Embed Size (px)
Citation preview

=
\rtideExpert systems made with neuralnetworks
Rafeek M. Kottai and A. TerryBahill
Systems and Industrial Engineering^ University ofArizona, Tucson, AZ 85721, USA '*
Abstract: Neural networks are useful for twodimensional picture processing^ while induction typeexpert system shells are good at inducing rules from alarge set of examples. This paper examines thedifferences and similarities of expert systems built witha neural network and those built with traditional expertsystem shells. Attempts are made to compare andcontrast the behavior of each with that of humans.
1, Introduction
Neural networks are good >for two dimensional pictureprocessing [1,2]. Induction type expert system shellsare good at inducing rules from a large set of examples,How are these two tasks similar? They are both doingpattern recognition. This similarity of function made usthink that a neural network could be used to make anexpert system,
This paper examines the differences and similaritiesof expert systems built with a neural network and thosebuilt with traditional expert system shells, Attemptsare made to compare and contrast the behavior of eachwith that of humans.
2. Neural networks
All of our neural network-based expert systems werebuilt using the back-propagation algorithm [3], Figure1 shows the architecture of a typical back-propagationnetwork. The neural network in this figure has an inputlayer with two units, a hidden layer with three units, andan output layer with two units. Theoretically there isno limit on the number of units in any layer, nor is therelimit on the number of hidden layers. For simplicity, weused one or two hidden layers for all our neural network-based expert systems. Each layer wa,c_ fully connected to
the succeeding layer, and each connection had a corre-sponding adjustable weight. For example, the weight ofthe connection between the first unit in the input layerand the second unit of the hidden layer are not labeledin Figure L During training, the weights between thelast hidden layer and the output layer were adjusted toreduce the difference between the desired output andthe actual output. Then, using the back-propagationalgorithm, the error was transformed by the derivativeof the transfer function and was back-propagated to theprevious layer and the weights in front of this hiddenlayer were adjusted. The process of back-propagatingerrors continued until the input layer was reached. Theback-propagation algorithm derives its name from thismethod of computing the error term. All the neuralnetwork-based expert systems described in this paperwere developed using ANSim — Artificial Neural Sys-tems Simulation program written by Science Applica-tions International Corporation, although we have sub-sequently used Neural works by Neural Ware Inc. withsimilar results. We note explicitly that ANSim is a neu-ral network simulation package, and it was never in-tended to be an expert system development tool. Soin this paper we point out some of the problems thatwould have to be overcome if someone were to use it asan expert system development tool,
3. Neural network-based expertsystems
We developed two score expert systems; some with aneural network, some with traditional expert systemshells. We used an IBM AT compatible computer with 4Mb of memory. All of these expert systems were basedon demonstration systems provided by the companieswho market the traditional expert system shells. Thesedemonstration systems were designed to show off thefeatures of their products. So if the neural network-based expert systems are better it is not because wechose straw men. These demonstration systems weredeveloped for the shells M.I by Teknowledge Inc., VP-Expert by Paperback Software International and 1stClass by Programs in Motion Inc. While M.I is a rule-based system, the other two are induction-based expertsystem shells, i.e. they form the rules by induction fromexamples given by the expert. These expert systemswere small and clear enough to illustrate the advantagesand disadvantages between a neural network-based ex-pert system and shell-based expert systems.
international Journal of Neural Networks, VoL 1, No. 4, October 1989 211

INPUT DATA
Figure 1:
ADAPTIVE WEIGHTS
\T DATA
INPUT LAYER OUTPUT LAYER
HIDDEN LAYER
4. Building neural network-based expert systems
The first step in building a neural network-based expertsystem was to identify the important attributes thatwere necessary for solving the problem. Then all thevalues associated with these attributes were identified.All the possible outputs were also listed. Then severalexamples were listed that mapped different values of theattributes to valid results. This set of examples formedthe training file for the network. The attributes and val-ues defined the input layer of the neural network. Theresults formed the output layer,
In this section a Wine Color Advisor that gave adviceon the color of wine to choose given the type of sauce,the preferred color and the main component of the mealis shown to illustrate the steps involved in creating aneural network-based expert system. For building thissystem the 13 examples shown in Table 1 were used.The steps involved in creating the neural network-basedWine Color Advisor are given below.
Step 1: Identify the attributes.
(A) Type of sauce
(B) Preferred color
(C) Main component
Step 2: Identify values for all the attributes.
(A) Type of sauce
1. Cream2. Tomato
(B) Preferred color
1. Red2. White
(C) Main component
L Meat2. Veal3. Turkey4. Poultry5. Fish6. Other
Step 3: Identify the outputs.
1. Red
2. White
Step 4: Make a set of examples as shown in Table 1.
Step 5: Use the example to train the network.
The input layer of the neural network consists of allattributes and values of the problem. Since there werethree attributes, (type of sauce, preferred color, andmain component) there are three rows in the input layer,
212 International Journal of Neural Networks, Vol. 1, No. 4, October 1989
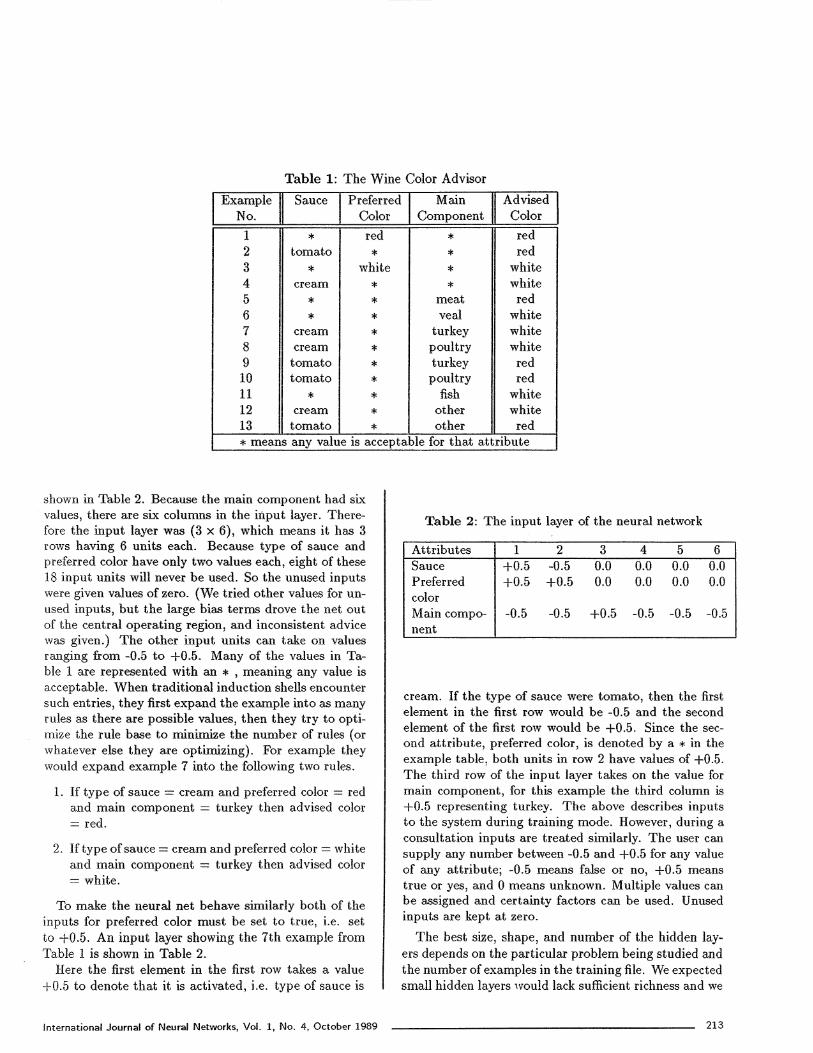
Table 1: The Wine Color Advisor
ExampleNo.
