Embed Size (px)
Citation preview
Fall 2003 Data Mining 1
Exploratory Data Mining and Data Preparation
Fall 2003 Data Mining 2
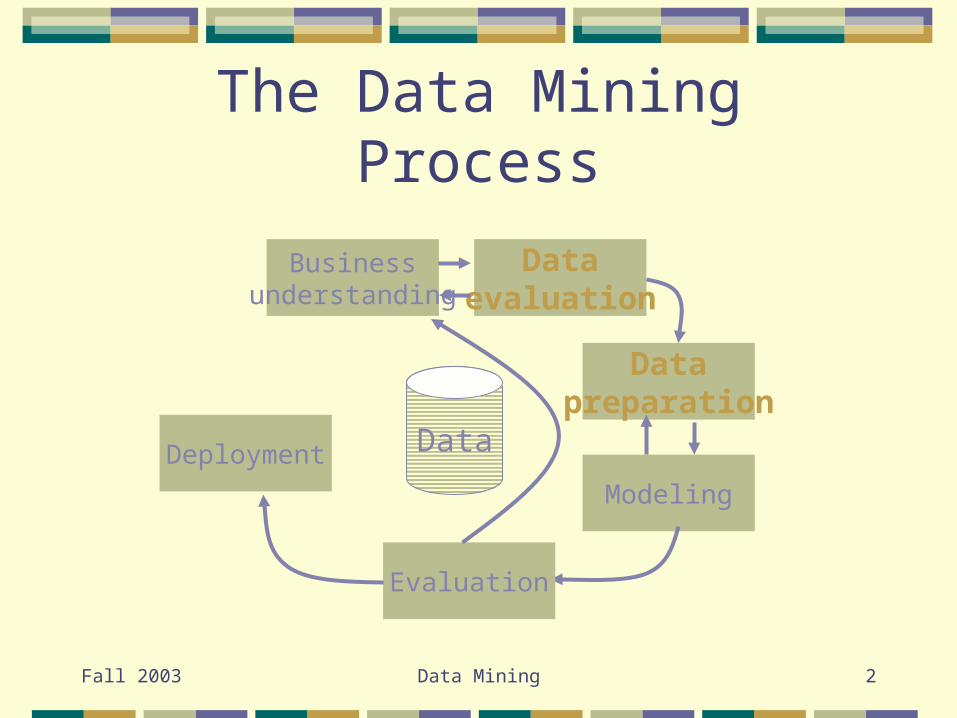
The Data Mining Process
Businessunderstanding
Deployment Data
Datapreparation
Modeling
Dataevaluation
Evaluation

