements of business intelligence namely, pie charts, cylindrical charts vertical and horizontal, and one data table..
Nowadays, BIRT was considered the top business intelligence tool [5] and recognized as leader in Mobile Business.
III. COMMERCIAL BUSINESS INTELLIGENCE TOOL
The commercial business intelligence solutions are usually more user friendly, but its higher costs for acquiring and maintaining their licenses are an obstacle to SMEs.
In this section we present the top commercial BI solutions of the pure play vendors, which are vendors focused primarily upon BI software and services that have typically been in business for more than 15 years [1]. The top commercial BI analyzed is Information Builders [4]. Other commercial tools consist of: MicroStrategy [11], QlikTech [12] and SAS Institute [13], which are not analyzed.
• A. Information Builders
Information Builders [4] is a private software company that was established in 1975 in New York.
Information Builders is currently operating in more than 60 global locations and has built an active customer base of more than 12.000 major installations in more than 8.000 organizations. Information Builders recently established a partnership with IBM, which allowed the company to have around 35.000 new installations.
Information Builders also provides software for vendors, some market leaders, such as: IBM, SAP, Oracle and others companies.
The business intelligence product of Information Builders is called WebFOCUS. WebFOCUS is an essential tool for managers, analysts, partners, employees and customers. This is a business intelligence tool that lets create dashboards, portable analytics and ad hoc reporting.
WebFOCUS also offers performance management, in out-of-the-box solutions for monitoring, tracking and performance control; advanced analytics, to improve decision-making; data integrity solutions, providing end-to-end management of all metadata; an integration infrastructure related with the ETL (Extraction Transform Load) processes; integration with other products, such as Microsoft Excel and Adobe PDF.
Information Builders have other product associated to the business intelligence processes, designated by iWay Software. The iWay software is responsible by the graphical elements of business intelligence (charts, dashboards, reports) and by the manipulation data processes such as ETL.
The Figure 5 show the ETL schema developed with iWay Software tool.
iWay Software ETL sample schema [21]
Figure 6 illustrates the filters of data in page header, data tables, and one pie chart. This elements are showed with resource to iWay Software features.
iWay Data Profiler screenshot [22]
Figure 7 shows one report with a several different elements. It is possible to view bar charts, pie charts, evolution charts, data tables and elements of GIS.
Information Builders have a mobile version, which is available for iPhone, iPad and Android tablets.
WebFOCUS Mobile presents a robust platform that has main advantages: the ease to manage content, e-mail alerts for content updates, user selected report intended format, intuitive interface, on-demand customization, no connection required, actionable applications, no device software to support, no additional hardware required, no