12345678910111213
Sauce
*tomato
#cream
**
creamcreamtomatotomato
*creamtomato
PreferredColor
red*
white**********
Main | AdvisedComponent | Color
****
meatveal
turkeypoultryturkeypoultry
fishotherother
redred
whitewhitered
whitewhitewhiteredred
whitewhitered
* means any value is acceptable for that attribute
shown in Table 2. Because the main component had sixvalues, there are six columns in the input layer, There-fore the input layer was (3x6) , which means it has 3rows having 6 units each. Because type of sauce andpreferred color have only two values each, eight of these18 input units will never be used. So the unused inputswere given values of zero. (We tried other values for un-used inputs, but the large bias terms drove the net outof the central operating region, and inconsistent advicewas given.) The other input units can take on valuesranging from -0.5 to +0.5. Many of the values in Ta-ble 1 are represented with an * , meaning any value isacceptable. When traditional induction shells encountersuch entries, they first expand the example into as manyrules as there are possible values, then they try to opti-mize the rule base to minimize the number of rules (orwhatever else they are optimizing). For example theywould expand example 7 into the following two rules.
1. If type of sauce = cream and preferred color — redand main component = turkey then advised color= red.
2. If type of sauce = cream and preferred color = whiteand main component = turkey then advised color— white.
To make the neural net behave similarly both of theinputs for preferred color must be set to true, i.e. setto +0.5. An input layer showing the 7th example fromTable 1 is shown in Table 2.
Here the first element in the first row takes a value+0.5 to denote that it is activated, i.e. type of sauce is
Table 2: The input layer of the neural network
AttributesSaucePreferredcolorMain compo-nent
1+0.5+0.5
-0.5
2-0.5+0.5
-0.5
30.00.0
+0.5
40.00.0
-0.5
50.00.0
-0.5
60.00.0
-0.5
cream. If the type of sauce were tomato, then the firstelement in the first row would be -0.5 and the secondelement of the first row would be +0.5. Since the sec-ond attribute, preferred color, is denoted by a * in theexample table, both units in row 2 have values of +0.5.The third row of the input layer takes on the value formain component, for this example the third column is+0.5 representing turkey. The above describes inputsto the system during training mode. However, during aconsultation inputs are treated similarly. The user cansupply any number between -0.5 and +0.5 for any valueof any attribute; -0.5 means false or no, +0.5 meanstrue or yes, and 0 means unknown. Multiple values canbe assigned and certainty factors can be used. Unusedinputs are kept at zero.
The best size, shape, and number of the hidden lay-ers depends on the particular problem being studied andthe number of examples in the training file. We expectedsmall hidden layers would lack sufficient richness and we
Internationa! Journal of Neural Networks, Vol. 1, No, 4, October 1989 213

Table 3: The output layerWine Color
RedWhite
Node Value
-0.5+0,5
expected large hidden layers to exhibit increased noisebecause they would be under constrained. However, inexperiments where we varied the size of the hidden layerform (1 x 1) (!) to (40 x 40) and computed the errorsbetween the outputs of these neural networks and theoutputs of a 1st Class-based expert system, we found nosignificant differences. Of course, the number of unitsin the hidden layer also depends upon the output layer,For an output layer of sise (n x m) the minimum numberof cells in the hidden layer would be Iog2(n x m) or, de-pending upon the particular knowledge being encoded,perhaps Iog2(max m, n). A more detailed discussion ofthe hidden layer is beyond the scope of this paper. Forbuilding the neural network-based expert systems of thispaper, we used either one or two square hidden layers.The hidden layer for our wine color advisor was arbi-trarily chosen to be (6x6).
The output layer was assize (2x1) because the soli-tary output (reeommended^colqr) had 2 values (red andwhite). The output vector for the above example isshown in Table 3.
Now that the knowledge was formulated, it was timeto train the neural network, The 13 examples of Ta-ble 1 were coded to form the input training file. Thisfile was repeatedly presented to the network until theroot mean squared error between the desired output andthe actual output dropped below a preset value (usually0.1). During the training process the network learnedand adapted the values of the weights to reduce the errorbetween the actual and desired outputs for the variouscombinations of inputs,
The output node values of the network ranged from-0.5 to 0.5. These values indicate how certain the net-work was in its answer. However, because M.I, VP-Expert and 1st Class used certainty factors that rangedfrom 0 to 100, for comparison purposes, we mapped theoutput node values of the neural network into a rangebetween 0 to 100.
In almost all cases the node values derived by theneural network-based expert systems were quite similarto the certainty factors derived by the traditional shell-based expert systems. We have found three exceptionsto this rule. The first of these is illustrated by graduallearning.
5. Gradual learning
As more examples were added to the input training filethe network changed its output node values. However,unlike induction-based expert systems where certaintyfactors changed abruptly, the neural network-based ex-pert systems changed their output node values gradu-ally, which shows gradual learning by the neural net-work. To demonstrate this property, the examples ofTable 4 were added incrementally to the Wine ColorAdvisors, developed using 1st Class and the neural net-work.
After each example was added the systems learnedor induced new rules, then a consultation was run witheach system with the user specifying a cream sauce, apreferred color of red, and the main component of fish.The changes in output certainty as these examples wereadded are shown in Table 5,
Table 5 illustrates the gradual change in the outputvalues of a neural network for each additional examplethat was used to teach the network. This shows thateach additional example increased the knowledge repre-sented among the connections in a neural network. Thisis analogous to a human gaining more experience. Herethe network behaves more human like than an induction-based expert system.