Fall 2003 Data Mining 3
Exploratory Data Mining
Preliminary process
Data summariesAttribute meansAttribute variationAttribute relationships
Visualization
Fall 2003 Data Mining 4
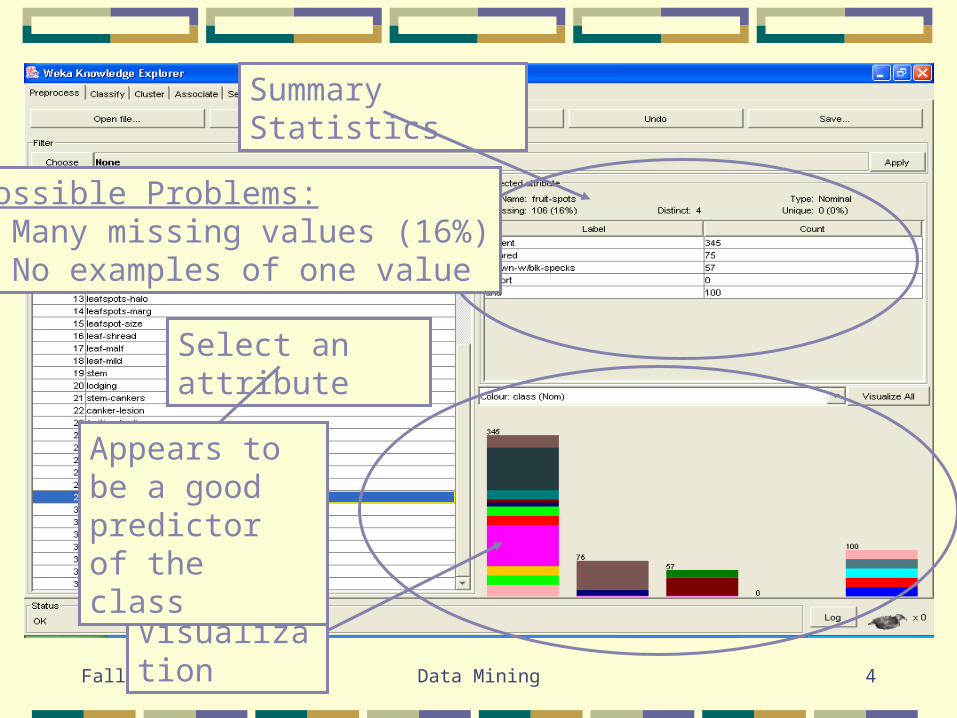
Select an attribute
Summary Statistics
Possible Problems:• Many missing values (16%)• No examples of one value
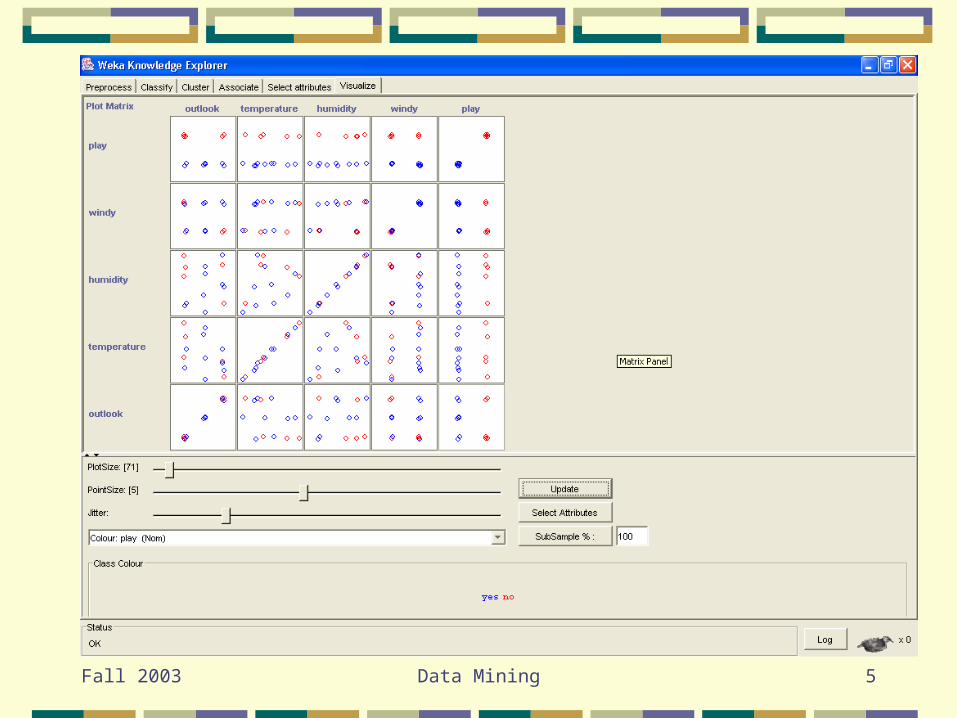
Visualization
Appears to be a good predictor of the class
Fall 2003 Data Mining 5

Fall 2003 Data Mining 6
Exploratory DM Process
For each attribute:Look at data summaries
Identify potential problems and decide if an action needs to be taken (may require collecting more data)
Visualize the distribution Identify potential problems (e.g., one dominant
attribute value, even distribution, etc.)Evaluate usefulness of attributes

