Embed Size (px)
Citation preview

Experimental Evaluation of Latency Induced inReal-Time Traffic by TCP Congestion Control
AlgorithmsAlana Huebner1
Centre for Advanced Internet Architectures, Technical Report 080818ASwinburne University of Technology
Melbourne, [email protected]
Abstract—This report contains an experimental eval-uation of the impact that congestion control algorithmsNewReno, HTCP and CUBIC have on the latency of VoIPtraffic. It was found that when a TCP flow and VoIP flowshare a bottleneck link the induced delay in the VoIP flowis related to the growth of the congestion window. CUBICinduced the highest average latency in the VoIP flow andHTCP the least.
Index Terms—TCP, NewReno, CUBIC, HTCP, VoIP
I. INTRODUCTION
The short comings of NewReno under particular trafficconditions has lead to the development of new TCP con-gestion control (CC) algorithms. The NewTCP project[1] aims to provide independent real-world evaluation ofthese competing CC algorithms.
The performance of a CC algorithm is commonlyevaluated by its interaction with other TCP flows withmetrics such as fairness, responsiveness and conver-gence. CC algorithms may also be evaluated by theirinteraction with unrelated and non-reactive traffic suchas real-time traffic.
This report will investigate the latency that a TCPflow induces in a VoIP flow. This report’s work extendsprevious empirical evaluation of latency induced in VoIPtraffic by NewReno and HTCP under FreeBSD [2].NewReno and HTCP under FreeBSD will be furtherinvestigated and the evaluation will be extended toinclude three congestion control algorithms under Linux,NewReno, HTCP and CUBIC, enabling a comparisonbetween operating systems.
1The author is currently an engineering student at SwinburneUniversity of Technology. This report was written during the author’swinter internship at CAIA in 2008.
H-TCP and CUBIC are algorithms designed to addressNewReno’s poor performance over high bandwidth andlong distance paths, as a result this report is mainlyconcerned with induced latency over large bandwidth×delay product (BDP) paths.
The dynamic nature of CC algorithms impacts on theoccupancy of network queues. This report will show thatqueue occupancy is related to TCP’s congestion window,and that the induced delay experienced by VoIP trafficis proportional to the queue occupancy.
Section 2 will begin with an brief discussion of con-gestion control algorithms and an overview of NewReno,HTCP and CUBIC.
Section 3 will cover the tools that were essential tothe experimental method.
The experimental set up will be detailed in Section4 with a description of the of the NewTCP testbed,hardware and software configuration and TCP tuning.
Section 5 describes the experimental method and howstatistics were collected.
An analysis of the observed behaviour of each al-gorithm will be performed in Section 6. This sectionwill also discuss differences between CC algorithmsimplemented under FreeBSD and Linux.
Section 7 will investigate the latency each algorithminduces in VoIP traffic.
Section 8 will conclude and identify areas for furtherwork.
II. CONGESTION CONTROL ALGORITHMS
TCP has four types of congestion control algorithm:Slow Start, Fast Retransmit, Fast Recovery and Conges-tion Avoidance. This report is primarily concerned withcongestion avoidance algorithms.
CAIA Technical Report 080818A August 2008 page 1 of 10

A congestion avoidance algorithm controls the valueof TCP’s congestion window variable cwnd adaptivelyto network conditions. The actual window size used willbe the minimum of the sender’s buffer size, the re-ceiver’s window size and cwnd. Traditionally congestionavoidance follows an Additive Increase MultiplicativeDecrease (AIMD) scheme.
The additive increase phase is generally specifiedin terms of the constant “alpha”, α. During additiveincrease cwnd grows incrementally, gently discoveringthe network’s capacity to support the TCP flow. Acommon approximation described in [3] is to grow cwndaccording to Equation 1 every time a non-duplicateacknowledgement arrives.
cwnd = cwnd +α(SMSS × SMSS)
cwnd(1)
The multiplicative decrease phase is generally spec-ified in terms of the constant “beta”, β, also referredto as the backoff factor. cwnd continues to grow untilcongestion is detected, typically inferred by packet loss.Multiplicative decrease reduces cwnd on packet loss tolessen the flow’s impact on the congested network. Thereduction of cwnd is given by Equation 2.
cwnd = β × cwnd (2)
The AIMD scheme results in cwnd cycling aroundthe capacity of the path. Examples of this behaviour foreach algorithm can be seen in Section VI.
A. NewReno
NewReno [4] is the most common variant of TCP.NewReno modified the Fast Recovery algorithm of stan-dard TCP to include partial acknowledgements. Partialacknowledgements improve the performance of Fast Re-covery when Selective Acknowledgements (SACK) areunavailable. Partial acknowledgements and SACK arejust two of the extensions included in the evolution ofTCP up to NewReno. TCP extensions are well docu-mented in RFC4614 [5].
The AIMD scheme of standard TCP is characterisedby α = 1 and β = 0.5. cwnd increases linearly by oneSender’s Maximum Segment Size (SMSS) every RTTand halves on congestion.
B. H-TCP
H-TCP [6] is a congestion avoidance algorithm de-veloped at the Hamilton Institute in Ireland to improveTCP performance over high-speed and long distance
networks. Unlike NewReno, α and β are no longerconstants.
H-TCP has high speed and low speed modes of op-eration for backwards compatibility with standard TCP.During low speed mode α = 1 causing cwnd to increaselinearly in the same way as NewReno. After one secondhas elapsed since congestion H-TCP enters high speedmode. α becomes a parabolic function of time since thelast congestion event and cwnd grows more aggressively.When the duration of a congestion epoch is less than onesecond, as for low BDP networks, H-TCP never exits lowspeed mode and behaves like NewReno.
To achieve fairness between flows of differing RTTsthrough a common bottleneck, HTCP can utilise RTTscaling [7] to make cwnd growth effectively invariantwith RTT.
H-TCP has an adaptive backoff factor which rangesfrom 0.5 to 0.8. There are two algorithms which controlthe backoff factor, together they try to reach a compro-mise between bandwidth utilisation and responsiveness.
