Embed Size (px)
Citation preview

Exploiting Relationships for Object Consolidation
Zhaoqi Chen Dmitri V. Kalashnikov Sharad Mehrotra
Computer Science DepartmentUniversity of California, Irvine
http://www.ics.uci.edu/~dvk/RelDChttp://www.itr-rescue.org (RESCUE)
ACM IQIS 2005
Copyright(c) by Dmitri V. Kalashnikov, 2005Work supported by NSF Grants IIS-0331707 and IIS-0083489

2
Talk Overview
• Examples – motivating data cleaning (DC)– motivating analysis of relationships for DC
• Object consolidation– one of the DC problems– this work addresses
• Proposed approach – RelDC framework– Relationship analysis and graph partitioning
• Experiments

3
Why do we need “Data Cleaning”?
q Hi, my name is Jane Smith.
I’d like to apply for a faculty
position at your university
Wow! Unbelievable! You must be a really
hard worker! I am sure we will
accept a candidate like
that!
Jane Smith – Fresh Ph.D. Tom - Recruiter
OK, let me check
something quickly …
???
Publications:1. ……2. ……3. ……
Publications:1. ……2. ……3. ……
CiteSeer Rank
4
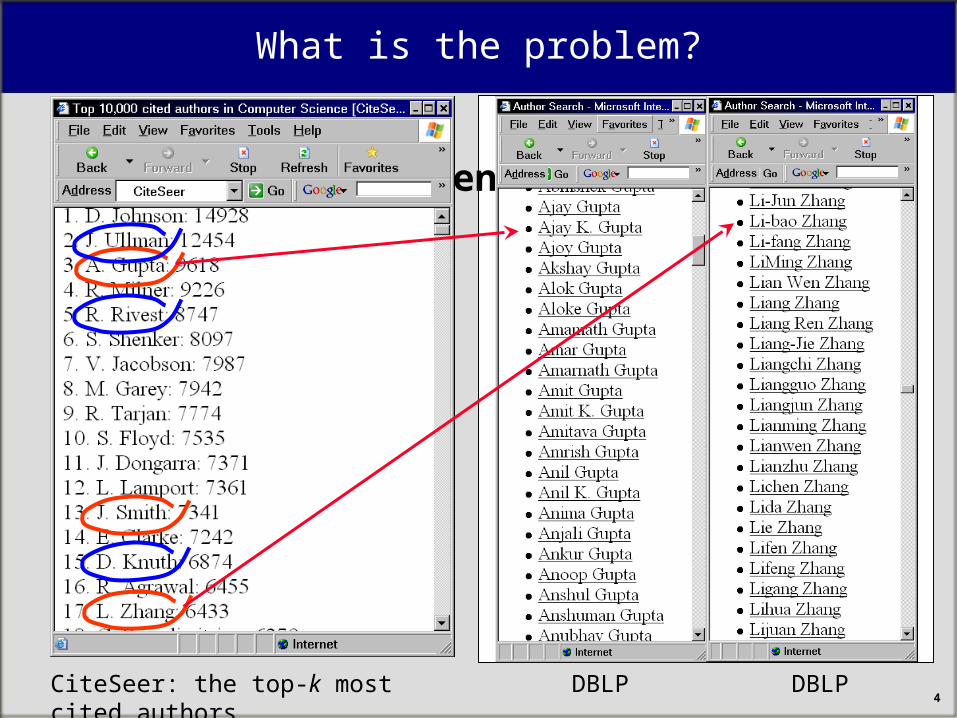
Suspicious entries– Lets go to DBLP website
– which stores bibliographic entries of many CS authors
– Lets check two people– “A. Gupta”
– “L. Zhang”
What is the problem?
