Embed Size (px)
Citation preview

Music Audio Information - Ellis 2007-11-02 p. /421
1. Motivation: Music Collections2. Music Information3. Music Similarity4. Music Structure Discovery
Extracting and UsingMusic Audio Information
Dan EllisLaboratory for Recognition and Organization of Speech and Audio
Dept. Electrical Engineering, Columbia University, NY USA
http://labrosa.ee.columbia.edu/

Music Audio Information - Ellis 2007-11-02 p. /422
LabROSA Overview
InformationExtraction
MachineLearning
SignalProcessing
Speech
Music EnvironmentRecognition
Retrieval
Separation

Music Audio Information - Ellis 2007-11-02 p. /423
1. Managing Music Collections
• A lot of music data availablee.g. 60G of MP3 ≈ 1000 hr of audio, 15k tracks
• Management challengehow can computers help?
• Application scenariospersonal music collectiondiscovering new music“music placement”

Music Audio Information - Ellis 2007-11-02 p. /42
Learning from Music• What can we infer from 1000 h of music?
common patternssounds, melodies, chords, formwhat is and what isn’t music
• Data driven musicology?
• Applicationsmodeling/description/codingcomputer generated musiccuriosity...
4
Scatter of PCA(3:6) of 12x16 beatchroma
10 20 30 40 50 60
10
20
30
40
50
60
10 20 30 40 50 60
10
20
30
40
50
60

Music Audio Information - Ellis 2007-11-02 p. /425
The Big Picture
.. so far
Music
audio
Tempo
and beat
Low-level
features Classification
and Similarity
Music
Structure
Discovery
Melody
and notes
Key
and chords
browsing
discovery
production
modeling
generation
curiosity

Music Audio Information - Ellis 2007-11-02 p. /42
2. Music Information• How to represent music audio?
• Audio featuresspectrogram, MFCCs, bases
• Musical elementsnotes, beats, chords, phrasesrequires transcription
• Or something inbetween?optimized for a certain task?
6
Time
Frequency
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 50
1000
2000
3000
4000

Music Audio Information - Ellis 2007-11-02 p. /427
Transcription as Classification• Exchange signal models for data
transcription as pure classification problem:
Poliner & Ellis ‘05,’06,’07
Classification:•N-binary SVMs (one for ea. note).•Independent frame-levelclassification on 10 ms grid.
•Dist. to class bndy as posterior.
classification posteriors
Temporal Smoothing:•Two state (on/off) independentHMM for ea. note. Parameters learned from training data.
•Find Viterbi sequence for ea. note.
hmm smoothing
Training data and features:•MIDI, multi-track recordings, playback piano, & resampled audio(less than 28 mins of train audio).
•Normalized magnitude STFT.
feature representation feature vector

Music Audio Information - Ellis 2007-11-02 p. /42
Polyphonic Transcription• Real music excerpts + ground truth
8
MIREX 2007
Frame-level transcriptionEstimate the fundamental frequency of all notes present on a 10 ms grid
Note-level transcriptionGroup frame-level predictions into note-level transcriptions by estimating onset/offset
0
0.25
0.50
0.75
1.00
1.25
Precision Recall Acc Etot Esubs Emiss Efa
0
0.25
0.50
0.75
1.00
1.25
Precision Recall Ave. F-measure Ave. Overlap
Music Audio Information - Ellis 2007-11-02 p. /42
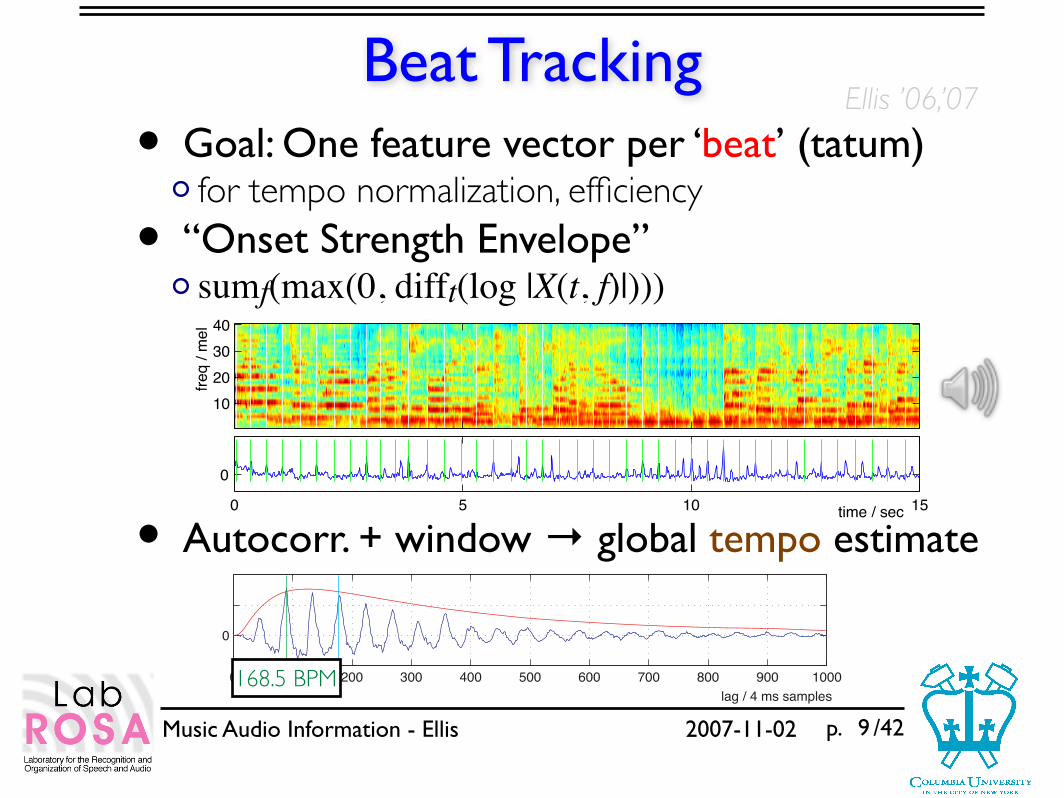
Beat Tracking• Goal: One feature vector per ‘beat’ (tatum)
for tempo normalization, efficiency
• “Onset Strength Envelope”sumf(max(0, difft(log |X(t, f)|)))
• Autocorr. + window → global tempo estimate
9
10203040
freq
/ mel
0
0
5 10 15time / sec
0 100 200 300 400 500 600 700 800 900lag / 4 ms samples
1000
0
168.5 BPM
Ellis ’06,’07