Bandwidth utilisation is maximised by reducing theidle time of the link caused by the reduction of cwndafter congestion. The backoff factor is calculated suchthat the queue has just enough time to drain beforecwnd increases again. The ratio of RTTmin/RTTmax isused in the calculation, where RTTmin is an estimateof the propagation delay and RTTmax is an estimate ofthe maximum additional queuing delay. This algorithmimproves throughput on links with small queues but atthe cost of responsiveness.
To achieve better responsiveness H-TCP can utilisean adaptive reset algorithm. The maximum value ofcwnd that was achieved just before a congestion eventis monitored over time. If cwndmax increases H-TCPdetects that more bandwidth is available and increasesthe backoff factor. If cwndmax decreases H-TCP detectsthat less bandwidth is available and the backoff factor isdecreased, releasing bandwidth to any new flows.
C. CUBIC
The CUBIC [8] congestion avoidance algorithm wasdeveloped by the Networking Research Lab at NorthCarolina State University. Like H-TCP it is also designedfor high-speed and long distance networks. CUBIC is arevision of the BIC algorithm which was found to betoo aggressive towards standard TCP [9]. CUBIC hasbeen the default CC algorithm in the Linux kernel sinceversion 2.6.19.
The cwnd growth is a cubic function of time sincethe last congestion event. CUBIC adaptively controls
CAIA Technical Report 080818A August 2008 page 2 of 10

the cubic function through selection of the inflectionpoint. The maximum value of cwnd recorded just beforecongestion becomes the value of the inflection point forthe next growth cycle. During the next cycle the cwndrapidly increases until it forms a plateau at the inflectionpoint, thus maximising the time spent at the point wherethroughput is highest.
CUBIC’s backoff factor is 0.8. CUBIC’s authors ac-knowledge that this choice was made with the knowl-edge that convergence would be slower than standardTCP, and that they will possibly address the issue withadaptive backoff in a future version of CUBIC. Currentversions of CUBIC somewhat mitigate the problem witha fast convergence algorithm. Fast convergence monitorsthe maximum value of cwnd just before congestionevents, if cwndmax decreases CUBIC will place theinflection point at 0.9 × cwndmax to release bandwidthto new flows.
III. EXPERIMENTAL TOOLS
A number of specially developed tools and patcheswere used to conduct the experiment described in thisreport. They can be downloaded from CAIA’s NewTCPproject web page [1]. Further mention of these tools inthis report refer to the modified versions discussed below.
A. Siftr and Web100
SIFTR [10] is a FreeBSD kernel module that operatesbetween the IPv4 and TCP layers of the network stack.When a TCP/IP packet is processed by the stack thestate of TCP variables are logged to a file. SIFTR allowsTCP statistics to be collected with very fine granularitymaking it ideal for TCP research.
Web100 [11] is a suite of TCP instruments for Linuxcreated for the purpose of optimizing TCP performance.The instruments are implemented in a kernel module andaccessed from userland.
Although each module is different in how and whatTCP statistics they collect, the provide comparable dataafter some post processing of the Web100 output de-scribed in Section V. The most important statistic thesetools allow us to collect is the instantaneous value ofcwnd.
B. Dummynet
Dummynet [12] is a FreeBSD utility for traffic shap-ing and simulating network conditions. It is controlledthrough FreeBSD’s IP firewall (ipfw). Packets are chan-nelled into a dummynet pipe object with a firewall rule.The pipe acts on the traffic to simulate the effects of
bandwidth, delay, packet loss and queue size. A patchdeveloped at CAIA logs statistics about each pipe suchas the occupancy of the pipe’s queue and when packetloss occurs.
C. Iperf
The Iperf [13] utility creates TCP flows between anIperf client and server. As of version 2.0.4 Iperf can beused to specify the congestion control algorithm usedfor a TCP flow. A patch developed at CAIA also allowssend and receive buffer sizes to be configured for a flow.
D. FreeBSD Modular Congestion Control and H-TCPModule
As part of the NewTCP project a light-weight mod-ularised congestion control framework has been devel-oped for FreeBSD 7.0 [14]. Modular congestion controlprovides a means for dynamically loading congestioncontrol algorithms into the TCP/IP stack. There weretwo CC modules available for FreeBSD at the time ofwriting, NewReno and HTCP. The HTCP module wasalso developed at CAIA [15].
IV. EXPERIMENTAL SETUP
A. The Testbed
Experiments were conducted over a testbed configuredin the dumbbell topology shown in Figure 1. The testbedemulates a bottleneck link between two Gigabit Ethernetnetworks.
The router between the networks runs FreeBSD 7.0on an Intel Celeron at 2.80GHz. Dummynet was used tosimulate a bottleneck link with configurable character-istics. All traffic between the networks passed throughtwo dummynet pipes in either direction. The first pipewas configured with a bandwidth and drop tail queue tocreate the congestion point. The second pipe introducedthe propagation delay of the link.
Host A and Host C acted as the sender and receiverof a TCP flow across the link. The hosts are dual-bootLinux 2.6.25 and FreeBSD 7.0-RELEASE. Linux wasinstrumented with Web100. FreeBSD was instrumentedwith the CAIA modular congestion control patch andthe H-TCP module. The specifications of these hosts arelisted in Table I.
Host B is a SmartBits2000 [16] industrial trafficgenerator and network performance analysis and testingsystem. It was used to generate a stream of pseudo VoIPtraffic equivalent to the G.711 encoding standard: 200Byte IP/UDP/RTP packets with inter-arrival times of20ms. The VoIP traffic was sent from Host B to Host D
CAIA Technical Report 080818A August 2008 page 3 of 10

Host ATCP sender
Host BSmartBits
Host CTCP receiver
Host D
EndaceDAG
bw, drop tail queue delay
delay bw, drop tail queue
Gigabit Ethernet
Mirrored traffic
Fig. 1. Logical topology of the TCP Testbed
Motherboard Intel Desktop Board DG965WHCPU Intel Core2 Duo E6320 1.86GHz 4MB L2 Cache
RAM 1GB (1 x 1GB) PC5300 DDR2-667HDD Seagate 250GB ST3250410AS SATA II
NIC Intel 82566DC PCIe gigabit Ethernet (onboard)Intel PRO/1000 GT 82541PI PCI gigabit Ethernet
TABLE ITESTBED PC SPECIFICATIONS
across the bottleneck link. Host D implemented a firewallto make it behave as a sink, accepting traffic from HostB but generating no reply traffic.
