Embed Size (px)
Citation preview

Chapter 25Multimodal Interfaces for Augmented Reality
Mark Billinghurst and Minkyung Lee
Abstract Recent research in multimodal speech and gesture input for AugmentedReality (AR) applications is described. Although multimodal input has been re-searched for desktop applications, 3D graphics and virtual reality interfaces, therehave been very few multimodal AR applications. We review previous work in thearea and then present our own multimodal interfaces and user studies conductedwith those interfaces. Based on these studies we provide design guidelines for de-veloping effective multimodal AR experiences.
25.1 Introduction
Augmented reality (AR) is a technology that overlays computer-generated informa-tion onto the real world (Azuma 1997). In 1965 Ivan Sutherland described his visionof the “Ultimate Display” in which computers can simulate reality, and he built ahead mounted display for viewing graphics in the real world (Sutherland 1965), cre-ating the first AR interface. In the forty years since there have been a wide range ofdifferent AR prototypes developed and the first commercial applications have begunappearing. However, in many ways AR interfaces for these applications are still intheir infancy.
As Ishii says, the AR field has been primarily concerned with “. . . consider-ing purely visual augmentations” (Ishii and Ullmer 1997) and while great advanceshave been made in display and tracking technologies, interaction has usually beenlimited to either passive viewing or simple browsing of virtual information. Fewsystems provide tools that let the user effectively interact, request or modify thisinformation. Furthermore, even basic AR interaction tasks have been poorly ad-dressed, such as manipulation, copying, annotating, and dynamically adding anddeleting virtual objects.
M. Billinghurst (�) · M. LeeHIT Lab NZ, University of Canterbury, Christchurch, New Zealande-mail: [email protected]
M. Leee-mail: [email protected]
J. Dill et al. (eds.), Expanding the Frontiers of Visual Analytics and Visualization,DOI 10.1007/978-1-4471-2804-5_25, © Springer-Verlag London Limited 2012
449

450 M. Billinghurst and M. Lee
Azuma points out that AR technology has three core attributes (Azuma 1997);it combines real and virtual images, the images are registered in three-dimensionalspace, and it is interactive in real time. Thus there is a strong connection betweenthe real and virtual worlds. In our research we have been developing AR interactiontechniques based on the user’s natural real world behavior, and in particular theirspeech and gestures. Many current AR applications adopt general Virtual Reality(VR) (Nakashima et al. 2005) or GUI interaction techniques (Broll et al. 2003).However, these methods are designed for fully immersive virtual environments ordesktop interfaces, and largely ignore the connection between AR content and thereal world. Thus, there is a need to research new interface metaphors ideally suitedfor AR.
Computer interfaces that combine speech and gesture input are an example ofa multimodal interface (MMI). MMI have previously been found to be an intuitiveway to interact with 2D and 3D graphics applications (Bolt 1980; Cohen and Sulli-van 1989; Oviatt et al. 2004). However, there has been little research on the use ofmultimodal input in AR interfaces, and especially usability evaluations of AR mul-timodal interfaces. In this chapter we provide an overview of multimodal input inAR, beginning with a summary of related work in the field and then describing ourown research in the area. We summarize our work in a set of guidelines for devel-oping effective multimodal interfaces for AR systems, and then describe directionsfor future work.
25.2 Related Work
The first research on multimodal interfaces dates back to the Bolt’s “Put-that-there”work (Bolt 1980). In this case a user was able to use pointing gestures and speechto manipulate 2D icons on a screen. Many multimodal interfaces after Bolt’s workwere map or screen-based 2D applications (Tse et al. 2006). For these, pen-based ortouch screen input and speech was enough to support a gesture based interface on a2D surface. For example, QuickSet (Cohen et al. 1997) supported multimodal inputin a military planning application.
Interfaces that combine speech and hand gesture input are an intuitive way tointeract with 2D and 3D graphics desktop applications (Hauptmann 1989). This isbecause the combination of natural language and direct manipulation can overcamethe limitations of unimodal input (Cohen and Sullivan 1989; Oviatt et al. 2004).Unlike gesture or mouse input, voice is not tied to a spatial metaphor (Cohen et al.1989), and so can be used to interact with objects regardless of whether they canbe seen or not. However, care must be taken to map the appropriate modality to theapplication input parameters. For example, Kay (1993) constructed a speech driveninterface for a drawing program in which even simple cursor movements required atime consuming combination of movements in response to vocal commands.
Earlier researchers have used speech input with hand tracking devices or Data-Gloves (Koons and Sparrell 1994; Latoschik 2001; LaViola 1999; Weimer and