CiteSeer: the top-k most cited authors DBLP DBLP
5
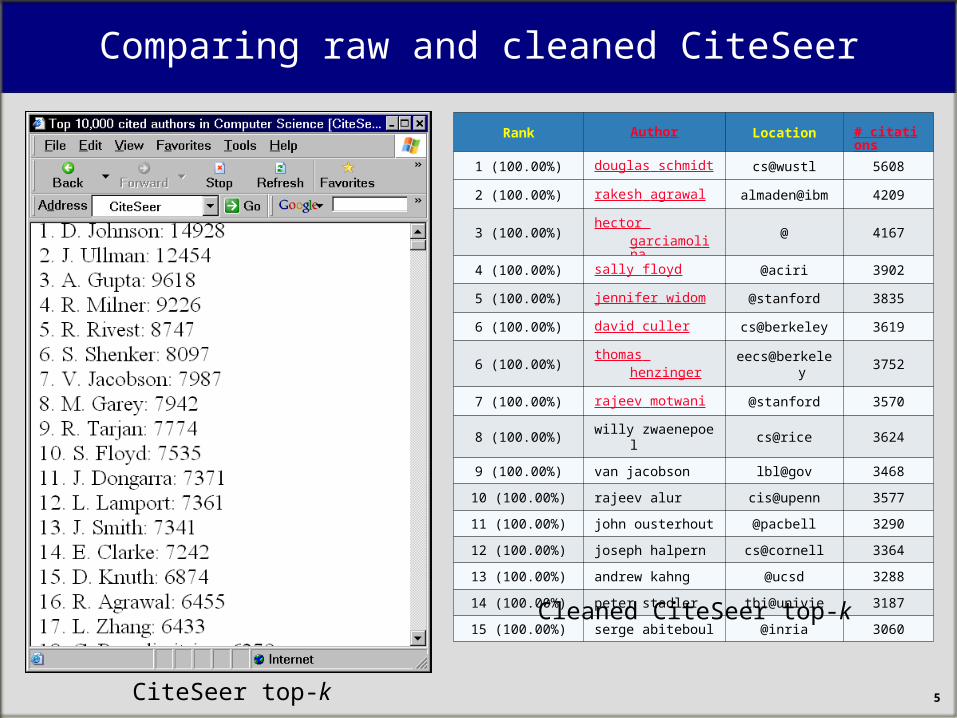
Comparing raw and cleaned CiteSeer
Rank Author Location # citations
1 (100.00%) douglas schmidt cs@wustl 5608
2 (100.00%) rakesh agrawal almaden@ibm 4209
3 (100.00%) hector garciamolina @ 4167
4 (100.00%) sally floyd @aciri 3902
5 (100.00%) jennifer widom @stanford 3835
6 (100.00%) david culler cs@berkeley 3619
6 (100.00%) thomas henzinger eecs@berkeley 3752
7 (100.00%) rajeev motwani @stanford 3570
8 (100.00%) willy zwaenepoel cs@rice 3624
9 (100.00%) van jacobson lbl@gov 3468
10 (100.00%) rajeev alur cis@upenn 3577
11 (100.00%) john ousterhout @pacbell 3290
12 (100.00%) joseph halpern cs@cornell 3364
13 (100.00%) andrew kahng @ucsd 3288
14 (100.00%) peter stadler tbi@univie 3187
15 (100.00%) serge abiteboul @inria 3060
CiteSeer top-k
Cleaned CiteSeer top-k
6
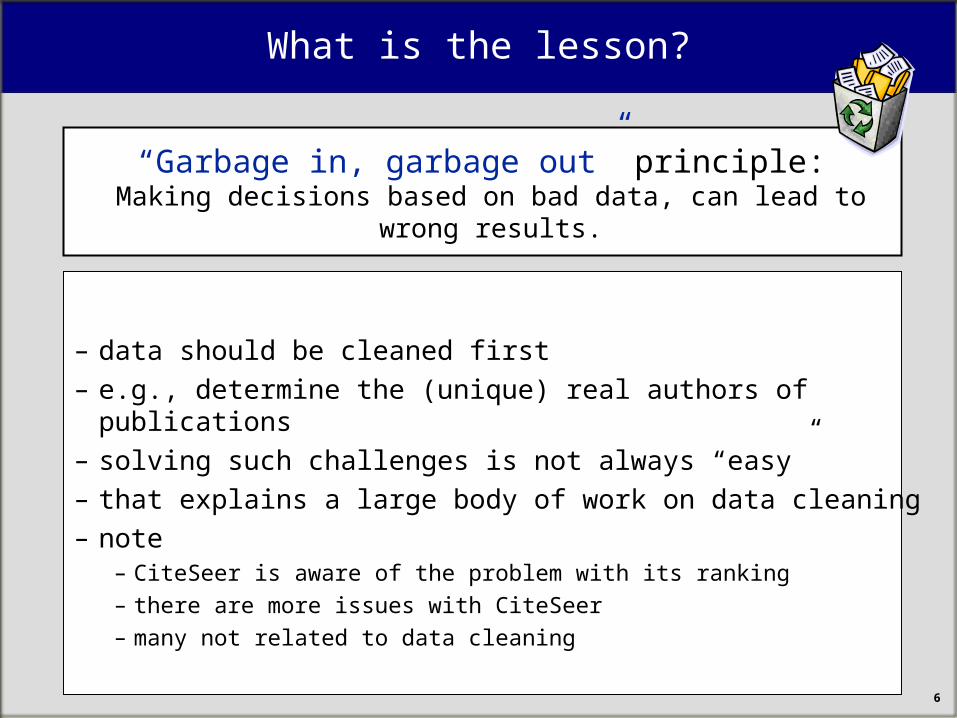
What is the lesson?