All ingress and egress traffic to and from the routerwas mirrored to a Endace DAG 3.7GF high perfor-mance capture card. The DAG host runs FreeBSD 7.0-RELEASE on a dual core Intel Pentium III at 1266MHz.Configuring the DAG card and capturing traffic with itis documented in [17]. The card was configured to timestamp packets with microsecond resolution.
B. TCP Tuning
As participants of the TCP flow Host A and Host Crequire a considerable amount of TCP tuning to revealthe growth of cwnd as determined by the congestioncontrol algorithm. TCP extensions, characteristics of theunderlying operating system and implementation fea-tures all have the potential to obfuscate the behaviourof the algorithm. See [18] for a discussion about TCPtuning for FreeBSD. Configuration options not in Listing1 were left at their default values.
C. H-TCP Tuning
The default operation of H-TCP varies between Linuxand FreeBSD. The features of H-TCP were tuned on
Listing 1 Tuning TCP on FreeBSDBoot loader tuningvm.kmem size=536870912vm.kmem size max=536870912kern.ipc.nmbclusters=32768kern.maxusers=256kern.hz=2000hw.em.rxd=4096hw.em.txd=4096net.inet.tcp.reass.maxsegments=75000htcp load=”YES”sysctl tuningkern.ipc.maxsockbuf=104857600net.inet.tcp.inflight.enable=0net.inet.tcp.hostcache.expire=1net.inet.tcp.hostcache.prune=5net.inet.tcp.recvbuf auto=0net.inet.tcp.sendbuf auto=0net.inet.tcp.tso=0net.inet.ip.fastforwarding=1net.isr.direct=1net.inet.tcp.delayed ack=0net.inet.tcp.reass.maxqlen=13900
Listing 2 Tuning TCP on Linuxethtool -K <experiment interface> tso offsysctl net.ipv4.tcp no metrics save=1
each operation system so that the implementations wouldbehave in the same way.
Adaptive backoff for bandwidth utilisation is enabledand not tunable on Linux, on FreeBSD it is tunablethrough the variable adaptive backoff but disabled bydefault. To enable a comparison between the implemen-tations adaptive backoff was enabled on FreeBSD asshown in Listing 4.
Adaptive reset is only implemented on Linux so itwas disabled as shown in Listing 3. It is controlledthrough the variable use bandwidth switch, which isenabled by default. This feature is not required as thetests involved only a single TCP flow across a constantbandwidth link.
RTT scaling is disabled by default on FreeBSD, but onLinux it is enabled by default. RTT Scaling is also un-necessary for tests involving single TCP flows so it wasdisabled in Linux through the variable use rtt scalingas shown in Listing 3.
CAIA Technical Report 080818A August 2008 page 4 of 10

Listing 3 Tuning H-TCP on Linuxmodprobe -r tcp htcpmodprobe tcp htcp use rtt scaling=0use bandwidth switch=0
Listing 4 Tuning H-TCP on FreeBSDsysctl net.inet.tcp.cc.htcp.adaptive backoff: 1
V. EXPERIMENTAL METHOD
Each test run consisted of a single TCP flow andsingle VoIP flow simultaneously sharing the bottlenecklink. A test run lasted 3 minutes and was performed atleast twice. Additional runs were performed if the testsshowed unexpected results as discussed in Section VII-A.
During each test run tcpdump captured all traffic onHosts A, C and DAG.
A range of path characteristics were tested using allcombinations of the parameters listed in Table II. TableIII provides a full list of the test variables, the list ofBDPs was derived from Table II.
A. Automated Test Scripts
A suite of scripts have been created as part of theNewTCP [1] project to automate the experimental pro-cess. The scripts configure the testbed, confirm connec-tivity, start and terminate logging, start and terminateTCP flows and transfer log files to a storage location.Some steps have been taken towards automating the dataprocessing stage as well.
B. Gathering Latency Data
The traffic capture on the DAG interface records eachpacket twice, once upon entering the congested linkand then again on leaving it. VoIP traffic was foundin the dump file by filtering on the MAC addressesof SmartBits and Host D. The two observations ofeach VoIP packet were found by pairing up identicalpacket hashes. By subtracting the timestamps of the twoobservations it can be determined how long the packetspent in the link. This value is referred to as the one waydelay (OWD).
C. Recording the Congestion Window
During the FreeBSD tests SIFTR was used to log TCPstatistics on hosts A and C, SIFTR was configured tocapture statistics for every TCP/IP packet processed by
Bandwidth 1Mbps, 10Mbps, 100MbpsQueue size 1 BDP, 1/4 BDP
Delay 16ms, 80ms, 160ms
TABLE IIDUMMYNET CONFIGURATION PARAMETERS AND VALUES
Operating Systems Linux 2.6.25, FreeBSD 7.0-RELEASEAlgorithms NewReno, H-TCP, CUBIC (Linux only)
BDPs (Bytes) 2 ∗ 103, 1 ∗ 104, 2 ∗ 104, 1 ∗ 105,2 ∗ 105, 1 ∗ 106, 2 ∗ 106
TABLE IIITEST VARIABLES
the stack ensuring the finest granularity possible. Duringthe Linux tests TCP statistics were logged with Web100.Web100 was polled every 1 ms to ensure a reasonablegranularity even with the lowest BDP test conducted.The Web100 output was logged to a file in the sameformat as the SIFTR log to allow us to easily processstatistics collected under both operating systems.