Fall 2003 Data Mining 7
Weka Filters
Weka has many filters that are helpful in preprocessing the data Attribute filters
Add, remove, or transform attributes Instance filters
Add, remove, or transform instances
Process Choose for drop-down menu Edit parameters (if any) Apply

Fall 2003 Data Mining 8
Data Preprocessing
Data cleaningMissing values, noisy or inconsistent data
Data integration/transformation
Data reductionDimensionality reduction, data
compression, numerosity reduction
Discretization

Fall 2003 Data Mining 9
Data Cleaning
Missing values Weka reports % of missing values Can use filter called ReplaceMissingValues
Noisy data Due to uncertainty or errors Weka reports unique values Useful filters include
RemoveMisclassified MergeTwoValues

Fall 2003 Data Mining 10
Data Transformation
Why transform data? Combine attributes. For example, the ratio of two
attributes might be more useful than keeping them separate
Normalizing data. Having attributes on the same approximate scale helps many data mining algorithms(hence better models)
Simplifying data. For example, working with discrete data is often more intuitive and helps the algorithms(hence better models)

Fall 2003 Data Mining 11
Weka Filters
The data transformation filters in Weka include:AddAddExpressionMakeIndicatorNumericTransformNormalizeStandardize

Fall 2003 Data Mining 12
Discretization
Discretization reduces the number of values for a continuous attribute
Why?Some methods can only use nominal data
E.g., in Weka ID3 and Apriori algorithmsHelpful if data needs to be sorted
frequently (e.g., when constructing a decision tree)

Fall 2003 Data Mining 13
Unsupervised Discretization
Unsupervised - does not account for classes
Equal-interval binning
Equal-frequency binning
64 65 68 69 70 71 72 75 80 81 83 85
Yes No Yes Yes Yes No NoYes
YesYes
No Yes Yes No
64 65 68 69 70 71 72 75 80 81 83 85
Yes No Yes Yes Yes No NoYes
YesYes
No Yes Yes No

Fall 2003 Data Mining 14
Take classification into account
Use “entropy” to measure information gain
Goal: Discretizise into 'pure' intervals
Usually no way to get completely pure intervals:
Supervised Discretization
64 65 68 69 70 71 72 75 80 81 83 85
Yes No Yes Yes Yes No NoYes
YesYes
No Yes Yes No
ABCDEF
9 yes & 4 no 1 no1 yes 8 yes & 5 no

Fall 2003 Data Mining 15
Error-Based Discretization
Count number of misclassifications Majority class determines prediction Count instances that are different
Must restrict number of classes.
Complexity Brute-force: exponential time Dynamic programming: linear time
Downside: cannot generate adjacent intervals with same label

