Embed Size (px)
Citation preview

Chapter 12
Knowledge Standardization in Evolutionary
Biology: The Comparative Data Analysis
Ontology
Francisco Prosdocimi, Brandon Chisham, Enrico Pontelli,
Arlin Stoltzfus, and Julie D. Thompson
Abstract In this chapter we describe the development of a new biomedical onto-
logy in the context of the modern knowledge representation research field. We also
present the modeled concepts and their relevance in the light of the history of
evolutionary biology. CDAO stands for “Comparative Data Analysis Ontology”
and allows the representation of data produced in evolutionary biology studies in
the form of a set of well-defined concepts and the relationships among them. CDAO
is not intended to be a glossary or a simple taxonomy of evolution-related termi-
nology. Since evolutionary theory provides a broad framework for almost all fields
of biology, the concepts in CDAO reflect a rich history of controversies stressed by
academics in philosophical analyses of the whole field of biology. The concept of
an evolutionary tree to represent relationships between organisms is credited to
Darwin. However, the nature of species and the operational taxonomic units (OTU)
used in evolutionary analysis are still a matter of controversy among scholars. The
same can be said for a number of other concepts modeled in CDAO. For instance,
the choice of a methodological basis for evolutionary analysis is still a matter of
debate: should researchers use simple “non-theory” based comparative approaches
to analyze their data? Should they assume parsimony to adapt phylogeny towards a
popperian concept of science? Should they consider likelihood or Bayesian meth-
ods as more appropriate to their endeavor? In the first part of this chapter we try to
understand the role of a knowledge representation task in the context of modern
F. Prosdocimi and J.D. Thompson
Institut de Genetique et de Biologie Moleculaire et Cellulaire (IGBMC), Department of Structural
Biology and Genomics, Strasbourg, France. 1 rue Laurent Fries/BP 10142/67404 Illkirch Cedex,
France
email: [email protected]
B. Chisham and E. Pontelli
Department of Computer Science, New Mexico State University, P.O. Box 30001, MSC CS Las
Cruces, NM 88003, USA
A. Stoltzfus
Center for Advanced Research in Biotechnology, University of Maryland Biotechnology Institute,
9600 Gudelsky Drive, Rockville, MD 20850, USA
P. Pontarotti (ed.), Evolutionary Biology: Concept, Modeling, and Application,DOI: 10.1007/978-3-642-00952-5_12, # Springer‐Verlag Berlin Heidelberg 2009
195

research in biology. The second part is devoted to the presentation of the concepts
modeled in CDAO and their specification using standard ontology descriptors.
Finally, the third part of the chapter deals with historical discussions in evolu-
tionary biology that influenced the genesis and development of CDAO’s forma-
lized concepts. This approach will be extended to show how evolutionary data can
be represented in ontologies in order to cope with the multiplicity of approaches
and philosophical backgrounds used in this endeavor. CDAO will prove to be a
very pluralistic ontology, allowing the representation of evolutionary data in a
number of different theoretical backgrounds normally assumed by evolutionary
biologists. Although further discussions and new software will be needed, we
believe that CDAO will become the standard way for describing evolutionary
biology concepts in the near future. This statement is based on the fact that (1)
CDAO is highly theoretical and describes the most relevant evolutionary biology
concepts; and (2) it is flexible enough to be able to represent, inter-relate and
allow further reasoning over the flood of data from the modern petabyte era of
biological research.
12.1 Introduction
12.1.1 Knowledge Representation as a Positive Heuristicin Biomedicine
At the intersection of information, computation and biological sciences, there exists
an interdisciplinary research field that has been growing steadily over the last
decade. This field is related to new techniques of ontology production for biomedi-
cal science. The term ontology is inherited from its original application in philoso-
phy and is frequently said to be related to the study of the nature of being, existenceand reality. From the point of view of information science (or knowledge represen-
tation), this new task can be understood as the formalization of the structure of
knowledge in some area of research. This formalization is frequently performed
through the definition of fixed words linked to rigorous concepts that researchers
consider to be relevant in some specific area (Gruber 1995). Furthermore, by
providing a common representation of interesting research topics, ontologies permit
data and knowledge to be integrated, reused and shared easily by both researchers
and computers (Harris 2008). If everybody uses the same terms and relations to
describe their data, they can understand each other better, exchange results, inte-
grate them in a common perspective and write algorithms to analyze the organized
information in a large-scale fashion.
One of the advantages of these ontologies inspired by information science, lies in
the fact that they allow the construction of structures similar to phrases by which
concepts link to each other using relations. The semantics appear and defined
entities are related to each other using explicit verbs or verbal-derived forms,
196 F. Prosdocimi et al.

such as is_a, has, contains. The creation of an ontology may be compared to the
description of a new language – in the sense that symbols (nouns or sets-of-nouns)
are defined to describe events and entities in the real world and other symbols
(actions or verbs) are created to relate these entities based on some theoretical
background. The relationships between the terms or symbols are generally built
using some kind of pre-defined formal rules. In a classical paper called Empiricism,semantics and ontology, the German philosopher Rudolf Carnap considered math-
ematics as a sort of ontology and suggests that mathematicians speak about
“symbols and formulas manipulated according to given formal rules” (Carnap
1950). From a modern knowledge representation point of view, the symbols
described by Carnap can be understood as the ontology concepts and the formal
rules are represented by the relations between the terms and some restrictions to
these relations. An example from molecular biology is the Gene Ontology in which
the relationships allow the hierarchical description of gene functions, such as:
“glycolysis” (GO:0006096) is part_of “hexose metabolic process” (GO:0019320)
(Ashburner et al. 2000). This concept-and-relations schema allows ontologies to
formalize and create meaning through such semantic sentences.
Although long-standing classical studies in epistemology and philosophy of
science have clearly demonstrated that this task of knowledge conceptualization
can never be consensual among all researchers in some area, well-designed formal
representation of natural, real-world entities can advance human knowledge and
generate new research fields. The Hungarian philosopher of science Imre Lakatos in
his classical book Methodology of scientific research programs argues that a
research (scientific) program is growing when it generates what he calls positiveheuristics, i.e., when it generates even more research and becomes more studied and
specialized over time (Lakatos 1978). Figure 12.1 demonstrates the exponential
growth in the study of biomedical ontologies, represented by the number of papers
with the word ontology in their title or abstract.
The data suggest that ontologies are deemed useful by the scientific community
and that the consideration of conceptualization issues in biological sciences brings
positive heuristics to this research field. In other words, the production of biomedi-
cal ontologies is a fertile research program that should promote the development of
the field.
12.1.2 Ontologies in the Petabyte Era of Biological Research
When initially describing some conceptual system, all the terms and relations must
be explicitly described as clearly as possible in order to solicit criticisms from the
community. These criticisms should generate discussions about the formalized
concepts in order to make them as clear, broad and consensual as possible. This
agreement among researchers is of critical importance to the general acceptance of
the ontology and thus, most scientific ontologies in use today are the result of
12 Knowledge Standardization in Evolutionary Biology 197