VI. ALGORITHM BEHAVIOUR ANALYSIS
Observing cwnd gives a direct insight into the be-haviour of each algorithm. The value of cwnd gatheredby SIFTR and Web100 is presented here across threetypical congestion epochs from the middle of the 3minute flow.
A congestion epoch is the time between congestionevents, where the congestion event is packet loss dueto a full queue at the congestion point. During a singleepoch we observe TCP in fast recovery and congestionavoidance mode. Due to the static network conditionsproduced by the testbed the behaviour of cwnd duringeach epoch is approximately identical for the duration ofthe flow1.
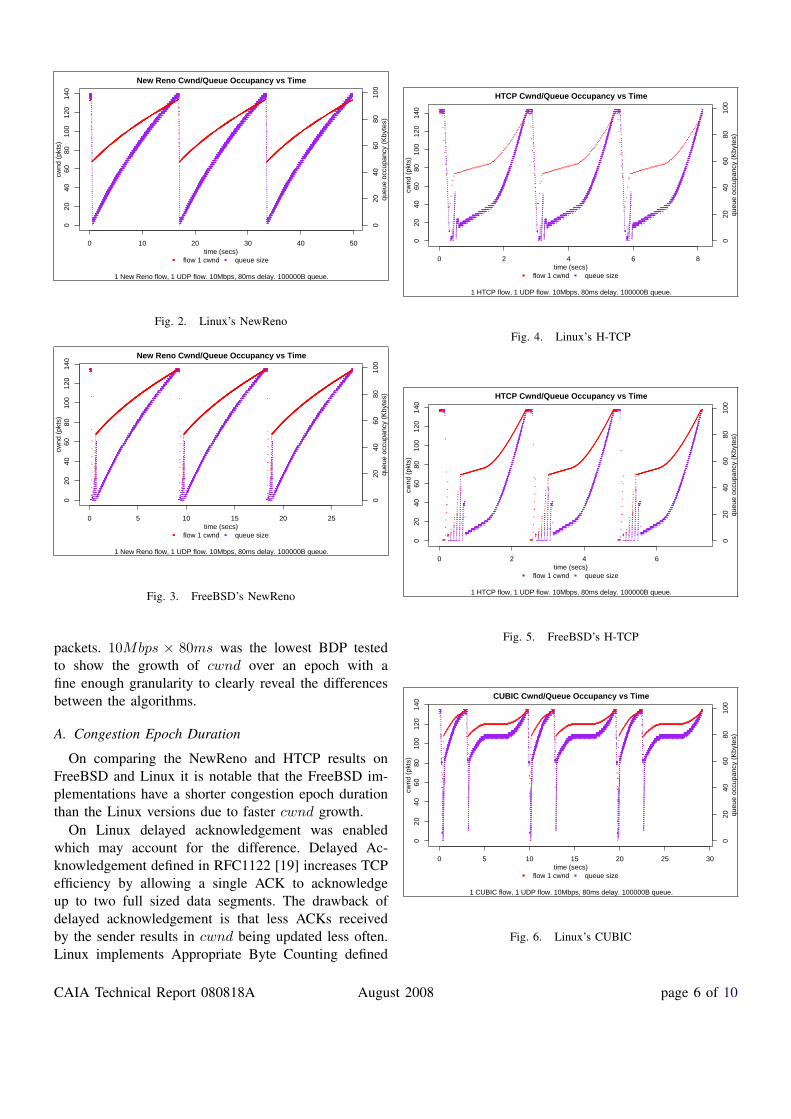
Figures 2, 3, 4, 5, and 6 show cwnd for tests with an10Mbps link, round trip time of 80ms and queuing ca-pacity equal to the BDP. For bottleneck links with a smallBDP, such as the lowest BDP tested (1Mbps × 16ms)there was no discernible difference between the algo-rithms because cwnd could not grow large. Differencesbegan to appear when cwnd could grow beyond 25
1Except at the start and end of each run, and allowing for smallanomalies which inevitably occur when experimenting with realequipment. A TCP flow starts in slow start mode and often endswith the congestion window suddenly opening in order to flush thesend buffer. As this behaviour is not determined by the congestionavoidance algorithm we do not explore it further in this report.
CAIA Technical Report 080818A August 2008 page 5 of 10
020
4060
8010
0qu
eue
occu
panc
y (K
byte
s)
0 10 20 30 40 50
020
4060
8010
012
014
0
time (secs)
cwnd
(pk
ts)
New Reno Cwnd/Queue Occupancy vs Time
1 New Reno flow, 1 UDP flow. 10Mbps, 80ms delay. 100000B queue.
flow 1 cwnd queue size
Fig. 2. Linux’s NewReno
020
4060
8010
0qu
eue
occu
panc
y (K
byte
s)
0 5 10 15 20 25
020
4060
8010
012
014
0
time (secs)
cwnd
(pk
ts)
New Reno Cwnd/Queue Occupancy vs Time
1 New Reno flow, 1 UDP flow. 10Mbps, 80ms delay. 100000B queue.
flow 1 cwnd queue size
Fig. 3. FreeBSD’s NewReno
packets. 10Mbps × 80ms was the lowest BDP testedto show the growth of cwnd over an epoch with afine enough granularity to clearly reveal the differencesbetween the algorithms.
A. Congestion Epoch Duration
On comparing the NewReno and HTCP results onFreeBSD and Linux it is notable that the FreeBSD im-plementations have a shorter congestion epoch durationthan the Linux versions due to faster cwnd growth.