25 Multimodal Interfaces for Augmented Reality 451
Ganapathy 1989) to explore multimodal input in 3D graphics environments. For ex-ample, Koons and Sparrell (1994) combined two-handed DataGlove gestures withspeech to allow users to arrange 3D objects in a virtual scene. LaViola (1999) de-veloped multimodal interfaces for virtual reality applications that allowed users tocreate, place, modify, and manipulate furniture using 3D hand gestures and speech.MMI was also used for interacting with 3D virtual content (Chu et al. 1997) or tonavigate through virtual worlds (Krum et al. 2002). Ciger et al. (2003) presented amultimodal user interface that combined a magic wand with spell casting. The usercould navigate in the virtual environment, grab and manipulate objects using a com-bination of speech and the magic wand. Although this research provides a naturalway for people to use their hands to interact with 3D virtual objects, they had towear encumbering data gloves and a number of tracking devices. This could reducethe naturalness of the hand gesture interfaces made.
More recently, computer vision-based hand tracking techniques have been usedin systems such as “VisSpace” (Lucente et al. 1998) to estimate where users werepointing (Rauschert et al. 2002). This overcomes the disadvantages of using Data-Gloves for capturing hand gesture input; however, these systems did not supportnatural manipulation of 3D objects as they were only concerned with where userswere pointing.
There has also been research conducted on how to combine speech and gestureinput. Latoschik (2001) presented a framework for modeling multimodal interac-tions, which enriched the virtual scene with linguistic and functional knowledgeabout the objects to allow the interpretation of complex multimodal utterances.Holzapfel et al. (2004) presented multimodal fusion for natural interaction witha humanoid robot. Their multimodal fusion is based on an information-based ap-proach by comparing object types defined in the ontology.
Although multimodal input has been studied in 3D graphics and VR, there hasbeen relatively little research in AR multimodal interfaces. One of the first sys-tems developed was Heidemann et al. (2004) who used an MMI to acquire visualknowledge and retrieve memorized objects. Speech input was used to select inter-face menu options and 3D pointing gestures were used to select the object. However,the main interaction was navigating in 2D, and their AR MMI did not involve any3D object manipulation.
Kölsch et al. (2006) developed a multimodal information visualization systemwith 2D natural hand gesture, speech, and trackball input in a wearable AR environ-ment. They used HandVu (Kölsch et al. 2004) to recognize the users’ hand gesturesin 2D. However, their MMI could not be used to manipulate virtual objects in 3Dspace and they did not evaluate the system usability.
Olwal’s SenseShape (Olwal et al. 2003) and its later extended version (Kaiser etal. 2003) were the first truly 3D AR multimodal interfaces. In this case users had towear a data glove and trackers to give gesture commands to the system. Howeverthe focus of their interface evaluation was on the system’s mutual disambiguationcapabilities and not usability.
Thus, there have only been only few examples of AR MMIs, and none of themhave used computer vision techniques for unencumbered 3D hand interaction. There

452 M. Billinghurst and M. Lee
has also been very little evaluation of AR MMIs, especially exploring the usabilityof AR MMIs. In the rest of the chapter we will present two multimodal AR sys-tems that we have developed, results from user studies evaluating those systems,and general lessons learned that could be applied to the design of multimodal ARinterfaces.
25.3 Speech and Paddle Gesture
The first system that we developed involved speech input and paddle gestures(Irawati et al. 2006a,b). This was based on extending the earlier VOMAR AR ap-plication for virtual furniture arranging (Kato et al. 2000). VOMAR allows usersto arrange virtual furniture in empty rooms using marker-attached paddle gestures.This was extended by adding speech input and a semantic multimodal fusion frame-work. The goal was to allow people to easily arrange AR content using a naturalmixture of speech and gesture inputs.
25.3.1 Multimodal System
The multimodal system developed was a modified version of the VOMAR appli-cation (Kato et al. 2000) based on the ARToolKit AR tracking library (ARToolKitwebsite 2012). We used the Microsoft Speech API (Microsoft Speech API 2012) forspeech input and Ariadne (Denecke 2002) as the spoken dialog system. Figure 25.1shows the system architecture. The AR Application allows a user to interact with thesystem using paddle gestures and speech. It is responsible for receiving the speechcommands from Ariadne, recognizing paddle gestures, and fusing the speech andpaddle gesture input into a single interpretation. Ariadne and the AR Applicationcommunicate with each other using the middleware ICE (ICE website 2012). A Mi-crosoft Access database was used to store the object descriptions, to specify thespeech grammar, and to enable the multimodal fusion.
The AR application involved the manipulation of virtual furniture in a virtualroom, although the multimodal interaction techniques could be applied to variousother domains. When the user looked at a set of menu pages through a head mounteddisplay with a camera attached to it, they saw different types of virtual furniture onthe pages (Fig. 25.2). Looking at the workspace, a large piece of paper with specifictracking markers, they saw the virtual room. The user could then pick furniture fromthe menu pages and place them into the room using paddle and speech commands.
Gesture input was through using a paddle held in the user’s hand, with an attachedmarker that was tracked by the AR system and allowed the user to make gesturesto interact with the virtual objects. A range of static and dynamic gestures wererecognized by tracking the paddle (Table 25.1).
Speech input was recognized by the Microsoft Speech API and sent to the Ari-adne spoken dialog system for spoken dialog understanding. To create a speech

25 Multimodal Interfaces for Augmented Reality 453
Fig. 25.1 Multimodal architecture
Fig. 25.2 Using the multimodal application
Table 25.1 Paddle gestures recognized
Static Gestures Paddle proximity to objectPaddle tilt/inclination
Dynamic Gestures Shaking: side to side motion of the paddleHitting: up and down motion of the paddlePushing: pushing paddle while touching an object
grammar structure, objects were imported from an SQL database which containedan OBJECT_NAME attribute for all the names of virtual objects that could be ma-nipulated by the user.
The following types of speech commands were recognized by the system:
• Create—“Make a blue chair”: to create a virtual object.• Duplicate—“Copy this”: to duplicate a virtual object.• Grab—“Grab table”: to select a virtual object.• Place—“Place here”: to place a selected object in the workspace.