collaborative scientific research efforts (Rodrigues et al. 2006; Leontis et al. 2006;
Gene Ontology Consortium 2001).
As a consequence, once a system of concepts is artificially created to represent
some area of human knowledge, empirical data should be described using this
prototype ontology. This in turn, allows the use of computational techniques, such
as the vast array of expert algorithms (Sirin et al. 2007; Tsarkov and Horrocks 2006)
developed to read large amounts of empirical data and to inter-relate and interpret
them under some rational perspective. These algorithms, which extract knowledge
from ontology-based resources, are frequently called reasoners. Computer
reasoning allows the production of higher-level information from large volumes
of raw data – for example, derived from hard-science molecular experiments – and
facilitates subsequent analyses and interpretation by humans. The extraction of
knowledge from high-throughput data clearly cannot be performed by a single
individual, or even by a trained group of experts. In order to develop modern
science, new computer-readable standards are urgently needed in a number of
research areas, including evolutionary biology.
In a recent set of reports published in Nature (Issue 7209 dated 4 September 2008)
about “big data,” the editors argue that biology will arrive soon in what they have
called the “Petabyte era” (the petabyte is a value corresponding to 1,024 terabytes
that, in turn, represents about 1,000,000 megabytes or 1015 bits of information). An
entirely new generation of super-fast DNA sequencers will soon be up and running
all over the world (Rothberg and Leamon 2008; Shendure and Ji 2008) and modern
DNA sequencers such as Illumina’s Solexa, the Applied Biosystems’ Sequencing by
Oligonucleotide Ligation and Detection (SOLiD) technology and the GS FLX
800
Gene Ontology (Title)
Gene Ontology (Abstract)
Ontology (Title)
Ontology (Abstract)
700
600
500
400
300
200
100
02000 2001 2002 2003 2004 2005 2006 2007 2008*
Fig. 12.1 Growth in ontology usage in biomedical science research measured by Pubmed searches
for terms “ontology” and “gene ontology” in abstracts and titles of papers since 2000
198 F. Prosdocimi et al.

instruments from Roche/454 Life Sciences will soon revolutionize the study of life
sciences (Marguerat et al. 2008). Some of these sequencers are capable of producing
the information necessary to build an entire human genome (3Gb) in about a week
(Dohm et al. 2008) but we still lack the informational and computational infrastruc-
ture to actually analyze all these sequences, in order to understand the biological
and evolutionary perspectives. Bioinformatics resources have begun to respond to
the challenges posed and are now addressing the issues of storage, availability,
reasoning and interpretation of this explosion of information (Cochrane et al. 2009).
The next decade will certainly see the rise of new ways of working in the so-called
“big science” field and it is probably not too risky to suppose that the graph shown in
Fig. 12.1 represents only the start of a more accentuated growth in the usage of
ontologies and ontology-based studies over the next decade.
12.1.3 The Central Role of Evolutionary Biology
The modern version of Darwinian evolutionary theory could be said to be the most
unifying conceptual system in the whole field of biology. “Nothing in biologymakes sense except in the light of evolution,” says one of most notorious biologists
from the 20th century and one of the architects of synthetic theory of evolution, orthe modern synthesis, the Russian geneticist Theodosius Dobzhansky (Dobzhansky
1973). If we assume that evolution is the explicative point of convergence of the
biological sciences, it follows that researchers in this crucial field must adapt their
methodology to today’s petabyte era. However, the long tradition of evolutionary
studies has highlighted a number of conceptual and philosophical discussions on its
main problems, concepts and data analysis paradigms. Recurrent academic discus-
sions in the evolutionary field concern, among others, (1) the nature of species, (2)
the strength of natural selection and the relevance of random processes in evolution
(selectionism versus neutralism), (3) the origin of life, (4) the rate of genomic and
anatomic modification over time (gradualism, punctuated equilibrium and salt-
ationism) and (5) the different empirical approaches to study and comprehend
evolutionary data (phenetics, cladistics, parsimony, likelihood, distance metrics,
etc.). Thus, in order to formalize the basic knowledge in the evolutionary biology
research field, most of these ideas, discussions and paradigms must be taken into
account. As we will see, most of these discussions are particularly relevant when
choosing and naming fundamental concepts in the evolutionary biology research
field and defining their scope and the relations between them. The terminology must
be exact and precise and must allow the multiplicity of approaches to be repre-
sented, so that every evolutionary biologist will be able to describe his data using
his preferred methodology. The goal of comparative data analysis ontology
(CDAO) is exactly this: to model a limited number of important concepts in the
field in such a way that researchers will feel free to describe their data from their
own perspective.
12 Knowledge Standardization in Evolutionary Biology 199