On Linux delayed acknowledgement was enabledwhich may account for the difference. Delayed Ac-knowledgement defined in RFC1122 [19] increases TCPefficiency by allowing a single ACK to acknowledgeup to two full sized data segments. The drawback ofdelayed acknowledgement is that less ACKs receivedby the sender results in cwnd being updated less often.Linux implements Appropriate Byte Counting defined
020
4060
8010
0qu
eue
occu
panc
y (K
byte
s)
0 2 4 6 8
020
4060
8010
012
014
0
time (secs)
cwnd
(pk
ts)
HTCP Cwnd/Queue Occupancy vs Time
1 HTCP flow, 1 UDP flow. 10Mbps, 80ms delay. 100000B queue.
flow 1 cwnd queue size
Fig. 4. Linux’s H-TCP
020
4060
8010
0qu
eue
occu
panc
y (K
byte
s)
0 2 4 6
020
4060
8010
012
014
0
time (secs)
cwnd
(pk
ts)
HTCP Cwnd/Queue Occupancy vs Time
1 HTCP flow, 1 UDP flow. 10Mbps, 80ms delay. 100000B queue.
flow 1 cwnd queue size
Fig. 5. FreeBSD’s H-TCP
020
4060
8010
0qu
eue
occu
panc
y (K
byte
s)
0 5 10 15 20 25 30
020
4060
8010
012
014
0
time (secs)
cwnd
(pk
ts)
CUBIC Cwnd/Queue Occupancy vs Time
1 CUBIC flow, 1 UDP flow. 10Mbps, 80ms delay. 100000B queue.
flow 1 cwnd queue size
Fig. 6. Linux’s CUBIC
CAIA Technical Report 080818A August 2008 page 6 of 10
in [20] which was designed to mitigate the problem byincreasing cwnd based on the number of bytes beingacknowledged.
Despite Appropriate Byte Counting there is still a cleardifference in the epoch duration between the FreeBSDand Linux NewReno tests, our results showed Linux’sNewReno epoch duration to be approximately 1.85 timesthe epoch duration of FreeBSD’s NewReno.
HTCP was less affected, Linux’s HTCP epoch dura-tion was approximately 1.14 times that of FreeBSD’s.This may be because HTCP’s high speed mode definesα as a function of time. Only the low speed NewRenomode of HTCP experienced noticeably slower growth.
B. Fast RecoveryFreeBSD and Linux implement different fast recovery
algorithms which can be most clearly seen in Figures4 and 5 near t = 3 seconds. FreeBSD implements thestandard fast recovery algorithm defined in RFC2581 [3]and Linux implements an algorithm called Rate-Halving[21].
Theoretically cwnd is set to β×cwnd after fast recov-ery but in implementation this can cause micro-bursts,a large burst of packets which may saturate the queue.Linux and FreeBSD solve this problem in a similar way,by incrementally yet rapidly increasing cwnd up to thebackoff value. The queue experiences a series of smallbursts during this process. Burst mitigation is discussedin [22].
C. CUBIC’s fast convergence modeAn interesting behaviour of CUBIC is the two-part
cwnd cycle shown in Figure 6. In our tests this wasobserved whenever the queuing capacity of the path was1 BDP and for all queue capacities of our largest BDPtests (100Mbps× 160ms).
The short epoch is the expected behaviour of CUBICduring congestion avoidance. We observe the concavetail of a cubic function with the inflection point set atcwndmax of the last epoch.
During the longer section of the cycle CUBIC appearsto have entered fast convergence mode as describedin [8]. CUBIC has detected a decrease in cwndmax
and lowered the inflection point to release bandwidthto new flows. The actual decrease experienced in thetest was no more than a few packets but the Linux2.6.25 implementation of CUBIC takes any decrease incwndmax to trigger fast convergence. For this trafficscenario CUBIC’s fast convergence algorithm incorrectlyassumes that even the slightest decrease in cwndmax
means new flows have entered the link.
020
4060
8010
0qu
eue
occu
panc
y (K
byte
s)
****
*
*
*
*************
*
***
*
*
*
*
*
**
*
*******************
************
************************************************************
*
*
*
*************
*
***
*
*
*
*
*
**
*
*****************
******************
*******************************************************
*
*
*
*
*************
*
***
**
**
***
*********
**********************
******************************************************
0 1 2 3 4 5 6 7
4060
8010
012
0
time (secs)
owd
(ms)
Delay/Queue Occupancy vs Time
1 HTCP flow, 1 UDP flow. 10Mbps, 80ms delay. 100000B queue.* owd 1 queue size
Fig. 7. OWD experienced by VoIP traffic sharing a congested linkwith Linux’s H-TCP
020
4060
8010
0qu
eue
occu
panc
y (K
byte
s)
*******
*
*
***
*
*
***
*
*
*
*
*
*
*
**
***************************************************************************************************************************
*
*
****
*
*
*
*
*
********************************************************************************************************************
***********************************************
**********************************************************************************************************************************************************************
*
*
***
*
*
***
*
**
*
*
*
*
**
***************************************************************************************************************************
*
****
*
**
*
*
*
************************************************************************************************************
******************************************************************************************************************
*********************************************************************************************************
*
*
****
*
*
***
*
*
*
*
*
*
**
***************************************************************************************************************************
*
*
****
*
*
*
*
*
******************************************************************************************************************************************
************************************************************************************
****************************************************************************************************
0 5 10 15 20 25 30
4060
8010
012
0
time (secs)
owd
(ms)
Delay/Queue Occupancy vs Time
1 CUBIC flow, 1 UDP flow. 10Mbps, 80ms delay. 100000B queue.* owd 1 queue size
Fig. 8. OWD experienced by VoIP traffic sharing a congested linkwith Linux’s CUBIC
VII. LATENCY ANALYSIS
Figures 2, 3, 4, 5, and 6 show the occupancy of thequeue at the congestion point as cwnd cycles. Thesefigures demonstrate the close relationship that exists be-tween the congestion window and the queue occupancy.As cwnd grows the throughput of the flow increasesand the queue fills. When the queue reaches maximumcapacity packets are dropped and within a few RTTsTCP reacts by multiplicatively decreasing cwnd. Withthe reduction in throughput the queue has time drain.The occupancy of the queue over time mimics the shapeof cwnd growth and has the same epoch frequency. Therate at which each algorithm fills the queue is as differentas the algorithms themselves.