6. Contradictory conclusion
Unlike traditional induction-based expert systems, aneural network-based expert system will not accept con-tradictory conclusions. To illustrate this, the original 13example Wine Color Advisors of Table 1 were trainedadding the new example shown in Table 6. Note thatthe new example, number 14, contradicts a previous ex-ample, number 13.
From these examples, the following rules were createdby the induction-based expert system shell 1st Class:
1. IF sauce = tomatoTHEN color = red.
2, IF sauce = tomatoTHEN color = white.
While the induction-based shell created rules fromthese examples, the neural network would not. Thetraining phase exhibited 20 cycles of transient behav-ior followed by steady-state behavior, where the out-put error oscillated between 0 and 0.5. This shows thatcontradictory conclusions cannot be taught to a neuralnetwork. We cannot conclude which behavior is morehuman like.
214 International Journal of Neural Networks, Vol. 1, Mo. 4, October 1989

Table 4: Examples added to the wine color advisors
Example | SauceNo. I1415161718
creamtomatotomatotomatocream
PreferredColor
*****
Main II AdvisedComponent J[ Color
meatveal
turkeyfish
meat
redredred
whitewhite
Table 5: Changes in output certainty
No. of last examplein training set
131415161718
1st Class CertaintyFactorsWhite
505050505075
Red
505050505025
Neural NetworkNode ValuesWhite
526280929598
Red
484327877
Table 6: Contradictory examples
ExampleNo.
Sauce
13 || tomato14 || tomato
PreferredColor
**
MainComponent
otherother
AdvisedColorred
white
International Journal of Neural Networks, Vol. 1, No. 4, October 1989 215

Table 7: Animal Classification Examples
1234567891011121314151617181920
Coat hairFeeds offspring milkCoat feathersFliesLays eggsEats meatPointed toothExtermities clawsEye position forwardExtermities hoovesChews cudHabitat shipsSwimsColor black & whiteLong neckLong legBlack stripesDark spotsColor tawnyDoes not fly
Albatross
••*
*
-
Penguin
*
*
*•
*
Ostrich
*
•
*••
*
Zebra• ••
*•
•
Giraffe•*
•*
••
•
Tiger
•
*
•
*
*
•
Cheetah
*• •**
•*
Note; The animals have the attributes indicated by the »?s
7. Continuous output
Traditional expert systems collect all the pertinent in-formation, and then at the end of the consultation, givetheir advice. The neural network-based expert systemsgave outputs continuously. As they collected more inputinformation they gradually become more certain of ananswer and they gave more certain advise. To demon-strate this, the Animal Classification Expert Systembased on Winston [4] was created using a neural net-work for identifying an animal given its features. Thesystem was trained to classify seven different animals,Twenty different features were used to identify these an-imals. The examples showing the features associatedwith each animal are given in Table 7.
The size of the input layer of this neural network-based expert system was (20 x 1). The one hidden layerwas of she (10 x 10), The output layer was (1x7) ,It took about 30 minutes to train this network. Duringone consultation, when the user had a tiger in mind, thefollowing six features were given:
1. Eats meat
2. Pointed tooth
3. Extremities claws
4. Eye position forward
5. Black stripes
6. Tawny color
To show the effect of adding .more and more featuresto an input vector, the network was first given one fea-ture, then two features, then three features etc. Theresult of this test is shown in Table 8^
As more and more attributes were added to the inputvectors, the output values of the units increased and theneural network grew more confident in its answer. It alsoeliminated other animals having similar features. Thisexample demonstrated that neural network will give agood answer even with partial input.
8. Erroneous inputs
To demonstrate the effect of erroneous data in the in-put, an input vector having the following attributes weregiven to the Animal Classification Expert System.
1. Eats meat
2. Extremities claws
3, Eye position forward
4, Black stripes
216 international Journal of Neural Networks, Vol. l rNo. 4, October 1989
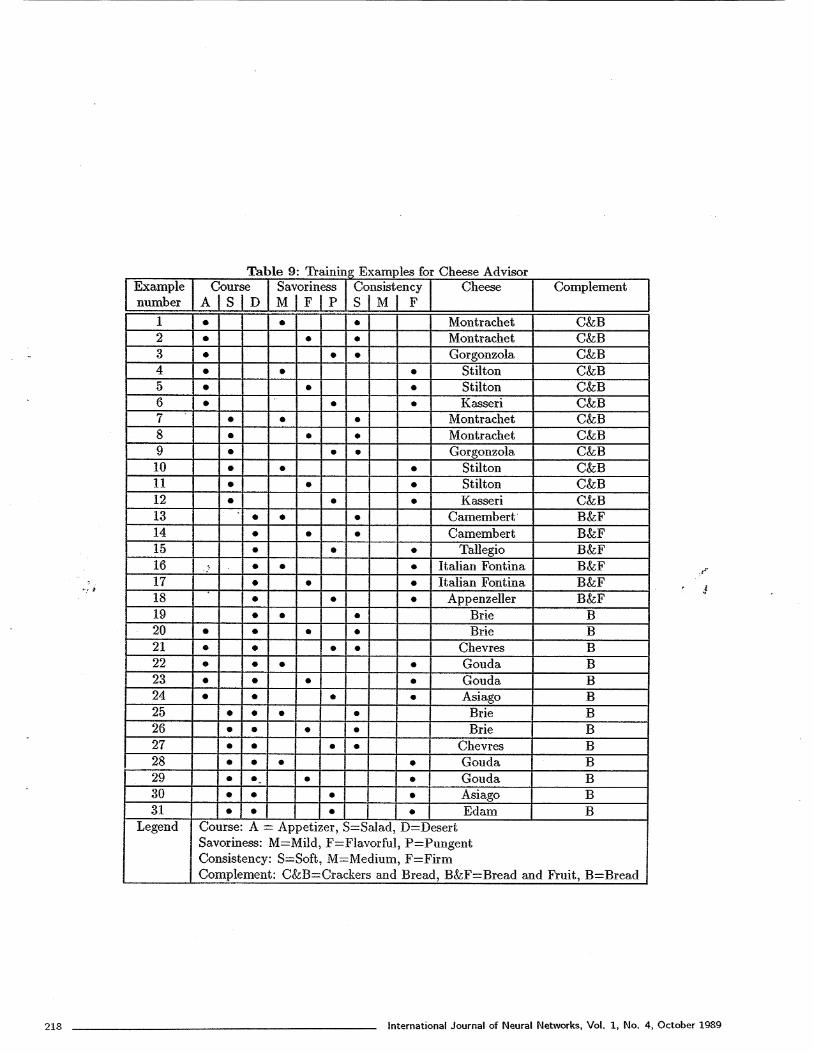
Table 9: Training Examples for Cheese AdvisorExamplenumber
12345678910111213141516171819202122232425262728293031
Legend
CoursA | S
*9
0
*
*
*****•
*•*••**
$eD
*•**********•****_**
SavM*
*
*
•
*
*
*
*
*
*
onnessF | P
*
•
*
*
•
*
*
*
*
*
*
*
*
*
*
*
*
*
•
*
*
ConsistencyS j M | F•*•
•**
•*
•*•
**•
•**
*••
•***
•••
****
Cheese
MontrachetMontrachetGorgonsola
StiltonStiltonKasseri
MontrachetMontrachetGorgonzola
StiltonStiltonKasseri
CamembertCamembert
TallegioItalian FontinaItalian Fontina
AppenzellerBrieBrie
ChevresGoudaGoudaAsiago
BrieBrie
ChevresGoudaGoudaAsiagoEdam
Complement
C&BC&BC&BC&BC&BC&BC&BC&BC&BC&BC&BC&BB&FB&FB&FB&FB&FB&F
BBBBBBBBBBBBB
Course: A = Appetizer, S=Salad, D— DesertSavoriness: M=MiId, F=Flavorful, P=PungentConsistency: S-Soft, M^Medium, F=FirmComplement: C&B=Crackers and Bread, B&F=Bread and Fruit, B=Bread
218 Internationa! Journal of Neural Networks, Vol. 1, No. 4, October 1989

Table 8: Neural Network Identifying a Tiger
Inputvector^
1
2
3
456
Featuresactivated5
5,6
5,6,1
5,6,1,25,6,1,2,35,6,1,2,3,4
Output
TigerZebraTigerZebraTigerZebraTigerTigerTiger
Nodevalue
141431866.7919198
5. Tawny color
6. Coat feathers
7. Animal swims
Here note that the attribute 2 was removed from theprevious set and incorrect additional attributes 7 and 8were added. In this case, even from partial informationthe neural network gave the correct answer, tiger, witha certainty of 87. Of course with a neural network allpossible outputs have some non-sero certainty factor.For example, the last two features in the above inputvector are true for a penguin. But the output nodevalue for this animal was only 12. So the net was prettysure that it was a tiger despite the erroneous inputs.
