Embed Size (px)
DESCRIPTION
Experimental Evidence on Partitioning in Parallel Data Warehouses. Pedro Furtado Prof. at Univ. of Coimbra & Researcher at CISUC DEI/CISUC-Universidade de Coimbra Portugal. Context. Parallelism used for major performance improvement in large Data warehouses - PowerPoint PPT Presentation
Citation preview

1
Experimental Evidence on Experimental Evidence on
Partitioning Partitioning
in Parallel Data Warehousesin Parallel Data Warehouses
Pedro FurtadoPedro FurtadoProf. at Univ. of CoimbraProf. at Univ. of Coimbra
& Researcher at CISUC& Researcher at CISUCDEI/CISUC-Universidade de CoimbraDEI/CISUC-Universidade de Coimbra
PortugalPortugal

2
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
ContextContext
• Parallelism used for major performance improvement in large Data warehouses
• Using simple low-cost shared-nothing architecture– Without any efficiency requirements on Network or Nodes
NODE PARTITIONED DATA WAREHOUSE
• Minimize inter-node data exchange requirements– Horizontally fully-partition facts (largest), rest of relations are
replicated
• Hope to obtain near-to-linear speedup

3
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
to run it n times faster …“Divide to conquer”
- Horizontally Partition Large Facts (randomly)
into n Nodes
- Replicate other Relations (Small Dimensions?)
Node 1
D2D1
D3 D4
Sales
Node 2
Sales
D2D1
D3 D4
Node 3
D2D1
D3 D4
Sales
Sales
D2D1
D3 D4

4
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
Why Replicate Dimensions?Why Replicate Dimensions?• We replicated because we would not need to repartition
nodesall
jn
n
_
1njAAA
nAAA
R R j
Fact
R R Fact
21j1
211
nodesall
jn
n
_
1nAAA
nAAA
R R j
Fact
R R Fact
211
211
Wouldn´t work with partitioned dimensions:
…and you can do other ops independently as well

5
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
Query processingQuery processing
SUM(X) over 1/n FACT, Ds GROUP BY dims
SUM(X) over 1/n FACT, DsGROUP BY dims
SUM(X) over 1/n FACT , DsGROUP BY dims
SUM(SUMs) SUM(X) over FACT, dims GROUP BY dims

6
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
Query Processing StepsQuery Processing Steps
RewriteQuery
Send Query
Compute Partial Result
Send Partial Results
Apply MergeQuery
Computing Nodes
1. 2.
3. 5.
6.
Redistribute
Submitter Node
Repartition
4.
7.
7
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
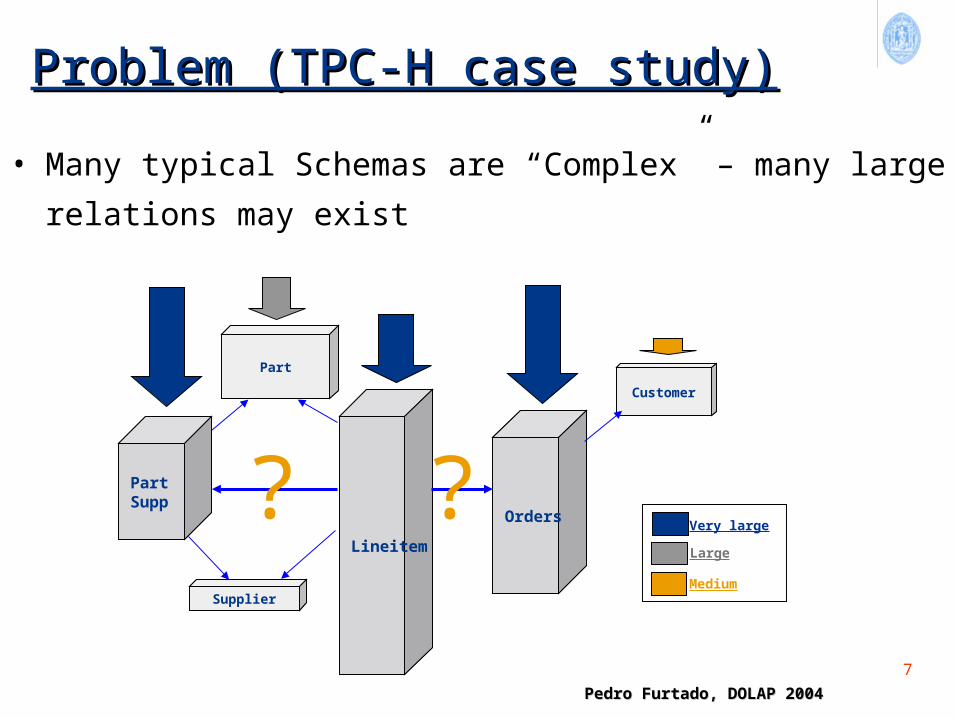
Problem (TPC-H case study)Problem (TPC-H case study)
PartSupp
Supplier
Customer
Orders
Lineitem
Part
Very large
Large
? ?
• Many typical Schemas are “Complex” – many large
relations may exist
Medium