454 M. Billinghurst and M. Lee
• Move—“Move the couch”: to attach a virtual object in the workspace to the pad-dle so that it follows the paddle movement.
As seen from the list above, some of the speech commands could only be understoodby considering the users gesture input as well. Thus there was a need to fuse gestureand speech input into a final unified command. This worked as follows: when aspeech recognition result was received from Ariadne, the AR Application checkedwhether the paddle was in view. Next, depending on the speech command type andthe paddle pose, a specific action was taken by the system. For example, if the usersaid “grab this” the system tested the paddle proximity to virtual objects. If thepaddle was close enough to an object, it was selected and attached to the paddle.
When fusing the multimodal input, our system considered object properties, suchas whether the object could have things placed on it or if there was space under it.These properties are used to resolve deictic references in the speech commands fromthe user. For example, if the user said “put here” while touching a virtual couch withthe paddle, the possible locations referred to by ‘here’ are ‘on the couch’ or ‘underthe couch’. By checking the object properties of the couch, the system understandsthat ‘here’ refers to the position ‘on top of the couch’. In case the object propertiescannot disambiguate user input, the position of the paddle is used by the system. Forexample, the system checks the paddle in the z (up-down) direction. If the z positionof the paddle was less than a threshold value (for example the height of a desk), thesystem understands ‘here’ as ‘under the desk’.
The system also provided visual and audio feedback to the user by showing thespeech recognition result, and an object bounding box when an object is touched. Inaddition, audio feedback is given after the speech and paddle gesture command, sothe user can immediately recognize if there is an incorrect result from the speech orgesture recognition system.
25.3.2 Evaluation
To evaluate our multimodal AR interface, we conducted a user study (Irawati et al.2006b). The goal was to compare user interaction with the multimodal interface tothat with a single input mode. There were 14 participants (3 female and 11 male).The user study took about forty-five minutes for each user during which users hadto build three different furniture configurations using three different interface con-ditions: (A) Paddle gestures only, (B) Speech with static paddle position, and (C)Speech with paddle gestures.
Before each trial, a brief demonstration was given so that the users were com-fortable with the interface. For each interface condition the subjects were trained byperforming object manipulation tasks until they were proficient enough to be ableto assemble a sample scene in less than five minutes. A list of speech commandswas provided on a piece of paper, so the user could refer to them throughout theexperiment.
25 Multimodal Interfaces for Augmented Reality 455
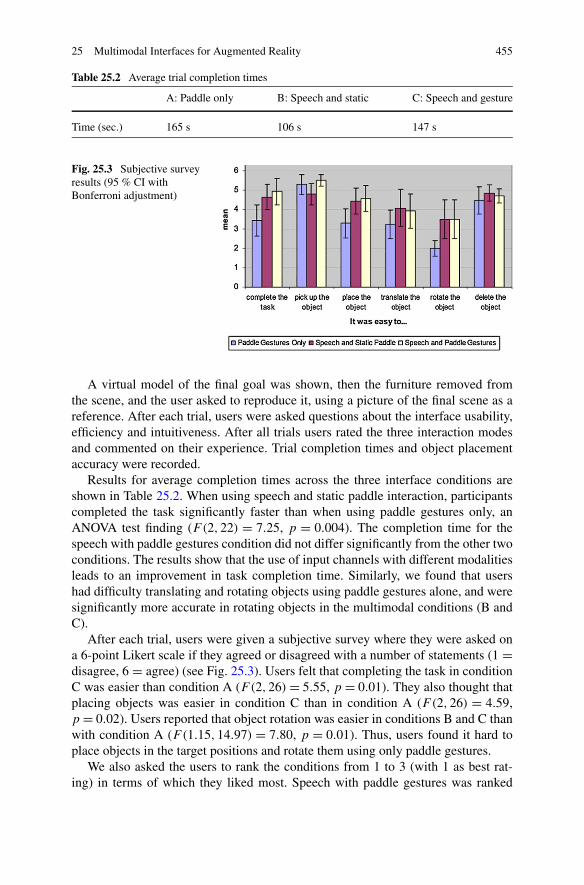
Table 25.2 Average trial completion times
A: Paddle only B: Speech and static C: Speech and gesture
Time (sec.) 165 s 106 s 147 s
Fig. 25.3 Subjective surveyresults (95 % CI withBonferroni adjustment)
A virtual model of the final goal was shown, then the furniture removed fromthe scene, and the user asked to reproduce it, using a picture of the final scene as areference. After each trial, users were asked questions about the interface usability,efficiency and intuitiveness. After all trials users rated the three interaction modesand commented on their experience. Trial completion times and object placementaccuracy were recorded.
Results for average completion times across the three interface conditions areshown in Table 25.2. When using speech and static paddle interaction, participantscompleted the task significantly faster than when using paddle gestures only, anANOVA test finding (F(2,22) = 7.25, p = 0.004). The completion time for thespeech with paddle gestures condition did not differ significantly from the other twoconditions. The results show that the use of input channels with different modalitiesleads to an improvement in task completion time. Similarly, we found that usershad difficulty translating and rotating objects using paddle gestures alone, and weresignificantly more accurate in rotating objects in the multimodal conditions (B andC).
After each trial, users were given a subjective survey where they were asked ona 6-point Likert scale if they agreed or disagreed with a number of statements (1 =disagree, 6 = agree) (see Fig. 25.3). Users felt that completing the task in conditionC was easier than condition A (F(2,26) = 5.55, p = 0.01). They also thought thatplacing objects was easier in condition C than in condition A (F(2,26) = 4.59,p = 0.02). Users reported that object rotation was easier in conditions B and C thanwith condition A (F(1.15,14.97) = 7.80, p = 0.01). Thus, users found it hard toplace objects in the target positions and rotate them using only paddle gestures.
We also asked the users to rank the conditions from 1 to 3 (with 1 as best rat-ing) in terms of which they liked most. Speech with paddle gestures was ranked

