Embed Size (px)
Citation preview

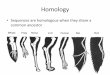
Family based approaches
Methods which also exploit
non-homology based information
Protein Annotations from Sequence DataProtein Annotations from Sequence Data
Network based analyses

a
a b
duplication
speciation
species 1 species 2
a a
paraloguesparalogues
orthologuesorthologues
Homology based inference of protein functionsHomology based inference of protein functions
orthologues - often have very similar functions
paralogues - may have related functions
ancestral protein

MKLNSHHIASNYEASKNFVNILQFEIRENYRSDKDSYKLDMVGSEQYASYP….
search for orthologues
search family resources
(ortholgues and paralogues)
analyse residue features to predict transmembrane, localisation etc
predict protein interactions
search for conserved residues

MKLNSHHIASNYEASKNFVNILQFEIRENYRSDKDSYKLDMVGSEQYASYP….
search for orthologuesHAMAP, EggNogg,
COGS, KOGS
search family resources
(ortholgues and paralogues)
analyse residue featurespredict
transmembrane, localisation etc
predict protein interactions
search for conserved residues

HAMAP familiesHAMAP families
• Orthologous protein families used for High-quality Automated and Manual Annotation of microbial Proteomes in UniProtKB.
• 1,448 families, from Bacteria, Archaea and Plastid covering over 180,000 UniProtKB/Swiss-Prot entries, available on:
http://www.expasy.org/sprot/hamap/families.html
Anne-Lise Veuthey, SIB

HAMAPHAMAP pipelinepipeline
UniProtKB/
TrEMBL
Profile
Automated annotation
Manual checking of warnings given by the system
HAMAP
family rules
Automatic retrieval of sequences
matching the profile

MKLNSHHIASNYEASKNFVNILQFEIRENYRSDKDSYKLDMVGSEQYASYP….
search for orthologues analyse residue featurespredict
transmembrane, localisation etc
predict protein interactions
search for conserved residues
search family resources
SMART, ProtoNet, Everest, Gene3D,
CATH, InterProPfam, TIGR, PRINTS,
SCOP

(1)(1)Cluster 4.5 million sequences (510 completed Cluster 4.5 million sequences (510 completed genomes) into protein superfamilies using APC genomes) into protein superfamilies using APC clustering algorithmclustering algorithm
(2) Map domains onto the sequences using HMM (2) Map domains onto the sequences using HMM technology technology (CATH & Pfam domains)(CATH & Pfam domains)
335,000 protein superfamilies (orthofams)(189,000 have >5 sequences)19% are singletons
~11,000 domain superfamilies(2100 CATH of known structure – account for ~85% of domains)
BLAST, APC
CATH, Pfam HMM libraries

Gene3D - OrthoFamsGene3D - OrthoFams
Functional annotation of selected node
Root Node
30% ID
95% ID
335,000 Protein families built using Affinity Propogation Clustering.
Annotated with FunCat, HAMAP, EC, KEGG, GO, IntACT, HPRD, and others.
Benchmarking – 99.9% map to single HAMAP

Functional Catalogue (FunCat) Functional Catalogue (FunCat)
• Organized hierarchically with up to six levels.Organized hierarchically with up to six levels.
• ~1307 categories ~1307 categories
• Currently 9 organisms incorporated: yeast, human, Currently 9 organisms incorporated: yeast, human,
A.thalianaA.thaliana, …, …
Dmitrj Frishmann, GSF

Number of Entries
100,000
1,000,000
10,000,000
100,000,000
SWP
U50 U90 KBU10
0M
ESPar
c
ProtoNet 5.1
EVEREST 2.0
Michal Linial, HUJI
2.5M sequences
Michal Linial, HUJI
ProtoNet and EVEREST family ProtoNet and EVEREST family resourcesresources