Music Audio Information - Ellis 2007-11-02 p. /42
Beat Tracking• Dynamic Programming finds beat times {ti}
optimizes i O(ti) + i W((ti+1 – ti – p)/)where O(t) is onset strength envelope (local score)W(t) is a log-Gaussian window (transition cost)p is the default beat period per measured tempoincrementally find best predecessor at every timebacktrace from largest final score to get beats
10
C*(t) = ! O(t) + (1–!)max{W((" – "p)/#)C*(")}"
P(t) = argmax{W((" – "p)/#)C*(")}"
t"
O(t)
C*(t)

Music Audio Information - Ellis 2007-11-02 p. /42
Beat Tracking
• DP will bridge gaps (non-causal)there is always a best path ...
• 2nd place in MIREX 2006 Beat Trackingcompared to McKinney & Moelants human data
11
10
20
30
40
0 5 10 150
20
40
freq / B
ark
band
Subje
ct #
time / s
test 2 (Bragg) - McKinney + Moelants Subject data
182 184 186 188 190 192 time / sec
10
20
30
40
freq / B
ark
band
Alanis Morissette - All I Want - gap + beats

Music Audio Information - Ellis 2007-11-02 p. /42
Chroma Features• Chroma features convert spectral energy
into musical weights in a canonical octavei.e. 12 semitone bins
• Can resynthesize as “Shepard Tones”all octaves at once
12
Piano scale
2 4 6 8 10 100 200 300 400 500 600 700time / sec
freq
/ k
Hz
0
1
2
3
4
time / frames
ch
rom
a
A
C
D
F
G
Piano chromatic scale IF chroma
0 500 1000 1500 2000 2500 freq / Hz-60-50-40-30-20-10
0
2 4 6 8 10 time / sec
freq
/ kH
z
leve
l / d
B
0
1
2
3
4Shepard tone resynth12 Shepard tone spectra

Music Audio Information - Ellis 2007-11-02 p. /42
Aligned Global model
Taxman Eleanor Rigby I'm Only Sleeping
She Said She Said Good Day Sunshine And Your Bird Can Sing
Love You To Yellow Submarine
alig
ned
chro
ma
A
CD
FG
A C D F GA
CD
FG
A C D F GA
CD
FG
A C D F GA
CD
FG
A C D F GA
CD
FG
A C D F GA
CD
FG
A C D F GA
CD
FG
A C D F GA
CD
FG
A C D F GA
CD
FG
aligned chroma
Key Estimation• Covariance of chroma reflects key• Normalize by transposing for best fit
single Gaussian model of one piecefind ML rotation of other piecesmodel all transposed piecesiterate until convergence
13
Ellis ICASSP ’07

Music Audio Information - Ellis 2007-11-02 p. /42
Chord Transcription• “Real Books” give chord transcriptions
but no exact timing.. just like speech transcripts
• Use EM to simultaneouslylearn and align chord models
14
# The Beatles - A Hard Day's Night #G Cadd9 G F6 G Cadd9 G F6 G C D G C9 G G Cadd9 G F6 G Cadd9 G F6 G C D G C9 G Bm Em Bm G Em C D G Cadd9 G F6 G Cadd9 G F6 G C D G C9 G D G C7 G F6 G C7 G F6 G C D G C9 G Bm Em Bm G Em C D G Cadd9 G F6 G Cadd9 G F6 G C D G C9 G C9 G Cadd9 Fadd9
ae1 ae2 ae3
dh1 dh2
Model inventory
Uniforminitializationalignments
Initializationparameters
Repeat until convergence
E-step:probabilitiesof unknowns
M-step:maximize viaparameters
Labelled training datadh ax k ae t
s ae t aa n
dh
dh
s ae t aa n
ax
ax
k
k
ae
ae
t!init
p(qn|X1,!old)i N
! : max E[log p(X,Q | !)]
Sheh & Ellis ’03

Music Audio Information - Ellis 2007-11-02 p. /42
Chord Transcription
• Needed more training data...
15
MFCCs are poor(can overtrain) PCPs better
(ROT helps generalization)
(random ~3%)
Feature Recog. Alignment
MFCC 8.7% 22.0%
PCP_ROT 21.7% 76.0%
Frame-level Accuracy
trueE G D Bm G
alignE G DBm G
recogE G Bm Am Em7 Bm Em7
16.27 24.84time / sec
intensity
A
#
B
C
#
D
#
E
F
#
G
#
pitch
cla
ss
Beatles - Beatles For Sale - Eight Days a Week (4096pt)
20
0
40
60
80
100
120