Fall 2003 Data Mining 16
Weka Filter

Fall 2003 Data Mining 17
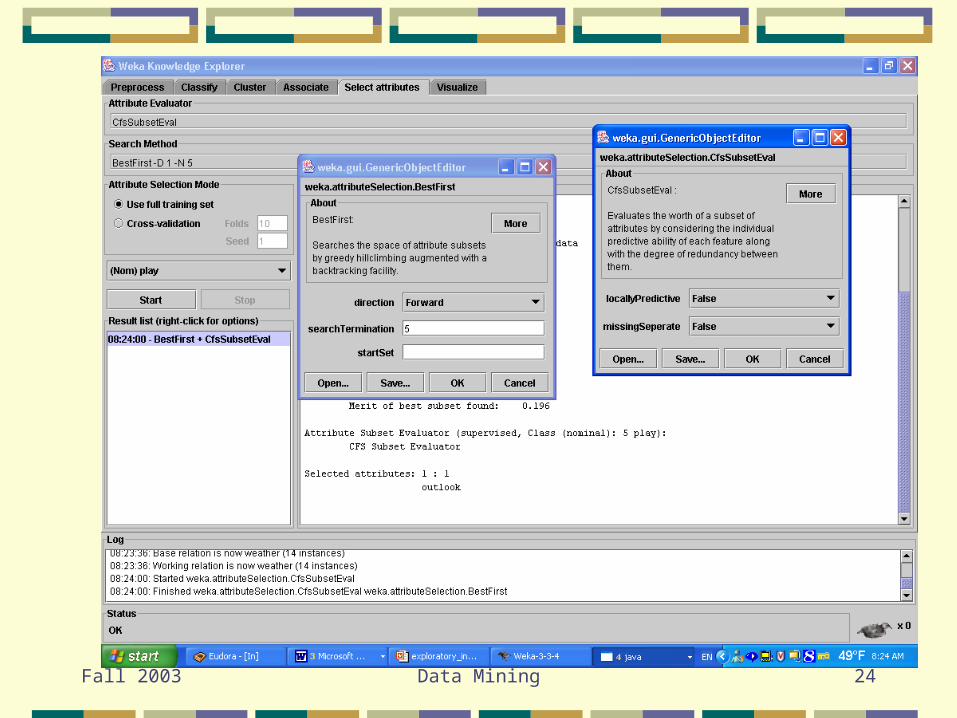
Attribute Selection
Before inducing a model we almost always do input engineeringThe most useful part of this is attribute selection (also called feature selection)Select relevant attributesRemove redundant and/or irrelevant
attributes
Why?

Fall 2003 Data Mining 18
Reasons for Attribute Selection
Simpler model More transparent Easier to interpret
Faster model induction What about overall time?
Structural knowledge Knowing which attributes are important may be
inherently important to the application
What about the accuracy?

Fall 2003 Data Mining 19
Attribute Selection Methods
What is evaluated?
AttributesSubsets of attributes
Evaluation Method
Independent
Filters Filters
Learning algorithm Wrappers

Fall 2003 Data Mining 20
Filters
Results in eitherRanked list of attributes
Typical when each attribute is evaluated individually
Must select how many to keepA selected subset of attributes
Forward selectionBest firstRandom search such as genetic algorithm

Fall 2003 Data Mining 21
Filter Evaluation Examples
Information Gain
Gain ration
Relief
CorrelationHigh correlation with class attributeLow correlation with other attributes

Fall 2003 Data Mining 22
Wrappers
“Wrap around” the learning algorithm
Must therefore always evaluate subsets
Return the best subset of attributes
Apply for each learning algorithm
Use same search methods as before
Select a subset of attributes
Induce learning algorithm on this subset
Evaluate the resulting model (e.g., accuracy)
Stop? YesNo

Fall 2003 Data Mining 23
How does it help?
Naïve Bayes
Instance-based learning
Decision tree induction
Fall 2003 Data Mining 24

Fall 2003 Data Mining 25
Scalability
Data mining uses mostly well developed techniques (AI, statistics, optimization)
Key difference: very large databases
How to deal with scalability problems?
Scalability: the capability of handling increased load in a way that does not effect the performance adversely

Fall 2003 Data Mining 26
Massive Datasets
Very large data sets (millions+ of instances, hundreds+ of attributes)
Scalability in space and timeData set cannot be kept in memory
E.g., processing one instance at a timeLearning time very long
How does the time depend on the input?Number of attributes, number of instances

Fall 2003 Data Mining 27
Two Approaches
Increased computational powerOnly works if algorithms can be sped upMust have the computing availability
Adapt algorithmsAutomatically scale-down the problem so
that it is always approximately the same difficulty

Fall 2003 Data Mining 28
Computational ComplexityWe want to design algorithms with good computational complexity
exponential
linear
logarithm
Number of instances
(Number of attributes)
Time
polynomial

Fall 2003 Data Mining 29
Example: Big-Oh Notation
Define n =number of instances m =number of attributes
Going once through all the instances has complexity O(n)Examples Polynomial complexity: O(mn2) Linear complexity: O(m+n) Exponential complexity: O(2n)