FIFO queues introduce delays proportional to thenumber of packets already in the queue. The one way
CAIA Technical Report 080818A August 2008 page 7 of 10

10 15 20
0.0
0.2
0.4
0.6
0.8
1.0
CDF of one way delay
delay (ms)
100Mbps, 16ms delay. 200000B queue.
Linux Reno FreeBSD Reno Linux HTCP FreeBSD HTCP CUBIC
Fig. 9. CDF of delay experienced by VoIP traffic sharing a congestedlink with a TCP flow
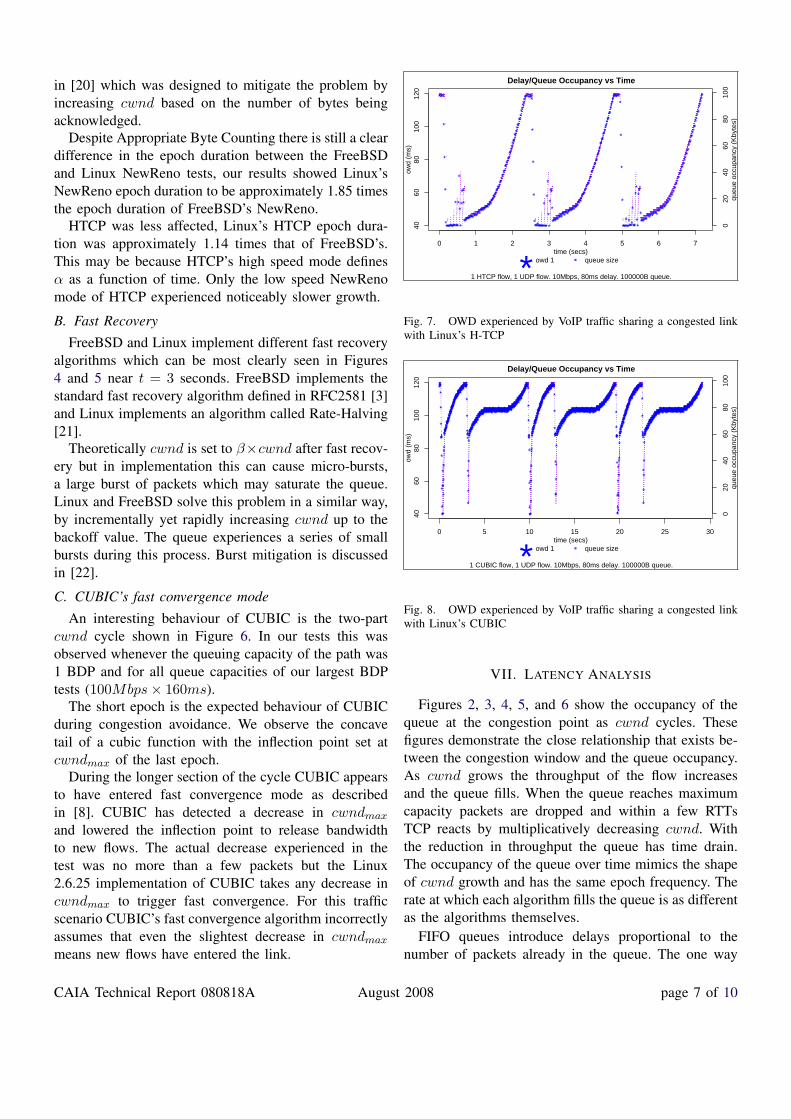
delay experienced by the VoIP traffic against queueoccupancy is shown in Figure 7 for H-TCP and in Figure8 for CUBIC. These figures confirm that delay and queueoccupancy are directly proportional. Therefore the delayexperienced by VoIP packets over time is also closelyrelated to cwnd growth of the TCP flow it shares thebottleneck link with.
Figures 9, 10 and 11 show the CDF of delay experi-enced by the VoIP traffic sharing the link with a TCPflow for three sets of link characteristics. The queuingcapacity was equal to the BDP for each link. The dataset was taken over three typical congestion epochs of theTCP flow.
Each algorithm has a unique distribution of induceddelay which is approximately consistent2 for the threelink scenarios presented here. The distribution of delayinduced by NewReno is approximately uniform due toits linear cwnd growth. HTCP’s slow then fast cwndgrowth distributes induced delay towards the minimumdelay. CUBIC’s initially agressive concave cwnd growthdistributes induced delay towards the maximum delay.
Each algorithm filled the queue to its maximum capac-ity causing the VoIP traffic to experience the maximumqueuing delay. NewReno and HTCP allowed the queueto completely drain before slowly filling it again. CUBICrarely allows the queue to become empty, keeping thequeue over 3/4 full 90% of the time.
The median induced delay for the three link scenariosis shown in Figure 12. At each BDP H-TCP induced thelowest median delay while CUBIC induced the largestmedian delay.
2Excluding HTCP under Linux, discussed in VII-A
40 60 80 100 120
0.0
0.2
0.4
0.6
0.8
1.0
CDF of one way delay
delay (ms)
10Mbps, 80ms delay. 100000B queue.
Linux Reno FreeBSD Reno Linux HTCP FreeBSD HTCP CUBIC
Fig. 10. CDF of delay experienced by VoIP traffic sharing acongested link with a TCP flow
40 60 80 100 120
0.0
0.2
0.4
0.6
0.8
1.0
CDF of one way delay
delay (ms)
100Mbps, 80ms delay. 1000000B queue.
FreeBSD Reno Linux HTCP FreeBSD HTCP CUBIC
Fig. 11. CDF of delay experienced by VoIP traffic sharing acongested link with a TCP flow
Fig. 12. Median delay experienced by VoIP traffic sharing acongested link with a TCP flow. 1 BDP queues.