Music Audio Information - Ellis 2007-11-02 p. /42
3. Music Similarity• The most central problem...
motivates extracting musical informationsupports real applications (playlists, discovery)
• But do we need content-based similarity?compete with collaborative filteringcompete with fingerprinting + metadata
• Maybe ... for the Future of Musicconnect listeners directly to musicians
16
Music Audio Information - Ellis 2007-11-02 p. /42
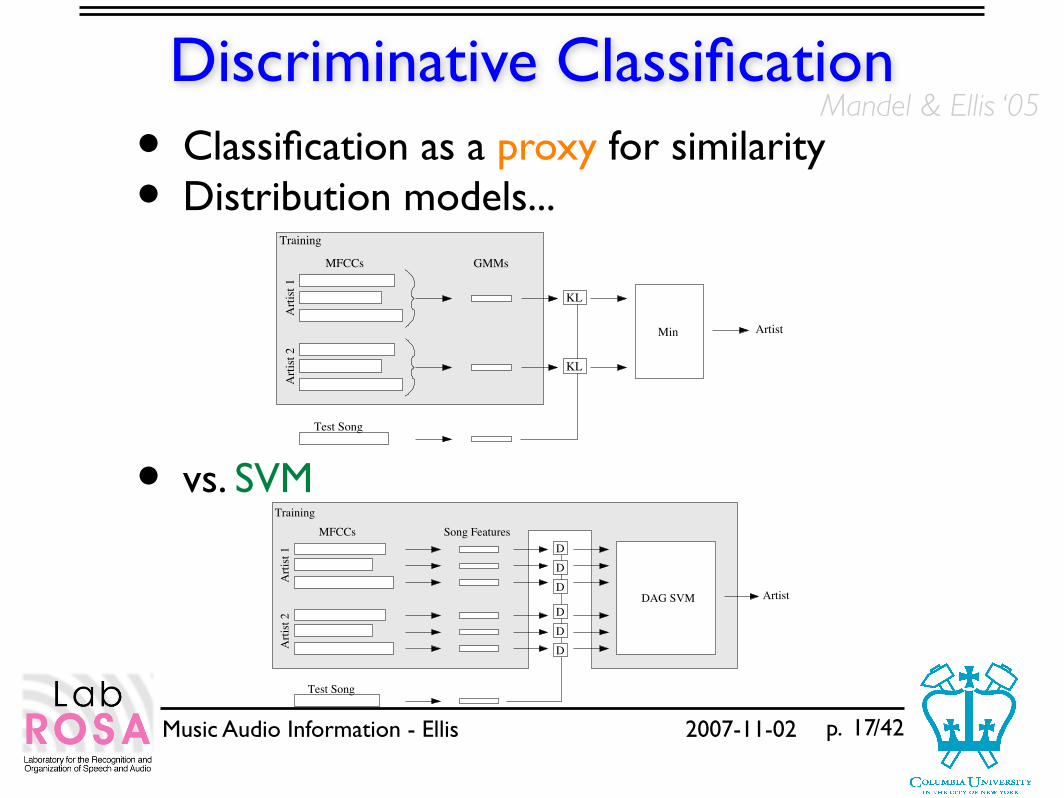
Discriminative Classification• Classification as a proxy for similarity• Distribution models...
• vs. SVM
17
KL
KL
MFCCs
Art
ist
1A
rtis
t 2
Test Song
Min Artist
Training
GMMs
D
D
D
D
D
D
MFCCs
Art
ist
1A
rtis
t 2
Song Features
DAG SVM
Test Song
Artist
Training
Mandel & Ellis ‘05

Music Audio Information - Ellis 2007-11-02 p. /42
Segment-Level Features• Statistics of spectra and envelope
define a point in feature spacefor SVM classification, or Euclidean similarity...
18
Mandel & Ellis ‘07
LabROSALaboratory for the Recognition andOrganization of Speech and Audio
LabROSA’s audio music similarity and classification systemsMichael I Mandel and Daniel P W Ellis
LabROSA · Dept of Electrical Engineering · Columbia University, New York{mim,dpwe}@ee.columbia.edu
1. Feature Extraction• Spectral features are the same as Mandel and Ellis (2005), mean and
unwrapped covariance of MFCCs• Temporal features are similar to those in Rauber et al. (2002)
• Break input into overlapping 10-second clips• Analyze mel spectrum of each clip, averaging clips’ features• Combine mel frequencies together to get magnitude bands for low,
low-mid, high-mid, and high frequencies• FFT in time gives modulation frequency, keep magnitude of low-
est 20% of frequencies• DCT in modulation frequency gives envelope cepstrum• Stack the four bands’ envelope cepstra into one feature vector
• Each feature is then normalized across all of the songs to be zero-mean, unit-variance.
2. Similarity and Classification• We use a DAG-SVM for n-way classification of songs (Platt et al., 2000)• The distance between songs is the Euclidean distance between their
feature vectors• During testing, some songs were a top similarity match for many songs• Re-normalizing each song’s feature vector avoided this problem
ReferencesM. Mandel and D. Ellis. Song-level features and support vector machines for music classification. In Joshua
Reiss and Geraint Wiggins, editors, Proc. ISMIR, pages 594–599, 2005.
John C. Platt, Nello Cristianini, and John Shawe-Taylor. Large margin DAGs for multiclass classification. InS.A. Solla, T.K. Leen, and K.-R. Mueller, editors, Advances in Neural Information Processing Systems 12,pages 547–553, 2000.
Andreas Rauber, Elias Pampalk, and Dieter Merkl. Using psycho-acoustic models and self-organizing mapsto create a hierarchical structuring of music by sound similarity. In Michael Fingerhut, editor, Proc. ISMIR,pages 71–80, 2002.
3. ResultsAudio Music Similarity Audio Classification
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
PS GT LB CB1 TL1 ME TL2 CB2 CB3 BK1 PC BK2
Greater0
Psum
Fine
WCsum
SDsum
Greater10
10
20
30
40
50
60
70
80
IMsvm
MEspec ME TL GT IM
knn KL CL GH
Genre ID Hierarchical
Genre ID Raw
Mood ID
Composer ID
Artist ID
PS = Pohle, Schnitzer; GT = George Tzane-takis; LB = Barrington, Turnbull, Torres, Lanckriet;CB = Christoph Bastuck; TL = Lidy, Rauber, Per-tusa, Inesta; ME = Mandel, Ellis; BK = Bosteels,Kerre; PC = Paradzinets, Chen
IM = IMIRSEL M2K; ME = Mandel, Ellis; TL = Lidy,Rauber, Pertusa, Inesta; GT = George Tzane-takis; KL = Kyogu Lee; CL = Laurier, Herrera;GH = Guaus, Herrera
MIREX 2007, 3rd Music Information Retrieval Evaluation eXchange, 26 September 2007, Vienna, Austria