ANEXO E
168
unique design and delivery tools needed and no special security considerations [6].
WebFOCUS Report [23]
The Figure 8 illustrates the Information Builder mobile app to run in a tablet and cellular devices.
Screenshot Information Builders mobile version [24]
CONCLUSIONS Competitiveness and efficiency are key features for
business to achieving the goal of business success. Nowadays, it is extremely important to SMEs to adhere to innovation and technological trends.
Consequently, it is important SMEs implement measures in order to stop consequences of the economic crisis. The inclusion of business intelligence processes by SMEs, allows identifying problems, detecting bad practices so that we can take steps to capitalize on work processes and business of the company. It is important SMEs implements business intelligence solutions to solidify in the market.
When choosing a Business Intelligence tool, there are several factors to take into consideration: costs, quality of service, availability of personnel with minimal knowledge and obligatory features (company can have requisites not supported by some analyzed tools), among others. In our point of view it is extremely important before deciding to have knowledge about the characteristics of each tool, to meet the requirements of the SME.
A commercial or open source solution is the question that SMEs want to see clarified. Through the studies on which we based our work, and taking into account the characteristics listed for each tool, we took some important conclusions.
Commercial tools are solid tools on the market and have a longer maturity. Its main advantages are the innovative concepts and a better user interaction. Overall,
the greatest advantage of the commercial solutions described in this paper, is that its use is easier and more intuitive to the user, excluding the need for the inclusion of specialist staff to work with such tools.
On the other hand, the open source tools have been gaining notoriety for its innovative technologies in its operation and because they are license free.
When choosing BI software it is important that companies realize the capacity of its staff to work with business intelligence tools and evaluate the costs that each tool may have directly or indirectly.
The choice should be measured taking into account the costs that companies can afford in the short and medium term. Open source solutions are clearly practicable solutions that follow the development of commercial tools, becoming even more profitable.
The future of business intelligence software is brilliant, since BI is changing how companies are managed, decisions are made and people perform their jobs. In addition, major vendors are increasing their commitment and investment in BI. New and improved means of data analysis allow organizations to identify new business trends, assess the spread of disease, or even combat crime, among many other opportunities that can be explored.
REFERENCES 2011 Wisdom of Crowds Business Intelligence Market Study.
Dresner Advisory Services, LLC. May 18, 2011 http://www.globalsmes.org/html/index.php?func=expo2010&la
n=en http://www.actuate.com/home/ http://www.informationbuilders.com/ The Forrester Wave: Open Source Business Intelligence (BI),
Q3 2010. Boris Evelson and Jeffrey S. Hammond. August 10, 2010
http://www.infobuild.fi/pdf/esitteet/Mobile_FS.pdf http://www.jaspersoft.com/ http://www.pentaho.com/ http://www.spagoworld.org/xwiki/bin/view/SpagoBI/ http://www.informationbuilders.com/ http://www.microstrategy.com/ http://www.qlikview.com/ http://www.sas.com/ The Forrester Wave: Open Source Business Intelligence (BI),
Q3 2010. Boris Evelson and Jeffrey S. Hammond. August 10, 2010
http://www.microstrategy.com/mobile/business-intelligence/ http://www.sas.com/technologies/bi/ http://www.talend.com/products-data-integration/talend-open-
studio.php http://birtworld.blogspot.com/2009/12/calling-client-side-
javascript-from.html http://birtworld.blogspot.com/2009/06/calling-birt-reports-from-
aspnet-using.html http://itunes.apple.com/fi/app/birt-mobile-
hd/id370914749?mt=8 http://www.iwaysoftware.com.au/solutions/man/ http://live.lewispr.com/informationbuilders/2010/04/12/informat
ion-builders-announces-webfocus-8-406 http://www.informationbuilders.com.cn/products/webfocus/repo
rt_output_formats.html http://www.informationbuilders.com/MES

1
BETTER DECISIONS WITH OPEN SOURCE BUSINESS INTELLIGENCE TOOLS
Jorge Bernardino*1, Marco Tereso1, Pedro Ribeiro1
1Instituto Politécnico de Coimbra ISEC – Instituto Superior de Engenharia de Coimbra
Departamento de Engenharia Informática e de Sistemas (DEIS) Rua Pedro Nunes
3030-199 Coimbra, Portugal *Email: [email protected]
Abstract
Business Intelligence is firmly established, in many organizations, as the methodology
of choice for delivering comprehensive views of business states and directions.
Deployed to complement the business processes of an organization, Business
Intelligence tools work with a database management system (DBMS) to improve both
responsiveness and competitiveness. Business Intelligence tools aims to support better
decision-making in organizations. Whereas in the past the Business Intelligence market
was strictly dominated by closed source and commercial tools, the last few years were
characterized by the birth of open source (OS) solutions. The present study evaluated
and compared six Open Source Business Intelligence tools: JasperSoft, OpenI, Palo,
Pentaho, SpagoBI and Vanilla. This way, we show which are the best available free
solutions for organizations, especially those with fewer financial resources in order to
maintain their advantage competitive in an increasingly global market.
Keywords: Business Intelligence; Open Source; On-line Analytic Processing (OLAP);
Decision Support Systems (DSS)

2
1. Introduction
The term Business Intelligence (BI) was first introduced in 1989 by Howard Dresner,
who defined intelligence as “a set of concepts and appropriate methods to support
decision making, using the data provided by support systems to business process”
(Power, 2007). The need to implement decision support systems in organizations is an
unavoidable reality. Currently, the majority of organizations have Information
Technology (IT) systems, designed to record and store massive amounts of data
resulting from the operational activity. This data set has to be transformed in
information and all that information will lead to knowledge useful for the organizations.
OLAP (On-line Analytic Processing) tools are used for querying large data sets
usually available in a data warehouse or a central data repository for obtaining decision
making information. These tools allow non-technical users to extract the information
using predefined analytical data models in the form of self-service information
extraction. On-line Analytic Processing, in combination with the front-end tools,
provides the decision support tools required by the enterprise management. OLAP tools
structure data hierarchically, allowing to visualize it in different ways, enabling analysts
to gain insight into data through fast and interactive access to a variety of possible views
on information. The data recorded in enterprises by the systems of information
technology (IT) can be processed and interpreted using OLAP applications in order to
manipulate and analyze data from multiple perspectives. OLAP is a process of
manipulation and linking of data that allows users to access useful information in a
more standardized way. The process accepts data from multiple sources, thus providing
even greater potential for this type of applications. OLAP is clearly a growing area, and
its evolution is due to the fact that related areas such as Business Intelligence (BI) and