CAIA Technical Report 080818A August 2008 page 8 of 10
020
040
060
080
010
00qu
eue
occu
panc
y (K
byte
s)
110 120 130 140 150 160 170
020
040
060
080
012
00
time (secs)
cwnd
(pk
ts)
HTCP Cwnd/Queue Occupancy vs Time
1 HTCP flow, 1 UDP flow. 100Mbps, 80ms delay. 1000000B queue.
flow 1 cwnd queue size
Fig. 13. Unexpected cwnd growth of Linux’s HTCP
050
100
150
200
queu
e oc
cupa
ncy
(Kby
tes)
9 10 11 12 13 14 15
050
100
150
200
250
time (secs)
cwnd
(pk
ts)
HTCP Cwnd/Queue Occupancy vs Time
1 HTCP flow, 1 UDP flow. 100Mbps, 16ms delay. 200000B queue.
flow 1 cwnd queue size
Fig. 14. Unexpected cwnd growth of Linux’s HTCP
A. HTCP Irregularities
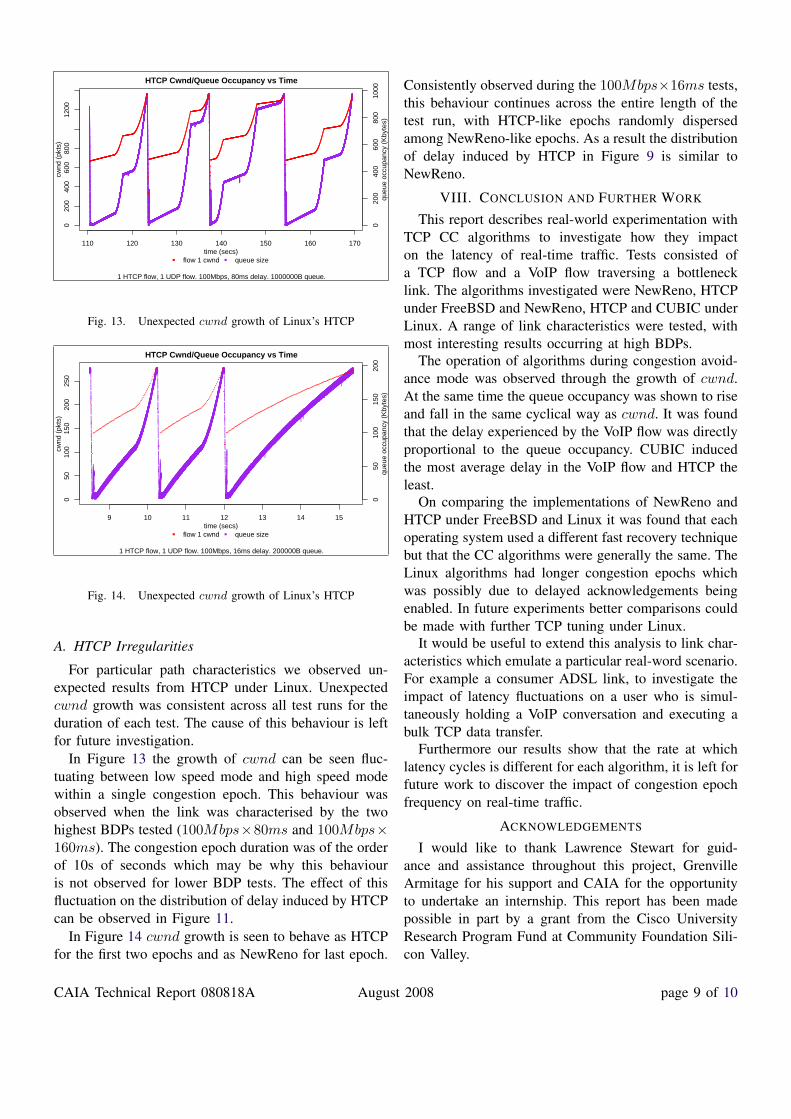
For particular path characteristics we observed un-expected results from HTCP under Linux. Unexpectedcwnd growth was consistent across all test runs for theduration of each test. The cause of this behaviour is leftfor future investigation.
In Figure 13 the growth of cwnd can be seen fluc-tuating between low speed mode and high speed modewithin a single congestion epoch. This behaviour wasobserved when the link was characterised by the twohighest BDPs tested (100Mbps×80ms and 100Mbps×160ms). The congestion epoch duration was of the orderof 10s of seconds which may be why this behaviouris not observed for lower BDP tests. The effect of thisfluctuation on the distribution of delay induced by HTCPcan be observed in Figure 11.
In Figure 14 cwnd growth is seen to behave as HTCPfor the first two epochs and as NewReno for last epoch.
Consistently observed during the 100Mbps×16ms tests,this behaviour continues across the entire length of thetest run, with HTCP-like epochs randomly dispersedamong NewReno-like epochs. As a result the distributionof delay induced by HTCP in Figure 9 is similar toNewReno.
VIII. CONCLUSION AND FURTHER WORK
This report describes real-world experimentation withTCP CC algorithms to investigate how they impacton the latency of real-time traffic. Tests consisted ofa TCP flow and a VoIP flow traversing a bottlenecklink. The algorithms investigated were NewReno, HTCPunder FreeBSD and NewReno, HTCP and CUBIC underLinux. A range of link characteristics were tested, withmost interesting results occurring at high BDPs.
The operation of algorithms during congestion avoid-ance mode was observed through the growth of cwnd.At the same time the queue occupancy was shown to riseand fall in the same cyclical way as cwnd. It was foundthat the delay experienced by the VoIP flow was directlyproportional to the queue occupancy. CUBIC inducedthe most average delay in the VoIP flow and HTCP theleast.
On comparing the implementations of NewReno andHTCP under FreeBSD and Linux it was found that eachoperating system used a different fast recovery techniquebut that the CC algorithms were generally the same. TheLinux algorithms had longer congestion epochs whichwas possibly due to delayed acknowledgements beingenabled. In future experiments better comparisons couldbe made with further TCP tuning under Linux.
It would be useful to extend this analysis to link char-acteristics which emulate a particular real-word scenario.For example a consumer ADSL link, to investigate theimpact of latency fluctuations on a user who is simul-taneously holding a VoIP conversation and executing abulk TCP data transfer.