In this example the user gave seemingly incorrect an-swers. It would be short sighted to say 4Well if the userscannot give the right answer, then they should not beusing our system.' There are many reasons for usersgiving incorrect answers: new experiences, cultural dif-ferences and developmental differences. When users trydifferent scenarios or experiment with unknown situa-tions they often give answers the expert system was notprepared for. Also in the real world, as opposed to nicewell defined model situations, complete knowledge of asituation is rare. So it is a desirable property for anexpert system to allow erroneous inputs from its users.The above example shows that a neural network-basedexpert system can handle erroneous inputs very well.
When we gave erroneous inputs to our traditional ex-pert systems, they responded with comments like Iden-tity of animal Is unknown5, and 'What is the value of:lays-eggs?'. Clearly the neural network-based expertsystem is friendlier and more human like.
9. Global knowledgerepresentation
The Cheese Advisor neural network-based expert sys-tem was created to give advice about what cheese andcomplement to choose given the main course, preferencein taste and preference in consistency of cheese. Theexample file, Table 9, was created from a VP-Expertdemonstration expert system.
An input layer of size (3 x 3), two hidden layers eachof size (10 x 10), and an output layer of size (13 x 1)were used to build this network. There were 12 200 con-nections in this network and it took about 5 hours totrain it.
The information about specific objects is spread outamong the connections in a neural network. So it hasthe natural ability to form categories and associationsamong these objects during the learning phase. Knowl-edge is represented in the form of weights throughoutthe network, Unlike a shell-based expert system, a neu-ral network considers all the knowledge encompassed inits connections to come to a conclusion. This is demon-strated by a modified example from the Cheese Advisor,Two of the rules in the VP-Expert knowledge base aregiven below,
1. IF Complement = bread-and-fruitAND Preference = MildOR Preference = FlavorfulAND Consistency = FirmTHEN The-Cheese = Italian-Fontina;
2, IF Complement = bread-and-fruitAND Preference = PungentTHEN The-Cheese = Appenzeller,
Because of the OR clause in the premise of the firstrule, VP-Expert actually considers the above knowledgebase as 3 rules. They are:
la. IF Complement = bread^andjruitAND Preference = MildAND Consistency = FirmTHEN The-Cheese = Italian-Fontina;
Ib. IF Complement = bread_andJruitAND Preference = FlavorfulAND Consistency = FirmTHEN The-Cheese = Italian-Fontina;
2. IF Complement = bread-andJfruitAND Preference == Pungent
International Journal of Neural Networks, Vol. 1, No, 4, October 1989 217

AND Consistency = FirmTHEN The-Cheese = Appenzeller;
When VP-Expert was asked to give advice about thetype of cheese using the above rules given the followinguser answers,
Complement = bread and fruitPreference = Flavorful with cf 50Preference = Pungent with cf 50Consistency = Firm
two of the three rules fired and the advice was
Cheese = Italian JPontina with cf 50 andCheese = Appenzeller with cf 50,
However, when the same input was given to a trainedneural network, the output was,
Cheese = Appenzeller with node value 89 andCheese = ltalian_Fontina with node value 38.
The VP-Expert system recommended Italian JPontinaand Appenzeller with equal certainty, whereas the neu-ral network-based expert system preferred Appenzellerwith a node value of 89. Which of these is more human-like? To answer this question, let us look at what eachsystem is doing logically. In the VP-Expert system,two of the three rules fired: one recommended Ital-ianJFontina and the other said Appenzeller. The thirdrule failed, so VP-Expert could gather no informationfrom that rule. Therefore VP-Expert concluded rulesIb and 2 fired, so we are about 50-50. The VP-Expertsystem, like most commercially available back-chainingexpert system shells, uses modns ponens logic. Withthis type of logic we can evaluate the truth value of theconclusion, if we know the truth value of the premise.For example in this rule:
IF Preference = PungentTHEN The-Cheese = Limberger
If we know that the person prefers pungent cheese thenwe can recommend Limberger. However, with modus po-nens we cannot go backward. For example, if we knowthat the recommended cheese is not Limberger, we knownothing about the person's preference. Furthermore, ifwe know that the recommendation was Limberger, westill do not know what the person's preference was be-cause some other rule could have caused the recommen-dation to be Limberger.
However, there are other types of logic. Some expertsystem shells use modus tolans logic. This is similar toif and only if (iff) rules. With modus tolans if you canprove that a conclusion is false then you know that thepremise is false. For example for the rule:
IF no gasOR no sparkOR starter badTHEN car will not start.
We can go forward, like modus ponens: if we find outthat the car has an empty gas tank we can concludethat the car will not start. However, in addition, if wefind out that the car does start, then with modus tolanslogic, we can conclude that the car has gas, has sparkand the starter is good.