3
Decision Support Systems (DSS) are also in constant expansion. OLAP technologies
are rather required for these two areas (BI and DSS), the functionality checking
information provided by these tools allow to extract information from business
processes. This information extracted from crossing data is extremely important to help
business managers in decision making, and defining metrics for optimization of
business processes. Regarding the difficulties in accessing data, were developed several
types of OLAP architectures, developed to facilitate access to data in specific cases. The
existing OLAP architectures are ROLAP (Relational On-line Analytical Processing),
MOLAP (Multidimensional On-line Analytical Processing) and HOLAP (Hybrid On-
line Analytical Processing). We are interested in open source software as been defined
by Open Source initiative (OpenSourceInitiative, 2010): software that is freely
distributed without any fees related to use and including the source code; amended
software including all modifications in the software source code must be made available
under the original license. Although the use of the open source software does not have
to involve license costs, the cost of use of any software should be always expressed by
sum of all cost related to software implementation, configuration, maintenance and
support. Besides the zero licence cost, open source software has the following qualities:
reliability, customisability, freedom of choice, support and scalability.
Knowledge is essential to managers and entrepreneurs for making better
decisions. Organizations have to make a big effort to keep pace with market trends,
strategies business and contend with their competitors. Given these problems, this work
aims to survey state of the art of open source Business Intelligence tools to support
managers to make better business decisions.

4
This study only analysed open source tools, free of charge, given that one of the
main objectives is to reduce costs and increase the competitiveness of organizations. We
evaluated and compared six Open Source Business Intelligence tools: (JasperSoft,
2011), (OpenI, 2011), (Palo, 2011), (Pentaho, 2011), (SpagoBI, 2011) and (Vanilla,
2011). We also hope that our study can help to reduce water consumption by the use of
open source business tools, contributing for a sustainable development and a better
world.
The rest of the paper is organized as follows: in Section 2, we describe some
benefits of using open source software instead of commercial solutions. Section 3
presents the summary of the six open source business tools evaluation. Finally the
concluding remarks are presented in section 4.
2. Open source or commercial solutions?
The increasing focus on open-source software has reached the mainstream business
intelligence market. As some organizations are looking to reduce costs in their large BI
deployments, they are hoping that open source gives them greater leverage for their
money. Application developers that are looking for a way to embed BI functionality
into their applications initiate other open-source BI deployments. Similarly,
organizations often cannot afford to roll out BI technology to hundreds or maybe
thousands of users, even from their preferred vendor, because of steep licensing costs
and are therefore considering an open-source solution to complement the current
infrastructure.

5
We must be aware of that evaluating BI is never cost-free. The nature and extent
of those costs can vary widely when evaluating open source and proprietary software.
Evaluating open source BI is not cost-free, even though the software is freely available
for download, and the labour costs should be dramatically lower. This is because the
evaluation of open source BI is more likely to be “bottom up” rather than “top down.”
This means that the technical evaluation and even a pilot implementation may occur at
minimal cost and effort before executives are involved.
One of the biggest problems with commercial solutions is that all the costs are
born upfront by the customer before there is any reward. This dynamic is one of the key
reasons for the growth and popularity of the open source movement. While open source
is evangelized on many fronts, including security, flexibility, and competitive
advantage, organizations adopt open source primarily because of the price/performance
ratio. With open source BI, organizations can adjust spending as they go, depending on
the perceived returns. Almost all of the investment is spent configuring or customizing
the solution to meet the organization’s needs, not on a generic system that needs to be
customized just to work.
Open Source Software / Free Software (OSS/FS) (also abbreviated as FLOSS – Free
and Libre Open Source Software) has risen to immense notoriety. Briefly, FLOSS
programs are those whose license allows the user to run and modify the program at will,
including the right to redistribute copies of both the original and the modified versions.
This kind of license usually requires that copyright notices are maintained but doesn’t
require royalty payments (Cossentino, 2007).
There are a multitude of FLOSS licenses, with varying degrees of openness or
freedom, but all those licenses give open source software the possibility of being freely