Music Audio Information - Ellis 2007-11-02 p. /42
MIREX’07 Results• One system for similarity and classification
19
LabROSALaboratory for the Recognition andOrganization of Speech and Audio
LabROSA’s audio music similarity and classification systemsMichael I Mandel and Daniel P W Ellis
LabROSA · Dept of Electrical Engineering · Columbia University, New York{mim,dpwe}@ee.columbia.edu
1. Feature Extraction• Spectral features are the same as Mandel and Ellis (2005), mean and
unwrapped covariance of MFCCs• Temporal features are similar to those in Rauber et al. (2002)
• Break input into overlapping 10-second clips• Analyze mel spectrum of each clip, averaging clips’ features• Combine mel frequencies together to get magnitude bands for low,
low-mid, high-mid, and high frequencies• FFT in time gives modulation frequency, keep magnitude of low-
est 20% of frequencies• DCT in modulation frequency gives envelope cepstrum• Stack the four bands’ envelope cepstra into one feature vector
• Each feature is then normalized across all of the songs to be zero-mean, unit-variance.
2. Similarity and Classification• We use a DAG-SVM for n-way classification of songs (Platt et al., 2000)• The distance between songs is the Euclidean distance between their
feature vectors• During testing, some songs were a top similarity match for many songs• Re-normalizing each song’s feature vector avoided this problem
ReferencesM. Mandel and D. Ellis. Song-level features and support vector machines for music classification. In Joshua
Reiss and Geraint Wiggins, editors, Proc. ISMIR, pages 594–599, 2005.
John C. Platt, Nello Cristianini, and John Shawe-Taylor. Large margin DAGs for multiclass classification. InS.A. Solla, T.K. Leen, and K.-R. Mueller, editors, Advances in Neural Information Processing Systems 12,pages 547–553, 2000.
Andreas Rauber, Elias Pampalk, and Dieter Merkl. Using psycho-acoustic models and self-organizing mapsto create a hierarchical structuring of music by sound similarity. In Michael Fingerhut, editor, Proc. ISMIR,pages 71–80, 2002.
3. ResultsAudio Music Similarity Audio Classification
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
PS GT LB CB1 TL1 ME TL2 CB2 CB3 BK1 PC BK2
Greater0
Psum
Fine
WCsum
SDsum
Greater10
10
20
30
40
50
60
70
80
IMsvm
MEspec ME TL GT IM
knn KL CL GH
Genre ID Hierarchical
Genre ID Raw
Mood ID
Composer ID
Artist ID
PS = Pohle, Schnitzer; GT = George Tzane-takis; LB = Barrington, Turnbull, Torres, Lanckriet;CB = Christoph Bastuck; TL = Lidy, Rauber, Per-tusa, Inesta; ME = Mandel, Ellis; BK = Bosteels,Kerre; PC = Paradzinets, Chen
IM = IMIRSEL M2K; ME = Mandel, Ellis; TL = Lidy,Rauber, Pertusa, Inesta; GT = George Tzane-takis; KL = Kyogu Lee; CL = Laurier, Herrera;GH = Guaus, Herrera
MIREX 2007, 3rd Music Information Retrieval Evaluation eXchange, 26 September 2007, Vienna, Austria

Music Audio Information - Ellis 2007-11-02 p. /42
Active-Learning Playlists• SVMs are well suited to “active learning”
solicit labels on items closest to current boundary
• Automatic player with “skip”= Ground truth data collectionactive-SVM automatic playlist generation
20

Music Audio Information - Ellis 2007-11-02 p. /42
Cover Song Detection• “Cover Songs” = reinterpretation of a piece
different instrumentation, characterno match with “timbral” features
• Need a different representation!beat-synchronous chroma features
21
Let It Be - The Beatles Let It Be - Nick Cave
time / sectime / sec
freq / k
Hz
Let It Be / Beatles / verse 1
2 4 6 8 100
1
2
3
4
freq / k
Hz
chro
ma
chro
ma
0
1
2
3
4Let It Be / Nick Cave / verse 1
2 4 6 8 10
Beat-sync chroma features
5 10 15 20 25 beats
Beat-sync chroma features
5 10 15 20 25 beats
A
C
D
F
G
A
C
D
F
G
Ellis & Poliner ‘07

Music Audio Information - Ellis 2007-11-02 p. /4222
Beat-Synchronous Chroma Features• Beat + chroma features / 30ms frames→ average chroma within each beatcompact; sufficient?
! "# "! $# $! %# %!
$
&
'
(
"#
"$
"#
$#
%#
&#
$
&
'
(
"#
"$
# ! "# "!)*+,-.-/,0
)*+,-.-1,2)/
34,5-.-6,7
89/,)-/)4,9:);
0;48+2-1*9/
0;48+2-1*9/
#

Music Audio Information - Ellis 2007-11-02 p. /42
Matching: Global Correlation• Cross-correlate entire beat-chroma matrices
... at all possible transpositionsimplicit combination of match quality and duration
• One good matching fragment is sufficient...?
23
100 200 300 400 500 beats @281 BPM
-500 -400 -300 -200 -100 0 100 200 300 400 skew / beats
-5
0
+5
G
E
D
C
A
ch
rom
a b
ins
G
E
D
C
A
ch
rom
a b
ins
ske
w /
se
mito
ne
s
Elliott Smith - Between the Bars
Glen Phillips - Between the Bars
Cross-correlation