. Root
B22
B40
B14
B31
B32
B13
B44
B 10
B37
B26
B16
B28
B11
B27
B29
B20
B25
B7
B30
B18
B9
B42
B36
B23
B19
B5
B21
B33
B39
B12
B38
B17
B35
B8
B43
B34
B41
B24
B6
B15
B4
B1
B3
AE
E1
A1
A3
A2
A4
A5
A10
B2
A6
A7
A9
A8
A11
E2
A12
2.5M sequences from UniProt
UPGMA efficient clustering algorithm
Benchmarked against Pfam, SCOP

ProtoName: ProtoName: ssafe inference of annotationafe inference of annotation
ProtoName: ProtoName: ssafe inference of annotationafe inference of annotation
For each cluster annotation assigned an Annotation Score if proteins achieve p-value <= 0.001
(b) Only clusters with > 5 proteins are considered
(c) Purity is >0.9 (TP/ TP+FN)
(d) Combination of functional keywords
For each protein, assign the annotations of its cluster and all parents
>40% of the clusters and 65% of proteins assigned a safe ProtoName

protein superfamily protein superfamily
~11%of PROTEIN superfamilies in a genome are common to all ~11%of PROTEIN superfamilies in a genome are common to all kingdoms, kingdoms,

protein superfamily protein superfamily
common domainscommon domains
nearly 60% of domains are from ~200 nearly 60% of domains are from ~200 superfamilies COMMON to all major kingdomssuperfamilies COMMON to all major kingdoms
these have been combined in different ways to modulate these have been combined in different ways to modulate function function
~11%of PROTEIN superfamilies in a genome are common to all ~11%of PROTEIN superfamilies in a genome are common to all kingdoms, kingdoms,

Evolution of functional subfamilies within superfamilies
.Root
B22
B40
B14
B31
B32
B13
B44
B 10
B37
B26
B16
B28
B11
B27
B29
B20
B25
B7
B30
B18 B9
B42
B36
B23
B19
B5
B21
B33
B39
B12
B38
B17
B35
B8
B43
B34
B41
B24
B6
B15
B4
B1
B3
AE
E1
A1
A3
A2
A4
A5
A10
B2
A6
A7
A9
A8
A11
E2
A12
Species tree built on the small subunit (SSU)
ribosomal RNA
superfamily
+
+++
+
++++++++
COG functional categoriesCOG functional categories

Percentage frequencies of functional shifts within domain superfamilies
Function is predominantly conserved within the same COG functional subcategory or major category
However, there are clearly cases of major functional shifts
[J] [L] [K] [A] [T] [M] [N] [O] [U] [D] [V] [E] [C] [H] [P] [F] [G] [I] [Q] [R] [S] [J] 29 1 0 0 1.9 0 0 0 0 9 0 0 0 2 0 2 0 0 0 0.8 7 [L] 5 41 2.5 100 0 0 0 10 0 18 0 0.7 0 0 0 2 0 3 0 1.5 0 [K] 5 3 40 0 21 0 0 3 12 0 0 5.2 1 2 5 4 9 0 0 1.5 7 [A] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 [T] 5 3 20 0 62 1.6 50 3 6 0 0 1.5 1 0 0 0 5 0 6 2.3 7 [M] 5 0 1.2 0 0 46 0 3 0 0 0 2.2 2 5 5 6 9 12 0 4.6 0 [N] 0 1 1.2 0 3.8 0 20 0 18 0 0 0 0 0 0 0 0 0 0 1.5 0 [O] 1 2 1.2 0 0 0 0 40 12 9 0 1.5 3 0 3 6 0 0 6 0.8 0 [U] 0 1 1.2 0 0 0 30 3 24 0 0 1.5 0 0 0 0 0 0 0 0.8 0 [D] 0 1 0 0 0 0 0 5 0 18 0 0 0 0 0 0 0 0 0 0 0 [V] 1 1 0 0 0.9 3.2 0 3 0 0 67 0 0 0 0 0 0 0 0 0 0 [E] 9 4 7.4 0 2.8 4.8 0 0 0 9 0 27 3 7 0 12 2 3 6 5.4 0 [C] 0 1 0 0 0 3.2 0 3 0 18 0 13 41 17 10 10 4 12 0 16 7 [H] 5 1 0 0 0 0 0 5 6 0 0 5.2 5 25 10 2 9 3 6 3.8 7 [P] 1 9 2.5 0 0 0 0 5 0 0 0 0.7 11 13 41 2 7 3 0 3.1 0 [F] 4 0 1.2 0 1.9 4.8 0 0 0 0 0 1.5 4 2 0 26 0 0 0 1.5 0 [G] 0 2 3.7 0 0.9 9.5 0 3 12 0 0 1.5 6 5 0 2 33 3 0 4.6 13 [I] 7 0 0 0 0 3.2 0 3 0 9 0 2.2 3 0 0 2 2 18 6 2.3 0 [Q] 0 1 1.2 0 1.9 1.6 0 3 0 0 0 2.2 1 2 10 2 2 30 41 2.3 0 [R] 16 19 8.6 0 0.9 14 0 8 12 0 0 25 11 20 10 22 14 9 24 39 47 [S] 4 8 7.4 0 1.9 7.9 0 5 0 9 33 8.9 6 2 5 0 5 3 6 7.7 7
Total number of shifts 75 91 81 2 106 63 10 40 17 11 3 135 97 60 39 50 57 33 17 130 15
Parent Functions
Child Functions
parent functionsch
ild f
unct
ions
metabolismsignal
transduction
protein biosynthesis
poorlycharacterised