Fall 2003 Data Mining 30
Classification
If no polynomial time algorithm exists to solve a problem it is called NP-completeFinding the optimal decision tree is an example of a NP-complete problemHowever, ID3 and C4.5 are polynomial time algorithms Heuristic algorithms to construct solutions to a
difficult problem “Efficient” from a computational complexity
standpoint but still have a scalability problem

Fall 2003 Data Mining 31
Decision Tree Algorithms
Traditional decision tree algorithms assume training set kept in memorySwapping in and out of main and cache memory expensiveSolution: Partition data into subsets Build a classifier on each subset Combine classifiers Not as accurate as a single classifier

Fall 2003 Data Mining 32
Other Classification Examples
Instance-Based LearningGoes through instances one at a timeCompares with new instancePolynomial complexity O(mn)Response time may be slow, however
Naïve BayesPolynomial complexityStores a very large model

Fall 2003 Data Mining 33
Data Reduction
Another way is to reduce the size of the data before applying a learning algorithm (preprocessing)
Some strategiesDimensionality reductionData compressionNumerosity reduction

Fall 2003 Data Mining 34
Dimensionality Reduction
Remove irrelevant, weakly relevant, and redundant attributes
Attribute selection Many methods available E.g., forward selection, backwards elimination,
genetic algorithm search
Often much smaller problem
Often little degeneration in predictive performance or even better performance