Music Audio Information - Ellis 2007-11-02 p. /42
MIREX 06 Results• Cover song contest
30 songs x 11 versions of each (!)(data has not been disclosed)# true covers in top 108 systems compared (4 cover song + 4 similarity)
• Found 761/3300= 23% recallnext best: 11%guess: 3%
24
MIREX 06 Cover Song Results:# Covers retrieved per song per system
CS DE KL1 KL2 KWL KWT LR TP
cover song systems similarity systems
so
ng
-se
t (e
ach
ro
w is o
ne
qu
ery
so
ng
)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
2
0correct
matchesretrieved
4
6
8

Music Audio Information - Ellis 2007-11-02 p. /42
Cross-Correlation Similarity• Use cover-song approach to find similarity
e.g. similar note/instrumentation sequencemay sound very similar to judges
• Numerous variantstry on chroma (melody/harmony) and MFCCs (timbre)try full search (xcorr) or landmarks (indexable)compare to random, segment-level stats
• Evaluate by subjective testsmodeled after MIREX similarity
25

Music Audio Information - Ellis 2007-11-02 p. /42
Cross-Correlation Similarity• Human web-based judgments
binary judgments for speed6 users x 30 queries x 10 candidate returns
• Cross-correlation inferior to baseline...... but is getting somewhere, even with ‘landmark’
26
that assigns a single time anchor or boundary within each seg-ment, then calculates the correlation only at the single skewthat aligns the time anchors. We use the BIC method [8] tofind the boundary time within the feature matrix that maxi-mizes the likelihood advantage of fitting separate Gaussiansto the features each side of the boundary compared to fit-ting the entire sequence with a single Gaussian i.e. the timepoint that divides the feature array into maximally dissimi-lar parts. While almost certain to miss some of the matchingalignments, an approach of this simplicity may be the onlyviable option when searching in databases consisting of mil-lions of tracks.
3. EXPERIMENTS AND RESULTS
The major challenge in developing music similarity systemsis performing any kind of quantitative analysis. As notedabove, the genre and artist classification tasks that have beenused as proxies in the past most likely fall short of accountingfor subjective similarity, particularly in the case of a systemsuch as ours which aims to match structural detail instead ofoverall statistics. Thus, we conducted a small subjective lis-tening test of our own, modeled after the MIREX music simi-larity evaluations [4], but adapted to collect only a single sim-ilar/not similar judgment for each returned clip (to simplifythe task for the labelers), and including some random selec-tions to allow a lower-bound comparison.
3.1. Data
Our data was drawn from the uspop2002 dataset of 8764 pop-ular music tracks. We wanted to work with a single, broadgenre (i.e. pop) to avoid confounding the relatively simplediscrimination of grossly different genres with the more sub-tle question of similarity. We also wanted to maximize thedensity of our database within the area of coverage.
For each track, we took a 10 s excerpt from 60 s into thetrack (tracks shorter than this were not included). We chose10 s based on our earlier experiments with clips of this lengththat showed this is an adequate length for listeners to get asense of the music, yet short enough that they will probablylisten to the whole clip [9]. (MIREX uses 30 s clips which arequite arduous to listen through).
3.2. Comparison systems
Our test involved rating ten possible matches for each query.Five of these were based on the system described above: weincluded (1) the best match from cross-correlating chromafeatures, (2) from cross-correlating MFCCs, (3) from a com-bined score constructed as the harmonic mean of the chromaand MFCC scores, (4) based on the combined score but ad-ditionally constraining the tempos (from the beat tracker) ofdatabase items to be within 5% of the query tempo, and (5)
Table 1. Results of the subjective similarity evaluation.Counts are the number of times the best hit returned by eachalgorithm was rated as similar by a human rater. Each al-gorithm provided one return for each of 30 queries, and wasjudged by 6 raters, hence the counts are out of a maximumpossible of 180.
Algorithm Similar count(1) Xcorr, chroma 48/180 = 27%(2) Xcorr, MFCC 48/180 = 27%(3) Xcorr, combo 55/180 = 31%(4) Xcorr, combo + tempo 34/180 = 19%(5) Xcorr, combo at boundary 49/180 = 27%(6) Baseline, MFCC 81/180 = 45%(7) Baseline, rhythmic 49/180 = 27%(8) Baseline, combo 88/180 = 49%Random choice 1 22/180 = 12%Random choice 2 28/180 = 16%
combined score evaluated only at the reference boundary ofsection 2.1. To these, we added three additional hits from amore conventional feature statistics system using (6) MFCCmean and covariance (as in [2]), (7) subband rhythmic fea-tures (modulation spectra, similar to [10]), and (8) a simplesummation of the normalized scores under these two mea-sures. Finally, we added two randomly-chosen clips to bringthe total to ten.
3.3. Collecting subjective judgments
We generated the sets of ten matches for 30 randomly-chosenquery clips. We constructed a web-based rating scheme, whereraters were presented all ten matches for a given query on asingle screen, with the ability to play the query and any ofthe results in any order, and to click a box to mark any of thereturns as being judged “similar” (binary judgment). Eachsubject was presented the queries in a random sequence, andthe order of the matches was randomized on each page. Sub-jects were able to pause and resume labeling as often as theywished. Complete labeling of all 30 queries took around onehour total. 6 volunteers from our lab completed the labeling,giving 6 binary votes for each of the 10 returns for each of the30 queries.
3.4. Results
Table 1 shows the results of our evaluation. The binary sim-ilarity ratings across all raters and all queries are pooled foreach algorithm to give an overall ‘success rate’ out of a possi-ble 180 points – roughly, the probability that a query returnedby this algorithm will be rated as similar by a human judge.A conservative binomial significance test requires a differenceof around 13 votes (7%) to consider two algorithms different.