– data should be cleaned first– e.g., determine the (unique) real authors of publications– solving such challenges is not always “easy”– that explains a large body of work on data cleaning– note
– CiteSeer is aware of the problem with its ranking– there are more issues with CiteSeer – many not related to data cleaning
“Garbage in, garbage out” principle: Making decisions based on bad data, can lead to wrong results.
7
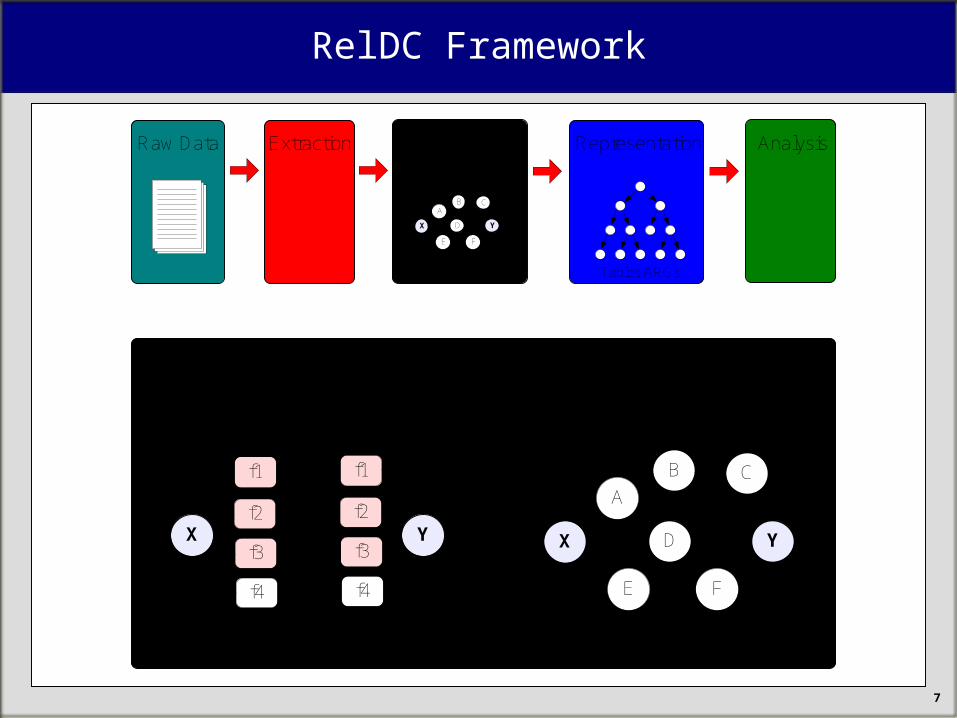
RelDC Framework
f1
f2
f3
?
?
?
f4
Y
f1
f2
f3
f4?
X
Traditional Methods
+ X Y
A
B C
D
E F
Relationship Analysis
ARG
Raw Data Representation
Tables/ARGs
RelDC Framework
ARG
X Y
AB C
D
E F
features and context
Data CleaningExtraction
Relationship-based Data Cleaning
Analysis
8
Object Consolidation
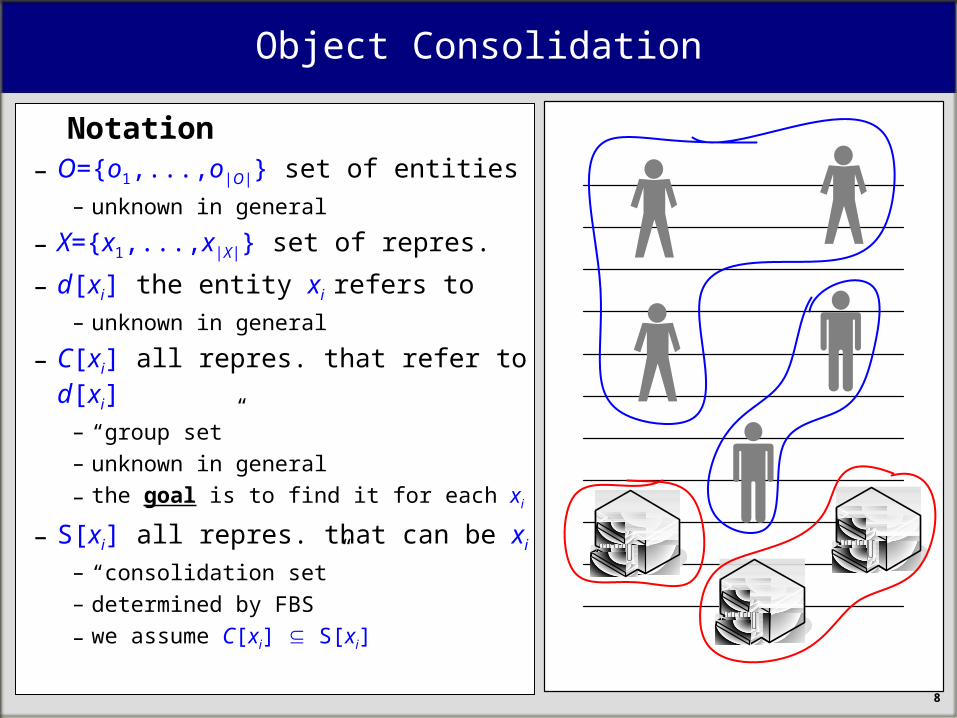
Notation– O={o1,...,o|O|} set of entities
– unknown in general
– X={x1,...,x|X|} set of repres.