We do not know what type of logic the neural networkuses, but it is not modus ponens or modus tolans. Theneural network saw that rule la was false. Therefore itconcluded that Italian-Fontina was not to be preferred.Hence it decreased the certainty for this cheese. Its rec-ommendation was therefore Appenzeller, The neuralnetwork, which considers all of the information storedin its connections, not just the rules that fire, gave dif-ferent certainty than the traditional expert system. Wehave not done a post mortem dissection of the neuralnet, so we cannot say exactly how the output valueswere derived, but they seem to be more human-like.
Human experts often have great difficulty providingcertainty factors to the knowledge engineer. We suggestthat this might be a good use of a neural network. Let itprovide numbers to help human experts formulate cer-tainty factors for their knowledge. These certainty fac-tors could then be used in a traditional expert system.
Usually neural network node values are pretty closeto traditional expert system certainty factors. How-ever, as previously stated, we have found three instanceswhere the neural network node values behaved differ-ently from traditional expert system certainty factors.We discussed these in the sections titled gradual learn-ing, continuous output and global knowledge represen-tation. Furthermore, we found that if an example in thetraining set exactly matched an example in the test set,then the node values of the neural network based ex-pert systems and the certainty factors of the traditionalexpert systems were the same.
10. LesionThe knowledge is widely distributed among the connec-tions in a neural network-based expert system. Becauseof this, damage to a few connections need not impairthe overall performance of the network. This is possi-ble because of the highly parallel nature of neural net-works that is analogous to biological neural networks,To demonstrate the degree of robustness of a network,the neural network-based Cheese Advisor was used. Theconnections from input layer to the first hidden layer are
Internationa) Journal of Neural Networks, Vol, 1, No. 4, October 1989 219

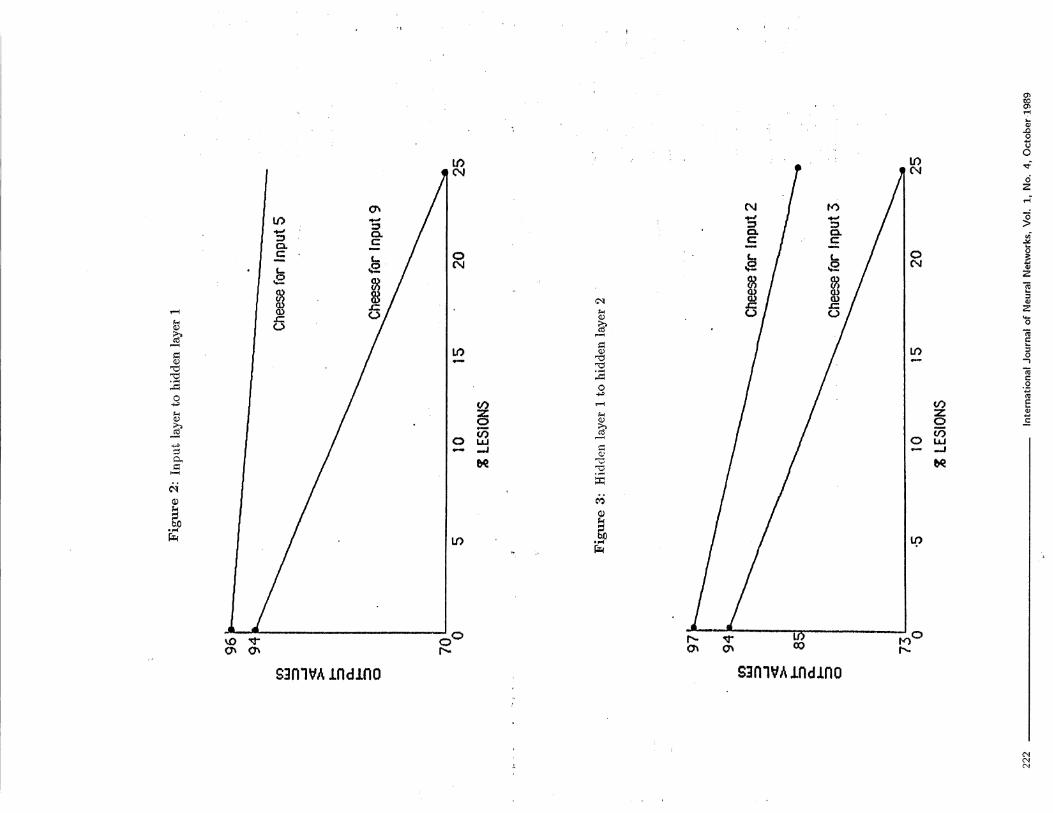
analogous to the axons of a sensory system of a humanbeing. The connections between hidden layer 1 and hid-den layer 2 are analogous to CNS interconnections andthe connections from hidden layer 2 to the output layerare analogous to axons of the motor system. All theconnections in the network had weights ranging from -5to 5, A lesion was afflicted on a connection by settingits weight to 0, Starting at the top left hand corner ofthe weight matrix, the connections were systematicallylesioned in increments of 5% of the total number of con-nections. The effect of varying degree of lesion on theconnections from input layer to hidden layer is shown inFigure 2,
The network was given the same 10 input vectors af-ter each increase in the amount of lesion. Reducing theweight values to 0 for some of the 900 weights betweeninput and the first hidden layer caused the final certaintyfor recommended cheese for some input vectors to de-crease more than others. For example Figure 2 showsthe input vectors that were affected the most, and theleast, vectors 9 and 5 respectively. This is similar towhat would happen as a result of a lesion in a biologi-cal system. The vectors that used the values that werelesioned out would be affected more than those that didnot.
Figure 3 shows the effects pf lesions in between the twohidden layers. As expected, different input vectors arenow rnbs^t and least affected. Vectors 3 and 2 respectively.More importantly we see that the effects are distributedmore evenly than in Figure 2, The most affected vectoronly drops to 73 (versus 70 for Figure 2) and the leastaffected vector drops all the way down to 85 (versus 93for Figure 2), These effects are also similar to lesionsin biological systems. Sensory lesions affect one aspectmore than others. But CNS lesions do not have suchprecise effects. Effects of CNS lesions are more generalor diffused.
In traditional expert systems, to make deficits similarto the sensory lesions, we could remove a few questions.If an input vector needed to invoke fliat question, thena deficit would be noticed. If it did not need that ques-tion no deficit would be seen. This is similar to neuralnetwork performance except that the degradation of theneural network is gradual and that of the traditional ex-pert system is abrupt.
Similarly, lesions in the motor output of a neural net-work would be akin to erasing the output advice of atraditional expert system. However, there seems to beno analog of CNS lesions in traditional expert systems.There are no rules that you can erase that will affect, allinput vectors marginally, without causing major effectsin some.