12.1.4 Current Biomedical Ontologies
Many ontologies have been developed recently in the biomedical field to represent
specific aspects of the real world, such as anatomical parts (Gaudet et al. 2008;
Maglia et al. 2007; Larson et al. 2007; Trelease 2006; Bard 2005; Lee and Sternberg
2003), development, disease, or DNA sequences (Segerdell et al. 2008; Schulz et al.
2007, 2008; Chabalier et al. 2007; Bard et al. 2005; Jaiswal et al. 2005). A
significant number of these ontologies are housed on the Open Biomedical Ontol-
ogies (OBO) web site, created by Ashburner and Lewis in 2001 as an umbrella body
for the developers of life science ontologies (Smith et al. 2007). Probably, the most
well-known and widely used ontology in the biomedical field is the Gene Ontology
(GO), which consists in three separate parts, describing different cellular structures,
molecular functions and biological processes of genes. GO has been very successful
as the first set of concepts to be actually applied in a large number of genome
projects, e.g., FlyBase (Drosophila), the Saccharomyces Genome Database (SGD),
the Mouse Genome Database (MGD) and modern scientific studies all over the
world.
Although GO allows a clear and concise representation of the human knowl-
edge associated with gene functions, it contains very simple semantic relation-
ships among the concepts described therein. The concepts are structured in a
hierarchy ranging from the most general to the most specific (Ashburner et al.
2000) and specific sub-concepts, such as “DNA recombination” (GO:0006310) or
“DNA repair” (GO:0006281), are related to their parents, such as “DNA metabo-
lism” (GO:0006259), using the is_a or part_of semantic relationships (http://wiki.
geneontology.org/index.php/Relation_composition). Most of the other accepted
ontologies in the biomedical field are also conservative in the use of new relations
among entities, illustrated by the fact that the Relation Ontology (Smith et al.
2005) contained only about a dozen relations in its latest release. However, it is
clear that some fields of knowledge cannot be represented by such a narrow set of
relations and a dedicated discussion list on the subject has recently been set up
(http://www.obofoundry.org/ro/) with proposals for a number of new relations
from scientific research organizations, such as the UCDHSC (University of
Colorado at Denver and Health Sciences Center) and the OBI (Open Biomedical
Investigations).
As we argued before, modern high-throughput methods will require that data is
described in terms of standard vocabularies and today’s substantial efforts to
produce consistent ontologies will be valuable for twenty-first-century biology.
Nevertheless, it is clear that ontology concepts that are clearly correlated to
the physical world (such as anatomical parts or even DNA-based descriptors)
are less interpretative in fashion than more general or abstract concepts, such as
the OTU or character in evolutionary theory. This makes the production of broad
theory ontologies a different task, requiring distinct formalisms, structures and
relations.
200 F. Prosdocimi et al.

12.2 The Comparative Data Analysis Ontology
12.2.1 History of CDAO Development
Taking into account the necessity to analyze modern high-throughput biology data
under an evolutionary perspective, the production of an ontology was envisioned by
the members of the Evolutionary Informatics group at NESCent (http://evoinfo.
nescent.org). The Evolutionary Informatics group includes many of the most
prominent world-leaders in software development for evolutionary analysis. The
members of the group have been meeting at Durham, NC biannually since early
2007 to discuss future infrastructure requirements in this research area. The idea of
developing an ontology to formalize the knowledge in the field and allow automatic
reasoning came in the early days. Although everyone had agreed that concepts in
evolutionary biology could be interpreted differently depending on the various
perspectives – as we shall discuss – a number of these experts decided to launch
this ambitious project of creating a broad-range ontology to describe this central
notion in biology: the evolutionary theory. The comparative data analysis ontology
(CDAO) represents the first step in this process.
CDAO was developed using the OWL language using the Stanford University
ontology editor Protege. OWL (Web-Ontology Language) was chosen as the most
modern, flexible and robust language in the field, being the standard recommended
by theWorldWideWeb consortium (W3C) for ontology implementation. Although
recent and still under development, the ontology editor Protege has been shown to
be a user-friendly, robust and powerful tool to build OWL ontologies. With more
than 100,000 registered users, this software is supported by numerous academic,
government and corporate users (http://protege.stanford.edu/).
The overall structure and the main concepts described in CDAO are shown in
Fig. 12.2.
12.2.2 CDAO: Some Evaluation Considerations
The main purpose of the first prototype release of CDAO is to describe the most
basic structure of knowledge underlying the key entities in evolutionary analysis.
Thus, it does not provide an extensive terminological coverage (e.g., covering
the complete set of concepts identified in the controlled vocabulary at https://
www.nescent.org/wg_evoinfo/ConceptGlossary). This distinguishes CDAO from
ontologies like the Gene Ontology – where there is a more limited emphasis on
structuring knowledge (e.g., by using only a very basic set of relations between
terms) but an extensive informational coverage, mostly expressed in terms of a deep
taxonomy.
Several schemes have been proposed to provide a classification of ontologies.
According to such schemes, CDAO can be classified as follows:
12 Knowledge Standardization in Evolutionary Biology 201

l Following the richness classification (Lassila and McGuiness 2001), CDAO is at
one of the highest levels of complexity, as it includes general logical constraints
and disjoint classes.l According to the subject-based classification (Gomes-Perez et al. 2004), CDAO
can be viewed as a domain-task ontology, as it describes concepts and relations
valid across one specific (although broad) domain: evolutionary analysis, with
a focus on specific tasks within the domain (e.g., phylogenetic inference and
description).l Van Heijst et al. (1997) provides two dimensions for the classification of
ontologies. The first dimension measures the amount of structure present in the
ontology; in this regard, CDAO can be viewed as a knowledge modeling
ontology, having less of a focus on extensive terminological coverage and
character state data matrix
character statedata matrix
character statedatum
state
state
unrootedtree
state
has
has
has
has
tree
haschild
hashas
haschild_node
hasright_node
hasright_state
hasleft_node
hasleft_state
hasparent_node
hasparent
hasdescendant
hasancestor
node
node
node
node
hasTU
represents_TU is_transformation_of
transformation
transformation
topology
part_of
part_of
part_of
is_a
is_a
is_a
part_of
belongs_tobelongs_tocharacter
Annotation:AlignmentProcedure
Annotation:
rootedtree
directededge
edge
connects_to
Annotation:
Annotation:taxonomic_link...
TreeProcedureModel...
Length...
Fig. 12.2 Main evolutionary biology concepts represented in CDAO. The ontology is divided in
three inter-related parts: (1) the character-state data matrix, representing data conceptualization
and description; (2) the tree topology, representing the ancestral relationships among the groups
analyzed; and (3) the transformation, representing the step-wise modification in characters along
evolutionary time. *2008 data collected on November 18, 2008
202 F. Prosdocimi et al.