– d[xi] the entity xi refers to– unknown in general
– C[xi] all repres. that refer to d[xi]– “group set”
– unknown in general
– the goal is to find it for each xi
– S[xi] all repres. that can be xi
– “consolidation set”
– determined by FBS
– we assume C[xi] S[xi]
9
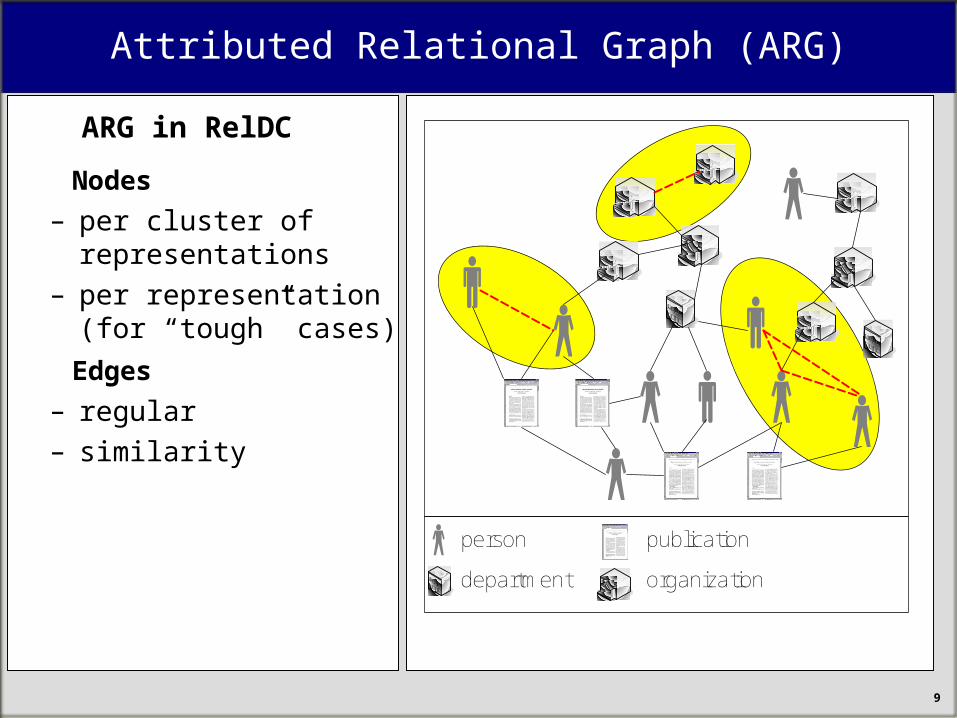
Attributed Relational Graph (ARG)
ARG in RelDC
Nodes
– per cluster of representations
– per representation (for “tough” cases)
Edges – regular– similarity
person publication
department organization

10
Context Attraction Principle (CAP)
Take a guess: Who is “J. Smith”
– Jane?– John?
Jane Smith
John Smith
J. Smith
Merging a new publication.
11
Questions to Answer
1. Does the CAP principle hold over real datasets? That is, if we consolidate objects based on it, will the
quality of consolidation improves?