Music Audio Information - Ellis 2007-11-02 p. /42
Cross-Correlation Similarity• Results are not overwhelming
.. but database is only a few thousand clips
27

Music Audio Information - Ellis 2007-11-02 p. /42
“Anchor Space”
• Acoustic features describe each song.. but from a signal, not a perceptual, perspective.. and not the differences between songs
• Use genre classifiers to define new spaceprototype genres are “anchors”
28
n-dimensionalvector in "Anchor
Space"Anchor
Anchor
AnchorAudioInput
(Class j)
p(a1|x)
p(a2|x)
p(an|x)
GMMModeling
Conversion to Anchorspace
n-dimensionalvector in "Anchor
Space"Anchor
Anchor
AnchorAudioInput
(Class i)
p(a1|x)
p(a2|x)
p(an|x)
GMMModeling
Conversion to Anchorspace
SimilarityComputation
KL-d, EMD, etc.
Berenzweig & Ellis ‘03

Music Audio Information - Ellis 2007-11-02 p. /4229
“Anchor Space”
• Frame-by-frame high-level categorizationscompare toraw features?
properties in distributions? dynamics?third cepstral coef
fifth
cep
stra
l coe
f
madonnabowie
Cepstral Features
1 0.5 0 0.5
0.8 0.6 0.4 0.2
00.20.40.6
Country
Elec
troni
ca
madonnabowie
10
5
Anchor Space Features
15 10 5
15
0

Music Audio Information - Ellis 2007-11-02 p. /4230
‘Playola’ Similarity Browser

Music Audio Information - Ellis 2007-11-02 p. /4231
Ground-truth data• Hard to evaluate Playola’s ‘accuracy’
user tests...ground truth?
• “Musicseer” online survey/game:ran for 9 months in 2002> 1,000 users, > 20k judgmentshttp://labrosa.ee.columbia.edu/projects/musicsim/
Ellis et al, ‘02

Music Audio Information - Ellis 2007-11-02 p. /42
“Semantic Bases”• Describe segment in human-relevant terms
e.g. anchor space, but more so
• Need ground truth...what words to people use?
• MajorMiner game:400 users7500 unique tags70,000 taggings2200 10-sec clips used
• Train classifiers...
32
Music Audio Information - Ellis 2007-11-02 p. /42
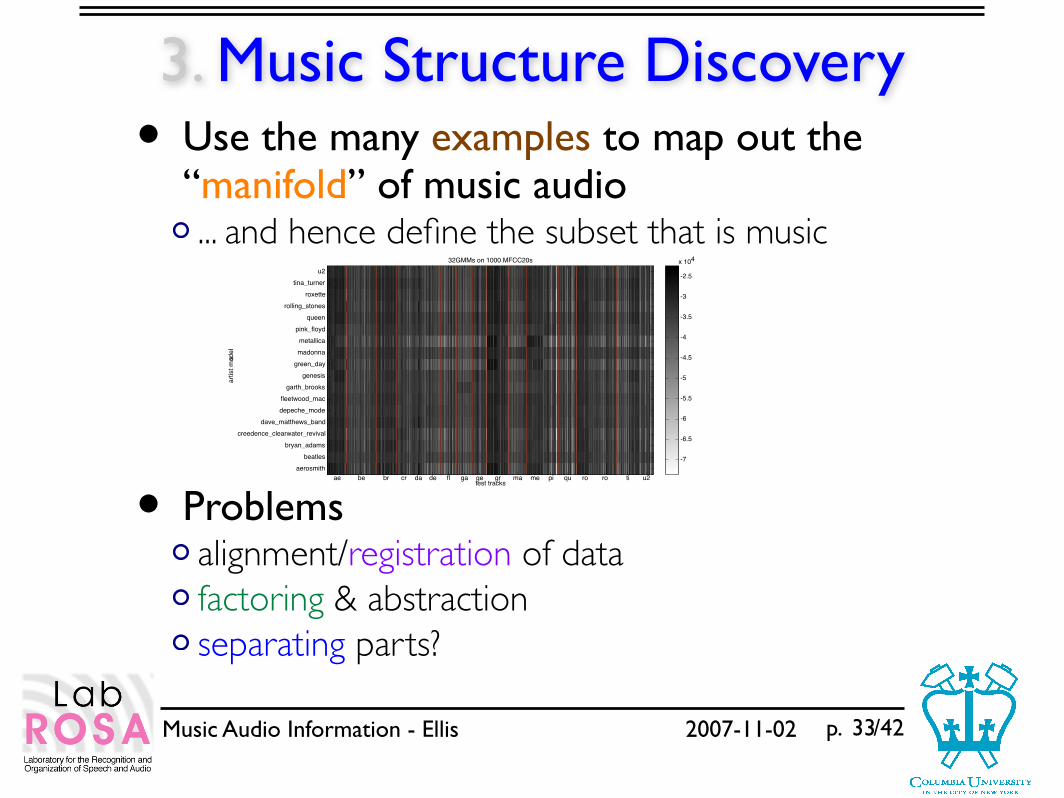
3. Music Structure Discovery• Use the many examples to map out the
“manifold” of music audio... and hence define the subset that is music
• Problemsalignment/registration of datafactoring & abstractionseparating parts?
33
test tracks
art
ist m
odel
s
32GMMs on 1000 MFCC20s
ae be br cr da de fl ga ge gr ma me pi qu ro ro ti u2
aerosmith
beatles
bryan_adams
creedence_clearwater_revival
dave_matthews_band
depeche_mode
fleetwood_mac
garth_brooks
genesis
green_day
madonna
metallica
pink_floyd
queen
rolling_stones
roxette
tina_turner
u2
-7
-6.5
-6
-5.5
-5
-4.5
-4
-3.5
-3
-2.5
x 104

