Embed Size (px)
Citation preview

Exploiting Unbalanced Thread Scheduling for Energy and Performance on a CMP of SMT ProcessorsMatt DeVuyst
Rakesh Kumar
Dean Tullsen

IPDPS: DeVuyst, Kumar, Tullsen 2
Some Definitions
Balanced schedule: A schedule of threads to
contexts such that the number of threads per core is equal
Unbalanced schedule: A schedule of threads to
contexts such that the number of threads per core is not equal
Core 1 Core 2 Core 3
Thread 1
Thread 2
Thread 3
Thread 4
Thread 5
Thread 6
Core 1 Core 2 Core 3
Thread 1
Thread 2
Thread 3
Thread 4 Thread 5
Thread 6
Thread 7
Thread 7

IPDPS: DeVuyst, Kumar, Tullsen 3
Why a CMP of SMT cores?
Chip makers are manufacturing more Chip Multiprocessors (CMP) with Simultaneous Multithreading (SMT) Power5 Niagra
Very little work has been done on thread scheduling for such an architecture
Scheduling on this architecture is challenging

IPDPS: DeVuyst, Kumar, Tullsen 4
Application Diversity
Different applications have different needs One way to effectively cope with application
diversity is hardware heterogeneity [Kumar03]

IPDPS: DeVuyst, Kumar, Tullsen 5
Hardware Heterogeneity
Threads
Cores

IPDPS: DeVuyst, Kumar, Tullsen 6
Application Diversity
Different applications have different needs One way to effectively cope with application
diversity is hardware heterogeneity Another way to deal with application diversity
is soft heterogeneity

IPDPS: DeVuyst, Kumar, Tullsen 7
Soft Heterogeneity
Threads
SMTCores

IPDPS: DeVuyst, Kumar, Tullsen 8
Scheduling Complexity
Given a 4 core CMP,with 4 contexts per core,and 12 threads
There are 15,400 balanced schedules There are 644,875 unbalanced schedules
Core
Context

IPDPS: DeVuyst, Kumar, Tullsen 9
Our Goals
Find good scheduling policies System-level scheduling
→ Granularity is an OS time-slice
Optimize for both power and performance Performance Power Energy Energy Delay Product (EDP)
= Energy * Performance

IPDPS: DeVuyst, Kumar, Tullsen 10
Outline
Architecture Methodology Scheduling Policies Conclusions

IPDPS: DeVuyst, Kumar, Tullsen 11
Architecture
4 SMT cores 4 contexts per core Shared L2, L3 Cores can be power-
gatedL2 and L3 Caches
Ctx Ctx
Ctx Ctx
Shared L1s
Ctx Ctx
Ctx Ctx
Shared L1s
Ctx Ctx
Ctx Ctx
Shared L1s
Ctx Ctx
Ctx Ctx
Shared L1s

IPDPS: DeVuyst, Kumar, Tullsen 12
Methodology
Benchmarks 12 SPEC 2k benchmarks TLP varied from 4,6,8,12,16 8 benchmark sets for each level of TLP
Each benchmark is given fair coverage Dynamic scheduling policies seeded with the best
static schedule A variant of SMTSIM and a CMP-aware version of
Wattch

IPDPS: DeVuyst, Kumar, Tullsen 13
Outline
Architecture Methodology Scheduling Policies
Naïve balanced scheduling policy Sampling-based policies Electron policies
Conclusions

IPDPS: DeVuyst, Kumar, Tullsen 14
Naïve Balanced Scheduling Policy Main idea
Spreading threads evenly across cores results in good resource utilization
How it works Each thread is assigned to a context such that the
resulting schedule is balanced. The schedule is changed randomly over time.
This was our baseline for comparison Easy to implement Most common

IPDPS: DeVuyst, Kumar, Tullsen 15
What We Learn From Static Schedules
0%
2%
4%
6%
8%
10%
12%
14%
16%
18%
20%
4 6 8 12
Number of Threads
ED
P S
avin
gs
Static Ideal
Static Balanced
Baseline isNaïve BalancedDynamic Policy

IPDPS: DeVuyst, Kumar, Tullsen 16
Outline
Architecture Methodology Scheduling Policies
Naïve balanced scheduling policy Sampling-based policies Electron policies
Conclusions

IPDPS: DeVuyst, Kumar, Tullsen 17
Sampling-based Policies
Main idea Try different schedules to find an effective one Oblivious to underlying hardware
How they work Two alternating phases
Sampling phase: different schedules are sampled Steady phase: best schedule from sampling phase is
used Steady phase is much longer than sampling phase