2. Can we design a generic solution to exploiting relationships for disambiguation?

12
Consolidation Algorithm
1. Construct ARG and identify all VCS’s– use FBS in constructing the ARG
2. Choose a VCS and compute c(u,v)’s– for each pair of repr. connected via a similarity edge
3. Partition VSC– use a graph partitioning algorithm– partitioning is based on c(u,v)’s– after partitioning, adjust ARG accordingly– go to Step 2, if more VCS exists
13
Connection Strength
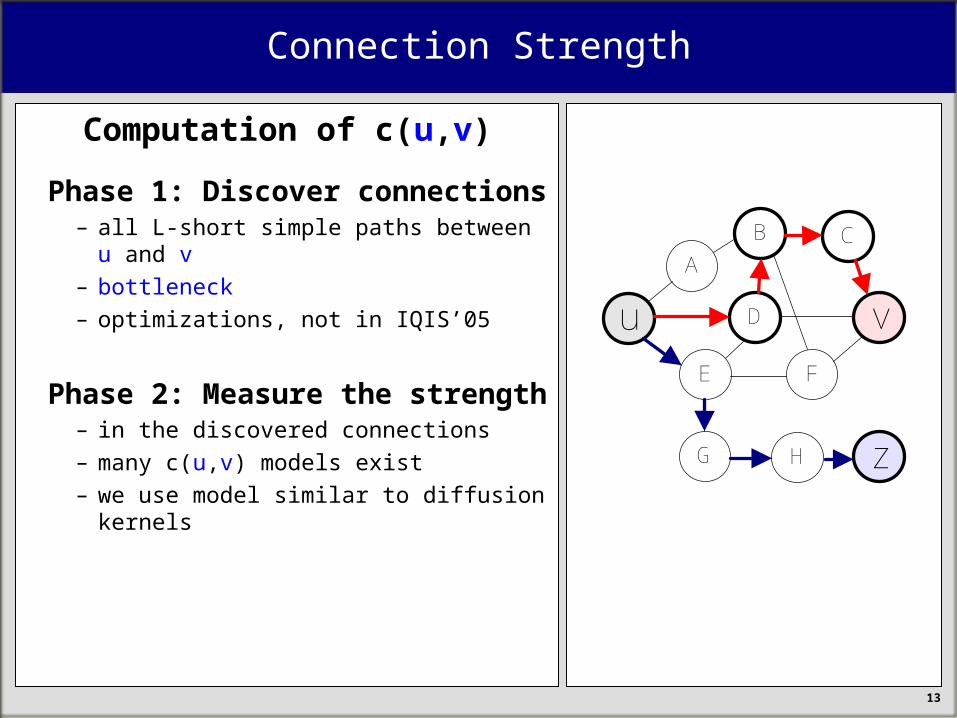
Computation of c(u,v)
Phase 1: Discover connections– all L-short simple paths between u and v
– bottleneck
– optimizations, not in IQIS’05
Phase 2: Measure the strength– in the discovered connections
– many c(u,v) models exist
– we use model similar to diffusion kernels
u v
A
B C
D
E F
G H z
14
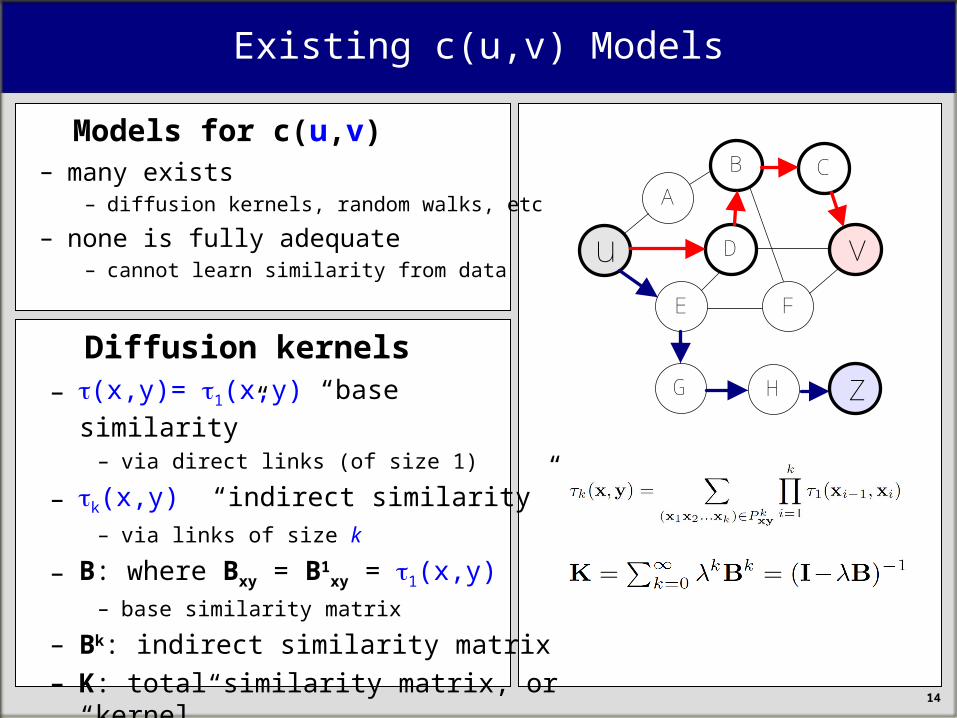
Existing c(u,v) Models
Models for c(u,v)– many exists
– diffusion kernels, random walks, etc
– none is fully adequate– cannot learn similarity from data
u v
A
B C
D
E F
G H z Diffusion kernels
– (x,y)= 1(x,y) “base similarity” – via direct links (of size 1)
– k(x,y) “indirect similarity”– via links of size k
– B: where Bxy = B1xy = 1(x,y)
– base similarity matrix
– Bk: indirect similarity matrix– K: total similarity matrix, or “kernel”

15
Our c(u,v) Model
T1
T2 T2
T1
N-2... ... ... ... ...