6
downloaded and used for any purpose that the user wishes, even if the developers never
intended or predicted such uses. Redistribution, modification and unrestricted access to
source code are also some possibilities present in every FLOSS license.
Nowadays, if a business enterprise has the needed skills to implement, use and
maintain the desired application, there are almost certainly one or two options of
enterprise-class open source software. Some common benefits associated with open
source software include:
• Short Product Cycle;
• Reliable and Secure;
• Freedom from Vendor Lock-In;
• No License Costs.
While Linux, Apache, MySQL, and other open source software are routinely
deployed in the enterprise, open source BI solutions are just at the point where they are
sufficient mature to satisfy user requirements. The major attraction of open source is to
save time and money, but there’s an extra dimension to open source BI – open source
BI allows interaction and evolution in a way that proprietary BI does not.
3. Open Source Business Intelligence Tools Comparison
Business intelligence tools have been created in order to help decision makers to
visualize data and find answers to the problems. The communities developing open
source business intelligence solutions are sought along with their employees to optimize
their tools, thus contributing to a steady development, making more functional
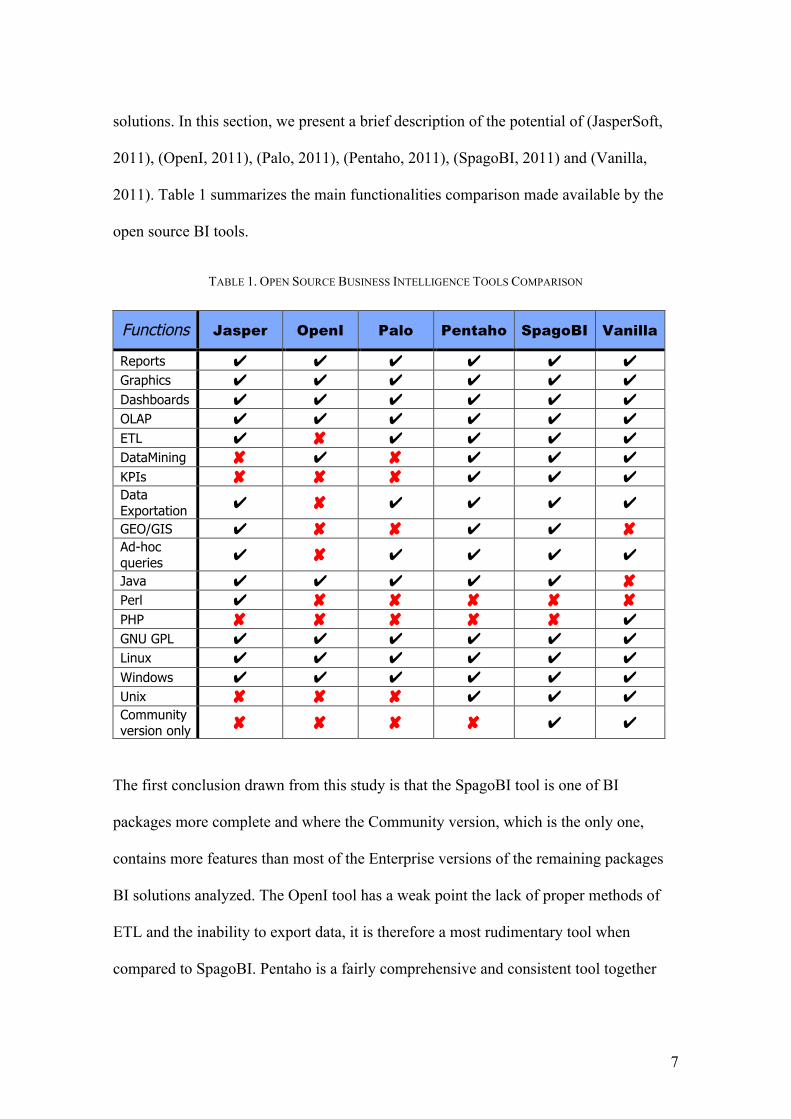
7
solutions. In this section, we present a brief description of the potential of (JasperSoft,
2011), (OpenI, 2011), (Palo, 2011), (Pentaho, 2011), (SpagoBI, 2011) and (Vanilla,
2011). Table 1 summarizes the main functionalities comparison made available by the
open source BI tools.
TABLE 1. OPEN SOURCE BUSINESS INTELLIGENCE TOOLS COMPARISON
Functions Jasper OpenI Palo Pentaho SpagoBI Vanilla
Reports ✔ ✔ ✔ ✔ ✔ ✔ Graphics ✔ ✔ ✔ ✔ ✔ ✔ Dashboards ✔ ✔ ✔ ✔ ✔ ✔ OLAP ✔ ✔ ✔ ✔ ✔ ✔ ETL ✔ ✘ ✔ ✔ ✔ ✔ DataMining ✘ ✔ ✘ ✔ ✔ ✔ KPIs ✘ ✘ ✘ ✔ ✔ ✔ Data Exportation ✔ ✘ ✔ ✔ ✔ ✔
GEO/GIS ✔ ✘ ✘ ✔ ✔ ✘ Ad-hoc queries ✔ ✘ ✔ ✔ ✔ ✔
Java ✔ ✔ ✔ ✔ ✔ ✘ Perl ✔ ✘ ✘ ✘ ✘ ✘ PHP ✘ ✘ ✘ ✘ ✘ ✔ GNU GPL ✔ ✔ ✔ ✔ ✔ ✔ Linux ✔ ✔ ✔ ✔ ✔ ✔ Windows ✔ ✔ ✔ ✔ ✔ ✔ Unix ✘ ✘ ✘ ✔ ✔ ✔ Community version only ✘ ✘ ✘ ✘ ✔ ✔
The first conclusion drawn from this study is that the SpagoBI tool is one of BI
packages more complete and where the Community version, which is the only one,
contains more features than most of the Enterprise versions of the remaining packages
BI solutions analyzed. The OpenI tool has a weak point the lack of proper methods of
ETL and the inability to export data, it is therefore a most rudimentary tool when
compared to SpagoBI. Pentaho is a fairly comprehensive and consistent tool together