11. Sparse input layer
The Flower Planning Guide was an expert system cre-ated using a neural network to give suggestions on theflowers for a garden based on: color, season, averageheight, flowering time and shade tolerance. The exam-ples used to train this system are shown in Table 10.
This table has five attributes, and one of them, aver-age height, has 33 possible values, ranging from 4 to 36inches. Therefore, we tried to create a network with aninput layer of size (33 x 5). Experience seems to indi-cate that the smallest edge of the hidden layer shouldbe at least as big as the biggest edge of the input layer.This would have required an hidden layer of 33 by 33.The output layer has to be (1 X 25) because 25 differ-ent flowers are specified. Such a neural net would haverequired 206910 connections, and with only 4 Mb ofRAM we were limited to 60000 connections. Therefore,we restricted the values for average height to be evennumbers, and an input layer of size (17 x 5) was built.The hidden layer was of size (17 x 17) and the outputlayer was (1 x 25). There were 31 790 connections in thisnetwork. This expert system correctly learned all 31 ex-amples. However, after 336 passes through the inputtraining file, which took 23 hours, the total root meansquared (rms) error was still decreasing.
We believe this long learning time was caused byjthesparse use of the input layer. In this network only ^theattribute average height used all the 17 units in its lowto encode information about different flowers. The restof the attributes all had less than six values. So the fullinput layer was not completely used by these attributes.
To eliminate the effect of sparse input layer, we madeanother network in which the different attributes formeda linear input vector. There were 30 units representingthe total number of values of all attributes. There weretwo values for life span, five values for color, three forflower season, 17 for average height, and three for shadetolerance. So the input layer for the network was of sige(30 x 1), the hidden layer was (17 x 17) and the outpuolayer was (25 x 1). However, this network got caughtin a local minimum during training; the total rms errorquickly dropped to 0,19, but then it stayed there forever(actually we stopped it after 18 hours).
We used several different techniques to shake networksout of local minima.
1. We added input noise that decayed away after a fewcycles, and then we started retraining,
2. We damaged some weights, and then started re-training,
3. We damaged weights and added input noise, andthen started retraining.
220 international Journal of Neural Networks, Vol, 1, No. 4, October 1989
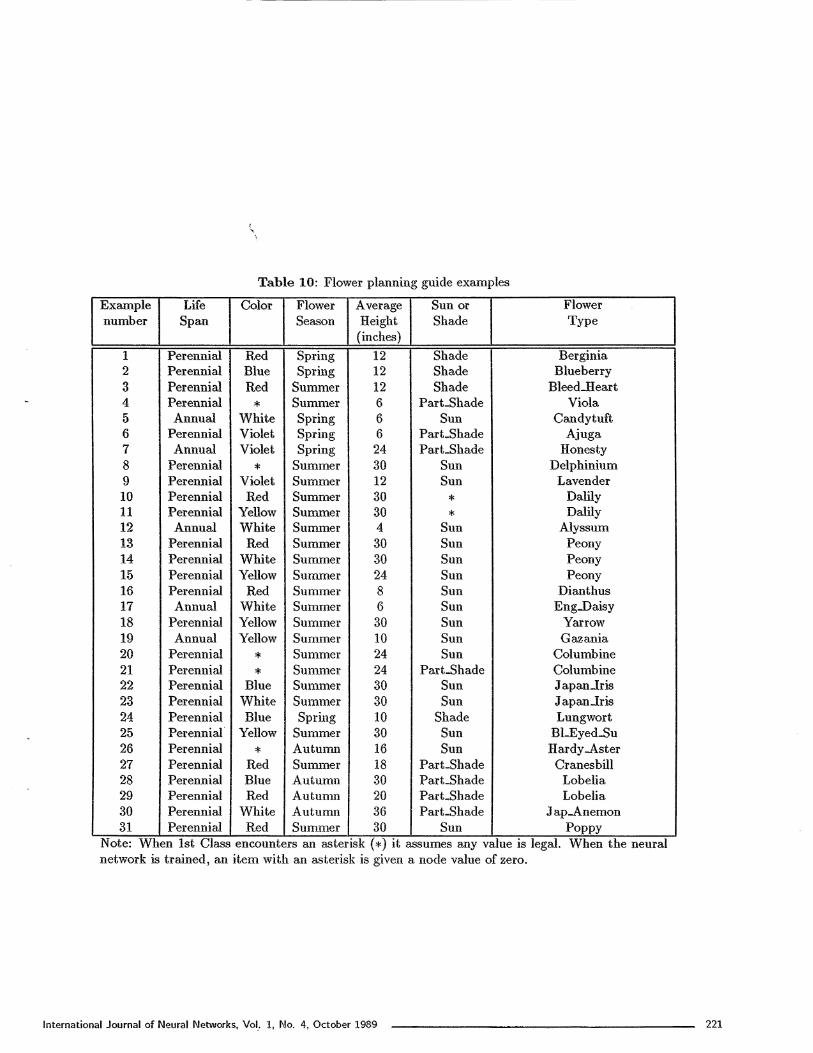
Table 10: Flower planning guide examples
Examplenumber
12345678910111213141516171819202122232425262728293.031
LifeSpan
PerennialPerennialPerennialPerennialAnnual
PerennialAnnual
PerennialPerennialPerennialPerennialAnnual
PerennialPerennialPerennialPerennialAnnual
PerennialAnnual
PerennialPerennialPerennialPerennialPerennialPerennialPerennialPerennialPerennialPerennialPerennialPerennial
Color
RedBlueRed
*WhiteVioletViolet
*VioletRed
YellowWhiteRed
WhiteYellow
RedWhiteYellowYellow
**
BlueWhiteBlue
Yellow*
RedBlueRed
WhiteRed
FlowerSeason
SpringSpring
SummerSummerSpringSpringSpring
SummerSummerSummerSummerSummerSummerSummerSummerSummerSummerSummerSummerSummerSummerSummerSummerSpring
SummerAutumnSummerAutumnAutumnAutumnSummer
AverageHeight(inches)
12121266624301230304303024863010242430301030161830203630
Sun orShade
ShadeShadeShade
Part-ShadeSun
PartJShadePart-Shade
SunSun
**
SunSunSunSunSunSunSunSunSun
Part-ShadeSunSun
ShadeSunSun
Part-ShadePart-ShadePart-ShadePart-Shade
Sun
FlowerType
BerginiaBlueberry
Bleed-HeartViola
CandytuftAjuga
HonestyDelphinium
LavenderDalilyDalily
AlyssumPeonyPeonyPeony
DianthusEngJDaisy
YarrowGazania
ColumbineColumbineJapan JrisJapanJrisLungwort
BLEyed-SuHardy-AsterCranesbill
LobeliaLobelia
Jap_AnemonPoppy
Note: When 1st Classnetwork is trained, an
encounters an asterisk (*) ititem with an asterisk is given
assumes any value is legal. When the neurala node value of zero.