Furthermore our results show that the rate at whichlatency cycles is different for each algorithm, it is left forfuture work to discover the impact of congestion epochfrequency on real-time traffic.
ACKNOWLEDGEMENTS
I would like to thank Lawrence Stewart for guid-ance and assistance throughout this project, GrenvilleArmitage for his support and CAIA for the opportunityto undertake an internship. This report has been madepossible in part by a grant from the Cisco UniversityResearch Program Fund at Community Foundation Sili-con Valley.
CAIA Technical Report 080818A August 2008 page 9 of 10

REFERENCES
[1] “The NewTCP Project,” August 2008, Accessed 8 Aug 2008.[Online]. Available: http://caia.swin.edu.au/urp/newtcp
[2] G. Armitage, L. Stewart, M. Welzl, and J. Healy, “An indepen-dent H-TCP implementation under FreeBSD 7.0 - descriptionand observed behaviour,” ACM SIGCOMM Computer Commu-nication Review, vol. 38, no. 3, 2008.
[3] M. Allman, V. Paxson, and W. Stevens, “TCP CongestionControl ,” RFC 2581 (Proposed Standard), Apr. 1999, updatedby RFC 3390. [Online]. Available: http://www.ietf.org/rfc/rfc2581.txt
[4] S. Floyd, T. Henderson, and A. Gurtov, “The NewRenoModification to TCP’s Fast Recovery Algorithm,” RFC3782 (Proposed Standard), Apr. 2004. [Online]. Available:http://www.ietf.org/rfc/rfc3782.txt
[5] M. Duke, R. Braden, W. Eddy, and E. Blanton, “A Roadmapfor Transmission Control Protocol (TCP) SpecificationDocuments,” RFC 4614 (Proposed Standard), Sep. 2006.[Online]. Available: http://www.ietf.org/rfc/rfc4614.txt
[6] D. Leith, R. Shorten, “H-TCP: TCP for high-speed andlong-distance networks,” in Second International Workshopon Protocols for Fast Long-Distance Networks, Argonne,Illinois USA, February 2004. [Online]. Available: http://www.hamilton.ie/net/htcp3.pdf
[7] D. J. Leith, R. N. Shorten, “On RTT Scaling in H-TCP,”Hamilton Institute, Tech. Rep., September 2005. [Online].Available: http://www.hamilton.ie/net/rtt.pdf
[8] I. Rhee, L. Xu and S. Ha, “CUBIC for Fast Long-Distance Networks,” North Carolina State University, Tech.Rep., August 2007. [Online]. Available: http://tools.ietf.org/id/draft-rhee-tcpm-cubic-00.txt
[9] “Bic and cubic,” Accessed 7 Aug 2008. [Online]. Available:http://netsrv.csc.ncsu.edu/twiki/bin/view/Main/BIC
[10] L. Stewart, J. Healy, “Characterising the Behaviour andPerformance of SIFTR v1.1.0,” CAIA, Tech. Rep. 070824A,August 2007. [Online]. Available: http://caia.swin.edu.au/reports/070824A/CAIA-TR-070824A.pdf
[11] “The Web100 Project,” November 2007, Accessed 19 Nov2007. [Online]. Available: http://web100.org/
[12] L. Rizzo, “Dummynet: a simple approach to the evaluation ofnetwork protocols,” ACM SIGCOMM Computer Communica-tion Review, vol. 27, no. 1, pp. 31–41, 1997.
[13] , “Iperf - The TCP/UDP Bandwidth Measurement Tool,”May 2005, Accessed 19 Nov 2007. [Online]. Available:http://dast.nlanr.net/Projects/Iperf/
[14] L. Stewart, J. Healy, “Light-Weight Modular TCP CongestionControl for FreeBSD 7,” CAIA, Tech. Rep. 071218A,December 2007. [Online]. Available: http://caia.swin.edu.au/reports/070717B/CAIA-TR-070717B.pdf
[15] J. Healy, L. Stewart, “H-TCP Congestion Control Algorithmfor FreeBSD,” December 2007. [Online]. Available: http://caia.swin.edu.au/urp/newtcp/tools/htcp-readme-0.9.txt
[16] “Spirent smartbits - trusted industry standard for router andswitch testing,” Accessed 11 Aug 2008. [Online]. Avail-able: http://www.spirent.com/analysis/technology.cfm?media=7&ws=325&ss=110&stype=15&a=1
[17] A. Heyde, L. Stewart, “Using the Endace DAG 3.7GF CardWith FreeBSD 7.0,” CAIA, Tech. Rep. 080507A, May 2008.[Online]. Available: http://caia.swin.edu.au/reports/080507A/CAIA-TR-080507A.pdf
[18] L. Stewart, J. Healy, “Tuning and Testing the FreeBSD6 TCP Stack,” CAIA, Tech. Rep. 070717B, July 2007.[Online]. Available: http://caia.swin.edu.au/reports/070717B/CAIA-TR-070717B.pdf
[19] R. Braden, “Requirements for Internet Hosts - CommunicationLayers,” RFC 1122 (Standard), Oct. 1989, updated by RFC1349. [Online]. Available: http://www.ietf.org/rfc/rfc1122.txt
[20] M. Allman, “TCP Congestion Control with Appropriate ByteCounting (ABC),” RFC 3465 (Experimental), Feb. 2003.[Online]. Available: http://www.ietf.org/rfc/rfc3465.txt
[21] Matt Mathis, Jeff Semke, Jamshid Mahdavi, KevinLahey, “The Rate-Halving Algorithm for TCP CongestionControl,” Internet Engineering Task Force, Tech. Rep.,June 1999. [Online]. Available: http://www.tools.ietf.org/html/draft-mathis-tcp-ratehalving-00.txt
[22] M. Allman and E. Blanton, “Notes on burst mitigation for trans-port protocols,” SIGCOMM Comput. Commun. Rev., vol. 35,no. 2, pp. 53–60, 2005.
CAIA Technical Report 080818A August 2008 page 10 of 10





