8
with SpagoBI. JasperSoft is a powerful BI tool, lacks only the process of Data Mining
and KPIs when compared with SpagoBI and Pentaho is still more balanced analysis
tools because it allows ad hoc queries and managing location GEO/GIS. The Palo tool
does not support data mining processes, KPIs and tracking features GEO/GIS. Palo
enables ad-hoc queries, which are a plus for this tool. Palo has a relevant factor in the
fact that you can add to Microsoft Excel and Open Office Calc. The Vanilla tool is
comparable to Pentaho package with similar features available. An important point to
note is that the Vanilla tool has a version for mobile devices, a factor that opens up
important perspectives for future functionalities in open source BI.
4. Conclusions
The main conclusion we can draw from a study conducted until the moment is that
despite the open source BI platforms can not be considered as sophisticated as the
commercial ones, they already have a high level of reliability and should be considered
a valid alternative in relation to commercial platforms. This is even more evident for
organizations where the amount of data and workload are not critical points. From our
analysis, we conclude that Open Source Business Intelligence platforms are growing
both in features, quality and visual appeal. Of the six tools analyzed, the OpenI is
arguably the least developed, and Pentaho, JasperSoft, and SpagoBI tools are those with
the greatest potential for use in non-profit organizations and Small and Medium
Enterprises environments.

9
References
Cossentino, M. (2007), “Open Source Software”, October,
http://www.pa.icar.cnr.it/cossentino/ICT/ppt/S11%20-
%20Open%20Source%20Software.pdf
JasperSoft (2011), http://www.jaspersoft.com/
OpenI (2011), http://openi.org/
OpenSourceInitiative (2010), http://www.opensource.org/
Palo (2011), http://www.jpalo.com/en/
Pentaho (2011), http://www.pentaho.com/
Power, D. J. (2007), “A Brief History of Decision Support Systems, version 4.0”.
DSSResources.COM. World Wide Web,
http://DSSResources.COM/history/dsshistory.html, version 4.0, March 10, 2007.
Raymond, E. S. (2010), “The Cathedral and the Bazaar”, November,
http://www.catb.org/~esr/writings/cathedral-bazaar/cathedral-bazaar/
SpagoBI (2011), http://www.spagoworld.org/xwiki/bin/view/SpagoBI/
Vanilla (2011), http://vanilla-bi.com/





