456 M. Billinghurst and M. Lee
Fig. 25.4 The architecture of the AR MMI
highest (mean rank 1.58), then speech with static paddle (mean rank = 1.91), andat last paddle gestures only (mean rank = 2.50). These rankings were significantlydifferent (χ2 = 7.00, df = 2, p = 0.03).
After each experiment was finished we asked the users to provide general com-ments about the system. Most agreed that it was difficult to place and rotate thevirtual objects using only paddle gestures. Many users were impressed with the ro-bustness of the speech recognition (the system was not trained for individual users).The users mentioned that accomplishing the task using combined speech and paddlecommands was a lot easier once they had learned and practiced the speech com-mands.
In summary, the results of our user study demonstrated how combining speechand paddle gestures improved performance in arranging virtual objects over usingpaddle input alone. Using multimodal input, users could orient the objects moreprecisely in the target position, and finished an assigned task a third faster thanusing paddle gestures alone. The users also felt that they could complete the taskmore efficiently. Paddle gestures allowed the users to interact intuitively with thesystem since they could in- teract directly with the virtual objects.
25.4 Speech and Free-Hand Input
More recently we have developed an AR MMI that combines 3D stereo vision-based natural hand gesture input and speech input. This system is made up of anumber of components that are connected together (see Fig. 25.4). They includemodules for capturing video, recognizing gesture and speech input, a fusion modulefor combining input modalities, an AR scene generation, and manager modules forgenerating the AR output and providing feedback to the user.
This system is based on an earlier study where we observed how people use nat-ural gesture and speech input in an AR environment (Lee and Billinghurst 2008).From this we found that the same gestures had different meanings based on the

25 Multimodal Interfaces for Augmented Reality 457
Fig. 25.5 Hand gestures interacting with a virtual object; (a) pointing gesture, (b) open handgesture, and (c) close hand gesture
context; the meaning of a gesture is varied according to its corresponding speechcommand. Users mostly triggered gestures before the corresponding speech input,meaning that a gesture-triggered time window is needed to capture related com-mands. We also found that people used three different types of gestures: (1) openhand, (2) closed hand, and (3) pointing.
In order to capture these gestures we developed a stereo computer vision systeminvolving five steps: (1) Camera calibration (off-line), (2) Skin color segmentation,(3) Fingertip detection, (4) Fingertip estimation in 3D, and (5) Gesture recognition.For camera input we used a BumbleBee camera (Point Grey Research Inc 2009) thatprovided two 320 × 240 pixel images at 25 frames per second.
Camera calibration (Borgefors 1986) and skin segmentation (Chai and Bouzer-doum 2000) was done using standard computer vision techniques. Fingertip posi-tions were estimated by (1) drawing the convex hull around the hand, (2) findingthe center point of the hand, (3) removing the palm area to leave only segmentedfingers, (4) finding the contour of each finger blob, (5) calculating the distance frompoints on each contours to the hand center, and (6) marking the furthest point oneach finger blob as a fingertip. When the fingertip locations and camera calibrationmatrices are known, we can estimate the 3D position of the fingertips in real-time,accurate from 4.5 mm to 26.2 mm depending on the distance between the user’shand and the cameras.
Finally, gesture recognition was performed by considering the number of fin-gertips visible; an open hand has five fingertips; closed hand has no fingertips; anda pointing gesture has only one fingertip. A moving gesture is recognized from acontinuous movement of the closed hand. The gesture recognition results in a se-mantic form that includes arrival time, type of gesture, position in 3D, and function.Figure 25.5 shows the three hand gestures we implemented.
For the speech input, we used the Microsoft Speech API 5.3 with the MicrosoftSpeech Recognizer 8.0, trained with a male voice to achieve accuracy of over 90 %.We use a set of speech commands that are integrated later with the gesture input(see Table 25.3).