deep hierarchical classification and a greater emphasis instead on the basic
conceptual structure of knowledge in the domain. The second dimension classi-
fies ontologies based on the subject of the conceptualization; in this regard,
CDAO is a domain ontology (like the majority of ontologies in the OBO
foundry).l Mizoguchi and Vanwelkenhuysen (1995) classify ontologies based on their use.
The four top levels of the classification distinguish between Content, Communi-
cation, Indexing and Meta ontologies. CDAO is clearly a Content ontology; its
aim is to enable the reuse of knowledge related to evolutionary analysis across
agents and applications (e.g., stages of an analysis pipeline). It is important to
observe that CDAO is not a Communication ontology, as the purpose is to
emphasize the structure of knowledge. Content ontologies are further classifiedas Workplace, Task, Domain and General ontologies. CDAO is a Domain
ontology, which is Task-independent (not being tied to one specific task),
Activity-related (since CDAO emphasizes, at this time, the representation of
knowledge related to phylogenetic analysis) and it represents an Object ontology
(since it describes structure, behavior and function of entities).
12.2.3 CDAO Version 2.0
Ontology development is a continuous, iterative process and work on version 2 of
CDAO has already begun. This version aims to provide a more complete structure
or classification of the concepts defined in CDAO 1.0, in order to facilitate more
complex querying of CDAO data sets. As an example, we have added a richer set of
classes to describe the topology of trees. Using this richer annotation set, higher-
order concepts such as “Fully Resolved Tree” or “Polytomy” can be easily deduced,
either by a researcher or by an automatic reasoning software system. Previously,
these concepts could be inferred from the topology of a tree, if the reasoning system
had information concerning the definition of a polytomy. Our goals in including
these definitions in CDAO are (1) to standardize the definition of these concepts
and (2) to allow the use of general reasoners that have no specific evolutionary
knowledge. The terminological/informational component of CDAO is also being
expanded to provide a more extensive coverage of evolutionary concepts. For
instance, CDAO 2.0 includes imports for MyGrid (http://www.mygrid.org.uk/)
terms, in order to facilitate its use within web services. The additional terms specify
a large number of phylogenetic file formats, repositories and web services in
common use. This change will hopefully contribute to early efforts to develop a
MIAPA (Minimal Information About a Phylogenetic Analysis) standard (Leebens-
Mack et al. 2006).
All the documents published and other relevant information can be found on our
web site (http://www.evolutionaryontology.org). Please refer to these documents
when searching for the development of CDAO-based applications.
12 Knowledge Standardization in Evolutionary Biology 203

12.3 Conceptual Revolutions in Evolutionary Biology
and Historical Analysis of CDAO Concepts
In this section our aim is to make a very brief recapitulation of the history of
evolutionary biology regarding some conceptual modifications in this discipline
since the work of Charles Darwin. We will discuss how these concepts have
evolved and how they are currently represented in CDAO. We hope to provide a
theoretical analysis of our conceptualization work, illustrating the theoretical plas-
ticity of our ontology and how it facilitates more practical tasks related to data
annotation and representation of trees and character matrices, for example.
The concepts formalized in CDAO represent a vast and rich history of contro-
versies. The theory of evolution, as the broadest conceptual model in biology, has
been the target of a number of theoretical revisions mainly during the twentieth
century, resulting in today’s rich version that encompasses and links together many
diverse research fields, including biochemistry, genetics, genomics, ecology, zool-
ogy, botany, microbiology, development, physiology and medicine. Every single
data collection made in biology can be viewed from an evolutionary perspective
and our goal is to represent them in a modern and scalable way.
12.3.1 Conceptual Reformulations in EvolutionaryBiology Since Darwin
The years that followed Darwin’s publication The Origin of Species (1859) revealeda number of misunderstandings about the meaning of his global theory. Although
evolution, as opposed to creationism and common ancestry were soon accepted by
most evolutionists in the nineteenth century, the other parts of the theory were still
seen skeptically. The first point of theoretical disagreement was resolved in the
nineteenth century by the German biologist August Weissmann in his book OnHeredity, finally bringing to an end the Lamarckian idea of the inheritance of
acquired characteristics and the use and disuse of characters (Lamarck 1809).
Weissmann advocated the “germ plasm” theory, in which inheritance could
only take place by modifications in germ cells, since the other cells of the body
do not influence future generations and therefore could not act as agents of
heredity (Weissmann 1889). The term Neodarwinism is frequently used to refer
to Weissmann’s view of evolutionary theory.
During the first decade of the twentieth century, the works of Mendel were
rediscovered, although the interpretation of his works, made mainly by the Dutch
botanist Hugo De Vries, turned this theory into a mutation or saltationistic view of
evolution as opposed to Darwinian gradualism (Jacob 1970). Further development
in this field in Britain, made mainly by William Bateson, led to the birth of genetics
as a scientific discipline and the proliferation of saltationism. Nevertheless, it was
only during the 1930s and 1940s that a new conceptual revolution in evolutionary
204 F. Prosdocimi et al.

biology would take place, based on the work of Thomas Morgan in New York. His
studies on heredity and evolution were mainly developed in fruit-flies of the genus
Drosophila, making this insect one of the most studied model organisms in the
whole field of biology. According to Mayr (1991), the studies of Morgan and his
students indicated that small mutations could allow a gradual modification in
populations; the sudden leaps predicted by saltation theory were no longer needed
to explain evolution. The subsequent revolution, integrating gradualism, Mendel-
ism and the recent population genetics from a Darwinistic perspective was named
the Fisherian synthesis (Mayr 2004). The next conceptual integration brought a
common perspective to population genetics, biodiversity, spatial-temporal patterns
and evolutionary theory. While population geneticists were interested in explaining
the evolution and allelic changes inside a population group (anagenesis), naturalists
were interested in how a population could differentiate into two groups, leading to a
new species (cladogenesis). The publication of Genetics and the Origin of Speciesby Dobzhansky in 1937 opened the doors for the integration of these two previously
inconsistent points-of-view into a single evolutionary framework. Julian Huxley
named this the synthetic theory of evolution, or new synthesis and it was better
understood and elaborated after the publication of books byMayr, Simpson, Huxley
and Stebbins.
Finally, the last great conceptual revolution in evolutionary biology resulted
from the development of molecular biology. Crick’s central dogma, predicting that
the flux of genetic information was unidirectional, finally explained the molecular
basis for why the information from the environment could not directly influence
DNA, corroborating Weissmann’s studies on heredity (Mayr 1991). The overall
similarity of the genetic code among all life forms could be seen as a final proof
corroborating all evolutionary theory. Moreover, the astonishing similarities
amongst the sequences of genes and proteins involved in the most basic metabolic
pathways between bacteria, archaeabacteria, protists, fungi, plants and animals may
be seen as the ultimate attestation that evolution occurs. The advent of molecular
biology, together with previous theoretical synthesis, has led to our modern evolu-
tionary theory, that Mayr suggests should be simply called Darwinism.
CDAO can only be envisioned today thanks to all of these theorists, who have
provided us with a solid theoretical basis. In the following sections, we will discuss
the history of some specific concepts formalized in CDAO.
12.3.2 History of CDAO Concepts: The Taxonomic Unit
A widely used term in the evolutionary analysis field is “OTU,” which stands for
“Operational Taxonomic Unit.” OTU generally refers to the organisms or group of
organisms the researcher is working on when he begins his studies. The problem of
the OTU concept is clearly related to the so-called “species problem.” For a long
time, species were considered to be biological organisms sharing some arbitrarily-
definedmorphological characteristics. However, with the development of biology in
12 Knowledge Standardization in Evolutionary Biology 205