0 20 40 60 80 100 120 140 1600
20
40
60
80
100
120
3.40.50.720
3.40.50.300
3.40.50.150
2.60.40.10
1.10.10.10
2.40.50.140
Superfamily Variation: Structure/Sequence
0-25 GO Terms26-50 GO Terms51-100 GO Terms101-200 GO Terms201+ GO Terms
Sequence Families
Str
uctu
ral D
iver
sity
Population in genomes (x 1000)
Str
uct
ura
l D
iver s
i ty
<10% of domain superfamilies (<200) are highly <10% of domain superfamilies (<200) are highly expanded in the genomes and functionally very diverseexpanded in the genomes and functionally very diverse
~2000superfamilies

N-fold increase in functional annotation using N-fold increase in functional annotation using pairwise sequence identity thresholdspairwise sequence identity thresholds
general thresholds family specific thresholds
0
2
4
6
8
Gene3D (6.8%) H.sapiens (5%) A.thaliana (2.7%) C.elegans (1.1%) B.anthracis (3.7%)
N-f
old
in
crea
se i
n c
ove
rag
e
Domain - 50/80 and 40/80 cut-offs if identical MDA Domain - Family specific cut-off
N-f
old
incr
ease
in
N-f
old
incr
ease
in
covera
ge
covera
ge
>50% sequence identity - 90% probability of having related functions
If the domains have the same multidomain context
>30% sequence identity – 90% probability of having related functions

Some superfamilies contain multiple diverse functional subfamilies

MKLNSHHIASNYEASKNFVNILQFEIRENYRSDKDSYKLDMVGSEQYASYP….
search for orthologuesanalyse residue
featurespredict
transmembrane, localisation etc
predict protein interactions
search family resources
(orthologues and paralogues)
search for conserved residues
TreeDet, ScoreCons, GEMMA
ETtrace, SCI-PHY, FunShift

Score conservation
for each position in the
alignment using an entropy measure
1 = highly conserved
0 = unconservedPutative functional site
Structural model
Identify functional subfamilies by using information on sequence conserved residue positions
Scorecons –Thornton TreeDet - Valencia
multiple sequence alignment of relatives
from functional subfamily

Phylogenetic trees derived from multiple sequence alignments can be used to identify functional subfamilies
TreeDet - ValenciaSCI-PHY – SjolanderFunShift – SonnhammerETtrace - Lichtarge

TreeDet method for identifying functional subfamiliesTreeDet method for identifying functional subfamiliesAlfonsoValencia group, CNIOAlfonsoValencia group, CNIO

domain superfamily
GEMMA: Compares sequence profiles (HMMs) between subfamilies using COMPASS method
sequence subfamily 90% seq. id
putative functional subfamily
clusters sequence relatives predicted to have related functions