John Smith Alan WhiteP1
MIT
Our c(u,v) model– regular edges have types T1,...,Tn
– types T1,...,Tn have weights w1,...,wn
– (x,y) = wi
– get the type of a given edge– assign this weigh as base similarity
– paths with similarity edges– might not exist, use heuristics
Our model & Diff. kernels– virtually identical, but...– we do not compute the whole matrix K
– we compute one c(u,v) at a time
– we limit path lengths by L– (x,y) is unknown in general
– the analyst assigns them– learn from data (ongoing work)
P1R1:John R2:J.SmithA4:Alan P3A5:MikeP2
R3:John A3:JohnA6:Tom StanfordP4 A7:Kate
P1 R1:JohnA1:John A4:AlanMITR3:John
(a)
(b)
(c)

16
Consolidation via Partitioning
Observations– each VCS contains representations of
at least 1 object– if a repr. is in VCS, then the rest of repr.
of the same object are in it too
Partitioning– two cases
– k, the number of entities in VSC, is known– k is unknown
– when k is known, use any partit. algo– maximize inside-con, minimize outside-con.– we use [Shi,Malik’2000]– normalized cut
– when k is unknown– split into two: just to see the cut– compare cut against threshold– decide “to split” or “not to split” actually
1
1
1
12
2 2
3
3
4
4
VCS 1
VCS 2
5
5
5
5
17
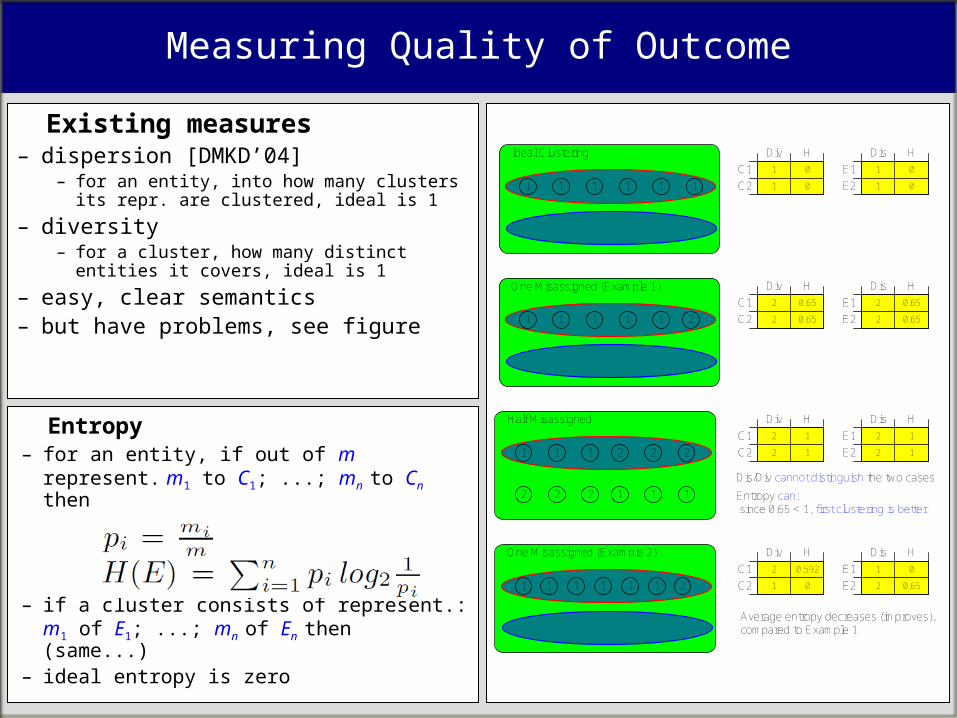
Measuring Quality of Outcome
Existing measures– dispersion [DMKD’04]
– for an entity, into how many clusters its repr. are clustered, ideal is 1
– diversity– for a cluster, how many distinct entities it
covers, ideal is 1
– easy, clear semantics– but have problems, see figure
Entropy– for an entity, if out of m represent.