8
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
Problem StatementProblem Statement
• Divide by N … would expect N times faster - Linear Speedup (LS)
• However, we don´t get the LS

9
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
Our Major ContributionsOur Major Contributions
• Show these problems experimentally – performance evaluation benchmark TPC-H: We EXPLAIN AND
ILLUSTRATE the LARGE RELATIONS problem
• Identify simple modifications to improve results
• Analyze the modifications experimentally

10
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
Partitioning Facts (Largest)Partitioning Facts (Largest)
• LI + PS Partitioned
PS
S
C
O Li
P
PS
S
C
O
Li
P
S
C
O
Li
P
PS
Node 1
Node N

11
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
• Generated TPC-H 50GB into 1 and 25 nodes
• Used PCs (Pentium III 866 MHz CPU) 512MB RAM
• Oracle 9i, tuned initial setting
• TPC-H 22 query set
• Measured Response Time: 1 node against 25 nodes
• We show that the speedup underachievement is explained mostly
by the size of replicated dimensions

12
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
Experimental ResultsExperimental Results
0 10 20 30
Q6
Q1
Q15
Que
ry
Speedup
LS Speedup: 25-30
0 5 10 15
Q19
Q11
Q14
Que
ry
Speedup
• Only a few queries exhibited near-to-LS!
Medium Speedup 6-15
0 1 2 3 4 5 6
Q7
Q5
Q9
Q3
Q16
Q12
Q10
Que
ry
Speedup
Low Speedup 2-6
0 0.5 1 1.5 2
Q8
Q22
Q4
Q13
Q21
Q2
Que
ry
Speedup
Very Low Speedup 0.4-1.9

13
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
Some had Linear Speedup…Some had Linear Speedup…
0 10 20 30
Q6
Q1
Q15
Que
ry
Speedup
LS Speedup 25-30
S
C
O
Li
P
Q15:
PS
•S is reasonably small relative to Li/N
S
C
O
P
Q1, Q6:
LiPS
•Access only fragments (Li/N)

14
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
Others had smaller speedup…Others had smaller speedup…
Medium Speedup 6-15
S
C
O
Li
P
S
C
O
Li
P
Q14, Q19: Q11
0 5 10 15
Q19
Q11
Q14
Que
ry
Speedup
PSPS
•P is not small relative to fragment (Li/N) •S is not small relative to PS/N

15
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
What Happened…What Happened…
• With N nodes we would like to:– process 1/N of the data, have about N times speedup
• However, we have replicated relations…
• The amount of speedup degradation depends on the size of
R2 relative to R1/N
21
1,21 RR
Nconst
N
R
N
R
constRN
R ,
21

16
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
Low Speedup Queries:Low Speedup Queries:Speedup 2-5.5
S
C
O
Li
P
S
C
O
Li
P
Q3, Q5, Q7, Q10, Q12:
Q16:
PS
PS
•O is large relative to Li/N
•P is large relative to PS/N0 1 2 3 4 5 6
Q7
Q5
Q9
Q3
Q16
Q12
Q10
Que
ry
Speedup
S
C
O
Li
P
Q9:
PS

17
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
Very Low or No Speedup Very Low or No Speedup Queries:Queries:
Speedup 0.4-2
S
C
O
Li
P
Q13, Q22:
PS
•Process only replicated relations
0 0.5 1 1.5 2
Q8
Q22
Q4
Q13
Q21
Q2
Que
ry
Speedup
S
C
O
Li
P
Q8:
PS
•Includes all replicated relations
Q4, Q21, Q2:
•Scenarios Similar to “Slow Queries”