Music Audio Information - Ellis 2007-11-02 p. /4234
Eigenrhythms: Drum Pattern Space
• Pop songs built on repeating “drum loop”variations on a few bass, snare, hi-hat patterns
• Eigen-analysis (or ...) to capture variations?by analyzing lots of (MIDI) data, or from audio
• Applicationsmusic categorization“beat box” synthesisinsight
Ellis & Arroyo ‘04

Music Audio Information - Ellis 2007-11-02 p. /4235
Aligning the Data• Need to align patterns prior to modeling...
tempo (stretch): by inferring BPM &
normalizing
downbeat (shift): correlate against ‘mean’ template
Music Audio Information - Ellis 2007-11-02 p. /4236
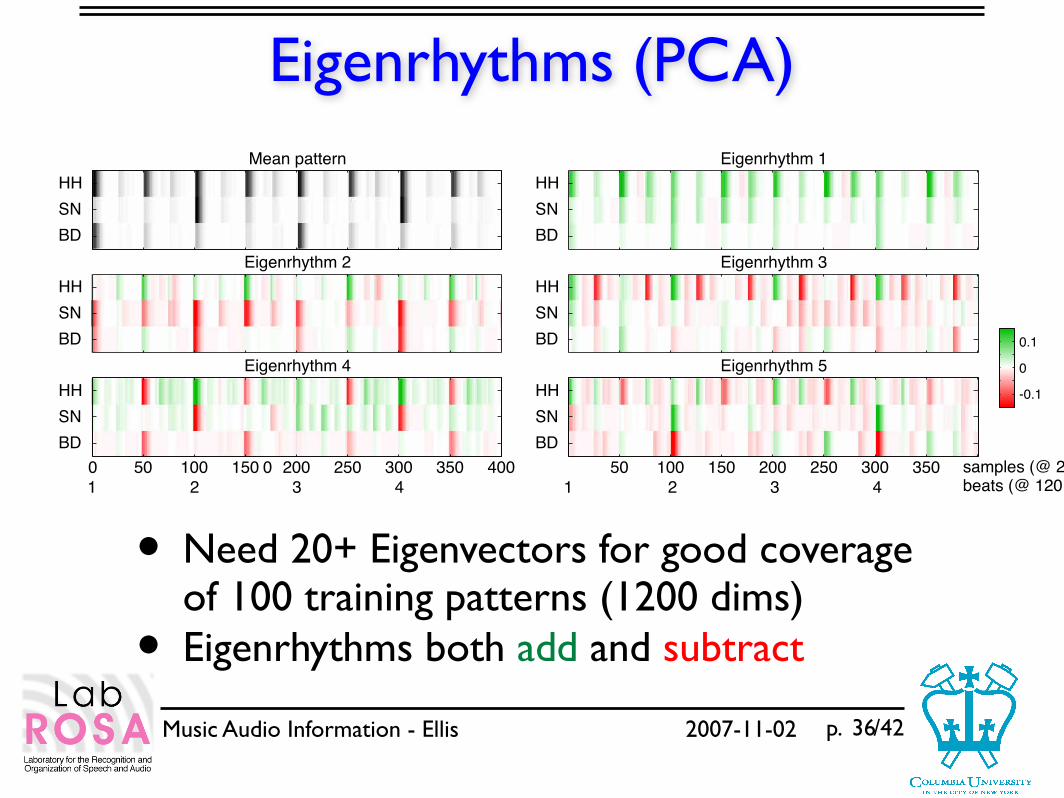
Eigenrhythms (PCA)
• Need 20+ Eigenvectors for good coverage of 100 training patterns (1200 dims)
• Eigenrhythms both add and subtract
Music Audio Information - Ellis 2007-11-02 p. /4237
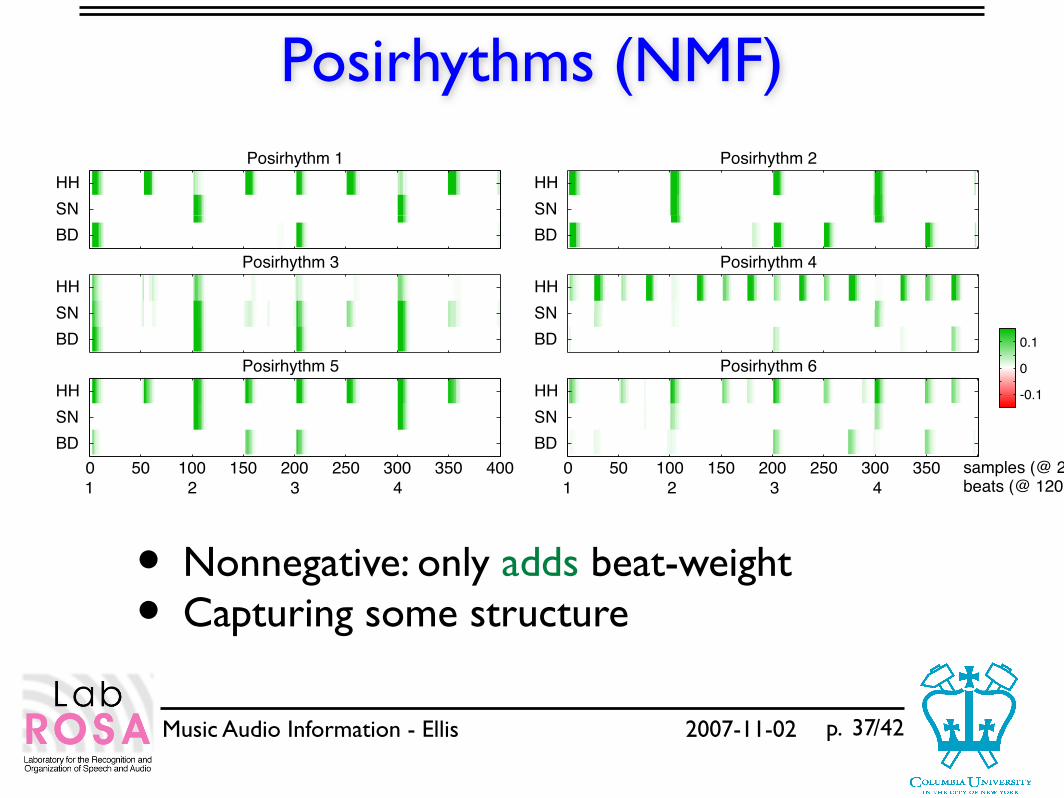
Posirhythms (NMF)
• Nonnegative: only adds beat-weight• Capturing some structure
Posirhythm 1
BDSNHH
BDSNHH
BDSNHH
BDSNHH
BDSNHH
BDSNHH
Posirhythm 2
Posirhythm 3 Posirhythm 4
Posirhythm 5
500 0 samples (@ 200 Hz)beats (@ 120 BPM)
100 150 200 250 300 350 4001 2 3 4 1 2 3 4
Posirhythm 6
50 100 150 200 250 300 350
-0.1
0
0.1