m1 to C1; ...; mn to Cn then
– if a cluster consists of represent.: m1 of E1; ...; mn of En then (same...)
– ideal entropy is zero
1 11 1
2 22 2 2 2
1 1
Ideal Clustering
1 11 1
2 22 2 2
21
1
One Misassigned (Example 1)
1
1
1 1
2 22
2 2 2
1 1
Half Misassigned
1 11 1
2 22 2 2
211
One Misassigned (Example 2)
C1
C2
Div H
1
1
0
0
E1
E2
Dis H
1
1
0
0
C1
C2
Div H
2
2
E1
E2
Dis H
2
2
0.65
0.65
C1
C2
Div H
2
2
1
1
E1
E2
Dis H
2
2
1
1
C1
C2
Div H
2
1
0.592
0
E1
E2
Dis H
1
2
0
0.65
0.65
0.65
Dis/Div cannot distinguish the two cases
Entropy can: since 0.65 < 1, first clustering is better
Average entropy decreases (improves), compared to Example 1

18
Experimental Setup
Parameters– L-short simple paths, L = 7– L is the path-length limit
Note– The algorithm is applied to
“tough cases”, after FBS already has successfully consolidated many entries!
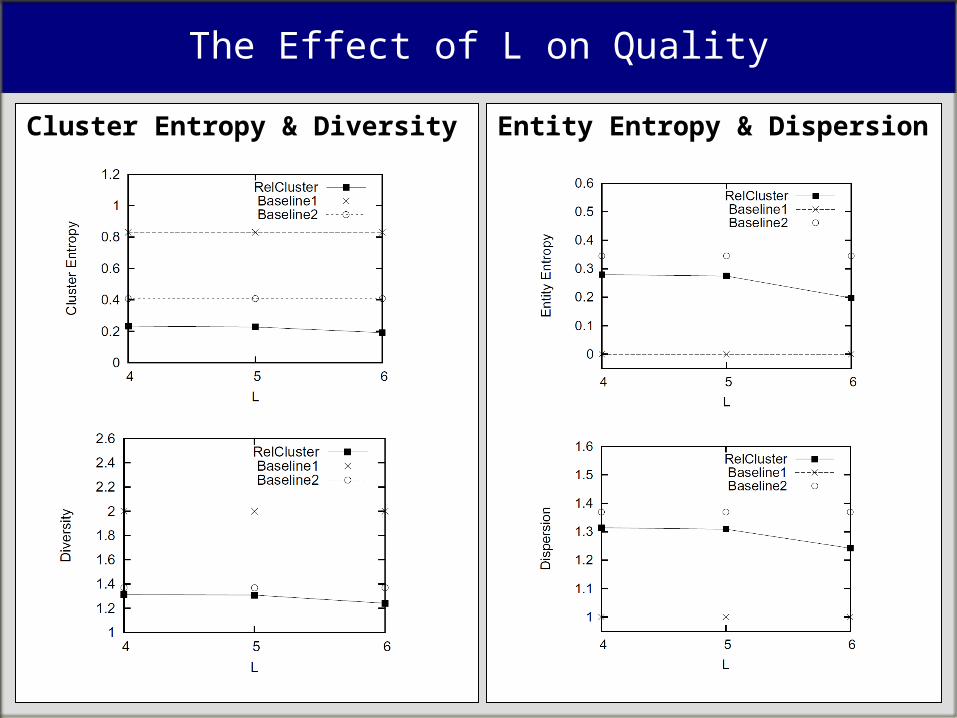
RealMov– movies (12K) – people (22K)
– actors– directors– producers
– studious (1K) – producing – distributing
Uncertainty– d1,d2,...,dn are director entities– pick a fraction d1,d2,...,d10– group, e.g. in groups of two
– {d1,d2}, ... ,{d9,d10}
– make all representations of d1,d2 indiscernible by FBS, ...