458 M. Billinghurst and M. Lee
Table 25.3 Supportedspeech commands Color Shape Direction
Green Sphere Backward
Blue Cylinder Forward
Red Cube Right
Yellow Cone Left
Up
Down
Fig. 25.6 The multimodal fusion architecture
To combine the gesture and speech input we implemented a multimodal fusionarchitecture more complex than in the earlier paddle interface (see Fig. 25.6). Rec-ognized speech and gesture input are passed to the semantic representation modulewith their arrival time, where they are given semantic tags. The output from the se-mantic representation module is passed to historians that store input for 10 secondsin case future commands need them. In around 95 % of AR multimodal commands,a gesture is issued up to one second earlier than the related speech input (Lee andBillinghurst 2008). If speech and gesture input occur within one second of eachother they are compared and passed to a filter module if they are complimentary. Ifthe time difference is bigger than one second or the command types not the same,the input is considered as a unimodal one and passed to the system feedback module.
The adaptive filter module combines commands of the same type into a singlemultimodal command by filling out the information needed as a result of the typecomparison. There is a Dynamic Filter for moving commands and a Static Filter

25 Multimodal Interfaces for Augmented Reality 459
Fig. 25.7 Multimodal AR application
for other commands such as pointing and touching. The Dynamic Filter handlescommands related to moving virtual objects and so needs to have the starting pointand the destination point as input. The Static Filter only needs to have a single inputpoint. Once all necessary information is successfully filled out, the output of theAdaptive Filter module is passed to the system feedback module that changes theAR scene according to the outputs.
The target AR multimodal application was for 3D object manipulation and sceneassembly. In the next section we describe the application developed with this systemand an evaluation conducted with it.
25.4.1 Evaluation
To test the AR multimodal architecture we developed a simple test application. Theuser sat in front of a large plasma screen, on which was shown the AR view fromthe BumbleBee camera located above them. The AR view showed their hand and acolor bar with several colors and a shape bar with several shapes. On the left side ofthe table was a colored object and the goal of the application was to select the sameshaped object from the shape bar, color it and move it to the target (see Fig. 25.7).
To test the system we used three different interface conditions: (1) a speech-onlyinterface, (2) a gesture-only interface, and (3) a MMI. For the speech- and gesture-only conditions, the subjects were asked to use only a single modality, however inthe MMI condition, they could use both of them in any way they wanted to. Therewere twenty participants in the experiment, eighteen male and two female, withages from 25 to 40 years old. They were familiar with AR applications but had littleexperience with speech interfaces, gesture interfaces, and MMI. A within-subjectsdesign was used so all participants experienced all conditions.

460 M. Billinghurst and M. Lee
1. Change the color of the pink cone to the color of the target object.2. Change the shape of the cone to the shape of the target object.3. Move the object to the target position.
Fig. 25.8 Trial command list
The subjects were asked to perform ten task trials three times each using thethree different conditions for a total of 90 trials. Each task trial involved using aparticular interface to interact with a sample virtual object in an AR application. Foreach trial users were given a short task list that involved them changing the visualcharacteristics of a virtual object and moving it to a target location (see Fig. 25.8).When the target object is moved to within 5 mm of the target position, the systemwill recognize it as a successful completion of the trial and reset the AR scene andstart another task automatically.
We compared the three interfaces using the usability factors of (1) efficiency,(2) effectiveness, and (3) satisfaction. The measured factors were (1) the task com-pletion time, (2) the number of user and system errors, and (3) user satisfaction(questionnaire), respectively. We used a one-way repeated measure ANOVA to testthe results for a significant difference and performed a post-hoc pairwise compari-son with the Bonferroni correction.
We measured the time between when users started and finished a trial with thegiven interface conditions. There was a significant difference in the task completiontime across conditions (F(2,18) = 8.78, p < 0.01). After post-hoc pairwise com-parisons we found that the task completion time with the gesture only interface wassignificantly different from the time with the speech interface (p < 0.01) and theMMI (p < 0.01). It took longer to complete the given tasks with the gesture inter-face (mean = 15.4 s) than the speech interface (mean = 12.4 s) and the MMI (mean= 11.9 s). However, we did not find any significant difference in task completiontime between the speech-only interface and the MMI condition.
User errors were used to measure the effectiveness of the system. To measurethis, we observed the video of users interacting with the system and counted thenumber of errors made. The average number of user errors with speech input was0.41 times per task, with gesture input was 0.50 times per task, and the averagenumber of user errors with MMI was 0.42 times per task. There was no signifi-cant difference in the average number of user errors across the different interfaces(F(2,18) = 0.73, p = 0.5).
System errors are dependent on the speech and gesture recognition accuracy andthe multimodal fusion accuracy, which is percentage of correctly recognized com-mands. This is also found from analyzing video of people using the application. Theaverage accuracy of the speech interface was 94 %, and of the gesture interface was86 %. We found experimentally that the accuracy of the MMI was 90 %, showingthat the fusion module helped to increase the system accuracy slightly from the rawgesture accuracy by capturing the related speech input and compensating for error.
We also collected user feedback using surveys of each modality, and the MMI.The subject answered questions on a Likert scale from 1 (very low) to 7 (very high).
25 Multimodal Interfaces for Augmented Reality 461
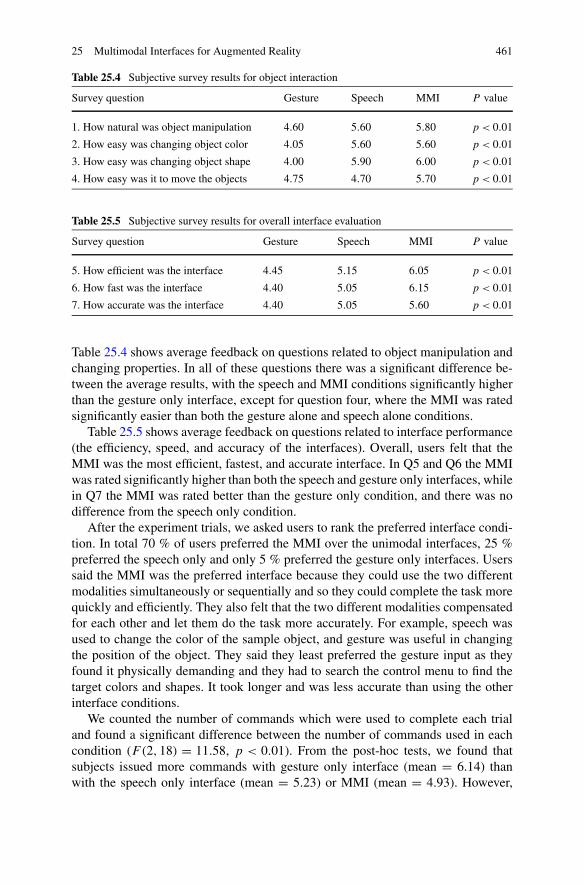
Table 25.4 Subjective survey results for object interaction
Survey question Gesture Speech MMI P value
1. How natural was object manipulation 4.60 5.60 5.80 p < 0.01
2. How easy was changing object color 4.05 5.60 5.60 p < 0.01
3. How easy was changing object shape 4.00 5.90 6.00 p < 0.01
4. How easy was it to move the objects 4.75 4.70 5.70 p < 0.01
Table 25.5 Subjective survey results for overall interface evaluation
Survey question Gesture Speech MMI P value
5. How efficient was the interface 4.45 5.15 6.05 p < 0.01
6. How fast was the interface 4.40 5.05 6.15 p < 0.01
7. How accurate was the interface 4.40 5.05 5.60 p < 0.01
Table 25.4 shows average feedback on questions related to object manipulation andchanging properties. In all of these questions there was a significant difference be-tween the average results, with the speech and MMI conditions significantly higherthan the gesture only interface, except for question four, where the MMI was ratedsignificantly easier than both the gesture alone and speech alone conditions.
Table 25.5 shows average feedback on questions related to interface performance(the efficiency, speed, and accuracy of the interfaces). Overall, users felt that theMMI was the most efficient, fastest, and accurate interface. In Q5 and Q6 the MMIwas rated significantly higher than both the speech and gesture only interfaces, whilein Q7 the MMI was rated better than the gesture only condition, and there was nodifference from the speech only condition.
After the experiment trials, we asked users to rank the preferred interface condi-tion. In total 70 % of users preferred the MMI over the unimodal interfaces, 25 %preferred the speech only and only 5 % preferred the gesture only interfaces. Userssaid the MMI was the preferred interface because they could use the two differentmodalities simultaneously or sequentially and so they could complete the task morequickly and efficiently. They also felt that the two different modalities compensatedfor each other and let them do the task more accurately. For example, speech wasused to change the color of the sample object, and gesture was useful in changingthe position of the object. They said they least preferred the gesture input as theyfound it physically demanding and they had to search the control menu to find thetarget colors and shapes. It took longer and was less accurate than using the otherinterface conditions.
We counted the number of commands which were used to complete each trialand found a significant difference between the number of commands used in eachcondition (F(2,18) = 11.58, p < 0.01). From the post-hoc tests, we found thatsubjects issued more commands with gesture only interface (mean = 6.14) thanwith the speech only interface (mean = 5.23) or MMI (mean = 4.93). However,