0
10
20
30
40
50
60
70
80
90
100
Amidohydrolase Crotonase Enolase Haloacid dehalogenase Vicinal oxygen chelate
SCI-PHY
GeMMA
0
5
10
15
20
25
Amidohydrolase Crotonase Enolase Haloacid dehalogenase Vicinal oxygen chelate
SCI-PHY
GeMMA
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
Amidohydrolase Crotonase Enolase Haloacid dehalogenase Vicinal oxygen chelate
SCI-PHY
GeMMA
0
1
2
3
4
5
6
Amidohydrolase Crotonase Enolase Haloacid dehalogenase Vicinal oxygen chelate
SCI-PHY
GeMMA
GeMMA v SCI-PHY using gold standard Babbitt benchmark of 5 large curated superfamilies
Purity(high isbest)
Editdistance(low)
VIdistance(low is best)
Deviationfrom no.singletons(low)

Annotation (EC number) coverage of MEGA family 3.90.1200.10
0
10
20
30
40
50
60
70
80
Database annotations Annotations inherited w ithin S60 clusters Annotations inherited w ithin GeMMAfunctional subfamilies
Source of annotation
Co
vera
ge
of
fam
ily (
%)
Covera
ge o
f su
perf
am
ily (
%)
experimentalannotations
inherit functions at 50% seq. id.
inherit functions by GEMMA
Functional annotation coverage using different strategies

MKLNSHHIASNYEASKNFVNILQFEIRENYRSDKDSYKLDMVGSEQYASYP….
search for orthologues
search family resources
(orthologues and paralogues)
analyse residue featurespredict
transmembraneMEMSAT, TMHMM, ENSEMBLE, PONGO
predict protein interactions
search for conserved residues
analyse residue features predict disorder, signal
peptides, localisationBarcello, DisoPred,
FFpred

A ’biological’ hydrophobicity scaleA ’biological’ hydrophobicity scale
(Hessa et al., Nature (Hessa et al., Nature 433433:377 & :377 & 450450:1026; Bernsel et al. PNAS in press):1026; Bernsel et al. PNAS in press)
Gunnar Von Heijne, STO

Pongo annotation enginePongo annotation engine
Seven predictors at the core: all-α TM topology;
(a) TMHMM 2.0 (b) MEMSAT (c) PRODIV (d) ENSEMBLE (e) ENSEMBLE 2.0(f) TMHMM DOMFIX
signal peptide; (a) SPEP
Rita Casadio, UNIBO
http://pongo.biocomp.unibo.it/pongo

Performance of the high scoring methods on the 121 high-resolved chains (from PDB)
Q topography Q topology
TMHMM 88/ 121 (73%) 67/ 121 (55%)
TMHMMdomfi x 87/ 121 (72%) 74/ 121 (61%)
PRODI V 99/ 121 (82%) 93/ 121 (77%)
MEMSAT 93/ 121 (77%) 90/ 121 (74%)
ENSEMBLE 1.0 105/ 121 (87%) 92/ 121 (76%)
ENSEMBLE 2.0 105/ 121 (87%) 95/ 121 (79%)
Correct Topography: Correct Position of TMhelices along the sequence
Correct Topology: Correct Position AND Correct Orientation with respect to the membrane plane

The PONGO engine:
http://pongo.biocomp.unibo.it
Amico M, Finelli M, Rossi I, Zauli A, Elofsson A, Viklund H, von Heijne G, Jones D, Krogh A, Fariselli P, Martelli PL, Casadio R -PONGO: a web server for multiple predictions of all-alpha transmembrane proteins- Nucleic Acids Res 34(Web server issue):169-172 (2006)

CBS prediction servers
Broad range of prediction servers
Amino acid sequence based methods within: Protein sorting
Post-translational modifications of proteins
Protein function and structure
Immunological features
Local protein features, e.g. “kinase-specific phosphorylation site”, “nuclear export signal”, “propeptide cleavage site”
Global properties, e.g. “cell cycle regulated”, “secreted via a non-classical pathway”, “member of the nucleolar subproteome”, GO categories, EC categories, ...
Soren Brunak, DTU