the nineteenth and twentieth centuries, a number of obstacles were identified, such as
(1) the description of a number of cryptic species, where organisms very similar in
form have completely different evolutionary origins; and (2) the enormous amount
of variation observed in organisms from the same species, linked to sex, age, or
particular environments. In the early twentieth century, the concept of reproductiveisolation was proposed and species came to be considered as closed genetic groups
changing gene alleles inside their reproductive group. But this concept has rapidly
presented problems too. How should this be applied to asexual species? And how
does this explain the formation of hybrids? No general consensus about the species
problem has been achieved yet and pragmatically speaking, taxonomists still use
morphological and physiological characters to describe new species.
Recently, molecules have been widely used as units for comparison. Although
molecules can be representative of species or organism groups, researchers must
take into account the fact that the evolution of a gene or protein may be biased by a
number of factors. The evolutionary history of a gene family can be compared to the
evolutionary history of the organisms harboring these genes but the evaluation of a
number of different genes would be necessary to actually infer a phylogeny of
species based on molecular data.
12.3.2.1 TU@CDAO
In the context of an ontology representation of evolutionary data, all these philo-
sophical problems concerning the definition of biological groups have been, of
course, inherited. It is clear that the definition of any entity, or “taxonomic unit,” to
be compared is entirely under the responsibility of the researcher and CDAO should
allow the representation of entities at the level of molecules, gene/protein families,
organisms, populations, species, or any other higher taxonomic level.
One particular problem that we encountered in the formalization of the taxo-
nomic unit concept in CDAO is that the term “OTU” is often used in phylogenetic
studies to indicate present-day entities (species, populations, individuals, mole-
cules, etc.) under study, while a different term “HTU,” or hypothetical taxonomic
unit, is used to refer to the ancestral entities. In some specialized phylogenetic
studies, for example in viral studies, the distinction between present-day entities
and ancestors is less clear, since it is possible that the ancestors of these rapidly
evolving organisms still exist. As a consequence, we decided to define a single
concept for both present-day and ancestral entities: the TU, or taxonomic unit.
12.3.3 History of CDAO Concepts: The Characterand the Character-State Data Matrix
Once the taxonomic units to be studied have been clearly defined, the next step in an
evolutionary analysis is the choice of the specific traits or characters to be used to
206 F. Prosdocimi et al.

classify these TUs. Until the theory of descent was actually accepted in biology and
used as a criterion for classification, morphological traits were employed as char-
acters to distinguish species by naturalists. David Hull credits to Hennig the first
serious attempt to claim that systematic classifications should be made using
evolutionary homologies (Hull 1988) and this has become one of the most relevant
concepts in evolution: the concept of character homology. Two characters are said
to be homologous if they descend from the same ancestral character present in an
ancestral organism. This argument was so strong that it was subsequently
incorporated by most evolutionary biologists and it could be said that systematics
today cannot be considered as separate from phylogenetics.
Maureen Kearney however points out that the identification and definition of
characters in species have led to the formation of two different schools in evolu-
tionary analysis and taxonomy (Kearney 2007). The first school was formed by the
pheneticists who claimed that both evolutionary analysis and systematics should be
done in a “theory-free” context. They claimed that a homology assumption would
create some sort of circularity in the methodology of evolution: if evolutionists
want to use phylogenetic trees to test hypotheses about evolution they should not
use evolutionary homology assumptions to build the trees. The second school of
cladists argues that both the evolutionary analysis of organism groups and the
biological nomenclature of them should be based on Darwinism, i.e., that characters
should be analyzed under an evolutionary context if and only if they can be assumed
to be homologous. In response to the tautology accusation made by pheneticists,
cladists advocate the philosophical principle of parsimony and the general scientific
principle known as the Occam’s razor normally understood as “Pluralitas non estponenda sine necessitate” (“plurality should not be posited without necessity”). Thecladists claim that their theory is closer to the popperian philosophy of science in
the sense that the most parsimonious tree is the representation of the evolutionary
history that could not be falsified by the available data in the light of modern
evolutionary theory.
12.3.3.1 Character@CDAO
In the face of this plurality, CDAO allows the user to define their characters
independently of any supposed homology among them. Although it has now
become almost a consensus that classification should be done using homologous
characters, whole-genome and multiple alignment comparisons are capable of
producing characters that seem more phenetic than cladistic. Once the user has
defined the characters, they can be annotated as being homologous or not.
Depending on the particular entities (TUs) under study, widely different
characters may be used to classify them, including morphological traits, molecular
characters, such as nucleotide residues or amino acids, gene functions, cellular
localizations or expression levels. The diverse types of data are taken into account
in CDAO by defining sub-classes of the more general character concept,
namely discrete_character, continuous_character, categorical_character and
12 Knowledge Standardization in Evolutionary Biology 207