18
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
What Happened…What Happened…
• Not only includes replicated relations…
• But also replicated relations included are very large in
comparison to fragments!
constRN
R ,
21
const
N
R
N
R ,21
N
RR 1
2

19
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
The same in pictures…The same in pictures…
• Medium speedup
• Low speedup
S
C
O
Li
P
PS
S
C
O
Li
P
PS
•O is large relative to Li/N
• Large speedup
S
C
O
Li
P
PS
• No speedup at all
S
C
O
Li
P
PS
•O is large relative to Li/N

20
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
Back to Partitioning Alternatives…Back to Partitioning Alternatives…• Placement alternatives: relation in Single Node vs Replicated (all nodes) vs
Partitioned
• Partitioning function (Round-robin/Random, Range, HASH)
• Choice of Partitioning attributes
ProductSupplyHistory
(PS)
Orders(O)Lineitem
(LI)
? ?PS_key
O key
Customer(C)?
C key
• Repartitioning = re-hash by exchanging rows between nodes
• When you partition more than 1 rel => will probably need to
repartition
• e.g.: If you partition LI and O by O_KEY = “equi-partitioned”
… LI join PS needs repartitioning of LI
… O join C needs repartitioning of O

21
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
Lets Review Related Work…Lets Review Related Work…• Replicate all but one relation – PRS [Yu et al., TKDE89]
– Similar to what we did: replicated all except LI
[Yu et al., TKDE89]: “Partition strategy for distributed query processing in fast local
networks”
• Partition using dependencies - PLACEMENT DEPENDENCY [Liu et al, ICDE96]
– e.g. partition ORDERs and Co-locate its LINEITEM rows (LI is the dependant relation)
[Liu et al, ICDE96]: “A Distributed Query Processing Strategy Using Placement Dependency”
[Chen et al, ICPADS 2000]: “An Efficient Algorithm for Distributed Queries Using
Partition Dependency”.
• Parallel Hash Join and Optimization - PHJ– Relations are hash-partitioned, Repartitioning required to re-hash in order to JOIN
[DeWitt et al., VLDB11]: “Multiprocessor Hash-Based Join Algorithms”
[Liu et al, EDBT96]: “A Hash Partition Strategy for Distributed Query Processing”
[Kitsuregawa et al., 1983 ], “Application of hash to database machine and its architecture”
[Shasha et al., TODS91]: “Optimizing Equijoin Queries In Distributed Databases … Hash
Partitioned”.
• Workload-based Partitioning and Placement– Determine best partitioning attributes automatically, based on the workload
• [Daniel Zilio et al. 1994], “Partitioning Key Selection for a Shared-Nothing Parallel Database System”
• [Rao et al., SIGMOD 2000]: Automating physical database design in a parallel database.

22
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
Local Replicated Join:Local Replicated Join:
• Join Fragment to replicated relation locally, no data
exchanged
• One Relation must be Replicated – E.g. LI(O_KEY), O()
Costlocal replicated join=
N
RR 2
1
N nodes, relations R, constant

23
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
Local Partitioned JoinLocal Partitioned Join• Join fragments locally, no data exchanged
• Relations must be equi-partitioned– E.g. LI(O_KEY), O(O_KEY)
Costlocal join=
N
R
N
R 21
N nodes, relations R, constant

24
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
Repartition JoinRepartition Join
• Re-hash with data exchange, then join locally
• Relation Partitions are not co-located– E.g. O(O_KEY), C(C_KEY)
CostRepartition join=
N
R
N
R
N
R
N
R 212
11
, constant weight factors
Depends on network configuration

25
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
Proposed SolutionProposed Solution
• “Very Small” Dimensions– Replicate
– “Very small” depends on relation sizes and nº of nodes
• Non-small Dimensions– Hash-Partition by PRIMARY KEY
• because they “always” join based on PK (with facts)
• like in placement-dependency, we take advantage of invariant
• Facts– Find hash-partitioning attribute that minimizes repartitioning costs
– Reasonable approximation: most frequent equi-join attr.