FFPred: An Integrated Feature based Function Prediction FFPred: An Integrated Feature based Function Prediction Server for Vertebrate ProteomesServer for Vertebrate Proteomes
Inferring function using patterns of native disorder in proteins. Lobley, A.E., Swindells, M.B., Orengo, C.A. & Jones, D.T. (2007) PLoS Comput. Biol. 3:e162.
posterior probability estimate
GO Term SVM
Amino acid sequence
Sec.str disorder motifs localisation
Novel sequence
Characteristics
Classification
aa transmem
> 300 GO Term Classifiers for both Molecular Process and Biological Function Categories
David Jones, UCL

Protein Annotations from Sequence DataProtein Annotations from Sequence Data
Network based analyses

CORUM:the comprehensive resource of mammalian protein complexes
No of Proteins/Protein complexes
• consists of 2100 protein complexes
• covers ~3000 different proteins, representing 15% of protein coding genes in mammals
Dmitrj Frishmann, GSF

MKLNSHHIASNYEASKNFVNILQFEIRENYRSDKDSYKLDMVGSEQYASYP….
search for orthologues
search family resources
(orthologues and paralogues)
analyse residue featurespredict
transmembrane,disorder etc
search interactions resources
CORUM, IntAct, HPRD, BIND
search for conserved residues
Predict interactionsSTRING, DIMA G3D-BioMiner
PROLINKS

Gene3D-BioMiner Gene3D-BioMiner
hiPPIhomology inherited
Protein-Protein Interactions
CODACo-Occurance of Domains Analysis
GECOGene Expression
Correlation
PhyloTunerDomain family co-evolution detection
Visualisation in CytoScape
Adding known functional associations i.e. from FunCat.
Weighted Integration

CODA: FUSED DOMAINS
Specie 1
Specie 2
Method adapted from Enright, Ouzounis but a new scoring scheme has been developed
BioMiner

Homology Inferred Protein Protein InteractionsInherit data provided by HPRD, IntAct, BIND, CORUM
HiPPI: Protein-protein physical interaction data
Superfamily A Superfamily B

Eisenberg Phylogenetic Profiles for Detecting Functional Eisenberg Phylogenetic Profiles for Detecting Functional AssociationsAssociations
Superfamily 1
Superfamily 2
Superfamily 3
CATH Domain Superfamily
Organism 1 2 3 4
35 0 12 60
12 13 14 11
6 0 0 0
Gene3D Phylogenetic Occurrence ProfilesGene3D Phylogenetic Occurrence Profiles
Superfamily 1
Superfamily 2
Superfamily 3
Superfamily Organism 1 2 3 4
1 0 1 0
1 0 1 0
0 0 1 1
FunctionallyFunctionallyLinked Linked presence or presence or
absence of absence of superfamily superfamily in organismin organism
number of number of sequence sequence relatives relatives
from from superfamily superfamily in organismin organism

Eisenberg Phylogenetic Profiles for Detecting Functional Eisenberg Phylogenetic Profiles for Detecting Functional AssociationsAssociations
Superfamily 1
Superfamily 2
Superfamily 3
CATH Domain Superfamily
Organism 1 2 3 4
7 0 3 0
3 6 4 5
6 0 2 0
Gene3D PhyloTuner Occurrence ProfilesGene3D PhyloTuner Occurrence Profiles
Superfamily 1
Superfamily 2
Superfamily 3
Superfamily Organism 1 2 3 4
1 0 1 0
1 0 1 0
0 0 1 1
FunctionallyFunctionallyLinked Linked presence or presence or
absence of absence of superfamily superfamily in organismin organism
number of number of sequence sequence relatives relatives
from from superfamily superfamily in organismin organism
Ranea et al.(2007) PLOS Comp. Biol.