compound_character. The compound_character provides a mechanism for combin-
ing individual characters into a single character, for example, to allow the definition
of different parts of a molecule as special characters in an evolutionary study.
For a given set of TUs, the state of each of the selected characters is entered into
a matrix, known as a “character-state data matrix,” where the rows of the matrix
correspond to TUs and the columns represent the characters. The “character-state”
data model is generic and can be applied to most data types, e.g., in a protein
sequence alignment, the TU represents a protein, the character represents a column
in the alignment and the character state is either a residue or a gap. The states of
high-level biological characters (morphology, development, anatomy, behavior)
are also typically encoded as discrete states. Many of these character states are
defined in existing bio-medical ontologies, often in OWL format and can be used in
conjunction with CDAO to annotate specific characters and character states.
Missing data and absent features, common in biological data, may be treated as
an extra state. Thus, a feature that is found only in some TUs, such as an intron, can
be represented by a binary character with “presence” and “absence” states. This
concept will become increasingly important with the more widespread use of
automatic phylogenetic inference approaches, as defined by (Eisen 1998).
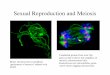
12.3.4 History of CDAO Concepts: The Tree
The fact that biological organisms relate to each other following a tree-like schema
was originally described by Darwin in The Origin of Species (1859). One of the
biggest pieces of scientific work in all the history of science, this paradigm-shift
book – in the words of the philosopher of science Thomas Kuhn (Kuhn 1962) – was
published exactly 150 years ago and contained only a single illustration. This
picture is the ancestor of all modern studies in evolution and opened the way for
a field mainly developed during the 1950s by Willi Hennig: cladistics (or phyloge-
netics). Figure 12.3 shows the original picture in Darwin’s publication and a
modern phylogenetic tree of life.
According to Mayr (2004), none of the Darwinian sub-theories was accepted so
enthusiastically as the so-called theory of common ancestry. This common ancestry
insight gave birth to the idea of building a tree to relate modern organisms back to
ancestors in the past. In his book What makes biology unique?, Mayr states: well-
known “similarities, such as the cord in tunicates and the brachial arcs in fishesand terrestrial vertebrates were completely disconcerting until they were inter-preted as vestiges of a common past.”
Since then, the common ancestry idea has been referred to as the theory ofdescent (Hennig 1950; Weissmann 1889) and formed the basis for the initial
formalization of methods in evolutionary biology. The methods for the description
of an evolutionary tree evolved relatively slowly during the twentieth century, until
recently when it converged on the graph theory originally developed in the com-
puter sciences. The origin of graph theory is frequently attributed to a paper of the
208 F. Prosdocimi et al.

Swiss mathematician Leonhard Euler, more than one century before Darwin. With
the multidisciplinary research fields growing at the end of the twentieth century,
information theorists started to work with evolutionary biology data and standard
methods to treat and represent tree-structured data in computer and information
sciences were introduced into evolutionary biology. The most widely used format
existing today to represent an evolutionary tree is the so-called Newick standard –
which makes use of the correspondence between nodes in a tree and nested
parentheses. This format was adopted in evolutionary biology in 1986 during an
informal meeting of the Society for the Study of Evolution in Durham, New
Hampshire.
12.3.4.1 Tree@CDAO
The traditional binary tree, where extant species evolved from a common ancestor,
is now being replaced by a more general representation, a phylogenetic network, for
example, in the case where horizontal gene transfer events produce complex trees
with criss-crossing branches. CDAO uses a semantic-based structure to represent
both networks and trees, with nodes and branches defined as separate concepts. The
trees can be either rooted or unrooted and branches in a rooted tree can be assigned
a “direction,” indicating the parent-child relationships between the associated
nodes.
The structure defined in CDAO allows researchers to annotate both branches and
nodes with specific information and in this way, character states can be associated
with specific tree lineages, present-day or ancestral TUs. Similarly, genetic events
(duplication, lateral transfer, inversion, transposition, deletion, insertion, etc.),
leading to modifications or transformations in the state of a character, can be
localized at specific branches of the tree. The existence of dedicated concepts
associated with ancestral TUs in an evolutionary tree allows the representation of
Fig. 12.3 The original and modern stages in phylogenetic tree building. (a) The very first
phylogenetic tree of organisms contained in the Origin of Species (Darwin 1859); (b) a modern
phylogenetic tree of life
12 Knowledge Standardization in Evolutionary Biology 209

the most likely status of characters in putatively ancestral organisms and can
help researchers to formulate better hypotheses about both living and non-living
organisms.
12.4 Conclusions
Most of the discussions in evolutionary biology made during the twentieth century
have produced what we now call modern Darwinism or, simply, Darwinism. Many
ancient controversies have been solved and the ones that have not been solved do
not seem to pose any practical problem to the modern evolutionary biologist.
Darwinism has been completely integrated theoretically with other broad fields in
biology, such as genetics and molecular biology. If an ontology can now be
envisaged to represent and annotate data in evolutionary biology, it is certainly
based on the work of numerous biologists and philosophers towards developing
unifying concepts in evolution. Even inside Darwinism, the controversies are now
well-understood and evolutionary biologists can work together, even though they
base their premises in different traditional schools. Modern evolutionists can switch
between theories, such as cladistics or phenetics, choosing the most pertinent
framework, without being accused of philosophical betray. In the twenty-first
century era of integrative biology, researchers have understood that no method is
superior in all cases and there will always be a number of variables or conditions
that will make one or another methodology more suitable for a particular case. And
although a number of controversies still exist, such as the nature of species (or
TUs), the best method to analyze data or the fact that characters should or should
not be homologies, evolutionary biologists can understand the limitations of their
methods and concepts in order to produce high-quality scientific understanding.
As a consequence, any modern method that aspires to unite evolutionary biol-
ogists must be able to cope with this diversity of definitions. CDAO was developed
with these discussions in mind and it should permit the representation of data in any
theoretical background currently available. Although general enough to allow the
representation of different paradigmatic views in evolution, CDAO represents a
well-defined structure of the knowledge in evolutionary biology that will facilitate
automatic reasoning by algorithms.
In conclusion, CDAO is the result of initial efforts made by members of the
NESCent Evolutionary Informatics consortium to conceptualize and define
the most pertinent concepts used in a comparative data analysis that focuses on
the evolution of biological organisms. Therefore CDAO allows a formal represen-
tation of evolutionary data, where annotations of any sort can be linked to the TUs,
characters, character-state data matrix and the branches of a tree. Thanks to the
formalisms defined in CDAO, most of this information can be subsequently parsed
and analyzed by automatic reasoning algorithms, with the goal of producing
new and high-level information. CDAO is intended to provide the basis for a
standardized file format for evolutionary data, promoting data reuse and data
210 F. Prosdocimi et al.