International Journal of Neural Networks, Vol. 1, No. 4, October 1989 221
OUTPUTVALUES OUTPUT VALUES
oO-J COm
II
$
0
4i
O
W
fflS-"
I
O-
1
a1toI-H
3
OJ3-

4. We set the learning rate for the input-to-hiddenlayer higher than the hidden-to-output layer andtrained the network until a plateau was reached,then we lowered the learning rate and proceeded toretrain. Often these techniques had to be repeatedfive or six times.
When we used these techniques on the (30 x 1) inputvector network, it learned 25 of the 31 examples andthe rms error dropped to 0.09, Therefore, we concludethat the linear input array is satisfactory, but it is notsuperior to the (17 x 5) input layer. Perhaps the problemwas that the edge of the input layer was larger than thatof the hidden layer.
In summary, the network with the (17x5) input layerwas convenient, because each attribute had its own row.This network worked well but wasted a lot of connec-tions with unused inputs. In an attempt to amelioratethis problem we changed the input layer to (30 x 1),but this network did not perform as well as the networkwith the (17x 5) input layer. It seems that we could nowtry several other configurations for the input layer, e.g.(10 x 3) or (6 x 5). However, rather than discuss theseother configurations, let us now look at a different wayof encoding the average height information. Instead ofbinning the average height data so that only one of the17 input units can be active at a time, let us encode theaverage height as a binary number so that from zero tosix input units will be active. In this representation thebinary number 0 is encoded with -0.5 and the binary 1is encoded with + 0.5. Table 11 shows this encoding forthe Viola, example 4 of Table 10. The average heightfor this example is six inches or 000110 binary, as shownin the fourth row of the following table.
When this binary coding was applied to the networkwith a (17 x 5) input layer, a network with a (6 x 5)input layer illustrated in Table 11 was produced. Thisnetwork also had problems getting stuck in local minimaduring training. It learned only 25 of the 31 examples.For completeness we also Lried the other combination;we applied the binary coding to the (30 x 1) input layernetwork to produce a network with a (19x 1) input layer.It also got stuck in local minima and it learned only 22of the 31 examples. Therefore we have shown that theshape of the input layer is important. We have not seensimilar reports in the literature.
So, summarizing this section, we can say that the net-work with a (17 x 5) input layer was the best. Networkswith linear input layers or binary coding did not workas well, unfortunately we cannot explain why, However,the techniques of using linear input layers and binarycoding worked well for our smaller Wine Color Advisor.As a second summarizing point we note that our pre-vious sections showed that a neural network may be an
Table 11: Input layer with binary coding for height
AttributesLifeSpan
Color
FlowerSeason
AverageHeight
ShadeTolerance
1+0.5
+0.5
-0.5
-0,5
-0,5
2-0.5
+0.5
+0.5
-0.5
+0.5
Values3 4
0.0
+0.5
-0.5
-0.5
-0.5
0.0
+0.5
0.0
+0.5
0.0
50.0
+0.5
0.0
+0.5
0.0
60.0
0.0
0.0
-0.5
0.0
appropriate tool for problems with discrete values forthe attributes, However, this flower selection system il-lustrates that they may be inappropriate for problemswhere the attributes have a continuous distribution ofvalues, such as weight, height and temperature, unlessthese attributes can be binned into a small number ofranges.
12. Time for training
The expert systems we created using a neural networkrequired 15 minutes to 23 hours for training. As thenumber of units in the network increased, the time fortraining also increased. This is due to the fact that allthe networks were simulated in software and trained ona sequential machine. The inherent property of paral-lelism in neural networks cannot be fully exploited ifthey are trained on this type of machine. This is a dis-advantage of a neural network-based expert system ifcreated in a sequential machine. The induction-basedsystems took only a few seconds to form the rule basefrom the examples. However, hardware implementationof neural networks which will consist of highly intercon-nected electronic components can be used to train itmuch faster. In this case, neural network-based expertsystems can be used for many real time applications.
International Journal of Neural Networks, Vol. 1, No. 4, October 1989 223

13. Comparison of experttern tools
sys-
Neural networks use a different technology for buildingexpert systems than other expert svstem shells. Whenusing a neural network-based expert system the domainneed not be as well understood as when using traditionalexpert system shells, Experts are not required to detailhow they arrive at a solution, since the system learnsthis on a stimulus/response basis and self configuresinto a structure capable of solving the problem. Themost significant advantage of using this type of expertsystem is that it requires no explicit algorithms or soft-ware. Hardware implementation of this technology willresult in more speed, reliability (robustness) and real-time adaptivity. However, there is no formal method tovalidate the results of this system. This is one major dis-advantage. Another problem with neural network-basedexpert systems is that the networks are not adaptive togrowth in problem size. Also the number of connectionsand thus memory and time requirements tend to growexponentially (especially in a sequential computer).
In this study we made expert systems using four com-mercial software packages: (1) M.I by Teknowledge, (2)VP-Expert by Paperback Software International, (3) 1stClass by Programs in Motion, and (4) AN Sim by ScienceApplications International Corporation. Once again weexplicitly note that ANSim was not designed to makeexpert systems so some of these comparisons may beunfair. To make a pinpoint comparison between thesefour tools, we made the same expert system using allfour tools. We chose to do this with the Wine ColorAdvisor. The results are shown in Table 12.
14. Putting it all together
In general neural networks were not designed to makeexpert systems. However, we have shown that they canbe used to successfully create expert systems. We haveshown several examples in this paper and we know ofone commercial system [5]. Although the expert sys-tems shown in this paper had only 13 to 31 examples,in general neural networks work better if they have farmore examples.
To make the expert systems we had to overcome someobstacles. For example, in this paper we showed how wetreated unknown and unused inputs. We also comparedand contrasted neural network-based expert systems toexpert systems made with traditional shells. A neuralnetwork-based approach may give us a system that es-sentially builds its rule base from examples given by thehuman expert. But unlike conventional expert systems,
this can be achieved with minimum of outside interven-tion, so that over time the network gradually takes overthe task of the human expert, However, we cautionthat the rules and generalizations made by the neuralnetworks are not open to examination, although toolsfor examining such networks will surely be forthcoming.Even if some of the connections are damaged the neuralnetwork will still give a reasonable answer. This is notthe case with the traditional expert system shells whereif some of the rules were taken out of the knowledge base,the system failed. They may not even give an answerat all. The neural networks behaves much better witherroneous or incomplete input than a shell-based expertsystem because it uses all the knowledge encompassed inits connections. In fact, neural networks-based expertsystems can be used to help suggest certainty factorsto humans. A neural network-based expert system willincrease the knowledge represented in its connectionsover time by learning from more examples. However,we again caution that we could not determine how thenode values were derived by the neural network.