462 M. Billinghurst and M. Lee
there was no significant difference in the number of commands between the speechonly interface and MMI.
We classified the commands into two types: (1) Characteristic—involving ob-ject characteristics such as the shape and color and (2) Movement—involving phys-ical motions such as grabbing, moving, and dropping. There was no significant dif-ference between the numbers of characteristic commands with the different typesof interfaces. However, we found a significant difference in the number of move-ment commands with each interface condition (F(2,18) = 3.82, p < 0.04). Thespeech only modality (mean = 28.5) required fewer commands than the gesture onlymodality (mean = 35.3) for moving the objects (p < 0.03). We found no significantdifference between number of speech and MMI commands or between number ofgesture and MMI commands for moving the objects.
We also measured the proportions of simultaneous and sequential multimodalcommands during the study. On average, only 21 % of MMI commands were issuedsimultaneously while 79 % were triggered sequentially. Speech commands precededgesture commands in only 1.1 % of a simultaneously integrated MMI.
By comparing the task completion times for the three different interface condi-tions, we found that the MMI significantly reduced interaction time compared tothe gesture only interface. This is partly because using the speech input in the MMItook less time than the gesture only condition. Previous research (Kaiser et al. 2003)has found that speech input is helpful for descriptive commands, such as changingthe color, while gesture input is useful for spatial commands, such as pointing ormoving an object. The MMI takes advantage of the complementary nature of thetwo input modalities, combining descriptive and spatial commands. As a result, weobserved that the MMI was more efficient than the gesture interface for this ARapplication. However, we did not find any significant difference in the efficiencybetween the speech only interface and the MMI.
These findings also agreed with the user feedback that we received. The sub-jects preferred the MMI condition over the gesture only interface. Although speechrecognition produced slightly fewer errors, they felt that the MMI was overall moreaccurate than the speech only input condition. This is because performing the taskswell typically required a combination of speech and gesture input.
25.5 Lessons Learned
From these two multimodal AR interfaces and user studies with the system, welearned a number of important design lessons that could help people develop bettermultimodal AR interfaces in the future.
Match Affordances: Firstly, it’s very important to match the speech and gestureinput modalities to the appropriate interaction methods. We were using speech tospecify commands and gestures to specify parameters (locations and objects) forthe commands. It is much easier to say “Put that there” rather than “Put the table atcoordinates x = 50, y = 60”.