interoperability. More importantly, it is hoped that it will eventually offer a
complete framework for both computer and human expert analyses.
12.5 Future Developments
CDAO is an ongoing project and we plan to add more specific concepts as new
versions of the ontology are built in the near future. Next steps on CDAO develop-
ment will include the addition of still missing standard evolutionary concepts, such
as (1) the ones used in systematics; (2) sister group relations; (3) standard homology
relationships, including molecular-based ones; and (4) homoplasy and evolutionary
convergence annotation. Additionally, since organism can be better understood in
ecological contexts, we also intend to associate CDAO with some environmental
ontology, such as the one provided at http://www.environmentontology.org/ has
been envisioned. Initially developed behavioral ontologies (Midford 2004) shall
also be used in association with CDAO instances to allow better description of
evolutionary features of complex organisms.
User-friendly algorithms to transform standard format of character-state data
matrices in CDAO formatted instances will soon be produced to facilitate the
representation of evolutionary data in the CDAO format. The production of these
algorithms for data representation is strikingly relevant to approximate the evolu-
tionary biologist in his lab to this new technology of data representation.
CDAO also aims to be integrated into a workflow-pipeline of evolutionary
software on which the users will be able to input their data, click in some buttons
to activate the methods they want to use and then run these methods on a grid
machine. The results shall be stored in the tree-structure part of CDAO and they
will be able to be analyzed automatically by a reasoner, returning the analyzed data
to the user for interpretation. Moreover, once CDAO stores the raw data, there is the
possibility of associating a number of different tree-topologies (and the methods
associated to them) for the same data set. Moreover, the statistical methods of re-
sampling will also be able to be annotated and values of confidence will be
associated on tree-branches. These developments however will depend on the
development of MIAPA and further submission of projects aiming to provide the
informatics structure for workflow development.
Furthermore, new digital representation of data matrices on evolutionary biology
has been produced and Ramırez et al. (2007) describes a data base of digital images
and character data matrices information that could be automatically transformed
into CDAO instances. The usage of CDAO as the standard file format for storing,
annotating and sharing evolutionary information may ease communication in the
near future, although standard algorithms and converting tools must be made
available as soon as possible.
At last, considering that we envision the possibility of getting together a number
of CDAO-annotated data sets produced by different research teams all over
the world, we strongly encourage evolutionary biology researchers to provide a
12 Knowledge Standardization in Evolutionary Biology 211

complete and accurate description of their represented data. The possibility of
joining a number of evolutionary data produced everywhere in the globe opens a
wonderful possibility of producing complete and powerful evolutionary informa-
tion using thousands of diverse characters, from the molecular to the morphologi-
cal, behavioral and ecological. To the best of our knowledge and belief that sort of
global, heterogeneous, joined data set information could never be achieved without
making use of a standard well-defined knowledge representation vocabulary, as the
one described on CDAO.
Acknowledgments We thank NESCent for financing our group meetings and the members of the
Evolutionary Informatics team for their stimulus and support. The French ANR (EvolHHuPro:
BLAN07-1_198915) are gratefully acknowledged for financial support. Francisco Prosdocimi and
Julie D. Thompson are supported by institute funds from the Institut National de la Sante et de la
Recherche Medicale, the Centre National de la Recherche Scientifique and the Universite Louis
Pasteur de Strasbourg. Enrico Pontelli has been supported by National Science Foundation grants
HRD-0420407 and CNS-0220590. Brandon Chisham is supported by an IGERT fellowship from
NSF grant DGE-0504304. The identification of specific commercial software products in this
paper is for the purpose of specifying a protocol and does not imply a recommendation or
endorsement by the National Institute of Standards and Technology.
References
Ashburner M, Ball CA, Blake JA, Botstein D, Butler H, Cherry JM, Davis AP, Dolinski K,
Dwight SS, Eppig JT, Harris MA, Hill DP, Issel-Tarver L, Kasarskis A, Lewis S, Matese JC,
Richardson JE, Ringwald M, Rubin GM, Sherlock G (2000) Gene ontology: tool for the
unification of biology. The Gene Ontology Consortium. Nat Genet 25(1):25–29
Bard J, Rhee SY, Ashburner M (2005) An ontology for cell types. Genome Biol 6(2):R21
Bard JB (2005) Anatomics: the intersection of anatomy and bioinformatics. J Anat 206(1):1–16
Carnap R (1950) Empiricism, Semantics, and Ontology. Revue Internationale de Philosophie
4:20–40. On the web: http://www.ditext.com/carnap/carnap.html
Chabalier J, Mosser J, Burgun A (2007) Integrating biological pathways in disease ontologies.
Stud Health Technol Inform 129(Pt 1):791–795
Cochrane G, Akhtar R, Bonfield J, Bower L, Demiralp F, Faruque N, Gibson R, Hoad G, Hubbard T,
Hunter C, Jang M, Juhos S, Leinonen R, Leonard S, Lin Q, Lopez R, Lorenc D, McWilliam H,
Mukherjee G, Plaister S, Radhakrishnan R, Robinson S, Sobhany S, Hoopen PT, Vaughan R,
Zalunin V, Birney E (2009) Petabyte-scale innovations at the European Nucleotide Archive.
Nucleic Acids Res 37(Database issue):D19–25
Darwin CR (1859) On the origin of species by means of natural selection, or the preservation of
favoured races in the struggle for life, 1st edn. John Murray, London. On the web: http://
darwin-online.org.uk/content/frameset?itemID = F373& viewtype = text&pageseq = 1
Dobzhansky T (1973) Nothing in biology makes sense except in the light of evolution. Am Biol
Teacher 35:125–129
Dohm JC, Lottaz C, Borodina T, Himmelbauer H (2008) Substantial biases in ultra-short read data
sets from high-throughput DNA sequencing. Nucleic Acids Res 36(16):e105
Eisen JA (1998) Phylogenomics: improving functional predictions for uncharacterized genes by
evolutionary analysis. Genome Res 8:163–167
Gaudet P, Williams JG, Fey P, Chisholm RL (2008) An anatomy ontology to represent biological
knowledge in Dictyostelium discoideum. BMC Genom 18(9):130
212 F. Prosdocimi et al.