15 * Acknowledgement
Research of this paper was partially supported by GrantNr. AFOSR-88-0076 from the Air Force Office of Scien-tific Research.
16. References
[1] J.J. Hopfield and D.W, Tank, 'Computing with neu-ral circuits: a model7, Science, 233, 1986, pp. 625-633.
[2] M. Caudill, 'Neural networks primer, part IV, AIExpert, 38, 1988, pp. 61 - 66.
[3] D.E. Rumelhart, G.E. Hinton and R.J. Williams,'Learning representations by back-propagating er-rors', Nature, 323, 1986, pp. 533 - 536.
[4] P.H. Winston, Artificial Intelligence, Addison-Wesley, 1977.
[5] E. Collins, S. Ghosh and C. Scofield, 'Risk Analysis',in DARPA Neural Network Study, 1988, FairfaxVA, Armed Forces Communications and Electron-ics Association (AFCEA), pp. 429 - 443.
224 International Journal of Neural Networks, Vol. 1, No. 4, October 1989
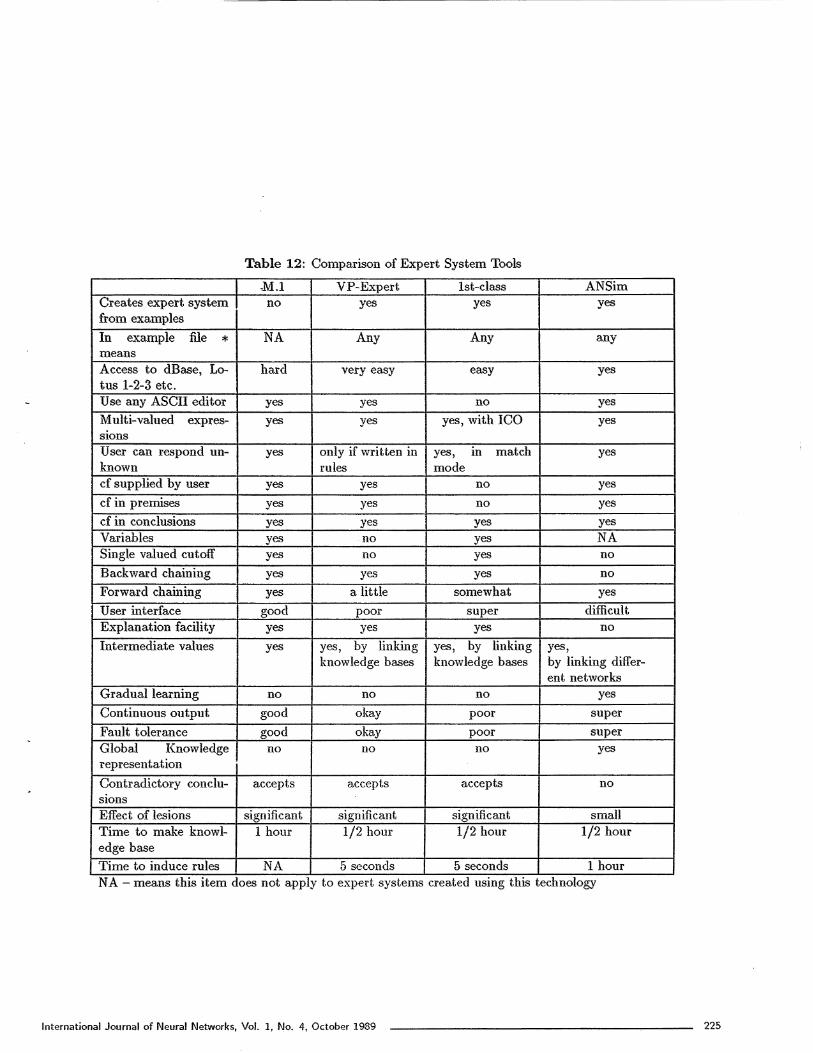
Table 12; Comparison of Expert System Tools
Creates expert systemfrom examplesIn example file *meansAccess to dBase, Lo-tus 1-2-3 etc.Use any ASCII editorMulti-valued expres-sionsUser can respond un-knowncf supplied by usercf in premisescf in conclusionsVariablesSingle valued cutoffBackward chainingForward chainingUser interfaceExplanation facilityIntermediate values
Gradual learningContinuous outputFault toleranceGlobal KnowledgerepresentationContradictory conclu-sionsEffect of lesionsTime to make knowl-edge baseTime to induce rules
M.Ino
NA
hard
yesyes
yes
yesyesyesyesyesyesyes
goodyesyes
nogoodgood
no
accepts
significant1 hour
NA
VP-Expertyes
Any
very easy
yesyes
only if written inrules
yesyesyesnonoyes
a littlepooryes
yes, by linkingknowledge bases
nookayokayno
accepts
significant1/2 hour
5 seconds
Ist-classyes
Any
easy
noyes, with ICO
yes, in matchmode
nonoyesyesyesyes
somewhatsuper
yesyes, by linkingknowledge bases
nopoorpoorno
accepts
significant1/2 hour
5 seconds
ANSimyes
any
yes
yesyes
yes
yesyesyesNAnonoyes
difficultno
yes,by linking differ-ent networks
yessupersuper
yes
no
small1/2 hour
1 hour |NA - means this item does not apply to expert systems created using this technology
International Journal of Neural Networks, Vol. 1, No, 4, October 1989 225

The authorsA. Terry Bahill
A. Terry Bahill was born in Washington, PA, on Jan-uary 31, 1946. He received a BS in electrical engineeringfrom the University of Arizona, Tucson, in 1967, an MSin electrical engineering from San Jose State University,in 1970, and a PhD in electrical engineering and com-puter science from the University of California, Berkeley,in 1975.
Since 1984 he has been a Professor of Systems and in-dustrial Engineering at the University of Arizona in Tuc-son. His research interests include systems engineeringtheory, modelling physiological systems, head and eyecoordination of baseball players, and expert systems.
Dr. Bahill is a member of the following IEEE soci-eties: Systems, Man and Cybernetics; Engineering inMedicine and Biology; Computer; Automatic Controlsand Professional Communications.
Rafeck Kottai
Rafeck Kottai was born in India on 28 May, 1964.He received a BTech degree from the Government En-gineering College, Trichur, India, in 1986, and an MSin systems engineering from the University of Arizona,Tucson, in 1988, He is now working as a systems engi-neer in San Francisco, CA.
226 International Journal of Neural Networks, Vol. 1, No. 4, October 1989





