Fall 2003 Data Mining 35
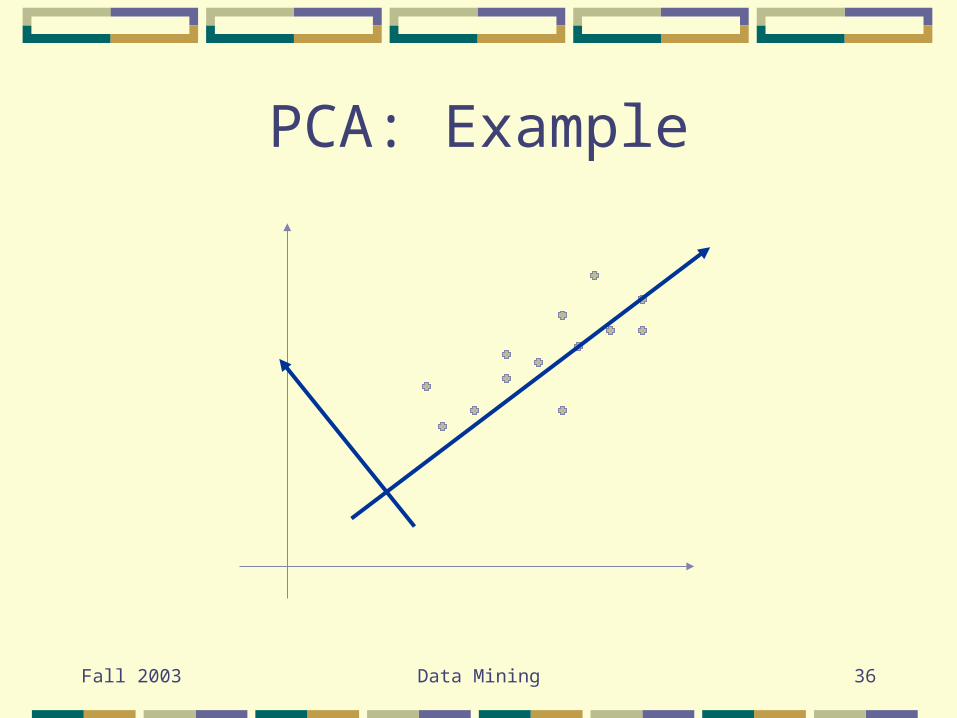
Data Compression
Also aim for dimensionality reduction
Transform the data into a smaller space
Principle Component Analysis Normalize data Compute c orthonormal vectors, or principle
components, that provide a basis for normalized data
Sort according to decreasing significance Eliminate the weaker components
Fall 2003 Data Mining 36
PCA: Example
Fall 2003 Data Mining 37
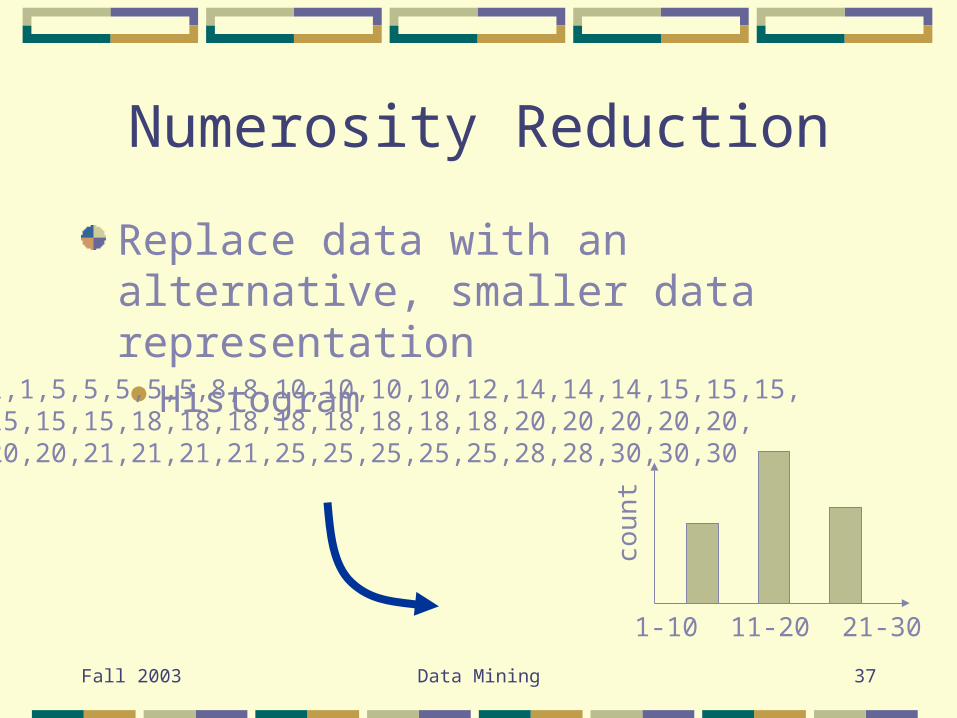
Numerosity Reduction
Replace data with an alternative, smaller data representationHistogram
1-10 11-20 21-30co
unt
1,1,5,5,5,5,5,8,8,10,10,10,10,12,14,14,14,15,15,15,15,15,15,18,18,18,18,18,18,18,18,20,20,20,20,20,20,20,21,21,21,21,25,25,25,25,25,28,28,30,30,30

Fall 2003 Data Mining 38
Other Numerosity Reduction
ClusteringData objects (instance) that are in the
same cluster can be treated as the same instance
Must use a scalable clustering algorithm
SamplingRandomly select a subset of the instances
to be used

Fall 2003 Data Mining 39
Sampling Techniques
Different samples Sample without replacement Sample with replacement Cluster sample Stratified sample
Complexity of sampling actually sublinear, that is, the complexity is O(s) where s is the number of samples and s<<n

Fall 2003 Data Mining 40
Weka Filters
PrincipalComponents is under the Attribute Selection tabAlready talked about filters to discretize the dataThe Resample filter randomly samples a given percentage of the data If you specify the same seed, you’ll get the
same sample again




















![arXiv:1712.01887v2 [cs.CV] 5 Feb 2018arXiv:1712.01887v2 [cs.CV] 5 Feb 2018 Published as a conference paper at ICLR 2018 Data Data Data Data Data Data Y Data Data Data Data Y ¢ ¢](https://img.pdfslide.us/doc/110x75/5edca87aad6a402d66676b01/arxiv171201887v2-cscv-5-feb-2018-arxiv171201887v2-cscv-5-feb-2018-published.jpg)