IPDPS: DeVuyst, Kumar, Tullsen 18
Sampling-based Policies

IPDPS: DeVuyst, Kumar, Tullsen 19
Sampling-based Policies

IPDPS: DeVuyst, Kumar, Tullsen 20
Sampling-based Policies

IPDPS: DeVuyst, Kumar, Tullsen 21
Outline
Architecture Methodology Scheduling Policies
Naïve balanced scheduling policy Sampling-based policies
Symbiosis policies [Snavely02] “Prefer Last” policies
Electron policies Conclusions

IPDPS: DeVuyst, Kumar, Tullsen 22
Symbiosis Policy
Main idea Some threads run well together, others do not
How it works Sampling phase: random schedules created,
performance sampled. Steady phase: the schedule in which threads
achieve the most symbiosis is run Two versions:
Balanced: only balanced schedules considered Unbalanced

IPDPS: DeVuyst, Kumar, Tullsen 23
Symbiosis Policy
-2%
0%
2%
4%
6%
8%
10%
4 6 8 12
Number of Threads
ED
P S
avin
gs
Symbiosis
Balanced Symbiosis
Baseline isNaïve Balanced

IPDPS: DeVuyst, Kumar, Tullsen 24
Outline
Architecture Methodology Scheduling Policies
Naïve balanced scheduling policy Sampling-based policies
Symbiosis policies “Prefer Last” policies
Electron policies Conclusions

IPDPS: DeVuyst, Kumar, Tullsen 25
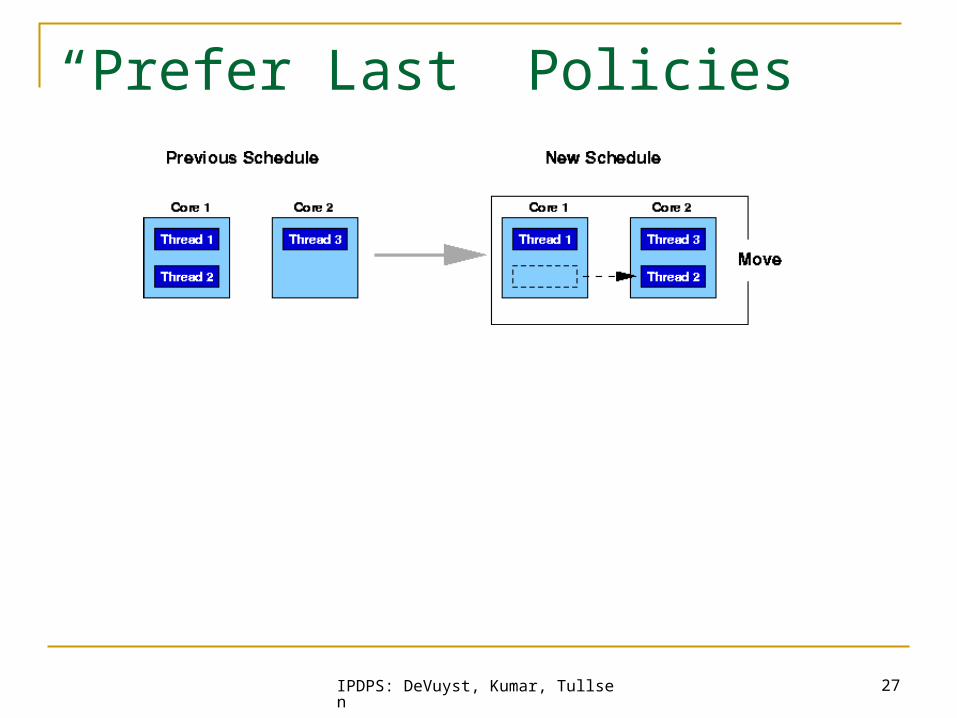
“Prefer Last” Policies
Main idea Current schedules has merit A similar schedule might be a little better
How they work Create multiple permutations on the current
schedule Create a few random samples to prevent
remaining in only local minima Sample schedules and pick the best

IPDPS: DeVuyst, Kumar, Tullsen 26
“Prefer Last” Policies
IPDPS: DeVuyst, Kumar, Tullsen 27
“Prefer Last” Policies