ClusterLevel
Genome Occurrence
Sp1 Sp2 Sp3
Superfam. 8 7 3
s30(a) 6 4 2
s30(b) 2 3 1
s35(a) 6 4 2
s35(b) 2 3 1
s40(a) 6 4 2
s40(b)(i) 0 3 0
s40(b)(ii) 2 0 1
s50(a) 6 4 2
s50(b)(i) 0 3 0
s50(b)(ii) 2 0 1
… … … …
Domain Superfamilies clustered at different levels of sequence identity:
Sup. S30 S35 S40 S50 … (S100)
Phylo-Tuner algorithm
Phylogenetic Occurrence Profile Matrix
Species1 Species2 Species3
Superfamily

Sup. S30 S35 S40 S50 … (S100)
Superfamily X
Sup. S30 S35 S40 S50 … (S100)
Superfamily Y
Sp1 Sp2 Sp3 Sp4 Sp5 … Spn
5
10Ematch
Ematch <<<< Eall_rest
Euclidian distance:
Phylo-Tuner
Sp1 Sp2 Sp3 Sp4 Sp5 … Spn
Cluster 1Cluster 2Cluster 3Cluster 4Cluster 5Cluster 6Cluster 7
.
.
.Cluster n
6 0 6 9 5 … 94 3 7 5 3 … 51 0 1 0 2 … 10 2 0 0 1 … 61 4 1 4 1 … 40 3 5 2 0 … 14 8 4 8 4 … 8. . . . . … .. . . . . … .. . . . . … .0 1 0 1 1 … 0
Sp1 Sp2 Sp3 Sp4 Sp5 … Spn
Cluster 1Cluster 2Cluster 3Cluster 4Cluster 5Cluster 6Cluster 7
.
.
.Cluster n
3 0 6 0 4 … 104 3 7 5 6 … 50 0 1 0 2 … 11 2 1 0 1 … 61 4 0 4 1 … 40 4 5 2 0 … 12 6 4 8 4 … 7. . . . . … .. . . . . … .. . . . . … .0 1 0 1 1 … 0
Zs calculations
xx
Xi
Zs =
Ematch

0
0.01
0.02
0.03
0.04
0.05
( ≥
-3.5
)
(-3.5
)-(-
3.0
)
(-3.0
)-(-
2.5
)
(-2.5
)-(-
2.0
)
(-2.0
)-(-
1.5
)
(-1.5
)-(-
1.0
)
(-1.0
)-(-
0.5
)
(-0.5
)-(0
.0)
(0.0
)-(0
.5)
(0.5
)-(1
.0)
(1.0
)-(1
.5)
(1.5
)-(2
.0)
(2.0
)-(2
.5)
(2.5
)-(3
.0)
(3.0
)-(3
.5)
(>=
3.5
) 0
10
20
30
40
50
60
70
80
90
100
Highly similar profiles correspond to pairs of families Highly similar profiles correspond to pairs of families with significant similarity in GO functions with significant similarity in GO functions
true positives false positives
ratio of true positives to false positives
Biological process
Ranea et al. (2007) PLOS Comp. Biol.

1
10
100
1000
10000
100000
0.8 0.85 0.9 0.95 1
Precision
# h
its
GEC
CODA-CATH
CODA-Pfam
hiPPI
Fisher W integration
Performance of Gene3D-BioMiner integrated methods assessed using a yeast genome dataset and semantic
similarity of GO terms

Phylogenetic domain profiling
PF1 100101110001110001PF2 011100011101001100PF3 100101110001110001PF4 110001000100100000
PPI → DDI (DPEA: Riley et al.)
460 completed genomes!
2 versions:
Domain interactions derived from PDB
Finn et al. 2005 Stein et al. 2005
SIMAP/BOINC for Pfam domain search
known PPIs
predicted PPIs

STRING – functional protein interactionsSTRING – functional protein interactions
378 genomes
Interaction evidence Genomic context Primary
experiments Pathway databases Literature mining
New network viewer Confidence view
vs. evidence view Miniature protein
structures
Peer Bork, EMBL