Gene Ontology Consortium (2001) Creating the gene ontology resource: design and implementa-
tion. Genome Res 11(8):1425–1433
Gomes-Perez A, Fernando-Lopez M, Corcho O (2004) Ontological engineering: theoretical
foundations of ontologies. Springer Verlag, New York
Gruber TR (1995) Toward principles for the design of ontologies used for knowledge sharing.
International Journal of Human-Computer Studies 43(4–5):907–928
Harris MA (2008) Chapter 5: developing an ontology. In: Jonathan M, Keith (ed) Bioinformatics
data, sequence analysis and evolution. Humana Press, New York, pp 111–124
HennigW (1950) Phylogenetic systematics. (trans. D. Davis and R. Zangerl). University of Illinois
Press, Urbana 1966, reprinted 1979
Hull D (1988) Science as Process. University of Chicago Press, Chicago, IL
Jacob F (1970) La logique du vivant: une histoire de l’heredite. Gallimard, Paris
Jaiswal P, Avraham S, Ilic K, Kellogg EA, McCouch S, Pujar A, Reiser L, Rhee SY, Sachs MM,
Schaeffer M, Stein L, Stevens P, Vincent L, Ware D, Zapata F (2005) Plant ontology (PO): a
controlled vocabulary of plant structures and growth stages. CompFunct Genom6(7–8): 388–397
Kearney M (2007) Phylosophy and phylogenetics: historical and current connections. In: David L
Hull, Michael Ruse (eds) The Cambridge companion to the philosophy of biology. Cambridge
University Press, Cambridge, pp 211–232
Kuhn TS (1962) The structure of scientific revolutions, 1st edn. University of Chicago Press,
Chicago, IL, p 168
Lakatos I (1978) The methodology of scientific research programmes: philosophical papers, vol 1.
Cambridge University Press, Cambridge
Lamarck chevalier de (Jean-Baptiste Pierre Antoine de Monet) (1809) Philosophie Zoologique.
On the web: http://fr.wikisource.org/wiki/Philosophie_zoologique
Larson SD, Fong LL, Gupta A, Condit C, Bug WJ, Martone ME (2007) A formal ontology of
subcellular neuroanatomy. Front Neuroinform 1:3
Lassila O, McGuinness DL (2001) The role of frame-based representation on the semantic web.
Linkoping Electron Art Computer Inform Sci 6:5
Leebens-Mack J, Vision T, Brenner E, Bowers JE, Cannon S, Clement MJ, Cunningham CW,
dePamphilis C, deSalle R, Doyle JJ, Eisen JA, Gu X, Harshman J, Jansen RK, Kellogg EA,
Koonin EV, Mishler BD, Philippe H, Pires JC, Qiu YL, Rhee SY, Sjolander K, Soltis DE,
Soltis PS, Stevenson DW, Wall K, Warnow T, Zmasek C (2006) Taking the first steps towards
a standard for reporting on phylogenies: minimum information about a phylogenetic analysis
(MIAPA). OMICS 10(2):231–237
Lee RY, Sternberg PW (2003) Building a cell and anatomy ontology of caenorhabditis elegans.
Comp Funct Genom 4(1):121–126
Leontis NB, Altman RB, Berman HM, Brenner SE, Brown JW, Engelke DR, Harvey SC,
Holbrook SR, Jossinet F, Lewis SE, Major F, Mathews DH, Richardson JS, Williamson JR,
Westhof E (2006) The RNA Ontology Consortium: an open invitation to the RNA community.
RNA 12(4):533–541
Maglia AM, Leopold JL, Pugener LA, Gauch S (2007) An anatomical ontology for amphibians.
Pac Symp Biocomput 367–378
Marguerat S, Wilhelm BT, Bahler J (2008) Next-generation sequencing: applications beyond
genomes. Biochem Soc Trans 36(Pt 5):1091–1096
Mayr E (1991) One long argument: Charles Darwin and the genesis of modern evolutionary
thought (questions of science). Harvard University Press, Cambridge
Mayr E (2004) What makes biology unique?: considerations on the autonomy of a scientific
discipline. Cambridge University Press, Cambridge
Midford PE (2004) Ontologies for behavior. Bioinformatics 20:3700–3701
Mizoguchi R, Vanwelkenhuysen J (1995) Task ontology for reuse of problem solving knowledge.
Proceedings of KB & KS, pp 46–59
Ramırez MJ, Coddington JA, Maddison WP, Midford PE, Prendini L, Miller J, Griswold CE,
Hormiga G, Sierwald P, Scharff N, Benjamin SP, Wheeler WC (2007) Linking of
12 Knowledge Standardization in Evolutionary Biology 213

digital images to phylogenetic data matrices using a morphological ontology. Syst Biol
56:283–294
Rodrigues JM, Rector A, Zanstra P, Baud R, Innes K, Rogers J, Rassinoux AM, Schulz S,
Trombert Paviot B, ten Napel H, Clavel L, van der Haring E, Mateus C (2006) An ontology
driven collaborative development for biomedical terminologies: from the French CCAM to the
Australian ICHI coding system. Stud Health Technol Inform 124:863–868
Rothberg JM, Leamon JH (2008) The development and impact of 454 sequencing. Nat Biotechnol
26(10):1117–1124
Schulz S, Marko K, Hahn U (2007) Spatial location and its relevance for terminological inferences
in bio-ontologies. BMC Bioinform 8:134
Schulz S, Stenzhorn H, Boeker M (2008) The ontology of biological taxa. Bioinformatics 24(13):
i313–321
Segerdell E, Bowes JB, Pollet N, Vize PD (2008) An ontology for Xenopus anatomy and
development. BMC Dev Biol 8:92
Shendure J, Ji H (2008) Next-generation DNA sequencing. Nat Biotechnol 26(10):1135–1145
Sirin S, Parsia B, Grau BC, Kalyanpur A, Katz Y (2007) Pellet: a practical OWL-DL reasoner.
Web Semantics 5:51–53
Smith B, Ceusters W, Klagges B, Kohler J, Kumar A, Lomax J, Mungall C, Neuhaus F, Rector AL,
Rosse C (2005) Relations in biomedical ontologies. Genome Biol 6(5):R46
Smith B, Ashburner M, Rosse C, Bard J, Bug W, Ceusters W, Goldberg LJ, Eilbeck K, Ireland A,
Mungall CJ; OBI Consortium, Leontis N, Rocca-Serra P, Ruttenberg A, Sansone SA, Scheuer-
mann RH, Shah N, Whetzel PL, Lewis S (2007) The OBO Foundry: coordinated evolution of
ontologies to support biomedical data integration. Nat Biotechnol 25(11):1251–1255
Trelease RB (2006) Anatomical reasoning in the informatics age: Principles, ontologies, and
agendas. Anat Rec B New Anat 289(2):72–84
Tsarkov D, Horrocks I (2006) FaCT + + description logic reasoner: system description. In:
Furbach U, Shankar N (eds) IJCAR 2006, LNAI 4130, pp 292–297
van Heijst G, Schreiber AT, Wielinga BJ (1997) Roles are not classes: a reply to Nicola Guarino.
Int J Hum-Comput Stud 46(2):311–318
Weissmann A (1889) Essays upon heredity, vols 1 and 2. Clarendon, Oxford. On the web: http://
www.esp.org/books/weismann/essays/facsimile/
214 F. Prosdocimi et al.