25 Multimodal Interfaces for Augmented Reality 463
Provide Feedback: With imprecise input recognition it is important to providefeedback to the user about what commands are being sent to the system. In the pad-dle application we showed the results of the speech recognition on-screen and gaveaudio feedback after the gesture commands. This enabled the user to immediatelyrecognize when the speech or gesture recognition was producing an error.
Simple Command Set: It is also important to use a speech and gesture commandset that is easy for users to remember. In our first case, we only had a limited speechgrammar and five paddle gestures. Using combined multimodal input reduces theamount of commands that users need to remember; for example it was possible tosay “Put that there”, rather than “Put the vase on the table”.
Use Context: The interaction context can be used to disambiguate speech andgesture input. In our case the fusion engine interprets combined speech and gestureinput based on the timing of the input events and domain semantics providing twotypes of contextual cues.
Use Gesture-Triggered Fusion: In the second application, in only 1 % of themultimodal commands did the speech input precede the gesture input. We also founda similar pattern in an earlier study where 94 % of gesture commands precededspeech input (Lee and Billinghurst 2008). Thus, multimodal AR applications mayneed to have a gesture-triggered MMI fusion architecture.
25.6 Conclusions and Future Work
In this chapter we have reported on developments in multimodal input for Aug-mented Reality applications. In general, although speech and gesture input hasproven useful for desktop and immersive graphics applications, there has been littleresearch on how multimodal techniques can be applied in an AR setting. Those fewinterfaces that have been developed have typically relied on special input hardwareand/or have not conducted user studies to evaluate the interface.
Over the past several years we have developed a range of different multimodalAR interfaces and we report on two of them; one that used paddle and speech inputfor furniture arranging, and one that supported free hand gesture input for changingobject properties. Both used a different system architecture, but both demonstratedhow combining speech and gestures improved performance over using gesture orspeech input alone.
In the future, we need to study task performance in a variety of AR environmentssuch as an AR navigation task or AR game application with different display types(HMD and handheld displays) and balanced user genders. Performance may be im-proved by adding a feedback channel to give the user information about the fusionresult and showing if there are system failures occurring. We could also use this tobuild a learning module into the multimodal fusion architecture that would improvethe accuracy of the MMI based on the users’ behavior. In this way we could developAR MMI that are even more effective.

464 M. Billinghurst and M. Lee
References
ARToolKit website (2012). http://www.hitl.washington.edu/artoolkit.Azuma, R. T. (1997). A survey of augmented reality. Presence: Teleoperators and Virtual Environ-
ments, 6(4), 355–385.Bolt, R. A. (1980). “Put-that-there”: Voice and gesture at the graphics interface. In Proc. annual
conference on computer graphics and interactive techniques (pp. 262–270).Borgefors, G. (1986). Distance transformations in digital images. In Computer vision, graphics
and image processing (pp. 344–371).Broll, W., Stoerring, M., & Mottram, C. (2003). The augmented round table—a new interface to
urban planning and architectural design. In Proc. INTERACT’03 (pp. 1103–1104).Chai, D., & Bouzerdoum, A. (2000). A Bayesian approach to skin color classification in YCbCr
color space. In Proceedings of IEEE TENCONO’00 (Vol. 2, pp. 421–424).Chu, C. P., Dani, T. H., & Gadh, R. (1997). Multimodal interface for a virtual reality based com-
puter aided design system. In Proceedings of 1997 IEEE international conference on roboticsand automation (Vol. 2, pp. 1329–1334).
Ciger, J., Gutierrez, M., Vexo, F., & Thalmann, D. (2003). The magic wand. In Proceedings of the19th spring conference on computer graphics (pp. 119–124).
Cohen, P. R., & Sullivan, J. W. (1989). Synergistic user of direct manipulation and natural language.In Proc. CHI ’89 (pp. 227–233).
Cohen, P. R., Dalrymple, M., Pereira, F. C. N., Sullivan, J. W., Gargan Jr., R. A., Schlossberg,J. L., & Tyler, S. W. (1989). Synergistic use of direct manipulation and natural language. InProceedings of ACM conference on human factors in computing systems (CHI ’89) (pp. 227–233).
Cohen, P. R., Johnston, M., McGee, D., & Oviatt, S. (1997). QuickSet: Multimodal interaction fordistributed applications. In Proc. international conference on multimedia (pp. 31–40).
Denecke, M. (2002). Rapid prototyping for spoken dialogue systems. In Proceedings of the 19thinternational conference on computational linguistics (Vol. 1, pp. 1–7).
Hauptmann, A. G. (1989). Speech and gestures for graphic image manipulation. In Proc. CHI ’89(pp. 241–245).
Heidemann, G., Bax, I., & Bekel, H. (2004). Multimodal interaction in an augmented reality sce-nario. In Proceedings of international conference on multimodal interfaces (ICMI’04) (pp. 53–60).
Holzapfel, H., Nickel, K., & Stiefelhagen, R. (2004). Implementation and evaluation of aconstraint-based multimodal fusion system for speech and 3D pointing gestures. In Proceed-ings of the 6th international conference on multimodal interfaces (pp. 175–182). New York:ACM Press.
ICE website (2012). http://www.zeroc.com/ice.html.Irawati, S., Green, S., Billinghurst, M., Duenser, A., & Ko, H. (2006a). Move the couch where?:
Developing an augmented reality multimodal interface. In Proc. ICAT ’06 (pp. 1–4).Irawati, S., Green, S., Billinghurst, M., Duenser, A., & Ko, H. (2006b). An evaluation of an aug-
mented reality multimodal interface using speech and paddle gestures. In Proc. of ICAT ’06(pp. 272–283).
Ishii, H., & Ullmer, B. (1997). Tangible bits: Towards seamless interfaces between people, bitsand atoms. In Proceedings of CHI ‘97, Atlanta, Georgia, USA (pp. 234–241). New York: ACMPress.
Kaiser, E., Olwal, A., McGee, D., Benko, H., Corradini, A., Li, X., Cohen, P., & Feiner, S. (2003).Mutual disambiguation of 3D multimodal interaction in augmented and virtual reality. In Pro-ceedings of international conference on multimodal interfaces (ICMI ‘03) (pp. 12–19).
Kato, H., Billinghurst, M., Poupyrev, I., Imamoto, K., & Tachibana, K. (2000). Virtual objectmanipulation on a table-top AR environment. In Proceedings of the international symposiumon augmented reality (ISAR 2000) (pp. 111–119).
Kay, P. (1993). Speech driven graphics: A user interface. Journal of Microcomputer Applications,16, 223–231.