Protein interaction networks
Over 2 million interactions in 184 genomes, previously uncharacterised
Filtering out promiscuous domains, excluding implausible interactions
Kamburov A et al. 2007) Denoising inferred functional association networks obtained by gene fusion analysis. BMC Genomics, 2007; 8(1):460
Denoising Protein Interaction Networks Christos Ouzounis, CERTH

Evaluation of graph-based clustering algorithms for extracting complexes from protein interaction networks
• Evaluation protocolo Reference complexes: MIPS databaseo Test with altered networks: various proportions of random edge addition/removal.o Testing of all parametric conditions.o Definition of assessment statistics (Sensitivity, Positive Predictive Value,
Accuracy)
Reference network: MIPS complexes Altered network (100% edge additions, 40% removal)
Sylvain Brohée and Jacques van Helden (2006). BMC Bioinformatics 7: 488

Acknowledgements
Protein Families
Michal Linial HUJI, Jerusalem Anne Lise Veuthey SIB, SwistzerlandDmitrij Frishmann GSF, GermanyAlfonso Valencia CNIO, Spain
Feature Based Prediction
Gunnar Von Heijne STO, SwedenRita Casadio UNIBO, ItalyDavid Jones UCL, LondonSoren Brunak DTU, Denmark
Protein Interactions
Christos Ouzounis CERTH, GreeceJacques Van Helden ULB, Brussels

Network Analysis Tools (NeAT)Network Analysis Tools (NeAT)
• A toolbox for the analysis of networks, clusters and pathwayso Graph-based
clustering o Path findingo Graph
comparisonso Graph
randomizationo Graph alterationo …
Web site: http://rsat.scmbb.ulb.ac.be/neat/
Jaques Van Helden, ULB

Network Analysis of QTLs in Mouse
QTL1
QTL2
QTL3
Novel genes can be discovered describing the trait in question
Maps protein interaction network to an inferred QTL network
Assigns functional roles to protein subnetworks on the basis of the phenotypic traits they are mapped to
Christos Ouzounis, CERTH

DASMI – Distributed Annotation System for Molecular Interactions
Based on the Distributed
Annotation System (DAS)
Interaction servers and
visualization clients
DASMI web: Client for inte-
gration of protein and domain
interactions and function, possible
application of quality measures
iPfam : Client for graphical
visualization of various domain
interaction data sets

0
10
20
30
40
50
60
70
80
90
100
Arabidopsis C.elegans Drosophila Human Mouse Yeast
Organism
Gen
es w
ith
str
uct
ura
l an
no
tati
on
Gene3D Genthreader
Proportion of genome sequences which can be assigned to
2100 domain families of known structure in CATH

Conservation of enzyme function for homologous Conservation of enzyme function for homologous domainsdomains
0
10
20
30
40
50
60
70
80
90
100
11--20 21-30 31-40 41-50 51-60 61-70 71-80 81-90 91-100
Sequence Identity (%)
Fu
nct
ion
co
nse
rvat
ion
(A
.B.C
.D/A
.B.C
.-)
(%)
0.0E+00
2.0E+05
4.0E+05
6.0E+05
8.0E+05
1.0E+06
1.2E+06
Identical MDA - minimum overlap 80% Different MDA - minimum overlap 80%
Distribution of pairwise homologous comparisons
Conse
rvati
on o
f C
onse
rvati
on o
f EC
nu
mber
to 3
EC
nu
mber
to 3
le
vels
(%
)le
vels
(%
)
Sequence identitysame MDA
CATH-1CATH-1Pfam-1Pfam-1 Pfam-2Pfam-2MDA
different MDA
Num
ber
of
pair
s N
um
ber
of
pair
s of
rela
tives
of
rela
tives
>50% sequence identity - 90% probability of having related functions
If the domains have the same multidomain architecture (MDA)
>30% sequence identity – 90% probability of having related functions


![Persistent Homology for Path Planning in Uncertain …in search-based path planning [2], [3]. A. Homology We specialize to (persistent) homology of 1-dimensional curves, which constitute](https://img.pdfslide.us/doc/110x75/6020af33240905668e123a61/persistent-homology-for-path-planning-in-uncertain-in-search-based-path-planning.jpg)