26
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
Result of Partitioning (TPC-H)Result of Partitioning (TPC-H)
O Li
P
PS
O_KEY
S
C
O_KEYP_KEY
P_KEY
Local Join (equi-partitioned)
Replicated Join (with small dimension)
Repartitioned Join
27
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
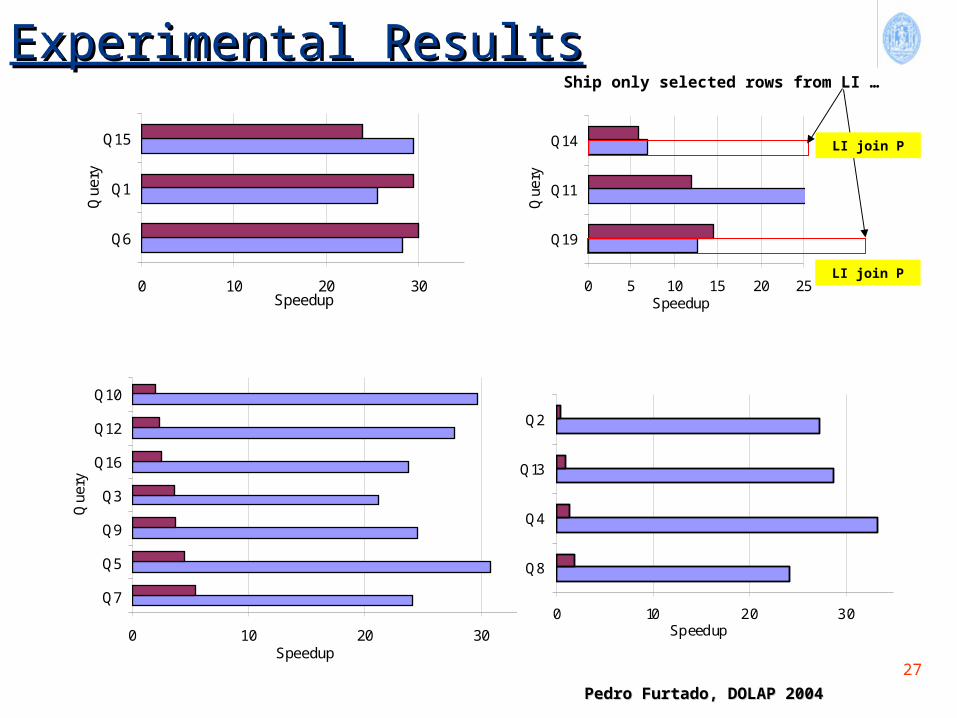
Experimental ResultsExperimental Results
0 10 20 30
Q6
Q1
Q15
Que
ry
Speedup0 5 10 15 20 25
Q19
Q11
Q14
Que
ry
Speedup
0 10 20 30
Q7
Q5
Q9
Q3
Q16
Q12
Q10
Que
ry
Speedup
0 10 20 30
Q8
Q4
Q13
Q2
Speedup
Ship only selected rows from LI …
LI join P
LI join P

28
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
Repartition VS Total RuntimeRepartition VS Total Runtime
• TC = total runtime
• RC = repartition time
• Repartition time is reasonably small…
• Depends on: number of nodes + selectivities
– (can be very dependent on selection conditions of specific query)
0
100
200
300
Q8 Q9 Q14 Q19Queries Requiring Repartitioning
runt
ime
(sec
s)
TC RC
0%10%20%30%40%
Q8 Q9 Q14 Q19Queries Requiring Repartitioning
% o
verh
ead
RC/TC

29
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
ConclusionsConclusions
• We have analyzed a basic partitioning strategy (PRS-like)– Largest Relation is partitioned, the others are replicated
– The speedup is totally unsatisfactory for many queries
• We analyzed why this happens: explained by access patterns to
replicated relations
• We tried very simple partitioning alternative– Only very small relations are replicated
– Dimensions are partitioned by Primary Key
– Hash-partition facts, partitioning key = most frequent join attr
• We have shown that it works well – prevents very low speedup
– provides near to linear speedup for most queries

30
Pedro Furtado, DOLAP 2004 Pedro Furtado, DOLAP 2004
•Thank You!
•Questions?
• www.eden.dei.uc.pt/~pnf





