Baseline 1– one cluster per VCS, regardless– dumb? ... but ideal disp & H(E)
Baseline 2– knows grouping statistics– guesses #ent in VCS – random assigns repr. to clusters
19
Sample Movies Data
20
The Effect of L on Quality
Cluster Entropy & Diversity Entity Entropy & Dispersion
21
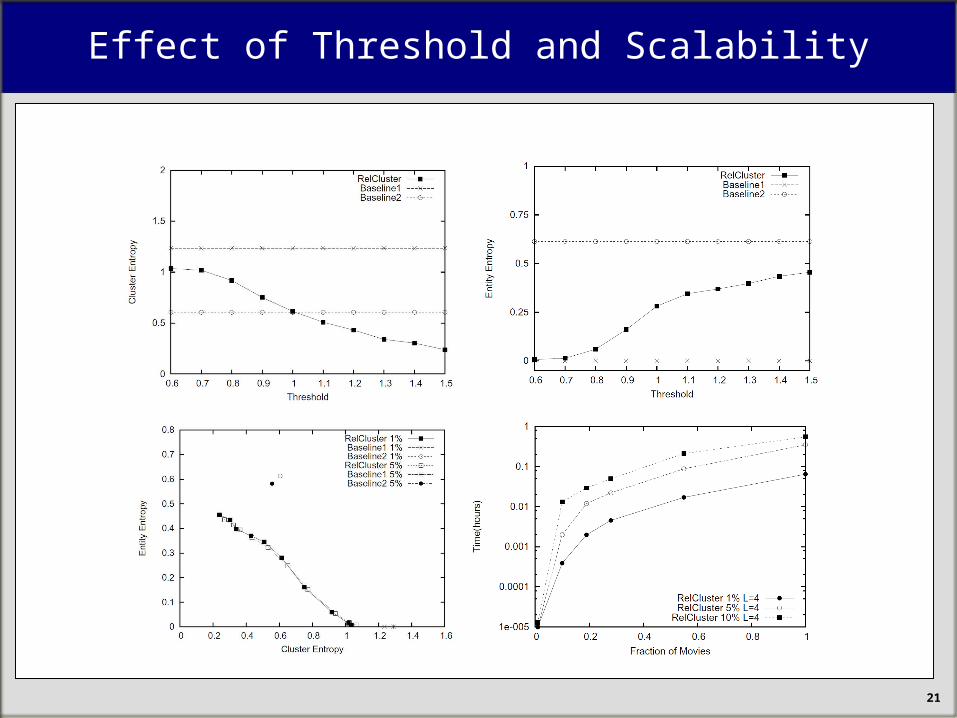
Effect of Threshold and Scalability
22
Summary
RelDC– developed in Aug 2003 (reference disambiguation)– domain-independent data cleaning framework– uses relationships for data cleaning
– reference disambiguation [SDM’05]– object consolidation [IQIS’05]
Ongoing work– “learning” the importance of relationships from data
23
Contact Information
RelDC projectwww.ics.uci.edu/~dvk/RelDC
www.itr-rescue.org (RESCUE)
Zhaoqi [email protected]
Dmitri V. Kalashnikovwww.ics.uci.edu/~dvk
Sharad Mehrotrawww.ics.uci.edu/~sharad

![Sveshnikov/Kalashnikov [B32 33] - Time to get classySveshnikov/Kalashnikov [B32−33] Written by GM John Fedorowicz, GM Tony Kosten & IM Richard Palliser Last updated Sunday, 17 July](https://img.pdfslide.us/doc/110x75/5e7ad9dd3d405f303e0335f3/sveshnikovkalashnikov-b32-33-time-to-get-classy-sveshnikovkalashnikov-b32a33.jpg)






![Sveshnikov/Kalashnikov [B32 33]terrycucf.weebly.com/uploads/1/9/2/9/19295043/sveshkalash.pdf · Sveshnikov/Kalashnikov ... he Lasker/Pelikan/Sveshnikov is one of Black's sharpest](https://img.pdfslide.us/doc/110x75/5a96ae7f7f8b9ad96f8cf7c7/sveshnikovkalashnikov-b32-33-he-laskerpelikansveshnikov-is-one-of-blacks.jpg)












![35481168 Soviet AKM 47 Assault Rifle Manual Kalashnikov 1970[1]](https://img.pdfslide.us/doc/110x75/547818dfb4af9f6e108b4b62/35481168-soviet-akm-47-assault-rifle-manual-kalashnikov-19701.jpg)