25 Multimodal Interfaces for Augmented Reality 465
Kölsch, M., Turk, M., & Tobias, H. (2004). Vision-based interfaces for mobility. In Proceedings ofMobiQuitous’04 (pp. 86–94).
Kölsch, M., Turk, M., & Tobias, H. (2006). Multimodal interaction with a wearable augmentedreality system. IEEE Computer Graphics and Applications, 26(3), 62–71.
Koons, D. B., & Sparrell, C. J. (1994). ICONIC: Speech and depictive gestures at the human-machine interface. In Proc. CHI ’94 (pp. 453–454).
Krum, D. M., Omotesto, O., Ribarsky, W., Starner, T., & Hodges, L. F. (2002). Speech and gesturecontrol of a whole earth 3D visualization environment. In Proceedings of joint Eurographics-IEEE TCVG symposium on visualization (pp. 195–200).
Latoschik, M. E. (2001). A gesture processing framework for multimodal interaction in virtualreality. In Proc. AFRIGRAPH 2001 (pp. 95–100).
LaViola, J. J. Jr. (1999). A multimodal interface framework for using hand gestures and speech invirtual environment applications. In Gesture-based communication in human-computer inter-action (pp. 303–341).
Lee, M., & Billinghurst, M. (2008). A wizard of oz study for an AR multimodal interface. InProceedings of international conference on multimodal interfaces (ICMI ‘08) (pp. 249–256).
Lucente, M., Zwart, G. J., & George, A. D. (1998). Visualization space: A testbed for devicelessmultimodal user interface. In Proceedings of AAAI spring symposium on intelligent environ-ments. AAAI TR SS-98-02.
Microsoft Speech API (2012). http://en.wikipedia.org/wiki/Microsoft_Speech_API.Nakashima, K., Machida, T., Kiyokawa, K., & Takemura, H. (2005). A 2D-3D integrated environ-
ment for cooperative work. In Proc. VRST ’05 (pp. 16–22).Olwal, A., Benko, H., & Feiner, S. (2003). SenseShapes: Using statistical geometry for object
selection in a multimodal augmented reality system. In Proceedings of international symposiumon mixed and augmented reality (ISMAR ’03) (pp. 300–301).
Oviatt, S., Coulson, R., & Lunsford, R. (2004). When do we interact multimodally? Cognitive loadand multimodal communication patterns. In Proc. ICMI ’04 (pp. 129–136).
Point Grey Research Inc (2009). http://www.ptgrey.com/products/stereo.asp.Rauschert, I., Agrawal, P., Sharmar, R., Fuhrmann, S., Brewer, I., MacEachren, A., Wang, H., &
Cai, G. (2002) Designing a human-centered, multimodal GIS interface to support emergencymanagement. In Proceedings of geographic information system (pp. 119–124).
Sutherland, I. (1965). The ultimate display. In International federation of information processing(Vol. 2, pp. 506–508).
Tse, E., Greenberg, S., & Shen, C. (2006). GSI DEMO: Multiuser gesture/speech interaction overdigital tables by wrapping single user applications. In Proc. ICMI ’06 (pp. 76–83).
Weimer, D., & Ganapathy, S. K. (1989). A synthetic visual environment with hand gesturing andvoice input. In Proc. CHI ’89 (pp. 235–240).



![Knowledge-aware Multimodal Dialogue Systemsstaff.ustc.edu.cn/~hexn/papers/mm18-multimodal-dialog.pdf · 2019-05-09 · base. [12] augmented conversation history with relevant unstruc-tured](https://img.pdfslide.us/doc/110x75/5ea41c5bd776717c992dd869/knowledge-aware-multimodal-dialogue-hexnpapersmm18-multimodal-dialogpdf-2019-05-09.jpg)