Music Audio Information - Ellis 2007-11-02 p. /4238
Eigenrhythm BeatBox• Resynthesize rhythms from eigen-space
Music Audio Information - Ellis 2007-11-02 p. /4239
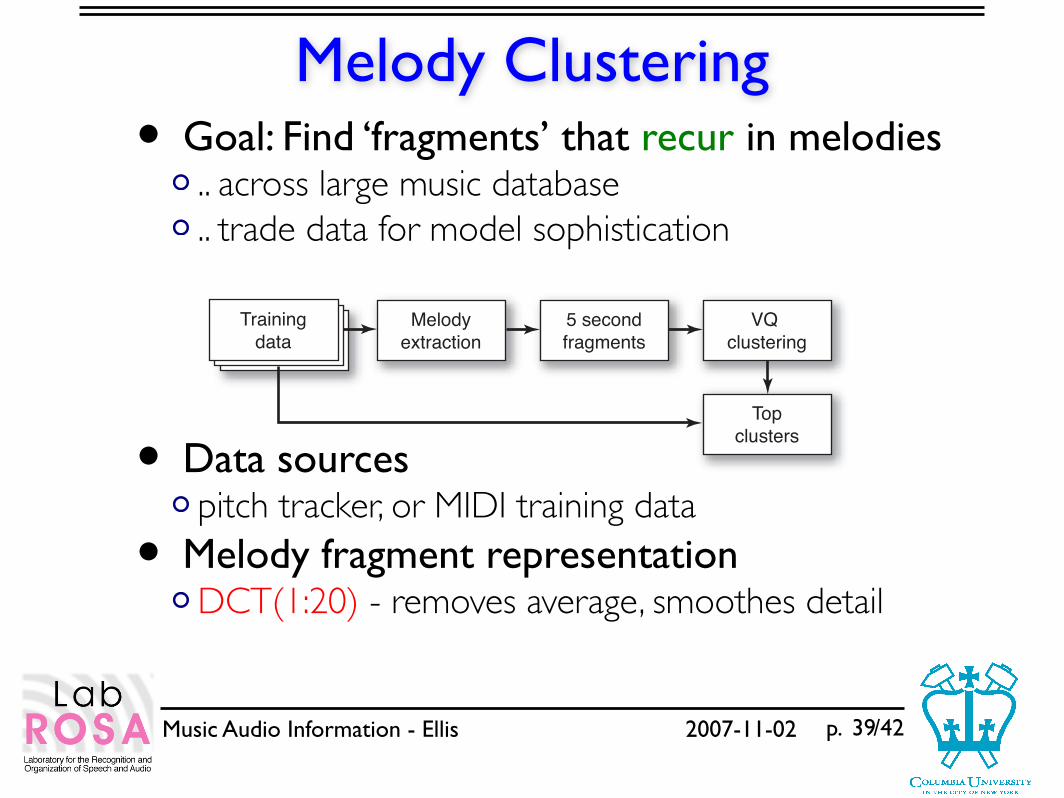
Melody Clustering• Goal: Find ‘fragments’ that recur in melodies
.. across large music database
.. trade data for model sophistication
• Data sourcespitch tracker, or MIDI training data
• Melody fragment representationDCT(1:20) - removes average, smoothes detail
Trainingdata
Melodyextraction
5 secondfragments
Topclusters
VQ clustering

Music Audio Information - Ellis 2007-11-02 p. /4240
Melody Clustering• Clusters match underlying contour:
• Some interesting matches:e.g. Pink + Nsync

Music Audio Information - Ellis 2007-11-02 p. /42
Beat-Chroma Fragment Codebook• Idea: Find the very popular music fragments
e.g. perfect cadence, rising melody, ...?
• Clustering a large enough database should reveal thesebut: registration of phrase boundaries, transposition
• Need to deal with really large datasetse.g. 100k+ tracks, multiple landmarks in eachbut: Locality Sensitive Hashing can help - quickly finds ‘most’ points in a certain radius
• Experiments in progress...
41

Music Audio Information - Ellis 2007-11-02 p. /4242
Conclusions
• Lots of data + noisy transcription + weak clustering⇒ musical insights?
Music
audio
Tempo
and beat
Low-level
features Classification
and Similarity
Music
Structure
Discovery
Melody
and notes
Key
and chords
browsing
discovery
production
modeling
generation
curiosity