IPDPS: DeVuyst, Kumar, Tullsen 28
“Prefer Last” Policies

IPDPS: DeVuyst, Kumar, Tullsen 29
“Prefer Last” Policies

IPDPS: DeVuyst, Kumar, Tullsen 30
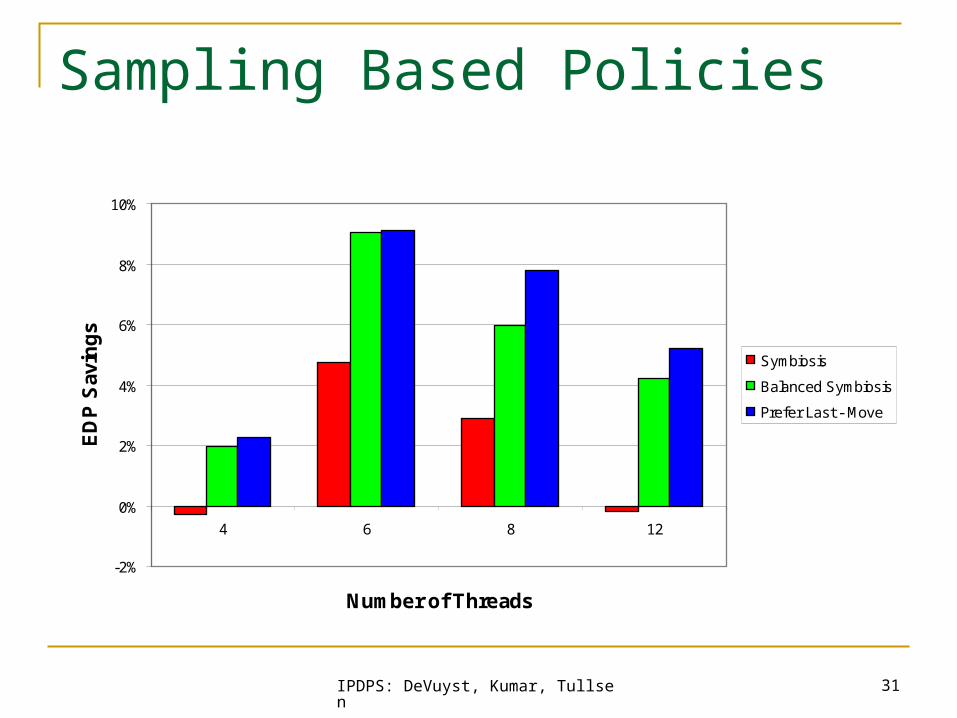
Sampling Based Policies
-2%
0%
2%
4%
6%
8%
10%
4 6 8 12
Number of Threads
ED
P S
avin
gs
Prefer Last - Numbers
Prefer Last - Sw ap
Prefer Last - Move
IPDPS: DeVuyst, Kumar, Tullsen 31
Sampling Based Policies
-2%
0%
2%
4%
6%
8%
10%
4 6 8 12
Number of Threads
ED
P S
avin
gs
Symbiosis
Balanced Symbiosis
Prefer Last - Move

IPDPS: DeVuyst, Kumar, Tullsen 32
Issues With Sampling Based Policies Non-scalable
Search space grows → number of samples grow Overhead of sampling
Some schedules result in improvement …but most just make things worse

IPDPS: DeVuyst, Kumar, Tullsen 33
Outline
Architecture Methodology Scheduling Policies
Naïve balanced scheduling policy Sampling-based policies Electron policies
Conclusions

IPDPS: DeVuyst, Kumar, Tullsen 34
Electron Policies
Main idea One core attracts a thread Another core repels a thread.
How it works (EDP) Highest EDP core identified Lowest EDP core identified A thread running on the low EDP core is moved to
the high EDP core

IPDPS: DeVuyst, Kumar, Tullsen 35
Electron Policies
t1 t2 t3
t4 t5 t6 t7
t8
Core 1 Core 2
Core 3 Core 4
Core with thehighest EDP
Core with thelowest EDP

IPDPS: DeVuyst, Kumar, Tullsen 36
Electron Policy Results
0%
2%
4%
6%
8%
10%
12%
4 6 8 12
Number of Threads
ED
P S
avin
gs
Balanced Symbiosis
Prefer Last - Move
Electron

IPDPS: DeVuyst, Kumar, Tullsen 37
Outline
Architecture Methodology Scheduling Policies
Naïve balanced scheduling policy Sampling-based policies Electron policies
Conclusions

IPDPS: DeVuyst, Kumar, Tullsen 38
Conclusions
A good scheduling policy for a CMP of SMTs must consider unbalanced schedules to achieve the most efficiency.
“Prefer Last” policies yield more energy savings than symbiotic scheduling policies and the naïve balanced policy.
Electron policies have low overhead and are particularly effective well when TLP is high.

Exploiting Unbalanced Thread Scheduling for Energy and Performance on a CMP of SMT ProcessorsMatt DeVuyst
Rakesh Kumar
Dean Tullsen





























